#webcrawling
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
How to Fix Crawl Budget Waste for Large E-Commerce Sites
Struggling with crawl budget waste on your massive e-commerce site?

Learn actionable strategies to fix crawl budget waste for large e-commerce sites, optimize Googlebot’s efficiency, and boost your SEO rankings without breaking a sweat.
Introduction: When Googlebot Goes on a Wild Goose Chase 🕵️♂️
Picture this: Googlebot is like an overworked librarian trying to organize a chaotic library. Instead of shelving bestsellers, it’s stuck rearranging pamphlets from 2012.
That’s essentially what happens when your e-commerce site suffers from crawl budget waste.
Your precious crawl budget—the number of pages Googlebot can and will crawl on your site—gets squandered on irrelevant, duplicate, or low-value pages. Yikes!
For large e-commerce platforms with millions of URLs, this isn’t just a minor hiccup; it’s a full-blown crisis.
Every second Googlebot spends crawling a broken filter page or a duplicate product URL is a second not spent indexing your shiny new collection.

So, how do you fix crawl budget waste for large e-commerce sites before your SEO rankings take a nosedive? Buckle up, buttercup—we’re diving in.
What the Heck Is Crawl Budget, Anyway? (And Why Should You Care?) 🤔
H2: Understanding Crawl Budget: The Lifeline of Your E-Commerce SEO
Before we fix crawl budget waste for large e-commerce sites, let’s break down the basics. Crawl budget refers to the number of pages Googlebot will crawl on your site during a given period. It’s determined by:
Crawl capacity limit: How much server strain Googlebot is allowed to cause.
Crawl demand: How “important” Google deems your site (spoiler: high authority = more crawls).
For e-commerce giants, a limited crawl budget means Googlebot might skip critical pages if it’s too busy crawling junk. Think of it like sending a scout into a maze—if they waste time on dead ends, they’ll never reach the treasure.
How to Fix Crawl Budget Waste for Large E-Commerce Sites: 7 Battle-Tested Tactics
1. Audit Like a Bloodhound: Find What’s Draining Your Budget 🕵️♀️
First things first—you can’t fix what you don’t understand. Run a site audit to uncover:
Orphaned pages: Pages with no internal links. (Googlebot can’t teleport, folks!)
Thin content: Product pages with 50-word descriptions. Cue sad trombone.
Duplicate URLs: Color variants? Session IDs? Parameter hell? Fix. Them.
Broken links: 404s and 500s that send Googlebot into a loop.
Pro Tip: Use Screaming Frog or Sitebulb to crawl your site like Googlebot. Export URLs with low traffic, high bounce rates, or zero conversions. These are prime suspects for crawl budget waste.
2. Wield the Robots.txt Sword (But Don’t Stab Yourself) ⚔️
Blocking Googlebot from crawling useless pages is a no-brainer. But tread carefully—misconfigured robots.txt files can backfire. Here’s how to do it right:
Block low-priority pages: Admin panels, infinite pagination (page=1, page=2…), and internal search results.
Avoid wildcard overkill: Disallow: /*?* might block critical pages with parameters.
Test with Google Search Console: Use the robots.txt tester to avoid accidental blockages.
3. Canonical Tags: Your Secret Weapon Against Duplicates 🔫
Duplicate content is the arch-nemesis of crawl budget. Fix it by:
Adding canonical tags to all product variants (e.g., rel="canonical" pointing to the main product URL).
Using 301 redirects for deprecated or merged products.
Consolidating pagination with rel="prev" and rel="next" (though Google’s support is spotty—proceed with caution).
4. XML Sitemaps: Roll Out the Red Carpet for Googlebot 🎟️
Your XML sitemap is Googlebot’s GPS. Keep it updated with:
High-priority pages: New products, seasonal collections, bestsellers.
Exclude junk: No one needs 50 versions of the same hoodie in the sitemap.
Split sitemaps: For sites with 50k+ URLs, split into multiple sitemaps (e.g., products, categories, blogs).
5. Fix Internal Linking: Turn Your Site into a Well-Oiled Machine ⚙️
A messy internal linking structure forces Googlebot to play hopscotch. Optimize by:
Adding breadcrumb navigation for layered category pages.
Linking to top-performing pages from high-authority hubs (homepage, blogs).
Pruning links to low-value pages (looking at you, outdated promo codes).
6. Dynamic Rendering: Trick Googlebot into Loving JavaScript 🎭
Got a JS-heavy site? Googlebot might struggle to render pages, leading to crawl inefficiencies. Dynamic rendering serves a static HTML snapshot to bots while users get the full JS experience. Tools like Prerender or Puppeteer can help.
7. Monitor, Tweak, Repeat: Crawl Budget Optimization Is a Marathon 🏃♂️
Fixing crawl budget waste isn’t a one-and-done deal. Use Google Search Console to:
Track crawl stats (pages crawled/day, response codes).
Identify sudden spikes in 404s or server errors.
Adjust your strategy quarterly based on data.
FAQs: Your Burning Questions, Answered 🔥
Q1: How often should I audit my site for crawl budget waste?
A: For large e-commerce sites, aim for quarterly audits. During peak seasons (Black Friday, holidays), check monthly—traffic surges can expose new issues.
Q2: Can crawl budget waste affect my rankings?
A: Absolutely! If Googlebot’s too busy crawling junk, your new pages might not index quickly, hurting visibility and sales.
Q3: Are pagination pages always bad?
A: Not always—but if they’re thin or duplicate, block them with robots.txt or consolidate with View-All pages.
Conclusion: Stop the Madness and Take Back Control 🛑
Fixing crawl budget waste for large e-commerce sites isn’t rocket science—it’s about playing smart with Googlebot’s time. By auditing ruthlessly, blocking junk, and guiding bots to your golden pages, you’ll transform your site from a chaotic maze into a well-organized powerhouse. Remember, every crawl Googlebot makes should count. So, roll up your sleeves, implement these tactics, and watch your SEO performance soar. 🚀
Still sweating over crawl budget issues? Drop a comment below—we’ll help you troubleshoot. Fix All Technical Issus Now
#SEO#CrawlBudget#EcommerceSEO#Googlebot#SEOTips#TechnicalSEO#SiteAudit#SEOFixes#EcommerceMarketing#DigitalMarketing#SearchEngineOptimization#SEOTools#CrawlOptimization#LargeSiteSEO#FixCrawlWaste#SEOAudit#EcommerceGrowth#SEORankings#WebCrawling#SEOBestPractices
1 note
·
View note
Text
Optimize Website Crawling with Robots.txt Validator
Optimize your website's crawling efficiency with a reliable robots.txt validator. Ensure search engines access the right pages while blocking sensitive or irrelevant content. A robots.txt validator checks for syntax errors and ensures compliance with search engine guidelines, helping improve SEO and website performance. Use this tool to streamline indexing and enhance your site's visibility online.
#ArissaInternational#RobotsTxtValidator#WebsiteSEO#SearchEngineOptimization#WebCrawling#SEOOptimization#WebsitePerformance
0 notes
Text
Google Explains How CDNs Impact Crawling & SEO
🌐 How Do CDNs Impact SEO and Crawling? 🚀 Google explains the role of Content Delivery Networks (CDNs) in improving website speed, performance, and search engine crawling efficiency. Dive into the details and optimize your site for better SEO results! 🔍✨

👉 Read more: Google Explains How CDNs Impact Crawling & SEO
#SEO#GoogleSEO#CDN#WebsitePerformance#DigitalMarketing#SEOOptimization#TechInsights#WebCrawling#SearchEngineOptimization#WebsiteSpeed
0 notes
Text
Requestkan pembuatan program kamu dengan chat ke Whatsapp 082321017426. 😍
.
#DaveFenley#HelpMeHoldOn#CountryMusic#MusicLovers#AcousticGuitar#LoveCode#FYP#FYPシ#FYPBoost#Trending#Python#Coding#Programming#Automation#WebScraping#WebCrawling#CodeLife
0 notes
Text
𝐖𝐡𝐞𝐫𝐞 𝐂𝐨𝐦𝐟𝐨𝐫𝐭 𝐌𝐞𝐞𝐭𝐬 𝐒𝐞𝐜𝐮𝐫𝐢𝐭𝐲: 𝐑𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐏𝐫𝐨𝐱𝐢𝐞𝐬, 𝐘𝐨𝐮𝐫 𝐃𝐢𝐠𝐢𝐭𝐚𝐥 𝐒𝐡𝐢𝐞𝐥𝐝

𝐖𝐡𝐚𝐭 𝐚𝐫𝐞 𝐫𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐩𝐫𝐨𝐱𝐢𝐞𝐬 𝐚𝐧𝐝 𝐡𝐨𝐰 𝐝𝐨 𝐭𝐡𝐞𝐲 𝐰𝐨𝐫𝐤❓
Residential proxies serve as a specialized type of proxy server, leveraging authentic residential IP addresses to obfuscate the user’s actual location and IP address. This renders them a more potent and secure alternative when juxtaposed with conventional datacenter proxies, as websites and online services are less prone to detecting or blocking them.
A distinctive trait of residential proxies lies in their association with a specific, unchanging IP address. This implies that even if the user disconnects and later reconnects to the proxy, they persistently employ the same IP address. This attribute proves particularly advantageous for endeavors demanding a consistent and unwavering connection, such as data scraping or market research.
Beyond their reliability, residential proxies furnish a heightened level of anonymity. By channeling internet traffic through an intermediary server, users can effectively conceal their genuine identity and location from websites and online platforms. This proves especially beneficial for individuals and businesses seeking to fortify their online privacy and security.
In essence, residential proxies stand as an invaluable instrument for those aiming to veil their online undertakings or circumvent geolocation restrictions. They furnish a dependable and secure solution for a diverse array of tasks, constituting an indispensable resource for those desiring to navigate the internet incognito.
𝐁𝐞𝐧𝐞𝐟𝐢𝐭𝐬 𝐨𝐟 𝐮𝐬𝐢𝐧𝐠 𝐫𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐩𝐫𝐨𝐱𝐢𝐞𝐬 𝐟𝐨𝐫 𝐰𝐞𝐛 𝐬𝐜𝐫𝐚𝐩𝐢𝐧𝐠
Residential proxies, employing authentic residential IP addresses, prove effective for web scraping by evading detection or blocking from websites. Their stability, tied to unchanging IP addresses, ensures a consistent connection even after disconnection and reconnection. Additionally, these proxies offer heightened anonymity, concealing users’ true identity and location from online services. Their reliability and security make static residential proxies an essential tool for individuals and businesses conducting web scraping tasks. Overall, they provide a stable and secure solution for data collection, minimizing the risk of detection or obstruction.
𝐇𝐨𝐰 𝐚 𝐫𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐩𝐫𝐨𝐱𝐲 𝐜𝐚𝐧 𝐢𝐦𝐩𝐫𝐨𝐯𝐞 𝐲𝐨𝐮𝐫 𝐨𝐧𝐥𝐢𝐧𝐞 𝐩𝐫𝐢𝐯𝐚𝐜𝐲 𝐚𝐧𝐝 𝐬𝐞𝐜𝐮𝐫𝐢𝐭𝐲❓
In an era marked by escalating concerns about online privacy and security, safeguarding personal information has become paramount for individuals and businesses. Addressing this challenge, residential proxies, utilizing genuine residential IP addresses, offer a robust solution. Their use reduces the likelihood of detection or blocking by websites, as they emulate typical residential internet connections. An integral aspect of how residential proxies enhance online privacy and security lies in obscuring the user’s authentic IP address and location. By directing internet traffic through a third-party server, these proxies act as intermediaries, fortifying privacy. Additionally, they contribute to heightened security by encrypting internet traffic, bolstering defenses against potential data breaches, hacking, and surveillance.
𝐂𝐨𝐦𝐩𝐚𝐫𝐢𝐧𝐠 𝐫𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐩𝐫𝐨𝐱𝐢𝐞𝐬 𝐭𝐨 𝐨𝐭𝐡𝐞𝐫 𝐭𝐲𝐩𝐞𝐬 𝐨𝐟 𝐩𝐫𝐨𝐱𝐢𝐞𝐬
🌐 **𝐒𝐭𝐚𝐭𝐢𝐜 𝐑𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐏𝐫𝐨𝐱𝐢𝐞𝐬 𝐯𝐬. 𝐎𝐭𝐡𝐞𝐫 𝐏𝐫𝐨𝐱𝐲 𝐓𝐲𝐩𝐞𝐬**
🏠**𝐒𝐭𝐚𝐭𝐢𝐜 𝐑𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐏𝐫𝐨𝐱𝐢𝐞𝐬:** Static residential proxies use genuine residential IP addresses, providing a stable and consistent connection. Tied to unchanging IP addresses, they are less likely to be detected or blocked by websites, making them ideal for tasks requiring reliability.
🏢**𝐃𝐚𝐭𝐚𝐜𝐞𝐧𝐭𝐞𝐫 𝐏𝐫𝐨𝐱𝐢𝐞𝐬:** Datacenter proxies are cost-effective and scalable, using IP addresses from datacenters. However, they face higher detection risks, making them less suitable for tasks where stealth is crucial.
🔄**𝐑𝐨𝐭𝐚𝐭𝐢𝐧𝐠 𝐑𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐏𝐫𝐨𝐱𝐢𝐞𝐬:** Rotating residential proxies dynamically assign new IP addresses from a pool, enhancing anonymity. While less stable, they offer increased privacy, making them suitable for tasks requiring a high level of anonymity.
🤔**𝐂𝐨𝐧𝐬𝐢𝐝𝐞𝐫𝐚𝐭𝐢𝐨𝐧𝐬:** Choose static residential proxies for stability and reliability, datacenter proxies for cost efficiency, and rotating residential proxies for enhanced anonymity. Tailor your choice to the specific needs of your task to ensure optimal performance and security.
𝐔𝐬𝐢𝐧𝐠 𝐬𝐭𝐚𝐭𝐢𝐜 𝐩𝐫𝐨𝐱𝐢𝐞𝐬 𝐟𝐨𝐫 𝐈𝐧𝐬𝐭𝐚𝐠𝐫𝐚𝐦 𝐚𝐮𝐭𝐨𝐦𝐚𝐭𝐢𝐨𝐧
Instagram’s widespread use of automation tools for account management faces challenges due to the platform’s strict anti-automation policies. To navigate these restrictions, static residential proxies become invaluable, utilizing authentic residential IP addresses to reduce the likelihood of detection or blocking by Instagram. A key advantage lies in their ability to mask the user’s true IP address and location, achieved by routing internet traffic through a third-party server. Additionally, static residential proxies enhance security by encrypting internet traffic, fortifying protection against potential data breaches and online threats.
𝐔𝐬𝐢𝐧𝐠 𝐬𝐭𝐚𝐭𝐢𝐜 𝐩𝐫𝐨𝐱𝐢𝐞𝐬 𝐟𝐨𝐫 𝐒𝐄𝐎 𝐚𝐧𝐝 𝐤𝐞𝐲𝐰𝐨𝐫𝐝 𝐫𝐞𝐬𝐞𝐚𝐫𝐜𝐡
Static proxies significantly enhance SEO and keyword research by providing stable, consistent connections that help in masking the user’s identity, ensuring uninterrupted data collection and analysis. Some of the key ways include:
𝐂𝐨𝐧𝐝𝐮𝐜𝐭𝐢𝐧𝐠 𝐦𝐚𝐫𝐤𝐞𝐭 𝐫𝐞𝐬𝐞𝐚𝐫𝐜𝐡
Utilizing static proxies for market research facilitates the collection of valuable data on consumer behavior and trends, aiding in identifying SEO and marketing opportunities. By leveraging static proxies to access various online platforms, businesses can seamlessly gather insights on keywords and trends, empowering informed decision-making for strategic marketing endeavors.
𝐁𝐲𝐩𝐚𝐬𝐬𝐢𝐧𝐠 𝐠𝐞𝐨𝐥𝐨𝐜𝐚𝐭𝐢𝐨𝐧 𝐫𝐞𝐬𝐭𝐫𝐢𝐜𝐭𝐢𝐨𝐧𝐬
Static proxies serve as a valuable tool for overcoming geolocation restrictions imposed by websites and online services, allowing users to access content from different locations by rerouting their internet traffic through a server in a desired region. This capability proves beneficial for tasks such as accessing localized search results, conducting market research in diverse regions, and more.
𝐄𝐭𝐡𝐢𝐜𝐚𝐥 𝐜𝐨𝐧𝐜𝐞𝐫𝐧𝐬 𝐰𝐢𝐭𝐡 𝐮𝐬𝐢𝐧𝐠 𝐬𝐭𝐚𝐭𝐢𝐜 𝐫𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐩𝐫𝐨𝐱𝐢𝐞𝐬
While static residential proxies can have legitimate uses, there are also several ethical concerns to consider when using them:
𝐁𝐲𝐩𝐚𝐬𝐬𝐢𝐧𝐠 𝐠𝐞𝐨𝐥𝐨𝐜𝐚𝐭𝐢𝐨𝐧 𝐫𝐞𝐬𝐭𝐫𝐢𝐜𝐭𝐢𝐨𝐧𝐬 𝐚𝐧𝐝 𝐨𝐧𝐥𝐢𝐧𝐞 𝐜𝐞𝐧𝐬𝐨𝐫𝐬𝐡𝐢𝐩
A notable ethical consideration associated with static residential proxies involves the possibility of circumventing geolocation restrictions. Many websites and online services implement such restrictions to control access to specific content based on users’ locations. Using a static residential proxy to reroute internet traffic through a server in a different location enables users to bypass these restrictions. However, this raises ethical concerns if it violates the terms of service of the website or contravenes laws and regulations. Careful consideration and adherence to ethical standards are crucial when employing such proxies to avoid potential misuse or legal implications.
𝐄𝐧𝐠𝐚𝐠𝐢𝐧𝐠 𝐢𝐧 𝐜𝐲𝐛𝐞𝐫𝐜𝐫𝐢𝐦𝐞
Another ethical concern associated with static residential proxies is their potential misuse in cybercrime. These proxies have the capability to conceal the user’s true IP address and location, creating a challenge for authorities to trace malicious activities. This feature may make static residential proxies attractive to individuals engaged in cybercrime, including activities such as hacking or online fraud. Addressing the ethical implications of using these proxies requires careful consideration of the potential misuse and the need for responsible and lawful utilization to prevent illicit activities.
𝐕𝐏𝐒 𝐏𝐫𝐨𝐱𝐢𝐞𝐬 𝐢𝐧𝐜❜𝐬 𝐒𝐭𝐚𝐭𝐢𝐜 𝐑𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐏𝐫𝐨𝐱𝐲 𝐏𝐨𝐨𝐥:
VPS Proxies Inc. proudly provides a diverse selection of static residential proxies tailored to cater to the diverse requirements of both businesses and individuals. Leveraging authentic residential IP addresses, our static proxies ensure a dependable and unwavering connection, coupled with a heightened level of anonymity.
Ideal for tasks demanding stability, such as web scraping, market research, and bolstering online privacy and security, our static residential proxies boast a reduced likelihood of detection or blocking by websites and online services. Beyond static residential proxies, we extend our offerings to encompass a variety of proxy types, including datacenter proxies, rotating residential proxies, and mobile proxies, ensuring a comprehensive solution for all your proxy needs.
Discover more about our static residential proxies and explore how they can elevate your business or personal endeavors by visiting our website at www.vpsproxies.com . Our dedicated team is ready to address any inquiries, guiding you towards the ideal proxy solution to meet your unique requirements.
𝐂𝐨𝐧𝐜𝐥𝐮𝐬𝐢𝐨𝐧:
VPS Proxies Inc. offers a versatile range of static residential proxies designed to meet the diverse needs of businesses and individuals. Our proxies, leveraging authentic residential IP addresses, guarantee a stable connection and heightened anonymity. Whether you’re involved in web scraping, market research, or enhancing online security, our proxies minimize the risk of detection by websites and online services. Explore our comprehensive suite of proxy solutions, including datacenter proxies, rotating residential proxies, and mobile proxies, to find the ideal fit for your specific requirements.
ℂ𝕠𝕟𝕥𝕒𝕔𝕥 𝕦𝕤:-: 👉🏻 Web: www.vpsproxies.com 👉🏻 Telegram: https://t.me/vpsproxiesinc 👉 Gmail: vpsproxiesinc@gmail.com 👉🏻 Skype: live:.cid.79b1850cbc237b2a
#ResidentialProxy#ProxyServices#StaticIP#OnlinePrivacy#ProxyNetwork#DigitalSecurity#InternetPrivacy#WebScraping#DataMining#ResidentialIP#ProxyServers#WebCrawling#ProxyTech#OnlineAnonymity#DataProtection#StaticProxy#ProxyProvider#ResidentialIPs#WebAutomation#SecureBrowsing
0 notes
Text
Texas Realtors Data Scraping

Data Scraping for Texas Realtors: Unleashing Potential in the Real Estate Landscape. With Texas witnessing a surge in its real estate market, there's a burgeoning need for businesses to harness precise and extensive data on Texas realtors. At Datascrapingservices.com, we take pride in offering cutting-edge Texas Realtors Data Scraping solutions, empowering businesses to augment their marketing endeavors and capitalize on the expansive opportunities within the Texas real estate sector. Our Texas Realtors Data Scraping service serves as a pivotal asset, enabling businesses to procure vital insights into real estate agents and brokers operating in Texas. This encompasses an array of data points, including contact information, professional backgrounds, specialized areas, and beyond.
List of Data Fields
When scraping data for Texas realtors, the following data fields could be valuable to collect:
Realtor Name: The full name of the realtor.
Agency/Brokerage Name: The name of the agency or brokerage the realtor is associated with.
Contact Information: This includes email addresses, phone numbers, and mailing addresses.
Client Testimonials: Feedback and testimonials from past clients about their experience working with the realtor.
Social Media Profiles: Links to the realtor's social media profiles, such as LinkedIn, Facebook, or Twitter.
Website URL: The URL of the realtor's website, if available.
These data fields can provide comprehensive information about Texas realtors, enabling analysis, comparison, and targeted outreach for various purposes such as market research, lead generation, and networking within the real estate industry.
Benefits of Texas Realtors Data Scraping
With this treasure trove of insights within reach, businesses can harness the Texas Realtors Data Scraping service to:
- Targeted Marketing: Leveraging the data, businesses in allied sectors like mortgage lending, home improvement, or property management can precisely aim their marketing endeavors. By connecting with realtors specializing in specific areas or property types, businesses can tailor their messaging and offerings to resonate with their intended audience.
- Market Analysis: Accessing data on Texas realtors offers invaluable insights into the state's real estate landscape, encompassing market trends, demand dynamics, and emerging prospects. Through meticulous analysis, businesses can make informed decisions regarding their expansion strategies, investment allocations, and market positioning.
- Partnerships and Collaborations: For enterprises seeking to forge alliances or collaborations within the real estate realm, the Texas Realtors Data Scraping service serves as a potent tool. By pinpointing realtors whose objectives align with theirs, companies can initiate dialogue for joint ventures, referral initiatives, or symbiotic partnerships.
Email List Scraping Services:
Live Boutique Stores Email List
Real Estate Brokers Email List
Bars Email List
Barbers Email List
Assisted Living Facilities Mailing List
Screen Printing Mailing List
Hobby Stores Email List
Air Duct Cleaning Email List
Window Cleaning Companies Email List
Prosthodontist Email List
Website: Datascrapingservices.com
Email: info@datascrapingservices.com
#texasrealestateagentsemaillist#texasrealtorsdatascrapingservice#texasrealtorsemaillist#webscrapingexpert#webscraper#datascrapingservices#webcrawling#websitedatascraping#webscraping#datascraping
0 notes
Text
Web Scraping: Unlocking the Power of Data
#WebScraping#DataExtraction#DataMining#DataAnalysis#BigData#BusinessIntelligence#DataInsights#DigitalMarketing#MarketResearch#DataAnalytics#WebCrawling#WebAutomation#InformationGathering#CompetitiveAnalysis#DataScience
0 notes
Text




meeting of the meows
#oneshot game#niko oneshot#hapi kitten burst#kitten burst#kelvin oneshot#magpie oneshot#webcrawler is so cute 🕷��� spido
49 notes
·
View notes
Text

FINALLY this beast is done
#THANK U JELLY FOR INSPIRING ME TO DRAW THIS#fabiart#oc: webcrawler#oc: rite the snivy#oc: owgee#oc: piecewise function#oc: deadmall#posca#gellyroll#my ocs
16 notes
·
View notes
Text
Search Engines:
Search engines are independent computer systems that read or crawl webpages, documents, information sources, and links of all types accessible on the global network of computers on the planet Earth, the internet. Search engines at their most basic level read every word in every document they know of, and record which documents each word is in so that by searching for a words or set of words you can locate the addresses that relate to documents containing those words. More advanced search engines used more advanced algorithms to sort pages or documents returned as search results in order of likely applicability to the terms searched for, in order. More advanced search engines develop into large language models, or machine learning or artificial intelligence. Machine learning or artificial intelligence or large language models (LLMs) can be run in a virtual machine or shell on a computer and allowed to access all or part of accessible data, as needs dictate.
#llm#large language model#search engine#search engines#Google#bing#yahoo#yandex#baidu#dogpile#metacrawler#webcrawler#search engines imbeded in individual pages or operating systems or documents to search those individual things individually#computer science#library science#data science#machine learning#google.com#bing.com#yahoo.com#yandex.com#baidu.com#...#observe the buildings and computers within at the dalles Google data center to passively observe google and its indexed copy of the internet#the dalles oregon next to the river#google has many data centers worldwide so does Microsoft and many others
11 notes
·
View notes
Text
do you like your computer?
i like it too.

#scopophobia#webcore#rainbowcore#oc: webcrawler#its been like two years since ive drawn this fella. it uses it/he btw :3#fabiart#posca
15 notes
·
View notes
Text
Spider-Titan and WebCrawler!
Here ya go lovely’s 💖 :]
@suspiciously-furry
@standard-human

30 notes
·
View notes
Text
You know what would be cool?
A search engine that allowed you to have permanently blocked sites
#what could you find if you weren't confined#tech solutions#ai#google ads#i'd get rid of youtube quora & twitter for starters#fuck google#recs?#i use Webcrawler as my secondary rn
2 notes
·
View notes
Text
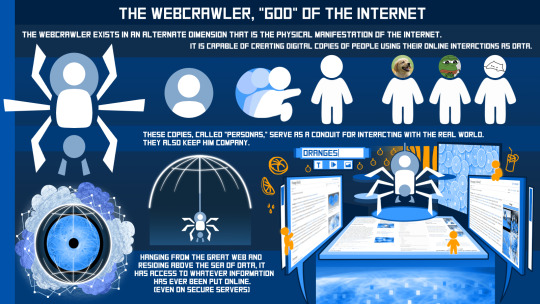
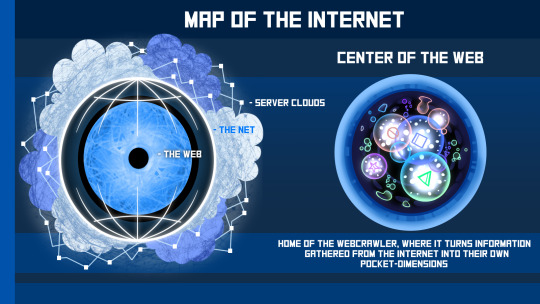

Redesign of the NON, now renamed to the Webcrawler.
I just wanted its design to fit more with its role in the story, especially since it's one of the most important characters in Muteshock.
4 notes
·
View notes
Text
𝐖𝐡𝐞𝐫𝐞 𝐂𝐨𝐦𝐟𝐨𝐫𝐭 𝐌𝐞𝐞𝐭𝐬 𝐒𝐞𝐜𝐮𝐫𝐢𝐭𝐲: 𝐑𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐏𝐫𝐨𝐱𝐢𝐞𝐬, 𝐘𝐨𝐮𝐫 𝐃𝐢𝐠𝐢𝐭𝐚𝐥 𝐒𝐡𝐢𝐞𝐥𝐝

𝐖𝐡𝐚𝐭 𝐚𝐫𝐞 𝐫𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐩𝐫𝐨𝐱𝐢𝐞𝐬 𝐚𝐧𝐝 𝐡𝐨𝐰 𝐝𝐨 𝐭𝐡𝐞𝐲 𝐰𝐨𝐫𝐤❓
Residential proxies serve as a specialized type of proxy server, leveraging authentic residential IP addresses to obfuscate the user’s actual location and IP address. This renders them a more potent and secure alternative when juxtaposed with conventional datacenter proxies, as websites and online services are less prone to detecting or blocking them.
A distinctive trait of residential proxies lies in their association with a specific, unchanging IP address. This implies that even if the user disconnects and later reconnects to the proxy, they persistently employ the same IP address. This attribute proves particularly advantageous for endeavors demanding a consistent and unwavering connection, such as data scraping or market research.
Beyond their reliability, residential proxies furnish a heightened level of anonymity. By channeling internet traffic through an intermediary server, users can effectively conceal their genuine identity and location from websites and online platforms. This proves especially beneficial for individuals and businesses seeking to fortify their online privacy and security.
In essence, residential proxies stand as an invaluable instrument for those aiming to veil their online undertakings or circumvent geolocation restrictions. They furnish a dependable and secure solution for a diverse array of tasks, constituting an indispensable resource for those desiring to navigate the internet incognito.
𝐁𝐞𝐧𝐞𝐟𝐢𝐭𝐬 𝐨𝐟 𝐮𝐬𝐢𝐧𝐠 𝐫𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐩𝐫𝐨𝐱𝐢𝐞𝐬 𝐟𝐨𝐫 𝐰𝐞𝐛 𝐬𝐜𝐫𝐚𝐩𝐢𝐧𝐠
Residential proxies, employing authentic residential IP addresses, prove effective for web scraping by evading detection or blocking from websites. Their stability, tied to unchanging IP addresses, ensures a consistent connection even after disconnection and reconnection. Additionally, these proxies offer heightened anonymity, concealing users’ true identity and location from online services. Their reliability and security make static residential proxies an essential tool for individuals and businesses conducting web scraping tasks. Overall, they provide a stable and secure solution for data collection, minimizing the risk of detection or obstruction.
𝐇𝐨𝐰 𝐚 𝐫𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐩𝐫𝐨𝐱𝐲 𝐜𝐚𝐧 𝐢𝐦𝐩𝐫𝐨𝐯𝐞 𝐲𝐨𝐮𝐫 𝐨𝐧𝐥𝐢𝐧𝐞 𝐩𝐫𝐢𝐯𝐚𝐜𝐲 𝐚𝐧𝐝 𝐬𝐞𝐜𝐮𝐫𝐢𝐭𝐲❓
In an era marked by escalating concerns about online privacy and security, safeguarding personal information has become paramount for individuals and businesses. Addressing this challenge, residential proxies, utilizing genuine residential IP addresses, offer a robust solution. Their use reduces the likelihood of detection or blocking by websites, as they emulate typical residential internet connections. An integral aspect of how residential proxies enhance online privacy and security lies in obscuring the user’s authentic IP address and location. By directing internet traffic through a third-party server, these proxies act as intermediaries, fortifying privacy. Additionally, they contribute to heightened security by encrypting internet traffic, bolstering defenses against potential data breaches, hacking, and surveillance.
𝐂𝐨𝐦𝐩𝐚𝐫𝐢𝐧𝐠 𝐫𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐩𝐫𝐨𝐱𝐢𝐞𝐬 𝐭𝐨 𝐨𝐭𝐡𝐞𝐫 𝐭𝐲𝐩𝐞𝐬 𝐨𝐟 𝐩𝐫𝐨𝐱𝐢𝐞𝐬
🌐 **𝐒𝐭𝐚𝐭𝐢𝐜 𝐑𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐏𝐫𝐨𝐱𝐢𝐞𝐬 𝐯𝐬. 𝐎𝐭𝐡𝐞𝐫 𝐏𝐫𝐨𝐱𝐲 𝐓𝐲𝐩𝐞𝐬**
🏠**𝐒𝐭𝐚𝐭𝐢𝐜 𝐑𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐏𝐫𝐨𝐱𝐢𝐞𝐬:** Static residential proxies use genuine residential IP addresses, providing a stable and consistent connection. Tied to unchanging IP addresses, they are less likely to be detected or blocked by websites, making them ideal for tasks requiring reliability.
🏢**𝐃𝐚𝐭𝐚𝐜𝐞𝐧𝐭𝐞𝐫 𝐏𝐫𝐨𝐱𝐢����𝐬:** Datacenter proxies are cost-effective and scalable, using IP addresses from datacenters. However, they face higher detection risks, making them less suitable for tasks where stealth is crucial.
🔄**𝐑𝐨𝐭𝐚𝐭𝐢𝐧𝐠 𝐑𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐏𝐫𝐨𝐱𝐢𝐞𝐬:** Rotating residential proxies dynamically assign new IP addresses from a pool, enhancing anonymity. While less stable, they offer increased privacy, making them suitable for tasks requiring a high level of anonymity.
🤔**𝐂𝐨𝐧𝐬𝐢𝐝𝐞𝐫𝐚𝐭𝐢𝐨𝐧𝐬:** Choose static residential proxies for stability and reliability, datacenter proxies for cost efficiency, and rotating residential proxies for enhanced anonymity. Tailor your choice to the specific needs of your task to ensure optimal performance and security.
𝐔𝐬𝐢𝐧𝐠 𝐬𝐭𝐚𝐭𝐢𝐜 𝐩𝐫𝐨𝐱𝐢𝐞𝐬 𝐟𝐨𝐫 𝐈𝐧𝐬𝐭𝐚𝐠𝐫𝐚𝐦 𝐚𝐮𝐭𝐨𝐦𝐚𝐭𝐢𝐨𝐧
Instagram’s widespread use of automation tools for account management faces challenges due to the platform’s strict anti-automation policies. To navigate these restrictions, static residential proxies become invaluable, utilizing authentic residential IP addresses to reduce the likelihood of detection or blocking by Instagram. A key advantage lies in their ability to mask the user’s true IP address and location, achieved by routing internet traffic through a third-party server. Additionally, static residential proxies enhance security by encrypting internet traffic, fortifying protection against potential data breaches and online threats.
𝐔𝐬𝐢𝐧𝐠 𝐬𝐭𝐚𝐭𝐢𝐜 𝐩𝐫𝐨𝐱𝐢𝐞𝐬 𝐟𝐨𝐫 𝐒𝐄𝐎 𝐚𝐧𝐝 𝐤𝐞𝐲𝐰𝐨𝐫𝐝 𝐫𝐞𝐬𝐞𝐚𝐫𝐜𝐡
Static proxies significantly enhance SEO and keyword research by providing stable, consistent connections that help in masking the user’s identity, ensuring uninterrupted data collection and analysis. Some of the key ways include:
𝐂𝐨𝐧𝐝𝐮𝐜𝐭𝐢𝐧𝐠 𝐦𝐚𝐫𝐤𝐞𝐭 𝐫𝐞𝐬𝐞𝐚𝐫𝐜𝐡
Utilizing static proxies for market research facilitates the collection of valuable data on consumer behavior and trends, aiding in identifying SEO and marketing opportunities. By leveraging static proxies to access various online platforms, businesses can seamlessly gather insights on keywords and trends, empowering informed decision-making for strategic marketing endeavors.
𝐁𝐲𝐩𝐚𝐬𝐬𝐢𝐧𝐠 𝐠𝐞𝐨𝐥𝐨𝐜𝐚𝐭𝐢𝐨𝐧 𝐫𝐞𝐬𝐭𝐫𝐢𝐜𝐭𝐢𝐨𝐧𝐬
Static proxies serve as a valuable tool for overcoming geolocation restrictions imposed by websites and online services, allowing users to access content from different locations by rerouting their internet traffic through a server in a desired region. This capability proves beneficial for tasks such as accessing localized search results, conducting market research in diverse regions, and more.
𝐄𝐭𝐡𝐢𝐜𝐚𝐥 𝐜𝐨𝐧𝐜𝐞𝐫𝐧𝐬 𝐰𝐢𝐭𝐡 𝐮𝐬𝐢𝐧𝐠 𝐬𝐭𝐚𝐭𝐢𝐜 𝐫𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐩𝐫𝐨𝐱𝐢𝐞𝐬
While static residential proxies can have legitimate uses, there are also several ethical concerns to consider when using them:
𝐁𝐲𝐩𝐚𝐬𝐬𝐢𝐧𝐠 𝐠𝐞𝐨𝐥𝐨𝐜𝐚𝐭𝐢𝐨𝐧 𝐫𝐞𝐬𝐭𝐫𝐢𝐜𝐭𝐢𝐨𝐧𝐬 𝐚𝐧𝐝 𝐨𝐧𝐥𝐢𝐧𝐞 𝐜𝐞𝐧𝐬𝐨𝐫𝐬𝐡𝐢𝐩
A notable ethical consideration associated with static residential proxies involves the possibility of circumventing geolocation restrictions. Many websites and online services implement such restrictions to control access to specific content based on users’ locations. Using a static residential proxy to reroute internet traffic through a server in a different location enables users to bypass these restrictions. However, this raises ethical concerns if it violates the terms of service of the website or contravenes laws and regulations. Careful consideration and adherence to ethical standards are crucial when employing such proxies to avoid potential misuse or legal implications.
𝐄𝐧𝐠𝐚𝐠𝐢𝐧𝐠 𝐢𝐧 𝐜𝐲𝐛𝐞𝐫𝐜𝐫𝐢𝐦𝐞
Another ethical concern associated with static residential proxies is their potential misuse in cybercrime. These proxies have the capability to conceal the user’s true IP address and location, creating a challenge for authorities to trace malicious activities. This feature may make static residential proxies attractive to individuals engaged in cybercrime, including activities such as hacking or online fraud. Addressing the ethical implications of using these proxies requires careful consideration of the potential misuse and the need for responsible and lawful utilization to prevent illicit activities.
𝐕𝐏𝐒 𝐏𝐫𝐨𝐱𝐢𝐞𝐬 𝐢𝐧𝐜❜𝐬 𝐒𝐭𝐚𝐭𝐢𝐜 𝐑𝐞𝐬𝐢𝐝𝐞𝐧𝐭𝐢𝐚𝐥 𝐏𝐫𝐨𝐱𝐲 𝐏𝐨𝐨𝐥:
VPS Proxies Inc. proudly provides a diverse selection of static residential proxies tailored to cater to the diverse requirements of both businesses and individuals. Leveraging authentic residential IP addresses, our static proxies ensure a dependable and unwavering connection, coupled with a heightened level of anonymity.
Ideal for tasks demanding stability, such as web scraping, market research, and bolstering online privacy and security, our static residential proxies boast a reduced likelihood of detection or blocking by websites and online services. Beyond static residential proxies, we extend our offerings to encompass a variety of proxy types, including datacenter proxies, rotating residential proxies, and mobile proxies, ensuring a comprehensive solution for all your proxy needs.
Discover more about our static residential proxies and explore how they can elevate your business or personal endeavors by visiting our website at www.vpsproxies.com . Our dedicated team is ready to address any inquiries, guiding you towards the ideal proxy solution to meet your unique requirements.
𝐂𝐨𝐧𝐜𝐥𝐮𝐬𝐢𝐨𝐧:
VPS Proxies Inc. offers a versatile range of static residential proxies designed to meet the diverse needs of businesses and individuals. Our proxies, leveraging authentic residential IP addresses, guarantee a stable connection and heightened anonymity. Whether you’re involved in web scraping, market research, or enhancing online security, our proxies minimize the risk of detection by websites and online services. Explore our comprehensive suite of proxy solutions, including datacenter proxies, rotating residential proxies, and mobile proxies, to find the ideal fit for your specific requirements.
ℂ𝕠𝕟𝕥𝕒𝕔𝕥 𝕦𝕤:-: 👉🏻 Web: www.vpsproxies.com 👉🏻 Telegram: https://t.me/vpsproxiesinc 👉 Gmail: vpsproxiesinc@gmail.com 👉🏻 Skype: live:.cid.79b1850cbc237b2a
#ResidentialProxy#ProxyServices#StaticIP#OnlinePrivacy#ProxyNetwork#DigitalSecurity#InternetPrivacy#WebScraping#DataMining#ResidentialIP#ProxyServers#WebCrawling#ProxyTech#OnlineAnonymity#DataProtection#StaticProxy#ProxyProvider#ResidentialIPs#WebAutomation#SecureBrowsing
0 notes
Text
Scraping Hospitals Directory Database

Scraping Hospitals Directory Database by Datascrapingservices.com: Unlocking Opportunities for Businesses in the Healthcare Industry. The healthcare industry is a vast and vital sector that requires strong connections and collaborations between businesses and hospitals. The Hospitals Directory Database offered by Datascrapingservices.com serves as a valuable resource for various businesses to connect with hospitals and unlock new opportunities for collaboration, partnership, and business growth. The Hospitals Directory Database comprises comprehensive and verified contact information of hospitals worldwide, including their addresses, phone numbers, email addresses, and key personnel details. This targeted database enables businesses to directly reach out to hospitals, establish meaningful connections, and drive effective marketing campaigns.
Various businesses can benefit from the Hospitals Directory Database. Medical equipment manufacturers and suppliers can connect with hospitals to showcase their products, negotiate supply contracts, and establish long-term business relationships. Pharmaceutical companies can leverage the database to identify potential hospital partners for clinical trials or to distribute their products. Service providers in the healthcare industry, such as IT solution providers or healthcare consultants, can reach out to hospitals to offer their specialized services and expertise.
Hospitals Directory Database
The Hospitals Directory Database is a valuable resource for email marketing campaigns. By utilizing the contact information provided in the database, businesses can create targeted email lists and send personalized emails to hospitals. This allows them to showcase their offerings, share industry insights, and establish themselves as trusted partners in the healthcare field. Email marketing campaigns can help businesses build relationships with hospitals, generate leads, and drive business growth by staying top-of-mind when hospitals are seeking new solutions or collaborations.
Datascrapingservices.com ensures the accuracy and reliability of the Hospitals Directory Database. In conclusion, the Hospitals Directory Database by Datascrapingservices.com provides businesses with a valuable resource to connect with hospitals and unlock opportunities in the healthcare industry. By leveraging this targeted database, businesses can enhance their networking efforts, forge partnerships, and contribute to the growth and success of the healthcare sector.
Email List Scraping Services:
Barbers Email List
Air Duct Cleaning Email List
Hobby Stores Email List
Bars Email List
Screen Printing Mailing List
Window Cleaning Companies Email List
Assisted Living Facilities Mailing List
Prosthodontist Email List
Live Boutique Stores Email List
Real Estate Brokers Email List
Website: Datascrapingservices.com
Email: info@datascrapingservices.com
#hospitalsmailinglist#hospitalsemaillist#hospitalemaildatabase#hospitaldirectoryscraper#hospitaldirectoryscraping#webscrapingexpert#webscraper#datascrapingservices#webcrawling#websitedatascraping#webscraping#datascraping
0 notes