#Cerebras
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Women make up for the other 50% of Tumblr’s audience.
Text
The risks behind the generative AI craze: Why caution is growing
New Post has been published on https://thedigitalinsider.com/the-risks-behind-the-generative-ai-craze-why-caution-is-growing/
The risks behind the generative AI craze: Why caution is growing
.pp-multiple-authors-boxes-wrapper display:none; img width:100%;
In the near future, Silicon Valley might look back at recent events as the point where the generative AI craze went too far.
This past summer, investors questioned whether top AI stocks could sustain their sky-high valuations, given the lack of returns on massive AI spending. As Autumn approaches, major AI sectors—such as chips, LLMs, and AI devices—received renewed confidence. Nonetheless, there are an increasing number of reasons to be cautious.
Cerebras: A chip contender with a major risk
Chip startup Cerebras is challenging Nvidia’s dominance by developing processors designed to power smarter LLMs. Nvidia, a major player in the AI boom, has seen its market cap skyrocket from $364 billion at the start of 2023 to over $3 trillion.
Cerebras, however, relies heavily on a single customer: the Abu Dhabi-based AI firm G42. In 2023, G42 accounted for 83% of Cerebras’ revenue, and in the first half of 2024, that figure increased to 87%. While G42 is backed by major players like Microsoft and Silver Lake, its dependency poses a risk. Even though Cerebras has signed a deal with Saudi Aramco, its reliance on one client may cause concerns as it seeks a $7-8 billion valuation for its IPO.
OpenAI’s record-breaking funding – but with strings attached
OpenAI made the news when it raised $6.6 billion at a $157 billion valuation, becoming the largest investment round in Silicon Valley history. However, the company has urged its investors not to back competitors such as Anthropic and Elon Musk’s xAI—an unusual request in the world of venture capital, where spread betting is common. Critics, including Gary Marcus, have described this approach as “running scared.”
OpenAI’s backers also include “bubble chasers” such as SoftBank and Tiger Global, firms known for investing in companies at their peak, which frequently results in huge losses. With top executives such as CTO Mira Murati departing and predicted losses of $5 billion this year despite rising revenues, OpenAI faces significant challenges.
Meta’s big bet on AI wearables
Meta entered the AI race by unveiling Orion, its augmented reality glasses. The wearables promise to integrate AI into daily life, with Nvidia’s CEO Jensen Huang endorsing the product. However, at a production cost of $10,000 per unit, the price is a major obstacle.
Meta will need to reduce costs and overcome consumer hesitation, as previous attempts at AI-powered wearables—such as Snapchat’s glasses, Google Glass, and the Humane AI pin—have struggled to gain traction.
The road ahead
What’s next for AI? OpenAI must prove it can justify a $157 billion valuation while operating at a loss. Cerebras needs to reassure investors that relying on one client isn’t a dealbreaker. And Meta must convince consumers to adopt a completely new way of interacting with AI.
If these companies succeed, this moment could mark a turning point in the AI revolution. However, as tech history shows, high-stakes markets are rarely easy to win.
(Photo by Growtika)
See also: Ethical, trust and skill barriers hold back generative AI progress in EMEA
Want to learn more about AI and big data from industry leaders? Check out AI & Big Data Expo taking place in Amsterdam, California, and London. The comprehensive event is co-located with other leading events including Intelligent Automation Conference, BlockX, Digital Transformation Week, and Cyber Security & Cloud Expo.
Explore other upcoming enterprise technology events and webinars powered by TechForge here.
Tags: artificial intelligence, llm, meta, microsoft, Nvidia, openai
#000#2023#2024#ai#ai & big data expo#AI Pin#AI Race#AI-powered#amp#anthropic#applications#approach#artificial#Artificial Intelligence#augmented reality#automation#background#betting#Big Data#billion#california#CEO#Cerebras#chip#chips#Cloud#cloud computing#Companies#comprehensive#computing
0 notes
Text
Yapay Zeka için 900.000 çekirdekli 125 PetaFLOPS gücünde işlemci üretildi

Cerebras, WSE-3 yonga levha ölçekli işlemci ve CS-3 süper bilgisayarını piyasaya sürdü. Cerebras Systems, selefi WSE-2'nin iki katı performansa sahip çığır açıcı bir yapay zeka yonga plakası ölçeği çipi olan Wafer Scale Engine 3'ü (WSE-3) tanıttı . Bu yeni cihaz, TSMS'nin 5nm sınıfı üretim süreciyle üretilen 4 trilyon transistör içeriyor; 900.000 yapay zeka çekirdeği; 44 GB çip üzerinde SRAM; ve 125 FP16 PetaFLOPS'luk zirve performansına sahip. Ceberas'ın WSE-3 endüstrinin en büyük yapay zeka modellerinden bazılarını eğitmek için kullanılacak. WSE-3, Cerebras'ın 24 trilyona kadar parametreye sahip yapay zeka modellerini eğitmek için kullanılabilen CS-3 süper bilgisayarına güç veriyor; bu, WSE-2 ve diğer modern yapay zeka işlemcileri tarafından desteklenen süper bilgisayarlar üzerinde önemli bir sıçrama . Süper bilgisayar, 1,5 TB, 12 TB veya 1,2 PB harici belleği destekleyebilir; bu, büyük modelleri bölümlendirmeye veya yeniden düzenlemeye gerek kalmadan tek bir mantıksal alanda depolamasına olanak tanıyarak eğitim sürecini kolaylaştırıyor ve geliştirici verimliliğini artırıyor. Ölçeklenebilirlik açısından CS-3, 2048'e kadar sistemden oluşan kümeler halinde yapılandırılabiliyor. Bu ölçeklenebilirlik, dört sistemli bir kurulumla yalnızca bir günde 70 milyar parametreli modele ince ayar yapmasına ve bir Llama 70B modelini aynı zaman diliminde tam ölçekte sıfırdan eğitmesine olanak tanır. En yeni Cerebras Yazılım Çerçevesi, PyTorch 2.0 için yerel destek sunar ve aynı zamanda eğitimi hızlandırabilen, geleneksel yöntemlere göre sekiz kata kadar daha hızlı olan dinamik ve yapılandırılmamış seyrekliği destekler. Cerebras, CS-3'ün üstün güç verimliliği ve kullanım kolaylığını vurguladı. Performansını iki katına çıkarmasına rağmen CS-3 önceki modelle aynı güç tüketimini koruyor. Ayrıca GPU'lara kıyasla 'ye kadar daha az kod gerektiren büyük dil modellerinin (LLM'ler) eğitimini de basitleştirir. Örneğin şirkete göre GPT-3 boyutlu bir model Cerebras platformunda yalnızca 565 satır kod gerektiriyor. Şirket halihazırda CS-3'e ciddi bir ilgi gördü ve kurumsal , kamu ve uluslararası bulutlar da dahil olmak üzere çeşitli sektörlerden önemli miktarda birikmiş sipariş yığınına sahip. Cerebras ayrıca Argonne Ulusal Laboratuvarı ve Mayo Kliniği gibi kurumlarla da işbirliği yaparak CS-3'ün sağlık alanındaki potansiyelini vurguluyor. Cerebras ve G42 arasındaki stratejik ortaklık, 64 CS-3 sistemine ( 57.600.000 çekirdeğe sahip) sahip bir yapay zeka süper bilgisayarı olan Condor Galaxy 3'ün yapımıyla da genişleyecek. İki şirket birlikte halihazırda dünyadaki en büyük yapay zeka süper bilgisayarlarından ikisini yarattı: Kaliforniya merkezli ve toplam performansı 8 kat olan Condor Galaxy 1 (CG-1) ve Condor Galaxy 2 (CG-2). ExaFLOP'lar. Bu ortaklık, dünya çapında onlarca exaFLOP yapay zeka hesaplaması sunmayı amaçlıyor. G42 Grup CTO'su Kiril Evtimov, "Cerebras ile olan stratejik ortaklığımız, G42'de inovasyonu ilerletmede etkili oldu ve yapay zeka devriminin küresel ölçekte hızlanmasına katkıda bulunacak" dedi. "8 exaFLOP'a sahip bir sonraki yapay zeka süper bilgisayarımız Condor Galaxy 3 şu anda yapım aşamasında ve yakında sistemimizin toplam yapay zeka hesaplama üretimini 16 exaFLOP'a çıkaracak." kaynak:https://www.tomshardware.com Read the full article
0 notes
Text
Wafer Scale Engine
Computational Fluid Dynamics is a promising application of Waferscale computing. If it becomes mainstream we may see the rebirth of the mainframe. But what's really exciting is this development along with chiplet and silicon to silicon bonding may herald the beginning of 3D logic in semiconductors. this is great in terms of reviving the push to increase transistor "density" by essentially doubling and tripling silicon "depth" without sacrificing latency or bandwidth. but the problem of heat remains and is exacerbated by this increased density. A couple solutions to this problem range from marginal adjustments to exotic reinventions of basic design. Among them are improved cooling systems, introducing thermal conductors in between layers to collect heat, reconfiguring transistor floorplans to better distribute heat, and switching to new materials with higher heat tolerances (GaN comes to mind). and with such massive size, and considerable heat, warping becomes a pressing concern. The ideal solution, therefore would be to consume less power in the first place. With the loss of Dennard scaling, traditional CMOS seems ill equipped to reduce its power consumption. Would the use of high temperature superconductors like YBCO (Yttrium-Barium-Copper Oxide) be able to usher in such power improvements?
0 notes
Text
Rhonda Snord's "Heavy Metal"
#dmitrytsoy#twelveofclubs#pixel animation#pixelart#aseprite#mechwarrior#battletech#cerebra its me or you
168 notes
·
View notes
Text












The Proudstar Family - Thunderbird (John Proudstar), Warpath (James Proudstar) and Grandma Lozen Proudstar, are in charge of Camp Gozhoo where they shelter the mutant refugees. However, the Orchis soldiers had invaded their place and they started to harass the mutants. This prompts the Proudstar Brothers to fight off the Orchis soldiers. Also, Grandma Lozen stood up to the Orchis soldiers showing no fear as she laughs in their faces defiantly.
X-Men Unlimited Infinity Comic # 121, 2024
#Thunderbird#John Proudstar#Warpath#James Proudstar#X Force#X Men#XForce#Somnus#Carl Valentino#Cerebra#Shakti Haddad#XMen#Orchis#Lozen Proudstar#X Men Unlimited Infinity Comic#X Men Unlimited#infinity comics#xmen unlimited#xmen unlimited infinity comic#infinity comic#marvel#digital comics#webcomic#digital comic
105 notes
·
View notes
Text

#X-Men 2099#Skullfire#Cerebra#Meanstreak#Metalhead#Bloodhawk#Krystalin#Xi'an Chi Xan#John Francis Moore#Tim Hildebrandt#Greg Hildebrandt#team shots
23 notes
·
View notes
Photo









More assorted X-Men characters!
You can see most of the ones i’ve done here: http://www.louiejoyce.com/xmen.html
#Louie Joyce#Illustration#Drawing#X-Men#Krakoa#Magneto#Maggot#Cerebra#Kid Gladiator#Cyber#Tempo#Rogue#Emma Frost#X-Man#90s#X-Men the Animated Series#X-Men 97#Marvel#MCU#Character Art
201 notes
·
View notes
Text

Marvel Masterpieces - Series 2 (1993) X-Men 2099 Dyna-Etch Subset Cerebra / Artist: Bob Larkin
12 notes
·
View notes
Text
The Hole


Contestants Index
#tournament of x#the hole bracket#round 3#cerebra#shakti haddad#thunderbird#john proudstar#x men#marvel comics#krakoa#x men comics#xmen#tournament#poll tournament#tournament poll#bracket#tumblr tournament#character tournament#tumblr bracket#tumblr polls#poll
21 notes
·
View notes
Text


Marvel Masterpieces cards #22: Cerebra
#marvel masterpieces#cerebra#marvel 2099#x-men 2099#green#greg hildebrandt#tim hildebrandt#r.i.p.#trading cards#comics trading cards#90s comics trading cards#marvel comics trading cards
4 notes
·
View notes
Text
Liquid AI Launches Liquid Foundation Models: A Game-Changer in Generative AI
New Post has been published on https://thedigitalinsider.com/liquid-ai-launches-liquid-foundation-models-a-game-changer-in-generative-ai/
Liquid AI Launches Liquid Foundation Models: A Game-Changer in Generative AI
In a groundbreaking announcement, Liquid AI, an MIT spin-off, has introduced its first series of Liquid Foundation Models (LFMs). These models, designed from first principles, set a new benchmark in the generative AI space, offering unmatched performance across various scales. LFMs, with their innovative architecture and advanced capabilities, are poised to challenge industry-leading AI models, including ChatGPT.
Liquid AI was founded by a team of MIT researchers, including Ramin Hasani, Mathias Lechner, Alexander Amini, and Daniela Rus. Headquartered in Boston, Massachusetts, the company’s mission is to create capable and efficient general-purpose AI systems for enterprises of all sizes. The team originally pioneered liquid neural networks, a class of AI models inspired by brain dynamics, and now aims to expand the capabilities of AI systems at every scale, from edge devices to enterprise-grade deployments.
What Are Liquid Foundation Models (LFMs)?
Liquid Foundation Models represent a new generation of AI systems that are highly efficient in both memory usage and computational power. Built with a foundation in dynamical systems, signal processing, and numerical linear algebra, these models are designed to handle various types of sequential data—such as text, video, audio, and signals—with remarkable accuracy.
Liquid AI has developed three primary language models as part of this launch:
LFM-1B: A dense model with 1.3 billion parameters, optimized for resource-constrained environments.
LFM-3B: A 3.1 billion-parameter model, ideal for edge deployment scenarios, such as mobile applications.
LFM-40B: A 40.3 billion-parameter Mixture of Experts (MoE) model designed to handle complex tasks with exceptional performance.
These models have already demonstrated state-of-the-art results across key AI benchmarks, making them a formidable competitor to existing generative AI models.
State-of-the-Art Performance
Liquid AI’s LFMs deliver best-in-class performance across various benchmarks. For example, LFM-1B outperforms transformer-based models in its size category, while LFM-3B competes with larger models like Microsoft’s Phi-3.5 and Meta’s Llama series. The LFM-40B model, despite its size, is efficient enough to rival models with even larger parameter counts, offering a unique balance between performance and resource efficiency.
Some highlights of LFM performance include:
LFM-1B: Dominates benchmarks such as MMLU and ARC-C, setting a new standard for 1B-parameter models.
LFM-3B: Surpasses models like Phi-3.5 and Google’s Gemma 2 in efficiency, while maintaining a small memory footprint, making it ideal for mobile and edge AI applications.
LFM-40B: The MoE architecture of this model offers comparable performance to larger models, with 12 billion active parameters at any given time.
A New Era in AI Efficiency
A significant challenge in modern AI is managing memory and computation, particularly when working with long-context tasks like document summarization or chatbot interactions. LFMs excel in this area by efficiently compressing input data, resulting in reduced memory consumption during inference. This allows the models to process longer sequences without requiring expensive hardware upgrades.
For example, LFM-3B offers a 32k token context length—making it one of the most efficient models for tasks requiring large amounts of data to be processed simultaneously.
A Revolutionary Architecture
LFMs are built on a unique architectural framework, deviating from traditional transformer models. The architecture is centered around adaptive linear operators, which modulate computation based on the input data. This approach allows Liquid AI to significantly optimize performance across various hardware platforms, including NVIDIA, AMD, Cerebras, and Apple hardware.
The design space for LFMs involves a novel blend of token-mixing and channel-mixing structures that improve how the model processes data. This leads to superior generalization and reasoning capabilities, particularly in long-context tasks and multimodal applications.
Expanding the AI Frontier
Liquid AI has grand ambitions for LFMs. Beyond language models, the company is working on expanding its foundation models to support various data modalities, including video, audio, and time series data. These advancements will enable LFMs to scale across multiple industries, such as financial services, biotechnology, and consumer electronics.
The company is also focused on contributing to the open science community. While the models themselves are not open-sourced at this time, Liquid AI plans to release relevant research findings, methods, and data sets to the broader AI community, encouraging collaboration and innovation.
Early Access and Adoption
Liquid AI is currently offering early access to its LFMs through various platforms, including Liquid Playground, Lambda (Chat UI and API), and Perplexity Labs. Enterprises looking to integrate cutting-edge AI systems into their operations can explore the potential of LFMs across different deployment environments, from edge devices to on-premise solutions.
Liquid AI’s open-science approach encourages early adopters to share their experiences and insights. The company is actively seeking feedback to refine and optimize its models for real-world applications. Developers and organizations interested in becoming part of this journey can contribute to red-teaming efforts and help Liquid AI improve its AI systems.
Conclusion
The release of Liquid Foundation Models marks a significant advancement in the AI landscape. With a focus on efficiency, adaptability, and performance, LFMs stand poised to reshape the way enterprises approach AI integration. As more organizations adopt these models, Liquid AI’s vision of scalable, general-purpose AI systems will likely become a cornerstone of the next era of artificial intelligence.
If you’re interested in exploring the potential of LFMs for your organization, Liquid AI invites you to get in touch and join the growing community of early adopters shaping the future of AI.
For more information, visit Liquid AI’s official website and start experimenting with LFMs today.
#ai#AI benchmarks#AI integration#AI models#AI systems#amd#API#apple#applications#approach#arc#architecture#Art#artificial#Artificial Intelligence#audio#benchmark#benchmarks#billion#biotechnology#Brain#Cerebras#challenge#channel#chatbot#chatGPT#Collaboration#Community#computation#consumer electronics
0 notes
Text

Tiny Somnus cameo in today's X-Men Unlimited!
#somnus#carl valentino#!!!#he lived!#i miss him#he doesn't have his cape right now but he's with cerebra so that's def him#his power set alone is cool#I hope he comes back#even if we don't get any more aki interactions/backstory for a while
11 notes
·
View notes
Text





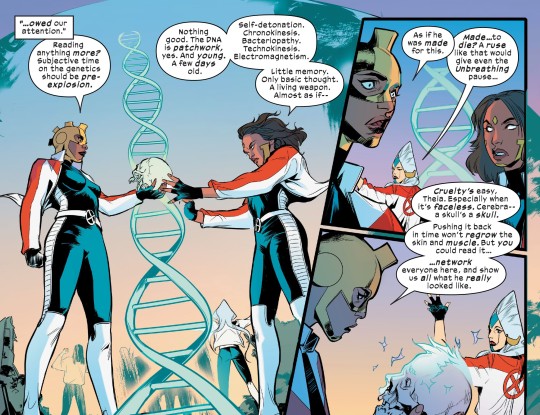









From X-Men: Before the Fall - Mutant First Strike #001
Art by Valentina Pinti and Frank William
Written by Steve Orlando
#x-men: before the fall - mutant first strike#bishop#professor x#black king#angel#triage#tempo#penance#jean grey#storm#cyclops#iceman#judas traveller#gio mack#cerebra#theia#northstar#aurora#life#marvel#comics#marvel comics
14 notes
·
View notes
Text

#Exiles#76#Ironclad#Quiver#Thing#Spider-Man 2099#Ghost Rider 2099#Krystalin#Cerebra#Skullfire#Punisher 2099#Sabertooth#Justice#Morph#Marvel#Jim Calafiore
4 notes
·
View notes
Text










More X-May art. All X-May digital prints are available for free when you join my Patreon All Access tier.
#x men#uncanny x men#magneto#juggernaut#legion#gambit#toad#forge#xmen#x men fanart#charles xavier#professor x#cerebra#digital painting#digital prints#clipstudiopaint#custom brushes#Patreon rewards
9 notes
·
View notes
Photo

Cerebra form X-Men 2099! #doodles #postitdrawing #postit #art #comic #comicbook #freehanddrawing #warmup #postitpopart #Marvel #marvelcomics #Cerebra #xmen #ShaktiHaddad #xmen2099 #xnation #icequeen https://www.instagram.com/p/Cnki3RouPV4/?igshid=NGJjMDIxMWI=
#doodles#postitdrawing#postit#art#comic#comicbook#freehanddrawing#warmup#postitpopart#marvel#marvelcomics#cerebra#xmen#shaktihaddad#xmen2099#xnation#icequeen
3 notes
·
View notes