#CUDA memory model
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
Master CUDA: For Machine Learning Engineers
New Post has been published on https://thedigitalinsider.com/master-cuda-for-machine-learning-engineers/
Master CUDA: For Machine Learning Engineers
CUDA for Machine Learning: Practical Applications
Structure of a CUDA C/C++ application, where the host (CPU) code manages the execution of parallel code on the device (GPU).
Now that we’ve covered the basics, let’s explore how CUDA can be applied to common machine learning tasks.
Matrix Multiplication
Matrix multiplication is a fundamental operation in many machine learning algorithms, particularly in neural networks. CUDA can significantly accelerate this operation. Here’s a simple implementation:
__global__ void matrixMulKernel(float *A, float *B, float *C, int N) int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x; float sum = 0.0f; if (row < N && col < N) for (int i = 0; i < N; i++) sum += A[row * N + i] * B[i * N + col]; C[row * N + col] = sum; // Host function to set up and launch the kernel void matrixMul(float *A, float *B, float *C, int N) dim3 threadsPerBlock(16, 16); dim3 numBlocks((N + threadsPerBlock.x - 1) / threadsPerBlock.x, (N + threadsPerBlock.y - 1) / threadsPerBlock.y); matrixMulKernelnumBlocks, threadsPerBlock(A, B, C, N);
This implementation divides the output matrix into blocks, with each thread computing one element of the result. While this basic version is already faster than a CPU implementation for large matrices, there’s room for optimization using shared memory and other techniques.
Convolution Operations
Convolutional Neural Networks (CNNs) rely heavily on convolution operations. CUDA can dramatically speed up these computations. Here’s a simplified 2D convolution kernel:
__global__ void convolution2DKernel(float *input, float *kernel, float *output, int inputWidth, int inputHeight, int kernelWidth, int kernelHeight) int x = blockIdx.x * blockDim.x + threadIdx.x; int y = blockIdx.y * blockDim.y + threadIdx.y; if (x < inputWidth && y < inputHeight) float sum = 0.0f; for (int ky = 0; ky < kernelHeight; ky++) for (int kx = 0; kx < kernelWidth; kx++) int inputX = x + kx - kernelWidth / 2; int inputY = y + ky - kernelHeight / 2; if (inputX >= 0 && inputX < inputWidth && inputY >= 0 && inputY < inputHeight) sum += input[inputY * inputWidth + inputX] * kernel[ky * kernelWidth + kx]; output[y * inputWidth + x] = sum;
This kernel performs a 2D convolution, with each thread computing one output pixel. In practice, more sophisticated implementations would use shared memory to reduce global memory accesses and optimize for various kernel sizes.
Stochastic Gradient Descent (SGD)
SGD is a cornerstone optimization algorithm in machine learning. CUDA can parallelize the computation of gradients across multiple data points. Here’s a simplified example for linear regression:
__global__ void sgdKernel(float *X, float *y, float *weights, float learningRate, int n, int d) int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < n) float prediction = 0.0f; for (int j = 0; j < d; j++) prediction += X[i * d + j] * weights[j]; float error = prediction - y[i]; for (int j = 0; j < d; j++) atomicAdd(&weights[j], -learningRate * error * X[i * d + j]); void sgd(float *X, float *y, float *weights, float learningRate, int n, int d, int iterations) int threadsPerBlock = 256; int numBlocks = (n + threadsPerBlock - 1) / threadsPerBlock; for (int iter = 0; iter < iterations; iter++) sgdKernel<<<numBlocks, threadsPerBlock>>>(X, y, weights, learningRate, n, d);
This implementation updates the weights in parallel for each data point. The atomicAdd function is used to handle concurrent updates to the weights safely.
Optimizing CUDA for Machine Learning
While the above examples demonstrate the basics of using CUDA for machine learning tasks, there are several optimization techniques that can further enhance performance:
Coalesced Memory Access
GPUs achieve peak performance when threads in a warp access contiguous memory locations. Ensure your data structures and access patterns promote coalesced memory access.
Shared Memory Usage
Shared memory is much faster than global memory. Use it to cache frequently accessed data within a thread block.
Understanding the memory hierarchy with CUDA
This diagram illustrates the architecture of a multi-processor system with shared memory. Each processor has its own cache, allowing for fast access to frequently used data. The processors communicate via a shared bus, which connects them to a larger shared memory space.
For example, in matrix multiplication:
__global__ void matrixMulSharedKernel(float *A, float *B, float *C, int N) __shared__ float sharedA[TILE_SIZE][TILE_SIZE]; __shared__ float sharedB[TILE_SIZE][TILE_SIZE]; int bx = blockIdx.x; int by = blockIdx.y; int tx = threadIdx.x; int ty = threadIdx.y; int row = by * TILE_SIZE + ty; int col = bx * TILE_SIZE + tx; float sum = 0.0f; for (int tile = 0; tile < (N + TILE_SIZE - 1) / TILE_SIZE; tile++) if (row < N && tile * TILE_SIZE + tx < N) sharedA[ty][tx] = A[row * N + tile * TILE_SIZE + tx]; else sharedA[ty][tx] = 0.0f; if (col < N && tile * TILE_SIZE + ty < N) sharedB[ty][tx] = B[(tile * TILE_SIZE + ty) * N + col]; else sharedB[ty][tx] = 0.0f; __syncthreads(); for (int k = 0; k < TILE_SIZE; k++) sum += sharedA[ty][k] * sharedB[k][tx]; __syncthreads(); if (row < N && col < N) C[row * N + col] = sum;
This optimized version uses shared memory to reduce global memory accesses, significantly improving performance for large matrices.
Asynchronous Operations
CUDA supports asynchronous operations, allowing you to overlap computation with data transfer. This is particularly useful in machine learning pipelines where you can prepare the next batch of data while the current batch is being processed.
cudaStream_t stream1, stream2; cudaStreamCreate(&stream1); cudaStreamCreate(&stream2); // Asynchronous memory transfers and kernel launches cudaMemcpyAsync(d_data1, h_data1, size, cudaMemcpyHostToDevice, stream1); myKernel<<<grid, block, 0, stream1>>>(d_data1, ...); cudaMemcpyAsync(d_data2, h_data2, size, cudaMemcpyHostToDevice, stream2); myKernel<<<grid, block, 0, stream2>>>(d_data2, ...); cudaStreamSynchronize(stream1); cudaStreamSynchronize(stream2);
Tensor Cores
For machine learning workloads, NVIDIA’s Tensor Cores (available in newer GPU architectures) can provide significant speedups for matrix multiply and convolution operations. Libraries like cuDNN and cuBLAS automatically leverage Tensor Cores when available.
Challenges and Considerations
While CUDA offers tremendous benefits for machine learning, it’s important to be aware of potential challenges:
Memory Management: GPU memory is limited compared to system memory. Efficient memory management is crucial, especially when working with large datasets or models.
Data Transfer Overhead: Transferring data between CPU and GPU can be a bottleneck. Minimize transfers and use asynchronous operations when possible.
Precision: GPUs traditionally excel at single-precision (FP32) computations. While support for double-precision (FP64) has improved, it’s often slower. Many machine learning tasks can work well with lower precision (e.g., FP16), which modern GPUs handle very efficiently.
Code Complexity: Writing efficient CUDA code can be more complex than CPU code. Leveraging libraries like cuDNN, cuBLAS, and frameworks like TensorFlow or PyTorch can help abstract away some of this complexity.
As machine learning models grow in size and complexity, a single GPU may no longer be sufficient to handle the workload. CUDA makes it possible to scale your application across multiple GPUs, either within a single node or across a cluster.
CUDA Programming Structure
To effectively utilize CUDA, it’s essential to understand its programming structure, which involves writing kernels (functions that run on the GPU) and managing memory between the host (CPU) and device (GPU).
Host vs. Device Memory
In CUDA, memory is managed separately for the host and device. The following are the primary functions used for memory management:
cudaMalloc: Allocates memory on the device.
cudaMemcpy: Copies data between host and device.
cudaFree: Frees memory on the device.
Example: Summing Two Arrays
Let’s look at an example that sums two arrays using CUDA:
__global__ void sumArraysOnGPU(float *A, float *B, float *C, int N) int idx = threadIdx.x + blockIdx.x * blockDim.x; if (idx < N) C[idx] = A[idx] + B[idx]; int main() int N = 1024; size_t bytes = N * sizeof(float); float *h_A, *h_B, *h_C; h_A = (float*)malloc(bytes); h_B = (float*)malloc(bytes); h_C = (float*)malloc(bytes); float *d_A, *d_B, *d_C; cudaMalloc(&d_A, bytes); cudaMalloc(&d_B, bytes); cudaMalloc(&d_C, bytes); cudaMemcpy(d_A, h_A, bytes, cudaMemcpyHostToDevice); cudaMemcpy(d_B, h_B, bytes, cudaMemcpyHostToDevice); int blockSize = 256; int gridSize = (N + blockSize - 1) / blockSize; sumArraysOnGPU<<<gridSize, blockSize>>>(d_A, d_B, d_C, N); cudaMemcpy(h_C, d_C, bytes, cudaMemcpyDeviceToHost); cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); free(h_A); free(h_B); free(h_C); return 0;
In this example, memory is allocated on both the host and device, data is transferred to the device, and the kernel is launched to perform the computation.
Conclusion
CUDA is a powerful tool for machine learning engineers looking to accelerate their models and handle larger datasets. By understanding the CUDA memory model, optimizing memory access, and leveraging multiple GPUs, you can significantly enhance the performance of your machine learning applications.
#AI Tools 101#algorithm#Algorithms#amp#applications#architecture#Arrays#cache#cluster#code#col#complexity#computation#computing#cpu#CUDA#CUDA for ML#CUDA memory model#CUDA programming#data#Data Structures#data transfer#datasets#double#engineers#excel#factor#functions#Fundamental#Global
0 notes
Text










”Flown across the ocean, leavin’ just a memory.”
/lyr
Mini comic ft. Some teasers towards Cuda’s backstory, shown through the eyes of his brother and nephew :]
Also took this as a chance to practice interior backgrounds without using blender models and I think they turned out good!
Also also this was just an excuse to draw Storme lmao
#jsab#just shapes and beats#jsab art#jsab au#art#aaaaaaaaaaaaa#oh no#fan art#jsab bmau#jsab barracuda#jsab oc#jsab triangle#triangle guy#jsab comic#jsab broken melodies#lore wooooooo#Also my favorite guy#Storme!!!!!
148 notes
·
View notes
Text
in general i feel like i understand OS bullshit pretty well but it all goes out the window with graphics libraries. like X/wayland is a userspace process. And like the standard model is that my process says "hey X Window System. how big is my window? ok please blit this bitmap to this portion of my window" and then X is like ok, and then it does the compositing and updates the framebuffer through some kernel fd or something
but presumably isn't *actually* compositing windows anymore because what if one of those windows is 3d, in which case that'll be handled by the GPU? so it seems pretty silly to like, grab a game's framebuffer from vram, load it into userspace memory, write it back out to vram for display? presumably the window just says 'hey x window system i am using openGL please blit me every frame" and then...
wait ok i guess i understand how it must work i think. ok so naturally the GPU doesn't know what the fuck a process is. so presumably there's some kernelspace thing that provides GPU memory isolation (and maybe virtualization?) which definitely exists because i got crashes in CUDA code from oob memory access. but in the abstract there's nothing to say it can't ignkre those restrictions in some cases?
and so ig the window compositor must run in like. some special elevated mode where it's allowed to query the kernel for "hey give me all of the other processes framebuffers"? or like OBS also has stuff for recording a window even if that window's occluded? so there must just be some state that can give a process the right to use other proc's gpu bufs?
the alternative is ig... some kind of way to pass framebuffers around (and part of being a X client is saying hi here's my framebuffer) . which ig if they are implemented as fd's with ioctl it'd be possible?
4 notes
·
View notes
Text
NVIDIA has introduced its premium RTX 50 "Blackwell" lineup, led by the RTX 5090 that offers 21,760 CUDA cores and a 575W power draw.

The collection incorporates GDDR7 memory across various models, topped by a massive 32GB configuration on the flagship card. Prices span from $549 for the entry-level RTX 5070 up to $1,999 for the top-tier option, providing multiple choices for different system budgets.
Scheduled to begin rolling out this month, the entire range features PCle 5.0 support, DisplayPort 2.1a connectivity, and a 16-pin power connector for next-generation performance.
Media: @nvidia

0 notes
Text
How AWS FSx for Lustre Boosts GPU Performance By 12x

Throughput to GPU instances is increased by up to 12x with Amazon FSx for Lustre.
AWS has announced that Amazon FSx for Lustre now supports the Elastic Fabric Adapter (EFA) and NVIDIA GPUDirect Storage (GDS). Applications needing large volumes of inter-node interactions can be executed at scale with the help of EFA, a network interface for Amazon EC2 instances. A direct data link between local or remote storage and GPU memory is made possible by the GDS technology. Compared to the prior FSx for Lustre version, Amazon FSx for Lustre with EFA/GDS support offers up to 12 times higher (up to 1200 Gbps) per-client throughput with these improvements.
The most performance-demanding applications, including financial modeling, drug discovery, deep learning training, and autonomous vehicle development, may be developed and executed using FSx for Lustre. You can use more potent GPU and HPC instances, like Amazon EC2 P5, Trn1, and HPC7a, as datasets expand and new technologies appear. Up until now, throughput for individual client instances was restricted to 100 Gbps when using typical TCP networking to access FSx for Lustre file systems. The necessity for FSx for Lustre file systems to offer the performance required to make the best use of the growing network bandwidth of these state-of-the-art EC2 instances while accessing big datasets is being driven by this adoption.
When employing P5 GPU instances and NVIDIA CUDA in your applications, you may now achieve up to 1,200 Gbps throughput per client instance (twelve times greater throughput than before) with FSx for Lustre’s support for Elastic Fabric Adapter and GDS.
With this new feature, you can speed up your HPC and machine learning (ML) workloads and make the most of the network bandwidth of the most potent computing instances. By avoiding the operating system and optimizing data transfer over the AWS Scalable Reliable Datagram (SRD) protocol, EFA improves performance. By removing superfluous memory copies and facilitating direct data transmission between the file system and GPU memory, GDS further enhances performance.
Let’s observe how this functions in real life.
Setting up Amazon FSx for Lustre with EFA turned on
You can start by selecting Create file system and then Amazon FSx for Lustre in the Amazon FSx panel.
Give the file system name. You can choose SSD, Persistent, and the new option with EFA enabled under the Deployment and Storage Type column. In the Throughput per unit of storage area, You can choose 1000 MB/s/TiB. The smallest storage capacity that these parameters allow is 4.8 TiB, therefore you enter that value.
Utilize an EFA-enabled security group and the default virtual private cloud (VPC) for networking. Keep every other option set to its default setting.
After going over every option, construct the file system. The file system is available for use after a few minutes.
Using an Amazon EC2 instance to mount an Amazon FSx for Lustre file system with EFA enabled
Select the Ubuntu Amazon Machine Image (AMI), type a name for the instance, then click Launch instance on the Amazon EC2 console. You can choose the instance type trn1.32xlarge.
Select the same subnet that the FSx Lustre file system uses in Network settings and change the default parameters. Then choose three pre-existing security groups under Firewall (security groups): the default security group, the security group that grants Secure Shell (SSH) access, and the EFA-enabled security group utilized by the FSx for Lustre file system.
Then select ENA and EFA as the interface types in Advanced Network Configuration. In the absence of this configuration, the instance would employ conventional TCP networking, and the throughput of the connection to the FSx for Lustre file system would remain restricted at 100 Gbps.
Depending on the instance type, you can add more EFA network interfaces to increase throughput.
When the instance is ready, you can connect using EC2 Instance Connect and follow the FSx for Lustre User Guide’s instructions for configuring EFA clients and installing the Lustre client.
Then mount an FSx for Lustre file system from an EC2 instance by following the directions.
To use as a mount point, make a folder:
sudo mkdir -p /fsx
In the FSx console, choose the file system and search for the DNS and mount names. Mount the file system using these values:sudo mount -t lustre -o relatime,flock file_system_dns_name@tcp:/mountname /fsx
When you access an EFA-enabled file system from client instances running Lustre 2.15 or later and supporting EFA, EFA is used automatically.
Things to be aware of
All AWS regions where persistent 2 is available now offer free EFA and GDS support for new Amazon FSx for Lustre file systems. Without requiring any further setup, FSx for Lustre uses EFA automatically when users access an EFA-enabled file system from client instances that support it. For instance types in the accelerated computing category, network bandwidths and EFA support are detailed in this table of network requirements.
Lustre 2.15 clients running Ubuntu 22.04 with kernel 6.8 or higher are required in order to use EFA-enabled instances with FSx for Lustre file systems.
It should be noted that within your Amazon Virtual Private Cloud (Amazon VPC) connection, your client instances and file systems need to be situated in the same subnet.
File systems with EFA enabled automatically support GDS. You must have the NVIDIA Compute Unified Device Architecture (CUDA) package, the open-source NVIDIA driver, and the NVIDIA GPUDirect Storage Driver installed on your client instance in order to use GDS with your FSx for Lustre file systems. The AWS Deep Learning AMI has these packages preloaded. After that, you can use GPUDirect storage to move data between your file system and GPUs using your CUDA-enabled application.
Keep in mind that EFA-enabled file systems have greater minimum storage capacity increments than non-EFA-enabled file systems when you plan your deployment. In contrast to 1.2TB for FSx for Lustre file systems without EFA enabled, the minimum storage capacity for EFA-enabled file systems starts at 4.8 TiB if you select the 1,000 MB/s/TiB throughput tier. AWS DataSync can be used to transfer data from an existing file system to a new one that supports EFA and GDS if you’re wanting to shift your current workloads.
FSx for Lustre preserves compatibility with both EFA and non-EFA workloads for optimal flexibility. All workloads can easily access an EFA-enabled file system without any extra setup thanks to the Elastic Network Adapter (ENA), which automatically routes traffic from non-EFA client instances over conventional TCP/IP networking.
Read more on Govindhtech.com
#AWSFSx#GDStechnology#FSxforLustre#NVIDIA#GPUDirectStorage#AmazonEC2#ML#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
0 notes
Text
On Thursday, AMD officially released its newest AI chip: Instinct MI325X. The company has positioned this product directly to take on Nvidia’s dominant data center GPUs. The MI325X pits against the upcoming Blackwell chips from Nvidia, whose shipment will begin early next year. This is AMD’s strategic move to seize more considerable shares of the booming AI chip space that Bloomberg places at $500 billion by 2028.
AMD has always been second in the race in data centre GPU. For the MI325X, the company is looking to force the hand of Nvidia. After all, Nvidia currently enjoys over 90% market share here. This could shake the price of Nvidia’s products, which have been enjoying high margins with the soaring demand for its GPUs, largely because of AI applications. Chief among them is OpenAI’s ChatGPT.
The demand for AI has been higher than expected and investments grow super-duper quickly in the industry,” said CEO Lisa Su. AMD did not introduce new major cloud customers, but it does partner with Meta and Microsoft and it is so far supplying its AI chips in some OpenAI applications.
The biggest challenge AMD is facing currently is Nvidia’s proprietary CUDA programming language, which has become the new standard for AI developers. To avoid getting locked into Nvidia’s own ecosystem, AMD has been working on increasing capabilities of ROCm software to make it easy for developers who are already on the Nvidia side. The MI325X advances its performance to up to 40% more than that of the Nvidia H200 by running Meta’s Llama AI models with much advanced memory.
The company also debuted its 5th Gen EPYC CPUs, further solidifying its place within the data center. These announcements suggest that AMD is planning to go head-to-head with both Nvidia and Intel rather assertively in the AI and data center spaces.
0 notes
Text
Asking ChatGPT Questions on GPU Graphics Card
What is ChatGPT? Before jumping to our topic, we can look at how ChatGPT introduces itself: “ChatGPT is a large language model that was trained by OpenAI. It is designed to be able to generate human-like text in response to prompts given to it, and it is capable of doing so in a variety of different styles and formats. It is based on the GPT-3 (Generative Pretrained Transformer 3) architecture, which is a type of machine learning model that uses deep learning algorithms to generate text. ChatGPT is designed to be able to generate conversational text that is similar to what a human might say in response to a given prompt, making it well-suited for applications such as chatbots and natural language processing tasks.”
What do you think? This sounds like a natural conversation. In fact, ChatGPT is a new AI-driven chatbot that can answer some questions and even write a paragraph of essays. When we search on Google for an answer, the search engine tries to retrieve webpages with higher matching scores to the questions. We need to check each webpage for a satisfactory answer. As humans write the content of webpages, the answer can be a good candidate. Unlike Google search, ChatGPT is trained with all webpage contents crawled from the internet. It learns the style of answering a question. Meanwhile, we can consider the content of an answer as the summarization of the major answers online. Hence, sometimes the answer can be wrong even though it reads like someone confidently answers a question. It is still too early to say it can answer questions with strong logic.
As we are a computer hardware company, let us start to “interview” ChatGPT with questions on GPU graphics cards. From the answers, we believe in the future, we can have a smart chatbot online to do customer service since most answers sound reasonable.
Question: Is it a good idea to buy a used GPU?
ChatGPT: It can be a good idea to buy a used GPU, but it’s important to be cautious and do your research. Here are a few things to consider when buying a used GPU:
Condition: Make sure the GPU is in good working condition. Check for any visible damage, such as bent pins or cracks in the PCB.
Compatibility: Make sure the GPU is compatible with your computer’s motherboard and power supply. Check the manufacturer’s website for the minimum requirements for the GPU.
Performance: Check the specs of the used GPU and compare it to a new one. You may be able to find a used GPU that performs just as well as a new one, but at a lower price.
Warranty: Consider whether the used GPU comes with a warranty or return policy. Some sellers may offer a limited warranty or return policy, which can give you some peace of mind.
Overall, it’s important to do your research and be cautious when buying a used GPU. It can be a good way to save money, but it’s important to make sure you’re getting a quality product.
Q: What kinds of GPUs are good for 4K PC gaming, and what kinds of GPUs are good for AI computing?
ChatGPT: For 4K PC gaming, you’ll want a GPU with a high amount of memory and a fast clock speed. Some examples of GPUs that are good for 4K gaming include the NVIDIA GeForce RTX 3080, the AMD Radeon RX 6800 XT, and the NVIDIA GeForce RTX 3090. These GPUs offer a high level of performance and can handle the demands of 4K gaming.
For AI computing, you’ll want a GPU with a high amount of memory and a fast clock speed, as well as support for parallel processing. Some examples of GPUs that are good for AI computing include the NVIDIA Tesla V100, the NVIDIA Quadro GV100, and the NVIDIA GeForce RTX 8000. These GPUs are specifically designed for AI and machine learning applications, and offer a high level of performance for these types of tasks.
It’s worth noting that the specific GPU you choose will depend on your specific needs and budget. There are many other factors to consider, such as the amount of memory, the number of CUDA cores, and the memory bandwidth. It’s important to do your research and choose the GPU that best meets your needs.
Question: Please recommend some good GPUs for 4K PC gaming in the year 2022
ChatGPT: In 2022, some good GPUs for 4K PC gaming are likely to include:
NVIDIA GeForce RTX 3080: This GPU offers excellent performance and is capable of running most games at 4K resolution with high graphics settings. It features 10GB of memory and 8704 CUDA cores.
AMD Radeon RX 6800 XT: This GPU also offers excellent performance and is capable of running most games at 4K resolution with high graphics settings. It features 16GB of memory and 4608 stream processors.
NVIDIA GeForce RTX 3090: This is the most powerful GPU currently available, and is ideal for 4K gaming. It features 24GB of memory and 10496 CUDA cores, making it capable of running even the most demanding games at 4K resolution with high graphics settings.
It’s worth noting that the specific GPU you choose will depend on your budget and specific needs. There are many other factors to consider, such as the amount of memory, the number of CUDA cores, and the memory bandwidth. It’s important to do your research and choose the GPU that best meets your needs.
Question: How about the year of 2023?
ChatGPT: It’s difficult to predict exactly what the best GPUs for 4K PC gaming in 2023 will be, as new products are constantly being released and technology is constantly improving. However, some factors that are likely to influence the performance of GPUs in 2023 include the number of CUDA cores, the amount of memory, and the clock speed.
In general, you’ll want to look for a GPU with a high number of CUDA cores, a large amount of memory, and a fast clock speed in order to get the best performance for 4K gaming. It’s also a good idea to keep an eye on the latest GPU releases from companies like NVIDIA and AMD, as they often release new products that offer improved performance and features.
Ultimately, the best GPU for 4K gaming in 2023 will depend on your budget and specific needs. It’s important to do your research and choose the GPU that best meets your needs.
Questions: How many GPUs have been employed to train ChatGPT?
ChatGPT: I’m sorry, but I don’t have information about the specific hardware used to train ChatGPT. ChatGPT is a large language model developed by OpenAI, and it’s likely that it was trained using a combination of CPU and GPU hardware. Training large language models like ChatGPT typically requires a lot of computational resources, including a large number of CPUs and GPUs. However, I don’t have specific details about the hardware used to train ChatGPT.
Conclusion: ChatGPT will deeply affect many areas, such as all QA websites, HowTo websites, and even online search and programming. Some people have demonstrated that ChatGPT can generate some basic AI framework to finish a simple AI task. It will change education in the future too. Students are not trained to memory knowledge, but how to ask the right questions, which is a very important capability. ChatGPT can also help small businesses. It can be employed as an online chatbot to answer questions from customers. For example, as an ITAD company, BuySellRam.com receives customer queries daily, so we may leverage an AI chatbot to help customers to get a quote or to solve common computer problems.
Originally published at https://www.buysellram.com on December 18, 2022.
0 notes
Text
Features: 2nd Gen Ray Tracing Cores 3rd Gen Tensor Cores Microsoft® DirectX® 12 Ultimate GDDR6X Graphics Memory NVIDIA DLSS NVIDIA® GeForce Experience™ NVIDIA G-SYNC® NVIDIA GPU Boost™ Game Ready Drivers Vulkan RT API, OpenGL 4.6 DisplayPort 1.4a, HDMI 2.1 HDCP 2.3 VR Ready NVIDIA® NVLink® (SLI Ready) 1-Click OC All photos, specifications, contents are used for reference only and are subject to change without notice. Reaching another new height with superior performance in the RTX™ 30 series family, the latest GeForce RTX™ 3090 Ti EX Gamer takes a great leap from the previous RTX™ 3090 EX Gamer model, featuring a record-breaking 10,752 CUDA cores and the max board power of 450W. In addition to a power boost to the CUDA cores and max board power, the brand-new GeForce RTX™ 3090 Ti EX Gamer graphics card emerges with an all-new power connector, fans, and cooling system ensuring an even greater balance between performance and heat dissipation efficiency, fulfilling the needs of hardcore gamers and overclocking enthusiasts worldwide. 1-Click OC allows you to boost your graphics cards with just one click! Download Xtreme Tuner now! Customize your RGB color with Xtreme Tuner, or synchronize with the rest of your system, by connecting the graphics card to +12V RGB header of your motherboard or other RGB control system, using the included cable.
0 notes
Text
Saturday Morning Coffee
Good morning from Charlottesville, Virginia! ☕️

I’ve been a bit obsessed with the idea of creating a CAD package for the Mac recently. For the challenge of it is why, but it would only be doable in a decent amount of time with financial backing large enough to hire a few folks to pull it off.
There is a way to jumpstart the process. The Open Design Alliance has portable libraries for reading and writing DWG files as well as rendering and so much more. All in portable C++.
Imagine a beautiful CAD app created just for the Mac. And yes, I know many already exist. 😁
Oh, right, I have a Mac app I need to finish.
Well, let’s get to it! Enjoy the links.
NBC News
DNC 2024 highlights: Kamala Harris accepts historic nomination in speech capping Democratic convention
We have our nominee! Now, let’s push her across the finish line and get our first Madame President!

Marc Palmer • Shareshot
Today we launched Shareshot! We’ve been working on this app for almost exactly a year, and we’re so pleased to be able to finally ship it. Here’s a little backstory and behind-the-scenes for those of you into app development.
Congratulations, Marc! Shareshot is a beautiful example of iOS craftsmanship. Go give it a try!
Alex Gaynor
I am an unrepentant advocate for migrating away from memory-unsafe languages (C and C++) to memory safe languages in security-relevant contexts. Many people reply that migrating large code bases to new languages is expensive, and we’d be better off making C++ safer. This is a reasonable response, after all there’s an enormous amount of C++ in the wild.
There is an enormous amount of C and C++ in the world. Too much to simply replace. I like Alex’s pragmatism on the matter. He has some proposals to improve the language without taking it too far down the path to incompatibility.
Just this week my interest in Rust began to grow. I’ve been using Swift daily since 2014, maybe 2015, and I really love the language and its ability to leverage the compiler to fix many of the memory issues seen in C and C++, like dangling pointers, forgotten allocations, and object lifetimes. We also have Rust to provide us with a solid memory protection model and the ability to be used for high performance code that is cross platform.
Rewriting software is costly and can also cost you your company. So taking that on should probably be avoided like the plague.
What if you picked your battles? How about writing new code in Rust or Swift? Perhaps improve public access to API’s by fronting it with Rust? How about picking some code known to cause a lot of crashes in your app and rewrite just that bit?
We can use tried and true methods in C++ to improve memory safety but it requires developers to be extremely disciplined.
Simple things like filling new memory allocations with known patterns. I prefer to fill the memory with zeros. You can also do the same when you delete it.
Reference counted pointers — AKA smart pointers — help.
Modern C++ has introduced mechanisms to transfer pointer ownership, always a tough problem to handle and the problem that lead to the creation of smart pointers.
Anywho, the piece is an easy read with good ideas. Go give it a gander.
Jess Weatherbed • The Verge
Many Procreate users can breathe a sigh of relief now that the popular iPad illustration app has taken a definitive stance against generative AI. “We’re not going to be introducing any generative AI into our products,” Procreate CEO James Cuda said in a video posted to X. “I don’t like what’s happening to the industry, and I don’t like what it’s doing to artists.”
I can really appreciate this stance. Artists often have a deep psychological attachment to their work and the creative process — hell — they go through to bring it to life. Taking that work, that style, and using it to train an AI to rip them off is just slimy.
Caleb Newton • Bipartisan Report
A dozen individuals who served as lawyers in Republican presidential administrations are bucking Republican presidential nominee Donald Trump and endorsing Democratic presidential pick Kamala Harris in a new letter that was publicized first at Fox News. The list includes prominent former judge J. Michael Luttig, who also served in the Reagan Administration.
Even with all of this at least half the country will vote for the Orange Man. It’s shocking, really.
Joe Brockmeier • lwn.net
The FreeBSD Project is, for the second time this year, engaging in a long-running discussion about the possibility of including Rust in its base system. The sequel to the first discussion included some work by Alan Somers to show what it might look like to use Rust code in the base tree. Support for Rust code does not appear much closer to being included in FreeBSD’s base system, but the conversation has been enlightening.
Speaking of Rust! Apparently Rust has found its way into the Linux Kernel and Microsoft has used it for Windows API development. It’s time for FreeBSD to get on board!
I wonder if Apple with push some Swift into Darwin or XNU at some point? Swift was written so it could be used for system level programming.
Carole Cadwalladr • The Guardian
Inciting rioters in Britain was a test run for Elon Musk. Just see what he plans for America
Musk has gone deep down the MAGA rabbit hole. His ketamine addled brain lives in its own world of conspiracies and white supremacy.
He’s unraveling in real time. Dumping his, often wacko, thoughts on X. He behaves more like a two year old than a man in his 50s.
Why do people still believe this man is some kind of genius? He’s a man child who throws hissy fits until he gets what he wants.
Money can’t buy happiness but it can buy politicians.

Matt Birchler • Birchtree
Why does Apple feel it’s worth trashing their relationship with creators and developers so that they can take 30% of the money I pay an up-and-coming creator who is trying to make rent in time each month? This isn’t a hypothetical, I genuinely want to know. Is the goal to turn into Microsoft, because this is how you turn into Microsoft.
Hate to say it Matt but Apple is today what Microsoft was in the 90’s. They are the 800lb gorilla in the room throwing their weight around.
I really love Apple products and their development tools and can’t see switching away from them. I just wish they’d be a bit kinder to the development community, that’s all.
Kelly Dobkin • Los Angeles Times
chef and co-owner Eric Park serves a black sesame misugaru drink that combines espresso, oat milk, the multigrain powder and gets topped with black sesame cream. It’s nutty, sweet and frothy, but not too rich thanks to the bitterness of the espresso.
Ok, now I really want to try misugaru. The one described above sounds incredible. 🤤
Alex Henderson • Raw Story
Reading through the Ohio Revised Code, Case Western Reserve University Law Professor Atiba Ellis couldn’t help looking for an alternative interpretation. Was there an error? Shoddy drafting? Because why on earth, he wondered, would a person clear that third bar, and submit documentation proving they broke the law by registering to vote?
This is just another GOP scheme to kick people off voter rolls. 🤬
Foone
ahh, another startup that burnt out trying to build some silly AI project on crap hardware. I wonder what they did? I check their URL: ahh. healthcare. great, great.
This Mastodon thread is an interesting read and a cautionary tale. Before you sale off old hardware make sure you remove its storage or at the very least wipe the storage with a destructive reformat.
Zarar
Around 2AM this morning I had a realization that this was the most stressed I have ever been. On verge of a complete breakdown.
Ahhh, the life of a software developer. I’ve seen and experienced this stress on numerous occasions. I don’t recommend it.
Daryl Baxter • iMore
This MacBook app generated $100,000 in seven days, now Stripe won’t pay up
This is a wild story and I hope the developer is able to get paid and save his company.


1 note
·
View note
Text
Card đồ họa NVIDIA T600 4GB 4mDP GFX - 340K9AA
CẠC ĐỒ HỌA HP NVIDIA T600 4GB 4MDP GFX_340K9AA Model T600 GPU Memory 4 GB GDDR6 Memory Interface 128-bit Memory Bandwidth Up to 160 GB/s NVIDIA CUDA Cores 640 Single-Precision Performance Up to 1.7 TFLOPs System Interface PCI Express 3.0 x 16 Max Power Consumption 40 W Thermal Solution Active Form Factor 2.713 inches H x 6.137 inches L , single slot Display Connectors 4 x mDP 1.4 with…
0 notes
Text
Model NameInno3D Geforce RTX 4080 Super Ichill x3/ 16GB GDDR6XModel NumberC408S3-166XX-187049HBrandINNO3D
GPU Engine Specs: CUDA Cores10240Boost Clock (MHz)2610Base Clock(MHz)2295Thermal and Power Spec: Minimum System Power Requirement (W)750Supplementary Power Connectors3x PCIe 8-pin cables (adapter in box) OR 320 W or greater PCIe Gen 5 cableMemory Specs: Memory Clock23GbpsStandard Memory Config16GBMemory InterfaceGDDR6XMemory Interface Width256-bitMemory Bandwidth (GB/sec)736
0 notes
Text
Huawei’s Ascend 910C: A Bold Challenge to NVIDIA in the AI Chip Market
New Post has been published on https://thedigitalinsider.com/huaweis-ascend-910c-a-bold-challenge-to-nvidia-in-the-ai-chip-market/
Huawei’s Ascend 910C: A Bold Challenge to NVIDIA in the AI Chip Market
The Artificial Intelligence (AI) chip market has been growing rapidly, driven by increased demand for processors that can handle complex AI tasks. The need for specialized AI accelerators has increased as AI applications like machine learning, deep learning, and neural networks evolve.
NVIDIA has been the dominant player in this domain for years, with its powerful Graphics Processing Units (GPUs) becoming the standard for AI computing worldwide. However, Huawei has emerged as a powerful competitor with its Ascend series, leading itself to challenge NVIDIA’s market dominance, especially in China. The Ascend 910C, the latest in the line, promises competitive performance, energy efficiency, and strategic integration within Huawei’s ecosystem, potentially reshaping the dynamics of the AI chip market.
Background on Huawei’s Ascend Series
Huawei’s entry into the AI chip market is part of a broader strategy to establish a self-reliant ecosystem for AI solutions. The Ascend series began with the Ascend 310, designed for edge computing, and the Ascend 910, aimed at high-performance data centers. Launched in 2019, the Ascend 910 was recognized as the world’s most powerful AI processor, delivering 256 teraflops (TFLOPS) of FP16 performance.
Built on Huawei’s proprietary Da Vinci architecture, the Ascend 910 offers scalable and flexible computing capabilities suitable for various AI workloads. The chip’s emphasis on balancing power with energy efficiency laid the groundwork for future developments, leading to the improved Ascend 910B and the latest Ascend 910C.
The Ascend series is also part of Huawei’s effort to reduce dependence on foreign technology, especially in light of U.S. trade restrictions. By developing its own AI chips, Huawei is working toward a self-sufficient AI ecosystem, offering solutions that range from cloud computing to on-premise AI clusters. This strategy has gained traction with many Chinese companies, particularly as local firms have been encouraged to limit reliance on foreign technology, such as NVIDIA’s H20. This has created an opportunity for Huawei to position its Ascend chips as a viable alternative in the AI space.
The Ascend 910C: Features and Specifications
The Ascend 910C is engineered to offer high computational power, energy efficiency, and versatility, positioning it as a strong competitor to NVIDIA’s A100 and H100 GPUs. It delivers up to 320 TFLOPS of FP16 performance and 64 TFLOPS of INT8 performance, making it suitable for a wide range of AI tasks, including training and inference.
The Ascend 910C delivers high computational power, consuming around 310 watts. The chip is designed for flexibility and scalability, enabling it to handle various AI workloads such as Natural Language Processing (NLP), computer vision, and predictive analytics. Additionally, the Ascend 910C supports high bandwidth memory (HBM2e), essential for managing large datasets and efficiently training complex AI models. The chip’s software compatibility, including support for Huawei’s MindSpore AI framework and other platforms like TensorFlow and PyTorch, makes it easier for developers to integrate into existing ecosystems without significant reconfiguration.
Huawei vs. NVIDIA: The Battle for AI Supremacy
NVIDIA has long been the leader in AI computing, with its GPUs serving as the standard for machine learning and deep learning tasks. Its A100 and H100 GPUs, built on the Ampere and Hopper architectures, respectively, are currently the benchmarks for AI processing. The A100 can deliver up to 312 TFLOPS of FP16 performance, while the H100 offers even more robust capabilities. NVIDIA’s CUDA platform has significantly advanced, creating a software ecosystem that simplifies AI model development, training, and deployment.
Despite NVIDIA’s dominance, Huawei’s Ascend 910C aims to offer a competitive alternative, particularly within the Chinese market. The Ascend 910C performs similarly to the A100, with slightly better power efficiency. Huawei’s aggressive pricing strategy makes the Ascend 910C a more affordable solution, offering cost savings for enterprises that wish to scale their AI infrastructure.
However, the software ecosystem remains a critical area of competition. NVIDIA’s CUDA is widely adopted and has a mature ecosystem, while Huawei’s MindSpore framework is still growing. Huawei’s efforts to promote MindSpore, particularly within its ecosystem, are essential to convince developers to transition from NVIDIA’s tools. Despite this challenge, Huawei has been progressing by collaborating with Chinese companies to create a cohesive software environment supporting the Ascend chips.
Reports indicate that Huawei has started distributing prototypes of the Ascend 910C to major Chinese companies, including ByteDance, Baidu, and China Mobile. This early engagement suggests strong market interest, especially among companies looking to reduce dependency on foreign technology. As of last year, Huawei’s Ascend solutions were used to train nearly half of China’s top 70 large language models, demonstrating the processor’s impact and widespread adoption.
The timing of the Ascend 910C launch is significant. With U.S. export restrictions limiting access to advanced chips like NVIDIA’s H100 in China, domestic companies are looking for alternatives, and Huawei is stepping in to fill this gap. Huawei’s Ascend 910B has already gained traction for AI model training across various sectors, and the geopolitical environment is driving further adoption of the newer 910C.
While NVIDIA is projected to ship over 1 million H20 GPUs to China, generating around $12 billion in revenue, Huawei’s Ascend 910C is expected to generate $2 billion in sales this year. Moreover, companies adopting Huawei’s AI chips may become more integrated into Huawei’s broader ecosystem, deepening reliance on its hardware and software solutions. However, this strategy may also raise concerns among businesses about becoming overly dependent on one vendor.
Strategic Partnerships and Alliances
Huawei has made strategic partnerships to drive the adoption of the Ascend 910C. Collaborations with major tech players like Baidu, ByteDance, and Tencent have facilitated the integration of Ascend chips into cloud services and data centers, ensuring that Huawei’s chips are part of scalable AI solutions. Telecom operators, including China Mobile, have incorporated Huawei’s AI chips into their networks, supporting edge computing applications and real-time AI processing.
These alliances ensure that Huawei’s chips are standalone products and integral parts of broader AI solutions, making them more attractive to enterprises. Additionally, this strategic approach allows Huawei to promote its MindSpore framework, building an ecosystem that could rival NVIDIA’s CUDA platform over time.
Geopolitical factors have significantly influenced Huawei’s strategy. With U.S. restrictions limiting its access to advanced semiconductor components, Huawei has increased its investments in R&D and collaborations with domestic chip manufacturers. This focus on building a self-sufficient supply chain is critical for Huawei’s long-term strategy, ensuring resilience against external disruptions and helping the company to innovate without relying on foreign technologies.
Technical Edge and Future Outlook
The Ascend 910C has gained prominence with its strong performance, energy efficiency, and integration into Huawei’s ecosystem. It competes closely with NVIDIA’s A100 in several key performance areas. For tasks that require FP16 computations, like deep learning model training, the chip’s architecture is optimized for high efficiency, resulting in lower operational costs for large-scale use.
However, challenging NVIDIA’s dominance is no easy task. NVIDIA has built a loyal user base over the years because its CUDA ecosystem offers extensive development support. For Huawei to gain more market share, it must match NVIDIA’s performance and offer ease of use and reliable developer support.
The AI chip industry will likely keep evolving, with technologies like quantum computing and edge AI reshaping the domain. Huawei has ambitious plans for its Ascend series, with future models promising even better integration, performance, and support for advanced AI applications. By continuing to invest in research and forming strategic partnerships, Huawei aims to strengthen its foundations in the AI chip market.
The Bottom Line
In conclusion, Huawei’s Ascend 910C is a significant challenge to NVIDIA’s dominance in the AI chip market, particularly in China. The 910C’s competitive performance, energy efficiency, and integration within Huawei’s ecosystem make it a strong contender for enterprises looking to scale their AI infrastructure.
However, Huawei faces significant hurdles, especially competing with NVIDIA’s well-established CUDA platform. The success of the Ascend 910C will rely heavily on Huawei’s ability to develop a robust software ecosystem and strengthen its strategic partnerships to solidify its position in the evolving AI chip industry.
#accelerators#adoption#ai#AI chip#AI chips#AI Infrastructure#ai model#AI models#amp#Analytics#applications#approach#architecture#artificial#Artificial Intelligence#background#benchmarks#billion#Building#Bytedance#challenge#China#chip#chips#Cloud#cloud computing#cloud services#clusters#Companies#competition
0 notes
Text
NVIDIA H100 vs. A100: Which GPU Reigns Supreme?

NVIDIA’s CEO, Jensen Huang, unveiled the NVIDIA H100 Tensor Core GPU at NVIDIA GTC 2022, marking a significant leap in GPU technology with the new Hopper architecture. But how does it compare to its predecessor, the NVIDIA A100, which has been a staple in deep learning? Let’s explore the advancements and differences between these two powerhouse GPUs.
NVIDIA H100: A Closer Look
The NVIDIA H100, based on the new Hopper architecture, is NVIDIA’s ninth-generation data center GPU, boasting 80 billion transistors. Marketed as “the world’s largest and most powerful accelerator,” it’s designed for large-scale AI and HPC models. Key features include:
Most Advanced Chip: The H100 is built with cutting-edge technology, making it highly efficient for complex tasks.
New Transformer Engine: Enhances network speeds by six times compared to previous versions.
Confidential Computing: Ensures secure processing of sensitive data.
2nd-Generation Secure Multi-Instance GPU (MIG): Extends capabilities by seven times over the A100.
4th-Generation NVIDIA NVLink: Connects up to 256 H100 GPUs with nine times the bandwidth.
New DPX Instructions: Accelerates dynamic programming by up to 40 times compared to CPUs and up to seven times compared to previous-generation GPUs.
NVIDIA asserts that the H100 and Hopper technology will drive future AI research, supporting massive AI models, deep recommender systems, genomics, and complex digital twins. Its enhanced AI inference capabilities cater to real-time applications like giant-scale AI models and chatbots.

NVIDIA A100: A Deep Dive
Introduced in 2020, the NVIDIA A100 Tensor Core GPU was heralded as the highest-performing elastic data center for AI, data analytics, and HPC. Based on the Ampere architecture, it delivers up to 20 times higher performance than its predecessor. The A100’s notable features include:
Multi-Instance GPU (MIG): Allows division into seven GPUs, adjusting dynamically to varying demands.
Third-Generation Tensor Core: Boosts throughput and supports a wide range of DL and HPC data types.
The A100’s ability to support cloud service providers (CSPs) during the digital transformation of 2020 and the pandemic was crucial, delivering up to seven times more GPU instances through its MIG virtualization and GPU partitioning capabilities.
Architecture Comparison NVIDIA Hopper
Named after the pioneering computer scientist Grace Hopper, the Hopper architecture significantly enhances the MIG capabilities by up to seven times compared to the previous generation. It introduces features that improve asynchronous execution, allowing memory copies to overlap with computation and reducing synchronization points. Designed to accelerate the training of Transformer models on H100 GPUs by six times, Hopper addresses the challenges of long training periods for large models while maintaining GPU performance.
NVIDIA Ampere
Described as the core of the world’s highest-performing elastic data centers, the Ampere architecture supports elastic computing at high acceleration levels. It’s built with 54 billion transistors, making it the largest 7nm chip ever created. Ampere offers L2 cache residency controls for data management, enhancing data center scalability. The third generation of NVLink® in Ampere doubles GPU-to-GPU bandwidth to 600 GB/s, facilitating large-scale application performance.
Detailed Specifications: H100 vs. A100

H100 Specifications:
8 GPCs, 72 TPCs (9 TPCs/GPC), 2 SMs/TPC, 144 SMs per full GPU
128 FP32 CUDA Cores per SM, 18432 FP32 CUDA Cores per full GPU
4 Fourth-Generation Tensor Cores per SM, 576 per full GPU
6 HBM3 or HBM2e stacks, 12 512-bit Memory Controllers
60MB L2 Cache
Fourth-Generation NVLink and PCIe Gen 5
Fabricated on TSMC’s 4N process, the H100 has 80 billion transistors and 395 billion parameters, providing up to nine times the speed of the A100. It’s noted as the first truly asynchronous GPU, extending A100’s asynchronous transfers across address spaces and growing the CUDA thread group hierarchy with a new level called the thread block cluster.
A100 Specifications:
8 GPCs, 8 TPCs/GPC, 2 SMs/TPC, 16 SMs/GPC, 128 SMs per full GPU
64 FP32 CUDA Cores/SM, 8192 FP32 CUDA Cores per full GPU
4 third-generation Tensor Cores/SM, 512 third-generation Tensor Cores per full GPU
6 HBM2 stacks, 12 512-bit memory controllers
The A100 is built on the A100 Tensor Core GPU SM architecture and the third-generation NVIDIA high-speed NVLink interconnect. With 54 billion transistors, it delivers five petaflops of performance, a 20x improvement over its predecessor, Volta. The A100 also includes fine-grained structured sparsity to double the compute throughput for deep neural networks.
Conclusion
When comparing NVIDIA’s H100 and A100 GPUs, it’s clear that the H100 brings substantial improvements and new features that enhance performance and scalability for AI and HPC applications. While the A100 set a high standard in 2020, the H100 builds upon it with advanced capabilities that make it the preferred choice for cutting-edge research and large-scale model training. Whether you choose the H100 or A100 depends on your specific needs, but for those seeking the latest in GPU technology, the H100 is the definitive successor.
FAQs
1- What is the main difference between NVIDIA H100 and A100?
The main difference lies in the architecture and capabilities. The H100, based on the Hopper architecture, offers enhanced performance, scalability, and new features like the Transformer Engine and advanced DPX instructions.
2- Which GPU is better for deep learning: H100 or A100?
The H100 is better suited for deep learning due to its advanced features and higher performance metrics, making it ideal for large-scale AI models.
3- Can the H100 GPU be used for gaming?
While the H100 is primarily designed for AI and HPC tasks, it can theoretically be used for gaming, though it’s not optimized for such purposes.
4- What are the memory specifications of the H100 and A100?
The H100 includes six HBM3 or HBM2e stacks with 12 512-bit memory controllers, whereas the A100 has six HBM2 stacks with 12 512-bit memory controllers.
5- How does the H100’s NVLink compare to the A100's?
The H100 features fourth-generation NVLink, which connects up to 256 GPUs with nine times the bandwidth, significantly outperforming the A100’s third-generation NVLink.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
0 notes
Link
$581.52 $ Leadtek NVIDIA T1000 4GB GDDR6 Professional WorkStation Graphics Card https://nzdepot.co.nz/product/leadtek-nvidia-t1000-4gb-gddr6-professional-workstation-graphics-card-2/?feed_id=150912&_unique_id=662f0e040b7d6 Features: NVIDIA T1000 – NVIDIA Turing GPU architecture – 896 NVIDIA® CUDA® Cores – 4GB GDDR6 Memory – Up to 160GB/s Memory Bandwidth – Max. Power Consumption: 50W – Graphics Bus: PCI-E 3.0 x16 – Thermal Solution: Active – Display Connectors: mDP 1.4 (4) NVIDIA GPUs power the world’s most advanced desktop workstations, providing the visual computing power required by millions of professionals as part of their daily workflow. All phases of the professional workflow, from creating, editing, and viewing 2D and 3D models and video, to working with multiple applications across several displays, benefit from the power that only […] #
0 notes
Text
NVIDIA RTX 6000 Ada Generation 48GB Graphics Card

The Best Graphics and AI Performance for Desktop Computers
NVIDIA RTX 6000 Ada Generation capability and performance handle AI-driven processes. Based on the NVIDIA Ada Lovelace GPU architecture, the RTX 6000 delivers unmatched rendering, AI, graphics, and compute performance with third-generation RT Cores, fourth-generation Tensor Cores, and next-generation CUDA Cores with 48GB of graphics RAM In demanding corporate contexts, NVIDIA RTX 6000 CPU workstations excel.
Highlights
Industry-Leading Performance
91.1 TFLOPS Single-Precision Performance
Performance of RT Core: 210.6 TFLOPS
Performance of Tensor: 1457 AI TOPS
Features
Powered by the NVIDIA Ada Lovelace Architecture
NVIDIA Ada Lovelace Architecture-Based CUDA Cores
With two times the speed of the previous generation for single-precision floating-point (FP32) operations, NVIDIA RTX 6000 Ada Lovelace Architecture-Based CUDA Cores offer notable performance gains for desktop graphics and simulation workflows, including intricate 3D computer-aided design (CAD) and computer-aided engineering (CAE).
Third-Generation RT Cores
Third-generation RT Cores offer enormous speedups for workloads such as photorealistic rendering of movie content, architectural design evaluations, and virtual prototyping of product designs, with up to 2X the throughput compared to the previous generation. Additionally, this approach speeds up and improves the visual correctness of ray-traced motion blur rendering.
Fourth-Generation Tensor Cores
Rapid model training and inferencing are made possible on RTX-powered AI workstations by fourth-generation Tensor Cores, which use the FP8 data format to give more than two times the AI performance of the previous generation.
NVIDIA RTX 6000 Ada 48GB GDDR6
Data scientists, engineers, and creative professionals may work with massive datasets and tasks including simulation, data science, and rendering with the NVIDIA RTX 6000 Ada 48GB GDDR6 memory.
AV1 Encoders
AV1 encoding gives broadcasters, streamers, and video conferences more options with the eighth-generation dedicated hardware encoder (NVENC). It is 40% more efficient than H.264, thus 1080p streamers can move to 1440p without losing quality.
Virtualization-Ready
A personal workstation can be transformed into several high-performance virtual workstation instances with support for NVIDIA RTX Virtual Workstation (vWS) software, enabling distant users to pool resources to power demanding design, artificial intelligence, and computation workloads.
Performance
Performance for Endless Possibilities
For modern professional workflows, the RTX 6000 delivers unrivaled rendering, AI, graphics, and computing performance. RTX 6000 delivers up to 10X more performance than the previous generation, helping you succeed at work.
NVIDIA RTX 6000 Ada Price
The NVIDIA RTX 6000 Ada Generation is a high-end workstation GPU primarily designed for professional tasks such as 3D rendering, architectural visualization, and engineering simulations. Its price varies based on the retailer and region but generally starts around $6,800 USD and can exceed $7,000 USD depending on configurations and add-ons.
Benefits
The NVIDIA RTX 6000 Ada is a top graphics card for complicated computing and visualization. Some of its key benefits:
Exceptional Performance
The Ada Lovelace-based RTX 6000 Ada excels at video editing, 3D rendering, and AI creation. Rendering and simulations are faster and more accurate because to its advanced RT cores and high core count.
Abundant Memory Space
Large datasets, intricate 3D models, and high-resolution textures can all be handled by the RTX 6000 Ada because to its 48 GB of GDDR6 ECC memory. This makes it perfect for fields like scientific inquiry, filmmaking, and architecture.
Improvements to AI and Ray Tracing
The card offers enhanced performance and realistic images because to its sophisticated ray-tracing capabilities and DLSS technology. This is particularly advantageous for VFX production, animation, and game development.
Efficiency in Energy Use
The RTX 6000 Ada’s effective Ada Lovelace architecture allows it to give excellent performance at a reduced power consumption than its predecessors, which lowers operating expenses for enterprises.
Improved Communication
It supports up to 8K resolution at high refresh rates and has DisplayPort 1.4a and HDMI 2.1 outputs. This is ideal for multi-display configurations and sophisticated visualization.
Read more on Govindhech.com
#NVIDIARTX#RTX6000#RTX6000Ada#NVIDIAGPU#GraphicsCard#48GBGPU#LovelaceGPU#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
0 notes
Text
Manli NVIDIA RTX Turbo 4090 with Blower Cooling

In the ever-evolving world of graphics cards, a new titan has emerged: the Manli NVIDIA RTX Turbo 4090 Blower Cooling. This powerhouse is not just a component; it’s a monumental leap in gaming and creative performance. Let’s dive into its specifications and features that set it apart.
Specifications:
Product Name: Manli NVIDIA RTX Turbo 4090 Blower Cooling
Model Name: M-NRTX4090G/6RHHPPP-M3530
Chipset: GeForce RTX™ 4090
Base/Boost Clock: 2235/2520MHz
CUDA® Cores: 16384
Memory: 24GB GDDR6X, 21Gbps
Memory Interface: 384-bit
Memory Bandwidth: 1008GB/s
Width: 3.5-Slot
Cooling: Heatsink with Triple Cooler
Display Output: 3 x DisplayPort, HDMI
Dimensions: 351 x 145 x 63mm
Power: 450W
Max GPU Temperature: 90℃
Packaging Size: 439.5 x 229 x 112mm
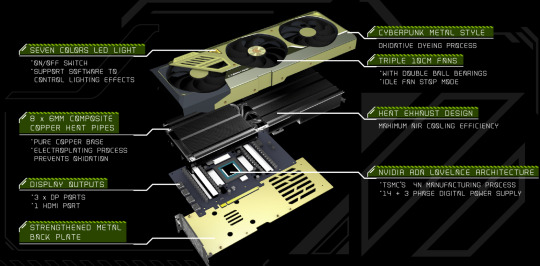
Unparalleled Performance
Model Name: M-NRTX4090G/6RHHPPP-M3530. At the heart of this beast lies the GeForce RTX™ 4090 chipset, renowned for its supreme capabilities. The card boasts an impressive base and boost clock of 2235/2520MHz, ensuring that it performs exceptionally under demanding scenarios.
CUDA® Cores: With a staggering 16384 NVIDIA CUDA® Cores, the RTX 4090 is built for speed and efficiency, catering to the most intense gaming sessions and demanding creative workloads.

Next-Gen Memory
Memory Specs: Equipped with 24GB of GDDR6X memory and a memory speed of 21Gbps, this graphics card is designed for ultra-high-resolution gaming and complex 3D rendering tasks. The 384-bit memory interface and a bandwidth of 1008GB/s further underscore its capabilities in handling large data sets smoothly.
Cutting-Edge Cooling and Design
Cooling: The card’s innovative heatsink with Triple Cooler design ensures optimal thermal performance, crucial for maintaining stability and longevity under load.
Build: It’s a 3.5-slot card, with dimensions of 351 x 145 x 63mm, signifying a robust and sturdy build quality. The design is not just functional but also aesthetically pleasing, fitting well into any high-end gaming rig.

Connectivity and Power
Display Outputs: Connectivity is versatile with 3 x DisplayPort and HDMI options, allowing for multiple monitor setups or high-resolution displays.
Power Requirements: The graphics card power stands at 450W, and it operates safely up to a maximum temperature of 90℃.
Beyond Fast: The NVIDIA® GeForce RTX® 4090 Experience
The Manli NVIDIA RTX Turbo 4090 is more than just fast; it’s a revolution in graphics card technology. It is powered by the NVIDIA Ada Lovelace architecture, which brings significant improvements in performance, efficiency, and AI-powered graphics.
AI and Ray Tracing Performance: With the fourth-gen Tensor Cores and third-gen RT Cores, the card offers up to 2x AI and ray tracing performance compared to previous generations. This means more realistic lighting, shadows, and reflections in games, as well as faster rendering times for creators.
Ultimate Experience for Gamers and Creators: The combination of its powerful specs and advanced architecture makes the RTX 4090 a top choice for gamers who want to experience ultra-high-performance gaming and for creators involved in detailed virtual worlds, unprecedented productivity, and innovative content creation.
Conclusion
The Manli NVIDIA RTX Turbo 4090 Blower Cooling 24GB is a testament to what modern technology can achieve in the realm of graphics cards. It’s not just an upgrade; it’s a transformation that redefines what’s possible in gaming and creative computing. For those who demand the best, the RTX 4090 is undoubtedly the ultimate choice.
M.Hussnain Visit us on social media: Facebook | Twitter | LinkedIn | Instagram | YouTube TikTok
0 notes