#datapreparation
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 27% of US Tumblr users had an annual household income of over $100,000.
Text
Alteryx Data & Analytics

Alteryx Data & Analytics Platform: A Comprehensive Report
Alteryx Data & Analytics provide a comprehensive self-service analytics solution that caters to various data blending, preparation, and advanced analytics tasks. It delivers powerful features, predictive modeling, and spatial analysis capabilities. Introduction Alteryx is a powerful and versatile data analytics and automation platform designed to empower businesses to transform raw data into actionable insights. By unifying data preparation, blending, analysis, and visualization capabilities in a user-friendly interface, Alteryx democratizes analytics, enabling both technical and non-technical users to participate in the data-driven decision-making process. Key Components and Features - Alteryx Designer: The core of the platform, Designer offers a drag-and-drop workflow environment with over 300 pre-built tools for data access, preparation, blending, analysis, and output. Its intuitive interface allows users to visually design and automate data workflows without extensive coding knowledge. - Alteryx Server: This component enables the sharing and scheduling of workflows built in Designer, facilitating collaboration and broader access to analytics across the organization. It also enhances performance by leveraging server resources for complex data processing tasks. - Alteryx Analytics Cloud: This cloud-based platform provides a unified environment for data preparation, blending, and advanced analytics. It integrates Designer Cloud powered by Trifacta, offering AI-driven data preparation capabilities and enhanced collaboration features. - Alteryx Machine Learning: This cloud-native solution democratizes machine learning by providing an intuitive interface for building, training, and deploying predictive models. It automates key tasks like feature engineering and model selection, making machine learning accessible to a wider audience. Key Capabilities and Benefits - Data Preparation and Blending: Alteryx excels at simplifying the often complex and time-consuming process of data preparation. It allows users to connect to and integrate data from various sources, cleanse and transform data, and prepare it for analysis. - Advanced Analytics: The platform supports a wide range of analytical techniques, including statistical analysis, predictive modeling, spatial analysis, and text mining. This enables users to uncover deeper insights and make more informed decisions. - Automation and Scalability: Alteryx enables the automation of repetitive data tasks, freeing up analysts to focus on higher-value activities. Its server-based architecture ensures scalability to handle growing data volumes and user demands. - Improved Decision-Making: By providing self-service access to data and analytics, Alteryx empowers users across the organization to make data-driven decisions, leading to improved business outcomes. Use Cases Alteryx finds applications across various industries and departments, including: - Marketing: Customer segmentation, campaign analysis, and marketing performance optimization. - Sales: Sales forecasting, lead scoring, and territory analysis. - Operations: Supply chain optimization, fraud detection, and risk management. - Finance: Financial reporting, budgeting, and forecasting. - Human Resources: Workforce analytics, talent acquisition, and employee retention. Competitive Landscape Alteryx competes with other data analytics and business intelligence platforms, including: - Tableau: Focuses on data visualization and exploration. - Power BI: Microsoft's business intelligence tool with strong integration with other Microsoft products. - Qlik Sense: Offers associative data exploration and visualization capabilities. - Dataiku: Provides a collaborative platform for data scientists and business analysts. Strengths and Weaknesses Strengths: - User-friendly interface with drag-and-drop functionality. - Wide range of pre-built tools for data preparation and analysis. - Strong automation capabilities for repetitive tasks. - Scalable architecture to handle large data volumes. - Extensive community and support resources. Weaknesses: - Can be expensive for smaller organizations or individual users. - Some advanced features require coding knowledge. - Integration with certain data sources can be challenging. Conclusion Alteryx is a comprehensive and powerful data analytics platform that simplifies the process of turning data into actionable insights. Its user-friendly interface, extensive capabilities, and automation features make it a valuable tool for businesses of all sizes. By empowering users across the organization to participate in the data-driven decision-making process, Alteryx helps drive business growth and improve outcomes. Additional Resources: - Alteryx Website: https://www.alteryx.com/ - Alteryx Community: https://community.alteryx.com/ - Alteryx Academy: https://community.alteryx.com/t5/Alteryx-Academy/ct-p/alteryx-academy Read the full article
#Businessintelligence#Datablending#datapreparation#DataScience#ETL#machinelearning#Predictiveanalytics#self-serviceanalytics#spatialanalysis#workflowautomation
0 notes
Text
Data Prep & Modeling Mastery with Tableau
youtube
0 notes
Text
AI-assisted BigQuery Data Preparation Is Now In Preview

A preview of BigQuery data preparation is now available.
What is Data preparation?
The process of cleaning and converting unprocessed data so that it can be used for additional processing and analysis is known as data preparation. As it guarantees that the data is correct, consistent, and usable, it is an essential stage in any data-driven endeavor.
The capacity to effectively convert unprocessed data into useful insights is critical in today’s data-driven environment. Data cleaning and preparation, however, can frequently be very difficult.
Reducing this time and effectively turning unprocessed data into insights is essential to maintaining competitiveness. Google Cloud unveiled BigQuery data preparation earlier this month as part of Gemini in BigQuery, an AI-first solution that simplifies and expedites the data preparation process.
BigQuery data preparation now in preview offers several features:
AI-powered recommendations: Gemini in BigQuery is used for data preparation, analyzing your data and schema to generate intelligent recommendations for data enrichment, transformation, and cleansing. As a result, the time and effort needed for manual data preparation chores is greatly decreased.
Cleaning and standardizing data: You may quickly find and fix formatting mistakes, missing values, and discrepancies in your data.
Data pipelines that are visual: Using BigQuery’s powerful and extendable SQL capabilities and designing complicated data pipelines is made simple for both technical and non-technical users by the user-friendly, low-code visual interface.
Data pipeline orchestration: Automate your data pipelines’ execution and oversight. You may use CI/CD to install and orchestrate a Dataform data engineering pipeline that includes the SQL produced by BigQuery data preparation, resulting in a collaborative development experience.
You may make better business decisions by ensuring the accuracy and dependability of your data with BigQuery data preparation. A consistent and scalable environment for your data needs is provided by BigQuery data preparation, which automates data quality checks and interfaces with other Google Cloud services like Dataform and Cloud Storage.
Data Preparation process
It’s simple to get going. In order to create data preparation recommendations, such as filter and transformation suggestions, when you sample a BigQuery table in BigQuery data preparation, it employs cutting-edge foundation models to assess the data and schema utilizing Gemini in BigQuery. For instance, it can quickly speed up the data engineering process by determining which columns can serve as join keys and which date formats are acceptable per nation.
Two distinct date formats are included in the Birthdate column of type STRING in the example above (which uses synthetic data). “Convert column Birthdate from type string to date with the following format(s): ‘%Y-%m-%d’,’%m/%d/%Y,” is the recommendation for BigQuery data preparation. The converted preview data can be checked in a DATE format column after applying the suggestion card.
BigQuery’s AI-powered data preparation allows you to:
Reduce the amount of time spent identifying and cleaning data quality concerns by using Gemini-assisted recommendation cards.
Use the data grid to create your own personalized suggestion cards by giving an example.
Use incremental data processing in conjunction with data preparation to boost operational efficiency.
Customer feedback on BigQuery
Numerous problems are already being resolved by customers using BigQuery data preparation.
In order to build data transformation pipelines on BigQuery, GAF, a significant roofing material company in North America, is implementing data preparation.
mCloud technologies assist companies in industries such as manufacturing, energy, and buildings in maximizing the sustainability, dependability, and performance of their assets.
A combined venture between two German public broadcasting organizations (ARD) is called Public Value Technologies.
Starting out
With its robust artificial intelligence capabilities, user-friendly interface, and close connection with the Google Cloud ecosystem, BigQuery data preparation is poised to transform how businesses handle and prepare their data. The time you spend preparing data decreases and your productivity increases with this creative solution that automates time-consuming procedures, enhances data quality, and empowers users.
Read more on Govindhtech.com
#BigQuery#Datapreparation#AI#SQL#CloudStorage#Gemini#BigQuerydata#CloudComputing#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text
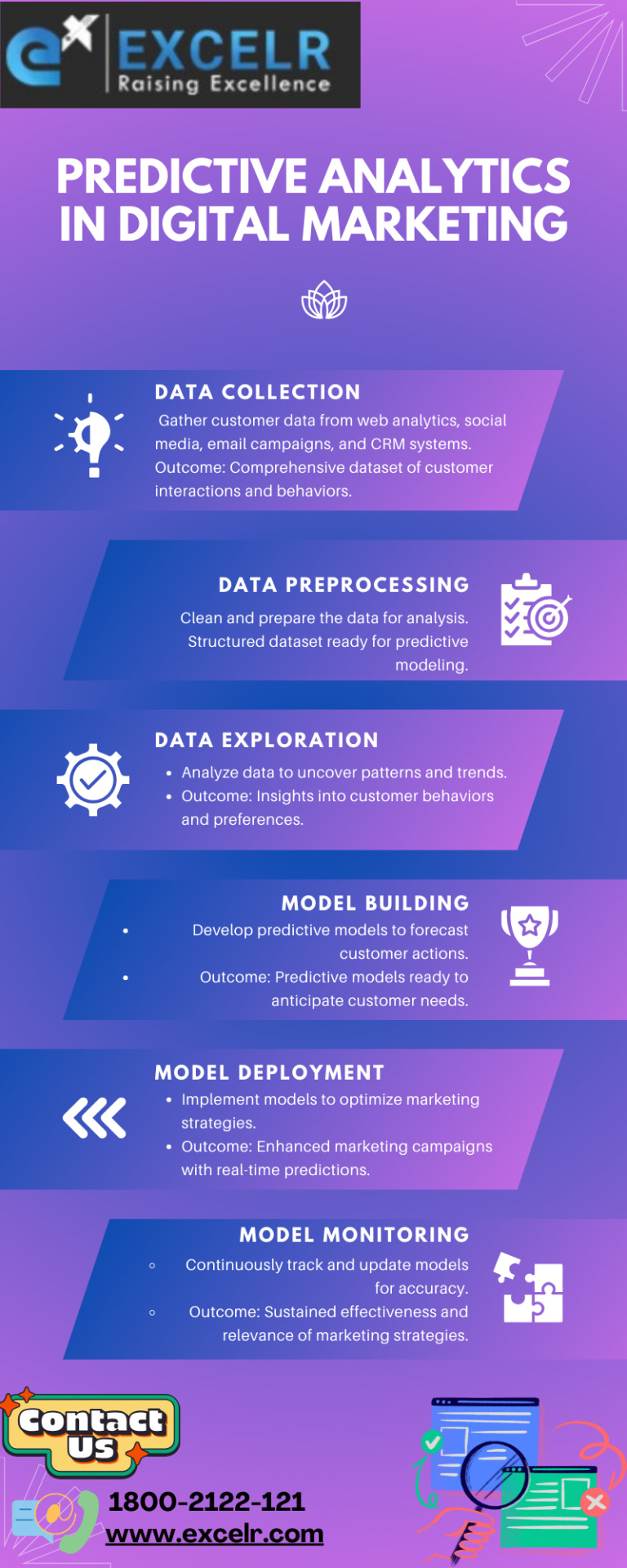
Predictive Analytics in Digital Marketing: Leveraging Data for Strategic Advantage
In the fast-paced world of digital marketing, understanding and anticipating customer behavior is crucial. Predictive analytics has emerged as a game-changer, empowering marketers to forecast future trends and optimize their strategies with precision. By harnessing the power of data-driven insights, businesses can enhance their marketing effectiveness and deliver personalized experiences that resonate with their audience.
Unveiling Predictive Analytics
Predictive analytics involves analyzing historical data, statistical algorithms, and machine learning techniques to predict future outcomes. In digital marketing, this means using past customer interactions, purchase patterns, and demographic data to foresee how customers might behave in the future. This proactive approach allows marketers to tailor their campaigns and strategies based on predictive insights, ultimately driving better results and ROI.
The Six Phases of Predictive Analytics in Digital Marketing
Data Collection: The journey begins with collecting data from various sources like website traffic, social media engagements, email interactions, and customer databases. This diverse dataset forms the foundation for predictive modeling by capturing comprehensive insights into customer preferences and behaviors.
Data Preprocessing: Once collected, the raw data undergoes preprocessing. This crucial step involves cleaning, transforming, and integrating the data to ensure accuracy and consistency. By addressing data inconsistencies and preparing it for analysis, marketers can derive meaningful insights that guide strategic decisions.
Data Exploration: In this phase, data analysts delve deep into the dataset to uncover hidden patterns and correlations. Through advanced analytics and visualization tools, they identify trends, customer segments, and predictive indicators that shape future marketing initiatives. This exploration phase is pivotal in gaining a nuanced understanding of customer behavior and market dynamics.
Model Building: Armed with insights from data exploration, marketers proceed to build predictive models. These models utilize sophisticated algorithms such as regression analysis and machine learning to forecast outcomes. By training these models on historical data and validating their accuracy, marketers can confidently predict customer responses and preferences in real-time scenarios.
Model Deployment: Once validated, predictive models are deployed into marketing strategies and operational workflows. Whether optimizing ad campaigns, personalizing content, or recommending products, these models enable marketers to deliver hyper-targeted experiences that resonate with individual customer needs. This deployment phase bridges predictive insights with actionable outcomes, driving tangible business results.
Model Monitoring and Refinement: Predictive analytics is an iterative process that requires continuous monitoring and refinement. Marketers closely monitor model performance, update algorithms with new data inputs, and recalibrate strategies based on evolving market dynamics. This proactive approach ensures that predictive models remain accurate, relevant, and responsive to changing customer behaviors and industry trends.
The Impact of Predictive Analytics on Digital Marketing
Enhanced Customer Engagement: By anticipating customer needs and preferences, predictive analytics enables personalized marketing strategies that foster deeper engagement and loyalty.
Optimized Marketing Spend: Through predictive modeling, marketers allocate resources more efficiently, focusing on channels and campaigns that yield the highest returns and conversions.
Strategic Decision-Making: Armed with predictive insights, businesses make informed decisions that drive growth, innovation, and competitive advantage in saturated markets.
Conclusion
Predictive analytics represents a paradigm shift in digital marketing, empowering businesses to anticipate, adapt, and innovate in response to customer demands. By embracing the six phases of data collection, preprocessing, exploration, model building, deployment, and refinement, marketers can harness the transformative power of predictive analytics to achieve sustainable growth and exceed customer expectations in today's dynamic marketplace. As technology continues to evolve, predictive analytics remains a cornerstone of strategic marketing efforts, paving the way for future success and market leadership.
#DataCollection#CustomerData#DigitalMarketing#DataCleaning#DataPreparation#DataQuality#DataExploration#CustomerInsights#DataAnalysis#ModelBuilding#PredictiveModels#MachineLearning#ModelDeployment#MarketingOptimization#RealTimeMarketing#ModelMonitoring#ContinuousImprovement#MarketingEfficiency#gene
0 notes
Text
Best way to learn data analysis with python
The best way to learn data analysis with Python is to start with the basics and gradually build up your skills through practice and projects. Begin by learning the fundamentals of Python programming, which you can do through online courses, tutorials, or books. Once you are comfortable with the basics, focus on learning key data analysis libraries such as Pandas for data manipulation, NumPy for numerical operations, and Matplotlib or Seaborn for data visualization.
After you grasp the basics, apply your knowledge by working on real datasets. Platforms like Kaggle offer numerous datasets and competitions that can help you practice and improve your skills. Additionally, taking specialized data analysis courses online can provide structured learning and deeper insights. Consistently practicing, participating in communities like Stack Overflow or Reddit for support, and staying updated with the latest tools and techniques will help you become proficient in data analysis with Python.
#Dataanalysis#Pythonprogramming#Learnpython#Datascience#Pandas#NumPy#Datavisualization#Matplotlib#Seaborn#Kaggle#Pythoncourses#CodingforBeginners#DataPreparation#StatisticsWithPython#JupyterNotebooks#VSCode#OnlineLearning#TechSkills#ProgrammingTutorials#DataScienceCommunity
0 notes
Text
Data preparation tools enable organizations to identify, clean, and convert raw datasets from various data sources to assist data professionals in performing data analysis and gaining valuable insights using machine learning (ML) algorithms and analytics tools.
#DataPreparation#RawData#DataSources#DataCleaning#DataConversion#DataAnalysis#MachineLearning#AnalyticsTools#BusinessAnalysis#DataCleansing#DataValidation#DataTransformation#Automation#DataInsights
0 notes
Text

0 notes
Text
What techniques can be used to handle missing values in datasets effectively?
Handling missing values in datasets is an important step in data cleaning and preprocessing. Here are some commonly used techniques to handle missing values effectively:

Deletion: In some cases, if the missing values are relatively few or randomly distributed, you may choose to delete the rows or columns containing missing values. However, be cautious as this approach may lead to the loss of valuable information.
Mean/Median/Mode Imputation: For numerical variables, missing values can be replaced with the mean, median, or mode of the available data. This approach assumes that the missing values are similar to the observed values in the variable.
Regression Imputation: Regression imputation involves predicting missing values using regression models. A regression model is built using other variables as predictors, and the missing values are estimated based on the relationship with the predictors.
Multiple Imputation: Multiple imputations generates multiple plausible values for missing data based on the observed data and their relationships. This approach accounts for the uncertainty associated with missing values and allows for more robust statistical analysis.
Hot-Deck Imputation: Hot-deck imputation involves filling missing values with values from similar records or observations. This can be done by matching records based on some similarity criteria or using nearest neighbors.
K-Nearest Neighbors (KNN) Imputation: KNN imputation replaces missing values with values from the k-nearest neighbors in the dataset. The similarity between records is measured based on variables that have complete data.
Categorical Imputation: For categorical variables, missing values can be treated as a separate category or imputed using the mode (most frequent category) of the available data.
Time-Series Techniques: If dealing with time-series data, missing values can be imputed using techniques like interpolation or forward/backward filling, where missing values are replaced with values from adjacent time points.
Domain Knowledge Imputation: Depending on the context and domain knowledge, missing values can be imputed using expert judgment or external data sources. This approach requires careful consideration and validation.
Model-Based Imputation: Model-based imputation involves building a predictive model using variables with complete data and using that model to impute missing values. This can include techniques such as decision trees, random forests, or Bayesian methods.

When handling missing values, it's essential to understand the nature of the missingness, assess the potential impact on the analysis, and choose an appropriate technique that aligns with the characteristics of the data and the research objectives. Additionally, it's crucial to be aware of potential biases introduced by the imputation method and to document the imputation steps taken for transparency and reproducibility.
#DataCleaning#DataScrubbing#DataCleansing#DataQuality#DataPreparation#DataValidation#DataIntegrity#DataSanitization#DataStandardization#DataNormalization#DataHygiene#DataAccuracy#DataVerification#CleanData#TidyData
0 notes
Text
What is Data Quality and Why is it Important?
The availability of enormous amounts of data comes with one major downside: management difficulty. So much information is being pumped in that finding the crucial bits and working on their quality is extremely difficult.
The quality of the data you have will be reflected in the business decisions you make both in the short run and in the long run.
Data quality will make or break your business, as the insights you get from it dictate the business moves you make. The higher the quality of data a company has in its hands, the better the results its campaign strategies are going to produce.
In a word, data quality is the whole multi-faceted process of styling data to align it with the needs of business users. A business can optimize its performances and promote user faith in its systems by working to improve the following six metrics of data quality:
Accuracy
Consistency
Completeness
Uniqueness
Timeliness
Validity
Bad data are inaccurate, unreliable, unsecured, static, uncontrolled, noncompliant, and dormant. While poor data can be a significant threat to data-driven brands, from another angle, it can be seen as a market gap and an opportunity for businesses to improve. Let’s take the example of a self-driving vehicle that makes use of artificial intelligence (AI) and machine learning to find directions, read signs, and maneuver streets. If the car lulls the user into driving into a traffic snarl-up, we can say that the data that led to that is inaccurate and unreliable. This will take a toll on the car maker’s reputation, especially if it happens to more than one person. They must be quick to redress the issue, or it will ultimately cripple the company and create an opportunity for rival businesses to rise and fill the void.
#data quality#datacuration#datamangement#datavisualization#datacatalog#mdm#dqlabs#aiplatform#datalake#datamart#datagovernance#datapreparation#dataintegration
6 notes
·
View notes
Text
KNIME Analytics Platform

KNIME Analytics Platform: Open-Source Data Science and Machine Learning for All In the world of data science and machine learning, KNIME Analytics Platform stands out as a powerful and versatile solution that is accessible to both technical and non-technical users alike. Known for its open-source foundation, KNIME provides a flexible, visual workflow interface that enables users to create, deploy, and manage data science projects with ease. Whether used by individual data scientists or entire enterprise teams, KNIME supports the full data science lifecycle—from data integration and transformation to machine learning and deployment. Empowering Data Science with a Visual Workflow Interface At the heart of KNIME’s appeal is its drag-and-drop interface, which allows users to design workflows without needing to code. This visual approach democratizes data science, allowing business analysts, data scientists, and engineers to collaborate seamlessly and create powerful analytics workflows. KNIME’s modular architecture also enables users to expand its functionality through a vast library of nodes, extensions, and community-contributed components, making it one of the most flexible platforms for data science and machine learning. Key Features of KNIME Analytics Platform KNIME’s comprehensive feature set addresses a wide range of data science needs: - Data Preparation and ETL: KNIME provides robust tools for data integration, cleansing, and transformation, supporting everything from structured to unstructured data sources. The platform’s ETL (Extract, Transform, Load) capabilities are highly customizable, making it easy to prepare data for analysis. - Machine Learning and AutoML: KNIME comes with a suite of built-in machine learning algorithms, allowing users to build models directly within the platform. It also offers Automated Machine Learning (AutoML) capabilities, simplifying tasks like model selection and hyperparameter tuning, so users can rapidly develop effective machine learning models. - Explainable AI (XAI): With the growing importance of model transparency, KNIME provides tools for explainability and interpretability, such as feature impact analysis and interactive visualizations. These tools enable users to understand how models make predictions, fostering trust and facilitating decision-making in regulated industries. - Integration with External Tools and Libraries: KNIME supports integration with popular machine learning libraries and tools, including TensorFlow, H2O.ai, Scikit-learn, and Python and R scripts. This compatibility allows advanced users to leverage KNIME’s workflow environment alongside powerful external libraries, expanding the platform’s modeling and analytical capabilities. - Big Data and Cloud Extensions: KNIME offers extensions for big data processing, supporting frameworks like Apache Spark and Hadoop. Additionally, KNIME integrates with cloud providers, including AWS, Google Cloud, and Microsoft Azure, making it suitable for organizations with cloud-based data architectures. - Model Deployment and Management with KNIME Server: For enterprise users, KNIME Server provides enhanced capabilities for model deployment, automation, and monitoring. KNIME Server enables teams to deploy models to production environments with ease and facilitates collaboration by allowing multiple users to work on projects concurrently. Diverse Applications Across Industries KNIME Analytics Platform is utilized across various industries for a wide range of applications: - Customer Analytics and Marketing: KNIME enables businesses to perform customer segmentation, sentiment analysis, and predictive marketing, helping companies deliver personalized experiences and optimize marketing strategies. - Financial Services: In finance, KNIME is used for fraud detection, credit scoring, and risk assessment, where accurate predictions and data integrity are essential. - Healthcare and Life Sciences: KNIME supports healthcare providers and researchers with applications such as outcome prediction, resource optimization, and patient data analytics. - Manufacturing and IoT: The platform’s capabilities in anomaly detection and predictive maintenance make it ideal for manufacturing and IoT applications, where data-driven insights are key to operational efficiency. Deployment Flexibility and Integration Capabilities KNIME’s flexibility extends to its deployment options. KNIME Analytics Platform is available as a free, open-source desktop application, while KNIME Server provides enterprise-level features for deployment, collaboration, and automation. The platform’s support for Docker containers also enables organizations to deploy models in various environments, including hybrid and cloud setups. Additionally, KNIME integrates seamlessly with databases, data lakes, business intelligence tools, and external libraries, allowing it to function as a core component of a company’s data architecture. Pricing and Community Support KNIME offers both free and commercial licensing options. The open-source KNIME Analytics Platform is free to use, making it an attractive option for data science teams looking to minimize costs while maximizing capabilities. For organizations that require advanced deployment, monitoring, and collaboration, KNIME Server is available through a subscription-based model. The KNIME community is an integral part of the platform’s success. With an active forum, numerous tutorials, and a repository of workflows on KNIME Hub, users can find solutions to common challenges, share their work, and build on contributions from other users. Additionally, KNIME offers dedicated support and learning resources through KNIME Learning Hub and KNIME Academy, ensuring users have access to continuous training. Conclusion KNIME Analytics Platform is a robust, flexible, and accessible data science tool that empowers users to design, deploy, and manage data workflows without the need for extensive coding. From data preparation and machine learning to deployment and interpretability, KNIME’s extensive capabilities make it a valuable asset for organizations across industries. With its open-source foundation, active community, and enterprise-ready features, KNIME provides a scalable solution for data-driven decision-making and a compelling option for any organization looking to integrate data science into their operations. Read the full article
#AutomatedMachineLearning#AutoML#dataintegration#datapreparation#datascienceplatform#datatransformation#datawrangling#ETL#KNIME#KNIMEAnalyticsPlatform#machinelearning#open-sourceAI
0 notes
Text

Unlocking the power of visual data with precise image annotation.
Visit: www.gts.ai
#Unlocking the power of visual data with precise image annotation.#Visit: www.gts.ai#imageannotation#visualdata#dataannotation#machinelearning#AI#computervision#datalabeling#DataManagement#datapreparation#DataAnnotationServices
0 notes
Text
Data Analytics Overview
Data Analytics is the process of analyzing data to derive insights and make informed decisions. The basics of data analytics include three main stages: data collection, cleaning, and preparation.
Data Collection
In this stage, data is collected from various sources such as databases, surveys, and sensors. The data can be structured, semi-structured, or unstructured. The goal is to gather as much relevant data as possible to ensure that the analysis can provide meaningful insights.
Data Cleaning
Once the data has been collected, the next step is to clean it. This involves identifying and removing any irrelevant, inaccurate, or inconsistent data. The goal of this stage is to make the data suitable for analysis.
Data Preparation
After the data has been cleaned, the next step is to prepare it for analysis. This includes transforming the data into a format that can be easily analyzed, such as converting text data into numerical data or grouping data into categories. The goal of this stage is to make the data ready for analysis and to ensure that it can be used to answer the questions being asked.
These three stages form the foundation of data analytics and are crucial to ensuring that the insights and decisions derived from the analysis are accurate and meaningful.
0 notes
Text
#DataCollection#CustomerData#DigitalMarketing#DataCleaning#DataPreparation#DataQuality#DataExploration#CustomerInsights#DataAnalysis#ModelBuilding#PredictiveModels#MachineLearning#ModelDeployment#MarketingOptimization#RealTimeMarketing#ModelMonitoring#ContinuousImprovement#MarketingEfficiency
0 notes
Text
Reduce Customer Dropouts with Enriched Catalogues
NeXT Wealth can help you increase sales and improve customer satisfaction. Explore and find out more about our Data preparation services.
#customerexperience#customersatisfaction#cx#increasesales#catalogue#ecommercebusiness#datapreparation
0 notes
Photo

Data Science and Consulting Service Provider
Our Data Science Consulting firm helps you to make data driven decisions in real time using Data Consulting, Data Preparation, Data Modelling, Data Performance Tuning and Data Migration.
To know more,
email us [email protected]
or
visit our website- https://7avp.com/
0 notes
Link
In this article, we will learn how to handle missing values in machine learning. Handling missing values is one of the most important steps that we need to cover in any machine learning project pipeline.
#scikitlearn#machinelearning#datapreparation#datascience#ai#artificial intelligence#python#programming#computerprogramming#computerscience
0 notes