#dataflow gen2
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Women make up for the other 50% of Tumblr’s audience.
Text
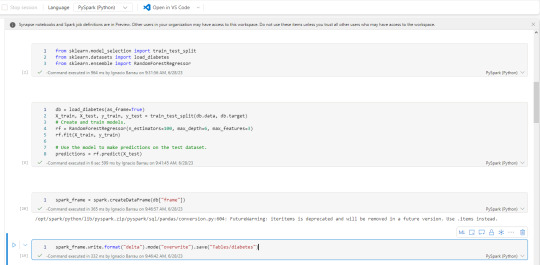
[Fabric] Dataflows Gen2 destino "archivos" - Opción 1
La mayoría de las empresas que utilizan la nube para construir una arquitectura de datos, se están inclinando por una estructura lakehouse del estilo "medallón" (bronze, silver, gold). Fabric acompaña esta premisa permitiendo estructurar archivos en su Lakehouse.
Sin embargo, la herramienta de integración de datos de mayor conectividad, Dataflow gen2, no permite la inserción en este apartado de nuestro sistema de archivos, sino que su destino es un spark catalog. ¿Cómo podemos utilizar la herramienta para armar un flujo limpio que tenga nuestros datos crudos en bronze?
Para comprender mejor a que me refiero con "Tablas (Spark Catalog) y Archivos" de un Lakehouse y porque si hablamos de una arquitectura medallón estaríamos necesitando utilizar "Archivos". Les recomiendo leer este post anterior: [Fabric] ¿Por donde comienzo? OneLake intro
Fabric contiene un servicio llamado Data Factory que nos permite mover datos por el entorno. Este servicio tiene dos items o contenidos que fortalecen la solución. Por un lado Pipelines y por otro Dataflow Gen2. Veamos un poco una comparación teórica para conocerlos mejor.
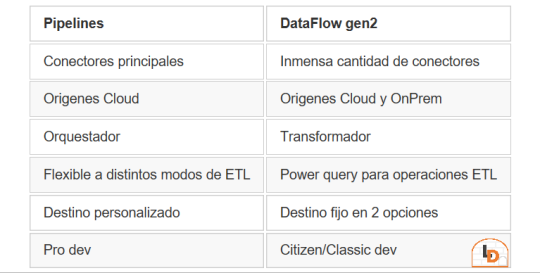
NOTA: al momento de conectarnos a origenes on premise, leer las siguientes consideraciones: https://learn.microsoft.com/es-es/fabric/data-factory/gateway-considerations-output-destinations
Esta tabla nos ayudará a identificar mejor cuando operar con uno u otro. Normalmente, recomendaria que si van a usar una arquitectura de medallón, no duden en intentarlo con Pipelines dado que nos permite delimitar el destino y las transformaciones de los datos con mayor libertad. Sin embargo, Pipelines tiene limitada cantidad de conectores y aún no puede conectarse onpremise. Esto nos lleva a elegir Dataflow Gen2 que dificilmente exista un origen al que no pueda conectarse. Pero nos obliga a delimitar destino entre "Tablas" del Lakehouse (hive metastore o spark catalog) o directo al Warehouse.
He en este intermedio de herramientas el gris del conflicto. Si queremos construir una arquitectura medallón limpia y conectarnos a fuentes onpremise o que no existen en Pipelines, no es posible por defecto sino que es necesario pensar un approach.
NOTA: digo "limpia" porque no considero prudente que un lakehouse productivo tenga que mover datos crudos de nuestro Spark Catalog a Bronze para que vaya a Silver y vuelva limpio al Spark Catalog otra vez.
¿Cómo podemos conseguir esto?
La respuesta es bastante simple. Vamos a guiarnos del funcionamiento que Dataflow Gen2 tiene en su background y nos fortaleceremos con los shortcuts. Si leemos con detenimiento que hacen los Dataflows Gen2 por detrás en este artículo, podremos apreciar un almacenamiento intermedio de pre viaje a su destino. Esa es la premisa que nos ayudaría a delimitar un buen orden para nuestro proceso.
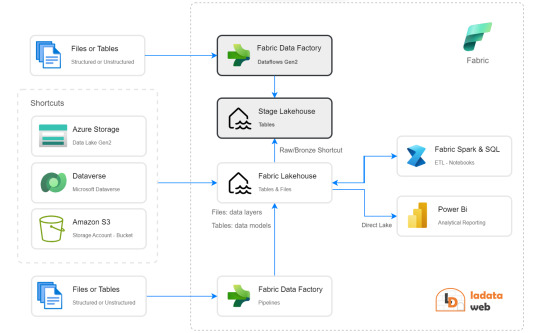
Creando un Lakehouse Stage (no es el que crea Fabric de caja negra por detrás sino uno creado por nosotros) que almacene los datos crudos provenientes del origen al destino de Tables. Nuestro Lakehouse definitivo o productivo haría un shortcut desde la capa Bronze a este apartado intermedio para crear este puntero a los datos crudos. De esta manera podemos trabajar sobre nuestro Lakehouse con un proceso limpio. Los notebooks conectados a trabajar en bronze para llevar a silver lo harían sin problema. Para cuando lleguemos a "Tables" (spark catalog o hive metastore), donde normalmente dejaríamos un modelo dimensional, tendríamos las tablas pertinentes a un modelo analítico bien estructurado.
Algunos ejemplos de orígenes de datos para los cuales esta arquitectura nos servirían son: Oracle, Teradata, SAP, orígenes onpremise, etc.
Espero que esto los ayude a delimitar el proceso de manera más limpia. Por lo menos hasta que Pipelines pueda controlarlo como lo hace Azure Data Factory hoy.
¿Otra forma?
Seguramente hay más, quien sabe, tal vez podamos mostrar un segundo approach más complejo de implementar, pero más caja negra para los usuarios en un próximo post.
#power bi#powerbi#ladataweb#fabric#microsoft fabric#fabric tips#fabric tutorial#fabric training#dataflow gen2#fabric data factory#data factory#data engineering
0 notes
Text
Dataflow Gen2 Transformations Tutorial
Are you curious about how to apply multi-table transformations in #MicrosoftFabric's Dataflow Gen2 pipelines? In this tutorial, I explain how to apply join and combine data from multiple data sources and demonstrate how to use fuzzy matching for cleansing data inaccuracies. Check out here:https://youtu.be/SaKlgAaxVd8

0 notes
Text

🔍 Calling all Data Analysts! 📊 Can you tackle this quick quiz challenge? 🚀 Discover which workload experience allows you to create a Dataflow Gen2. Test your knowledge and join the conversation! Let's dive in: [Quiz Link Here] 🧠💡 Source: https://lnkd.in/ejpCsrE4
0 notes
Text
Microsoft and MongoDB Cloud Services

Microsoft and MongoDB Alliance: Key Customer Benefits
Microsoft must remember that data fuels AI as Microsoft enter the AI era. This explains why Microsoft want Azure to be the best data destination. Customers can choose from relational, non-relational, open source, and caching databases in Azure. Microsoft also have strong partnerships with MongoDB Inc. to allow digital transformation leveraging their databases as Azure managed services.
MongoDB, a renowned data platform, makes data modeling easy for developers. Microsoft connection with MongoDB has grown over the years, culminating in a multiyear strategic partnership deal this year. Microsoft are proud of their collaboration to offer Azure a wonderful place to run MongoDB Atlas. The popularity of the MongoDB Atlas on Azure pay-as-you-go self-service has made MongoDB one of our top Azure Marketplace partners in the previous six months.
Microsoft wants to empower everyone to succeed, and their customers prefer using MongoDB to build apps. In year one of Microsoft’s strategic collaboration, Microsoft worked with MongoDB to help their customers do more with Microsoft services and MongoDB Atlas on Azure. Developers now use MongoDB Atlas in 40+ Azure areas worldwide, including Doha, Qatar, which Microsoft announced last month at Ignite. It’s not just about the data center developers need an easy way to start with MongoDB Atlas on Azure. With its code suggestions, GitHub Copilot makes it easy to build MongoDB applications on Azure. They are working together to optimize its performance utilizing MongoDB schema, among other things.
Customers are already benefiting from their strategic partnership. Their collaboration with Temenos helped their banking customers rise to historic levels. Another collaborative intelligence business, Mural, highlighted their MongoDB Atlas and Microsoft Azure experience to help clients communicate smarter.
Microsoft Ignite 2023: MongoDB
MongoDB Atlas on Azure client experience is improved by ongoing efforts. Microsoft and MongoDB announced three major integrations at Microsoft Ignite 2023 in November: Microsoft Semantic Kernel, Microsoft Fabric, and EF Core. How can customers profit from each?
Semantic Kernel, an open-source SDK, integrates OpenAI, Azure OpenAI, and Hugging Face with C# and Python. At Ignite, MongoDB revealed Semantic Kernel native support for Atlas Vector Search. Customers may integrate operational data and vectors in a single, managed platform with MongoDB Atlas Vector Search. Semantic Kernel lets customers add Atlas Vector Search to apps. This allows Atlas Vector Search to engage with retrieval-augmented generation (RAG) in large language models (LLMs), minimizing AI hallucinations and other benefits.
By uniting your teams on an AI-powered platform optimized for AI, Microsoft Fabric can transform how they work with data. Many applications use MongoDB Atlas as their operational data layer to store data from internal enterprise apps, customer-facing services, and third-party APIs across numerous channels. With interfaces for Microsoft Fabric pipelines and Dataflow Gen2, Microsoft customers can mix MongoDB Atlas data with relational data from traditional applications and unstructured data from logs, clickstreams, and more.
At Microsoft Ignite, innovative announcements made this integration seamless and straightforward for MongoDB clients. Microsoft revealed that Fabric is now broadly accessible and introduced Mirroring, a frictionless approach to integrate and manage cloud data warehouses and databases like MongoDB, in Fabric, during the first presentation. Now MongoDB customers can replicate a snapshot of their database to One Lake, which will automatically sync it in near real-time. Learn how Microsoft Fabric intelligent analytics can uncover MongoDB Atlas data value here.
Many of the millions of C# developers use Entity Framework (EF) Core, a lightweight, extensible, open source, and cross-platform data access technology. MongoDB revealed MongoDB Provider for EF Core in Public Preview. This lets EF Core developers construct C#/.NET apps with MongoDB using their preferred APIs and design patterns.
Each time, Microsoft worked with MongoDB to make it easy for developers, data engineers, and data scientists to connect MongoDB data to Microsoft services.
A year of collaboration improvement
These new integrations follow a successful year of Microsoft-MongoDB collaboration. Microsoft highlighted great developer news outside Microsoft Ignite:
August 2023 saw the general release of MongoDB for VS Code Extension. During its public preview, developers downloaded the MongoDB extension over 1 million times in VS Code, the world’s most popular IDE. This free, downloadable add on lets developers build apps and manage MongoDB data from VS Code.
MongoDB integrates with many Microsoft Intelligent Data Platform (MIDP) services, such as Azure Synapse Analytics for operational data analysis, Microsoft Purview for data security, and Power BI for data analysts to create and share dashboards using live MongoDB Atlas data.
Data Federation: Atlas Data Federation supports Azure Blob Storage in private preview on Microsoft Azure.
Microsoft have published tutorials on building server less functions with MongoDB Atlas and Azure Functions, creating MongoDB applications with Azure App Service, building Flask and MongoDB applications with Azure App Container Apps, developing IoT data hubs for smart manufacturing, and connecting MongoDB Atlas and Azure Data Studio for Azure customers.
The year has been terrific for Microsoft and MongoDB, helping enterprises of all sizes do more with their data.
Read more on Govindhtech.com
0 notes
Text
What are the basic concepts of the Power BI service for beginners?
The five major structure blocks of Power BI are dashboards, reports, workbooks, datasets, and dataflows. They are all organized into workspaces, and they are created on capacities. It's important to understand capacities and workspaces before we dig into the five structure blocks, so let's start there.
Capacities:
Capacities are a core Power BI concept representing a set of coffers( storehouse, processor, and memory) used to host and deliver your Power BI content. Capacities are moreover participated or reserved. A participating capacity is participated with other Microsoft guests, while a reticent capacity is reserved for a single client. Reserved capacities bear a subscription and are completely described in the Managing Premium capacities composition.
By dereliction, workspaces are created in a participating capacity. In the participating capacity, workloads run on computational coffers participated with other guests. As the capacity must partake in coffers, limitations are assessed to insure" fair play", similar to the maximum model size( 1 GB) and maximum diurnal refresh frequency( eight times per day).
Workspaces:
Workspaces are created on capacities. Basically, they're holders for dashboards, reports, workbooks, datasets, and dataflows in Power BI. There are two types of workspaces: My workspace and workspaces. My workspace is the particular workspace for any Power BI client to work with their own content. Only you have access to your My workspace. You can partake in dashboards and reports from your MyWorkspace. However, or produce an app, also want to work in a workspace, If you want to unite on dashboards and reports. Workspaces are used to connect and partake in content with associates.
You can add associates to your workspaces and unite on dashboards, reports, workbooks, and datasets. With one exception, each workspace member needs a Power BI Pro or Premium Per stoner( PPU) license. Read further about workspaces. Workspaces are also where you produce, publish, and manage apps for your association. suppose workspaces are staging areas and holders for the content that will make up a Power BI app.
So what's an app? It's a collection of dashboards and reports erected to deliver crucial criteria to the Power BI consumers in your association. Apps are interactive, but consumers can not edit them. App consumers, the associates who have access to the apps, do not inescapably need Pro or Premium Per stoner( PPU) licenses.
Dataflows:
A dataflow helps associations to unify data from distant sources. They're voluntary and are frequently used in complex or larger systems. They represent data sets and are offered for use by datasets. Dataflows are surfaced in Power BI Desktop with a devoted connector to enable reporting. When you connect to a dataflow, your dataset can use the preliminarily prepared data and business sense, promoting a single source of the variety and data reusability.
They work the expansive collection of Microsoft data connectors, enabling the ingestion of data from on- demesne and pall- grounded data sources. Dataflows are only created and managed in workspaces( but not My Workspace), and they're stored as realities in the Common Data Model( CDM) in Azure Data Lake Storage Gen2.
generally, they are listed to refresh on a recreating base to store over- to- date data. They are great for preparing data for use ��� and implicit play — by your datasets. For further information, see the tone- service data fix in Power BI composition.
Datasets:
A dataset is a collection of data that you import or connect to. Power BI lets you connect to and import all feathers of datasets and bring all of it together in one place. Datasets can also reference data from dataflows.
Datasets are associated with workspaces and a single dataset can be part of numerous workspaces. When you open a workspace, the associated datasets are listed under the Datasets tab. Each listed dataset is a source of data available for one or further reports, and the dataset may contain data that comes from one or further sources. For illustration, an Excel workbook on OneDrive, or an on- demesne SSAS irregular dataset, or a Salesforce dataset. There are numerous different data sources supported, and we are adding new bones all the time.
0 notes
Text
Microsoft DP-500 Practice Test Questions
If you pass the DP-500 Designing and Implementing Enterprise-Scale Analytics Solutions Using Microsoft Azure and Microsoft Power BI exam you will gain Microsoft Certified: Azure Enterprise Data Analyst Associate Certification. The latest DP-500 Practice Test Questions are new cracked by PassQuestion team to help you understand and learn the right source to clear in the Microsoft DP-500 Exam and to get good grades. To get guaranteed result in DP-500 Exam, the best DP-500 Practice Test Questions for candidates who just by preparing with DP-500 exam for two weeks can easily clear the DP-500 Exam without difficulty. After studying our DP-500 Practice Test Questions, you can take your Microsoft DP-500 exam with confidence.
DP-500: Designing and Implementing Enterprise-Scale Analytics Solutions Using Microsoft Azure and Microsoft Power BI
Candidates who have subject matter knowledge in developing, creating, and executing enterprise-scale data analytics solutions should take the Microsoft DP-500 exam. This exam requires advanced Power BI skills, such as managing data repositories and processing data both in the cloud and on-premises, as well as using Power Query and Data Analysis Expressions (DAX). Furthermore, candidates should be able to utilize data from Azure Synapse Analytics and have previous expertise in querying relational databases, analyzing data with Transact-SQL (T-SQL), and visualizing data.
Exam Details
There are 40-60 questions in the Microsoft DP-500 exam. Questions on the Microsoft DP-500 can be:
scenario-based single-answer questions,
multiple-choice questions, arrange in the correct sequence type questions
drag & drop questions
mark review
drag, and drop
A candidate must, however, achieve a score of 700 or better in order to pass the exam. Furthermore, the exam is only offered in English and will cost you $165 USD.
Exam Content
Implement and manage a data analytics environment (25–30%) Query and transform data (20–25%) Implement and manage data models (25–30%) Explore and visualize data (20–25%)
View Online Microsoft Azure Enterprise Data Analyst DP-500 Free Questions
You have a Power Bl dataset that has only the necessary fields visible for report development. You need to ensure that end users see only 25 specific fields that they can use to personalize visuals. What should you do? A.From Tabular Editor, create a new role. B.Hide all the fields in the dataset. C.Configure object-level security (OLS). D.From Tabular Editor, create a new perspective. Answer : B
You plan to generate a line chart to visualize and compare the last six months of sales data for two departments. You need to increase the accessibility of the visual. What should you do? A.Replace long text with abbreviations and acronyms. B.Configure a unique marker for each series. C.Configure a distinct color for each series. D.Move important information to a tooltip. Answer : B
You are creating a Power 81 single-page report. Some users will navigate the report by using a keyboard, and some users will navigate the report by using a screen reader. You need to ensure that the users can consume content on a report page in a logical order. What should you configure on the report page? A.the bookmark order B.the X position C.the layer order D.the tab order Answer : B
You have a Power Bl workspace named Workspacel that contains five dataflows. You need to configure Workspacel to store the dataflows in an Azure Data Lake Storage Gen2 account What should you do first? A.Delete the dataflow queries. B.From the Power Bl Admin portal, enable tenant-level storage. C.Disable load for all dataflow queries. D.Change the Data source settings in the dataflow queries. Answer : D
You are using GitHub as a source control solution for an Azure Synapse Studio workspace. You need to modify the source control solution to use an Azure DevOps Git repository. What should you do first? A.Disconnect from the GitHub repository. B.Create a new pull request. C.Change the workspace to live mode. D.Change the active branch. Answer : A
You plan to modify a Power Bl dataset. You open the Impact analysis panel for the dataset and select Notify contacts. Which contacts will be notified when you use the Notify contacts feature? A.any users that accessed a report that uses the dataset within the last 30 days B.the workspace admins of any workspace that uses the dataset C.the Power Bl admins D.all the workspace members of any workspace that uses the dataset Answer : C
0 notes
Link
With the release of dataflows in Power BI, you being an intended user, may have a few queries in mind: what exactly are dataflows, how are they different from datasets, how should I take advantage of them, and more. Through this blog, I will attempt to address these queries you have and make an idea of dataflows accessible to you.
What are dataflows?
With the advancement of Power BI, you can create a collection of data called dataflow. It is an online data storage and collection tool. With its help, you can add and edit entities and brings semantic understanding and consistency to data across many sources, by mapping it to standard CDM entities.
Use of dataflows in an organization:
Main reasons to introduce dataflows:
1. It helps organizations to unify data from disparate sources and prepare it for modeling.
With the help of dataflows, organizations can directly link their data from different data sources to Power BI with just a few steps. Organizations can map their data to the Common Data Model or create their custom entities. Organizations can then use these entities as building blocks to create reports, dashboards, and apps and distribute them to users across their organization.
Further, organizations use Dataflows to transform and add value to big data by defining data source connections. With the help of a large variety of data connectors provided by Power BI and PowerApps, organizations can directly map their data from the data source.
Once you load the data in dataflow, the creation of reports and dashboards in the Power BI desktop becomes easy.
2. Self-service data prep in Power BI while dealing with large datasets:
As data volume grows, so does the need to have insights into it.
With the introduction to self-service data prep for large data in Power BI, it is now easy to have insights into any collection of data instantly. Dataflows help organizations combine data from various data sources and perform the task.
Organizations can now have their Data from multiple sources stored in Azure Data Lake Storage Gen2. Organizations can manage dataflows in workspaces by using the Power BI service. They can also map data to standard entities in the Common Data Model, which gives them the flexibility to modify data. It further helps its users work upon existing entities to customize them.
3. Different data source with a different schedule of refresh:
Dataflows play a vital role, especially when our data contain two tables with unique schedule options. Dataflows help build mechanisms that can schedule refresh according to the organization plan. Dataflows can run, extract, and load data entities in workspaces. They allow the transformation of the data process on a different schedule for every query or table.
4. An online data collection and storage tool
Collection: Dataflows use Power Query to connect to the data at the source and transform that data when needed. You can access the data through either a cloud service (such as Dynamics 365) or a PC/Network via an on-premise gateway.
Storage: Dataflows stores data in a table in the cloud so you can use it directly inside Power BI, to be more specific from Power BI Desktop.
5. Transformation of large data volume
While handling past or obsolete data, let us say a two-year-old sales record, you could come across files containing many rows or columns. Such data normally take hours to refresh. Dataflow proves to be the quicker option in such cases. You can seamlessly switch from the database to the dataflow option. You may further make use of the incremental refresh settings option in dataflow, which ensures that only updated data get refreshed.
Dataflow and Azure Data lake integration:
With the use of dataflows, users and organizations can connect data from disparate sources, and prepare it for modeling.
For using Azure Data Lake storage for dataflows, you need to have an Azure subscription and have the Data Lake Storage Gen2 Feature enabled.
After setting the Azure account, you must go to the dataflow settings tab of the Power BI admin portal wherein you must select Connect Your Azure Data Lake Storage Gen2 button. Once you do that, the system will ask you for the user credentials to initiate the Azure Data Lake. Finally, click the connect button to begin.
After the completion of this step, azure data lake storage is ready to use in Power BI.
Connect to different data sources for Power BI dataflows
With Power BI dataflows, we can connect to multiple data sources to create dataflows or add new entities to an existing dataflow.
Step1: To create the dataflow, click on the +Create menu button and select the dataflow option. You will now see several options related to entity creation. If your dataflow already exists, you can select the Add Entity or select Get Data in the dataflow authoring tool.
Step2: Now, select the data sources from the dialog box and search for the data source categories from the given options. Broadly, there are five categories from which you could choose your data: file, database, power platform, azure, and online platform.
Step 3: After successful sign in, click the next button to continue. It will open a Power Query Online where you can perform the basic editing of your data. Finally, load the model and save the dataflow.
Summary
In this blog, I have explained multiple features of dataflow to show you how it has the upper hand over datasets. However, a lot depends on the user’s choice, especially the choice of the environment which the user prefers.
There are situations in which dataflow enables you, the user, to have better control over and insight into your business data.
By using the standard data model, schema, as defined by the Common Data Model, dataflows import the user’s business data and help in reshaping and combining data across different data sources and have them ready for modeling and creation of dashboards and reports in a short period, which earlier used to take months, or years, to create.
However, there are a few constraints that restrict the use of dataflows:
· One of the primary constraints that the dataflow faces is the type of available data, namely: date/time, decimal number, text, whole number, date/time/zone, true/false, date, time, and others.
· To access Power BI dataflow, the user either needs access to the admin or the other members of the workspace wherein the dataflow resides or needs access to the workspace of contributor or viewer where the data is visible.
0 notes
Text
[Fabric] ¿Cómo funciona Dataflow gen2? ¿Qué es staging?
Fabric ya es una materia frecuente en la comunidad de datos y cada vez se analiza en mayor profundidad. En esta oportunidad iremos al servicio de Data Factory que cuenta con dos tipos de procesos de movimientos de datos. Pipelines, que vimos un ejemplo de la simpleza de su asistente para copiar datos y por otro lado, dataflows gen2.
Tal vez el nombre resuene porque fue usada en varias oportunidades dentro de diferentes servicios. No nos confundamos con los que existían en Azure Data Factory, éstos son creados con la experiencia de Power Query Online. En este artículo nos vamos a enfocar en Dataflow gen2. Vamos a conocerlos y en particular describir sobre su característica de "Staging" que podría ser la más influeyente y distinta a los conceptos que manejaban en la primera generación.
Indiscutiblemente, la experiencia de power query online, permite a diversos tipos de profesionales realizar una ingesta de datos con complejas transformaciones. Tanto usuarios expertos (que usan mucho código) como convencionales (que prefieren más clicks que código) puede aprovechar la buena experiencia de usuario de la herramienta para desarrollar joins, agregaciones, limpieza y transformaciones de datos, etc.
Dataflows gen2 es la evolución de los Power Bi Dataflows con mejores capacidades de computo y preparado con capacidades de movimientos de datos a diversos destinos de Fabric y Azure. Aquí la primera gran diferencia, establecer un destino para el job de power query online. Podemos apreciar la nueva sección en la siguiente imagen:
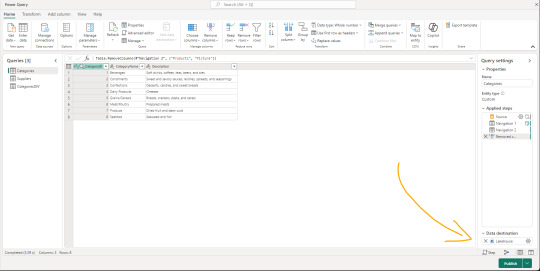
Los proyectos de movimientos de datos suelen tener algunos desafíos que hacen variar el modo en que construimos. Algunos escenarios buscan transformar datos para ingestarlos en un limpio almacenamiento, mientras que otros prefieren pasar por estapas o stages que tengan distintas granularidad o limpieza de datos. Otro gran desafío es la orquestación. Garantizar que la ingesta y transforaciones puedan calendarizarse apropiadamente.
Como todo proyecto de datos es distinto, depende de cada uno cual sería la forma apropiada de mover datos. Si bien datalfows gen2 puede realizarlo, no significa que siempre sea la mejor opción. Por ejemplo, los escenarios de big data cuando grandes volumenes deben ser ingestados con complejos patrones para tomar la información de diversos origenes de datos, tal vez sea mejor dejar ese lugar a Pipelines de Data Factory. Dataflows gen2 también puede usarse para transformaciones dentro de Fabric. Esto significa que podemos tener de origen de un dataflow gen2 a nuestros archivos de Lakehouse crudos y limpiarlos para llevarlos a un warehouse.
Una de las fortaleza más grande de dataflows gen2, pasa por la cantidad de conectores que power query tiene desarrollado. Indudablemente, una de las herramientas con mayor integración del mercado.
¿Cómo funcionan?
Para inciar, llamaremos al proceso que interpreta Power Query y ejecuta su lenguaje como "Mashup engine". Los dataflow gen2 nos permiten obtener datos de muchos origenes diversos y a cada uno de ellos delimitar un destino. Ese destino puede ser reemplazando/pisando la tabla de arribo o puede ser haciendo append de lo que lea. En medio de este proceso, existe la posibilidad de poner un almacenamiento intermedio que llamaremos Staging. El staging llega a nosotros para fortalecer a power query para algunas operaciones que eran muy complejas de resolver de un solo tirón dentro del Mashup Engine como por ejemplo "merges".
La nueva característica Staging viene activada por defecto y podemos elegir si usarla o no, con un simple click derecho "Enagle Staging". Cuando no esté activada el título de la tabla estará en cursiva.
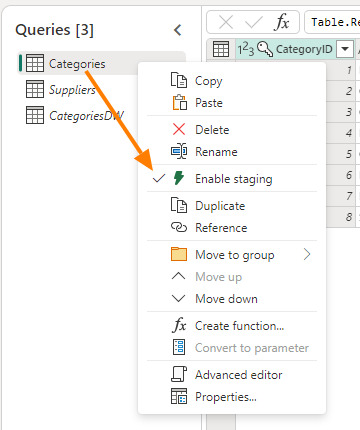
Activar esa opción hará que los pasos ejecutados por el Mashup Engine se depositen primero en un Lakehouse Staging oculto para nosotros. Si tenemos configurado el destino, el paso siguiente sería llevarlo a destino. Según activemos la característica, nuestro dato podría viajar de dos formas:
Sin Staging
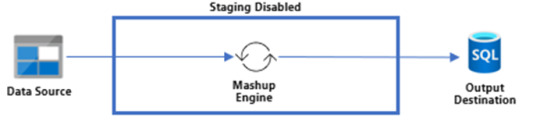
Con Staging
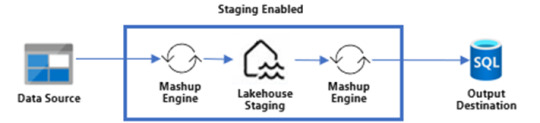
Puede que estén pensando ¿Por qué guardaríamos dos veces nuestra data? Cierto es que puede sonar redundante, pero en realidad es muy provechoso si lo utilizamos a nuestro favor. Como dije antes, hacer merge es algo que Power Query tenía muy dificil de lograr en una sola ejecución del Mashup Engine contra el origen. Ahora bien, ¿que tal si obtenemos datos de dos tablas, prendemos su staging pero no activamos su destino?. Eso dejaría nuestra dos tablas en staging oculto sin destino. Esto nos da pie para crear una tercer consulta en la interfaz de Power Query que haga el Merge de ambas tablas con destino. De este modo, realizaríamos un segundo Mashup Engine que esta vez tiene como origen Tablas de un Lakehouse oculto a nuestro destino. Ejecutar el merge contra el lakehouse oculto será más performante que contra el origen que no siempre dispone de las mejores capacidades de joins. Algo asi:
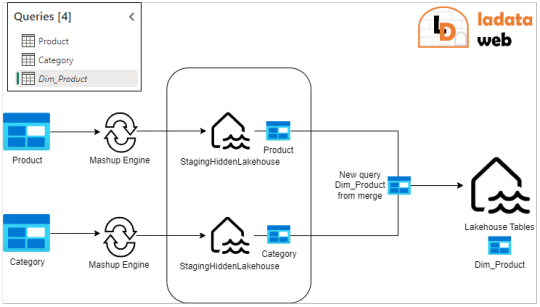
Fíjense como Product y Category tienen staging prendido. La nueva query que hace un merge de Table.Combine esta cursiva, lo que significa que no tiene Staging. Ésta última es la única con un destino configurado.
Algunas pautas para no hacer staging son:
Si tu fuente de datos no contiene grandes volúmenes de datos
Si no estás uniendo datos de diferentes fuentes de datos (joins/merges)
Si no estás realizando transformaciones intensivas en computo/memoria como unir o agregar grandes volúmenes de datos
Destino
La nueva característica de destino tiene cuatro asociados pero seguramente la usaríamos para hacer ingesta de Fabric Warehouse o Fabric Lakehouse. Cuando hablamos de warehouse su funcionamiento es tal y como se lo imaginen. Sin embargo, para lakehouse hay que prestar atención a un detalle. Cuando nuestro destino es el Lakehouse de Fabric, nuestra tablas será almacenadas en formato delta parquet sobre la carpeta "Tables". Hoy no podemos configurar que el destino sea "Files". Si no estan seguros de lo que hablo, pueden repasarlo en este post anterior sobre OneLake.
Esto ha sido todo nuestro artículo para introducirlos a la nueva generación de Dataflows en Fabric Data Factory. Espero les sea útil y los ayude a mover datos.
#power bi#powerbi#fabric#fabric data factory#fabric dataflows#fabric dataflows gen2#dataflows gen2#fabric argentina#fabric cordoba#fabric jujuy#fabric tutorial#fabric tips#fabric training#ladataweb
0 notes
Text
[Fabric] Fast Copy con Dataflows gen2
Cuando pensamos en integración de datos con Fabric está claro que se nos vienen dos herramientas a la mente al instante. Por un lado pipelines y por otro dataflows. Mientras existía Azure Data Factory y PowerBi Dataflows la diferencia era muy clara en audiencia y licencias para elegir una u otra. Ahora que tenemos ambas en Fabric la delimitación de una u otra pasaba por otra parte.
Por buen tiempo, el mercado separó las herramientas como dataflows la simple para transformaciones y pipelines la veloz para mover datos. Este artículo nos cuenta de una nueva característica en Dataflows que podría cambiar esta tendencia.
La distinción principal que separa estas herramientas estaba basado en la experiencia del usuario. Por un lado, expertos en ingeniería de datos preferían utilizar pipelines con actividades de transformaciones robustas d datos puesto que, para movimiento de datos y ejecución de código personalizado, es más veloz. Por otro lado, usuarios varios pueden sentir mucha mayor comodidad con Dataflows puesto que la experiencia de conectarse a datos y transformarlos es muy sencilla y cómoda. Así mismo, Power Query, lenguaje detrás de dataflows, ha probado tener la mayor variedad de conexiones a datos que el mercado ha visto.
Cierto es que cuando el proyecto de datos es complejo o hay cierto volumen de datos involucrado. La tendencia es usar data pipelines. La velocidad es crucial con los datos y los dataflows con sus transformaciones podían ser simples de usar, pero mucho más lentos. Esto hacía simple la decisión de evitarlos. ¿Y si esto cambiara? Si dataflows fuera veloz... ¿la elección sería la misma?
Veamos el contexto de definición de Microsoft:
Con la Fast Copy, puede ingerir terabytes de datos con la experiencia sencilla de flujos de datos (dataflows), pero con el back-end escalable de un copy activity que utiliza pipelines.
Como leemos de su documentación la nueva característica de dataflow podría fortalecer el movimiento de datos que antes frenaba la decisión de utilizarlos. Todo parece muy hermoso aun que siempre hay frenos o limitaciones. Veamos algunas consideraciones.
Origenes de datos permitidos
Fast Copy soporta los siguientes conectores
ADLS Gen2
Blob storage
Azure SQL DB
On-Premises SQL Server
Oracle
Fabric Lakehouse
Fabric Warehouse
PostgreSQL
Snowflake
Requisitos previos
Comencemos con lo que debemos tener para poder utilizar la característica
Debe tener una capacidad de Fabric.
En el caso de los datos de archivos, los archivos están en formato .csv o parquet de al menos 100 MB y se almacenan en una cuenta de Azure Data Lake Storage (ADLS) Gen2 o de Blob Storage.
En el caso de las bases de datos, incluida la de Azure SQL y PostgreSQL, 5 millones de filas de datos o más en el origen de datos.
En configuración de destino, actualmente, solo se admite lakehouse. Si desea usar otro destino de salida, podemos almacenar provisionalmente la consulta (staging) y hacer referencia a ella más adelante. Más info.
Prueba
Bajo estas consideraciones construimos la siguiente prueba. Para cumplir con las condiciones antes mencionadas, disponemos de un Azure Data Lake Storage Gen2 con una tabla con información de vuelos que pesa 1,8Gb y esta constituida por 10 archivos parquet. Creamos una capacidad de Fabric F2 y la asignaciones a un área de trabajo. Creamos un Lakehouse. Para corroborar el funcionamiento creamos dos Dataflows Gen2.
Un dataflow convencional sin FastCopy se vería así:

Podemos reconocer en dos modos la falta de fast copy. Primero porque en el menú de tabla no tenemos la posibilidad de requerir fast copy (debajo de Entable staging) y segundo porque vemos en rojo los "Applied steps" como cuando no tenemos query folding andando. Allí nos avisaría si estamos en presencia de fast copy o intenta hacer query folding:
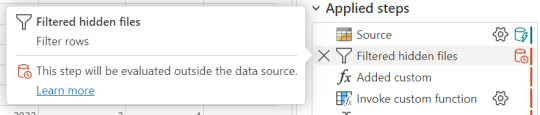
Cuando hace query folding menciona "... evaluated by the datasource."
Activar fast copy
Para activarlo, podemos presenciar el apartado de opciones dentro de la pestaña "Home".
Allí podemos encontrarlo en la opción de escalar o scale:
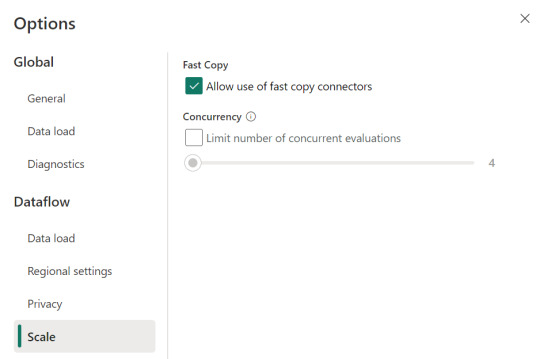
Mientras esa opción esté encendida. El motor intentará utilizar fast copy siempre y cuando la tabla cumpla con las condiciones antes mencionadas. En caso que no las cumpla, por ejemplo la tabla pese menos de 100mb, el fast copy no será efectivo y funcionaría igual que un dataflow convencional.
Aquí tenemos un problema, puesto que la diferencia de tiempos entre una tabla que usa fast copy y una que no puede ser muy grande. Por esta razón, algunos preferiríamos que el dataflow falle si no puede utilizar fast copy en lugar que cambie automaticamente a no usarlo y demorar muchos minutos más. Para exigirle a la tabla que debe usarlo, veremos una opción en click derecho:

Si forzamos requerir fast copy, entonces la tabla devolverá un error en caso que no pueda utilizarlo porque rompa con las condiciones antes mencionadas a temprana etapa de la actualización.
En el apartado derecho de la imagen tambien podemos comprobar que ya no está rojo. Si arceramos el mouse nos aclarará que esta aceptado el fast copy. "Si bien tengo otro detalle que resolver ahi, nos concentremos en el mensaje aclarando que esta correcto. Normalmente reflejaría algo como "...step supports fast copy."
Resultados
Hemos seleccionado exactamente los mismos archivos y ejecutado las mismas exactas transformaciones con dataflows. Veamos resultados.
Ejecución de dataflow sin fast copy:

Ejecución de dataflow con fast copy:

Para validar que tablas de nuestra ejecución usan fast copy. Podemos ingresar a la corrida

En el primer menú podremos ver que en lugar de "Tablas" aparece "Actividades". Ahi el primer síntoma. El segundo es al seleccionar una actividad buscamos en motor y encontramos "CopyActivity". Así validamos que funcionó la característica sobre la tabla.
Como pueden apreciar en este ejemplo, la respuesta de fast copy fue 4 veces más rápida. El incremento de velocidad es notable y la forma de comprobar que se ejecute la característica nos revela que utiliza una actividad de pipeline como el servicio propiamente dicho.
Conclusión
Seguramente esta característica tiene mucho para dar e ir mejorando. No solamente con respecto a los orígenes sino tambien a sus modos. No podemos descargar que también lo probamos contra pipelines y aqui esta la respuesta:
En este ejemplo los Data Pipelines siguen siendo superiores en velocidad puesto que demoró 4 minutos en correr la primera vez y menos la segunda. Aún tiene mucho para darnos y podemos decir que ya está lista para ser productiva con los origenes de datos antes mencionados en las condiciones apropiadas. Antes de terminar existen unas limitaciones a tener en cuenta:
Limitaciones
Se necesita una versión 3000.214.2 o más reciente de un gateway de datos local para soportar Fast Copy.
El gateway VNet no está soportado.
No se admite escribir datos en una tabla existente en Lakehouse.
No se admite un fixed schema.
#fabric#microsoft fabric#fabric training#fabric tips#fabric tutorial#data engineering#dataflows#fabric dataflows#fabric data factory#ladataweb
0 notes
Text
[SimplePBI] Como armar un histórico de Fabric Capacity Metrics App
Cada día me llegan más solicitudes de instalar una herramienta de monitoreo para administrar una capacidad dedicada. Allí es cuando aparece la App de Microsoft. Sin embargo, la herramienta, o debería decir el modelo semántico, cuenta con una limitada historia para monitorear. Resulta que el informe resguarda pocos días hacia atrás y algunas instituciones prefieren contar con valores históricos para poder analizar tendencias o dar explicaciones a sucesos pasados y no solamente a lo que ocurre ahora.
En este artículo veremos como podemos extraer datos del modelo semántico de Fabric Capacity Metrics App para construir un histórico utilizando la librería SimplePBI de Python en un jupyter notebook.
Si tenemos nuestros desarrollos desplegados en una capacidad, seguramente estamos utilizando Fabric Capacity Metrics App. Digo "seguro" porque la aplicación del store de Microsoft provee un informe para monitorear el uso de nuestra capacidad (Unidades de procesamiento/capacity CUs). A diferencia del Admin Monitoring que provee un detalle de lo que esta desplegado en la organización y las operaciones o actividades que se ejecutan, la Capacity metrics nos ayuda a entender cuantos recursos de la capacidad esta utilizando un contenido como un modelo semantico, un dataflow gen2, un Fabric notebook o un pipeline de Fabric Data Factory.
Cuando disponemos de una capacidad la administración cambia completamente. Las acciones diarias y los hitos por proyectos o deploys nuevos deben tenerse en cuenta. Si queremos comparar o analizar cambios en deploys mensuales de proyectos complejos, necesitamos almacenar un histórico. Si necesitamos analizar si una tendencia actual que esta relentizando o consumiendo todos los recursos estaba sucediendo en el pasado y no es excepcional, necesitamos histórico. Por esta y muchas otras razones que me comentaron algunos clientes se me ocurrió escribir este artículo.
Prerequisitos
Lo primero que necesitamos será definir nuestro almacenamiento. Si ya utilizamos Fabric es posible usar lakehouse o warehouse con Fabric notebooks, sin embargo tal vez querramos aislar este desarrollo para que no tenga la más mínima influencia en la capacidad. Una vez definido el almacenamiento debemos asegurarnos que podemos usar la Power Bi Rest API. Este artículo puede ayudarlos. Por último, instalar en el entorno donde correremos código Python la librería SimplePBI.
¿Qué vamos a extraer?
El modelo semántico de la Capacity Metrics esta lleno de tablas y contiene parámetros dinámicos. Sin embargo, hoy nos vamos a concentrar en lo más usados.
Timepoints: puntos temporales donde ocurre un movimiento de la capacidad.
Items: contenido que ha utilizado la capacidad al menos una vez.
Background Operations: operaciones de código que incluyen procesamientos o transformaciones.
Interactive Operations: refiere a las interacciones de los usuarios explorando y utilizando los informes.
Vamos a iniciar importando librería, recolectando valores de nuestra Aplicacion Registrada en Azure para usar la API. También podemos buscar el id de la capacidad en el portal de administración de Fabric, administrando capacidades.
Para obtener los datos vamos a ejecutar una consulta/query contra el modelo de datos. Veamos por ejemplo una función para traer los Timepoints de un día específico.
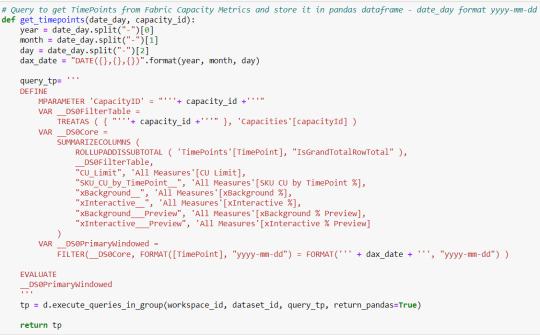
Para comenzar debemos mandar un parámetro dinámico de M PowerQuery. Mandamos el id de capacidad y ejecutamos un SUMMARIZECOLUMNS buscando el listado de timepoints y algunas columnas más de operaciones.
A partir de los timepoints podremos buscar las operaciones puesto que se desencadenan para cada timepoint. Entonces hay muchas operaciones por cada timepoint. El primer desafío es que la API nos limita a 1.000.000 de celdas o registros. Calculando cuantas filas podemos traer para la cantidad de columnas que conllevan ese volumen, hablamos de 66.666 filas aproximadamente. Esta información es clave para iterar operaciones de nuestra capacidad.
NOTA: Esto solo será necesario si tenemos mucha cantidad de contenido o usuarios operando.
Comenzaremos ejecutando un COUNT de filas de las operaciones para partir la cantidad de iteraciones cada 66.666 filas.
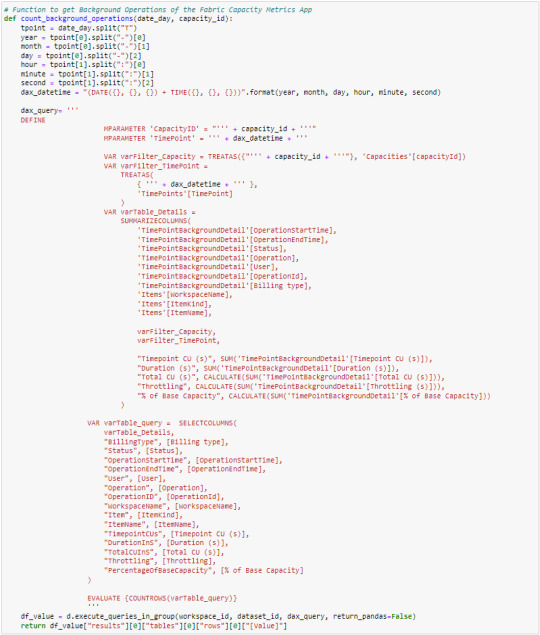
La consulta para saber las filas y traer los resultados es similar. Ambas pasarán los parámetros dinámicos de M (id de capacidad y timepoint) y buscaran las columnas esperadas, las renombraremos y al final cambiará si buscamos contar las filas o traer los resultados en "ventanas" de 66.666 filas.

Con las funciones que nos den las filas y la ejecución de cada timepoint, vamos a construir la iteración.
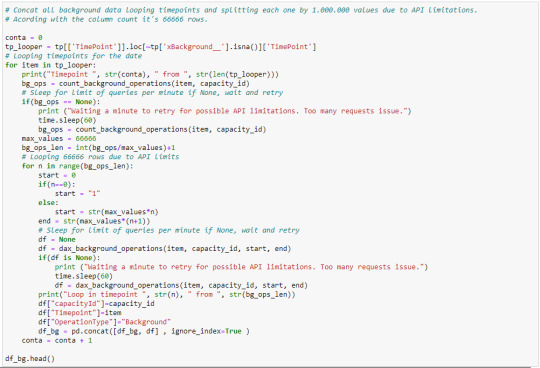
En caso que las operaciones lleguen en "None", lo más probable es que sea porque la librería SimplePBI no hay podido traer los resultados por limitación de cantidad de requests ejecutados con la API. Entonces desencaderá una espera de 1 minuto para reanudar. Pueden observar cada paso con sus comentarios para ir comprendiendo el código o construir uno propio. Aqui iteramos dos veces, por un lado una lista timepoints "tp_looper" y por cada una de ella la limitación de filas de la API. Agregamos tres columnas que nos ayuden a reconocer el resultado, el id de capacidad (por si tenemos más de una capacidad), el timepoint (para conocer la fecha con exactitud) y tipo de operación (si es de back o interactiva). Vamos agregando los resultados en un solo pandas dataframe.
Así formamos un frame de operaciones background. Para las operaciones interactive es realmente muy similar, cambian un par de nombre de columnas y tablas.
Finalmente, traemos los items involucrados para constituir una dimensión de ellos. Sería bueno que al integrarlos comparemos el destino para ver de agregar únicamente las filas nuevas.

Así constituimos las 4 tablas que podrán ejecutarse cada día para ir construyendo un histórico.
Pueden repasar el Notebook completo en mi GitHub.
Espero que les sea de utilidad y puedan almacenar las operaciones historicas ordenadas en este modelo estrella sencillo de dimensiones de timepoints e items con hechos de operaciones background e interactivas.
#fabric metrics#fabric#microsoft fabric#power bi premium#power bi#powerbi#power bi cordoba#power bi jujuy#power bi argentina#ladataweb#simplepbi#fabric capacity
0 notes
Text
Mastering Dataflow Gen2 In Microsoft Fabric (part 2)
Data transformations are an important part of any #Lakehouse project, and with #Dataflow Gen2 In Microsoft Fabric, you can start building your transformation pipelines without much training, using an easy graphical interface. In this tutorial, I explain how to apply aggregations,de-duplications and pivoting/unpivoting transformations in Dataflow Gen2. Check out here:https://youtu.be/0upqIqKlpDk

0 notes
Text
Mastering Dataflow Gen2 In Microsoft Fabric (part 1)
Building your first Azure data pipeline is easier than you might have expected! With Data Flow Gen2 In Microsoft Fabric, you can quickly build powerful data pipelines without coding skills. Check out the first tutorial in this end-to-end tutorial series: https://youtu.be/rJMBd5iZj4k

0 notes
Text
[Fabric] Dataflows Gen2 destino “archivos” - Opción 2
Continuamos con la problematica de una estructura lakehouse del estilo “medallón” (bronze, silver, gold) con Fabric, en la cual, la herramienta de integración de datos de mayor conectividad, Dataflow gen2, no permite la inserción en este apartado de nuestro sistema de archivos, sino que su destino es un spark catalog. ¿Cómo podemos utilizar la herramienta para armar un flujo limpio que tenga nuestros datos crudos en bronze?
Veamos una opción más pythonesca donde podamos realizar la integración de datos mediante dos contenidos de Fabric
Como repaso de la problemática, veamos un poco la comparativa de las características de las herramientas de integración de Data Factory dentro de Fabric (Feb 2024)
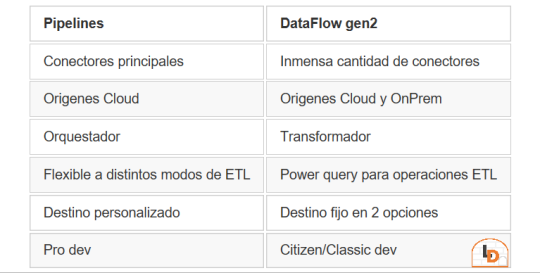
Si nuestro origen solo puede ser leído con Dataflows Gen2 y queremos iniciar nuestro proceso de datos en Raw o Bronze de Archivos de un Lakehouse, no podríamos dado el impedimento de delimitar el destino en la herramienta.
Para solucionarlo planteamos un punto medio de stage y un shortcut en un post anterior. Pueden leerlo para tener más cercanía y contexto con esa alternativa.
Ahora vamos a verlo de otro modo. El planteo bajo el cual llegamos a esta solución fue conociendo en más profundidad la herramienta. Conociendo que Dataflows Gen2 tiene la característica de generar por si mismo un StagingLakehouse, ¿por qué no usarlo?. Si no sabes de que hablo, podes leer todo sobre staging de lakehouse en este post.
Ejemplo práctico. Cree dos dataflows que lean datos con "Enable Staging" activado pero sin destino. Un dataflow tiene dos tablas (InternetSales y Producto) y otro tiene una tabla (Product). De esa forma pensaba aprovechar este stage automático sin necesidad de crear uno. Sin embargo, al conectarme me encontre con lo siguiente:
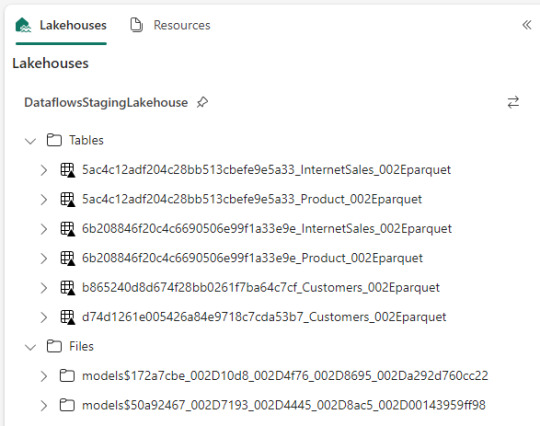
Dataflow gen2 por defecto genera snapshots de cada actualización. Los dataflows corrieron dos veces entonces hay 6 tablas. Por si fuera aún más dificil, ocurre que las tablas no tienen metadata. Sus columnas están expresadas como "column1, column2, column3,...". Si prestamos atención en "Files" tenemos dos models. Cada uno de ellos son jsons con toda la información de cada dataflow.
Muy buena información pero de shortcut difícilmente podríamos solucionarlo. Sin perder la curiosidad hablo con un Data Engineer para preguntarle más en detalle sobre la información que podemos encontrar de Tablas Delta, puesto que Fabric almacena Delta por defecto en "Tables". Ahi me compartió que podemos ver la última fecha de modificación con lo que podríamos conocer cual de esos snapshots es el más reciente para moverlo a Bronze o Raw con un Notebook. El desafío estaba. Leer la tabla delta más reciente, leer su metadata en los json de files y armar un spark dataframe para llevarlo a Bronze de nuestro lakehouse. Algo así:
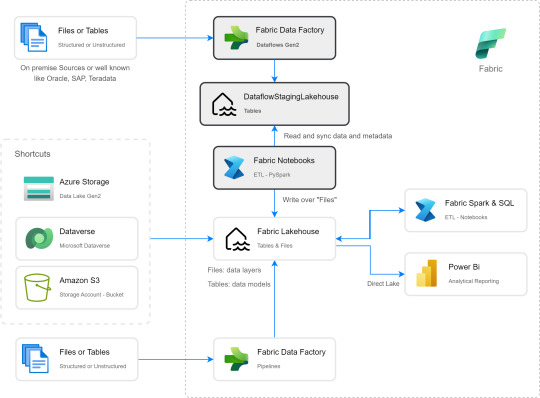
Si apreciamos las cajas con fondo gris, podremos ver el proceso. Primero tomar los datos con Dataflow Gen2 sin configurar destino asegurando tener "Enable Staging" activado. De esa forma llevamos los datos al punto intermedio. Luego construir un Notebook para leerlo, en mi caso el código está preparado para construir un Bronze de todas las tablas de un dataflow, es decir que sería un Notebook por cada Dataflow.
¿Qué encontraremos en el notebook?
Para no ir celda tras celda pegando imágenes, puede abrirlo de mi GitHub y seguir los pasos con el siguiente texto.
Trás importar las librerías haremos los siguientes pasos para conseguir nuestro objetivo.
1- Delimitar parámetros de Onelake origen y Onelake destino. Definir Dataflow a procesar.
Podemos tomar la dirección de los lake viendo las propiedades de carpetas cuando lo exploramos:

La dirección del dataflow esta delimitado en los archivos jsons dentro de la sección Files del StagingLakehouse. El parámetro sería más o menos así:
Files/models$50a92467_002D7193_002D4445_002D8ac5_002D00143959ff98/*.json
2- Armar una lista con nombre de los snapshots de tablas en Tables
3- Construimos una nueva lista con cada Tabla y su última fecha de modificación para conocer cual de los snapshots es el más reciente.
4- Creamos un pandas dataframe que tenga nombre de la tabla delta, el nombre semántico apropiado y la fecha de modificación
5- Buscamos la metadata (nombre de columnas) de cada Tabla puesto que, tal como mencioné antes, en sus logs delta no se encuentran.
6- Recorremos los nombre apropiados de tabla buscando su más reciente fecha para extraer el apropiado nombre del StagingLakehouse con su apropiada metadata y lo escribimos en destino.
Para más detalle cada línea de código esta documentada.
De esta forma llegaríamos a construir la arquitectura planteada arriba. Logramos así construir una integración de datos que nos permita conectarnos a orígenes SAP, Oracle, Teradata u otro onpremise que son clásicos y hoy Pipelines no puede, para continuar el flujo de llevarlos a Bronze/Raw de nuestra arquitectura medallón en un solo tramo. Dejamos así una arquitectura y paso del dato más limpio.
Por supuesto, esta solución tiene mucho potencial de mejora como por ejemplo no tener un notebook por dataflow, sino integrar de algún modo aún más la solución.
#dataflow#data integration#fabric#microsoft fabric#fabric tutorial#fabric tips#fabric training#data engineering#notebooks#python#pyspark#pandas
0 notes
Text
[Fabric] Integración de datos al OneLake
Ya viste todos los videos con lo que Fabric puede hacer y queres comenzar por algo. Ya leiste nuestro post sobre Onelake y como funciona. Lo siguiente es la ingesta de datos.
En este artículos vamos a ver muchas formas y opciones que pueden ser usadas para añadir datos a onelake. No vamos a ver la profundidad de como usar cada método, sino una introducción a ellos que nos permita elegir. Para que cada quien haga una instrospección de la forma deseada.
Si aún tenes dudas sobre como funciona el Onelake o que es todo eso que apareció cuando intentaste crear uno, pasa por este post para informarte.
Ingesta de datos
Agregar datos al Onelake no es una tarea difícil pero si analítica puesto que no se debe tomar a la ligera por la gran cantidad de formas disponibles. Algunas serán a puro click click click, otras con más o menos flexibilidad en transformaciones de datos, otras con muchos conectores o tal vez con versatilidad de destino. Cada forma tiene su ventaja y posibilidad, incluso puede que haya varias con la que ya tengan familiaridad.
Antes de iniciar los métodos repasemos que para usar nuestro Onelake primero hay que crear una Lakehouse dentro de un Workspace. Ese Lakehouse (almacenado en onelake) tiene dos carpetas fundamentales, Files y Tables. En Files encontrabamos el tradicional filesystem donde podemos construir una estructura de carpetas y archivos de datos organizados por medallones. En Tables esta nuestro spark catalog, el metastore que puede ser leído por endpoint.

Nuestra ingesta de datos tendrá como destino una de estos dos espacios. Files o Tables.
Métodos
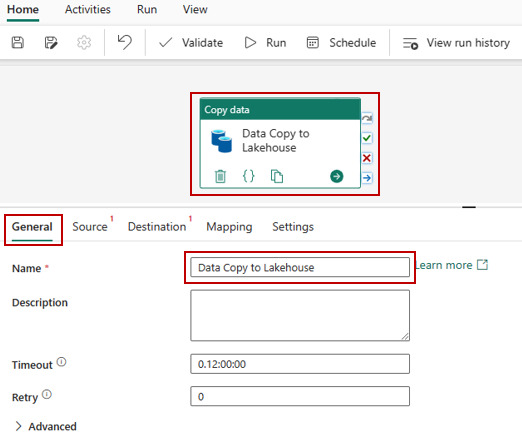
Data Factory Pipelines (dentro de Fabric o Azure): la herramienta clásica de Azure podría ser usada como siempre lo fue para este escenario. Sin embargo, hay que admitir que usarla dentro de Fabric tiene sus ventajas. El servicio tiene para crear "Pipelines". Como ventaja no sería necesario hacer configurationes como linked services, con delimitar la forma de conexión al origen y seleccionar destino bastaría. Por defecto sugiere como destino a Lakehouse y Warehouse dentro de Fabric. Podemos comodamente usar su actividad estrella "Copy Data". Al momento de determinar el destino podremos tambien elegir si serán archivos en Files y de que extensión (csv, parquet, etc). Así mismo si determinamos almacenarlo en Tables, automáticamente guardará una delta table.
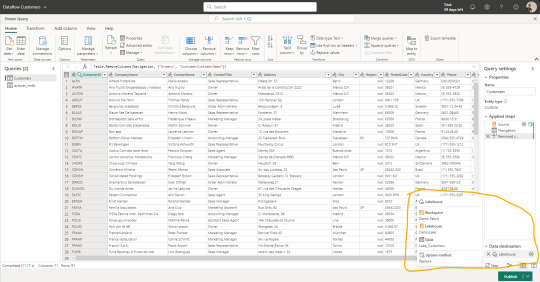
Data Factory Dataflows Gen2: una nueva incorporación al servicio de Data Factory dentro de Fabric son los Dataflows de Power Query online. A diferencia de su primera versión esta nueva generación tiene fuertes prestaciones de staging para mejor procesamiento, transformación y merge de datos junto a la determinación del destino. Así mismo, la selección del destino nos permite determinar si lo que vamos a ingestar debería reemplazar la tabla destino existente o hacer un append que agregue filas debajo. Como ventaja esta forma tiene la mayor cantidad de conectores de origen y capacidades de transformación de datos. Su gran desventaja por el momento es que solo puede ingestar dentro de "Tables" de Lakehouse bajo formato delta table. Mientras este preview también crea unos elementos de staging en el workspace que no deberíamos tocar. En un futuro serán caja negra y no los veremos.
Notebooks: el hecho de tener un path a nuestro onelake, path al filesystem con permisos de escritura, hace que nuestro almacenamiento pueda ser accedido por código. El caso más frecuente para trabajarlo sería con databricks que, indudablemente, se convirtió en la capa de procesamiento más popular de todas. Hay artículos oficiales de la integración. En caso de querer usar los notebooks de fabric también son muy buenos y cómodos. Éstos tienen ventajas como clickear en files o tablas que nos genere código de lectura automáticamente. También tiene integrada la herramienta Data Wrangler de transformación de datos. Además cuenta con una muy interesante integración con Visual Studio code que pienso podría integrarse a GitHub copilot.
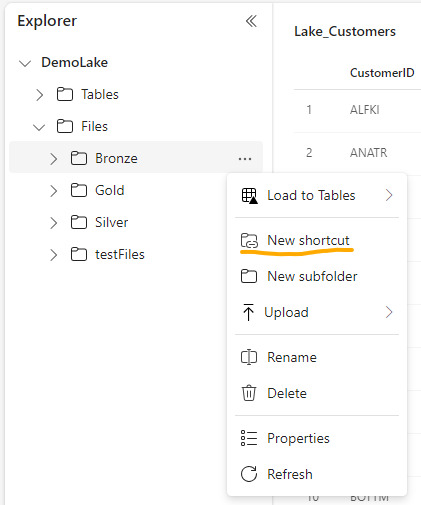
Shortcuts (accesos directos): esta nueva opción permite a los usuarios hacer referencia a datos sin copiarlos. Genera un puntero a archivos de datos de otro lakehouse del onelake, ADLS Gen2 o AWS S3 para tenerlo disponible como lectura en nuestro Lakehouse. Nos ayuda a reducir los data silos evitando replicación de datos, sino punteros de lectura para generar nuevas tablas transformadas o simplemente lectura para construcción de un modelo o lo que fuere. Basta con clickear en donde lo queremos (tables o files) y agregarlo.
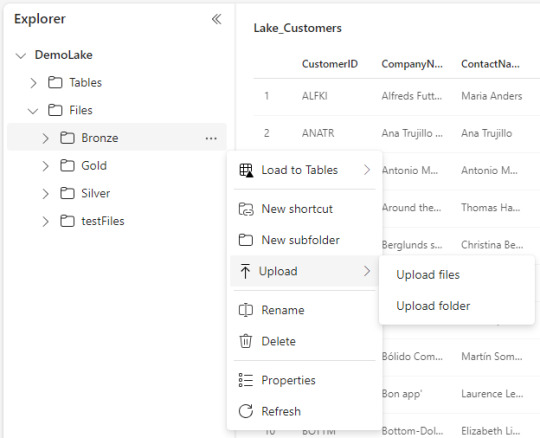
Upload manual: con la vista en el explorador de archivos (Files) como si fuera un Azure Storage explorer. Tenemos la clásica posibilidad de simplemente agregar archivos locales manualmente. Esta posibilidad solo estaría disponible para el apartado de Files.
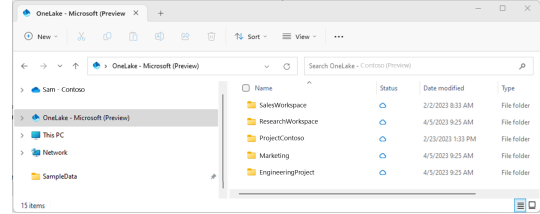
Explorador de archivos Onelake (file explorer): una de las opciones más atractivas en mi opinión es este cliente para windows. Es incontable la cantidad de soluciones de datos que conllevan ingresos manuales de hojas de cálculo de distintas marcas en distintas nubes. Todas son complicadas de obtener y depositar en lake. Esta opción solucionaría ese problema y daría una velocidad impensada. El cliente de windows nos permite sincronizar un workspace/lakehouse que hayan compartido con nosotros como si fuera un Onedrive o Sharepoint. Nunca hubo una ingesta más simple para usuarios de negocio como ésta que a su vez nos permita ya tener disponible y cómodamente habilitado el RAW del archivo para trabajarlo en Fabric. Usuarios de negocio o ajenos a la tecnología podrían trabajar con su excel cómodos locales y los expertos en data tenerlo a mano. Link al cliente.
Conclusión
Como pudieron apreciar tenemos muchas formas de dar inicio a la carga del onelake. Seguramente van a aparecer más formas de cargarlo. Hoy yo elegí destacar éstas que son las que vinieron sugeridas e integradas a la solución de Fabic porque también serán las formas que tendrán integrados Copilot cuando llegue el momento. Seguramente los pipelines y notebooks de Fabric serán sumamente poderosos el día que integren copilot para repensar si estamos haciendo esas operaciones en otra parte. Espero que les haya servido y pronto comiencen a probar esta tecnología.
#fabric#fabric tutorial#fabric tips#fabric training#data fabric#data engineer#data engineering#microsoft fabric#fabric argentina#fabric jujuy#fabric cordoba#ladataweb#power query#power query online#powerbi#power bi#power bi dataflows#data factory#data factory data flows#power bi service
0 notes
Text
Licenciamiento Power Bi
¿Que licencias existe y que puedo hacer con ellas? Últimamente me estoy encontrando con muchas dudas de parte de nuevos usuarios respecto a que pueden hacer con su licencia en Power Bi. Tal vez las constantes actualizaciones de la herramienta están mareando un poco a quienes recién se introducen en este mundo puesto que todos los meses y algunas fechas de eventos especiales hay más y más anuncios de nuevas características.
Pese a la gran cantidad de documentación de Microsoft me parece que falta un documento base para establecer las principales diferencias entre las licencias. Por esto mismo escribo este post explicado con mis palabras para intentar dar luz a los iniciantes en Power Bi o aquellos con dudas de licencias.
Intro
Seguramente que leer la documentación de Microsoft sobre cada una de ellas prevería mayor detalle que este post, aún así creo que es de utilidad tener un pantallazo práctico y rápido que ayude a los usuarios a entender que pueden hacer con una licencia. Cabe destacar que estamos hablando sobre un despliegue en Power Bi Service que es puramente Nube. Antes de explicar cada licencia necesitamos conocer un mínimo de Power Bi. Con esto me refiero a sus componentes principales del Servicio. Para no tener un post muy largo copiando y pegando mucha documentación voy a intentar explicar brevemente con mis palabras. Todo el trabajo que se construye en Power Bi se maneja entorno a Areas de Trabajo. Espacios colaborativos para compartir cuatro componentes (dataset, informe, panel, dataflow y paginated reports) con distintos permisos para cada integrante (admin, member, contributor, viewer).
Datasets: son el conjunto de datos construido en un Power Bi Desktop que contiene la totalidad de un modelo. Metadata, tablas, relaciones, medidas, etc.
Informe: páginas interactivas con visualizaciones varias dinámicas conectadas a un dataset.
Panel: pizarrón que extrae momentos prefiltrados de visualizaciones de los informes y los fija estáticamente (los datos si fluyen las interacciones no)
DataFlows: almacenamiento en el area que permite transformaciones de Power Query para crear entidades (como tablas). Puede usar almacenamiento compartido o Azure Data Lake gen2.
Paginated Reports: reportes creados a partir de la herramienta Power Bi paginated reports. Son estáticos e ideales para imprimir.
Comenzamos destacando que la herramienta principal para el desarrollo que construye el 50% de lo antes mencionado es totalmente gratuita. Me refiero a Power Bi Desktop. Podremos usarla de pies a cabeza por completo dado que todas sus características están libres. Conociendo un poco y mínimo de esta teoría podremos encontrar sentido a las características varias de las licencias. Por mi lado voy a explicar las licencias separándolas en tres tipos. Por usuario, por capacidad e híbrida. Una no quita a la otra, sino que pueden coexistir juntas. Por ejemplo: para desarrollar usamos una licencia Pro aunque estemos sobre un area de trabajo Premium.
Licencias por usuario
Son compradas y asignadas a un usuario en particular. El tenant registra el número de licencias compradas y se pueden quitar y re-asignar entre usuarios a medida que uno y otro vaya necesitando. Todas ellas pueden utilizar la herramienta de Puerta de enlace (gateway) para actualizar datos de entornos locales. Las dos primeras almacenan su contenido en espacios de procesamiento compartido de Microsoft.
Power Bi Free: si el tenant lo permite, esta licencia puede ser autogestionada por cualquier usuario con cuenta profesional de Microsoft. Es perfecta para aprender o generar proyectos personales. Tenemos la mayoría de las características de creación de datasets, informes y paneles. Esta licencia NO permite la participación de areas de trabajo convencional ni tampoco compartir o ser compartido por otra licencia de usuario. Sus características de desarrollo son casi las mismas que con PRO per dentro del area de trabajo PERSONAL para uno mismo. La única forma de compartir con esta licencia no es muy segura puesto que hablo de la característica "Publish to Web" que genera un link público. Permite hasta 8 actualizaciones por día en datos importados.
Power Bi Pro: asignadas por un administrador de office 365. Esta licencia nos permite la mayor cantidad de características de datasets, informes, paneles y dataflows. Podemos generar areas de trabajo y administrarlas. Puede compartir y ser compartido por otros desarrollos de licencia pro. Ésta, o la siguiente, es OBLIGATORIA en vistas de una auditoria de Microsoft para los usuarios que desarrollen en un area de trabajo cualquiera de los componentes mencionados. El límite de ésta licencia llega con cuestiones de tamaño, tanto en operaciones como en modelo. No se le permite operaciones de mucho procesamiento como XMLA endpoints o AI ni tampoco superar 1Gb de tamaño de modelo. Permite hasta 8 actualizaciones por día en datos importados.
Licencia Híbrida
Este es un nuevo tipo de licencia que podrá abordar un poco de las características de ambos mundos y debe ser asignada como lo hacen en ambos lugares.
Power Bi Premium Per User (PPU): asignadas por un administrador de office 365. Esta licencia es una mezcla de Premium y Pro. El uso efectivo de esta licencia se aplica prendiendo la opción PPU en la Configuración de Area de trabajo bajo la pestaña Premium y se representa con una personita delante de un diamante. Tiene todas las características que tiene una licencia PRO más las opciones de procesamiento pesadas como compute entities en dataflows o scale large datasets para generar enormes modelos además de las antes mencionadas. Añade el componente faltante Paginated Reports. Un detalle a prestar atención en ella es que el contenido dentro de un Area de trabajo PPU solo puede ser accedido por usuarios con PPU. Permite hasta 48 actualizaciones por el portal y sin límites con API.
Licencias por capacidad
Son compradas y asignadas a una Area de Trabajo en particular que reflejará un diamante a lado de su nombre como representación de la capacidad dedicada. Una capacidad puede aplicarse en N Areas de Trabajo. No es una a una como las de usuario. El contenido creado en ellas permite la totalidad de características que Power Bi provee. Determinadas y variantes por un procesamiento y almacenamiento dedicado. La principal diferencia entre ellas es el compartir. Cuando el area de trabajo tiene capacidad asignada, tanto PPU como las siguientes, puede implementar y compartir Paginated Reports.
Power Bi Embedded: se licencia mediante el portal de azure como si fuera un recurso más. Al igual que la PPU debe activarse dentro del area de trabajo. Todas las características de modelado y procesamiento será posibles con esta licencia. No habrá limites en que podemos hacer respecto a transformaciones o manipulación de datos. La particularidad de las licencias de capacidad está enfocada en el modo de compartir componentes del area. Tal como su nombre lo indica el objetivo esta en embeber. Con la misma podremos incluir nuestro contenido de Power Bi (reportes, paneles y visualizaciones) totalmente personalizado sobre un desarrollo web en gran poder de manipulación con javascript. No se refiere a pegar un link en un iframe sino a la total libertad de control de cada detalle con javascript. La aplicación puede construir dos tipos de autenticación, la integrada con Microsoft (los usuarios loguean con su cuenta profesional de office) o una personalizada (el desarrollo es dueño del login y controlar la seguridad de quien ve que). Microsoft establece que las cuentas que desarrollen los tableros en el servicio deben ser PRO. Para ver un poco más las características podemos entrar al siguiente sitio: https://playground.powerbi.com/
Power Bi Premium: se licencia mediante office. Al igual que la PPU debe activarse dentro del area de trabajo. Esta es la madre de las licencias. Todo lo que exista disponible en Power Bi y se nombró antes puede hacerse con esta licencia. Su particularidad a diferencia de las anteriores es que un area de trabajo catalogada como Premium puede compartirse a usuarios de licencias free con rol viewer. Permite construir areas de trabajo y contenido con cuentas pro y compartir a cuentas free que tengan rol de viewer. Esta es el único caso que una cuenta free puede recibir contenido compartido (a menos que desarrollemos la app anterior que no necesita ni cuenta). La otra particularidad que tiene respecto de las anteriores es que incorpora una licencia de Power Bi Report Server para implementar los informes en un entorno local.
Fabric Capacity: se licencia mediante Azure. Tiene dos tipos de pagos, con compromiso anual (gran descuento) o pay as you go (permitiendo prender y apagar). Al igual que la PPU debe activarse dentro del area de trabajo. Esta es la madre con esteroides de las licencias. Todo lo que exista disponible en Power Bi y se nombró antes puede hacerse con esta licencia. Además, incluye toda una suite de analítica end to end para que ingenieros de datos y científicos puedan integrar datos, crear experimentos y almacenar datos en lake. Fabric trae nuevo contenido para crear adicional al de PowerBi. Por ejemplo, notebooks, lakehouse, warehouse, experimentos, alertas, etc. Su particularidad a diferencia de las anteriores es que un area de trabajo catalogada como Fabric puede tener cualquier tipo de usuario desarrollando contenido Fabric. Para mantener la característica de compartir informes de PowerBi a usuarios de licencias free con rol viewer, hay un mínimo de plan que es F64. Así mismo a partir de ese plan se incluye la característica de Copilot, la IA de microsoft parar optimizar el desarrollo en la plataforma. Las cuentas pro nos permiten generar contenido PowerBi como modelos semánticos o informes de PowerBi. Esta licencia cuenta con una gran variedad de planes (SKUs). Lo que permite que a bajo costo podamos incorporarla. No está demás repetir que cuanta con todas las características antes mencionadas como capacidad para embeber en una web app.
Bonus: SQL Server Enterprise
La mayor de las licencias de SQL Server trae junto a sus servicios la posibilidad de instalar Power Bi Report Server. El mismo es semejante al antiguo Reporting Services con la diferencia que provee el renderizado de informes de Power Bi y solo informes. No tiene paneles, ni dataflows, etc. Para conocer más en detalle la diferencia entre este servicio y todas las anteriores opciones de implementación en nube podemos revisar esta documentación: https://docs.microsoft.com/en-us/power-bi/report-server/compare-report-server-service
Extra
Todo lo antes mencionado aplica para cualquier implementación sobre productos de Microsoft. Con esto me refiero a que si queremos presentar nuestros informes dentro de teams o Sharepoint, no vamos a ganar nada de distinto a lo anterior. Si lo expone un usuario pro, solo los usuarios pro con acceso a esa area de trabajo lo verán en la aplicación de Microsoft y del mismo modo si implementáramos otra de las licencias. Se considera exactamente igual a teams/sharepoint a una area de trabajo en la que hay que ser participe con la licencia correspondiente para poder ver el contenido.
Para ver en mayor detalles las características técnicas que tanto englobo y di ejemplos sin entrar en lo especifico, aquí podemos encontrar una tabla exponiendo más en detalle y comparando tres de las licencias más usadas:
https://powerbi.microsoft.com/en-us/pricing/
Tengamos presente que la licencia Fabric podría estar ocupando el lugar de Premium entre el periodo 2024-2025, puesto que a precio similar cuenta con más capacidades.
NOTA: Recordemos que Free hace lo mismo que Pro sin compartir, Embed hace lo mismo que premium sin compartir a usuarios free sino que va por medio de una aplicación creada.
Espero que esto ayude a aclarar las dudas al momento de iniciarse en Power Bi.
#powerbi#power bi#power bi service#power bi tutorial#power bi argentina#power bi cordoba#power bi jujuy
0 notes
Text
¿En que región esta mi Power Bi?
Cuando nuestro Bi comienza a crecer y comenzamos a encontrarnos con soluciones nube de Azure data plaform es importante conocer la región donde nuestro Power Bi Service, del Tenant que usamos, esta alojado. Sea porque vamos a realizar algún desarrollo o relacionarlo con un almacenamiento de Data Lake Gen2 para DataFlows.
Para ellos nos dirigimos al menú superior derecho donde se encuentra el signo de pregunta “?” y seleccionamos “Acerca de Power Bi”.

En dicha ventana encontraremos donde se encuentra ubicado nuestro tenant dentro del servicio de Power Bi.
0 notes