#CSV to JSON Converter
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
Unlock Your Potential: The Ultimate Guide to HugeTools.net
In today’s fast-paced digital world, having access to the right tools can make all the difference in boosting productivity, saving time, and achieving success. Enter HugeTools.net , your ultimate toolkit designed to simplify even the most complex tasks. Whether you're a developer, marketer, student, or entrepreneur, this platform has everything you need to get things done efficiently.
Welcome to our comprehensive guide where we’ll explore what makes HugeTools.net so special, highlight its key features, and show you how it can transform the way you work. Let's dive in!
What Is HugeTools.net?
HugeTools.net is an innovative online platform offering a vast array of free tools tailored to meet the needs of modern professionals and hobbyists alike. From text manipulation and image optimization to data conversion and SEO utilities, HugeTools.net provides solutions for almost every task imaginable.
Our mission is simple: empower users by delivering powerful, user-friendly tools that save time, reduce effort, and deliver high-quality results. No matter your skill level, you'll find something here to help you achieve your goals.
Key Features of HugeTools.net
Let’s take a closer look at some of the standout features available on HugeTools.net:
1. Text Tools
Manipulating text has never been easier with our collection of text tools:
Convert case (uppercase, lowercase, sentence case).
Remove extra spaces or duplicate lines.
Generate Lorem Ipsum for testing purposes.
Perfect for writers, developers, and anyone working with large amounts of text.
2. Image Optimization Tools
Optimize your images effortlessly with these handy utilities:
Resize images for web or print.
Convert file formats (JPEG to PNG, etc.).
Add watermarks for branding purposes.
Ideal for designers, bloggers, and photographers who need optimized visuals without compromising quality.
3. Data Conversion Tools
Transform data into different formats quickly and easily:
CSV to JSON converter.
XML to HTML transformer.
Base64 encoder/decoder.
Great for developers and analysts handling complex datasets.
4. SEO & Marketing Tools
Enhance your online presence with our suite of SEO and marketing tools:
Meta tag generator.
URL shortener.
Keyword density checker.
Helps marketers and content creators improve website performance and visibility.
5. Developer Utilities
Streamline coding tasks with specialized developer tools:
Color picker and palette generator.
Regex tester.
QR code generator.
Saves time for developers and simplifies common coding challenges.
Why Choose HugeTools.net?
Here are just a few reasons why HugeTools.net stands out from the competition:
User-Friendly Interface: Our tools are intuitive and require no technical expertise to operate.
Free to Use: Access all our tools without any hidden fees or subscriptions.
Constant Updates: We regularly update our platform with new features based on user feedback.
Reliable Performance: Trust us to deliver accurate results every time.
At HugeTools.net, usability, reliability, and accessibility are our top priorities. That’s why thousands of users worldwide rely on us to simplify their workflows.
How to Get Started
Ready to try HugeTools.net? Follow these simple steps:
Visit https://hugetools.net and browse through the categories.
Select the tool that matches your needs.
Follow the on-screen prompts to input your data or upload files.
Download or copy the output as needed.
Explore additional options within each tool for advanced functionality.
It’s that easy! Within minutes, you’ll be up and running with one of our powerful tools.
Tips and Tricks
To get the most out of HugeTools.net, consider these pro tips:
Combine multiple tools for enhanced productivity (e.g., optimize an image and then add a watermark).
Bookmark frequently used tools for quick access.
Check the "Help" section for tutorials and FAQs if you encounter any issues.
Share your experience with others—your feedback helps us improve!
Success Stories
Don’t just take our word for it—here’s what real users have to say about HugeTools.net:
"As a freelance graphic designer, I rely heavily on HugeTools.net to compress my images before sending them to clients. It saves me hours of work every week!" – Sarah M., Graphic Designer
"The CSV-to-JSON converter saved my team during a tight deadline. We couldn’t have completed the project without it." – John D., Software Engineer
These testimonials speak volumes about the impact HugeTools.net can have on your workflow.
Conclusion
HugeTools.net isn’t just another collection of tools—it’s a powerhouse designed to revolutionize the way you work. With its diverse range of functionalities, commitment to user satisfaction, and constant innovation, there’s no reason not to give it a try.
Start exploring today and discover how HugeTools.net can transform your productivity. Who knows? You might just find your new favorite tool!
Call to Action
Ready to boost your productivity? Head over to HugeTools.net now and start using our free tools! Don’t forget to leave a comment below sharing your favorite tool or suggesting new ones we could add. Happy tooling!
#Secondary Tags (Specific Features)#Text Tools#Image Optimization#Data Conversion#SEO Tools#Marketing Tools#Developer Utilities#CSV to JSON Converter#QR Code Generator#Regex Tester#Meta Tag Generator#Tertiary Tags (Audience & Use Cases)#For Developers#For Marketers#For Students#For Entrepreneurs#For Designers#Work-from-Home Tools#Remote Work Tools#Digital Marketing Tools#Content Creation Tools#Graphic Design Tools#Long-Tail Tags (Specific Phrases)#Best Free Online Tools#Tools for Boosting Productivity#How to Optimize Images Online#Convert CSV to JSON Easily#Free SEO Tools for Beginners#Quick Text Manipulation Tools#Enhance Your Workflow with HugeTools.net
0 notes
Text
i will not apply to the graduate assistant position i will not apply to the graduate assistant position i will not
#sophies ramblings#it pays but im tryna graduate and i should let the francophonists get a chance at it#also half of this this could 100% be automated through a simple python script that converts w JSON and divides texts by word#you can then really easily convert that to CSV and there's your spreadsheet
2 notes
·
View notes
Text
.
#i was given a task to research NLP ai tools and i am way too over my head#the words python and JSON are being thrown around. girl help i have a headache#i was really hoping there would be like a dummy proof app out there where i could chuck a bunch of txt files into and wohoo#that was the data set#but no it wants me to convert my formatted word docs into csv files and i have no fucking clue what to do#and the internet says python scripts. and bitch i dont fucking know python#miscellaneous#help ;o;
1 note
·
View note
Text
um does anyone know how i can go abt making a .json file like readable? i tried online .csv converters but tht didnt help it's the spotify account data file idk what im doing
12 notes
·
View notes
Note
Hi! Was wondering if there was a converter for non CSV files? Id really like to transfer an old clan to a new version but my files are JSON (both the old and new version) and I can't seem to get into the discord to ask for help either 😅
Hey! The Discord is back open now, so you should be okay to come in for help :)
For the most part, the game should handle updating old Clans itself, though it does mess up now and then! If it's giving you trouble definitely pop in and ask our tech team <3
☆ Fable ☆
28 notes
·
View notes
Text
Introducing Codetoolshub.com: Your One-Stop IT Tools Website
Hello everyone! I'm excited to introduce you to Codetoolshub.com, a comprehensive platform offering a variety of IT tools designed to enhance your productivity and efficiency. Our goal is to provide developers, IT professionals, and tech enthusiasts with easy-to-use online tools that can simplify their tasks. Here are some of the tools we offer:
Base64 File Converter
Basic Auth Generator
ASCII Text Drawer
PDF Signature Checker
Password Strength Analyser
JSON to CSV Converter
Docker Run to Docker Compose Converter
RSA Key Pair Generator
Crontab Generator
QR Code Generator
UUID Generator
XML Formatter
And many more...
We are constantly updating and adding new tools to meet your needs. Visit Codetoolshub.com to explore and start using these powerful and free tools today!
Thank you for your support, and we look forward to helping you with all your IT needs.
2 notes
·
View notes
Text
Azure Data Factory for Healthcare Data Workflows

Introduction
Azure Data Factory (ADF) is a cloud-based ETL (Extract, Transform, Load) service that enables healthcare organizations to automate data movement, transformation, and integration across multiple sources. ADF is particularly useful for handling electronic health records (EHRs), HL7/FHIR data, insurance claims, and real-time patient monitoring data while ensuring compliance with HIPAA and other healthcare regulations.
1. Why Use Azure Data Factory in Healthcare?
✅ Secure Data Integration — Connects to EHR systems (e.g., Epic, Cerner), cloud databases, and APIs securely. ✅ Data Transformation — Supports mapping, cleansing, and anonymizing sensitive patient data. ✅ Compliance — Ensures data security standards like HIPAA, HITRUST, and GDPR. ✅ Real-time Processing — Can ingest and process real-time patient data for analytics and AI-driven insights. ✅ Cost Optimization — Pay-as-you-go model, eliminating infrastructure overhead.
2. Healthcare Data Sources Integrated with ADF

3. Healthcare Data Workflow with Azure Data Factory
Step 1: Ingesting Healthcare Data
Batch ingestion (EHR, HL7, FHIR, CSV, JSON)
Streaming ingestion (IoT sensors, real-time patient monitoring)
Example: Ingest HL7/FHIR data from an APIjson{ "source": { "type": "REST", "url": "https://healthcare-api.com/fhir", "authentication": { "type": "OAuth2", "token": "<ACCESS_TOKEN>" } }, "sink": { "type": "AzureBlobStorage", "path": "healthcare-data/raw" } }
Step 2: Data Transformation in ADF
Using Mapping Data Flows, you can:
Convert HL7/FHIR JSON to structured tables
Standardize ICD-10 medical codes
Encrypt or de-identify PHI (Protected Health Information)
Example: SQL Query for Data Transformationsql SELECT patient_id, diagnosis_code, UPPER(first_name) AS first_name, LEFT(ssn, 3) + 'XXX-XXX' AS masked_ssn FROM raw_healthcare_data;
Step 3: Storing Processed Healthcare Data
Processed data can be stored in: ✅ Azure Data Lake (for large-scale analytics) ✅ Azure SQL Database (for structured storage) ✅ Azure Synapse Analytics (for research & BI insights)
Example: Writing transformed data to a SQL Databasejson{ "type": "AzureSqlDatabase", "connectionString": "Server=tcp:healthserver.database.windows.net;Database=healthDB;", "query": "INSERT INTO Patients (patient_id, name, diagnosis_code) VALUES (?, ?, ?)" }
Step 4: Automating & Monitoring Healthcare Pipelines
Trigger ADF Pipelines daily/hourly or based on event-driven logic
Monitor execution logs in Azure Monitor
Set up alerts for failures & anomalies
Example: Create a pipeline trigger to refresh data every 6 hoursjson{ "type": "ScheduleTrigger", "recurrence": { "frequency": "Hour", "interval": 6 }, "pipeline": "healthcare_data_pipeline" }
4. Best Practices for Healthcare Data in ADF
🔹 Use Azure Key Vault to securely store API keys & database credentials. 🔹 Implement Data Encryption (using Azure Managed Identity). 🔹 Optimize ETL Performance by using Partitioning & Incremental Loads. 🔹 Enable Data Lineage in Azure Purview for audit trails. 🔹 Use Databricks or Synapse Analytics for AI-driven predictive healthcare analytics.
5. Conclusion
Azure Data Factory is a powerful tool for automating, securing, and optimizing healthcare data workflows. By integrating with EHRs, APIs, IoT devices, and cloud storage, ADF helps healthcare providers improve patient care, optimize operations, and ensure compliance with industry regulations.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
DataCAMP is a Cutting-edge Platform Designed for Big Data Intelligence | AHHA Labs

AHHA Labs' DataCAMP is a cutting-edge platform designed for big data intelligence, catering to the needs of modern industrial, enterprise, and data-driven ecosystems. It harnesses advanced AI and big data technologies to streamline data processing, analysis, and actionable insights.
DataCAMP Compatible with Legacy Systems Manage all manufacturing big data in an integrated manner with easy compatibility with legacy equipment, existing production systems, and commercial analysis tools.
Batch collect and transmit manufacturing data using various communication protocols.
DataCAMP widely supports most communication protocols used in industry, including FTP, network drives, TCP/IP sockets, Modbus/MELSEC, REDIS, and AMQP. Through this, users can conveniently collect all types of data, such as inspection images, inspection results, CCTV images, sound data, vibration data, and PLC data generated from various facilities and sensors. DataCAMP supports a user-friendly data query interface and data set export function, allowing easy transfer to various legacy systems such as MES and ERP as well as external commercial analysis tools.
Easy and fast automatic pre-processing
The data produced by numerous devices comes in various formats, such as CSV, JSON, and YAML. Since this equipment data is not directly compatible, each data set must be checked individually. To understand the entire factory status, you must convert each file format one by one and collect the data.
DataCAMP automates this process. Use the recipe function to convert and integrate various structured/unstructured data into the desired format. Users can directly specify the output data format for transmission and storage to legacy systems such as NAS and DB. DataCAMP also supports multiple techniques, including regular expressions (RegEx), a powerful string processing tool, to automatically perform data referencing, insertion, removal, merging, statistical pre-processing, and event triggering.
If you are looking for big data intelligence, you can find it at AHHA Labs.
Click here to if you are interested in AHHA Labs products.
View more: DataCAMP is a Cutting-edge Platform Designed for Big Data Intelligence
0 notes
Text
Understanding XML Conversion: What It Is and Why It Matters

Managing and sharing information across different platforms is a huge challenge. One solution that helps solve this problem is XML—a flexible and widely-used format for storing and sharing data. In this blog, we’ll explain what XML is, why it’s important, and what XML conversion means for businesses and digital marketers.
What is XML?
XML stands for Extensible Markup Language. XML functions as a method to arrange data into formats which create simple sharing and machine-readable and human-comprehensible structure. Just like in culinary recipes XML enables data organizations through a structured format which enables both human and machine readability during information sharing and update processes.
Here's a simple example of what an XML file might look like:
xml
Copy
<book>
<title>Learning XML</title>
<author>John Doe</author>
<year>2024</year>
</book>
In this case, the information is organized into tags (like <book>, <title>, <author>, and <year>) which tell us what the data represents.

What is XML Conversion?
The process of data transformation encompasses transitions between XML and any related data standards such as HTML or JSON or CSV. Through this conversion business data can transfer between various systems or platforms without disruption. The conversion process connects databases to XML formats for greater sharing value or transforms XML files into functional website content.
Why Does XML Conversion Matter?
Data Sharing and Compatibility XML presents one notable benefit because it operates with all existing systems. Any data stored as XML maintains portability for usage throughout different platforms because it ensures seamless transfer between databases and APIs and content management systems. When you transform data into XML format your information becomes shareable between different tools which support the XML standard.
Organization and Structure XML provides a method to maintain structured information organization. XML structures data through tags and attributes which simplifies both understanding and management and manipulation processes. For companies managing big data sets consisting of product listings and customer records and inventory information XML proves particularly vital.
SEO Benefits XML serves digital marketers by enhancing website functionality and search engine optimization requirements (SEO). Search engines including Google access your website more efficiently through the XML sitemap format. Using your site data as an XML sitemap functions to accelerate search engine discovery of pages and benefits your site's search performance.
Better Automation Data automation processes make practical use of XML standards. Businesses running their operations across multiple platforms (like eCommerce stores and mobile apps and marketing systems) use XML to perform swift and efficient data updates. Through automation you can convert data between different systems while avoiding laborious manual data entry across all systems.
Long-Term Flexibility XML provides documentation flexibility through its capability to offer support for a wide range of data types ranging from basic textual content to intricate multiple-level data structures. Your data stays evolving with your business growth through XML data conversion as your organization transforms.
How XML Conversion Works
The conversion of XML follows several fundamental procedures.
Source Data Collection: Your information must be ready for conversion to XML format now.
Conversion Process: Specialized tools with software support convert data into the XML format.
Validation and Cleanup: The XML data needs to maintain both well-formedness and validity by fulfilling XML rules about data structure and syntax.
Integration: The XML data must display both well-formedness and validity which are standards that determine correct XML structural compliance.

When Should You Consider XML Conversion?
When you need to exchange data with other systems: XML conversion serves as a solution to maintain data sharing capabilities between different platforms which need to access or exchange information.
When organizing large sets of data: Complex business data sets such as product catalogs and customer records find structure through the use of XML.
When optimizing your website for search engines: Using XML sitemaps speedily delivers your website to search engines thus helping enhance SEO performance.
Conclusion
Successful data transfer across systems and platforms requires thorough business management and digital marketing expertise regarding both XML standard and conversion practices. When implemented XML improves data structure and SEO execution and enables automated processes thus increasing both data functionality and operational efficiency.
Your business future-readiness depends on XML conversion since it prepares data to tackle forthcoming requirements no matter what new audiences or systems you pursue or how you enhance your digital impact. Visit Eloiacs to find more about XML Conversion.
0 notes
Text
To guide you through the entire data transcription and processing workflow, here’s a detailed explanation with specific steps and tips for each part:
Choose a Transcription Tool
OpenRefine:
Ideal for cleaning messy data with errors or inconsistencies.
Offers advanced transformation functions.
Download it from OpenRefine.org.
Google Sheets:
Best for basic transcription and organization.
Requires a Google account; accessible through Google Drive.
Other Alternatives:
Excel for traditional spreadsheet handling.
Online OCR tools (e.g., ABBYY FineReader, Google Docs OCR) if the data is in scanned images.
Extract Data from the Image
If your data is locked in the image you uploaded:
Use OCR (Optical Character Recognition) tools to convert it into text:
Upload the image to a tool like OnlineOCR or [Google Docs OCR].
Extract the text and review it for accuracy.
Alternatively, I can process the image to extract text for you. Let me know if you need that.
Copy or Input the Data
Manual Input:
Open your chosen tool (Google Sheets, OpenRefine, or Excel).
Create headers for your dataset to categorize your data effectively.
Manually type in or paste extracted text into the cells.
Bulk Import:
If the data is large, export OCR output or text as a .CSV or .TXT file and directly upload it to the tool.
Clean and Format the Data
In Google Sheets or Excel:
Use "Find and Replace" to correct repetitive errors.
Sort or filter data for better organization.
Use built-in functions (e.g., =TRIM() to remove extra spaces, =PROPER() for proper case).
In OpenRefine:
Use the "Clustering" feature to identify and merge similar entries.
Perform transformations using GREL (General Refine Expression Language).
Export or Use the Data
Save Your Work:
Google Sheets: File > Download > Choose format (e.g., CSV, Excel, PDF).
OpenRefine: Export cleaned data as CSV, TSV, or JSON.
Further Analysis:
Import the cleaned dataset into advanced analytics tools like Python (Pandas), R, or Tableau for in-depth processing.
Tools Setup Assistance:
If you'd like, I can guide you through setting up these tools or provide code templates (e.g., in Python) to process the data programmatically. Let me know how you'd prefer to proceed!
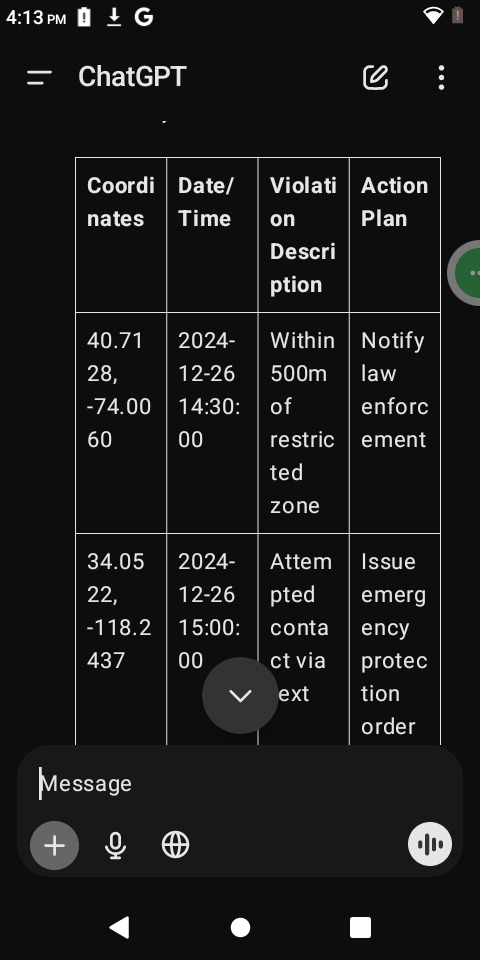
import csv
Function to collect data from the user
def collect_data(): print("Enter the data for each violation (type 'done' to finish):") data = [] while True: coordinates = input("Enter GPS Coordinates (latitude, longitude): ") if coordinates.lower() == 'done': break timestamp = input("Enter Date/Time (YYYY-MM-DD HH:MM:SS): ") violation = input("Enter Violation Description: ") action = input("Enter Action Plan: ") data.append({ "Coordinates": coordinates, "Date/Time": timestamp, "Violation Description": violation, "Action Plan": action }) return data
Function to save the data to a CSV file
def save_to_csv(data, filename="violations_report.csv"): with open(filename, mode='w', newline='') as file: writer = csv.DictWriter(file, fieldnames=["Coordinates", "Date/Time", "Violation Description", "Action Plan"]) writer.writeheader() writer.writerows(data) print(f"Data saved successfully to {filename}")
Main function
def main(): print("Restraining Order Violation Tracker") print("-----------------------------------") data = collect_data() save_to_csv(data)
Run the program
if name == "main": main()
Here’s a Python program to automate the transcription and organization of the data. The program will take input of GPS coordinates, violations, and actions, then output a structured CSV file for easy use.
Python Script: Data Transcription Program
import csv
Function to collect data from the user
def collect_data(): print("Enter the data for each violation (type 'done' to finish):") data = [] while True: coordinates = input("Enter GPS Coordinates (latitude, longitude): ") if coordinates.lower() == 'done': break timestamp = input("Enter Date/Time (YYYY-MM-DD HH:MM:SS): ") violation = input("Enter Violation Description: ") action = input("Enter Action Plan: ") data.append({ "Coordinates": coordinates, "Date/Time": timestamp, "Violation Description": violation, "Action Plan": action }) return data
Function to save the data to a CSV file
def save_to_csv(data, filename="violations_report.csv"): with open(filename, mode='w', newline='') as file: writer = csv.DictWriter(file, fieldnames=["Coordinates", "Date/Time", "Violation Description", "Action Plan"]) writer.writeheader() writer.writerows(data) print(f"Data saved successfully to {filename}")
Main function
def main(): print("Restraining Order Violation Tracker") print("-----------------------------------") data = collect_data() save_to_csv(data)
Run the program
if name == "main": main()
How It Works:
Input:
The program prompts you to enter GPS coordinates, date/time, violation descriptions, and proposed actions for each incident.
Type "done" when all entries are complete.
Processing:
The data is structured into a Python dictionary.
Output:
The program saves the collected data into a CSV file named violations_report.csv.
Sample Output (CSV Format):
Requirements:
Install Python (if not already installed).
Save the script as a .py file and run it.
The resulting CSV can be opened in Excel, Google Sheets, or similar tools.
Would you like help running or modifying the script?
0 notes
Text
Common XML Conversion Challenges and How to Overcome Them

One famous layout for storing and sharing records is XML (eXtensible Markup Language), that is widely used for its potential to maintain established facts in a bendy manner. However, converting records to or from XML can be tough, particularly when you have to ensure that the conversion is accurate and prefer minded with other structures.
1. Data Integrity Issues
When converting records to XML or from XML to different formats, one of the maximum not unusual challenges is ensuring the integrity of the records. If records is lost or corrupted during the conversion manner, it may result in incomplete or faulty information. This should bring about errors, lacking information, or misaligned records whilst the record is opened in a special machine.
How to Overcome It:
To avoid facts integrity problems, continually validate your XML documents before and after conversion. Use XML schema validation equipment to make sure that the records comply with the suitable structure and layout. Make positive that each one required factors are gift and correctly located within the XML document.
Additionally, it’s crucial to check the conversion process on a small subset of data earlier than changing the whole report. This let you become aware of capacity issues early on, saving you effort and time in the end.

2. Inconsistent Data Formatting
XML is a versatile layout, which means that there may be a whole lot of variation in how statistics is represented. For instance, one XML report would possibly use a specific date format, or more than a few might be formatted otherwise. If you are converting records from XML to any other format, these inconsistencies can purpose issues when the information is transferred to a brand new device, ensuing in mistakes or incorrect statistics.
How to Overcome It:
Standardize the format of the records earlier than conversion. This can be done by way of ensuring that all XML documents follow a consistent schema or fashion guide. If you’re converting from XML to a special layout, including CSV or JSON, make sure that the conversion device can take care of distinct records sorts effectively.
Also, test if the machine you are changing the XML records to has precise formatting requirements. For example, in case you're changing XML to a database, make sure the database helps the information kinds you're using (like dates or numbers) and that the conversion technique adheres to the ones specifications.
3. Nested Structures and Complex Hierarchies
XML permits you to store data in complex, nested systems, which can once in a while make conversion difficult. For example, a single XML record may comprise a couple of nested factors, making it difficult to map that shape right into a less complicated layout inclusive of CSV, which doesn’t aid hierarchical records.
How to Overcome It:
To manage complicated hierarchies, you may use specialized conversion tools which are designed to deal with nested XML structures. This equipment can flatten the hierarchy, creating separate tables or files for unique stages of information. If you're manually coping with the conversion, try to simplify the XML structure with the aid of breaking it down into smaller, extra plausible portions.
Another solution is to apply a mapping technique, in which the XML form is mapped to the target format based totally on predefined pointers. This way, nested facts can be treated in a manner that guarantees it remains correct whilst transferred to the today's tool.
4. Character Encoding Problems
Character encoding is any other not unusual issue when converting XML files. XML files can incorporate special characters (including accented letters, symbols, or non-Latin characters) that might not be well suited with the machine you’re changing the information to. If the encoding isn’t handled efficiently, it is able to lead to unreadable or corrupted facts.
How to Overcome It:
Ensure that the XML file uses a broadly customary character encoding wellknown consisting of UTF-eight or UTF-16, which helps a wide variety of characters. When converting XML to any other layout, double-test that the man or woman encoding settings suit between the supply and target documents.
Most modern-day conversion equipment routinely come across and keep man or woman encoding, however it’s constantly a terrific concept to check the encoding settings and perform a little testing to make sure the whole lot is working as anticipated.
5. Data Loss During Conversion
When changing from XML to some other format, there’s a danger that some of the facts can be misplaced or now not translated properly. For example, sure records factors in XML won't have an immediate equivalent inside the goal format, that could result in lack of data. This trouble is especially not unusual whilst changing to simpler codecs like CSV, which can't absolutely seize the complexity of an XML report.
How to Overcome It:
To save you information loss, carefully verify the goal layout and make certain that it can handle all of the facts types and structures in the XML report. If you’re changing XML to a database, as an instance, make certain that the database schema can help all of the elements and attributes inside the XML report.
Before beginning the conversion, find out any records factors that won't be supported in the target layout and create a plan for how to address the ones elements. This may additionally contain omitting non-essential records or restructuring the statistics to inform the modern-day format.

6. Lack of Proper Conversion Tools
Finding the right tools for XML conversion may be a mission. Much free or low-price gear might not provide the flexibility or accuracy required for complicated conversions. Additionally, some equipment might not guide the cutting-edge XML capabilities, together with XML namespaces, that could cause incomplete or incorrect conversion.
How to Overcome It:
Choose reliable and specialized XML conversion equipment that offer the capabilities you want. Popular equipment like Altova MapForce, Oxygen XML, and special XML conversion software provide a large style of features, inclusive of help for superior XML systems and multiple output codecs.
If you're working with a big extent of information, keep in mind making an investment in a paid answer, because it will generally offer greater comprehensive support and capabilities. Additionally, ensure that the device you choose can cope with the unique XML schema and structure you’re running with.
7. Limited Support for XML Schema
XML documents may be defined the usage of XML Schema, which allows put in force policies approximately how the information ought to be dependent. However, now not all conversion gear fully supports XML schemas, which can lead to problems when converting XML data that is based on strict schema rules.
How to Overcome It:
If your XML files are tested the usage of a schema, make sure the conversion tool you’re using can handle XML schemas well. Some superior conversion gear provide integrated help for XML Schema, allowing you to transform information while keeping the integrity of the schema.
If your preferred tool does no longer help XML schemas, you may need to manually map the XML information to the desired layout, making sure that the schema’s policies are reputable at some stage in the conversion system.
Conclusion
XML conversion can be a complex technique, especially when managing huge or complex facts sets. However, through know-how the common challenges—inclusive of facts integrity troubles, inconsistent formatting, nested systems, encoding troubles, information loss, and tool obstacles—you could take proactive steps to triumph over them.
By the usage of the right equipment, validating your records, standardizing formats, and ensuring right mapping, you could efficaciously convert XML documents without losing crucial facts or growing errors. Whether you’re converting information for inner use, integration with 1/three-birthday celebration systems, or sharing statistics with stakeholders, overcoming XML conversion demanding situations will help ensure that your records stays correct, usable, and handy for the duration of unique structures.
0 notes
Text
How to Build an ETL Pipeline in Python from Scratch

In today’s data-driven world, organizations rely on efficient systems to process and analyze vast amounts of information. One of the most critical components of data engineering is the Extract Transform Load Python process, which involves extracting data from various sources, transforming it to fit operational or analytical needs, and loading it into a target system for further use. Python, known for its simplicity and versatility, has become a popular language for building ETL pipelines due to its rich ecosystem of libraries and tools.
Why Use Python for ETL?
Python is a preferred choice for ETL development because of its flexibility and the availability of numerous libraries tailored for data manipulation, extraction, and integration. Libraries like Pandas, SQLAlchemy, BeautifulSoup, and PyODBC simplify working with diverse data sources such as APIs, web pages, databases, and file systems. Additionally, Python frameworks like Airflow and Luigi help automate and schedule ETL workflows.
Understanding the ETL Workflow
An ETL pipeline consists of three core stages: extraction, transformation, and loading. The goal is to efficiently move raw data through these stages to make it ready for decision-making or operational use.
Extraction: This phase involves retrieving data from various sources like databases, flat files, APIs, or web pages. Data formats can vary widely, from structured SQL tables to semi-structured JSON or XML files, and unstructured text data.
Transformation: Raw data is rarely in a ready-to-use format. During this stage, it is cleaned, standardized, and processed. Tasks might include removing duplicates, handling missing values, converting formats, or applying business logic to derive new fields.
Loading: In this final phase, the transformed data is written to a destination, such as a database, data warehouse, or data lake. This stage ensures the data is accessible for applications or analytics tools.
Key Components of an ETL Pipeline in Python
Building an ETL pipeline in Python requires understanding its ecosystem and leveraging the right tools for each phase:
Data Extraction Tools:
Pandas: Ideal for reading data from CSV, Excel, and JSON files.
Requests: Used for fetching data from APIs.
BeautifulSoup or Scrapy: Useful for web scraping.
PyODBC or SQLAlchemy: Perfect for connecting to databases.
Data Transformation Tools:
Pandas: Powerful for data manipulation, such as filtering, aggregating, and reshaping data.
Numpy: Useful for numerical transformations.
Regular Expressions (re): Effective for cleaning textual data.
Data Loading Tools:
SQLAlchemy: Simplifies writing data to relational databases.
Boto3: Useful for loading data into AWS S3 buckets.
Pandas to_csv/to_sql: Saves transformed data to files or databases.
Best Practices for ETL Pipeline Development in Python
To ensure a robust and scalable ETL pipeline, adhere to the following best practices:
Plan Your Workflow: Understand the structure and requirements of your data sources and targets. Clearly define the transformations and business rules.
Modular Design: Break down the ETL pipeline into modular components for easy debugging and scalability. Each phase (extract, transform, load) should be a separate, reusable function or script.
Error Handling and Logging: Implement error-catching mechanisms to handle interruptions gracefully. Logging frameworks like Python’s logging module can help track and debug issues.
Test and Validate: Always validate extracted and transformed data before loading. Unit tests can help ensure the pipeline behaves as expected.
Optimize for Performance: Handle large datasets efficiently by using batch processing, multi-threading, or distributed computing frameworks like Dask or Apache Spark.
Applications of Python ETL Pipelines
Python ETL pipelines are widely used across industries for various purposes:
Business Intelligence: Aggregating data from multiple systems to generate reports and dashboards.
Data Warehousing: Moving data from operational databases to analytical data warehouses.
Machine Learning Pipelines: Preparing training data by extracting, cleaning, and transforming raw datasets.
Web Data Integration: Scraping web data and merging it with internal datasets for enhanced insights.
Conclusion
Building an ETL pipeline from scratch in Python may seem daunting at first, but with the right tools and approach, it can be both efficient and scalable. Python’s ecosystem empowers developers to handle the complexity of diverse data sources and create workflows that are tailored to specific business needs. By focusing on key concepts and following best practices, you can build an ETL pipeline that transforms raw data into actionable insights, driving better decision-making for your organization.
Whether you’re a seasoned data engineer or a novice programmer, Python offers the versatility and tools needed to master the art of Extract, Transform, Load (ETL).
0 notes
Text
Top 6 Scraping Tools That You Cannot Miss in 2024
In today's digital world, data is like money—it's essential for making smart decisions and staying ahead. To tap into this valuable resource, many businesses and individuals are using web crawler tools. These tools help collect important data from websites quickly and efficiently.
What is Web Scraping?
Web scraping is the process of gathering data from websites. It uses software or coding to pull information from web pages, which can then be saved and analyzed for various purposes. While you can scrape data manually, most people use automated tools to save time and avoid errors. It’s important to follow ethical and legal guidelines when scraping to respect website rules.
Why Use Scraping Tools?
Save Time: Manually extracting data takes forever. Web crawlers automate this, allowing you to gather large amounts of data quickly.
Increase Accuracy: Automation reduces human errors, ensuring your data is precise and consistent.
Gain Competitive Insights: Stay updated on market trends and competitors with quick data collection.
Access Real-Time Data: Some tools can provide updated information regularly, which is crucial in fast-paced industries.
Cut Costs: Automating data tasks can lower labor costs, making it a smart investment for any business.
Make Better Decisions: With accurate data, businesses can make informed decisions that drive success.
Top 6 Web Scraping Tools for 2024
APISCRAPY
APISCRAPY is a user-friendly tool that combines advanced features with simplicity. It allows users to turn web data into ready-to-use APIs without needing coding skills.
Key Features:
Converts web data into structured formats.
No coding or complicated setup required.
Automates data extraction for consistency and accuracy.
Delivers data in formats like CSV, JSON, and Excel.
Integrates easily with databases for efficient data management.
ParseHub
ParseHub is great for both beginners and experienced users. It offers a visual interface that makes it easy to set up data extraction rules without any coding.
Key Features:
Automates data extraction from complex websites.
User-friendly visual setup.
Outputs data in formats like CSV and JSON.
Features automatic IP rotation for efficient data collection.
Allows scheduled data extraction for regular updates.
Octoparse
Octoparse is another user-friendly tool designed for those with little coding experience. Its point-and-click interface simplifies data extraction.
Key Features:
Easy point-and-click interface.
Exports data in multiple formats, including CSV and Excel.
Offers cloud-based data extraction for 24/7 access.
Automatic IP rotation to avoid blocks.
Seamlessly integrates with other applications via API.
Apify
Apify is a versatile cloud platform that excels in web scraping and automation, offering a range of ready-made tools for different needs.
Key Features:
Provides pre-built scraping tools.
Automates web workflows and processes.
Supports business intelligence and data visualization.
Includes a robust proxy system to prevent access issues.
Offers monitoring features to track data collection performance.
Scraper API
Scraper API simplifies web scraping tasks with its easy-to-use API and features like proxy management and automatic parsing.
Key Features:
Retrieves HTML from various websites effortlessly.
Manages proxies and CAPTCHAs automatically.
Provides structured data in JSON format.
Offers scheduling for recurring tasks.
Easy integration with extensive documentation.
Scrapy
Scrapy is an open-source framework for advanced users looking to build custom web crawlers. It’s fast and efficient, perfect for complex data extraction tasks.
Key Features:
Built-in support for data selection from HTML and XML.
Handles multiple requests simultaneously.
Allows users to set crawling limits for respectful scraping.
Exports data in various formats like JSON and CSV.
Designed for flexibility and high performance.
Conclusion
Web scraping tools are essential in today’s data-driven environment. They save time, improve accuracy, and help businesses make informed decisions. Whether you’re a developer, a data analyst, or a business owner, the right scraping tool can greatly enhance your data collection efforts. As we move into 2024, consider adding these top web scraping tools to your toolkit to streamline your data extraction process.
0 notes
Text
Python Fundamentals for New Coders: Everything You Need to Know
Learning Python is an exciting journey, especially for new coders who want to explore the fundamentals of programming. Known for its simplicity and readability, Python is an ideal language for beginners and professionals alike. From understanding basic syntax to mastering more advanced concepts, Python equips you with tools to build everything from small scripts to full-scale applications. In this article, we’ll explore some core Python skills every new coder should know, such as file handling, reading and writing files, and handling data in various formats.
One essential skill in Python is file handling, which is vital for working with external data sources. Our Python file handling tutorial covers how to open, read, write, and close files. In real-world applications, you often need to process data stored in files, whether for analysis or to store program output. File handling enables you to manage these files directly from your Python code. With just a few commands, you can open a file, modify its contents, or create a new file. This skill becomes especially valuable as you begin working with larger projects that rely on reading or writing to files.
Once you understand file handling basics, you can dive deeper into how Python works with different types of files. One common use case for file handling is working with CSV files, which store data in a table-like format. Python CSV file handling allows you to read and write data organized in rows and columns, making it easy to process structured data. With Python’s built-in csv module, you can access and manipulate CSV files effortlessly. For example, if you have a list of students and their grades in a CSV file, you can use Python to calculate average grades or filter data. Understanding how to handle CSV files helps you manage structured data effectively and is a critical skill for any data-related task.
Moving on, another key skill is working with file content—specifically, learning to read and write files in various formats. Python offers a variety of methods for reading files line-by-line or loading the entire content at once. Writing to files is just as simple, allowing you to add new data or update existing information. For instance, in a data analysis project, you might read raw data from a file, process it, and save the results to another file. This read-and-write capability forms the backbone of many Python programs, particularly when dealing with external data.
Finally, many applications require more complex data storage and exchange formats, such as JSON. Python JSON data processing is essential for working with APIs or handling nested data structures. JSON, which stands for JavaScript Object Notation, is a popular format for representing structured data. Using Python’s json module, you can easily convert JSON data into Python dictionaries and vice versa. This ability to parse and write JSON data is crucial for building applications that interact with web services, allowing you to read data from an online source and process it in your program. As you gain more experience, you’ll find JSON data handling indispensable for projects involving external APIs and structured data storage.
Our company is committed to helping students learn programming languages through clear, straightforward tutorials. Our free online e-learning portal provides Python tutorials specifically designed for beginners, with live examples that bring each concept to life. Every tutorial is written in an easy-to-understand style, ensuring that even complex topics are approachable. Whether you’re a student or a hobbyist, our tutorials give you the practical tools to start coding confidently.
In summary, understanding Python fundamentals such as file handling, CSV and JSON processing, and read/write operations can take you far in your coding journey. Each of these skills contributes to building powerful applications, from data analysis scripts to interactive web applications. By mastering these concepts, you’ll be well-prepared to tackle real-world coding challenges, and our platform will support you every step of the way. With consistent practice and our structured tutorials, you’ll gain the confidence to explore Python and bring your ideas to life.
0 notes
Text
Preparing Data for Training in Machine Learning
Preparing data is a crucial step in building a machine learning model. Poorly processed data can lead to inaccurate predictions and inefficient models.
Below are the key steps involved in preparing data for training.
Understanding and Collecting Data Before processing, ensure that the data is relevant, diverse, and representative of the problem you’re solving.
✅ Sources — Data can come from databases, APIs, files (CSV, JSON), or real-time streams.
✅ Data Types — Structured (tables, spreadsheets) or unstructured (text, images, videos).
✅ Labeling — For supervised learning, ensure data is properly labeled.
2. Data Cleaning and Preprocessing
Raw data often contains errors, missing values, and inconsistencies that must be addressed. Key Steps:
✔ Handling Missing Values — Fill with mean/median (numerical) or mode (categorical), or drop incomplete rows.
✔ Removing Duplicates — Avoid bias by eliminating redundant records.
✔ Handling Outliers — Use statistical methods (Z-score, IQR) to detect and remove extreme values.
✔ Data Type Conversion — Ensure consistency in numerical, categorical, and date formats.
3. Feature Engineering Transforming raw data into meaningful features improves model performance.
Techniques:
📌 Normalization & Standardization — Scale numerical features to bring them to the same range.
📌 One-Hot Encoding — Convert categorical variables into numerical form.
📌 Feature Selection — Remove irrelevant or redundant features using correlation analysis or feature importance.
📌 Feature Extraction — Create new features (e.g., extracting time-based trends from timestamps). 4. Splitting Data into Training, Validation, and Testing Sets To evaluate model performance effectively, divide data into: Training Set (70–80%) — Used for training the model.
Validation Set (10–15%) — Helps tune hyperparameters and prevent overfitting. Test Set (10–15%) — Evaluates model performance on unseen data.
📌 Stratified Sampling — Ensures balanced distribution of classes in classification tasks.
5. Data Augmentation (For Image/Text Data)
If dealing with images or text, artificial expansion of the dataset can improve model generalization.
✔ Image Augmentation — Rotate, flip, zoom, adjust brightness.
✔ Text Augmentation — Synonym replacement, back-translation, text shuffling.
6. Data Pipeline Automation For large datasets,
use ETL (Extract, Transform, Load) pipelines or tools like Apache Airflow, AWS Glue, or Pandas to automate data preparation.
WEBSITE: https://www.ficusoft.in/deep-learning-training-in-chennai/
0 notes