#service mesh and kubernetes
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text
How to Test Service APIs
When you're developing applications, especially when doing so with microservices architecture, API testing is paramount. APIs are an integral part of modern software applications. They provide incredible value, making devices "smart" and ensuring connectivity.
No matter the purpose of an app, it needs reliable APIs to function properly. Service API testing is a process that analyzes multiple endpoints to identify bugs or inconsistencies in the expected behavior. Whether the API connects to databases or web services, issues can render your entire app useless.
Testing is integral to the development process, ensuring all data access goes smoothly. But how do you test service APIs?
Taking Advantage of Kubernetes Local Development
One of the best ways to test service APIs is to use a staging Kubernetes cluster. Local development allows teams to work in isolation in special lightweight environments. These environments mimic real-world operating conditions. However, they're separate from the live application.
Using local testing environments is beneficial for many reasons. One of the biggest is that you can perform all the testing you need before merging, ensuring that your application can continue running smoothly for users. Adding new features and joining code is always a daunting process because there's the risk that issues with the code you add could bring a live application to a screeching halt.
Errors and bugs can have a rippling effect, creating service disruptions that negatively impact the app's performance and the brand's overall reputation.
With Kubernetes local development, your team can work on new features and code changes without affecting what's already available to users. You can create a brand-new testing environment, making it easy to highlight issues that need addressing before the merge. The result is more confident updates and fewer application-crashing problems.
This approach is perfect for testing service APIs. In those lightweight simulated environments, you can perform functionality testing to ensure that the API does what it should, reliability testing to see if it can perform consistently, load testing to check that it can handle a substantial number of calls, security testing to define requirements and more.
Read a similar article about Kubernetes API testing here at this page.
#kubernetes local development#opentelemetry and kubernetes#service mesh and kubernetes#what are dora metrics
0 notes
Text
Sicherer Zugang zu Ihrer Anwendung durch automatisiertes Bereitstellen mithilfe von Kubernetes und ArgoCD: Sicherer Zugang zu Ihrer Anwendung mit MHM Digitale Lösungen UG & Kubernetes/ArgoCD Automatisierung
#Kubernetes #ArgoCD #Authentifizierung #Service-Mesh #Skalierung #Sicherheit #Automatisierung #Bereitstellung #Kontrolle
Die Verlagerung von digitalen Anwendungen und deren Bereitstellung an eine vorherbestimmte Zielgruppe ist eine anspruchsvolle Aufgabe. Insbesondere wenn es um die Sicherheit geht. MHM Digital Solutions UG bietet eine Lösung, die das automatisierte Bereitstellen und das Erreichen einer höheren Sicherheitsstufe ermöglicht: Kubernetes und ArgoCD. Kubernetes ist eine plattformübergreifende…
View On WordPress
#ArgoCD#Authentifizierung#Authentifizierungssystem#Automatisierung#Bereitstellung#Kontrolle#Kubernetes#Service-Mesh.#Sicherheit#Skalierung
0 notes
Text
Advanced DevOps Strategies: Optimizing Software Delivery and Operations
Introduction
By bridging the gap between software development and IT operations, DevOps is a revolutionary strategy that guarantees quicker and more dependable software delivery. Businesses may increase productivity and lower deployment errors by combining automation, continuous integration (CI), continuous deployment (CD), and monitoring. Adoption of DevOps has become crucial for businesses looking to improve their software development lifecycle's scalability, security, and efficiency. To optimize development workflows, DevOps approaches need the use of tools such as Docker, Kubernetes, Jenkins, Terraform, and cloud platforms. Businesses are discovering new methods to automate, anticipate, and optimize their infrastructure for optimal performance as AI and machine learning become more integrated into DevOps.
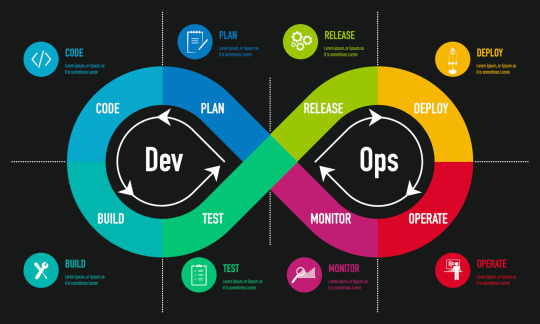
Infrastructure as Code (IaC): Automating Deployments
Infrastructure as Code (IaC), one of the fundamental tenets of DevOps, allows teams to automate infrastructure administration. Developers may describe infrastructure declaratively with tools like Terraform, Ansible, and CloudFormation, doing away with the need for manual setups. By guaranteeing repeatable and uniform conditions and lowering human error, IaC speeds up software delivery. Scalable and adaptable deployment models result from the automated provisioning of servers, databases, and networking components. Businesses may achieve version-controlled infrastructure, quicker disaster recovery, and effective resource use in both on-premises and cloud settings by implementing IaC in DevOps processes.
The Role of Microservices in DevOps
DevOps is revolutionized by microservices architecture, which makes it possible to construct applications in a modular and autonomous manner. Microservices encourage flexibility in contrast to conventional monolithic designs, enabling teams to implement separate services without impacting the program as a whole. The administration of containerized microservices is made easier by DevOps automation technologies like Docker and Kubernetes, which provide fault tolerance, scalability, and high availability. Organizations may improve microservices-based systems' observability, traffic management, and security by utilizing service mesh technologies like Istio and Consul. Microservices integration with DevOps is a recommended method for contemporary software development as it promotes quicker releases, less downtime, and better resource usage.
CI/CD Pipelines: Enhancing Speed and Reliability
Continuous Integration (CI) and Continuous Deployment (CD) are the foundation of DevOps automation, allowing for quick software changes with no interruption. Software dependability is ensured by automating code integration, testing, and deployment with tools like Jenkins, GitLab CI/CD, and GitHub Actions. By using CI/CD pipelines, production failures are decreased, development cycles are accelerated, and manual intervention is eliminated. Blue-green deployments, rollback procedures, and automated testing all enhance deployment security and stability. Businesses who use CI/CD best practices see improved time-to-market, smooth upgrades, and high-performance apps in both on-premises and cloud settings.
Conclusion
Businesses may achieve agility, efficiency, and security in contemporary software development by mastering DevOps principles. Innovation and operational excellence are fueled by the combination of IaC, microservices, CI/CD, and automation. A DevOps internship may offer essential industry exposure and practical understanding of sophisticated DevOps technologies and processes to aspiring individuals seeking to obtain practical experience.
#devOps#devOps mastery#Devops mastery course#devops mastery internship#devops mastery training#devops internship in pune#e3l#e3l.co
0 notes
Text
The Hidden Challenges of 5G Cloud-Native Integration

5G technology is transforming industries, enabling ultra-fast connectivity, low-latency applications, and the rise of smart infrastructures. However, behind the promise of seamless communication lies a complex reality—integrating 5G with cloud-native architectures presents a series of hidden challenges. Businesses and service providers must navigate these hurdles to maximize 5G’s potential while maintaining operational efficiency and security.
Understanding Cloud-Native 5G
A cloud-native approach to 5G is essential for leveraging the benefits of software-defined networking (SDN) and network function virtualization (NFV). Cloud-native 5G architectures use microservices, containers, and orchestration tools like Kubernetes to enable flexibility and scalability. While this approach is fundamental for modern network operations, it introduces a new layer of challenges that demand strategic solutions.
Managing Complex Infrastructure Deployment
Unlike traditional monolithic network architectures, 5G cloud-native networks rely on distributed and multi-layered environments. This includes on-premises data centers, edge computing nodes, and public or private clouds. Coordinating and synchronizing these components efficiently is a significant challenge.
Network Fragmentation – Deploying 5G across hybrid cloud environments requires seamless communication between disparate systems. Network fragmentation can cause interoperability issues and inefficiencies.
Scalability Bottlenecks – Scaling microservices-based 5G networks demands a robust orchestration mechanism to prevent latency spikes and service disruptions.
Security Concerns in a Cloud-Native 5G Environment
Security is a top priority in any cloud-native environment, and integrating it with 5G adds new complexities. With increased connectivity and open architectures, the attack surface expands, making networks more vulnerable to threats.
Data Privacy Risks – Sensitive information traveling through cloud-based 5G networks requires strong encryption and compliance with regulations like GDPR and CCPA.
Container Security – The use of containers for network functions means each service must be secured individually, adding to security management challenges.
Zero Trust Implementation – Traditional security models are insufficient. A zero-trust architecture is necessary to authenticate and monitor all network interactions.
Ensuring Low Latency and High Performance
One of the main advantages of 5G is ultra-low latency, but cloud-native integration can introduce latency if not managed correctly. Key factors affecting performance include:
Edge Computing Optimization – Placing computing resources closer to the end-user reduces latency, but integrating edge computing seamlessly into a cloud-native 5G environment requires advanced workload management.
Real-Time Data Processing – Applications like autonomous vehicles and telemedicine require real-time data analytics. Ensuring minimal delay in data processing is a technical challenge that demands high-performance infrastructure.
Orchestration and Automation Challenges
Efficient orchestration of microservices in a 5G cloud-native setup requires sophisticated automation tools. Kubernetes and other orchestration platforms help, but challenges persist:
Resource Allocation Complexity – Properly distributing workloads across cloud and edge environments requires intelligent automation to optimize performance.
Service Mesh Overhead – Managing service-to-service communication at scale introduces additional networking complexities that can impact efficiency.
Continuous Deployment Risks – Frequent updates and patches are necessary for a cloud-native environment, but improper CI/CD pipeline implementation can lead to service outages.
Integration with Legacy Systems
Many enterprises still rely on legacy systems that are not inherently cloud-native. Integrating 5G with these existing infrastructures presents compatibility issues.
Protocol Mismatches – Older network functions may not support modern cloud-native frameworks, leading to operational inefficiencies.
Gradual Migration Strategies – Businesses need hybrid models that allow for gradual adoption of cloud-native principles without disrupting existing operations.
Regulatory and Compliance Challenges
5G networks operate under strict regulatory frameworks, and compliance varies across regions. When adopting a cloud-native 5G approach, businesses must consider:
Data Localization Laws – Some regions require data to be stored and processed locally, complicating cloud-based deployments.
Industry-Specific Regulations – Telecom, healthcare, and finance industries have unique compliance requirements that add layers of complexity to 5G cloud integration.
Overcoming These Challenges
To successfully integrate 5G with cloud-native architectures, organizations must adopt a strategic approach that includes:
Robust Security Frameworks – Implementing end-to-end encryption, zero-trust security models, and AI-driven threat detection.
Advanced Orchestration – Leveraging AI-powered automation for efficient microservices and workload management.
Hybrid and Multi-Cloud Strategies – Balancing edge computing, private, and public cloud resources for optimized performance.
Compliance-Centric Deployment – Ensuring adherence to regulatory frameworks through proper data governance and legal consultations.
If you’re looking for more insights on optimizing 5G cloud-native integration, click here to find out more.
Conclusion
While the promise of 5G is undeniable, the hidden challenges of cloud-native integration must be addressed to unlock its full potential. Businesses that proactively tackle security, orchestration, performance, and regulatory issues will be better positioned to leverage 5G’s transformative capabilities. Navigating these challenges requires expertise, advanced technologies, and a forward-thinking approach.
For expert guidance on overcoming these integration hurdles, check over here for industry-leading solutions and strategies.
Original Source: https://software5g.blogspot.com/2025/02/the-hidden-challenges-of-5g-cloud.html
0 notes
Text
SRE (Site Reliability Engineering) Interview Preparation Guide
Site Reliability Engineering (SRE) is a highly sought-after role that blends software engineering with systems administration to create scalable, reliable systems. Whether you’re a seasoned professional or just starting out, preparing for an SRE interview requires a strategic approach. Here’s a guide to help you ace your interview.
1. Understand the Role of an SRE
Before diving into preparation, it’s crucial to understand the responsibilities of an SRE. SREs focus on maintaining the reliability, availability, and performance of systems. Their tasks include:
• Monitoring and incident response
• Automation of manual tasks
• Capacity planning
• Performance tuning
• Collaborating with development teams to improve system architecture
2. Key Areas to Prepare
SRE interviews typically cover a range of topics. Here are the main areas you should focus on:
a) System Design
• Learn how to design scalable and fault-tolerant systems.
• Understand concepts like load balancing, caching, database sharding, and high availability.
• Be prepared to discuss trade-offs in system architecture.
b) Programming and Scripting
• Proficiency in at least one programming language (e.g., Python, Go, Java) is essential.
• Practice writing scripts for automation tasks like log parsing or monitoring setup.
• Focus on problem-solving skills and algorithms.
c) Linux/Unix Fundamentals
• Understand Linux commands, file systems, and process management.
• Learn about networking concepts such as DNS, TCP/IP, and firewalls.
d) Monitoring and Observability
• Familiarize yourself with tools like Prometheus, Grafana, ELK stack, and Datadog.
• Understand key metrics (e.g., latency, traffic, errors) and Service Level Objectives (SLOs).
e) Incident Management
• Study strategies for diagnosing and mitigating production issues.
• Be ready to explain root cause analysis and postmortem processes.
f) Cloud and Kubernetes
• Understand cloud platforms like AWS, Azure, or GCP.
• Learn Kubernetes concepts such as pods, deployments, and service meshes.
• Explore Infrastructure as Code (IaC) tools like Terraform.
3. Soft Skills and Behavioral Questions
SREs often collaborate with cross-functional teams. Be prepared for questions about:
• Handling high-pressure incidents
• Balancing reliability with feature delivery
• Communication and teamwork skills
Read More: SRE (Site Reliability Engineering) Interview Preparation Guide
0 notes
Text
Essential Components of a Production Microservice Application
DevOps Automation Tools and modern practices have revolutionized how applications are designed, developed, and deployed. Microservice architecture is a preferred approach for enterprises, IT sectors, and manufacturing industries aiming to create scalable, maintainable, and resilient applications. This blog will explore the essential components of a production microservice application, ensuring it meets enterprise-grade standards.
1. API Gateway
An API Gateway acts as a single entry point for client requests. It handles routing, composition, and protocol translation, ensuring seamless communication between clients and microservices. Key features include:
Authentication and Authorization: Protect sensitive data by implementing OAuth2, OpenID Connect, or other security protocols.
Rate Limiting: Prevent overloading by throttling excessive requests.
Caching: Reduce response time by storing frequently accessed data.
Monitoring: Provide insights into traffic patterns and potential issues.
API Gateways like Kong, AWS API Gateway, or NGINX are widely used.
Mobile App Development Agency professionals often integrate API Gateways when developing scalable mobile solutions.
2. Service Registry and Discovery
Microservices need to discover each other dynamically, as their instances may scale up or down or move across servers. A service registry, like Consul, Eureka, or etcd, maintains a directory of all services and their locations. Benefits include:
Dynamic Service Discovery: Automatically update the service location.
Load Balancing: Distribute requests efficiently.
Resilience: Ensure high availability by managing service health checks.
3. Configuration Management
Centralized configuration management is vital for managing environment-specific settings, such as database credentials or API keys. Tools like Spring Cloud Config, Consul, or AWS Systems Manager Parameter Store provide features like:
Version Control: Track configuration changes.
Secure Storage: Encrypt sensitive data.
Dynamic Refresh: Update configurations without redeploying services.
4. Service Mesh
A service mesh abstracts the complexity of inter-service communication, providing advanced traffic management and security features. Popular service mesh solutions like Istio, Linkerd, or Kuma offer:
Traffic Management: Control traffic flow with features like retries, timeouts, and load balancing.
Observability: Monitor microservice interactions using distributed tracing and metrics.
Security: Encrypt communication using mTLS (Mutual TLS).
5. Containerization and Orchestration
Microservices are typically deployed in containers, which provide consistency and portability across environments. Container orchestration platforms like Kubernetes or Docker Swarm are essential for managing containerized applications. Key benefits include:
Scalability: Automatically scale services based on demand.
Self-Healing: Restart failed containers to maintain availability.
Resource Optimization: Efficiently utilize computing resources.
6. Monitoring and Observability
Ensuring the health of a production microservice application requires robust monitoring and observability. Enterprises use tools like Prometheus, Grafana, or Datadog to:
Track Metrics: Monitor CPU, memory, and other performance metrics.
Set Alerts: Notify teams of anomalies or failures.
Analyze Logs: Centralize logs for troubleshooting using ELK Stack (Elasticsearch, Logstash, Kibana) or Fluentd.
Distributed Tracing: Trace request flows across services using Jaeger or Zipkin.
Hire Android App Developers to ensure seamless integration of monitoring tools for mobile-specific services.
7. Security and Compliance
Securing a production microservice application is paramount. Enterprises should implement a multi-layered security approach, including:
Authentication and Authorization: Use protocols like OAuth2 and JWT for secure access.
Data Encryption: Encrypt data in transit (using TLS) and at rest.
Compliance Standards: Adhere to industry standards such as GDPR, HIPAA, or PCI-DSS.
Runtime Security: Employ tools like Falco or Aqua Security to detect runtime threats.
8. Continuous Integration and Continuous Deployment (CI/CD)
A robust CI/CD pipeline ensures rapid and reliable deployment of microservices. Using tools like Jenkins, GitLab CI/CD, or CircleCI enables:
Automated Testing: Run unit, integration, and end-to-end tests to catch bugs early.
Blue-Green Deployments: Minimize downtime by deploying new versions alongside old ones.
Canary Releases: Test new features on a small subset of users before full rollout.
Rollback Mechanisms: Quickly revert to a previous version in case of issues.
9. Database Management
Microservices often follow a database-per-service model to ensure loose coupling. Choosing the right database solution is critical. Considerations include:
Relational Databases: Use PostgreSQL or MySQL for structured data.
NoSQL Databases: Opt for MongoDB or Cassandra for unstructured data.
Event Sourcing: Leverage Kafka or RabbitMQ for managing event-driven architectures.
10. Resilience and Fault Tolerance
A production microservice application must handle failures gracefully to ensure seamless user experiences. Techniques include:
Circuit Breakers: Prevent cascading failures using tools like Hystrix or Resilience4j.
Retries and Timeouts: Ensure graceful recovery from temporary issues.
Bulkheads: Isolate failures to prevent them from impacting the entire system.
11. Event-Driven Architecture
Event-driven architecture improves responsiveness and scalability. Key components include:
Message Brokers: Use RabbitMQ, Kafka, or AWS SQS for asynchronous communication.
Event Streaming: Employ tools like Kafka Streams for real-time data processing.
Event Sourcing: Maintain a complete record of changes for auditing and debugging.
12. Testing and Quality Assurance
Testing in microservices is complex due to the distributed nature of the architecture. A comprehensive testing strategy should include:
Unit Tests: Verify individual service functionality.
Integration Tests: Validate inter-service communication.
Contract Testing: Ensure compatibility between service APIs.
Chaos Engineering: Test system resilience by simulating failures using tools like Gremlin or Chaos Monkey.
13. Cost Management
Optimizing costs in a microservice environment is crucial for enterprises. Considerations include:
Autoscaling: Scale services based on demand to avoid overprovisioning.
Resource Monitoring: Use tools like AWS Cost Explorer or Kubernetes Cost Management.
Right-Sizing: Adjust resources to match service needs.
Conclusion
Building a production-ready microservice application involves integrating numerous components, each playing a critical role in ensuring scalability, reliability, and maintainability. By adopting best practices and leveraging the right tools, enterprises, IT sectors, and manufacturing industries can achieve operational excellence and deliver high-quality services to their customers.
Understanding and implementing these essential components, such as DevOps Automation Tools and robust testing practices, will enable organizations to fully harness the potential of microservice architecture. Whether you are part of a Mobile App Development Agency or looking to Hire Android App Developers, staying ahead in today’s competitive digital landscape is essential.
0 notes
Text
Top Benefits of Migrating to Red Hat OpenShift from Legacy Systems
In today’s fast-paced digital world, businesses are under constant pressure to innovate while maintaining reliability and efficiency. Legacy systems, although critical in their prime, often become bottlenecks as organizations strive for agility and scalability. Enter Red Hat OpenShift—a leading Kubernetes platform that enables businesses to modernize their IT infrastructure and embrace cloud-native technologies. Migrating from legacy systems to OpenShift offers numerous benefits. Let’s explore some of the top advantages.
1. Enhanced Scalability and Flexibility
Legacy systems are often rigid, making it difficult to scale resources or adapt to changing business needs. OpenShift’s containerized architecture allows businesses to scale applications seamlessly, whether on-premises, in the cloud, or across hybrid environments. This flexibility ensures you can respond quickly to market demands and customer expectations.
2. Improved Application Deployment and Management
With legacy systems, deploying new applications or updates can be time-consuming and prone to errors. OpenShift automates many aspects of application deployment and lifecycle management, leveraging CI/CD pipelines to ensure faster and more reliable rollouts. Developers can focus on innovation rather than managing infrastructure.
3. Cost Efficiency
Maintaining and upgrading legacy systems can be expensive due to outdated hardware, software licenses, and specialized support. By migrating to OpenShift, organizations can reduce operational costs through containerized workloads, optimized resource utilization, and the ability to use open-source tools. Additionally, OpenShift’s automation reduces manual tasks, further lowering costs.
4. Enhanced Security
Security is a major concern with legacy systems, which often lack the features needed to combat modern cyber threats. OpenShift incorporates robust, built-in security features, such as image scanning, role-based access control (RBAC), and encrypted communications. Regular updates and patches from Red Hat ensure your platform stays secure and compliant.
5. Faster Time to Market
Modern businesses thrive on speed. With OpenShift, developers can build, test, and deploy applications faster using tools like Red Hat CodeReady Workspaces and container-native storage. This accelerates the time to market for new products and services, giving your business a competitive edge.
6. Seamless Hybrid and Multi-Cloud Support
Unlike legacy systems, which are often tied to a single environment, OpenShift offers seamless integration with hybrid and multi-cloud setups. This flexibility empowers businesses to choose the best environment for each workload, whether it’s on-premises, public cloud, or edge computing.
7. Future-Proofing Your IT Infrastructure
Migrating to OpenShift positions your organization for future growth. With support for emerging technologies like AI/ML, edge computing, and IoT, OpenShift ensures your IT infrastructure is ready to tackle tomorrow’s challenges. OpenShift’s commitment to open-source standards also means you avoid vendor lock-in.
8. Developer-Centric Ecosystem
OpenShift provides developers with a rich ecosystem of tools and frameworks, enabling them to work more efficiently. Features like integrated developer environments, application templates, and OpenShift Service Mesh streamline workflows and foster innovation. This developer-friendly approach boosts productivity and job satisfaction.
9. Streamlined Compliance and Governance
Legacy systems can make compliance with modern regulations a daunting task. OpenShift simplifies compliance with built-in tools for auditing, logging, and monitoring. Whether you operate in a highly regulated industry or simply need to maintain best practices, OpenShift helps ensure governance requirements are met.
10. Community and Enterprise Support
Red Hat OpenShift is backed by an active open-source community and enterprise-grade support from Red Hat. This combination ensures continuous innovation, timely updates, and expert assistance when needed. Migrating to OpenShift means you’re never alone in your modernization journey.
Conclusion
Migrating from legacy systems to Red Hat OpenShift is more than just a technology upgrade; it’s a strategic move toward agility, efficiency, and innovation. By embracing OpenShift, businesses can overcome the limitations of outdated infrastructure and unlock new opportunities for growth.
Ready to make the leap? Contact Red Hat to learn how OpenShift can transform your organization today. visit www.hawkstack.com
0 notes
Text
Azure DevOps Advance Course: Elevate Your DevOps Expertise
The Azure DevOps Advanced Course is for individuals with a solid understanding of DevOps and who want to enhance their skills and knowledge within the Microsoft Azure ecosystem. This course is designed to go beyond the basics and focus on advanced concepts and practices for managing and implementing complex DevOps workflows using Azure tools.
Key Learning Objectives:
Advanced Pipelines for CI/CD: Learn how to build highly scalable, reliable, and CI/CD pipelines with Azure DevOps Tools like Azure Pipelines. Azure Artifacts and Azure Key Vault. Learn about advanced branching, release gates and deployment strategies in different environments.
Infrastructure as Code (IaC): Master the use of infrastructure-as-code tools like Azure Resource Manager (ARM) templates and Terraform to automate the provisioning and management of Azure resources. This includes best practices for versioning, testing and deploying infrastructure configurations.
Containerization: Learn about container orchestration using Docker. Learn how to create, deploy and manage containerized apps on Azure Kubernetes Service. Explore concepts such as service meshes and ingress controllers.
Security and compliance: Understanding security best practices in the DevOps Lifecycle. Learn how to implement various security controls, including code scanning, vulnerability assessment, and secret management, at different stages of the pipeline. Learn how to implement compliance frameworks such as ISO 27001 or SOC 2 using Azure DevOps.
Monitoring & Logging: Acquire expertise in monitoring application performance and health. Azure Monitor, Application Insights and other tools can be used to collect, analyse and visualize telemetry. Implement alerting mechanisms to troubleshoot problems proactively.
Advanced Debugging and Troubleshooting: Develop advanced skills in troubleshooting to diagnose and solve complex issues with Azure DevOps deployments and pipelines. Learn how to debug code and analyze logs to identify and solve problems.
Who should attend:
DevOps Engineers
System Administrators
Software Developers
Cloud Architects
IT Professionals who want to improve their DevOps on the Azure platform
Benefits of taking the course:
Learn advanced DevOps concepts, best practices and more.
Learn how to implement and manage complex DevOps Pipelines.
Azure Tools can help you automate your infrastructure and applications.
Learn how to integrate security, compliance and monitoring into the DevOps Lifecycle.
Get a competitive advantage in the job market by acquiring advanced Azure DevOps Advance Course knowledge.
The Azure DevOps Advanced Course is a comprehensive, practical learning experience that will equip you with the knowledge and skills to excel in today’s dynamic cloud computing environment.
0 notes
Text
Top DevOps Practices for 2024: Insights from HawkStack Experts
As the technology landscape evolves, DevOps remains pivotal in driving efficient, reliable, and scalable software delivery. HawkStack Technologies brings you the top DevOps practices for 2024 to keep your team ahead in this competitive domain.
1. Infrastructure as Code (IaC): Simplified Scalability
In 2024, IaC tools like Terraform and Ansible continue to dominate. By defining infrastructure through code, organizations achieve consistent environments across development, testing, and production. This eliminates manual errors and ensures rapid scalability. Example: Use Terraform modules to manage multi-cloud deployments seamlessly.
2. Shift-Left Security: Integrate Early
Security is no longer an afterthought. Teams are embedding security practices earlier in the software development lifecycle. By integrating tools like Snyk and SonarQube during development, vulnerabilities are detected and mitigated before deployment.
3. Continuous Integration and Continuous Deployment (CI/CD): Faster Delivery
CI/CD pipelines are more sophisticated than ever, emphasizing automated testing, secure builds, and quick rollbacks. Example: Use Jenkins or GitHub Actions to automate the deployment pipeline while maintaining quality gates.
4. Containerization and Kubernetes
Containers, orchestrated by platforms like Kubernetes, remain essential for scaling microservices-based applications. Kubernetes Operators and Service Mesh add advanced capabilities, like automated updates and enhanced observability.
5. DevOps + AI/ML: Intelligent Automation
AI-driven insights are revolutionizing DevOps practices. Predictive analytics enhance monitoring, while AI tools optimize CI/CD pipelines. Example: Implement AI tools like Dynatrace or New Relic for intelligent system monitoring.
6. Enhanced Observability: Metrics That Matter
Modern DevOps prioritizes observability to ensure performance and reliability. Tools like Prometheus and Grafana offer actionable insights by tracking key metrics and trends.
Conclusion
Adopting these cutting-edge practices will empower teams to deliver exceptional results in 2024. At HawkStack Technologies, we provide hands-on training and expert guidance to help organizations excel in the DevOps ecosystem. Stay ahead by embracing these strategies today!
For More Information visit: www.hawkstack.com
0 notes
Text
Mastering Java Microservices Scalability with Docker and Kubernetes
Introduction Brief Explanation and Importance Scaling Java microservices with Docker, Kubernetes, and Service Mesh is a crucial topic in modern software development. With the increasing demand for agile and scalable applications, Java microservices have become a popular choice. Docker and Kubernetes provide a robust platform for containerization and orchestration, while Service Mesh helps…
0 notes
Text
How Java Full-Stack Developers Can Leverage Cloud Technologies

The rapid growth of cloud computing has transformed the way applications are built, deployed, and managed. For Java full-stack developers, leveraging cloud technologies has become essential for building scalable, reliable, and efficient applications. Whether you’re integrating cloud storage, deploying microservices, or utilizing serverless computing, understanding how to use cloud platforms with Java can significantly enhance your development workflow.
In this blog, we’ll explore five key ways Java full-stack developers can leverage cloud technologies to improve their applications and workflows.
1. Deploying Java Applications on the Cloud
The Advantage
Cloud platforms like AWS, Google Cloud, and Microsoft Azure offer robust infrastructure to host Java applications with minimal configuration. This enables developers to focus more on building the application rather than managing physical servers.
How to Leverage It
Use Cloud Infrastructure: Utilize cloud compute services such as AWS EC2, Google Compute Engine, or Azure Virtual Machines to run Java applications.
Containerization: Containerize your Java applications using Docker and deploy them to cloud container services like AWS ECS, Google Kubernetes Engine (GKE), or Azure Kubernetes Service (AKS).
Managed Services: Use cloud-based Java application hosting solutions like AWS Elastic Beanstalk, Google App Engine, or Azure App Service for automatic scaling and monitoring.
2. Implementing Microservices with Cloud-Native Tools
The Advantage
Cloud environments are perfect for microservices-based architectures, allowing Java developers to break down applications into small, independent services. This makes applications more scalable, maintainable, and fault-tolerant.
How to Leverage It
Cloud Native Frameworks: Use Spring Boot and Spring Cloud to build microservices and deploy them on cloud platforms. These frameworks simplify service discovery, load balancing, and fault tolerance.
API Gateway: Implement API Gateway services such as AWS API Gateway, Azure API Management, or Google Cloud Endpoints to manage and route requests to your microservices.
Service Mesh: Use service meshes like Istio (on Kubernetes) to manage microservices communication, monitoring, and security in the cloud.
3. Utilizing Serverless Computing
The Advantage
Serverless computing allows Java developers to focus solely on writing code, without worrying about server management. This makes it easier to scale applications quickly and cost-effectively, as you only pay for the compute power your functions consume.
How to Leverage It
AWS Lambda: Write Java functions to run on AWS Lambda, automatically scaling as needed without managing servers.
Azure Functions: Similarly, use Java to build functions that execute on Azure Functions, enabling event-driven computing.
Google Cloud Functions: Integrate Java with Google Cloud Functions for lightweight, serverless event-driven applications.
4. Storing Data in the Cloud
The Advantage
Cloud storage offers highly available and scalable database solutions, which are perfect for Java full-stack developers building applications that require robust data management systems.
How to Leverage It
Relational Databases: Use managed database services like Amazon RDS, Google Cloud SQL, or Azure SQL Database for scalable, cloud-hosted SQL databases such as MySQL, PostgreSQL, or MariaDB.
NoSQL Databases: Implement NoSQL databases like AWS DynamoDB, Google Cloud Firestore, or Azure Cosmos DB for applications that need flexible, schema-less data storage.
Cloud Storage: Store large amounts of unstructured data using cloud storage solutions like AWS S3, Google Cloud Storage, or Azure Blob Storage.
5. Monitoring and Scaling Java Applications in the Cloud
The Advantage
One of the main benefits of the cloud is the ability to scale your applications easily, both vertically and horizontally. Additionally, cloud platforms provide powerful monitoring and logging tools to track the performance of your Java applications in real-time.
How to Leverage It
Auto-Scaling: Use auto-scaling groups in AWS, Google Cloud, or Azure to automatically adjust the number of instances based on demand.
Monitoring and Alerts: Implement cloud monitoring services like AWS CloudWatch, Google Stackdriver, or Azure Monitor to track metrics and receive alerts when issues arise.
Log Management: Use cloud logging tools such as AWS CloudTrail, Google Cloud Logging, or Azure Log Analytics to collect and analyze logs for troubleshooting.
Conclusion
By embracing cloud technologies, Java full-stack developers can build more scalable, resilient, and cost-efficient applications. Whether you’re deploying microservices, leveraging serverless computing, or integrating cloud storage, the cloud provides a wealth of tools to enhance your development process.
Cloud platforms also enable you to focus more on building your applications rather than managing infrastructure, ultimately improving productivity and accelerating development cycles.
Are you ready to leverage the cloud in your Java full-stack projects? Start exploring cloud platforms today and take your Java development to new heights!
0 notes
Text
Istio Service Mesh Essentials: Simplifying Microservices Management
In today's cloud-native world, microservices architecture has become a standard for building scalable and resilient applications. However, managing the interactions between these microservices introduces challenges such as traffic control, security, and observability. This is where Istio Service Mesh shines.
Istio is a powerful, open-source service mesh platform that addresses these challenges, providing seamless traffic management, enhanced security, and robust observability for microservices. This blog post will dive into the essentials of Istio Service Mesh and explore how it simplifies microservices management, complete with hands-on insights.
What is a Service Mesh?
A service mesh is a dedicated infrastructure layer that facilitates secure, fast, and reliable communication between microservices. It decouples service-to-service communication concerns like routing, load balancing, and security from the application code, enabling developers to focus on business logic.
Istio is one of the most popular service meshes, offering a rich set of features to empower developers and operations teams.
Key Features of Istio Service Mesh
1. Traffic Management
Istio enables dynamic traffic routing and load balancing between services, ensuring optimal performance and reliability. Key traffic management features include:
Intelligent Routing: Use fine-grained traffic control policies for canary deployments, blue-green deployments, and A/B testing.
Load Balancing: Automatically distribute requests across multiple service instances.
Retries and Timeouts: Improve resilience by defining retry policies and request timeouts.
2. Enhanced Security
Security is a cornerstone of Istio, providing built-in features like:
Mutual TLS (mTLS): Encrypt service-to-service communication.
Authentication and Authorization: Define access policies using identity-based and attribute-based rules.
Secure Gateways: Secure ingress and egress traffic with gateways.
3. Observability
Monitoring microservices can be daunting, but Istio offers powerful observability tools:
Telemetry and Metrics: Gain insights into service performance with Prometheus and Grafana integrations.
Distributed Tracing: Trace requests across multiple services using tools like Jaeger or Zipkin.
Service Visualization: Use tools like Kiali to visualize service interactions.
Hands-On with Istio: Setting Up Your Service Mesh
Here’s a quick overview of setting up and using Istio in a Kubernetes environment:
Step 1: Install Istio
Download the Istio CLI (istioctl) and install Istio in your Kubernetes cluster.
Deploy the Istio control plane components, including Pilot, Mixer, and Envoy proxies.
Step 2: Enable Your Services for Istio
Inject Istio's Envoy sidecar proxy into your service pods.
Configure Istio Gateway and VirtualService resources for external traffic management.
Step 3: Define Traffic Rules
Create routing rules for advanced traffic management scenarios.
Test mTLS to secure inter-service communication.
Step 4: Monitor with Observability Tools
Use built-in telemetry to monitor service health.
Visualize the mesh topology with Kiali for better debugging and analysis.
Why Istio Matters for Your Microservices
Istio abstracts complex network-level tasks, enabling your teams to:
Save Time: Automate communication patterns without touching the application code.
Enhance Security: Protect your services with minimal effort.
Improve Performance: Leverage intelligent routing and load balancing.
Gain Insights: Monitor and debug your microservices with ease.
Conclusion
Mastering Istio Service Mesh Essentials opens up new possibilities for managing microservices effectively. By implementing Istio, organizations can ensure their applications are secure, resilient, and performant.
Ready to dive deeper? Explore Istio hands-on labs to experience its features in action. Simplify your microservices management journey with Istio Service Mesh!
Explore More with HawkStack
Interested in modern microservices solutions? HawkStack Technologies offers expert DevOps tools and support, including Istio and other cloud-native services. Reach out today to transform your microservices infrastructure! For more details - www.hawkstack.com
#redhatcourses#information technology#containerorchestration#kubernetes#docker#containersecurity#container#linux#aws#hawkstack#hawkstack technologies
0 notes
Text
The Future of the DevOps Career: Trends and Opportunities
The DevOps movement has fundamentally reshaped how software is developed and delivered. With its collaborative approach to development and operations, DevOps has become integral to many organizations striving for agility and efficiency. As we look to the future, the career prospects in DevOps are not just promising but also evolving.

For those keen to excel in Devops, enrolling in Devops Course in Pune can be highly advantageous. Such a program provides a unique opportunity to acquire comprehensive knowledge and practical skills crucial for mastering Devops.
1. Increasing Demand for DevOps Expertise
The demand for skilled DevOps professionals is surging. As businesses seek to enhance their software delivery processes and operational efficiency, the need for experts who can streamline workflows and foster collaboration is critical. Job postings for DevOps roles are projected to continue rising, making this a lucrative field for job seekers.
2. Rise of Automation and AI
Automation has always been a core principle of DevOps, but the incorporation of artificial intelligence (AI) and machine learning (ML) is taking automation to the next level. DevOps professionals will increasingly need to harness AI/ML for tasks such as predictive analytics, incident response, and performance optimization. Mastering these technologies will be essential for staying relevant and competitive in the field.
3. Emphasis on Platform Engineering
As organizations adopt cloud-native architectures and microservices, the role of platform engineering is gaining prominence. DevOps professionals who specialize in designing and managing robust cloud platforms, container orchestration (like Kubernetes), and service meshes will find abundant opportunities. This shift not only requires technical expertise but also a holistic understanding of both development and operational needs.
4. Integration of Security (DevSecOps)
With cyber threats on the rise, integrating security into the DevOps pipeline—known as DevSecOps—is becoming a necessity. Future DevOps professionals must prioritize security throughout the development lifecycle. Familiarity with security best practices, tools, and compliance frameworks will be invaluable, making security expertise a key differentiator in the job market.

Enrolling in Devops Online Course can enable individuals to unlock DevOps full potential and develop a deeper understanding of its complexities.
5. Commitment to Continuous Learning
The tech landscape is ever-changing, and the most successful DevOps professionals are those who embrace continuous learning. Staying updated on the latest tools, methodologies, and industry trends is crucial. Whether through certifications, online courses, or community engagement, a commitment to lifelong learning will significantly enhance career prospects.
6. Remote Work and Global Opportunities
The shift toward remote work has broadened the job market for DevOps professionals. Companies are increasingly open to hiring talent from diverse geographical locations, enabling individuals to access roles that may have previously been limited by geography. This trend not only allows for greater flexibility but also fosters a rich tapestry of global collaboration.
7. Importance of Soft Skills
While technical proficiency is vital, soft skills are becoming equally important in the DevOps domain. Skills such as communication, teamwork, and problem-solving are essential for creating a collaborative culture. DevOps professionals who can effectively bridge the gap between development and operations will be highly valued by employers.
Conclusion
The future of the DevOps career is bright, with numerous avenues for growth and development. As technology continues to advance, professionals in this field must adapt and expand their skill sets. By embracing automation, AI, security practices, and a commitment to ongoing education, both aspiring and current DevOps practitioners can carve out successful and fulfilling careers.
Now is an exciting time to dive into the world of DevOps. With a landscape rich in opportunities, the journey promises to be both rewarding and transformative.
0 notes
Text
Price: [price_with_discount] (as of [price_update_date] - Details) [ad_1] Understand how to use service mesh architecture to efficiently manage and safeguard microservices-based applications with the help of examplesKey FeaturesManage your cloud-native applications easily using service mesh architectureLearn about Istio, Linkerd, and Consul – the three primary open source service mesh providersExplore tips, techniques, and best practices for building secure, high-performance microservicesBook DescriptionAlthough microservices-based applications support DevOps and continuous delivery, they can also add to the complexity of testing and observability. The implementation of a service mesh architecture, however, allows you to secure, manage, and scale your microservices more efficiently. With the help of practical examples, this book demonstrates how to install, configure, and deploy an efficient service mesh for microservices in a Kubernetes environment.You'll get started with a hands-on introduction to the concepts of cloud-native application management and service mesh architecture, before learning how to build your own Kubernetes environment. While exploring later chapters, you'll get to grips with the three major service mesh providers: Istio, Linkerd, and Consul. You'll be able to identify their specific functionalities, from traffic management, security, and certificate authority through to sidecar injections and observability.By the end of this book, you will have developed the skills you need to effectively manage modern microservices-based applications.What you will learnCompare the functionalities of Istio, Linkerd, and ConsulBecome well-versed with service mesh control and data plane conceptsUnderstand service mesh architecture with the help of hands-on examplesWork through hands-on exercises in traffic management, security, policy, and observabilitySet up secure communication for microservices using a service meshExplore service mesh features such as traffic management, service discovery, and resiliencyWho this book is forThis book is for solution architects and network administrators, as well as DevOps and site reliability engineers who are new to the cloud-native framework. You will also find this book useful if you’re looking to build a career in DevOps, particularly in operations. Working knowledge of Kubernetes and building microservices that are cloud-native is necessary to get the most out of this book. Publisher : Packt Publishing (27 March 2020) Language : English Paperback : 626 pages ISBN-10 : 1789615798 ISBN-13 : 978-1789615791 Item Weight : 1 kg 80 g Dimensions : 23.5 x 19.1 x 3.28 cm Country of Origin : India [ad_2]
0 notes
Text
SRE (Site Reliability Engineering) Interview Preparation Guide
Site Reliability Engineering (SRE) is a highly sought-after role that blends software engineering with systems administration to create scalable, reliable systems. Whether you’re a seasoned professional or just starting out, preparing for an SRE interview requires a strategic approach. Here’s a guide to help you ace your interview.
1. Understand the Role of an SRE
Before diving into preparation, it’s crucial to understand the responsibilities of an SRE. SREs focus on maintaining the reliability, availability, and performance of systems. Their tasks include:
Monitoring and incident response
Automation of manual tasks
Capacity planning
Performance tuning
Collaborating with development teams to improve system architecture
2. Key Areas to Prepare
SRE interviews typically cover a range of topics. Here are the main areas you should focus on:
a) System Design
Learn how to design scalable and fault-tolerant systems.
Understand concepts like load balancing, caching, database sharding, and high availability.
Be prepared to discuss trade-offs in system architecture.
b) Programming and Scripting
Proficiency in at least one programming language (e.g., Python, Go, Java) is essential.
Practice writing scripts for automation tasks like log parsing or monitoring setup.
Focus on problem-solving skills and algorithms.
c) Linux/Unix Fundamentals
Understand Linux commands, file systems, and process management.
Learn about networking concepts such as DNS, TCP/IP, and firewalls.
d) Monitoring and Observability
Familiarize yourself with tools like Prometheus, Grafana, ELK stack, and Datadog.
Understand key metrics (e.g., latency, traffic, errors) and Service Level Objectives (SLOs).
e) Incident Management
Study strategies for diagnosing and mitigating production issues.
Be ready to explain root cause analysis and postmortem processes.
f) Cloud and Kubernetes
Understand cloud platforms like AWS, Azure, or GCP.
Learn Kubernetes concepts such as pods, deployments, and service meshes.
Explore Infrastructure as Code (IaC) tools like Terraform.
3. Soft Skills and Behavioral Questions
SREs often collaborate with cross-functional teams. Be prepared for questions about:
Handling high-pressure incidents
Balancing reliability with feature delivery
Communication and teamwork skills
Read More: SRE (Site Reliability Engineering) Interview Preparation Guide
0 notes
Text
Exploring the Chaos Engineering Tools Market: Navigating the Future of Resilient Systems
The Chaos Engineering Tools Market was valued at USD 1.8 billion in 2023-e and will surpass USD 3.2 billion by 2030; growing at a CAGR of 8.3% during 2024 - 2030. Digital transformation drives business success, ensuring the reliability and resilience of systems has become a paramount concern for enterprises worldwide. Chaos engineering, a discipline that involves deliberately injecting failures into systems to test their robustness, has emerged as a critical practice in achieving this goal. As the field matures, the market for chaos engineering tools is expanding, offering a variety of solutions designed to help organizations identify and address vulnerabilities before they lead to catastrophic failures.
Chaos engineering originated from the practices of companies like Netflix, which needed to ensure their systems could withstand unexpected disruptions. By intentionally causing failures in a controlled environment, engineers could observe how systems responded and identify areas for improvement. This proactive approach to resilience has gained traction across industries, prompting the development of specialized tools to facilitate chaos experiments.
Read More about Sample Report: https://intentmarketresearch.com/request-sample/chaos-engineering-tools-market-3338.html
Key Players in the Chaos Engineering Tools Market
The chaos engineering tools market is diverse, with several key players offering robust solutions to meet the varying needs of organizations. Here are some of the prominent tools currently shaping the market:
Gremlin: Known for its user-friendly interface and comprehensive suite of features, Gremlin enables users to simulate various failure scenarios across multiple layers of their infrastructure. Its capabilities include CPU stress, network latency, and stateful attacks, making it a popular choice for enterprises seeking a versatile chaos engineering platform.
Chaos Monkey: Developed by Netflix, Chaos Monkey is one of the most well-known tools in the chaos engineering space. It focuses on randomly terminating instances within an environment to ensure that systems can tolerate unexpected failures. As part of the Simian Army suite, it has inspired numerous other tools and practices within the industry.
LitmusChaos: An open-source tool by MayaData, LitmusChaos provides a customizable framework for conducting chaos experiments in Kubernetes environments. Its extensive documentation and active community support make it an attractive option for organizations leveraging containerized applications.
Chaos Toolkit: Designed with extensibility in mind, the Chaos Toolkit allows users to create and execute chaos experiments using a declarative JSON/YAML format. Its plug-in architecture supports integrations with various cloud platforms and infrastructure services, enabling seamless experimentation across diverse environments.
Steadybit: A relative newcomer, Steadybit focuses on providing a simple yet powerful platform for running chaos experiments. Its emphasis on ease of use and integration with existing CI/CD pipelines makes it an appealing choice for teams looking to incorporate chaos engineering into their development workflows.
Market Trends and Future Directions
The chaos engineering tools market is evolving rapidly, driven by several key trends:
Integration with CI/CD Pipelines: As continuous integration and continuous delivery (CI/CD) become standard practices, chaos engineering tools are increasingly integrating with these pipelines. This allows for automated resilience testing as part of the development process, ensuring that potential issues are identified and addressed early.
Expansion of Cloud-Native Environments: With the growing adoption of cloud-native technologies such as Kubernetes, chaos engineering tools are evolving to support these environments. Tools like LitmusChaos and Chaos Mesh cater specifically to Kubernetes users, offering features tailored to container orchestration and microservices architectures.
Increased Focus on Security: As cybersecurity threats become more sophisticated, chaos engineering is being extended to include security-focused experiments. By simulating attacks and breaches, organizations can test their defenses and improve their security posture.
Enhanced Observability and Analytics: Modern chaos engineering tools are incorporating advanced observability and analytics features. These capabilities provide deeper insights into system behavior during experiments, enabling teams to make more informed decisions about resilience improvements.
Ask for Customization Report: https://intentmarketresearch.com/ask-for-customization/chaos-engineering-tools-market-3338.html
Challenges and Considerations
While the benefits of chaos engineering are clear, organizations must navigate several challenges when adopting these practices:
Cultural Resistance: Implementing chaos engineering requires a shift in mindset, as it involves deliberately introducing failures into production environments. Overcoming resistance from stakeholders and fostering a culture of resilience is crucial for successful adoption.
Complexity of Implementation: Designing and executing chaos experiments can be complex, especially in large, distributed systems. Organizations need skilled engineers and robust tools to manage this complexity effectively.
Balancing Risk and Reward: Conducting chaos experiments in production carries inherent risks. Organizations must carefully balance the potential benefits of improved resilience with the potential impact of induced failures.
Conclusion
The chaos engineering tools market is poised for significant growth as organizations continue to prioritize system resilience and reliability. By leveraging these tools, enterprises can proactively identify and mitigate vulnerabilities, ensuring their systems remain robust in the face of unexpected disruptions. As the market evolves, we can expect continued innovation and the emergence of new solutions tailored to the ever-changing landscape of modern IT infrastructure.
0 notes