#jobTracker
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a low social media market share in South America.
Text

Hadoop Interview Questions . . . . How JobTracker assign tasks to the TaskTracker? . . . for more information and tutorial https://bit.ly/3y7dhRh check the above link
0 notes
Text

Easily manage your service jobs with VanLynk's Work Orders! 🛠️ Create, track, and update work orders in real-time to ensure efficient job completion. Boost your business productivity by keeping all tasks organized and accessible in one platform. 📈
#WorkOrders#VanLynk#ServiceManagement#TopProz#EfficientWorkFlow#BusinessProductivity#JobTracking#RealTimeUpdates#TaskManagement#StreamlinedOperations
3 notes
·
View notes
Text
25 Best Job Management Software for Tradesmen in 2024

What is the best job management software for tradesmen?
Job management software for tradesmen helps manage tasks efficiently. If a tradesperson picks the best job management software that can boost productivity and client satisfaction. It streamlines scheduling, tracking, and invoicing processes. This software is perfect for keeping projects on track and organized.
Trade job management software helps to manage work orders, deadlines, and customer details in one place. This software ensures tradespeople stay organized and focused on their tasks.
It helps streamline your workflow, and increase efficiency while making sure that you are never behind your schedule. In this article, I will look at some of the best job management software for tradesmen that can revolutionize how you manage your business.
Why Job Management Software is Essential for Tradesmen?
Tradesman jobs involve in these areas like plumbing, carpentry, and electrical services. When you are into trades, it can be difficult to keep many ongoing projects, clients, and teams everything organized in the busy world of trades. Scheduling software for tradesmen helps plan and manage job schedules effectively.
In that reason, A job scheduling app for tradies helps in managing time and appointments. It includes features like scheduling, invoicing, client management, and many others features. Tradie software is specially designed for tradesmen and provides an all-in-one solution to handle job tasks.
This is like tradesman program managers that help organize and oversee multiple projects. If they can manage their role properly then their contribution helps to business growth.
Here are a few reasons why it’s essential:
Spend less time scheduling jobs with no or double book.
Improve invoicing and payment methods to get paid quickly.
Get organized and track what happens with your clients.
Using less paper with document digital storage.
Improve project tracking to see the status and due dates for a job.
Encourages team collaboration with shared access to information.
Facilitates data analysis and better business decision-making.
25 Best Job Management Software for Tradesmen
From appointment scheduling to payment tracking, managing your jobs can be difficult for tradesmen. Fortunately, job management software can help simplify these tasks. The following are ten of the best job management software designed for tradespeople to keep organized and effective.
Best Job Management Software for Tradesmen
Tradify
Tradify is an easy-to-use solution that makes it super simple for tradespeople to manage their jobs. It is designed to speed up the daily process of scheduling, quoting, and invoicing. It is a business growth app for tradies that helps to improve work efficiency.
Tradify is aimed at smaller trade businesses looking to get organized without too many complicated features. You can operate your business from anywhere on any device, which the platform is accessible from.
Tradify Key Features:
Quotes & Invoices: Create and send professional-looking quotes & invoices in minutes. You can also modify your quotes to suit your branding.
Timesheets: Record the hours your team has worked, which is automatically incorporated into job costing and payroll.
Client Management: Maintain all pertinent client information, job history, and communication records in one place to serve them better.
Mobile App: Handle everything from your phone to track your business on the go, even when you are present in a physical capacity.
Tradify Pros and Cons:
Pros:
Very easy to use and set up.
Low cost for small businesses
Access on a mobile device to manage your business anywhere you go.
Cons:
Not very powerful for larger companies.
Not as many integrations as other platforms
Best for: Small-to-medium trade businesses seeking a simple, mobile-friendly solution to manage jobs.
Tradify Pricing: Starts at $45 per month, per user. Other Pro and plans with more features are available respectively $49 and $59 per month.
SimPRO
SimPRO is a cloud-based job management app for trades and service businesses. Excellent for anyone who has to juggle between small jobs and bigger projects.
SimPRO is a cloud-based solution, which means you can access it anywhere and anytime. Combines functions to manage everything from job scheduling, inventory tracking, invoicing & reporting.
Key Features:
Job Scheduling and Tracking: Seamlessly scheduled jobs making it easier for efficient planning of your team, tracking all in real time!! It allows you to assign tasks, and deadlines and notify you when the jobs are completed.
Project Management: Handle large-scale projects with native budgeting, scheduling, and resource-tracking capabilities.
Manage Inventory: Tool, parts, and material management to ensure those tools are available for the next job.
Contract & Quote & Invoice: Create Striking quotes, and convert them into an invoice with one click. You can follow up on unpaid invoices too.
Integration: Includes integration with accounting applications such as QuickBooks, Xero & MYOB for easier financial management.
SimPRO Pros and Cons:
Pros:
Built for trade and field services.
All-in-one features that handle every part of job management.
Great support for more extensive teams and multi-users.
Cons:
The beginner learning curve is a little more steep.
Costlier compared to some other tools on this list.
Ideal for: Larger trades businesses or those with multiple jobs and staff to manage simultaneously; electricians, plumbers, and HVAC technicians
SimPRO Pricing: Request SimPRO for their pricing.
ServiceM8
ServiceM8 is made for tradesmen looking to manage their workflow better. With your quoting, scheduling, and job-invoicing process, it is full-fledged software.
It works seamlessly with top payment processors and accounting software, simplifying finance management. The mobile app is great for tradesmen (and other businesses) who are always on the move.
Key Features:
Job Assignment and Scheduling: Effortlessly allocate jobs to the workforce, along with a job status. You can use the dispatch board to see who is free and where.
Quotes and Invoicing: Draft quotes annotably, then turn one into an invoice in seconds. Another great feature is the ability to automate reminders for unpaid invoices.
Customer Communication: Update clients on job status, reminders, and follow-ups without having to leave the app.
Job History: Save documents from numerous job records with annotations, images, and files. It organizes everything and offers a lot of information regarding your work.
Mobile Accessibility: Use the mobile app to update job status, capture images, and do the tasks onsite helping you to stay connected wherever you are.
ServiceM8 Pros and Cons:
Pros:
Ideal for companies doing remote or fieldwork.
Great mobile app to manage jobs while on the move.
User-friendly and simple interface.
Cons:
Not as robust of project management options for big projects.
Higher-priced plans offer features like automated reporting.
Ideal For: Tradesmen looking for a mobile tool to manage jobs out of the office.
ServiceM8 Pricing: Starts at $29 per month, per user. Higher plans with more features are available for up to $349 per month.
Read Full Article: Click Here
#jobmanagement#tradesmen#software#bestjobmanagement#tradesmensoftware#jobtools#joborganization#jobefficiency#jobproductivity#jobplanning#jobtracking#jobautomation#jobtechnology#jobinnovation
1 note
·
View note
Text
Entry Level Data Entry Clerk
The Data Entry Specialist is responsible for accurately entering and maintaining lists, records, or other data points into electronic formats using data entry devices. This role also involves supporting the department with daily tasks such as monitoring email inboxes, creating, updating, and managing spreadsheets, and ensuring data accuracy.Key Responsibilities: Enter and update data accurately…
0 notes
Text
Top Recruitment Agencies in Oman, Muscat, Dubai, Abu Dhabi, and the UAE

Finding the right recruitment agency can be the key to a successful hiring process for employers and job seekers alike. From Oman to the UAE, including prominent cities like Muscat, Dubai, and Abu Dhabi, the region boasts a variety of top-tier recruitment agencies catering to diverse industries. This article explores the leading agencies, their services, and tips for choosing the best fit for your needs.
1. Top Recruitment Agencies in Oman
Oman’s thriving economy and growing industries make it a hub for skilled professionals. The leading recruitment agencies in Oman here specialize in sectors like oil and gas, construction, healthcare, and IT.
Key Agencies in Oman
Talent Arabia
Known for its tailored recruitment solutions in oil, gas, and engineering sectors.
Offers temporary, permanent, and executive placement services.
Job Oman
Focuses on local and international recruitment, especially in healthcare and hospitality.
Elite Recruitment Oman
Specializes in matching high-caliber talent with leading companies across various sectors.
Why Choose Recruitment Agencies in Oman?
Deep understanding of the local market.
Access to a network of qualified professionals.
Expertise in navigating Oman’s labor laws and regulations.

2. Recruitment Agencies in Muscat
Muscat, Oman’s capital, serves as the central hub for recruitment activity in the country. Recruitment agencies in Oman here are known for their professional approach to sourcing talent across various industries.
Popular Agencies in Muscat
Gulf Talent
Offers services across a broad range of industries, including finance and education.
JobTrack Oman
Specializes in mid-level to senior-level positions for both local and international companies.
Focus HR Muscat
Provides strategic recruitment solutions tailored to the city’s diverse economic sectors.
Advantages of Working with Muscat-Based Agencies
Proximity to businesses and industries in the capital.
Expertise in Muscat’s economic landscape.
Efficient hiring processes tailored to client needs.

3. Recruitment Agencies in Dubai
Dubai is a global business hub, attracting talent from around the world. Recruitment agencies in Dubai here cater to a variety of industries, including finance, technology, real estate, and hospitality.
Top Agencies in Dubai
Michael Page Middle East
Known for executive search and specialist recruitment services.
Robert Half UAE
Focuses on accounting, finance, and IT talent.
Hays Dubai
Offers personalized recruitment solutions for technical, managerial, and executive positions.
Why Dubai is a Recruitment Hotspot
Thriving industries with high demand for skilled professionals.
International workforce with a dynamic job market.
Excellent career growth opportunities for expatriates.

4. Recruitment Agencies in Abu Dhabi
Abu Dhabi, the capital of the UAE, is a growing center for oil and gas, healthcare, and government-related sectors. Recruitment agencies in Abu Dhabi here often work closely with both public and private organizations.
Notable Agencies in Abu Dhabi
ManpowerGroup UAE
Offers recruitment and workforce solutions for large-scale projects.
TASC Outsourcing
Focuses on staffing solutions for industries like IT, telecom, and retail.
NADIA Recruitment
A leader in administrative and executive placements across the city.
Unique Benefits of Abu Dhabi Agencies
Strong focus on government and semi-government sectors.
Specialized expertise in oil, gas, and renewable energy recruitment.
Efficient handling of visa and labor regulations.
5. Recruitment Agencies in the UAE
The UAE as a whole offers a robust recruitment ecosystem, catering to its diversified economy. From startups to multinational corporations, agencies here are equipped to address varied hiring needs.
Leading Agencies Across the UAE
Bayt.com
One of the largest job portals in the Middle East, offering recruitment services for all industries.
Charterhouse Middle East
Specializes in hiring mid-to-senior-level management professionals.
LinkedIn Talent Solutions
Utilizes LinkedIn’s extensive network to connect employers with top candidates.
Benefits of Choosing UAE-Wide Agencies
Access to a broader talent pool.
Expertise in handling multinational recruitment.
Comprehensive understanding of UAE labor laws and visa processes.
How to Choose the Right Recruitment Agency?
Selecting the best recruitment agencies in UAE is crucial to ensure a successful hiring process. Here are some tips:
Define Your Needs
Are you looking for temporary or permanent staff?
What industry expertise do you require?
Check Agency Reputation
Research online reviews and client testimonials.
Look for certifications or industry affiliations.
Evaluate Their Process
Ask about their candidate sourcing and screening methods.
Ensure they understand your specific requirements.
Consider Their Network
Agencies with a vast talent network are more likely to find the right match quickly.

FAQs About Recruitment Agencies in Dubai
1. What industries do recruitment agencies in Oman and the UAE specialize in?
Recruitment agencies in these regions specialize in industries like oil and gas, IT, healthcare, construction, finance, and hospitality.
2. How do recruitment agencies in Dubai differ from those in Abu Dhabi?
While Dubai agencies cater to a broader international workforce, Abu Dhabi agencies often focus more on government and oil and gas sectors.
3. Are recruitment agencies in Muscat only for local hiring?
No, recruitment agencies in Muscat also facilitate international recruitment for companies looking to hire expatriates.
4. What is the cost of using a recruitment agency?
The cost varies based on the agency and the role being filled. Employers typically pay a percentage of the candidate’s annual salary as a recruitment fee.
5. How long does it take to hire through a recruitment agency?
The timeline can vary but generally ranges from a few weeks to a few months, depending on the role and candidate availability.
Conclusion — Recruitment Agencies in UAE
Recruitment agencies in Oman, Muscat, Dubai, Abu Dhabi, and the UAE play a pivotal role in connecting employers with top talent. Whether you are looking for specialized hiring in the oil and gas sector or broad recruitment services across industries, these agencies offer tailored solutions to meet your needs. By understanding their expertise and leveraging their networks, you can streamline your hiring process and find the perfect match for your organization.
If you’re ready to take the next step in your hiring journey, consider partnering with Talent Arabia or one of the other leading recruitment agencies mentioned in this article. They bring the expertise, efficiency, and network necessary for successful talent acquisition.
#Recruitment Agencies in Oman#Muscat#Dubai#Abu Dhabi#employees#recruitment#recruitment agency in gurgaon#recruitment agency#recruitment agency in india#recruitment company
0 notes
Text
A good understanding of Hadoop Architecture is required to leverage the power of Hadoop. Below are few important practical questions which can be asked to a Senior Experienced Hadoop Developer in an interview. I learned the answers to them during my CCHD (Cloudera Certified Haddop Developer) certification. I hope you will find them useful. This list primarily includes questions related to Hadoop Architecture, MapReduce, Hadoop API and Hadoop Distributed File System (HDFS). Hadoop is the most popular platform for big data analysis. The Hadoop ecosystem is huge and involves many supporting frameworks and tools to effectively run and manage it. This article focuses on the core of Hadoop concepts and its technique to handle enormous data. Hadoop is a huge ecosystem and referring to a good hadoop book is highly recommended. Below list of hadoop interview questions and answers that may prove useful for beginners and experts alike. These are common set of questions that you may face at big data job interview or a hadoop certification exam (like CCHD). What is a JobTracker in Hadoop? How many instances of JobTracker run on a Hadoop Cluster? JobTracker is the daemon service for submitting and tracking MapReduce jobs in Hadoop. There is only One Job Tracker process run on any hadoop cluster. Job Tracker runs on its own JVM process. In a typical production cluster its run on a separate machine. Each slave node is configured with job tracker node location. The JobTracker is single point of failure for the Hadoop MapReduce service. If it goes down, all running jobs are halted. JobTracker in Hadoop performs following actions(from Hadoop Wiki:) Client applications submit jobs to the Job tracker. The JobTracker talks to the NameNode to determine the location of the data The JobTracker locates TaskTracker nodes with available slots at or near the data The JobTracker submits the work to the chosen TaskTracker nodes. The TaskTracker nodes are monitored. If they do not submit heartbeat signals often enough, they are deemed to have failed and the work is scheduled on a different TaskTracker. A TaskTracker will notify the JobTracker when a task fails. The JobTracker decides what to do then: it may resubmit the job elsewhere, it may mark that specific record as something to avoid, and it may may even blacklist the TaskTracker as unreliable. When the work is completed, the JobTracker updates its status. Client applications can poll the JobTracker for information. How JobTracker schedules a task? The TaskTrackers send out heartbeat messages to the JobTracker, usually every few minutes, to reassure the JobTracker that it is still alive. These message also inform the JobTracker of the number of available slots, so the JobTracker can stay up to date with where in the cluster work can be delegated. When the JobTracker tries to find somewhere to schedule a task within the MapReduce operations, it first looks for an empty slot on the same server that hosts the DataNode containing the data, and if not, it looks for an empty slot on a machine in the same rack. What is a Task Tracker in Hadoop? How many instances of TaskTracker run on a Hadoop Cluster A TaskTracker is a slave node daemon in the cluster that accepts tasks (Map, Reduce and Shuffle operations) from a JobTracker. There is only One Task Tracker process run on any hadoop slave node. Task Tracker runs on its own JVM process. Every TaskTracker is configured with a set of slots, these indicate the number of tasks that it can accept. The TaskTracker starts a separate JVM processes to do the actual work (called as Task Instance) this is to ensure that process failure does not take down the task tracker. The TaskTracker monitors these task instances, capturing the output and exit codes. When the Task instances finish, successfully or not, the task tracker notifies the JobTracker. The TaskTrackers also send out heartbeat messages to the JobTracker, usually every few minutes, to reassure the JobTracker that it is still alive.
These message also inform the JobTracker of the number of available slots, so the JobTracker can stay up to date with where in the cluster work can be delegated. What is a Task instance in Hadoop? Where does it run? Task instances are the actual MapReduce jobs which are run on each slave node. The TaskTracker starts a separate JVM processes to do the actual work (called as Task Instance) this is to ensure that process failure does not take down the task tracker. Each Task Instance runs on its own JVM process. There can be multiple processes of task instance running on a slave node. This is based on the number of slots configured on task tracker. By default a new task instance JVM process is spawned for a task. How many Daemon processes run on a Hadoop system? Hadoop is comprised of five separate daemons. Each of these daemon run in its own JVM. Following 3 Daemons run on Master nodes NameNode - This daemon stores and maintains the metadata for HDFS. Secondary NameNode - Performs housekeeping functions for the NameNode. JobTracker - Manages MapReduce jobs, distributes individual tasks to machines running the Task Tracker. Following 2 Daemons run on each Slave nodes DataNode – Stores actual HDFS data blocks. TaskTracker - Responsible for instantiating and monitoring individual Map and Reduce tasks. What is configuration of a typical slave node on Hadoop cluster? How many JVMs run on a slave node? Single instance of a Task Tracker is run on each Slave node. Task tracker is run as a separate JVM process. Single instance of a DataNode daemon is run on each Slave node. DataNode daemon is run as a separate JVM process. One or Multiple instances of Task Instance is run on each slave node. Each task instance is run as a separate JVM process. The number of Task instances can be controlled by configuration. Typically a high end machine is configured to run more task instances. What is the difference between HDFS and NAS ? The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. Following are differences between HDFS and NAS In HDFS Data Blocks are distributed across local drives of all machines in a cluster. Whereas in NAS data is stored on dedicated hardware. HDFS is designed to work with MapReduce System, since computation are moved to data. NAS is not suitable for MapReduce since data is stored seperately from the computations. HDFS runs on a cluster of machines and provides redundancy usinga replication protocal. Whereas NAS is provided by a single machine therefore does not provide data redundancy. How NameNode Handles data node failures? NameNode periodically receives a Heartbeat and a Blockreport from each of the DataNodes in the cluster. Receipt of a Heartbeat implies that the DataNode is functioning properly. A Blockreport contains a list of all blocks on a DataNode. When NameNode notices that it has not recieved a hearbeat message from a data node after a certain amount of time, the data node is marked as dead. Since blocks will be under replicated the system begins replicating the blocks that were stored on the dead datanode. The NameNode Orchestrates the replication of data blocks from one datanode to another. The replication data transfer happens directly between datanodes and the data never passes through the namenode. Does MapReduce programming model provide a way for reducers to communicate with each other? In a MapReduce job can a reducer communicate with another reducer? Nope, MapReduce programming model does not allow reducers to communicate with each other. Reducers run in isolation. Can I set the number of reducers to zero? Yes, Setting the number of reducers to zero is a valid configuration in Hadoop. When you set the reducers to zero no reducers will be executed, and the output of each mapper will be stored to a separate file on HDFS.
[This is different from the condition when reducers are set to a number greater than zero and the Mappers output (intermediate data) is written to the Local file system(NOT HDFS) of each mappter slave node.] Where is the Mapper Output (intermediate kay-value data) stored ? The mapper output (intermediate data) is stored on the Local file system (NOT HDFS) of each individual mapper nodes. This is typically a temporary directory location which can be setup in config by the hadoop administrator. The intermediate data is cleaned up after the Hadoop Job completes. What are combiners? When should I use a combiner in my MapReduce Job? Combiners are used to increase the efficiency of a MapReduce program. They are used to aggregate intermediate map output locally on individual mapper outputs. Combiners can help you reduce the amount of data that needs to be transferred across to the reducers. You can use your reducer code as a combiner if the operation performed is commutative and associative. The execution of combiner is not guaranteed, Hadoop may or may not execute a combiner. Also, if required it may execute it more then 1 times. Therefore your MapReduce jobs should not depend on the combiners execution. What is Writable & WritableComparable interface? org.apache.hadoop.io.Writable is a Java interface. Any key or value type in the Hadoop Map-Reduce framework implements this interface. Implementations typically implement a static read(DataInput) method which constructs a new instance, calls readFields(DataInput) and returns the instance. org.apache.hadoop.io.WritableComparable is a Java interface. Any type which is to be used as a key in the Hadoop Map-Reduce framework should implement this interface. WritableComparable objects can be compared to each other using Comparators. What is the Hadoop MapReduce API contract for a key and value Class? The Key must implement the org.apache.hadoop.io.WritableComparable interface. The value must implement the org.apache.hadoop.io.Writable interface. What is a IdentityMapper and IdentityReducer in MapReduce ? org.apache.hadoop.mapred.lib.IdentityMapper Implements the identity function, mapping inputs directly to outputs. If MapReduce programmer do not set the Mapper Class using JobConf.setMapperClass then IdentityMapper.class is used as a default value. org.apache.hadoop.mapred.lib.IdentityReducer Performs no reduction, writing all input values directly to the output. If MapReduce programmer do not set the Reducer Class using JobConf.setReducerClass then IdentityReducer.class is used as a default value. What is the meaning of speculative execution in Hadoop? Why is it important? Speculative execution is a way of coping with individual Machine performance. In large clusters where hundreds or thousands of machines are involved there may be machines which are not performing as fast as others. This may result in delays in a full job due to only one machine not performaing well. To avoid this, speculative execution in hadoop can run multiple copies of same map or reduce task on different slave nodes. The results from first node to finish are used. When is the reducers are started in a MapReduce job? In a MapReduce job reducers do not start executing the reduce method until the all Map jobs have completed. Reducers start copying intermediate key-value pairs from the mappers as soon as they are available. The programmer defined reduce method is called only after all the mappers have finished. If reducers do not start before all mappers finish then why does the progress on MapReduce job shows something like Map(50%) Reduce(10%)? Why reducers progress percentage is displayed when mapper is not finished yet? Reducers start copying intermediate key-value pairs from the mappers as soon as they are available. The progress calculation also takes in account the processing of data transfer which is done by reduce process, therefore the reduce progress starts
showing up as soon as any intermediate key-value pair for a mapper is available to be transferred to reducer. Though the reducer progress is updated still the programmer defined reduce method is called only after all the mappers have finished. What is HDFS ? How it is different from traditional file systems? HDFS, the Hadoop Distributed File System, is responsible for storing huge data on the cluster. This is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets. HDFS is designed to support very large files. Applications that are compatible with HDFS are those that deal with large data sets. These applications write their data only once but they read it one or more times and require these reads to be satisfied at streaming speeds. HDFS supports write-once-read-many semantics on files. What is HDFS Block size? How is it different from traditional file system block size? In HDFS data is split into blocks and distributed across multiple nodes in the cluster. Each block is typically 64Mb or 128Mb in size. Each block is replicated multiple times. Default is to replicate each block three times. Replicas are stored on different nodes. HDFS utilizes the local file system to store each HDFS block as a separate file. HDFS Block size can not be compared with the traditional file system block size. What is a NameNode? How many instances of NameNode run on a Hadoop Cluster? The NameNode is the centerpiece of an HDFS file system. It keeps the directory tree of all files in the file system, and tracks where across the cluster the file data is kept. It does not store the data of these files itself. There is only One NameNode process run on any hadoop cluster. NameNode runs on its own JVM process. In a typical production cluster its run on a separate machine. The NameNode is a Single Point of Failure for the HDFS Cluster. When the NameNode goes down, the file system goes offline. Client applications talk to the NameNode whenever they wish to locate a file, or when they want to add/copy/move/delete a file. The NameNode responds the successful requests by returning a list of relevant DataNode servers where the data lives. What is a DataNode? How many instances of DataNode run on a Hadoop Cluster? A DataNode stores data in the Hadoop File System HDFS. There is only One DataNode process run on any hadoop slave node. DataNode runs on its own JVM process. On startup, a DataNode connects to the NameNode. DataNode instances can talk to each other, this is mostly during replicating data. How the Client communicates with HDFS? The Client communication to HDFS happens using Hadoop HDFS API. Client applications talk to the NameNode whenever they wish to locate a file, or when they want to add/copy/move/delete a file on HDFS. The NameNode responds the successful requests by returning a list of relevant DataNode servers where the data lives. Client applications can talk directly to a DataNode, once the NameNode has provided the location of the data. How the HDFS Blocks are replicated? HDFS is designed to reliably store very large files across machines in a large cluster. It stores each file as a sequence of blocks; all blocks in a file except the last block are the same size. The blocks of a file are replicated for fault tolerance. The block size and replication factor are configurable per file. An application can specify the number of replicas of a file. The replication factor can be specified at file creation time and can be changed later. Files in HDFS are write-once and have strictly one writer at any time. The NameNode makes all decisions regarding replication of blocks.
HDFS uses rack-aware replica placement policy. In default configuration there are total 3 copies of a datablock on HDFS, 2 copies are stored on datanodes on same rack and 3rd copy on a different rack. Can you think of a questions which is not part of this post? Please don't forget to share it with me in comments section & I will try to include it in the list.
0 notes
Text
What is Job Tracker in Hadoop?
What is Job Tracker in Hadoop Framework? #analytics #engineering #distributedcomputing #dataengineering #science #news #technology #data #trends #tech #hadoop #spark #hdfs #bigdata
JobTracker is a daemon service that is used for submitting and tracking MapReduce(MR) jobs in the Apache Hadoop framework. In a typical production cluster, JobTracker runs on a separate machine through its own JVM process. It is an essential daemon for MR v1 but is replaced by Resource Manager/Application Manager in MR V2. It is the single point of failure for the Hadoop MapReduce service, as it…
View On WordPress
0 notes
Text
When someone says that they “work in finance” and then narrows it down by saying they focus on “Fintech,” their daily routine still feels pretty vague. At least for people who work outside that realm, it can be hard to imagine a financial planner’s responsibilities.
So if you’re finding your place in finance, who do you ask for advice?! Where do you apply?
So here is Jackfruit’s List of 10 High-Paying Finance Jobs in 2022
0 notes
Photo

Business owners who employ field staff are well aware of the challenges. When the staff leaves the office and stays out of sight, finding them can be challenging.
Even more problematic is finding out whether they are even working on the task, their location, and if they have reached the customer site.
Informap's field staff tracking gives the full visibility to locate your field staff, assign tasks on the go, receive key task alerts and greater control to ensure that your field staff is carrying out their tasks in much greater efficiency and effectiveness. Our Field Staff Tracking APP called MiTrack will be installed on your field staff Android phone and your Back Office Manager will use desktop iTrack Web Application to monitor them
Contact Informap to know more: +97165770099 or +971 55 3347845
Or visit: http://informapuae.com/field-staff-tracking/
For any queries email us at [email protected] , [email protected]
#jobtracker'#fieldstafftracking#tracker#salesstafftracker#salesmeetingtracker#employeeattendancetracking#employeetracking#gpstrackingsystem#employee#gpstracker#gps
0 notes
Text
How Mr. Manasranjan Murlidhar Rana Helped Union Bank Switzerland as a Certified Hadoop Administrator
Mr. Manasranjan Murlidhar Rana is a certified Hadoop Administrator and an IT professional with 10 years of experience. During his entire career, he has contributed a lot to Hadoop administration for different organizations, including the famous Union Bank of Switzerland.
Mr. Rana’s Knowledge in Hadoop Architecture and its Components
Mr. Manasranjan Murlidhar Rana has vast knowledge and understanding of various aspects related to Hadoop Architecture and its different components. These are MapReduce, YARN, HDFS, HBase, Pig, Flume, Hive, and Zookeeper. He even has the experience to build and maintain multiple clusters in Hadoop, like the production and development of diverse sizes and configurations.

His contribution is observed in the establishment of rack topology to deal with big Hadoop clusters. In this blog post, we will discuss in detail about the massive contribution of Manasranjan Murlidhar Rana as a Hadoop Administrator to deal with various operations of the Union Bank of Switzerland.
Role of Mr. Rana in Union Bank of Switzerland
Right from the year 2016 to until now, Mr. Manasranjan Murlidhar Rana played the role of a Hadoop Administrator with 10 other members for his client named Union Bank of Switzerland. During about 4 years, he worked a lot to enhance the process of data management for his client UBS.
1. Works for the Set up of Hadoop Cluster
Manasranjan Murlidhar Rana and his entire team were involved in the set up of the Hadoop Cluster in UBS right from the beginning to the end procedure. In this way, the complete team works hard to install, configure, and monitor the complete Hadoop Cluster effectively. Here, the Hadoop cluster refers to a computation cluster designed to store and analyze unstructured data in a well-distributed computational environment.
2. Handles 4 Different Clusters and Uses Ambari Server
Mr. Manasranjan Murlidhar Rana is responsible for handling four different clusters of the software development process. These are DEV, UAT, QA, and Prod. He and his entire team even used the innovative Ambari server extensively to maintain different Hadoop cluster and its components. The Ambari server collects data from a cluster and thereby, controls each host.
3. Cluster Maintenance and Review of Hadoop Log Files
Mr. Manasranjan Murlidhar Rana and his team have done many things to maintain the entire Hadoop cluster, along with commissioning plus decommissioning of data nodes. Moreover, he contributed to monitoring different software development related clusters, troubleshoot and manage the available data backups, while reviewed log files of Hadoop. He also reviewed and managed log files of Hadoop as an important of the Hadoop administration to communicate, troubleshoot, and escalate tons of issues to step ahead in the right direction.
4. Successful Installation of Hadoop Components and its Ecosystem
Hadoop Ecosystem consists of Hadoop daemons. Hadoop Daemons in terms of computation imply a process operating in the background and they are of five types, i.e. DataNode, NameNode, TaskTracker, JobTracker, and Secondary NameNode.
Besides, Hadoop has few other components named Flume, Sqoop and HDFS, all of which have specific functions. Indeed, installation, configuration, and maintenance of each of the Hadoop daemons and Hadoop ecosystem components are not easy.
However, based on the hands-on experience of Mr. Manasranjan Rana, he succeeded to guide his entire team to install Hadoop ecosystems and its components named HBase, Flume, Sqoop, and many more. Especially, he worked to use Sqoop to import and export data in HDFS, while to use Flume for loading any log data directly into HDFS.
5. Monitor the Hadoop Deployment and Other Related Procedures
Based on the vast knowledge and expertise to deal with Hadoop elements, Mr. Manasranjan Murlidhar Rana monitored systems and services, work for the architectural design and proper implementation of Hadoop deployment and make sure of other procedures, like disaster recovery, data backup, and configuration management.
6. Used Cloudera Manager and App Dynamics
Based on the hands-on experience of Mr. Manasranjan Murlidhar Rana to use App Dynamics, he monitored multiple clusters and environments available under Hadoop. He even checked the job performance, workload, and capacity planning with the help of the Cloudera Manager. Along with this, he worked with varieties of system engineering aspects to formulate plans and deploy innovative Hadoop environments. He even expanded the already existing Hadoop cluster successfully.
7. Setting Up of My-SQL Replications and Maintenance of My-SQL Databases
Other than the expertise of Mr. Manasranjan Murlidhar Rana in various aspects of Bigdata, especially the Hadoop ecosystem and its components, he has good command on different types of databases, like Oracle, Ms-Access, and My-SQL.
Thus, according to his work experience, he maintained databases by using My-SQL, established users, and maintained the backup or recovery of available databases. He was also responsible for the establishment of master and slave replications for the My-SQL database and helped business apps to maintain data in various My-SQL servers.
Therefore, with good knowledge of Hadoop Ambari Server, Hadoop components, and demons, along with the entire Hadoop Ecosystem, Mr. Manasranjan Murlidhar Rana has given contributions towards the smart management of available data for the Union Bank of Switzerland.

Find Mr. Manasranjan Murlidhar Rana on Social Media. Here are some social media profiles:-
https://giphy.com/channel/manasranjanmurlidharrana https://myspace.com/manasranjanmurlidharrana https://mix.com/manasranjanmurlidhar https://www.meetup.com/members/315532262/ https://www.goodreads.com/user/show/121165799-manasranjan-murlidhar https://disqus.com/by/manasranjanmurlidharrana/
1 note
·
View note
Text

Hadoop Interview Questions . . . . What is the functionality of JobTracker in Hadoop? How many instances of a JobTracker run on Hadoop cluster? . . . for more information and tutorial https://bit.ly/3y7dhRh check the above link
0 notes
Text
🚀 Simplify job management with VanLynk's Dispatch Board! 📋 Organize, assign, and track service jobs effortlessly in one place. Stay on top of your schedule and boost productivity by streamlining operations for your service business. ✅ Manage jobs, teams, and deadlines all in real-time!
#DispatchBoard#VanLynk#ServiceManagement#TopProz#JobTracking#EfficientOperations#TeamManagement#BoostProductivity#ServiceBusiness#StreamlineWorkflow
3 notes
·
View notes
Text

Java is mostly every app developers favorite object-oriented language for lots of motives. One of the many reasons to go for Java is that it offers a host of other Java web development frameworks consisting of MyBatis a persistence framework a gaming framework. A Java framework is unique to the Java programming language which is used for web developers Java software development company and programs.
1. Struts
In a traditional servlet JSP approach, if a user submits, say, a form with their details, the data then is going to a servlet for processing, or the control goes over to the next JSP. The controller is an ActionServlet where models can be written for the view and user registrations are managed using the JavaBean ActionForm. The Action object is responsible for transmitting the web development flow.
2. Java Server Faces
It is the Java-based web app developers framework mainly used for Java web app developers near me. JSF is maintained by Oracle technology that especially simplifies creating person interfaces for Java app developers. The web development framework simplifies the development of user interfaces for server-facet applications by assembling reusable user interface components on a single page. The framework simplifies the web development of user interfaces for server-facet applications by assembling reusable user interface components on a single page. JSF is a thing-based MVC framework that encompasses several front-end technologies and focuses more on the presentation layer.
3. Apache Hadoop
Apache Hadoop is not a full-stack framework, it offers a software developers framework and works at the MapReduce programming version. Hadoop helps in distributed data storage and processing the usage of the master-slave design pattern. The Hadoop HDFS layer of the master node has the records node. The MapReduce layer has the JobTracker and the task tracker. The slave nodes have the Data node and the task tracker respectively.
4. Grails
Grails is clean to learn full-stack framework much suitable for those who are just beginning their programming career. Although Grails is a web development framework written in the Groovy programming language, it runs on the Java platform and is fully compatible with the Java syntax. It is easy to learn and is one of the most beginner-friendly Java frameworks. Grails is written in Groovy and it can run on the Java platform.
5. Dropwizard
This is a lightweight Java framework that provides advanced help for complex setups and lets you complete your app developers in the fastest way possible Any novice programmer can broaden high-performance RESTful web development apps without problems with the Dropwizard Java framework. Flutter developers are able to set up faster due to less sophistication and the abundance of gear to make app developers.
6. Vaadin
Vaadin is a lightweight Java framework, which allows developers to create complete Java app developers and interfaces for laptops and mobile app developers. Vaadin is a cross-platform web development JavaScript framework that lets you bundle native mobile app developers, web apps, or even laptop app developers with a single codebase. Vaadin’s cross-platform portability allows users to expand network infrastructures quickly and hassle-free. Provides a platform for simplified Java development. Data visualization is another aspect of Vaadin that contributes to the success of your app developers.
7. Micronaut
Micronaut is leading the serverless app developers. Micronaut is a contemporary JVM-based, full-stack framework for software developers modular, readily tested microservice and serverless programs. Micronaut is a Polyglot framework, which means it can be used to create programs in a wide range of programming languages. Micronaut is not only a coding web framework however it’s also a performance booster. It also resolved all complex browser-based utility challenges and with its rich libraries offers faster working java web development companies applications.
Conclusion
To develop amazing multi-featured web development, you can choose any of the Java frameworks for web development mentioned above. The proper Java framework not only will support you in meeting your unique business requirements but also give you a special level of flexibility with high performance and security.
0 notes
Text
$150K boost for Guelph's emergency rescue, youth and jobs programs
$150K boost for Guelph’s emergency rescue, youth and jobs programs
The donation from the Grand River Agricultural Society will support important Equine Guelph programs including Equine JobTrack, Large Animal Emergency Rescue (LAER) and the EquiMania! youth programs. Image by Pezibear A Canadian agricultural society has given Equine Guelph a gift of $150,000 over three years that will go towards its Large Animal Emergency Rescue (LAER), Equine JobTrack and…

View On WordPress
0 notes
Photo
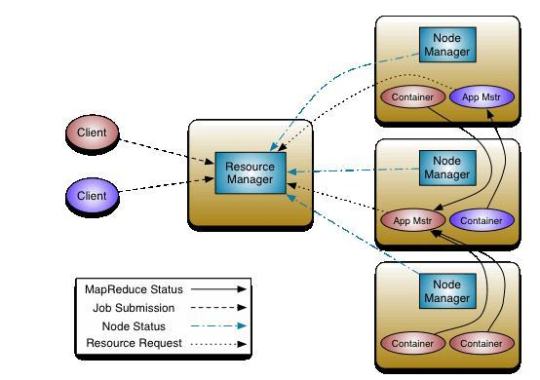
Hadoop YARN Architecture Author(s): Vivek Chaudhary ProgrammingYARN stands for Yet Another Resource Negotiator. YARN became part of Hadoop ecosystem with the advent of Hadoop 2.x, and with it came the major architectural changes in Hadoop.YARNYARN manages resources in the cluster environment. That’s it? Didn’t we had any resource manager before Hadoop 2.x? Of course, we had a resource manager before Hadoop 2.x and it was called Job Tracker.So what is Job Tracker?JobTracker (JT) use to manage both cluster resources and perform MapR or MapReduce job execution which means Data processing. JT configures and monitors every running task. If a task fails, it reallocates a new slot for the task to start again. On completion of tasks, it releases resources and cleans up #MachineLearning #ML #ArtificialIntelligence #AI #DataScience #DeepLearning #Technology #Programming #News #Research #MLOps #EnterpriseAI #TowardsAI #Coding #Programming #Dev #SoftwareEngineering https://bit.ly/3GHPsyt #programming
0 notes
Text
“Over the weekend our network servers suffered a severe attack and some computers are still infected. Our email is also down and jobtracker status is not known.”
you mean in ADDITION to the weeks long bullshit spam that our emails have been getting AND sending???
god at least i actually have shit to do that doesnt require email or the servers
0 notes