#Autograder Python
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text

The Python Assignment Autograder is a cutting-edge system designed to automate the grading of Python programming assignments, providing instant feedback and plagiarism detection. Developed using Streamlit and Flask, it offers educators a streamlined platform to create, manage, and evaluate assignments efficiently. The Autograder ensures accurate and consistent grading based on predefined test cases and generates detailed reports, including performance metrics and potential plagiarism findings. Students receive timely, actionable feedback, enhancing their learning experience and fostering engagement. This tool supports academic integrity by identifying similarities between submissions. By modernizing the grading process, the Python Assignment Autograder aims to improve the quality and efficiency of programming education for both educators and students.
Omar Almutairi
2 notes
·
View notes
Note
Could you recommend a beginner's book or books for someone who wants to get into programming as a hobby? I know HTML and CSS, working on learning JS, but I kinda wanna get into mainline programming for kicks, and I'm unsure about how to branch out of web development.
Hello!
There's lots of things programming as a hobby can mean: do you want to do leetcode for fun? do you want to write programs to automate workflows? write mini video games? write programs for microcontrollers to affect the world outside your computer? do things with data analysis? figuring this out is likely to making learning way more interesting to you!
I have zero frontend experience with doing anything on web. My only experience with JS is figuring out what to block on websites. So if you want to add functionality to websites, keep at JS? I hear that the gold standard for learning web related technologies for free is freecodecamp.org so might be worth looking at if you haven't already!
In 2023, 75% of what you want to do can be done with python, so imo it is worth picking up! It's also a very intuitive language to start with if you feel like JS is slippery.
I picked up python from MIT's 6.001x, when it was still for free on edX with the autograder but all the material is still available here on OCW. This is a very traditional course so I think you get a sense of whether you'll like classic problem solving in the leetcode way.
A friend of mine had a good time using Automate the Boring Stuff with Python which is a non programmers introduction to writing scripts to do useful things for python, which is much more practical course.
A more language agnostic approach might be looking through the introductory stuff in OSSU's Computer Science self taught curriculum.
Once you feel reasonably comfortable with any language, this link leads to some curated tutorials to program projects in different languages. Pick anything that you find interests you :)
16 notes
·
View notes
Text
PyTorch/XLA 2.4: Pallas & developer experience, “eager mode”

PyTorch/XLA 2.4
For deep learning academics and practitioners, the open-source PyTorch machine learning (ML) library and XLA ML compiler provide flexible, powerful model training, fine-tuning, and serving. The PyTorch/XLA team is happy to announce the release of PyTorch/XLA 2.4 today. This version includes several noteworthy enhancements to address issues raised by developers and builds on the previous release. Here, we go over a few of the most recent additions that facilitate using PyTorch/XLA:
Pallas, a proprietary kernel language that supports GPUs and TPUs, has been improved.
Fresh calls to the API
The “eager mode” experiment is introduced.
The TPU command line interface has been updated.
Pallas improvements
Although the XLA compiler can optimize your current models, there are situations in which bespoke kernel code can provide model authors with superior performance. Pallas is a bespoke kernel language that supports TPU and GPUs, so instead of requiring you to use a more complex and lower-level language like C++, you can write more performant code in Python that is closer to the hardware. Pallas is comparable to the Triton library, but it makes porting your model from one machine learning accelerator to another easier because it runs on both TPUs and GPUs.
The latest version of PyTorch/XLA 2.4 brings improvements to Pallas’ functionality and user experience.
Flash Attention is now completely integrated with PyTorch autograd, allowing for automatic gradient calculation.
Integrated assistance for Paged Focus on Inference.
Support for group matrix multiplication using Mega blocks’ block sparse kernels as an Autograd function, eliminating the requirement for backpropagation to be done manually.
API modifications
A few new calls are included in PyTorch/XLA 2.4 to facilitate integration with your current PyTorch workflow, such as:device = torch_xla.device()
And now you can call torch_xla.sync() in place of having to do xm.mark_step(). The developer workflow is enhanced and the process of converting your code to PyTorch/XLA is made simpler by these enhancements.
import torch_xla.core.xla_model as xm device = xm.device()
Try out the eager mode
If you’ve worked with PyTorch/XLA for any length of time, you are aware of the term “lazily executed” models. This implies that before models are sent to be performed on the XLA device target hardware, PyTorch/XLA 2.4 builds the compute graph of operation. Operations are compiled and then instantly carried out on the target hardware with the new eager mode.
The drawback of this feature is that, because each instruction is not conveyed to the TPU immediately by default, TPUs themselves lack a real eager mode. In order to compel the compilation and execution, Google cloud add a “mark step” call to each PyTorch action on TPUs. As a result, eager mode functions, albeit as an emulator rather than a built-in feature.
With this release, Google cloud want for eager mode to be used in your local surroundings rather than in your production environment. Eager mode is intended to simplify local model debugging on your PCs without requiring you to deploy it to a broader fleet of devices, as is the case with most production systems.
CLI to view Cloud TPU information
The nvidia-smi tool, which you can use to troubleshoot your GPU workloads, determine which cores are being used, and check how much memory a particular workload is consuming, may be familiar to you if you’ve previously used Nvidia GPUs. Additionally, a comparable command line tool has been developed for Cloud TPUs that facilitates the retrieval of device and utilization data.
Start using PyTorch/XLA 2.4 right now
The best aspect is that your current code is still compatible with PyTorch/XLA 2.4, despite the fact that it has certain API changes. Additionally, the new API methods will make your future development processes easier. What are you waiting for? Try the most recent version.
The PyTorch logo: Key Features
Prepared for Production
Use TorchScript to switch between eager and graph modes with ease, and TorchServe to quicken the production process.
Dispersed Instruction
The torch.distributed backend enables scalable distributed training and performance optimisation in research and production.
Sturdy Ecosystem
A plethora of tools and frameworks complement PyTorch/XLA 2.4 Improved Pallas and developer experience, “eager mode” and facilitate its development in computer vision, natural language processing, and other fields.
Cloud Assistance
Major cloud platforms support PyTorch well, enabling easy scaling and frictionless development.
XLA Features
Accelerated Linear Algebra, or XLA, is an open-source machine learning compiler. Models from well-known frameworks like PyTorch, TensorFlow, and JAX are imported into the XLA compiler, which then optimises them for high-performance execution on a variety of hardware platforms, including GPUs, CPUs, and ML accelerators. For instance, employing XLA with 8 Volta V100 GPUs produced a ~7x performance boost and ~5x batch-size improvement over the same GPUs without XLA in a BERT MLPerf submission.
Leading ML hardware and software companies, including as Alibaba, Amazon Web Services, AMD, Apple, Arm, Google, Intel, Meta, and NVIDIA, are working together to develop XLA as part of the OpenXLA initiative. Principal advantages
Construct anywhere: Prominent machine learning frameworks like TensorFlow, PyTorch, and JAX have already incorporated XLA.
Run anywhere: It has pluggable infrastructure to offer support for other backends, such as GPUs, CPUs, and ML accelerators, among other backends.
Optimise and scale performance: It makes use of automated partitioning for model parallelism and production-tested optimization stages to maximize a model���s performance.
Reduce complexity: By utilising MLIR, it combines the greatest features into a single compiler toolchain, saving you from having to handle a variety of domain-specific compilers.
Future-ready: XLA is an open-source project that was developed in conjunction with top ML software and hardware providers. Its goal is to be the industry leader in machine learning.
Read more on Govindhtech.com
#pytorch#govindhtech#xla#googlecloud#pallas#machinelearning#news#technews#technology#technologytrends#technologynews
0 notes
Text
Getting Started with PyTorch
Installation and Setup
To start with PyTorch, first, ensure you have Python installed (preferably 3.6 or later). Then, install PyTorch using pip or conda. For example, with pip, you can run: pip install torch torchvision torchaudio.
For GPU support, ensure you have CUDA installed and use the appropriate PyTorch version. You can verify the installation by importing the torch in a Python environment.
Finally, set up your development environment with your preferred text editor or IDE. PyTorch offers extensive documentation and tutorials to help you get started with deep learning projects efficiently.
Introduction to PyTorch's Autograd
Autograd is an automatic differentiation system in PyTorch that enables computing gradients of tensors. This functionality is crucial for training and optimizing deep learning models.
0 notes
Text
Data Science Homework 3 Solution
In general your homework will be autograded, i.e. you must not modify the signature of the defined functions (same inputs and outputs). For questions involving Numpy and Pandas, you must handle any iteration through calls to relevant functions in the libraries. This means you may not use any native Python for loops, while loops, list comprehension, etc. when something could have been done with a…

View On WordPress
0 notes
Text
Demystifying the World of Code: An Educational Standpoint

Coding education is essential for success in today's digital world. Learning to code enables individuals to develop in-demand and useful skills that benefit their careers and society. This article provides the following: - An overview of why coding is important. - Methods for learning to code. - The role of teachers - Innovative teaching approaches. - Challenges within coding education.
The Basics of Coding
Coding refers to writing instructions that direct computers to perform specific tasks. Coders use programming languages like Python, JavaScript, and C++ to develop software, websites, and mobile apps. Learning to code allows you to become a programmer and build digital solutions. Coding is essential today because so much of how we live, work, and communicate depends on technology. Programmers create the software and apps that power these technologies. Some of the most useful languages for beginners include Python, JavaScript, Java, and C/C++:
Benefits of Learning to Code
Learning to code provides many benefits. Coding is a highly valued skill, with many high-paying software engineering and web development jobs. The US Bureau of Labor Statistics projects over 22% growth for software developer jobs over the next ten years. Building software and apps requires strong problem-solving skills useful in any field. Programmers learn how to break down problems and create solutions logically. Coding education fosters creativity by teaching how to build new technologies, websites, mobile apps, and software. Programmers can design digital solutions to meet all types of needs. Programming languages demand precise syntax and logic to function. Learning to code strengthens analytical abilities through debugging code, understanding algorithms, and developing software. These mindsets translate broadly.
Methods of Learning to Code
Massive open online courses or MOOCs offer free or affordable coding classes on platforms. These interactive courses allow you to learn on schedule but provide deadlines and accountability. Intensive boot camps typically take 2-6 months. They teach tech skills for a software engineer or web developer job placement. Coding schools also provide structured education and career support. These programs charge tuition but often aid in job placement. They offer a quick path to a career in tech for those who still need a formal degree.
An Efficient Teacher Toolkit
To teach students coding, teachers employ various technological tools to streamline and enhance instruction. For example, auto grading systems automatically grade student code so teachers can provide individualized guidance. Coding platforms give students opportunities for the practical application of skills. Tutorials and online lessons allow for self-paced learning. Team collaboration software facilitates group work. These tools, including autograding, coding environments, videos, and collaboration platforms, comprise a robust toolkit for teachers to teach coding engagingly. By leveraging autograding software, hands-on coding platforms, video tutorials, and team collaboration tools, teachers are equipped with technology to teach students coding and help them develop strong computational thinking abilities.
Innovative Approaches to Coding Education
Students learn to code by working on real-world projects and building software and apps. Project-based learning is an engaging method that provides practical experience. Students can collaborate on group projects or work individually on portfolio projects. Incorporating elements like points, badges, and levels, gamification uses game design in non-game contexts like education. For coding, gamification may involve interactive coding challenges, hackathons, or platforms featuring progress meters and achievement-unlocked messages. Studies show gamification can increase motivation and participation. Group work enables students to learn from each other by exchanging ideas, asking questions, explaining concepts, and problem-solving together. For coding, students may work in pairs or small groups to complete hands-on projects, evaluate each other's code, or study programming language documentation together. Social interactions keep students actively engaged and strengthen understanding. Innovative teaching methods will make learning to code more engaging and effective for students. Approaches like project-based learning, gamification, and collaborative coding education could motivate more people to learn programming skills.
Challenges in Coding Education
While coding education is crucial for the future, there are challenges to address. Coding education can be expensive, whether pursuing degrees, boot camps, or self-study. More affordable high-quality options are needed to reach all students. Underrepresented groups like women, minorities, and people with disabilities face barriers to learning to code and entering tech careers. Inclusive outreach and addressing systemic biases are required. Programming languages, frameworks, and other technologies continually evolve. Coding education must keep up to teach relevant and in-demand skills. Updating courses and resources requires an ongoing investment of time and money. Solutions could include public-private partnerships to fund education, tailoring courses to reach underserved groups, and developing flexible programs that adapt quickly to new technologies. With a focus on access and inclusion, coding education can demystify the world of technology for all.
Conclusion
Coding is important because software powers many of the tools we use daily. Coders help build solutions that improve lives and productivity. Coding also promotes critical thinking skills that are useful across fields. However, learning to code can only be challenging with the right educational support. Read the full article
0 notes
Text
Mini-project 2: Write your own blocks
The goal of the previous section was to exploit PyTorch to build a network. Here you’ll build your framework for denoising images without using autograd or torch.nn modules. We allow 1 from torch import empty , cat , arange from torch . nn . f u n c t i o n a l import fold , unfold and the Python Standard Library1 only. We could consider additional operations if you…

View On WordPress
0 notes
Text
Automated Code Grading
Automated code grading system of Codequiry is easy to use, integrate, and implement. All you need to do is set up rules around your coding and then the autograder will do the rest of the task. It will compile, run, test, and grade through self-destroying sandbox instances. One of the highlights of this tool is that it seamlessly integrates with Codequiry’s plagiarism checker.

1 note
·
View note
Text
How to Grade Programming Assignments
With numerous types of code auto graders, Codequiry regulates the coding system within a few minutes. Right from the work of organization, gathering, going through and inputting grades, the Automated Grading system generates codes with the motive of saving precious time of an educator. Know more about how to Grade Programming Assignments on our website and call us today for more details.

1 note
·
View note
Link
#Automated code grading#Autograder Python#Github Classroom Grading#Automatic Grading Of Programming Assignments#Grading Code#Code Submission Evaluation System
0 notes
Link
5 notes
·
View notes
Text
How to Find a Perfect Deep Learning Framework

Many courses and tutorials offer to guide you through building a deep learning project. Of course, from the educational point of view, it is worthwhile: try to implement a neural network from scratch, and you’ll understand a lot of things. However, such an approach does not prepare us for real life, where you are not supposed to spare weeks waiting for your new model to build. At this point, you can look for a deep learning framework to help you.
A deep learning framework, like a machine learning framework, is an interface, library or a tool which allows building deep learning models easily and quickly, without getting into the details of underlying algorithms. They provide a clear and concise way for defining models with the help of a collection of pre-built and optimized components.
Briefly speaking, instead of writing hundreds of lines of code, you can choose a suitable framework that will do most of the work for you.
Most popular DL frameworks
The state-of-the-art frameworks are quite new; most of them were released after 2014. They are open-source and are still undergoing active development. They vary in the number of examples available, the frequency of updates and the number of contributors. Besides, though you can build most types of networks in any deep learning framework, they still have a specialization and usually differ in the way they expose functionality through its APIs.
Here were collected the most popular frameworks
TensorFlow

The framework that we mention all the time, TensorFlow, is a deep learning framework created in 2015 by the Google Brain team. It has a comprehensive and flexible ecosystem of tools, libraries and community resources. TensorFlow has pre-written codes for most of the complex deep learning models you’ll come across, such as Recurrent Neural Networks and Convolutional Neural Networks.
The most popular use cases of TensorFlow are the following:
NLP applications, such as language detection, text summarization and other text processing tasks;
Image recognition, including image captioning, face recognition and object detection;
Sound recognition
Time series analysis
Video analysis, and much more.
TensorFlow is extremely popular within the community because it supports multiple languages, such as Python, C++ and R, has extensive documentation and walkthroughs for guidance and updates regularly. Its flexible architecture also lets developers deploy deep learning models on one or more CPUs (as well as GPUs).
For inference, developers can either use TensorFlow-TensorRT integration to optimize models within TensorFlow, or export TensorFlow models, then use NVIDIA TensorRT’s built-in TensorFlow model importer to optimize in TensorRT.
Installing TensorFlow is also a pretty straightforward task.
For CPU-only:
pip install tensorflow
For CUDA-enabled GPU cards:
pip install tensorflow-gpu
Learn more:
An Introduction to Implementing Neural Networks using TensorFlow
TensorFlow tutorials
PyTorch

PyTorch
Facebook introduced PyTorch in 2017 as a successor to Torch, a popular deep learning framework released in 2011, based on the programming language Lua. In its essence, PyTorch took Torch features and implemented them in Python. Its flexibility and coverage of multiple tasks have pushed PyTorch to the foreground, making it a competitor to TensorFlow.
PyTorch covers all sorts of deep learning tasks, including:
Images, including detection, classification, etc.;
NLP-related tasks;
Reinforcement learning.
Instead of predefined graphs with specific functionalities, PyTorch allows developers to build computational graphs on the go, and even change them during runtime. PyTorch provides Tensor computations and uses dynamic computation graphs. Autograd package of PyTorch, for instance, builds computation graphs from tensors and automatically computes gradients.
For inference, developers can export to ONNX, then optimize and deploy with NVIDIA TensorRT.
The drawback of PyTorch is the dependence of its installation process on the operating system, the package you want to use to install PyTorch, the tool/language you’re working with, CUDA and others.
Learn more:
Learn How to Build Quick & Accurate Neural Networks using PyTorch — 4 Awesome Case Studies
PyTorch tutorials
Keras

Keras was created in 2014 by researcher François Chollet with an emphasis on ease of use through a unified and often abstracted API. It is an interface that can run on top of multiple frameworks such as MXNet, TensorFlow, Theano and Microsoft Cognitive Toolkit using a high-level Python API. Unlike TensorFlow, Keras is a high-level API that enables fast experimentation and quick results with minimum user actions.
Keras has multiple architectures for solving a wide variety of problems, the most popular are
image recognition, including image classification, object detection and face recognition;
NLP tasks, including chatbot creation
Keras models can be classified into two categories:
Sequential: The layers of the model are defined in a sequential manner, so when a deep learning model is trained, these layers are implemented sequentially.
Keras functional API: This is used for defining complex models, such as multi-output models or models with shared layers.
Keras is installed easily with just one line of code:
pip install keras
Learn more:
The Ultimate Beginner’s Guide to Deep Learning in Python
Keras Tutorial: Deep Learning in Python
Optimizing Neural Networks using Keras
Caffe

The Caffe deep learning framework created by Yangqing Jia at the University of California, Berkeley in 2014, and has led to forks like NVCaffe and new frameworks like Facebook’s Caffe2 (which is already merged with PyTorch). It is geared towards image processing and, unlike the previous frameworks, its support for recurrent networks and language modeling is not as great. However, Caffe shows the highest speed of processing and learning from images.
The pre-trained networks, models and weights that can be applied to solve deep learning problems collected in the Caffe Model Zoo framework work on the below tasks:
Simple regression
Large-scale visual classification
Siamese networks for image similarity
Speech and robotics applications
Besides, Caffe provides solid support for interfaces like C, C++, Python, MATLAB as well as the traditional command line.
To optimize and deploy models for inference, developers can leverage NVIDIA TensorRT’s built-in Caffe model importer.
The installation process for Caffe is rather complicated and requires performing a number of steps and meeting such requirements, as having CUDA, BLAF and Boost. The complete guide for installation of Caffe can be found here.
Learn more:
Caffe Tutorial
Choosing a deep learning framework
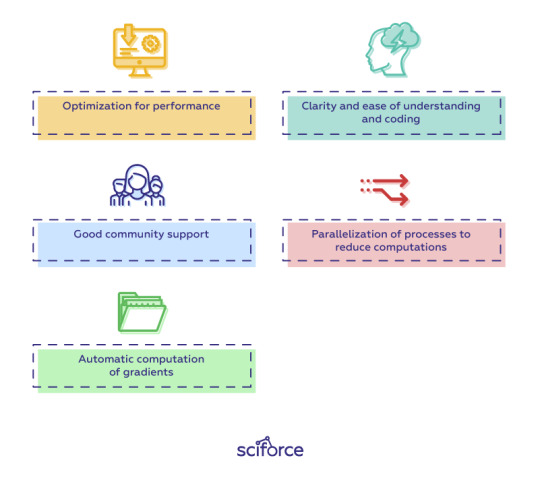
You can choose a framework based on many factors you find important: the task you are going to perform, the language of your project, or your confidence and skillset. However, there are a number of features any good deep learning framework should have:
Optimization for performance
Clarity and ease of understanding and coding
Good community support
Parallelization of processes to reduce computations
Automatic computation of gradients
Model migration between deep learning frameworks
In real life, it sometimes happens that you build and train a model using one framework, then re-train or deploy it for inference using a different framework. Enabling such interoperability makes it possible to get great ideas into production faster.
The Open Neural Network Exchange, or ONNX, is a format for deep learning models that allows developers to move models between frameworks. ONNX models are currently supported in Caffe2, Microsoft Cognitive Toolkit, MXNet, and PyTorch, and there are connectors for many other popular frameworks and libraries.
New deep learning frameworks are being created all the time, a reflection of the widespread adoption of neural networks by developers. It is always tempting to choose one of the most common one (even we offer you those that we find the best and the most popular). However, to achieve the best results, it is important to choose what is best for your project and be always curious and open to new frameworks.
10 notes
·
View notes
Text
Github Classroom Grading
For the teachers and educators, it becomes easy to analyze the codes of their students at once. With Github Classroom Grading teachers can easily select files all students at once. It will analyze and check the codes within the peer and provides you with effective data. Contact us immediately for more information
#Automated Code Grading#Github Classroom Grading#Code Submission Evaluation System#Autograder Python
0 notes
Photo

PyTorch Autograd ☞ https://towardsdatascience.com/pytorch-autograd-understanding-the-heart-of-pytorchs-magic-2686cd94ec95 #python #PyTorch
2 notes
·
View notes
Text
Data Science Homework 1
In general your homework will be autograded, i.e. you must not modify the signature of the defined functions (same inputs and outputs). For questions involving Numpy and Pandas, you must handle any iteration through calls to relevant functions in the libraries. This means you may not use any native Python for loops, while loops, list comprehension, etc. Submitting To submit the files, please…

View On WordPress
0 notes
Text
What is PyTorch? Python machine learning on GPUs
What is PyTorch? Python machine learning on GPUs
PyTorch is an open source, machine learning framework used for both research prototyping and production deployment. According to its source code repository, PyTorch provides two high-level features: Tensor computation (like NumPy) with strong GPU acceleration. Deep neural networks built on a tape-based autograd system. Originally developed at Idiap Research Institute, NYU, NEC Laboratories…

View On WordPress
0 notes