#StatModeling
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile Tumblr US users spend an average of 4.04 minutes per session on the app.
Text
DATA SCIENCE COURSE IN CHANDIGARH
The Data Science course in chandigarh offered by ThinkNext is a comprehensive program that covers a wide range of topics relevant to data science, utilizing Python as a primary tool. The course is structured to cater to both beginners and advanced learners, aiming to master data science skills.
Key features of the ThinkNext Data Science course include:
A detailed curriculum that starts with an introduction to Data Science, covering analytics, data warehousing, OLAP, MIS reporting, and the relevance of analytics in various industries. It also discusses the critical success drivers and provides an overview of popular analytics tools.
The course delves into core Python programming, including syntax, variables, data types, operators, conditional statements, and more advanced topics like function & modules, file handling, exception handling, and OOP concepts in Python.
It covers Python libraries and modules essential for Data Science, such as Numpy, Scify, pandas, scikitlearn, statmodels, and nltk, ensuring students are well-versed in data manipulation, cleansing, and analysis.
The program includes modules on data analysis and visualization, statistics, predictive modeling, data exploration for modeling, data preparation, solving segmentation problems, linear regression, logistic regression, and time series forecasting.
Additional benefits of the course include life-time validity learning and placement card, practical and personalized training with live projects, multiple job interviews with 100% job assistance, and the opportunity to work on live projects.
ThinkNext also offers a professional online course with international certifications from Microsoft and Hewlett Packard, providing step-by-step live demonstrations, personalized study and training plans, 100% placement support, and grooming sessions for personality development and spoken English.
The course has received recognition and awards, highlighting its quality and the institute's commitment to providing valuable learning experiences.
Contact us for more Information:
Company Name: ThinkNEXT Technologies Private Limited
Corporate Office (India) Address: S.C.F. 113, Sector-65, Mohali (Chandigarh)
Contact no: 78374-02000
Email id: [email protected]

best data science institute in chandigarh
0 notes
Text
♲ Tarik Abou-Chadi ([email protected])2021-05-08 10:44:16:
@jrhopkin @simonjhix @gabyhinsliff @StatModeling @chrishanretty @benwansell @drjennings @StephenDFisher This is what party attachment and vote look like based on Oesch class groups in the last round of the ESS. No idea how one would spin this into "Labour has lost all of its working class appeal" you will probably get something a little longer on the comparative perspective soon😉
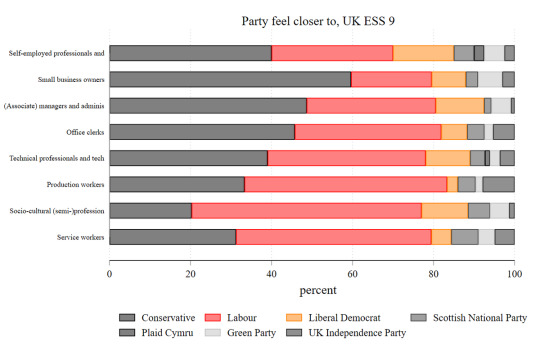
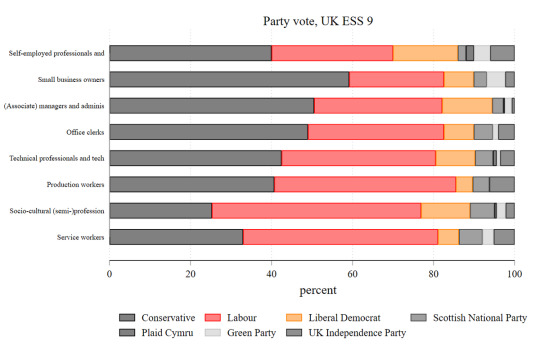
#Simon Hix#gabyhinsliff#Will Jennings#Jonathan Hopkin#Ben W. Ansell#Chris Hanretty#StatModeling#StephenDFisher
0 notes
Photo

"I am using excel in daily working but many things were unknown in excel which I have learnt in this session." - Pankaj Panchal Completed 2-Day workshop on "MS Excel to Boost Productivity" at Yanfeng Seating (India) Pvt. Ltd. (Supplier of MG Motors) We have covered, • Saving, Sharing, Protecting, Inspecting Workbook • Basic Formula & Functions • Cell Reference • Advanced Sorting & Filtering • Conditional Formatting • Data Validation • Advanced Formulas • Excel Charts & Excel Table • Dashboard Thank you Mr. Jay Gohil for giving this opportunity. 𝗪𝗮𝗻𝘁 𝘁𝗼 𝗱𝗼 𝗶𝘁 𝗳𝗼𝗿 𝘆𝗼𝘂𝗿 𝗼𝗿𝗴𝗮𝗻𝗶𝘇𝗮𝘁𝗶𝗼𝗻? 𝗽𝗹𝗲𝗮𝘀𝗲 𝗰𝗼𝗻𝘁𝗮𝗰𝘁 𝘂𝘀. 📧 : [email protected] 💬 : https://lnkd.in/dpTmMwzg 📞 : +91 98982 33268 🌐 : www.statmodeller.com #statmodeller #datascience #operationalexcellence #training #consultancy #statistics #powerbi #datavisualization #dataanalytics #dashboard #excel #microsoft #microsoftexcel #office #word #o #powerpoint #business #cursodeexcel #data #msexcel #powerbi #exceltips #datascience #microsoftoffice #dashboard #exceltraining #excelbasico #dataanalytics https://www.instagram.com/p/Cnvu-sNtcKX/?igshid=NGJjMDIxMWI=
#statmodeller#datascience#operationalexcellence#training#consultancy#statistics#powerbi#datavisualization#dataanalytics#dashboard#excel#microsoft#microsoftexcel#office#word#o#powerpoint#business#cursodeexcel#data#msexcel#exceltips#microsoftoffice#exceltraining#excelbasico
2 notes
·
View notes
Photo

Data scientists come from a wide range of educational backgrounds, but the majority of them will have technical schooling of some kind.
.
.
.
Register Now www.infogrex.com
Contact : 9347412456, 040 - 6771 4400/4444
.
.
.
,, , ,, , , , ,,
#Tesseract#Ipython#chennai#bangalore#hyderabad#mumbai#kolkata#lucknow#nagpur#ahmedabad#Delhi#OpenCV#PIL#Keras#Tensorflow#Scikit-learn#Statmodels#Plotly#Seaborn#nerdmemes#nerd#geekmemes#geeks#memes#machine learning algorithms#softwaredeveloper#software#coderhumor#computersciencememes
0 notes
Text
Sample
The sample is from the National Stock Exchange’s leading Index, NIFTY 50 since this index is used by most of the investors in India. 41 companies have been studied out of the 50 companies since these companies have consistently been a part of NIFTY 50 over the years. Observations (N=1978) represented the OHLC (opening, high, low and closing) of stock prices for these 41 companies, which included 1025 days of Bullish period and 953 days of Bearish period. The data analytic sample for this study included stock prices for 1978 days from 1st April 2008 to 31st March 2016 for the 41 companies under Bearish and Bullish periods.
Procedure
Data were collected from (https://www1.nseindia.com/products/content/equities/equities/eq_security.htm), the website of National Stock Exchange of India Ltd. on daily stock prices of 41 companies out of NIFTY 50 companies from 1st April 2008 to 31st March 2016.
Measures
Here the response variable is Herd Mentality in Indian stock market data using explanatory variable Cross-Sectional Absolute Deviation (CSAD). Herd Mentality was assessed on the basis of daily stock market data of NIFTY 50 companies during Bearish and Bullish period for the given time period. Least Squares technique was applied to find the corresponding p values for Bearish, Bullish and the whole period using statmodels in Python. Also, by using matplotlib in Python, a non-increasing non-linear relationship between CSAD and absolute values on market return was observed in a scatter plot.
1 note
·
View note
Photo

via @hankagosa
ブログ更新しました → COVID-19 日本人の潜在的な陽性者数を推定する試み - StatModeling Memorandum https://t.co/tO1YUBreSX
— Kentaro Matsuura (@hankagosa) April 4, 2020
0 notes
Text
RT @NAChristakis: For example, for a very sophisticated estimate of the CFR, based on all data and using a good method, see this discussion (and link to paper) by @StatModeling (CFR is ~1.5% in this estimate!): https://t.co/z3D25i2UqM 7/ https://t.co/MufUezFgFc
RT @NAChristakis: For example, for a very sophisticated estimate of the CFR, based on all data and using a good method, see this discussion (and link to paper) by @StatModeling (CFR is ~1.5% in this estimate!): https://statmodeling.stat.columbia.edu/2020/03/07/coronavirus-age-specific-fatality-ratio-estimated-using-stan/ 7/ from @gueringreen - twitter https://twitter.com/GuerinGreen/status/1240047639615262720
0 notes
Text
RT @NAChristakis: For example, for a very sophisticated estimate of the CFR, based on all data and using a good method, see this discussion (and link to paper) by @StatModeling (CFR is ~1.5% in this estimate!): https://t.co/z3D25i2UqM 7/ https://t.co/MufUezFgFc
RT @NAChristakis: For example, for a very sophisticated estimate of the CFR, based on all data and using a good method, see this discussion (and link to paper) by @StatModeling (CFR is ~1.5% in this estimate!): https://statmodeling.stat.columbia.edu/2020/03/07/coronavirus-age-specific-fatality-ratio-estimated-using-stan/ 7/ from FB Mashes https://twitter.com/GuerinGreen/status/1240047639615262720 https://ift.tt/3b2Dkbm
0 notes
Text
Hands-on python: my preamble
#ICYDK: I prefer to structure my code the same way as an article, and if have academic background as well, you can relate. Hence, I usually start with preamble, where I put all the packages and toolkits I would like to use. Then, the main part follows and subsequently the rest (for example, where the result of the model should go, all the connections). Especially if you are getting started and learn python, I recommend to structure and comment your code as clear as possible. With Jupiter you have several options for headings and comments already implemented in the notebook. Clear structure and sufficient comments would help you to write the code which you can easily recap (and follow) in months or even years. My experience is that good codes are often (partly) recycled. In this blog post, I summarized what I call, (1) general preamble and (2) visualization preamble. Although I post (3) my map and (4) analysis preamble as well, I will be more detailed about them in the forthcoming posts. 1. General preamble import pandas as pd import numpy as np import datetime as dt I need pandas and numpy always. Therefore, I always start with these two. I work often with time series. That’s why I need the third line. With datetime you can define the date, set an index on date and do all other date relevant manipulations. 2. Visualization import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline These lines are the very general, with seaborn and matplotlib we will cover most of visualizations, of any kind. Then, we can become more specific and define the style and context. Refer to seaborn page for details. I prefer ‘whitegrid’ and ‘talk’ and set them in the beginning as my personized default framework. Refer to the seaborn for further options. sns.set_style('whitegrid') sns.set_context('talk') Furthermore, if you work for the company which have corporate identity with predefined colors, it is useful to create your own palette with company colors. The graphs would automatically get these colors (as long as you not overrule it). The corporate identity colors at my company are ordered in an agreed way. So, by the ordering in the list you define the order in which the colors are applied automatically. mycolors = ['#0076a7','#ae5b3a','#CD997C','#EDD195'] #list of colors, I prefer hex numbers for colors sns.set_palette(mycolors) # define the palette sns.palplot(sns.color_palette()) # display 3. Maps Maps are special kind of visualization, they worth a separate blog post (forthcoming). You will find my preamble for them below. import folium from folium.plugins import MarkerCluster #if you want to cluster from folium.plugins import MiniMap # cool minimap in the low right corner of the big map from folium import plugins from folium import FeatureGroup #if you customize 4. Analysis I am time series econometrician. Therefore, my analysis preamble is very time series biased. You start time series analysis with tests to understand the autocorrelation structure of your variables. I would be more detailed on data analysis with python in my forthcoming blogs. import statsmodels.api as sm from statsmodels.tsa.stattools import adfuller #Augmented Dickey-Fuller unit root test from statsmodels.graphics.tsaplots import plot_acf #autocorrelation function from statsmodels.graphics.tsaplots import plot_pacf #partial autocorrelation from statsmodels.tsa.api import VAR, DynamicVAR #for time series analysis You will find a lot useful explanations and relavant packages on statmodels webpage. http://bit.ly/36CUlre
0 notes
Photo

Age Heaping(エイジ・ヒーピング)とは、図1(※インドネシアの人口ピラミッド)に見られるように、人口ピラミッドなどの年齢各歳別の統計において、例えば50 歳、55歳など、0または5で終わる年齢において、人口が突出して多くなる現象のことである。
この現象が起こる原因は、その国において、自分の年齢を正確に知らない人が多いことである。このため、自分の年齢を回答する場合には、50歳、55歳などと、自分の年齢に近いと思われる、切りの良い数字で回答することになるわけである。
この現象は、発展途上国に多く見られる。ただし、発展途上国であっても、十二支が社会的習慣として浸透している国では、この現象は見られない。
(via 人口ピラミッドのAge Heapingを階層ベイズで補正する - StatModeling Memorandum)
4 notes
·
View notes
Text
TensorFlowで統計モデリング - StatModeling Memorandum [はてなブックマーク]

TensorFlowで統計モデリング - StatModeling Memorandum

とある勉強会で「TensorFlowで統計モデリング」というタイトルで講義をしました。聴衆はPythonユーザが多く、データ量が大きい問題が多そうだったので、StanよりもTensorFlowで点推定するスキルを伸ばすとメリットが大きいだろうと思ってこのようなタイトルになりました。 発表資料は以下になります。 TensorFlowで統計...


from kjw_junichiのはてなブックマーク https://ift.tt/2L4XS7m
0 notes
Text
Replace missing values within fraction of time using *Go to Special Options*
Go to Special is a *Special* tool for time saving tasks. Use *Go To* tool to find & select cells which are matching with criteria, such as Blank Cells, Cells with Formulas / Formatting / Data Validation etc.,
Subscribe to our channel https://lnkd.in/f3NhafJ
To get updates from Stat Modeller, please join our WhatsApp group. https://lnkd.in/dQwRymft
We at Stat Modeller provides training and consultancy in the following domains,
• Data Science (R, Python, SPSS, Minitab, PowerBI, Tableau, SAS, Excel etc.)
• Research Projects (Survey Analysis, Individual Research, Market Research etc.)
• Operational Excellence (Six Sigma, Lean, 5-S, Kaizen, TPM, Inventory Optimization)
• Universities and Institutes (Certification courses for Students, Training, Workshops)
To know more about us, please visit our website www.statmodeller.com For any enquiries, please reach out to us on 9898233268 or email at [email protected]
Follow us:
LinkedIn - https://lnkd.in/dy5f22p3
Facebook - https://lnkd.in/dWcRRq53
Twitter - https://lnkd.in/d4WEX2R2
Instagram - https://lnkd.in/d3TikXWY
#statmodeller #datascience #operationalexcellence #training #consultancy #statistics #powerbi #datavisualization #dataanalytics #dashboard
#statisticalanalysis #statistics #dataanalysis #statistical #data #dataanalyst #statistician #analysis #excel #datascience #jamovi #nonparametric #exceltips #exceltricks #microsoftexcel # #tableau #lean #python #research #universities #projects #universities #facebook #linkedin #marketresearch #email #students #instagram
🌐 : www.statmodeller.com
#datascience#statmodeller#operationalexcellence#statistics#training#consultancy#datavisualization#powerbi#business#data
3 notes
·
View notes
Photo

***Infogrex Offers workable Free Webinar on Data Science***
A data scientist’s level of experience and knowledge in each, often varies along a scale ranging from beginner to proficient, and to expert, in the ideal case.
.
.
.
Register Now www.infogrex.com
Contact : 9347412456, 040 - 6771 4400/4444
.
1:best data analytics course online:
2: learn data science online :
3: data analytics courses online :
4: python for data science online :
5: python for data science online :
#geekmemes#computersciencememes#coderhumor#software#softwaredeveloper#algorithm#memes#geeks#nerd#nerdmemes#Seaborn#Plotly#Statmodels#Scikit-learn#Tensorflow#Keras#PIL#OpenCV#Tesseract#Ipython#Delhi#ahmedabad#nagpur#lucknow#kolkata#mumbai#hyderabad#bangalore#chennai
0 notes
Video
youtube
How to import CSV File in python and does stat model - in Tamil
For more visit my Blog : : http://annaarticles.blogspot.com/ Subscribe and Like #Python #Pythontutorial #Tutorial #machinelearning #csv #statmodel #Tamil
0 notes
Quote
Favorite tweets: So about that miraculous prediction from Michael Levitt.Via @StatModeling https://t.co/SBsuWpb8fT pic.twitter.com/w22pOZc6BK— Carl T. Bergstrom (@CT_Bergstrom) April 1, 2020
http://twitter.com/CT_Bergstrom
0 notes