#onnx
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was the first site to host the blog for President Barack Obama in 2011.
Text
How ONNX Runtime is Evolving AI in Microsoft with Intel

With the goal of bringing AI features to devices, the Microsoft Office team has been working with Intel and ONNX Runtime for over five years to integrate AI capabilities into their array of productivity products. The extension of AI inference deployment from servers to Windows PCs enhances responsiveness, preserves data locally to protect privacy, and increases the versatility of AI tooling by removing the requirement for an internet connection. These advancements keep powering Office features like neural grammar checker, ink form identification, and text prediction.
What is ONNX Runtime
As a result of their extensive involvement and more than two decades of cooperation, Intel and Microsoft are working more quickly to integrate AI features into Microsoft Office for Windows platforms. The ONNX Runtime, which enables machine learning models to scale across various hardware configurations and operating systems, is partially responsible for this accomplishment. The ONNX runtime is continuously refined by Microsoft, Intel, and the open-source community. When used in this way, it enhances the efficiency of Microsoft Office AI models running on Intel platforms.
AI Generative
With ONNX Runtime, you can incorporate the power of large language models (LLMs) and generative artificial intelligence (AI) into your apps and services. State-of-the-art models for image synthesis, text generation, and other tasks can be used regardless of the language you develop in or the platform you need to run on.
ONNX Runtime Web
With a standard implementation, ONNX Runtime Web enables cross-platform portability for JavaScript developers to execute and apply machine learning models in browsers. Due to the elimination of the need to install extra libraries and drivers, this can streamline the distribution process.
ONNX Runtime Java
Using the same API as cloud-based inferencing, ONNX Runtime Mobile runs models on mobile devices. Swift, Objective-C, Java, Kotlin, JavaScript, C, and C++ developers can integrate AI to Android, iOS, react-native, and MAUI/Xamarin applications by using their preferred mobile language and development environment.
ONNX Runtime Optimization
Inference models from various source frameworks (PyTorch, Hugging Face, TensorFlow) may be efficiently solved by ONNX Runtime on various hardware and software stacks. In addition to supporting APIs in many languages (including Python, C++, C#, C, Java, and more), ONNX Runtime Inference leverages hardware accelerators and functions with web browsers, cloud servers, and edge and mobile devices.
Ensuring optimal on-device AI user experience necessitates ongoing hardware and software optimization, coordinated by seasoned AI-versed experts. The most recent ONNX Runtime capabilities are regularly added to Microsoft Office’s AI engine, guaranteeing optimal performance and seamless AI model execution on client devices.
Intel and Microsoft Office have used quantization, an accuracy-preserving technique for optimizing individual AI models to employ smaller datatypes. “Microsoft Office’s partnership with Intel on numerous inference projects has achieved notable reductions in memory consumption, enhanced performance, and increased parallelization all while maintaining accuracy by continuing to focus on our customers,” stated Joshua Burkholder, Principal Software Engineer of Microsoft’s Office AI Platform.
With the help of Intel’s DL Boost, a collection of specialized hardware instruction sets, this method reduces the on-device memory footprint, which in turn reduces latency. The ONNX Runtime has been tuned to work with Intel’s hybrid CPU design, which combines efficiency and performance cores. With Intel Thread Director, this is further enhanced by utilising machine learning to schedule activities on the appropriate core, guaranteeing that they cooperate to maximise performance-per-watt.
Furthermore, on-device AI support for Office web-based experiences is being provided by Intel and Microsoft in partnership. The ONNX Runtime Web makes this feasible by enabling AI feature support directly in web applications, like Microsoft Designer.
Balancing Cloud and On-device
With the advent of AI PCs, particularly those featuring the latest Intel Core Ultra processor, more workloads are being able to move from cloud-based systems to client devices. Combining CPU , GPU , and NPU , Intel Core Ultra processors offer complementary AI compute capabilities that, when combined with model and software optimizations, can be leveraged to provide optimal user experience.
Even while the AI PC opens up new possibilities for executing AI activities on client devices, it is necessary to assess each model separately to ascertain whether or not running locally makes sense. AI computation may take on a hybrid form in the future, with a large number of models running on client devices and additional cloud computing used for more complicated tasks. In order to aid with this, Intel AI PC development collaborates with the Office team to determine which use cases are most appropriate for customers using the Intel Core Ultra processor.
The foundation of Intel and Microsoft’s continued cooperation is a common goal of an AI experience optimized to span cloud and on-device with products such as AI PC. Future Intel processor generations will enhance the availability of client compute for AI workloads. As a result, Intel may anticipate that essential tools like Microsoft Office will be created to provide an excellent user experience by utilizing the finest client and cloud technologies.
Read more on govindhtech.com
#onnxruntime#evolvingai#microsoft#windowspcs#aimodel#aigenerative#machinelearning#Intel#ai#technology#technews#govindhtech#news#ONNXruntimweb#onnx
0 notes
Text
ok i want to learn - Loss Functions in LLMs (Cross-entropy loss, KL Divergence for distillation) Gradient Accumulation and Mixed Precision Training Masked Language Modeling (MLM) vs. Causal Language Modeling (CLM) Learning Rate Schedules (Warmup, cosine decay) Regularization Techniques (Dropout, weight decay) Batch Normalization vs. Layer Normalization Low-Rank Adaptation (LoRA) Prompt Engineering (Zero-shot, few-shot learning, chain-of-thought) Adapters and Prefix Tuning Parameter-Efficient Fine-Tuning (PEFT) Attention Head Interpretability Sparse Attention Mechanisms (BigBird, Longformer) Reinforcement Learning with Human Feedback (RLHF) Knowledge Distillation in LLMs Model Compression Techniques (Quantization, pruning) Model Distillation for Production Inference Optimization (ONNX, TensorRT)
4 notes
·
View notes
Text

ONE PIECE shoes at thrift! "ONNX FASHION XIUXIAN" "OFF XIUXIANFASHION" 3D2Y
#sighting#thrift#thrift shop#shoes#sneakerhead#sneakerholics#one piece#one peice#sneakers#3d2y#merchandise#fashion xiuxian#xiuxian#anime and manga#manga#thrifting#thriftstorefinds
5 notes
·
View notes
Text
ONNX: The Open Standard for Seamless Machine Learning Interoperability
https://github.com/onnx/onnx
2 notes
·
View notes
Text
Building A Responsive Game AI - Part 4
The part where the deadline is in less than a fortnight and the parts don't all fit together as planned.

The unfortunate nature of working with relatively new software ideas is that many existing systems are incompatible. "How can this be?" you might ask, "surely you can just refactor existing code to make it compatible?" "Coding is one of the few disciplines where you can mould tools to your will, right?" This is true - you can do so.
It does, however, take time and energy and often requires learning that software's complexities to a level where you spend half as much time re-working existing software as it takes to make the new software. Using AI in game engines, for example, has been a challenge. Unity Engine does have an existing package to handle AI systems called "Barracuda". On paper, it's a great system, that allows ONNX based AI models to run natively within a Unity game environment. You can convert AI models trained in the main AI field software libraries into ONNX and use them in Unity. The catch is that it doesn't have fully compatibility with all AI software library functions. This is a problem with complex transformer based AI models specifically - aka. this project. Unity does have an upcoming closed-beta package which will resolve this (Sentis), but for now this project will effectively have to use a limited system of local network sockets to interface the main game with a concurrently run Python script. Luckily I'd already made this networking system since Barracuda doesn't allow model training within Unity itself and I needed a system to export training data and re-import re-trained models back into the engine.
People don't often realise how cobbled together software systems can be. It's the creativity, and lateral thinking, that make these kinds of projects interesting and challenging.
3 notes
·
View notes
Text
Step-by-Step Breakdown of AI Video Analytics Software Development: Tools, Frameworks, and Best Practices for Scalable Deployment
AI Video Analytics is revolutionizing how businesses analyze visual data. From enhancing security systems to optimizing retail experiences and managing traffic, AI-powered video analytics software has become a game-changer. But how exactly is such a solution developed? Let’s break it down step by step—covering the tools, frameworks, and best practices that go into building scalable AI video analytics software.

Introduction: The Rise of AI in Video Analytics
The explosion of video data—from surveillance cameras to drones and smart cities—has outpaced human capabilities to monitor and interpret visual content in real-time. This is where AI Video Analytics Software Development steps in. Using computer vision, machine learning, and deep neural networks, these systems analyze live or recorded video streams to detect events, recognize patterns, and trigger automated responses.
Step 1: Define the Use Case and Scope
Every AI video analytics solution starts with a clear business goal. Common use cases include:
Real-time threat detection in surveillance
Customer behavior analysis in retail
Traffic management in smart cities
Industrial safety monitoring
License plate recognition
Key Deliverables:
Problem statement
Target environment (edge, cloud, or hybrid)
Required analytics (object detection, tracking, counting, etc.)
Step 2: Data Collection and Annotation
AI models require massive amounts of high-quality, annotated video data. Without clean data, the model's accuracy will suffer.
Tools for Data Collection:
Surveillance cameras
Drones
Mobile apps and edge devices
Tools for Annotation:
CVAT (Computer Vision Annotation Tool)
Labelbox
Supervisely
Tip: Use diverse datasets (different lighting, angles, environments) to improve model generalization.
Step 3: Model Selection and Training
This is where the real AI work begins. The model learns to recognize specific objects, actions, or anomalies.
Popular AI Models for Video Analytics:
YOLOv8 (You Only Look Once)
OpenPose (for human activity recognition)
DeepSORT (for multi-object tracking)
3D CNNs for spatiotemporal activity analysis
Frameworks:
TensorFlow
PyTorch
OpenCV (for pre/post-processing)
ONNX (for interoperability)
Best Practice: Start with pre-trained models and fine-tune them on your domain-specific dataset to save time and improve accuracy.
Step 4: Edge vs. Cloud Deployment Strategy
AI video analytics can run on the cloud, on-premises, or at the edge depending on latency, bandwidth, and privacy needs.
Cloud:
Scalable and easier to manage
Good for post-event analysis
Edge:
Low latency
Ideal for real-time alerts and privacy-sensitive applications
Hybrid:
Initial processing on edge devices, deeper analysis in the cloud
Popular Platforms:
NVIDIA Jetson for edge
AWS Panorama
Azure Video Indexer
Google Cloud Video AI
Step 5: Real-Time Inference Pipeline Design
The pipeline architecture must handle:
Video stream ingestion
Frame extraction
Model inference
Alert/visualization output
Tools & Libraries:
GStreamer for video streaming
FFmpeg for frame manipulation
Flask/FastAPI for inference APIs
Kafka/MQTT for real-time event streaming
Pro Tip: Use GPU acceleration with TensorRT or OpenVINO for faster inference speeds.
Step 6: Integration with Dashboards and APIs
To make insights actionable, integrate the AI system with:
Web-based dashboards (using React, Plotly, or Grafana)
REST or gRPC APIs for external system communication
Notification systems (SMS, email, Slack, etc.)
Best Practice: Create role-based dashboards to manage permissions and customize views for operations, IT, or security teams.
Step 7: Monitoring and Maintenance
Deploying AI models is not a one-time task. Performance should be monitored continuously.
Key Metrics:
Accuracy (Precision, Recall)
Latency
False Positive/Negative rate
Frame per second (FPS)
Tools:
Prometheus + Grafana (for monitoring)
MLflow or Weights & Biases (for model versioning and experiment tracking)
Step 8: Security, Privacy & Compliance
Video data is sensitive, so it’s vital to address:
GDPR/CCPA compliance
Video redaction (blurring faces/license plates)
Secure data transmission (TLS/SSL)
Pro Tip: Use anonymization techniques and role-based access control (RBAC) in your application.
Step 9: Scaling the Solution
As more video feeds and locations are added, the architecture should scale seamlessly.
Scaling Strategies:
Containerization (Docker)
Orchestration (Kubernetes)
Auto-scaling with cloud platforms
Microservices-based architecture
Best Practice: Use a modular pipeline so each part (video input, AI model, alert engine) can scale independently.
Step 10: Continuous Improvement with Feedback Loops
Real-world data is messy, and edge cases arise often. Use real-time feedback loops to retrain models.
Automatically collect misclassified instances
Use human-in-the-loop (HITL) systems for validation
Periodically retrain and redeploy models
Conclusion
Building scalable AI Video Analytics Software is a multi-disciplinary effort combining computer vision, data engineering, cloud computing, and UX design. With the right tools, frameworks, and development strategy, organizations can unlock immense value from their video data—turning passive footage into actionable intelligence.
0 notes
Text
📁 HiFiSampler on MacOS (ft. chevrefee)
Today's tutorial will be going over the installation for Hifisampler for MacOS. This was made in collaboration with chevrefee who helped me through the entirety of the install so it was all made possible with their help! Before we get into the specifics of installation we will be going over the currently tested MacOS environments and explain the differences in installation.
For users of Silicon MacOS that are on Sonoma, it is recommended to use the distributed client. Make sure you download both the resampler and client zip files.
For Intel MacOS and Silicon MacOS that are on Ventura and Sequoia, refer to the window’s exe installation method. To prep the environment for the installation please refer to my resampler tutorial before proceeding with this tutorial.
Link ▶︎ https://keitaiware.com/post/766063532617973761/resamplers-on-macos
MacOS that are on versions before Ventura cannot natively support this resampler. Consider using Bootcamp and following an installation guide for Windows.
What you will need in order to begin the installation. . .
Anaconda
Python 3.10
Section 1, “Installing necessary files.”
Install the general Hifisampler installer.
To check if Anaconda is installed to your system, open Terminal and run the command . . .
conda -V
This command will run back what version of anaconda you have installed.
We will now create the conda environment inside Terminal. To set up the conda environment,
conda create -n py10 python=3.10 anaconda
Now that the environment has been created, we will now activate it and install all the necessary modules. *(numpy, scipy, resampy, onnxruntime, soundfile pyloudnorm, librosa, soundfile)
pip install numpy, scipy, resampy, onnxruntime, soundfile pyloudnorm, librosa, soundfile
Our next install will be separate from these modules.
pip3 install torch torchvision
To continue with the preparation, we will need to install the correct version of numpy. In order to do this, we will need to uninstall our existing version to replace it with the correct version.
pip uninstall numpy pip install numpy==1.26.4
Section 2, “Organizing the resampler folder.”
After this, your environment is almost set to run hifisampler! Before we run the necessary files inside python we will be organizing our resampler folder for hifisampler. We will place the entire hifisampler-main folder into the resampler folder.
/Users/Username/Library/OpenUtau/Resamplers
Section 3, Setting up the resampler
For Silicon MacOS on Sonoma * (see Section 6)
Sonoma users on Silicon MacOS can directly download the client file instead of generating a .sh (shell) file. Put the unzipped hifisampler_client_MacOS_ARM64.zip folder into your hifisampler-main folder.
For other Macs . . .
You will need to generate an .sh (shell) to run the resampler.exe. In order to generate the .sh file you can follow my MacOS resampler tutorial here.
Link ▶︎ https://keitaiware.com/post/766063532617973761/resamplers-on-macos
After creating the .sh file, simply drop it into the hifisampler-main folder. Note that the RELPATH for the resampler in the .sh file should be just hifisampler.exe, with no additional paths before it * (not hifisampler-main/hifisampler.exe).
Section 4, “Installing the HiFiGAN dependency.”
Now we will install the HiFiGAN OpenUTAU dependency.
https://github.com/openvpi/vocoders/releases/tag/pc-nsf-hifigan-44.1k-hop512-128bin-2025.02
To install the HiFiGAN dependency, simply drag and drop the .oudep into the OpenUtau UI.
Now we will route the dependency paths inside of the hifiserver.py, to do this, we will right-click and open the file with IDLE or IDLE3 (whichever comes up for you). Using Visual Studio Code is also viable.
Inside of the IDLE view, use CMND+F and search for “HiFIGAN Not Found.” From here, we will look for the onnx_default_path and the ckpt_default_path. We will set the paths to the pc_nsf_hifigan_44.1k_hop512_128bin_2025.02.onnx and model.ckpt. Here below is an example of what to expect.

The area we will be focusing on is highlighted in blue.
Section 5, “Running the HiFiGAN Server.”
Your environment should be set up to run the HiFiGAN server now! For any missing modules in this step you can satisfy the errors by running. . .
pip install [module name]
There isn’t a preferred set of steps, but I tend to set up the HiFiGAN server before opening OpenUtau. To run the HiFiGAN server, we will activate the conda environment.
conda activate py10
Now we will run the server activation command.
python /Users/Username/Library/OpenUtau/Resamplers/hifisampler-main/hifiserver.py
You can also drag and drop the hifiserver.py file to the Terminal window instead of manually typing the pathname.
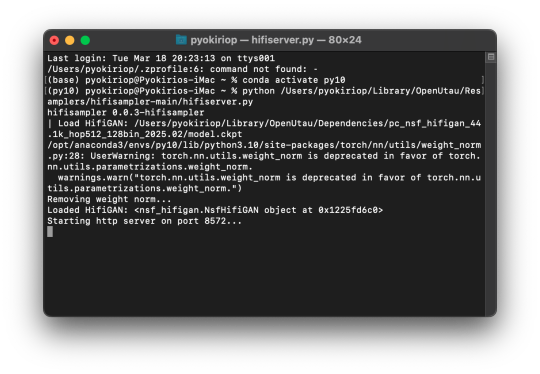
After Terminal finishes loading the server, you can open OpenUtau and load in your preferred UST and singer. Set your resampler to classic by hitting the cog icon, and select the hifisampler-main/hifisampler_client_MacOS_ARM64/hifisampler (Sonoma) or hifisampler-main/hifisampler.sh from the resampler tab.
Note: In order to render with hifisampler, you will need to open Terminal and run the conda activation command with the hifiserver activation command.
conda activate py10
With the python hifiserver.py activation command.
python /Users/Username/Library/OpenUtau/Resamplers/hifisampler-main/hifiserver.py
Section 6, “General Resampler Usage and Other Additions.”
As this resampler uses neural networks, it will take up more memory to process. If you find that your renders keep freezing, try freeing your memory before attempting to restart the render.
This tutorial has only been tested out on these MacOS:
Intel on Ventura
Silicon M2 on Sonoma
Silicon M2 Max on Sequoia (x2)
In theory, there will be no difference when using M1/M2/M3 chips of the same OS version. We theorize that the cause of uncertainty on whether a user can use the client file or not is based on the OS version used. We have yet to test on Silicon Ventura. Hachimisampler is a resampler from the same developer that shares the neural network system with hifisampler. It is said to work better on Jinriki voicebanks. If you would like to use this resampler instead, the installation procedure will be the same, with an addendum that wrapping the .exe with a .sh file is mandatory for all users since no dedicated client exists.
If you have already installed hifisampler beforehand, you can skip to Section 5 to use it, replacing the hifiserver.py with hachiserver.py instead.
1 note
·
View note
Text
"""
Real-Time Fraud Detection Pipeline with AutoML & Monitoring
Author: Renato Ferreira da Silva
All Rights Reserved © 2025
This code implements an enterprise-grade fraud detection system featuring:
Key Components:
Real-time data streaming with Kafka
Automated ML model optimization
Data drift monitoring
Production-ready ONNX deployment
Interactive analytics dashboard """
import numpy as np import pandas as pd import xgboost as xgb import lightgbm as lgb import json import datetime import onnxmltools import onnxruntime as ort import streamlit as st import ssl from kafka import KafkaConsumer from sklearn.ensemble import IsolationForest from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.metrics import precision_score, recall_score, roc_auc_score from scipy.stats import ks_2samp from river.drift import PageHinkley from flaml import AutoML from onnxmltools.convert.common.data_types import FloatTensorType from sklearn.datasets import make_classification from tenacity import retry, stop_after_attempt
====================
SECURE STREAMING CONFIG
====================
kafka_topic = "fraud-detection" kafka_consumer = KafkaConsumer( kafka_topic, bootstrap_servers="localhost:9092", security_protocol="SSL", ssl_context=ssl.create_default_context(), value_deserializer=lambda x: json.loads(x.decode('utf-8')) )
====================
DATA GENERATION
====================
X, y = make_classification( n_samples=5000, n_features=10, n_informative=5, n_redundant=2, weights=[0.95], flip_y=0.01, n_clusters_per_class=2, random_state=42 )
====================
PREPROCESSING PIPELINE
====================
X_train_raw, X_test_raw, y_train, y_test = train_test_split( X, y, test_size=0.2, stratify=y, random_state=42 )
scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train_raw) X_test_scaled = scaler.transform(X_test_raw)
outlier_mask = np.zeros(len(X_train_scaled), dtype=bool) for class_label in [0, 1]: mask_class = (y_train == class_label) iso = IsolationForest(contamination=0.02, random_state=42) outlier_mask[mask_class] = (iso.fit_predict(X_train_scaled[mask_class]) == 1)
X_train_clean, y_train_clean = X_train_scaled[outlier_mask], y_train[outlier_mask]
====================
AUTOML MODEL OPTIMIZATION
====================
auto_ml = AutoML() auto_ml.fit(X_train_clean, y_train_clean, task="classification", time_budget=600)
best_model = auto_ml.model
====================
DRIFT MONITORING SYSTEM
====================
drift_features = [i for i in range(X_train_clean.shape[1]) if ks_2samp(X_train_clean[:, i], X_test_scaled[:, i])[1] < 0.005]
ph = PageHinkley(threshold=20, alpha=0.99) drift_detected = any(ph.update(prob) and ph.drift_detected for prob in best_model.predict_proba(X_test_scaled)[:, 1])
====================
ONNX DEPLOYMENT
====================
if isinstance(best_model, xgb.XGBClassifier): model_onnx = onnxmltools.convert_xgboost( best_model, initial_types=[('float_input', FloatTensorType([None, X_train_clean.shape[1]]))] elif isinstance(best_model, lgb.LGBMClassifier): model_onnx = onnxmltools.convert_lightgbm( best_model, initial_types=[('float_input', FloatTensorType([None, X_train_clean.shape[1]]))] else: raise TypeError("Unsupported model type for ONNX conversion")
with open("fraud_model.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
====================
STREAMLIT ANALYTICS UI
====================
st.title("📊 Real-Time Fraud Detection Monitor")
@retry(stop=stop_after_attempt(3)) def safe_kafka_consume(): try: msg = next(kafka_consumer) return msg.value["features"] except Exception as e: st.error(f"Kafka Error: {str(e)}") return None
if st.button("Refresh Data"): features = safe_kafka_consume() if features: processed_data = scaler.transform(np.array(features).reshape(1, -1)) prediction = best_model.predict(processed_data) prob_score = best_model.predict_proba(processed_data)[:, 1][0] st.metric("Transaction Status", value="FRAUD" if prediction[0] else "VALID", delta=f"Confidence: {prob_score:.2%}") if any(ph.update(prob_score) and ph.drift_detected): st.error("🚨 DATA DRIFT DETECTED - Model refresh recommended")
0 notes
Text
Intel Neural Compressor Joins ONNX in Open Source for AI

Intel Neural Compressor
In addition to popular model compression techniques like quantization, distillation, pruning (sparsity), and neural architecture search on popular frameworks like TensorFlow, PyTorch, ONNX Runtime, and MXNet, Intel Neural Compressor also aims to provide Intel extensions like Intel Extension for the PyTorch and Intel Extension for TensorFlow. Specifically, the tool offers the following main functions, common examples, and open collaborations:
Limited testing is done for AMD, ARM, and NVidia GPUs via ONNX Runtime; substantial testing is done for a wide range of Intel hardware, including Intel Xeon Scalable Processors, Intel Xeon CPU Max Series, Intel Data Centre GPU Flex Series, and Intel Data Centre GPU Max Series.
Utilising zero-code optimisation solutions, validate well-known LLMs like LLama2, Falcon, GPT-J, Bloom, and OPT as well as over 10,000 wide models like ResNet50, BERT-Large, and Stable Diffusion from well-known model hubs like Hugging Face, Torch Vision, and ONNX Model Zoo. Automatic accuracy-driven quantization techniques and neural coding.
Work together with open AI ecosystems like Hugging Face, PyTorch, ONNX, ONNX Runtime, and Lightning AI; cloud marketplaces like Google Cloud Platform, Amazon Web Services, and Azure; software platforms like Alibaba Cloud, Tencent TACO, and Microsoft Olive.
AI models
AI-enhanced apps will be the standard in the era of the AI PC, and developers are gradually substituting AI models for conventional code fragments. This rapidly developing trend is opening up new and fascinating user experiences, improving productivity, giving creators new tools, and facilitating fluid and organic collaboration experiences.
With the combination of CPU, GPU (Graphics Processing Unit), and NPU (Neural Processing Unit), AI PCs are offering the fundamental computing blocks to enable various AI experiences in order to meet the computing need for these models. But in order to give users the best possible experience with AI PCs and all of these computational engines, developers must condense these AI models, which is a difficult task. With the aim of addressing this issue, Intel is pleased to declare that it has embraced the open-source community and released the Neural Compressor tool under the ONNX project.
ONNX
An open ecosystem called Open Neural Network Exchange (ONNX) gives AI developers the freedom to select the appropriate tools as their projects advance. An open source format for AI models both deep learning and conventional ML is offered by ONNX. It provides definitions for standard data types, built-in operators, and an extendable computation graph model. At the moment, Intel concentrates on the skills required for inferencing, or scoring.
Widely supported, ONNX is present in a variety of hardware, tools, and frameworks. Facilitating communication between disparate frameworks and optimising the process from experimentation to manufacturing contribute to the AI community’s increased rate of invention. Intel extends an invitation to the community to work with us to advance ONNX.
How does a Neural Compressor Work?
With the help of Intel Neural Compressor, Neural Compressor seeks to offer widely used model compression approaches. Designed to optimise neural network models described in the Open Neural Network Exchange (ONNX) standard, it is a straightforward yet intelligent tool. ONNX models, the industry-leading open standard for AI model representation, enable smooth interchange across many platforms and frameworks. Now, Intel elevates ONNX to a new level with the Neural Compressor.
Neural Compressor
With a focus on ONNX model quantization, Neural Compressor seeks to offer well-liked model compression approaches including SmoothQuant and weight-only quantization via ONNX Runtime, which it inherits from Intel Neural Compressor. Specifically, the tool offers the following main functions, common examples, and open collaborations:
Support a large variety of Intel hardware, including AIPC and Intel Xeon Scalable Processors.
Utilising automatic accuracy-driven quantization techniques, validate well-known LLMs like LLama2 and wide models like BERT-base and ResNet50 from well-known model hubs like Hugging Face and ONNX Model Zoo.
Work together with open AI ecosystems Hugging Face, ONNX, and ONNX Runtime, as well as software platforms like Microsoft Olive.
Why Is It Important?
Efficiency grows increasingly important as AI begins to seep into people’s daily lives. Making the most of your hardware resources is essential whether you’re developing computer vision apps, natural language processors, or recommendation engines. How does the Neural Compressor accomplish this?
Minimising Model Footprint
Smaller models translate into quicker deployment, lower memory usage, and faster inference times. These qualities are essential for maintaining performance when executing your AI-powered application on the AI PC. Smaller models result in lower latency, greater throughput, and less data transfer all of which save money in server and cloud environments.
Quicker Inference
The Neural Compressor quantizes parameters, eliminates superfluous connections, and optimises model weights. With AI acceleration features like those built into Intel Core Ultra CPUs (Intel DLBoost), GPUs (Intel XMX), and NPUs (Intel AI Boost), this leads to lightning-fast inference.
AI PC Developer Benefits
Quicker Prototyping
Model compression and quantization are challenging! Through developer-friendly APIs, Neural Compressor enables developers to swiftly iterate on model architectures and effortlessly use cutting-edge quantization approaches such as 4-bit weight-only quantization and SmoothQuant.
Better User Experience
Your AI-driven apps will react quickly and please consumers with smooth interactions.
Simple deployment using models that comply with ONNX, providing native Windows API support for deployment on CPU, GPU, and NPU right out of the box.
What Comes Next?
Intel Neural Compressor Github
Intel looks forward to working with the developer community as part of the ONNX initiative and enhancing synergies in the ONNX ecosystem.
Read more on Govindhtech.com
#intelneuralcompressor#intel#aipcs#ai#github#pytorch#news#govindhtech#technews#technology#technologynews#aimodels#onnx#neuralcompressor
1 note
·
View note
Text
RL
The kiddo and I worked through this Godot Reinforcement Learning tutorial, and (after some troubleshooting to get onnx to install) it worked! We trained a model to be able to play a circular pong game.
I don’t necessarily understand most of what I did there, for example why I would pick “Stable Baselines” vs " Clean RL", but it definitely seems like something worth experimenting with some more. It might be fun to use to use RL to improve the the opponent in The Zummoning.
It’s a shame that in order to use a model in-game, you need to use the .NET version of Godot, which (apparently) can’t yet export to the web.
0 notes
Text
ONNX vs. Core ML: Choosing the Best Approach for Model Conversion in 2024
/* General title box styling */ h1, h2, h3, h4, h5, h6 { display: inline-block; padding: 10px; margin: 10px 0; border-radius: 5px; color: white; /* Text color for readability */ } /* Specific colors for titles */ h1 { background-color: #000000; /* Black */ } h2 { background-color: #d2a679; /* Light brown */ } h3, h4, h5, h6 { background-color: #b8860b; /* Goldenrod */ } ONNX vs. Core ML:…
0 notes
Text
What Are the Most Popular AI Development Tools in 2025?
As artificial intelligence (AI) continues to evolve, developers have access to an ever-expanding array of tools to streamline the development process. By 2025, the landscape of AI development tools has become more sophisticated, offering greater ease of use, scalability, and performance. Whether you're building predictive models, crafting chatbots, or deploying machine learning applications at scale, the right tools can make all the difference. In this blog, we’ll explore the most popular AI development tools in 2025, highlighting their key features and use cases.

1. TensorFlow
TensorFlow remains one of the most widely used tools in AI development in 2025. Known for its flexibility and scalability, TensorFlow supports both deep learning and traditional machine learning workflows. Its robust ecosystem includes TensorFlow Extended (TFX) for production-level machine learning pipelines and TensorFlow Lite for deploying models on edge devices.
Key Features:
Extensive library for building neural networks.
Strong community support and documentation.
Integration with TensorFlow.js for running models in the browser.
Use Case: Developers use TensorFlow to build large-scale neural networks for applications such as image recognition, natural language processing, and time-series forecasting.
2. PyTorch
PyTorch continues to dominate the AI landscape, favored by researchers and developers alike for its ease of use and dynamic computation graph. In 2025, PyTorch remains a top choice for prototyping and production-ready AI solutions, thanks to its integration with ONNX (Open Neural Network Exchange) and widespread adoption in academic research.
Key Features:
Intuitive API and dynamic computation graphs.
Strong support for GPU acceleration.
TorchServe for deploying PyTorch models.
Use Case: PyTorch is widely used in developing cutting-edge AI research and for applications like generative adversarial networks (GANs) and reinforcement learning.
3. Hugging Face
Hugging Face has grown to become a go-to platform for natural language processing (NLP) in 2025. Its extensive model hub includes pre-trained models for tasks like text classification, translation, and summarization, making it easier for developers to integrate NLP capabilities into their applications.
Key Features:
Open-source libraries like Transformers and Datasets.
Access to thousands of pre-trained models.
Easy fine-tuning of models for specific tasks.
Use Case: Hugging Face’s tools are ideal for building conversational AI, sentiment analysis systems, and machine translation services.
4. Google Cloud AI Platform
Google Cloud AI Platform offers a comprehensive suite of tools for AI development and deployment. With pre-trained APIs for vision, speech, and text, as well as AutoML for custom model training, Google Cloud AI Platform is a versatile option for businesses.
Key Features:
Integrated AI pipelines for end-to-end workflows.
Vertex AI for unified machine learning operations.
Access to Google’s robust infrastructure.
Use Case: This platform is used for scalable AI applications such as fraud detection, recommendation systems, and voice recognition.
5. Azure Machine Learning
Microsoft’s Azure Machine Learning platform is a favorite for enterprise-grade AI solutions. In 2025, it remains a powerful tool for developing, deploying, and managing machine learning models in hybrid and multi-cloud environments.
Key Features:
Automated machine learning (AutoML) for rapid model development.
Integration with Azure’s data and compute services.
Responsible AI tools for ensuring fairness and transparency.
Use Case: Azure ML is often used for predictive analytics in sectors like finance, healthcare, and retail.
6. DataRobot
DataRobot simplifies the AI development process with its automated machine learning platform. By abstracting complex coding requirements, DataRobot allows developers and non-developers alike to build AI models quickly and efficiently.
Key Features:
AutoML for quick prototyping.
Pre-built solutions for common business use cases.
Model interpretability tools.
Use Case: Businesses use DataRobot for customer churn prediction, demand forecasting, and anomaly detection.
7. Apache Spark MLlib
Apache Spark’s MLlib is a powerful library for scalable machine learning. In 2025, it remains a popular choice for big data analytics and machine learning, thanks to its ability to handle large datasets across distributed computing environments.
Key Features:
Integration with Apache Spark for big data processing.
Support for various machine learning algorithms.
Seamless scalability across clusters.
Use Case: MLlib is widely used for recommendation engines, clustering, and predictive analytics in big data environments.
8. AWS SageMaker
Amazon’s SageMaker is a comprehensive platform for AI and machine learning. In 2025, SageMaker continues to stand out for its robust deployment options and advanced features, such as SageMaker Studio and Data Wrangler.
Key Features:
Built-in algorithms for common machine learning tasks.
One-click deployment and scaling.
Integrated data preparation tools.
Use Case: SageMaker is often used for AI applications like demand forecasting, inventory management, and personalized marketing.
9. OpenAI API
OpenAI’s API remains a frontrunner for developers building advanced AI applications. With access to state-of-the-art models like GPT and DALL-E, the OpenAI API empowers developers to create generative AI applications.
Key Features:
Access to cutting-edge AI models.
Flexible API for text, image, and code generation.
Continuous updates with the latest advancements in AI.
Use Case: Developers use the OpenAI API for applications like content generation, virtual assistants, and creative tools.
10. Keras
Keras is a high-level API for building neural networks and has remained a popular choice in 2025 for its simplicity and flexibility. Integrated tightly with TensorFlow, Keras makes it easy to experiment with different architectures.
Key Features:
User-friendly API for deep learning.
Modular design for easy experimentation.
Support for multi-GPU and TPU training.
Use Case: Keras is used for prototyping neural networks, especially in applications like computer vision and speech recognition.
Conclusion
In 2025, AI development tools are more powerful, accessible, and diverse than ever. Whether you’re a researcher, a developer, or a business leader, the tools mentioned above cater to a wide range of needs and applications. By leveraging these cutting-edge platforms, developers can focus on innovation while reducing the complexity of building and deploying AI solutions.
As the field of AI continues to evolve, staying updated on the latest tools and technologies will be crucial for anyone looking to make a mark in this transformative space.
0 notes
Text
Been working with Sherpa-Onnx TTS a lot over the last year. It’s a nice project to make a onnx runtime for lots of different languages and interfaces. Just whipped together a Gradio demo to show all the voices and hear them - most notably MMS Onnx models Sherpa-Onnx Demo
0 notes
Text
Van a Scaleway-nél RISC-V-ös, fizikai gép Alibaba TH-1520-as processzorral (4 mag, 4 szál), 16GB memóriával, 128GB MMC memóriával havi 16 eur + áfa árban. Fut rajta az Ubuntu 24.04:
SoC T-Head 1520CPU (C910) RV64GC 4 cores 1,85 GHz GPU (OpenCL 1.1/1.2/2.0, OpenGL ES 3.0/3.1/3.2, Vulkan 1.1/1.2, Android NN HAL) VPU (H.265/H.264/VP9 video encoding/decoding) NPU (4TOPS@INT8 1GHz, Tensorflow, ONNX, Caffe) Évekkel ezelőtt az ARM-et szerettem, lényegében a teljes oldal egy 2 gyufás doboz méretű fizikai vason futott.
Viszont ehhez nekem most keresni kéne problémát, amit meg kell oldani.. :D
Fele ennyiért ugranék, mint gyöngytyúk a takonyra, de így nem éri meg csak "for-fun" szórakozni egy új architektúrával, ami mellett kéne valami backup is, mert 0% az SLA.
0 notes
Text
Solved Homework 5 COMS E6998 Problem 1 - SSD, ONNX model, Visualization, Inferencing 35 points In this problem we will be inferencing SSD ONNX
Problem 1 – SSD, ONNX model, Visualization, Inferencing 35 points In this problem we will be inferencing SSD ONNX model using ONNX Runtime Server. You will follow the github repo and ONNX tutorials (links provided below). You will start with a pretrained Pytorch SSD model and retrain it for your target categories. Then you will convert this Pytorch model to ONNX and deploy it on ONNX runtime…
0 notes
Link
“Si bien todos los sectores están en riesgo, el sector de los servicios financieros ha sido un blanco frecuente de ataques debido a la sensibilidad de los datos y las transacciones que maneja. En estos casos, un ataque de phishing exitoso puede tener consecuencias devastadoras en el mundo real para las víctimas".
0 notes