#Databricks Platform
Text
Maximizing Manufacturing Efficiency with Databricks Platform
Databricks Platform is a game-changer for the manufacturing industry. Its ability to integrate and process vast amounts of data, provide predictive maintenance, offer real-time analytics, and enhance quality control makes it an essential tool for modern manufacturers.
#Databricks Platform#Databricks#databricks developers#databricks solutions#databricks services#lagozon technologies
0 notes
Text
Unlocking Business Potential with Databricks: Comprehensive Solutions for the Modern Enterprise
In the era of big data and cloud computing, the Databricks platform stands out as a transformative force, enabling businesses to unlock the full potential of their data. With its robust capabilities, Databricks empowers organizations across various sectors to harness data-driven insights and drive innovation. From Databricks cloud solutions to specialized Databricks financial services, Databricks professional services, and Databricks managed services, we explore how this powerful platform can revolutionize business operations and strategies.
Understanding the Databricks Platform: A Unified Approach to Data and AI
The Databricks platform is a cloud-based solution designed to streamline and enhance data engineering, data science, and machine learning processes. It offers a unified interface that integrates various data tools and technologies, making it easier for businesses to manage their data pipelines, perform analytics, and deploy machine learning models. Key features of the Databricks platform include:
Unified Analytics: Bringing together data processing, analytics, and machine learning in a single workspace, facilitating collaboration across teams.
Scalability: Leveraging cloud infrastructure to scale resources dynamically, accommodating growing data volumes and complex computations.
Interactive Workspaces: Providing a collaborative environment where data scientists, engineers, and business analysts can work together seamlessly.
Advanced Security: Ensuring data protection with robust security measures and compliance with industry standards.
Leveraging the Power of Databricks Cloud Solutions
Databricks cloud solutions are integral to modern enterprises looking to maximize their data capabilities. By utilizing the cloud, businesses can achieve:
Flexible Resource Management: Allocate and scale computational resources as needed, optimizing costs and performance.
Enhanced Collaboration: Cloud-based platforms enable global teams to collaborate in real-time, breaking down silos and fostering innovation.
Rapid Deployment: Implement and deploy solutions quickly without the need for extensive on-premises infrastructure.
Continuous Availability: Ensure data and applications are always accessible, providing resilience and reliability for critical operations.
Databricks Financial Services: Transforming the Financial Sector
Databricks financial services are tailored to meet the unique needs of the financial industry, where data plays a pivotal role in decision-making and risk management. These services provide:
Risk Analytics: Leveraging advanced analytics to identify and mitigate financial risks, enhancing the stability and security of financial institutions.
Fraud Detection: Using machine learning models to detect fraudulent activities in real-time, protecting businesses and customers from financial crimes.
Customer Insights: Analyzing customer data to gain deep insights into behavior and preferences, driving personalized services and engagement.
Regulatory Compliance: Ensuring compliance with financial regulations through robust data management and reporting capabilities.
Professional Services: Expert Guidance and Support with Databricks
Databricks professional services offer specialized expertise and support to help businesses fully leverage the Databricks platform. These services include:
Strategic Consulting: Providing insights and strategies to integrate Databricks into existing workflows and maximize its impact on business operations.
Implementation Services: Assisting with the setup and deployment of Databricks solutions, ensuring a smooth and efficient implementation process.
Training and Enablement: Offering training programs to equip teams with the skills needed to effectively use Databricks for their data and AI projects.
Ongoing Support: Delivering continuous support to address any technical issues and keep Databricks environments running optimally.
Databricks Managed Services: Streamlined Data Management and Operations
Databricks managed services take the complexity out of managing data environments, allowing businesses to focus on their core activities. These services provide:
Operational Management: Handling the day-to-day management of Databricks environments, including monitoring, maintenance, and performance optimization.
Security and Compliance: Ensuring that data systems meet security and compliance requirements, protecting against threats and regulatory breaches.
Cost Optimization: Managing cloud resources efficiently to control costs while maintaining high performance and availability.
Scalability Solutions: Offering scalable solutions that can grow with the business, accommodating increasing data volumes and user demands.
Transforming Data Operations with Databricks Solutions
The comprehensive range of Databricks solutions enables businesses to address various challenges and opportunities in the data landscape. These solutions include:
Data Engineering
Pipeline Automation: Automating the extraction, transformation, and loading (ETL) processes to streamline data ingestion and preparation.
Real-Time Data Processing: Enabling the processing of streaming data for real-time analytics and decision-making.
Data Quality Assurance: Implementing robust data quality controls to ensure accuracy, consistency, and reliability of data.
Data Science and Machine Learning
Model Development: Supporting the development and training of machine learning models to predict outcomes and automate decision processes.
Collaborative Notebooks: Providing interactive notebooks for collaborative data analysis and model experimentation.
Deployment and Monitoring: Facilitating the deployment of machine learning models into production environments and monitoring their performance over time.
Business Analytics
Interactive Dashboards: Creating dynamic dashboards that visualize data insights and support interactive exploration.
Self-Service Analytics: Empowering business users to perform their own analyses and generate reports without needing extensive technical skills.
Advanced Reporting: Delivering detailed reports that combine data from multiple sources to provide comprehensive insights.
Maximizing the Benefits of Databricks: Best Practices for Success
To fully leverage the capabilities of Databricks, businesses should adopt the following best practices:
Define Clear Objectives: Establish specific goals for how Databricks will be used to address business challenges and opportunities.
Invest in Training: Ensure that teams are well-trained in using Databricks, enabling them to utilize its full range of features and capabilities.
Foster Collaboration: Promote a collaborative culture where data scientists, engineers, and business analysts work together to drive data initiatives.
Implement Governance Policies: Develop data governance policies to manage data access, quality, and security effectively.
Continuously Optimize: Regularly review and optimize Databricks environments to maintain high performance and cost-efficiency.
The Future of Databricks Services and Solutions
As data continues to grow in volume and complexity, the role of Databricks in managing and leveraging this data will become increasingly critical. Future trends in Databricks services and solutions may include:
Enhanced AI Integration: More advanced AI tools and capabilities integrated into the Databricks platform, enabling even greater automation and intelligence.
Greater Emphasis on Security: Continued focus on data security and privacy, ensuring robust protections in increasingly complex threat landscapes.
Expanded Cloud Ecosystem: Deeper integrations with a broader range of cloud services, providing more flexibility and choice for businesses.
Real-Time Insights: Greater emphasis on real-time data processing and analytics, supporting more immediate and responsive business decisions.
#databricks platform#databricks cloud#databricks financial services#databricks professional services#databricks managed services
0 notes
Text

Contact CT Shift - Automate Migration from SAS (celebaltech.com)
0 notes
Text
Amazing Dream Machine
New Post has been published on https://thedigitalinsider.com/amazing-dream-machine/
Amazing Dream Machine
A text-to-video model freely available to everyone.
Image Credit: Luma AI
Next Week in The Sequence:
Edge 405: Our series about autonomous agents starts diving into the topic of memory. We discuss a groundbreaking paper published by Google and Stanford University demonstrating that memory-augmented LLMs are computationally universal. We also provide an overview of the Camel framework for building autonomous agents.
The Sequence Chat: An interesting interview with one of the engineers behind the Azure OpenAI Service.
Edge 406: Dive into Anthropic’s new LLM interpretability method.
You can subscribe to The Sequence below:
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
📝 Editorial: Amazing Dream Machine
Video is highly regarded as one of the next frontiers for generative AI. Months ago, OpenAI dazzled the world with its minute-long videos, while startups such as Runway and PikaLabs are being widely adopted across different industries. The challenges with video generation are many, ranging from physics understanding to the lack of high-quality training datasets.
This week, we had a surprising new entrant in the generative video space. A few days ago, Luma AI unveiled Dream Machine, a text-to-video generation model that produces high-quality, physically accurate short videos. Luma claims that Dream Machine is based on a transformer architecture trained directly on videos and attributes this approach to the high quality of the outputs. Beyond the high quality, the most impressive aspect of Dream Machine is that it is freely available. This contrasts with other text-to-video models such as OpenAI’s Sora and Kuaishou’s Kling, which remain available only to a select group of partners. The distribution model is particularly impressive when we consider that video generation requires very high computational costs. This reminded me of the Stable Diffusion release at a time when most text-to-image models were still closed source.
The generative video space is in its very early stages, and my prediction is that most of the players will be acquired by the largest generative AI providers. Mistral, Anthropic, and Cohere have all raised tremendous sums of venture capital but remain constrained to language models. In order to compete with OpenAI, the acquisition of the early innovative startups working on generative video makes a lot of sense.
For now, you should definitely try Dream Machine. It makes you dream of the possibilities.
📽 Recommended webinar
Do you still rely on ‘vibe checks’ or ChatGPT for your GenAI evaluations? See the future of instant, accurate, low-cost evals in our upcoming webinar, including:
How to conduct GenAI evaluations
The problem with human and LLM-as-a-judge approaches
The future of ultra-low cost and latency evaluations
🔎 ML Research
LiveBench
Researchers from Abacus.AI , NVIDIA, UMD, USC and NYU published LiveBench, a new multidimensional benchmark that addresses LLM benchmark memorization. LiveBench benchmark changes regularly with new questions and objective evaluations —> Read more.
Husky
Researchers from Meta AI, Allen AI and University of Washington published a paper introducing Husky, an LLM agent for multi-step reasoning. Husky is able to reason over a given action space to perform tasks that include different datasets such as numerical, tabular or knowledge-based —> Read more.
Mixture of Agents
Researchers from Together.ai, Duke and Stanford University published a paper introducing mixture-of-agents(MoA), an architecture that combines different LLMs for a given task. Some of the initial results showed MoA outperforming GPT-4o across different benchmarks —> Read more.
Test of Time
Researchers from Google DeepMind published a paper introducing Test of Time, a benchmark for evaluating LLMs on temporal reasoning capabilities in scenarios that require temporal logic. The benchmarks use synthetic datasets to avoid previous memorization that could produce misleading results —> Read more.
TextGrad
Researchers from Stanford University published a paper unveiling TextGrad, an automatic differentiation technique for multi-LLM systems. TextGrad works similar to backpropagation in neural networks distributing textual feedback from LLMs to improve individual components of the system —> Read more.
Transformers and Neural Algorithmic Reasoners
Researchers from Google DeepMind published a paper proposing a technique that combine transformers with GNN-based neural algorithmic reasoners. The results are models that could be more effective at reasoning tasks —> Read more.
🤖 Cool AI Tech Releases
Dream Machine
Luma Labs release Dream Machine, a text-to-video model with impressive high quality —> Read more.
Stable Diffusion 3 Medium
Stability AI open sourced Stable Diffusion 3 Medium, a 2 billion parameter text-to-image model —> Read more.
Unity Catalog
Databricks open sourced its Unity Catalog for datasets and AI models —> Read more.
🛠 Real World AI
Red Teaming at Anthropic
Anthropic shares practical advice learned from red teaming its Claude models —> Read more.
Serverless Notebooks at Meta
Meta engineering discusses how they use Bento and Pyodide to enable serverless interaction of Jupyter notebooks —> Read more.
📡AI Radar
Apple unveiled its highly anticipated Applied Intelligence strategy.
Mistral announced a monster $640 million round.
Google scientist Francois Chollet announced a new $1M prize for models that beat his famous ARC benchmark.
OpenAI added a former NSA director to its board.
GPTZero announced $10 million in new funding for its AI content detection platform.
Databricks unveiled new features to its Mosaic AI platform for building compound AI systems.
AI healthcare company Tempus AI had a stellar public market debut.
Camb.ai introduced Mars5, a voice cloning model with support for 140 languages.
Flow Computing raised $4.3 million for its parallel CPU platform.
Amazon announced a $230 million commitment to generative AI startups.
Particle, an AI news reader platform announced $10 million in ne
AI finance platform AccountIQ raised $65 million in new funding.
AI warehouse platform Retail Ready raised a $3.3 million seed round.
AI powered general ledger platform Light announced a $13 million round.
Financial research platform Lina raised $6,6 million to enable AI for financial analysts.
South Korean AI chip developers Robellion and Sapeon merged.
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
#Advice#agent#agents#ai#AI chip#AI models#ai news#ai platform#AI systems#amazing#Amazon#anthropic#approach#arc#architecture#autonomous agents#azure#azure openai#benchmark#benchmarks#billion#board#Building#chatGPT#claude#compound AI#computing#content#cpu#databricks
0 notes
Text
0 notes
Text
From Siloed Systems to Scalable Agility: A Financial Services Company's Journey Migrating Teradata and Hadoop to Google Cloud Platform
For many financial services companies, managing data sprawl across disparate systems like Teradata and Hadoop can be a significant hurdle. This was the case for one such company, facing challenges with:
Limited Scalability: Traditional on-premises infrastructure struggled to handle the ever-growing volume and complexity of financial data.
Data Silos: Siloed data across Teradata and Hadoop hindered a holistic view of customer information and market trends.
High Operational Costs: Maintaining and managing separate systems proved expensive and resource-intensive.
Seeking a Modernized Data Architecture:
Recognizing the need for a more agile and scalable solution, the company embarked on a strategic migration journey to Google Cloud Platform (GCP). This migration involved:
Teradata to GCP Migration: Leveraging GCP's data warehousing solutions, the company migrated its data from Teradata, consolidating it into a central and scalable platform.
Hadoop Migration to GCP: For its big data processing needs, the company migrated its Hadoop workloads to Databricks on GCP. Databricks, a cloud-native platform, offered superior scalability and integration with other GCP services.
Benefits of Moving to GCP:
Migrating to GCP yielded several key benefits:
Enhanced Scalability and Agility: GCP's cloud-based infrastructure provides the scalability and elasticity needed to handle fluctuating data volumes and processing demands.
Unified Data Platform: Consolidated data from Teradata and Hadoop within GCP enables a holistic view of customer information, market trends, and risk factors, empowering data-driven decision-making.
Reduced Operational Costs: By eliminating the need to maintain separate on-premises infrastructure, the company achieved significant cost savings.
Advanced Analytics Capabilities: GCP's suite of data analytics tools allows the company to extract deeper insights from their data, driving innovation and improving risk management strategies.
Lessons Learned: Planning and Partnership are Key
The success of this migration hinged on two crucial aspects:
Meticulous Planning: A thorough assessment of the existing data landscape, along with a well-defined migration strategy, ensured a smooth transition.
Partnership with a Cloud Migration Expert: Collaborating with a Google Cloud Partner provided the necessary expertise and resources to navigate the migration process efficiently.
Conclusion:
teradata to databricks migration and Hadoop to Databricks Migration provided financial services company achieved a more scalable, agile, and cost-effective data architecture. The consolidated data platform and access to advanced analytics empower them to make informed decisions, optimize operations, and gain a competitive edge in the ever-evolving financial landscape. Their story serves as a testament to the transformative power of cloud migration for the financial services industry.
0 notes
Text
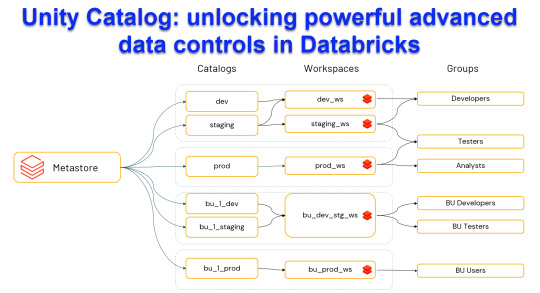
Unity Catalog: Unlocking Powerful Advanced Data Control in Databricks
Harness the power of Unity Catalog within Databricks and elevate your data governance to new heights. Our latest blog post, "Unity Catalog: Unlocking Advanced Data Control in Databricks," delves into the cutting-edge features
View On WordPress
#Advanced Data Security#Automated Data Lineage#Cloud Data Governance#Column Level Masking#Data Discovery and Cataloging#Data Ecosystem Security#Data Governance Solutions#Data Management Best Practices#Data Privacy Compliance#Databricks Data Control#Databricks Delta Sharing#Databricks Lakehouse Platform#Delta Lake Governance#External Data Locations#Managed Data Sources#Row Level Security#Schema Management Tools#Secure Data Sharing#Unity Catalog Databricks#Unity Catalog Features
0 notes
Text
#Apache Spark#big data processing#cloud data analytics#collaborative data analytics#data analytics best practices#data analytics platform#data engineering#data processing tools#data science#DataBricks#DataBricks examples#machine learning#scalable data processing
1 note
·
View note
Link
For data integration, loading, analysis, and sharing, we need a data platform that makes our task easy. Snowflake And Databricks are popular data platforms in 2022, used by several cloud data warehousing services providers and IT companies.
0 notes
Text
Move over, Salesforce and Microsoft! Databricks is shaking things up with their game-changing AI/BI tool. Get ready for smarter, faster insights that leave the competition in the dust.
Who's excited to see what this powerhouse can do?
2 notes
·
View notes
Text
Azure Data Factory Training In Hyderabad
Key Features:
Hybrid Data Integration: Azure Data Factory supports hybrid data integration, allowing users to connect and integrate data from on-premises sources, cloud-based services, and various data stores. This flexibility is crucial for organizations with diverse data ecosystems.
Intuitive Visual Interface: The platform offers a user-friendly, visual interface for designing and managing data pipelines. Users can leverage a drag-and-drop interface to effortlessly create, monitor, and manage complex data workflows without the need for extensive coding expertise.

Data Movement and Transformation: Data movement is streamlined with Azure Data Factory, enabling the efficient transfer of data between various sources and destinations. Additionally, the platform provides a range of data transformation activities, such as cleansing, aggregation, and enrichment, ensuring that data is prepared and optimized for analysis.
Data Orchestration: Organizations can orchestrate complex workflows by chaining together multiple data pipelines, activities, and dependencies. This orchestration capability ensures that data processes are executed in a logical and efficient sequence, meeting business requirements and compliance standards.
Integration with Azure Services: Azure Data Factory seamlessly integrates with other Azure services, including Azure Synapse Analytics, Azure Databricks, Azure Machine Learning, and more. This integration enhances the platform's capabilities, allowing users to leverage additional tools and services to derive deeper insights from their data.
Monitoring and Management: Robust monitoring and management capabilities provide real-time insights into the performance and health of data pipelines. Users can track execution details, diagnose issues, and optimize workflows to enhance overall efficiency.
Security and Compliance: Azure Data Factory prioritizes security and compliance, implementing features such as Azure Active Directory integration, encryption at rest and in transit, and role-based access control. This ensures that sensitive data is handled securely and in accordance with regulatory requirements.
Scalability and Reliability: The platform is designed to scale horizontally, accommodating the growing needs of organizations as their data volumes increase. With built-in reliability features, Azure Data Factory ensures that data processes are executed consistently and without disruptions.
2 notes
·
View notes
Text
From Math to Machine Learning: A Comprehensive Blueprint for Aspiring Data Scientists
The realm of data science is vast and dynamic, offering a plethora of opportunities for those willing to dive into the world of numbers, algorithms, and insights. If you're new to data science and unsure where to start, fear not! This step-by-step guide will navigate you through the foundational concepts and essential skills to kickstart your journey in this exciting field. Choosing the Best Data Science Institute can further accelerate your journey into this thriving industry.

1. Establish a Strong Foundation in Mathematics and Statistics
Before delving into the specifics of data science, ensure you have a robust foundation in mathematics and statistics. Brush up on concepts like algebra, calculus, probability, and statistical inference. Online platforms such as Khan Academy and Coursera offer excellent resources for reinforcing these fundamental skills.
2. Learn Programming Languages
Data science is synonymous with coding. Choose a programming language – Python and R are popular choices – and become proficient in it. Platforms like Codecademy, DataCamp, and W3Schools provide interactive courses to help you get started on your coding journey.
3. Grasp the Basics of Data Manipulation and Analysis
Understanding how to work with data is at the core of data science. Familiarize yourself with libraries like Pandas in Python or data frames in R. Learn about data structures, and explore techniques for cleaning and preprocessing data. Utilize real-world datasets from platforms like Kaggle for hands-on practice.
4. Dive into Data Visualization
Data visualization is a powerful tool for conveying insights. Learn how to create compelling visualizations using tools like Matplotlib and Seaborn in Python, or ggplot2 in R. Effectively communicating data findings is a crucial aspect of a data scientist's role.
5. Explore Machine Learning Fundamentals
Begin your journey into machine learning by understanding the basics. Grasp concepts like supervised and unsupervised learning, classification, regression, and key algorithms such as linear regression and decision trees. Platforms like scikit-learn in Python offer practical, hands-on experience.
6. Delve into Big Data Technologies
As data scales, so does the need for technologies that can handle large datasets. Familiarize yourself with big data technologies, particularly Apache Hadoop and Apache Spark. Platforms like Cloudera and Databricks provide tutorials suitable for beginners.
7. Enroll in Online Courses and Specializations
Structured learning paths are invaluable for beginners. Enroll in online courses and specializations tailored for data science novices. Platforms like Coursera ("Data Science and Machine Learning Bootcamp with R/Python") and edX ("Introduction to Data Science") offer comprehensive learning opportunities.
8. Build Practical Projects
Apply your newfound knowledge by working on practical projects. Analyze datasets, implement machine learning models, and solve real-world problems. Platforms like Kaggle provide a collaborative space for participating in data science competitions and showcasing your skills to the community.
9. Join Data Science Communities
Engaging with the data science community is a key aspect of your learning journey. Participate in discussions on platforms like Stack Overflow, explore communities on Reddit (r/datascience), and connect with professionals on LinkedIn. Networking can provide valuable insights and support.
10. Continuous Learning and Specialization
Data science is a field that evolves rapidly. Embrace continuous learning and explore specialized areas based on your interests. Dive into natural language processing, computer vision, or reinforcement learning as you progress and discover your passion within the broader data science landscape.

Remember, your journey in data science is a continuous process of learning, application, and growth. Seek guidance from online forums, contribute to discussions, and build a portfolio that showcases your projects. Choosing the best Data Science Courses in Chennai is a crucial step in acquiring the necessary expertise for a successful career in the evolving landscape of data science. With dedication and a systematic approach, you'll find yourself progressing steadily in the fascinating world of data science. Good luck on your journey!
3 notes
·
View notes
Text
Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
New Post has been published on https://thedigitalinsider.com/datasets-matter-the-battle-between-open-and-closed-generative-ai-is-not-only-about-models-anymore/
Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
Two major open source datasets were released this week.
Created Using DALL-E
Next Week in The Sequence:
Edge 403: Our series about autonomous agents continues covering memory-based planning methods. The research behind the TravelPlanner benchmark for planning in LLMs and the impressive MemGPT framework for autonomous agents.
The Sequence Chat: A super cool interview with one of the engineers behind Azure OpenAI Service and Microsoft CoPilot.
Edge 404: We dive into Meta AI’s amazing research for predicting multiple tokens at the same time in LLMs.
You can subscribe to The Sequence below:
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
📝 Editorial: Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
The battle between open and closed generative AI has been at the center of industry developments. From the very beginning, the focus has been on open vs. closed models, such as Mistral and Llama vs. GPT-4 and Claude. Less attention has been paid to other foundational aspects of the model lifecycle, such as the datasets used for training and fine-tuning. In fact, one of the limitations of the so-called open weight models is that they don’t disclose the training datasets and pipeline. What if we had high-quality open source datasets that rival those used to pretrain massive foundation models?
Open source datasets are one of the key aspects to unlocking innovation in generative AI. The costs required to build multi-trillion token datasets are completely prohibitive to most organizations. Leading AI labs, such as the Allen AI Institute, have been at the forefront of this idea, regularly open sourcing high-quality datasets such as the ones used for the Olmo model. Now it seems that they are getting some help.
This week, we saw two major efforts related to open source generative AI datasets. Hugging Face open-sourced FineWeb, a 44TB dataset of 15 trillion tokens derived from 96 CommonCrawl snapshots. Hugging Face also released FineWeb-Edu, a subset of FineWeb focused on educational value. But Hugging Face was not the only company actively releasing open source datasets. Complementing the FineWeb release, AI startup Zyphra released Zyda, a 1.3 trillion token dataset for language modeling. The construction of Zyda seems to have focused on a very meticulous filtering and deduplication process and shows remarkable performance compared to other datasets such as Dolma or RedefinedWeb.
High-quality open source datasets are paramount to enabling innovation in open generative models. Researchers using these datasets can now focus on pretraining pipelines and optimizations, while teams using those models for fine-tuning or inference can have a clearer way to explain outputs based on the composition of the dataset. The battle between open and closed generative AI is not just about models anymore.
🔎 ML Research
Extracting Concepts from GPT-4
OpenAI published a paper proposing an interpretability technique to understanding neural activity within LLMs. Specifically, the method uses k-sparse autoencoders to control sparsity which leads to more interpretable models —> Read more.
Transformer are SSMs
Researchers from Princeton University and Carnegie Mellon University published a paper outlining theoretical connections between transformers and SSMs. The paper also proposes a framework called state space duality and a new architecture called Mamba-2 which improves the performance over its predecessors by 2-8x —> Read more.
Believe or Not Believe LLMs
Google DeepMind published a paper proposing a technique to quantify uncertainty in LLM responses. The paper explores different sources of uncertainty such as lack of knowledge and randomness in order to quantify the reliability of an LLM output —> Read more.
CodecLM
Google Research published a paper introducing CodecLM, a framework for using synthetic data for LLM alignment in downstream tasks. CodecLM leverages LLMs like Gemini to encode seed intrstructions into the metadata and then decodes it into synthetic intstructions —> Read more.
TinyAgent
Researchers from UC Berkeley published a detailed blog post about TinyAgent, a function calling tuning method for small language models. TinyAgent aims to enable function calling LLMs that can run on mobile or IoT devices —> Read more.
Parrot
Researchers from Shanghai Jiao Tong University and Microsoft Research published a paper introducing Parrot, a framework for correlating multiple LLM requests. Parrot uses the concept of a Semantic Variable to annotate input/output variables in LLMs to enable the creation of a data pipeline with LLMs —> Read more.
🤖 Cool AI Tech Releases
FineWeb
HuggingFace open sourced FineWeb, a 15 trillion token dataset for LLM training —> Read more.
Stable Audion Open
Stability AI open source Stable Audio Open, its new generative audio model —> Read more.
Mistral Fine-Tune
Mistral open sourced mistral-finetune SDK and services for fine-tuning models programmatically —> Read more.
Zyda
Zyphra Technologies open sourced Zyda, a 1.3 trillion token dataset that powers the version of its Zamba models —> Read more.
🛠 Real World AI
Salesforce discusses their use of Amazon SageMaker in their Einstein platform —> Read more.
📡AI Radar
Cisco announced a $1B AI investment fund with some major positions in companies like Cohere, Mistral and Scale AI.
Cloudera acquired AI startup Verta.
Databricks acquired data management company Tabular.
Tektonic, raised $10 million to build generative agents for business operations —> Read more.
AI task management startup Hoop raised $5 million.
Galileo announced Luna, a family of evaluation foundation models.
Browserbase raised $6.5 million for its LLM browser-based automation platform.
AI artwork platform Exactly.ai raised $4.3 million.
Sirion acquired AI document management platform Eigen Technologies.
Asana added AI teammates to complement task management capabilities.
Eyebot raised $6 million for its AI-powered vision exams.
AI code base platform Greptile raised a $4 million seed round.
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
#agents#ai#AI-powered#amazing#Amazon#architecture#Asana#attention#audio#automation#automation platform#autonomous agents#azure#azure openai#benchmark#Blog#browser#Business#Carnegie Mellon University#claude#code#Companies#Composition#construction#data#Data Management#data pipeline#databricks#datasets#DeepMind
0 notes
Text
Azure Data Engineering Tools For Data Engineers

Azure is a cloud computing platform provided by Microsoft, which presents an extensive array of data engineering tools. These tools serve to assist data engineers in constructing and upholding data systems that possess the qualities of scalability, reliability, and security. Moreover, Azure data engineering tools facilitate the creation and management of data systems that cater to the unique requirements of an organization.
In this article, we will explore nine key Azure data engineering tools that should be in every data engineer’s toolkit. Whether you’re a beginner in data engineering or aiming to enhance your skills, these Azure tools are crucial for your career development.
Microsoft Azure Databricks
Azure Databricks is a managed version of Databricks, a popular data analytics and machine learning platform. It offers one-click installation, faster workflows, and collaborative workspaces for data scientists and engineers. Azure Databricks seamlessly integrates with Azure’s computation and storage resources, making it an excellent choice for collaborative data projects.
Microsoft Azure Data Factory
Microsoft Azure Data Factory (ADF) is a fully-managed, serverless data integration tool designed to handle data at scale. It enables data engineers to acquire, analyze, and process large volumes of data efficiently. ADF supports various use cases, including data engineering, operational data integration, analytics, and data warehousing.
Microsoft Azure Stream Analytics
Azure Stream Analytics is a real-time, complex event-processing engine designed to analyze and process large volumes of fast-streaming data from various sources. It is a critical tool for data engineers dealing with real-time data analysis and processing.
Microsoft Azure Data Lake Storage
Azure Data Lake Storage provides a scalable and secure data lake solution for data scientists, developers, and analysts. It allows organizations to store data of any type and size while supporting low-latency workloads. Data engineers can take advantage of this infrastructure to build and maintain data pipelines. Azure Data Lake Storage also offers enterprise-grade security features for data collaboration.
Microsoft Azure Synapse Analytics
Azure Synapse Analytics is an integrated platform solution that combines data warehousing, data connectors, ETL pipelines, analytics tools, big data scalability, and visualization capabilities. Data engineers can efficiently process data for warehousing and analytics using Synapse Pipelines’ ETL and data integration capabilities.
Microsoft Azure Cosmos DB
Azure Cosmos DB is a fully managed and server-less distributed database service that supports multiple data models, including PostgreSQL, MongoDB, and Apache Cassandra. It offers automatic and immediate scalability, single-digit millisecond reads and writes, and high availability for NoSQL data. Azure Cosmos DB is a versatile tool for data engineers looking to develop high-performance applications.
Microsoft Azure SQL Database
Azure SQL Database is a fully managed and continually updated relational database service in the cloud. It offers native support for services like Azure Functions and Azure App Service, simplifying application development. Data engineers can use Azure SQL Database to handle real-time data ingestion tasks efficiently.
Microsoft Azure MariaDB
Azure Database for MariaDB provides seamless integration with Azure Web Apps and supports popular open-source frameworks and languages like WordPress and Drupal. It offers built-in monitoring, security, automatic backups, and patching at no additional cost.
Microsoft Azure PostgreSQL Database
Azure PostgreSQL Database is a fully managed open-source database service designed to emphasize application innovation rather than database management. It supports various open-source frameworks and languages and offers superior security, performance optimization through AI, and high uptime guarantees.
Whether you’re a novice data engineer or an experienced professional, mastering these Azure data engineering tools is essential for advancing your career in the data-driven world. As technology evolves and data continues to grow, data engineers with expertise in Azure tools are in high demand. Start your journey to becoming a proficient data engineer with these powerful Azure tools and resources.
Unlock the full potential of your data engineering career with Datavalley. As you start your journey to becoming a skilled data engineer, it’s essential to equip yourself with the right tools and knowledge. The Azure data engineering tools we’ve explored in this article are your gateway to effectively managing and using data for impactful insights and decision-making.
To take your data engineering skills to the next level and gain practical, hands-on experience with these tools, we invite you to join the courses at Datavalley. Our comprehensive data engineering courses are designed to provide you with the expertise you need to excel in the dynamic field of data engineering. Whether you’re just starting or looking to advance your career, Datavalley’s courses offer a structured learning path and real-world projects that will set you on the path to success.
Course format:
Subject: Data Engineering
Classes: 200 hours of live classes
Lectures: 199 lectures
Projects: Collaborative projects and mini projects for each module
Level: All levels
Scholarship: Up to 70% scholarship on this course
Interactive activities: labs, quizzes, scenario walk-throughs
Placement Assistance: Resume preparation, soft skills training, interview preparation
Subject: DevOps
Classes: 180+ hours of live classes
Lectures: 300 lectures
Projects: Collaborative projects and mini projects for each module
Level: All levels
Scholarship: Up to 67% scholarship on this course
Interactive activities: labs, quizzes, scenario walk-throughs
Placement Assistance: Resume preparation, soft skills training, interview preparation
For more details on the Data Engineering courses, visit Datavalley’s official website.
#datavalley#dataexperts#data engineering#data analytics#dataexcellence#data science#power bi#business intelligence#data analytics course#data science course#data engineering course#data engineering training
3 notes
·
View notes
Text
Unlocking Full Potential: The Compelling Reasons to Migrate to Databricks Unity Catalog
In a world overwhelmed by data complexities and AI advancements, Databricks Unity Catalog emerges as a game-changer. This blog delves into how Unity Catalog revolutionizes data and AI governance, offering a unified, agile solution .
View On WordPress
#Access Control in Data Platforms#Advanced User Management#AI and ML Data Governance#AI Data Management#Big Data Solutions#Centralized Metadata Management#Cloud Data Management#Data Collaboration Tools#Data Ecosystem Integration#Data Governance Solutions#Data Lakehouse Architecture#Data Platform Modernization#Data Security and Compliance#Databricks for Data Scientists#Databricks Unity catalog#Enterprise Data Strategy#Migrating to Unity Catalog#Scalable Data Architecture#Unity Catalog Features
0 notes
Text
DataBricks: Empowering Data Analytics at Scale
Check out this informative blog on DataBricks, the cloud-based data analytics platform transforming the way we process and analyze big data! #DataBricks #BigData #DataAnalytics #MachineLearning #CloudComputing
DataBricks is a cloud-based unified data analytics platform that enables organizations to process, analyze, and derive insights from large-scale data sets. It was founded by the creators of Apache Spark, an open-source big data processing framework. DataBricks integrates Spark with a range of other data analytics tools, making it a popular choice for big data processing and machine learning…

View On WordPress
#Apache Spark#big data processing#cloud data analytics#collaborative data analytics#data analytics best practices#data analytics platform#data engineering#data processing tools#data science#DataBricks#DataBricks examples#machine learning#scalable data processing
1 note
·
View note
Last Seen Blogs

jacobpackert
jacobpackert

dadbot3034
Untitled
dadbot3034
Untitled

off3131
İsimsiz

kpop-blossom
kpopblossom