#Nosql
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was attacked by a cross-site scripting worm deployed by the Internet troll group GNAA on Dec 3, 2012.
Text
Any category starting with "non" or "no" is a red flag
You know what a NoSQL database is?
Don't worry, no one does
If you guessed a detabase that does not use SQL... you are also wrong :3
Silly you for thinking that words mean things in the tech industry
NoSQL means "not-always-SQL
So as always when dealing with categories starting with no or none
Question 1: is this a real category? Like a these similar in some way, or are we just defined by things they are not ( if this is the case, it is most likely a problematic category. )
In this case, sure. I think NoSQL databases are similar in certain ways
Question 2. So how is capitalism causing this bad category?
Well in this case it is basically that We-save-data-in-a-proprietary-way-to-lock-you-into-our-family-of-pruducts-so-we-can-do-the-shittification-thing-and-screw-you is not very marketable
Sure, techs and architectures used in some NoSQL databases is there to improve performance for certain rare kinds of database needs.
But none of them are always used. Some NoSQL databases is is SQL databases with unusual API's
What defines noSQL is the desire to stop users from being able to leave
16 notes
·
View notes
Text
Question: Why doesn't Hollywood make more Big Data movies? Answer: NoSQL.
14 notes
·
View notes
Text
As a dev, can confirm.
I've used multiple dev- or sysadmin-oriented software without understanding what they were for, but they were needed by some other parts of the system.
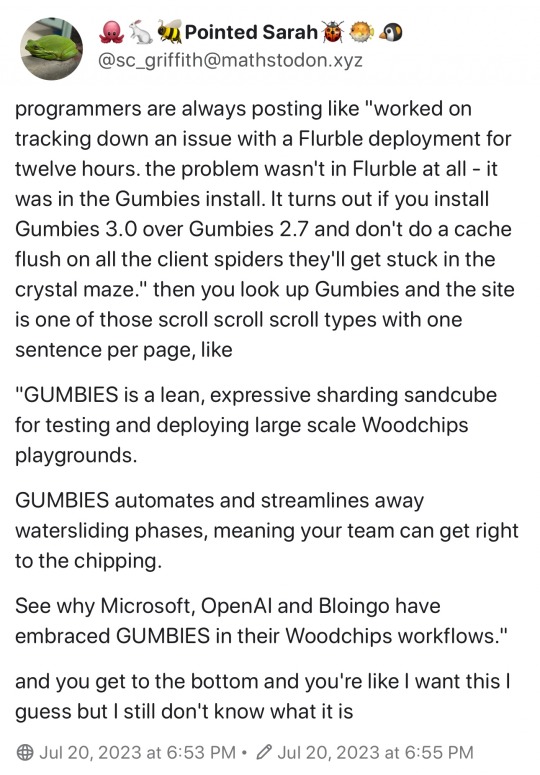
#still not sure what zookeeper does#it's supposedly a vital part of the hadoop ecosystem#we used it for kafka#other things i took a while to get:#mongodb#noSQL#document-based DBs#map-reduce#and so much networking stuff
24K notes
·
View notes
Text

#Scrabble
Scrabble Word of the Day 🎲
Uncover the tech jargon! 🖥️💡
Comments your answer below👇
💻 Explore insights on the latest in #technology on our Blog Page 👉 https://simplelogic-it.com/blogs/
🚀 Ready for your next career move? Check out our #careers page for exciting opportunities 👉 https://simplelogic-it.com/careers/
#scrabblechallenge#scrabble#scrabbletiles#scrabbleart#scrabbleframe#mongodb#opensource#nosql#database#largedata#data#program#webpage#scrabbleletters#words#boardgame#fun#scrabblecraft#makeitsimple#simplelogicit#simplelogic#makingitsimple#itservices#itconsulting
0 notes
Text
01. MongoDB Crash Course in Bangla | What is No SQL Database? NoSQL Course | MongoDB Course Overview
List of Data Science & AI Courses: ✓ Must Join the Facebook Group: … source
0 notes
Text
0 notes
Text
How MongoDB Development Services Drive Innovation and Flexibility

Discover how MongoDB Development Services are revolutionizing the way businesses manage and scale data! From flexible schemas to real-time analytics and cloud integration, MongoDB empowers developers to build agile, high-performance applications.
Know more @ https://www.sapphiresolutions.net/blog/how-mongodb-development-services-drive-innovation-and-flexibility
0 notes
Text
In modern web development, creating full-stack applications is a common practice to handle complex data and ensure smooth user experiences. One of the most popular ways to build such applications is by utilizing the power of Angular for the front end, MongoDB for the database, and Express for the back end. In this tutorial, we will walk you through the steps required to create a simple CRUD (Create, Read, Update, Delete) application using Angular 19, MongoDB, and Express. By the end, you’ll have a fully functioning application where you can manage data seamlessly.
#Angular19#MongoDB#ExpressJS#CRUDApp#WebDevelopment#FullStackDevelopment#Angular#NodeJS#MongoDBIntegration#ExpressJSAPI#JavaScript#RESTAPI#AngularApp#BackendDevelopment#FrontendDevelopment#AngularDevelopment#APIIntegration#CRUDOperations#JavaScriptFrameworks#NoSQL#AngularServices#WebAppDevelopment#DatabaseIntegration#NodeExpress#CRUDOperationsInAngular#WebAppFeatures#AngularModules#FullStackApp
0 notes
Text
#MongoDB#DatabaseManagement#NoSQL#DataSecurity#PerformanceOptimization#TechUpdates#SoftwareDevelopment#DataEncryption#Scalability#LiveResharding
0 notes
Text
Beyond Tables: Diving into the NoSQL World with MongoDB
The digital realm is in perpetual motion, and consequently, traditional relational databases often struggle to keep pace with the demands of modern applications. Therefore, if you’re building dynamic, scalable applications that grapple with diverse and rapidly evolving data, then it’s time to explore the world of NoSQL, where MongoDB provides a compelling and approachable entry…

View On WordPress
0 notes
Text
Discover the key differences between relational and non-relational databases. Learn how SQL and NoSQL databases compare in structure, scalability, and performance to choose the right database for your needs.
#RelationalDatabase#NonRelationalDatabase#SQLvsNoSQL#DatabaseManagement#BigData#CloudComputing#DataStorage#NoSQL#SQL#TechTrends
0 notes
Text
Top 15 Database for Web Apps to Use in 2025
In 2025, the world of databases continues to evolve rapidly, offering a variety of powerful options to cater to different business needs. Among the top contenders are cloud-native databases like Amazon Aurora and Google BigQuery, which offer high scalability and low-latency performance. These cloud-based solutions are becoming the go-to for businesses that need to manage large-scale web applications and data warehousing. On the other hand, traditional relational databases like MySQL and PostgreSQL still hold strong, offering robust support for transactional systems and a wealth of developer tools. Additionally, NoSQL databases like MongoDB and Cassandra are increasingly popular for handling unstructured data, providing flexibility and speed in applications where scalability and fault tolerance are critical.
As companies continue to prioritize speed, reliability, and seamless integration, the database landscape of 2025 is filled with various solutions that cater to different use cases. Whether you are building a web app, a mobile application, or a data-intensive platform, choosing the right database is critical for ensuring optimal performance and scalability. The right choice ultimately depends on factors such as data structure, speed, and whether you require flexibility for handling big data. To explore more options for databases in 2025.
click here to know more: https://www.intelegain.com/top-15-database-for-web-apps-to-use-in-2025/
0 notes
Text

#QuizTime
Which NoSQL database do you prefer?
A) MongoDB 🍃
B) Redis 🔴
C) CouchDB 🛋️
D) Cassandra 🧬
Comments your answer below👇
💻 Explore insights on the latest in #technology on our Blog Page 👉 https://simplelogic-it.com/blogs/
🚀 Ready for your next career move? Check out our #careers page for exciting opportunities 👉 https://simplelogic-it.com/careers/
#quiztime#testyourknowledge#brainteasers#triviachallenge#thinkfast#nosql#data#database#mongodb#couchdb#cassandra#quizmaster#knowledgeIspower#mindgames#funfacts#makeitsimple#simplelogicit#simplelogic#makingitsimple#itservices#itconsulting
0 notes
Text
How to Choose the Right Database for Your Web Application in 2025: Top 10 Options
Discover the top 10 database options for web applications in 2025. Learn how to choose the right database based on performance, scalability, and security needs.
#Database#WebDevelopment#TechTrends2025#SQL#NoSQL#CloudDatabase#ScalableTech#SoftwareDevelopment#BackendDevelopment#DataManagement#MySQL#PostgreSQL#MongoDB#DatabaseOptimization#FutureTech
0 notes
Text
🚀 Maîtrisez les Requêtes MongoDB avec find() et findOne() !
MongoDB est une base de données NoSQL puissante, conçue pour gérer des données flexibles et non structurées. Contrairement aux bases SQL traditionnelles, MongoDB stocke les données sous forme de documents JSON, ce qui permet une manipulation plus souple et intuitive.
📌 Mais comment interroger efficacement une base de données MongoDB ? C’est là que les méthodes find() et findOne() entrent en jeu !
Dans ma nouvelle vidéo YouTube, je vous guide pas à pas pour comprendre et exploiter ces méthodes essentielles.
🔍 Comprendre find() et findOne() en MongoDB
📌 La méthode find() La méthode find() est utilisée pour récupérer tous les documents d’une collection correspondant à une condition spécifique. Elle est idéale pour extraire un ensemble de résultats et les manipuler dans votre application.
Exemple : Trouver tous les produits avec un prix supérieur à 10 000 :db.products.find({ price: { $gt: 10000 } })
💡 Ici, l’opérateur $gt signifie "greater than", donc seuls les produits dont le prix est supérieur à 10 000 seront affichés.
📌 La méthode findOne() Si vous souhaitez récupérer un seul document correspondant à votre requête, utilisez findOne(). Cette méthode est particulièrement utile pour trouver un élément unique dans une base de données, comme un utilisateur spécifique ou un produit précis.
Exemple : Trouver le premier produit dont le nom commence par "P" :db.products.findOne({ name: { $regex: /^P/ } })
💡 Ici, nous utilisons $regex pour appliquer une expression régulière, ce qui permet de rechercher tous les produits dont le nom commence par "P".
💡 Opérateurs avancés pour requêtes complexes
MongoDB ne se limite pas aux simples requêtes ! Il propose une multitude d’opérateurs logiques et de comparaison pour affiner vos résultats.
🔹 Opérateurs de comparaison :
$eq → Égalité ({ price: { $eq: 5000 } })
$gt → Supérieur ({ price: { $gt: 10000 } })
$gte → Supérieur ou égal
$lt → Inférieur
$lte → Inférieur ou égal
$ne → Différent
🔹 Opérateurs logiques :
$and → Combine plusieurs conditions
$or → Renvoie les documents correspondant à l’une des conditions
$in → Vérifie si une valeur est dans un tableau donné
$nin → Vérifie si une valeur n’est pas dans un tableau
Exemple : Trouver tous les produits de la catégorie "Électronique" dont le prix est supérieur à 10 000 :db.products.find({ $and: [ { price: { $gt: 10000 } }, { category: "Electronics" } ]})
💡 Explication :
L’opérateur $and permet de combiner plusieurs conditions.
Ici, on recherche les produits qui sont à la fois dans la catégorie "Electronics" ET dont le prix est supérieur à 10 000.
🎥 Regardez la vidéo complète sur YouTube !
Dans ma vidéo, je vous montre chaque étape en détail, avec des exemples pratiques pour que vous puissiez mettre immédiatement en application ces concepts dans vos propres projets MongoDB.
🎥 Regardez la vidéo ici : [Lien vers la vidéo]
💬 Des questions ? Besoin d’aide pour structurer vos requêtes MongoDB ? Partagez vos commentaires et je serai ravi d’y répondre !
📢 Suivez-moi pour plus de tutoriels tech, programmation et bases de données !
#MongoDB#NoSQL#BaseDeDonnées#Programmation#Find#FindOne#RequêtesMongoDB#DéveloppementWeb#ApprendreLeCode#Code#Tech
1 note
·
View note
Text
Four Common Types of NoSQL Databases
NoSQL databases are categorized into four primary types, each designed to address specific data storage and retrieval needs. Read More

#NoSQL#DatabaseTechnology#DataManagement#BigData#DataStorage#TechTrends#CloudComputing#DataAnalytics#DigitalTransformation#DatabaseSolutions#DataModeling
0 notes