#Ready-Made Scraping APIs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Average visit duration of Tumblr.com is 10 mins and 25 secs.
Text
E-commerce Web Scraping | Data Scraping for eCommerce
Are you in need of data scraping for eCommerce industry? Get expert E-commerce web scraping services to extract real-time data. Flat 20%* off on ecommerce data scraping.
0 notes
Text
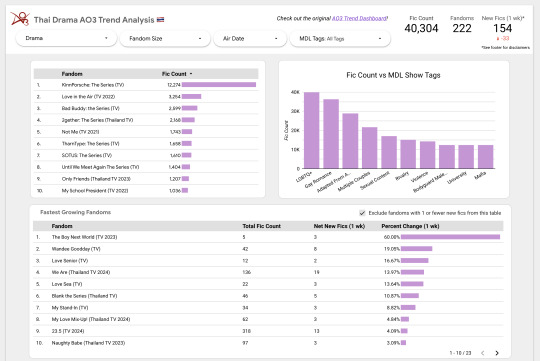
Introducing the Thai Drama AO3 Trends Dashboard! (Beta) 🇹🇭
Over the last several weeks or so I've been building an auto-scraping setup to get AO3 stats on Thai Drama fandoms. Now I finally have it ready to share out!
Take a look if you're interested and let me know what you think :)
(More details and process info under the cut.)
Main Features
This dashboard pulls in data about the quantity of Thai Drama fics over time.
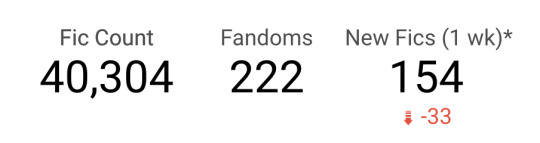
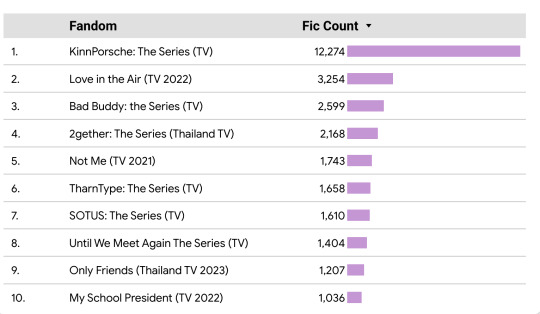
Using filters, it allows you to break that data down by drama, fandom size, air date, and a select number of MyDramaList tags.
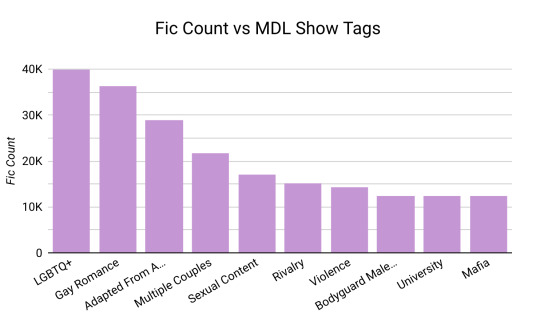
You can also see which fandoms have had the most new fics added on a weekly basis, plus the growth as a percentage of the total.
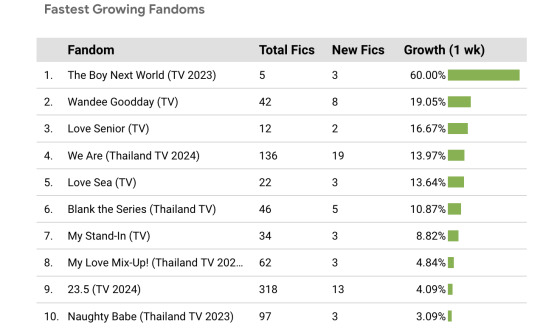
My hope is that this will make it easier to compare Thai Drama fandoms as a collective and pick out trends that otherwise might be difficult to see in an all-AO3 dataset.
Process
Okay -- now for the crunchy stuff...
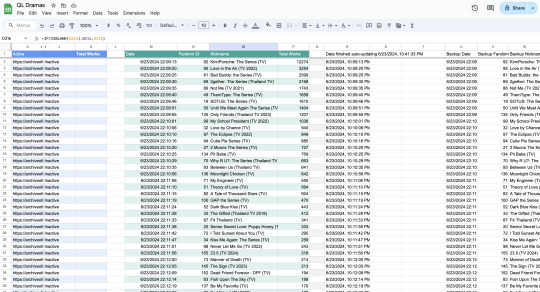
Scraping 🔎
Welcome to the most over-complicated Google Sheets spreadsheet ever made.
I used Google Sheets formulas to scrape certain info from each Thai Drama tag, and then I wrote some app scripts to refresh the data once a day. There are 5 second breaks between the refreshes for each fandom to avoid overwhelming AO3's servers.
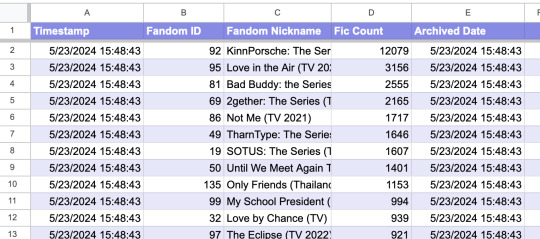
Archiving 📁
Once all the data is scraped, it gets transferred to a different Archive spreadsheet that feeds directly into the data dashboard. The dashboard will update automatically when new data is added to the spreadsheet, so I don't have to do anything manually.
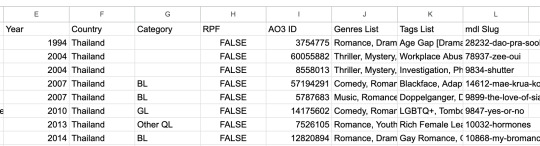
Show Metadata 📊
I decided to be extra and use a (currently unofficial) MyDramaList API to pull in data about each show, such as the year it came out and the MDL tags associated with it. Fun! I might pull in even more info in the future if the mood strikes me.
Bonus - Pan-Fandom AO3 Search
Do you ever find it a bit tedious to have like, 15 different tabs open for the shows you're currently reading fic for?
While making this dash, I also put together this insane URL that basically serves as a "feed" for any and all new Thai drama fics. You can check it out here! It could be useful if you like checking for new fics in multiple fandoms at once. :)
Other Notes
Consider this dashboard the "beta" version -- please let me know if you notice anything that looks off. Also let me know if there are any fandoms missing! Thanks for checking it out!
The inspiration for this dashboard came from @ao3-anonymous 's AO3 Fandom Trend Analysis Dashboard, which I used as a jumping off point for my own data dash. Please give them some love <3
#in which i am the biggest nerd ever#thai bl#thai drama#lgbt drama#ql drama#data science#acafan#fandom data visualization#fanfiction data
279 notes
·
View notes
Text
Why Python Reigns Supreme: A Comprehensive Analysis
Python has grown from a user-friendly scripting language into one of the most influential and widely adopted languages in the tech industry. With applications spanning from simple automation scripts to complex machine learning models, Python’s versatility, readability, and power have made it the reigning champion of programming languages. Here’s a comprehensive look at why Python has reached this esteemed position and why it continues to dominate.
Considering the kind support of Learn Python Course in Hyderabad Whatever your level of experience or reason for switching from another programming language, learning Python gets much more fun.

1. Readable Syntax, Rapid Learning Curve
Python is celebrated for its straightforward, readable syntax, which resembles English and minimizes the use of complex symbols and structures. Unlike languages that can be intimidating to beginners, Python's design philosophy prioritizes readability and simplicity, making it approachable for people new to programming. This ease of understanding is crucial in educational settings, where Python has become a top choice for teaching programming fundamentals.
Python’s gentle learning curve allows beginners to focus on mastering logic and problem-solving rather than wrestling with complicated syntax, making it a universal favorite.
2. A Thriving Ecosystem of Libraries and Tools
Python boasts a rich ecosystem of libraries and tools, which provide ready-made functionalities that allow developers to get straight to work without reinventing the wheel. For instance:
Data Science and Machine Learning: Libraries like pandas, NumPy, scikit-learn, and TensorFlow offer robust tools for data manipulation, statistical analysis, and machine learning.
Web Development: Frameworks like Django and Flask make it simple to build and deploy scalable web applications.
Automation: Tools like Selenium and BeautifulSoup enable developers to automate tasks, scrape websites, and handle repetitive processes efficiently.
Visualization: Libraries such as Matplotlib and Seaborn offer powerful ways to create data visualizations, a crucial feature for data analysts and scientists.
These libraries, created and maintained by a vast community, save developers time and effort, allowing them to focus on innovation rather than the details of implementation.
3. Multi-Paradigm Language with Versatile Use Cases
Python is inherently a multi-paradigm language, which means it supports procedural, object-oriented, and functional programming. This flexibility allows developers to choose the best approach for their projects and adapt their programming style as necessary. Python is ideal for a wide range of applications, including:
Web and App Development: Python’s frameworks, such as Django and Flask, are widely used for building web applications and APIs.
Data Science and Analytics: With its powerful libraries, Python is the language of choice for data analysis, manipulation, and visualization.
Machine Learning and Artificial Intelligence: Python has become the industry standard for machine learning, AI, and deep learning, with major frameworks optimized for Python.
Automation and Scripting: Python excels in automating repetitive tasks, from data scraping to system administration.
This adaptability means that developers can work across projects in different domains, without needing to switch languages, increasing productivity and consistency.
. Enrolling in the Best Python Certification Online can help people realise Python's full potential and gain a deeper understanding of its complexities.

4. The Power of the Community
Python’s growth and success are deeply rooted in its active, vibrant community. This worldwide community contributes to Python’s extensive documentation, support forums, and open-source projects, ensuring that resources are available for developers at all levels. Additionally, Python’s open-source nature allows anyone to contribute to its libraries, frameworks, and core features. This constant improvement means Python stays relevant, innovative, and well-supported.
The Python community is also highly collaborative, hosting events, tutorials, and conferences like PyCon, which facilitate learning and networking. With a community of developers continuously advancing the language and sharing their knowledge, Python remains a constantly evolving, resilient language.
5. Dominance in Data Science, Machine Learning, and AI
Python’s popularity surged with the rise of data science, machine learning, and AI. As industries recognized the value of data-driven decision-making, demand for data analytics and predictive modeling grew rapidly. Python, with its well-developed libraries like pandas, scikit-learn, TensorFlow, and Keras, became the preferred language in these fields. These libraries allow developers and researchers to experiment, build, and scale machine learning models with ease, fostering innovation in AI-driven industries.
The popularity of Jupyter Notebooks also propelled Python’s use in data science. This interactive development environment allows users to combine code, visualizations, and explanations in a single document, making data exploration and sharing more efficient. As a result, Python has become a staple in data science courses, research, and industry applications.
6. Cross-Platform Compatibility and Open Source Advantage
Python’s cross-platform compatibility allows it to run on various operating systems like Windows, macOS, and Linux, making it ideal for development in diverse environments. Python code is generally portable, which means that scripts written on one platform can often run on another with little to no modification, providing developers with added flexibility and ease of deployment.
As an open-source language, Python is free to use and backed by a vast global community. The lack of licensing costs makes Python an accessible choice for startups, educational institutions, and corporations alike, contributing to its widespread adoption. Python’s open-source nature also allows the language to evolve rapidly, with new features and libraries continuously added by its active user base.
Python’s Future as a Leading Language
Python’s blend of readability, flexibility, and community support has catapulted it to the top of the programming world. Its stronghold in data science, AI, web development, and automation ensures it will remain relevant across a broad spectrum of industries. With its rapid development, Python is poised to tackle emerging challenges, from ethical AI to quantum computing. As more people turn to Python to solve complex problems, it will continue to be a language that’s easy to learn, powerful to use, and versatile enough to stay at the cutting edge of technology.
Whether you’re a newcomer or a seasoned developer, Python is a language that opens doors to endless possibilities in the world of programming.
0 notes
Text
Top 6 Scraping Tools That You Cannot Miss in 2024
In today's digital world, data is like money—it's essential for making smart decisions and staying ahead. To tap into this valuable resource, many businesses and individuals are using web crawler tools. These tools help collect important data from websites quickly and efficiently.
What is Web Scraping?
Web scraping is the process of gathering data from websites. It uses software or coding to pull information from web pages, which can then be saved and analyzed for various purposes. While you can scrape data manually, most people use automated tools to save time and avoid errors. It’s important to follow ethical and legal guidelines when scraping to respect website rules.
Why Use Scraping Tools?
Save Time: Manually extracting data takes forever. Web crawlers automate this, allowing you to gather large amounts of data quickly.
Increase Accuracy: Automation reduces human errors, ensuring your data is precise and consistent.
Gain Competitive Insights: Stay updated on market trends and competitors with quick data collection.
Access Real-Time Data: Some tools can provide updated information regularly, which is crucial in fast-paced industries.
Cut Costs: Automating data tasks can lower labor costs, making it a smart investment for any business.
Make Better Decisions: With accurate data, businesses can make informed decisions that drive success.
Top 6 Web Scraping Tools for 2024
APISCRAPY
APISCRAPY is a user-friendly tool that combines advanced features with simplicity. It allows users to turn web data into ready-to-use APIs without needing coding skills.
Key Features:
Converts web data into structured formats.
No coding or complicated setup required.
Automates data extraction for consistency and accuracy.
Delivers data in formats like CSV, JSON, and Excel.
Integrates easily with databases for efficient data management.
ParseHub
ParseHub is great for both beginners and experienced users. It offers a visual interface that makes it easy to set up data extraction rules without any coding.
Key Features:
Automates data extraction from complex websites.
User-friendly visual setup.
Outputs data in formats like CSV and JSON.
Features automatic IP rotation for efficient data collection.
Allows scheduled data extraction for regular updates.
Octoparse
Octoparse is another user-friendly tool designed for those with little coding experience. Its point-and-click interface simplifies data extraction.
Key Features:
Easy point-and-click interface.
Exports data in multiple formats, including CSV and Excel.
Offers cloud-based data extraction for 24/7 access.
Automatic IP rotation to avoid blocks.
Seamlessly integrates with other applications via API.
Apify
Apify is a versatile cloud platform that excels in web scraping and automation, offering a range of ready-made tools for different needs.
Key Features:
Provides pre-built scraping tools.
Automates web workflows and processes.
Supports business intelligence and data visualization.
Includes a robust proxy system to prevent access issues.
Offers monitoring features to track data collection performance.
Scraper API
Scraper API simplifies web scraping tasks with its easy-to-use API and features like proxy management and automatic parsing.
Key Features:
Retrieves HTML from various websites effortlessly.
Manages proxies and CAPTCHAs automatically.
Provides structured data in JSON format.
Offers scheduling for recurring tasks.
Easy integration with extensive documentation.
Scrapy
Scrapy is an open-source framework for advanced users looking to build custom web crawlers. It’s fast and efficient, perfect for complex data extraction tasks.
Key Features:
Built-in support for data selection from HTML and XML.
Handles multiple requests simultaneously.
Allows users to set crawling limits for respectful scraping.
Exports data in various formats like JSON and CSV.
Designed for flexibility and high performance.
Conclusion
Web scraping tools are essential in today’s data-driven environment. They save time, improve accuracy, and help businesses make informed decisions. Whether you’re a developer, a data analyst, or a business owner, the right scraping tool can greatly enhance your data collection efforts. As we move into 2024, consider adding these top web scraping tools to your toolkit to streamline your data extraction process.
0 notes
Text
SPSS Statistics, R And Python Develops Statistical Workflow

Breaking down silos: Combining statistical power with R, Python, and SPSS Statistics.
One of the top statistical software programs is IBM SPSS Statistics, which offers sophisticated statistical methods and prediction models to extract useful information from data. SPSS Statistics is the industry standard for statistical analysis for a large number of companies, academic institutions, data scientists, data analyst specialists, and statisticians.
The following features of SPSS Statistics may empower its users:
Comprehending data via in-depth analysis and visualization.
Regression analysis and other statistical techniques are used to identify patterns in trends.
Making accurate predictions about the future by using methods such as time-series analysis
Using reliable statistical models and customized statistical tests to validate hypotheses generating precise findings that direct important commercial endeavors.
A variety of datasets may be easily accessed, managed, and analyzed using IBM SPSS Statistics‘ low-code methodology and user-friendly interface. It is a strong and effective statistical program made to support data-driven decision-making in a variety of domains, including social science, policymaking, medical research, and more.
Users may follow a whole analytical journey from data preparation and management to analysis and reporting using IBM SPSS Statistics‘ data visualization features, sophisticated statistical analysis methodologies, and modeling tools. Data practitioners may perform a broad range of statistical tests and analyses using SPSS Statistics’ sophisticated visualization and reporting capabilities, as well as produce high-resolution graphs and presentation-ready reports that make findings simple to understand.
Derive maximum value from your data
Scalability, database connection, better output quality, and the ability to share techniques with non-programmers are common goals of advanced analytical software experts who employ open source programming languages like R and Python
On the other hand, it experts like its wide variety of data analysis and modeling methods, short learning curve for quick mastery of statistical processes, and user-friendly interface. Certain R or Python functions may be integrated by nonprogrammers without the need to learn complex code.
Numerous specialists in data science and analytics are aware of the distinct advantages of R, Python, and IBM SPSS Statistics. Scalable statistical analysis is an area in which SPSS Statistics shines, supporting data preparation, analysis, and visualization. Python is renowned for its extensive automation and web scraping modules, whereas R is known for its speed and performance in machine learning.
Because they are unsure of which tool is appropriate for a given job, how to choose the best plug-ins or extensions, and how to seamlessly integrate them while dealing with complicated and huge datasets, some users may still find combining SPSS Statistics with R and Python intimidating. These technologies may, however, be carefully combined to provide potent synergy for sophisticated data analysis techniques, data visualization, and data manipulation.
While R and Python give the ability for more complex customization and machine learning, SPSS Statistics provides a strong basis for fundamental statistical operations. This integrated strategy enables users to use state-of-the-art methods, extract meaningful insights from complicated data, and provide very dependable outcomes.
Additionally, professionals working in data analysis and data science have access to useful materials and lessons with to the robust community support found on all three platforms, which functions as if it were part of an ecosystem that facilitates knowledge exchange and data analysis.
How can R and Python be integrated with SPSS Statistics?
Using APIs to conduct data analyses from external programs: Users may conduct statistical analysis straight from an external R or Python application by using the SPSS Statistics APIs. To do your analysis, you don’t have to be in it the interface. You may use the robust capabilities of R or Python to perform a variety of statistical operations and link it to open source applications.
Including R or Python code: It proprietary language enables users to embed R or Python code. This implies that you may undertake particular data analysis by writing and executing bespoke R or Python code inside SPSS Statistics. It allows users to stay in the SPSS Statistics interface while using the sophisticated statistical features of R or Python.
Developing custom extensions: Plug-in modules (extensions) created in R or Python may be used to expand SPSS Statistics. By deploying bespoke code modules, these extensions allow customers to meet certain demands, functioning as built-in tools inside the system. The capability of it may be increased by using extensions to provide interactive features, automate analytic processes, and generate additional dialogs.
Combine R and Python with SPSS Statistics to maximize the results of data analysis
Improved integration The data science process may be streamlined by combining SPSS Statistics with R and Python to improve interaction with other storage systems like databases and cloud storage.
Faster development: By allowing users to execute custom R and Python scripts and create new statistical models, data visualizations, and web apps using its preconfigured libraries and current environment, SPSS Statistics helps speed up the data analysis process.
Improved functionality: It functionality may be expanded and certain data analysis requirements can be met by using extensions, which let users develop and implement unique statistical methods and data management tools.
Combining R or Python with SPSS Statistics has many benefits. The statistical community as a whole benefits from the robust collection of statistical features and functions provided by both SPSS Statistics and open source alternatives.
By handling bigger datasets and providing access to a wider range of graphical output choices, SPSS Statistics with R or Python enables users to improve their complicated data analysis process.
Lastly, SPSS Statistics serves as a perfect deployment tool for R or Python applications. This enables users of sophisticated statistical tools to fully use both open source and private products. They can address a greater variety of use cases, increase productivity, and achieve better results because to this synergy.
Read more on govindhtech.com
#SPSSStatistics#PythonDevelops#StatisticalWorkflow#machinelearning#datascience#ibm#dataanalysis#cloudstorage#Python#CombineR#Derivemaximum#technology#technews#news#govindhtech
1 note
·
View note
Text
Scrape Google Results - Google Scraping Services

In today's data-driven world, access to vast amounts of information is crucial for businesses, researchers, and developers. Google, being the world's most popular search engine, is often the go-to source for information. However, extracting data directly from Google search results can be challenging due to its restrictions and ever-evolving algorithms. This is where Google scraping services come into play.
What is Google Scraping?
Google scraping involves extracting data from Google's search engine results pages (SERPs). This can include a variety of data types, such as URLs, page titles, meta descriptions, and snippets of content. By automating the process of gathering this data, users can save time and obtain large datasets for analysis or other purposes.
Why Scrape Google?
The reasons for scraping Google are diverse and can include:
Market Research: Companies can analyze competitors' SEO strategies, monitor market trends, and gather insights into customer preferences.
SEO Analysis: Scraping Google allows SEO professionals to track keyword rankings, discover backlink opportunities, and analyze SERP features like featured snippets and knowledge panels.
Content Aggregation: Developers can aggregate news articles, blog posts, or other types of content from multiple sources for content curation or research.
Academic Research: Researchers can gather large datasets for linguistic analysis, sentiment analysis, or other academic pursuits.
Challenges in Scraping Google
Despite its potential benefits, scraping Google is not straightforward due to several challenges:
Legal and Ethical Considerations: Google’s terms of service prohibit scraping their results. Violating these terms can lead to IP bans or other penalties. It's crucial to consider the legal implications and ensure compliance with Google's policies and relevant laws.
Technical Barriers: Google employs sophisticated mechanisms to detect and block scraping bots, including IP tracking, CAPTCHA challenges, and rate limiting.
Dynamic Content: Google's SERPs are highly dynamic, with features like local packs, image carousels, and video results. Extracting data from these components can be complex.
Google Scraping Services: Solutions to the Challenges
Several services specialize in scraping Google, providing tools and infrastructure to overcome the challenges mentioned. Here are a few popular options:
1. ScraperAPI
ScraperAPI is a robust tool that handles proxy management, browser rendering, and CAPTCHA solving. It is designed to scrape even the most complex pages without being blocked. ScraperAPI supports various programming languages and provides an easy-to-use API for seamless integration into your projects.
2. Zenserp
Zenserp offers a powerful and straightforward API specifically for scraping Google search results. It supports various result types, including organic results, images, and videos. Zenserp manages proxies and CAPTCHA solving, ensuring uninterrupted scraping activities.
3. Bright Data (formerly Luminati)
Bright Data provides a vast proxy network and advanced scraping tools to extract data from Google. With its residential and mobile proxies, users can mimic genuine user behavior to bypass Google's anti-scraping measures effectively. Bright Data also offers tools for data collection and analysis.
4. Apify
Apify provides a versatile platform for web scraping and automation. It includes ready-made actors (pre-configured scrapers) for Google search results, making it easy to start scraping without extensive setup. Apify also offers custom scraping solutions for more complex needs.
5. SerpApi
SerpApi is a specialized API that allows users to scrape Google search results with ease. It supports a wide range of result types and includes features for local and international searches. SerpApi handles proxy rotation and CAPTCHA solving, ensuring high success rates in data extraction.
Best Practices for Scraping Google
To scrape Google effectively and ethically, consider the following best practices:
Respect Google's Terms of Service: Always review and adhere to Google’s terms and conditions. Avoid scraping methods that could lead to bans or legal issues.
Use Proxies and Rotate IPs: To avoid detection, use a proxy service and rotate your IP addresses regularly. This helps distribute the requests and mimics genuine user behavior.
Implement Delays and Throttling: To reduce the risk of being flagged as a bot, introduce random delays between requests and limit the number of requests per minute.
Stay Updated: Google frequently updates its SERP structure and anti-scraping measures. Keep your scraping tools and techniques up-to-date to ensure continued effectiveness.
0 notes
Text
How to Extract Google Search Results: A Comprehensive Tutorial
How to Extract Google Search Results: A Comprehensive Tutorial
Jan 23, 2024

Introduction
In an era where our phones have seamlessly integrated into our daily lives, Google stands out as the catalyst behind this evolutionary shift. Recognized for delivering answers with unparalleled speed and accessibility, Google represents not only billions of dollars but also a colossal volume of users, clicks, searches, and terabytes of invaluable data. This data, a treasure trove of information, can be automatically and effortlessly extracted using the right tools and methods.
In this concise how-to blog, we'll unveil the secrets of scraping data from the world's most extensive information repository, Google. Utilizing the Real Data API platform's Google Search Results Scraper, a powerful ready-made tool, we'll guide you step-by-step on how to scrape diverse information from Google. This includes organic and paid results, ads, queries, People Also Ask boxes, prices, and reviews. Let's embark on this journey of mastering Google search results scraping together!
Mastering Google SERPs: Efficiently Scrape and Extract Search Results
Google SERPs, or Search Engine Results Pages, represent the curated list of outcomes that Google presents upon entering a search query. While Google dominates 90% of the search engine market, other platforms like Bing and Yahoo also feature SERPs. Understanding this term is crucial for harnessing the power of web scraping on the Google Search Engine. Throughout this guide, we'll explore the interchangeability of terms such as Google page, Google search page, and Google SERP, opting for the latter for precision.
The Evolution of Google SERPs

How to extract Google SERP?
To effectively scrape Google search results, it's crucial to delve into how Google perceives and prioritizes our search queries. Google's evolution from a mere index of pages to a dynamic platform focused on delivering quick, efficient, and visually appealing answers has reshaped the landscape of search results.
In the past, search results were straightforward, primarily consisting of indexed pages and URLs. However, Google's primary goal has always been to swiftly address user queries while capturing attention and maintaining readability. This commitment to user-centricity has led to the creation of a multilayered structure in search results, resembling a complex layer cake.

Elements of a Google Search Page and How to Scrape Them
In the contemporary Google Search Engine Results Page (SERP), a diverse array of content awaits users, including featured snippets, snap packs, ads, and organic results. Additional elements like product ads, related searches, and various types of snap packs (Google Maps, Wikipedia, YouTube videos, etc.) may also appear depending on the nature of the search query. The complexity of Google SERP is further highlighted when considering the type of search, ensuring tailored content for scientific and educational queries like the James Webb Telescope, as opposed to everyday items like shoes or headphones that may feature paid ads and product carousels.
This intricate structure of Google SERP presents a valuable opportunity for data extraction, offering access to a wealth of helpful information. In this guide, we'll explore the elements comprising a Google search page and provide insights into how to scrape and extract data from these dynamic results effectively.
Maximizing Google-Extracted Data for Businesses and Marketing Agencies
In today's digital landscape, where Google is the primary gateway to the internet for billions, securing a prominent spot in Google Search results is critical for nearly every business. For local businesses, the impact of Google reviews and ratings on their online profiles is monumental. Marketing agencies, primarily those catering to diverse industries, heavily depend on reliable SEO tools, including advanced AI tools, to efficiently manage and analyze results.
This guide explores the strategic utilization of data extracted from Google through scraping methods. Discover how businesses can leverage this information to optimize their online presence and understand the competitive landscape. Whether analyzing top-ranking pages for page title strategies, identifying targeted keywords, studying content formatting, or conducting deeper link analysis, this guide provides actionable insights for successfully managing and analyzing Google-extracted data.
Use Cases of Google Search Scraping
Google Search scraping offers a myriad of use cases across various industries, providing valuable insights and opportunities for businesses and individuals. Here are several noteworthy use cases for Google Search scraping:
SEO Optimization:
Extracting data from Google Search results allows businesses to analyze top-ranking pages, identify relevant keywords, and understand competitor strategies. This information is crucial for optimizing website content, meta tags, and overall SEO performance.
Competitor Analysis:
Scraping Google Search results enables businesses to gather intelligence on their competitors. Analyzing competitor keywords, content strategies, and backlink profiles can inform strategic decision-making and help maintain a competitive edge.
Market Research:
Extracting data from Google Search results provides insights into market trends, consumer preferences, and emerging topics. Businesses can use this information to adapt their products, services, and marketing strategies to meet market demands.
Reputation Management:
Monitoring Google Search results for brand mentions, reviews, and ratings is crucial for effective reputation management. Scraping this information allows businesses to promptly address issues, capitalize on positive feedback, and maintain a positive online image.
Content Strategy Development:
Analyzing search results helps in understanding user intent and preferences. By scraping Google Search, businesses can identify popular topics, format their content effectively, and create content that resonates with their target audience.
Lead Generation:
Extracting contact information of businesses or individuals from Google Search results can be used for lead generation. This is particularly valuable for sales and marketing teams looking to expand their client base.
Price Monitoring and E-commerce:
E-commerce businesses can use scraping to monitor product prices, availability, and competitor pricing on Google Search. This data helps adjust pricing strategies, stay competitive, and make informed business decisions.
Academic and Scientific Research:
Researchers can utilize Google Search scraping to gather data on specific topics, track scholarly articles, and monitor academic trends. This assists in staying updated with the latest research in a particular field.
News Aggregation:
News websites and aggregators can use Google Search scraping to gather real-time information on trending topics, news articles, and relevant sources. This helps in providing up-to-date content to their audience.
Legal and Compliance Monitoring:
Law firms and regulatory bodies can monitor Google Search results for legal cases, regulatory changes, and compliance issues. This ensures that legal professionals stay informed and can respond promptly to legal developments.
While Google's terms of service prohibit automated scraping, it's crucial to respect ethical and legal considerations when extracting data from Google Search or any other website. Continually review and adhere to the terms of service of the website you are scraping to avoid legal issues.
Navigating the Legal Landscape: Extracting Insights from Google Search Results
Scraping Google search results is generally legal as this information falls under publicly available data. However, it's crucial to exercise caution and adhere to ethical practices. While gathering data, avoid accumulating personal information or copyrighted content to ensure compliance with legal guidelines. Utilizing web scraping services, businesses can employ a Google web scraper or Google search results scraper to extract valuable insights for SEO optimization, competitor analysis, and market research. It's essential to stay informed about legal considerations, respect Google's terms of service, and uphold ethical standards when extracting Google search results.
Harnessing AI for Google Search Results Scraping: A Code Generation Approach
While AI cannot directly scrape websites, it is crucial in facilitating the process by generating code for scraping Google when provided with specific target elements. This innovative approach assists in creating scraping scripts tailored to extract desired information. However, it's important to note that the generated code may require adjustments and may be affected by changes in website structure. For effective Google search results scraping, businesses can leverage web scraping services, employing a Google web scraper or Google search results scraper, to extract valuable insights for SEO, competitor analysis, and market research.
Unraveling Google Search: The Role of Scraping and Customized Data Extraction
Delving into the intricacies of Google Search, the absence of a direct API for search results prompts exploring alternative methods, with scraping emerging as a critical solution. This process enables the creation of a personalized Google SERP API for data extraction, offering insights into the evolving dynamics of how Google displays results. In this exploration, we navigate through the limitations of manual searches, the significance of scraping Google search results, and the factors contributing to the personalized nature of modern Google search outcomes.
Challenges of Manual Searches
Attempting to gain insights into Google's functioning through manual searches is time-consuming, especially when scalability is required. Even in incognito mode, the subjectivity of results poses challenges to obtaining objective data. Google's algorithms have evolved significantly since the early 2000s, when search results were relatively uniform across localized Google versions for each country.
Evolution of Google Search
Algorithmic advancements mark Google's progression from uniform search results to highly personalized outcomes. Several factors now influence the presentation of search results, shaping the user experience:
Type of Device
Since 2015, Google has favored displaying mobile-optimized web pages when users search via smartphones, altering the appearance of search results.
Registration: User-logged Google accounts align search results with individual histories and behaviors, respecting data-related settings.
Browser History: Infrequent clearing of browser cache allows Google to consider past search queries with cookies, influencing and customizing search results.
Location: They are activating geo-localization, which results in SERPs aligned with the user's location. Local searches combine data from both Google Search and Google Maps.
The Role of Scraping in Data Extraction
Addressing the inefficiencies of manual searches, web scraping services and tools like a Google web scraper or Google search results scraper become instrumental. Scraping allows for efficient and objective data extraction from Google, providing businesses and researchers with the necessary insights for analysis and decision-making.
They are creating a personalized Google SERP API through scraping as a gateway to understanding the intricate dynamics of modern Google Search. As personalized search results become the norm, using web scraping services and tools becomes essential for businesses and researchers aiming to decode the complexities of online visibility and user engagement. In navigating the ever-evolving digital landscape, the ethical use of scraping practices and continual adaptation to technological advancements are pivotal in unlocking the full potential of Google search results extraction.
Unleashing the Power of Automated Data Extraction: Google Search Results Scraping Simplified
In the quest for a comprehensive and objective solution to Google search result extraction, the challenges of manual work and the absence of an official Google API pave the way for automated alternatives. Enter the Google Search Results Scraper, an innovative solution that simplifies the process of scraping massive websites like Google, providing users with a programmatic alternative SERP API. In this exploration, we delve into the capabilities of this tool, highlighting its support for diverse data extraction, from organic and paid results to queries, ads, People Also Ask, prices, and reviews.
Automated Data Extraction with Google Search Results Scraper:
The Google Search Results Scraper addresses the limitations of manual work by automating the data extraction process. Acting as an alternative SERP API, this tool is user-friendly and sophisticated enough to navigate the intricacies of Google's vast website. Its primary functionalities include:
Extraction of Organic and Paid Results:
The scraper efficiently gathers organic and paid search results data, providing a comprehensive overview of a given query's landscape.
Ads and Queries Extraction: Beyond standard results, the tool captures information related to ads and user queries, enabling a thorough analysis of advertising strategies and user search patterns.
People Also Ask Insights: The scraper retrieves data from the "People Also Ask" section, offering valuable insights into related queries and user interests.
Prices and Reviews Collection: For e-commerce and business analysis, the tool supports extracting prices and reviews associated with specific products or services.
Customization with JavaScript Snippets: The flexibility of the Google Search Results Scraper extends further with the option to include JavaScript snippets. This feature allows users to extract additional attributes from the HTML, providing a tailored approach to data extraction based on specific requirements.
Automated data extraction from search engines, specifically Google, is made accessible and efficient through tools like the Google Search Results Scraper. As an alternative SERP API, this tool empowers users to scrape, extract, and analyze diverse data sets, unlocking valuable insights for SEO optimization, competitor analysis, and market research. As the digital landscape continues to evolve, automated solutions like the Google Search Results Scraper have become indispensable for businesses and individuals seeking a reliable and comprehensive approach to Google search result data extraction.
Conclusion
Get on to your inaugural month with Real Data API by leveraging the capabilities of our Google Search Scraper. Seamlessly scrape, extract, and analyze Google search results with our user-friendly and efficient tool. For a more comprehensive exploration of the vast Google landscape, explore our array of Google scrapers available at the Real Data API Store. Elevate your web scraping endeavors with our services, which provide valuable insights for SEO optimization, competitor analysis, and market research. Embrace the power of our Google web scraper and Google search results scraper to enhance your data extraction experience. Contact us for more details!
#GoogleSearchScraping#ExtractGoogleSearchData#ScrapeGoogleSearchResults#ExtractGoogleSearchResults#GoogleSearchResultsCollection
0 notes
Text
Unleashing the Power of Data: Scrape and Monitor Websites with No Code In the age of information, harnessing data has become a pivotal factor in making informed decisions. Businesses, researchers, and individuals alike seek efficient ways to extract, monitor, and analyze data from the vast expanse of the internet. This is where Browse AI steps in, offering a revolutionary solution that requires no coding expertise. With its innovative approach, Browse AI empowers users to effortlessly scrape and monitor data from any website. The Essence of Browse AI Seamlessly Monitor Web Changes With Browse AI, monitoring changes on websites becomes an effortless task. Be it news articles, stock prices, or product listings, the platform enables users to keep a vigilant eye on dynamic content. [su_button url="https://bit.ly/46mSbtJ" target="blank" background="#ff3e3e" size="6" center="yes" text_shadow="0px 0px 0px #000000" title="Download"]Get Started for Free[/su_button] Download Web Data as Spreadsheets One of the platform's standout features is its ability to transform web data into structured spreadsheets. This facilitates easy organization, analysis, and sharing of information. Transform Websites into APIs Turning a website into an API is no longer a complex ordeal. Browse AI simplifies this process, offering a seamless method to access and utilize web data. Unveiling Prebuilt Robots Ready-Made Solutions for Common Tasks Browse AI introduces the concept of Prebuilt Robots, preconfigured automation solutions that cater to various use cases. From scraping job listings to extracting app details, these robots are ready to tackle a multitude of tasks. Embrace the Power of Extraction The platform offers an array of extraction capabilities. It empowers users to effortlessly extract specific data from websites and convert it into spreadsheet format, eliminating manual data entry. Scheduled Monitoring for Informed Decisions Stay updated with the latest changes using Browse AI's monitoring feature. Receive notifications on scheduled data extractions and stay ahead of the curve. Why Choose Browse AI? Embracing a Code-Free Approach The platform's hallmark feature lies in its ability to scrape structured data without the need for coding skills. Users can now delve into data extraction without the complexities of programming. Bulk Automation for Efficiency Efficiency is paramount in data-related tasks. Browse AI enables users to run an impressive 50,000 robots in one go, streamlining data collection on a massive scale. Seamless Integration with Applications Integration is key to leveraging data. Browse AI offers integration with over 7,000 applications, ensuring that extracted data seamlessly fits into existing workflows. Adapting to Change with Ease The ever-evolving nature of websites can pose challenges. Browse AI's robots possess the ability to auto-adapt to site layout changes, ensuring consistent data collection. Trust in Numbers A Legacy of Excellence Browse AI's track record is a testament to its efficiency. Trusted by over 250,000 individuals and teams, the platform has automated more than 11.9 million tasks, saving countless hours. An Array of Accomplishments From extracting over 2.1 billion rows of data to saving 17.6 million hours and serving a user base of 250,000+, the impact of Browse AI is profound. Endorsement from Users Customers rate Browse AI highly, with a recommendation rate of 9.6/10. The platform's prebuilt robots and intuitive interface have garnered immense praise. A Glimpse of Prebuilt Robots Unveiling the Possibilities Browse AI's prebuilt robots simplify complex tasks. Extract app details from platforms like Zapier, gather job posting specifics from Monster.com and Glassdoor, and access a list of job postings from Upwork. Crafting Custom Workflows Browse AI doesn't stop at extraction—it extends to customization. The platform enables users to create custom workflows, seamlessly integrating with tools like Google Sheets and Zapier.
Trend Monitoring with Precision Stay ahead of trends using Browse AI's robots. Monitor emerging trends in a specific country using data from Google Trends and empower your decision-making. Empowering Data-Driven Choices Unveiling the Path to Automation Browse AI's user-friendly process streamlines automation. Sign up, set up the browser extension, and train a robot—all in a matter of minutes. A World Without Coding Coding prowess is not a prerequisite. Browse AI empowers users of all backgrounds to embark on data automation journeys with ease. Understanding Credits Each plan includes credits that correspond to data extraction and tasks. From scraping to capturing screenshots, credits fuel Browse AI's capabilities. Crafting a Secure Environment Prioritizing Data Security Browse AI takes data security seriously. With bank-level encryption, stringent access management, and TLS 1.2, your data's privacy is safeguarded. Ensuring Privacy Sensitive data, such as passwords, is encrypted with AES-256. Only the platform's founder and DevOps team leadership possess decryption keys. Robust Monitoring Browse AI's support team adheres to stringent access protocols. Temporary access keys are in the pipeline to grant limited task access when support is needed. Conclusion In a world inundated with data, harnessing its power requires innovative solutions. Browse AI transcends the limitations of coding, offering a comprehensive platform for scraping and monitoring data from websites. From extraction to transformation and customization, Browse AI is the ally in data-driven decision-making. Trust its legacy of excellence, embrace its simplicity, and unlock the transformative potential of web data. The journey to data empowerment begins with Browse AI.
0 notes
Text
Revolutionizing Grocery Shopping: The Power of Fresh Direct Grocery Data Extraction
In the age of digital convenience, online grocery shopping has emerged as a game-changer for consumers seeking a hassle-free and efficient way to stock their kitchens. Fresh Direct, a prominent player in the online grocery market, has become synonymous with quality, freshness, and convenience. Behind the scenes, the extraction of valuable data from Fresh Direct's platform has become pivotal for enhancing customer experiences, optimizing inventory management, and fueling data-driven decisions. In this article, we explore the world of Fresh Direct grocery data extraction and its transformative impact.
Why Fresh Direct Data Extraction Matters

At its core, Fresh Direct's success relies on the ability to offer an extensive range of products, maintain competitive pricing, and ensure product availability. Data extraction from the Fresh Direct platform facilitates several critical functions that benefit both the company and its customers:
Real-time Inventory Management: Fresh Direct's vast inventory of fresh produce, groceries, and specialty items requires precise tracking. Data extraction enables real-time monitoring of inventory levels, helping the company avoid stockouts and maintain optimal stock levels.
Pricing Strategy Optimization: Pricing is a crucial factor in the grocery industry. Fresh Direct can use data extracted from its platform to analyze pricing trends, evaluate the competition, and adjust its pricing strategies to remain competitive.
Enhanced Customer Experience: For customers, having access to accurate and up-to-date information about product availability, prices, and promotions is essential. Data extraction ensures that customers can make informed decisions and enjoy a seamless shopping experience.
Personalized Recommendations: Extracted data can be analyzed to understand customer preferences and behaviors, allowing Fresh Direct to offer personalized product recommendations, thereby increasing customer satisfaction and loyalty.
Market Insights: Fresh Direct can gain valuable insights into market trends, customer demands, and emerging product categories by analyzing the data extracted from its platform. This information can drive strategic decision-making and expansion efforts.
Methods of Fresh Direct Grocery Data Extraction
Data extraction from Fresh Direct's platform can be achieved using several methods, including:
Web Scraping: Web scraping involves using specialized tools or software to extract data from websites. In the case of Fresh Direct, web scraping can collect information such as product details, prices, and stock levels directly from the website.
API Access: Some websites, including Fresh Direct, offer Application Programming Interfaces (APIs) that allow authorized users to access data in a structured format. This method is more reliable and secure, as it follows the website's intended data-sharing protocols.
Data Integration Services: Third-party data integration services can be employed to automate the extraction of data from Fresh Direct's platform. These services often provide ready-made connectors and can streamline the data extraction process.
In-house Data Extraction Tools: Fresh Direct may develop its own in-house tools and scripts for data extraction, customizing them to suit its specific needs. This approach offers flexibility and control over the extraction process.
Challenges and Ethical Considerations
While data extraction offers numerous benefits, it also comes with challenges and ethical considerations. Fresh Direct and other websites may have terms of service that prohibit or restrict data extraction, and exceeding these limitations could result in legal consequences. Additionally, respecting user privacy and adhering to data protection regulations is paramount when dealing with extracted data.
Conclusion
Fresh Direct grocery data extraction is a dynamic and transformative process that fuels the company's commitment to providing high-quality products and exceptional service to its customers. Real-time inventory management, pricing optimization, personalized recommendations, and market insights are just a few of the advantages that stem from this practice.
However, it's essential to approach data extraction ethically, within the bounds of legal and ethical guidelines, and with respect for user privacy. When harnessed responsibly, Fresh Direct's grocery data extraction capabilities can drive innovation and efficiency in the online grocery shopping landscape, benefiting both the company and its valued customers. As the digital grocery industry continues to evolve, data extraction will remain a cornerstone of Fresh Direct's commitment to delivering quality groceries right to your doorstep.
#grocerydatascraping#restaurant data scraping#food data scraping services#fooddatascrapingservices#food data scraping#zomato api#web scraping services#grocerydatascrapingapi#usa#restaurantdataextraction
0 notes
Text

Our APIs easily extract data from the webpages to provide prompt responses in seconds. Program the business procedures through RPA to power internal applications as well as work flows using data integration. This can be made with customized and ready-to-use API
0 notes
Link
For just $16.00 A excellent metal basket was made in the USSR in the 60s. Made of aluminum with gold finish finish finish. It has four small carved legs. Stable if you want to put it. On the back is a mark of the manufacturer. The handle does not rotate and is stationary. You can use in many ways and styles. It is not overloaded with unnecessary details and looks very elegant. Condition: Good vintage condition with little signs of wear. (small scrapes of gold paint). Please look at the photo to rate the condition for yourself. Dimensions: The height with the handle is 20 cm (7,87 "), Height without handle -10 cm (3.94 "), Handle height - 10 cm (3.94 "). The upper diameter of the basket is about 15 cm (5,91"), The bottom diameter is 8 cm. (3.15"). Buy 3 items in my shop and you will get a 10% discount! Please, tell me about selected things before buying! In addition, I will combine them into one parcel and shipping will be cheaper. ✔I ACCEPT PAYMENT THROUGH PAYPAL ONLY !!! Please, see other products in my store: https://www.etsy.com/ru/shop/RAGMAN770?ref=hdr_shop_menu If you buy more than one product, we are ready to unite in one package and reduce shipping costs.
1 note
·
View note
Text
Not Known Facts About PHP currency Exchange Script
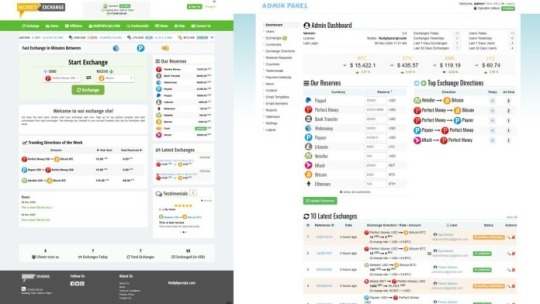
I'd a short while ago obtained a script from Up coming Hyip. The script fitted me pretty nicely and was precisely as explained on their web site. Thank you Up coming hyip for that superb encounter! An prolonged license enables an item to be used in limitless assignments for possibly personal or industrial use. The merchandise can't be made available for resale "as-is". It really is permitted to distribute/sublicense the supply data files as portion of a larger undertaking. Near Then it can vanish soon after a while for it to return soon after some time and wishes once again one click. You should don't react using a duplicate previous concept but produce down your method and how you're thinking that you can reach it as part of your reaction or to me in chat. Many thanks! CSS HTML JavaScript Python Website Scraping $33 (Avg Bid) $33 Avg Bid 23 bids This tutorial will evaluation The fundamental code snippets necessary for use with PHP, Python, Ruby, and Java Script apps. RapidAPI supports 19 common programming languages with code automobile-technology facilities geared toward software developers. Exchange Rix is effective and characteristics rich php script which will help you to run your personal bitcoin or other cryptocurrencies exchange internet site. Basically make order and start it currently. It’s uncomplicated. We will likely be employing PHP like a scripting language and interpreter that is mainly utilized on any World-wide-web server, such as xamp, wamp, and so on. It's being used to any common Web-sites, and it's got a contemporary know-how that can certainly be utilized by the following era. Our currency converter is Search engine optimization optimized and ready to be uploaded in minutes, No coding information desired, Well documented and easy to create, Install, and operate. VERIFIED I really need to scrap uncomplicated look for results of mom Ondo services. I do not should extract details - I need just html just after JavaScript execution.- I'll extract alone Classification: MLM Description Added info Testimonials (3) Cryptocurrency is turn into a long run for that miners, it can be impossible to mine the crypto currency Using the list of time frame, only the facility comprehensive server miners can mine considerably quicker than other, so Here's the answer with the cryptocurrency miners, purchase the highly effective server for an rent to mine the crypto currency. The primary API command may be the “GET exchange” connect with which is utilized to specify the currencies for that exchange prices. Developers will require to include both their Rapi API crucial and the two variables for the currency pair in Every single API simply call. Detect that we're utilizing the set Param approach which specifies the parameter and price, which is a comma divided listing of currency codes. The currency codes can be found by following the website link for supported currencies presented above. As it is possible to see, we can easily do a great deal with our free of charge access to the currency Layer products and services because we might get the two Stay and historical facts. If you need a lot more than 1,000 API accesses in a month then you need to choose the high quality approach that most closely fits your preferences. The web site admin can PHP currency Exchange Script regulate the many exercise like increase and take away cash, payment gateways, edit buyers interface plus much more. Also, There may be all the following stats are available: Brightery Currency converter, The very best currency exchange script in 2020 you could find. Get simpler now currency rate, dollar exc. https://www.exchangerix.com/
0 notes
Text
Extract Amazon Product Data using Web Scraper

Scraping Amazon product data assists you focus on the competitors’ pricing research, real-time cost checking as well as seasonal shifts to offer customers with superior product offers. Data scraping helps you scrape data from Amazon as well as save that in the JSON format or spreadsheet. You may even automate the procedure of updating data regularly, weekly or monthly.
Presently, there are no ways of exporting products data from Amazon website to a spreadsheet. Whether it’s used for competitor’s testing, comparison shopping, making an API for app project or other needs, the problem can be easily solved using web scraping.
Compare as well as contrast offerings with your competitors
Find the trending products and look at the best-selling products lists for the group
Use data from different product results for improving Amazon SEO rank or Amazon marketing campaigns
Utilize reviews data to do reviews management as well as product’s optimization for manufacturers and retailers
Extracting Amazon is a fascinating business today, having a huge number of companies providing goods, analysis, price, as well as other kinds of monitoring services especially for Amazon? Trying to extract Amazon data on a huge scale, although is a difficult procedure, which often gets obstructed by the anti-scraping technology. It’s not easy to extract such a huge site if you’re a novice.
Extracting Amazon product data using a web scraper can be very easy as you don’t need any technical expertise and the ready-made web scraper will work on its own.
To know more about Amazon product data web scraper, contact Retailgators or ask for a free quote!
>> Know More: Extract Amazon Product Data using Web Scraper
| Phone: +1 (832) 251 7311
| Email: [email protected]
#Extract Amazon Product Data#Amazon Product Data Scraper#Scrape Amazon Product Data#scrape data from Amazon#Amazon Data Scraping Services
0 notes
Photo

This is an intro to a social media project I’m working on, although I don’t think it’s of interest to most tumblr users because tumblr doesn’t really do comment threads; not exactly.
Introducing Project "Echommentary"
tl;dr - Echommentary is a multi-site writer/reader with a crosscommenting "echobot" to unify discussion threads between multiple social media sites. Since all comments are echoed to other sites, everyone participates in the same unified discussion.
= = =
ECHOMMENTARY CORE FUNCTIONALITY
With the impending end of Google+, I've looked at various social media alternatives and have decided none are a perfect fit for what I really want. So...I'm rolling my own multi-site writer/reader solution. The features of the core system will include:
1) Echobot python console app uses web scraping or API to load new posts/comments from each source, to local storage. Core functionality is to scrape from your own profile pages, but you can also scrape followed profile pages to local storage.
2) Echobot echos new posts/comments to all other sources, so all followers participate in the same comment threads (rather than separate discussions on each site).
3) Local storage means it's possible to autopost everything to a new social media site/account if desired.
4) Ability to block users via delblock or shadowblock. A delblock auto-deletes comments by a user. A shadowblock simply doesn't echo a user's comments to other sites.
Project Echommentary's primary mission is to solve the problem of interoperability between diaspora, Mastodon, Google+ (while it exists), and other social media sites. It's an open source project so others are invited to help - especially with Python code for various sources.
There are, of course, a lot of products to multipost to many different social media sites, but these are more designed for commercial publicity rather than to foster cohesive community discussion. In particular, each copy of a post on the different social media sites has its own independent comment thread. I find this frustrating, because a lot of the best ideas are developed in comment threads, and only users from the same site will see those comments. Often, I find that one discussion thread on one site will have some interesting comments, while another discussion thread on another site will have other interesting comments. I wish that they could see each others comments!
So, my core idea is a comment echobot. It will take a comment from Sam on G+, and echo it on other sites with something that looks like:
Sam @ GooglePlus: Yeah, I noticed Aunt Cass in the sassy housewives ad. Actually a kind of subtle running theme of the movie that things on the Internet are often not quite true.
This is an "echo" comment, which appears to be made by the echobot user's account, rather than the original account. Unfortunately, this has some issues. For one thing, it may be best for the echo system to be opt-in. By default, everyone is shadowblocked. Their comments are NOT forwarded to other sites. But you could use a pinned post or something to ask folks whether it's okay to add them into the "echommentary" by echoing their comments to other sites.
Another issue - blocking. Let's say Anna wants to block Hans, so she never sees any comments by Hans. The problem is that she follows Elsa, and Elsa's echobot may echo a comment made by Hans on another site. Anna follows Elsa on G+, but Hans follows Elsa on Mastodon. Anna would see a comment on G+ like:
Hans @ mastodon.social: (@ Elsa @ mastodon.social) Hey Anna, chill out, babe!
The problem? This comment is seen on G+ as made by Elsa, not Hans. So Anna can't block these comments without blocking Elsa entirely. Unfortunately, the best solution may be for Anna to ask Elsa to block Hans. Elsa could block Hans with delblocking or shadowblocking; this prevents Hans's comments from being visible to Anna via echoing.
= = =
BEYOND THE CORE
The echobot stores what it scrapes to a SQLite3 database, as well as a static HTML file tree. This file tree is considered a source just like diaspora or Mastodon, but it offers no built in way to write posts or comments. It's mostly just for troubleshooting. Nevertheless, it can be a somewhat useful tool, and you can optionally serve it up with a web server for others to browse.
Far more flexible and powerful is the SQLite3 database, which stores all posts and comments, as well as their echoes (both pending and completed). This database can be accessed and modified by other programs, such as a writer/commenter, and a "universal reader".
My own interest is in a simple blog writer. It would have very basic functionality...just bold, italic, and inline images. This way, I could compose blog entries that would be directly inserted into the SQLite3 database for transmission to all sources. In addition to the basic functionality, I'd have automatic tag addition to include my own personalized hashtags. For example, if I have #myart in the post, it would auto-add #ijkmyart. That way, diaspora users could click on #ijkmyart to see just my own "myart" posts - like a Collection.
With this simple writer, I could compose blog posts offline and then publish them when I'm ready or on a schedule. I'd still go to diaspora or somewhere to actually read and write comments. The big advantage of the writer is that it could be lean and mean - relatively simple to develop and modify.
A universal reader, however, could be a very powerful tool because it uses SQL queries. You could filter things in powerful ways, including blocking users in ways unavailable in the source systems (such as diaspora, which still lets you see comments made by a blocked user on someone else's post). You could filter followees by hashtag or content matches; you could filter out spoilers by hiding (temporarily) content matching a show you haven't caught up on yet. Stuff like that.
With a universal reader, you could define numerous "read only" sources - not your own profile pages, but followee profile pages. Maybe even blog pages also. Maybe even including RSS feeds, and such.
I feel like a universal reader/writer/commenter is a more complex project than a simple blog composer, but it's also something that a lot of people would really want. As such, it's important for me to think about the SQLite database design in a way that accommodates it from the start. In particular, it needs to understand that some sources are read/write, while other sources are read only. The user owned read/write sources are all that's needed for Echommentary's core functionality, but followed read-only sources are critical for universal reader/writer/commenter functionality.
= = =
AND BEYOND ... ?
Project Echommentary could be taken a step further to become its own independent peer-to-peer social media network, by exposing read-only SELECT functionality to a custom port. That way, echobots could directly pull posts/comments from each other's SQLite3 databases. Even with no outside sources, it could be possible to create an independent social media network somewhat similar to USENET - each node connects with a small number of trusted neighbor nodes.
One node connects to another node via an encrypted (ssh) connection, and then each node can send SELECT statements to the other side. Each node can pull new posts and comments. The reason I specify that it goes both ways, is because of the problem of NAT routers. Most users are behind NAT routers, and there's generally no way to connect to a "server" behind a NAT. But a user behind a NAT can connect to a server out there with a true permanent IP address (either standalone or behind a specifically configured router). So, only a small fraction of nodes need to be out there with permanent IP addresses.
Now, this is truly ambitious. But is it even necessary? I hope not. It's not like we desperately need yet another internet protocol "standard". But it's a potential thing to do which might be useful just in case.
= = =
TECH THOUGHTS
The core Echommentary echobot will be a simple Python console program, to make it very portable and easy to develop/run/maintain remotely. Remote troubleshooting can be assisted by running Python's built in http.server on the local storage file tree. But for most users, it will be easiest and best to simply run and maintain it locally. Using SQLite3 makes it possible for savvy users to do a lot of powerful things with the database directly. I do understand that not everyone knows SQL, though.
For the universal writer and reader, I think that a native Python program would be better than web based...but I'm not sure. I feel like it would streamline development to keep most everything Python + SQLite3. Avoiding web based client functionality means avoiding a lot of extra complexity, maybe - and also it could be more readily adapted to mobile iOS/Android versions.
= = =
So, anyone interested in contributing, or just suggesting thoughts? Concerns?
#echommentary #socialmedia #python #sqlite #diaspora
1 note
·
View note
Text
Outsource Job Sites Web Scraping Companies
Outsource Bigdata believes in ‘Automation First’ approach. We are one of the web scraping companies that understands automation is the first step towards digital transformation to improve efficiency and reduce cost. In this digital and information age, we have evolved from library expansion to different layers of computation and now we are in the era of data revolution. Leverage reusable and ready-to-use BOTS to scrape job data and save cost. Outsource Bigdata has experience in working with global customers for various web scraping job descriptions, data scraping job descriptions, and indeed scraper needs.
We look at every process to scale using automation and reusable AI-driven solutions. Outsource Bigdata is one of the web scraping companies that follows ‘Automation First’ approach. Web scraping companies understand that sourcing data from internal and external sources including job websites is not always easy. Web scraping companies have experts in job site web scraping and offer services as per your requirement. We have experts in our system who automate job site scraping and integrate the data with IT systems and processes. As an automation company, Outsource Bigdata practically applies automation in every activity we perform related to data scraping. These include job site scraping, data extraction, data processing, data formatting, data enrichment, file transfer, data integration, reporting, and many more.
Outsource Bigdata is one of the web scraping companies that adhere to ISO 9001 standards to ensure quality in our services. We have job scraping experts who have years of experience with web scraping companies. Web scraping companies use reusable BOTS to provide automated services. We are one of the web scraping companies that automate processes and provide self-serving dashboards and reports for your business.
Contact our engagement manager and he can help you with a customized solution.
Why Choose Outsource Bigdata Over Other Web Scraping Companies?
Outsource Bigdata can scrape job data for your company as per your needs. We can create quality business leads that are critical for business. We have experience in crawling different job websites of multi-level complexities over a period of time and we can scrape job data as per your needs to benefit your company. Outsource Bigdata understands the confidentiality nature of the data that we handle, and hence we adhere to ISO 27001 standard to protect data.
Contact our web data scraping engagement manager today for more details.
How Can Web Scraping Companies Scrape Job Data To Benefit Your Company?
Web scraping companies scrape job data from various job sites and provide it in the required format. Outsource Bigdata has years of experience in indeed scraper and has scraped job data from complex websites. Here is how we can scrape job data to benefit your company
Job Site Extraction: Outsource Bigdata is among the web scraping companies that offer bundled and comprehensive job site scraping and data solutions. After the job site data is crawled, we cleanse, merge, enrich, classify, format, and analyze the data before reporting the data with a visual representation.
Ready to consume Job Site Data: Web scraping companies scrape job data as per your requirement and offer the data is ready to consume format. Outsource Bigdata understands that various companies adopt different data formats, hence we provide data that is suitable for your in-house IT systems and applications.
Various data Formats from Job Site: Outsource Bigdata leverages job site scraping scripts, API’s and updated technology to source data from various job sites. We are one of the web scraping companies that can provide you data in various formats including Excel, XML, JSON, and CSP among others.
Highly Scalable Job Site Scraping Services: As web scraping companies, we have years of experience in job site scraping and made our data scraping job description, web scraping job description, and job site scraping services highly scalable.
Reasonable Price for Job Site Data Scraping: Outsource Bigdata is committed to offering a reasonable price for job scraping service that is fair to both parties involved in the transaction. This enables you to choose us over web scraping companies.
Experienced in Job Site Data Extraction: Hire one of the web scraping companies with years of experience in scraping various websites of multi-level complexities.
Scrape Job Sites with our Low-Cost Structure Services
Highly automated and AI-Augmented services enable us to offer our job scraping services at lower prices. Outsource Bigdata is one of the web scraping companies that offer job scraping services at a fractional cost.
Job Site Data Scraping – Price Starts with 100 USD
Bulk Job Site Data Scraping – Price Starts with 250 USD
Scheduled Data Scraping – Price Starts with 50 USD/Schedule (Daily/Weekly/Monthly)
0 notes