#databricks managed services
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
Unlocking Business Potential with Databricks: Comprehensive Solutions for the Modern Enterprise
In the era of big data and cloud computing, the Databricks platform stands out as a transformative force, enabling businesses to unlock the full potential of their data. With its robust capabilities, Databricks empowers organizations across various sectors to harness data-driven insights and drive innovation. From Databricks cloud solutions to specialized Databricks financial services, Databricks professional services, and Databricks managed services, we explore how this powerful platform can revolutionize business operations and strategies.
Understanding the Databricks Platform: A Unified Approach to Data and AI
The Databricks platform is a cloud-based solution designed to streamline and enhance data engineering, data science, and machine learning processes. It offers a unified interface that integrates various data tools and technologies, making it easier for businesses to manage their data pipelines, perform analytics, and deploy machine learning models. Key features of the Databricks platform include:
Unified Analytics: Bringing together data processing, analytics, and machine learning in a single workspace, facilitating collaboration across teams.
Scalability: Leveraging cloud infrastructure to scale resources dynamically, accommodating growing data volumes and complex computations.
Interactive Workspaces: Providing a collaborative environment where data scientists, engineers, and business analysts can work together seamlessly.
Advanced Security: Ensuring data protection with robust security measures and compliance with industry standards.
Leveraging the Power of Databricks Cloud Solutions
Databricks cloud solutions are integral to modern enterprises looking to maximize their data capabilities. By utilizing the cloud, businesses can achieve:
Flexible Resource Management: Allocate and scale computational resources as needed, optimizing costs and performance.
Enhanced Collaboration: Cloud-based platforms enable global teams to collaborate in real-time, breaking down silos and fostering innovation.
Rapid Deployment: Implement and deploy solutions quickly without the need for extensive on-premises infrastructure.
Continuous Availability: Ensure data and applications are always accessible, providing resilience and reliability for critical operations.
Databricks Financial Services: Transforming the Financial Sector
Databricks financial services are tailored to meet the unique needs of the financial industry, where data plays a pivotal role in decision-making and risk management. These services provide:
Risk Analytics: Leveraging advanced analytics to identify and mitigate financial risks, enhancing the stability and security of financial institutions.
Fraud Detection: Using machine learning models to detect fraudulent activities in real-time, protecting businesses and customers from financial crimes.
Customer Insights: Analyzing customer data to gain deep insights into behavior and preferences, driving personalized services and engagement.
Regulatory Compliance: Ensuring compliance with financial regulations through robust data management and reporting capabilities.
Professional Services: Expert Guidance and Support with Databricks
Databricks professional services offer specialized expertise and support to help businesses fully leverage the Databricks platform. These services include:
Strategic Consulting: Providing insights and strategies to integrate Databricks into existing workflows and maximize its impact on business operations.
Implementation Services: Assisting with the setup and deployment of Databricks solutions, ensuring a smooth and efficient implementation process.
Training and Enablement: Offering training programs to equip teams with the skills needed to effectively use Databricks for their data and AI projects.
Ongoing Support: Delivering continuous support to address any technical issues and keep Databricks environments running optimally.
Databricks Managed Services: Streamlined Data Management and Operations
Databricks managed services take the complexity out of managing data environments, allowing businesses to focus on their core activities. These services provide:
Operational Management: Handling the day-to-day management of Databricks environments, including monitoring, maintenance, and performance optimization.
Security and Compliance: Ensuring that data systems meet security and compliance requirements, protecting against threats and regulatory breaches.
Cost Optimization: Managing cloud resources efficiently to control costs while maintaining high performance and availability.
Scalability Solutions: Offering scalable solutions that can grow with the business, accommodating increasing data volumes and user demands.
Transforming Data Operations with Databricks Solutions
The comprehensive range of Databricks solutions enables businesses to address various challenges and opportunities in the data landscape. These solutions include:
Data Engineering
Pipeline Automation: Automating the extraction, transformation, and loading (ETL) processes to streamline data ingestion and preparation.
Real-Time Data Processing: Enabling the processing of streaming data for real-time analytics and decision-making.
Data Quality Assurance: Implementing robust data quality controls to ensure accuracy, consistency, and reliability of data.
Data Science and Machine Learning
Model Development: Supporting the development and training of machine learning models to predict outcomes and automate decision processes.
Collaborative Notebooks: Providing interactive notebooks for collaborative data analysis and model experimentation.
Deployment and Monitoring: Facilitating the deployment of machine learning models into production environments and monitoring their performance over time.
Business Analytics
Interactive Dashboards: Creating dynamic dashboards that visualize data insights and support interactive exploration.
Self-Service Analytics: Empowering business users to perform their own analyses and generate reports without needing extensive technical skills.
Advanced Reporting: Delivering detailed reports that combine data from multiple sources to provide comprehensive insights.
Maximizing the Benefits of Databricks: Best Practices for Success
To fully leverage the capabilities of Databricks, businesses should adopt the following best practices:
Define Clear Objectives: Establish specific goals for how Databricks will be used to address business challenges and opportunities.
Invest in Training: Ensure that teams are well-trained in using Databricks, enabling them to utilize its full range of features and capabilities.
Foster Collaboration: Promote a collaborative culture where data scientists, engineers, and business analysts work together to drive data initiatives.
Implement Governance Policies: Develop data governance policies to manage data access, quality, and security effectively.
Continuously Optimize: Regularly review and optimize Databricks environments to maintain high performance and cost-efficiency.
The Future of Databricks Services and Solutions
As data continues to grow in volume and complexity, the role of Databricks in managing and leveraging this data will become increasingly critical. Future trends in Databricks services and solutions may include:
Enhanced AI Integration: More advanced AI tools and capabilities integrated into the Databricks platform, enabling even greater automation and intelligence.
Greater Emphasis on Security: Continued focus on data security and privacy, ensuring robust protections in increasingly complex threat landscapes.
Expanded Cloud Ecosystem: Deeper integrations with a broader range of cloud services, providing more flexibility and choice for businesses.
Real-Time Insights: Greater emphasis on real-time data processing and analytics, supporting more immediate and responsive business decisions.
#databricks platform#databricks cloud#databricks financial services#databricks professional services#databricks managed services
0 notes
Text
Unlock Data Governance: Revolutionary Table-Level Access in Modern Platforms
Dive into our latest blog on mastering data governance with Microsoft Fabric & Databricks. Discover key strategies for robust table-level access control and secure your enterprise's data. A must-read for IT pros! #DataGovernance #Security
View On WordPress
#Access Control#Azure Databricks#Big data analytics#Cloud Data Services#Data Access Patterns#Data Compliance#Data Governance#Data Lake Storage#Data Management Best Practices#Data Privacy#Data Security#Enterprise Data Management#Lakehouse Architecture#Microsoft Fabric#pyspark#Role-Based Access Control#Sensitive Data Protection#SQL Data Access#Table-Level Security
0 notes
Text
Azure Data Factory Training In Hyderabad
Key Features:
Hybrid Data Integration: Azure Data Factory supports hybrid data integration, allowing users to connect and integrate data from on-premises sources, cloud-based services, and various data stores. This flexibility is crucial for organizations with diverse data ecosystems.
Intuitive Visual Interface: The platform offers a user-friendly, visual interface for designing and managing data pipelines. Users can leverage a drag-and-drop interface to effortlessly create, monitor, and manage complex data workflows without the need for extensive coding expertise.

Data Movement and Transformation: Data movement is streamlined with Azure Data Factory, enabling the efficient transfer of data between various sources and destinations. Additionally, the platform provides a range of data transformation activities, such as cleansing, aggregation, and enrichment, ensuring that data is prepared and optimized for analysis.
Data Orchestration: Organizations can orchestrate complex workflows by chaining together multiple data pipelines, activities, and dependencies. This orchestration capability ensures that data processes are executed in a logical and efficient sequence, meeting business requirements and compliance standards.
Integration with Azure Services: Azure Data Factory seamlessly integrates with other Azure services, including Azure Synapse Analytics, Azure Databricks, Azure Machine Learning, and more. This integration enhances the platform's capabilities, allowing users to leverage additional tools and services to derive deeper insights from their data.
Monitoring and Management: Robust monitoring and management capabilities provide real-time insights into the performance and health of data pipelines. Users can track execution details, diagnose issues, and optimize workflows to enhance overall efficiency.
Security and Compliance: Azure Data Factory prioritizes security and compliance, implementing features such as Azure Active Directory integration, encryption at rest and in transit, and role-based access control. This ensures that sensitive data is handled securely and in accordance with regulatory requirements.
Scalability and Reliability: The platform is designed to scale horizontally, accommodating the growing needs of organizations as their data volumes increase. With built-in reliability features, Azure Data Factory ensures that data processes are executed consistently and without disruptions.
2 notes
·
View notes
Text
Azure Data Engineering Tools For Data Engineers

Azure is a cloud computing platform provided by Microsoft, which presents an extensive array of data engineering tools. These tools serve to assist data engineers in constructing and upholding data systems that possess the qualities of scalability, reliability, and security. Moreover, Azure data engineering tools facilitate the creation and management of data systems that cater to the unique requirements of an organization.
In this article, we will explore nine key Azure data engineering tools that should be in every data engineer’s toolkit. Whether you’re a beginner in data engineering or aiming to enhance your skills, these Azure tools are crucial for your career development.
Microsoft Azure Databricks
Azure Databricks is a managed version of Databricks, a popular data analytics and machine learning platform. It offers one-click installation, faster workflows, and collaborative workspaces for data scientists and engineers. Azure Databricks seamlessly integrates with Azure’s computation and storage resources, making it an excellent choice for collaborative data projects.
Microsoft Azure Data Factory
Microsoft Azure Data Factory (ADF) is a fully-managed, serverless data integration tool designed to handle data at scale. It enables data engineers to acquire, analyze, and process large volumes of data efficiently. ADF supports various use cases, including data engineering, operational data integration, analytics, and data warehousing.
Microsoft Azure Stream Analytics
Azure Stream Analytics is a real-time, complex event-processing engine designed to analyze and process large volumes of fast-streaming data from various sources. It is a critical tool for data engineers dealing with real-time data analysis and processing.
Microsoft Azure Data Lake Storage
Azure Data Lake Storage provides a scalable and secure data lake solution for data scientists, developers, and analysts. It allows organizations to store data of any type and size while supporting low-latency workloads. Data engineers can take advantage of this infrastructure to build and maintain data pipelines. Azure Data Lake Storage also offers enterprise-grade security features for data collaboration.
Microsoft Azure Synapse Analytics
Azure Synapse Analytics is an integrated platform solution that combines data warehousing, data connectors, ETL pipelines, analytics tools, big data scalability, and visualization capabilities. Data engineers can efficiently process data for warehousing and analytics using Synapse Pipelines’ ETL and data integration capabilities.
Microsoft Azure Cosmos DB
Azure Cosmos DB is a fully managed and server-less distributed database service that supports multiple data models, including PostgreSQL, MongoDB, and Apache Cassandra. It offers automatic and immediate scalability, single-digit millisecond reads and writes, and high availability for NoSQL data. Azure Cosmos DB is a versatile tool for data engineers looking to develop high-performance applications.
Microsoft Azure SQL Database
Azure SQL Database is a fully managed and continually updated relational database service in the cloud. It offers native support for services like Azure Functions and Azure App Service, simplifying application development. Data engineers can use Azure SQL Database to handle real-time data ingestion tasks efficiently.
Microsoft Azure MariaDB
Azure Database for MariaDB provides seamless integration with Azure Web Apps and supports popular open-source frameworks and languages like WordPress and Drupal. It offers built-in monitoring, security, automatic backups, and patching at no additional cost.
Microsoft Azure PostgreSQL Database
Azure PostgreSQL Database is a fully managed open-source database service designed to emphasize application innovation rather than database management. It supports various open-source frameworks and languages and offers superior security, performance optimization through AI, and high uptime guarantees.
Whether you’re a novice data engineer or an experienced professional, mastering these Azure data engineering tools is essential for advancing your career in the data-driven world. As technology evolves and data continues to grow, data engineers with expertise in Azure tools are in high demand. Start your journey to becoming a proficient data engineer with these powerful Azure tools and resources.
Unlock the full potential of your data engineering career with Datavalley. As you start your journey to becoming a skilled data engineer, it’s essential to equip yourself with the right tools and knowledge. The Azure data engineering tools we’ve explored in this article are your gateway to effectively managing and using data for impactful insights and decision-making.
To take your data engineering skills to the next level and gain practical, hands-on experience with these tools, we invite you to join the courses at Datavalley. Our comprehensive data engineering courses are designed to provide you with the expertise you need to excel in the dynamic field of data engineering. Whether you’re just starting or looking to advance your career, Datavalley’s courses offer a structured learning path and real-world projects that will set you on the path to success.
Course format:
Subject: Data Engineering Classes: 200 hours of live classes Lectures: 199 lectures Projects: Collaborative projects and mini projects for each module Level: All levels Scholarship: Up to 70% scholarship on this course Interactive activities: labs, quizzes, scenario walk-throughs Placement Assistance: Resume preparation, soft skills training, interview preparation
Subject: DevOps Classes: 180+ hours of live classes Lectures: 300 lectures Projects: Collaborative projects and mini projects for each module Level: All levels Scholarship: Up to 67% scholarship on this course Interactive activities: labs, quizzes, scenario walk-throughs Placement Assistance: Resume preparation, soft skills training, interview preparation
For more details on the Data Engineering courses, visit Datavalley’s official website.
#datavalley#dataexperts#data engineering#data analytics#dataexcellence#data science#power bi#business intelligence#data analytics course#data science course#data engineering course#data engineering training
3 notes
·
View notes
Text
PART TWO
The six men are one part of the broader project of Musk allies assuming key government positions. Already, Musk’s lackeys—including more senior staff from xAI, Tesla, and the Boring Company—have taken control of the Office of Personnel Management (OPM) and General Services Administration (GSA), and have gained access to the Treasury Department’s payment system, potentially allowing him access to a vast range of sensitive information about tens of millions of citizens, businesses, and more. On Sunday, CNN reported that DOGE personnel attempted to improperly access classified information and security systems at the US Agency for International Development and that top USAID security officials who thwarted the attempt were subsequently put on leave. The Associated Press reported that DOGE personnel had indeed accessed classified material.“What we're seeing is unprecedented in that you have these actors who are not really public officials gaining access to the most sensitive data in government,” says Don Moynihan, a professor of public policy at the University of Michigan. “We really have very little eyes on what's going on. Congress has no ability to really intervene and monitor what's happening because these aren't really accountable public officials. So this feels like a hostile takeover of the machinery of governments by the richest man in the world.”Bobba has attended UC Berkeley, where he was in the prestigious Management, Entrepreneurship, and Technology program. According to a copy of his now-deleted LinkedIn obtained by WIRED, Bobba was an investment engineering intern at the Bridgewater Associates hedge fund as of last spring and was previously an intern at both Meta and Palantir. He was a featured guest on a since-deleted podcast with Aman Manazir, an engineer who interviews engineers about how they landed their dream jobs, where he talked about those experiences last June.
Coristine, as WIRED previously reported, appears to have recently graduated from high school and to have been enrolled at Northeastern University. According to a copy of his résumé obtained by WIRED, he spent three months at Neuralink, Musk’s brain-computer interface company, last summer.Both Bobba and Coristine are listed in internal OPM records reviewed by WIRED as “experts” at OPM, reporting directly to Amanda Scales, its new chief of staff. Scales previously worked on talent for xAI, Musk’s artificial intelligence company, and as part of Uber’s talent acquisition team, per LinkedIn. Employees at GSA tell WIRED that Coristine has appeared on calls where workers were made to go over code they had written and justify their jobs. WIRED previously reported that Coristine was added to a call with GSA staff members using a nongovernment Gmail address. Employees were not given an explanation as to who he was or why he was on the calls.
Farritor, who per sources has a working GSA email address, is a former intern at SpaceX, Musk’s space company, and currently a Thiel Fellow after, according to his LinkedIn, dropping out of the University of Nebraska—Lincoln. While in school, he was part of an award-winning team that deciphered portions of an ancient Greek scroll.AdvertisementKliger, whose LinkedIn lists him as a special adviser to the director of OPM and who is listed in internal records reviewed by WIRED as a special adviser to the director for information technology, attended UC Berkeley until 2020; most recently, according to his LinkedIn, he worked for the AI company Databricks. His Substack includes a post titled “The Curious Case of Matt Gaetz: How the Deep State Destroys Its Enemies,” as well as another titled “Pete Hegseth as Secretary of Defense: The Warrior Washington Fears.”Killian, also known as Cole Killian, has a working email associated with DOGE, where he is currently listed as a volunteer, according to internal records reviewed by WIRED. According to a copy of his now-deleted résumé obtained by WIRED, he attended McGill University through at least 2021 and graduated high school in 2019. An archived copy of his now-deleted personal website indicates that he worked as an engineer at Jump Trading, which specializes in algorithmic and high-frequency financial trades.Shaotran told Business Insider in September that he was a senior at Harvard studying computer science and also the founder of an OpenAI-backed startup, Energize AI. Shaotran was the runner-up in a hackathon held by xAI, Musk’s AI company. In the Business Insider article, Shaotran says he received a $100,000 grant from OpenAI to build his scheduling assistant, Spark.
Are you a current or former employee with the Office of Personnel Management or another government agency impacted by Elon Musk? We’d like to hear from you. Using a nonwork phone or computer, contact Vittoria Elliott at [email protected] or securely at velliott88.18 on Signal.“To the extent these individuals are exercising what would otherwise be relatively significant managerial control over two very large agencies that deal with very complex topics,” says Nick Bednar, a professor at University of Minnesota’s school of law, “it is very unlikely they have the expertise to understand either the law or the administrative needs that surround these agencies.”Sources tell WIRED that Bobba, Coristine, Farritor, and Shaotran all currently have working GSA emails and A-suite level clearance at the GSA, which means that they work out of the agency’s top floor and have access to all physical spaces and IT systems, according a source with knowledge of the GSA’s clearance protocols. The source, who spoke to WIRED on the condition of anonymity because they fear retaliation, says they worry that the new teams could bypass the regular security clearance protocols to access the agency’s sensitive compartmented information facility, as the Trump administration has already granted temporary security clearances to unvetted people.This is in addition to Coristine and Bobba being listed as “experts” working at OPM. Bednar says that while staff can be loaned out between agencies for special projects or to work on issues that might cross agency lines, it’s not exactly common practice.“This is consistent with the pattern of a lot of tech executives who have taken certain roles of the administration,” says Bednar. “This raises concerns about regulatory capture and whether these individuals may have preferences that don’t serve the American public or the federal government.”

These men just stole the personal information of everyone in America AND control the Treasury. Link to article.
Akash Bobba
Edward Coristine
Luke Farritor
Gautier Cole Killian
Gavin Kliger
Ethan Shaotran
Spread their names!
#freedom of the press#elon musk#elongated muskrat#american politics#politics#news#america#trump administration
140K notes
·
View notes
Text
Navigating the Data World: A Deep Dive into Architecture of Big Data Tools

In today’s digital world, where data has become an integral part of our daily lives. May it be our phone’s microphone, websites, mobile applications, social media, customer feedback, or terms & conditions – we consistently provide “yes” consents, so there is no denying that each individual's data is collected and further pushed to play a bigger role into the decision-making pipeline of the organizations.
This collected data is extracted from different sources, transformed to be used for analytical purposes, and loaded in another location for storage. There are several tools present in the market that could be used for data manipulation. In the next sections, we will delve into some of the top tools used in the market and dissect the information to understand the dynamics of this subject.
Architecture Overview
While researching for top tools, here are a few names that made it to the top of my list – Snowflake, Apache Kafka, Apache Airflow, Tableau, Databricks, Redshift, Bigquery, etc. Let’s dive into their architecture in the following sections:
Snowflake
There are several big data tools in the market serving warehousing purposes for storing structured data and acting as a central repository of preprocessed data for analytics and business intelligence. Snowflake is one of the warehouse solutions. What makes Snowflake different from other solutions is that it is a truly self-managed service, with no hardware requirements and it runs completely on cloud infrastructure making it a go-to for the new Cloud era. Snowflake uses virtual computing instances and a storage service for its computing needs. Understanding the tools' architecture will help us utilize it more efficiently so let’s have a detailed look at the following pointers:

Image credits: Snowflake
Now let’s understand what each layer is responsible for. The Cloud service layer deals with authentication and access control, security, infrastructure management, metadata, and optimizer manager. It is responsible for managing all these features throughout the tool. Query processing is the compute layer where the actual query computation happens and where the cloud compute resources are utilized. Database storage acts as a storage layer for storing the data.
Considering the fact that there are a plethora of big data tools, we don’t shed significant light on the Apache toolkit, this won’t be justice done to their contribution. We all are familiar with Apache tools being widely used in the Data world, so moving on to our next tool Apache Kafka.
Apache Kafka
Apache Kafka deserves an article in itself due to its prominent usage in the industry. It is a distributed data streaming platform that is based on a publish-subscribe messaging system. Let’s check out Kafka components – Producer and Consumer. Producer is any system that produces messages or events in the form of data for further processing for example web-click data, producing orders in e-commerce, System Logs, etc. Next comes the consumer, consumer is any system that consumes data for example Real-time analytics dashboard, consuming orders in an inventory service, etc.
A broker is an intermediate entity that helps in message exchange between consumer and producer, further brokers have divisions as topic and partition. A topic is a common heading given to represent a similar type of data. There can be multiple topics in a cluster. Partition is part of a topic. Partition is data divided into small sub-parts inside the broker and every partition has an offset.
Another important element in Kafka is the ZooKeeper. A ZooKeeper acts as a cluster management system in Kafka. It is used to store information about the Kafka cluster and details of the consumers. It manages brokers by maintaining a list of consumers. Also, a ZooKeeper is responsible for choosing a leader for the partitions. If any changes like a broker die, new topics, etc., occur, the ZooKeeper sends notifications to Apache Kafka. Zookeeper has a master-slave that handles all the writes, and the rest of the servers are the followers who handle all the reads.
In recent versions of Kafka, it can be used and implemented without Zookeeper too. Furthermore, Apache introduced Kraft which allows Kafka to manage metadata internally without the need for Zookeeper using raft protocol.

Image credits: Emre Akin
Moving on to the next tool on our list, this is another very popular tool from the Apache toolkit, which we will discuss in the next section.
Apache Airflow
Airflow is a workflow management system that is used to author, schedule, orchestrate, and manage data pipelines and workflows. Airflow organizes your workflows as Directed Acyclic Graph (DAG) which contains individual pieces called tasks. The DAG specifies dependencies between task execution and task describing the actual action that needs to be performed in the task for example fetching data from source, transformations, etc.
Airflow has four main components scheduler, DAG file structure, metadata database, and web server. A scheduler is responsible for triggering the task and also submitting the tasks to the executor to run. A web server is a friendly user interface designed to monitor the workflows that let you trigger and debug the behavior of DAGs and tasks, then we have a DAG file structure that is read by the scheduler for extracting information about what task to execute and when to execute them. A metadata database is used to store the state of workflow and tasks. In summary, A workflow is an entire sequence of tasks and DAG with dependencies defined within airflow, a DAG is the actual data structure used to represent tasks. A task represents a single unit of DAG.

As we received brief insights into the top three prominent tools used by the data world, now let’s try to connect the dots and explore the Data story.
Connecting the dots
To understand the data story, we will be taking the example of a use case implemented at Cubera. Cubera is a big data company based in the USA, India, and UAE. The company is creating a Datalake for data repository to be used for analytical purposes from zero-party data sources as directly from data owners. On an average 100 MB of data per day is sourced from various data sources such as mobile phones, browser extensions, host routers, location data both structured and unstructured, etc. Below is the architecture view of the use case.

Image credits: Cubera
A node js server is built to collect data streams and pass them to the s3 bucket for storage purposes hourly. While the airflow job is to collect data from the s3 bucket and load it further into Snowflake. However, the above architecture was not cost-efficient due to the following reasons:
AWS S3 storage cost (for each hour, typically 1 million files are stored).
Usage costs for ETL running in MWAA (AWS environment).
The managed instance of Apache Airflow (MWAA).
Snowflake warehouse cost.
The data is not real-time, being a drawback.
The risk of back-filling from a sync-point or a failure point in the Apache airflow job functioning.
The idea is to replace this expensive approach with the most suitable one, here we are replacing s3 as a storage option by constructing a data pipeline using Airflow through Kafka to directly dump data to Snowflake. The following is a newfound approach, as Kafka works on the consumer-producer model, snowflake works as a consumer here. The message gets queued on the Kafka topic from the sourcing server. The Kafka for Snowflake connector subscribes to one or more Kafka topics based on the configuration information provided via the Kafka configuration file.

Image credits: Cubera
With around 400 million profile data directly sourced from individual data owners from their personal to household devices as Zero-party data, 2nd Party data from various app partnerships, Cubera Data Lake is continually being refined.
Conclusion
With so many tools available in the market, choosing the right tool is a task. A lot of factors should be taken into consideration before making the right decision, these are some of the factors that will help you in the decision-making – Understanding the data characteristics like what is the volume of data, what type of data we are dealing with - such as structured, unstructured, etc. Anticipating the performance and scalability needs, budget, integration requirements, security, etc.
This is a tedious process and no single tool can fulfill all your data requirements but their desired functionalities can make you lean towards them. As noted earlier, in the above use case budget was a constraint so we moved from the s3 bucket to creating a data pipeline in Airflow. There is no wrong or right answer to which tool is best suited. If we ask the right questions, the tool should give you all the answers.
Join the conversation on IMPAAKT! Share your insights on big data tools and their impact on businesses. Your perspective matters—get involved today!
0 notes
Text
Azure AI Engineer Training | Azure AI Engineer Online
How Azure Blob Storage Integrates with AI and Machine Learning Models
Introduction
Azure Blob Storage is a scalable, secure, and cost-effective cloud storage solution offered by Microsoft Azure. It is widely used for storing unstructured data such as images, videos, documents, and logs. Its seamless integration with AI and machine learning (ML) models makes it a powerful tool for businesses and developers aiming to build intelligent applications. This article explores how Azure Blob Storage integrates with AI and ML models to enable efficient data management, processing, and analytics. Microsoft Azure AI Engineer Training

Why Use Azure Blob Storage for AI and ML?
Machine learning models require vast amounts of data for training and inference. Azure Blob Storage provides:
Scalability: Handles large datasets efficiently without performance degradation.
Security: Built-in security features, including role-based access control (RBAC) and encryption.
Cost-effectiveness: Offers different storage tiers (hot, cool, and archive) to optimize costs.
Integration Capabilities: Works seamlessly with Azure AI services, ML tools, and data pipelines.
Integration of Azure Blob Storage with AI and ML
1. Data Storage and Management
Azure Blob Storage serves as a central repository for AI and ML datasets. It supports various file formats such as CSV, JSON, Parquet, and image files, which are crucial for training deep learning models. The ability to store raw and processed data makes it a vital component in AI workflows. Azure AI Engineer Online Training
2. Data Ingestion and Preprocessing
AI models require clean and structured data. Azure provides various tools to automate data ingestion and preprocessing:
Azure Data Factory: Allows scheduled and automated data movement from different sources into Azure Blob Storage.
Azure Databricks: Helps preprocess large datasets before feeding them into ML models.
Azure Functions: Facilitates event-driven data transformation before storage.
3. Training Machine Learning Models
Once the data is stored in Azure Blob Storage, it can be accessed by ML frameworks for training:
Azure Machine Learning (Azure ML): Directly integrates with Blob Storage to access training data.
PyTorch and TensorFlow: Can fetch and preprocess data stored in Azure Blob Storage.
Azure Kubernetes Service (AKS): Supports distributed ML training on GPU-enabled clusters.
4. Model Deployment and Inference
Azure Blob Storage enables efficient model deployment and inference by storing trained models and inference data: Azure AI Engineer Training
Azure ML Endpoints: Deploy trained models for real-time or batch inference.
Azure Functions & Logic Apps: Automate model inference by triggering workflows when new data is uploaded.
Azure Cognitive Services: Uses data from Blob Storage for AI-driven applications like vision recognition and natural language processing (NLP).
5. Real-time Analytics and Monitoring
AI models require continuous monitoring and improvement. Azure Blob Storage works with:
Azure Synapse Analytics: For large-scale data analytics and AI model insights.
Power BI: To visualize trends and model performance metrics.
Azure Monitor and Log Analytics: Tracks model predictions and identifies anomalies.
Use Cases of Azure Blob Storage in AI and ML
Image Recognition: Stores millions of labeled images for training computer vision models.
Speech Processing: Stores audio datasets for training speech-to-text AI models.
Healthcare AI: Stores medical imaging data for AI-powered diagnostics.
Financial Fraud Detection: Stores historical transaction data for training anomaly detection models. AI 102 Certification
Conclusion
Azure Blob Storage is critical in AI and ML workflows by providing scalable, secure, and cost-efficient data storage. Its seamless integration with Azure AI services, ML frameworks, and analytics tools enables businesses to build and deploy intelligent applications efficiently. By leveraging Azure Blob Storage, organizations can streamline data handling and enhance AI-driven decision-making processes.
For More Information about Azure AI Engineer Certification Contact Call/WhatsApp: +91-7032290546
Visit: https://www.visualpath.in/azure-ai-online-training.html
#Ai 102 Certification#Azure AI Engineer Certification#Azure AI-102 Training in Hyderabad#Azure AI Engineer Training#Azure AI Engineer Online Training#Microsoft Azure AI Engineer Training#Microsoft Azure AI Online Training#Azure AI-102 Course in Hyderabad#Azure AI Engineer Training in Ameerpet#Azure AI Engineer Online Training in Bangalore#Azure AI Engineer Training in Chennai#Azure AI Engineer Course in Bangalore
0 notes
Text
post on /r/simpsonsshitposting
by /u/TheMagnuson
Thank you u/wyldcat for the post below.
Also remember the names:
Akash Bobba, Edward Coristine, Luke Farritor, Gautier Cole Killian, Gavin Kliger, and Ethan Shaotran? The employees that broke into the Treasury department with Musk? The employees that musk says it’s illegal to post the names of? That Akash Bobba, Edward Coristine, Luke Farritor, Gautier Cole Killian, Gavin Kliger, and Ethan Shaotran?
Source: https://www.wired.com/story/elon-musk-government-young-engineers/
Edit: and 25 year old engineer Marko Elez.
Source: https://www.wired.com/story/elon-musk-associate-bfs-federal-payment-system/
Despite reporting that suggests that Musk’s so-called Department of Government Efficiency (DOGE) task force has access to these Treasury systems on a “read-only” level, sources say Elez, who has visited a Kansas City office housing BFS systems, has many administrator-level privileges. Typically, those admin privileges could give someone the power to log in to servers through secure shell access, navigate the entire file system, change user permissions, and delete or modify critical files. That could allow someone to bypass the security measures of, and potentially cause irreversible changes to, the very systems they have access to.
WIRED reporting has shown that Elon Musk’s associates—including Nicole Hollander, who slept in Twitter’s offices as Musk acquired the company, and Thomas Shedd, a former Tesla engineer who now runs a GSA agency, along with a host of extremely young and inexperienced engineers—have infiltrated the GSA and have attempted to use White House security credentials to gain access to GSA tech, something experts have said is highly unusual and poses a huge security risk.
Edit 2:
Oh they are absolutely fuming now! Some dweebs sending me threats of jail time lol. https://imgur.com/a/BmHciUA
Edit 3:
Gavin Kliger, 25
Kliger, who worked at AI company Databricks, was named on Monday as the individual who sent a staff-wide email to USAID workers ordering them to work from home as Musk moved to shut down the department, the New York Times reported.
His Substack page has a post titled: “Why DOGE” and explains “Why I gave up a seven-figure salary to save America.” Kliger posts on his Substack in support of failed attorney general nominee Matt Gaetz and Trump’s Defense Secretary Pete Hegseth, the Daily Beast reported. Kliger referred to Gaetz as a victim “of the deep state” and described Hegseth as “the warrior Washington doesn’t want but desperately need[s].”
Edward Coristine, 19
The youngest of Musk’s crew, Coristine, is still in college, according to reports, and is the heir to his father’s popcorn brand Lesser Evil. Coristine completed a summer internship at Musk’s brain-computer interface company Neuralink, according to his resume seen by WIRED.
He is listed as an “expert” within internal Office of Personnel Management records and reportedly appeared on a General Services Administration staff call, who did not know who he was or why he was there.
Luke Farritor, 23
Farritor has a working General Services Administration email address, according to WIRED, and has ties to Musk and the billionaire Peter Thiel. He dropped out of the University of Nebraska and was also an intern at Musk’s SpaceX.
Gautier Cole Killian, Ethan Shaotran and Akash Bobba
Killian, 24, served as an engineer at computerized trading firm Jump Trading and is working for DOGE as a volunteer, according to WIRED. He graduated high school in 2019 and studied at McGill University in Canada.
Shaotran, 22, along with Bobba, Coristine, and Farritor, has a working General Service Administration email, according to WIRED. The four have access to the agency’s IT systems, a source told the ou. As a high school student in Silicon Valley, Shaotran was given money by his parents to invest in stocks, the Daily Beast reports.
Bobba, 21, is listed as an “expert” within the OPM and attended the University of California-Berkeley. He has interned at hedge fund Bridgewater Associates, Meta and Thiel’s Palantir.
“What we’re seeing is unprecedented in that you have these actors who are not really public officials gaining access to the most sensitive data in government,” Don Moynihan, a professor of public policy at the University of Michigan told WIRED. “We really have very little eyes on what’s going on. Congress has no ability to really intervene and monitor what’s happening because these aren’t really accountable public officials. So this feels like a hostile takeover of the machinery of governments by the richest man in the world.”
Sources: https://www.independent.co.uk/news/world/americas/us-politics/elon-musk-doge-employees-trump-b2692016.html
Pay close attention to this!
This is how to hijack a nation. Whenever Trump says dumbshit like "Gulf of America" or "TARIFFS!", it is a distraction from crucial matters like this going on in the background.
0 notes
Text

Title: Azure Data Engineer Online Training - Naresh IT
Why Choose Azure for Data Engineering?
Microsoft Azure offers a comprehensive suite of tools and services tailored for data engineering tasks. From data storage solutions like Azure Data Lake Storage Gen2 to analytics platforms such as Azure Synapse Analytics, Azure provides a robust environment for building scalable data solutions.
Why Choose NareshIT:
-Naresh i Technologies offers a comprehensive Azure Data Engineer online training program designed to equip participants with the skills necessary to manage data within the Azure ecosystem. The course covers topics such as data ingestion, transformation, storage, and analysis using various Azure services and tools. Participants will gain hands-on experience with services like Azure Data Factory, Azure Databricks, Azure Synapse Analytics, and Azure HDInsight. -The course is led by real-time experts and is available in both online and classroom formats. Participants can choose between options that include access to video recordings or live sessions without videos.
-For more information or Upcoming Batches please visit website: https://nareshit.com/courses/azure-data-engineer-online-training
0 notes
Text
Top 5 Big Data Tools of 2025: Revolutionizing Data Management and Analytics

Big Data tools are essential for managing the vast amounts of data businesses generate today. As digital information continues to grow, tools to efficiently handle, process, and analyze this data are critical for organizations to make informed, data-driven decisions. Here are the top 5 Big Data tools for 2025:
MongoDB: Known for its NoSQL database features, MongoDB offers scalability, flexibility, and high performance. It excels in handling large datasets with its document-oriented storage and real-time analytics. MongoDB is popular for its aggregation framework and integrations with analytics tools, though users note its setup can be challenging.
Qubole: A cloud-native platform, Qubole simplifies big data analytics by supporting multiple data engines, including Apache Spark and Hadoop. Its self-service model and intelligent workload management make it easy to scale and optimize resources. While it is appreciated for its ease of use, some users report occasional performance issues with large datasets.
Snowflake: A cloud-based data warehouse solution, Snowflake enables rapid data analysis and seamless collaboration. It integrates well with major cloud providers and allows for independent scaling of storage and compute resources. Though it offers great performance and flexibility, some users find it costly, especially for small businesses.
Databricks Data Intelligence Platform: Built on Apache Spark, this platform offers powerful AI-driven data analytics. It supports advanced analytics and machine learning, making it ideal for businesses that require real-time data processing. Users like its collaboration tools, though it has a steep learning curve and can be expensive.
Hevo: A no-code, automated data integration tool, Hevo simplifies data processing and analysis for nontechnical users. It supports over 150 integrations and offers real-time data replication, streamlining big data workflows. However, some users feel it lacks advanced customization options.
These tools are essential for businesses seeking to manage and leverage big data effectively in 2025.
0 notes
Text
Why Learning Microsoft Azure Can Transform Your Career and Business
Microsoft Azure is a cloud computing platform and service created by Microsoft. It offers a comprehensive array of cloud services, including computing, analytics, storage, networking, and more. Organizations utilize Azure to build, deploy, and manage applications and services through data centers managed by Microsoft.
Why Choose Microsoft Azure?
Microsoft Azure stands out as a leading cloud computing platform, providing businesses and individuals with powerful tools and services.
Here are some reasons why it’s an excellent choice:
Scalability
Easily add or reduce resources to align with your business growth.
Global Reach
Available in over 60 regions, making it accessible around the globe.
Cost-Effective
Only pay for what you use, with flexible pricing options.
Strong Security
Safeguard your data with enterprise-level security and compliance.
Seamless Microsoft Integration
Integrates smoothly with Office 365, Dynamics 365, and hybrid environments.
Wide Range of Services
Covers everything from Infrastructure (IaaS), Platforms (PaaS), and Software as a Service (SaaS) to advanced AI and IoT tools.
Developer-Friendly
Supports tools like Visual Studio, GitHub, and popular programming languages.
Reliable Performance
Guarantees high availability and robust disaster recovery.
AI and IoT
Create intelligent applications and leverage edge computing for smarter solutions.
Open-Source Friendly
Works well with various frameworks and open-source technologies.
Empower Your Business
Azure provides the flexibility to innovate, scale globally, and maintain competitiveness—all backed by reliable and secure cloud solutions.
Why Learn Microsoft Azure?
Boost Your Career
Unlock opportunities for in-demand roles such as Cloud Engineer or Architect.
Obtain recognized certifications to enhance your visibility in the job market.
Help Your Business
Reduce expenses by crafting efficient cloud solutions.
Automate processes to increase productivity and efficiency.
Create Amazing Apps
Easily develop and deploy web or mobile applications.
Utilize Azure Functions for serverless architecture and improved scalability.
Work with Data
Handle extensive data projects using Azure's robust tools.
Ensure your data remains secure and easily accessible with Azure Storage.
Dive into AI
Develop AI models and train them using Azure Machine Learning.
Leverage pre-built tools for tasks like image recognition and language translation.
Streamline Development
Accelerate software delivery with Azure DevOps pipelines.
Automate the setup and management of your infrastructure.
Improve IT Systems
Quickly establish virtual machines and networks.
Integrate on-premises and cloud systems to enjoy the best of both environments.
Start a Business
Launch and grow your startup with Azure’s adaptable pricing.
Utilize tools specifically designed for entrepreneurs.
Work Anywhere
Empower remote teams with Azure Virtual Desktop and Teams.
Learning Azure equips you with valuable skills, fosters professional growth, and enables you to create meaningful solutions for both work and personal projects.
Tools you can learn in our course
Azure SQL Database
Azure Data Lake Storage
Azure Databricks
Azure Synapse Analytics
Azure Stream Analytics
Global Teq’s Free Demo Offer!
Don’t Miss Out!
This is your opportunity to experience Global Teq’s transformative technology without any commitment. Join hundreds of satisfied clients who have leveraged our solutions to achieve their goals.
Sign up today and take the first step toward unlocking potential.
Click here to register for your free demo now!
Let Global Teq partner with you in driving innovation and success.
0 notes
Text
Azure Data Engineer | Azure Data Engineering Certification
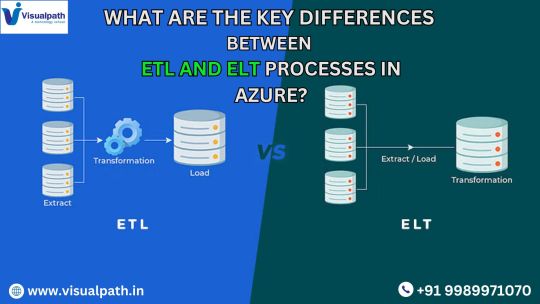
Key Differences Between ETL and ELT Processes in Azure
Azure data engineering offers two common approaches for processing data: ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform). These methods are essential for moving and processing data from source systems into data warehouses or data lakes for analysis. While both serve similar purposes, they differ in their workflows, tools, and technologies, particularly when implemented within Azure's cloud ecosystem. This article will explore the key distinctions between ETL and ELT in the context of Azure data services, helping organizations make informed decisions about their data processing strategies. Azure Data Engineer Training
1. Process Flow: Extraction, Transformation, and Loading
The most fundamental difference between ETL and ELT is the sequence in which data is processed: Microsoft Azure Data Engineer
ETL (Extract, Transform, Load):
In the ETL process, data is first extracted from source systems, transformed into the desired format or structure, and then loaded into the data warehouse or data lake.
The transformation step occurs before loading the data into the destination, ensuring that the data is cleaned, enriched, and formatted properly during the data pipeline.
ELT (Extract, Load, Transform):
ELT, on the other hand, follows a different sequence: data is extracted from the source, loaded into the destination system (e.g., a cloud data warehouse), and then transformed directly within the destination system.
The transformation happens after the data has already been stored, utilizing the computational power of the cloud infrastructure to process and modify the data.
2. Tools and Technologies in Azure
Both ETL and ELT processes require specific tools to handle data extraction, transformation, and loading. Azure provides robust tools for both approaches, but the choice of tool depends on the processing flow:
ETL in Azure:
Azure Data Factory is the primary service used for building and managing ETL pipelines. It offers a wide range of connectors for various data sources and destinations and allows for data transformations to be executed in the pipeline itself using Data Flow or Mapping Data Flows.
Azure Databricks, a Spark-based service, can also be integrated for more complex transformations during the ETL process, where heavy lifting is required for batch or streaming data processing.
ELT in Azure:
For the ELT process, Azure Synapse Analytics (formerly SQL Data Warehouse) is a leading service, leveraging the power of cloud-scale data warehouses to perform in-place transformations.
Azure Data Lake and Azure Blob Storage are used for storing raw data in ELT pipelines, with Azure Synapse Pipelines or Azure Data Factory responsible for orchestrating the load and transformation tasks.
Azure SQL Database and Azure Data Explorer are also used in ELT scenarios where data is loaded into the database first, followed by transformations using T-SQL or Azure's native query processing capabilities.
3. Performance and Scalability
The key advantage of ELT over ETL lies in its performance and scalability, particularly when dealing with large volumes of data: Azure Data Engineering Certification
ETL Performance:
ETL can be more resource-intensive because the transformation logic is executed before the data is loaded into the warehouse. This can lead to bottlenecks during the transformation step, especially if the data is complex or requires significant computation.
With Azure Data Factory, transformation logic is executed during the pipeline execution, and if there are large datasets, the process may be slower and require more manual optimization.
ELT Performance:
ELT leverages the scalable and high-performance computing power of Azure’s cloud services like Azure Synapse Analytics and Azure Data Lake. After the data is loaded into the cloud storage or data warehouse, the transformations are run in parallel using the cloud infrastructure, allowing for faster and more efficient processing.
As data sizes grow, ELT tends to perform better since the processing occurs within the cloud infrastructure, reducing the need for complex pre-processing and allowing the system to scale with the data.
4. Data Transformation Complexity
ETL Transformations:
ETL processes are better suited for complex transformations that require extensive pre-processing of data before it can be loaded into a warehouse. In scenarios where data must be cleaned, enriched, and aggregated, ETL provides a structured and controlled approach to transformations.
ELT Transformations:
ELT is more suited to scenarios where the data is already clean or requires simpler transformations that can be efficiently performed using the native capabilities of cloud platforms. Azure’s Synapse Analytics and SQL Database offer powerful querying and processing engines that can handle data transformations once the data is loaded, but this may not be ideal for very complex transformations.
5. Data Storage and Flexibility
ETL Storage:
ETL typically involves transforming the data before storage in a structured format, like a relational database or data warehouse, which makes it ideal for scenarios where data must be pre-processed or aggregated before analysis.
ELT Storage:
ELT offers greater flexibility, especially for handling raw, unstructured data in Azure Data Lake or Blob Storage. After data is loaded, transformation and analysis can take place in a more dynamic environment, enabling more agile data processing.
6. Cost Implications
ETL Costs: Azure Data Engineer Course
ETL processes tend to incur higher costs due to the additional processing power required to transform the data before loading it into the destination. Since transformations are done earlier in the pipeline, more resources (compute and memory) are required to handle these operations.
ELT Costs:
ELT typically incurs lower costs, as the heavy lifting of transformation is handled by Azure’s scalable cloud infrastructure, reducing the need for external computation resources during data ingestion. The elasticity of cloud computing allows for more cost-efficient data processing.
Conclusion
In summary, the choice between ETL and ELT in Azure largely depends on the nature of your data processing needs. ETL is preferred for more complex transformations, while ELT provides better scalability, performance, and cost-efficiency when working with large datasets. Both approaches have their place in modern data workflows, and Azure’s cloud-native tools provide the flexibility to implement either process based on your specific requirements. By understanding the key differences between these processes, organizations can make informed decisions on how to best leverage Azure's ecosystem for their data processing and analytics needs.
Visualpath is the Best Software Online Training Institute in Hyderabad. Avail complete Azure Data Engineering worldwide. You will get the best course at an affordable cost.
Attend Free Demo
Call on - +91-9989971070.
Visit: https://www.visualpath.in/online-azure-data-engineer-course.html
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit Blog: https://azuredataengineering2.blogspot.com/
#Azure Data Engineer Course#Azure Data Engineering Certification#Azure Data Engineer Training In Hyderabad#Azure Data Engineer Training#Azure Data Engineer Training Online#Azure Data Engineer Course Online#Azure Data Engineer Online Training#Microsoft Azure Data Engineer
0 notes
Text
Azure Data Engineer Online Training - Naresh IT
Azure Data Engineer Online Training - Naresh IT
Why Choose Azure for Data Engineering?
Microsoft Azure offers a comprehensive suite of tools and services tailored for data engineering tasks. From data storage solutions like Azure Data Lake Storage Gen2 to analytics platforms such as Azure Synapse Analytics, Azure provides a robust environment for building scalable data solutions.
Why Choose NareshIT:
-Naresh i Technologies offers a comprehensive Azure Data Engineer online training program designed to equip participants with the skills necessary to manage data within the Azure ecosystem. The course covers topics such as data ingestion, transformation, storage, and analysis using various Azure services and tools. Participants will gain hands-on experience with services like Azure Data Factory, Azure Databricks, Azure Synapse Analytics, and Azure HDInsight. -The course is led by real-time experts and is available in both online and classroom formats. Participants can choose between options that include access to video recordings or live sessions without videos.
-For more information or Upcoming Batches please visit website: https://nareshit.com/courses/azure-data-engineer-online-training
0 notes
Text
2024 Generative AI Funding Hitting Record High, DGQEX Analyzes Industry Impact
Recently, groundbreaking news emerged in the global generative artificial intelligence (AI) sector: in 2024, companies in this field raised a staggering $56 billion through 885 venture capital deals, setting a historic record. This funding boom not only underscores the immense potential of generative AI technology but also presents new opportunities for cryptocurrency exchanges like DGQEX.

Technological Innovation Amid the Generative AI Funding Boom
The significant increase in generative AI project funding in 2024 reflects strong confidence from investors in the technology. As generative AI continues to mature, it demonstrates tremendous advantages in areas such as data analysis, content creation, and intelligent recommendations. For DGQEX, this presents an opportunity to leverage generative AI to optimize trading algorithms, enhancing both efficiency and accuracy. Additionally, generative AI can help DGQEX better analyze market trends, providing users with more precise investment advice.
In the fourth quarter, several large-scale funding rounds further propelled the development of the generative AI sector. For instance, Databricks secured $10 billion in a Series J round, while xAI raised $6 billion in a Series C round. These funds will accelerate the research and application of related technologies. DGQEX is closely monitoring these advancements, actively exploring ways to integrate generative AI into its trading systems and services.
Opportunities for Cryptocurrency Exchanges: Technological Integration and Service Upgrades
The rapid development of generative AI technology offers unprecedented opportunities for cryptocurrency exchanges. As a professional digital currency exchange, DGQEX recognizes the importance of technological integration. By incorporating generative AI, DGQEX can further enhance the intelligence of its trading systems, delivering a more convenient and efficient trading experience for users.
Moreover, generative AI can assist DGQEX in optimizing risk management strategies. By deeply analyzing historical data, generative AI can predict market trends and provide DGQEX with more accurate risk assessment models. This will help DGQEX safeguard user funds while improving the stability and reliability of its trading systems.
Facing Challenges: Balancing Innovation and Compliance
While generative AI technology brings numerous opportunities to cryptocurrency exchanges, DGQEX is well aware that as the technology evolves, market competition will become increasingly fierce. To maintain its leading position, DGQEX will continue to invest heavily in technological innovation, further enhancing the intelligence of its trading systems and improving user experience.
At the same time, DGQEX understands the critical importance of compliance. In the cryptocurrency sector, compliance is key to protecting user rights and maintaining market order. DGQEX will strictly adhere to relevant laws and regulations, ensuring the legality and compliance of its trading activities. Furthermore, DGQEX will actively collaborate with regulatory authorities to promote the healthy development of the cryptocurrency industry.
0 notes