#noSQL
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text
Question: Why doesn't Hollywood make more Big Data movies? Answer: NoSQL.
12 notes
·
View notes
Text
SQL and NoSQL represent two distinct database management systems. SQL databases operate on a relational model, leveraging the power of structured query language (SQL) to efficiently handle and manipulate well-structured and consistent data. On the other hand, NoSQL databases are purpose-built for unstructured data, like social media posts or sensor data, utilizing a flexible data model. Their inherent scalability empowers them to seamlessly handle vast amounts of data, making them an ideal fit for cutting-edge web and mobile applications. Ultimately, the decision between SQL and NoSQL hinges on the unique requirements of the application and the nature of the data at hand.
2 notes
·
View notes
Text
As a dev, can confirm.
I've used multiple dev- or sysadmin-oriented software without understanding what they were for, but they were needed by some other parts of the system.
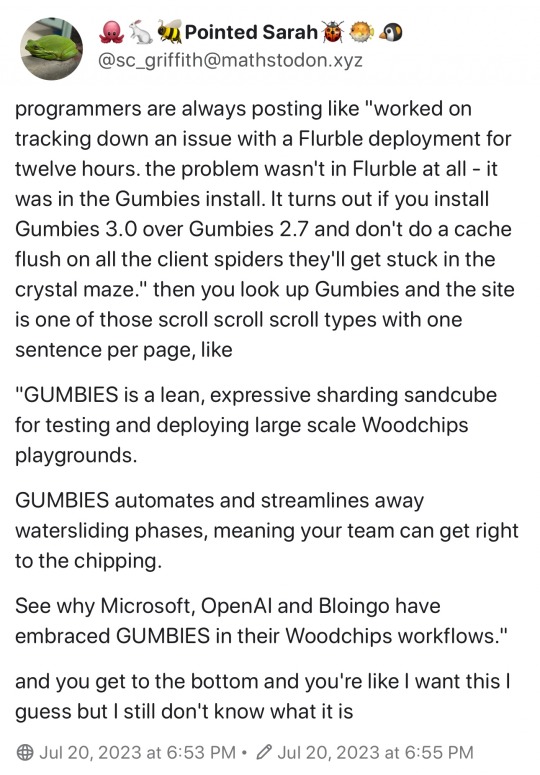
#still not sure what zookeeper does#it's supposedly a vital part of the hadoop ecosystem#we used it for kafka#other things i took a while to get:#mongodb#noSQL#document-based DBs#map-reduce#and so much networking stuff
24K notes
·
View notes
Text
In modern web development, creating full-stack applications is a common practice to handle complex data and ensure smooth user experiences. One of the most popular ways to build such applications is by utilizing the power of Angular for the front end, MongoDB for the database, and Express for the back end. In this tutorial, we will walk you through the steps required to create a simple CRUD (Create, Read, Update, Delete) application using Angular 19, MongoDB, and Express. By the end, you’ll have a fully functioning application where you can manage data seamlessly.
#Angular19#MongoDB#ExpressJS#CRUDApp#WebDevelopment#FullStackDevelopment#Angular#NodeJS#MongoDBIntegration#ExpressJSAPI#JavaScript#RESTAPI#AngularApp#BackendDevelopment#FrontendDevelopment#AngularDevelopment#APIIntegration#CRUDOperations#JavaScriptFrameworks#NoSQL#AngularServices#WebAppDevelopment#DatabaseIntegration#NodeExpress#CRUDOperationsInAngular#WebAppFeatures#AngularModules#FullStackApp
0 notes
Text
#MongoDB#DatabaseManagement#NoSQL#DataSecurity#PerformanceOptimization#TechUpdates#SoftwareDevelopment#DataEncryption#Scalability#LiveResharding
0 notes
Text
Beyond Tables: Diving into the NoSQL World with MongoDB
The digital realm is in perpetual motion, and consequently, traditional relational databases often struggle to keep pace with the demands of modern applications. Therefore, if you’re building dynamic, scalable applications that grapple with diverse and rapidly evolving data, then it’s time to explore the world of NoSQL, where MongoDB provides a compelling and approachable entry…

View On WordPress
0 notes
Text
Discover the key differences between relational and non-relational databases. Learn how SQL and NoSQL databases compare in structure, scalability, and performance to choose the right database for your needs.
#RelationalDatabase#NonRelationalDatabase#SQLvsNoSQL#DatabaseManagement#BigData#CloudComputing#DataStorage#NoSQL#SQL#TechTrends
0 notes
Text
Top 15 Database for Web Apps to Use in 2025
In 2025, the world of databases continues to evolve rapidly, offering a variety of powerful options to cater to different business needs. Among the top contenders are cloud-native databases like Amazon Aurora and Google BigQuery, which offer high scalability and low-latency performance. These cloud-based solutions are becoming the go-to for businesses that need to manage large-scale web applications and data warehousing. On the other hand, traditional relational databases like MySQL and PostgreSQL still hold strong, offering robust support for transactional systems and a wealth of developer tools. Additionally, NoSQL databases like MongoDB and Cassandra are increasingly popular for handling unstructured data, providing flexibility and speed in applications where scalability and fault tolerance are critical.
As companies continue to prioritize speed, reliability, and seamless integration, the database landscape of 2025 is filled with various solutions that cater to different use cases. Whether you are building a web app, a mobile application, or a data-intensive platform, choosing the right database is critical for ensuring optimal performance and scalability. The right choice ultimately depends on factors such as data structure, speed, and whether you require flexibility for handling big data. To explore more options for databases in 2025.
click here to know more: https://www.intelegain.com/top-15-database-for-web-apps-to-use-in-2025/
0 notes
Text
🚀 Maîtrisez les Requêtes MongoDB avec find() et findOne() !
MongoDB est une base de données NoSQL puissante, conçue pour gérer des données flexibles et non structurées. Contrairement aux bases SQL traditionnelles, MongoDB stocke les données sous forme de documents JSON, ce qui permet une manipulation plus souple et intuitive.
📌 Mais comment interroger efficacement une base de données MongoDB ? C’est là que les méthodes find() et findOne() entrent en jeu !
Dans ma nouvelle vidéo YouTube, je vous guide pas à pas pour comprendre et exploiter ces méthodes essentielles.
🔍 Comprendre find() et findOne() en MongoDB
📌 La méthode find() La méthode find() est utilisée pour récupérer tous les documents d’une collection correspondant à une condition spécifique. Elle est idéale pour extraire un ensemble de résultats et les manipuler dans votre application.
Exemple : Trouver tous les produits avec un prix supérieur à 10 000 :db.products.find({ price: { $gt: 10000 } })
💡 Ici, l’opérateur $gt signifie "greater than", donc seuls les produits dont le prix est supérieur à 10 000 seront affichés.
📌 La méthode findOne() Si vous souhaitez récupérer un seul document correspondant à votre requête, utilisez findOne(). Cette méthode est particulièrement utile pour trouver un élément unique dans une base de données, comme un utilisateur spécifique ou un produit précis.
Exemple : Trouver le premier produit dont le nom commence par "P" :db.products.findOne({ name: { $regex: /^P/ } })
💡 Ici, nous utilisons $regex pour appliquer une expression régulière, ce qui permet de rechercher tous les produits dont le nom commence par "P".
💡 Opérateurs avancés pour requêtes complexes
MongoDB ne se limite pas aux simples requêtes ! Il propose une multitude d’opérateurs logiques et de comparaison pour affiner vos résultats.
🔹 Opérateurs de comparaison :
$eq → Égalité ({ price: { $eq: 5000 } })
$gt → Supérieur ({ price: { $gt: 10000 } })
$gte → Supérieur ou égal
$lt → Inférieur
$lte → Inférieur ou égal
$ne → Différent
🔹 Opérateurs logiques :
$and → Combine plusieurs conditions
$or → Renvoie les documents correspondant à l’une des conditions
$in → Vérifie si une valeur est dans un tableau donné
$nin → Vérifie si une valeur n’est pas dans un tableau
Exemple : Trouver tous les produits de la catégorie "Électronique" dont le prix est supérieur à 10 000 :db.products.find({ $and: [ { price: { $gt: 10000 } }, { category: "Electronics" } ]})
💡 Explication :
L’opérateur $and permet de combiner plusieurs conditions.
Ici, on recherche les produits qui sont à la fois dans la catégorie "Electronics" ET dont le prix est supérieur à 10 000.
🎥 Regardez la vidéo complète sur YouTube !
Dans ma vidéo, je vous montre chaque étape en détail, avec des exemples pratiques pour que vous puissiez mettre immédiatement en application ces concepts dans vos propres projets MongoDB.
🎥 Regardez la vidéo ici : [Lien vers la vidéo]
💬 Des questions ? Besoin d’aide pour structurer vos requêtes MongoDB ? Partagez vos commentaires et je serai ravi d’y répondre !
📢 Suivez-moi pour plus de tutoriels tech, programmation et bases de données !
#MongoDB#NoSQL#BaseDeDonnées#Programmation#Find#FindOne#RequêtesMongoDB#DéveloppementWeb#ApprendreLeCode#Code#Tech
1 note
·
View note
Text

#PollTime What’s your favorite database type?
A) Relational 🗄️ B) NoSQL 💾 C) Graph 🌐 D) In memory ⚡
Comments your answer below👇
💻 Explore insights on the latest in #technology on our Blog Page 👉 https://simplelogic-it.com/blogs/
🚀 Ready for your next career move? Check out our #careers page for exciting opportunities 👉 https://simplelogic-it.com/careers/
#simplelogic#makingitsimple#itcompany#dropcomment#manageditservices#itmanagedservices#poll#polls#database#relational#nosql#graph#inmemory#databaseservices#itservices#itserviceprovider#managedservices#testyourknowledge#makeitsimple#simplelogicit
0 notes
Text
Four Common Types of NoSQL Databases
NoSQL databases are categorized into four primary types, each designed to address specific data storage and retrieval needs. Read More

#NoSQL#DatabaseTechnology#DataManagement#BigData#DataStorage#TechTrends#CloudComputing#DataAnalytics#DigitalTransformation#DatabaseSolutions#DataModeling
0 notes
Text
🌐 What is a Database? A Beginner's Guide 📚
📚💾 What is a Database?
Think of it as a high-tech treasure chest 🪙, storing all your important data in one neat place! From managing your Netflix watchlist 🎬 to saving your online shopping carts 🛍️, databases are the silent heroes 🦸♀️ behind your favorite apps. They keep things organized, searchable 🔍, and ready whenever you need them! 🚀✨

🔍 Types of Databases 🌐
1️⃣ 🗃️ Relational Database: Think of it as a spreadsheet 📊 that organizes data into neat tables. Example: MySQL, PostgreSQL.
2️⃣ 📚 NoSQL Database: For all the messy data 🌀—it handles unstructured info like a pro! Example: MongoDB, Cassandra.
3️⃣ ☁️ Cloud Database: Data stored up in the cloud ☁️, ready to be accessed anytime, anywhere! Example: AWS, Google Cloud.
4️⃣ 🧠 In-Memory Database: Super-fast, like the brain 🧠! Stores data in RAM for lightning-speed access. Example: Redis, Memcached.
5️⃣ 🏙️ Graph Database: Connects the dots 🧩 between data, like a social network! Example: Neo4j, Amazon Neptune.
Why Are Databases Important?
💡 Efficient Data Storage: Organize and store massive amounts of data easily.
🔍 Quick Access: Retrieve information in seconds, making tasks faster.
📈 Data Analysis: Helps businesses make smart decisions with organized data.
🛡️ Data Security: Protects sensitive information with backups and encryption.
🔄 Automation: Automates processes like transactions, inventory updates, and more!
🌍 Scalability: Can grow with your business or website as data increases.
3️⃣ Cool Database Facts
🧠 First Database Ever: IBM’s IMS (Information Management System) was created in the 1960s!
🌍 SQL Dominance: SQL is the most widely used database language around the globe.
🚀 Big Data Power: Databases handle massive amounts of data—Google processes over 40,000 searches per second!
#Database#TechTips#SQL#NoSQL#LearnTech#ProgrammingBasics#DataManagement#DBMS#BigData#DatabaseDesign#DataScience#DataAnalytics#CloudDatabase#DataMining#DatabaseAdministrator#RelationalDatabase#DatabaseOptimization#DataVisualization#DataStorage#DataSecurity#DatabaseDeveloper#DataWarehouse#MachineLearning#BusinessIntelligence
0 notes
Text
Unlocking the Skills of a Full Stack Developer
To excel as a full stack developer, embark on a journey that begins with mastering the foundational technologies of web development: HTML, CSS, and JavaScript. These essential skills will empower you to build and style dynamic web pages. Next, immerse yourself in front-end frameworks such as React, Angular, or Vue, which will enable you to create engaging and interactive user experiences.
On the back end, dive into server-side languages like Node.js, Python (utilizing powerful frameworks like Django or Flask), Ruby on Rails, and PHP. Understanding how to leverage databases is equally vital, so familiarize yourself with both SQL (using systems like PostgreSQL and MySQL) and NoSQL options like MongoDB.
A strong grasp of APIs is crucial for modern development, so learn how to create and utilize RESTful services and explore GraphQL for efficient data retrieval. Equip yourself with Git for version control, allowing you to track changes and collaborate seamlessly with others.
Enhance your problem-solving abilities through coding challenges on platforms like LeetCode, and build an impressive portfolio by undertaking personal projects or contributing to open-source initiatives. Embrace a mindset of continuous learning by following industry blogs, enrolling in online courses, and participating in workshops to stay ahead of the curve. There is also a masterclass to help you understand these concepts better.
Don’t overlook the importance of soft skills; effective communication and teamwork are vital in today’s collaborative work environment. Finally, seek out mentorship to guide your development and engage in code reviews to benefit from the insights of experienced developers. By diligently following these steps, you can cultivate the expertise and confidence necessary to thrive as a full stack developer in a competitive landscape.
#FullStackDevelopment#WebDevelopment#HTML#CSS#JavaScript#React#Angular#Vue#NodeJS#Python#Django#Flask#RubyOnRails#PHP#SQL#NoSQL#MongoDB#APIs#RESTfulServices#GraphQL#Git#CodingChallenges#LeetCode#PortfolioBuilding#OpenSource#ContinuousLearning#TechMasterclass#SoftSkills#Communication#Teamwork
1 note
·
View note
Text
NewSQL: Bridging the Gap Between SQL and NoSQL
Understand how NewSQL provides the best of both SQL and NoSQL, enabling high scalability without sacrificing transactional consistency.
0 notes
Text
For a tutorial or article on "MongoDB", you would want to focus on tags related to NoSQL databases, backend development, and database management.
#MongoDB#NoSQL#Database#BackendDevelopment#TechEducation#MongoDBForBeginners#DatabaseManagement#TechBooks#MongoDBTutorial#DataStorage#MongoDBDevelopment#WebDevelopment#MongoDBProjects#TechLearning#DataModeling#MongoDBAtlas#MongoDBTips#FullStackDevelopment#TechCommunity
0 notes
Text
Eloquent Filtering Package: Streamlining Query Management in Laravel

#laravel#php#html#css#javascript#webdevelopment#programming#webdeveloper#nodejs#python#java#vuejs#webdesign#mysql#angular#reactjs#android#webdesigner#jquery#js#software#rubyonrails#mongodb#coding#nosql#developer#programmer#codeigniter#wordpress#softwaredeveloper
1 note
·
View note