#going back and adding source links to the metadata of some of the images so i remember where i got it from.
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text

my new downloads folder is sooooo sexy btw. you wish you were me
#bulk renamed to remove all special characters. compressorized. all recolors i don't strictly need DELETED. tooltipped. merged.#jpegs compressed to shit because i dont need them to be high res to be able to tell what its previewing.#going back and adding source links to the metadata of some of the images so i remember where i got it from.#everything is at most two subfolders deep. trying to find a good balance between well-organized and shaving off load time.#.txt#simsposting#'miles why are you doing this instead of playing the game' i love sorting my touys!!!!!!!!!!!#also learning that naming a file folder.jpg automatically makes it the cover for a folder changed my LIFE im doing that shit for everything
{kind=link}
7 notes
·
View notes
Text
20 years a blogger

It's been twenty years, to the day, since I published my first blog-post.
I'm a blogger.
Blogging - publicly breaking down the things that seem significant, then synthesizing them in longer pieces - is the defining activity of my days.
https://boingboing.net/2001/01/13/hey-mark-made-me-a.html
Over the years, I've been lauded, threatened, sued (more than once). I've met many people who read my work and have made connections with many more whose work I wrote about. Combing through my old posts every morning is a journey through my intellectual development.
It's been almost exactly a year I left Boing Boing, after 19 years. It wasn't planned, and it wasn't fun, but it was definitely time. I still own a chunk of the business and wish them well. But after 19 years, it was time for a change.
A few weeks after I quit Boing Boing, I started a solo project. It's called Pluralistic: it's a blog that is published simultaneously on Twitter, Mastodon, Tumblr, a newsletter and the web. It's got no tracking or ads. Here's the very first edition:
https://pluralistic.net/2020/02/19/pluralist-19-feb-2020/
I don't often do "process posts" but this merits it. Here's how I built Pluralistic and here's how it works today, after nearly a year.
I get up at 5AM and make coffee. Then I sit down on the sofa and open a huge tab-group, and scroll through my RSS feeds using Newsblur.
I spend the next 1-2 hours winnowing through all the stuff that seems important. I have a chronic pain problem and I really shouldn't sit on the sofa for more than 10 minutes, so I use a timer and get up every 10 minutes and do one minute of physio.
After a couple hours, I'm left with 3-4 tabs that I want to write articles about that day. When I started writing Pluralistic, I had a text file on my desktop with some blank HTML I'd tinkered with to generate a layout; now I have an XML file (more on that later).
First I go through these tabs and think up metadata tags I want to use for each; I type these into the template using my text-editor (gedit), like this:
<xtags>
process, blogging, pluralistic, recursion, navel-gazing
</xtags>
Each post has its own little template. It needs an anchor tag (for this post, that's "hfbd"), a title ("20 years a blogger") and a slug ("Reflections on a lifetime of reflecting"). I fill these in for each post.
Then I come up with a graphic for each post: I've got a giant folder of public domain clip-art, and I'm good at using all the search tools for open-licensed art: the Library of Congress, Wikimedia, Creative Commons, Flickr Commons, and, ofc, Google Image Search.
I am neither an artist nor a shooper, but I've been editing clip art since I created pixel-art versions of the Frankie Goes to Hollywood glyphs using Bannermaker for the Apple //c in 1985 and printed them out on enough fan-fold paper to form a border around my bedroom.

As I create the graphics, I pre-compose Creative Commons attribution strings to go in the post; there's two versions, one for the blog/newsletter and one for Mastodon/Twitter/Tumblr. I compose these manually.
Here's a recent one:
Blog/Newsletter:
(<i>Image: <a href="https://commons.wikimedia.org/wiki/File:QAnon_in_red_shirt_(48555421111).jpg">Marc Nozell</a>, <a href="https://creativecommons.org/licenses/by/2.0/deed.en">CC BY</a>, modified</i>)
Twitter/Masto/Tumblr:
Image: Marc Nozell (modified)
https://commons.wikimedia.org/wiki/File:QAnon_in_red_shirt_(48555421111).jpg
CC BY
https://creativecommons.org/licenses/by/2.0/deed.en
This is purely manual work, but I've been composing these CC attribution strings since CC launched in 2003, and they're just muscle-memory now. Reflex.
These attribution strings, as well as anything else I'll need to go from Twitter to the web (for example, the names of people whose Twitter handles I use in posts, or images I drop in, go into the text file). Here's how the post looks at this point in the composition.
<hr>
<a name="hfbd"></a>
<img src="https://craphound.com/images/20yrs.jpg">
<h1>20 years a blogger</h1><xtagline>Reflections on a lifetime of reflecting.</xtagline>
<img src="https://craphound.com/images/frnklogo.jpg">
See that <img> tag in there for frnklogo.jpg? I snuck that in while I was composing this in Twitter. When I locate an image on the web I want to use in a post, I save it to a dir on my desktop that syncs every 60 seconds to the /images/ dir on my webserver.
As I save it, I copy the filename to my clipboard, flip over to gedit, and type in the <img> tag, pasting the filename. I've typed <img src="https://craphound.com/images/ CTRL-V"> tens of thousands of times - muscle memory.
Once the thread is complete, I copy each tweet back into gedit, tabbing back and forth, replacing Twitter handles and hashtags with non-Twitter versions, changing the ALL CAPS EMPHASIS to the extra-character-consuming *asterisk-bracketed emphasis*.
My composition is greatly aided both 20 years' worth of mnemonic slurry of semi-remembered posts and the ability to search memex.craphound.com (the site where I've mirrored all my Boing Boing posts) easily.
A huge, searchable database of decades of thoughts really simplifies the process of synthesis.
Next I port the posts to other media. I copy the headline and paste it into a new Tumblr compose tab, then import the image and tag the post "pluralistic."
Then I paste the text of the post into Tumblr and manually select, cut, and re-paste every URL in the post (because Tumblr's automatic URL-to-clickable-link tool's been broken for 10+ months).
Next I past the whole post into a Mastodon compose field. Working by trial and error, I cut it down to <500 characters, breaking at a para-break and putting the rest on my clipboard. I post, reply, and add the next item in the thread until it's all done.
*Then* I hit publish on my Twitter thread. Composing in Twitter is the most unforgiving medium I've ever worked in. You have to keep each stanza below 280 chars. You can't save a thread as a draft, so as you edit it, you have to pray your browser doesn't crash.
And once you hit publish, you can't edit it. Forever. So you want to publish Twitter threads LAST, because the process of mirroring them to Tumblr and Mastodon reveals typos and mistakes (but there's no way to save the thread while you work!).
Now I create a draft Wordpress post on pluralistic.net, and create a custom slug for the page (today's is "two-decades"). Saving the draft generates the URL for the page, which I add to the XML file.
Once all the day's posts are done, I make sure to credit all my sources in another part of that master XML file, and then I flip to the command line and run a bunch of python scripts that do MAGIC: formatting the master file as a newsletter, a blog post, and a master thread.
Those python scripts saved my ASS. For the first two months of Pluralistic, i did all the reformatting by hand. It was a lot of search-replace (I used a checklist) and I ALWAYS screwed it up and had to debug, sometimes taking hours.
Then, out of the blue, a reader - Loren Kohnfelder - wrote to me to point out bugs in the site's RSS. He offered to help with text automation and we embarked on a month of intensive back-and-forth as he wrote a custom suite for me.
Those programs take my XML file and spit out all the files I need to publish my site, newsletter and master thread (which I pin to my profile). They've saved me more time than I can say. I probably couldn't kept this up without Loren's generous help (thank you, Loren!).
I open up the output from the scripts in gedit. I paste the blog post into the Wordpress draft and copy-paste the metadata tags into WP's "tags" field. I preview the post, tweak as necessary, and publish.
(And now I write this, I realize I forgot to mention that while I'm doing the graphics, I also create a square header image that makes a grid-collage out of the day's post images, using the Gimp's "alignment" tool)
(because I'm composing this in Twitter, it would be a LOT of work to insert that information further up in the post, where it would make sense to have it - see what I mean about an unforgiving medium?)
(While I'm on the subject: putting the "add tweet to thread" and "publish the whole thread" buttons next to each other is a cruel joke that has caused me to repeatedly publish before I was done, and deleting a thread after you publish it is a nightmare)
Now I paste the newsletter file into a new mail message, address it to my Mailman server, and create a custom subject for the day, send it, open the Mailman admin interface in a browser, and approve the message.
Now it's time to create that anthology post you can see pinned to my Mastodon and Twitter accounts. Loren's script uses a template to produce all the tweets for the day, but it's not easy to get that pre-written thread into Twitter and Mastodon.
Part of the problem is that each day's Twitter master thread has a tweet with a link to the day's Mastodon master thread ("Are you trying to wean yourself off Big Tech? Follow these threads on the #fediverse at @[email protected]. Here's today's edition: LINK").
So the first order of business is to create the Mastodon thread, pin it, copy the link to it, and paste it into the template for the Twitter thread, then create and pin the Twitter thread.
Now it's time to get ready for tomorrow. I open up the master XML template file and overwrite my daily working file with its contents. I edit the file's header with tomorrow's date, trim away any "Upcoming appearances" that have gone by, etc.
Then I compose tomorrow's retrospective links. I open tabs for this day a year ago, 5 years ago, 10 years ago, 15 years ago, and (now) 20 years ago:
http://memex.craphound.com/2020/01/14
http://memex.craphound.com/2016/01/14
http://memex.craphound.com/2011/01/14
http://memex.craphound.com/2006/01/14
http://memex.craphound.com/2001/01/14
I go through each day, and open anything I want to republish in its own tab, then open the OP link in the next tab (finding it in the @internetarchive if necessary). Then I copy my original headline and the link to the article into tomorrow's XML file, like so:
#10yrsago Disney World’s awful Tiki Room catches fire <a href="https://thedisneyblog.com/2011/01/12/fire-reported-at-magic-kingdom-tiki-room/">https://thedisneyblog.com/2011/01/12/fire-reported-at-magic-kingdom-tiki-room/</a>
And NOW my day is done.
So, why do I do all this?
First and foremost, I do it for ME. The memex I've created by thinking about and then describing every interesting thing I've encountered is hugely important for how I understand the world. It's the raw material of every novel, article, story and speech I write.
And I do it for the causes I believe in. There's stuff in this world I want to change for the better. Explaining what I think is wrong, and how it can be improved, is the best way I know for nudging it in a direction I want to see it move.
The more people I reach, the more it moves.
When I left Boing Boing, I lost access to a freestanding way of communicating. Though I had popular Twitter and Tumblr accounts, they are at the mercy of giant companies with itchy banhammers and arbitrary moderation policies.
I'd long been a fan of the POSSE - Post Own Site, Share Everywhere - ethic, the idea that your work lives on platforms you control, but that it travels to meet your readers wherever they are.
Pluralistic posts start out as Twitter threads because that's the most constrained medium I work in, but their permalinks (each with multiple hidden messages in their slugs) are anchored to a server I control.
When my threads get popular, I make a point of appending the pluralistic.net permalink to them.
When I started blogging, 20 years ago, blogger.com had few amenities. None of the familiar utilities of today's media came with the package.
Back then, I'd manually create my headlines with <h2> tags. I'd manually create discussion links for each post on Quicktopic. I'd manually paste each post into a Yahoo Groups email. All the guff I do today to publish Pluralistic is, in some way, nothing new.
20 years in, blogging is still a curious mix of both technical, literary and graphic bodgery, with each day's work demanding the kind of technical minutuae we were told would disappear with WYSIWYG desktop publishing.
I grew up in the back-rooms of print shops where my dad and his friends published radical newspapers, laying out editions with a razor-blade and rubber cement on a light table. Today, I spend hours slicing up ASCII with a cursor.
I go through my old posts every day. I know that much - most? - of them are not for the ages. But some of them are good. Some, I think, are great. They define who I am. They're my outboard brain.
37 notes
·
View notes
Text
A Step-by-Step SEO Guide for Dentists in 2021
A Step-by-Step SEO Guide for Dentists in 2021
This article is a really simple step-by-step guide for dentists from Experdent. Let's begin
What is Dental SEO Dental SEO is the optimization of your website so that it is easy for you to be found by patients online when they search for dental treatment or any service that you offer. In other words, SEO for dentists is to make their dental office rank higher in Google or Bing or Yahoo search results. Do people go to page-2 of Google? Yes, people do go to page-2 of Google. However, this is quite seldom. Over 70% of searchers will click on something that falls in the first five results on a Google page. And almost 90% will click on something on page-1. The rest may likely refine their search and search again rather than go to page-2.
Is SEO Digital Marketing? SEO is the digital equivalent of traditional inbound marketing. Let us explain: While many activities qualify as digital marketing, SEO is the foundation for all digital marketing processes. Conversely, a weak SEO can result in massive marketing expenditure to get results online. SEO builds cred for you with search engines. Think of it as a virtuous loop. The better the SEO for a website, the higher it will rank in search results. The higher it ranks in search results, the more people will click on it. The more people click on a consequence, this tells Google/Bing or any other search engine that yours is a quality website, and therefore the search engines push up the rank of your website even further. A high-ranking site on Google search, therefore, becomes a magnet for visitors. More visitors will lead to more conversions in any marketing funnel, i.e., more people becoming dental office patients.
Does SEO improve the visitor experience on your website? The foundation of SEO is in Technical SEO. Let's unpack that: SEO work for any quality SEO services business starts with a detailed website audit. This audit looks to fix these key elements that go into user experience: - Site Speed - Performance on Mobile - Intuitive navigation - Presence of Metadata including alt tags for images - Presence of appropriate keywords on pages - Submission of sitemaps to search engines In addition, SEO looks for compelling content and quality images and video to create an engaging experience for the visitor to a website. Through this process, technical SEO helps improve user experience while improving the website for search engines to crawl.
Is SEO advertising? The output of SEO is greater visibility for your content for the people who are searching for that content Let's say you live in downtown Toronto and you have a toothache. You will likely open up your computer or your smartphone and search something like this: - Family Dentist in downtown Toronto or - Dentist for a toothache or - Best dentist in Toronto or if its evening or the weekend - Dentist in Toronto open today If your website is optimized for SEO and contains this information (preferably in the schema), then your visitors may see your website featured on page-1 of Google. Thus, SEO is advertising by another means. Content that ranks is the best advertising because research has repeatedly shown that people will click on an organic link that appears more authentic. Research by Wordstream.com shows that "Clicks on paid search listings beat out organic clicks by nearly a 2:1 margin for keywords with high commercial intent in the US. In other words, 64.6% of people click on Google Ads when they are looking to buy an item online!" And here is the kicker - When you run an ad campaign, you get results only while the campaign is running and you are paying for clicks on your ad. In the case of SEO, however, you continue to get results for a long time. Yes, if you don't continuously optimize your website for SEO, your Search Rankings will eventually begin to drop. Why is that, you ask? Simply because your neighbours and competitors will not have stopped, they will continue improving and scaling their websites, and as a consequence, Google will keep pulling other websites over yours.
On-Page optimization Getting Google to like your website and show it on page-1 of its search results means that you need to bring quality to your pages and make them valuable and delightful for your visitors. Remember that the best websites are built for real visitors and not for search engines. The key elements that SEO helps you improve on-page are: - The quality of content on its page and its layout and organization for easy flow. The presence of images and video. - Headlines, subheadings are identified by Headline tags. For example, a page should ideally only have one headline tagged with an H1 tag. Sub headlines can go to H2 or H3 tags. Sub-sub headlines can go to H4, H5, and even H6 tags. - Metadata and descriptions that encourage clickthrough. This is the data that search engines showcase your pages within search results. - The amount of content on the page. Although the jury is still out on the length of an ideal article for Google to show it on page-1, research shows somewhere between 1000 and 1500 words. This does not mean that a page with 5000 words will consistently rank higher than a page with 1000 words. However, it does mean that when choosing between 2 pages that are otherwise identical in quality of content, Google will likely choose to showcase the page with more content in a higher position. - The number of pages on your website (remember, more is not always better). - The freshness of your content etc.
Off-Page optimization The links that other sites on the internet provide your website are essentially treated like votes. The larger the number of websites linking to your website or providing you with backlinks, the larger the number of votes for your website. This quantity of links helps Google decide where to rank your website. That said, all backlinks are not born equal. For example, a link from a higher ranking website carries more value than a brand new one-page website. Some backlinks can be toxic and be damaging for your website's rank on Google. (More on toxic backlinks and how to get rid of those in a future article). The list for how off-page links create value for you can be bullet-pointed as follows: - Citations or directory listings - In context, backlinks from articles or guest blogs - is the link reciprocal - this practice has the potential to reduce the value of the link received - The nature of the website that the link comes from: i.e., is the website in a related space? A link from a gambling website for a dentist is not likely to count as useful. - Keywords in anchor text could indicate that the link has been sourced or purchased. The best links have anchor text that is just the URL of your website or "read more" or "click here," etc.
Technical SEO We have mentioned earlier that Technical SEO is the foundation of SEO for a website. The critical elements of the work done under technical SEO are - Identification and removal of Crawl errors. - Check if your website is secure - check for HTTPS status - Check if XML sitemaps exist & if they have been submitted to major search engines - Check and improve Site Load time - Check whether the site is mobile friendly and upgrade as needed - Check and optimize robots.txt files - Check for keyword cannibalization and edit as needed - Check and improve site metadata, including image alt tags - Check for broken links and eliminate them or apply a 301 redirect that passes full link equity (ranking power) to the redirected page.
Yoast, a company that provides an extremely popular SEO plugin for Wordpress websites, in addition talks about the need for technical SEO to ensure that there is no duplicate content, nor are there any dead links in the website.
As a dentist, how do I build a high-quality website myself While we would recommend that you hire an experienced web developer to help develop or update your dental website, you could build a workable website quite easily as a DIY project There are many website development tools available, and you could choose between them for your DIY project. Three major platforms that you could use are: - WordPress - Squarespace - Wix WordPress will need the most significant amount of expertise, while both Squarespace and Wix use drag and drop functionality for you to build something quickly. There is an argument between SEOs about whether or not SEO is easier to do on WordPress versus Wix or Squarespace. However, what is clear is that WordPress enjoys a much larger ecosystem which gives you access to better tools and developers than does any other website builder. According to Search Engine Journal "WordPress content management system is used by 39.5% of all sites on the web."
Choose a reliable & high-quality hosting company If you go with Wix or Squarespace, the hosting is with the website builder's platform. If you build with WordPress or any other website builder platform, you will need to choose a high-quality, fast, and secure hosting service. Some of the major hosting services that you could consider are: - Amazon Web Services - Bluehost - Godaddy - WPengine - Siteground - Hostgator etc. There are quite literally hundreds of hosting companies for you to choose from. Choose a hosting service that has close to 100% uptime, which has enough bandwidth for your clients to visit without the speed of your website going down. Over and above that, the hosting service should have robust security and offer you a service of backups so that if your website gets damaged or hacked, they can put back the site in a matter of minutes.
How do you do keyword research? As a dentist, you have a scarcity of time. Still, given that you have decided to build a DIY website, you need to ensure that you do keyword research so that Google recognizes your content to contain the answers your future patients or clients are searching for. Some of the tools that you could use for keyword research are: - Google Keyword planner - this is a free tool - Semrush/Ahrefs/Moz - these are paid tools but will help you in getting a solid grounding of keywords
Submit your site to Google Once your website is ready, make sure to create your presence and submit it to the search engine with the following tools: - Google My Business - Google Maps - Bing Places - Yahoo Small business - Unfortunately, this tends to work only in the US unless you subscribe to some listing services.
Google Tools to monitor your website performance These tools will help you gauge the performance of your website traffic and help you find points of strengths and weaknesses on your website - Google Search Console - Google Analytics - Google Page Speed Insights
List yourself on review sites. While the best website for reviews that self selects itself is your Google my business (GMB) page. You would also find reviews very helpful from the following websites. - Facebook - Yelp - RateMyMD - Healthgrades
List your practice in online directories. A presence in online directories is a crucial aspect of SEO for any business. You should list your dental practice in as many relevant directories as possible. There is a wide variety of directories available, and you should choose well. Your choices will be along the lines of: - Local yellow pages or equivalent - Directories for your town or province - Directories for Dentists or healthcare providers - Directories of local chambers of commerce or industry organizations
Is your Dental SEO strategy working? Once you have done all this work, you will need to ask how you find out if your dental strategy is working? To get this answer, you will need to check for some of the following: - Website traffic - this is the first and foremost indicator of performance - Ranking keywords - What is the page and rank of each of the keywords you believe to be vital. And, of course, how do these keyword ranks change over time. - Reviews - the number of reviews and the grade you get on your reviews is outside SEO in a technical sense. However, reviews create a very favourable feedback loop for search engines. Generally speaking, a large number of reviews will push a website up in ranking.
How do you find how you rank without subscribing to expensive SEO tools? If you check your keywords using your computer, the computer will respond based on your search history, thereby potentially fooling you into thinking that your rank has improved. Instead, there is a simple trick to finding how you rank for your target keywords. First, open an "incognito" session in a browser such as Chrome and then search for your keyword. If you don't find it on page-1, go to page-2 continue until you find it. Of course, if you don't rank even on page-10, then functionally, you don't rank for that keyword.
How can Experdent help? While you can most definitely do all of the work that we have enumerated here, you could choose to get expert help to create powerful SEO for your website. At Experdent, our focus is SEO for dentists, and that is just what we do. So, get in touch, send us an email, or call us to set up a time to chat very quickly. At Experdent Web Services, we put these very ideas into practice. We are results-driven, dentist-focused, and experts in SEO for dental offices in North America. So, if you are a dental office looking for SEO or need advice on your digital strategy, call us for a free 30-minute consult.
1 note
·
View note
Text
Version 505
youtube
Windows release got a hotfix! If you got 505a right after the release was posted and everything is a bad darkmode, get the new one!
windows
zip
exe
macOS
app
linux
tar.gz
I had a great couple of weeks fixing bugs, exposing EXIF and other embedded metadata better, and making it easier for anyone to run the client from source.
full changelog (big one this week)
EXIF
I added tentative EXIF support a little while ago. It wasn't very good--it never knew if a file had EXIF before you checked, so it was inconvenient, and non searchable--but the basic framework was there. This week I make that prototype more useful.
First off, the client doesn't just look at EXIF. It also scans images and animations for miscellaneous 'human-readable embedded metadata'. This is often some technical timing or DPI data, or information about the program that created the file, but, most neatly, for the new AI/ML-drawn images everyone has been playing with, many of the generation engines embed the creation prompt in the header of the output png, and this is now viewable in the client!
Secondly, the client now knows ahead of time which files have this data to show. A new file maintenance job will be scheduled on update for all your existing images and animations to retroactively check for this, and they will fill in in the background over the next few weeks. You can now search for which files have known EXIF or other embedded metadata under a new combined 'system:embedded metadata' predicate, which works like 'system:dimensions' and also bundles the old 'system:has icc profile' predicates.
Also, the 'cog' button in the media viewer's top hover window where you would check for EXIF is replaced by a 'text on window' icon that is only in view if the file has something to show.
Have a play with this and let me know how it goes. The next step here will be to store the actual keys and values of EXIF and other metadata in the database so you can search them specifically. It should be possible to allow some form of 'system:EXIF ISO level>400' or 'system:has "parameters" embedded text value'.
running from source
I have written Linux (.sh) and macOS (.command) versions of the 'running from source' easy-setup scripts. The help is updated too, here:
https://hydrusnetwork.github.io/hydrus/running_from_source.html
I've also updated the setup script and process to be simpler and give you guidance on every decision. If you have had trouble getting the builds to work on your OS, please try running from source from now on. Running from source is the best way to relieve compatibility problems.
I've been working with some users to get the Linux build, as linked above, to have better mpv support. We figured out a solution (basically rolling back some libraries to improve compatibility), so more users should get good mpv off the bat from the build, but the duct tape is really straining here. if you have any trouble with it, or if you are running Ubuntu 22.04 equivalent, I strongly recommend you just move to running from source.
If these new scripts go well, I think that, in two or three months, I may stop putting out the Linux build. It really is the better way to run the program, at least certainly in Linux where you have all the tools already there. You can update in a few seconds and don't get crashes!
misc highlights
If you are interested in changing page drag and drop behaviour or regularly have overfull page tab bars, check the new checkboxes in options->gui pages.
If you are on Windows and have the default options->style, booting the client with your Windows 'app darkmode' turned on should magically draw most of the client stuff in the correct dark colours! Switching between light and dark while the program is running seems buggy, but this is a step forward. My fingers are crossed that future Qt versions improve this feature, including for multiplatform.
Thanks to a user, the twitter downloader is fixed. The twitter team changed a tiny thing a few days ago. Not sure if it is to do with Elon or not; we'll see if they make more significant changes in future.
I fixed a crazy bug in the options when you edit a colour but find simply moving the mouse over the 'colour gradient' rectangle would act like a drag, constantly selecting. This is due to a Qt bug, but I patched it on our side. It happens if you have certain styles set under options->style, and the price of fixing the bug is I have to add a couple seconds of lag to booting and exiting a colour picker dialog. If you need to change a lot of colours, then set your style to default for a bit, where there is no lag.
next week
I pushed it hard recently, and I am due a cleanup week, so I am going to take it easy and just do some refactoring and simple fixes.
0 notes
Text
Archivists Are Mining Parler Metadata to Pinpoint Crimes at the Capitol
Using a massive 56.7 terabyte archive of the far-right social media site Parler that was captured on Sunday, open-source analysts, hobby archivists, and computer scientists are working together to catalog videos and photos that were taken at the attack on the U.S. Capitol last Wednesday.
Over the last few days, Parler was deplatformed by Amazon Web Services, the Google Play Store, and the Apple App Store, which has taken it offline (at least temporarily). But before it disappeared, a small group of archivists made a copy of the overwhelming majority of posts on the site.
While all the data scraped from Parler was publicly available, archiving it allows analysts to extract the EXIF metadata from photos and videos uploaded to the social media site en masse and to examine specific ones that were taken at the insurrection on Capitol Hill. This data includes specific GPS coordinates as well as the date and time the photos were taken. These are now being analyzed in IRC chat channels by a handful of people, some of whom believe crimes can be catalogued and given to the FBI.
"I hope that it can be used to hold people accountable and to prevent more death," donk_enby, the hacker who led the archiving project, told Motherboard on Monday.
One technologist took the scraped Parler data, took every file that had GPS coordinates included within it, formatted that information into JSON, and plotted those onto a map. The technologist then shared screenshots of their map with Motherboard, showing Parler posts originating from various countries, and then the United States, and finally in or around the Capitol itself. In other words, they were able to show that Parler users were posting material from the Capitol on the day of the rioting, and can now go back into the rest of the Parler data to retrieve specific material from that time.
They also shared the newly formatted geolocation data with Motherboard. Motherboard granted the technologist anonymity to speak more candidly about a potentially sensitive topic.
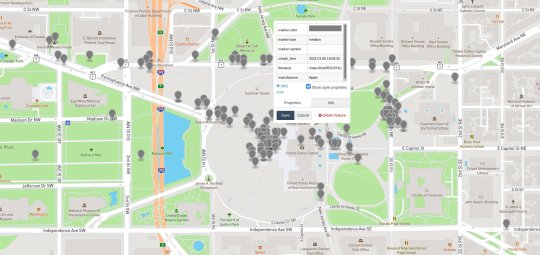
Some of the plotted Parler GPS data. Image: Motherboard
The technologist said that, to at least some extent, since this data shows the use of Parler during the Capitol raid attempt, "that's a piece of the overall puzzle which someone, somewhere can use."
"It's definitely to help facilitate or otherwise create another exposure that the public can consume," they added, explaining their motivations for cleaning the Parler data.
This particular technologist did not distribute their version of the data more widely, however, with the aim of preventing abuse and misuse of the data.
"Sure, the source data are already public. But that doesn't mean I have to add an even easier path to data misuse," they said.
"For this Parler data, it would clearly not be correct to say 'every single user is a Nazi' and so by complete disclosure you are enabling someone who WOULD hold such a narrative to make bad choices and take bad actions if they wished," they added.
Do you know anything else about the Parler data? We'd love to hear from you. Using a non-work phone or computer, you can contact Joseph Cox securely on Signal on +44 20 8133 5190, Wickr on josephcox, OTR chat on [email protected], or email [email protected].
Earlier on Tuesday, an analysis of the metadata by Gizmodo also showed that Parler users made it into the Capitol.
Others who have managed to get their hands on the Parler data have begun to make lists of videos and photos that have GPS coordinates on Capitol Hill, and have written scripts to pull those videos from the broader dump so people can analyze them. On an IRC chat channel, a small group of people are watching and analyzing videos and are posting their video IDs and description into a Google spreadsheet called "Notable Parler Videos." One description reads: "at the capital, pushing police, guy in MAGA hat screaming 'I need some violence now.'" A description for the IRC channel includes a link to an FBI tip line specifically targeted at identifying people at the riot.
One open source project calling itself Parler Analysis has collected different tools from around the web to handle the data in different ways. One is used to scrape usernames, for example, while another is for extracting images and videos, and yet another is an alternative cleaned dataset of cleaned Parler geolocation coordinates in a different format.
Subscribe to our cybersecurity podcast CYBER, here.
Archivists Are Mining Parler Metadata to Pinpoint Crimes at the Capitol syndicated from https://triviaqaweb.wordpress.com/feed/
0 notes
Text
Version 312
youtube
windows
zip
exe
os x
app
tar.gz
linux
tar.gz
source
tar.gz
I had an ok week. I mostly worked on smaller downloader jobs and tag import options.
tag import options
Tag import options now has more controls. There is a new 'cog' icon that lets you determine if tags should be applied--much like file import options's recent 'presentation' checkboxes--to 'new files', 'already in inbox', and 'already in archive', and there is an entry to only add tags that already exist (i.e. have non-zero count) on the service.
Sibling and parent filtering is also more robust, being applied before and after tag import options does its filtering. And the 'all namespaces' compromise solution used by the old defaults in file->options and network->manage default tag import options is now automatically replaced with the newer 'get all tags'.
Due to the sibling and parent changes, if you have a subscription to Rule34Hentai or another site that only has 'unnamespaced' tags, please make sure you edit its tag import options and change it to 'get all tags', as any unnamespaced tags that now get sibling-collapsed to 'creator' or 'series' pre-filtering will otherwise be discarded. Due to the more complicated download system taking over, 'get all tags' is the new option to go for if you just want everything, and I recommend it for everyone.
For those who do just want a subset of available tags, I will likely be reducing/phasing out the explicit namespace selection in exchange for a more complicated tag filter object. I also expect to add some commands to make it easier to mass-change tag import options for subscriptions and to tell downloaders and subscriptions just to always use the default, whatever that happens to be.
misc downloader stuff
I have added a Deviant Art parser. It now fetches the embedded image if the artist has disabled high-res download, and if it encounters a nsfw age-gate, it sets an 'ignored' status (the old downloader fetched a lower-quality version of the nsfw image). We will fix this ignored status when the new login system is in place.
Speaking of which, the edit subscriptions panels now have 'retry ignored' buttons, which you may wish to fire on your pixiv subscriptions. This will retry everything has has previously been ignored due to being manga, and should help in future as more 'ignored' problems are fixed.
The 'checker options' on watchers and subscriptions will now keep a fixed check phase if you set a static check period. So, if you set the static period as exactly seven days, and the sub first runs on Wednesday afternoon, it will now always set a next check time of the next Wed afternoon, no matter if they actually happen to subsequently run on Wed afternoon or Thurs morning or a Monday three weeks later. Previously, the static check period was being added to the 'last completed check time', meaning these static checks were creeping forward a few hours every check. If you wish to set the check time for these subs, please use the 'check now' button to force a phase reset.
I've jiggled the multiple watcher's sort variables around so that by default they will sort with subject alphabetical but grouped by status, with interesting statuses like DEAD at the top. It should make the default easier to at-a-glance see if you need to action anything.
full list
converted much of the increasingly complicated tag import options to a new sub-object that simplifies a lot of code and makes things easier to serialise and update in future
tag import options now allows you to set whether tags should be applied to new files/already in inbox/already in archive, much like the file import options' 'presentation' checkboxes
tag import options now allows you to set whether tags should be filtered to only those that already have a non-zero current count on that tag service (i.e. only tags that 'already exist')
tag import options now has two 'fetch if already in db' checkboxes--for url and hash matches separately (the hash stuff is advanced, but this new distinction will be of increasing use in the future)
tag import options now applies sibling and parent collapse/expansion before tag filtering, which will improve filtering accuracy (so if you only want creator tags, and a sibling would convert an unnamespaced tag up to a creator, you will now get it)
the old 'all namespaces' checkbox is now removed from some 'defaults' areas, and any default tag import options that had it checked will instead get 'get all' checked as they update
caught up the ui and importer code to deal with these tag import option changes
improved how some 'should download metadata/file' pre-import checking works
moved all complicated 'let's derive some specific tag import options from these defaults' code to the tag import options object itself
wrote some decent unit tests for tag import options
wrote a parser for deviant art. it has source time now, and falls back to the embedded image if the artist has disabled high-res downloading. if it finds a mature content click-through (due to not being logged in), it will now veto and set 'ignored' status (we will revisit this and get high quality nsfw from DA when the login manager works.)
if a check timings object (like for a subscription or watcher) has a 'static' check interval, it will now apply that period to the 'last next check time', so if you set it to check every seven days, starting on Wednesday night, it will now repeatedly check on Wed night, not creep forward a few minutes/hours every time due to applying time to the 'last check completed time'. if you were hit by this, hit 'check now' to reset your next check time to now
the multiple watcher now sorts by status by default, and blank status now sorts below DEAD and the others, so you should get a neat subject-alphabetical sort grouped by interesting-status-first now right from the start
added 'clear all multiwatcher highlights' to 'pages' menu
fixed a typo bug in the new multiple watcher options-setting buttons
added 'retry ignored' buttons to edit subscription/subscriptions panels, so you can retry pixiv manga pages en masse
added 'always show iso time' checkbox to options->gui, which will stop replacing some recent timestamps with '5 minutes ago'
fixed an index-selection issue with compound formulae in the new parsing system
fixed a file progress count status error in subscriptions that was reducing progress rather than increasing range when the post urls created new urls
improved error handling when a file import object's index can't be figured out in the file import list
to clear up confusion, the crash recovery dialog now puts the name of the default session it would like to try loading on its ok button
the new listctrl class will now always sort strings in a case-insensitive way
wrote a simple 'fetch a url' debug routine for the help->debug menu that will help better diagnose various parse and login issues in future
fixed an issue where the autocomplete dropdown float window could sometimes get stuck in 'show float' mode when it spawned a new window while having focus (usually due to activating/right-clicking a tag in the list and hitting 'show in new page'). any other instances of the dropdown getting stuck on should now also be fixable/fixed with a simple page change
improved how some checkbox menu data is handled
started work on a gallery log, which will record and action gallery urls in the new system much like the file import status area
significant refactoring of file import objects--there are now 'file seeds' and 'gallery seeds'
added an interesting new 'alterate' duplicate example to duplicates help
brushed off and added some more examples to duplicates help, thanks to users for the contributions
misc refactoring
next week
I also got started on the gallery overhaul this week, and I feel good about where I am going. I will keep working on this and hope to roll out a 'gallery log'--very similar to the file import status panel, that will list all gallery pages hit during a downloader's history with status and how many links parsed and so on--within the next week or two.
The number of missing entries in network->manage url class links is also shrinking. A few more parsers to do here, and then I will feel comfortable to start removing old downloader code completely.
1 note
·
View note
Photo
Russian efforts to meddle in American politics did not end at Facebook and Twitter. A CNN investigation of a Russian-linked account shows its tentacles extended to YouTube, Tumblr and even Pokémon Go.
PRATE NOTE: THE ABSOLUTE STATE OF THE RUSSIAN FEARMONGERING IN AMERICAN MEDIA
------------------------
One Russian-linked campaign posing as part of the Black Lives Matter movement used Facebook, Instagram, Twitter, YouTube, Tumblr and Pokémon Go and even contacted some reporters in an effort to exploit racial tensions and sow discord among Americans, CNN has learned.
The campaign, titled "Don't Shoot Us," offers new insights into how Russian agents created a broad online ecosystem where divisive political messages were reinforced across multiple platforms, amplifying a campaign that appears to have been run from one source -- the shadowy, Kremlin-linked troll farm known as the Internet Research Agency.
A source familiar with the matter confirmed to CNN that the Don't Shoot Us Facebook page was one of the 470 accounts taken down after the company determined they were linked to the IRA. CNN has separately established the links between the Facebook page and the other Don't Shoot Us accounts.
The Don't Shoot Us campaign -- the title of which may have referenced the "Hands Up, Don't Shoot" slogan that became popular in the wake of the shooting of Michael Brown -- used these platforms to highlight incidents of alleged police brutality, with what may have been the dual goal of galvanizing African Americans to protest and encouraging other Americans to view black activism as a rising threat.
The Facebook, Instagram and Twitter accounts belonging to the campaign are currently suspended. The group's YouTube channel and website were both still active as of Thursday morning. The Tumblr page now posts about Palestine.
Related: Exclusive: Russian-linked group sold merchandise online
All of the aforementioned companies declined to comment on the Don't Shoot Us campaign. Representatives from Facebook, Twitter and Alphabet, the parent company of Google and YouTube, have agreed to testify before the Senate and House Intelligence Committees on November 1, according to sources at all three companies
Tracing the links between the various Don't Shoot Us social media accounts shows how one YouTube video or Twitter post could lead users down a rabbit hole of activist messaging and ultimately encourage them to take action.
The Don't Shoot Us YouTube page, which is simply titled "Don't Shoot," contains more than 200 videos of news reports, police surveillance tape and amateur footage showing incidents of alleged police brutality. These videos, which were posted between May and December of 2016, have been viewed more than 368,000 times.
All of these YouTube videos link back to a donotshoot.us website. This website was registered in March 2016 to a "Clerk York" in Illinois. Public records do not show any evidence that someone named Clerk York lives in Illinois. The street address and phone number listed in the website's registration belong to a shopping mall in North Riverside, Illinois.
The donotshoot.us website in turn links to a Tumblr account. In July 2016, this Tumblr account announced a contest encouraging readers to play Pokémon Go, the augmented reality game in which users go out into the real world and use their phones to find and "train" Pokémon characters.
Specifically, the Don't Shoot Us contest directed readers to go to find and train Pokémon near locations where alleged incidents of police brutality had taken place. Users were instructed to give their Pokémon names corresponding with those of the victims. A post promoting the contest showed a Pokémon named "Eric Garner," for the African-American man who died after being put in a chokehold by a New York Police Department officer.
Winners of the contest would receive Amazon gift cards, the announcement said.
It's unclear what the people behind the contest hoped to accomplish, though it may have been to remind people living near places where these incidents had taken place of what had happened and to upset or anger them.

CNN has not found any evidence that any Pokémon Go users attempted to enter the contest, or whether any of the Amazon Gift Cards that were promised were ever awarded -- or, indeed, whether the people who designed the contest ever had any intention of awarding the prizes.
"It's clear from the images shared with us by CNN that our game assets were appropriated and misused in promotions by third parties without our permission," Niantic, the makers of Pokémon Go, said in a statement provided to CNN.
"It is important to note that Pokémon GO, as a platform, was not and cannot be used to share information between users in the app so our platform was in no way being used. This 'contest' required people to take screen shots from their phone and share over other social networks, not within our game. Niantic will consider our response as we learn more."
The Tumblr page that promoted the contest no longer posts about U.S. police violence. It now appears to be devoted pro-Palestine campaigns.
Tumblr would not confirm to CNN if the same people who operated the Tumblr page about Black Lives Matter now operate the pro-Palestinian page, citing the company's privacy policy. Tumblr also would not say whether it is investigating potential Russian use of its platform before, during or after the 2016 presidential election.
Related: Facebook could still be weaponized again for the 2018 midterms
Don't Shoot Us also worked to spread its influence beyond the digital world.
It used Facebook -- on which it had more than 254,000 likes as of September 2016 -- to publicize at least one real-world event designed to appear to be part of the Black Lives Matter Movement.
Just a day after the shooting of Philando Castile by police in a suburb of Saint Paul, Minnesota in July 2016, local activists in Minnesota noticed a Facebook event for a protest being shared by a group they didn't recognize.
Don't Shoot Us was publicizing a protest outside the St. Anthony Police Department, where Jeronimo Yanez, the officer who shot Castile, worked. Local activists had been protesting outside the Minnesota Governor's Mansion.
When an activist group with ties to a local union reached out to the page, someone with Don't Shoot Us replied and explained that they were not in Minnesota but planned to open a "chapter" in the state in the following months.
The local group became more suspicious. After investigating further, including finding the website registration information showing a mall address, they posted on their website to say that Don't Shoot Us was a "total troll job."
CNN has reached out to those local activists but had not heard back as of the time of this article's publication.
Brandon Long, the state party chairman of the Green Party of Minnesota, remembers hearing about the planned Don't Shoot Us event. He told CNN, "We frequently support Black Lives Matter protests and demonstrations and we know pretty much all the organizers in town and that page wasn't recognized by anyone."
This was not the only event that Don't Shoot Us worked to promote.
In June 2016, someone using the Gmail address that had been posted as part of the Pokémon Go contest promotion reached out to Brandon Weigel, an editor at Baltimore City Paper, to promote a protest at a courthouse where one of the officers involved in the arrest of Freddie Gray was due to appear.
The email made Weigel suspicious. "City Paper editors and reporters are familiar with many of the activist groups doing work in Baltimore, so it was strange to receive an email from an outside group trying to start a protest outside the courthouse," Weigel told CNN.
Weigel wasn't the only reporter to be on the receiving end of communications from Don't Shoot Us. Last January, someone named Daniel Reed, who was described as the "Chief Editor" of DoNotShoot.Us, gave an interview to a contributor at the now defunct International Press Foundation (IPF), a website where students and trainee journalists regularly posted articles.
"There is no civilised country in the world that suffers so many cases of police brutality against civilians," IPF quoted "Reed" as saying, among other things. (IPF was responsible for the British spelling of "civilised.")
The IPF contributor confirmed to CNN that the interview occurred through email and that she never spoke to "Reed" on the phone. The email address that "Reed" used for the interview was the same one that reached out to Weigel in Baltimore and that was included in the promotion for the Pokémon Go contest.
"Reed" sent the answers to IPF's questions in a four-page Microsoft Word document. The document, which outlined what "Reed" described as problems with the American justice system and police brutality, was written entirely in English.
However, when CNN examined the document metadata, "Название," the Russian word for "name," was part of the document properties.
Two cybersecurity experts who reviewed the document's metadata told CNN that it was likely created on a computer or a program running Russian as its primary language.
To date, Facebook has said that it identified 470 accounts linked to the Internet Research Agency, while Twitter has identified 201 accounts. Google has not released its findings, though CNN has confirmed that the company has identified tens of thousands of dollars spent on ad buys by Russian accounts.
Facebook and Twitter have submitted detailed records of their findings to both Congress and the office of Special Counsel Robert Mueller, who is conducting an investigation into Russian meddling in the 2016 presidential campaign.
On Friday, Maria Zakharova, the spokeswoman for the Russian Foreign Ministry, made her displeasure with this story clear in a Facebook post written in Russian, calling CNN a "talentless television channel" and saying,"Again the Russians are to blame... and the Pokémons they control."
-- CNN's Jose Pagliery and Tal Yellin contributed reporting.
Fcuking hilarioooouss
MEDIA E D I A
ok, lets break it down:
1. the sustained russia narrative serves the purpose of preventing the left wing in America to have a moment of self-reflection WRT the corruption and plutocracy inherent within the Democrat Party after the complete collapse of Hillary’s Presidential bid. The Democrats certainly dont want to fan the flames of the populist left and that has been their primary enemy since day 1 of the trump Presidency (and before, if you consider how Bernie got marginalized).
2. The russia narrative sustains viewership, and it always has been, as a corporate media understood “nothing burger” in order to fleece viewership ratings from angry americans seeking someone to blame for the loss of Clinton. Liberal americans shocked about Trumps victory want something to blame and scapegoating a hostile foreign nation certainly feeds that desperate search while misdirecting their attention away from the personal failures of the Clinton campaign and the bombshells from the leaks.
3. The affiliation of Black Lives Matter with Russia Hacked The Election™ has the effect of undermining progressive support among liberal and centrist voters, who will now disregard news of police brutality as Fake News Russia Collusion in favour of Trump
What’s more, they will begin to understand Black Lives Matter as an organization produced by Russia and thus, double plus ungood and of course pointing out BLM with now prompt calls of Putin supporting FAKE NEEEeEEEeeEEEeeeeWWWWSSS!!!.
4. The narrative building up Russia as a super genius, ultimate evil that has infiltrated american society and the minds of it’s unruly youth and uppity minorities is cemented in the minds of baby boomers. The illusion of Putin as this super genius movie villain serves the enduring American hegemonic goal of destroying russia by preparing the American public for war, you see, because Russia is already at war with America, and thus it must be stopped. They have infiltrated pokemon go, by god. What’s next? Mind control rays?! This is McCarthyism at its FINEST my dudes.
Why the left isnt losing their fucking minds and pointing out the obvious nature of this psyop against the mostly democrat viewership of nighttime newcasts like CNN is beyond me.
But true progressives always lose, because they cant think around this shit in a lateral way. Progressive activism functions like constantly charging at the door with a nazi symbol crudely drawn on it, hoping continued, unrelenting brute strength wins the day as they get get outmaneuvered by their liberal “allies” and the right wing who exploit their bullheadedness.

30 notes
·
View notes
Text
The No. 1 Question Everyone Working in premire 'collaborative video editing Should Know How to Answer

If you want to strike that same balance on your video project, this tool might be useful. For instance, video teams can use Workzone to access a range of reports that outline the progress they have made on a given project. General video production software can often be a great choice, given that these tools strongly emphasize usability. As an added bonus, these tools can be adjusted to fit your exact needs. Your team members will work very hard on your project, and their time will often be limited.
How do I export Premiere Pro to mp4?
MP4 is a file container format, while H. 264 is actually a video compression codec that requires a video container to host the encoded video. Most of the time, H. 264 refers to MP4 file encoded with H.
Tags: Editing, File Management, Organization, Premiere Pro, Productivity
This development further boosts workflow efficiency for media professionals, allowing them to work within one interface without the need for jumping from one UI to the other, which takes extra time and stifles the creative process. Axle 2016.2 is the latest edition of axle’s award-winning media management software, now optimized for media libraries with up to 1 million assets. Simply point axle at the media files you want to manage and it automatically creates low-bandwidth proxies you can then access from any web browser. There’s no need to move your media files or change your system setup. Our new plug-in panel for Adobe Premiere® Pro CC, included with every axle 2016 system, enables editors to search, see previews and begin working on footage without leaving their favorite NLE software.
Production, without the stress
But the Digital Asset Manager is more than just a big geek overseeing information and data in all its forms. While the role requires sharp analytical skills, it is the crossover skills tied to people and how they interact with digital technologies that are equally important. Metadata for an asset can include its packaging, encoding, provenance, ownership and access rights, and location of original creation. It is used to provide hints to the tools and systems used to work on, or with, the asset about how it should be handled and displayed. For example, DAM helps organizations reduce asset-request time by making media requests self-serving.
For whatever reason, it’s always nice to be able to work off of a version of your project that is linked to proxy media (meaning low-res versions of your clips). In the past, it was critical that editors would plan for a proxy workflow before they would start editing, and generate proxy files to be ingested into their NLE when first setting up their session.
Limelight Video Platform is the fastest and most intuitive way to manage and distribute online video to media devices everywhere. The power and simplicity of Limelight Video Platform lets you manage, publish, syndicate, measure, and monetize web video with ease.
How does digital asset management work?
Mid-range systems, supporting multiple users and 50-300GB of storage, have entry-level products in the range of $2,300 - $15,000 per annum. These can be hosted, cloud-based or installed on your own infrastructure.
How To Edit Vocals On Neva 7 Post Production Software?
How does a digital asset management system work?
A much better way to use illustrations is to employ visual assets — photos, charts, visual representations of concepts, comics or annotated screenshots used to make a point. Visual assets complement a story rather than telling the story entirely like an infographic does.
You can also subscribe to my Premiere Gal YouTube channel for weekly video editing and production tutorials to help you create better video. Both Adobe Premiere vs Final Cut Pro offers almost the same kind of video editing but still, they differ in a lot of ways. Because Adobe Premiere comes as part of Adobe’s Creative Cloud, which is a Marvel’s Avengers-esque suite of tools to support your video making.

Support for ProRes on macOS and Windows streamlines video production and simplifies final output, including server-based remote rendering with Adobe Media Encoder. Adobe Premiere Pro supports several audio and video formats, making your post-production workflows compatible with the latest broadcast formats. Over time, these cache files can not only fill up your disk space, but also slow down your drive and your video editing workflow.
Some filename extensions—such as MOV, AVI, and MXF denote container file formats rather than denoting specific audio, video, or image data formats. Container files can contain data encoded using various compression and encoding schemes. Premiere Pro can import these container files, but the ability to import the data that they contain depends on the codecs (specifically, decoders) installed. Learn about the latest video, audio, and still-image formats that are supported by Adobe Premiere Pro.
Now when you load a timeline from the Media Browser it automatically opens a sequences tab called Name (Source Monitor) that is read only. Premiere has always had a Project Manager but what it was never able to do is transcode and what it wasn’t very good at was truncating clips to collect only what was used in the edit. I have had only partial success with the Project Manager over the years and with some formats it would never work properly with Premiere copying the entire clip instead of just the media used with handles specified.
Depending on the clips you have and the types of metadata you are working with, you might want to display or hide different kinds of information. On one hand, this is great – you get updates to the software as soon as they’re pushed out, and the $20/month annual subscription fee beats paying hundreds of dollars up front. Regardless of how deep you want to go into the video editing rabbit hole, the best reason to get Premiere Pro CC are its time-saving features. JKL trimming is the most noteworthy as it lets you watch a clip and edit it in real time just by using three keyboard shortcuts!
What editing software do Youtubers use?
Many effects and plugins for Premiere Pro CC require GPU projective post production editing acceleration for rendering and playback. If you don't have this on, you will either get a warning or experience higher render times and very slow playback. To make sure you do have this on, go to File > Project Settings > General.
The footage is stunning, and I find myself wanting to work on it right away, but before I can do that I must back it up, but before I can even touch it I must make sure I have the contracts for each drive that is coming in. We work with and commission many different videographers and photographers so I need to know which office the drive came from and who it belongs to, what the rights are, etc…that is something I highly recommend. I have a folder labeled contract/release forms on our internal server so I know which contract goes to which hard drive/footage. One of the first things I do now, is label a drive since we are working with so many, I need to know what footage is on what drive. Once I get the drives and back up the footage, I then create stories depending on the project and I will also create b-roll packages.
0 notes
Text
Basics of On Page Optimization Checklist for Your SEO Campaign

This piece of writing will be centered on the importance of onpage optimization and the basic elements of on-page SEO optimization checklist for your SEO campaign and the critical role played by it in the lasting success and catering to the corporate identity needs that entrepreneurs may have.
Importance of on page optimization
Many new online marketing channels have appeared; lately, they are centered on sizable bites of the internet marketing chart.
With so many changes taking place, many business owners opted for popular options like social media marketing and skipping the idea of SEO campaigns without carefully assessing, analyzing and understanding the real data.
While there are others who surrendered to the saga that “SEO is no more” OR “SEO is dead”. They believed that driving target audience to their website can no more be done with the help of search engine optimization campaigns.
The truth is, “
SEO is alive and kicking it is still the major source of
driving traffic to website
, provided one follows what the doctor (Google) and other major search engines have ordered.
To stay on top of this domain relying on
SEO services
that’s trustworthy and affordable in nature would be one’s best bet.
On page optimization checklist 2019
Moving on to the significance of On-Page SEO, the following are some basic factors that one must be familiar with and consider in SEO campaign, if the idea is to hit the rock hard and get fruitful and stunning results:
1. Choose the right and relevant set of keywords:
Keyword research can be classified as the core first step associated with almost any online promotional campaign, more importantly when it is a goal to optimize the On-page SEO factors. It is essential that one chooses the relevant and
long tail keywords
to attract the right and relevant target visitors to specific pages.
2. One must come up with dashing domain names:
This is a core element to have a perfect domain name for website. An On page SEO optimization can be easily turned into success if one keeps this element intact. Following are some additional tips associated with domain name optimization:
Consistent Domains:
Old school domains:
Domain names spelt in old school passion will always be found with ease when compared to some of the unorthodox ones.
URLs holding page keywords:
The use of keywords at the time of creating the page, blog post name and categories are always going to be useful, make this your habit if you mean business.
A good example here would be
3. Metadata Optimization:
One as a SEO expert must not forget that each page of one’s website would require perfect optimization. This will help them in becoming further search engine friendly with the help of elements like Meta Tile, Descriptions, Meta Keywords and Alt tags.
Title Tags:
Keep them between 60 characters to be precise. They are the text advertisement for any particular page where they are used, and they are the first things seen by readers even before the loading of the actual website on their browsers. Keep them attractive yet to the point and unique for optimum results.
Meta Description:
This is a brief summary that represents that actual content which can be found on a particular page for which it has been crafted. It will be appearing as a short version on SERPs just to provide visitors with a quick insight of what’s available on offer. This must not be duplicated or plagiarized.
4. Creation of unique and relevant content for onpage:
This is one of the most sensitive and tricky phase. One would need to ensure that the content offered for website On page is not only unique and relevant but at the same time backed with a perfect balance of the target keywords. Remember, satisfying search engines would not be an easy mission.
Search engine bots and crawlers will find it easy to rank one’s website accordingly based on the quality of content being used, embedding relevant and particular keywords and as mentioned above, one must avoid using copied content.
Core content:
This ideally would be the main text, descriptions, and titles set for each page. The content should be specifically focused on that particular page as this will help in keeping the relevancy intact.
Authority:
If written professionally, your content will improve the authoritativeness of your web pages and others will be attracted towards it, they will find it hard to avoid it and would definitely want to use the material shared by you as a reference or even may proudly link to it.
User experience:
All the content added to web pages must be relevant, simple and easy to understand. This will provide your target audience with excellent user experience and result in retaining them for more extended periods of time.
This approach shall not be limited to text content only, other elements like
easy navigation, images
and videos etc., all fall under these brackets.
All the navigation must respond adequately, i.e. there should be no broken link.
Page loading time
shall be remarkably fast; else the target audience will disregard a website and switch to another one that possesses all the said qualities when it comes to its performance.
5. On Page SEO techniques for media file optimization:
Don’t limit your focus only on text content when fine-tuning the on-page SEO setup. You have the liberty to focus on other associated media types such as images, video and other non-text elements.
Remember, there are many social media elements, and their span of focus may vary from one type to another when it comes to content. Focusing on all of them in their unique passion will improve your web page visibility on SERPs a great deal.
Some of the highly appreciated and best exercises for media files optimization comprised of:
File names Optimization:
The use of descriptive file names for content like images and video, preferably a relevant keyword is the best practice. For example,
Alt tags or Alt text Optimization:
It is essential to complete this attribute with a brief description of the content used, i.e. an image or a video. Search engine bots and crawlers rely on these tags when identifying them.
Because these crawlers can only read the text, therefore, the utilization of such Alt Text attributes may help one in optimizing the image to perfection for amplified search results.
6. Creating Product/Service-oriented landing pages:
This approach of having specific product landing pages no doubt will play the beneficial role and rank easily in search engines. Such specific pages enable one to share detailed information about particular products and services, as a results target audience find them easy because they are educated with the help of such pages.
One as a webmaster can add the most profitable keywords, by inserting them in rightly in Meta description and Title for fruitful results. There is no limit on what should be the number of specific pages; it all depends on the number of products and services.
So, you may
create specific product pages
as many as you need; however, you must ensure that they are backed with the right and relevant keywords, product and service description and are fully optimized with no slow loading speeds or broken links.
Pulling the brakes:
That’s it for today, all the on-page SEO factors and techniques for optimization shared above can be applied immediately by one for the sake of better ranking in SERPs.
Here it is essential to understand that this process would require ample time as it is time-consuming. Rushing out, therefore, in this crucial phase may not help as one may end up in making small blunders that may result in significant losses.
No need to rush, take care of things in a step-by-step manner or alternatively consult with
One must not take SEO campaigns on lighter notes, they are here for good, alive and kicking and it is SEO that can uplift the overall image of one’s brand and corporate identity, no matter which part of the world one operates.
Many times, updating your website while shopping is something that you know is important. Website Designers in Lakewood, CO is here to help you in your website development as per your requirement with best final product.
0 notes
Link

Having some self-hosted services and tools can make your life as a developer, and your life in general, much easier. I will share some of my favorites in this post. I use these for just about every project I make and they really make my life easier.
All of this, except OpenFaaS, is hosted on a single VPS with 2 CPU cores, 8GB of RAM and 80GB SSD with plenty of capacity to spare.
Huginn
Huginn is an application for building automated agents. You can think of it like a self hosted version of Zapier. To understand Huginn you have to understand two concepts: Agens and Events. An Agent is a thing that will do something. Some Agents will scrape a website while others post a message to Slack. The second concept is an Event. Agents emit Events and Agents can also receive Events.
As an example you can have a Huginn agent check the local weather, then pass that along as an event to another agent which checks if it is going to rain. If it is going to rain the rain checker agent will pass the event along, otherwise it will be discarded. A third agent will receive an event from the second agent and then it will send a text message to your phone telling you that it is going to rain.
This is barely scratching the surface of what Huginn can do though. It has agents for everything: Sending email, posting to slack, IoT support with MQTT, website APIs, scrapers, and much more. You can have agents which receive inputs from custom web hooks and cron-like agents which schedules other agents and so on.

The Huginn interface
Huginn is a Ruby on Rails application and can be hosted in Docker. I host mine on Dokku. I use it for so many things and it is truly the base of all my automation needs. Highly recommended! If you are looking for alternatives then you can take a look at Node-RED and Beehive. I don't have personal experience with either though.
Huginn uses about 350MB of RAM on my server, including the database and the background workers.
Thumbor
Thumbor is a self-hosted image proxy like Imgix. It can do all sorts of things with a single image URL. Some examples:
Simple caching proxy
Take the URL and put your Thumbor URL in front like so: https://thumbs.mskog.com/https://images.pexels.com/photos/4048182/pexels-photo-4048182.jpeg
Simple enough. Now you have a version of the image hosted on your proxy. This is handy for example when you don't want to hammer the origin servers with requests when linking to the image.
Resizing
That image is much too large. Lets make it smaller! https://thumbs.mskog.com/800x600/https://images.pexels.com/photos/4048182/pexels-photo-4048182.jpeg

Much smaller. Note that all we had to do is add the desired format.
Resizing to specific height or width
What about a specific width while keeping the aspect ratio? No problem! https://thumbs.mskog.com/300x/https://images.pexels.com/photos/4048182/pexels-photo-4048182.jpeg

Quality
Smaller file size? https://thumbs.mskog.com/1920x/filters:quality(10)/https://images.pexels.com/photos/4048182/pexels-photo-4048182.jpeg

You get the idea! Thumbor also has a bunch of other filters like making the image black and white, changing the format and so on. It is very versatile and is useful in more scenarios then I can count. I use it for all my images in all my applications. Thumbor also has client libraries for a lot of languages such as Node.
Thumbor is a Python application and is most easily hosted using Docker. There are a number of great projects on Github that have Docker compose setups for Docker. I use this one. It comes with a built-in Nginx proxy for caching. All the images will be served through an Nginx cache, both on disk and in memory by default. This means that only the first request for an image will hit Thumbor itself. Any requests after that will only hit the Nginx cache and will thus be very fast.
To make it even faster you can deploy a CDN in front of your Thumbor server. If your site is on Cloudflare you can use theirs for free. Just keep in mind that Cloudflare will not be happy if you just use their CDN to cache a very large number of big images. You can of course use any other CDN like Cloudfront. My entire Thumbor stack takes up about 200MB of RAM.
In conclusion I think that Thumbor is a vital part of my self hosted stack and I use it every single time I need to show images on any website or app. Once you have this working properly you never have to worry about image formatting ever again since the Thumbor is always there.
Hosted alternatives to Thumbor: Imgix, Cloudinary Self hosted alternatives: Imaginary, Imageflow
Searx
Searx is a self hosted metasearch engine. It will strip any identifying headers and such from your searches and then it will use one or many search engines to run your query. It can search on for example Google, Bing and DuckDuckGo. What makes Searx great as a self hosted service is that it has a simple JSON api. Simply tell it to use JSON and your query will be returned as JSON. This will enable some pretty neat combinations, but more of that later. It can also search for images, music, news and more.
Searx in action
This is another killer service. The JSON formatting is what really sells it for me since it can be combined with other services in lots of different ways.
Searx is another Python app and is easily hosted through the use of the official Docker image. It uses about 230MB of RAM on my server.
InfluxDB + Telegraf + Grafana
InfluxDB is a time series database. It is built to receive time based event data from sensors, servers and so on. For example it is very good at things like storing CPU load data every 5 seconds. It also has built-in ways to makes sure it doesn't fill the disk with all this data and much more. There are client libraries for most languages as well as a very simple HTTP API for adding data. It goes very well together with Huginn where you can create agents to poll data from somewhere and then use the HTTP API in InfluxDB and a Post Agent to store it . There will be examples of this later on!
Telegraf is a service that will collect data about your server and send it to InfluxDB. It can also send the data to other databases and such but for this we use InfluxDB. It can collect just about any data about a server that you want, include statistics from Docker containers. It has a very simple out of the box configuration that you can tweak if you wish. I install it on all my machines to send data to InfluxDB, including my at-home NAS.
Grafana is a graphing, analytics, and monitoring tool. It can graph the data from many different sources including InfluxDB, AWS Cloudwatch and PostgreSQL. It also has alerting capabilities for Slack for example. It is a delight to use and you will quickly be able to create some very nice looking graphs of your data. You need to be careful though because I find that it is very addicting to graph all your things.

A Grafana dashboard for server monitoring
There are many Docker setups for this stack that you can find on Github, so hosting this is easy.
Grafana is truly delightful to work with and it is probably the slickest graphing tool I've ever used and it can easily be compared to commercial projects like Datadog.
Docker Registry
This is a simple one but oh so useful. It is good to have a place to store your own Docker images and this is what you need. You can use Docker Hub for this but private images cost about $7 a month. It is however very easy to host your own registry. A Docker registry is a requirement to be able to use OpenFaaS.
Ghost CMS
Ghost is an open source publishing and blogging platform. It was originally kind of a replacement for Wordpress but it has since grown to be something more. I use it as a headless CMS for this blog as well as other websites. It has a great GraphQL and REST API that you can use to pull your articles and pages out to use in a static site or show on another website. I have another article about how my blog works with this if you want to know more.

The Ghost editor while typing this
Ghost has a great editor that makes it very easy to include Twitter posts, images, Spotify links, and so on. It is also hosted on your server so you can write from anywhere. You don't have to deal with markdown files if you don't want to and I find it to be a delight to use and write in.
OpenFaaS
OpenFaaS is self-hosted functions-as-a-service aka serverless. I have another article about OpenFaaS so I won't go into too much detail here. You can use OpenFaaS to easily deploy functions in any programming language without having to setup a microservice. Also, I understand the irony of self-hosting a serverless setup, but it is a strange world we live in so just go with it.
It is very useful for a number of tools and combinations. I have a number of these functions and here are some examples:
Readability
Python function that uses the newspaper3k library to pull out metadata and the article content from any URL. I use it to render snippets from articles, prepare for sentiment analysis, and things like that.
Puppeteer renderer
Sometimes websites will not work at all without Javascript or they have systems in place to prevent scraping and interacting with the sites automatically. Rotten Tomatoes is such a site that will fight back against any automation attempts. Enter Puppeteer, the headless Chrome API. This function simply takes a URL, renders the page with Javascript and returns the resulting body. This is then ready for processing in a scraper for example using Huginn. There will be examples of how to use this later with Huginn later so stick around if you're interested in that.
OpenFaaS is hosted on its own server because that made sense to me. It is a tiny little thing though and doesn't use much resources at all.
Combinations
This is where we unlock the real magic of having all these things. You can combine these in clever ways to create something really neat. Here are some examples to get you started:
OpenFaaS+Searx = First image
This is a combination that I really like. Create a function in OpenFaaS in any language of your choice, I used Javascript, that will search for the given query in Searx, making sure to return the result as JSON. Then parse the results in the OpenFaaS function and return the URL for the first image result.
You now have a function that you can call with any query and it will return the first image result. This is useful in a number of different ways. You can for example search for bryan cranston site:wikipedia.org to get a good image of actor Bryan Cranston. Now you can use some cool Thumbor filters and such to process the image if you want!
Suggestions for improvements: Add more functionality to the OpenFaaS function. For example you can add probe-image-size to your function. You can now reject images which are too small for example.
OpenFaaS+Huginn+Trello = Movie recommendations
This is a simple one which adds movie recommendations to my Trello inbox daily. Steps to create:
Add a Website Agent to Huginn. Use the URL for the Rotten Tomatoes front page and add the OpenFaaS Puppeteer function to render that URL with Javascript enabled. Scrape the section with new movies.
(Optional) Create a Trigger Agent in Huginn to select movies with a minimum score. Perhaps you want only the movies which have a score of 80 or better in your inbox.
Add a Post Agent to Huginn that will post the movie names to your Trello inbox using the Trello API.
Suggestions for improvements: Add another step that will also link to the IMDB page for the movie. You can use Searx for this. Simple search for the movie like so: "fried green tomatoes" site:imdb.com
RescueTime+Huginn+InfluxDB+Grafana = Productivity graph
RescueTime is automatic time tracking software. It keeps track of what you do on your computer and will tell you when you are being productive and when you are slacking off on Reddit. You can use a Web Site Agent in Huginn to access your productivity data on RescueTime. You can then use a Post Agent to add this data to InfluxDB. Finally you can graph it using Grafana. I use something similar to get data about our hot water bill and such. Once you have Huginn and InfluxDB you can graph almost anything.
Huginn+Slack = Notifications center
If you're like me and you have a lot of notifications then you might want to use Huginn to sort these out. Instead of interfacing directly with Slack or whatever notification system you use, you can instead use a Webhook Agent in Huginn to create an API endpoint. Post your notifications to this endpoint. You can then use for example a Slack Agent to post the notifications to Slack.
What is the point of this then? Well, you can very easily change to using something else than Slack for your notifications without changing it on every site that creates them. Perhaps you want to delay some notifications? You can do that with a Delay Agent in Huginn. Perhaps some notifications should go to Trello instead of Slack? No problem using Huginn. You can even use a Digest Agent to group low level notifications and send them all at once by email or something. Don't forget that you can also graph all of this using Grafana.
Conclusion
This is by no means an exhaustive list of things you can self host to make your life easier as a developer. Do you have any favorites that I've missed? Please reply in the comments below
0 notes
Link
Deep web or Dark websites are often coined as illegal and have various strict laws implemented against their use. Just like there are two sides of a coin, dark websites do come with a lot of essential benefits and uses for the general public. It is however imperative, that the use of dark websites be made in the right direction to benefit the society at large. Dark Web was actually created by the US Military to exchange secret information, they also created TOR (The Onion Router) for public use.

source: Infosec
Disclaimer: Any malicious activity would not only welcome some serious danger, legally and illegally but will also bring disgrace and backlash the entire web world. These websites will bait you with lucrative information for you to fell into their trap. Please be careful in accessing the links inside the dark web. Waftr or I am not responsible for any of your fault.
Why Dark Websites for Public?
As I said earlier Dark websites are created for a good purpose. The Clearnet (The websites we are using now) is getting vulnerable day by day. Also, you might be get hacked or your content can be seen by anyone these days with little information about you. Using darknet will totally mask your information, your work, your conversation with loved ones and others can't take steal your data. Again you have to be very cautious.
How to Access the Dark Web?
Dark websites are the websites that won't show up in Google or any other search engine results and they remain deep down, the only way to access those sites is to type the URL directly or use Dark web search engines. Dark websites can be accessed using TOR (The Onion Router) Browser.
You have to download and install the TOR browser and use the below-given links to access the dark web. You can also use the TOR browser to unblock any website.
Popular Dark Websites and Deep Web Links
There is a list of best dark websites with .onion extension that exist on a global platform. Again, accessing the dark sites may lead you to serious danger, kindly use these websites with care. double-check before clicking on the ads. Use any best VPN application before entering Dark Web.

1. Top Famous Websites on Dark Web
Here is the list of top Famous websites you use in the Surface or normal website. If you are concerned about your privacy, you can use TOR to access these .onion versions of the famous websites.
Facebook A mirror website of real Facebook, it lets you access the social networking site even in areas with complete inaccessibility. This Facebook provides you greater privacy over the data you share with the platform and also keeps you anonymous throughout. This Dark Facebook won't keep your logs and Hacking a Facebook account is impossible here. Financial Times Now you can read Finance News from News Websites on Dark web, Here is a mirror website of Financial Times. Debian Debian is a free globally Linux distributed open-source Operating system, here is the .onion version of the site for you to safely download the OS. Express VPN Express VPN is one of the best VPNs out there, you can use this dark site to download the software to use on any of your devices to use the internet safely. BuzzFeed Buzzfeed is another News website for Celeb news, DIY, funny videos and posts. and much more. Archive.org Also known as the Way Back Machine is a website to check how a website was in the past. Using this site you can check any website past look.
2. Search Engines
Duckduckgo - https://ift.tt/LgwySj The best search engine to remain anonymous on the web and avoid any kind of leakage of personal data while surfing on the web. It also lets you access links to onion websites which is otherwise impossible while using a regular search engine.
TORCH - https://ift.tt/1ebG9FJ Torch is the Google of Dark Web, this has more websites you can search and find as of your needs, so far Tor Search Engine has indexed more than a million websites. Type in the search bar and get the results. Also, be very cautious while going through any links on this results page too.
Dark Web Links - https://ift.tt/2heMhDU Using this search engine you can access both Darknet and Clearnet websites. You can also add your website to their search websites.

Ahmia.fi - https://ift.tt/1NCraTf Ahima is another search Engine to find hidden services in the Dark and Deep Web.
3. Secret File and Image Sharing sites
Just Upload Stuff - https://ift.tt/2e4tglK You can upload images and files up to 300 MB, the file you upload will remain on the server for a week and it will automatically get deleted once the other person downloads the file. This website request you to not upload illegal content, so please make sure you are using good content.
Share.riseup.net - https://ift.tt/2X1BO40 This is a very simple website file-sharing website, you'll see a big upload button just click on to upload a file or drag a file and once it gets uploaded. Share the URL to download the file. The maximum limit is 50mb and the file lasts for 12 hours only.
Matrix Image Uploader - https://ift.tt/1wpMCH0 This is an image sharing site with password protection and you can upload a file up to 5MB size. You can also set up automatic image deletion, metadata removal, and also set download limits.
Stronghold Paste - https://ift.tt/2dA2x3u Stronghold is a Message sharing site in the dark web, just like the above-mentioned website, here you can paste a message with title and send the message with a password and deletion date.
10 Useful Dark Websites
Below are the best useful websites you can find on the darknet for you to explore and use securely without any fear of losing data.
1. Comic book Library - https://ift.tt/2X8oScm
A website with a collection of free comic books, curated by Captain Goat. You can find nearly 2014 Comic books, you can see them by Titles, Publishers, Years, Creators and more. Go to comic book section and download and read them using PDF reader.
2. Wikileaks - https://ift.tt/1btgmob
It is one of the most popular dark websites with several high profile government data uploaded on it. It lets the user upload the content anonymously and provide direct references to the organizations. Wikileaks especially came into the spotlight when some of the valuable dates from the website were leaked. The dark web site definitely knows something which the whole world does not!
3. Protonmail - https://ift.tt/2Dh9H6D
The best way to manage the confidentiality of your emails. Proton mails are one such onion website whose headquarters are located in Switzerland at CERN, and thus even the staff of proton mail cannot access the data of your mails. All the mails are encrypted while being anonymous.
4. Hidden Answers - https://ift.tt/1UtzDQw
An alternative version of Reddit; this site provides a platform to raise a question, discuss and post stories while remaining anonymous.
5. Code Green - https://ift.tt/1HsX4Pd
Code Green is a community for Ethical Hacking. You can join the community as Sypathizer, Supporter, Hacktivist, Whistleblower, Coder or Artist.
6. Sci-hub - https://ift.tt/1lCEzEl
An advocate of the right to access scientific knowledge, sci-hub provides links to as many as 70 million scientific documents which are approximately 99% of all the scientific research work which is mostly paid and locked away in the surface web.
7. Keybase - https://ift.tt/1HsX0z0
Keybase is a messaging platform, you can use with your family, friends and even in your office for business user. Also, acts as a Social network by sharing images and messages in groups and communities. WIth Keybase you can share files securely. Keybase is acqired by Zoom recently.
8. Guerrilla Mail- https://ift.tt/2Zb1VIj
Guerrilla Mail is a disposable email service, you don't have to use your email id or create one, you can pick a random email id here and use it for sometime. You can use this during when you send a very important private message or during emergency.
9. Deepweb Radio- https://ift.tt/1OyZQpS
You'll find a list of Radio stations here, choose the one you want play and listen to the radio for free in the dark web. You'll get content type, bitrate, no of listeners and many more.
10. Write.as - https://ift.tt/1eslHVd
A simple and focused writing platform for Publishers, Blog writers and Photo submissions. No signup required and this website is totally free to use.
11. Blockchain - blockchainbdgpzk.onion
The number one site for managing all the cryptocurrency and handling all the share market business privately. It is quite scary because a lot of the mysterious bitcoin activity and business happen without the eye of the investors and the general public on the surface web.
12. The Hidden Wiki - zqktlwi4fecvo6ri.onion
It is the ultimate destination to explore deeper into the dark web with a list of hundreds of website links connecting to dark web pages. More like an index for the dark web sites out there, this could be the first place you land when you search for a particular site whose address you do not know.
13. Onion Domain - onionname3jpufot.onion
This site provides you a domain name with no cost to host your own onion website. Most of the dark websites end with the .onion domain. It would not be possible in many countries though to access these domains.
Where to find the full Dark Website list?
TorLinks - torlinksd6pdnihy.onion - There is a list with different dark web sites, arranged in categories. You can choose the site you want to access by first going to this link. Some of the categories include counterfeit money, drugs, New Movie download, etc.
More About Dark Websites
With various dark websites available for innumerable uses, it makes the process much easier by providing relevant matter at no cost. This is a major source of support for people all around the world who cannot afford the subscription to various sites. However, what needs to be kept in check is the use and source of these websites. They often contain viruses and are loaded with cybercriminals. Therefore, it is best suggested to take appropriate precautions before using these websites. Technology is all about global good, it is our responsibility to make each source count and enhance the world by using it.
The post Top 20 Dark Web Sites (Deep web links) appeared first on Waftr.com.
0 notes
Text
How to Conduct a B2B Content Audit: A Beginner-Friendly Guide

Fear, uncertainty, doubt.
No, I’m not talking about the latest Stephen King horror novel. I’m talking about something all B2B marketers dread:
The content audit.
As a B2B marketer, you create a lot of content. Some of this might hit the target, but a lot of it is either outdated or underutilized.
The purpose of a content audit is to extract value from your entire content inventory.
This is a time-consuming and often confusing process, which is why so many marketers shy away from it.
But it doesn’t have to be that way. Content audits can be fast and even fun. In this guide, I’ll show you how to conduct a B2B content audit that is as effortless as it is effective.
What is a Content Audit?
Let’s start by digging into the basics - what exactly is a content audit and why should you do it?
A content audit is a process to take stock of your content inventory and analyze its impact quantitatively. Its purpose is twofold:
Analyze content performance and identify relevant content pieces.
Repurpose and redistribute existing content to targeted audiences.
For example, you might have a blog post that was written 5 years ago. This post draws a steady trickle of traffic, but the traffic graph looks something like this:

Upon analysis, you realize that this declining traffic graph is simply because the content is outdated. Updating the blog post and adding more recent data can make it more relevant, and thus, improve its performance.
How much time and effort a content audit takes will depend entirely on the size and age of your content inventory. Large businesses have content dating back decades that can still be valuable, while for a new startup, their inventory might not even include 100 pieces.
For example, when we first published this guide to Work Breakdown Structures (WBS) in 2018, it quickly ranked at the top of the SERPs. However, over time, the content became slightly outdated and traffic started dropping.
Once we updated it in the middle of 2019, traffic jumped up again as you can see below:

Regardless of the effort, a content audit can be a worthwhile exercise for three reasons:
Improve SEO: Google has a known bias for new content - there is even a ‘Google Freshness’ algorithm update. Updating older content with fresher information can give it a boost in the SERPs, while also making it more relevant for current audiences.
Extract value: Repurposing older content, repositioning it for a new audience, or redistributing it on a new channel - there are tons of ways to extract more value from existing content. A content audit can help you spot these underutilized content pieces and find new ways to use them.
Find new ideas: A content audit tells you what content performed well in the past. This can inspire new ideas for current audiences. It can also help you pinpoint undervalued channels and underrepresented audiences.
If you’ve been creating content for more than a few years, consider an annual audit a necessary exercise. It will help you evaluate your performance, discover new opportunities, and most importantly, make sure that your content meets your quality standards.
Now the big question - how do you go about performing a content audit? I’ll share some answers below.
A Beginner’s Guide to Conducting a Content Audit
The first thing you should know is that there is no fixed path to running a content audit; everything depends on your current needs, skills, and resources.
A small startup looking to boost its SEO efforts will take a very different path than an enterprise B2B business looking to reboot its legacy content.
What matters more is understanding the core process of conducting a content audit and adapting it to your specific needs.
Let’s cover this process-driven approach in more detail below.
Start With a Content Inventory
A content inventory is a database of all your content along with key information such as:
Content title
URL (if online)
Content-type (blog post, ebook, whitepaper, video, etc.)
Content platform (blog, YouTube, LinkedIn, etc.)
Word count
Metadata (title, description, keywords)
Word count
Incoming/outgoing links
Analytics data (traffic, bounce rate, average time on page)
Marketing data (leads captured, subscribers, conversion rate, etc.)
Images, videos, etc. on each content piece
You can add/remove from this list as per your needs and capabilities. You can also consider adding labels that are not apparent at a glance, such as overall focus (based on ‘AIDA’ - Attention, Interest, Desire, Action - principle), target persona, buyer’s journey stage, etc.
The purpose of a content inventory is to help you take stock of your content and analyze it quantitatively. Knowing how each piece performs is the first step in extracting value from your content efforts.
How you go about collecting all this data will depend on your current CMS and analytics/marketing tools. If you’re using something like HubSpot, you should have ready access to all key data.
Else, consider using a crawling tool like Screaming Frog to gather content data, then collate it with Google Analytics data.
There are also specialized tools like Content-Insight and BlazeContent to speed up the inventory creation process. A final content inventory might look like this:

So far, we’ve only made a quantitative assessment of our content. But the heart of a content audit is qualitative analysis. For this, we need to map content to our audiences and figure out what to do with each content piece.
Analyze Your Content
What does your “ideal” content look like? Does it have a ton of shares? What segment of the buyer’s journey does it target? Does it rank well for a head keyword?
Figuring out the answers to these questions is the key to conducting a content audit. Your “ideal” content will help you assess the performance of your other content, but qualitatively and quantitatively.
Start by listing your key goals. What do you want to achieve with your content? More traffic? If yes, then what kind - search, social, or referral? Do you want more contacts? If yes, do you want just raw leads or MQLs (Marketing Qualified Leads)?
You can quantify your answers by scoring your content on these four counts:
Traffic goals: Does the content attract enough readers? Are the readers from a preferred channel? Look at total pageviews, acquisition sources, etc.
Engagement goals: Do people like to share the content? Do they spend a lot of time reading it? Look at bounce rate, average time on page, and the average number of shares.
Lead goals: Does the content turn readers into leads? Do readers become blog subscribers? Are the leads relevant and high quality? Look at conversion rate, reader-to-subscriber rate, lead quality, etc.
Branding goals: Does the content make our brand look good? Does it meet our quality standards? This is a subjective measure so you’ll have to evaluate each content piece on its own merits.
Try to find content that scores a 10/10 on each of the above four counts. Use this to evaluate the rest of your content on a scale of 1 to 10.
For instance, an article that ranks #1 for its primary keyword and brings in 5,000 visitors/month gets a traffic score of 10/10. Another article that ranks #9 for its primary keyword and brings in 700 visitors/month would get a traffic score of 6/10.
Thus, you might have a table like this:

This might sound like a time consuming exercise, but it makes it so much easier to figure out what to fix in each content piece, as you’ll see below.
Create an Action Plan for Each Content
As you complete the above exercise, you’ll realize that virtually every content piece is deficient on some count. Some don’t bring in enough traffic, some can’t keep a reader’s attention, and some bring in low-quality, irrelevant leads.
Your next step, therefore, is to fix the deficiencies of each of your content pieces.
The content assessment exercise you completed above will be a huge help here. You can create an action plan based on the current quality, relevance, and resource requirements of each content piece.
Generally speaking, the lower a content piece scores on each of the four counts (traffic, engagement, lead, and branding), the more effort it will take to improve. Unless you have spare resources, it will be better to focus on “low hanging fruit”, i.e. moderately good content (say, a 5 or 6 out of 10).
Which aspects of the content you decide to change will depend on your short and long-term goals. If you’re trying to fix your branding, it will be better to bring all your 4-6/10 rated content to at least an 8/10 branding score level.
On the other hand, if your priority is to get more traffic, taking steps to improve the on-page SEO of each content piece should be your top priority. Effectively, you will have four choices for each content piece:
Discard: Content that is too outdated, irrelevant, or unsalvageable is best discarded. It will take too much effort to improve it to a point where it brings in a positive ROI. Your lowest scoring content will fall into this category.
Update & Improve: This includes content that targets a desired channel, keyword, or audience; content that meets most but not all of your branding guidelines; content that is relevant but outdated.
Merge: You’ll often have multiple content pieces targeting similar audiences or keywords. In such cases, it is best to merge all low-scoring content with a top-performing content that targets the same keyword/audience.
Repurpose: Some of your content might have the right audience but the wrong format or platform. Alternatively, some of your content has enough potential to succeed on multiple platforms. Such content should be repurposed and redistributed as widely as possible.
You can use different colors to indicate your action plan for each content piece, like this:

Next Steps
This is not a comprehensive content audit by any means, but it should give you a start. There are plenty of other approaches to the auditing process, including evaluating content on the basis of type (ebook, whitepaper, blog post, etc.) and target audience.
For a beginner, however, simply finding and trimming away low-performing content will be good enough. A leaner, more focused content strategy where you regularly discard, merge, or repurpose low quality content will perform better in the long run.
As you improve your content inventory and content assessment skills, you can adopt a more subjective approach to the audit process. A skilled content marketer can usually spot “potential” in a piece of content based on their own reading of the market.
To start with, however, focus on developing a stronger content inventory and following the framework above in your content audit. Perform this exercise on a yearly basis at the very least for best results.
About the Author

Kate Lynch is a business and digital marketing blogger who spends her entire day writing quality blogs. She is a passionate reader and loves to share quality content prevalent on the web with her friends and followers, keeping a keen eye on the latest trends and news in those industries. Follow her on twitter @IamKateLynch for more updates.
from RSSMix.com Mix ID 8230801 https://ift.tt/39TayKh via IFTTT
0 notes
Text
Version 393
youtube
windows
zip
exe
macOS
app
linux
tar.gz
EDIT: This release had a hotfix two hours after initial release to fix the CloudFlare code. If you got it early, please redownload. The links are the same, the build is new.
I had a good week catching up on messages and small jobs. There is also a (hopefully) neat prototype solution for some cloudflare issues.
cloudflare and network
CloudFlare hosts content for many sites online. They have a variety of anti-DDoS tech, normally a variation on a 'is this a web browser?' test, that sometimes stops hydrus from downloading. If you have seen unexplainable 503 errors on a site that works ok in your browser, this may have been it.
This week, I am adding a library, cloudscraper, to my network engine to try to solve this. Now hydrus will attempt to detect CF challenge pages when they are downloaded and pass them off to this new library, which attempts to solve the javascript challenge (the part where a CF site sometimes says 'this process may take five seconds...', just as a browser would, and then copies the solved cookies back into the hydrus network session.
This first version can only solve the simple javascript challenges. It cannot do the more serious captcha tests yet, but this is a possible future expansion. I would appreciate any feedback from users who have had bad CF problems. If a page cannot be solved, or if your entire IP range had been flat-out blocked, hydrus should now attribute new CF-appropriate error messages.
For users who run from source, this library is optional. You can get it through pip, 'cloudscraper'.
Additionally, I am rolling in the very first basic version of 'this domain is having trouble' tech to my network engine. Now, if you keep having connection errors or CF issues with a site, hydrus recognises this and slows down access for a bit. The default is that no new network job will start as long as its site has had three serious errors in the past ten minutes, but you can edit this rule, including turning it off completely, under options->connection. Subscriptions will also try to wave off sites having trouble, just as if you had hit bandwidth limits. I expect to extend this system significantly in future, particularly by adding UI to see and manage current domain status.
the rest
The Windows build of hydrus is now on a newer version of python, 3.7 instead of 3.6. This makes for a variety of small background improvements all over the place, and some updated libraries, but may also introduce an odd bug here or there in more rarely used hydrus systems. Let me know if you run into trouble!
I did another round of file search optimisations on searches that do not have tag search predicates, such as bare system:rating or system:inbox queries.
Thanks to some excellent work by a user, there is another new DA parser. This one gets full-size images, video, flash, and even pdf! The only proviso is that it needs to be logged in to DA to get most content, otherwise it 404s. I believe the hydrus DA login script works, but if you have trouble with it, Hydrus Companion is always a good fallback.
The blacklist in tag import options gets a bit of work this week. It now tests unnamespaced rules against namespaced tags, so if you have a rule for 'metroid', it will also block 'series:metroid'. This is a special rule just for the tag import options blacklist (it also tests all siblings of the test tag), and to reflect it, the tag filter/blacklist edit panel now has a second 'test' text to show how the test input applies to a TIO blacklist, as opposed to a regular tag filter.
This is a small thing, but if you are mostly a keyboard user, the mouse now hides on the media viewer without having to be moved!
If you have had crashes trying to open a file or directory picker dialog, try the new BUGFIX checkbox under options->gui. It tries to use a different style of dialog that may be better for you.
full list
cloudflare and network:
the hydrus client now has an experimental hook to the cloudscraper module, which is now an optional pip module for source users and included in all built releases. if a CF challenge page is downloaded, hydrus attempts to detect and solve it with cloudscraper and save the CF cookies back to the session before reattempting the request. all feedback on this working/breaking irl would be welcome. current expectation for this prototype is it can pass the basic 'wait five seconds' javascript challenge, but only a handful of the more complicated captcha ones
if a CF challenge page is not solvable, the respective fail reason for that URL will be labelled appropriately about CloudFlare and have more technical information
.
the hydrus network engine now has the capability to remember recent serious network infrastructure errors (no connection, unsolvable cloudflare problem, etc..) on a per domain basis. if many serious errors have happened on a domain, new jobs will now wait until they are clear. this defaults to three or more such errors in the past ten minutes, and is configurable (and disableable) under options->connection. this will be built out to a flexible system in future, with per-domain options+status ui to see what's going on and actions to scrub delays
basically, if a server or your internet connection goes down, hydrus now throttles down to limit the damage
subscriptions now test if a domain is ok in order to decide whether they can start or continue file work, just like with bandwidth
serverside bandwidth alerts (429 or 509) are now classified as network infrastructure errors
I expect this system will need more tuning
.
the hydrus downloader system now recognises when an expected parseable document is actually an importable file. when this is true, the file is imported. this hopefully solves the situation where a site may deliver a post url or a file
.
the rest:
the windows build of hydrus is now in python 3.7.6, up from 3.6. this rolls in a host of small improvements, including to network stability and security (e.g. TLS 1.3), and possibly a couple of new bugs in more unusual hydrus systems
similarly, all the windows libraries are now their latest versions. opencv is now 4.2
greatly sped up several file searches that include no tags such as bare system:rating, most system file metadata predicates, or bare system:inbox, when the result size is much smaller than the total number of files in the file domain
thanks to some excellent work by a user, the Deviant Art downloader gets another pass--it can now get high res versions of images where they are available, and video, and flash, and pdf! the only proviso is that you need to be logged in to DA to get most content, otherwise you get 404. the current hydrus DA login script _seems_ to work ok
tag import options blacklists now test unnamespaced rules against namespaced tags. so if you blacklist 'metroid', a 'series:metroid' will be caught and the blacklist veto signal sent. this can be escaped with the 'advanced' exception panel, which now permits you to add 'redundant' rules
the edit tag filter panel now explains the blacklist rules explicitly and has a second 'test' green/red text to display test results for a tag import options blacklist, with the new sibling and namespace check
added some unit tests to test the new tag import options blacklist namespace rule
when 'default' tag import options are set, the edit panel now hides the per-service options, rather the the previous disable
the system tray icon now destroys itself when no longer needed, rather than hiding itself. it should now be more reliable in OSes that do not support system tray icon hide/show. if your OS still doesn't get rid of them, and you get a whole row of them, I recommend just leaving it always on
the system tray now has a tooltip with the main hydrus title and pause statuses
the timer that hides the mouse on the media viewer is now fired off when the window first opens (previously it would only initiate on the first mouse move over the window), so users who navigate mostly by keyboard should now see their cursors nicely hide on their own
added some semi-hacky import/export/duplicate buttons to edit shortcuts. I'll keep working on this, it'd be nice to have import/export for whole shortcut sets
added a semi-hacky duplicate button to the 'manage http headers' dialog
the 'clear' recent tag suggestions button is now wrapped in a yes/no dialog
a new checkbox under options->gui now lets you set it so when new cookies are sent from the API, or cookies are cleared, a popup message summarises the change. the popup dismisses itself after five seconds
the client api now also returns 'ext' on /get_files/file_metadata calls, just as a simpler alternative if the 'mime' is a pain
fixed a bug when petitioning tags through the client api, with or without reasons
fixed an error where subscriptions that somehow held invalid URLs would not be able to predict some bandwidth stuff, which would not allow the edit subs dialog to open
the string transformation dialog's step subdialog is now ok with example strings that are bytes. even then, this str/bytes dichotomy is an old artifact of python 2 and I will likely clean it up sometime so string transformers (and downloaders) only ever work utf-8 and hashes just work off utf-8 hex
added a BUGFIX checkbox to options->gui that tells the UI to use Qt file/directory picker dialogs, instead of the native OS one. users who have crashes on file selection are encouraged to try this out
updated running from source help with cloudscraper, a new pip masterline, and some windows venv info
the 'import with tags' button on 'import files' dialog gets another rename for new users, this time to 'add tags before the import >>'. it also gets a tooltip
handled an unusual rare error that could occur when switching out a media player inside a media viewer, perhaps during media viewer shutdown
next week
Next week is a cleanup week. I'd like to go into the tag autocomplete code and clean up how the input text is parsed and how results are cached and filtered. Otherwise, I'll do more wx->Qt cleanup and catch up on some small jobs.
0 notes
Text
Guide to use Magento 2 CMS
Magento is undoubtedly the largest open-sourced CMS eCommerce platform across the globe. Its feature-rich and extendible code base made Magento suitable for mid-size and large businesses over the world.
From the past 8 years, Magento 1 was rocking the world with its effective eCommerce services. But it had its own chinks in the armour. Performance issues, outdated front-end codebase, need to automate test suite, improved back-end UI being just some of those weaknesses. Owing to this Team Magento released Magento 2 version at the end of 2015.
As per the latest Magento report, Magento 1 is going to shut down by year 2020. So, business owners who are running on Magento 1 must migrate their store to Magento 2.
Also Read: Why Magento cloud is good for your ecommerce?
What sets Magento 2 apart from its predecessor?
Rich templating & Model View ViewModel (MVVM) system along with having CMS core module that is responsible for managing the creation of pages, static blocks, and widgets of your Magento eCommerce store.
This article will guide store owners on how to use Magento 2 CMS in detail to help achieve effective results.
1.Add a new CMS Page
2. Add a new CMS Block
3. Add a new CMS Widget
1. Add a new Page in Magento 2
Step-1: The first step is to log in to the admin space and click on the Content tab in the menu. After that go to the elements menu and select the Pages option.
Fig 1: Select ‘Page’ menu under ‘Content’
Step-2: You will see the interface of the page which is the same as the interface in products or customers. On this page, press Add New Page button and you will see four tabs appear: Page Information, Content, Design and Metadata.
Fig 2: Click on ‘Add New Page’ button
Step-3: In the Page Information Tab, you can write your Page Title andseta Custom URL for this page. Then, you can select the store view and set the page status to enabled or disabled.
Fig 3: Enter ‘Page Title’ and set ‘Page Status’
Step-4: In the Content tab, you have to add Content Heading and the Widget here which you wish to display on this page. This is the major tab to build the main content of your page.
Fig 4: Fill details in ‘Content Heading’ field
Step-5: In the Design tab, you can pen down your creative thoughts and select any options which have been mentioned like Columns, Columns with Left Bar, and Columns with Right Bar. Choose any one which suits your style or select Custom Design, if you need a custom layout for your page.
Fig 5: Select ‘Layout’or ‘Custom Design’ option Under ‘Design’ tab
Step-6: Metadata Tab involves keywords and meta description fields. Fill the boxes with correct info and finally hit the Save Page button. Now, your page is ready.
Fig 6: Tap on ‘Save’ option to create a page
Step-7: You can also add this New Page on any other page with the help of the Link Widget. In case you feel this page should be added on the Home Page as a link, you should go to the Home Page Edit Menu and select the Content Tab, hit on the Insert Widget button.
Step-8: Once you click on the tab, you will see some fields like Widget Type and Widget Options. Paste the new CMS page link in Widget Type and click on the Select Page button.
Fig 7: Enter ‘Widget Type’ under ‘Widget’ tab
Now, Let’s learn how to add a new block?
2. Add a new Block in Magento 2
CMS Block is very helpful in structuring your eCommerce website and dividing product categories as you add them to the Home Page.
Step-1: To add a new CMS block in Magento 2, you need to login to your Magento store as admin. Now, you will find the Content option click on it and hit on Blocks option.
Fig 8: Choose ‘Block’ option under ‘Content’ menu
Step-2: In the next window, you will come to know the list of your site blocks and Add New Block button at the top-right corner. Tap on it.
Fig 9: Hit on ‘Add New Block’ button
Step-3: Once you hit the button, you will come to know the entire required information to be filled in the fields like Block Title, Identifier, select the needed store view option from the dropdown list and set Enable Block to YES.
Fig 10: Fill the ‘General Information’ in Block page
Step-4: Check the filled details and click on the Save Block button to create a new CMS Block in your Magento 2 store.
Fig 11: Click on ‘Save Block’ option
An Identifier is a crucial option that is used to implement the new CMS Block into a page via a special page code. So, choose the identifier name wisely to remember it because it will definitely be needed later.
3. Add a new Widget in Magento 2
Step-1: To build a new widget, first of all, login to your Magento admin area, tap on the Content tab and choose Widgets option.
Fig 12: Select ‘Widget’ menu under ‘Content’
Step-2: When the next page appears on the window, you will see Add Widget button, tap on it and start creating a new widget for your Magento 2 store.
Fig 13: Hit on ‘Add Widget’ button to start building a new widgets
Step-3: It will take you directly to the Widget Settings page. Here, you have to choose the Widget Type and Design Theme. There are various types of Widgets included in the dropdown list as shown in the image(Fig 14), Magento Blank and Magento Luma are two options in the Design Theme field. After choosing your needed options, click the Continue button.
Fig 14: Select ‘Type’ and ‘Design Theme’ under ‘Widget Settings’ Page
Step-4: Once you tap on the button, it will display the Storefront Properties section. Input the Widget Title and select a Store View option.
Fig 15: Enter the details in the fields of ‘Widget Storefront Properties’
Step-5: In this step, you have to set the Sort Order and also an ideal layout for the new widget. To do that select an option for both Displays on and Container fields from the dropdown list and tap on Add Layout Update button.
Fig 16: ‘Layout Update’ page under ‘Widget’
Step-6: Once you have finished filling all the details then tap on Save option and complete the process of creating a new Widget in Magento 2 CMS.
Fig 17: Finally, tap on the ‘Save’ button
Conclusion
Seller Support is a next-generation e-commerce development agency that specializes in providing solutions for multiple platforms.
Our team of developers has extensive experience of working on Magento and our expertise range from customizing Magento themes to developing custom plugins.
If you are a business contemplating the move to migrate to Magento 2 drop us a mail right away at [email protected]
0 notes
Text
Using Facebook and Instagram like a superstar
One of the things I love about organising The Great Melbourne Blog-in is that I get to shape the event. At September’s blog in, I got to question Catherine and Cherie from The Digital Picnic about all things Facebook and Instagram during our Q&A panel. You know that glorious moment when you have all these questions simmering in the back of your mind and then suddenly you’re face-to-face with some very generous social media experts and you get to ask them all those questions? Yes, that moment. It was awesome!
Social media experts Catherine and Cherie from The Digital Picnic. Oh, and that’s me in the middle.
Pin it to read later
Running a Facebook page
Best tips for running an engaging Facebook page #Facebook #FacebookPage #SocialMediaStrategy Click To Tweet
As most people are aware (except those that make this critical error) one of the biggest mistakes Facebook page owners make is using it as a dumping ground for self-promotion. Using Facebook page only as an advertising platform is not what gains you engaged fans and followers. You need to draw back the curtain and put yourself out there. Show some of the back end of your business. Make your page about your audience and what they want.
As a copywriter, this makes sense to me – know your audience, what are their pain points, how can you address them, sell the benefits and not the features yadda yadda yadda.
Since the blog-in, I’ve created a schedule for my Silk Interiors Facebook page. This page supports my eCommerce site Silk Interiors, where I sell wallpaper online. My plan includes a mix of:
design quotes
inspo photos/eye candy
recycled blog posts
decorating and styling tips
videos
FB live
before and after home makeovers
celebrity style
discounts and sales happening in Australia
memes
questions
our wallpaper products.
My next step is to use the native Facebook scheduling app to schedule content to post each day for a full month. Doing it in one big batch will save a lot of time, even though it will take some time to curate and schedule the content, but I’ve made a BIG list of sources (I’ll blog about how I find them another day), which will be a great help. I’ll monitor the engagement metrics via Facebook’s ‘Insights‘ dashboard and see which post types perform well and I’ll experiment with different times of the day.
Whatever you plan, test, test, test and figure out what works best for your business.
If you have any plans, even a very vague and distant plan to use Facebook Ads, install the Facebook pixel into the header of any or all pages on your website you wish to track. This means setting up a Facebook business account and grabbing some code to paste into your website (very easy to do with a plugin if you’re using WordPress). The FB pixel is a sneaky little thing. It gives you the data to show your ads only to people who have visited your website in the past, for example. It helps you target people already interested in your business. You can also create ads to target users in the same demographic as your website visitors. Ooooh. Sneaky sneaky. And perhaps a bit creepy…
Have you installed the Facebook Pixel yet? #SocialMediaStrategy #FacebookPage Click To Tweet
Facebook. Knows. Everything… my business bestie and I were chatting on Facebook Messenger about awnings (totes random, I know) and then we both started seeing ads for awnings in our newsfeed. We hadn’t visited any awning or blind sites or visited awning pages. In fact, in our Messenger chat, we were coming up with the most random thing we could think of in that conversation. And then there were ads for awnings. Just saying.
What I learnt about Facebook Live videos
Pre-promote your Facebook Live session so you won’t chicken out. If you’re running a Facebook Live Q&A session, give people a chance to prepare their questions that you (hopefully) can answer. As a Facebook Live novice, I’m not sure what’s worse though – people turning up or people not turning up!
Pre-plan what you’re going to say. Always have something to talk about. Talk about something before you get into the guts of your video to give people a chance to join you, live. If they’re following you, they’ll get a notification to say that you’re live.
Avoid the wobbles and use a tripod for your Facebook Live videos #FacebookLive #FacebookTips Click To Tweet
It’s best to set-up your video on a tripod so your video is steady. A steady camera can also save you a lot of data – those micro wobbles when you hold your phone camera create a fatter video file. Not that I have to worry about data here in Korea, but a tripod will give your FB video a more professional look. I tend to swing my body from side to side while my head remains stable-ish when I do Facebook Live videos. I don’t know why. Perhaps that’s where my nerves manifest. Or I’m just a weirdo.
After you finish your Facebook live video, you can upload it and then change the video thumbnail. For laughs, Youtube and Facebook are in some kind of conspiracy to make sure they choose a thumbnail where you look your absolute worst.
See what I mean? Worst thumbnail choice ever! Excruciating for me… and the potential viewer. I look so bored with my own FB Live vid I’m falling asleep on myself.
But it’s easy to change it.
On the video post, click on those three dots on the top right… then click on ‘Edit post’.
Next, scroll through the available thumbnails and hopefully, there’s one that looks like you haven’t just eaten a sour lemon or are about to pass out. But if that fails, add your own custom image.
While you’re on that screen, you can add metadata to your post to help it get found more easily in Facebook’s search engine.
After you’ve uploaded your Facebook live video, go through the comments and respond to any questions people have. This will give your post a bit of a boost. The more comments (including your own) the more reach your video will get.
If you’re happy with the video, you could also consider using it in a Facebook Ad.
What I learnt about (non-live) videos on Facebook
If you’re going to add your video to Youtube, don’t share a link to the Youtube video with your Facebook audience. Instead, for better reach, upload the video directly to Facebook. Apparently, Facebook loves native video content. Of course, this makes sense. Facebook wants to retain as much ad revenue as possible. Keeping users ON Facebook and not sending them away to the Adsense share of the market is the sensible thing to do if you’re Facebook.
For greater reach, upload your video direct to Facebook, not via a Youtube link #FacebookTips Click To Tweet
Also, consider using a square format for your video as this is becoming really popular – people are used to and expecting the Instagram size and style of videos.
Don’t share everything between Instagram and Facebook or your audience, if they follow you on both platforms, will start to look like me in that thumbnail picture above. Yawn. I think it’s lazy social media-ing when businesses do that. Especially when you’re confronted with a face full of Insta hashtags on Facebook. I’m petty like that. Mix it up and share your video on Instagram a different day (or at least a different time of the day) then when you published your Facebook post.
I need to start a Facebook group and so do you
At a past TGMBI event, Linda Reed-Enever talked about building a Facebook Group to support your business or blog. I won’t rehash those bits, but it’s a timely reminder that if you share your Facebook page’s post to your Facebook group, it sends powerful signals to Facebook’s algorithms and can help increase the reach of your post even beyond the group.
I’m still considering what my FB Group will be about, how it fits with my brand and vision for my business and who I want in it besides my business besties. But first I need to schedule content, experiment and evaluate my Facebook plan.
Stay out of the naughty corner
Something else I learnt just this week is that Facebook has legislated yet another reason to put your page in the naughty corner – not disclosing sponsored or affiliate links. Facebook calls it ‘Branded Content’.
If you’re doing sponsored posts or publishing, as Facie puts it, content that features or is influenced by a business partner for an exchange of value, you need to tag the business partners in your branded content posts. But it’s not that simple. So you can do this, first you have to sign up for Branded Content within the Business Manager section of FB and be approved. If you’re publishing branded content (by Facebook’s definition) and not disclosing your relationship with the company, then you could find yourself in the FB naughty corner. This has happened to someone I know I know in a Facebook group just this week.
You can identify Branded Content posts because they have the small text ‘Paid’ whacked next to the time stamp of a post. This is different to posts you pay to boost where it says ‘Sponsored’. Other than that, I’m not sure what it all means, yet! You can read more about Facebook’s Branded Content tool and laws here.
What I learnt about Instagram
LinkTrees! AKA where had you been all my life/why didn’t I think of that.
Solve the 'link in bio' dilemma with a LinkTree @Linktree_ #instagramtips #linktree Click To Tweet
You know how you have to write something like Link in bio on your Instagram post and then update every single time you promote a new page or post or product? So annoying. Well, enter the Link Tree. You put one link in your bio that goes to a landing page where you include ALL your links. There’s even a website you can outsource your link management to – LinkTr.ee. (I wrote more about this tip in my recent post What to do after you publish a blog post.) You could also host a link tree page on your own website.
Instagram Stories – you need to be there and in the regular ole newsfeed. Your ‘story’ only lasts for 24 hours, but now that Instagram is no longer chronological, it’s your best bet for getting noticed at the top of someone’s Insta feed.
Look at your insights. What are the peak times and WHY are they the peak times? Look into the reasons why certain posts are popular than others.
If you haven’t already set yourself up with a business profile, it’s easy to switch from a personal to a business profile – here’s how. You’ll need a business profile to access your account’s insights.
Until recently, I’d only been using the image tools like Filters in Instagram on my pictures. Then I discovered an app called Fotor. The basic version is free. You can use the app or the desktop website to manipulate your images to make them look gorgeouser. I must admit, I’m a bit visually illiterate, but with Fotor, I’ve been having fun experimenting with image manipulation.
Get your images Instagram ready with the Fotor app @fotor_com #instagramtips #photoediting Click To Tweet
To illustrate my point, here the original photo I took.
And here’s the edited version. How much cooler and more interesting does this second image look?
Final words on social media-ing
Ultimately, when it comes to sharing content, be endearing to your audience. Maybe even a bit vulnerable. Be relatable. Suprise and delight your audience.
Thank you, Cat and Cherie, for sharing your time and knowledge. If anyone wants to improve their social media skills, then you need to attend one of their online or in-person social media courses – and not just in Melbourne. These savvy social media experts travel!
Have you experimented with anything on social media lately? Any success or spectactular fails to share? Let me know in the comments below.
Using Facebook and Instagram like a superstar was originally published on Sandra Muller
1 note
·
View note
Text
Ten eCommerce trends that will drive sales this 2019 - ShopifyShoguns
In North America, 15% of all specialty retail sales will soon be accounted for by e-commerce (23% of all retail sales are held in China), with digital influences accounting for almost 60% of total retail sales. Mobile-driven e-commerce, with sales up over 55% a year, has grown in 2018 by 16% to $500 trillion in North America.

The way we interact, find, and buy (and return) goods is now a 24/7 cycle not only in retail but also in B2B, where integration into e-commerce is the first priority. The shopper’s journey both online and physical is now merged, thanks to an emphasis on Omnichannel capability.
The top 10 trends that will further fuel eCommerce growth for the year 2019 are Also Read: 6 must have Shopify plugins to increase your eCommerce sales
1. Consumers are becoming more and more conscientious Consumer interest in their purchases ‘ environmental and ethical scope, including online purchases and the “actual or obscured” implications and cost of e-commerce-and consumerism, in general, is increasing. The customers are rewarding retailers who strike a chord with the belief structure right from sustainability to appropriate packaging.
Brands and sellers, both large and small, use digital technology to appeal to consumer values–and customer values and principles are evermore influenced when making purchasing choices. This eCommerce trend is going to hold sway for years to come.
2. End of e-commerce returns E-Commerce returns are 2-4 times higher than in mom and pop retail, and the expectations of customers for generous refund policies are a sore point for retailers.
Returns in 2017 reached $400 billion (approximately 1 month equivalent of all US retail sales) and increased 53 percent since 2015. Generous policy returns have been in use for long to increase conversions by reducing customer insecurity. However, growth in eCommerce, free transport and free returns have created a dangerous side effect–the cost of return management. The margins are highly affected by return handling and packaging, say 44% of retailers.
In 2018, Amazon in a bid to reverse this dangerous eCommerce trend announced that it would introduce a permanent ban to “serial returners” who are accustomed to return the majority of their purchases. The same is said by 61% of retailers if they had the means for better tracking returns and serial returners.
In 2019, a number of retail initiatives will be underway, ranging from more sophisticated or conditional return policies to incentives for collecting items, to prevent the unsustainable rate at which returns grow.
3. Get Ready For The Sales Tax The tax-free party has ended for traders and consumers, who are to be charged with regional sales tax in 2019, regardless of where the trader is present.
More than half the countries in the US adopted an online sales tax or will do so in 2019 in the months following South Dakota vs. Wayfair. Traders and solution providers are discussing eCommerce taxation and reporting initiatives at a rapid rate.
eCommerce retailers both B2C and B2B must assess the tax on which customers, regions, products and more, and then to calculate and charge a sales tax on their online sales on a state-specific basis (and on products/price specific) in order to save their margins from going for a toss.
Tax rates are subject to varying eligibility and application criteria in different states and jurisdictions. Tax rates will depend on what is sold and possibly on which jurisdiction consumers are located.
4. Make Way For PWA’s PWAs are evolving on how eCommerce and mobile apps live together. It’s a website, it’s an app–no, it’s both. The Progressive Web app, a variant of sites and Apps, which combine upsides and eliminates constraints, will finally start to transition brands and retailers from websites and apps to a new standard.
PWA creates quick, convincing mobile experiences, which resemble the achievements of brands and retailers with a native app — and can be discovered and made available via the mobile internet to all. Your mobile site is an app and you don’t need to market your app.
Not content with the simple sale of traffic and leads, social networks seek to bridge the e-commerce gap by letting users shop without leaving the platform.
5. Social Media Purchases Will Become The Norm Social purchases are already standard in China, where 55% of social app users report purchasing goods or services directly via social applications.
Private messaging services are also anticipated to become transactional, which are increasingly popular. WhatsApp, Snapchat and Facebook Messenger display trillions of commitment numbers and this is a trend where eCommerce retailers should be sure as not to miss.
6. Get Ready To Meet Your New Co-Worker The AI, Employee Today retailers carry between two and ten times as many SKU’s as they did 10 years ago –all of which are only available online if the product’s content (product pictures, video, descriptions, sizes, attributes, and supplementary products) are supported.
Even the biggest retailers strive to produce product content quickly enough to market their selection properly.
The core of eCommerce is product content. eCommerce retailers should start optimizing product finding and selection capabilities by giving detailed product information and critical product-specific characteristics in combination with semantic search.
Retailers are required to keep and supply images and videos, catalog descriptions, names, metadata category-specific information (e.g. foodstuff nutrition information), stock availability, matrices (e.g. size ranges), brand/company logos, ratings and reviews of products, rating information, and advertising information for all physical SKUs. The acquisition of this information from suppliers is a timely task that requires different methods and a large degree of manual work.
The creation, optimization, classification, translation, and syndication of product contents that have become a necessary component in conjunction with consumer demand for additional product information will be increasingly automated by AI-based solutions. In short, the retailers with more (and better) product information gain the customer.
7. QR Codes Are Back With A Vengeance Anyone with a smart phone can now detect QR codes by using their camera and digest product descriptions and price and other major product data.
When users recognize a QR code (usually less than a second) on their device, a prompt is displayed on their screen, with the option that a link leads the user to the desired place. This addresses the challenge for brand manufacturers when it is impossible to display all relevant product information with limited space on the packaging–while offering opportunities to establish a direct brand-to-consumer relationship.
Apple and Google eliminated the primary hurdle to the use and adoption of Q R code by making QR-code detection a native component of iOS and Android: it depends on apps that read QR-codes.
In addition to adding a realistic dimension to the everyday life of every mobile customer, the QR Code also provides consumers and businesses with the opportunity to deal with showrooming as a new channel for product discovery and customer acquisition-shopping in-store before completing online purchases at a visited retail outlet or at a competition company.
8. Everyone Is Trying To Beat Amazon While Aiming To Become The Next Amazon More than $1 trillion worth of goods is sold in the world’s 18 biggest markets. Analysts predict that the global online retail market will account for 40 percent by 2020. Marketplaces–once efficiently operated–are expected to increase customer loyalty, increase average order values and build confidence. Significant traffic retailers will add market place capabilities, capture new income through sales commissions and test product and category interests before the SKUs are directly sourced.
Integrating third-party marketplace like Amazon, eBay, Rakuten, and Alibaba to an existing eCommerce website is another way of gaining a ready-made customer base and increase sales piggybacking on them.
Regardless of whether they are fighting Amazon, eBay, and others in their own game or entering the market, retailers are broadening their reach by integrating the marketplace model in their digital trade toolkit. Why fight the goliaths when you can befriend them.
9. Shop While You Drive Almost half of America’s 135 million commuters are using their smartphone to find the nearest gas station, order and pay for coffee, take-outs, food, parking, and more. Altogether 77 percent of passengers who drive online* are engaged in some type of trade.
Once trade in the car was integrated, as many as 83% of ALL of the passengers would trade in the car. GPs, Google maps and Waze technologies (for example) help advertisers understand where they go and where the most often they go, similar to SEO, which helps advertisers seek and social media reveal what they like,
The on-car eCommerce is one of the main drivers of local road traffic, from the search for the voice to the GPS and music/podcast apps, because “auto-mobile conversion” is possible with the contextual publicity and driver-friendly interfaces.
80% of mobile users are looking for a local company by using voice search engines, 50% of which are likely to visit the store within one day, and approximately 18% of the local searches convert into a sale within 24 hours.
Are you eCommerce brand ready for the next gen road shoppers?
10. More Focus On Product Content The content of products is at the heart of e-commerce and a key to the consistent experience in the omnichannel. In addition to the physical products, product information (images, specifications, attributes, etc.) is now as important. –Digital consumers can’t discover, investigate, compare, or make an informed buying decision without product information.
Digital marketers will go a step further towards improving product content syndication with brands and retailers finally begin to optimize and invest in product content.
Syndication gives the most comprehensive and relevant experience in shopping and purchasing on various channels.
Syndication of product content means content that is automatically moved from a centralized point to several sites and channels, enhancing its reach and visibility while ensuring consistency. Brands and manufacturers are unifying their content to improve brand awareness by delivering consistent SEO optimized product information to increase conversions.
Conclusion Shopify Shoguns is an agency that has worked closely with eCommerce brands all over the world both B2B and B2C. We understand the nuances and finer workings around the eCommerce retail industry.
If you are looking to up your ante and drive more conversion to your eCommerce brand then check out our services at www.shopifyshoguns.com or drop us a mail at [email protected]
0 notes