#cicd pipeline
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was the first site to host the blog for President Barack Obama in 2011.
Text
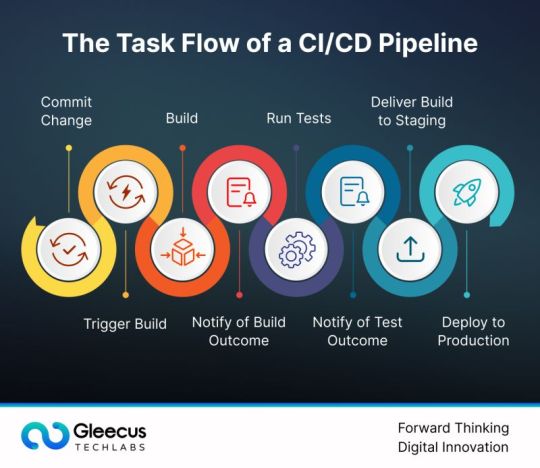
The CI/CD pipeline is a foundational element of modern software development that plays a vital role in ensuring rapid time-to-market and seamless delivery of high-quality software products, especially in today's fast-paced and highly competitive landscape. By automating various stages of development, testing, and deployment, a CI/CD pipeline helps organizations continuously integrate new code changes, conduct thorough testing, and deliver updates more efficiently, all while minimizing risks and maintaining software reliability.
To dive deeper into how CI/CD pipelines can transform your development process, explore the essential components of a successful CI/CD pipeline in this detailed guide.
0 notes
Text
Streamline development with OneTab’s AI CI/CD platform. Leverage powerful CI/CD tools, dashboards, and continuous integration testing for iOS. Boost DevOps efficiency with cutting-edge CI/CD pipeline tools and software development solutions.
#ai-cicd#ci-cd-dashboard#cicd-ai#continuous-integration-tools-ios#ci/cd-tools#cicd-platform#Continuous-Integration-Testing-Tools#Devops-Ci-Cd#Cicd-Pipeline-Tools#Ci-Cd-Platform#Ci-Cd-Software-Development
0 notes
Text
How to connect GitHub and Build a CI/CD Pipeline with Vercel
Gone are the days when it became difficult to deploy your code for real-time changes. The continuous integration and continuous deployment process has put a stop to the previous archaic way of deployment. We now have several platforms that you can use on the bounce to achieve this task easily. One of these platforms is Vercel which can be used to deploy several applications fast. You do not need…

View On WordPress
#AWS#Azure CI/CD build Pipeline#cicd#deployment#development#Github#Google#Pipeline#Pipelines#Repository#software#vercel#Windows
0 notes
Text
Elevate your CI pipelines with Playwright integration!
Learn how to streamline testing processes and ensure seamless performance with this powerful tool.
0 notes
Text

Ready to take your development process to the next level in 2024? Explore the top 20 CI/CD pipeline tools for mastering seamless development.
0 notes
Text
Said with the exact same intonation as Emil's dad at the start of "Hujedamej sånt barn han var"
DEEEEEEEVOPS!
1 note
·
View note
Text
[SimplePBI][CD] Auto Deploy informes de PowerBi con Azure Devops Pipelines
CI/CD, DataOps, Devops y muchos otros nombres han recorrido las redes para referirse al proceso más continuo y automático de deploy. Hoy luego de tanto tiempo de dos herramientas como Azure Devops y PowerBi existen muchos posts y artículos que nos hablan de esto.
¿Qué diferencia este artículo de otro? que haremos el deploy continuo con SimplePBI (librería de python para usar la PowerBi Rest API) dentro de Azure Devops. Solo prácticas de CD. Luego compartiré pensamientos sobre CI. Para esto nos acompañaremos de un repositorio Git en Azure Devops.
No se si llamarle algo “Ops” o simplemente CD PowerBi. Asique sin más charla que dar seguí leyendo si te interesa este mix de temas.
Si hay algo de lo que estoy seguro sobre todo esto de Ops, CI o CD es que tiene un origen y base en software que consiste en facilitar la experiencia del desarrollador. Con ese objetivo vamos a mantener la metodología de un post anterior. El desarrollador no necesita saber más nada. Todo lo siguiente lo configuraría un admin o persona que se dedique a “Ops”.
NOTA: Antes de iniciar aclaro que para que funcione la metodología anterior vamos a quitar el “tracking” del archivo y mantener unicamente el lock. Debemos quitarlo puesto que modifica la metadata guardada en gitattributes y le impide a la API de PowerBi importar el informe. Código: git lfs untrack "Folder/File_name.pbix"
Proceso
Intentando simular metodologías de desarrollo de software es que vamos a plantear este artículo. Cabe aclarar que funcionaría en tradicionales esquemas que siguen el hilo de “Origenes -> Power Bi Desktop -> Power Bi Service”. Nuestro enfoque aquí esta centrado en que los desarrolladores no tengan contacto con Power Bi Service. Su herramienta de desarrollo Desktop y Git serían la diaria. De este modo solo deben preocuparse por tomar la última versión desarrollada, efectuar modificaciones bloqueando el archivo y devolverlo al repositorio modificado y desbloqueado.
La responsabilidad del profesional Ops será la de asegurar que esos desarrollos publicados se disponibilicen en el servicio de PowerBi con flujos automáticos. Con este propósito, y aprovechando nuestro repositorio, vamos a utilizar la herramienta de Azure Devops Pipelines. Para tener acceso a los procesamientos paralelos que nos permiten ejecutar el pipeline, será necesario llenar una encuesta especificada en la documentación de Microsoft como nueva política. Forms y doc para más info en el siguiente link: https://learn.microsoft.com/en-us/azure/devops/pipelines/licensing/concurrent-jobs?view=azure-devops&tabs=ms-hosted
Si bien existen muchas formas y procesos de generar deploys automáticos, la que vamos a generar es la siguiente:
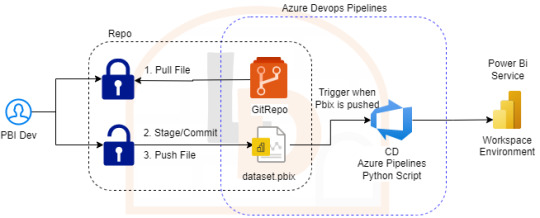
Nos vamos a concentar en importar archivos de PowerBi Desktop ni bien hayan sido pusheados al repositorio. Nuestro enfoque consiste en tener un Pipeline por Área de Trabajo, lo que llevaría a un archivo .yml por area de trabajo. Para mejorar la consistencia de nuestros desarrollos les recomiendo ordenar las carpetas para que coincidan con las areas de trabajo, datasets/reportes o ambientes. Por ejemplo:
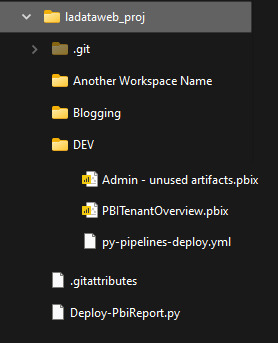
De ese modo podríamos controlar ambientes, shared datasets o simplemente informes con el dataset. Cada quien conoce sus desarrollos para aplicar la complejidad deseada. Vamos a ver el ejemplo con un solo ambiente que tiene informes en areas de trabajo sin separación de shared datasets.
Configuración
Para iniciarnos en este camino abrimos dev.azure.com y creamos un proyecto. El proyecto trae muchos componentes. De momento a nosotros nos interesan dos. Repos y Pipelines. Asumiendo que saben de lo que hablo y ya tienen un repositorio en esta tecnología o Github, procedemos a crear el pipeline eligiendo el repo:
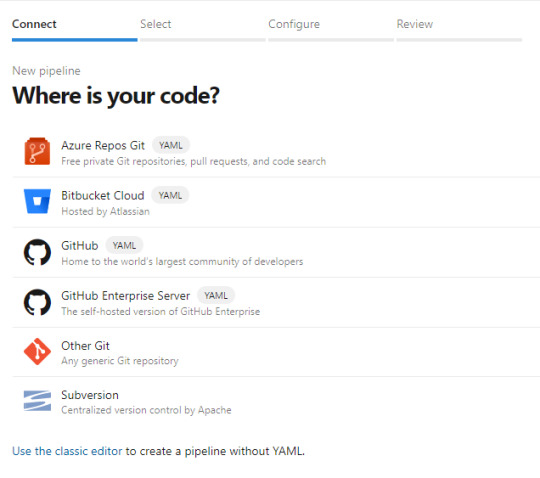
Luego nos preguntará si tenemos una acción concreta de creación incial para nuestro archivo yaml (archivos de configuración de pipelines que orientan el proceso). Podemos elegir iniciar en blanco e ir completando o descarguen el código que veremos en el artículo, ponganlo en el repositorio y creen el pipeline a partir de un archivo existente
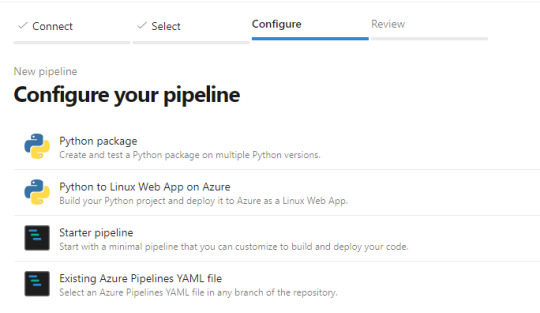
Ahora si tendremos nuestro archivo yml en el repositorio listo para modificarlo. Veamos como hacemos la configuración.
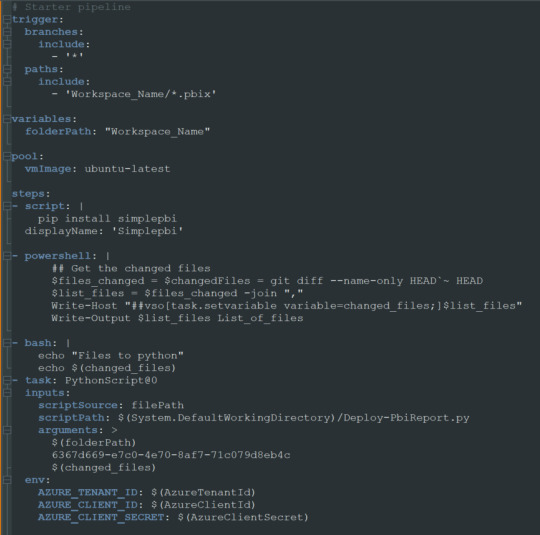
Enlace de github del archivo.
Nuestro pequeño pipeline cuenta con una serie de pasos.
Trigger
Variables
Pool
Steps
NOTA: Estos son un mínimo viable para correr una automatización. Si desean leer más y conocer mayor profundidad puede adentrarse en la documentación de microsoft: https://learn.microsoft.com/es-es/azure/devops/pipelines/yaml-schema/?view=azure-pipelines
Trigger nos mencionará en que parte del repositorio y sobre que branch tiene que prestar atención. En nuestro caso dijimos cualquier branch del path con carpeta “Workspace_Name” y al modificar cualquier archivo PBIX de dicha carpeta. Eso significa que al realizar un commit y push de un archivo de Power Bi Desktop dentro de esa carpeta, se ejecutará el pipeline.
Variables nos permite definir un texto que podremos reutilizar más adelante. En este caso el path de la carpeta. Si bien es una sola carpeta, la práctica de la variable puede ser útil si queremos usar paths más largos. IMPORTANTE: los nombres de carpetas en la variable path no pueden contener espacios dado que la captura de python posterior los reconoce como argumentos separados. Recomiendo usar “_” en lugar de espacios.
Pool viene por defecto y es el trasfondo que correrá el pipeline. Recomiendo dejarlo en ubuntu-latest.
Steps aquí estan los pasos ejecutables de nuestro pipeline. La plataforma nos permite ayudarnos a escribir esta parte cuando elegimos basarnos de la ayuda del wizard. En este caso podemos basarnos en lo que proveemos en ladataweb. Hablemos más de estos pasos.
Detalle de Steps
Primero haremos la instalación de la librería de Python que nos permite utilizar la Power Bi Rest API de manera sencilla en el paso Script.
El paso powershell puesto que nos permite jugar con una consola directa sobre el repositorio. Aqui aprovecharemos para ejecutar un comando git que nos informe cuales fueron los últimos archivos afectados entre el commit anteriores y el actual. Tengamos en cuenta que para poder realizar esta comparación necesitamos cambiar el shallow fetch de nuestro repositorio. Esto significa la memoria de cambio reciente que normalmente viene resguardando 1 commit “más reciente���. Para realizar este cambio necesitamos guardar el pipeline. Luego lo editamos nuevamente y nos dirigimos a triggers:

Una vez allí en la pestaña Yaml podremos encontrar la siguiente opción que igualaremos a 3 como el mínimo necesario para la comparativa.
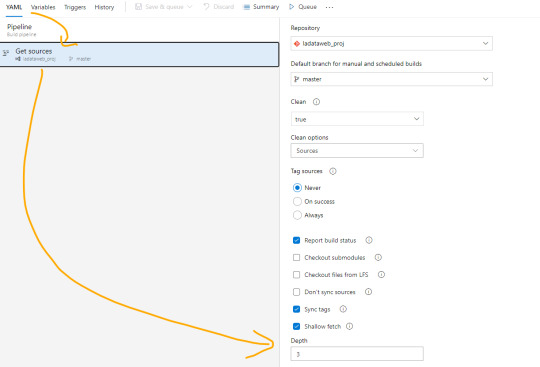
Esta operación también se puede realizar con un Bach de Git local, pero este modo me parece más simple y visual. Para más información pueden leer aqui: https://learn.microsoft.com/es-es/azure/devops/pipelines/repos/azure-repos-git?view=azure-devops&tabs=yaml#shallow-fetch
El paso bash es simplemente para mostrarnos en la consola los archivos que reconoció el script y estan listos para pasar entre pasos.
El paso crítico es Task que llamará a un python script. Para ser más ordenado vamos a llamar a un archivo en el repositorio que nos permita leer un código que cambie con unos parámetros que envía el pipeline para no estar reescribiendolo en cada pipeline de cada workspace/carpeta. Aqui completamos que en script source del file path definido podemos encontrar el script path hasta el archivo puntual que usuará los siguientes tres argumentos. La lista de argumentos refiere al path de los archivos pbix, el id del workspace en donde publicaremos y los archivos que se modificaron según el último commit. Cierra definiendo unas variables de entorno para garantizar la seguridad del script evitando la exposición de la autenticación de la API. En el menú superior derecho veremos la posibilidad de agregar variables:

Sugiero mantener oculto el secret del cliente y visible el id del cliente. Visible este segundo para reconocer con que App Registrada de Azure AD nos estamos conectado a usar la Power Bi Rest API.
Ya definido nuestro Pipeline creemos el script de python que hará la operación de publicar el archivo. En nuestro script lo dejé en la Raíz del repositorio $(System.DefaultWorkingDirectory)/Deploy-PbiReport.py para reutilizarlo en los pipelines de las carpetas/workspaces. Veamos el script

Enlace de github del archivo.
Primero importaremos simplepbi y otras dos librerías. OS para reconocer las variables del entorno y SYS para recibir argumentos.
Iniciarmos recibiendo los argumentos de pipeline con sys.argv en el orden correspondiente. Como la recepción de python lee los argumentos separados por espacios como distintos, vamos a asumir que el parámetro 3 o más se unan separados por espacios (puesto que llegaron como argumentos separados. Luego tomamos la lista de archivos en cadena de texto para construir una lista de python que nos permita recorrerla. En este proceso aprovecharemos para quitar archivos modificados en el commit que no pertenezcan a la carpeta/workspace deseada y sean de extensión “.pbix”. Leemos las variables de entorno para loguear nuestro Power Bi Rest API y todo lo siguiente es mágia de SimplePBI. Pedimos el token para nuestra operaciones, hacemos un for de archivos a importar y realizamos la importación con cuidados de capturas de excepciones y condiciones. Todos los prints nos ayudarán a ver los mensajes al termino de la ejecución para reconocer alguna eventualidad. Esto apunta a no cortar si uno de los archivos falla en publicar no corte al resto. Sino que seguirá y al finalizar podremos lanzar la excepción para que falle el pipeline general a pesar que tal vez corrieran 4/5. Por supuesto que esta decisión podría cambiarse a que si uno falla ninguno continue, o que siga pero al final lanzar una excepción
NOTA: Claro que si es la primera vez que colocamos el archivo.pbix en el repositorio no bastará solo con la importación automática. Será necesario ir a ingresar las credenciales para las actualizaciones manualmente. De momento eso no es posible hacerlo automáticamente.
Para ejecutar la prueba solo bastaría con modificar un archivo .pbix dentro de la carpeta del repo, commit y push. Ese debería ejecutar la acción y publicar el archivo.
De ese modo el desarrollador solo se enfoca en desarrollar con Power Bi Desktop de manera apropiada contra un repositorio y nada más. Un profesional Ops y Administrador serían quienes tendrían licencias PRO que administren el entorno de Áreas de trabajo, apps y distribución de audiencias y permisos.
Demo final commiteando con visual studio code:
Conclusión
Estas posibilidades llevan no solo a buenas prácticas en desarrollo sino también a mantener una linea de desarrolladores que no necesitarían licencias pro a menos que querramos que tengan más responsabilidades en el servicio.
Todo este ejemplo puede expandirse mucho más. Podríamos desarrollar los informes con Parametros para apuntar a distintas bases de datos y tener ambientes de desarrollo. Los desarrolladores no cambiarían más que agregar parametros y tal vez tener otro branch o repositorio. Los profesionales Ops podrían incorporar en el script de importación el cambio del parámetro en service. Incluso podrían efectuarse prácticas de CI moviendo automáticamente versiones estables de un repo a otro. Hablar de CI no me gusta porque no podemos hacer build ni correr tests, pero dejen volar su imaginación. Cada día las prácticas de desarrollo son más posibles y cercanas en proyectos de datos.
En ese archivo python podríamos usar todo el poder de SimplePBI para ajustar nuestro escenario a la práctica Ops deseada.
#powerbi#power bi#power bi devops#power bi cicd#azure devops#azure devops pipelines#power bi tips#power bi tutorial#power bi training#power bi versioning#simplepbi#ladataweb#power bi jujuy#power bi argentina#power bi cordoba#power bi rest api
0 notes
Text
AI-Enabled Testing Tools – The $7.5B Market You Need to Watch! 🤯🤖
AI-Enabled Testing Tools Market is projected to expand from $1.9 billion in 2024 to $7.5 billion by 2034, growing at a CAGR of 14.7%. This market focuses on integrating AI-driven automation, machine learning, and predictive analytics into software testing, ensuring efficiency, accuracy, and scalability in DevOps and agile environments.
To Request Sample Report : https://www.globalinsightservices.com/request-sample/?id=GIS23261 &utm_source=SnehaPatil&utm_medium=Article
Market Trends & Performance
Functional testing tools lead the market, leveraging AI to automate test case generation, execution, and bug detection.
Performance testing solutions are the second-largest segment, ensuring software stability under varying loads.
Security testing tools are gaining traction due to increasing cybersecurity risks and regulatory compliance needs.
North America dominates, driven by early AI adoption and strong software development ecosystems.
Europe ranks second, emphasizing quality assurance and compliance-driven AI testing adoption.
Asia-Pacific is emerging, fueled by digital transformation, IT expansion, and cloud adoption.
Key Growth Drivers
Rise of DevOps & Agile Testing — Increasing demand for continuous integration and continuous delivery (CI/CD) pipelines.
Growing Software Complexity — Need for end-to-end automation to handle diverse software ecosystems.
Advancements in AI & ML — AI-powered self-healing test automation and intelligent defect prediction.
Cybersecurity & Compliance Focus — AI-enhanced security testing to detect vulnerabilities in real-time.
Cloud & API Testing Growth — Adoption of cloud-native and microservices architectures driving automated testing demand.
Market Segmentation
Products: Automated Testing Tools, API Testing Tools, Mobile Testing Tools, Web Testing Tools
Technologies: AI, ML, NLP, Deep Learning, RPA, Computer Vision
Applications: BFSI, Healthcare, Retail, Telecom, Government, Manufacturing
Deployment: Cloud, On-Premises, Hybrid
Solutions: Test Automation, Test Execution, Test Management
The future of AI-enabled testing is driven by intelligent automation, predictive insights, and cloud-based solutions, creating significant growth opportunities for enterprises worldwide.
#aiinsoftwaretesting #testautomation #aienabledtesting #functionaltesting #performancetesting #agiletesting #devopstesting #cloudtesting #machinelearning #automationtools #artificialintelligence #cicd #softwarequality #apiintegration #mobiletesting #predictiveanalytics #intelligenttesting #roboticprocessautomation #deeplearning #cybersecuritytesting #bugtracking #aiqa #smartautomation #nlpforqa #autonomousqa #testingefficiency #cloudbasedqa #continuousdelivery #lowcodetesting #softwaretestingtrends #qualityengineering #testdatamanagement #cloudqa #aibasedtestautomation #microservicestesting #qaautomationtools #enterpriseqa #aiforsecurity #nextgentesting #smarttesting
0 notes
Text
20 project ideas for Red Hat OpenShift
1. OpenShift CI/CD Pipeline
Set up a Jenkins or Tekton pipeline on OpenShift to automate the build, test, and deployment process.
2. Multi-Cluster Management with ACM
Use Red Hat Advanced Cluster Management (ACM) to manage multiple OpenShift clusters across cloud and on-premise environments.
3. Microservices Deployment on OpenShift
Deploy a microservices-based application (e.g., e-commerce or banking) using OpenShift, Istio, and distributed tracing.
4. GitOps with ArgoCD
Implement a GitOps workflow for OpenShift applications using ArgoCD, ensuring declarative infrastructure management.
5. Serverless Application on OpenShift
Develop a serverless function using OpenShift Serverless (Knative) for event-driven architecture.
6. OpenShift Service Mesh (Istio) Implementation
Deploy Istio-based service mesh to manage inter-service communication, security, and observability.
7. Kubernetes Operators Development
Build and deploy a custom Kubernetes Operator using the Operator SDK for automating complex application deployments.
8. Database Deployment with OpenShift Pipelines
Automate the deployment of databases (PostgreSQL, MySQL, MongoDB) with OpenShift Pipelines and Helm charts.
9. Security Hardening in OpenShift
Implement OpenShift compliance and security best practices, including Pod Security Policies, RBAC, and Image Scanning.
10. OpenShift Logging and Monitoring Stack
Set up EFK (Elasticsearch, Fluentd, Kibana) or Loki for centralized logging and use Prometheus-Grafana for monitoring.
11. AI/ML Model Deployment on OpenShift
Deploy an AI/ML model using OpenShift AI (formerly Open Data Hub) for real-time inference with TensorFlow or PyTorch.
12. Cloud-Native CI/CD for Java Applications
Deploy a Spring Boot or Quarkus application on OpenShift with automated CI/CD using Tekton or Jenkins.
13. Disaster Recovery and Backup with Velero
Implement backup and restore strategies using Velero for OpenShift applications running on different cloud providers.
14. Multi-Tenancy on OpenShift
Configure OpenShift multi-tenancy with RBAC, namespaces, and resource quotas for multiple teams.
15. OpenShift Hybrid Cloud Deployment
Deploy an application across on-prem OpenShift and cloud-based OpenShift (AWS, Azure, GCP) using OpenShift Virtualization.
16. OpenShift and ServiceNow Integration
Automate IT operations by integrating OpenShift with ServiceNow for incident management and self-service automation.
17. Edge Computing with OpenShift
Deploy OpenShift at the edge to run lightweight workloads on remote locations, using Single Node OpenShift (SNO).
18. IoT Application on OpenShift
Build an IoT platform using Kafka on OpenShift for real-time data ingestion and processing.
19. API Management with 3scale on OpenShift
Deploy Red Hat 3scale API Management to control, secure, and analyze APIs on OpenShift.
20. Automating OpenShift Cluster Deployment
Use Ansible and Terraform to automate the deployment of OpenShift clusters and configure infrastructure as code (IaC).
For more details www.hawkstack.com
#OpenShift #Kubernetes #DevOps #CloudNative #RedHat #GitOps #Microservices #CICD #Containers #HybridCloud #Automation

0 notes
Text
youtube
Summary
🚀 Torq's No-Code Automation for Security – Torq enables security teams to automate security processes without requiring software engineering expertise.
🔥 Challenges in Cybersecurity – Organizations face a growing number of security events, including threat intelligence, vulnerability reports, and privilege escalations.
⚖ Scalability Dilemma – Teams can either handle security events manually (inefficient) or use traditional automation tools (costly and complex).
🎯 Torq’s Visual No-Code Solution – Security practitioners can create automations in minutes using an intuitive, visual workflow.
🌐 Cloud-Native Architecture – Inspired by modern CICD pipelines, Torq transforms security automation into containerized jobs that run across any environment.
🛠 Seamless Security Stack Integration – Torq functions as a "central nervous system", connecting security tools without plugins or add-ons.
🤝 Community & Long-Term Vision – Torq aims to revolutionize security automation by fostering a community of professionals committed to transforming cybersecurity.
0 notes
Text
youtube
🚀Master in-demand QA automation skills in six months and secure your next role with hands-on automation projects and real-world testing experience! 🔑
What You'll Learn: Automation Testing Tools: Master Selenium, Appium, and more Programming Languages: Learn Python, Java, and C# for automation scripting CI/CD Pipelines: Integrate automation testing into continuous deployment processes Test Frameworks: Understand frameworks like TestNG, JUnit, and PyTest API Testing: Use Postman and REST Assured for end-to-end testing Real-World Projects: Build a portfolio showcasing your automation testing expertise
🎯 Why Choose Us?
Expert Mentorship from industry professionals Hands-on, practical learning Job Placement Assistance Flexible online learning with live sessions This bootcamp is your fast track to becoming a QA Automation Engineer with job-ready skills and real-world project experience! Enroll Now and start your career in QA Automation today!
🔗 Link to Register : https://tutorac.com/
#QAAutomation #QABootcamp #AutomationEngineer #LearnAutomationTesting #Selenium #Appium #TestAutomation #APITesting #CICD #QAEngineer #SoftwareTesting #TechCareer #AutomationFrameworks #QAJobs #JobReadySkills #CareerInTech
0 notes
Text

CICD introduces agile practices to the product development culture and brings in interesting features like automated builds, automated testing, continuous integration, and continuous testing. The CICD pipeline is a significant feature of the broader DevOps/ DevSecOps framework.
#technology#digital transformation#tech#it consulting#it services#mobile app developers#software development#technology trends#cicd#ci cd tools#product development service#automated testing#cicd pipeline
0 notes
Text
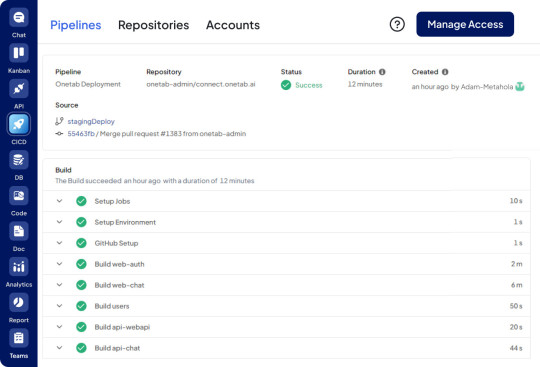
Optimize your development process with OneTab's AI CI/CD platform. Access powerful CI/CD pipeline tools, DevOps CI/CD integration, continuous integration testing tools, and more for seamless software development.
#ai-cicd#ci-cd-dashboard#cicd-ai#continuous-integration-tools-ios#ci/cd-tools#cicd-platform#Continuous-Integration-Testing-Tools#Devops-Ci-Cd#Cicd-Pipeline-Tools#Ci-Cd-Platform#Ci-Cd-Software-Development
0 notes
Text
🌐 Optimize Your Infrastructure with DevOps as a Service!
🚀 Unlock your operation's full potential with our expertise:
Pilot Framework Creation: Seamlessly integrate your tools with open-source and licensed software.
Process Implementation: Design, build, and automate workflows for efficiency.
CI/CD Pipeline: Continuously develop, test, and deploy for flawless delivery.
Process Automation: Automate every step from code to production.
Monitoring & Logging: Stay ahead with real-time alerts and performance insights.
Answer 5 simple questions and get a personalized consultation to streamline your lifecycle, enhance reliability, and reduce costs.
#DevOps #Automation #InfrastructureOptimization #CICD #TechInnovation
0 notes
Text
"We wanted certified templates with immutable stages to show our compliance and auditing teams that anyone going through this certified template automatically meets compliance gates."
0 notes
Text
Docker Prune Automating Cleanup Across Multiple Container Hosts
Docker Prune Automating Cleanup Across Multiple Container Hosts @vexpert #vmwarecommunities #automation #cicd #dockerprune #docker #dockercontainers #pipeline #overlay2 #dockerimages #bestdockercommands #homelab #virtualization
If you run many Docker hosts or multiple hosts in a Swarm cluster, if you are updating and respinning your containers (and you should be), you will have space accumulated on your Docker hosts from things like old container images, container overlay storage, and other things that can add up to a significant amount of storage. There is a helpful built-in command called docker prune that helps to…
0 notes