#Data Transfer
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text
Hey erm…. Idk if anyone has an answer for this but if I get a new phone (iPhone) and transfer my data will my genshin data save?? Like will my genshin reset or will I be able to continue where I left off.
7 notes
·
View notes
Text

The first attempt to transfer memories between the brain and an 8-bit computer.
#vaporwave#80s aesthetic#synthwave#retrowave#retrofuture#glitch#glitch gif#gif#glitchart#glitch art#art#abstract#abstract art#corrupted data#computer art#computing#data transfer#data transmission#data tracking#trippy gif
23 notes
·
View notes
Text
57 notes
·
View notes
Text
DeepSeek-V3: How a Chinese AI Startup Outpaces Tech Giants in Cost and Performance
New Post has been published on https://thedigitalinsider.com/deepseek-v3-how-a-chinese-ai-startup-outpaces-tech-giants-in-cost-and-performance/
DeepSeek-V3: How a Chinese AI Startup Outpaces Tech Giants in Cost and Performance

Generative AI is evolving rapidly, transforming industries and creating new opportunities daily. This wave of innovation has fueled intense competition among tech companies trying to become leaders in the field. US-based companies like OpenAI, Anthropic, and Meta have dominated the field for years. However, a new contender, the China-based startup DeepSeek, is rapidly gaining ground. With its latest model, DeepSeek-V3, the company is not only rivalling established tech giants like OpenAI’s GPT-4o, Anthropic’s Claude 3.5, and Meta’s Llama 3.1 in performance but also surpassing them in cost-efficiency. Besides its market edges, the company is disrupting the status quo by publicly making trained models and underlying tech accessible. Once secretly held by the companies, these strategies are now open to all. These developments are redefining the rules of the game.
In this article, we explore how DeepSeek-V3 achieves its breakthroughs and why it could shape the future of generative AI for businesses and innovators alike.
Limitations in Existing Large Language Models (LLMs)
As the demand for advanced large language models (LLMs) grows, so do the challenges associated with their deployment. Models like GPT-4o and Claude 3.5 demonstrate impressive capabilities but come with significant inefficiencies:
Inefficient Resource Utilization:
Most models rely on adding layers and parameters to boost performance. While effective, this approach requires immense hardware resources, driving up costs and making scalability impractical for many organizations.
Long-Sequence Processing Bottlenecks:
Existing LLMs utilize the transformer architecture as their foundational model design. Transformers struggle with memory requirements that grow exponentially as input sequences lengthen. This results in resource-intensive inference, limiting their effectiveness in tasks requiring long-context comprehension.
Training Bottlenecks Due to Communication Overhead:
Large-scale model training often faces inefficiencies due to GPU communication overhead. Data transfer between nodes can lead to significant idle time, reducing the overall computation-to-communication ratio and inflating costs.
These challenges suggest that achieving improved performance often comes at the expense of efficiency, resource utilization, and cost. However, DeepSeek demonstrates that it is possible to enhance performance without sacrificing efficiency or resources. Here’s how DeepSeek tackles these challenges to make it happen.
How DeepSeek-V3 Overcome These Challenges
DeepSeek-V3 addresses these limitations through innovative design and engineering choices, effectively handling this trade-off between efficiency, scalability, and high performance. Here’s how:
Intelligent Resource Allocation Through Mixture-of-Experts (MoE)
Unlike traditional models, DeepSeek-V3 employs a Mixture-of-Experts (MoE) architecture that selectively activates 37 billion parameters per token. This approach ensures that computational resources are allocated strategically where needed, achieving high performance without the hardware demands of traditional models.
Efficient Long-Sequence Handling with Multi-Head Latent Attention (MHLA)
Unlike traditional LLMs that depend on Transformer architectures which requires memory-intensive caches for storing raw key-value (KV), DeepSeek-V3 employs an innovative Multi-Head Latent Attention (MHLA) mechanism. MHLA transforms how KV caches are managed by compressing them into a dynamic latent space using “latent slots.” These slots serve as compact memory units, distilling only the most critical information while discarding unnecessary details. As the model processes new tokens, these slots dynamically update, maintaining context without inflating memory usage.
By reducing memory usage, MHLA makes DeepSeek-V3 faster and more efficient. It also helps the model stay focused on what matters, improving its ability to understand long texts without being overwhelmed by unnecessary details. This approach ensures better performance while using fewer resources.
Mixed Precision Training with FP8
Traditional models often rely on high-precision formats like FP16 or FP32 to maintain accuracy, but this approach significantly increases memory usage and computational costs. DeepSeek-V3 takes a more innovative approach with its FP8 mixed precision framework, which uses 8-bit floating-point representations for specific computations. By intelligently adjusting precision to match the requirements of each task, DeepSeek-V3 reduces GPU memory usage and speeds up training, all without compromising numerical stability and performance.
Solving Communication Overhead with DualPipe
To tackle the issue of communication overhead, DeepSeek-V3 employs an innovative DualPipe framework to overlap computation and communication between GPUs. This framework allows the model to perform both tasks simultaneously, reducing the idle periods when GPUs wait for data. Coupled with advanced cross-node communication kernels that optimize data transfer via high-speed technologies like InfiniBand and NVLink, this framework enables the model to achieve a consistent computation-to-communication ratio even as the model scales.
What Makes DeepSeek-V3 Unique?
DeepSeek-V3’s innovations deliver cutting-edge performance while maintaining a remarkably low computational and financial footprint.
Training Efficiency and Cost-Effectiveness
One of DeepSeek-V3’s most remarkable achievements is its cost-effective training process. The model was trained on an extensive dataset of 14.8 trillion high-quality tokens over approximately 2.788 million GPU hours on Nvidia H800 GPUs. This training process was completed at a total cost of around $5.57 million, a fraction of the expenses incurred by its counterparts. For instance, OpenAI’s GPT-4o reportedly required over $100 million for training. This stark contrast underscores DeepSeek-V3’s efficiency, achieving cutting-edge performance with significantly reduced computational resources and financial investment.
Superior Reasoning Capabilities:
The MHLA mechanism equips DeepSeek-V3 with exceptional ability to process long sequences, allowing it to prioritize relevant information dynamically. This capability is particularly vital for understanding long contexts useful for tasks like multi-step reasoning. The model employs reinforcement learning to train MoE with smaller-scale models. This modular approach with MHLA mechanism enables the model to excel in reasoning tasks. Benchmarks consistently show that DeepSeek-V3 outperforms GPT-4o, Claude 3.5, and Llama 3.1 in multi-step problem-solving and contextual understanding.
Energy Efficiency and Sustainability:
With FP8 precision and DualPipe parallelism, DeepSeek-V3 minimizes energy consumption while maintaining accuracy. These innovations reduce idle GPU time, reduce energy usage, and contribute to a more sustainable AI ecosystem.
Final Thoughts
DeepSeek-V3 exemplifies the power of innovation and strategic design in generative AI. By surpassing industry leaders in cost efficiency and reasoning capabilities, DeepSeek has proven that achieving groundbreaking advancements without excessive resource demands is possible.
DeepSeek-V3 offers a practical solution for organizations and developers that combines affordability with cutting-edge capabilities. Its emergence signifies that AI will not only be more powerful in the future but also more accessible and inclusive. As the industry continues to evolve, DeepSeek-V3 serves as a reminder that progress doesn’t have to come at the expense of efficiency.
#Affordable AI#ai#AI sustainability#anthropic#approach#architecture#Article#Artificial Intelligence#attention#benchmarks#billion#China#claude#claude 3#claude 3.5#communication#Companies#competition#comprehension#computation#contextual understanding#cost efficiency#Cost-efficient AI#cutting#data#data transfer#deepseek#DeepSeek-V3#deployment#Design
2 notes
·
View notes
Text
Exploring the Best SIM Card for Game Cameras with EIOTCLUB
Hello, fellow outdoor enthusiasts!
I’m excited to share my thoughts on the importance of choosing the best SIM card for game cameras, and I believe EIOTCLUB has some fantastic options to consider.
When setting up your game camera, having a reliable SIM card is crucial for seamless connectivity and quick data transfer. EIOTCLUB offers SIM cards that are specifically designed for outdoor use, ensuring that you can capture all the wildlife action without missing a beat.
One of the standout features of EIOTCLUB’s SIM cards is their extensive coverage. This means that whether you’re in a remote location or a popular hunting ground, you can count on a strong connection. Plus, their plans are affordable, making it easy to stay connected without breaking the bank.
Another great aspect of EIOTCLUB is their customer support. If you ever have questions or need assistance, their team is ready to help you get the most out of your game camera experience.
In conclusion, if you’re looking for the best SIM card for your game camera, I highly recommend checking out EIOTCLUB. You’ll appreciate the reliable service, great coverage, and supportive customer care that they offer. Happy hunting and capturing those amazing moments!
0 notes
Text

180 degree bend magnetic data cable:. 1.Support PD240W fast charging + data transfer 2.Output: 48V/5A,28V/5A,20V5A,9V2A,5V3A 3.Cable gauge: 6 core/48 stock nylon braided 4.OD: 3.8 80*0.1BCx4+15*0.08BC*2 5.Regular color: black and grey
0 notes
Text
Data Migration Services in USA: Mckinsol Consulting Inc
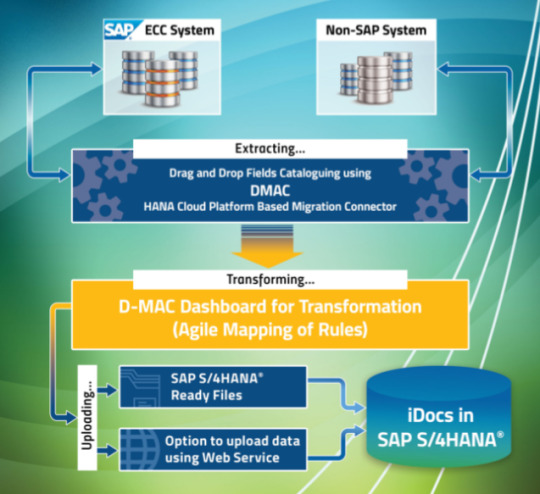
In today’s fast-evolving digital landscape, businesses across the Data Migration Services in USA are seeking efficient solutions for transferring and integrating their data. Data migration services have become critical for organizations upgrading their systems, consolidating databases, or transitioning to advanced platforms like SAP. McKinsol Consulting Inc., a trusted name in the field, offers comprehensive data migration and integration services tailored to meet the unique needs of businesses. With our proprietary product, DMAC, we ensure seamless, secure, and accurate data migration across industries.
Understanding Data Migration Services
Data migration is the process of transferring data between systems, platforms, or databases. It’s not just about moving information—it’s about maintaining accuracy, security, and usability throughout the process. A successful migration enables businesses to improve operational efficiency and leverage modern technologies without compromising data integrity.
McKinsol Consulting Inc. specializes in:
Database Migration: Transferring data from outdated systems to modern, efficient databases.
Database Transfer: Consolidating and streamlining data to improve accessibility and reduce redundancy.
Data Migration in SAP: Helping businesses transition to SAP systems, including SAP S/4HANA, with minimal downtime.
DMAC: Powering Data Migration
Our flagship product, DMAC, revolutionizes how businesses handle data migration. With DMAC, McKinsol ensures:
Automation: Reducing manual intervention for faster, error-free migration.
Data Security: Protecting sensitive data with advanced encryption protocols.
Scalability: Supporting businesses of all sizes, from startups to large enterprises.
Accuracy: Maintaining data integrity to ensure operational continuity post-migration.
Compatibility: Seamless integration with platforms like SAP, enabling smoother transitions.
Why Choose McKinsol Consulting Inc.?
Comprehensive Services Across the USA We provide end-to-end data migration services in the USA, catering to diverse industries such as retail, manufacturing, and fashion. From planning to post-migration support, we deliver unparalleled expertise.
Expertise in SAP Data Migration With years of experience in data migration in SAP, McKinsol is a trusted partner for businesses transitioning to SAP platforms. We handle every aspect, from system analysis to data validation, ensuring a smooth transition.
Tailored Solutions for Every Business We understand that every organization has unique requirements. Our team offers customized solutions that align with your goals, ensuring your data migration project delivers maximum value.
Innovation with DMAC DMAC simplifies complex migration processes, making McKinsol the preferred choice for businesses seeking reliable and efficient data migration solutions.
Benefits of Professional Data Migration Services
Improved System Performance: Modern platforms offer faster and more reliable operations.
Centralized Data Management: Streamlined databases enhance data accessibility and usability.
Future-Ready Systems: Transitioning to platforms like SAP prepares businesses for growth and innovation.
Cost Savings: Eliminating redundant systems reduces operational expenses.
The McKinsol Advantage
At McKinsol Consulting Inc., we combine cutting-edge technology with industry expertise to deliver exceptional results. Whether it’s database migration, database transfer, or data migration in SAP, our services are designed to help businesses achieve seamless transitions with minimal disruption.
Ready to Transform Your Data?
McKinsol Consulting Inc. is your trusted partner for data migration services in the USA. With DMAC at the forefront, we guarantee a secure, accurate, and efficient data migration experience. Contact us today to learn how our solutions can support your digital transformation journey.
0 notes
Text
Newly developed 100Gbps data transfer system for accelerating Open Science through industry-university collaboration in Japan
Osaka University and NEC Corporation (NEC; TSE: 6701) are moving forward with efforts to realize a data infrastructure supporting Open Science. In 2021, The Joint Research Laboratory for Integrated Infrastructure of High Performance Computing and Data Analysis was established within the D3 Center, Osaka University (Director: Professor Susumu Date*1) by Osaka University and NEC. The result of the…
0 notes
Text

cloud MFT
1 note
·
View note
Text
Understanding the Difference Between 4G and 5G Networks
As our reliance on mobile connectivity grows, so does the need for faster, more efficient networks. Understanding the difference between 4G and 5G networks is crucial as 5G technology becomes more widely available, promising to revolutionise how we interact with the digital world. From browsing the web to powering autonomous vehicles and smart cities, 5G is set to offer significant advancements…
#4G#5G#5G applications#5G benefits#5G rollout#5G security#AI#AR#automation#autonomous vehicles#bandwidth#cell towers#cloud#Connected Devices#connectivity#cyber threats#data transfer#digital#download speed#emerging tech#encryption#firewalls#Healthcare#infrastructure#innovation#IoT#IT leaders#latency#low latency#Mobile
0 notes
Text
🚀 Unlock the Future with AI Services! 🚀
Transform your business with cutting-edge AI solutions that drive efficiency, automation, and growth.

From AI-powered analytics to smart automation tools, we offer customized services tailored to your needs.
🔹 Boost Productivity 🔹 Enhance Customer Experience 🔹 Streamline Operations
Partner with us and stay ahead of the competition with innovative AI technology.
Contact us today!
📞 Call: (877)431–0767
🌐 Visit: https://www.cirruslabs.io/
Address: 5865 North Point Pkwy,Suite 100, Alpharetta, GA 30022
Don’t miss out on the AI revolution — Elevate your business now!
0 notes
Text
What is Docker and how it works
#docker#container#data transfer#application#website#web development#technology#software#information technology
0 notes
Text
Kamatera Review – The Best Scalable Cloud Host Yet?
New Post has been published on https://thedigitalinsider.com/kamatera-review-the-best-scalable-cloud-host-yet/
Kamatera Review – The Best Scalable Cloud Host Yet?
This Kamatera review will help you decide whether the web host is the best option for you!
Being able to scale your resource demand effortlessly as your website grows… paying only for the resources you use… no-single-point-of-failure security guarantee… what’s not to love about cloud hosting?
As a web hosting consultant I have helped hundreds of my clients choose the best web hosts to migrate their websites to – and many times, they were also upgrading from a shared or VPS plan to cloud hosting. Kamatera has always been high up in the list of options when we were considering cloud hosts, so I decided to check out their service and take you along.
In the rest of this Kamatera review, I’ll discuss all the web host’s plans, features you can expect to enjoy, how much you should budget, real-time performance figures, their dedication to customer support, and other important factors you should look out for.
Kamatera Review
Founded in 1995, Kamatera is no new kid on the block. They offer generic cloud hosting and every other cloud hosting hybrid you can think of – from managed and unmanaged cloud servers to virtual private cloud (VPC) services and cloud VPS hosting. They also offer reseller hosting for mini hosting companies and web professionals who want to cross-sell this with their core services.
I get it. The differences between their virtual private cloud hosting and cloud VPS hosting can be subtle but don’t worry we’ll discuss them in detail.
Kamatera’s cloud hosting plans are incredibly affordable too. I also like that on all their core plans, you can choose between ready-made packages or customize your plan yourself by setting the number of CPUs, memory (RAM), traffic, storage, and bandwidth. Kamatera also allows you to choose where you want your servers to be located.
Kamatera has been reviewed by 200 users on TrustPilot and users give them a rather decent 3.2 stars. Their positive reviews are from users praising how easy it to set up a server, transparent pricing, and uncommon level of support.
Kamatera Ratings – My Personal Take
It’s been a tradition for me to always give my personal ratings of each host I recommend – and Kamatera will be no different. there’s really no guarantee you can trust the reviews that many web hosts publish on their websites. Plus many businesses doctor reviews on popular platforms like TrustPilot.
The best approach to know exactly how great a web host’s services are? A non-biased overall rating of the web host through expert eyes.
Considering Kamatera’s key features and their real-life performance, here’s how I’d rate the web host on a scale of 1-5. Note that these scores are not static and only reflect their offerings at the time of this writing:
Quality My rating Why I gave this score Features and specs 5.0 Exceptional scalability, a cloud firewall, load balancing tech, and their specialized disaster recovery service makes Kamatera one of the most reliable cloud hosts on the market. They get a resounding 5.0 stars here. Pricing 4.9 Starting at $4/month for their cloud servers, Kamatera’s services are also undoubtedly some of the cheapest on the market. Many VPS plans from other hosting providers even cost more. Performance stats 4.7 My personal tests of Kamatera’s servers recorded a response time of 270 ms. That’s really decent and up there, even though a good number of hosts still perform better so they get a 4.7 in this category. Ease of use 4.0 One of the chief complaints users filed about Kamatera was how it logged you out repeatedly with an IP error message and I experienced this first-hand. Asides that, Kamatera makes it easy to manage your website backend using cPanel, Plesk, Vesta, and CyberPanel. I give them a 4.0 here Customer support guarantee 4.5 Several call lines for their different support portals, email addresses, ticketing, and a knowledgebase are how Kamatera caters to its users’ inquiries. However, I’d have loved to see a live chat option for real-time support. I give them a 4.5 here.
Kamatera Hosting Plans and Prices – 2024
Kamatera offers cloud servers, managed cloud services, virtual private cloud hosting, cloud VPS hosting, and reseller hosting. One small caveat you need to know about Kamatera’s plans is they don’t have a money back guarantee and even if you cancel your plans within the first month, they still charge you the full month’s fee.
You can pay for any Kamatera hosting plan you’ve decided on using your credit card or via Paypal.
Kamatera cloud servers
Kamatera ‘Simple’ cloud hosting plans come in three tiers and allow you to choose your server location and server specs – Windows, Linux, or SSD-optimized.
These plans start at $4/month and you get between 1-2 vCPUs, 1-2 GB RAM of memory, 20-30 GB SSD storage, and 5TB of data transfer on all plans. I love just how much server flexibility you get with Kamatera’s hosting.
Custom cloud servers on Kamatera
What’s more? Kamatera also allows you to configure your hosting plan – you can choose the number of processors you want, where you want your data centers to be located, the amount of memory you need, amount of storage, your OS, amount of traffic, and number of IPs. You also get to decide whether you want to pay for their services per month or per hour. Amazing!
Who this is for:
Kamatera’s cloud servers are for businesses that need to be able to add or remove hosting resources when necessary. With these plans, you can manage your spending exceptionally and don’t have to pay for infrastructure you may not use. Monthly payment drives home your control over what you spend even further.
Kamatera’s managed cloud hosting
Pro Managed
Features – OS monitoring, firewall & networking management, DNS setup, server resources performance metrics, apps installation and configuration, 24/7 NOC support, dedicated account manager on plans with 10+ servers.
Price – $50/month
Premium Managed
Features – Everything in Pro Managed plus custom and application monitoring, database high availability setup, application/service updates, quicker customer agent response times, and dedicated account managers on all plans.
Price – $150/month
Who this is for:
Kamatera’s managed cloud hosting plans take the hassle of managing the technical aspect of your cloud servers out of your hands. From monitoring and setup, to technical support, reporting, and application management, the host does these critical processes for you. What’s more? Kamatera also dedicates a particular human support agent to you who’ll be in charge of your account and you can count on to respond to any inquiries you might have.
Don’t know much about the server-side of websites? Kamatera’s managed cloud hosting plans might just be for you.
Kamatera’s virtual private cloud hosting
Kamatera’s virtual private cloud (VPC) packages are exactly identical to their cloud server plans on both the ‘Simple’ and ‘Customized’ fronts. They are also priced similarly and give you the same features.
Kamatera’s reseller hosting plans
Want to create your own web hosting business or are you a web dev, IT guy, or marketing professional looking to sell web hosting with your core services as a comprehensive package to your clients? Kamatera’s reseller hosting plans are just for you.
Here are some of the benefits you get to enjoy:
Managed setup
With Kamatera’s reseller hosting, their agents support you through setting up your servers and handling client requests.
Outsourced support
You have access to Kamatera’s support team to service your clients whenever they have inquiries.
Less as you grow
The more customers you get, the more discounts you get and the less you have to pay, meaning more profitability for your business.
Ready to get started with Kamatera’s reseller hosting? You’ll need to contact their sales department by creating a support ticket:
Who this is for:
Selling web hosting is one of the best ways to scale your business as a web dev, marketer, or IT professional. You can offer these as part of a comprehensive package and your clients are more likely to buy from you since they already buy your core services from you.
And for web-hosting-only businesses, you can rest assured that you have a business that’s evergreen. Websites will always need website hosting to stay online and it’s an excellent recurring revenue model.
Kamatera Features
Here’s an overview of some of Kamatera’s main features:
SSD storage
Custom hosting plans
Superior load balancing technology
High-performance block storage
Cloud firewall
Transparent pricing
Kamatera, as a cloud-only host, provides premium features that emphasize superior performance and security with its packages.
But some of its more unique features are the load balancers that instantly distribute workloads across a network of servers, ensuring high speeds and quick response times.
Kamatera’s block storage technology emulates a virtual private disk for your cloud plans and ensures there’s no single point of failure. It also ensures extremely low latency (or very quick response times and data transfer) further improving the performance of your website.
Kamatera Performance Tests
Your web host’s servers are your website home and how they perform are exactly how your website will perform. Some important factors to consider when choosing a hosting provider like Kamatera are the server response speeds and uptime.
The web host’s server speed is a measure of how quickly their servers respond and send back your website data to a visitor. On the other hand, the uptime measures the availability of their servers – i.e how much of the time their servers are online to serve up your website’s content to visitors.
The quicker the server speeds are, the less time it will take for your website to load. And the higher the uptime, the more reliable your website will be and you won’t risk losing traffic just because your website was down.
To measure Kamatera’s speed and uptime, I tested a website hosted on their platform and these were the results I got:
Kamatera’s servers started sending the first byte of data back in 276 ms. Quite impressive, even though I still expected better as some high performers respond in sub 100ms.
For the uptime, the website I tested has been available 100% of the time over the last 30 days:
This confirms their 99.9% uptime guarantee!
Kamatera’s Customer Support
It’s easy for web hosts to promise heaven and earth but once many of them take your money, it’s cricket-y silence. Kamatera does well though in terms of customer support. You can reach out to their agents via:
Phone
Kamatera has phone lines for its sales and account managers, technical support, and billing departments.
Email
You can also reach out to Kamatera via email at [email protected], [email protected], and [email protected].
I tried reaching out to their technical support agents via email and got a response in a few hours – quite decent!
Support ticket
Create a support ticket to talk with an agent, fill in your details and phone, and write down your inquiry. Kamatera will reach out to you via email.
Knowledgebase
Simple and straight-to-the-point, Kamatera’s knowledgebase is just how I like it. The built-in search engine also makes it easy to find answers to questions around server setup and security.
Blog
And finally, Kamatera has an up-to-date blog with relevant posts on latest industry information for website and business owners.
Kamatera Security Features
If there’s one thing I like about Kamatera, it’s their security guarantee. First, is their native Cloud Firewall designed to protect your website from attacks while monitoring your servers in real time.
Kamatera’s Cloud Firewall allows you to set rules and filter data packets, exclusively authorizing the entry of certified and approved data packets to your servers. What’s more? The firewall can also function as a VPN giving you even more functionality!
Another core part of Kamatera’s security is the disaster recovery portal. Unforeseen events can impact your website severely. Kamatera’s disaster recovery provides backups, recovery, and failover systems to minimize service disruptions.
Your website’s database is archived at restore points for immediate recovery. And finally, Kamatera’s backup machines are automatically triggered in the event of a system failure to ensure your user experience is not affected.
Kamatera’s hosting plans also allow you to install a free Lets Encrypt SSL certificate, giving your website the padlock seal of trust in the eyes of search engines.
Kamatera User Friendliness – Ease of Use
How to register an account on Kamatera
Setting up an account on Kamatera is super easy. Simply select the plan you want and click on ‘Create server’. You’ll be redirected to the sign up page:
Fill in your email and choose a password you can remember easily – your password should contain at least one lowercase letter, one uppercase letter, a number, and should be at least 8 characters long. Click on ‘Create Free Account’
You’ll receive a confirmation link in your email. Click on it and your account should be ready to go!
How to create a server on Kamatera
To create a new server on Kamatera, from your account dashboard, navigate to “My Cloud” on the left and under the dropdown options, select “Create New Server”
Next, select your preferred data center location and then the operating system you want on the server.
Once that’s done, choose the number of CPUs and specify your server specs – RAM and SSD storage amount.
And finally, configure the fine print – backup, select whether you want a dedicated account manager, set a password, and select your billing schedule. Click on ‘Create server’ and it should be done in a few minutes.
Kamatera control panel
Kamatera doesn’t come with a custom control panel like some other high performing hosts – SiteGround, Hostinger, and A2Hosting – however, Kamatera gives you access to cPanel, Plesk, Vesta, and CyberPanel.
How to install WordPress on Kamatera
The swiftest way to deploy WordPress on Kamatera is via your control panel. Using cPanel as an example, we’ll use the Softaculous installer:
In your cPanel account, navigate to ‘Tools’ and click on ‘Softaculous Apps Installer’.
In the search engine, type in ‘WordPress’. Click ‘Install’ and then ‘Choose protocol’.
Next, choose the domain name you want WordPress installed on and configure the directory. If you’re not sure, just choose the default values and proceed.
Configure your ‘Site Name’ and ‘Site description’. Whatever you put here will be shown in the title bar of a website visitor’s browser.
Next, configure your ‘Admin Username’, ‘Admin password’, and ‘Admin Email’. These are the login details you will use to access your WordPress dashboard once it is installed.
Select the auto update boxes for WordPress, plugins, and themes.
Now configure where you want your website backups to be stored and check the ‘Automated backups’ so Softaculous makes backups of your website at specified intervals.
Review all the installation options and click ‘Install’. Voila!
Kamatera Server Footprint
If Kamatera had just one thing going for them, it’d be their continent-wide server footprint. Their servers are spread across dozens of data centers in Europe, the Americas, and Asia and several countries in between.
This guarantees exceptional website performance for businesses targeting audiences spread across the globe.
Conclusion – Should You Choose Kamatera?
Kamatera is a very decent dedicated cloud host and their performance and built-in features are no joke. I recommend Kamatera if you’re looking for affordable packages and have outgrown your shared/VPS plans.
Their block storage, load balancers, cloud firewall, and disaster recovery ensure your website performs exceptionally and is protected from bad actors.
My only fault with Kamatera would be their account creation process. Their IP address protocol system glitches often and may log you out for no reason at all.
Visit Kamatera →
FAQs
What is Kamatera?
Kamatera is a cloud hosting company that provides web hosting infrastructure mainly to eCommerce businesses and other enterprises that require exceptionally scalable resources.
What is cloud server monitoring?
Cloud server monitoring is one of the services offered by Kamatera to customers. The host constantly monitors your website servers to prevent malware and minimize service disruptions.
What payment methods does Kamatera accept?
Kamatera accepts payments for their hosting plans via credit cards and standing order. They also accept Paypal payments.
#A2Hosting#admin#agent#agents#amazing#Americas#amp#approach#apps#Asia#backup#backups#Best cloud hosting#Blog#browser#Business#Byte#Cloud#Cloud hosting#cloud services#Companies#comprehensive#content#control panel#credit card#dashboard#data#Data Center#Data Centers#data transfer
2 notes
·
View notes
Text
Migrating from Joomla to WordPress: A Comprehensive Guide
Explore the complete process of Joomla to WordPress migration seamlessly. This guide covers planning, data migration, theme customization, plugin integration, and post-migration optimization. Upgrade your website's functionality and usability with this essential Joomla to WordPress migration tutorial.
0 notes
Video
youtube
How to Transfer Data from Android to iPhone [2 FREE Ways]
0 notes