#hbase
Text

What is HBase?
.
.
.
.
for more information and tutorial
https://bit.ly/3UU2Ucw
check the above link
0 notes
Link
0 notes
Text

Are you looking for comprehensive HBase Training in Noida? Look no further than APTRON Solutions Noida, a leading training institute offering top-notch HBase courses. With a proven track record of excellence and a dedicated team of industry experts, APTRON Solutions Noida is the ideal choice for individuals and organizations seeking to enhance their HBase skills.
0 notes
Text
Hbase archive cleaner

#Hbase archive cleaner update
#Hbase archive cleaner archive
For storing the network, we used a triple-store database to record different types of edges and relationships in the graph. This entailed doing research into the types of database that are appropriate for this graph. In addition to the aforementioned tasks, our responsibilities also included building a network of tweets. Finally, after the data is indexed by the SOLR team, the Front-End team visualizes the tweets to users, and provides access for searching and browsing. Collection Management Webpage team uses the extracted URLs from the tweets for further processing. The cleaned data in HBase from this task is provided to the Classification team for spam detection and to the Clustering and Topic Analysis team for topic analysis. We introduced parallelization in our tweet cleaning process with the help of Scala and the Hadoop cluster, and made use of different Natural Language Processing libraries for stop word and profanity removal C) Along with tweet cleaning we also identified and stored Named-Entity-Recognition (NER) entries and Part-of-speech (POS) tags, with the tweets which was not done by the previous team. This becomes very slow when the dataset scales up. Previously, the cleaning part, e.g., removing profanity words, plus extracting hashtags and mentions, utilized Python.
#Hbase archive cleaner update
For the first part, our work included: A) Making use of the work done by the previous year's class group, where incremental update was done, to introduce a faster development process of data collection and storing B) Improving the performance of work done by the group from last year. The mission of the CMT team had two parts: 1) Cleaning 6.2 million tweets from two 2017 event collections named "Solar Eclipse" and "Las Vegas Shooting", and loading them into HBase, an open source, non-relational, distributed database that runs on the Hadoop distributed file system, in support of further use and 2) Building and storing a social network for the tweet data using a triple-store.
#Hbase archive cleaner archive
The report included in this submission documents the work by the Collection Management Tweets (CMT) team, which is a part of the bigger effort in CS5604 on building a state-of-the-art information retrieval and analysis system for the IDEAL (Integrated Digital Event Archiving and Library) and GETAR (Global Event and Trend Archive Research) projects.
0 notes
Text
Yay - I get to share my love for tidbit Hazbin lore while sharing knowledge that makes me look like a millennial boomer XD
Ahem...
Alastor, our favorite overlord, for all intents and purposes, is a fucking elemental.
His abilities are absolutely terrifying from a scientific standpoint.
Okay, so remember how during the "Stayed Gone" number, Vox starts glitching out and "loses his signal" - then the Pride ring subsequently has a blackout?
That is entirely Alastor's (or whatever-the-fuck-is-benefactoring-him's) doing.
A powerful enough radio signal can do that. No horseshoe magnet required. IRL real shiz.
Despite being digital enough to render a bluescreen while compromised, Vox might still have older hardware from his former days as a rabbit-eared, extra-thick thick cathode-ray tube.

And Alastor is our radio demon. Keep this in mind.
IRL, once upon a time during the 1940s - before digital television - there was no "Channel 1".
That's because in the US, a very long time ago, both radio and TV shared the band that we call "Channel One":
"Until 1948, Land Mobile Radio and television broadcasters shared the same frequencies, which caused interference. This shared allocation was eventually found to be unworkable, so the FCC reallocated the Channel 1 frequencies for public safety and land mobile use and assigned TV channels 2–13 exclusively to broadcasters. Aside from the shared frequency issue, this part of the VHF band was (and to some extent still is) prone to higher levels of radio-frequency interference (RFI) than even Channel 2 (System M)."
(https://en.wikipedia.org/wiki/Channel_1_(North_American_TV))
Then for a short stint, Channel One was exclusively reserved for radio:
Channel 1 was allocated at 44–50 MHz between 1937 and 1940. Visual and aural carrier frequencies within the channel fluctuated with changes in overall TV broadcast standards prior to the establishment of permanent standards by the National Television Systems Committee.
In 1940, the FCC reassigned 42–50 MHz to the FM broadcast band. Television's channel 1 frequency range was moved to 50–56 MHz. Experimental television stations in New York, Chicago, and Los Angeles were affected.
(https://en.wikipedia.org/wiki/Channel_1_(North_American_TV))
Every local TV channel and radio station has a frequency range on the electromagnetic spectrum.
For those who still listen to radio on non-internet-reliant radios devices, those funny little numbers next to a station's name are a ballpark number for the frequency the station broadcasts in the Hertz unit.
A Hertz (Hz) is one wave per second.
A KiloHertz (KHz) is 1,000 waves per second.
A GigaHertz (GHz) is 1 billion waves per second.
Modern AM radio stations are 535-1605 kHz
Modern FM radio stations are 88-108 MHz
TV VHF Channels 2 thru 13 are 54-216 MHz
TV UHF Channels 14 thru 36 are 470-608 MHz
And no, that's not a discrepancy between VHF and FM radio: the frequencies designated for FM radio are nestled right in there with TV ones - between Channels 6 and 7.
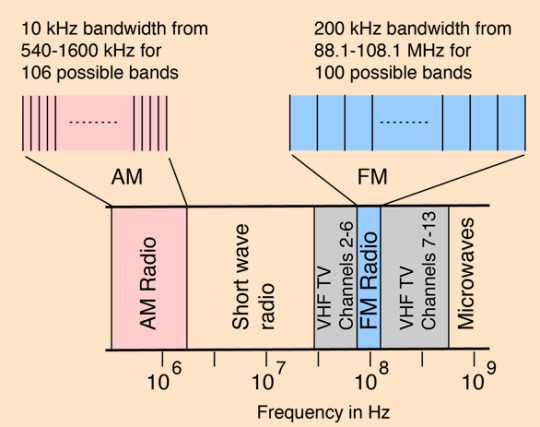
(chart from http://hyperphysics.phy-astr.gsu.edu/hbase/Audio/radio.html)
Even today, radio and TV are slightly shuffled in there in regards to designated frequencies.
This implies that depending on Alastor's band of preference, if Vox still has some of his older hardware, Vox could, in his sleep, theoretically be able to hear Alastor's broadcasts of screaming victims without a physical radio nearby.
IRL in fact, in older televisions where a knob is used to change channels, much of the static you'd hear in-between channels is actually background radiation from deep space - along with any radio interference from man-made sources nearby.
No wonder Vox is obsessed with Alastor. Alastor can torment him in an in-between realm-channel daily, like Freddy Kruger.

Yet, if radio signals were only a Vox problem, why did nearly every light and electronic device go out in the Pride except the emergency lights at the Heaven embassy?




It might depend on how we define the word "radio".
Is it radio, as in "those radio stations we can listen to without the internet"?
Maybe radio, as in "any frequency utilized in modern communications, including TV and Radio"?
Or is it radio, as in "almost any signal on the electromagnetic spectrum with a frequency lower than friggin' heat?"
People, below is an IRL over-simplified chart of the electromagnetic spectrum and its usages by human.
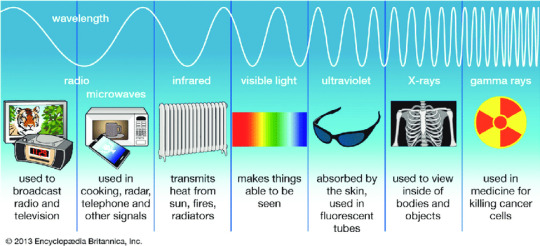
When radio is defined as a specific part of the electromagnetic spectrum, it is basically any frequency below infrared. ***
Cellphone service and WiFi use radio signals within this range.
Most cellular services are between 600 MHz and 39 GHz
WiFi routers are about 2.4-5 GHz (6 GHz in newer models)
That's where the "G" in "4G" and "5G" come from - the "G" stands for "Gigahertz"
Radio, local television, cellphone service, WiFi, and basically any point in the internet that isn't linked by a landline - these are all safely within the part of the electromagnetic spectrum that the scientists would call "radio".
If Hell's technology is supposed to mirror the real world, then most electronic devices need radio frequencies in order to communicate.
The VVV's empire is truly fucked, should Alastor so choose.
The only plot hole in this explanation I see is why all the lights went out. These devices don't run on radio - they communicate using it.
My best-educated guess is that the on/off switch for Hell's power grid is on an open network and at least part of it wireless.
Or maybe Alastor's radio attack works like a general EMP and he can just break stuff by "brute force".
(I am not an expert on these sorts of things like telecommunication... or network security... or physics.... I politely ask that someone in the comments, please enlighten me U.U )
-------------------------------------
Also, notice that Alastor's Tower, Cannibal Town and the Heaven Embassy were the only regions with lights on during the blackout.
is that...?

Cannibal Town?

If this is, in fact, Cannibal Town, then my only guess is that the Cannibals are so hipster, many of them only light their homes and businesses with candlelight and leviathan whale oil. Neither candlelight nor oil-burning rely on wifi.
Only some of their region's light was lost in the blackout. They might use some electricity (as many during the Victorian era did, which Cannibal Town seems to be inspired by), but they don't fully rely upon electricity.
This suggests that Alastors friendship with Rosie might be less of an organic friendship and more like a strategically slick alliance.
Rosie's territory is one part of Pride that Alastor can't completely shut down (other than the Embassy).
But, who knows?

Alastor's derision of modern tech now seems to have more merit than just being "hipster", or avoiding leaving a digital footprint that Vox can manipulate, (the latter of which I once head-canoned before this epiphany).
Alastor can literally just shut most of Hell's tech down.
This might also suggest why Alastor is homies with Zestial - another known old-timey prick.

Alastor makes alliances with demons he can't easily overpower with his abilities.
This might seem self-contradictory to Alastor's seeming over-confidence in teasing Lucifer - until you realize he did this only after he learned angels could be killed during the Overlords' meeting.
(And yes, I know what I wrote about Alastor a couple of tumbl notes back with the "popsicle" evaluation. I do not consider flip-flopping a moral issue if done so by epiphany. That note stays, because it's funny XD )
-----------------------
Another theory!
Ok, so this theory isn't entirely my own-own, I'm just building off of it based on what I've just said (mostly Roo stuff).
So IRL, scientists decided to take an image of the observable universe in the microwave range. Microwave energy is in the upper ends of radio, but just below infrared in frequency.
What they found was cosmic background radiation - a lot of energy that isn't coming from the stars themselves.

(Image source: https://www.space.com/33892-cosmic-microwave-background.html)
Some scientists theorize this is because this particular energy is left over from the formation of the universe.
So about Roo:
In the first non-pilot episode, The Story of Hell, as read by Charlie, states that the angels of pure light "worshipped good and shielded all from evil."
During this line, imagery of two faces are shown before the angels: one face of light and another face of twisted red and black.

Subsequent lines and imagery in the episode suggest that this "evil" existed before Lucifer fell or Eve allowed this evil to enter the world - even before the Earth was created.
Some Tumblrs who have been in this fandom longer than I have may know of Roo, a character that appears in some of VivziePop's older works within the Hazbin/Hellaverse.
Some of Roo's monikers include "The Root of All Evil" and the "Tree of Knowledge".
I'm wondering if in the Hellaverse, the cosmic background radiation of the universe is a manifestation of Roo when she isn't bound to a tree.
Could Alastor's radio powers come Roo, the background "dark" energy of the universe's birth?
Did Alastor bite the apple the second third time for mankind? XD
-------------------------------------------------
While researching for this paper, I learned that microwave ovens and 2G cell phones operate within the same frequencies at around 2 GHz.
Apparently, the only reason cell phones don't cook our brains is because the wattage is too low.
(I dunno what wattage means. I'm not a scientist.)
But now, Alastors singing lines in S1E8 had me thinking:
"The constraints of my deal surely have a back door
Once I figure out how to unclip my wings,
guess who will be pulling all the strings"
Knowing what Alastor is capable of with radio, this has me wondering if Alastor's radio powers are coming from one source, all while be is being chained by another entity entirely.
Someone might have gone out of their way to get Alastor into a contract - if only to keep him from literally baking the universe for his viewing pleasure... on a rotating glass plate.

Being able to cook a soul in microwaves would require that they be at least partially made of water, however.
Buuuut... I guess if there are working ACs in Hell, I really shouldn't read too much into it XD
-------------
Do you think the mad scientists from Helluva Boss, Lyle Lipton and Loopty Goopty, ever chat over coffee about the abilities of the overlords based on casual observation?

One day, Alastor's name comes up...
...and after four minutes of discussing facts over coffee, they're both just like "Nope"?
XD
{END}
*** Note: Googling "Electromagnetic Spectrum charts" will yield different results. Some charts will have different designations frequencies lower than radio, like Extremely Low Frequencies (ELF).
I do not know whether this difference is a reflection of a newer categorization, or if most charts online are made for laymen such as myself. Most charts I saw years ago only designated "radio" as "everything below microwave".
I want to assume that the "only radio below microwave" categorization went into the writer's designing of Alastor's character simply because such charts are more common (while also making for a more interesting power scaling).
______________
Disclaimer: I am composed of chauffeur knowledge. I know nearly nothing about communication science little about radiation stuff. I took an astronomy elective in college once, so I sorta knew where to look when it came to frequency stuff. I have no idea what the fuck I'm talking about. I know that I confused frequency and wavelength somewhere. Please, #sciencesideoftumblr feel free to correct me.
-----------------
TLDR:
Most tech IRL uses radio waves to communicate. That Includes TVs, WiFi and cell phones. Alastor can make the Pride Ring go kaploowee if he looks at it funny. I don't know what he's cooking.
#hazbin hotel#hazbin hotel theory#hazbin hotel alastor#hazbin hotel vox#hazbin hotel vvv#hazbin hotel vees#science#science side of tumblr#please help me#i'm absolutly sure i mixed up frequency and wavelength somewhere#I'm not a communications expert#i flunked chemistry in high school and i can't write my name in cursive#chauffeur knowledge#hazbin hotel rosie#hazbin hotel lucifer#hazbin hotel zestial#hazbin hotel roo#sciencesideoftumblr#science side help me#radio#electromagnetic waves
84 notes
·
View notes
Text
What is big Data Science?
Big Data Science is a specialized branch of data science that focuses on handling, processing, analyzing, and deriving insights from massive and complex datasets that are too large for traditional data processing tools. The field leverages advanced technologies, algorithms, and methodologies to manage and interpret these vast amounts of data, often referred to as "big data." Here’s an overview of what Big Data Science encompasses:
Key Components of Big Data Science
Volume: Handling massive amounts of data generated from various sources such as social media, sensors, transactions, and more.
Velocity: Processing data at high speeds, as the data is generated in real-time or near real-time.
Variety: Managing diverse types of data, including structured, semi-structured, and unstructured data (e.g., text, images, videos, logs).
Veracity: Ensuring the quality and accuracy of the data, dealing with uncertainties and inconsistencies in the data.
Value: Extracting valuable insights and actionable information from the data.
Core Technologies in Big Data Science
Distributed Computing: Using frameworks like Apache Hadoop and Apache Spark to process data across multiple machines.
NoSQL Databases: Employing databases such as MongoDB, Cassandra, and HBase for handling unstructured and semi-structured data.
Data Storage: Utilizing distributed file systems like Hadoop Distributed File System (HDFS) and cloud storage solutions (AWS S3, Google Cloud Storage).
Data Ingestion: Collecting and importing data from various sources using tools like Apache Kafka, Apache Flume, and Apache Nifi.
Data Processing: Transforming and analyzing data using batch processing (Hadoop MapReduce) and stream processing (Apache Spark Streaming, Apache Flink).
Key Skills for Big Data Science
Programming: Proficiency in languages like Python, Java, Scala, and R.
Data Wrangling: Techniques for cleaning, transforming, and preparing data for analysis.
Machine Learning and AI: Applying algorithms and models to large datasets for predictive and prescriptive analytics.
Data Visualization: Creating visual representations of data using tools like Tableau, Power BI, and D3.js.
Domain Knowledge: Understanding the specific industry or field to contextualize data insights.
Applications of Big Data Science
Business Intelligence: Enhancing decision-making with insights from large datasets.
Predictive Analytics: Forecasting future trends and behaviors using historical data.
Personalization: Tailoring recommendations and services to individual preferences.
Fraud Detection: Identifying fraudulent activities by analyzing transaction patterns.
Healthcare: Improving patient outcomes and operational efficiency through data analysis.
IoT Analytics: Analyzing data from Internet of Things (IoT) devices to optimize operations.
Example Syllabus for Big Data Science
Introduction to Big Data
Overview of Big Data and its significance
Big Data vs. traditional data analysis
Big Data Technologies and Tools
Hadoop Ecosystem (HDFS, MapReduce, Hive, Pig)
Apache Spark
NoSQL Databases (MongoDB, Cassandra)
Data Ingestion and Processing
Data ingestion techniques (Kafka, Flume, Nifi)
Batch and stream processing
Data Storage Solutions
Distributed file systems
Cloud storage options
Big Data Analytics
Machine learning on large datasets
Real-time analytics
Data Visualization and Interpretation
Visualizing large datasets
Tools for big data visualization
Big Data Project
End-to-end project involving data collection, storage, processing, analysis, and visualization
Ethics and Privacy in Big Data
Ensuring data privacy and security
Ethical considerations in big data analysis
Big Data Science is essential for organizations looking to harness the power of large datasets to drive innovation, efficiency, and competitive advantage
0 notes
Text
Pinterest Shuts Down One of the World's Largest HBase Deployments
https://www.infoq.com/news/2024/06/pinterest-deprecates-hbase/?utm_campaign=infoq_content&utm_source=dlvr.it&utm_medium=tumblr&utm_term=AI%2C%20ML%20%26%20Data%20Engineering-news
0 notes
Text

Hadoop Training in Hyderabad: Master Big Data in 60 Days
Join our intensive Hadoop training in Hyderabad to excel in Apache Hadoop, the leading framework for distributed processing of large datasets. At Kelly Technologies, our 60-day program covers advanced concepts including MapReduce, HBase, Hive, and Sqoop. Prepare for lucrative career opportunities in Big Data with hands-on learning and expert guidance.
1 note
·
View note
Text

What is MapReduce?
.
.
.
.
for more information and tutorial
https://bit.ly/3QD5K2Z
check the above link
0 notes
Link
0 notes
Text
HBase Deprecation at Pinterest
This blog marks the first of a three-part series describing our journey at Pinterest transition from managing multiple online storage services supported by HBase to a brand new serving architecture with a new datastore and a unified storage service.
— https://ift.tt/ugN7MIq
0 notes
Text
Data Science Tools and Technologies
In the rapidly evolving world of data science, the array of tools and technologies available to professionals and enthusiasts alike is vast and constantly expanding. These tools are integral to transforming raw data into meaningful insights, driving decision-making, and fostering innovation across industries. In this blog, we'll explore some of the most prominent data science tools and technologies that are shaping the field today.
Programming Languages
Python
Python is the de facto language for data science, known for its simplicity and versatility. Its extensive library ecosystem, including NumPy, pandas, and Scikit-learn, makes it a powerhouse for data analysis, machine learning, and statistical modeling.
R
R is another leading language in data science, particularly favored in academia and research. It excels in statistical analysis and visualization, with packages like ggplot2 and dplyr providing robust capabilities for data manipulation and graphical representation.
Data Visualization Tools
Tableau
Tableau is a premier data visualization tool that allows users to create interactive and shareable dashboards. Its user-friendly interface and ability to connect to various data sources make it a popular choice for businesses looking to extract actionable insights from their data.
Power BI
Microsoft’s Power BI is a powerful tool for creating visualizations and business intelligence reports. It integrates seamlessly with other Microsoft products and offers robust data modeling capabilities, making it ideal for enterprise-level data analytics.
Matplotlib and Seaborn
For those who prefer coding, Matplotlib and Seaborn are essential Python libraries for creating static, animated, and interactive visualizations. While Matplotlib provides the foundation, Seaborn builds on it to produce more aesthetically pleasing and informative graphics.
Machine Learning Frameworks
TensorFlow
Developed by Google, TensorFlow is an open-source framework that enables the building and training of machine learning models. Its flexibility and scalability make it suitable for both research and production environments, supporting a wide range of applications from image recognition to natural language processing.
PyTorch
PyTorch, developed by Facebook's AI Research lab, is another open-source machine learning framework gaining popularity for its dynamic computation graph and ease of use. It's widely used in both academia and industry for developing deep learning models.
Scikit-learn
Scikit-learn is a Python library that offers simple and efficient tools for data mining and data analysis. It's built on NumPy, SciPy, and matplotlib and is ideal for implementing classical machine learning algorithms like regression, classification, and clustering.
Big Data Technologies
Apache Hadoop
Hadoop is a framework that allows for the distributed processing of large data sets across clusters of computers. It is designed to scale up from a single server to thousands of machines, each offering local computation and storage.
Apache Spark
Spark is an open-source, distributed computing system that provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. It's much faster than Hadoop due to its in-memory processing capabilities and supports various languages including Java, Scala, and Python.
NoSQL Databases
NoSQL databases, such as MongoDB, Cassandra, and HBase, are designed to handle large volumes of unstructured data. They offer high scalability and flexibility, making them suitable for real-time web applications and big data analytics.
Data Warehousing Solutions
Amazon Redshift
Amazon Redshift is a fully managed data warehouse service in the cloud. It allows users to run complex queries against large datasets and integrates seamlessly with other AWS services, providing a robust platform for big data analytics.
Google BigQuery
BigQuery is Google’s fully managed, serverless data warehouse that enables super-fast SQL queries using the processing power of Google’s infrastructure. It's designed to analyze terabytes of data in seconds and scales seamlessly to handle petabytes of data.
Conclusion
The landscape of data science tools and technologies is ever-growing and continually evolving. By leveraging these powerful resources, data scientists can extract meaningful insights from vast amounts of data, driving innovation and informed decision-making across various industries. Whether you are just starting in data science or are a seasoned professional, staying abreast of these tools and technologies is crucial for harnessing the full potential of your data.
0 notes
Text
[ad_1]
As of late, the demand for NoSQL databases is on the rise. The rationale behind their immense recognition is that corporations want NoSQL databases to deal with a large quantity of buildings in addition to unstructured information. This isn't potential to attain with conventional relational or SQL databases.
With elevated digitization, trendy companies must take care of large information commonly, coping with hundreds of thousands of customers whereas ensuring that there aren't any interruptions in delivering the information administration providers. All these expectations are the explanations behind the recognition of NoSQL databases in nearly each business. There may be all kinds of NoSQL databases accessible, companies usually get confused with NoSQL vs SQL and search instruments which might be extra succesful, agile, and versatile to handle big huge information.
This weblog specifies the highest 7 NoSQL databases that companies can choose as per their distinctive wants. All these NoSQL databases are open supply and encompass free variations. All the restrictions of conventional relational databases comparable to efficiency, velocity, scalability, and even huge information administration may be dealt with with these NoSQL databases. Nevertheless, it's crucial to think about that these databases are used to fulfill solely superior necessities of the organizations as frequent purposes can nonetheless be constructed by conventional SQL databases.
So, let’s try the highest 7 NoSQL databases that may even change into widespread in 2024.
Apache Cassandra:
Apache Cassandra is an open-source, free, and high-performance database. That is also called scalable and fault tolerant for each cloud infrastructure and commodity hardware. It might simply handle failed node replacements and replicate the information for a number of nodes mechanically. On this NoSQL database, you too can have the choice to decide on both synchronous replication or asynchronous replication.
Apache HBase:
Apache HBase can also be the perfect NoSQL database, which is Referred to as an open-source distributed Hadoop database. That is utilized to put in writing and skim the massive information. It has been developed to handle even the billions of rows and columns by way of the commodity hardware cluster. The options of Apache HBase embody computerized sharding of tables, scalability, constant writing & studying capabilities, and even nice assist for server failure.
Apache CouchDB:
Apache CouchDB can also be an open supply in addition to a single node database that helps in storing and managing the information. It might additionally scale up complicated initiatives right into a cluster of nodes on a number of servers. Firms can anticipate its integration with HTTP proxy servers together with the assist of HTTP protocol and JSON information format. This database is designed with crash-resistant options and reliability that saves information redundancy, which implies companies by no means lose their information and entry it each time wanted.
MarkLogic Server:
The MarkLogic server is the main NoSQL doc database that's designed for managing giant volumes of unstructured information and complicated information buildings. It boasts an amazing mixture of options for information-intensive apps and complicated content material administration necessities. It's broadly used for storing in addition to managing XML info. Companies can outline schemas of their information utilizing the MarkLogic server whereas accommodating variations within the doc construction. Furthermore, it provides extra flexibility as in comparison with relational SQL databases.
Amazon DynamoDB:
Amazon DynamoDB is the important thing worth, serverless, and doc database, which is obtainable by AWS (Amazon Net providers. This database is designed for increased scalability and efficiency. It's in excessive demand amongst companies to construct trendy purposes that want ultra-fast accessi
bility of knowledge in addition to the potential to deal with large information and consumer visitors, DynamoDB additionally gives restricted assist for ACID, the place ACID implies as Atomicity, Consistency, Isolation, and Sturdiness.
IBM Cloudant:
IBM Cloudant is one other widespread NoSQL database that's provided by IBM within the type of a cloud-based service. It's a full-featured and versatile JSON doc database used for cell, net, and serverless purposes that want better flexibility, scalability, and efficiency. This NoSQL database can also be developed for horizontal scaling. it's simpler so as to add extra servers on this database to handle unprecedented ranges of knowledge and consumer visitors.
MongoDB:
MongoDB is the greatest NoSQL database accessible available in the market. Like many different NoSQL databases, it shops and manages information in JSON-like paperwork. The versatile schema method helps companies leverage the evolving information fashions with none want for typical desk buildings. It may also be scaled horizontally by including extra shards to the cluster. Companies can simply deal with large quantities of knowledge and visitors with MongoDB.
The Remaining Thought
Utilizing NoSQL databases that match completely to your wants ends in effectivity beneficial properties. It makes it simpler for companies to retailer, course of, and handle large quantities of unstructured information effectively.
The put up Prime 7 NoSQL Databases You Can Use in 2024 appeared first on Vamonde.
[ad_2]
Supply hyperlink
0 notes
Text
Top 5 Big Data Databases in 2024: Features, Benefits, Pricing
In 2024, the top 5 Big Data databases are Apache Cassandra, MongoDB, Amazon DynamoDB, Google Bigtable, and Apache HBase. Apache Cassandra offers high availability and fault tolerance with a decentralized architecture. MongoDB provides flexibility and scalability for handling unstructured data. Amazon DynamoDB offers seamless scalability and low-latency performance with managed infrastructure. Google Bigtable excels in handling massive datasets with low-latency access. Apache HBase provides consistent read and write performance for large-scale applications. Pricing varies based on usage and additional services, with options for both pay-as-you-go and subscription models.
0 notes
Video
youtube
Spark Interview Part 1 - Why is Spark preferred over MapReduce?
Apache Spark is an open-source distributed computing system meant for large data processing and analytics.
It offers a single engine for distributed data processing that prioritizes speed, simplicity of use, and customization.
Spark was developed at UC Berkeley's AMPLab and eventually submitted to the Apache Software Foundation.
Here are some of Apache Spark's main characteristics:
1. In-Memory Computation
2. Distributed Data Processing
3. Rich Collection of APIs
4. Fault Tolerance
5. Integration with Hadoop
Let's understand each point
In-Memory Computation
Unlike disk-based systems like MapReduce, Spark retains intermediate data in memory, enabling quicker processing. Interactive data analysis and iterative algorithms are ideal applications for this in-memory processing approach.
Distributed Data Processing
Spark has the ability to spread data among a group of computers and process it in parallel. It is available to a broad spectrum of developers, offering high-level APIs in several programming languages, including Scala, Java, Python, and R.
Rich Collection of APIs
Spark provides a wide range of APIs for machine learning (MLlib), streaming data (Spark Streaming), batch processing (Spark Core), SQL queries (Spark SQL), and graph analysis (GraphX). Because of this, it's a flexible platform that can handle different large data processing jobs within of one framework.
Fault Tolerance
Spark enables fault tolerance via resilient distributed datasets (RDDs), which are distributed collections of data that may be processed concurrently. If a node breaks, RDDs may be automatically recreated using lineage information, offering fault tolerance without requiring operator intervention.
Integration with Hadoop
Spark can operate on top of Hadoop YARN, taking use of Hadoop's resource management features. It may also access data stored on Hadoop Distributed File System (HDFS), HBase, and other Hadoop-compatible storage systems.
Overall, Apache Spark's speed enhancements, simplicity of use, diversity, and strong community support have contributed to its broad acceptance and preference over classic MapReduce for many large-scale data processing jobs.
0 notes
Last Seen Blogs




