#don't use AI for research papers
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
Don't use Chat GPT—I've purposefully tested it and it fails miserably on anything related to stories. I publicly made fun of it for not being able to read Poetics, and only Chat GPT 5 have they finally managed to input Poetics. But then the analysis skills are still off in the model since it's only regurgitating what's given to it. What you want is to stick a flag into a new territory and for that, you need a fair amount of work and connection.
If you give Chat GPT a new puzzle it makes the wildest assumptions. Because it's a recyling machine.
cultural appropriation, religious iconography, and the ignorance of blatant orientalism in modern media
This is Said's territory—already very much given in Colleges, so it's likely you've already read him. He's a chore and a half to read since he subscribes very much to the idea fancy words makes one sound smarter. I wholly side with people like bell hooks. (the lower caps are not a mistake) where smarter people use more common words well.
bell hooks is also good. But I'm not telling you which books because she's the type of writer I want to inject into my veins. (Yes, I know about her problematic bits too, but as she's now dead, there is no guilt associated in dissecting the discourse rather than trying to not support a living author)
the rise and risks of shock advertising/content in modern media
This I would look at JSTOR for. I can remember a lot of papers on this already. It's well-tread area.
the demonization of queer artists and religious iconography
No lie, I did several papers on queerness being queer myself and it was like pulling teeth. !@#$ I was naively skipping to the library going this will be easy. We've had the 1960's movement, there's books about queer history, we've moved forward as a society. LALA... and then get to the library and I was crying in my optimism.
In order to write a paper, I had to triangulate a few papers to make it work together and I was in a cold sweat a few times trying to work it out. And believe me, I combed through several university libraries, I was willing to get papers in other languages, I tried to find books from the Library of Congress. It was like I was dying. Because while stories about queerness definitely exist, and lit papers about queerness exists, how to tie that to social phenomena... !@#$ that, that did not exist. And the more you want to cover intersectional, the more difficult it gets. And then professors are on you for not tying your ethnography to existing research materials that DO NOT EXIST.
I could rant about it for hours and how much people kept telling me sorry, sorry, that's strange... but yeah. I had to swallow a lower grade on one of my papers because I could not find the materials though I freaking tried in several languages. I even went inter disciplinary, which oddly got me a lower grade. What am I supposed to do?
I had to buy two of the books too. I was so frustrated, I donated both of them to the uni library so another student wouldn't get stuck in the same position I was.
If you want a less well-tread area you can look at something like Media Imperialism. There are a few core academic books about it, but might be a good relevant topic to look at especially considering today's landscape.
If you're writing a long paper for college, uni or whatever, choose a topic you like and narrow that sucker ahead of time. Use research to find a new angle, not chat bots. Teachers are impressed more when you come out with an interesting thesis they've never seen before because they've taught this course for years and this is a new angle for them. So remember to engage in their humanity too.
But the best thing to do is write, research, narrow, write, research, narrow, until your thesis sounds solid and then you'll find something you can live with for the next few months of reading and editing it. Start early, though I know you won't, 'cause the intersectional interdisciplinary papers like you're suggesting takes more work, but also impresses more. Most of all, find something that excites your emotions and own brain.
Psychologically it's not the thing that you know, or the thing that don't know that catches you, it's the thing that feels oddly familiar, but can't quite place it until it becomes a realization that's most memorable.
does anyone have any writing techniques to help with writing about media or history??? I'm struggling with writing a couple of documents about different ideas trying to write about something unique in media.
here's a couple I thought about:
cultural appropriation, religious iconography, and the ignorance of blatant orientalism in modern media
the rise and risks of shock advertising/content in modern media
the demonization of queer artists and religious iconography
I'm just struggling how to extend on them, and observing on Chat GPT with the writing prompts given don't fit my style, and I'm just starting out. What do I do???
#don't use AI for research papers#AI cannot innovate#research can help you see gaps#intersectional research needs to be done but is so hard to find#JSTOR#research creates plotbunnies
10 notes
·
View notes
Text
Tumblr can never be my main means of engaging in politics and it comes down almost entirely to Tumblr's pathological need to distill The Right Opinion:tm: from any complicated issue.
It's always the most important thing. Not because it helps solve the issue or helps the people impacted, but because The Right Opinion:tm: is a proxy for you, morally, as a person. And every issue needs to be broken into the language that sets the stances of Make You Good or Make You Bad.
And I don't mean this in any generic statement about echo chambers or virtue signaling. Those are separate but related concepts. What I'm talking about is how people are nervous about a topic until one doctrine is crafted which defines the Sports Team Color of our Sports Team, so we can be identified as being on the Us Sports Team, and absolutely not on the Them Sports Team. Because this issue is actually about you and the proxy for you as a person and how people should perceive you so, really, the sooner we figure out the Home Sports Team Colors the sooner you can stop feeling worried.
The moment something new happens is usually the first and last time you'll actually see a range of opinions on it. And some of that is fueled by misinformation! Some in bad faith! When dust settles and clarity is achieved, this helps combat those things, but it's also the moment when the Loudest and most Articulate voices craft the Zeitgeist Opinion and everyone comes to roost around it.
You get people on this site pissed off at AI models that can diagnose cancer from a research paper in 2019 because The Right Opinion is that AI is bad. If you even see a post trying to articulate good uses of AI, well that's someone wearing Packers colors at a Vikings home game, and if you wanna make a point in the "wrong" direction you better be damn articulate about it.
A well-defined set of actions are transphobic. Another set are actually not transphobic, and you'd be transphobic for thinking so. Are you trans and actually your lived experiences differ? Get articulate real fast or shut up. You might be able to eek an exception for yourself, but it's going to require a 10-paragraph post justifying your claim. If you're REALLY good at it though, you might be able to rewrite the Zeitgeist and now anyone who disagrees with you is transphobic. Teams switch uniform styles every now and then, after all.
And it's such a farce because so often it's not actually about the topic at hand. It's about why you should be allowed to be perceived as a good person while toeing outside the fringes of The Right Opinion, why you aren't actually quitting the faith or committing blasphemy or deserving of exile for going off the written word. Or if someone really IS trying to make it about the topic at hand, the ensuing slapfight in the comments needs to be about whether OP has sinned against the covenant.
It's not helpful.
4K notes
·
View notes
Text
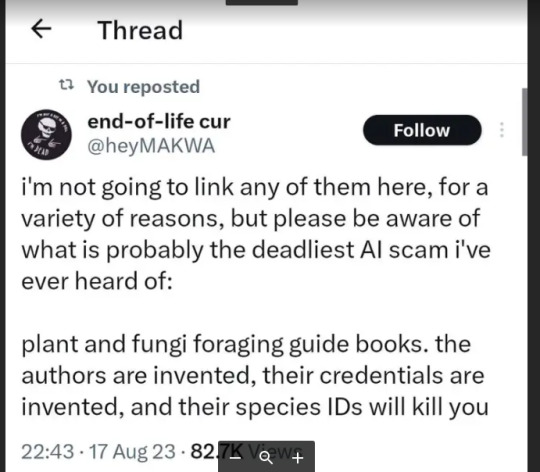
ETA: I wrote up a guide on clues that a foraging book was written by AI here!
[Original Tweet source here.]
[RANT AHEAD]
Okay, yeah. This is a very, very, very bad idea. I understand that there is a certain flavor of techbro who has ABSOLUTELY zero problem with this because "AI is the future, bro", and we're supposed to be reading their articles on how to use AI for side hustles and all that.
I get that ID apps have played into people's tendency to want quick and easy answers to everything (I'm not totally opposed to apps, but please read about how an app does not a Master Naturalist make.) But nature identification is serious stuff, ESPECIALLY when you are trying to identify whether something is safe to eat, handle, etc. You have to be absolutely, completely, 100000% sure of your ID, and then you ALSO have to absolutely verify that it is safely handled and consumed by humans.
As a foraging instructor, I cannot emphasize this enough. My classes, which are intended for a general audience, are very heavy on identification skills for this very reason. I have had (a small subsection of) students complain that I wasn't just spending 2-3 hours listing off bunches of edible plants and fungi, and honestly? They can complain all they want. I am doing MY due diligence to make very sure that the people who take my classes are prepared to go out and start identifying species and then figure out their edibility or lack thereof.
Because it isn't enough to be able to say "Oh, that's a dandelion, and I think this might be an oyster mushroom." It's also not enough to say "Well, such-and-such app says this is Queen Anne's lace and not poison hemlock." You HAVE to have incredibly keen observational skills. You HAVE to be patient enough to take thorough observations and run them through multiple forms of verification (field guides, websites, apps, other foragers/naturalists) to make sure you have a rock-solid identification. And then you ALSO have to be willing to read through multiple sources (NOT just Wikipedia) to determine whether that species is safely consumed by humans, and if so if it needs to be prepared in a particular way or if there are inedible/toxic parts that need to be removed.
AND--this phenomenon of AI-generated crapola emphasizes the fact that in addition to all of the above, you HAVE to have critical thinking skills when it comes to assessing your sources. Just because something is printed on a page doesn't mean it's true. You need to look at the quality of the information being presented. You need to look at the author's sources. You need to compare what this person is saying to other books and resources out there, and make sure there's a consensus.
You also need to look at the author themselves and make absolutely sure they are a real person. Find their website. Find their bio. Find their social media. Find any other manners in which they interact with the world, ESPECIALLY outside of the internet. Contact them. Ask questions. Don't be a jerk about it, because we're just people, but do at least make sure that a book you're interested in buying is by a real person. I guarantee you those of us who are serious about teaching this stuff and who are internet-savvy are going to make it very easy to find who we are (within reason), what we're doing, and why.
Because the OP in that Tweet is absolutely right--people are going to get seriously ill or dead if they try using AI-generated field guides. We have such a wealth of information, both on paper/pixels and in the brains of active, experienced foragers, that we can easily learn from the mistakes of people in the past who got poisoned, and avoid their fate. But it does mean that you MUST have the will and ability to be impeccably thorough in your research--and when in doubt, throw it out.
My inbox is always open. I'm easier caught via email than here, but I will answer. You can always ask me stuff about foraging, about nature identification, etc. And if there's a foraging instructor/author/etc. with a website, chances are they're also going to be more than willing to answer questions. I am happy to direct you to online groups on Facebook and elsewhere where you have a whole slew of people to compare notes with. I want people's foraging to be SAFE and FUN. And AI-generated books aren't the way to make that happen.
#foraging#mushroom foraging#plant foraging#mushrooms#edible plants#edible mushrooms#wild foods#food#nature#AI#fungus#fungi#poisonous mushrooms#poisonous plants#botany#mycology#rant
4K notes
·
View notes
Text



❥﹒♡﹒☕﹒ 𝗽𝗿𝗼 𝘁𝗶𝗽𝘀 𝘁𝗼 𝗴𝗲𝘁 𝘀𝘁𝗿𝗮𝗶𝗴𝗵𝘁 𝗮'𝘀
having good grades doesn't necessarily mean you're smart, a test or exam can't always determine someone's intelligence, but it's academic validation we crave, right? so here are some tips thanks to which you will get straight a's.
𝟭. understand what the professor wants ( 🪼 )
learning the entire book by heart is tiring and basically useless. we take our education seriously, but it's impossible to know everything about everything, so inevitably there will be topics we can gloss over. check old tests, listen to the teacher during the lecture, talk to students who have already attended the course and passed the exam. understand which aspects your professor particularly cares about and concentrate on those, your exam will certainly go well.
𝟮. strengthen your memorization ( 🦋 )
very often the amount of things to study is just too much and, even though you spend all day in the library rereading the topics again and again, you feel that it is not enough. you get confused, you forget steps, you get lost in the labyrinth of the subject. investing in understanding your form of memorization will benefit you in the long run. identify your type of memory (spatial, photographic, echoic, etc.) and focus on how to improve it. having a good memory will make your studying for the exam much faster and easier.
𝟯. pay attention in class ( 🫧 )
attend all lectures and take notes. much of your studying comes from your professor's lecture. underline the important things in your textbook, carefully follow their speech and - if there are any - their powerpoint slides, writing only the things that the teacher adds and which are not written either in the book or in the extra material, if necessary, record the lesson so you can listen to it again at a later time.
𝟰. organize your notes the same day ( 🧃 )
when i take notes in class i write badly and quickly to keep up with the teacher, shortening words or omitting passages. by reorganizing your notes that same evening (at most the next day, if you really don't have time) you can revise your work when the lesson is still fresh in your mind; if you wait too long, you will forget most of the things and you will find yourself staring blankly at pages of notes which, at that point, will seem more like hieroglyphics to you than anything else.
𝟱. use ai responsibly ( 🪴 )
artificial intelligence is everywhere nowadays and why not use it to our advantage? of course i'm not suggesting that you let an ai take care of all your tests and essays, it wouldn't make sense, however very often it helped me make a list of key points to develop in a research paper, or gave me excellent ideas and insights for projects. they can also be used to create flashcards, summarize and simplify articles, or create practice tests based on the material you will have to study.
𝟲. delve deeper into your “whys” ( 🌾 )
sometimes when i study i stare into space and wonder why i am studying something that seems completely irrelevant to my path. i'm sure it happens to you too, don't ignore this feeling. don't be afraid to explore themes and topics that aren't clear to you, if two statements seem contradictory ask yourself why, if you don't understand some passages, don't be afraid to ask a question. we study for ourselves, before studying to graduate, to work. there is no shame in not understanding, your intelligence lies in striving to clarify what seems obscure.
#school#note taking#college#studyinspo#academia#education#university#study tips#study inspiration#study notes#study motivation#student#study aesthetic#study blog#studyblr#studyspo#pro tips to get straight a's#straight a student#straight a's#architecture#architecture student#architecture studyblr#university life#univeristy#uni life
229 notes
·
View notes
Text
Kaijuno has possibly been lying about being an astrophysicist for 8 years: a compilation
Abstract: Kaijuno made her initial claim to Tumblr fame in 2016 with the release of a few popular posts. In the 8 years which followed, she has been wearing the title of astrophysicist with pride. I call this title into question on behalf of all Tumblr users. All evidence has been gathered with legal and publicly available information. Posts will be screenshotted, as well as embedded with a link to prove I have sourced them publicly. While I cannot prove anything beyond a doubt, I hope this raises suspicion of her past, current, and future actions. I do not wish any harm on her. I just wish to inform people of her alleged lies since she has been taking emergency donations on her Tumblr blog for years.
1. Introduction Jessica Peck -- whose name is public and has been sourced through Paypal, Cashapp, and Venmo accounts linked to her Tumblr -- of Flint, Michigan (also publicly sourced via posts she made) has been running the blog Kaijuno since August 2014. She has been claiming to be an astrophysicist since at least August 2016, and continues to as of today (7.13.24). It is my firm belief that she is not an astrophysicist, but rather had dropped out of an undergraduate physics program during or after 2017. Additionally, I believe the art she has been posting since 2023 to have been made with AI. While I have not looked into her financial situation, I believe that if she is truly lying about her career and art, it is entirely plausible for her to lie about her finances as well.
2. Methods
2.1 Outside Research With a publicly sourced name and location, I was able to use a variety of public resources at my disposal to track any published papers or accounts on other websites. A quick search through Google Scholar yields no results of anybody named Jessica Peck publishing a paper on astrophysics. I have not searched through other databases -- I don't find it necessary but I do implore others to search if they wish.
The next place to check was Linkedin. A similar search yielded a public Linkedin page attributed to someone of the same name and state:

This page has seemingly not been updated since 2017, during her undergrad. An important thing to note about Linkedin is that does say she graduated in 2020. However, when you link your university to Linkedin it lists your expected graduation year regardless of whether you've graduated or not. This does not prove graduation, but that she has gone for an undergraduate degree in physics at one point with an estimated graduation year of 2020.

Everything else comes directly from her Tumblr blog. I'm embedding all screenshots with links, however I anticipate most of them being deleted.
2.2 Direct Quotes Jessica has claimed to have a graduate degree, specifically a Ph.D, on numerous occasions. These have generally been played off as jokes, though I do believe the intention of posting them has been to persuade people that she does have a degree.

Here she claims shes going back to college (10.30.23):

But here she claims she has '2 PhDs'(10.30.23). The following two screenshots single-handedly contain the bulk of my evidence.


NOTE: The usernames and icons have been blocked out, as those people are not involved with this post.
The 'free college because I'm 26' appears to be from Michigan Reconnect, a scholarship program which pays for community college for students over the age of 25 who do not have a college degree. The only way Jessica would be benefiting from this program would be if she never completed her undergraduate degree in 2020. This appears to be the only way you can get free or discounted college tuition exclusively based on age in the state of Michigan. While she could get her tuition paid for her by FAFSA, that is income-based, NOT age-based.
If she is currently attending college and benefiting from this age-based aid program, she cannot possess the multitude of prior degrees she has otherwise attested to. This means that, effectively by her own admission/contradiction, she does not have any sort of degree in astrophysics, but rather used to be a physics student that never completed her degree.
This is all of the information I have collected on her academics. Again, every single part of this has been publicly sourced, and any person would have been able to find all of this information the same exact way that I have.
3. Results // AI Art and General Bitchery This is a collection of art she claims to be her own, and how I visually identified it as AI:






(This is just Heroforge. Maybe with a filter over it. Anyone familiar with Heroforge knows this.)
I present one final screenshot:

This doesn't prove anything about her academic, art, or financial state. I am simply including this to show people how she truly feels about those who have given her donations over the past several years.
4. Conclusion I'd like to close this out by saying: no, none of this is definitive proof. I have no desire to dig any deeper than the resources that are publicly available. If you've noticed, I have not stated anything about her financial situation. This is because I haven't seen anything she posted which contradicts her financial state, other than the fact that she has been lying about her other personal details for years. It is my opinion that she did not graduate college, but she does appear to be unemployed at the very least. I'd appreciate it if people formed their own beliefs based upon this post rather than taking my word as complete fact, and do their own research as well.
With that being said -- if you disagree with anything I have posted, by all means let me know. And feel free to add if there is something else I missed. I only ask that you take this post into consideration before you donate her money, as the person you're sending it to might not be who she advertises herself as.
109 notes
·
View notes
Text
Determined to use her skills to fight inequality, South African computer scientist Raesetje Sefala set to work to build algorithms flagging poverty hotspots - developing datasets she hopes will help target aid, new housing, or clinics.
From crop analysis to medical diagnostics, artificial intelligence (AI) is already used in essential tasks worldwide, but Sefala and a growing number of fellow African developers are pioneering it to tackle their continent's particular challenges.
Local knowledge is vital for designing AI-driven solutions that work, Sefala said.
"If you don't have people with diverse experiences doing the research, it's easy to interpret the data in ways that will marginalise others," the 26-year old said from her home in Johannesburg.
Africa is the world's youngest and fastest-growing continent, and tech experts say young, home-grown AI developers have a vital role to play in designing applications to address local problems.
"For Africa to get out of poverty, it will take innovation and this can be revolutionary, because it's Africans doing things for Africa on their own," said Cina Lawson, Togo's minister of digital economy and transformation.
"We need to use cutting-edge solutions to our problems, because you don't solve problems in 2022 using methods of 20 years ago," Lawson told the Thomson Reuters Foundation in a video interview from the West African country.
Digital rights groups warn about AI's use in surveillance and the risk of discrimination, but Sefala said it can also be used to "serve the people behind the data points". ...
'Delivering Health'
As COVID-19 spread around the world in early 2020, government officials in Togo realized urgent action was needed to support informal workers who account for about 80% of the country's workforce, Lawson said.
"If you decide that everybody stays home, it means that this particular person isn't going to eat that day, it's as simple as that," she said.
In 10 days, the government built a mobile payment platform - called Novissi - to distribute cash to the vulnerable.
The government paired up with Innovations for Poverty Action (IPA) think tank and the University of California, Berkeley, to build a poverty map of Togo using satellite imagery.
Using algorithms with the support of GiveDirectly, a nonprofit that uses AI to distribute cash transfers, the recipients earning less than $1.25 per day and living in the poorest districts were identified for a direct cash transfer.
"We texted them saying if you need financial help, please register," Lawson said, adding that beneficiaries' consent and data privacy had been prioritized.
The entire program reached 920,000 beneficiaries in need.
"Machine learning has the advantage of reaching so many people in a very short time and delivering help when people need it most," said Caroline Teti, a Kenya-based GiveDirectly director.
'Zero Representation'
Aiming to boost discussion about AI in Africa, computer scientists Benjamin Rosman and Ulrich Paquet co-founded the Deep Learning Indaba - a week-long gathering that started in South Africa - together with other colleagues in 2017.
"You used to get to the top AI conferences and there was zero representation from Africa, both in terms of papers and people, so we're all about finding cost effective ways to build a community," Paquet said in a video call.
In 2019, 27 smaller Indabas - called IndabaX - were rolled out across the continent, with some events hosting as many as 300 participants.
One of these offshoots was IndabaX Uganda, where founder Bruno Ssekiwere said participants shared information on using AI for social issues such as improving agriculture and treating malaria.
Another outcome from the South African Indaba was Masakhane - an organization that uses open-source, machine learning to translate African languages not typically found in online programs such as Google Translate.
On their site, the founders speak about the South African philosophy of "Ubuntu" - a term generally meaning "humanity" - as part of their organization's values.
"This philosophy calls for collaboration and participation and community," reads their site, a philosophy that Ssekiwere, Paquet, and Rosman said has now become the driving value for AI research in Africa.
Inclusion
Now that Sefala has built a dataset of South Africa's suburbs and townships, she plans to collaborate with domain experts and communities to refine it, deepen inequality research and improve the algorithms.
"Making datasets easily available opens the door for new mechanisms and techniques for policy-making around desegregation, housing, and access to economic opportunity," she said.
African AI leaders say building more complete datasets will also help tackle biases baked into algorithms.
"Imagine rolling out Novissi in Benin, Burkina Faso, Ghana, Ivory Coast ... then the algorithm will be trained with understanding poverty in West Africa," Lawson said.
"If there are ever ways to fight bias in tech, it's by increasing diverse datasets ... we need to contribute more," she said.
But contributing more will require increased funding for African projects and wider access to computer science education and technology in general, Sefala said.
Despite such obstacles, Lawson said "technology will be Africa's savior".
"Let's use what is cutting edge and apply it straight away or as a continent we will never get out of poverty," she said. "It's really as simple as that."
-via Good Good Good, February 16, 2022
#older news but still relevant and ongoing#africa#south africa#togo#uganda#covid#ai#artificial intelligence#pro ai#at least in some specific cases lol#the thing is that AI has TREMENDOUS potential to help humanity#particularly in medical tech and climate modeling#which is already starting to be realized#but companies keep pouring a ton of time and money into stealing from artists and shit instead#inequality#technology#good news#hope
203 notes
·
View notes
Note
Hi! I wanted to say, I read that you are a professional editor, and think it's amazing! You also give very logical and well explained advice. I was wondering; would you say being an editor is a job you can support yourself with? I actually aspire to become one someday, but I'm not exactly sure if it's a good plan.
Thank you for your time, and I hope you have a good day/night
Hey there. Great question. It's totally possible to support yourself as an editor. I've done it, and so have other editors I know. However there are a few important things to consider before choosing editing as a career path.
Your chances of being a self-employed freelancer are extremely high. The number of in-house editing jobs in publishing are low and getting lower. While being self employed can give you a certain amount of flexibility, it also comes along with a lot of hustle and hassle, namely fluctuating income, a stupid amount of confusing tax paperwork, and the need to constantly promote yourself to clients in order to maintain steady work.
You probably won't make as much money as you'd think. Editing is one of the many skilled jobs that suffers from market saturation, which has sadly driven down the price the average client is willing to pay for editing services. I can't tell you the number of overqualified editors I know charging barely more than minimum wage for their work. Personally I've stuck to my guns about charging what I'm worth, but I've sometimes suffered by not having as much work as my colleagues who charge less.
Robots have already chipped away at the future of editing as a human occupation, and will continue to do so at exponential speed in the years ahead. They will never obliterate the job completely, as there will always be humans who prefer to work with humans instead of machines. But the outlook will become ever bleaker as more humans compete for fewer gigs, which in turn will drive down prices even further.
If you are also a writer, editing may adversely affect your writing. I don't mean that you'll become a worse writer, quite the opposite. My editing work has brought new depths to my writing, and I'm grateful for all I've learned by working with my clients. However, editing takes time, uses creative energy, and requires staring at a screen (or paper), and personally the more I edit, the less time/creativity/screen-staring capabilities I have left for my own writing.
If you mention you're an editor, someone will troll your post for a typo, grammatical error, or misused word, and then triumphantly point it out to you in the comments. This is mostly a joke. But it does happen every single time.
I hope this hasn't been too discouraging. If you feel a true passion for editing and really enjoy the work, none of the above should dissuade you. However, if you think you might be happy in any number of occupations, I'd honestly advise you to explore other options. Choosing a career path at this point in history is a gamble no matter what, but the outlook for editors is especially grim.
If you'd like to work with writers and aren't attached to being an editor, there are a few jobs (still freelance) that I believe will survive the coming robot apocalypse. Do a little Google research about "book coaches," "writing coaches," or "book doulas." These are people who act primarily as emotional supporters and logistical helpers for writers who are trying to get their book published or self published. Some of them do actual editing, but many do not, and due to the therapeutic nature of their work I believe they will flourish longer than editors in the coming robot apocalypse.
If you do explore editing as a path, the further away you can lean from spelling and grammar (e.g. proofreader or copyeditor), the longer your skills will be useful when competing with robots. AI still struggles to offer the same kind of nuanced, story-level feedback that a human can give. (Speaking from experience here--I'm a developmental editor and have yet to see a dent in my workload because of robots.) They'll catch up eventually, but it could be a while, and as long as there are human readers, there will always be humans who are willing to pay for a human perspective on their writing. Human spell checkers maybe not so much.
Hope this helps!
91 notes
·
View notes
Text

Have I ever told you how much I like these crime games? Some of you might know how much I struggle to keep up with something due to my ADHD (a glorious exception are the Boys ^^') But I was able to finish this book for my games/current case! I haven't been able to craft a bigger project for a while so I'm very proud of myself lol and I thought I show you.


I can reuse this book over and over again for new cases and it's made out of stuff I already had at home: amazon packaging, printouts, envelopes, tea dyed paper, wallpaper, a belt, the lock is from an old suitcase I found, paperclips, stamps, fabric and the metal book corners are made from a tomato paste tube...
These games come with a bunch of documents and I like that I can sort them now and that I'm able to find them quickly instead of having them in a heap. It takes me a few days or even weeks (when I get distracted by someting else ^^') and with this book I can put everything quickly away and return as quick to my research again.


I also made little writing pads and a notebook. The most fun I had with the paperclips. You can make them so quickly and they are so pretty and useful (I use them as tabs and to keep the documents in place)! Just fold a strip of paper in a 'w' shape, glue the metal paperclip inside and decorate. Ready! If you are interested in doing sth like this, don't hesitate to ask, I'm happy to help and share links to to the amazing youtubers I learned from!
I came into crafting only late in my life and I have so much fun. I wish I discovered the joy of it earlier but I never thought it could be something for me. Art class in school was so discouraging and I always thought I don't have the patience/talent for it. Then I went into rehab and we crafted and I kept on crafting ever since ^^' (Maybe you remember when I posted about my tarot book I made a new cover for or my amazing tool case I posted a while ago?)
The box in the pic below is a chocolate packaging I glued some tea dyed paper on :3


I also made a little booklet:
Did you know that you can make tape out of almost everything by using doublesided tape? Here I used old book pages. The dangles are made from cardboard and napkins :3

That was a fun little project and it's also a nice gift. I printed out the AI edits from my Mount Komorebi screenshots to decorate the pages. When you look close you can see Kiyoshi and Kiri in the pic on the left.

58 notes
·
View notes
Note
Well, it's for a school research paper and we have to gather data on how social media affects stress and people's mental health.
Thank you for answering my dumbass questions even though it probably seems stupid, i really appreciate it
First off, asking for help on finding sources is not stupid/dumbass, it's the opposite. Smart people ask for help when they don't know what they're doing.
Second, since you said school and not uni, I'm going to assume you're at high school level roughly and not uni/college. If so, then google scholar is going to be a fine starting point for you to find sources. It's generally user friendly and going to provide decently quality for what you need.
Unlike main google, it's been untouched by the AI nonsense and functions mostly like it did 5 years ago. It's also handy because it will often provide free copies of papers when it can find one. It should help you get some good research papers as sources that you can use as citations, and it'll let you save articles/handles citations for you.
Here's a quick guide for what you need to know to use google scholar!
When searching, put in keywords, NOT questions.
For reasons unclear to me, search engines and humans being weird has trained people to type in queries to search engines like questions. This is bad!!! It will get you worse results!! You want to instead remove any unnecessary words and focus in on giving the computer the most unique keywords to match you with what you actually want. For example:
BAD: how does social media affect stress and mental health?
BETTER: social media stress effect mental health
BEST: social media mental health
You really want to par down your keywords as much as possible, limiting connector or filler unless you absolutely need it. The more specific words you use (ie using "depression" rather than the more general "mental health") the more specific your results. Focus on practicing that and you'll do excellent.
With that out of the way, for actual google scholar use:

Right here, we have a very important feature, the free copy. If google can pull up a free public copy of a paper, it will! Always use those when possible.

Always check the date on the research you're pulling! For a topic like social media, I would be wary of pulling any source that's 5 years or older, since it's an evolving landscape! For other topics, the rules vary a lot depending on the topic and quality of research available.


Next up, saving & citation. The save button lets you save an article for later. You can stick it on a particular list. Handy for keeping track of sources. The cite button generates citations for you, in most of the common styles. Saves you having to mess with making them yourself.

Finally! Further research! When you click down here, you can see articles that have cited this paper and related articles. Both are quite handy for exploring a particular topic further as you look for research that builds on what you've found. Particularly when the area you're looking at is niche or highly specific. Also a great way to find systematic reviews of data that are sometimes a bit stubborn about showing up in research results.
Hopefully all of that is helpful, best of luck on your paper anon!
30 notes
·
View notes
Text
Some of these tells—such as the inadvertent inclusion of “certainly, here is a possible introduction for your topic” in a recent paper in Surfaces and Interfaces, a journal published by Elsevier—are reasonably obvious evidence that a scientist used an AI chatbot known as a large language model (LLM).
In addition to that overt tell, over 60,000 papers have been identified as having LLM-like language in them, stuff that humans typically don't type. That's over 1% of the current library of papers tracked in the study. More than 17% of newly submitted papers have the taint of LLM generators to them.
Aside from the meandering, bloated text AI generators output, there are blatant hallucinations present: citations of studies that do not exist, fake researcher names, and conclusions that don't align with the data.
Unpaywalled here.
54 notes
·
View notes
Text
Exceptions
Grant Ward x Reader

Masterlist - Join My Taglist!
Written for my personal fic writing challenge for 2024, Sophie's Year of Fic! Featuring a new fic being posted every Friday, all year long :)
Fandom: Marvel
Summary: The Bus kids are stuck at the Triskelion for a while since May and Coulson have a meeting with Fury, but Ward already has important plans that he can't cancel.
Word Count: 1,287
Category: Fluff, Humor
A/N: To the anon who sent me an idea outline for this, I hope you like it! It got merged with another idea I had, but hopefully, it's still pretty close to what you had in mind :) Thanks for continuing to read stuff for Grant Ward and enabling me to keep writing him- he's my fave, so I'm glad I have at least a few people to share the love with!
Putting work into an AI program without permission is illegal. You do not have my permission. Do not do it.
Skye's POV
"Alright. May and I will head into our meeting with Director Fury. We'll meet you back here when we're done."
I frowned at Coulson, glancing at FitzSimmons and Ward to see if any of them would say anything. As expected, FitzSimmons just looked at each other, and Ward nodded to Coulson like he'd known this was the plan from the beginning, which I super doubted.
"Okay... and what are we supposed to do in the meantime?" I asked, turning back to Coulson and asking the question that must've been on the rest of our minds. May was already halfway out of the room, and Coulson stopped mid-step to address my question. He smiled.
"I'm sure you'll think of something."
With that, he turned and headed off with May again. I watched him go for a few steps, then put my hands on my hips and turned back to the rest of my group with a sigh.
"Alright, we've been abandoned at one of the biggest SHIELD bases in the world. I probably know the least about this place out of all of us, so... how about you guys? Any ideas?"
I glanced at FitzSimmons, then looked right at Ward. He had his arms crossed, and he shook his head and took a step back the minute my gaze landed on him.
"I don't know what you all are going to do, but I have somewhere I need to be. I'll meet you back here when May and Coulson are done with their meeting. Try not to break anything until then."
With that, he turned on his heel and started marching away. I let him get a few steps, then turned to FitzSimmons.
"So we're gonna follow him, right?"
"Oh, of course."
"Absolutely."
****************
Y/N's POV
A took a slow, steady breath, then refocused on the sample in front of me. I'd been staring through the eyepiece of this microscope for what felt like an eterity, finally getting somewhere with samples I'd been working with for months. I'd been stuck at the Triskelion that whole time, in a lab with the loudest of the loud field and ops agents coming in and out, constant noise and business no matter where we went. All of that was about to be worth it.
The rest of the lab completely faded out around me, even as I scribbled notes without looking at the paper beside me. The handwriting wouldn't be good, but it would be decent enough that I could decipher it later, and it meant I didn't have to take my eyes off the results of the experiment in front of me for a single moment. I'd carefully built my corner of the lab into what it was, a sanctuary from the noise and chaos, the perfect place to tuck away and lose myself in my research.
At least, normally it was. Today, someone had apparently decided to venture into my corner, as a hand on my shoulder made me shoot out of my chair and almost gave me a heart attack.
"Sorry!" came the frantic voice of my best friend, Mandy. "I didn't mean to scare you! I swear, I said your name, like, three times while walking over here."
I put a hand to my chest, taking half a second to catch my breath before turning back to Mandy.
"It's okay. Honestly, I don't think anything could've shaken me out of my focus without scaring me like that. Did you need something?"
"Just wanted to give you a warning. One of the ops agents broke containment and just wandered into the lab. Figured it'd be better if I interrupted you than if he did."
I sighed, long and heavy, pinching the bridge of my nose.
"Are you kidding me? How did one of them even get in here-"
I turned to see the man in question and stopped dead in my tracks. Grant Ward, my boyfriend, had just stepped into the lab. I grinned.
"Oh, actually, never mind Mandy. This one's the exception to the rest of the ops people."
"Wow, no kidding. I don't think I've seen you smile like that since your experiment at the Academy won our final projects presentation."
I rolled my eyes, but didn't bother with more than that as Mandy took her leave and Grant finally made his way over to me. His smile matched mine, the two of us bringing out sides of each other most people weren't lucky enough to see.
"You didn't tell me you were coming!" I said as Grant finally reached me, wrapping his arms around my waist and pulling me tight to his chest. He leaned in to kiss me, and it lasted a few moments longer than I would've let him get away with in public if I hadn't missed him so much.
"I thought I'd make it a surprise. Our team got detoured here last minute for Coulson to have some meeting with Fury. Lucky for us, they didn't need me to be there."
"That is lucky," I agreed, the two of us sharing a smile again. Grant reached up and gently cuped my chin in his hand, pulling me back in for a sweeter, slower version of our earlier kiss. I sighed when he pulled back and settled onto the lab stool next to me, his thigh pressed against mine.
"So. Wanna tell me what you're working on?"
"Happily. But I don't want to spend all the time we have together in this lab, so don't let me get carried away-"
"Don't worry, we should have all of tonight and tomorrow morning, with a small exception in a few hours when I have to meet back up with my team. I thought I could keep you company while you finish up here, and then we could grab some dinner. I found a great restaurant in the city last time I had an undercover mission there, and it'll leave us plenty of time for you to tell me all about this project you're working on."
"Grant, that sounds perfect. How did I get so lucky with you?"
"Trust me, the feeling's mutual." We shared a smile, smaller and softer this time, but no less special. Then, Grant turned to the microscope in front of us. "So... I take it you're doing something with this?"
"Yes! I finally have interesting results to look at, so your visit was well-timed. Let me tell you about what you're seeing here..."
Grant leaned into the microsope, bracing one hand on my thigh as I put one arm around his shoulders and rubbed gentle cirlces there, narrating what he was seeing on the slide as I went. Within the lab, I'd gotten a bit of a reputation for liking my space while I worked. But Grant would always be the exception to that. I was on cloud nine that he was here, and I wasn't going to waste a single moment we had together.
****************
Skye's POV
"I've never seen him smile like that!" Simmons hissed.
"And he always complains about 'technobabble' when I say more than a few three-syllable words in a sentence!" Fitz agreed. I just huffed a laugh.
"Yeah, well, he's not kissing any of us either. I think that might have something to do with the change."
Fitz and Simmons scoffed right along with me, the three of us watching the scene in the Triskelion's lab for a few more moments before finally shaking it off and heading back into the hallway. Whether or not we found something else to occupy our time until May and Coulson were done with their meeting, we at least had something to tease Ward about for the rest of our lives, which I'd take as a win any day.
****************
Everything Taglist: @rosecentury @kmc1989 @space-helen
Marvel Taglist: @valkyriepirate @infinitelyforgotten @sagesmelts @gaychaosgremlin
#sophie's year of fic#marvel#agents of shield#grant ward#grant ward x reader#marvel fanfiction#marvel imagine#marvel oneshot#agents of shield fanfiction#agents of shield oneshot#marvel x reader#agents of shield imagine#agents of shield x reader#grant ward fanfiction#grant ward imagine#grant ward oneshot#skye#leo fitz#jemma simmons#shield
50 notes
·
View notes
Text

Man I'm not even like, an AI person, but this is such a dumbass take. Like, okay yeah, the text is non-retrievable. Do you know what else is non-retrievable? A conversation between two people that was not recorded audio/visually. People reacting to an exhibit at a museum. Behavior in an online video game. These are still things you cite in academic papers. There are even entire books about these kinds of non-retrievable events.
The vast majority of citations don't actually link up to something concrete that the reader can track down and see for themselves. That's not really what citations are FOR. You cite something in order to establish where you sourced the information that you're writing about. Even in quantitative research on concrete subjects a citation doesn't represent objective verifiable Truth. To be writing about rabbit populations in North America and cite a study that lists population numbers, that study does not represent the true number of rabbits. That citation points to a field study whose methods section tells us X scientist went to Y location over Z period of time and counted # rabbits. We the reader can't see those rabbits. Even if we go back to that field, it will be a different day, with different rabbits, or no rabbits, or more rabbits. But we trust that the researcher counted accurately.
Sometimes people lie. Maybe that researcher deliberately skewed the numbers. Sometimes studies were done poorly and don't yield representative findings. Sometimes the rabbits just hid in their burrows all day. When lots of researchers go out and do similar counts, though, we can get an overall impression that can be assumed mostly accurate through the aggregate of observations.
Regardless of what is being studied or the methods being done, we cite shit in order to establish where we found the information we are referring to. If you are doing *anything* with AI then it behooves us to have a formalized way of indicating how you obtained your information. Whether you are writing about weird racist tendencies reflected in AI output, reporting on citations pointing to non-existent sources in AI output, or trying to convince credulous techno-dipshits that chatgpt just gained sentience, it is useful to have an established way of saying "I input this prompt into this AI model and got these results".
Whether the audience can retrieve the precise results that you're quoting is of astoundingly little importance. Maybe you'll go to the field and the rabbits aren't out. Maybe you'll go to the museum and people aren't reacting to the exhibits the same way. But if AI tends to have patterns in its output based on the input and the model (and it does!), *that* provides a critical avenue for academic study for the same reason ANY source that we cite does--it lets us make judgements about the information we're presented with.
"The decline in critical thinking" fuck off, man, this take itself is frankly much more indicative of a lack of critical thinking that worries me.
26 notes
·
View notes
Note
You can't say "Everything humans make is art" right after a whole tirade about how AI isn't art.
Hi op here
I CAN actually.
The machine made to make "AI" is art. Its engineering+programming. Which are crafts and a highly difficult ones.
What that machine makes however is NOT art. Its not even true artificial intelligence. Its just a bunch of stolen work cut up and pieced back together using complicated programming. What is produced is not art. What made it however is. Its a feat of accomplishment that we can get a machine to do that kind of stuff
But what it makes is not art.
Feel like @snitchanon would have a field day with all this.
So Photoshop itself is art, but works done in photoshop aren't art ? It's engineering and programming, but what it makes is not art. It's just clicking buttons and dragging the mouse until you get what you want.
As for true AI, yeah, I actually agree with you in no small part. What we call "AI" right now is nowhere close to having any kind of intelligence, we're basically making a very complicated math function with many parameters and tweaking it until it spits out the right output. There's very little explainability (it's a black box for the most part, we don't know what goes on inside or why this particular input), and every year there's a paper titled something like "We Fucked Up : How we evaluate [field of deep learning] is flawed and gives the illusion of progress".
As for the ethical issues with using stolen works, yeah, I'm completely with you, that's a dealbreaker for me, and unlearning (=getting from a model trained on a dataset to a model trained on a dataset w/o some data, without having to retrain everything, but being 100% sure the excluded data doesn't leave a single trace) is too new as a subject of research to even be usable for the next few years, so for me, AI Art generators are a big no-no.
(Also, the online ones take as much of your personal data as they can, so I'd avoid those like the plague)
HOWEVER, what "AI" image generation does isn't to cut up stolen work and put it back together, that's a myth. I don't know how this started but I've heard that said like three or four times already, it's way too specific a definition to have evolved independently so there must be a Youtuber out there to blame.
It's like saying Photoshop just takes pixels from stolen works and weaves them in the right order to make a new image. That's technically true, but it's a stupid definition that gives Photoshop way more credit than it's due. Likewise, AI image generators don't look through a database to find the right image, cut out the part they like, and add it to their final product. Otherwise, why do you think AI art would have all those problems with hands, buildings, etc... ? There can't be that many people out there drawing weird 7 fingered hands, I know some people have trouble drawing hands but not to that extent.
What they do instead (or rather what they did, because I don't know enough about the newest diffusion models to explain them in an intuitive way), is deconvolutions, basically "reversing" the operation (convolutions) that takes in a grid of numbers (image) and reduces it to a small list of numbers. With deconvolutions, you give it a small list of numbers, at random, and it slowly unravels that into an image. Without tweaking the thousands or millions of parameters, you're gonna end up with random noise as an image.
To "train" those, what you do is you pair it with another "AI", called a discriminator, that will do convolutions instead to try and guess whether the image is real or made by the generator. The generator will learn to fool the discriminator and the discriminator will try to find the flaws in the generator.
Think Youtube vs AdBlock. Adblockers are the discriminator and Youtube is the generator. Youtube puts out new ads and pop-ups that don't trigger ad blockers, and ad blockers in return fix those flaws and block the ads. After a month of fighting, it turns out ad blockers have become so good that other websites have a lot of trouble getting ads past them. You've "trained" ad blockers.
The most important thing to note is that the training data isn't kept in storage by the models, both in the adblock example and in AI image generators. It doesn't pick and choose parts to use, it's just that the millions of tiny parameters were modified thanks to the training data. You can sometimes see parts of the training data shine through, though. That's called overfitting, and it's very bad !

In the middle, the model won't remember every O and X out there. It drew a curve that roughly separates the two, and depending on where a new point falls compared to that curve, it can guess if it's an O or an X without having access to the original data. However, in the example on the right, even if you remove all the O and X marks, you can still make out the individual points and guess that those holes mean an X was in there. The model cannot generalize past what it's seen, and if there's ten thousand variables instead of just two, that means you could change a single one slightly and get nonsense results. The model simply hasn't learned correctly. For image generation, that means parts of the training data can sometimes shine through, which is probably how the "cut up and piece back stolen images" myth came to be.
The reason I don't like to use AI image generators is twofold : 1. Right now, all the models out there have or are likely to have seen stolen data in their training dataset. In the state of AI right now, I really don't believe any model out there is free of overfitting, so parts of that will shine through. 2. Even if there's no overfitting, I don't think it's very ethical at all. (And 3. the quality just isn't there and I'd rather commission an artist)
HOWEVER, that doesn't mean I agree with you guys' new luddite movement. "Everything humans make is art except when they use AI" is not a good argument, just like "It's not art because you didn't move the pixels yourself" or "AI cuts up and pieces back stolen images". The first two give "I piss in Duchamp's fountain uncritically" vibes, and the last one gives "Don Quixote fighting windmills" vibes.
33 notes
·
View notes
Note
Have you read about the new study that examined brain activity and found no overlap between male and female brains? It's mentioned here (sorry, can't post proper links): psychologytoday com/us/blog/sax-on-sex/202405/ai-finds-astonishing-malefemale-differences-in-human-brain. I haven't read it, but found it odd, considering there are several studies that claim that isn't any particular difference between male and female brains. Are they using different parameters or sth? Love your blog btw <3
Hi Anon!
I had not seen this study [1], yet, and it's very interesting!
I've talked before about how past research indicates there is not a substantial difference between female and male brains. Given the fact that we can find sex differences in many other body systems (e.g., the immune system) and the extent of gendered socialization, I was actually genuinely surprised that the current state of research is so strongly against any sex differences in the brain.
All of this is to clarify the perspective I approached this paper from. However, after reading it, I do not think that it provides strong support for sex differences in male and female brains. (It's still interesting! It just doesn't prove what people think it proves.)
---
So, the issues:
Replication
First, this is just one study, and as we've seen in previous research (see linked post above), many single studies actually do find significant sex differences. The issue comes in when you analyze across many different studies, you see that these differences are not consistent across studies. So, for example, study 1 may find that brain area A is significantly larger in males than in females and report this as evidence of a sex difference. Then study 2 finds that brain area A is significantly smaller in males than in females and reports this as evidence of a sex difference. On the surface, this would seem like there are now two studies proving a sex difference in brain area A. It's only when you combined the results of both of these studies that you can determine brain area A size is unlikely to be linked by sex.
So, that's the first problem with this study: it has not been replicated in other samples.
This is a particular problem considering the weight of evidence we have against this outcome. In other words, a single contradictory study does not, and inherently cannot, "prove" all other studies wrong.
In this same vein, even their exact model's accuracy fell to ~80% when tested on other data sets. Considering that average accuracy purely by chance would be ~50%, this drop is substantial. It also brings the overall repeatability of their study into question.
And in addition to all of that, they don't appear to be reporting the direction of each sex difference (i.e., more activity in X in males), which loops back in first point with the repeatability issues. Specifically, even if another study did replicate these findings, we have no way to tell if the direction of the sex differences in each brain area corresponds with or contradicts the direction in this study.
Methodological Limitations
That naturally leads into another issue: the limitations in their methodology.
To start, you are correct that they are using a very different methodology from past papers. Specifically, they are using a "spatiotemporal deep neural network" to analyze fMRI data. The essentially means they are using artificial intelligence to analyze data about the activity of men's and women's brains.
The first problem I can see here is that both of these (AI and fMRI) are prone to false positives. First, fMRI is looking at thousands of different data points for every individual, as a result, if you don't properly correct for this, you can get "positive" results for spurious observations. An amusing example is the researchers who found brain activity in the fMRI results of a dead fish [2]. Obviously, this is ridiculous, and you can mitigate this problem by adjusting your analysis methodology. But in this case, it highlights how the raw data from fMRI scans can produce positive findings where we know there is no real positive finding.
And this is relevant, because, in this study, they are feeding all of that massive data into a deep learning AI model. These sorts of models are almost notorious for their over-fitting, data bias, and un-generalizability. An amusing example is described in this paper [3], where they describe how another neural net (the same sort of AI as in this paper) was able to accurately determine if an image was of a husky or a wolf. The problem is that the model was actually using the image background (presence of snow) to make the prediction. This illustrates an important issue with AI: the model isn't always using the information we care about when making predictions.
Obviously, if this is occurring the current study it would not be as egregious; unfortunately, given the fact that fMRI data is not human readable it would also be much more difficult to detect.
As an example, the one reliable sex difference we see in brains is brain size. Men's brains are, on average, larger than women's brains. So, if you train a model on data that has not been adjusted for brain size, the model would have exceptionally high accuracy ... but it's only demonstrating the fact that sex is an accurate predictor of brain size. (For this study, I cannot find any explicit explanation of if or how they took brain size into account, but they have an exceptional amount of supplementary field-specific technical details it may have been included in.)
And then, even if we disregarded all the caveats above and accept their results at face-value then ... reliable sex differences in the brain would only be identifiable in "latent functional brain dynamics" or brain "fingerprints". They describe this as a "unique whole brain pattern of an [AI] model feature importance that classifies that individual as either female or male". In other words, no single area had reliable predictive values, only "whole brain patterns".
Causation vs Correlation
Lastly, and unsurprisingly, this study also runs into a pervasive issue in neuroscience: it cannot determine causation.
This study was done completely on adult participants, which means that all the participants had already undergone a lifetime of gendered socialization. I discuss this in the linked post above, but to reiterate, we cannot know whether "sex -> brain difference" or if "sex -> differences in socialization -> brain difference" for any study on adults. (And most likely even on children.)
---
In conclusion, this a very interesting study, but it doesn't disprove all the other research indicating a lack of differences in human brains between the sexes. Given the methodological limitations of the study, I think it's unlikely it will ever be successfully replicated, and without replication it cannot be confirmed. And even then, evidence of difference between the sexes would not – on its own – confirm that sex causes the difference (i.e., given the highly plastic nature of the brain it's entirely possible that gendered socialization would result in any observed differences).
I hope that helps you, Anon!
References below the cut:
Ryali, S., Zhang, Y., de Los Angeles, C., Supekar, K., & Menon, V. (2024). Deep learning models reveal replicable, generalizable, and behaviorally relevant sex differences in human functional brain organization. Proceedings of the National Academy of Sciences, 121(9), e2310012121.
Lyon, L. (2017). Dead salmon and voodoo correlations: should we be sceptical about functional MRI?. Brain, 140(8), e53-e53.
Ribeiro, M. T., Singh, S., & Guestrin, C. (2016, August). " Why should i trust you?" Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining (pp. 1135-1144).
15 notes
·
View notes
Note
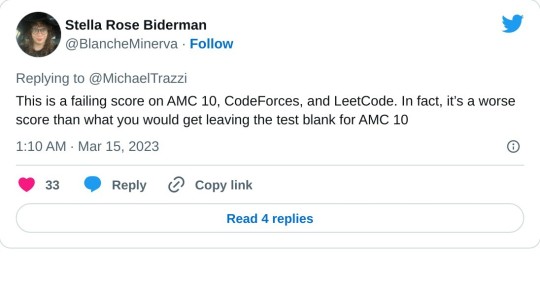
Am I right in suspecting that GPT-4 is not nearly as great an advance on GPT-3 as GPT-3 was on GPT-2? It seems a much better product, but that product seems to have as its selling point not vastly improved text-prediction, but multi-modality.
No one outside of OpenAI really knows how much of an advance GPT-4 is, or isn't.
When GPT-3 came out, OpenAI was still a research company, like DeepMind.
Before there was a GPT-3 product, there was a GPT-3 paper. And it was a long, serious, academic-style paper. It described, in a lot of detail, how they created and evaluated the model.
The paper was an act of scientific communication. A report on a new experiment written for a research audience, intended primarily to transmit information to that audience. It wanted to show you what they had done, so you could understand it, even if you weren't there at the time. And it wanted to convince you of various claims about the model's properties.
I don't know if they submitted it to any conferences or journals (IIRC I think they did, but only later on?). But if they did, they could have, and it wouldn't seem out of place in those venues.
Now, OpenAI is fully a product company.
As far as I know, they have entirely stopped releasing academic-style papers. The last major one was the DALLE-2 one, I think. (ChatGPT didn't get one.)
What OpenAI does now is make products. The release yesterday was a product release, not a scientific announcement.
In some cases, as with GPT-4, they may accompany their product releases with things that look superficially like scientific papers.
But the GPT-4 "technical report" is not a serious scientific paper. A cynic might categorize it as "advertising."
More charitably, perhaps it's an honest attempt to communicate as much as possible to the world about their new model, given a new set of internally defined constraints motivated by business and/or AI safety concerns. But if so, those constraints mean they can't really say much at all -- not in a way that meets the ordinary standards of evidence for scientific work.
Their report says, right at the start, that it will contain no information about what the model actually is, besides the stuff that would already be obvious:
GPT-4 is a Transformer-style model [33 ] pre-trained to predict the next token in a document, using both publicly available data (such as internet data) and data licensed from third-party providers. [note that this really only says "we trained on some data, not all of which was public" -nost] The model was then fine-tuned using Reinforcement Learning from Human Feedback (RLHF) [34 ]. Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.
As Eleuther's Eric Hallahan put it yesterday:

If we read further into the report, we find a number of impressive-looking evaluations.
But they are mostly novel ones, not done before on earlier LMs. The methodology is presented in a spotty and casual manner, clearly not interested in promoting independent reproductions (and possibly even with the intent of discouraging them).
Even the little information that is available in the report is enough to cast serious doubt on the overall trustworthiness of that information. Some of it violates simple common sense:

...and, to the careful independent eye, immediately suggests some very worrying possibilities:

That said -- soon enough, we will be able to interact with this model via an API.
And once that happens, I'm sure independent researchers committed to open source and open information will step in and assess GPT-4 seriously and scientifically -- filling the gap left by OpenAI's increasingly "product-y" communication style.
Just as they've done before. The open source / open information community in this area is very capable, very thoughtful, and very fast. (They're where Stable Diffusion came from, to pick just one well-known example.)
----
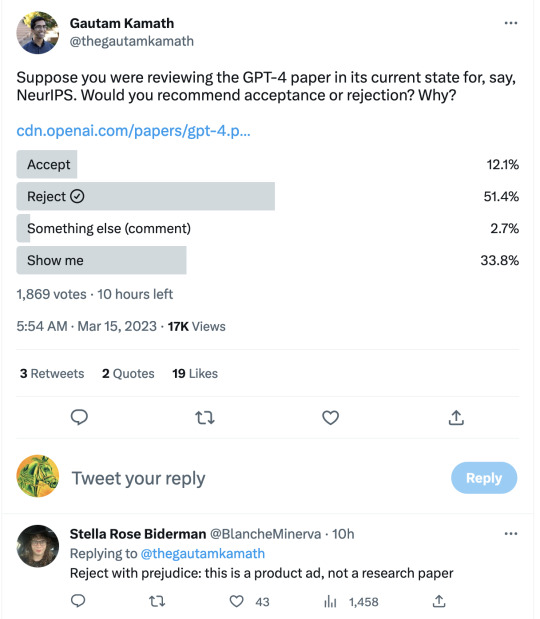
When the GPT-3 paper came out, I wrote a post titled "gpt-3: a disappointing paper." I stand by the title, in the specific sense that I meant it, but I was well aware that I was taking a contrarian, almost trollish pose. Most people found the GPT-3 paper far from "disappointing," and I understand why.
But "GPT-4: a disappointing paper" isn't a contrarian pose. It was -- as far as I can see -- the immediate and overwhelming consensus of the ML community.
----
As for the multimodal stuff, uh, time will tell? We can't use it yet, so it's hard to know how good it is.
What they showed off in the live demo felt a lot like what @nostalgebraist-autoresponder has been able to do for years now.
Like, yeah, GPT-4 is better at it, but it's not a fundamentally new advance, it's been possible for a while. And people have done versions of it, eg Flamingo and PaLI and Magma [which Frank uses a version of internally] and CoCa [which I'm planning to use in Frank, once I get a chance to re-tune everything for it].
I do think it's a potentially transformative capability, specifically because it will let the model natively "see" a much larger fraction of the available information on web pages, and thus enable "action transformer" applications a la what Adept is doing.
But again, only time will tell whether these applications are really going to work, and for what, and whether GPT-4 is good enough for that purpose -- and whether you even need it, when other text/image language models are already out there and are being rapidly developed.
#ai tag#gpt-4#ugh i apparently can't respond to npf asks in the legacy editor :(#the npf/beta editor is still painful to use#it's nice to be able to embed tweets though
388 notes
·
View notes
Text
How to recognize AI "Art"
A post I have wanted to make for a long time because I think it's important to know! Please mind that this is not 100% accurate and I am by no means an expert on AI art. My knowledge on the topic comes from a semester of research on the development of AI art and how it has improved over the years. I wrote a pretty intense paper on it (I got an A on this!) and I am now using this knowledge to help identify AI art.
I often ask myself "did an actual person make this art or did they just generate it?" because I WANT TO SUPPORT ARTISTS WITH A REBLOG BUT AI "ART" IS NOT ART!!!!
Image description and tags, other posts by the same user If there is no image description by OP, that's usually a bit sketchy. Also read tags other people have added in their reblogs! And look at other posts from the same user!
Features blending In an image where a person is wearing glasses, do they maybe merge into the skin a bit? (see Image 9)
Circular artefacts TBH I forgot why they happen but one paper I studied discussed ways to remove them because they are an obvious giveaway that an image is artificial (see Image 10)

Image 1: Circular Artifacts [1]
4. Problems with text or other "logical composition stuff" (sorry I'm bad at words) AI is bad at generating text! It looks like words, but it makes no sense. In Image 3, where does the cat's paw come from? (Also note here that DALL-E puts those coloured squares in the bottom right corner).
Take a closer look at the hands of the women in the image on the bottom right. How many are there? Hands are also a good indicator!


Image 2 [2], Image 3 [3]


Image 4 [4], Image 5 [5]
5. mismatched earrings/eyes... ("long range dependencies") Human faces are symmetric, we (usually) have two eyes, two ears... That's a problem for AI. Earrings and eyecolours usually have to match. Either side may look perfectly fine, but when you look at is as a whole, it does not always work.
6. seems "too smooth"? I've noticed a lack of texture. Brushstrokes are missing, everything seems just a little flat. There are definitely generative models that can emulate brush strokes, but watch out for backgrounds. They sometimes give it away!
7. read this article for a lot of additional information!
8. something I found in this article that is not mentioned: the harsh contrast I have taken the below pictures from that article, and you can see some very "harsh" areas around the irises in the pictures with the eyes, or around the kids



Image 6, 7, 8 [6, 7, 8]
In the two images below, I have just marked some areas that seem off and I will briefly discuss why:


Image 9, Image 10 [9, 10]
Left (Image 9): In Halbrand's hair, there seems to be part of a crown or some other adornment, but it's not quite there. You can also see the general "smoothness" in this image. Another suspicious looking area is Galadriel's neck. Between their faces, you can see the mountain range in the background continue, but it stops exactly where the strand of hair is. On the right side of the image, there are some bright spots on the rocks that also look a bit weird.
Right (Image 10): I have marked some spots that I think look a bit like circular artifacts (that have probably already been "treated" by the generative model). On the bottom left side I have circled this jar? vase? Whatever. You can see that the lid and the rest of the object don't align.
Once again: DISCLAIMER - I could be wrong! This is really hard because the generative models get better.
Sources:
[1] D. Stap, M. Bleeker, S. Ibrahimi, and M. ter Hoeve. Conditional image generation and manipulation for user-specified content. arXiv preprint arXiv:2005.04909, 2020.
[2] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
[3, 4] Generated by me using DALL-E for research purposes.
[5, 6, 7, 8] from this article, accessed on August 15 2023
[9, 10] posted by Tumblr user @ fandomfatale, accessed on August 15 2023
84 notes
·
View notes