#hdfs tutorial
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
70% of Tumblr users say the Dashboard is their favorite place to spend time online.
Text
i am trying to play this

but the process of installing it. mein gott
commodore emulation on a handheld is possible but i can't find a comprehensive tutorial for my situation (anbernic 40 running muOS). i am engaged in mortal fucking combat with retroarch which keeps saying FEED ME KICKSTART ROMS BOY. kickstarts from what i can tell are little bonus files that tell the emulator how to process big deal software. so i was like Fine. you can have those. but the muOS file structure is uniquely odd (especially compared to windows) and the folder where the kickstarts should live does not exist. i think the solution here is to fiddle around with another OS or use an emulator that doesn’t rely on retroarch
ONTO OTHER PROBLEMS! mind walker is only available in .adf. the reddit jury’s general consensus seems to be that .adf is the most annoying commodore rom format due to the load times (long) and emulator compatibility (variable). i have no idea if some brave angel with a neocities site has created an adf -> hdf converter. worst case scenario if the adf rom doesn't work would involve nixing the handheld plan entirely and pivoting to windows emu (more documentation and much easier to troubleshoot). there is a way to screenshare from PC but it wouldn't feel true to the vision. i am desperate to make this work on handheld if at all possible. dunno why. the idea of a portable geometric mad scientist game is just supremely appealing to me on so many levels. if i manage to get this thang up and running i will be so happy. ONWARDS!
35 notes
·
View notes
Text
Data Engineering User Guide
Data Engineering User Guide #sql #database #language #query #schema #ddl #dml#analytics #engineering #distributedcomputing #dataengineering #science #news #technology #data #trends #tech #hadoop #spark #hdfs #bigdata
Even though learning about Data engineering is a daunting task, one can have a clear understanding of this filed by following a step-by-step approach. In this blog post, we will go over each of the steps and relevant steps you can follow through as a tutorial to understand Data Engineering and related topics. Concepts on Data In this section, we will learn about data and its quality before…
0 notes
Text
Hadoop Docker

You’re interested in setting up Hadoop within a Docker environment. Docker is a platform for developing, shipping, and running applications in isolated environments called containers. On the other hand, Hadoop is an open-source framework for the distributed storage and processing of large data sets using the MapReduce programming model.
To integrate Hadoop into Docker, you would typically follow these steps:
Choose a Base Image: Start with a base Docker image with Java installed, as Hadoop requires Java.
Install Hadoop: Download and install Hadoop in the Docker container. You can download a pre-built Hadoop binary or build it from the source.
Configure Hadoop: Modify the Hadoop configuration files (like core-site.xml, hdfs-site.xml, mapred-site.xml, and yarn-site.xml) according to your requirements.
Set Up Networking: Configure the network settings so the Hadoop nodes can communicate with each other within the Docker network.
Persistent Storage: Consider setting up volumes for persistent storage of Hadoop data.
Cluster Setup: If you’re setting up a multi-node Hadoop cluster, you must create multiple Docker containers and configure them to work together.
Run Hadoop Services: Start Hadoop services like NameNode, DataNode, ResourceManager, NodeManager, etc.
Testing: Test the setup by running Hadoop examples or your MapReduce jobs.
Optimization: Optimize the setup based on the resource allocation and the specific use case.
Remember, the key to not getting your emails flagged as spam when sending bulk messages about course information or technical setups like this is to ensure that your emails are relevant, personalized, and provide value to the recipients. Also, adhere to email marketing best practices like maintaining a clean mailing list, using a reputable email service provider, avoiding spammy language, and including an easy way for recipients to unsubscribe.
Look at specific tutorials or documentation related to Hadoop and Docker for a more detailed guide or troubleshooting.
Hadoop Training Demo Day 1 Video:
youtube
You can find more information about Hadoop Training in this Hadoop Docs Link
Conclusion:
Unogeeks is the №1 IT Training Institute for Hadoop Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Hadoop Training here — Hadoop Blogs
Please check out our Best In Class Hadoop Training Details here — Hadoop Training
S.W.ORG
— — — — — — — — — — — -
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
#unogeeks #training #ittraining #unogeekstraining
0 notes
Text
Streamlining Big Data Analytics with Apache Spark

Apache Spark is a powerful open-source data processing framework designed to streamline big data analytics. It's specifically built to handle large-scale data processing and analytics tasks efficiently. Here are some key aspects of how Apache Spark streamlines big data analytics:
In-Memory Processing: One of the significant advantages of Spark is its ability to perform in-memory data processing. It stores data in memory, which allows for much faster access and processing compared to traditional disk-based processing systems. This is particularly beneficial for iterative algorithms and machine learning tasks.
Distributed Computing: Spark is built to perform distributed computing, which means it can distribute data and processing across a cluster of machines. This enables it to handle large datasets and computations that would be impractical for a single machine.
Versatile Data Processing: Spark provides a wide range of libraries and APIs for various data processing tasks, including batch processing, real-time data streaming, machine learning, and graph processing. This versatility makes it a one-stop solution for many data processing needs.
Resilient Distributed Datasets (RDDs): RDDs are the fundamental data structure in Spark. They are immutable, fault-tolerant, and can be cached in memory for fast access. This simplifies the process of handling data and makes it more fault-tolerant.
Ease of Use: Spark provides APIs in several programming languages, including Scala, Java, Python, and R, making it accessible to a wide range of developers and data scientists. This ease of use has contributed to its popularity.
Integration: Spark can be easily integrated with other popular big data tools, like Hadoop HDFS, Hive, HBase, and more. This ensures compatibility with existing data infrastructure.
Streaming Capabilities: Spark Streaming allows you to process real-time data streams. It can be used for applications like log processing, fraud detection, and real-time dashboards.
Machine Learning Libraries: Spark's MLlib provides a scalable machine learning library, which simplifies the development of machine learning models on large datasets.
Graph Processing: GraphX, a library for graph processing, is integrated into Spark. It's useful for tasks like social network analysis and recommendation systems.
Community Support: Spark has a vibrant and active open-source community, which means that it's continuously evolving and improving. You can find numerous resources, tutorials, and documentation to help with your big data analytics projects.
Performance Optimization: Spark provides various mechanisms for optimizing performance, including data partitioning, caching, and query optimization.
1 note
·
View note
Text

HDFS Tutorial – A Complete Hadoop HDFS Overview
The objective of this Hadoop HDFS Tutorial is to take you through what is HDFS in Hadoop, what are the different nodes in Hadoop HDFS, how data is stored in HDFS, HDFS architecture, HDFS features like distributed storage, fault tolerance, high availability, reliability, block, etc.
1 note
·
View note
Text
Features of Hadoop Distributed File System
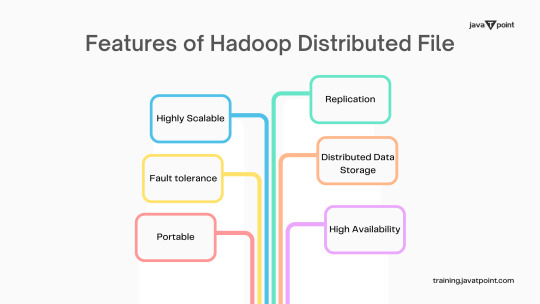
HDFS is a distributed file system that handles big data sets on commodity hardware. Big data is a group of enormous datasets that cannot be processed with the help of using traditional computing methods. Learn Big Data Hadoop from the Best Online Training Institute in Noida. JavaTpoint provides Best Big Data Hadoop Online Training with live projects, full-time job assistance, interview preparation and many more. Address: G-13, 2nd Floor, Sec-3 Noida, UP, 201301, India Email: [email protected] Contact: (+91) 9599321147, (+91) 9990449935
#datascience#bigdata#hdfs#coding#programming#tutorial#python#corejava#awstraining#meanstacktraining#webdesigningtraining#networkingtraining#digitalmarketingtraining#devopstraining#javatraining#traininginstitute#besttraininginstitute#education#online#onlinetraining#training#javatpoint#traininginnoida#trainingspecialization#certification#noida#trainingprogram#corporatetraining#internshipprogram#summertraining
1 note
·
View note
Text
Amiga Workbench 3.1 Hdf

A step-by-step tutorial on how to make then burn an SD or CF card image for your Amiga that is fully loaded and configured with Amiga OS 3.1.4 and 1000's gam. Anyway, all good now and have tested on a freshly installed / bog-standard Workbench 3.1.HDF and also a Classic Workbench 3.1 Lite.HDF. So, just extract the archive to the root of your hard drive and when in the folder 'onEscapee' it's looks like this: Workbench 3.1: Classic Workbench 3.1 Lite.
This article will probably repeat some points in the piStorm – basic configuration guide. It’s meant as a quickstart for those who not at this time want to explore all the possibilities the piStorm gives.
Be sure to put the files (kickstart and hdf) in the right location on the SD-card, whatever you want, or follow my directions and put them in /home/pi/amiga-files. The important thing is that the paths in the configuration is set to the same.
Installation of AmigaOS 3.1 on a small hard drive
For this installation, I have choosen AmigaOS 3.1 for several reasons. The main reason is its availability, in reach for everyone through Amiga Forever Plus edition, and also because its low amount of installation disks (6 disks needed, instead of 17 or similar for 3.2).
Conditions: Configuration files are given a descriptive name and put into /home/pi/cfg. At start of the emulator, the actual config is copied as “default.cfg” and put into /home/pi. This is part of what I did to make it possible to switch config files using the keyboard attached to the Pi (Linux: how to run commands by keypress on the local console). Amiga-related files (kickstart and hdf) are stored in /home/pi/amiga-files

With “floppy”/”disk” (or drive) in this guide, any Amiga compatible replacement, such as a GoTek drive with Flashfloppy, can be used.
For a basic AmigaOS 3.1 installation, have these disks (in this order) available. amiga-os-310-install amiga-os-310-workbench amiga-os-310-locale amiga-os-310-extras amiga-os-310-fonts amiga-os-310-storage
These disks are available from your legally acquired Amiga Forever Plus Edition (or above), any release from 2008 (my oldest one) and up is recent enough. Look for the adf files in the “Amiga files/System/adf” or “Amiga files/Shared/adf” folder. You also need the kickstart ROM from the same base folder (“System” or “Shared”). The file you want is the “amiga-os-310-a1200.rom”. I have renamed the kickstart file to “kick-31-a1200-40.68.rom” and then put it in my “amiga-files” folder on the pi.
Start by setting up the piStorm configuration for using the correct ROM and for enabling hard drive support: Copy the configuration template “pistorm/default.cfg” to “/home/pi/cfg/a1200_4068_os31.cfg”, then change/add:
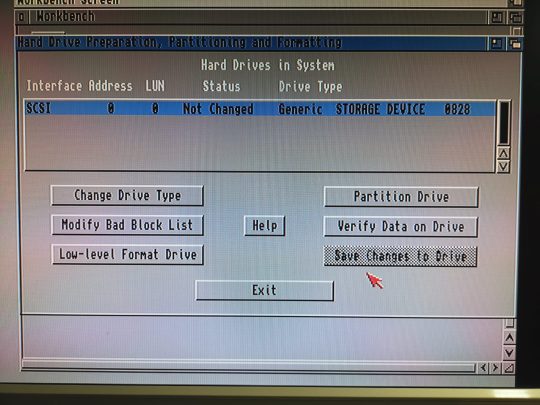
It’s also important to use a the first available free SCSI id here (piscsi0), as there is a unique feature in piscsi that hides all drives configured following a gap in the SCSI id sequence, so that they won’t be seen in HDToolBox. piscsi0 must always be used by any disk, otherwise, you will get an empty list of drives in HDToolBox.
After saving the changes, go ahead and create an empty hdf for the installation:
504MB is enormous in Amiga-terms 🙂 The bs (block size) of 504k gives the piStorm the optimal number of heads (16) and blocks per track (63) on auto-detecting the hard drive geometry.
Insert the amiga-os-310-install floppy and start up the emulator: (and start with stopping it if it’s running, “killall -9 emulator” or use systemctl if you have followed my instructions on setting it up as a service)
Workbench will load from the installation disk. Copy HDToolBox from HDTools (put it on the RAM-disk). Change the tooltype SCSI_DEVICE_NAME (to pi-scsi.device). Run HDToolBox from RAM:, and you will see a new unknown disk. Use “Change Drive Type”, “Define New…” and then “Read Configuration”. Return to the main window (click the “OK” buttons). Partition the drive. Remove the second partition, and set the size of the first to something large enough for AmigaOS. 80MB is plenty of space (AmgiaOS 3.1 takes up 2.8MB fully installed). Create another partition of the rest of the space. Change the device names of the partitions if you wish. Save changes and soft-reboot the Amiga (it will boot up from the install floppy again). You will see the two unformatted (PDH0 and PDH1:NDOS) drives. Format PDH0 (or whatever you set as device names), the smaller one, and name it “System”, uncheck “Put Trashcan”, check “Fast File System”, uncheck “International Mode”, then click “Quick Format” and accept all the warnings).
Start the installation from the Install-floppy (select “Intermediate user” to have some control of the options), use whatever language you wish for the installation process and select languages and keymaps as desired. Change floppy when the installer asks for it. Once done, remove the install floppy and let the installer reboot your Amiga. It will boot up from the hard drive to your fresh installation of AmigaOS 3.1. Format the other partition and name it “Work” or whatever you want. Follow the instructions above (FFS, no trash, no intl, quick format).
That’s it.
a314: access to a folder on the pi as a drive on the Amiga
Most of below is a rewrite of the documentation for a314 for the pistorm.
Amiga Workbench 3.1 Hdf Download
To make it a lot easier to transfer files over to the Amiga, a folder can be shared as a drive through a314 emulation.
On the pi-side: To keep contents and configuration files safe when updating the piStorm software, I put the config files in /home/pi/cfg and content in /home/pi/amiga-files/a314-shared. If you do not, and keep the configuration unchanged, the shared files will be in the “data” folder inside the pistorm binary directory (/home/pi/pistorm/data/a314-shared).
Copy the files that needs to be changed for keeping the content safe:
In a314d.conf, change the a314fs line (add the -conf-file part):
In a314fs.conf, change the location for the shared folder:
Then, in the pistorm computer configuration (your copy of ‘default.cfg’), enable a314 and the custom configuration for it:
On the Amiga-side: The needed files are on the pistorm utility hdf (pistorm.hdf, disk named “PiStorm”) pre-set in the default.cfg and you should have had it available since activation of piscsi above.
Amiga Workbench 3.1 Hdf Software
From the a314 folder on the utility hdf, copy “a314.device” to DEVS:, “a314fs” to L: and append the content of “a314fs-mountlist” to DEVS:mountlist:
Then after a restart of the emulator (with the newly modified configuration in place), you should be able to mount the shared folder using “execute command” or from a shell:
RTG with Picasso96 (old version)
RTG is a standard feature of the piStorm since ‘long’ ago. It requires the Picasso96 (2.0 from Aminet, or the more recent one, renamed P96, from Individual Computer) software to be installed before adding the necessary drivers from the piStorm utility hdf.
On the Amiga-side: Using Picasso96 2.0 from Aminet, go through the installation process and do not install application drivers or the printer patch, then from the piStorm utility hdf, the installation script for the needed drivers can be found in the “RTG” folder. You need to have the extracted content of the Picasso96 installation files available during this step of the installation.
On the pi-side: Activate rtg in the configuration:
Restart the emulator. The Amiga will be rebooted at that point. After a reboot, you will have the RTG sceenmodes available in Prefs/Screenmode.
Be sure to test the screenmodes before saving. Some of the modes are less useable because of the way the scaling is handled. I recommend sticking to mainly two resulotions on a 1080p capable screen: 960×540 (and any color depth) and 1920×1080 (up to 16 bit).
a314: networking
How to set up the network using the a314 emulation is well described in the a314 documentation on Github, execpt from how to set it up on “any” Amiga TCP/IP stack.
Amiga Workbench 3.1 Install Disk Download
On the pi-side: Follow the directions in the documentation for the pi-side, mainly as below: Enable the a314 emulation in your configuration (should already have been done if you followed this guide):
Then install pip3, pytun and copy the tap0 interface:
Add the firewall rules for forwarding packages, and make the rules persistant:
Enable IPv4 forwarding (in the /etc/sysctl.conf file):
Amiga Workbench 3.1 Hdfc Bank
(remove the # from the commented out line)
Add to the end of /etc/rc.local, but before the “exit 0” line:
Amiga Workbench 3.1 Download
Reboot the pi.
On the Amiga-side: If not already done so, copy the a314.device from the piStorm utility hdf to DEVS:
Copy the a314 SANA-II driver to devs:
For the rest of the configuration on the Amiga, you need a TCP/IP stack such as Roadshow or AmiTCP as documented on Github. For any other stack you’re “on your own”. Here are the settings you have to enter in the correct places: SANA-II driver: a314eth.device (in Miami, it’s the last option “other SANA-II driver”) Unit: 0 Your IP address: 192.168.2.2 Netmask: 255.255.255.0 Gateway: 192.168.2.1 DNS: 8.8.8.8, 4.4.4.4, 1.1.1.1, 1.0.0.1 or similar (any public DNS will work, these are the Google public DNS servers)
Installing Miami 3.2b
Miami 3.2b is a GUI-based TCP/IP stack for the Amiga available from Aminet. You need three archives to make the installation complete: Miami32b2-main.lha Miami32b-020.lha Miami32b-GTL.lha
Extract these files to RAM: (lha x (archive name) ram:), and start the Miami installer from there. The next step is the configuration. From the folder where Miami was installed, start MiamiInit and follow the guide, giving the values as listed above for IP address, netmask, gateway and DNS. When you reach the end of MiamiInit, you should input “Name” and “user name”, then save the configuration (you can uncheck the “Save information sheet” and “Print information sheet”.
Start Miami and import the just saved settings. Click the “Database” button and choose “hosts” from the pull-down menu. Click on “Add” and fill in your IP-address (192.168.2.2) and name (for example “amiga”). Click “Ok”, then choose “Save as default” from the Settings menu. Click on “Online” whenever you want to be connected (auto-online is available only for registered users but I assume you could launch Miami and put it online from ARexx).
4 notes
·
View notes
Text
Core Components of HDFS
There are three components of HDFS:
1. NameNode
2. Secondary NameNode
3. DataNode
NameNode:
NameNode is the master node in the Apache Hadoop HDFS Architecture that maintains and manages the blocks present on the DataNode (slave node). NameNode is a very highly available server that manages the File System Namespace and controls access to files by clients. I will be discussing this High Availability feature of Apache Hadoop HDFS in my next blog. The HDFS architecture is built in such a way that the user data never resides on the NameNode. The data resides on DataNode only.
1. NameNode is the centerpiece of HDFS.
2. NameNode is also known as the Master.
3. NameNode only stores the metadata of HDFS – the directory tree of all files in the file system, and tracks the files across the cluster.
4. NameNode does not store the actual data or the data set. The data itself is actually stored in the DataNode.
5. NameNode knows the list of the blocks and its location for any given file in HDFS. With this information NameNode knows how to construct the file from blocks.
6. NameNode is so critical to HDFS and when the NameNode is down, HDFS/Hadoop cluster is inaccessible and considered down.
7. NameNode is a single point of failure in Hadoop cluster.
8. NameNode is usually configured with a lot of memory (RAM). Because the block locations are help in main memory.
Functions of NameNode:
It is the master daemon that maintains and manages the DataNode (slave node).
It records each change that takes place to the file system metadata. For example, if a file is deleted in HDFS, the NameNode will immediately record this in the EditLog.
It regularly receives a Heartbeat and a block report from all the DataNode in the cluster to ensure that the DataNode is live.
It keeps a record of all the blocks in HDFS and in which nodes these blocks are located.
The NameNode is also responsible to take care of the replication factor of all the blocks which we will discuss in detail later in this HDFS tutorial blog.
In case of the DataNode failure, the NameNode chooses new DataNode for new replicas, balance disk usage and manages the communication traffic to the DataNode.
It records the metadata of all the files stored in the cluster, e.g. The location of blocks stored, the size of the files, permissions, hierarchy, etc.
There are two files associated with the metadata:
FsImage: It contains the complete state of the file system namespace since the start of the NameNode.
EditLog: It contains all the recent modifications made to the file system with respect to the most recent FsImage.
Secondary NameNode:
Apart from these two daemons, there is a third daemon or a process called Secondary NameNode. The Secondary NameNode works concurrently with the primary NameNode as a helper daemon. And don’t be confused about the Secondary NameNode being a backup NameNode because it is not.

Functions of Secondary NameNode:
The Secondary NameNode is one which constantly reads all the file systems and metadata from the RAM of the NameNode and writes it into the hard disk or the file system.
It is responsible for combining the EditLog with FsImage from the NameNode.
It downloads the EditLog from the NameNode at regular intervals and applies to FsImage. The new FsImage is copied back to the NameNode, which is used whenever the NameNode is started the next time.
Hence, Secondary NameNode performs regular checkpoints in HDFS. Therefore, it is also called Check Point Node.
DataNode:
DataNode is the slave node in HDFS. Unlike NameNode, DataNode is a commodity hardware, that is, a non-expensive system which is not of high quality or high-availability. The DataNode is a block server that stores the data in the local file ext3 or ext4.
1. DataNode is responsible for storing the actual data in HDFS. 2. DataNode is also known as the Slave Node. 3. NameNode and DataNode are in constant communication. 4. When a DataNode starts up it announce itself to the NameNode along with the list of blocks it is responsible for. 5. When a DataNode is down, it does not affect the availability of data or the cluster. 6. NameNode will arrange for replication for the blocks managed by the DataNode that is not available. 7. DataNode is usually configured with a lot of hard disk space. Because the actual data is stored in the DataNode.
Functions of DataNode:
These are slave daemons or process which runs on each slave machine.
The actual data is stored on DataNode.
The DataNode perform the low-level read and write requests from the file system’s clients.
They send heartbeats to the NameNode periodically to report the overall health of HDFS, by default, this frequency is set to 3 seconds.
Till now, you must have realized that the NameNode is pretty much important to us. If it fails, we are doomed. But don’t worry, we will be talking about how Hadoop solved this single point of failure problem in the next Apache Hadoop HDFS Architecture blog. So, just relax for now and let’s take one step at a time.
#Check this out
0 notes
Text
Spark vs Hadoop, which one is better?
Hadoop
Hadoop is a project of Apache.org and it is a software library and an action framework that allows the distributed processing of large data sets, known as big data, through thousands of conventional systems that offer power processing and storage space. Hadoop is, in essence, the most powerful design in the big data analytics space.
Several modules participate in the creation of its framework and among the main ones we find the following:
Hadoop Common (Utilities and libraries that support other Hadoop modules)
Hadoop Distributed File Systems (HDFS)
Hadoop YARN (Yet Another Resource Negociator), cluster management technology.
Hadoop Mapreduce (programming model that supports massive parallel computing)
Although the four modules mentioned above make up the central core of Hadoop, there are others. Among them, as quoted by Hess, are Ambari, Avro, Cassandra, Hive, Pig, Oozie, Flume, and Sqoop. All of them serve to extend and extend the power of Hadoop and be included in big data applications and processing of large data sets.
Many companies use Hadoop for their large data and analytics sets. It has become the de facto standard in big data applications. Hess notes that Hadoop was originally designed to handle crawling functions and search millions of web pages while collecting information from a database. The result of that desire to browse and search the Web ended up being Hadoop HDFS and its distributed processing engine, MapReduce.
According to Hess, Hadoop is useful for companies when the data sets are so large and so complex that the solutions they already have cannot process the information effectively and in what the business needs define as reasonable times.
MapReduce is an excellent word-processing engine, and that's because crawling and web search, its first challenges, are text-based tasks.
We hope you understand Hadoop Introduction tutorial for beginners. Get success in your career as a Tableau developer by being a part of the Prwatech, India’s leading hadoop training institute in btm layout.
Apache Spark Spark is also an open source project from the Apache foundation that was born in 2012 as an enhancement to Hadoop's Map Reduce paradigm . It has high-level programming abstractions and allows working with SQL language . Among its APIs it has two real-time data processing (Spark Streaming and Spark Structured Streaming), one to apply distributed Machine Learning (Spark MLlib) and another to work with graphs (Spark GraphX).
Although Spark also has its own resource manager (Standalone), it does not have as much maturity as Hadoop Yarn, so the main module that stands out from Spark is its distributed processing paradigm.
For this reason it does not make much sense to compare Spark vs Hadoop and it is more accurate to compare Spark with Hadoop Map Reduce since they both perform the same functions. Let's see the advantages and disadvantages of some of its features:
performance Apache Spark is up to 100 times faster than Map Reduce since it works in RAM memory (unlike Map Reduce that stores intermediate results on disk) thus greatly speeding up processing times.
In addition, the great advantage of Spark is that it has a scheduler called DAG that sets the tasks to be performed and optimizes the calculations .
Development complexity Map Reduce is mainly programmed in Java although it has compatibility with other languages . The programming in Map Reduce follows a specific methodology which means that it is necessary to model the problems according to this way of working.
Spark, on the other hand, is easier to program today thanks to the enormous effort of the community to improve this framework.
Spark is compatible with Java, Scala, Python and R which makes it a great tool not only for Data Engineers but also for Data Scientists to perform analysis on data .
Cost In terms of computational costs, Map Reduce requires a cluster that has more disks and is faster for processing. Spark, on the other hand, needs a cluster that has a lot of RAM.
We hope you understand Apache Introduction tutorial for beginners. Get success in your career as a Tableau developer by being a part of the Prwatech, India’s leading apache spark training institute in Bangalore.
1 note
·
View note
Text
A Day in The Life of A Data Scientist
Data Science is rising as a disruptive consequence of the digital revolution. As instruments are evolving, Data science job roles are maturing and turning into extra mainstream in corporations. The number of openings that corporations have for Data science roles can be on an all-time excessive. Given the variety of alternatives out there, these are being expanded to professionals with a non-technical background as properly. Whereas there are various positions with a shortage of excellent candidates, it has made it quite doable for one candidate touchdown up with a couple of job supply in hand for comparable roles.
ExcelR Solutions. So, on the one hand now we have a really wealthy useful resource for learning about data science, and on the opposite, there are a lot of individuals who need to learn data science but aren't certain methods to get started. Our Kaggle meetups have confirmed to be a great way to convey these elements collectively. In the following we outline what has worked for us, within the hope that it is going to be helpful for others who wish to do one thing comparable.
This can be a sector the place the applications are countless. Data science is used as a part of research. It is utilized in sensible purposes like using genetic and genome data to personalize therapies, utilized in picture evaluation to catch tumours and progress. Predictive analysis is a boon to drug testing and improvement course of. It's even used for buyer support in hospitals and provides virtual assistants as chatbots and apps.
Data science is a combination of ideas that unify data, machine learning and other useful technologies to derive some meaningful outcomes from the pattern knowledge. That's it! Keep in mind this workflow - you will use it quite often throughout my Python for Data Science tutorials. On-line lessons can be an effective way to shortly (and on your own time) study the good things, from technical expertise like Python or SQL to fundamental data evaluation and machine studying. That said, it's possible you'll need to invest to get the real deal.
ExcelR Solutions Data Scientist Course In Pune With Placement. SQL remains a really beneficial talent, even on this planet of HDFS and different distributed Data systems. These modern data methods like Hadoop have Presto and Hive layered on high which lets you use SQL to work together with Hadoop as an alternative of Java or Scala. SQL is the language of Data and it allows data scientists and Data engineers to easily manipulate, rework and switch knowledge between techniques. In contrast to programming, it's almost the same between all databases. There are a number of which have determined to make very drastic modifications. General, SQL is value learning, even in as we speak panorama.
Use the list I've offered below to be taught some new data science expertise and construct portfolio tasks. If you are new to knowledge science and need to work out if you want to start the method of learning to grow to be a knowledge scientist, this e book will make it easier to. That is another nice hands-on the right track on Data Science from ExcelR Solutions. It promises to show you Data Science step by step by way of real Analytics examples. Knowledge Mining, Modelling, Tableau Visualization and more.
ExcelR Solutions. Selecting a language to learn, particularly if it's your first, is a crucial resolution. For those of you serious about learning Python for inexperienced persons and beyond, it can be a extra accessible path to programming and data science. It is relatively straightforward to be taught, scalable, and powerful. It is even referred to as the Swiss Army knife of programming languages.
1 note
·
View note
Link
In this Apache Hadoop tutorial you will learn Hadoop from the basics to pursue a big data Hadoop job role. Through this tutorial you will know the Hadoop architecture, its main components like HDFS, MapReduce, HBase, Hive, Pig, Sqoop, Flume, Impala, Zookeeper and more. You will also learn Hadoop installation, how to create a multi-node Hadoop cluster and deploy it successfully. Learn Big Data Hadoop from Intellipaat Hadoop training and fast-track your career.
Hadoop Tutorial – Learn Hadoop from Experts
In this Apache Hadoop tutorial you will learn Hadoop from the basics to pursue a big data Hadoop job role. Through this tutorial you will know the Hadoop architecture, its main components like HDFS, MapReduce, HBase, Hive, Pig, Sqoop, Flume, Impala, Zookeeper and more. You will also learn Hadoop installation, how to create a multi-node Hadoop cluster and deploy it successfully. Learn Big Data Hadoop from Intellipaat Hadoop training and fast-track your career.
Overview of Apache Hadoop
As Big Data has taken over almost every industry vertical that deals with data, the requirement for effective and efficient tools for processing Big Data is at an all-time high. Hadoop is one such tool that has brought a paradigm shift in this world. Thanks to the robustness that Hadoop brings to the table, users can process Big Data and work around it with ease. The average salary of a Hadoop Administrator which is in the range of US$130,000 is also very promising.
Become a Spark and Hadoop Developer by going through this online Big Data Hadoop training!
Watch this Hadoop Tutorial for Beginners video before going further on this Hadoop tutorial.
Apache Hadoop is a Big Data ecosystem consisting of open source components that essentially change the way large datasets are analyzed, stored, transferred and processed. Contrasting to traditional distributed processing systems, Hadoop facilitates multiple kinds of analytic workloads on same datasets at the same time.
Qualities That Make Hadoop Stand out of the Crowd
Single namespace by HDFS makes content visible across all the nodes
Easily administered using High-Performance Computing (HPC)
Querying and managing distributed data are done using Hive
Pig facilitates analyzing the large and complex datasets on Hadoop
HDFS is designed specially to give high throughput instead of low latency.
Interested in learning Hadoop? Click here to learn more from this Big Data Hadoop Training in London!
What is Apache Hadoop?
Apache Hadoop is an open-source data platform or framework developed in Java, dedicated to store and analyze the large sets of unstructured data.
With the data exploding from digital mediums, the world is getting flooded with cutting-edge big data technologies. However, Apache Hadoop was the first one which caught this wave of innovation.
Recommended Audience
Intellipaat’s Hadoop tutorial is designed for Programming Developers and System Administrators
Project Managers eager to learn new techniques of maintaining large datasets
Experienced working professionals aiming to become Big Data Analysts
Mainframe Professionals, Architects & Testing Professionals
Entry-level programmers and working professionals in Java, Python, C++, eager to learn the latest Big Data technology.
If you have any doubts or queries related to Hadoop, do post them on Big Data Hadoop and Spark Community!
Originally published at www.intellipaat.com on August 12, 2019
1 note
·
View note
Photo

Is This The Best HDF Terrain? Tabletop Scenics Chapel Unbox & Build Don't miss Kromlech's Tabletop Scenics line of terrain, as we unbox and build the Chapel and you just how detailed it is! More Hobby Unboxings: https://www.youtube.com/playlist?list=PL_OTD5XD7saAqjej4bzlDP8UdBWFZcBEq Get yours here ►http://bit.ly/Kromlech Models provided for promotion & review. Twitch ► https://www.twitch.tv/spikeybitstv SUBSCRIBE ►https://www.youtube.com/subscription_center?add_user=rbaer0002 Become a VETERAN OF THE LONG WAR ► http://www.thelongwar.net LIKE US ON FACEBOOK ► https://www.facebook.com/pages/Spikey... TWITTER ► https://twitter.com/spikeybits INSTAGRAM ► http://instagram.com/spikeybits VISIT OUR SITE ► http://www.spikeybits.com TWITCH ►https://www.twitch.tv/spikeybitstv Unboxing Hobby Tutorials pdf Instructions. First Look Airbrushing Battle Reports. Rob Baer Kenny Boucher warhammer 40k
1 note
·
View note
Text
youtube
Action TESA HDF Laminate Flooring Installation Tutorial Video
Laminate Flooring is popular due to its ease of installation & its simple maintenance, easy cleaning methods, resistance to stains & a very durable surface due to the "WEAR RESISTANT LAYER".
0 notes