#they also have ENORMOUS genomes
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
12.7% of mobile users access Tumblr.
Note
Quick, while the frog purists aren't looking, what's your favorite salamander?
No question, salamanders of the genus Thorius, the smallest salamanders in the world.

[Thorius pennatulus — src]

[Thorius sp. — src]
Truly astonishing creatures.
#Thorius#salamanders#caudata#amphibians#herpetology#these salamanders have a really shit surface:volume ratio#but they are LUNGLESS#so they respire entirely over that tiny surface#which is just astonishing#they also have ENORMOUS genomes#which means that they have huge cells#but they're small#so they don't have a lot of cells#they are pushing the limit to how small a vertebrate can be#and this is what I am going to be working on with my lab#how small can you get and still function as a vertebrate?#surely not much smaller than this#answers by Mark#anon#anonymous
908 notes
·
View notes
Text
CTVT and a weird niche theory I fell down the rabbit hole about - giant transforming retroviruses???
This is a story about how a single line on a wikipedia page sent me down a rabbit hole of finding one scientist's fringe theory that's juuuust plausible enough to make me question everything while almost certainly being absolute fucking bunk.
Some background
So, on parts of tumblr at least we all know about Canine Transmissible Venereal Tumour, aka The Immortal Cancer Dog. For those who don't know, it's a cancer dogs get, usually on their junk, that unlike most other cancers, isn't made up of their own cells. The cells are actually all descended from this one dog or wolf that lived like 11,000 years ago and are, arguably, all technically that one dog. A dog that became a single-celled infectious disease.
We have a wealth of genetic, histological and observational evidence for this. As in, we know it what population of canids it came from, we know it's got a weird chromosomal structure compared to normal dogs, we know it's genetically distinct from the hosts. We also know it's not the only one out there: There's a similar thing in Syrian hamsters and also the famous Tasmanian Devil Facial Tumour Disease (DFTD).
Which made me pause when I was reading something on wikipedia about the devil facial tumour and saw a line mentioning that it was now known to be caused by a giant virus, much like CTVT. Which...huh? Oh I hadn't heard that afore.
Giant viruses
Ok so giant viruses are a thing and they're fuckin cool. They're a relatively recent discovery and comparatively huge, i.e. bigger than a bunch of bacteria. They were only discovered in 1981 and we still don't know an enormous amount about them but they're big and have large genomes and because of the way viruses are they're not easy to detect unless you're specifically looking for them.
They show up under microscopy (sometimes) and you can find them with genetic probes but you gotta already be looking for them to see that really. Current research though basically says they're more common than we think, just overlooked, and there's software out there that scans through genomic data to find sequences that might indicate their presence. There's even a possibility that one group might be involved in some cases of pneumonia in humans, though I need to stress that that's extremely not confirmed right now.
The "wait, what?" moment
So I mentioned that it was a line in the wiki article for DFTD that had me going "wait, really?", the line in question was this:
A study found evidence for an infectious agent resembling a giant virus that was capable of turning heathy cells into cancer cells. It was found to be a huge retrovirus with similar viruses being found in human and canine cancer cells.
Big If True.
So of course I check the source, which was a 2020 paper by Lusi et al. titled "A transforming giant virus discovered in Canine Transmissible Venereal Tumour: Stray dogs and Tasmanian devils opening the door to a preventive cancer vaccine".
Hang on, CTVT not DFTD? This is where some alarm bells went off because uh, as mentioned at the start, we know a shit ton about CTVT. Including the fact that it's all one specific dog. Which doesn't fit at all with the idea that it's caused by a virus transforming host cells into cancer cells.
So what fucking gives? What is this research that fully overturns decades of pretty conclusive research to the contrary?
Is this another case of Dr Barbara McClintock? Who spent decades being ridiculed by the scientific community over her wild theory that was, in fact, 100% right even if it seemed to fly in the fact of all prior evidence?
Or is this a Dr Donald I. Williamson situation wherein a scientist with appropriate training is just wildly but extremely vehemently wrong?
#science#genetics#cancer#canine transmissible venereal tumour#devil facial tumour disease#niche science#I'm breaking this up into several sections for readability#stay tuned for more#also feel free to ask any questions about stuff#I'll provide links to things as well but I know tumblr can bury posts with certain links in and idk if researchgate counts
34 notes
·
View notes
Text
I've posted many times before about how surrogacy exploits vulnerable women and turns their babies into commodities. This article is about the impact of the fertility industry on the children themselves.
‘I slept with my half-sibling’: Woman’s horror story reflects loosely regulated nature of US fertility industry
By Rob Kuznia, Allison Gordon, Nelli Black and Kyung Lah, CNN | Photographs by Laura Oliverio, CNN
Published 10:00 AM EST, Wed February 14, 2024CNN —
Victoria Hill never quite understood how she could be so different from her father – in looks and in temperament. The 39-year-old licensed clinical social worker from suburban Connecticut used to joke that perhaps she was the mailman’s child.
Her joke eventually became no laughing matter. Worried about a health issue, and puzzled because neither of her parents had suffered any of the symptoms, Hill purchased a DNA testing kit from 23andMe a few years ago and sent her DNA to the genomics company.
What should have been a routine quest to learn more about herself turned into a shocking revelation that she had many more siblings than just the brother she grew up with – the count now stands at 22. Some of them reached out to her and dropped more bombshells: Hill’s biological father was not the man she grew up with but a fertility doctor who had been helping her mother conceive using donated sperm. That doctor, Burton Caldwell, a sibling told her, had used his own sperm to inseminate her mother, allegedly without her consent.
But the most devastating revelation came this summer, when Hill found out that one of her newly discovered siblings had been her high school boyfriend – one she says she easily could have married.
“I was traumatized by this,” Hill told CNN in an exclusive interview. “Now I’m looking at pictures of people thinking, well, if he could be my sibling, anybody could be my sibling.”
Hill’s story appears to represent one of the most extreme cases to date of fertility fraud in which fertility doctors have misled their female patients and their families by secretly using their own sperm instead of that of a donor. It also illustrates how the huge groups of siblings made possible in part by a lack of regulation can lead to a worst-case scenario coming to pass: accidental incest.
In this sense, say advocates of new laws criminalizing fertility fraud, Hill’s story is historic.
“This was the first time where we’ve had a confirmed case of someone actually dating, someone being intimate with someone who was their half-sibling,” said Jody Madeira, a law professor at Indiana University and an expert on fertility fraud.
A CNN investigation into fertility fraud nationwide found that most states, including Connecticut, have no laws against it. Victims of this form of deception face long odds in getting any kind of recourse, and doctors who are accused of it have an enormous advantage in court, meaning they rarely face consequences and, in some cases, have continued practicing, according to documents and interviews with fertility experts, lawmakers and several people fathered by sperm donors.
CNN also found that Hill’s romantic relationship with her half-brother wasn’t the only case in which she or other people in her newly discovered sibling group interacted with someone in their community who turned out to be a sibling.
At a time when do-it-yourself DNA kits are turning donor-conceived children into online sleuths about their own origins – and when this subset of the American population has reached an estimated one million people – Hill’s situation is a sign of the times. She is part of a larger groundswell of donor-conceived people who in recent years have sought to expose practices in the fertility industry they say have caused them distress: huge sibling pods, unethical doctors, unreachable biological fathers, a lack of information about their biological family’s medical history.
The movement has been the main driver in getting about a dozen new state laws passed over the past four years. Still, the legal landscape is patchy, and the US fertility industry is often referred to by critics as the “Wild West” for its dearth of regulation relative to other western countries.
“Nail salons are more regulated than the fertility industry,” said Eve Wiley, who traced her origins to fertility fraud and is a prominent advocate for new laws.
Accountability in short supply
More than 30 doctors around the country have been caught or accused of covertly using their own sperm to impregnate their patients, CNN has confirmed; advocates say they know of at least 80.
Accountability for the deception has been in short supply. The near-absence of laws criminalizing the practice of fertility fraud until recently means no doctors have yet been criminally charged for the behavior. In 2019, Indiana became the second state, more than 20 years after California, to pass a statute making fertility fraud a felony.
Even in civil cases that have been settled out of court, the affected families have typically signed non-disclosure agreements, effectively shielding the doctors from public scrutiny.
Meanwhile, some doctors who have been found out were allowed to keep their medical licenses.
In Kentucky, retired fertility doctor Marvin YussmanMarvin Yussman admitted using his own sperm to inseminate about half a dozen patients who at the time were unaware that he was the donor. One of them filed a complaint to the state’s board of medical licensure when her daughter – who was born in 1976 – learned Yussman was the likely father after submitting her DNA to Ancestry.com.
“I feel betrayed that Dr. Yussman knowingly deceived me and my husband about the origin of the sperm he injected into my body,” the woman wrote in a letter to the board in 2019. “Although I realize Dr. Yussman did not break any laws as such, I certainly feel his actions were unconscionable and depraved.”
In his response to the medical board, Yussman said that during that era, fresh sperm was prioritized over frozen sperm, meaning donors had to arrive on a schedule.
“On very rare occasions when the donor did not show and no frozen specimen was available, I used my own sperm if I otherwise would have been an appropriate donor: appropriate blood type, race, physical characteristics,” Yussman wrote.
He added some of his biological children have “expressed gratitude for their existence” to him and even sent him photos of their own children. Yussman, who noted in his defense that he didn’t remember the woman who made the complaint, said his policy decades ago was to inform patients that physicians could be among the possible donors, though neither he nor the complainant could provide records that clarified the protocol.
The board declined to discipline him, citing insufficient evidence, according to case documents. Reached on the phone by CNN, Yussman declined to comment.
The story that really put fertility fraud on the national radar was that of Dr. Donald Cline, who fathered at least 90 children in Indiana. Cline’s case spurred lawmakers to pass legislation that outlawed fertility fraud but wasn’t retroactive, meaning he was never prosecuted for it. But he was convicted of obstruction of justice after lying to investigators in the state attorney general’s office who briefly looked into the case. Following that conviction in 2018, Cline surrendered his license. Cline’s lawyer did not respond to an email seeking comment.
Netflix followed up with a documentary about Cline in 2022 that inspired two members of Congress – Reps. Stephanie Bice, an Oklahoma Republican, and Mikie Sherrill, a New Jersey Democrat – to coauthor the first federal bill outlawing fertility fraud. If passed, the Protecting Families from Fertility Fraud Act would establish a new federal sexual-assault crime for knowingly misrepresenting the nature or source of DNA used in assisted reproductive procedures and other fertility treatments. The bill has found dozens of backers – 28 Republicans and 20 Democrats – amid a renewed effort to push it on Capitol Hill.

In this March 29, 2007 file photo, Dr. Donald Cline, a reproductive endocrinologist and fertility specialist, speaks at a news conference in Indianapolis.Kelly Wilkinson/The Indianapolis Star/AP/File
A group of advocates including Hill plans to go to DC to champion the bill on Wednesday.
To be sure, passage wouldn’t mean that any of the dozens of doctors who have already been accused of fertility fraud would go to prison, as the crime would have occurred before the law existed. But the measure would provide more pathways for civil litigation in such cases.
The push to better regulate the fertility industry isn’t without critics. It inspires unease – if not outright opposition – from some who fear any industry crackdown could have the unintended effect of making the formation of families less accessible to the LGBTQ community, which comprises an outsized share of the donor-recipient clientele.
“I think we should pause before creating additional criminal liability for people practicing reproductive medicine,” said Katherine L. Kraschel, assistant professor of law and health sciences at Northeastern University. “It gives me great pause … to say we want the government to try to step in and regulate what amounts to a reproductive choice.”
Some experts also point out that the advent of take-at-home DNA tests by companies such as 23andMe and Ancestry has pretty much stamped out fertility fraud in the modern era.
“To my knowledge, the majority of fertility fraud cases took place before 2000,” said Julia T. Woodward, a licensed clinical psychologist and associate professor in psychiatry and OBGYN in the Duke University Health System, in an email to CNN. “I think it is highly unlikely any person would engage in such practices today (it would be too easy to be exposed). So this part of the landscape has improved significantly.”
But activists in the donor-conceived community still want laws, in part to provide pathways for civil litigation, and also to send a message to any medical professional who might feel emboldened by the lack of accountability.
“Let’s say arguably that it doesn’t happen anymore,” said Laura High, a donor-conceived person and comedian who, with more than 600,000 followers on TikTok, has carved out something of a niche as a fertility-industry watchdog on social media. “Pass the f**king legislation just in case.
“Why not just out of the optics – just out of a, ‘Hey we’re going to stand by the victims.’ Let’s just do this. We know it’s never going to happen anymore, but let’s just make this illegal.”

Victoria Hill and her two children play with toys in the living room of her mother's house in Wethersfield. Laura Oliverio/CNN
‘You are my sister’
The lack of a law in Connecticut appears to have been a stumbling block for a pair of siblings seeking recourse for what they allege is a case of fertility fraud.
The half-siblings – a sister and brother – sued OBGYN Narendra Tohan of New Britain in 2021, saying he deceived their mothers when using his own sperm in the fertility treatments.
He has derailed the suit with a novel defense, arguing successfully that it amounts to a “wrongful life” case, which typically pertains to people born with severe life-limiting conditions and isn’t recognized in Connecticut. Tohan, who is still practicing, did not return an email or call to his office seeking comment. The siblings are appealing the ruling.
Madeira, the expert in fertility fraud from Indiana University, called the “wrongful life” decision absurd.
“In fertility fraud, no parent is saying that – no parent is saying I would have gotten an abortion,” she said. “Every parent is saying, ‘I love my child. I just wish that my wishes would have been respected and my doctor wouldn’t have used his sperm.’”
And then there is Dr. Burton Caldwell, who declined CNN’s request for an interview. One of his apparent biological children decided to sue him last year, even though she knows it will be an uphill battle without a fertility fraud law on the books. Janine Pierson and her mother, Doreen Pierson, accuse Caldwell – who stopped practicing in the early 2000s – of impregnating Doreen with his own sperm after having falsely told her that the donor would be a Yale medical student.

Half-sisters Alyssa Denniston, Victoria Hill and Janine Pierson pose for a portrait in Hartford, Connecticut. The three of them say they — and at least 20 others — all share a biological father, Dr. Burton Caldwell. Laura Oliverio/CNN
Janine Pierson, a social worker, thought she was an only child until she took a 23andMe test in the summer of 2022 and was floored to learn she had 19 siblings. (That number has since grown to 22.)
“It was like my entire life just came to this screeching halt,” she told CNN.
When she learned through one of her siblings that Caldwell was the likely father, Pierson said she immediately phoned her mom, who was stunned.
“We both just cried for a few minutes because it just felt like such a violation,” Pierson said.
Pierson said she decided to pursue the lawsuit even though she knows the lack of a fertility-fraud law in Connecticut could pose a challenge.
“It shouldn’t just be, you know, the Wild West where these doctors can just do whatever it is that they want,” she said.
Hill is watching her newly discovered half-sister’s case closely.
For her, the first surprise was learning the dad she grew up with wasn’t her biological father. Although her mom had told her when Hill was younger that she’d sought help conceiving at a fertility clinic, she also said – falsely – that the doctor had used her dad’s sperm.
When Hill learned that the biological father appeared to be Caldwell a few years ago, she contacted lawyers to inquire about filing a suit, but was told she doesn’t have much of a case, so she didn’t pursue it. Now, she said, her statute of limitations is about to expire.
Last year, Hill was hit with another shattering revelation.
In May, she and her three closest friends were celebrating their 20-year high school reunion over dinner.
She was sharing the tale with them of how she learned about her biological father. Everyone was captivated, except one person – her former boyfriend. He looked like he was turning something over in his head. Then he noted that his parents, too, had sought help conceiving from a fertility clinic.
A couple months later, in July, as Hill was leaving for a summer vacation with her husband and two young children, the ex-boyfriend texted her a screenshot showing their 23andMe connection.
“You are my sister,” he said.
Fertility industry regulations in US lax relative to other countries
Hill’s high school boyfriend isn’t the only person she knew in the community who turned out to be a sibling.
“I have slept with my half-sibling,” Hill said. “I went to elementary school with another.”
What’s more, Hill said, back in the early 2000s, she lived across the street from a deli in Norwalk she often went to that was owned by twins who she later learned are her siblings.
Pierson, too, discovered recently that she’d crossed paths with a sibling long ago. She said she has a group photo from when she was a kid at summer camp that shows her on a stage and a boy in the audience. In 2022, she learned that he is her older half-brother.
“Within 20 feet of one another, and we have no idea,” she said.
In general, the bigger the sibling pool, the greater the risk of accidental incest – regardless of whether fertility fraud came into play.
“I don’t date people my age. I can’t do it,” said Jamie LeRose, a 23-year-old singer from New Jersey who has at least 150 siblings from a regular sperm donor, not a doctor. “I look at people my age and I’m automatically unattracted to them because I just, I go, that could be my sibling.”
With this in mind, activists also often advocate for laws that cap the number of siblings per donor – and that do away with donor anonymity. (Neither of these restrictions are included in the proposed federal bill.)
Other countries have instituted such regulations. Norway for instance limits the number of children to eight; Germany, to 15. Germany and the UK have banished anonymity at sperm banks.
The United States government has no such requirements – and the professional association that represents the fertility industry wants to keep it that way.
“What we have not done very much in this country is pass regulations about who gets to have children,” said Sean Tipton, the chief advocacy and policy officer for the American Society for Reproductive Medicine. “If you’re going to say you should only be able to have 50 children, that’s fine. But that should apply to everybody. It shouldn’t apply just to sperm donors.”
Regarding the concern among donor-conceived people about accidental incest, Tipton added, “if you want to be sure that before you have children with somebody, you can run DNA tests to make sure you’re not related.”
The ASRM, which often clashes with donor-conceived activists, has not taken a stance on the federal bill, Tipton told CNN.
The organization does offer nonbinding guidelines that address concerns about incest, recommending for instance no more than 25 births per donor in a population of 800,000.
Although most of the donor-conceived people who spoke with CNN for this story said they wanted to see legislative change, they also described an emotional aspect of the topic that no new law or regulation could begin to quell: a yearning to better understand one’s origins and identity. For Pierson, it was this desire, coupled with a mix of anger and curiosity, that compelled her to pay Caldwell an unannounced visit one day in 2022 – weeks after she’d learned he was most likely her biological father.
Confronting Caldwell
“I woke up that day and I had decided I didn’t want to call him,” Pierson said. “I didn’t want to give him the opportunity to say no. So I just drove directly to his house from work.”
Pierson, who lived in Cheshire at the time, describes an experience that was equal parts surreal and awkward.
After an hourlong trip, she pulled up to a large, stately house with a long driveway not far from the Connecticut coast. When she knocked on the door, nobody answered. But when a neighbor stopped by to drop something off, Caldwell opened the door. Seizing the moment, Pierson introduced herself. He let her in.
Laying eyes for the first time on her biological father, Pierson, 36, saw a man in his 80s with a slight tremor due to Parkinson’s, sporting a blue golf shirt.
He invited her inside and they sat at his dining room table.
Caldwell, she said, didn’t seem surprised – likely because Hill had made a similar visit a couple of years earlier.
“He was not in any way apologetic,” Pierson said, but she added that he did not deny using his own sperm when working in the 1980s at a New Haven clinic. She said Caldwell confessed that he “never gave it the thought that he should have … that there would be so many (children), and that it would have any kind of an impact on us.”
Pierson said Caldwell asked her questions that gave her pause.
“One thing that really has always bothered me is that he asked me how many grandchildren he had,” she said. “And he was very curious about my scholastic achievements and what I made of myself. … Like how intelligent I was, basically.”
She said their conversation ended abruptly when, looking uncomfortable, Caldwell stood up, which she took as a signal that the visit was over. Before parting ways, she asked if he would pose for a photo with her. He consented.
“I knew it would be the only time that I actually ever had that opportunity to take a picture,” she said. “Not that I wanted like a relationship with him in any way because – it was just like mixed of emotions of, you know, like, I despise you, but at the same time, I’m grateful to be here.”

Janine Pierson displays a selfie she took with Caldwell on her phone in Hartford, Connecticut. Pierson took the photo during a visit with Caldwell in 2022 and it is the only photograph she has with him. Laura Oliverio/CNN
#usa#Fertility industry#Burton Caldwell#Fertility fraud#huge groups of siblings made possible in part by a lack of regulation#Accidental incest#Most states have no laws against fertility fraud#huge sibling pods#unethical doctors#unreachable biological fathers#a lack of information about their biological family’s medical history#Nail salons are more regulated than the fertility industry#At least 80 doctors have used their own sperm to impregnate their patients#Marvin Yussman#Dr. Donald Cline fathered at least 90 children#Protecting Families from Fertility Fraud Act still hasn't passed into law#wrongful life#OBGYN Narendra Tohan is still practicing#Large sibling pods in the same community#Norway limits the number of donor conceived children to eight#Germany limits donor conceived children to 15#Germany and the UK have banished anonymity at sperm banks
16 notes
·
View notes
Text




ID: a Facebook post by Em Jay:
“Do any of you remember when I was posting about the recent scientific revelation that Cheddar Man was actually very dark-skinned and how pale skin is soooo much of a newer phenomenon (according to studies, pale skin began appearing in the human genome roughly 4,000 years ago as opposed to the previous assumption of 40,000 years ago) than originally surmised? A new genome sequencing study adds the famous 'Otzi the Iceman' to the list of incorrectly reconstructed (referring to the long-haired, pale-skinned rendering of him found in the Italian museum next to his real remains) ancient humans, as it has been revealed he was dark skinned and balding! The initial discovery of Otzi the Iceman in 1991 (on the Italian side of the Italian/Austrian border) was of enormous import for the scientific community for several reasons; Otzi is the oldest 'wet mummy' yet found and the clothes and equipment he was unearthed with are incomprehensibly unique as no other organic material from the Copper Age has survived. He also became popular for his 61 tattoos, which are the oldest preserved tattoos known to date. I absolutely love studies/revelations like this because (borrowing a lovely sentiment from co-author of the study Johannes Krause) they truly reflect our own biases in assuming what a person from that time looked like, and to use my own words, challenges many of us to re- examine the appearance of our ancient human ancestors in general. "The Iceman's new genome also reveals he had male-pattern baldness and much darker skin than artistic representations suggest. Genes conferring light skin tones didn't become prevalent until 4,000 to 3,000 years ago when early farmers started eating plant-based diets and didn't get as much vitamin D from fish and meat as hunter-gathers did, Krause says.
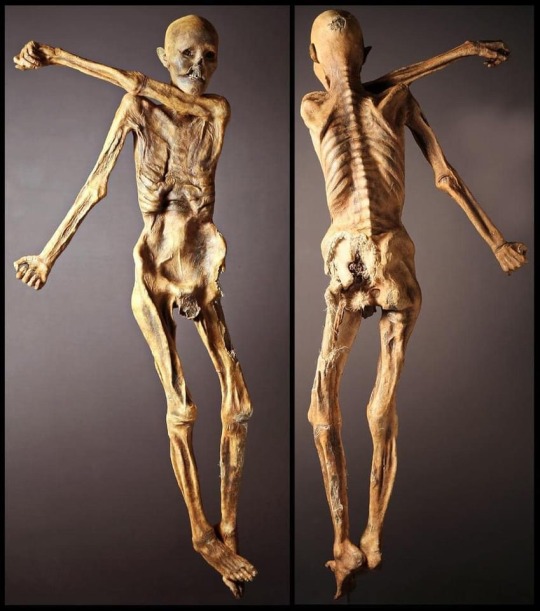
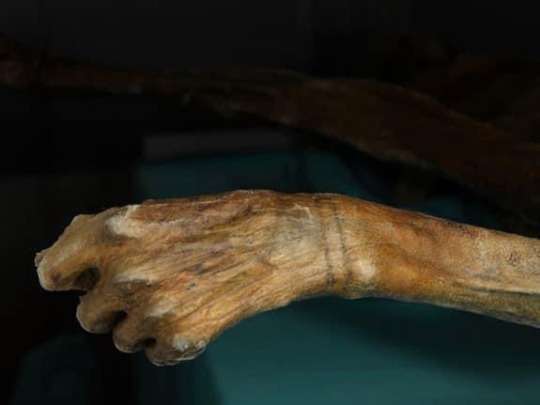
“As Ötzi and other ancient people's DNA illustrate, the skin color genetic changes took thousands of years to become commonplace in Europe. 'People that lived in Europe between 40,000 years ago and 8,000 years ago were as dark as people in Africa, which makes a lot of sense because [Africa is] where humans came from," he says. "We have always imagined that [Europeans] became light-skinned much faster. But now it seems that this happened actually quite late in human history!" (excerpt in quotations from Science News article by Tina Hesman Seay) Below are photos of Otzi, the first taken in 1991 shortly after he was discovered by 2 hikers, his naturally mummified body after he was carefully unearthed from the ice and his incorrect/false rendering with pale skin of 2011, and I hope to return to add a correct/more accurate rendering of him if/when a new one is made!”
Photos show 1) a pair of light-skinned, brown-haired hikers with brown beards, dressed in very 1980s clothing, with the exposed body of Otzi in situ in the ice where they found his body; 2) two photographs of Otzi’s preserved body from the top and back, 3) a close-up photo of Otzi’s preserved hand 4) an inaccurate reconstruction of Otzi in life, showing him as a light-skinned white man.
#otzi#otzi the iceman#historical racism#scientific racism#prehistoric humans#human physiology#whiteness is a construct and a really shitty one we should do everything possible to denaturalise and deconstruct#whiteness is a construct#male pattern baldness
44 notes
·
View notes
Text
latest Freddie DeBoer seems odd. It's very focused on a sort of consumer-facing understanding of technology for a lot of its runtime. He's not wrong that the changes are smaller than they were in the 1800's but like. That's the low hanging fruit, we all know this, the jump from "not having trains" to "having trains" beats almost any improvement in "trains"
A major change technology has brought to the modern world imo is heavily streamlined manufacturing all across the industrial stack.
If you read like, Bunie Huang's Made in China blog series, in the early 2000's getting a piece of technology made required enormous in-person investment of time and effort working with your manufacturing teams across a pretty broad number of suppliers and industries, you had to get PCB's made, components sourced, moulds designed and set up for injection.
I know people manufacturing small to medium run commercial and industrial electronics, and I did that at my last job. You order machine populated PCB's from your favourite Chinese PCB solutions provider over a web form. If you need ten thousand buttons, you can get that delivered with three emails. Hell, if you want a custom genome to use for some experimental bioreactor, there's multiple competing suppliers who will mail you plasmids that you can customise from online templates and you don't even have to talk to anyone.
And that's just mass manufacturing. If you're making a few thousand of some high end medical equipment, or still in the development phase of design, you can order a titanium laser print to be delivered by the end of the week, or run off a dozen prototypes on your company's fleet of printers using body safe plastics.
Consumer needs don't change much because people are people, we have limited capacity to need things and do things. I've long said that no human can digest more than 50Mbps of media in real time, really. One home cook can only economise their movements so much. A food processor and a pressure cooker can save you some time but the solution to"I want to spend less time cooking at home" will eventually become "don't cook at home, lean on industrial manufacturing of food" and that's fine. There's only so much tech can improve your individual experience before you become the bottleneck.
Faster computers sure, means you can edit video on your phone a little quicker (also hey people ARE editing video on their phone, despite what this blog post says) but it also means Netflix can serve their 4 Petabytes of video library at 400+Gbps from a single server occupying less than 50 liters of space.
It seems disingenuous to act like consumer products feeling stagnant means technology is stagnant.
21 notes
·
View notes
Note
Have you seen the coconut crab? It's a type of massive crab that I believe got it's name from it crushing coconuts with its pinchers, they are enormous and walk around on land and in neighborhoods of people
It makes me think of haboobs crab population and if they get to that size or larger
yes! i've seen those, they are so fucky <3 that one picture with a coconut on a trashbin, right?? dear gods... aren't they also the ones people speculate ate Amelia Earhart.. but also didn't know that name fact, that's fun! did know they can break a man's arm which is just. fuck. nature really Can be just like that, huh
awgh Haboob's crabs,,,
those stay small, usually! they are based off of the sand bubbler crabs, look him face

they are native to where Fish lives and Haboob asked him for a genome sample or whatevs so she could make her own. they live strictly Inside her structure and their job is to crawl around and make those sand balls that would be easier to clean out for Haboob's mechanications. poor girl is full of sand- it's where it has no business being and it's very uncomfortable for her, so the crabs were her solution
her pet crab Bub grew bigger than all the others for some reason and when she spotted him with her overseers during a clean up she decided to move him from cleaning duty to lap dog duty. after of course a talk with Euros and Fish on what should she do with the lil guy
10 notes
·
View notes
Text
Ah yeah sorry for the misread! Yes, the imprinting issue unfortunately still applies whether you're trying to put a sperm nucleus into an egg or an egg nucleus into a sperm, though: the basic problem is that you have two different sets of genes, right? In egg genomes, set A is turned off but set B remains on. In sperm genomes, set A is still on, but set B is turned off. You need exactly one functional copy of set A and exactly one functional copy of set B to develop normally, and we do not currently have a way to easily re-imprint a haploid genome to suit the end stage germ cell we want to stick it in. The big problem is the data packets themselves.
Swapping nuclei out is comparatively easy; we already do that with eggs sometimes in human IVF, although it's usually easier to just inject an egg directly with a single viable sperm cell than to try and do something similar if you're trying to fix problems with stuff like sperm motility. I am actually not sure if you could replace the nucleus of a sperm, because we literally do it with teeny tiny needles for eggs and sperm are much smaller and more wiggly. It's hard to think of things that could be fucked up about sperm cells that would not be fixed by just.... injecting one directly into the egg.
note: this imprinting thing is a problem specific to mammals. therian mammals--marsupials and placental mammals--are the only animals that do this kind of thing, and in other taxa it is way easier to switch between egg and sperm production or do deeply weird things with sex determination.
there are some researchers who have kind of succeeded at this kind of thing, but it is really difficult and it is nowhere near ready for human work. it's worth noting that the techniques necessary for people to pull this off in mice also essentially create--how do I put this--you wind up creating something like a Prader-Willi or Angelman Syndrome carrier but harder, such that in order to have only healthy offspring you'd have to go through the eggs of the child mouse and select just ones that don't have the whole-ass deletions in place that were used to create the artificial 'sperm'.
basically, what they did was they took egg cells from a female mouse, they used stem cell techniques to wipe off all the existing methylation and imprinting on those egg cells, and then they manually cut out a bunch of the imprinted regions and deleted them entirely to create a "father-like" imprinting profile. Then they took the "egg with a sperm-imprinted-packet" and they injected it into a regular female mouse. For a single generation, that works fine; it's going to give you some fertility and birth defect issues down the line, though, because all those regions that were outright deleted rather than just imprinted into silence are now going to show up as big old deletions in the space. As long as they're staying in a female-to-female set, that's fine--those genes are all turned off in the offspring of females anyway. But the sons of those females are going to have enormous fertility problems, because the gametes they produce will have some unknown number of deletions from the pseudo-sperm-imprinted parent and those have to be turned on in their offspring.
people today with access to more raw information than any other period: the earth is flat
german artilleryman in 1916, who barely washes his own ass: I need to account for the curvature and rotation of the earth when plotting my firing plans
322K notes
·
View notes
Text
Fwd: Job: IndianaU.Evo_Genomics
Begin forwarded message: > From: [email protected] > Subject: Job: IndianaU.Evo_Genomics > Date: 29 January 2025 at 07:19:03 GMT > To: [email protected] > > > Research Associate in Chromosome Evolution in Beetles and Flies > (Bracewell Lab) > > A full-time Research Associate (RA) position is available in the > laboratory of Dr. Ryan Bracewell in the EEB program at Indiana University > Bloomington to help study functional genomics and chromosome evolution > in beetles and flies (Drosophila). The RA will oversee insect colony > maintenance, will perform DNA/RNA extraction, lllumina sequencing > and long-read sequencing library preparation (RNA-seq, Hi-C, Nanopore, > PacBio), chromosome squash and fluorescent in situ hybridization (FISH), > and general data collection/management. The RA will also be responsible > for ordering lab supplies, maintaining lab equipment, and helping to > mentor undergraduate students. Some fieldwork is also possible for those > interested but will not be required. Information about the Bracewell > lab is available at https://ift.tt/RZfwHoA. B.S. in Biology or a > related field with previous research experience in genetics, genomics, > molecular biology, and/or evolution is required. M.S. or Ph.D. applicants > will also be considered. Good communication skills and the ability to > work independently as well as part of a team are expected. Salary will > be commensurate with education and experience, benefits included. Best > consideration date is March 1st, 2025. The expected start date is late > spring/negotiable. Please submit a cover letter describing interest > and previous experience, a curriculum vitae, and the names of at > least three references (including email addresses and phone numbers) > to https://ift.tt/Wa8tF5T. For questions about > the position and more details on the research, please contact Dr. Ryan > Bracewell ([email protected]). > > The department of Biology is a large, unified department with strong > undergraduate degrees, nationally-ranked graduate programs, and > world-class research spanning the breadth of biological questions and > experimental systems - from ecosystems to microbiology and developmental > biology, from evolution to cell biology, from molecular biology to > systems biology, bioinformatics, and genomics. It is always an exciting > time for Biology - enormous advances in global genome analysis coupled > with unprecedented developments in interdisciplinary research have made > the 21st century the Century of Biology. For more information about > the department, you can find it here: About: Department of Biology: > Indiana University Bloomington. > > The Department of Biology is part of The College of Arts+ Sciences, > the oldest and largest academic division of Indiana University. The > College values diversity, equity, and inclusion as a core strength and > essential element in the success of its educational mission. For the > full statement, click here. Indiana University is an equal employment > and affirmative action employer and a provider of ADA services. All > qualified applicants will receive consideration for employment based on > individual qualifications. Indiana University prohibits discrimination > based on age, ethnicity, color, race, religion, sex, sexual orientation, > gender identity or expression, genetic information, marital status, > national origin, disability status or protected veteran status. > > > "Bracewell, Ryan Russell"
0 notes
Text
Of Bats, Bytes, and Bloodlines: How a Vampire Hunter Discovered Bioinformatics
My dear students of the strange and the scholarly, I must share with you a tale so absurd, so brimming with modern nonsense, that even the most skeptical among you may think me mad. Imagine, if you will, your esteemed professor—hunter of the undead, guardian of the mortal realm, scourge of Dracula himself—sitting in a fluorescent-lit university library, grappling not with the forces of darkness but with a contraption known as a "laptop," while a bespectacled undergraduate who smelled faintly of energy drinks attempted to explain the concept of "data analysis."
But I am leaping ahead, much as a vampire leaps from a castle parapet to avoid the light. Let me start at the beginning.
The ordeal began one fateful evening at a dreadful cocktail party. (Never attend these things; they are more draining than the undead themselves.) I had been cornered by a technocrat who, between sips of artisanal kombucha, informed me with the smugness of one who has never faced a vampire that the "future of humanity lies in big data."
"Big data?" I replied, mistaking this for a new breed of demonic entity. "What is it? Does it drain the blood of the innocent or merely their patience?"
The man, undeterred by my skepticism, launched into a jargon-laden sermon about the marvels of computational biology. "Think of it," he said, "as mapping the genetic instructions that make us who we are. It’s all about finding patterns in massive datasets to unlock the mysteries of life!"
Unlock mysteries, indeed. His words stuck in my mind, pestering me like the infernal buzzing of a mosquito. Patterns, you say? Mysteries to be unlocked? It all sounded suspiciously like my line of work. And so, dear students, I found myself in a coffee shop the next morning, staring at an article on "bioinformatics" while the Wi-Fi mocked me by refusing to load.
To my astonishment, bioinformatics appeared to be the modern-day equivalent of tracking a vampire’s movements across Europe but with DNA sequences instead of shipping manifests. It involved the use of algorithms—magical incantations, if you will—to sift through enormous quantities of genetic data in search of answers. This was not so different from my own investigations, which have often required discerning the subtle clues that lead to a vampire’s crypt.
Naturally, I was intrigued. The parallels between bioinformatics and vampire hunting were undeniable. Where I once searched for puncture marks, these scientists sought genetic markers. Where I once pored over dusty tomes in forgotten libraries, they scoured databases with names like "GenBank" and "BLAST." And where I once used a stake, they wielded tools like CRISPR to pierce the very fabric of the genome. It was as though fate had conspired to make me a scholar of this new and eerie discipline.
But my path to enlightenment was not without its challenges. My initial attempts to download genomic datasets were thwarted by passwords and "two-factor authentication," which, as far as I could tell, involved begging the machine for mercy. When I finally succeeded, the resulting files were an incomprehensible tangle of letters—A, T, C, and G. It was as though someone had spilled alphabet soup onto my screen and declared it a miracle of modern science.
Undeterred, I sought help from a gaggle of graduate students, who explained the basics with the exasperation of those who know their wisdom will be immediately misunderstood. They taught me to use software called Python, which, I was disappointed to discover, did not involve actual snakes. They spoke of algorithms and machine learning with the fervor of cultists describing their deity, and though much of it was gibberish to me, I began to see the potential.
It was while wrestling with these arcane tools that the true revelation struck me. If bioinformatics could unravel the genetic secrets of disease, might it also shed light on the mysteries of vampirism? After all, what is a vampire if not an aberration of the human genome—a mutation gone rogue? With the right data, perhaps we could identify the genetic markers of vampirism, predict outbreaks, and develop treatments to cure the afflicted. Imagine a world where no one need fear the bite of the undead!
My excitement, however, was dampened by the realization that modern society is woefully unprepared for such revelations. We live in an age where people believe that wearing crystals will ward off viruses, where "wellness influencers" hawk garlic pills without understanding the ancient lore behind them. I have seen parents refuse life-saving vaccines for their children while simultaneously consulting astrologers about their dietary choices. These are not the minds ready to grapple with the genetic intricacies of vampirism—or anything else, for that matter.
And so, my dear students, I resolved to write an article. If humanity is to be saved from both genetic and supernatural threats, it must first be educated. I would explain bioinformatics in terms that even the most befuddled technophobe could understand, drawing upon my own adventures to illuminate the parallels. With wit and wisdom, I would arm my readers with knowledge, much as I have armed you with stakes and crucifixes.
Thus, I invite you to read on, to immerse yourselves in the strange and wonderful world of bioinformatics. May it inspire you to seek out the secrets of the genome with the same fervor that we hunt the undead. And remember, my fearless scholars: whether you face a genetic mutation or a vampire lord, knowledge is the greatest weapon of all.
1 note
·
View note
Text
man i have no fucking idea where to talk about this but i miss working in a marine invert genome sequencing lab. like the work itself was Fine it was a lot of repetitive detail work but more than that it felt Important. like i know the phylogeny of parasitic snails isn't exactly a highly valued subject amongst the general public but it felt important to me. categorizing the unknown diversity of these animals in the deep sea. becoming a budding voice in the community that's willing and able to work towards understanding ocean ecosystems. discovering species! increasing knowledge of the ocean! learning! also developing niche and petty academic grudges and getting lost in the sauce of like. defining species and the validity of linnaean taxonomy and the most accurate way of analyzing phylogenomic data. at my best i felt way in over my head in the most interesting and fun way possible.
and i know i'm idealizing all of this because it was incredibly stressful and awful a lot of the time. i was a nervous wreck constantly and kept fucking up, my pi was a nightmare to work with, and the grad student i was trained under was so incredibly overworked that i was unable to make progress as expected, which brought more scrutiny onto me from my pi. he ended up telling me that i hadn't made sufficient progress and not to come back after the quarter had ended. almost everyone in that lab was under enormous pressure, hated working with my pi, and toughing it out so that they could move onto the next thing with a LOR. i ended up working in the invertebrate collections, which were overseen by this lab, and my supervisor (an angel and i love her) straight up admitted to me that even though she loves her job she has very little financial security and a house is not in her future. idk. i was frustrated with myself for a long time for not being able to cut it in that lab and just turning into an anxious stupid wreck when everyone else still there was able to ride it out. even past that (not uniquely) shitty environment, being in the autoclave of academia seems kind of like hell. even though i've wanted to be a scientist for many years, i feel like the reality of being one may have been incongruent with the life i want to live overall. but maybe i'm just telling myself that to temper the disappointment i feel when i think about not going down that path. idk. i just want to be a marine biologist, but idk if it's worth pursuing for me personally.
#idk. espeically since i now technically have a chronic health condition thats really sensitive to stress.#combined with the fact that people at my other marine-bio-unrelated internship were just leagues nicer and opened up more doors for me#it seems like a sign that maybe that path wasn't for me. at least for now#but i can't help resenting that i'm not Following My Passion. whatever the fuck that means#like idk!!! pretty much all my friends in college were also essentially Stupid undergrads that fucked up lab work occasionally#so it's not like i'm objectively uniquely incompetent. but it sure felt like it in the walls of that lab!!!#delete later. probably
1 note
·
View note
Text
AI’s Life-Changing, Measurable Impact on Cancer
New Post has been published on https://thedigitalinsider.com/ais-life-changing-measurable-impact-on-cancer/
AI’s Life-Changing, Measurable Impact on Cancer
Leveraging Big Data to Enhance AI in Cancer Detection and Treatment
Integrating AI into the healthcare decision making process is helping to revolutionize the field and lead to more accurate and consistent treatment decisions due to its virtually limitless ability to identify patterns too complex for humans to see.
The field of oncology generates enormous data sets, from unstructured clinical histories to imaging and genomic sequencing data, at various stages of the patient journey. AI can “intelligently” analyze large-scale data batches at faster speeds than traditional methods, which is critical for training the machine learning algorithms that are foundational for advanced cancer testing and monitoring tools. AI also has tremendous inherent pattern recognition capabilities for efficiently modeling data set complexities. This is important because it enables deeper, multi-layered understandings of the impact of nuanced molecular signatures in cancer genomics and tumor microenvironments. Discovering a pattern between genes only found in a certain subset of cancer cases or cancer progression patterns can lead to a more tailored, patient-specific approach to treatment.
What is the ultimate goal? AI-powered cancer tests that support clinical decision-making for doctors and their patients at every step of the cancer journey – from screening and detection, to identifying the right treatment, and for monitoring patients’ response to interventions and predicting recurrence.
Data Quality and Quantity: The Key to AI Success
Ultimately, an AI algorithm will only be as good as the quality of data that trains it. Poor, incomplete or improperly labeled data can hamstring AI’s ability to find the best patterns (garbage in, garbage out). This is especially true for cancer care, where predictive modeling relies on impeccable precision – one gene modification out of thousands, for example, could signal tumor development and inform early detection. Ensuring that high level of quality is time-consuming and costly but leads to better data, which results in optimal testing accuracy. However, developing a useful goldmine of data comes with significant challenges. For one, collecting large-scale genomic and molecular data, which can involve millions of data points, is a complex task. It begins with having the highest quality assays that measure these characteristics of cancer with impeccable precision and resolution. The molecular data collected must also be as diverse in geography and patient representation as possible to expand the predictive capacity of the training models. It also benefits from building long-term multi-disciplinary collaborations and partnerships that can help gather and process raw data for analysis. Finally, codifying strict ethics standards in data handling is of paramount importance when it comes to healthcare information and adhering to strict patient privacy regulations, which can sometimes present a challenge in data collection.
An abundance of accurate, detailed data will not only result in testing capabilities that can find patterns quickly and empower physicians with the best opportunity to address the unmet needs for their patients but will also improve and advance every aspect of clinical research, especially the urgent search for better medicines and biomarkers for cancer.
AI Is Already Showing Promise in Cancer Care and Treatment
More effective ways to train AI are already being implemented. My colleagues and I are training algorithms from a comprehensive array of data, including imaging results, biopsy tissue data, multiple forms of genomic sequencing, and protein biomarkers, among other analyses – all of which add up to massive quantities of training data. Our ability to generate data on the scale of quadrillions rather than billions has allowed us to build some of the first truly accurate predictive analytics in clinical use, such as tumor identification for advanced cancers of unknown primary origin or predictive chemotherapy treatment pathways involving subtle genetic variations.
At Caris Life Sciences, we’ve proven that extensive validation and testing of algorithms are necessary, with comparisons to real-world evidence playing a key role. For example, our algorithms trained to detect specific cancers benefit from validation against laboratory histology data, while AI predictions for treatment regimens can be cross compared with real-world clinical survival outcomes.
Given the rapid advancements in cancer research, experience suggests that continuous learning and algorithm refinement is an integral part of a successful AI strategy. As new treatments are developed and our understanding of the biological pathways driving cancer evolves, updating models with the most up-to-date information offers deeper insights and enhances detection sensitivity.
This ongoing learning process highlights the importance of broad collaboration between AI developers and the clinical and research communities. We’ve found that developing new tools to analyze data more rapidly and with greater sensitivity, coupled with feedback from oncologists, is essential. Bottom-line: the true measure of an AI algorithm’s success is how accurately it equips oncologists with reliable, predictive insights they need and how adaptable the AI strategy is to ever-changing treatment paradigms.
Real-World Applications of AI Are Already Increasing Survival Rates and Improving Cancer Management
Advances in data scale and quality have already had measurable impacts by expanding the physician decision-making toolkit, which has had real-world positive results on patient care and survival outcomes. The first clinically validated AI tool for navigating chemotherapy treatment choices for a difficult-to-treat metastatic cancer can potentially extend patient survival by 17.5 months, compared to standard treatment decisions made without predictive algorithms1. A different AI tool can predict with over 94% accuracy the tumor of origin for dozens of metastatic cancers2 – which is critical to creating an effective treatment plan. AI algorithms are also predicting how well a tumor will respond to immunotherapy based on each person’s unique tumor genetics. In each of these cases, AI toolkits empower clinical decision-making that improves patient outcomes compared with current standards of care.
Expect An AI Revolution in Cancer
AI is already changing how early we can detect cancer and how we treat it along the way. Cancer management will soon have physicians working side-by-side with integrated AI in real time to treat and monitor patients and stay one step ahead of cancer’s attempts to outwit medicines with mutations. In addition to ever-improving predictive models for detecting cancer earlier and providing more effective personalized treatment paradigms, physicians, researchers, and biotech companies are hard at work today to leverage data and AI analyses to drive new therapeutic discoveries and molecular biomarkers for tomorrow.
In the not-too-distant future, these once-impossible advances in AI will reach far beyond cancer care to all disease states, ending an era of uncertainty and making medicine more accurate, more personalized, and more effective.
#ADD#ai#AI in healthcare#AI strategy#AI-powered#algorithm#Algorithms#analyses#Analysis#Analytics#applications#approach#Big Data#biomarkers#biopsy#biotech#Building#Cancer#Cancer Care#cancers#challenge#chemotherapy#clinical#clinical research#Collaboration#Companies#comprehensive#continuous#data#data collection
0 notes
Text
A causal theory for studying the cause-and-effect relationships of genes
New Post has been published on https://sunalei.org/news/a-causal-theory-for-studying-the-cause-and-effect-relationships-of-genes/
A causal theory for studying the cause-and-effect relationships of genes

By studying changes in gene expression, researchers learn how cells function at a molecular level, which could help them understand the development of certain diseases.
But a human has about 20,000 genes that can affect each other in complex ways, so even knowing which groups of genes to target is an enormously complicated problem. Also, genes work together in modules that regulate each other.
MIT researchers have now developed theoretical foundations for methods that could identify the best way to aggregate genes into related groups so they can efficiently learn the underlying cause-and-effect relationships between many genes.
Importantly, this new method accomplishes this using only observational data. This means researchers don’t need to perform costly, and sometimes infeasible, interventional experiments to obtain the data needed to infer the underlying causal relationships.
In the long run, this technique could help scientists identify potential gene targets to induce certain behavior in a more accurate and efficient manner, potentially enabling them to develop precise treatments for patients.
“In genomics, it is very important to understand the mechanism underlying cell states. But cells have a multiscale structure, so the level of summarization is very important, too. If you figure out the right way to aggregate the observed data, the information you learn about the system should be more interpretable and useful,” says graduate student Jiaqi Zhang, an Eric and Wendy Schmidt Center Fellow and co-lead author of a paper on this technique.
Zhang is joined on the paper by co-lead author Ryan Welch, currently a master’s student in engineering; and senior author Caroline Uhler, a professor in the Department of Electrical Engineering and Computer Science (EECS) and the Institute for Data, Systems, and Society (IDSS) who is also director of the Eric and Wendy Schmidt Center at the Broad Institute of MIT and Harvard, and a researcher at MIT’s Laboratory for Information and Decision Systems (LIDS). The research will be presented at the Conference on Neural Information Processing Systems.
Learning from observational data
The problem the researchers set out to tackle involves learning programs of genes. These programs describe which genes function together to regulate other genes in a biological process, such as cell development or differentiation.
Since scientists can’t efficiently study how all 20,000 genes interact, they use a technique called causal disentanglement to learn how to combine related groups of genes into a representation that allows them to efficiently explore cause-and-effect relationships.
In previous work, the researchers demonstrated how this could be done effectively in the presence of interventional data, which are data obtained by perturbing variables in the network.
But it is often expensive to conduct interventional experiments, and there are some scenarios where such experiments are either unethical or the technology is not good enough for the intervention to succeed.
With only observational data, researchers can’t compare genes before and after an intervention to learn how groups of genes function together.
“Most research in causal disentanglement assumes access to interventions, so it was unclear how much information you can disentangle with just observational data,” Zhang says.
The MIT researchers developed a more general approach that uses a machine-learning algorithm to effectively identify and aggregate groups of observed variables, e.g., genes, using only observational data.
They can use this technique to identify causal modules and reconstruct an accurate underlying representation of the cause-and-effect mechanism. “While this research was motivated by the problem of elucidating cellular programs, we first had to develop novel causal theory to understand what could and could not be learned from observational data. With this theory in hand, in future work we can apply our understanding to genetic data and identify gene modules as well as their regulatory relationships,” Uhler says.
A layerwise representation
Using statistical techniques, the researchers can compute a mathematical function known as the variance for the Jacobian of each variable’s score. Causal variables that don’t affect any subsequent variables should have a variance of zero.
The researchers reconstruct the representation in a layer-by-layer structure, starting by removing the variables in the bottom layer that have a variance of zero. Then they work backward, layer-by-layer, removing the variables with zero variance to determine which variables, or groups of genes, are connected.
“Identifying the variances that are zero quickly becomes a combinatorial objective that is pretty hard to solve, so deriving an efficient algorithm that could solve it was a major challenge,” Zhang says.
In the end, their method outputs an abstracted representation of the observed data with layers of interconnected variables that accurately summarizes the underlying cause-and-effect structure.
Each variable represents an aggregated group of genes that function together, and the relationship between two variables represents how one group of genes regulates another. Their method effectively captures all the information used in determining each layer of variables.
After proving that their technique was theoretically sound, the researchers conducted simulations to show that the algorithm can efficiently disentangle meaningful causal representations using only observational data.
In the future, the researchers want to apply this technique in real-world genetics applications. They also want to explore how their method could provide additional insights in situations where some interventional data are available, or help scientists understand how to design effective genetic interventions. In the future, this method could help researchers more efficiently determine which genes function together in the same program, which could help identify drugs that could target those genes to treat certain diseases.
This research is funded, in part, by the MIT-IBM Watson AI Lab and the U.S. Office of Naval Research.
0 notes
Text
Next Generation Sequencing Market — Forecast(2024–2030)

Key Takeaways
In the coming years, growing interest in the Next Generation Sequencing by Healthcare industry and Medical technology firms is anticipated to drive development in the Next Generation Sequencing industry.
Key sustainability strategies such as mergers or acquisitions, product and service launch are being adopted by the market players to ensure the growth of Next Generation Sequencing market.
Asia-pacific is estimated to record the fastest CAGR during the forecast period for New Generation Sequencing Market.
Request Sample
By Sequence Type — Segment Analysis
In 2018, Whole Genome Sequencing segment dominated the NGS market in terms of revenue. Its popularity can be attributed to the fact that it allows researchers to sequence genes and genomes, and allow them to look for mutations which cause diseases at a faster pace than traditional testing methods.
By Product Type — Segment Analysis
Services Segment is estimated to dominate the NGS Market in 2018 in terms of revenue. It accounted for a significant share in 2018. This market is projected to grow owing to the increasing use of NGS software and services for sequencing procedures in the healthcare field.
End User — Segment Analysis
In End user segment, Clinical Diagnostic Laboratories featured to show the largest growth among others. This is attributed to substantial growth in the number of research and diagnostic laboratories all round the world. Hospitals and Healthcare Institutions are also an aiding factor for the NGS Market.
By Application — Segment Analysis
The Diagnostics/Infectious Diseases segment displayed the largest share of the overall NGS market in 2018, and it is forecast to grow the fastest, at a CAGR of 9.32% during the period under consideration. The application of NGS technology in Diagnostics/Infectious Diseases is due to the growing cancer incidence and increased prevalence of genetic disorders in children. NGS technology helps to obtain better conclusions in medical diagnostic procedures.
Geography — Segment Analysis
In 2018, the North America region occupied 54% of the global Next Generation Sequencing market in terms of revenue. North America Next Generation Sequencing market is mainly attributed to the increasing technological developments in the countries, which has allowed growth in medical technology. The clinical use of this technology plays a significant part in shaping the healthcare industry and provides much precise, efficient, and safer alternatives to disease management which is driving the market as incidence. However, the Asia-pacific region is estimated to record the fastest growth rate during the forecast period.
Inquiry Before Buying
Drivers — Next Generation Sequencing Market
High Investments In The Sector
The new investments in the field by various companies have spun-up the growth of the NGS Market. The main reason firms invest in the technology is due to its high accuracy rates and capability to accurately spot the infected organs. As investment increases, advancements in the field also tend to grow aiding the growth of the market.
Rising Application of Next Generation Sequencing
NGS is expected to have various applications in the healthcare and medical technology market. The growth and dominance of new generation sequencing technology has caused a shift in the framework of scientific research, opening the doors to a new era of oncology research and diagnostics, as well as requiring scientists with stronger molecular knowledge alongside computational skills to carryout complex researches.
Challenges — Next Generation Sequencing Market
High setup costs for laboratories.
Diagnostic laboratories would have to invest enormous sums for the procurement and setting up of the equipment, software and consumables required for NGS. This often discourages small scale laboratories to adopt the new technology and forces then to continue using the traditional methods of identifying diseases.
Market Landscape
Strategic partnerships and acquisitions along with product development and service launches are the key strategies of the players in the Next Generation Sequencing market. Some Key players in the market include, PierianDx, Saphetor, Macrogen Inc, Illumina Inc, GATC Biotech AG, F. Hoffmann-La Roche Ltd, DNASTAR Inc., Agilent , Technologies, Thermo Fisher Scientific Inc., Qiagen, PerkinElmer Inc and others.
Buy Now
Next Generation Sequencing Market Research Scope:
The base year of the study is 2018, with forecast done up to 2025. The study presents a thorough analysis of the competitive landscape, taking into account the market shares of the leading companies. These provide the key market participants with the necessary business intelligence and help them understand the future of the Next Generation Sequencing market. The assessment includes the forecast, an overview of the competitive structure, the market shares of the competitors, as well as the market trends, market demands, market drivers, market challenges, and product analysis. The market drivers and restraints have been assessed to fathom their impact over the forecast period. This report further identifies the key opportunities for growth while also detailing the key challenges and possible threats. The key areas of focus include the Sequence Type, Product Type, End User, Application & Geography.
0 notes
Text
Artificial Intelligence in the Biological Sciences: Revolutionizing Research and Discovery
AI in Genomics: Accelerating DNA Analysis
One of the most significant impacts of AI in biological sciences is in genomics, where it is helping to decode the complexities of the human genome. Sequencing an organism's DNA generates enormous amounts of data, which require complex analyses to draw meaningful conclusions. AI algorithms, particularly those in machine learning (ML) and deep learning, can process this data quickly and efficiently.
For example, AI models are now being used to identify genetic mutations associated with diseases, predict the functional consequences of these mutations, and even model the likely evolutionary pathways of certain genes. In human health, this can translate into better understanding of genetic diseases, improved diagnostics, and the identification of personalized treatment options based on an individual's unique genetic makeup.
AI has also been instrumental in genome editing technologies such as CRISPR. By analyzing large datasets, AI helps improve the accuracy of gene editing techniques, reducing off-target effects and ensuring precise modifications. Artificial Intelligence in The Biological Science These advancements have significant implications for agriculture, medicine, and evolutionary biology.
AI in Drug Discovery: Reducing Time and Cost
Traditional drug discovery processes are often long, expensive, and fraught with uncertainty. AI is changing this by accelerating the identification of potential drug candidates and optimizing their development. Machine learning models can sift through databases of known compounds to predict which molecules might interact with specific biological targets. This allows scientists to focus on the most promising candidates for further research, significantly reducing the time and cost involved in drug development.
Pharmaceutical companies have already begun using AI to identify new drugs for diseases such as cancer, Alzheimer’s, and viral infections. By simulating molecular interactions, AI systems can predict how a drug will behave in a biological system, minimizing the need for expensive and time-consuming laboratory tests. Additionally, AI can be used to repurpose existing drugs for new therapeutic applications, a process known as drug repositioning.
AI and Systems Biology: Understanding Complex Biological Networks
AI is also playing a crucial role in systems biology, an interdisciplinary field that seeks to understand complex interactions within biological systems. Traditional approaches to biology often focus on individual components such as genes, proteins, or cells. However, these components do not function in isolation but interact within networks that regulate biological processes.
By applying AI algorithms, researchers can model these networks to understand how different biological systems behave in health and disease. For example, AI can analyze gene expression data to identify regulatory networks involved in cancer progression, allowing for more targeted treatments. It can also help in the modeling of metabolic networks, enabling researchers to better understand how organisms respond to environmental changes.
AI and Biophysics: Modeling Protein Structures
Understanding the structure of proteins is critical for many areas of biological research, including drug discovery and disease diagnostics. Proteins are complex molecules that perform a wide range of functions in cells, and their structure determines how they function. However, determining protein structures experimentally is a time-consuming and expensive process.
AI has revolutionized this area with models like AlphaFold, which can predict protein structures with unprecedented accuracy. Book For AI in Drug Discovery This has opened up new avenues for research into diseases caused by misfolded proteins, such as Alzheimer's, Parkinson’s, and Huntington's disease. By understanding how proteins fold and function, researchers can develop more effective therapies.
Future Prospects: AI and Synthetic Biology
Looking forward, the integration of AI into synthetic biology holds exciting prospects. Synthetic biology involves designing and constructing new biological systems or modifying existing ones for useful purposes, such as producing biofuels, developing new materials, or engineering cells to produce therapeutic compounds. AI can assist in the design and optimization of synthetic biological systems, making the process more efficient and predictable.

0 notes
Text
From Gene Editing to Personalized Medicine: The Next Frontier in Biotech

Biotechnology has long been at the forefront of medical innovation, but the field is now entering an exciting phase where the combination of gene editing and personalized medicine is revolutionizing healthcare. The promise of gene editing tools like CRISPR and advancements in personalized therapies are bringing us closer to a future where treatments are tailored specifically to individual genetic profiles. Let’s explore how these groundbreaking technologies are shaping the next frontier in biotech.
The Evolution of Gene Editing: CRISPR and Beyond
Gene editing has moved from the realm of research labs to clinical applications, thanks in large part to CRISPR-Cas9. This technology allows scientists to make precise changes to DNA, offering potential cures for genetic disorders. In 2024, gene editing is being applied to blood disorders like sickle cell disease and beta-thalassemia, with treatments already approved in some regions. CRISPR enables doctors to "edit out" faulty genes, replacing them with functional versions, making it a cornerstone of future therapies.
As we look ahead, new gene-editing technologies are emerging. Techniques like prime editing and base editing offer even more precise ways to correct genetic mutations, reducing the risk of unintended changes to the genome. These advancements are expanding the possibilities of gene editing far beyond the original applications of CRISPR.
In Vivo Gene Editing: The Next Big Step
Most current gene-editing therapies involve taking cells from a patient, editing them in a lab, and then reintroducing them to the body (ex vivo editing). However, researchers are now developing methods to edit genes directly inside the body (in vivo editing). This could significantly broaden the scope of diseases that can be treated, particularly for conditions where it is not feasible to remove and modify cells outside the body.
For example, in vivo editing is being explored for treating inherited liver diseases by delivering CRISPR components directly to the liver via nanoparticles. The potential for in vivo therapies is enormous, as they could make gene editing more accessible and less invasive for patients.
Personalized Medicine: Tailoring Treatment to Individuals
The rise of personalized medicine is one of the most exciting developments in healthcare. Rather than using a one-size-fits-all approach, personalized medicine uses a patient’s genetic, environmental, and lifestyle factors to tailor treatments. Advances in gene sequencing have made it easier to identify the genetic mutations responsible for diseases, allowing doctors to design highly specific therapies.
For instance, in cancer treatment, personalized medicine allows oncologists to choose drugs based on the unique genetic profile of a patient’s tumor. This not only improves the effectiveness of the treatment but also reduces side effects, as therapies are more targeted to the cancer cells.
Gene Editing in Oncology: Fighting Cancer at the Genetic Level
Gene editing is also making waves in the fight against cancer. Researchers are using CRISPR to modify immune cells to better recognize and destroy cancer cells. This form of treatment, known as CAR-T therapy, has already shown promising results in treating certain types of leukemia and lymphoma. By modifying a patient’s own immune cells, scientists can create a more potent and personalized defense against cancer.
Moreover, gene editing is being used to identify new drug targets for cancer treatment. By editing specific genes in cancer cells, researchers can study how these changes affect tumor growth and drug resistance, leading to the development of more effective therapies.
Gene Therapies for Rare Diseases
One of the most compelling applications of gene editing is in the treatment of rare genetic disorders. These diseases, often caused by a single genetic mutation, are prime candidates for gene therapy. In 2024, clinical trials are underway for conditions like Duchenne muscular dystrophy, cystic fibrosis, and hemophilia.
The ability to directly correct the genetic mutation that causes these diseases represents a major leap forward in medicine. While there are still challenges—such as ensuring the safety and long-term effectiveness of these therapies—gene editing offers hope for patients who previously had few treatment options.
Overcoming Challenges in Gene Editing
Despite the incredible promise of gene editing, there are still challenges to overcome. One of the biggest concerns is off-target effects, where unintended parts of the genome are altered, potentially causing harmful side effects. Researchers are working to improve the precision of gene-editing tools, with newer methods like prime editing showing promise in reducing these risks.
Additionally, making gene-editing therapies widely available is a challenge due to the high cost of these treatments. As gene-editing technologies mature, there is hope that they will become more affordable and accessible to a broader range of patients.
The Role of AI in Advancing Personalized Medicine
Artificial intelligence (AI) is playing an increasingly important role in biotech, particularly in personalized medicine. AI can analyze vast amounts of genetic data to identify patterns and predict how a patient might respond to different treatments. This is helping researchers design more effective personalized therapies.
For example, AI algorithms can help identify which patients are likely to benefit from gene-editing therapies based on their genetic profiles. This not only speeds up the development of new treatments but also ensures that patients receive the most appropriate care for their unique needs.
Key Innovations in Gene Editing and Personalized Medicine
CRISPR-based therapies for genetic disorders
In vivo gene editing for direct treatment inside the body
Personalized cancer treatments based on genetic profiling
AI-driven insights for tailored therapies
Gene therapies for rare diseases
In Conclusion
The fusion of gene editing and personalized medicine is opening up a new frontier in biotechnology, one where treatments are not just innovative but also highly individualized. From the precision of CRISPR to the predictive power of AI, we are witnessing the dawn of an era where medicine can be tailored to the individual’s genetic makeup, providing more effective and targeted treatments.
As these technologies continue to evolve, we can expect to see even more breakthroughs that will change the way we approach healthcare, offering hope for curing diseases once thought untreatable. The future of biotech is here, and it’s transforming medicine one gene at a time.
1 note
·
View note
Text
Navigating AI's Innovative Approaches In Biotechnology

Let’s take a step back in time.
Do you remember how things used to be? Back then, doctors didn’t have the advanced tools and knowledge we now enjoy. Many diseases we can treat today were once fatal, and people generally didn’t live as long because medical science was still in its infancy.
But look how far we’ve come! Today’s doctors can detect genetic issues, design treatments based on personal medical histories, and create vaccines that prevent the spread of diseases. What sparked such a massive shift?
Enter Artificial Intelligence in biotechnology. AI is making waves by assisting doctors in diagnosing patients, analyzing medical data, and even helping scientists manipulate DNA as easily as we write text in a document—well, almost that easily!
In this article, we’re diving into how AI is poised to revolutionize biotechnology. Are you ready?
Biotech companies and healthcare organizations today rely heavily on analyzing enormous amounts of data. To develop new biological processes, drugs, and understand DNA sequences, these technologies need faster and more precise data handling. This is where AI steps in.
Artificial Intelligence makes processes in biotech faster and more reliable. It reduces human error, which is crucial when it comes to handling life-changing data and research. AI is not just streamlining drug discovery but also advancing disease research. As the future unfolds, AI and biotechnology will continue to unlock groundbreaking innovations in healthcare, pushing the boundaries of what's possible.
Now, before we explore these exciting advancements, let’s clarify what AI in biotechnology really is.
What Is AI in Biotechnology?
Artificial Intelligence is transforming biotechnology by accelerating processes like drug discovery and research. Machine learning algorithms can sift through massive clinical trial data sets to identify drug targets and predict their effectiveness. AI also speeds up drug screening and automates data analysis, drastically shortening development timelines.
By leveraging AI’s analytical power, biotech companies gain valuable insights and reduce costs. Some major pharmaceutical companies are already investing heavily in AI. According to GlobalData, the pharma industry is expected to spend around USD 3 billion on AI for drug discovery by 2025—clear evidence of AI’s potential in biotech!
As traditional research methods hit their limits, AI is becoming indispensable in biotechnology, enabling revolutionary progress. With that in mind, let’s explore how AI is being used in various sectors of the biotechnology field.
How Is AI Used in Biotechnology?
AI is transforming the biotechnology industry in several ways, including:
3D Protein Structure Prediction Identifying the 3D structure of proteins is crucial but time-consuming. AI tools can quickly predict unknown protein structures from available data, making it easier to develop drugs that target those proteins. This breakthrough speeds up drug development and deepens our understanding of disease-related proteins.
Gene Editing and Genetic Coding AI enhances our ability to edit genes selectively, helping to eliminate harmful genes and enable personalized medicine. AI is significantly advancing our ability to treat genetic disorders and customize treatments based on individual genomes—an impressive leap in biotechnology.
AI-Powered Lab Assistants AI programs are acting as lab assistants, automating tedious tasks and performing complex data analyses. Robotic AI devices are already assisting in labs and hospitals, taking on routine duties so scientists can focus on innovation and discovery.
As AI is integrated into the biotech industry’s workflow, it accelerates the development of new treatments and ensures more precise results in clinical applications. Let’s explore how biotech companies are using AI to drive innovation!
How Can Biotech Companies Leverage AI for Innovation?
Biotech companies are using AI in several ways to accelerate research and innovation, including:
New Vaccines and Drugs AI is enabling faster identification of potential vaccines and drugs. Vaccine development, which traditionally took over a decade, has been shortened to just a few years with AI’s help. In the future, AI will continue to accelerate biopharmaceutical research.
Agricultural Biotechnology AI and robotics are improving crop yields by providing automated harvesting systems and data-driven insights into optimal growth conditions. Additionally, AI is helping biotech companies create hybrids and genetically modified organisms (GMOs), advancing agricultural research.
Personalized Medicine AI is revolutionizing medicine by analyzing patient genetics and symptoms to discover treatments tailored to individuals. This shift from "one-size-fits-all" treatments to personalized medicine is a game changer, especially for rare diseases.
As AI enhances the speed, accuracy, and efficiency of biotech workflows, it will continue to revolutionize the industry. On that note, let’s wrap up this article!
Conclusion
Artificial Intelligence in biotechnology is already offering immense benefits by accelerating drug discovery, enabling personalized medicine, and automating complex processes. AI’s ability to analyze big data and enhance human capabilities is transforming patient care and driving innovation in biotech. While challenges remain, the future is incredibly promising, as AI helps biotech make life-saving advances that will impact people worldwide.
Want to learn more about the exciting world of AI and biotech? Click here to explore the latest innovations!
0 notes