#it's essentially a parsing error
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
70% of Tumblr users say the Dashboard is their favorite place to spend time online.
Text

The result of that flash poll I did the other day, Riv wound up winning so here he is!
Random OC lore below for anyone interested.
Riv is the oldest of the aur, a species unintentionally formed from the energetic aftershocks of the creation of his planet. Because there was only so much of that energy to go around, there are a limited number of "souls" available for their species, and thus the aur have a static population. Although functionally immortal, they do lose neuroelasticity over time, which eventually makes living pretty unpleasant, so they inevitably opt to pass away and allow a new member of the species to be born.
Several thousand years ago, Riv contracted a particularly dangerous magical condition that left him discolored—he used to be a very pale apricot color and his hair was opalescent white—and with chronic pain, but also keeps him from losing neuroelasticity, allowing him to live basically forever without experiencing the ennui that is the literal death of the rest of his species.
Travelers of other species who came across the aur in ancient times wound up essentially engaging in a millennia-long game of telephone that led to a gross misunderstanding of what they actually looked like, which is where the concept of unicorns comes from. When the aur finally went public as a species to get people to stop killing each other, everyone was very surprised to find that they look nothing like horses or deer. (Although they do have hooves, which is what led to the mistranslation that brought about that misconception in the first place.)
#original character#original art#artists on tumblr#lavayel-en riv#art tag#in spite of all that#it should be mentioned#that I refer to riv affectionately as#prince hold my beer#he's very old#ie: too old to care what anyone thinks#and too old to worry about consequences#what happens happens#might as well make it happen yourself#random extra lore:#the aur do not have mouths#but they do have teeth#if you were to like...cut into that space and look#there's teeth in there#it's essentially a parsing error#they're modeled loosely after the gods that made the planet#but it didn't all come through correctly#a copy of a copy of a copy#internally they're pretty close#but the externals are...ehhhhh#the indori cycle#TIC
29 notes
·
View notes
Text
One phrase encapsulates the methodology of nonfiction master Robert Caro: Turn Every Page. The phrase is so associated with Caro that it’s the name of the recent documentary about him and of an exhibit of his archives at the New York Historical Society. To Caro it is imperative to put eyes on every line of every document relating to his subject, no matter how mind-numbing or inconvenient. He has learned that something that seems trivial can unlock a whole new understanding of an event, provide a path to an unknown source, or unravel a mystery of who was responsible for a crisis or an accomplishment. Over his career he has pored over literally millions of pages of documents: reports, transcripts, articles, legal briefs, letters (45 million in the LBJ Presidential Library alone!). Some seemed deadly dull, repetitive, or irrelevant. No matter—he’d plow through, paying full attention. Caro’s relentless page-turning has made his work iconic.
In the age of AI, however, there’s a new motto: There’s no need to turn pages at all! Not even the transcripts of your interviews. Oh, and you don’t have to pay attention at meetings, or even attend them. Nor do you need to read your mail or your colleagues’ memos. Just feed the raw material into a large language model and in an instant you’ll have a summary to scan. With OpenAI’s ChatGPT, Google’s Gemini, and Anthropic’s Claude as our wingmen, summary reading is what now qualifies as preparedness.
LLMs love to summarize, or at least that’s what their creators set them about doing. Google now “auto-summarizes” your documents so you can “quickly parse the information that matters and prioritize where to focus.” AI will even summarize unread conversations in Google Chat! With Microsoft Copilot, if you so much as hover your cursor over an Excel spreadsheet, PDF, Word doc, or PowerPoint presentation, you’ll get it boiled down. That’s right—even the condensed bullet points of a slide deck can be cut down to the … more essential stuff? Meta also now summarizes the comments on popular posts. Zoom summarizes meetings and churns out a cheat sheet in real time. Transcription services like Otter now put summaries front and center, and the transcription itself in another tab.
Why the orgy of summarizing? At a time when we’re only beginning to figure out how to get value from LLMs, summaries are one of the most straightforward and immediately useful features available. Of course, they can contain errors or miss important points. Noted. The more serious risk is that relying too much on summaries will make us dumber.
Summaries, after all, are sketchy maps and not the territory itself. I’m reminded of the Woody Allen joke where he zipped through War and Peace in 20 minutes and concluded, “It’s about Russia.” I’m not saying that AI summaries are that vague. In fact, the reason they’re dangerous is that they’re good enough. They allow you to fake it, to proceed with some understanding of the subject. Just not a deep one.
As an example, let’s take AI-generated summaries of voice recordings, like what Otter does. As a journalist, I know that you lose something when you don’t do your own transcriptions. It’s incredibly time-consuming. But in the process you really know what your subject is saying, and not saying. You almost always find something you missed. A very close reading of a transcript might allow you to recover some of that. Having everything summarized, though, tempts you to look at only the passages of immediate interest—at the expense of unearthing treasures buried in the text.
Successful leaders have known all along the danger of such shortcuts. That’s why Jeff Bezos, when he was CEO of Amazon, banned PowerPoint from his meetings. He famously demanded that his underlings produce a meticulous memo that came to be known as a “6-pager.” Writing the 6-pager forced managers to think hard about what they were proposing, with every word critical to executing, or dooming, their pitch. The first part of a Bezos meeting is conducted in silence as everyone turns all 6 pages of the document. No summarizing allowed!
To be fair, I can entertain a counterargument to my discomfort with summaries. With no effort whatsoever, an LLM does read every page. So if you want to go beyond the summary, and you give it the proper prompts, an LLM can quickly locate the most obscure facts. Maybe one day these models will be sufficiently skilled to actually identify and surface those gems, customized to what you’re looking for. If that happens, though, we’d be even more reliant on them, and our own abilities might atrophy.
Long-term, summary mania might lead to an erosion of writing itself. If you know that no one will be reading the actual text of your emails, your documents, or your reports, why bother to take the time to dig up details that make compelling reading, or craft the prose to show your wit? You may as well outsource your writing to AI, which doesn’t mind at all if you ask it to churn out 100-page reports. No one will complain, because they’ll be using their own AI to condense the report to a bunch of bullet points. If all that happens, the collective work product of a civilization will have the quality of a third-generation Xerox.
As for Robert Caro, he’s years past his deadline on the fifth volume of his epic LBJ saga. If LLMs had been around when he began telling the president’s story almost 50 years ago—and he had actually used them and not turned so many pages—the whole cycle probably would have been long completed. But not nearly as great.
23 notes
·
View notes
Text
ChoiceScript Savepoint System Very Quickly
Hey guys,
@hpowellsmith made a great template for save points! It requires you to create another variable for every variable you have in your ChoiceScript game, so that it can store the old values to essentially "save"! This won't rely on third-party saving systems but is rather hard-coded into the game itself.
I realize that it can be a daunting task to create a whole other set of variables, especially if you already have many, many of them. (Looking at TSS' code, there are thousands!)
But I propose two super quick ways to automatically create all the variables you need for save points.
Find and replace.
Copy all your *create variables
Paste it into a Google Docs
On, PC, Ctrl+H to open up the dialog box for Find and Replace (link on how to find and replace on different platforms)
Search for "*create " (space included at the end) and replace it with *create save_
Hit "Replace All" and there you have your duplicated variables to paste into your startup (do so without replacing any of your old variables).
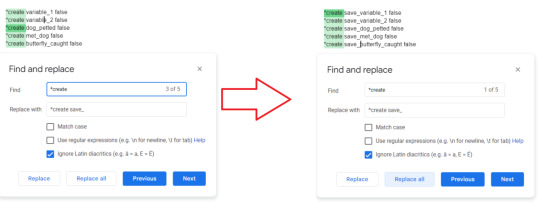
Bonus: you can instead replace it with *create save1_ , *create save2_ , etc. to have multiple save slots.
You can create all your needed variables in startup quickly with this, but there is still the issue of having to *set the variables to the new variables (when you're saving) or vice versa (when loading).
Hence the other way:
Save System Generator
I also made a program where, if you copy and paste all of your *create variables, it will automatically:
Give you code to put in your startup (the duplicated save variables)
Give you code that you use to save.
Give you code that you use to load.
I recommend you do it the way Hannah PS does in their template by calling a *gosub_scene.

Here are the step by step instructions on how to do this:
1. Prepare your *create variables. To clarify, you will only put in *create stuff into the program. Copy from your very first *create to your very last *create (the variables you want to save at least). Do not add any comments or additional code that is NOT *create. Do not have any additional spaces at the end (line breaks in between *create should be fine, but be more aware for potential errors).
2. Create a .txt file. In Hannah's template, the file is called "savegame.txt". You will want to make a *label save and a *label load that each *return (as depicted above).
3. Load up the program. Here is the link.
4. Pasting in your code. Paste in your code and immediately after your last *create, press enter, press $, and press enter again.
Note 1: You cannot use Ctrl+V or shortcut keys to paste in the code. You have to right click and paste it. Do not do this on mobile.
Note 2: You might want to do this in segments, as the program might have difficulty parsing through it, and you will more easily find errors in case they happen. Maybe every 30-50 variables to keep them bite-sized. I've tested inputting up to 70 unique variables to success.

5. Startup variables. After reading your input, it will give you code that you then have to add to your startup. Copy it by highlighting and right-clicking on it (do not use shortcut keys or do this on mobile).
6. Save. If you press S and enter, it will give you the code that you need to put in your savegame.txt under your *label save .

7, Load. If you press L and enter, it will give you the code you need to put in your savegame.txt under your *label load .

8. Using it. As in the template, you'll want to call on this with a *gosub_scene savegame load (if you want to load) or *gosub_scene savegame save (if you want to save).
And that's it! Please let me know if the program works incorrectly! 💕💕
#choicescript#choicescript resources#cs coding resources#choicescript coding resources#choicescript saving#choicescript save system
132 notes
·
View notes
Text
MokaHR: A Leading ATS for Enterprise Recruitment Management
In today's competitive business landscape, attracting and hiring top talent is more critical than ever. For large enterprises, managing the recruitment process efficiently and effectively can be a significant challenge. This is where Applicant Tracking Systems (ATS) come into play. One such leading solution is MokaHR, designed specifically to address the needs of enterprise-level recruitment management. In this article, we will explore what an ATS is, how MokaHR stands out in the market, and why it is essential for modern recruitment strategies.
What is an Applicant Tracking System (ATS)?
An Applicant Tracking System is a software solution that streamlines the recruitment process. It helps HR teams manage job postings, track candidate applications, screen resumes, schedule interviews, and communicate with candidates. The primary goals of an ATS include:
Centralizing Recruitment Data: All candidate information is stored in one place, making it easy to manage and retrieve.
Enhancing Efficiency: Automating routine tasks such as resume screening and interview scheduling saves time and reduces administrative workload.
Improving Candidate Experience: A well-designed ATS provides a smooth application process, which can enhance the employer’s brand and attract high-quality candidates.
Introduction to MokaHR
MokaHR (https://www.mokahr.io/) is a leading ATS that has been specifically engineered for enterprise-level recruitment management. It offers a robust and scalable platform tailored to meet the demands of large organizations. With its comprehensive suite of features, MokaHR ensures that every stage of the hiring process is optimized for efficiency and effectiveness.
Key Attributes of MokaHR:
Enterprise Focus: MokaHR is built to handle the complex recruitment needs of large companies, offering high performance even when processing thousands of applications.
User-Friendly Interface: The platform is designed with usability in mind, making it easy for HR teams to navigate and operate, regardless of their technical expertise.
Integration Capabilities: MokaHR seamlessly integrates with other HR systems and tools, ensuring a cohesive and efficient human resource management ecosystem.
Key Features and Benefits of MokaHR
1. Streamlined Recruitment Process
MokaHR automates many aspects of recruitment, such as resume parsing, candidate screening, and scheduling interviews. This automation reduces manual errors and allows HR professionals to focus on strategic decision-making rather than administrative tasks.
2. Enhanced Data Management
With centralized data storage, HR teams can easily access and analyze candidate information. This helps in tracking recruitment metrics, monitoring candidate progress, and making data-driven hiring decisions.
3. Improved Candidate Experience
The platform provides candidates with a smooth and transparent application process. Features like real-time application tracking and prompt communication ensure that candidates remain engaged and informed throughout the recruitment cycle.
4. Scalability and Flexibility
Designed for enterprise-level needs, MokaHR scales effortlessly as the organization grows. Whether handling a high volume of applications or integrating with various other HR systems, MokaHR adapts to evolving business requirements.
5. Advanced Analytics and Reporting
MokaHR’s built-in analytics tools allow HR teams to generate detailed reports on key recruitment metrics. These insights help in refining recruitment strategies and improving overall hiring effectiveness.
Why Enterprise-Level Recruitment Management Needs MokaHR
For large organizations, the recruitment process is complex and requires a system that can manage high volumes of data and candidates efficiently. MokaHR meets these challenges by offering:
Automation of Routine Tasks: Frees up HR professionals to focus on strategic planning and candidate engagement.
Data-Driven Decision Making: Provides actionable insights through advanced analytics, enabling continuous improvement in recruitment strategies.
Seamless Integration: Works harmoniously with other HR tools and systems, ensuring a unified approach to talent management.
Enhanced Employer Branding: A smooth and professional recruitment experience can significantly boost the company’s reputation in the talent market.
Conclusion
In the realm of enterprise recruitment management, having a robust and reliable ATS is not just an advantage—it’s a necessity. MokaHR stands out as a leading solution, offering an integrated, efficient, and user-friendly platform that addresses the complex needs of large organizations. By automating key recruitment processes, managing vast amounts of data, and providing actionable insights, MokaHR empowers enterprises to attract, assess, and hire the best talent in a competitive market.
Adopting a system like MokaHR can transform recruitment from a cumbersome, manual process into a strategic advantage, ensuring that enterprises are well-equipped to meet current and future hiring challenges.
2 notes
·
View notes
Text
Why Should You Do Web Scraping for python

Web scraping is a valuable skill for Python developers, offering numerous benefits and applications. Here’s why you should consider learning and using web scraping with Python:
1. Automate Data Collection
Web scraping allows you to automate the tedious task of manually collecting data from websites. This can save significant time and effort when dealing with large amounts of data.
2. Gain Access to Real-World Data
Most real-world data exists on websites, often in formats that are not readily available for analysis (e.g., displayed in tables or charts). Web scraping helps extract this data for use in projects like:
Data analysis
Machine learning models
Business intelligence
3. Competitive Edge in Business
Businesses often need to gather insights about:
Competitor pricing
Market trends
Customer reviews Web scraping can help automate these tasks, providing timely and actionable insights.
4. Versatility and Scalability
Python’s ecosystem offers a range of tools and libraries that make web scraping highly adaptable:
BeautifulSoup: For simple HTML parsing.
Scrapy: For building scalable scraping solutions.
Selenium: For handling dynamic, JavaScript-rendered content. This versatility allows you to scrape a wide variety of websites, from static pages to complex web applications.
5. Academic and Research Applications
Researchers can use web scraping to gather datasets from online sources, such as:
Social media platforms
News websites
Scientific publications
This facilitates research in areas like sentiment analysis, trend tracking, and bibliometric studies.
6. Enhance Your Python Skills
Learning web scraping deepens your understanding of Python and related concepts:
HTML and web structures
Data cleaning and processing
API integration
Error handling and debugging
These skills are transferable to other domains, such as data engineering and backend development.
7. Open Opportunities in Data Science
Many data science and machine learning projects require datasets that are not readily available in public repositories. Web scraping empowers you to create custom datasets tailored to specific problems.
8. Real-World Problem Solving
Web scraping enables you to solve real-world problems, such as:
Aggregating product prices for an e-commerce platform.
Monitoring stock market data in real-time.
Collecting job postings to analyze industry demand.
9. Low Barrier to Entry
Python's libraries make web scraping relatively easy to learn. Even beginners can quickly build effective scrapers, making it an excellent entry point into programming or data science.
10. Cost-Effective Data Gathering
Instead of purchasing expensive data services, web scraping allows you to gather the exact data you need at little to no cost, apart from the time and computational resources.
11. Creative Use Cases
Web scraping supports creative projects like:
Building a news aggregator.
Monitoring trends on social media.
Creating a chatbot with up-to-date information.
Caution
While web scraping offers many benefits, it’s essential to use it ethically and responsibly:
Respect websites' terms of service and robots.txt.
Avoid overloading servers with excessive requests.
Ensure compliance with data privacy laws like GDPR or CCPA.
If you'd like guidance on getting started or exploring specific use cases, let me know!
2 notes
·
View notes
Text
Psychosis is not a mark of intellect.
Psychopathic people mistake the ability to manipulate other people and exploit their emotions to be a mark of intelligence. They have a belief in their own superiority and flatter themselves with the idea that because they can break the rules of how feelings work, trick people into thinking they're emotionally neuro typical only to deceive them for their own ends, it makes them a smarter, more mature person.
That's not how intelligence works. People like this aren't smarter, they're broken. Just as the ability to lie and disrupt communications doesn't make you more intelligent, it makes you a violent predator. Just using a different means to exploit, trap and deprive your prey. And when it's your own family or species, that's just virtually cannibalism.
Exploiting somebody's trust is not a mark of intelligence, it's a mark of someone that does not have those inhibitions natural in a functioning brain. The willingness to suspend them for selfish reasons is not something to praise. And that's kind of why you have all these disgusting assholes calling themselves empaths or "dark empaths." You aren't some gifted genius, you're a monster. And because of people like yours predations, others have to learn to reign in their emotions in disbelief you could act like this, just to deal with you.
It's easy as pie to deceive and manipulate people that trust you or think you also share those healthy social and emotional inhibitions. The same ones that go off like error messages in your brain if you kill someone. Those same ones that make you sleepless if you unknowingly engage in cannibalism- even if it's necessary to survive. You can rationalize it all you want, but objectively speaking, we're animals. We're hard wired for certain things, and to not do certain things. People not missing these essential things have to cultivate violating them in order to condition themselves to continue doing them. It's not a mark of supremacy or cleverness to exploit another person by deception or manipulation. It comes natural to people that are broken and willing to engage in that sort of behavior.
Often I've come across people that thought they were superior for their willingness to exploit someone else. That being able to extract something from another and get away with it was proof of their supremacy, or at least, that of another's inferiority. If you confront them and tell them you know they're being dishonest and deceptive, their brains interpret that as, "Hey! You took advantage of how I'm too dumb to comprehend what you did!" And take it as a compliment. The inexperienced person confronting the deceiver expects the person receiving this to come clean or acknowledge they did wrong and panic because they've been caught. But that's not how a person built like this reacts, unless it's also another form of manipulation.
I'm lucky enough that as a child I had a firsthand experience with a peer like this that was a rowdy little boy. Because it meant, not only did I get the hard, cold life lessons of what dealing with a manipulative psychopath meant pushed on me, and the time to parse it out, it also meant I got to beat his fucking ass for being a manipulative and violent shit. So badly, he screamed hysterically for his mother. And then I never saw his disgusting, psychotic self again.
4 notes
·
View notes
Text
New Android Malware SoumniBot Employs Innovative Obfuscation Tactics

Banking Trojan Targets Korean Users by Manipulating Android Manifest
A sophisticated new Android malware, dubbed SoumniBot, is making waves for its ingenious obfuscation techniques that exploit vulnerabilities in how Android apps interpret the crucial Android manifest file. Unlike typical malware droppers, SoumniBot's stealthy approach allows it to camouflage its malicious intent and evade detection. Exploiting Android Manifest Weaknesses According to researchers at Kaspersky, SoumniBot's evasion strategy revolves around manipulating the Android manifest, a core component within every Android application package. The malware developers have identified and exploited vulnerabilities in the manifest extraction and parsing procedure, enabling them to obscure the true nature of the malware. SoumniBot employs several techniques to obfuscate its presence and thwart analysis, including: - Invalid Compression Method Value: By manipulating the compression method value within the AndroidManifest.xml entry, SoumniBot tricks the parser into recognizing data as uncompressed, allowing the malware to evade detection during installation. - Invalid Manifest Size: SoumniBot manipulates the size declaration of the AndroidManifest.xml entry, causing overlay within the unpacked manifest. This tactic enables the malware to bypass strict parsers without triggering errors. - Long Namespace Names: Utilizing excessively long namespace strings within the manifest, SoumniBot renders the file unreadable for both humans and programs. The Android OS parser disregards these lengthy namespaces, facilitating the malware's stealthy operation.
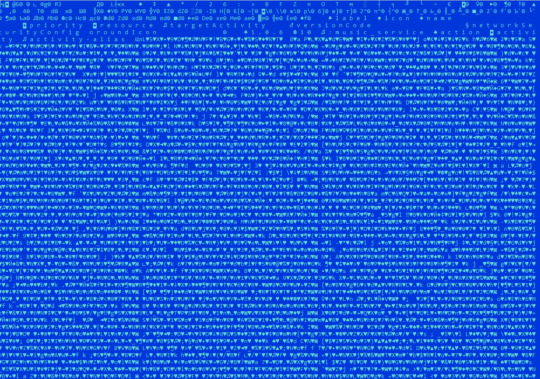
Example of SoumniBot Long Namespace Names (Credits: Kaspersky) SoumniBot's Malicious Functionality Upon execution, SoumniBot requests configuration parameters from a hardcoded server, enabling it to function effectively. The malware then initiates a malicious service, conceals its icon to prevent removal, and begins uploading sensitive data from the victim's device to a designated server. Researchers have also highlighted SoumniBot's capability to search for and exfiltrate digital certificates used by Korean banks for online banking services. This feature allows threat actors to exploit banking credentials and conduct fraudulent transactions. Targeting Korean Banking Credentials SoumniBot locates relevant files containing digital certificates issued by Korean banks to their clients for authentication and authorization purposes. It copies the directory containing these digital certificates into a ZIP archive, which is then transmitted to the attacker-controlled server. Furthermore, SoumniBot subscribes to messages from a message queuing telemetry transport server (MQTT), an essential command-and-control infrastructure component. MQTT facilitates lightweight, efficient messaging between devices, helping the malware seamlessly receive commands from remote attackers. Some of SoumniBot's malicious commands include: - Sending information about the infected device, including phone number, carrier, and Trojan version - Transmitting the victim's SMS messages, contacts, accounts, photos, videos, and online banking digital certificates - Deleting contacts on the victim's device - Sending a list of installed apps - Adding new contacts on the device - Getting ringtone volume levels With its innovative obfuscation tactics and capability to target Korean banking credentials, SoumniBot poses a significant threat to South Korean Android users. Read the full article
2 notes
·
View notes
Note
So something terrible happens which makes future Crowley go back to try to fix it and there's just 2 Crowleys running around in the present? Oh, and thanks for explaining!
Regarding not taking yourself seriously: I may not be entirely convinced by this particular theory - or any, yet - but I don't think time travel is completely out there or impossible either. Considering the way Adam resets things after the failed Apocalypse, the timeline clearly can be messed with, as can time itself, as Crowley repeatedly demonstrates. I saw the post you reblogged about the rugs and we are rapidly moving out of the territory of plausible deniability regarding the sheer number of bizarre continuity errors. Any one or two of them on their own, yes, but collectively?
If you do go looking back through the minisodes, Crowley's hair seems to go shorter-longer-shorter in Job and his sideburns look like they get quite a bit shorter in the crypt in the Resurrectionists. I didn't see anything in the Nazis minisode, but that doesn't meant nothing's there.
further ask:
hi anon!!!✨ first of all, im so sorry for not getting round to your asks until now!!!
re: first ask - mhm that's the half-baked idea, anyhow!!! and tbh 💀 im not completely convinced either but i like to entertain the possibility just out of Fun, so here we are!!!✨ oh god The Rugs - so the red one, that appears during the ball? okay sure i can accept that it is part of the Austen Aesthetic, and once the magic lifts it shifts back to the normal s2.
as for the s1 one... im torn. because i saw the amazing post where they hand-painted the mf sink tiles bc they would be in the background of a couple of shots, and wanted to at least be as close to the s1 ones as possible (GO crew honestly do the Mostest). and yeah okay, re: the difference between the s1 and s2 rugs, maybe it's that they thought 'well it's going to be on the floor most of the time and therefore out of shot' but. there are two shots that literally focus on it. as the focal point. so to my mind, they either literally couldn't find a like for like replacement (completely valid), or something Fishy is going on.
ive seen a couple of people remark on the flashbacks potentially being skewed because they're from aziraphale's perspective, but ive genuinely had the half-baked idea that the whole season is. there's so many in-story indicators, to my mind - biased red/yellow colour grading, the cartoony loch ness animation in ep3, and tbh the whole ball thing - and i do wonder if this whole rug sitch (as well as other Unexplained Things) might be chalked up to this very thing; that we are seeing s2 for the mostly part literally through aziraphale's eyes, and that what we see is a little... altered. magicked. as i said, half-baked idea, but there we are.
i did end up going through ACtO, and it's currently sat in my drafts at the moment because... well, idk what to make of it. the scenes where - by my estimation - he has the longer, more defined-curl wig, is every shot in job's house (three scenes, iirc), and so it might actually, if you consider that these scenes were likely filmed in alternative days to the other ACtO scene, a plain continuity/wig-availability issue. plus, when looking at the dialogue, all the scenes in some way link together (so i don't, essentially, think it can feasibly be the same time-travel theory). the only thing, i guess, that still remains valid is that we are seeing a recount of the events of ACtO as per aziraphale's retelling... but even then, there are plenty of scenes where they are very heavy in the crowley perspective (ie it doesn't feel like aziraphale is fudging anything), so this doesn't 100% feel like a true explanation either imo.
i do still need to look at the resurrectionists minisode though, so may well be able to parse some crackpot musing once ive done that!!!✨
1 note
·
View note
Text
I would also like to add regarding these tags: the sentiments about creative failure being indelible and cancelling out all your good work are not true and accurate to all or even most environments. There are a couple environments where they may feel true or where some bad actors may behave in a way where they become as good as true:
- in abusive relationships, including caregiver relationships you might experience early in life, you may have received the kinds of criticism that teach you never to try because failure cancels out success
- on the internet in extremely high visibility contexts - viral posts or for celebrities - some people will take it upon themselves to mock or cancel people just for making understandable errors, particularly where those errors can be parsed as a failure to care enough about the needs of everyone else on the damn planet everywhere, OR where those errors may involve having some trait that is mockable according to conventional societal standards of various flavours (eg “oh look this person screwed up while being non-normative in their social performance or gender or looks, we are shitty bullies so we’re gonna mock them”)
The vast majority of functional human beings do not agree that “if you draw a line wrong you’re a fraud and an impostor” or “you are your mistakes” or “everyone hates you forever”. These are beliefs that arise from a distorted world view, potentially arising from negative prior experiences but sometimes just arising from your brain fucking with you by way of anxiety disorder.
Running events in a way where there’s an error is a matter of scale. If you mess up something about the physical safety of an event and people are injured that may be a big deal, but if you undercater, or forget to invite someone, or your accessibility could use improvement, these are not indelible failures, they’re errors where we can learn iteratively.
If you give advice and you give incorrect advice, the scale of the error matters a lot, but often your prior training can help you heaps. If giving advice as a hobby or calling stresses you out enormously because of the potential risk to others, it’s ok to not prioritise that option. But there are low stakes areas where an error is just not a big deal, or where the advice you’re giving is a matter of taste.
In terms of combatting the belief that any failure is essentially terminal, cognitive strategies - the kind you might find in therapies like CBT or ACT - can be really helpful. Another thing that can help is low stakes practice - trying out failure in a controlled safe environment in small doses with people you trust, to give your brain and nervous system the experience of feeling, over and over again, that failure can be ok.
I think people get mixed up a lot about what is fun and what is rewarding. These are two very different kinds of pleasure. You need to be able to tell them apart because if you don't have a balanced diet of both then it will fuck you up, and I mean that in a "known cause of persistent clinical depression" kind of way.
46K notes
·
View notes
Text
Google reCAPTCHA Integration in Salesforce Visualforce Page using Apex
In the modern digital world, securing online forms from bots and spam is more important than ever. Whether you're capturing leads, handling contact requests, or managing user registrations through a Visualforce page in Salesforce, protecting your forms from automated submissions is essential. Google reCAPTCHA is a powerful tool that helps identify and block such unwanted activity.
This article explains how to integrate Google reCAPTCHA into a Salesforce Visualforce page and validate user submissions using Apex, without diving into code.
What is Google reCAPTCHA?
Google reCAPTCHA is a free service by Google that protects websites from spam and abuse by verifying if a user is a human or a bot. It can be displayed as a simple checkbox, an invisible check, or a challenge-based interaction (like identifying traffic lights in images). It works on both the client-side (user's browser) and the server-side (your Apex controller).
How Integration Works
Integrating reCAPTCHA in Salesforce involves a few simple steps:
Register Your Website: Go to the Google reCAPTCHA admin console and generate a site key and a secret key.
Add reCAPTCHA to Visualforce Page: The site key is used on the Visualforce page to show the reCAPTCHA widget.
Form Submission: When a user fills out the form and submits it, a token is generated by reCAPTCHA and passed along with the form data.
Server-Side Verification: The Apex controller receives the token and uses the secret key to verify the token by sending a request to Google’s reCAPTCHA API.
Response Handling: Based on the verification result from Google, the form is either accepted or rejected.
Why Use Two Apex Classes?
To keep the integration clean and maintainable, the logic is split into two classes:
1. Visualforce Page Controller: This handles form inputs, manages user interactions, and calls the reCAPTCHA validation logic.
2. reCAPTCHA Service Class: This makes the callout to Google’s verification API, parses the response, and sends back a success or failure status.
This approach follows Salesforce best practices: separation of concerns, code reusability, and easy testing.
Benefits of Using reCAPTCHA with Visualforce
Prevents spam: Stops bots from submitting fake entries.
Improves security: Ensures only real users can interact with your forms.
Better user experience: The invisible or checkbox method is smooth for users.
Easy integration: With just a small setup, your forms become much safer.
Best Practices
Always store the secret key securely using Custom Metadata, Custom Settings, or Named Credentials.
Handle errors and timeouts gracefully in your Apex logic.
Use HTTP mocks in test classes for callout testing.
Log or monitor verification failures for auditing or debugging.
Final Thoughts
Implementing Google reCAPTCHA in a Visualforce form using Apex is a smart way to secure your Salesforce application from bots and spam. It not only enhances the trustworthiness of your system but also ensures a smoother experience for real users.
By separating responsibilities between a controller and a helper class, you follow clean architecture principles that make your solution scalable and easier to maintain in the long run.
read more:https://scideassolutions.com/google-recaptcha-integration-in-salesforce-visualforce-page-using-apex/
#SalesforcereCAPTCHAintegration, #Visualforcesecurity, #GooglereCAPTCHAApex, #spampreventionSalesforce
Looking to grow your business? Connect with us for a free consultation and discover how we can help you succeed online.
📌 Website: www.scideassolutions.com 📧 Email: [email protected] 💬 Skype: skumar25dec
1 note
·
View note
Text
Streamlining Hiring for Small Businesses
In today’s competitive market, small and medium-sized enterprises (SMEs) need every advantage they can get to attract and retain top talent. The recruitment process plays a pivotal role in shaping a company's workforce, and managing this process efficiently can often be the difference between success and missed opportunities. Especially for small business owners juggling multiple roles, optimizing hiring with the right tools can bring significant relief.
Small Business Recruitment
Small businesses often face unique challenges when it comes to recruitment. Limited budgets, smaller HR teams, and the need for fast hiring decisions can put pressure on employers to streamline their approach. Unlike large corporations, small businesses may not have the luxury of extended hiring timelines or broad brand recognition, making it essential to focus on strategic recruitment.
A key component of small business recruitment is defining job roles clearly and understanding exactly what kind of candidate the business needs. In smaller teams, every new hire has a noticeable impact, so there is little room for error. Precise job descriptions not only help attract the right candidates but also deter those who may not be a good fit, saving time for both the employer and the applicant.
Leveraging technology is another essential strategy. Digital platforms and recruitment software help small businesses post jobs to multiple boards, screen applications quickly, and manage communications with applicants in a professional manner. This technological shift has leveled the playing field, allowing smaller companies to compete with larger firms in attracting skilled talent.
ATS for Small Business
After posting a job and receiving applications, the next challenge is managing the flow of information effectively. For small teams, the hiring process can quickly become overwhelming. This is where an ats for small business steps in as a crucial asset.
An Applicant Tracking System (ATS) automates and organizes many parts of the recruitment journey, helping small businesses track candidates from the moment they apply to the final decision. For businesses with limited HR resources, an ATS is not a luxury—it’s a necessity. It eliminates the chaos of spreadsheets, scattered emails, and manual follow-ups, offering instead a centralized dashboard for all hiring activities.
ATS platforms like Hirenga are designed with simplicity and efficiency in mind. They’re intuitive and require minimal training, which is ideal for small teams without dedicated HR departments. From resume parsing to automated emails and customizable pipelines, these tools help businesses save hours of manual work while maintaining a professional approach toward applicants.
Job Application Tracking
One often overlooked aspect of recruitment is the meticulous task of tracking job applications. When applications start pouring in, small businesses can find themselves drowning in resumes, losing track of promising candidates, or missing follow-up deadlines. This is why job application tracking is essential to any effective hiring strategy.
At its core, job application tracking involves maintaining an organized and up-to-date record of all applicants and where they are in the hiring process. It sounds simple, but doing it manually can be time-consuming and error-prone, especially when handling multiple roles or sudden spikes in applicants. Automation becomes a powerful ally here.
Tools like Hirenga simplify job application tracking by offering a visual representation of the hiring funnel. With drag-and-drop features and status updates, employers can instantly see which candidates are in the screening, interview, or offer stages. This clarity reduces back-and-forth within hiring teams and ensures timely communication with candidates.
Another key benefit of job application tracking is improved candidate experience. Applicants appreciate transparency and responsiveness. When their information is well-tracked, businesses can send timely updates, reducing the common frustration of being left in the dark. A positive candidate experience not only boosts the company’s reputation but also increases the chances of securing top talent.
0 notes
Text
Global Address Verification API: 245+ Countries Address Database
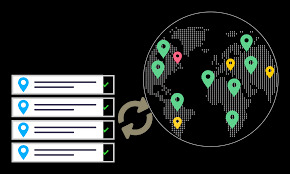
Operating in a global market requires an address verification solution that supports worldwide address formats and postal regulations. A global address verification API enables businesses to validate addresses from over 245 countries and territories.
What Is a Global Address Verification API?
It’s a software interface that allows developers and systems to send address data for validation, standardization, and correction in real-time or batch mode.
Key Capabilities
Multilingual input and output support
Transliteration and standardization for non-Latin scripts
Validation against international postal authorities
Geolocation enrichment
Why Use It?
Avoid delivery delays and customs issues
Increase international customer satisfaction
Ensure accurate billing and shipping records
Challenges in Global Address Verification
Different address structures per country
Non-standardized postal codes or city names
Language and script variations
Frequent changes in administrative divisions
Global Address Database Coverage
Includes official postal data from:
United States (USPS)
Canada (Canada Post)
United Kingdom (Royal Mail)
Australia (Australia Post)
Germany (Deutsche Post)
Japan Post
And 240+ others
Top Global Address Verification API Providers
Loqate
Melissa Global Address Verification
SmartyStreets International API
Google Maps Places API (for autocomplete and partial validation)
HERE Technologies
How It Works
Input Collection: User enters address via web form or app.
API Call: The address is sent to the global verification API.
Data Processing:
Parsed and matched against local country address rules
Standardized and corrected
Output: Returns validated address, possible corrections, and geolocation data.
Use Cases
Ecommerce platforms shipping worldwide
Subscription box services with international clients
Financial institutions verifying global customer records
Travel agencies handling cross-border bookings
Compliance and Data Privacy
Ensure your API vendor complies with:
GDPR (Europe)
CCPA (California)
PIPEDA (Canada)
Data localization laws (as applicable)
Tips for Choosing the Right API
Evaluate global coverage accuracy
Look for uptime and support availability
Consider ease of integration (RESTful API, SDKs, plugins)
Prioritize scalability and speed
Final Thoughts
Investing in robust global address verification API is essential for businesses operating across borders. Not only does it streamline logistics and reduce errors, but it also builds trust with customers by ensuring reliable communication and delivery.
By implementing these address checking solutions and leveraging modern tools tailored for both local and international use, businesses can dramatically improve operational efficiency, cut costs, and deliver a superior customer experience.
youtube
SITES WE SUPPORT
Validate USPS Address – Wix
1 note
·
View note
Text
Tumblr API
In the digital age, APIs (Application Programming Interfaces) have become crucial tools for developers, enabling them to build richer, more dynamic experiences by integrating and leveraging external services. One such API that has garnered attention is the Tumblr API, which allows developers to access the vast functionalities of Tumblr's microblogging platform to create custom applications and solutions. Tumblr, a platform known for its vibrant community and highly customizable blogs, offers an API that provides programmatic access to its features. This enables developers to read and write Tumblr data, including posts, likes, follows, and more. By using the Tumblr API, developers can automate processes or create entirely new applications that interact with Tumblr in innovative ways. The Tumblr API is RESTful, meaning it follows the representational state transfer architectural style. This makes it straightforward for developers to work with, as it uses standard HTTP methods like GET, POST, PUT, and DELETE. The responses from the API are returned in JSON format, which is lightweight and easy to parse in various programming languages. To start using the Tumblr API, a developer must first obtain credentials by registering their application with Tumblr. This process involves creating an app on the Tumblr website, which provides the necessary OAuth consumer key and secret needed for authentication. OAuth is a standard protocol for authorization that ensures secure access to server resources without exposing user credentials. Once authenticated, developers can make requests to the API to perform different actions. For example, they can fetch public information about a blog, retrieve posts by type (text, photo, quote, link, chat, audio, or video), or even post new content directly to a Tumblr blog programmatically. This opens up possibilities for apps that integrate features like live blogging events, managing multiple blogs simultaneously, or curating content automatically based on specific criteria. Moreover, the Tumblr API supports several useful endpoints. The `/user/info` endpoint retrieves information about the authenticated user, while `/blog/{blog-identifier}/info` gets information about a specific blog. There are also endpoints for retrieving or posting likes and follows, which can be particularly useful for social media analytics and engagement tools. One of the strengths of using the Tumblr API is its flexibility. Developers can build a wide range of applications, from simple scripts that automate daily tasks to complex systems that analyze and interact with Tumblr data in real-time. Additionally, since Tumblr hosts a diverse array of content and communities, applications built with the Tumblr API can cater to niche interests or broad audiences alike. However, working with any API comes with challenges. Rate limits are a common issue; these are restrictions on the number of requests that can be made to the API within a certain time frame. Exceeding these limits can result in temporary blocks or slower response times. Therefore, developers need to handle these limits gracefully in their applications by implementing proper error handling and possibly queuing requests. Security is another critical aspect when dealing with APIs. Since applications using the Tumblr API might handle sensitive user data, ensuring data privacy and security through encryption and secure storage practices is paramount. Furthermore, maintaining compliance with data protection regulations like GDPR is essential when operating in or targeting users from certain regions. In conclusion, the Tumblr API offers extensive capabilities for developers looking to harness the power of social blogging for their applications. Whether it's enhancing existing products with Tumblr integration or building specialized tools for tumblr users, the potential uses are as varied as they are exciting. As with any development project involving third-party services, success often hinges on understanding and navigating the technical requirements and limitations effectively. wordpress By embracing these technologies and adhering to best practices in software development and data security, developers can unlock new creative potentials and deliver exceptional value to users.
wordpress
1 note
·
View note
Text
Top 7 Features to Look for in an SME HRMS Solution

Small and medium enterprises (SMEs) face unique challenges in managing their human resources. With limited budgets and lean HR teams, SMEs need a powerful yet cost-effective solution to handle HR operations efficiently.
This is where HRMS solutions for small businesses come into play. The right HRMS can automate tedious HR processes, ensure compliance, and enhance workforce productivity. But with so many options available, what should SMEs look for in an HRMS? Here are the top seven must-have features:
1. Automated Payroll Processing and Compliance Management
One of the most critical functions of an HRMS for small businesses is payroll automation. Payroll errors can be costly and time-consuming to rectify, especially for businesses that lack a dedicated payroll department. The HRMS should be capable of:
Automatically calculating salaries, tax deductions, and bonuses
Ensuring compliance with labour laws and tax regulations
Generating payslips and reports with ease
Integrating with accounting software to streamline financial processes
A strong HRMS ensures that payroll processing is accurate and compliant with government regulations, reducing the risk of penalties and employee dissatisfaction.
2. Employee Self-Service (ESS) Portal
An efficient SME HRMS should empower employees with a self-service portal that allows them to:
Access payslips and tax documents
Apply for leaves and check leave balances
Update personal information
Track attendance and work hours
This reduces the administrative burden on HR teams and improves employee satisfaction by offering transparency and easy access to HR-related tasks.
3. Attendance and Leave Management
For SMEs, tracking employee attendance and leave manually can be a hassle. A good HRMS should have:
Biometric attendance integration
Geofencing and GPS-based tracking for remote workers
Automated leave tracking and approval workflows
Real-time dashboards to monitor workforce availability
An integrated system helps in reducing absenteeism, ensuring compliance with leave policies, and maintaining accurate records.
4. Recruitment and Onboarding Automation
Hiring and onboarding new employees efficiently is essential for SMEs that want to scale. The HRMS should simplify recruitment by offering:
Job posting and applicant tracking
Resume parsing and candidate evaluation tools
Digital onboarding with e-signatures and document uploads
Automated background verification and compliance checks
A streamlined recruitment and onboarding process ensures that new hires can quickly integrate into the company and become productive members of the team.
5. Performance Management System
An SME HRMS should facilitate a structured approach to performance evaluation. Key features to look for include:
Goal setting and performance tracking
360-degree feedback and peer reviews
Automated performance review cycles
Integration with Learning & Development (L&D) modules for upskilling employees
A data-driven performance management system helps SMEs nurture talent, improve employee engagement, and drive organisational growth.
6. Mobile Accessibility and Cloud-Based Functionality
In today’s digital era, HR teams and employees need access to HR functions on the go. A cloud-based, mobile-friendly HRMS enables:
Remote access to HR data and processes
Real-time notifications and alerts
Seamless integration with other business applications
Secure data storage with automated backups
With a mobile-ready HRMS, SMEs can ensure flexibility, efficiency, and data security while reducing dependency on manual paperwork.
7. Advanced Analytics and Reporting
SMEs need data-driven insights to make strategic HR decisions. The right HRMS solution should offer:
Customisable dashboards and real-time analytics
Employee productivity tracking and trend analysis
Turnover and retention insights
Compliance and payroll audit reports
Having access to actionable insights helps SMEs optimise workforce management, reduce costs, and improve decision-making.
Finishing Up
Selecting the right HRMS can significantly enhance HR efficiency for SMEs, reducing manual work, improving employee experience, and ensuring compliance. Opportune HR provides a comprehensive and scalable HRMS designed to meet the unique needs of SMEs. From payroll automation to advanced analytics, our solution enables small businesses to streamline HR processes effortlessly.
If you're looking for the best HRMS for small businesses, contact Opportune HR today and take the first step toward transforming your HR operations!
0 notes
Text
How to Beat ATS & Get Your Resume Seen | Maven Jobs
Have you ever sent out hundreds of job applications and heard… nothing? You’re not alone. Your resume might be stuck in a bottleneck known as the Applicant Tracking System (ATS). These systems are the first hurdle job seekers face when applying online, and more than 60% of resumes get rejected before they even land on a recruiter’s desk.

Stuck in the ATS black hole? MavenJobs helps job seekers bypass ATS filters and get direct interviews. Skip the struggle — Get Job Placement Help Now!
What is an ATS?
An Applicant Tracking System (ATS) is recruitment software companies use to streamline the hiring process. Essentially, it acts as a digital gatekeeper, scanning and filtering resumes to save hiring managers time when dealing with hundreds (or sometimes thousands) of applications.
Why Do Companies Use ATS?
ATS helps companies:
Save time by automating the initial screening process.
Organize applications for easy retrieval and comparisons.
Identify top candidates by ranking resumes based on specific criteria like keywords, skills, and qualifications.
With 75% and 98% of Fortune 500 companies using ATS, these systems have become a non-negotiable part of modern job applications.
The Problem for Job Seekers
For applicants, ATS can be a double-edged sword. While it ensures that companies can quickly zero in on qualified candidates, it often eliminates poorly formatted resumes or missing the “right” keywords. Even highly skilled candidates may get filtered out if their resumes aren’t optimized for ATS.
Section 1: Understanding How ATS Works
Before you can beat ATS, you need to understand how it operates. Here’s a breakdown:
How ATS Scans Resumes
ATS doesn’t just “read” resumes like a recruiter would. These systems:
Parse your resume into sections (e.g., experience, education, skills).
Scan for keywords that match the job description.
Rank your resume based on how well it fits the job posting.
Filter out resumes with formatting errors or missing key elements.
Common Reasons for ATS Rejection
Keyword Mismatch: Missing important job-specific or industry-relevant terms.
Unscannable Formatting: Using tables, graphics, or non-standard fonts that ATS can’t process.
Wrong File Format: Some systems fail to read PDFs properly; .DOCX is usually safer.
Gaps in Employment: Unexplained employment gaps can raise red flags.
Understanding these basics is essential to crafting a resume that gets through the system.
Section 2: How to Create an ATS-Friendly Resume
Now that you understand how ATS works, here’s how to craft a resume that gets noticed.
Choose the Right Resume Format
Do this: Use a reverse chronological format, first listing your most recent experiences.
Avoid this: Functional resumes that focus on skills but omit specific experiences. ATS often can’t process them effectively.
Use Proper ATS-Compatible Formatting
Stick to standard fonts like Arial, Calibri, or Times New Roman.
Save your file in .DOCX format unless the job posting specifies otherwise.
Keep a clean, simple layout. Avoid images, graphics, headers, or columns.
Optimize Your Resume with ATS Keywords
One of the best ways to beat ATS is by using the right keywords:
Extract keywords from the job description.
Incorporate these keywords naturally throughout your resume.
Use synonyms and variations like “SEO” and “Search Engine Optimization.”
Example
Instead of “Managed a team,” write, “Team Management | Led cross-functional teams to deliver $2M in revenue projects.”
Include the Right Resume Sections
A well-structured resume is ATS-friendly. Make sure to include:
Summary: Use 2–3 powerful sentences that include job-specific keywords.
Skills: Include a mix of hard skills (specific to the job) and soft skills.
Work Experience: Focus on quantifiable results (e.g., “Boosted sales by 20% in 6 months”).
Education: Include degrees, certifications, and any relevant training.
Avoid ATS Killers
Here’s what you should NEVER do:
Use graphics, photos, or icons.
Include fancy or non-standard fonts.
Add text in headers or footers (ATS can’t read them).
Leave unexplained gaps in your employment history.
Section 3: How to Test Your Resume Before Applying
Don’t risk submitting a resume that doesn’t pass ATS scrutiny. Here’s how to test its compatibility:
Use ATS Resume Checkers
Take advantage of free tools like:
Jobscan.co: Optimize your resume keywords for specific job descriptions.
Zety Resume Scanner: Offers recommendations for ATS-friendly formatting.
Resunate: Helps refine your resume based on ATS preferences.
Conduct a Plain Text Test
Copy-paste your resume into a plain text file like Notepad. If the formatting looks messy or unreadable, ATS will likely struggle to process it.
Use LinkedIn’s “Easy Apply” Feature
Some job applications on LinkedIn bypass ATS entirely, giving you another edge.
Section 4: Should You Use a Placement Agency for ATS Success?
Still struggling to get noticed? Consider working with a placement agency.
Benefits of Recruitment Agencies
Bypass ATS: Many agencies send resumes directly to hiring managers.
Expert Guidance: Agencies often rewrite your resume based on ATS algorithms.
Tailored Opportunities: They match your skills with the right job openings.
At MavenJobs, we help job seekers optimize resumes and connect directly with recruiters to fast-track the hiring process. Interested? Reach out to us for tailored support!
Maximize Your Chances of Landing an Interview
Creating an ATS-friendly resume doesn’t just help you get noticed; it’s a critical step in today’s competitive job market. By understanding how ATS works, optimizing your resume formatting and keywords, and testing your resume with ATS tools, you can significantly improve your chances of landing your dream job.
Need help fine-tuning your resume? Let MavenJobs guide you through the process! We’ll help you beat the bots, get more interviews, and secure the role you’ve been waiting for.
#job#job interview#resume#resume writing tips#job hunting#ats resume#jobs#job opportunities#job seekers
1 note
·
View note
Text
Selenium, JMeter, Postman: Essential Tools for Full Stack Testers Using Core Java
Testing in software development has evolved into a critical discipline, especially for full-stack testers who must ensure applications function seamlessly across different layers. To achieve this, mastering automation and performance testing tools like Selenium, JMeter, and Postman is non-negotiable. When paired with Core Java, these tools become even more powerful, enabling testers to automate workflows efficiently.
Why Core Java Matters for Full Stack Testing?
Core Java provides the foundation for automation testing due to its:
Object-Oriented Programming (OOP) concepts that enhance reusability.
Robust exception handling mechanisms to manage errors effectively.
Multi-threading capabilities for parallel execution in performance testing.
Rich library support, making interactions with APIs, databases, and UI elements easier.
Let's explore how these three tools, powered by Core Java, fit into a tester’s workflow.
1. Selenium: The Backbone of UI Automation
Selenium is an open-source tool widely used for automating web applications. When integrated with Java, testers can write scalable automation scripts that handle dynamic web elements and complex workflows.
How Core Java Enhances Selenium?
WebDriver API: Java simplifies handling elements like buttons, forms, and pop-ups.
Data-driven testing: Java’s file handling and collections framework allow testers to manage test data effectively.
Frameworks like TestNG & JUnit: These Java-based frameworks provide structured reporting, assertions, and test case organization.
Example: Automating a Login Page with Selenium & Java

This simple script automates login validation and ensures that the dashboard page loads upon successful login.
2. JMeter: Performance Testing Made Simple
JMeter is a powerful performance testing tool used to simulate multiple users interacting with an application. Core Java aids in custom scripting and result analysis, making JMeter tests more versatile.
Java’s Role in JMeter
Writing custom samplers for executing complex business logic.
Integrating with Selenium for combined UI and performance testing.
Processing JTL results using Java libraries for deep analysis.
Example: Running a Load Test with Java

This Java-based JMeter execution script sets up a test plan with 100 virtual users.
3. Postman: API Testing and Core Java Integration
Postman is widely used for API testing, allowing testers to validate RESTful and SOAP services. However, for advanced automation, Postman scripts can be replaced with Java-based REST clients using RestAssured or HTTPClient.
Core Java’s Power in API Testing
Sending GET/POST requests via Java’s HTTP libraries.
Parsing JSON responses using libraries like Jackson or Gson.
Automating API test suites with JUnit/TestNG.
Example: Sending an API Request Using Java

This snippet retrieves a JSON response from a dummy API and prints its contents.
Key Takeaways
Selenium + Core Java = Robust UI Automation.
JMeter + Core Java = Advanced Load Testing.
Postman + Core Java = Scalable API Automation.
Mastering these tools with Core Java sets full-stack testers apart, enabling them to build comprehensive, scalable, and efficient test automation frameworks.
Frequently Asked Questions (FAQ)
Q1: Why is Core Java preferred over other languages for testing? A: Java’s portability, object-oriented features, and vast libraries make it an ideal choice for automation testing.
Q2: Can I use Postman without Java? A: Yes, but using Java-based libraries like RestAssured provides more control and scalability in API automation.
Q3: How do I choose between Selenium and JMeter? A: Selenium is for UI automation, while JMeter is for performance testing. If you need both, integrate them.
Q4: Is Java mandatory for Selenium? A: No, Selenium supports multiple languages, but Java is the most widely used due to its reliability.
Q5: What are the best Java frameworks for test automation? A: TestNG, JUnit, Cucumber, and RestAssured are the most popular for various types of testing.
#TestingTools#AutomationTesting#FullStackTesting#Selenium#JMeter#Postman#CoreJava#JavaTesting#SoftwareTesting#APITesting#PerformanceTesting#TestAutomation#QA#QualityAssurance#TechBlog#Coding#DevLife
1 note
·
View note