#AI search
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 411 employees.
Text
Googles ai search is going great
11K notes
·
View notes
Text
Even if you think AI search could be good, it won’t be good

TONIGHT (May 15), I'm in NORTH HOLLYWOOD for a screening of STEPHANIE KELTON'S FINDING THE MONEY; FRIDAY (May 17), I'm at the INTERNET ARCHIVE in SAN FRANCISCO to keynote the 10th anniversary of the AUTHORS ALLIANCE.

The big news in search this week is that Google is continuing its transition to "AI search" – instead of typing in search terms and getting links to websites, you'll ask Google a question and an AI will compose an answer based on things it finds on the web:
https://blog.google/products/search/generative-ai-google-search-may-2024/
Google bills this as "let Google do the googling for you." Rather than searching the web yourself, you'll delegate this task to Google. Hidden in this pitch is a tacit admission that Google is no longer a convenient or reliable way to retrieve information, drowning as it is in AI-generated spam, poorly labeled ads, and SEO garbage:
https://pluralistic.net/2024/05/03/keyword-swarming/#site-reputation-abuse
Googling used to be easy: type in a query, get back a screen of highly relevant results. Today, clicking the top links will take you to sites that paid for placement at the top of the screen (rather than the sites that best match your query). Clicking further down will get you scams, AI slop, or bulk-produced SEO nonsense.
AI-powered search promises to fix this, not by making Google search results better, but by having a bot sort through the search results and discard the nonsense that Google will continue to serve up, and summarize the high quality results.
Now, there are plenty of obvious objections to this plan. For starters, why wouldn't Google just make its search results better? Rather than building a LLM for the sole purpose of sorting through the garbage Google is either paid or tricked into serving up, why not just stop serving up garbage? We know that's possible, because other search engines serve really good results by paying for access to Google's back-end and then filtering the results:
https://pluralistic.net/2024/04/04/teach-me-how-to-shruggie/#kagi
Another obvious objection: why would anyone write the web if the only purpose for doing so is to feed a bot that will summarize what you've written without sending anyone to your webpage? Whether you're a commercial publisher hoping to make money from advertising or subscriptions, or – like me – an open access publisher hoping to change people's minds, why would you invite Google to summarize your work without ever showing it to internet users? Nevermind how unfair that is, think about how implausible it is: if this is the way Google will work in the future, why wouldn't every publisher just block Google's crawler?
A third obvious objection: AI is bad. Not morally bad (though maybe morally bad, too!), but technically bad. It "hallucinates" nonsense answers, including dangerous nonsense. It's a supremely confident liar that can get you killed:
https://www.theguardian.com/technology/2023/sep/01/mushroom-pickers-urged-to-avoid-foraging-books-on-amazon-that-appear-to-be-written-by-ai
The promises of AI are grossly oversold, including the promises Google makes, like its claim that its AI had discovered millions of useful new materials. In reality, the number of useful new materials Deepmind had discovered was zero:
https://pluralistic.net/2024/04/23/maximal-plausibility/#reverse-centaurs
This is true of all of AI's most impressive demos. Often, "AI" turns out to be low-waged human workers in a distant call-center pretending to be robots:
https://pluralistic.net/2024/01/31/neural-interface-beta-tester/#tailfins
Sometimes, the AI robot dancing on stage turns out to literally be just a person in a robot suit pretending to be a robot:
https://pluralistic.net/2024/01/29/pay-no-attention/#to-the-little-man-behind-the-curtain
The AI video demos that represent "an existential threat to Hollywood filmmaking" turn out to be so cumbersome as to be practically useless (and vastly inferior to existing production techniques):
https://www.wheresyoured.at/expectations-versus-reality/
But let's take Google at its word. Let's stipulate that:
a) It can't fix search, only add a slop-filtering AI layer on top of it; and
b) The rest of the world will continue to let Google index its pages even if they derive no benefit from doing so; and
c) Google will shortly fix its AI, and all the lies about AI capabilities will be revealed to be premature truths that are finally realized.
AI search is still a bad idea. Because beyond all the obvious reasons that AI search is a terrible idea, there's a subtle – and incurable – defect in this plan: AI search – even excellent AI search – makes it far too easy for Google to cheat us, and Google can't stop cheating us.
Remember: enshittification isn't the result of worse people running tech companies today than in the years when tech services were good and useful. Rather, enshittification is rooted in the collapse of constraints that used to prevent those same people from making their services worse in service to increasing their profit margins:
https://pluralistic.net/2024/03/26/glitchbread/#electronic-shelf-tags
These companies always had the capacity to siphon value away from business customers (like publishers) and end-users (like searchers). That comes with the territory: digital businesses can alter their "business logic" from instant to instant, and for each user, allowing them to change payouts, prices and ranking. I call this "twiddling": turning the knobs on the system's back-end to make sure the house always wins:
https://pluralistic.net/2023/02/19/twiddler/
What changed wasn't the character of the leaders of these businesses, nor their capacity to cheat us. What changed was the consequences for cheating. When the tech companies merged to monopoly, they ceased to fear losing your business to a competitor.
Google's 90% search market share was attained by bribing everyone who operates a service or platform where you might encounter a search box to connect that box to Google. Spending tens of billions of dollars every year to make sure no one ever encounters a non-Google search is a cheaper way to retain your business than making sure Google is the very best search engine:
https://pluralistic.net/2024/02/21/im-feeling-unlucky/#not-up-to-the-task
Competition was once a threat to Google; for years, its mantra was "competition is a click away." Today, competition is all but nonexistent.
Then the surveillance business consolidated into a small number of firms. Two companies dominate the commercial surveillance industry: Google and Meta, and they collude to rig the market:
https://en.wikipedia.org/wiki/Jedi_Blue
That consolidation inevitably leads to regulatory capture: shorn of competitive pressure, the companies that dominate the sector can converge on a single message to policymakers and use their monopoly profits to turn that message into policy:
https://pluralistic.net/2022/06/05/regulatory-capture/
This is why Google doesn't have to worry about privacy laws. They've successfully prevented the passage of a US federal consumer privacy law. The last time the US passed a federal consumer privacy law was in 1988. It's a law that bans video store clerks from telling the newspapers which VHS cassettes you rented:
https://en.wikipedia.org/wiki/Video_Privacy_Protection_Act
In Europe, Google's vast profits lets it fly an Irish flag of convenience, thus taking advantage of Ireland's tolerance for tax evasion and violations of European privacy law:
https://pluralistic.net/2023/05/15/finnegans-snooze/#dirty-old-town
Google doesn't fear competition, it doesn't fear regulation, and it also doesn't fear rival technologies. Google and its fellow Big Tech cartel members have expanded IP law to allow it to prevent third parties from reverse-engineer, hacking, or scraping its services. Google doesn't have to worry about ad-blocking, tracker blocking, or scrapers that filter out Google's lucrative, low-quality results:
https://locusmag.com/2020/09/cory-doctorow-ip/
Google doesn't fear competition, it doesn't fear regulation, it doesn't fear rival technology and it doesn't fear its workers. Google's workforce once enjoyed enormous sway over the company's direction, thanks to their scarcity and market power. But Google has outgrown its dependence on its workers, and lays them off in vast numbers, even as it increases its profits and pisses away tens of billions on stock buybacks:
https://pluralistic.net/2023/11/25/moral-injury/#enshittification
Google is fearless. It doesn't fear losing your business, or being punished by regulators, or being mired in guerrilla warfare with rival engineers. It certainly doesn't fear its workers.
Making search worse is good for Google. Reducing search quality increases the number of queries, and thus ads, that each user must make to find their answers:
https://pluralistic.net/2024/04/24/naming-names/#prabhakar-raghavan
If Google can make things worse for searchers without losing their business, it can make more money for itself. Without the discipline of markets, regulators, tech or workers, it has no impediment to transferring value from searchers and publishers to itself.
Which brings me back to AI search. When Google substitutes its own summaries for links to pages, it creates innumerable opportunities to charge publishers for preferential placement in those summaries.
This is true of any algorithmic feed: while such feeds are important – even vital – for making sense of huge amounts of information, they can also be used to play a high-speed shell-game that makes suckers out of the rest of us:
https://pluralistic.net/2024/05/11/for-you/#the-algorithm-tm
When you trust someone to summarize the truth for you, you become terribly vulnerable to their self-serving lies. In an ideal world, these intermediaries would be "fiduciaries," with a solemn (and legally binding) duty to put your interests ahead of their own:
https://pluralistic.net/2024/05/07/treacherous-computing/#rewilding-the-internet
But Google is clear that its first duty is to its shareholders: not to publishers, not to searchers, not to "partners" or employees.
AI search makes cheating so easy, and Google cheats so much. Indeed, the defects in AI give Google a readymade excuse for any apparent self-dealing: "we didn't tell you a lie because someone paid us to (for example, to recommend a product, or a hotel room, or a political point of view). Sure, they did pay us, but that was just an AI 'hallucination.'"
The existence of well-known AI hallucinations creates a zone of plausible deniability for even more enshittification of Google search. As Madeleine Clare Elish writes, AI serves as a "moral crumple zone":
https://estsjournal.org/index.php/ests/article/view/260
That's why, even if you're willing to believe that Google could make a great AI-based search, we can nevertheless be certain that they won't.
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/05/15/they-trust-me-dumb-fucks/#ai-search
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
--
djhughman https://commons.wikimedia.org/wiki/File:Modular_synthesizer_-_%22Control_Voltage%22_electronic_music_shop_in_Portland_OR_-_School_Photos_PCC_%282015-05-23_12.43.01_by_djhughman%29.jpg
CC BY 2.0 https://creativecommons.org/licenses/by/2.0/deed.en
#pluralistic#twiddling#ai#ai search#enshittification#discipline#google#search#monopolies#moral crumple zones#plausible deniability#algorithmic feeds
1K notes
·
View notes
Text

Nuff said my friend. Ok. Just give me a minute to sort this wild message out.
Ok… it could be more than that. This runs all over the board which could be exactly the point or super ironic given the tattoo. How much weight do we give intention here? Can someone with a paid subscription to a visual AI service run this through? It you can afford the subscription, you have the time. Just sayin.
…You know, I’m betting either myself or a fireman might be coming for this guy and not for any reason anyone is thinking right now.
#awkwardbros#awkward guys#awkward#something is off#oh woah#awkward moment#cactus#fucking prick#prickly pear#careful there#any scorpions or snakes nearby#what are you saying#what is this#thongbutt#men in thongs#give me a minute#open invitation#safety concerns#giving directions#compass#unclear#really awkward#awkward situations#this is awkward#really really really awkward#i’m not sure#do I call somebody#visual aids#ai services#ai search
60 notes
·
View notes
Text

Who Is Hecate (Hekate)?
Hecate is a Greek goddess associated with magic, witchcraft, the night, and the underworld:
Domains
Hecate's domains include the sky, earth, and sea. She is also associated with crossroads, doorways, and the protection of women and childbirth.
Appearance
Hecate is often depicted with three faces, representing her role as a guardian of boundaries and crossroads. She is also sometimes shown with three bodies, or as a single body with three faces. She is often depicted holding torches, a key, or snakes, and accompanied by dogs.
Powers
Hecate's powers include witchcraft, necromancy, and the ability to open portals between realms. She is said to have allowed the living to communicate with the dead and other supernatural beings.
Family
Hecate's parentage is unclear, with different sources giving different accounts. Some say she is the daughter of Perses and Asteria, while others say she is the daughter of Zeus and Demeter, Aristaion, or Night.
History
Hecate originated in Thrace, an area that is now part of Bulgaria, Greece, and Turkey. She was worshipped in ancient Greece, and was popular among the witches of Thessaly.
Symbolism
In Macbeth, the Weïrd Sisters are said to answer to Hecate, rather than the devil. This symbolizes the idea that there is always an “other side” to the world.
Roman Counterpart
Trivia
🌑🌑🌑
#witchblr#witch#witches#witchcraft#paganblr#pagan#paganism#moon#dark moon#ai search#ai artwork#magick#goddess#hecate#hekate#greek gods#greek mythology#greek goddess#goddess hecate#goddess hekate#bomwhoarethemoongoddesses#goddess trivia#trivia
35 notes
·
View notes
Text

Duck.ai!!?! What the fuck? I just had my first ai generated result in DuckDuckGo and I feel so betrayed. Not to mention it was inaccurate as fuck. Like totally wrong. 😑 I hate generative ai. No generative ai. It just makes people stupid. Use your brain. You don’t need to be spoon fed bullshit wrong information. I am sick of ai being forced down our throats at every turn!
#duckduckgo#search engine#ai search#fuck you man#generative ai#ai is trash#death to ai#ai#ai is stupid#ai is shit#fuck ai#i fucking hate it here#DuckDuckGo I trusted you#i feel so betrayed#how dare they#this was supposed to be a trustworthy search engine#nothing is safe#hate hate hate#ai writing is theft#ai art is not art#ai is theft#ai is a plague#ai is bad#ai is bullshit#ai is evil#ai is plagiarism#ai is dangerous#anti generative ai#anti ai#ugh 🙄🙄🙄
8 notes
·
View notes
Text
Google Search Has Actually Gotten Better, Thanks to AI
In recent months (yes, months!; this is very recent; and it has especially kicked up just in the past one or two months), Google Search has become significantly more useful! This is entirely due to the integration of AI into their search results.
For years now, the usefulness graph of Google Search as a function of time has looked like the stock price of a dying company. Ruthlessly self-interested, low-quality SEO efforts by the marketing industry, together with Google's own strategic decision to turn its once-legendary search engine from the online equivalent of the Great Library of Alexandria into a portal for buying things and asking Jeeves simple questions, had diminished Google's usefulness for most search applications to almost nil. I had been reduced to using it to find links to Reddit and Quora posts, or doing much more in-depth searches to find good information sources directly with only a broken search engine to aid me.
Now, with the advent of AI integration into a new "AI Google Search" (I don't know what it's formally called, though the search results page labels it as "AI Overview"), one of the most important lost functions has been substantially restored: namely, the ability to ask more complicated questions—"complicated" either by way of complexity or obscurity—and get good answers!
This is huge.
For me, this has been coming up frequently in my Galaxy Federal research. I first noticed it earlier this year when I needed to find out how Cherry's voice pitch would be affected if she were in an atmosphere with a different composition from that of our own air. I hadn't been aware of the AI search functionality at the time, so had figured the answer out by myself the hard way—for good measure being hobbled in my efforts by the contemporary uselessness of conventional Google Search to return search results from the kinds of websites / sources I was looking for. And then I phrased one of my search queries as a question (I guess to see if Reddit had been over this at some point), and lo and behold Google AI answered me and confirmed my findings.
You can now ask Google Search some pretty complicated questions. Just a couple days ago I was curious about a sunscreen that could absorb X-rays, and wanted to learn more about the absorption of other wavelengths of electromagnetic radiation (the way sunscreen absorbs some ultraviolet light), and AI Google Search gave me a refreshingly serviceable set of answers. Nor are these cherry-picked examples; I've been benefitting from AI search results to my queries for some time now, on dozens of queries if not hundreds, and only just today I noticed that I should mention it. I wish I had written down the specifics of some of the best examples, because memory is a fickle thing. Needless to say, though, I have been both impressed and, more so, relieved. I have become used to enshittification as the default paradigm these days, so it is a genuine breath of fresh air whenever an application changes to actually be more useful.
These AI results are not magical. They are...let's put them in the slightly-better-than-Wikipedia league of "verify it for yourself." But usually that's all I need! For one thing, these AI results often include useful links where I can verify the information immediately. For another, just having a starter answer is usually enough to give me what I need to figure out how to arrive at the final answer. The other day I needed to know what the term is (presuming there is one) for transforming a signal from a higher frequency to a lower one. This kind of question has become needlessly and exceedingly difficult to answer through conventional Google Search, but the AI figured it out instantly, and gave me an answer that is correct for its domain. (It though I was talking about electronics. I wasn't, but having the answer ("downconversion") was all I needed to resolve my query.
The AI is very good. It genuinely parses my queries correctly—"understands my meaning," to use the anthropomorphic framing. I am genuinely impressed.
Conventional Google Search is only good for a few things nowadays. I still use it daily for some of those purposes. But to be able to ask these more complex questions again and get good answers is lovely! It's a sorely-needed victory for Information Retrieval in a very dark time for that domain. And, indeed, being able to phrase my queries as queries is basically new. In that narrower respect, this new search capability is even better than what we used to have in years past.
The Caveat
There is, of course, a caveat, and it's the same caveat that always arises with using the current crop of AI systems for information:
The answers it gives are not indexed / saved / learned. If you leave the tab open and come back to it a few days later, Google will generate a new AI answer to the same query. That is incredibly wasteful, not to mention frustrating for the end user, because it means you have to copy-paste those answers if you want to save them. You'll never see them again, otherwise.
The answers it gives are not consistent. In the above scenario, the new answer the AI generates will be different from the original one. For instance, with the X-ray query I mentioned earlier, I generated a new answer just now with the exact same query, and the new answer was missing a key piece of information that made the original one particularly useful. This means you might end up having to run the same query a few different times / different ways (i.e. phrasings), just in case the first answer that comes up isn't the one with the good info—and, many times, how would you know?
The answers it gives are not guaranteed to be accurate or complete. It has not been uncommon for me to encounter situations where I have independently known that the answers that AI Google Search was giving me were some combination of outright wrong and fatally incomplete. So you have to be careful. I want to say that AI Google Search has given higher-integrity answers than, say, ChatGPT. But it also might be that I'm biased because I've mainly been asking technical questions that perhaps aren't representative of questions in general with regard to the accuracy of answers. (And I only played around with ChatGPT very briefly, earlier this year.)
11 notes
·
View notes
Text
Looking at the Google AI overview fails, and just thinking... how the fuck did Google not realize how absolutely stupid this idea was? Even I, a 15 year old who can't even drive a car yet, has enough common sense to realize that AI using the internet as reference for it's answers is going to end horribly. The interent is a cesspool, and although there can be helpful things found on it, it's more than obvious that the AI is getting it's information from a lot of memes.



A lot of these have managed to correct their mistake, but you can see where they got their original misinformation from.

(A fruit that ends in um is plum in case you're curious)
Here's my test. As you can see it's STILL wrong,

and here's the comment that the AI originally mistaked for true information.

Anyways, AI is stupid, it can only really gather data and steal from other people, it doesn't have the common sense and intuition and experience that we have that helps us determine what's true and what's obviously not, it will never understand as much as us, and companies are failing us. Ok bye!!
#google ai#ai overview#ai#google search#ai search#technology fail#google ai overview#tw ai#fuck ai#fuck ai art#fuck ai writing#fuck ai everything
35 notes
·
View notes
Text
Only Works on Chrome Currently...
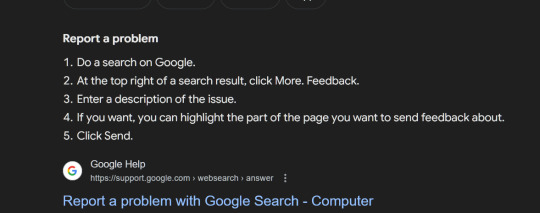
Report a problem
Do a search on Google.
At the top right of a search result, click More. Feedback.
Enter a description of the issue.
If you want, you can highlight the part of the page you want to send feedback about.
Click Send.
Report Overview results that have nothing to do with your search, results of a dangerous, harmful or wrong nature. Racist suggestions, Hate Speech, threats, etc. Report it. Prove to Google how wrong they are about their "AI Search"
6 notes
·
View notes
Text
Why are there generative Ai search results in front of me when I open a new tab in Firefox and how do I kill it?
I've torn through several threads trying to figure out how to remove Google's new "SGE" in search feature and everyone asking is getting sandbagged by customer support.
I've tried using other search engines but none really present decent results when compared to Google, as that's how monopoly works unfortunately.
#hack the planet#anti google#kill google#anti ai#fuck ai#fuck google#google sge#sge#ai search#browser#firefox#web development
6 notes
·
View notes
Text

Google ai is going great @auntieerin
2 notes
·
View notes
Text
Dinkclump Linkdump

I'm on tour with my new novel The Bezzle! Catch me TONIGHT in LA (Saturday night, with Adam Conover), Seattle (Monday, with Neal Stephenson), then Portland, Phoenix and more!

Some Saturday mornings, I look at the week's blogging and realize I have a lot more links saved up than I managed to write about this week, and then I do a linkdump. There've been 14 of these, and this is number 15:
https://pluralistic.net/tag/linkdump/
Attentive readers will note that this isn't Saturday. You're right. But I'm on a book tour and every day is shatterday, because damn, it's grueling and I'm not the spry manchild who took Little Brother on the road in 2008 – I'm a 52 year old with two artificial hips. Hence: an out-of-cycle linkdump. Come see me on tour and marvel at my verticality!
https://pluralistic.net/2024/02/16/narrative-capitalism/#bezzle-tour
Best thing I read this week, hands down, was Ryan Broderick's Garbage Day piece, "AI search is a doomsday cult":
https://www.garbageday.email/p/ai-search-doomsday-cult
Broderick makes so many excellent points in this piece. First among them: AI search sucks, but that's OK, because no one is asking for AI search. This only got more true later in the week when everyone's favorite spicy autocomplete accidentally loaded the James Joyce module:
https://arstechnica.com/information-technology/2024/02/chatgpt-alarms-users-by-spitting-out-shakespearean-nonsense-and-rambling/
(As Matt Webb noted, Chatbots have slid rapidly from Star Trek (computers give you useful information in a timely fashion) to Douglas Adams (computers spout hostile, impenetrable nonsense at you):
https://interconnected.org/home/2024/02/21/adams
But beyond the unsuitability of AI for search results and beyond the public's yawning indifference to AI-infused search, Broderick makes a more important point: AI search is about summarizing web results so you don't have to click links and read the pages yourself.
If that's the future of the web, who the fuck is going to write those pages that the summarizer summarizes? What is the incentive, the business-model, the rational explanation for predicting a world in which millions of us go on writing web-pages, when the gatekeepers to the web have promised to rig the game so that no one will ever visit those pages, or read what we've written there, or even know it was us who wrote the underlying material the summarizer just summarized?
If we stop writing the web, AIs will have to summarize each other, forming an inhuman centipede of botshit-ingestion. This is bad news, because there's pretty solid mathematical evidence that training a bot on botshit makes it absolutely useless. Or, as the authors of the paper – including the eminent cryptographer Ross Anderson – put it, "using model-generated content in training causes irreversible defects":
https://arxiv.org/abs/2305.17493
This is the mathematical evidence for Jathan Sadowski's "Hapsburg AI," or, as the mathematicians call it, "The Curse of Recursion" (new band-name just dropped).

But if you really have your heart set on living in a ruined dystopia dominated by hostile artificial life-forms, have no fear. As Hamilton Nolan writes in "Radical Capital," a rogues gallery of worker-maiming corporations have asked a court to rule that the NLRB can't punish them for violating labor law:
https://www.hamiltonnolan.com/p/radical-capital
Trader Joe’s, Amazon, Starbucks and SpaceX have all made this argument to various courts. If they prevail, then there will be no one in charge of enforcing federal labor law. Yes, this will let these companies go on ruining their workers' lives, but more importantly, it will give carte blanche to every other employer in the land. At one end of this process is a boss who doesn't want to recognize a union – and at the other end are farmers dying of heat-stroke.
The right wing coalition that has put this demand before the court has all sorts of demands, from forced birth to (I kid you not), the end of recreational sex:
https://www.lawyersgunsmoneyblog.com/2024/02/getting-rid-of-birth-control-is-a-key-gop-agenda-item-for-the-second-trump-term
That coalition is backed by ultra-rich monopolists who want wreck the nation that their rank-and-file useful idiots want to wreck your body. These are the monopoly cheerleaders who gave us the abomination that is the Pharmacy Benefit Manager – a useless intermediary that gets to screw patients and pharmacists – and then let PBMs consolidate and merge with pharmacy monopolists.
One such inbred colossus is Change Healthcare, a giant PBM that is, in turn, a mere tendril of United Healthcare, which merged the company with Optum. The resulting system – held together with spit and wishful thinking – has access to the health records of a third of Americans and processes 15 billion prescriptions per day.
Or rather, it did process that amount – until the all-your-eggs-in-one-badly-maintained basket strategy failed on Wednesday, and Change's systems went down due to an unspecified "cybersecurity incident." In the short term, this meant that tens of millions of Americans who tried to refill their prescriptions were told to either pay cash or come back later (if you don't die first). That was the first shoe dropping. The second shoe is the medical records of a third of the country.
Don't worry, I'm sure those records are fine. After all, nothing says security like "merging several disparate legacy IT systems together while simultaneously laying off half your IT staff as surplus to requirements and an impediment to extracting a special dividend for the private equity owners who are, of course, widely recognized as the world's greatest information security practitioners."
Look, not everything is terrible. Some computers are actually getting better. Framework's user-serviceable, super-rugged, easy-to-repair, powerful laptops are the most exciting computers I've ever owned – or broken:
https://pluralistic.net/2022/11/13/graceful-failure/#frame
Now you can get one for $500!
https://frame.work/blog/first-framework-laptop-16-shipments-and-a-499-framework
And the next generation is turning our surprisingly well, despite all our worst efforts. My kid – now 16! – and I just launched our latest joint project, "The Sushi Chronicles," a small website recording our idiosyncratic scores for nearly every sushi restaurant in Burbank, Glendale, Studio City and North Hollywood:
https://sushichronicles.org/
This is the record of two years' worth of Daughter-Daddy sushi nights that started as a way to get my picky eater to try new things and has turned into the highlight of my week. If you're in the area and looking for a nice piece of fish, give it a spin (also, we belatedly realized that we've never reviewed our favorite place, Kuru Kuru in the CVS Plaza on North Hollywood Way – we'll be rectifying that soon).
And yes, we have a lavishly corrupt Supreme Court, but at least now everyone knows it. Glenn Haumann's even set up a Gofundme to raise money to bribe Clarence Thomas (now deleted, alas):
https://www.gofundme.com/f/pzhj4q-the-clarence-thomas-signing-bonus-fund-give-now
The funds are intended as a "signing bonus" in the event that Thomas takes up John Oliver on his offer of a $2.4m luxury RV and $1m/year for life if he'll resign from the court:
https://www.youtube.com/watch?v=GE-VJrdHMug
This is truly one of Oliver's greatest bits, showcasing his mastery over the increasingly vital art of turning abstruse technical issues into entertainment that negates the performative complexity used by today's greatest villains to hide their misdeeds behind a Shield of Boringness (h/t Dana Clare).
The Bezzle is my contribution to turning abstruse scams into a high-impact technothriller that pierces that Shield of Boringness. The key to this is to master exposition, ignoring the (vastly overrated) rule that one must "show, not tell." Good exposition is hard to do, but when it works, it's amazing (as anyone who's read Neal Stephenson's 1,600-word explanation of how to eat Cap'n Crunch cereal in Cryptonomicon can attest). I wrote about this for Mary Robinette Kowal's "My Favorite Bit" this week:
https://maryrobinettekowal.com/journal/my-favorite-bit/my-favorite-bit-cory-doctorow-talks-about-the-bezzle/
Of course, an undisputed master of this form is Adam Conover, whose Adam Ruins Everything show helped invent it. Adam is joining me on stage in LA tomorrow night at Vroman's at 5:30PM, to host me in a book-tour event for my novel The Bezzle:
https://www.vromansbookstore.com/Cory-Doctorow-discusses-The-Bezzle
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/02/23/gazeteer/#out-of-cycle
Image: Peter Craven (modified) https://commons.wikimedia.org/wiki/File:Aggregate_output_%287637833962%29.jpg
CC BY 2.0 https://creativecommons.org/licenses/by/2.0/deed.en
#pluralistic#the bezzle#ryan broderick#mary robinette kowal#exposition#john oliver#margot robbie#adam conover#ai#ai search#change healthcare#centralization#pharma#pbms#pharmacy benefit managers#corruption#scotus#crowdfunding#clarence thomas
39 notes
·
View notes
Text

Who is Selene?
In Greek and Roman mythology, Selene is the goddess of the moon:
Who she is:
Selene is the daughter of the Titans Hyperion and Theia, and the sister of Helios, the sun god, and Eos, the goddess of dawn. She is also known as Mene.
What she does:
Selene is often depicted driving a chariot drawn by winged horses across the night sky, with the moon on her head.
Who she loves:
Selene had many lovers, including Zeus, Pan, and the mortal Endymion. She and Endymion had 50 daughters.
How she is worshipped:
Selene was worshipped at the new and full moons.
Her Roman counterpart:
Selene's Roman counterpart is Luna.
How she is associated with other goddesses:
Selene is often associated with the goddesses Artemis and Hecate, but only Selene was considered the personification of the moon.
Why she doesn't have a temple:
Unlike other major Greek goddesses, Selene didn't have her own temple sites because she could be seen from almost everywhere.
🌘🌖🌕🌔🌒
#pagan#paganblr#paganism#witchblr#witchcraft#witch community#witch#witches#goddess#goddess selene#greek mythology#greek gods#ai search#ai artwork#moon#full moon#waning moon#waxing moon#new moon#bomwhoarethemoongoddesses#artemis#luna#hecate#hekate
22 notes
·
View notes
Text
I love how this is the worst thing tumblr's search function has
I love how the search function on this site is absolute garbage. I can look up a post word for word and I will NEVER find it
335K notes
·
View notes
Text
no i don't want to use your ai assistant. no i don't want your ai search results. no i don't want your ai summary of reviews. no i don't want your ai feature in my social media search bar (???). no i don't want ai to do my work for me in adobe. no i don't want ai to write my paper. no i don't want ai to make my art. no i don't want ai to edit my pictures. no i don't want ai to learn my shopping habits. no i don't want ai to analyze my data. i don't want it i don't want it i don't want it i don't fucking want it i am going to go feral and eat my own teeth stop itttt
#i don't want it!!!!#ai#artificial intelligence#there are so many positive uses for ai#and instead we get ai google search results that make me instantly rage#diz says stuff
138K notes
·
View notes
Text
Algolia vs. Connector Search Tools: A Comprehensive Comparison
Evaluating Performance, Features, and Usability to Help You Choose the Right Search Solution.
When it comes to implementing a powerful search and discovery solution for eCommerce, two major players often come up: Algolia and Constructor. While both provide advanced search capabilities, their workflows, implementations, and approach to AI-driven product discovery set them apart. This blog takes a deep dive into their differences, focusing on real-world applications, technical differentiators, and the impact on business KPIs.
Overview of Algolia and Constructor
Algolia
Founded in 2012, Algolia is a widely recognized search-as-a-service platform.
It provides instant, fast, and reliable search capabilities with an API-first approach.
Commonly used in various industries, including eCommerce, SaaS, media, and enterprise applications.
Provides keyword-based search with support for vector search and AI-driven relevance tuning.
Constructor
A newer entrant in the space, Constructor focuses exclusively on eCommerce product discovery.
Founded in 2015 and built from the ground up with clickstream-driven AI for ranking and recommendations.
Used by leading eCommerce brands like Under Armour and Home24.
Aims to optimize business KPIs like conversion rates and revenue per visitor.
Key Differences in Implementation and Workflows
1. Search Algorithm and Ranking Approach
Algolia:
Uses keyword-based search (TF-IDF, BM25) with additional AI-driven ranking enhancements.
Supports vector search, semantic search, and hybrid approaches.
Merchandisers can fine-tune relevance manually using rule-based controls.
Constructor:
Built natively on a Redis-based core rather than Solr or ElasticSearch.
Prioritizes clickstream-driven search and personalization, focusing on what users interact with.
Instead of purely keyword relevance, it optimizes for "attractiveness", ranking results based on a user’s past behavior and site-wide trends.
Merchandisers work with AI, using a human-interpretable dashboard to guide search ranking rather than overriding it.
2. Personalization & AI Capabilities
Algolia:
Offers personalization via rules and AI models that users can configure.
Uses AI for dynamic ranking adjustments but primarily relies on structured data input.
Constructor:
Focuses heavily on clickstream data, meaning every interaction—clicks, add-to-cart actions, and conversions—affects future search results.
Uses Transformer models for context-aware personalization, dynamically adjusting rankings in real-time.
AI Shopping Assistant allows for conversational product discovery, using Generative AI to enhance search experiences.
3. Use of Generative AI
Algolia:
Provides semantic search and AI-based ranking but does not have native Generative AI capabilities.
Users need to integrate third-party LLMs (Large Language Models) for AI-driven conversational search.
Constructor:
Natively integrates Generative AI to handle natural language queries, long-tail searches, and context-driven shopping experiences.
AI automatically understands customer intent—for example, searching for "I'm going camping in Yosemite with my kids" returns personalized product recommendations.
Built using AWS Bedrock and supports multiple LLMs for improved flexibility.
4. Merchandiser Control & Explainability
Algolia:
Provides rule-based tuning, allowing merchandisers to manually adjust ranking factors.
Search logic and results are transparent but require manual intervention for optimization.
Constructor:
Built to empower merchandisers with AI, allowing human-interpretable adjustments without overriding machine learning.
Black-box AI is avoided—every recommendation and ranking decision is traceable and explainable.
Attractiveness vs. Technical Relevance: Prioritizes "what users want to buy" over "what matches the search query best".
5. Proof-of-Concept & Deployment
Algolia:
Requires significant setup to run A/B tests and fine-tune ranking.
Merchandisers and developers must manually configure weighting and relevance.
Constructor:
Offers a "Proof Schedule", allowing retailers to test before committing.
Retailers install a lightweight beacon, send a product catalog, and receive an automated performance analysis.
A/B tests show expected revenue uplift, allowing data-driven decision-making before switching platforms.
Real-World Examples & Business Impact
Example 1: Searching for a Hoodie
A user searches for "hoodie" on an eCommerce website using Algolia vs. Constructor:
Algolia's Approach: Shows hoodies ranked based on keyword relevance, possibly with minor AI adjustments.
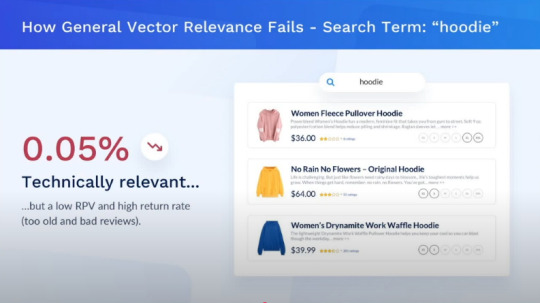
Source : YouTube - AWS Partner Network
Constructor's Approach: Learns from past user behavior, surfacing high-rated hoodies in preferred colors and styles, increasing the likelihood of conversion.

Source : YouTube - AWS Partner Network
Example 2: Conversational Search for Camping Gear
A shopper types, "I'm going camping with my preteen kids for the first time in Yosemite. What do I need?"
Algolia: Requires manual tagging and structured metadata to return relevant results.
Constructor: Uses Generative AI and Transformer models to understand the context and intent, dynamically returning the most relevant items across multiple categories.
Which One Should You Choose?
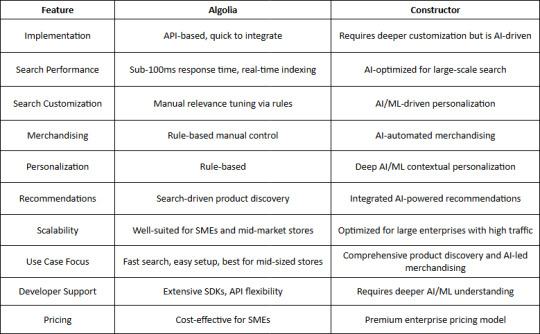
Why Choose Algolia?
Ease of Implementation – Algolia provides a quick API-based setup, making it ideal for eCommerce sites looking for a fast integration process.
Speed & Performance – With real-time indexing and instant search, Algolia is built for speed, ensuring sub-100ms response times.
Developer-Friendly – Offers extensive documentation, SDKs, and a flexible API for developers to customize search behavior.
Rule-Based Merchandising – Allows businesses to manually tweak search relevance with robust rules and business logic.
Cost-Effective for SMEs – More affordable for smaller eCommerce businesses with straightforward search needs.
Enterprise-Level Scalability – Can support growing businesses but requires manual optimization for handling massive catalogs.
Search-Driven Recommendations – While Algolia supports recommendations, they are primarily based on search behaviors rather than deep AI.
Manual Control Over Search & Merchandising – Provides businesses the flexibility to define search relevance and merchandising manually.
Strong Community & Developer Ecosystem – Large user base with extensive community support and integrations.
Why Choose Constructor?
Ease of Implementation – While requiring more initial setup, Constructor offers pre-trained AI models that optimize search without extensive manual configurations.
Speed & Performance – Uses AI-driven indexing and ranking to provide high-speed, optimized search results for large-scale retailers.
Developer-Friendly – Requires deeper AI/ML understanding but provides automation that reduces manual tuning efforts.
Automated Merchandising – AI-driven workflows reduce the need for manual intervention, optimizing conversion rates.
Optimized for Large Retailers – Designed for enterprises requiring full AI-driven control over search and discovery.
Deep AI Personalization – Unlike Algolia’s rule-based system, Constructor uses advanced AI/ML to provide contextual, personalized search experiences.
End-to-End Product Discovery – Goes beyond search, incorporating personalized recommendations, dynamic ranking, and automated merchandising.
Scalability – Built to handle massive catalogs and high traffic loads with AI-driven performance optimization.
Integrated AI-Powered Recommendations – Uses AI-driven models to surface relevant products in real-time based on user intent and behavioral signals.
Data-Driven Decision Making – AI continuously optimizes search and merchandising strategies based on real-time data insights.
Conclusion
Both Algolia and Constructor are excellent choices, but their suitability depends on your eCommerce business's needs:
If you need a general-purpose, fast search engine, Algolia is a great fit.
If your focus is on eCommerce product discovery, personalization, and revenue optimization, Constructor provides an AI-driven, clickstream-based solution designed for maximizing conversions.
With the evolution of AI and Generative AI, Constructor is positioning itself as a next-gen alternative to traditional search engines, giving eCommerce brands a new way to drive revenue through personalized product discovery.
This Blog is driven by our experience with product implementations for customers.
Connect with US
Thanks for reading Ragul's Blog! Subscribe for free to receive new posts and support my work.
1 note
·
View note