#axi4 dma
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Photo

I2C Master IP
I2C Master IP is a type of Intellectual Property (IP) that implements the I2C Master protocol. It is used to interface a device as a master on an I2C bus and allows the device to communicate with slave devices. An I2C Master IP core sends commands and data to the I2C slaves and receives data from them. It provides a standardized interface for communication between the master device and the slave devices, enabling communication and control of the slave devices. The I2C Master IP is commonly used in a wide range of applications, such as in embedded systems, IoT devices, and consumer electronics. To know more visit us at https://www.digitalblocks.com/i2c-ip-core-reference-design/
0 notes
Text
Improving Design Productivity and Quality with Specification Automation

Designing semiconductor devices has always been a distinct specialty of engineering, but today’s designers face immeasurably greater challenges. A typical system-on-chip (SoC) design has billions of transistors, thousands of intellectual property (IP) blocks, hundreds of I/O channels, and dozens of embedded processors. Chip designers need all the help they can get.
Three Keys for Faster, Better Design
Assistance comes in three forms: abstraction, automation, and reuse. Virtually all chip design today occurs at the register transfer level (RTL), enabling much greater productivity than manually crafting gates or transistors. This level of abstraction is therefore much more efficient, making it possible for a single designer to create entire IP blocks or even subsystems.
RTL design is also amenable to automation; generating gate-level netlists automatically via logic synthesis is part of what makes the design process so efficient and productive. Just about every aspect of the test insertion, power management, layout, and signoff flow that follows RTL design is automated as well. Without this approach, modern SoCs simply would not be possible.
The third form of assistance is design reuse. Especially for standard IP blocks and interfaces, there is no value-add in reinventing the wheel by designing from scratch. EDA vendors and dedicated IP providers offer a huge range of reusable designs, most in RTL form. Designers often need this IP to be configurable and customizable, so it may come from a generator rather than as a fixed design.
Register Automation Is the Foundation
All three forms of designer assistance come together in specification automation, starting with the registers in the design. SoCs typically have a huge number of addressable (memory-mapped) registers defined by the chip specifications. These registers form the hardware-software interface (HSI) by which the embedded software and system drivers control the operation of the hardware.
Manually writing RTL code for all these registers is tedious and error-prone. Fortunately, the Agnisys IDesignSpec™ Suite makes it easy to automatically generate the register RTL design. Using the IDesignSpec GDI interactive tool or the IDS-Batch™ CLI Batch Tool, designers create their RTL files at the push of a button every time the register specification changes.
These tools accept many register and memory specification formats, including spreadsheets,��SystemRDL, IP-XCAT, and the Portable Stimulus Standard (PSS). Designers can specify many widely used special register types, including indirect, indexed, read-only/write-only, alias, lock, shadow, FIFO, buffer, interrupt, counter, paged, virtual, external, and read/write pairs.

Registers are just one part of a chip that can be specified abstractly and generated automatically, fostering reuse and improving quality of results (QoR) with proven design IP. Another example is interfaces to standard buses such as APB, AHB, AHB-Lite, AXI4, AXI4-Lite, TileLink, Avalon, and Wishbone. The RTL design generated by IDesignSpec Suite includes any interfaces requested.
Any necessary clock-domain-crossing (CDC) logic across asynchronous clock boundaries is also included in the generated design. For safety-critical chip applications, designers can request that safety mechanisms such as parity, error-correcting code (ECC), cyclic redundancy check (CRC), and triple module redundancy (TMR) logic be included as well.
Most chips contain standard design elements such as AES, DMA, GPIO, I2C, I2S, PIC, PWM, SPI, Timer, and UART. Designers specify these blocks with many degrees of configuration and customization, and the Agnisys IDS-IPGen™ design tool generates the RTL design code. IDS-IPGen also generates finite state machines (FSMs) and other design elements for custom IP blocks.

Automating SoC Assembly
As noted earlier, SoCs contain thousands of standard and custom IP blocks. All of these must be connected together into the top-level chip design. Like register design, manually writing the RTL code for this stage is a tedious and error-prone process. Block inputs and outputs change many times over the course of a project, and updating the top-level RTL code by hand is extremely inefficient.
The Agnisys IDS-Integrate™ design tool, another part of the IDesignSpec Suite, automates the chip assembly process. Designers specify the desired hookup using a simple but powerful format that includes wildcards to handle buses and collections of signals with similar names. IDS-Integrate automatically generates the complete top-level RTL design.
For IP blocks with standard buses, IDS-Integrate automatically generates any required aggregators, bridges, and multiplexors, including them in the top-level RTL design. For example:
AHB interfaces on two IP blocks can be aggregated into a single bus
An AHB-to-APB bridge can connect IP using AHB and IP using APB

With the burden on SoC designers growing all the time, they need to specify at the highest possible level of abstraction, take advantage of automation, and reuse whenever possible. The specification automation capabilities of the Agnisys IDesignSpec Suite provide all three forms of designer assistance, providing the industry’s most complete solution.
Designers no longer have to hand-write RTL code for registers, memories, standard bus interfaces, aggregators, and bridges, CDC logic, safety mechanisms, custom IP elements, standard IP blocks, and top-level design. Abstract specification and automation improves productivity; reuse of proven IP improves quality of results.
Customization and configuration options ensure that designers do not have to sacrifice any flexibility to achieve these benefits. Many other project teams—verification, validation, embedded software, bringup, and documentation—also benefit from specification automation. The reasons to select Agnisys as a design partner are truly compelling.
0 notes
Text
T2M发布7nm PCIe 4.0 PHY IP Cores
全球独立的半导体IP供应商和授权专业公司T2MIP高兴地宣布,来自其伙伴的PCIe 4.0 PHY IP与配套的PCIe 4.0控制器IP已通过7nm工艺的量产验证,这个设计符合PCI-SIG规范,已经在多种芯片及场景中得到使用和应用。
这个PCIe 4.0 PHY IP设计符合PCIe 4.0规范的要求,兼容PIPE 4.4.1接口规范,以低功耗、多通道和高性能为设计目标,支持各种高带宽的传输应用场景。这个设计集成了高速混合信号电路,可实现16Gbps速率的PCIe 4.0数据传输;除此之外这个设计还包含额外的PLL控制电路、参考时钟控制电路及嵌入式电源选通电路;支持PIPE4.4.1规范中所规定的所有省电模式(P0、P0s、P1、P2)。配合7nm的生产工艺,整个设计实现了低功耗的产品要求。

这个PCIe 4.0 SerDes PHY IP核的数据传输速率可达16Gbps,并兼容PCIe 3.1、PCIe 2.1和PCIe 1.1规范等旧版本所规定的2.5Gbps、5.0Gbps和8.0Gbps速率。这个设计在收发通路都采用了可均衡的四倍速物理通道配置,根据应用场景也可配置为x1、x2、x4、x8、x16的分叉架构,这个设计需要100MHz的输入参考时钟配合32位的并行数据接口工作,这个输入参考时钟还可以配置为62.5MHz、125MHz、250MHz和500MHz。
客户可以根据其芯片的需求将这个PCIe 4.0控制器IP的设计配置为endpoint, root port和双模架构等场景用例。配置工作是通过可编程的、灵活的AMBA AXI总线接口完成。对于极端高性能场景应用,这个设以512位的控制器架构和64字节宽度的PIPE接口,支持AXI4/原生总线接口、可编程的DMA通道,实现用户对接口和高效的选通控制器的各种定制要求。
T2M带来的这一7nm PCIe 4.0 PHY IP设计,是工业界在PCI Express领域的标准产品,已在主要制造工厂的主要节点的多款芯片组实现量产,并得到了广泛的应用,包���SSD控制器、数字电视、Setup Box、台式机、工作站、服务器、汽车、嵌入式系统、网络交换机和企业计算等。
除了PCIe IP核,T2M广泛的硅接口IP核组合包括USB、HDMI、显示端口、MIPI(CSI、UniPro、UFS、RFFE、I3C)、PCIe、DDR、1G以太网、V-by-One、可编程SerDes、OnFi等,在主流代工厂的工艺节点可达7nm。可以根据客户的具体要求定制或者移植到其他晶圆厂的相应工艺节点上生产。
可用性:这些半导体IP核可以立即进行客户授权,既可以单独授权,也可与预集成的控制器和PHY组合授权。有关授权的选择和报价等更多信息,请发送邮件至[email protected],进行了解。
关于T2M:T2MIP是全球独立的半导体专业授权技术公司,提供复杂的半导体IP核、软件、KGD和颠覆性技术,帮助客户加速开发可穿戴设备、物联网、通信、存储、服务器、网络、电视、机顶盒和卫星SoC。欲了解更多信息,请访问:www.t-2-m.com
0 notes
Text
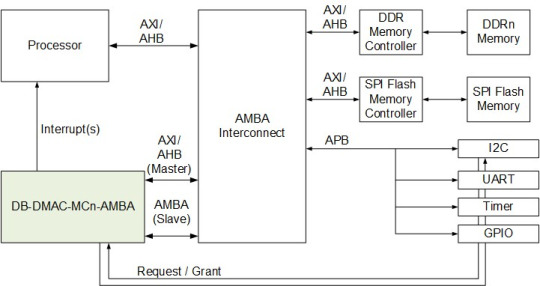
AXI DMA Controller IP Cores

Beginning direct memory access with digital blocks is quite amazing. The AXI DMA Controller IP gives high-data transfer capacity direct memory access amongst memory and AXI4-Stream-type target peripherals. Its discretionary disperse accumulate capacities additionally offload information development undertakings from the Central Processing Unit in processor based frameworks. We offer 1-16 Channels for every channel CPU descriptor-driven interface controlling the information exchange between memory subsystems or amongst memory and a peripheral. The AXI DMA Controller highlights Scatter-Gather capacity, with per channel Finite State Control and single-or double check FIFOs parameterized top to bottom and width, interfere with controller, and discretionary information equality generator and checker. The AXI Master Data Interface scales from 32-to 256-bits, with programmable information blasts of 1, 4, 8, 16 words with the little information exchange bolstered is 1 byte, and up to 16 exceptional read demands, and for AXI4, the accessibility of programmable Quos and longer information burst lengths. The AXI DMA Controller additionally gives an APB or AXI-lite Slave Interface for CPU access to Control Status Registers. The DB-DMAC-MC-AXI is tuned as elite DMA Engine, for huge and little data blocks transfers. Digital Blocks DMA Controller IP Cores offer an adaptable CPU programming interface and superior exchange rates with driving AMBA Interconnects and standard or redid fringe interfaces. Our DMA Controllers are rich with Multi-Channel, Axi Dma Scatter Gather ability with IP discharges focusing on CPU AXI/AHB spine DMA Engines, PCI Express DMA, and Peripheral high or low information rate DMA exchanges. Reach us today to get more news @ https://www.digitalblocks.com/dma.html.
0 notes
Photo

AXI DMA Scatter Gather
The Digital Block AXI DMA Scatter Gather is a type of Direct Memory Access (DMA) engine that uses scatter-gather DMA to efficiently move data between devices and memory. It is designed for use in digital signal processing and video processing applications, where high-speed data transfer is critical. The scatter-gather DMA technique allows for the transfer of multiple non-contiguous blocks of data in a single transaction, which reduces the overhead associated with multiple DMA transfers. The AXI interface provides a high-speed, low-latency interface for connecting to other components in a system-on-chip (SoC) design.Get more details about us from https://www.digitalblocks.com/dma/
#Display Controller IP#LCD Controller IP#i3C Basic IP#I2C Master IP#I2C Slave IP#AXI DMA IP#axi dma scatter gather#AXI Stream DMA#AXI4 Stream DMA
0 notes
Photo

"Accelerating Data Transfer with AXI Stream DMA, AXI4 Stream DMA, and i3C Basic IP: An In-Depth Analysis"
This article delves into the world of high-speed data transfer using AXI Stream DMA, AXI4 Stream DMA, and i3C Basic IP. The article provides a detailed analysis of these three technologies and their applications in various domains. The article also explores the benefits of using these technologies, including improved throughput, reduced latency, and lower power consumption. Additionally, the article discusses the key features and functionalities of each technology, and provides examples of how they can be used in real-world scenarios. Whether you are a hardware engineer, a software developer, or just someone interested in the latest advancements in data transfer technology, this article is a must-read.for more visit digitalblocks.com .
#AXI4 Stream DMA#AXI Stream DMA#eSPI IP#AXI DMA Scatter Gather#AXI DMA IP#I2C Slave IP#i3C Basic IP#LCD Controller IP
0 notes
Photo

"Advanced Techniques for IP Design: i3C Basic IP and AXI DMA Scatter Gather with AXI Stream DMA"
Digital Blocks makes building your next-gen hardware easy with i3C Basic IP, AXI DMA Scatter Gather, and AXI Stream DMA all integrated into one product. Say goodbye to complicated design processes and hello to a simpler solution!
#AXI4 Stream DMA IP#AXI4 Stream DMA#AXI Stream DMA#eSPI IP#AXI DMA Scatter Gather#AXI DMA IP#I2C Slave IP#I2C Master IP
0 notes
Photo

AXI Stream DMA
The AXI Stream DMA IP module is a system-on-chip that supports the Direct Memory Access Protocol, allowing data to be transferred between a CPU and an external device such as a memory module or another system-on-chip. Axi4 Stream DMA IP the Axi4 Stream DMA IP is a 16-bit asynchronous stream controller. To know more visit our website at https://www.digitalblocks.com/dma/
#Display Controller IP#AXI4 Stream DMA#AXI Stream DMA#eSPI IP#AXI DMA Scatter Gather#AXI DMA IP#I2C Master IP#LCD Controller IP
0 notes
Photo

I3C Basic IP
While maintaining backward compatibility for the majority of devices, i3C Basic IP is a serial communication interface protocol that enhances the features, functionality, and power consumption of I2C. i3C basic IP with 12C specification quickly and easily integrated into any mobile embedded system on a chip. It increases the communication capabilities and sensor communication. To know more visit us at https://www.digitalblocks.com/mipi-i3c-ip/
0 notes
Photo

I3C Basic IP
While maintaining backward compatibility for the majority of devices, i3C Basic IP is a serial communication interface protocol that enhances the features, functionality, and power consumption of I2C. i3C basic IP with 12C specification quickly and easily integrated into any mobile embedded system on a chip. It increases the communication capabilities and sensor communication. To know more visit us at https://www.digitalblocks.com/mipi-i3c-ip/
#Display Controller IP#LCD Controller IP#I2C Master IP#I2C Slave IP#AXI DMA IP#AXI DMA Scatter Gather#eSPI IP#AXI Stream DMA#AXI4 Stream DMA
0 notes
Text
The Advantages of Using i3C Basic IP and AXI DMA IPs for Streamlining Data Transfer
As technology continues to advance, data transfer has become an increasingly important aspect of modern computing. Efficient data transfer is critical to the performance of many devices and systems, from high-performance computing to embedded systems. That's where i3C Basic IP and AXI DMA IPs come into play.

i3C Basic IP is a communication interface standard that supports multiple data and control lines in a single interface. It is designed to streamline communication between devices, reducing the complexity and cost of system design. AXI DMA IPs, on the other hand, are Direct Memory Access (DMA) controllers that enable high-speed data transfer between memory and the various peripherals in a system.
Combining i3C Basic IP and AXI DMA IPs can provide significant advantages for streamlining data transfer. One of the most significant benefits is the ability to use scatter-gather DMA, which allows data to be transferred from multiple sources to multiple destinations in a single operation. This can greatly reduce the number of DMA transactions required to transfer data, resulting in faster transfer times and reduced system overhead.
AXI Stream DMA and AXI4 Stream DMA are two additional DMA controllers that can be used in conjunction with i3C Basic IP and AXI DMA IPs. These controllers are optimized for high-bandwidth, high-throughput data transfer and can be used to move large amounts of data quickly and efficiently.
One of the key advantages of using i3C Basic IP and AXI DMA IPs is their compatibility with a wide range of devices and peripherals. They are widely used in a variety of applications, from mobile devices to high-performance computing systems, and are supported by many different hardware and software vendors.
In addition to their technical advantages, i3C Basic IP and AXI DMA IPs are also cost-effective. By reducing the complexity of system design and enabling faster data transfer, they can help to reduce the overall cost of system development and operation.
In conclusion, i3C Basic IP and AXI DMA IPs are powerful tools for streamlining data transfer in modern computing systems. By enabling scatter-gather DMA and high-speed data transfer, they can greatly improve system performance and reduce system overhead. With their wide compatibility and cost-effectiveness, they are an excellent choice for a wide range of applications.
#lcd#LCD Controller IP#AXI4 Stream DMA#AXI Stream DMA#eSPI IP#AXI DMA Scatter Gather#AXI DMA IP#i2c master ip#Display Controller IP
0 notes
Text
Benefits of AXI4 Stream DMA:
AXI4 Stream DMA (Direct Memory Access) is a type of hardware block that is used in digital circuits and computer systems to transfer data between a peripheral device and memory without involving the main CPU.

In an AXI4 Stream DMA, the peripheral device sends data to the DMA engine, which then transfers the data to the memory. Similarly, when the peripheral device needs to receive data, it sends a request to the DMA engine, which retrieves the data from memory and sends it to the peripheral device. This process allows for faster data transfers and frees up the CPU to perform other tasks.
The AXI4 Stream DMA is part of the ARM Advanced Microcontroller Bus Architecture (AMBA), which is a set of interconnect protocols for creating complex SoCs (System on Chips). The AXI4 Stream DMA is designed to work with the AXI4 interconnect protocol, which is widely used in modern SoCs.
The benefits of using AXI4 Stream DMA include
Faster data transfer speeds compared to traditional CPU-based transfers
Reduced CPU usage, which allows the CPU to focus on other tasks
More efficient use of system resources, which can lead to improved overall system performance
Lower power consumption compared to traditional CPU-based transfers
Scalability and flexibility, allowing for easy integration with various peripheral devices and memory architectures.
Overall, AXI4 Stream DMA is a useful hardware block for achieving high-speed and efficient data transfer in digital circuits and computer systems.
#AXI4 Stream DMA IP#AXI Stream DMA#eSPI IP#axi dma scatter gather#AXI DMA IP#I2C Slave IP#i2C Master IP#i3C Basic IP#LCD Controller IP#Display Controller IP
0 notes
Photo

I3C Basic IP
I3C (Improved Inter-Integrated Circuit) is a new standard for communication between integrated circuits (ICs) that builds upon the widely used I2C (Inter-Integrated Circuit) standard. I3C aims to address some of the limitations of I2C and to provide a more robust and efficient communication protocol for modern ICs.
One of the key features of I3C is its support for multiple data rates, which allows for faster communication between ICs. I3C also supports dynamic addressing, which makes it easier to connect multiple ICs together and to add or remove ICs from a system without disrupting the communication between them.
I3C also includes support for advanced features such as hot-joining and sleep modes, which can help reduce power consumption in devices that use I3C. Additionally, I3C provides backward compatibility with I2C devices, which means that I3C devices can communicate with I2C devices using the same communication bus.
Overall, I3C is a significant improvement over I2C and is expected to become increasingly popular in the coming years as more ICs adopt the standard.
0 notes
Text
AXI DMA with Scatter-Gather: Streamlining Data Transfer in Embedded Systems
In the world of embedded systems, efficient and fast data transfer is of utmost importance. This is where Direct Memory Access (DMA) comes into play. DMA technology allows data to be transferred directly between memory and peripherals, bypassing the need for the CPU to handle each transfer individually. This greatly speeds up the transfer process and frees up the CPU to focus on other tasks. But what if the data you need to transfer is not stored in contiguous blocks in memory? The capacity of AXI DMA scatter gather to capture data in this situation is useful.
Scatter-Gather: Breaking Down Data into Smaller Blocks
The scatter-gather feature of AXI DMA enables the transfer of non-contiguous blocks of data in a single transaction. Instead of transferring the data as a whole, it breaks it down into smaller, contiguous blocks and transfers them individually. This allows for a more flexible and efficient data transfer process, especially for applications that require large amounts of data transfer, such as video and image processing.
Efficiency and Performance Boost with Scatter-Gather
The scatter-gather feature of AXI DMA has several benefits for embedded systems.
Firstly, it eliminates the need for copying data into contiguous blocks in memory, saving both time and resources.
Secondly, it provides a more efficient use of memory, as non-contiguous data can be stored in its original form, without being rearranged into contiguous blocks.
Finally, the scatter-gather feature greatly improves the performance of data transfer, as it allows for parallel processing of multiple blocks of data. This results in faster transfer speeds and a more efficient use of resources, making it ideal for applications with large amounts of data transfer.
In short, AXI DMA's scatter-gather capability offers an adaptable and effective method for data transfer in embedded systems. This capability can simplify the procedure and significantly enhance the performance of your system, whether you're working with non-contiguous blocks of data or need to transfer massive volumes of data.
Digital Blocks provides semiconductor Intellectual Property (IP) cores for ASSP, ASIC, System-on-Chip (SoC), and FPGA designers. For more info, visit website.
#AXI DMA Scatter Gather#eSPI IP#display controller ip#AXI4 Stream DMA IP#LCD Controller IP#I2C Master IP#i3C Basic IP
0 notes
Text

AXI4 Stream DMA IP
Optimize Data Transfer with the AXI4 Stream DMA IP Block Say goodbye to cumbersome data transfer processes and hello to seamless efficiency with our AXI4 Stream DMA IP block! Built to optimize data transfer within your digital system, this lightweight module enables swift and reliable communication between different components. Whether you're working on complex multi-channel audio or video processing, our AXI4 Stream DMA IP block ensures precise and efficient data handling every step of the way. Upgrade your system's performance and enhance your workflow with this high-performance IP block now!
#i3c controller ip#display controller ip#i3c master#lcd controller ip#axi dma scatter gather#i2c controller ip#i2c master ip#espi ip#i2c slave ip#axi dma ip
0 notes
Text
"Accelerating System Performance with AXI4 Stream DMA, AXI Stream DMA, and eSPI IP Digital Blocks"
Digital blocks play a crucial role in modern electronic systems, providing essential functionality for communication, data transfer, and control. Among these blocks, the AXI4 Stream DMA, AXI Stream DMA, and eSPI IP are three critical components that enable efficient data transfer and communication between different modules in a system. In this blog, we will explore these digital blocks and their features, applications, and benefits.

AXI4 Stream DMA: The AXI4 Stream Direct Memory Access (DMA) is a digital block that facilitates high-speed data transfer between different modules in a system. It is a flexible and scalable interface that allows the transfer of large amounts of data between a source and a destination without involving the CPU. The AXI4 Stream DMA block is designed to be integrated into an AXI4-based system and supports a wide range of data transfer modes and burst sizes.
One of the main advantages of using the AXI4 Stream DMA block is its ability to offload data transfer tasks from the CPU, thereby reducing the workload on the processor and improving system performance. This makes it ideal for applications that require high-speed data transfer, such as video processing, audio processing, and network data transfer.
AXI Stream DMA: Similar to the AXI4 Stream DMA, the AXI Stream DMA is a digital block that provides a high-bandwidth, low-latency interface for data transfer in an AXI-based system. The AXI Stream DMA block is optimized for streaming data transfer and is ideal for applications that require real-time data transfer, such as audio and video processing, image processing, and machine learning.
One of the key features of the AXI Stream DMA block is its support for multiple channels, which enables simultaneous data transfer between different modules in a system. This feature makes it ideal for applications that require parallel data transfer, such as multi-camera video processing and multi-channel audio processing.
eSPI IP: The Enhanced Serial Peripheral Interface (eSPI) is a digital block that provides a high-speed, low-latency interface for communication between different modules in a system. The eSPI IP block is designed to replace the legacy Low Pin Count (LPC) interface and improve system performance by providing faster data transfer rates, higher bandwidth, and improved scalability.
One of the key features of the eSPI IP block is its support for multiple devices, which enables communication between different modules in a system, such as the CPU, chipset, and peripherals. This feature makes it ideal for applications that require efficient communication between multiple devices, such as server systems, high-performance computing systems, and embedded systems.
In conclusion, the AXI4 Stream DMA, AXI Stream DMA, and eSPI IP are three critical digital blocks that enable efficient data transfer and communication between different modules in a system. These blocks are designed to improve system performance, reduce CPU workload, and enable real-time data transfer and communication. As digital systems continue to evolve, these blocks will play an increasingly important role in enabling faster, more efficient, and more scalable systems.
0 notes