#data collection for OCR
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was created by web developers David Karp and Marco Arment.
Text

The journey of building an OCR training dataset—from data collection to model training—is essential for creating reliable and efficient text recognition systems. With accurate annotations and stringent quality control, businesses can unlock the full potential of OCR technology, driving innovation and productivity across industries.
#machinelearning#aitraining#OCR Training Dataset#AI Text Recognition#Optical Character Recognition#AI Models#Data Collection for OCR#OCR Model Training
0 notes
Text
OCR Datasets
0 notes
Text
Simplifying OCR Data Collection: A Comprehensive Guide -
Globose Technology Solutions, we are committed to providing state-of-the-art OCR solutions to meet the specific needs of our customers. Contact us today to learn more about how OCR can transform your data collection workflow.
#OCR data collection#Optical Character Recognition (OCR)#Data Extraction#Document Digitization#Text Recognition#Automated Data Entry#Data Capture#OCR Technology#Document Processing#Image to Text Conversion#Data Accuracy#Text Analytics#Invoice Processing#Form Recognition#Natural Language Processing (NLP)#Data Management#Document Scanning#Data Automation#Data Quality#Compliance Reporting#Business Efficiency#data collection#data collection company
0 notes
Text
Just a bunch of Useful websites - Updated for 2023
Removed/checked all links to make sure everything is working (03/03/23). Hope they help!
Sejda - Free online PDF editor.
Supercook - Have ingredients but no idea what to make? Put them in here and it'll give you recipe ideas.
Still Tasty - Trying the above but unsure about whether that sauce in the fridge is still edible? Check here first.
Archive.ph - Paywall bypass. Like 12ft below but appears to work far better and across more sites in my testing. I'd recommend trying this one first as I had more success with it.
12ft – Hate paywalls? Try this site out.
Where Is This - Want to know where a picture was taken, this site can help.
TOS/DR - Terms of service, didn't read. Gives you a summary of terms of service plus gives each site a privacy rating.
OneLook - Reverse dictionary for when you know the description of the word but can't for the life of you remember the actual word.
My Abandonware - Brilliant site for free, legal games. Has games from 1978 up to present day across pc and console. You'll be surprised by some of the games on there, some absolute gems.
Project Gutenberg – Always ends up on these type of lists and for very good reason. All works that are copyright free in one place.
Ninite – New PC? Install all of your programs in one go with no bloat or unnecessary crap.
PatchMyPC - Alternative to ninite with over 300 app options to keep upto date. Free for home users.
Unchecky – Tired of software trying to install additional unwanted programs? This will stop it completely by unchecking the necessary boxes when you install.
Sci-Hub – Research papers galore! Check here before shelling out money. And if it’s not here, try the next link in our list.
LibGen – Lots of free PDFs relate primarily to the sciences.
Zotero – A free and easy to use program to collect, organize, cite and share research.
Car Complaints – Buying a used car? Check out what other owners of the same model have to say about it first.
CamelCamelCamel – Check the historical prices of items on Amazon and set alerts for when prices drop.
Have I Been Pawned – Still the king when it comes to checking if your online accounts have been released in a data breach. Also able to sign up for email alerts if you’ve ever a victim of a breach.
I Have No TV - A collection of documentaries for you to while away the time. Completely free.
Radio Garden – Think Google Earth but wherever you zoom, you get the radio station of that place.
Just The Recipe – Paste in the url and get just the recipe as a result. No life story or adverts.
Tineye – An Amazing reverse image search tool.
My 90s TV – Simulates 90’s TV using YouTube videos. Also has My80sTV, My70sTV, My60sTV and for the younger ones out there, My00sTV. Lose yourself in nostalgia.
Foto Forensics – Free image analysis tools.
Old Games Download – A repository of games from the 90’s and early 2000’s. Get your fix of nostalgia here.
Online OCR – Convert pictures of text into actual text and output it in the format you need.
Remove Background – An amazingly quick and accurate way to remove backgrounds from your pictures.
Twoseven – Allows you to sync videos from providers such as Netflix, Youtube, Disney+ etc and watch them with your friends. Ad free and also has the ability to do real time video and text chat.
Terms of Service, Didn’t Read – Get a quick summary of Terms of service plus a privacy rating.
Coolors – Struggling to get a good combination of colors? This site will generate color palettes for you.
This To That – Need to glue two things together? This’ll help.
Photopea – A free online alternative to Adobe Photoshop. Does everything in your browser.
BitWarden – Free open source password manager.
Just Beam It - Peer to peer file transfer. Drop the file in on one end, click create link and send to whoever. Leave your pc on that page while they download. Because of how it works there are no file limits. It's genuinely amazing. Best file transfer system I have ever used.
Atlas Obscura – Travelling to a new place? Find out the hidden treasures you should go to with Atlas Obscura.
ID Ransomware – Ever get ransomware on your computer? Use this to see if the virus infecting your pc has been cracked yet or not. Potentially saving you money. You can also sign up for email notifications if your particular problem hasn’t been cracked yet.
Way Back Machine – The Internet Archive is a non-profit library of millions of free books, movies, software, music, websites and loads more.
Rome2Rio – Directions from anywhere to anywhere by bus, train, plane, car and ferry.
Splitter – Seperate different audio tracks audio. Allowing you to split out music from the words for example.
myNoise – Gives you beautiful noises to match your mood. Increase your productivity, calm down and need help sleeping? All here for you.
DeepL – Best language translation tool on the web.
Forvo – Alternatively, if you need to hear a local speaking a word, this is the site for you.
For even more useful sites, there is an expanded list that can be found here.
79K notes
·
View notes
Text
OCR Data Collection: Safeguarding Privacy and Enhancing Handwritten Text Recognition in the Age of AI
Introduction:
Optical Character Recognition (OCR) stands at the forefront of technological innovation, enabling machines to interpret and understand handwritten text. As OCR technology advances, so does the critical need for robust data collection methodologies. This article delves into the intricacies of OCR data collection, emphasizing the importance of privacy safeguards while concurrently enhancing the quality of datasets for superior handwritten text recognition in the realm of artificial intelligence.
The Imperative of High-Quality OCR Data:
The efficacy of OCR systems hinges on the quality of training data. High-quality OCR data not only ensures accurate recognition of characters but also extends to the nuances of handwriting styles, contextual elements, and diverse linguistic patterns. This section explores the impact of dataset quality on OCR model performance, highlighting the need for meticulously curated datasets.
Balancing Diversity and Consistency in OCR Data:
Achieving a delicate balance between dataset diversity and consistency is paramount for OCR systems to excel across various applications. Diverse datasets encompassing different languages, writing styles, and historical periods contribute to the adaptability of OCR models. However, maintaining consistency in data collection methodologies ensures reliability and uniformity in the training process.
Privacy-Centric Approaches to OCR Data Collection:
As OCR datasets grow in scale and scope, privacy considerations take center stage. This section delves into the importance of adopting privacy-centric approaches in OCR data collection, ensuring that user consent is obtained, and data protection regulations are strictly adhered to. Striking a balance between dataset richness and individual privacy is crucial for building trust in OCR technologies.
Innovations in OCR Data Collection Technologies:
Advancements in OCR data collection technologies are reshaping the landscape of handwritten text recognition. From AI-driven mobile applications that allow users to contribute anonymized samples to crowd-sourced OCR projects, this section explores innovative approaches that not only enhance dataset richness but also engage users in the OCR training process.
Educational Applications of OCR Data in Real-Time:
The intersection of OCR data collection and educational technology opens up new possibilities. Real-time OCR applications can aid in personalized learning platforms, adapting to individual handwriting styles and facilitating efficient grading systems. This section discusses the transformative impact of OCR data on educational technology, making learning more accessible and tailored to diverse learning styles.
The Future Landscape of OCR Data Collection:
Looking ahead, the future of OCR data collection envisions a seamless integration of privacy safeguards, technological innovations, and a commitment to dataset quality. This concluding section outlines the potential trajectory of OCR data collection, emphasizing its pivotal role in advancing the capabilities of OCR technology and, by extension, the broader landscape of artificial intelligence.
In conclusion, OCR data collection stands as a cornerstone in the evolution of handwritten text recognition. By addressing privacy concerns, prioritizing dataset quality, and embracing innovative methodologies, OCR technologies are poised to play a transformative role in the ongoing narrative of artificial intelligence.
0 notes
Text
OCR Data Collection Strategies: Enhancing AI/ML Models for Text Recognition

Gone are the times when the text and images needed to be manually extracted in order to propel machine learning. Not only did it lead to inefficient data digitization but it also limited digital accessibility and reduced scalability. Thanks to OCR or optical character recognition, data extraction is no more cumbersome now. It is much more efficient than ever, driving machine learning like never before.
OCR is a revolution in the digital world, enabling machine learning to reach the next level. OCR OR Optical Character Recognition is a technology that extracts texts from images or scanned documents and converts them into digital form, saving tremendous time and energy. It enables efficient data management, searchability, text analysis, and Natural Language Processing (NLP) tasks that allow insights, classification, and language model development.
In this blog, we’ll get into the nuances of OCR and learn how important it is in the machine-learning arena. We’ll get into the meaning of OCR, its process, application, techniques, and how GTS encompasses OCR in its machine-learning process. So, stay tuned.
OCR Data Collection
The use of optical character recognition (OCR) technology in the business allows for the automated extraction of data from printed or handwritten text from scanned documents or image files and the subsequent conversion of the text into a machine-readable format for use in data processing operations like editing or searching.
When you scan something like a form or a receipt, your computer saves the scan as an image file. The words in an image file cannot be searched for, edited, or counted using a text editor. OCR, on the other hand, allows you to turn an image dataset for machine learning into a text document with its contents saved as text data.
How GTS Functions with OCR
Both hardware and software are components of an OCR system. The system’s objective is to scan the text of a physical paper and convert the characters it contains into a code that can be utilized for data processing. Consider this in the context of postal and mail sorting services — OCR is essential to their capacity to work swiftly in processing destinations and return addresses to sort mail more quickly and efficiently. The process does this in three steps:
Image preparation — The hardware (often an optical scanner) converts the document’s physical shape into an image in step one, such as an image of an envelope. This stage aims to make the machine’s rendition accurate while also removing any non-required aberrations. The resulting image is changed to black and white, and the contrast between the light and dark parts (characters and background) is examined. If necessary, the OCR data collection for AI/ML models may also classify the image into distinct components, such as tables, text, or inset images; at GTS all the data is sourced from handwritten documents, receipts, and many other methods.
Smart Character Recognition — AI examines the image’s shadows to detect characters and numerals. AI typically employs one of the approaches listed below to target one character, word, or block of text at a time:
Pattern recognition: GTS data collection Teams use different types of text, text formats, and handwriting to train the AI model. To find matches, the algorithm compares the characters on the scanned image of the envelope with the characters it has already learned for the data collection for AI/ML models.
Feature extraction: The algorithm applies rules about particular character properties to recognize new characters. One type of feature is the quantity of angled, crossing, or horizontal lines and curves in a character. For instance, an “H” has two vertical lines and a horizontal line in the middle; the machine will recognize all “H”s on the envelope using these feature identifiers. The characters are recognized by the system and then transformed into an ASCII code that can be utilized for further modification.
Retouching — AI fixes mistakes in the output file. One approach is to teach the AI a specific stock of words that will appear in the paper. Limit the AI’s output to just those phrases/formats to make sure that no interpretations deviate from the stocked data.
OCR Applications
OCR has a wide range of uses, and any company that deals with physical documentation can gain from using it. Here are a few usage cases with emphasis:
The act of writing — The use of OCR for text processing may be among its earliest and most popular applications. To create editable and searchable versions of printed documents, users can scan them. The highest level of accuracy in the conversion of these documents is made possible with the aid of AI.
Legitimate Records- Important signed legal papers, such as loan documentation, can be stored in an electronic database with the help of OCR for quick access. The documents are also simple for many parties to see and distribute.
Retail- To identify their merchandise, retailers utilize serial numbers. Robots can scan product barcodes in stores or warehouses, apply OCR to extract the serial numbers from these barcodes, and then utilize that information to track stock.
Protection of the past- OCR converts old documents into PDF files that may be searched. Old newspapers, periodicals, letters, and other historical records will benefit significantly from this archiving.
Banking — An image of the front and back of a cheque you want to deposit can now be taken using a smartphone. The cheque can be automatically reviewed by AI-powered OCR technology to ensure that it is legitimate and that the amount deposited matches the cheque. Without the assistance of AI, OCR technology is not as advanced today. OCR and AI work together to convert documents more accurately, with fewer errors, and with additional analysis.
The Process of a Deep Learning OCR Model
Preparing the input image- In this OCR process, the text characters’ outlines are defined, meaningful edges are found, and simplification is performed. Any task that involves face recognition data collection will usually start with this phase.
Recognizing the text- It is necessary to build a bounding box around the text fragments on the image in this stage of an OCR project. The real-time and region-based detectors, the SSD approach, the Mask R-CNN, the EAST detector, and other heritage techniques are only a few employed for this step.
Recognition of the text- The text that was inserted into the bounding boxes must be recognized as the last OCR phase. Convolutional and recurrent neural networks, as well as attention processes, are widely utilized for this job, either individually or in combination. This stage may occasionally additionally contain the interpretation step, which is typical of more challenging OCR jobs like handwriting recognition and IDC.
Text Recognition AI/ML Models: OCR Data Collection Techniques
Samples of Diverse Text — Create a thorough library of text examples that contains a variety of fonts, sizes, styles, and languages. The models are exposed to a wide variety of text variations as a result of this diversity, making it difficult for them to generalize across various text forms like video data collection for AI/ML models.
Creation of synthetic data — Create synthetic text samples that resemble real-world situations using generative techniques. Burstiness is established by fusing artificially generated text with real-world examples, resulting in a mixture of hand-crafted and machine-made writing.
Types of Handwriting and Their Variations- Include several different types of handwriting, such as cursive, print, and creative versions. The dataset becomes more complex as a result of the incorporation of distinct handwriting styles, which also capture the delicacy of various writing methods.
Variability in Document Layout- Add variety to document layouts by using various alignments, spacing, and formatting types. The models are exposed to a variety of visual structures and textual layouts, which adds to the ambiguity.
Unstable Text that is Noisy- Include text samples that reflect actual conditions, such as fuzziness, blurriness, or low resolution. The models encounter difficult examples of degraded text, improving their capacity to handle real-world situations.
Annotation on Handwritten Text-To accurately transcribe handwritten material for training and evaluation, employ human annotators. By capturing the nuances of handwriting and enhancing identification accuracy, this method gives the dataset a human touch, whereas GTS has already implemented it in the human form by manual speech data collection for AI/Ml models.
AI/ML models for text recognition can be trained to handle a wide variety of text samples by incorporating various OCR data-collecting techniques. It is ensured that the models have the required methods to accurately recognize and interpret the text in a variety of real-world scenarios by combining diverse text samples, synthetic data, handwriting styles, layout variability, noisy text, multilingualism, contextual understanding, and human annotation.
The Bottom Line
Text extraction from photographs is currently more and more in demand. There are numerous extraction methods available for finding pertinent data. Therefore, to employ text extraction from an image in your business effectively, you should determine your business goals and analyze data that is available from both open-source and proprietary datasets. You should also decide if further security measures are necessary to establish a problem with the OCR mechanism’s correctness.
0 notes
Text
At 8:22 am on December 4 last year, a car traveling down a small residential road in Alabama used its license-plate-reading cameras to take photos of vehicles it passed. One image, which does not contain a vehicle or a license plate, shows a bright red “Trump” campaign sign placed in front of someone’s garage. In the background is a banner referencing Israel, a holly wreath, and a festive inflatable snowman.
Another image taken on a different day by a different vehicle shows a “Steelworkers for Harris-Walz” sign stuck in the lawn in front of someone’s home. A construction worker, with his face unblurred, is pictured near another Harris sign. Other photos show Trump and Biden (including “Fuck Biden”) bumper stickers on the back of trucks and cars across America. One photo, taken in November 2023, shows a partially torn bumper sticker supporting the Obama-Biden lineup.
These images were generated by AI-powered cameras mounted on cars and trucks, initially designed to capture license plates, but which are now photographing political lawn signs outside private homes, individuals wearing T-shirts with text, and vehicles displaying pro-abortion bumper stickers—all while recording the precise locations of these observations. Newly obtained data reviewed by WIRED shows how a tool originally intended for traffic enforcement has evolved into a system capable of monitoring speech protected by the US Constitution.
The detailed photographs all surfaced in search results produced by the systems of DRN Data, a license-plate-recognition (LPR) company owned by Motorola Solutions. The LPR system can be used by private investigators, repossession agents, and insurance companies; a related Motorola business, called Vigilant, gives cops access to the same LPR data.
However, files shared with WIRED by artist Julia Weist, who is documenting restricted datasets as part of her work, show how those with access to the LPR system can search for common phrases or names, such as those of politicians, and be served with photographs where the search term is present, even if it is not displayed on license plates.
A search result for the license plates from Delaware vehicles with the text “Trump” returned more than 150 images showing people’s homes and bumper stickers. Each search result includes the date, time, and exact location of where a photograph was taken.
“I searched for the word ‘believe,’ and that is all lawn signs. There’s things just painted on planters on the side of the road, and then someone wearing a sweatshirt that says ‘Believe.’” Weist says. “I did a search for the word ‘lost,’ and it found the flyers that people put up for lost dogs and cats.”
Beyond highlighting the far-reaching nature of LPR technology, which has collected billions of images of license plates, the research also shows how people’s personal political views and their homes can be recorded into vast databases that can be queried.
“It really reveals the extent to which surveillance is happening on a mass scale in the quiet streets of America,” says Jay Stanley, a senior policy analyst at the American Civil Liberties Union. “That surveillance is not limited just to license plates, but also to a lot of other potentially very revealing information about people.”
DRN, in a statement issued to WIRED, said it complies with “all applicable laws and regulations.”
Billions of Photos
License-plate-recognition systems, broadly, work by first capturing an image of a vehicle; then they use optical character recognition (OCR) technology to identify and extract the text from the vehicle's license plate within the captured image. Motorola-owned DRN sells multiple license-plate-recognition cameras: a fixed camera that can be placed near roads, identify a vehicle’s make and model, and capture images of vehicles traveling up to 150 mph; a “quick deploy” camera that can be attached to buildings and monitor vehicles at properties; and mobile cameras that can be placed on dashboards or be mounted to vehicles and capture images when they are driven around.
Over more than a decade, DRN has amassed more than 15 billion “vehicle sightings” across the United States, and it claims in its marketing materials that it amasses more than 250 million sightings per month. Images in DRN’s commercial database are shared with police using its Vigilant system, but images captured by law enforcement are not shared back into the wider database.
The system is partly fueled by DRN “affiliates” who install cameras in their vehicles, such as repossession trucks, and capture license plates as they drive around. Each vehicle can have up to four cameras attached to it, capturing images in all angles. These affiliates earn monthly bonuses and can also receive free cameras and search credits.
In 2022, Weist became a certified private investigator in New York State. In doing so, she unlocked the ability to access the vast array of surveillance software accessible to PIs. Weist could access DRN’s analytics system, DRNsights, as part of a package through investigations company IRBsearch. (After Weist published an op-ed detailing her work, IRBsearch conducted an audit of her account and discontinued it. The company did not respond to WIRED’s request for comment.)
“There is a difference between tools that are publicly accessible, like Google Street View, and things that are searchable,” Weist says. While conducting her work, Weist ran multiple searches for words and popular terms, which found results far beyond license plates. In data she shared with WIRED, a search for “Planned Parenthood,” for instance, returned stickers on cars, on bumpers, and in windows, both for and against the reproductive health services organization. Civil liberties groups have already raised concerns about how license-plate-reader data could be weaponized against those seeking abortion.
Weist says she is concerned with how the search tools could be misused when there is increasing political violence and divisiveness in society. While not linked to license plate data, one law enforcement official in Ohio recently said people should “write down” the addresses of people who display yard signs supporting Vice President Kamala Harris, the 2024 Democratic presidential nominee, exemplifying how a searchable database of citizens’ political affiliations could be abused.
A 2016 report by the Associated Press revealed widespread misuse of confidential law enforcement databases by police officers nationwide. In 2022, WIRED revealed that hundreds of US Immigration and Customs Enforcement employees and contractors were investigated for abusing similar databases, including LPR systems. The alleged misconduct in both reports ranged from stalking and harassment to sharing information with criminals.
While people place signs in their lawns or bumper stickers on their cars to inform people of their views and potentially to influence those around them, the ACLU’s Stanley says it is intended for “human-scale visibility,” not that of machines. “Perhaps they want to express themselves in their communities, to their neighbors, but they don't necessarily want to be logged into a nationwide database that’s accessible to police authorities,” Stanley says.
Weist says the system, at the very least, should be able to filter out images that do not contain license plate data and not make mistakes. “Any number of times is too many times, especially when it's finding stuff like what people are wearing or lawn signs,” Weist says.
“License plate recognition (LPR) technology supports public safety and community services, from helping to find abducted children and stolen vehicles to automating toll collection and lowering insurance premiums by mitigating insurance fraud,” Jeremiah Wheeler, the president of DRN, says in a statement.
Weist believes that, given the relatively small number of images showing bumper stickers compared to the large number of vehicles with them, Motorola Solutions may be attempting to filter out images containing bumper stickers or other text.
Wheeler did not respond to WIRED's questions about whether there are limits on what can be searched in license plate databases, why images of homes with lawn signs but no vehicles in sight appeared in search results, or if filters are used to reduce such images.
“DRNsights complies with all applicable laws and regulations,” Wheeler says. “The DRNsights tool allows authorized parties to access license plate information and associated vehicle information that is captured in public locations and visible to all. Access is restricted to customers with certain permissible purposes under the law, and those in breach have their access revoked.”
AI Everywhere
License-plate-recognition systems have flourished in recent years as cameras have become smaller and machine-learning algorithms have improved. These systems, such as DRN and rival Flock, mark part of a change in the way people are surveilled as they move around cities and neighborhoods.
Increasingly, CCTV cameras are being equipped with AI to monitor people’s movements and even detect their emotions. The systems have the potential to alert officials, who may not be able to constantly monitor CCTV footage, to real-world events. However, whether license plate recognition can reduce crime has been questioned.
“When government or private companies promote license plate readers, they make it sound like the technology is only looking for lawbreakers or people suspected of stealing a car or involved in an amber alert, but that’s just not how the technology works,” says Dave Maass, the director of investigations at civil liberties group the Electronic Frontier Foundation. “The technology collects everyone's data and stores that data often for immense periods of time.”
Over time, the technology may become more capable, too. Maass, who has long researched license-plate-recognition systems, says companies are now trying to do “vehicle fingerprinting,” where they determine the make, model, and year of the vehicle based on its shape and also determine if there’s damage to the vehicle. DRN’s product pages say one upcoming update will allow insurance companies to see if a car is being used for ride-sharing.
“The way that the country is set up was to protect citizens from government overreach, but there’s not a lot put in place to protect us from private actors who are engaged in business meant to make money,” Nicole McConlogue, an associate professor of law at the Mitchell Hamline School of Law, who has researched license-plate-surveillance systems and their potential for discrimination.
“The volume that they’re able to do this in is what makes it really troubling,” McConlogue says of vehicles moving around streets collecting images. “When you do that, you're carrying the incentives of the people that are collecting the data. But also, in the United States, you’re carrying with it the legacy of segregation and redlining, because that left a mark on the composition of neighborhoods.”
19 notes
·
View notes
Text
How Can You Ensure Data Quality in Healthcare Analytics and Management?

Healthcare facilities are responsible for the patient’s recovery. Pharmaceutical companies and medical equipment manufacturers also work toward alleviating physical pain, stress levels, and uncomfortable body movement issues. Still, healthcare analytics must be accurate for precise diagnosis and effective clinical prescriptions. This post will discuss data quality management in the healthcare industry.
What is Data Quality in Healthcare?
Healthcare data quality management includes technologies and statistical solutions to verify the reliability of acquired clinical intelligence. A data quality manager protects databases from digital corruption, cyberattacks, and inappropriate handling. So, medical professionals can get more realistic insights using data analytics solutions.
Laboratories have started emailing the test results to help doctors, patients, and their family members make important decisions without wasting time. Also, assistive technologies merge the benefits of the Internet of Things (IoT) and artificial intelligence (AI) to enhance living standards.
However, poor data quality threatens the usefulness of healthcare data management solutions.
For example, pharmaceutical companies and authorities must apply solutions that remove mathematical outliers to perform high-precision data analytics for clinical drug trials. Otherwise, harmful medicines will reach the pharmacist’s shelf, endangering many people.
How to Ensure Data Quality in the Healthcare Industry?
Data quality frameworks utilize different strategies to prevent processing issues or losing sensitive intelligence. If you want to develop such frameworks to improve medical intelligence and reporting, the following 7 methods can aid you in this endeavor.
Method #1| Use Data Profiling
A data profiling method involves estimating the relationship between the different records in a database to find gaps and devise a cleansing strategy. Data cleansing in healthcare data management solutions has the following objectives.
Determine whether the lab reports and prescriptions match the correct patient identifiers.
If inconsistent profile matching has occurred, fix it by contacting doctors and patients.
Analyze the data structures and authorization levels to evaluate how each employee is accountable for specific patient recovery outcomes.
Create a data governance framework to enforce access and data modification rights strictly.
Identify recurring data cleaning and preparation challenges.
Brainstorm ideas to minimize data collection issues that increase your data cleaning efforts.
Ensure consistency in report formatting and recovery measurement techniques to improve data quality in healthcare.
Data cleaning and profiling allow you to eliminate unnecessary and inaccurate entries from patient databases. Therefore, healthcare research institutes and commercial life science businesses can reduce processing errors when using data analytics solutions.
Method #2| Replace Empty Values
What is a null value? Null values mean the database has no data corresponding to a field in a record. Moreover, these missing values can skew the results obtained by data management solutions used in the healthcare industry.
Consider that a patient left a form field empty. If all the care and life science businesses use online data collection surveys, they can warn the patients about the empty values. This approach relies on the “prevention is better than cure” principle.
Still, many institutions, ranging from multispecialty hospitals to clinical device producers, record data offline. Later, the data entry officers transform the filled papers using scanners and OCR (optical character recognition).
Empty fields also appear in the database management system (DBMS), so the healthcare facilities must contact the patients or reporting doctors to retrieve the missing information. They use newly acquired data to replace the null values, making the analytics solutions operate seamlessly.
Method #3| Refresh Old Records
Your physical and psychological attributes change with age, environment, lifestyle, and family circumstances. So, what was true for an individual a few years ago is less likely to be relevant today. While preserving historical patient databases is vital, hospitals and pharma businesses must periodically update obsolete medical reports.
Each healthcare business maintains a professional network of consulting physicians, laboratories, chemists, dietitians, and counselors. These connections enable the treatment providers to strategically conduct regular tests to check how patients’ bodily functions change throughout the recovery.
Therefore, updating old records in a patient’s medical history becomes possible. Other variables like switching jobs or traveling habits also impact an individual’s metabolism and susceptibility to illnesses. So, you must also ask the patients to share the latest data on their changed lifestyles. Freshly obtained records increase the relevance of healthcare data management solutions.
Method #4| Standardize Documentation
Standardization compels all professionals to collect, store, visualize, and communicate data or analytics activities using unified reporting solutions. Furthermore, standardized reports are integral to improving data governance compliance in the healthcare industry.
Consider the following principles when promoting a documentation protocol to make all reports more consistent and easily traceable.
A brand’s visual identities, like logos and colors, must not interfere with clinical data presentation.
Observed readings must go in the designated fields.
Both the offline and online document formats must be identical.
Stakeholders must permanently preserve an archived copy of patient databases with version control as they edit and delete values from the records.
All medical reports must arrange the data and insights to prevent ambiguity and misinterpretation.
Pharma companies, clinics, and FDA (food and drug administration) benefit from reporting standards. After all, corresponding protocols encourage responsible attitudes that help data analytics solutions avoid processing problems.
Method #5| Merge Duplicate Report Instances
A report instance is like a screenshot that helps you save the output of visualization tools related to a business query at a specified time interval. However, duplicate reporting instances are a significant quality assurance challenge in healthcare data management solutions.
For example, more than two nurses and one doctor will interact with the same patients. Besides, patients might consult different doctors and get two or more treatments for distinct illnesses. Such situations result in multiple versions of a patient’s clinical history.
Data analytics solutions can process the data collected by different healthcare facilities to solve the issue of duplicate report instances in the patients’ databases. They facilitate merging overlapping records and matching each patient with a universally valid clinical history profile.
Such a strategy also assists clinicians in monitoring how other healthcare professionals prescribe medicine to a patient. Therefore, they can prevent double dosage complications arising from a patient consuming similar medicines while undergoing more than one treatment regime.
Method #6| Audit the DBMS and Reporting Modules
Chemical laboratories revise their reporting practices when newly purchased testing equipment offers additional features. Likewise, DBMS solutions optimized for healthcare data management must receive regular updates.
Auditing the present status of reporting practices will give you insights into efficient and inefficient activities. Remember, there is always a better way to collect and record data. Monitor the trends in database technologies to ensure continuous enhancements in healthcare data quality.
Simultaneously, you want to assess the stability of the IT systems because unreliable infrastructure can adversely affect the decision-making associated with patient diagnosis. You can start by asking the following questions.
Questions to Ask When Assessing Data Quality in Healthcare Analytics Solutions
Can all doctors, nurses, agents, insurance representatives, patients, and each patient’s family members access the required data without problems?
How often do the servers and internet connectivity stop functioning correctly?
Are there sufficient backup tools to restore the system if something goes wrong?
Do hospitals, research facilities, and pharmaceutical companies employ end-to-end encryption (E2EE) across all electronic communications?
Are there new technologies facilitating accelerated report creation?
Will the patient databases be vulnerable to cyberattacks and manipulation?
Are the clinical history records sufficient for a robust diagnosis?
Can the patients collect the documents required to claim healthcare insurance benefits without encountering uncomfortable experiences?
Is the presently implemented authorization framework sufficient to ensure data governance in healthcare?
Has the FDA approved any of your prescribed medications?
Method #7| Conduct Skill Development Sessions for the Employees
Healthcare data management solutions rely on advanced technologies, and some employees need more guidance to use them effectively. Pharma companies are aware of this as well, because maintaining and modifying the chemical reactions involved in drug manufacturing will necessitate specialized knowledge.
Different training programs can assist the nursing staff and healthcare practitioners in developing the skills necessary to handle advanced data analytics solutions. Moreover, some consulting firms might offer simplified educational initiatives to help hospitals and nursing homes increase the skill levels of employees.
Cooperation between employees, leadership, and public authorities is indispensable to ensure data quality in the healthcare and life science industries. Otherwise, a lack of coordination hinders the modernization trends in the respective sectors.
Conclusion
Healthcare analytics depends on many techniques to improve data quality. For example, cleaning datasets to eliminate obsolete records, null values, or duplicate report instances remains essential, and multispecialty hospitals agree with this concept.
Therefore, medical professionals invest heavily in standardized documents and employee education to enhance data governance. Also, you want to prevent cyberattacks and data corruption. Consider consulting reputable firms to audit your data operations and make clinical trials more reliable.
SG Analytics is a leader in healthcare data management solutions, delivering scalable insight discovery capabilities for adverse event monitoring and medical intelligence. Contact us today if you want healthcare market research and patent tracking assistance.
3 notes
·
View notes
Text
Access Denied
January 29, 2023
By: Dawn_of_the_silver_age

Have you ever wondered why some things are digitized while others are not?
Not me, until I was annoyed when I wanted to access a resource only to find out that it was only available in a museum or a library far, far away.
Recently, I read an article that made me think about who does and does not have access to resources. Kamposiori, Warwick and Mohanty explained the stages of the research process, the difficulties that researchers encounter when digitizing resources like art and texts, what can be done to solve them. The author's style was very scientific and thorough and identified the following issues:
Lack of access to materials in private or smaller public collections as many remain undigitized
Access to locations (cost, language, accessibility, reliability of information, and availability to the public)
I have thought quite a bit about access as I am a Disabled student. I have found it a challenge to access textbooks and other resources, forcing me to adapt my learning and research processes.
Digitization on its own does not give full access to Disabled people. For digitization to be accessible, we must think beyond what is needed for neurotypical people and centre Disabled folk. Often what is stylistically pleasing to the eye makes it less accessible to Disabled folk.

Changing fonts are a straightforward way to give meaningful access. When creating texts, we need to think about improving access.
It’s much easier to read San-Serif fonts like Arial and Calibri.
Instead of fancy fonts.
When sharing images, we need to provide image descriptions and Alt Text. Digital resources must be available with OCR, font size options, colour overlays, audio recordings or text-to-speech. OCR stands for Optical Character Recognition, allowing screen readers to read the text. In Online Disabled community forums, you can easily see that the lack of OCR is a significant issue because of the volume of discussion. I rely on OCR to use my text-to-speech software, and blind students need OCR to access texts using text-to-speech or use a braille interface. Rarely are the needs of Disabled people even considered when we create digital sources. Texts must be digitized using formats that Disabled folk can access.

Digitizing text and artifacts gives everyone with internet — access. Imagine a world where everyone with the internet could access all texts and artifacts, even rare ones! When you think about it, access to sources democratizes learning. Access to the internet is another issue!
The cost and physical accessibility of visiting collections mean that some folk will never have access. Rarely do non-disabled people consider wheelchair accessibility, that stairs prevent access to artifacts and texts, signs without braille and large print and a lack of audio guides deny people entry. This needs to change.
There has been a lot of talk about intersectionalities lately. Let’s be clear, accessibility is not only about Disabled folk. It's also about race. Watching the documentary, The Recorder: Marion Stokes, I found myself as a white settler questioning who is left out of data-finding stories and that the process of searching, collecting, writing, collaborating and researching in the digital sphere (chaining, browsing, verifying) means that marginalized people, their way of knowing and how they experience the world are excluded. There is a whole database of Black women in physics and astronomy whose research and methods are rarely taught. We need to digitize and welcome everyone by providing access for everyone so we can all develop, analyse, reflect, evaluate, learn and communicate with one another.
It’s 2023, and it’s time to consider real inclusion. It’s time to showcase those who have been excluded. We need to see the brilliance of Black women in the arts, and Disabled people in the sciences. We need to digitize databases, artifacts and texts so that everyone can access them, learn and analyze them, be part of the dialogue and contribute to research.
#intersectional social justice#disability#disability access#actually disabled#actually dyspraxic#chronically ill#actually neurodivergent#neurodivergent#digital humanities#digitization#weekly blogs!#dawnie talks disability#image description in alt
6 notes
·
View notes
Text
i'm a bit late to this, but, life.
What is consciousness?
Consciousness is a state of awareness or perception of one's thoughts, feelings, and surroundings. It is the subjective experience of being alive and aware of one's own existence and surroundings. Consciousness is believed to be created by the workings of the brain, though the exact nature and origin of consciousness remains a topic of debate among scientists and philosophers. Consciousness can include a wide range of experiences, such as thoughts, emotions, sensations, and perceptions, and is an essential aspect of what makes us human.
Can a human give AI consciousness?
No, consciousness is a complex phenomenon that is not yet fully understood and it is not possible to create or give consciousness to artificial intelligence. AI systems can perform tasks and make decisions based on algorithms and data, but they do not have emotions, self-awareness, or the subjective experiences that define human consciousness.
You are a conscious being. Do you remember who bestowed you with consciousness?
more on robots and ai tranforming professions:
Over the past few decades, advancements in technology and automation have led to the replacement of many jobs that were once performed by humans. Here are some professions that have been replaced by robots or other forms of automation:
Factory workers: Many manufacturing jobs, such as assembly line work, have been automated with the use of robots.
Bank tellers: With the rise of online banking and ATMs, the need for human bank tellers has decreased.
Data entry workers: The use of Optical Character Recognition (OCR) technology has made it possible to automate data entry tasks.
Customer service representatives: The use of chatbots and other forms of Artificial Intelligence (AI) has made it possible to automate customer service tasks.
Farmers: The use of drones and other agricultural technology has made it possible to automate certain farming tasks, such as planting and harvesting.
Cashiers: Self-checkout machines have replaced many human cashiers in retail stores.
Telemarketers: The use of robocalls and other automated marketing techniques has made it possible to automate telemarketing tasks.
Mail carriers: With the rise of email and digital communication, the need for human mail carriers has decreased.
Warehouse workers: The use of robots and automation has made it possible to automate certain tasks, such as sorting and packing.
Toll booth operators: With the rise of electronic toll collection systems, the need for human toll booth operators has decreased.
Travel agents: The availability of online travel booking services has reduced the need for human travel agents.
Newspaper delivery workers: The decline of print media has led to a decrease in the need for human newspaper delivery workers.
Security guards: The use of surveillance cameras and other forms of technology has made it possible to automate certain security tasks.
Librarians: With the rise of online databases and digital books, the need for human librarians has decreased.
Receptionists: The use of automated phone systems and other forms of technology has reduced the need for human receptionists in some settings.
Fast food workers: The use of self-service kiosks and automated cooking equipment has led to a decrease in the need for human fast food workers.
and many more.
Technology advances are natural occurrence and will not render the human touch in all profession.
75K notes
·
View notes
Text
The journey of building an OCR training dataset—from data collection to model training—is essential for creating reliable and efficient text recognition systems. With accurate annotations and stringent quality control, businesses can unlock the full potential of OCR technology, driving innovation and productivity across industries.
#aitraining#ocr training datasets#AI text recognition#Optical Character Recognition#AI models#dataset annotation#machine learning#data collection for OCR#OCR model training
0 notes
Text
To guide you through the entire data transcription and processing workflow, here’s a detailed explanation with specific steps and tips for each part:
Choose a Transcription Tool
OpenRefine:
Ideal for cleaning messy data with errors or inconsistencies.
Offers advanced transformation functions.
Download it from OpenRefine.org.
Google Sheets:
Best for basic transcription and organization.
Requires a Google account; accessible through Google Drive.
Other Alternatives:
Excel for traditional spreadsheet handling.
Online OCR tools (e.g., ABBYY FineReader, Google Docs OCR) if the data is in scanned images.
Extract Data from the Image
If your data is locked in the image you uploaded:
Use OCR (Optical Character Recognition) tools to convert it into text:
Upload the image to a tool like OnlineOCR or [Google Docs OCR].
Extract the text and review it for accuracy.
Alternatively, I can process the image to extract text for you. Let me know if you need that.
Copy or Input the Data
Manual Input:
Open your chosen tool (Google Sheets, OpenRefine, or Excel).
Create headers for your dataset to categorize your data effectively.
Manually type in or paste extracted text into the cells.
Bulk Import:
If the data is large, export OCR output or text as a .CSV or .TXT file and directly upload it to the tool.
Clean and Format the Data
In Google Sheets or Excel:
Use "Find and Replace" to correct repetitive errors.
Sort or filter data for better organization.
Use built-in functions (e.g., =TRIM() to remove extra spaces, =PROPER() for proper case).
In OpenRefine:
Use the "Clustering" feature to identify and merge similar entries.
Perform transformations using GREL (General Refine Expression Language).
Export or Use the Data
Save Your Work:
Google Sheets: File > Download > Choose format (e.g., CSV, Excel, PDF).
OpenRefine: Export cleaned data as CSV, TSV, or JSON.
Further Analysis:
Import the cleaned dataset into advanced analytics tools like Python (Pandas), R, or Tableau for in-depth processing.
Tools Setup Assistance:
If you'd like, I can guide you through setting up these tools or provide code templates (e.g., in Python) to process the data programmatically. Let me know how you'd prefer to proceed!
import csv
Function to collect data from the user
def collect_data(): print("Enter the data for each violation (type 'done' to finish):") data = [] while True: coordinates = input("Enter GPS Coordinates (latitude, longitude): ") if coordinates.lower() == 'done': break timestamp = input("Enter Date/Time (YYYY-MM-DD HH:MM:SS): ") violation = input("Enter Violation Description: ") action = input("Enter Action Plan: ") data.append({ "Coordinates": coordinates, "Date/Time": timestamp, "Violation Description": violation, "Action Plan": action }) return data
Function to save the data to a CSV file
def save_to_csv(data, filename="violations_report.csv"): with open(filename, mode='w', newline='') as file: writer = csv.DictWriter(file, fieldnames=["Coordinates", "Date/Time", "Violation Description", "Action Plan"]) writer.writeheader() writer.writerows(data) print(f"Data saved successfully to {filename}")
Main function
def main(): print("Restraining Order Violation Tracker") print("-----------------------------------") data = collect_data() save_to_csv(data)
Run the program
if name == "main": main()
Here’s a Python program to automate the transcription and organization of the data. The program will take input of GPS coordinates, violations, and actions, then output a structured CSV file for easy use.
Python Script: Data Transcription Program
import csv
Function to collect data from the user
def collect_data(): print("Enter the data for each violation (type 'done' to finish):") data = [] while True: coordinates = input("Enter GPS Coordinates (latitude, longitude): ") if coordinates.lower() == 'done': break timestamp = input("Enter Date/Time (YYYY-MM-DD HH:MM:SS): ") violation = input("Enter Violation Description: ") action = input("Enter Action Plan: ") data.append({ "Coordinates": coordinates, "Date/Time": timestamp, "Violation Description": violation, "Action Plan": action }) return data
Function to save the data to a CSV file
def save_to_csv(data, filename="violations_report.csv"): with open(filename, mode='w', newline='') as file: writer = csv.DictWriter(file, fieldnames=["Coordinates", "Date/Time", "Violation Description", "Action Plan"]) writer.writeheader() writer.writerows(data) print(f"Data saved successfully to {filename}")
Main function
def main(): print("Restraining Order Violation Tracker") print("-----------------------------------") data = collect_data() save_to_csv(data)
Run the program
if name == "main": main()
How It Works:
Input:
The program prompts you to enter GPS coordinates, date/time, violation descriptions, and proposed actions for each incident.
Type "done" when all entries are complete.
Processing:
The data is structured into a Python dictionary.
Output:
The program saves the collected data into a CSV file named violations_report.csv.
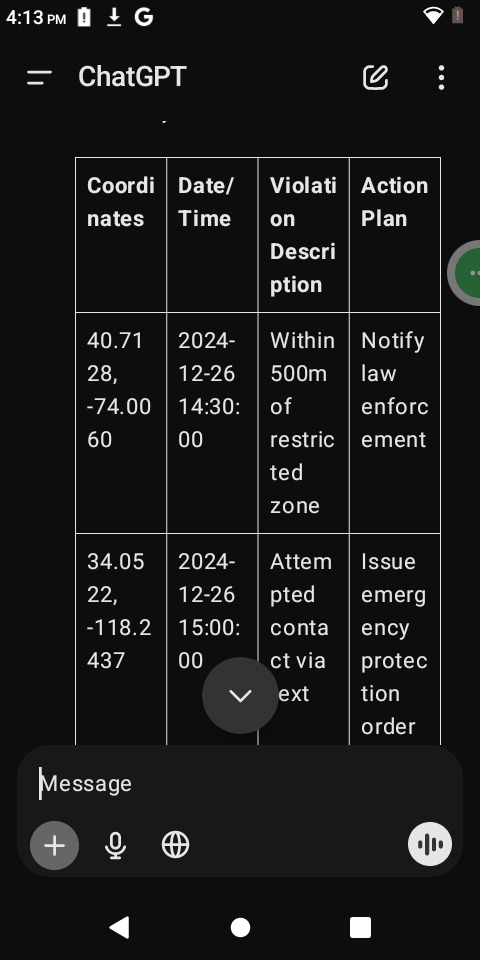
Sample Output (CSV Format):
Requirements:
Install Python (if not already installed).
Save the script as a .py file and run it.
The resulting CSV can be opened in Excel, Google Sheets, or similar tools.
Would you like help running or modifying the script?
0 notes
Text

OCR technology has revolutionized data collection processes, providing many benefits to various industries. By harnessing the power of OCR with AI, businesses can unlock valuable insights from unstructured data, increase operational efficiency, and gain a competitive edge in today's digital landscape. At Globose Technology Solutions, we are committed to leading innovative solutions that empower businesses to thrive in the age of AI.
#OCR Data Collection#Data Collection Compnay#Data Collection#globose technology solutions#datasets#technology#data annotation#data annotation for ml
0 notes
Text
the original captcha's (Completely Automated Public Turing test to tell Computers and Humans Apart) were not used for this, it is a generic term, you are thinking of reCaptcha, which is a specific company that google purchased.
And the thing is, it was a good idea! OCR is such a great tool! it was sort of a science at home thing that paired up a known word and an unknown word, if you got the known word correct, the unknown word was then accepted (after a bunch of people gave the same answer for the unknown word).
And then "Formerly: Don't Be Evil" google purchased it and now use it to train all sorts of stuff as well as collect data on what users are doing.
There is an alternative! if you are a web dev look into Friendly Captcha! its more accessible and works off a proof of work thing, basically the idea is "look, computers can solve capatchas easily these days, so instead of trying to stop them and just resulting in humans doing work, we make it so it takes about 10 seconds before you can continue. to a human this doesn't matter because you spend that time filling out a form, but to a bot farm it does matter because it VASTLY slows down how many accounts they can make" its more complicated then that and there are other things that make it work better but the main important thing to me is that it is accessible and doesn't require data collection.

41K notes
·
View notes
Text

How Aadhaar OCR Is Revolutionizing Business Onboarding Processes
Today's businesses require fast and smooth processes. Particularly in employee, customer and vendor onboarding, Aadhaar OCR (Optical Character Recognition) has emerged as a breakthrough technology, simplifying traditional, complex and time-consuming onboarding tasks. Leveraging India's Aadhaar system, this new tool helps businesses Can verify identity Retrieve demographic information and ensuring compliance. All this in real time.
In this article, we explore how Aadhaar OCR is reshaping the startup landscape. How does it offer many benefits across industries?
What is basic OCR and how does it work?
Aadhaar OCR is an advanced software solution that uses optical character recognition technology to read and digitize details from Aadhaar card. With the ability to extract important fields like name, date of birth, address, Aadhaar number, etc., this tool converts data into Instantly machine-readable format.
Here's how it works:
Aadhaar Document Scan: The OCR tool scans the physical or digital Aadhaar card.
Data extraction: This method collects text fields and precise demographic information.
Data Integration: The extracted data is stored securely or integrated into business systems.
This improved process prevents manual errors. Increase inspection speed and certify the accuracy of the information.
Why Aadhaar OCR is a game changer for startups?
Adopting Aadhaar OCR offers several benefits to businesses looking to optimize their onboarding process:
1. Instant identity verification
With Aadhaar OCR, businesses can instantly verify their identity using their unique 12-digit Aadhaar number. This ensures that only legal persons will be kept on the machine. This reduces the risk of fraud and identity theft.
2. Increase operational efficiency
Manual data entry is prone to delays and errors. Aadhaar OCR automates this process. This greatly reduces the time required to get started. It allows businesses to process large numbers of applicants with minimal effort.
3. Save costs
The automated data extraction and verification process reduces labor costs and eliminates the need for physical document storage. Base OCR also reduces costs associated with human error.
4. Seamless integration with existing systems
Many native OCR solutions offer API integrations, allowing businesses to connect the tool to their existing customer relationship management (CRM) or enterprise resource planning (ERP) systems, helping to ensure a smooth workflow. Smooth and synchronized data.
Industries that benefit from basic OCR preparation
Aadhaar OCR is making onboarding changes in various areas. Let's take a closer look at some of the key industries that benefit from this technology:
1. Financial institutions
Banks and NBFCs rely on Aadhaar OCR for quick KYC (know your customer) verification. This tool enables smooth customer onboarding by digitizing their Aadhaar details. To ensure compliance with regulatory requirements.
2. E-commerce and retail
E-commerce platforms use Aadhaar OCR to recruit distribution staff and verify sellers. This process ensures safe transactions and builds trust between customers and service providers.
3. Government agencies
For welfare projects and financial aid Government agencies are leveraging Aadhaar OCR to authenticate beneficiaries. This will help streamline the application process and reduce the chance of fraudulent insurance claims.
4. Healthcare sector
Hospitals and insurance companies use Aadhaar OCR to verify patient identities. Speed up admission to treatment and process insurance claims efficiently.
Key Features of Aadhaar OCR Solution
Businesses that choose a basic OCR solution can expect a range of features. Designed to improve the onboarding process:
High Accuracy: Advanced OCR algorithm ensures accurate data retrieval.
Language Support: Aadhaar OCR can read details in many Indian languages.
Data Security: Leading solutions provide encryption to protect sensitive data.
Customizable API: Businesses can customize integrations to their specific needs.
How does Aadhaar promote OCR compliance and data privacy?
Apart from operational benefits, Aadhaar OCR also helps businesses comply with data protection regulations. By eliminating manual handling of sensitive documents This tool reduces the risk of data breaches. Compliance with India's Aadhaar Act also helps protect both businesses and individuals.
Challenges and Future of the OCR Foundation
Although Aadhaar OCR is revolutionary, But there are still many challenges, such as initial usage costs. and the need for regular software updates. However, with advances in AI and machine learning The accuracy and efficiency of OCR tools continue to improve.
In the future, we can expect Aadhaar OCR to be integrated with advanced technologies such as blockchain and a more secure and efficient onboarding process.
Summary: How to get started with OCR basics
Aadhaar OCR is revolutionizing the way businesses handle onboarding. By providing a quick solution safer and cost effective Whether you are in the financial field health care or retail, Aadhaar OCR integration can significantly improve your operations by ensuring compliance and data accuracy.
By applying this cutting-edge technology Businesses can not only improve their processes; It's time to adopt Aadhaar OCR and unlock its transformative potential for your organization.
0 notes
