#AV1
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Post activity is at the highest at 4:00 pm EDT; notes peak at 10:00 pm EDT.
Text
I downloaded an entire 20-Season series via a torrent. The torrent came in around 160+ GB. After re-encoding everything as AV1 via Shutter Encoder, it's currently on path to being around 55 GB when it's complete.
This shit's crazy. I wish torrent makers would utilize modern codecs and file types before seeding them. It'd sure save a lot of bandwidth, data, and time downloading 7zips and AV1 media, rather than ZIP and H.264/5 media. And, like, given that 7zip is open-source and VLC supports AV1, and both are free and open-source, there's literally no excuse.
#rambles#media#data#data compression#compression#data hoarding#av1#h.264#h.265#shutter encoder#video#video media
35 notes
·
View notes
Text






Aveyond: Rhen's Quest Edit Set → [ PART 5 / ?]
"It was foretold that a child of Thais would be born and that this child would defeat a great demon. (...) When Ahriman found out about the child, the demon destroyed the kingdom and leveled the city." "And the child? Did Ahriman kill the child?" "The child lives. She lives." "YOU live."
Picture: (The Trail - Wojtek Fus)
#aveyond#av1#rhen darzon#rhen pendragon#ok so i got a rare break from work#and i could feel my soul just draining and i NEEDED to whip up a quick edit#shoutout to Iz and Tei for leading me to the juiciest media kits of the AV universe#HIGHRES VERSION OF TITLE SCREEN RHEN YOOOOO#mine: avworld
26 notes
·
View notes
Text

Part of my gift to @annelaurant for the Aveyond Winter Exchange! This was the greatest prompt I could have fulfilled. I did, in fact, go back and play all of AV1 again just so I could immerse myself in the game and its mechanics just for this bit.
tbh some of the best warmups I've ever done for a piece of art lol
#fanart#aveyond fanart#av1#aveyond 1#rhen's quest#dameon maurva#lars tenobor#galahad teomes#i had no other choice than to do the family guy death pose for galahad i'm sorry#it had to be done#posting a little late because my computer died :/ for a few days
17 notes
·
View notes
Text

Aight my first art piece done for 2024! This one was actually a wip back in 2022 so I’m not sure if this actually counts lol.
Anyway just enjoy the beautiful view with these babies as they live this happy moment. They picked an undiscovered location near Clearwater which was a whole meadow with flowers everywhere.
Remember that small cave in Clearwater that we go through to enter the forest? Lars accidentally blew the wall using those dynamites to prove a point during an argument (I don’t know what that argument was though lol), and VOILA! Secret location unlocked.
Of course they had to make a flower crown. Where there’s a field of flowers, a floral crown shall be made. Obviously Rhen was the one who made them and taught Lars as she was crafting them.
#aveyond#av1#rhen darzon#rhen pendragon#lars tenobor#larshen#remi’s art#This concludes my larshen art for now!#I wanna draw random other stuff too hehe
11 notes
·
View notes
Text
Me just making complicated wild ideas because it's fun. I mentioned that I like the headcanon idea that AV summoners have different "ways "poses" for summoning, so here they are.
Summoning hand gesture:
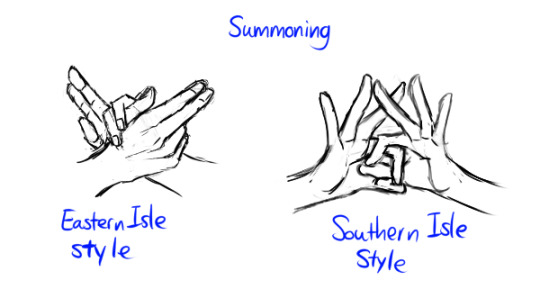
Lore(ish) headcanon that to "contract" higher rank demons (e.g the daeva) they need to actually know the demon's personal names. If the demon is in front of them they can do this to find out their names with this spell (cannot be done long distance):
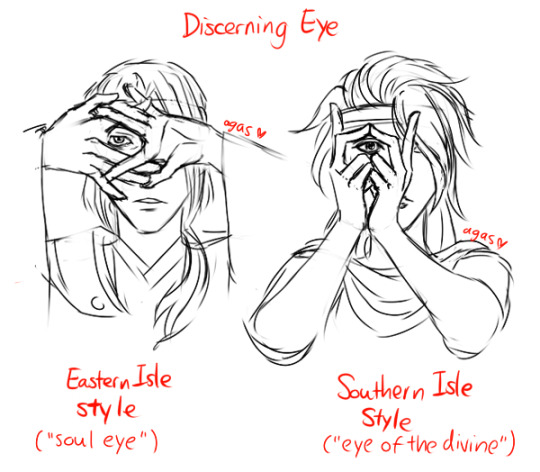
All this for drama purposes that I don't really know how to write LOL.
24 notes
·
View notes
Photo


A perfect duo
44 notes
·
View notes
Text
changing my mind on webm (we'll see about webp) but the filesize difference between two identical video streams in mp4 and webm, plus vp8/9 and vorbis/opus being open codecs (even if vp8/9 was developed by a company google acquired, and vorbis is kinda old now). i hope av1 ends up making it as standard in webm since it's completely open (no google offering it openly but also holding patents on some parts nonsense).
i do wish they'd pick a different file extension (i'm a bikeshedder, alright ? )
#daemon.md#techblr#webm#webp#vp8#vp9#vorbis#opus#av1#av codecs#maybe webm is actually the answer#and heck maybe webp but idk much about webp#other than support issues#and my friends jay pegg and pe'n gee being there for me always
9 notes
·
View notes
Text
Intel Arc B580 / Intel Arc B570

A Intel anunciou o lançamento de duas novas placas-gráficas da geração "Arc B-Series". As placas B580 e B570 destinam-se ao segmento intermédio e possuem novas tecnologias de processamento gráfico que optimizam o seu uso em contexto profissional e doméstico (incluindo "ray tracing" e inteligência artificial melhorados).
A placa-gráfica Intel B580 inclui 12GB de VRAM dedicada e a placa Intel B570 inclui 10GB de VRAM dedicada, estando estas disponíveis em breve no mercado.
Saiba tudo na página oficial da Intel localizada em: https://www.intel.com/content/www/us/en/newsroom/news/intel-launches-arc-b-series-graphics-cards.html
______ Direitos de imagem: © Intel (via https://www.intel.com/content/www/us/en/newsroom/)
#intel#intelb580#intelb570#intelgraphics#graphics#intelarc#arc#raytracing#frame#resolution#ai#ia#b580#b570#av1#h265#h264#vp9#gpu
1 note
·
View note
Text
Disney Research Offers Improved AI-Based Image Compression – But It May Hallucinate Details
New Post has been published on https://thedigitalinsider.com/disney-research-offers-improved-ai-based-image-compression-but-it-may-hallucinate-details/
Disney Research Offers Improved AI-Based Image Compression – But It May Hallucinate Details
Disney’s Research arm is offering a new method of compressing images, leveraging the open source Stable Diffusion V1.2 model to produce more realistic images at lower bitrates than competing methods.
The Disney compression method compared to prior approaches. The authors claim improved recovery of detail, while offering a model that does not require hundreds of thousands of dollars of training, and which operates faster than the nearest equivalent competing method. Source: https://studios.disneyresearch.com/app/uploads/2024/09/Lossy-Image-Compression-with-Foundation-Diffusion-Models-Paper.pdf
The new approach (defined as a ‘codec’ despite its increased complexity in comparison to traditional codecs such as JPEG and AV1) can operate over any Latent Diffusion Model (LDM). In quantitative tests, it outperforms former methods in terms of accuracy and detail, and requires significantly less training and compute cost.
The key insight of the new work is that quantization error (a central process in all image compression) is similar to noise (a central process in diffusion models).
Therefore a ‘traditionally’ quantized image can be treated as a noisy version of the original image, and used in an LDM’s denoising process instead of random noise, in order to reconstruct the image at a target bitrate.
Further comparisons of the new Disney method (highlighted in green), in contrast to rival approaches.
The authors contend:
‘[We] formulate the removal of quantization error as a denoising task, using diffusion to recover lost information in the transmitted image latent. Our approach allows us to perform less than 10% of the full diffusion generative process and requires no architectural changes to the diffusion model, enabling the use of foundation models as a strong prior without additional fine tuning of the backbone.
‘Our proposed codec outperforms previous methods in quantitative realism metrics, and we verify that our reconstructions are qualitatively preferred by end users, even when other methods use twice the bitrate.’
However, in common with other projects that seek to exploit the compression capabilities of diffusion models, the output may hallucinate details. By contrast, lossy methods such as JPEG will produce clearly distorted or over-smoothed areas of detail, which can be recognized as compression limitations by the casual viewer.
Instead, Disney’s codec may alter detail from context that was not there in the source image, due to the coarse nature of the Variational Autoencoder (VAE) used in typical models trained on hyperscale data.
‘Similar to other generative approaches, our method can discard certain image features while synthesizing similar information at the receiver side. In specific cases, however, this might result in inaccurate reconstruction, such as bending straight lines or warping the boundary of small objects.
‘These are well-known issues of the foundation model we build upon, which can be attributed to the relatively low feature dimension of its VAE.’
While this has some implications for artistic depictions and the verisimilitude of casual photographs, it could have a more critical impact in cases where small details constitute essential information, such as evidence for court cases, data for facial recognition, scans for Optical Character Recognition (OCR), and a wide variety of other possible use cases, in the eventuality of the popularization of a codec with this capability.
At this nascent stage of the progress of AI-enhanced image compression, all these possible scenarios are far in the future. However, image storage is a hyperscale global challenge, touching on issues around data storage, streaming, and electricity consumption, besides other concerns. Therefore AI-based compression could offer a tempting trade-off between accuracy and logistics. History shows that the best codecs do not always win the widest user-base, when issues such as licensing and market capture by proprietary formats are factors in adoption.
Disney has been experimenting with machine learning as a compression method for a long time. In 2020, one of the researchers on the new paper was involved in a VAE-based project for improved video compression.
The new Disney paper was updated in early October. Today the company released an accompanying YouTube video. The project is titled Lossy Image Compression with Foundation Diffusion Models, and comes from four researchers at ETH Zürich (affiliated with Disney’s AI-based projects) and Disney Research. The researchers also offer a supplementary paper.
Method
The new method uses a VAE to encode an image into its compressed latent representation. At this stage the input image consists of derived features – low-level vector-based representations. The latent embedding is then quantized back into a bitstream, and back into pixel-space.
This quantized image is then used as a template for the noise that usually seeds a diffusion-based image, with a varying number of denoising steps (wherein there is often a trade-off between increased denoising steps and greater accuracy, vs. lower latency and higher efficiency).
Schema for the new Disney compression method.
Both the quantization parameters and the total number of denoising steps can be controlled under the new system, through the training of a neural network that predicts the relevant variables related to these aspects of encoding. This process is called adaptive quantization, and the Disney system uses the Entroformer framework as the entropy model which powers the procedure.
The authors state:
‘Intuitively, our method learns to discard information (through the quantization transformation) that can be synthesized during the diffusion process. Because errors introduced during quantization are similar to adding [noise] and diffusion models are functionally denoising models, they can be used to remove the quantization noise introduced during coding.’
Stable Diffusion V2.1 is the diffusion backbone for the system, chosen because the entirety of the code and the base weights are publicly available. However, the authors emphasize that their schema is applicable to a wider number of models.
Pivotal to the economics of the process is timestep prediction, which evaluates the optimal number of denoising steps – a balancing act between efficiency and performance.
Timestep predictions, with the optimal number of denoising steps indicated with red border. Please refer to source PDF for accurate resolution.
The amount of noise in the latent embedding needs to be considered when making a prediction for the best number of denoising steps.
Data and Tests
The model was trained on the Vimeo-90k dataset. The images were randomly cropped to 256x256px for each epoch (i.e., each complete ingestion of the refined dataset by the model training architecture).
The model was optimized for 300,000 steps at a learning rate of 1e-4. This is the most common among computer vision projects, and also the lowest and most fine-grained generally practicable value, as a compromise between broad generalization of the dataset’s concepts and traits, and a capacity for the reproduction of fine detail.
The authors comment on some of the logistical considerations for an economic yet effective system*:
‘During training, it is prohibitively expensive to backpropagate the gradient through multiple passes of the diffusion model as it runs during DDIM sampling. Therefore, we perform only one DDIM sampling iteration and directly use [this] as the fully denoised [data].’
Datasets used for testing the system were Kodak; CLIC2022; and COCO 30k. The dataset was pre-processed according to the methodology outlined in the 2023 Google offering Multi-Realism Image Compression with a Conditional Generator.
Metrics used were Peak Signal-to-Noise Ratio (PSNR); Learned Perceptual Similarity Metrics (LPIPS); Multiscale Structural Similarity Index (MS-SSIM); and Fréchet Inception Distance (FID).
Rival prior frameworks tested were divided between older systems that used Generative Adversarial Networks (GANs), and more recent offerings based around diffusion models. The GAN systems tested were High-Fidelity Generative Image Compression (HiFiC); and ILLM (which offers some improvements on HiFiC).
The diffusion-based systems were Lossy Image Compression with Conditional Diffusion Models (CDC) and High-Fidelity Image Compression with Score-based Generative Models (HFD).
Quantitative results against prior frameworks over various datasets.
For the quantitative results (visualized above), the researchers state:
‘Our method sets a new state-of-the-art in realism of reconstructed images, outperforming all baselines in FID-bitrate curves. In some distortion metrics (namely, LPIPS and MS-SSIM), we outperform all diffusion-based codecs while remaining competitive with the highest-performing generative codecs.
‘As expected, our method and other generative methods suffer when measured in PSNR as we favor perceptually pleasing reconstructions instead of exact replication of detail.’
For the user study, a two-alternative-forced-choice (2AFC) method was used, in a tournament context where the favored images would go on to later rounds. The study used the Elo rating system originally developed for chess tournaments.
Therefore, participants would view and select the best of two presented 512x512px images across the various generative methods. An additional experiment was undertaken in which all image comparisons from the same user were evaluated, via a Monte Carlo simulation over 10,0000 iterations, with the median score presented in results.
Estimated Elo ratings for the user study, featuring Elo tournaments for each comparison (left) and also for each participant, with higher values better.
Here the authors comment:
‘As can be seen in the Elo scores, our method significantly outperforms all the others, even compared to CDC, which uses on average double the bits of our method. This remains true regardless of Elo tournament strategy used.’
In the original paper, as well as the supplementary PDF, the authors provide further visual comparisons, one of which is shown earlier in this article. However, due to the granularity of difference between the samples, we refer the reader to the source PDF, so that these results can be judged fairly.
The paper concludes by noting that its proposed method operates twice as fast as the rival CDC (3.49 vs 6.87 seconds, respectively). It also observes that ILLM can process an image within 0.27 seconds, but that this system requires burdensome training.
Conclusion
The ETH/Disney researchers are clear, at the paper’s conclusion, about the potential of their system to generate false detail. However, none of the samples offered in the material dwell on this issue.
In all fairness, this problem is not limited to the new Disney approach, but is an inevitable collateral effect of using diffusion models – an inventive and interpretive architecture – to compress imagery.
Interestingly, only five days ago two other researchers from ETH Zurich produced a paper titled Conditional Hallucinations for Image Compression, which examines the possibility of an ‘optimal level of hallucination’ in AI-based compression systems.
The authors there make a case for the desirability of hallucinations where the domain is generic (and, arguably, ‘harmless’) enough:
‘For texture-like content, such as grass, freckles, and stone walls, generating pixels that realistically match a given texture is more important than reconstructing precise pixel values; generating any sample from the distribution of a texture is generally sufficient.’
Thus this second paper makes a case for compression to be optimally ‘creative’ and representative, rather than recreating as accurately as possible the core traits and lineaments of the original non-compressed image.
One wonders what the photographic and creative community would make of this fairly radical redefinition of ‘compression’.
*My conversion of the authors’ inline citations to hyperlinks.
First published Wednesday, October 30, 2024
#000#2023#2024#adoption#ai#AI image#AI image generation#app#approach#architecture#arm#Art#Article#Artificial Intelligence#av1#Best Of#Capture#cdc#challenge#character recognition#chess#code#coding#Community#comparison#complexity#compress#compression#compromise#compute cost
0 notes
Text
AVIF: O novo formato de imagem que vai transformar a web
O formato de imagem AVIF é um novo formato de imagem que vem ganhando popularidade nos últimos anos. Ele oferece uma série de vantagens sobre os formatos de imagem existentes, como JPEG e PNG, incluindo maior compactação, melhor qualidade de imagem e suporte a HDR. O que é AVIF? O AVIF é a sigla para AV1 Image File Format, ou seja, um formato de arquivo de imagem baseado no codec de vídeo AV1.…

View On WordPress
0 notes
Text
Virtual Desktop 驚人更新:支援Quest 3、AV1技術、臉部/眼睛追踪及多項進階功能!
Virtual Desktop 驚人更新:支援Quest 3、AV1技術、臉部/眼睛追踪及多項進階功能! Amazing update to Virtual Desktop: supports Quest 3, AV1 technology, face/eye tracking and many advanced features!
對於不少VR愛好者而言��Virtual Desktop 已是一款不可或缺的工具。這款應用允許用戶通過無線方式將PC桌面串流至VR裝置,使得用戶能夠在虛擬現實中體驗桌面應用、遊戲和多媒體內容。它不僅提供了無縫的桌面體驗,還有諸多特色功能如高解析度支援、低延遲串流等,為使用者帶來了前所未有的沉浸感。 首先,這次更新正式為 Quest 3 提供了支援,同時還加入了以下專為 Quest 3 設計的性能提升: 引進了AV1支援,但需要Nvidia 4000或AMD 7000系列GPU。 相較於HEVC,AV1提供相同比特率下更好的影像品質。 更穩定的編碼/解碼時間,減少遊戲中的卡頓現象。 不過,使用AV1會增加對GPU的需求。 最大比特率增加至200 Mbps,對於H.264+則達到400 Mbps。 新增了與Quest Pro相似的“Godlike”品質,但支援至120…

View On WordPress
0 notes
Text
As much as I hate the idea of having to torrent 700+ GB and store 200+ GB, the difference in 480p and 1080p for this TV show I'm watching is absolutely necessary.
480p was practically unwatchable. Maybe the torrent creator used an intense amount of bitrate compression, but it doesn't matter. I felt like I was watching a podcast with a colorful screensaver. 720p and 1080p are so much better. Not to mention the 16:9 aspect ratio looks so much better.
However, this is another case of AV1 saving the day. 200+ GB is a lot, but 700+ GB would've been a deal breaker. As a result, I am once again asking torrent makers to use modern, fucking, video codecs. That 700+ GB is with H.265 (HEIC). I can't imagine what it would be with H.264. AV1 & Opus are really coming in clutch with this show.
#rambles#torrent#torrenting#piracy#pirating#av1#video codec#codec#codecs#video codecs#audio codec#audio codecs#data#data hoarding#data storage
8 notes
·
View notes
Text
Time to vote for your fave battle theme of the series! (sorry AP fans xD). I know many of us grew up playing with the default RPG Maker Battle02 theme in AV1 (I know I did!), but to make things consistent, I'm using all of Aaron Walz's versions of the battle themes.
To refresh your memory, I've inserted the themes below:
AVEYOND 1
AVEYOND 2
AVEYOND 3
AVEYOND 4
VOTE AWAY!
13 notes
·
View notes
Text

The part in AV1 where I've just graduated and I'm heading towards the Wildwood Forest again always sticks in my mind. I think it's when I felt the most pride in on my first playthrough - I made it here all on my own!
Yes, I know the trees are all wrong for Wildwood Forest. I just hate drawing pine trees lmao. Can u do me a favor and pretend I did?
BTW this is a redraw (original from 2018):

I think we can all agree I got better at art.
#aveyond#aveyond 1#rhen's quest#av1#fanart#rhen darzon#rhen pendragon#2023#x#have I mentioned that this is my favorite game#I got it into the top 100 games of all time on a friends' podcast through pure nostalgia
43 notes
·
View notes
Text
Been doing some video encoder tests for recording, and AV1 is freaking black magic. I took an 18GB bluray rip down to 5GB and I can totally do better. And it still looks good! This totally throws off my math on how much I could fit on a future home media server - if I wanted to, I could fit hundreds, if not a few thousand titles onto my future build plan.
My streams could, if Twitch decides to support it and transcoding for all soon, be a good 1080p60 or a stellar 720p60/900p60. The recordings of those could go from 20+ gigs to maybe 10.
It feels so wrong to make a video that small and yet still look incredible. Like, I'm breaking some forbidden tech law that says videos can't be that small ever.
1 note
·
View note
Text

This mod adds a new spell into the Necromancer guild's spell book. With this Lars can resurrect dead party members as "zombies" in battle (because, you know, necromancer).
Zombie party members will have attack and defense stat boost, but they cannot be controlled by you. They will just auto-attack the enemy.
(not necessarily the most useful of spells and is mostly just there for the sake of fun and laughs, install and use at your own risk)
Instruction:
Backup your Aveyond 1 game first, just in case
Unzip the mod file
Place in Aveyond 1 game folder
If prompted, select "replace file"
[Get the mod file here]
Additional mechanics notes (don't read if you want to surprise yourself with the mod):
a. Spell is specifically learned at level 60. Just like with the built-in spells, you learn it by reading the spell book at the appropriate level (not auto-learned).
b. Since your zombie friends are technically "dead", they will just go back to being "dead" after battle. Use Cassia leaf or normal Revive spells to bring them back to life as usual.
#av1#aveyond 1#aveyond#Can mods be shared outside of discord tho#If this shouldn't be here I'll delete the post
21 notes
·
View notes