#Llama.cpp
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
AMD Ryzen AI 300 Series Improves LM Studio And llama.cpp

Using AMD Ryzen AI 300 Series to Speed Up Llama.cpp Performance in Consumer LLM Applications.
What is Llama.cpp?
Meta’s LLaMA language model should not be confused with Llama.cpp. It is a tool, nonetheless, that was created to improve Meta’s LLaMA so that it can operate on local hardware. Because of their very high computational expenses, LLaMA and ChatGPT currently have trouble operating on local computers and hardware. Despite being among of the best-performing models available, they are somewhat demanding and inefficient to run locally since they need a significant amount of processing power and resources.
Here’s where llama.cpp is useful. It offers a lightweight, resource-efficient, and lightning-fast solution for LLaMA models using C++. It even eliminates the need for a GPU.
Features of Llama.cpp
Let’s examine Llama.cpp’s features in further detail and see why it’s such a fantastic complement to Meta’s LLaMA language paradigm.
Cross-Platform Compatibility
One of those features that is highly valued in any business, whether it gaming, artificial intelligence, or other software types, is cross-platform compatibility. It’s always beneficial to provide developers the flexibility to execute applications on the environments and systems of their choice, and llama.cpp takes this very seriously. It is compatible with Windows, Linux, and macOS and works perfectly on any of these operating systems.
Efficient CPU Utilization
The majority of models need a lot of GPU power, including ChatGPT and even LLaMA itself. Because of this, running them most of the time is quite costly and power-intensive. This idea is turned on its head by Llama.cpp, which is CPU-optimized and ensures that you receive respectable performance even in the absence of a GPU. Even while a GPU will provide superior results, it’s still amazing that running these LLMs locally doesn’t cost hundreds of dollars. Additionally encouraging for the future is the fact that it was able to tweak LLaMA to operate so effectively on CPUs.
Memory Efficiency
Llama.cpp excels at more than just CPU economy. Even on devices without strong resources, LLaMA models can function successfully by controlling the llama token limit and minimizing memory utilization. Successful inference depends on striking a balance between memory allocation and the llama token limit, which is something that llama.cpp excels at.
Getting Started with Llama.cpp
The popularity of creating beginner-friendly tools, frameworks, and models is at an all-time high, and llama.cpp is no exception. Installing it and getting started are rather simple processes.
You must first clone the llama.cpp repository in order to begin.
It’s time to create the project when you’ve finished cloning the repository.
Once your project is built, you may use your LLaMA model to do llama inference. The following code must be entered in order to utilize the llama.cpp library to do inference:
./main -m ./models/7B/ -p “Your prompt here” To change the output’s determinism, you may play about with the llama inference parameters, such llama temperature. The llama prompt format and prompt may be specified using the -p option, and llama.cpp will take care of the rest.
An overview of LM Studio and llama.cpp
Since GPT-2, language models have advanced significantly, and users may now rapidly and simply implement very complex LLMs using user-friendly programs like LM Studio. These technologies, together with AMD, enable AI to be accessible to all people without the need for technical or coding skills.
The llama.cpp project, a well-liked framework for rapidly and simply deploying language models, is the foundation of LM Studio. Despite having GPU acceleration available, it is independent and may be accelerated only using the CPU. Modern LLMs for x86-based CPUs are accelerated by LM Studio using AVX2 instructions.
Performance comparisons: throughput and latency
AMD Ryzen AI provides leading performance in llama.cpp-based programs such as LM Studio for x86 laptops and speeds up these cutting-edge tasks. Note that memory speeds have a significant impact on LLMs in general. When the compared the two laptops, the AMD laptop had 7500 MT/s of RAM while the Intel laptop had 8533 MT/s.Image Credit To AMD
Despite this, the AMD Ryzen AI 9 HX 375 CPU outperforms its rivals by up to 27% when considering tokens per second. The parameter that indicates how fast an LLM can produce tokens is called tokens per second, or tk/s. This generally translates to the amount of words that are shown on the screen per second.
Up to 50.7 tokens per second may be produced by the AMD Ryzen AI 9 HX 375 CPU in Meta Llama 3.2 1b Instruct (4-bit quantization).
The “time to first token” statistic, which calculates the latency between the time you submit a prompt and the time it takes for the model to begin producing tokens, is another way to benchmark complex language models. Here, it can see that the AMD “Zen 5” based Ryzen AI HX 375 CPU is up to 3.5 times quicker than a similar rival processor in bigger versions.Image Credit To AMD
Using Variable Graphics Memory (VGM) to speed up model throughput in Windows
Every one of the AMD Ryzen AI CPU’s three accelerators has a certain workload specialty and set of situations in which they perform best. On-demand AI activities are often handled by the iGPU, while AMD XDNA 2 architecture-based NPUs provide remarkable power efficiency for permanent AI while executing Copilot+ workloads and CPUs offer wide coverage and compatibility for tools and frameworks.
With the vendor-neutral Vulkan API, LM Studio’s llama.cpp port may speed up the framework. Here, acceleration often depends on a combination of Vulkan API driver improvements and hardware capabilities. Meta Llama 3.2 1b Instruct performance increased by 31% on average when GPU offload was enabled in LM Studio as opposed to CPU-only mode. The average uplift for larger models, such as Mistral Nemo 2407 12b Instruct, which are bandwidth-bound during the token generation phase, was 5.1%.
In comparison to CPU-only mode, it found that the competition’s processor saw significantly worse average performance in all but one of the evaluated models while utilizing the Vulkan-based version of llama.cpp in LM Studio and turning on GPU-offload. In order to maintain fairness in the comparison, it have excluded the GPU-offload performance of the Intel Core Ultra 7 258v from LM Studio’s Vulkan back-end, which is based on Llama.cpp.
Another characteristic of AMD Ryzen AI 300 Series CPUs is Variable Graphics Memory (VGM). Programs usually use the second block of memory located in the “shared” section of system RAM in addition to the 512 MB block of memory allocated specifically for an iGPU. The 512 “dedicated” allotment may be increased by the user using VGM to up to 75% of the system RAM that is available. When this contiguous memory is present, memory-sensitive programs perform noticeably better.
Using iGPU acceleration in conjunction with VGM, it saw an additional 22% average performance boost in Meta Llama 3.2 1b Instruct after turning on VGM (16GB), for a net total of 60% average quicker speeds when compared to the CPU. Performance improvements of up to 17% were seen even for bigger models, such as the Mistral Nemo 2407 12b Instruct, when compared to CPU-only mode.
Side by side comparison: Mistral 7b Instruct 0.3
It compared iGPU performance using the first-party Intel AI Playground application (which is based on IPEX-LLM and LangChain) in order to fairly compare the best consumer-friendly LLM experience available, even though the competition’s laptop did not provide a speedup using the Vulkan-based version of Llama.cpp in LM Studio.
It made use of the Microsoft Phi 3.1 Mini Instruct and Mistral 7b Instruct v0.3 models that came with Intel AI Playground. To observed that the AMD Ryzen AI 9 HX 375 is 8.7% quicker in Phi 3.1 and 13% faster in Mistral 7b Instruct 0.3 using a same quantization in LM Studio.Image Credit To AMD
AMD is committed to pushing the boundaries of AI and ensuring that it is available to everybody. Applications like LM Studio are crucial because this cannot occur if the most recent developments in AI are restricted to a very high level of technical or coding expertise. In addition to providing a rapid and easy method for localizing LLM deployment, these apps let users to experience cutting-edge models almost immediately upon startup (if the architecture is supported by the llama.cpp project).
AMD Ryzen AI accelerators provide amazing performance, and for AI use cases, activating capabilities like variable graphics memory may result in even higher performance. An amazing user experience for language models on an x86 laptop is the result of all of this.
Read more on Govindhtech.com
#AMDRyzen#AMDRyzenAI300#ChatGPT#MetaLLaMA#Llama.cpp#languagemodels#MetaLlama#AMDXDNA#IntelCoreUltra7#MistralNemo#LMStudio#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text
I tried running the hot new small 32B-parameter reasoning model QwQ locally, and it's still just a bit too big for my rig to handle - using Ollama (whose backend is llama.cpp), it flooded my VRAM and a fair chunk of my RAM, and ended up generating at about 1 token/s (roughly, not measured), but unfortunately my mouse was also moving at about 1fps at the same time - though maybe whatever microsoft did to the task manager is the real culprit here since it surprisingly cleared up after a bit. in any case, I looked into VLLM, which is the qwen team's recommended server for inference, but it doesn't play nice on windows, so it will have to wait until I can get it running on Linux, or maybe get WSL up and running.
anyway, prompting it with a logic puzzle suggested by a friend -
I have three eggs. I eat one. One hatches into a chicken. The chicken lays an egg. How many eggs do I have?
led to it generating a seemingly infinitely long chain of thought as it kept going round and round nuances of the problem like whether you own a chicken that hatches from your egg. I decided to cut it off rather than let it terminate. here's a sample though.
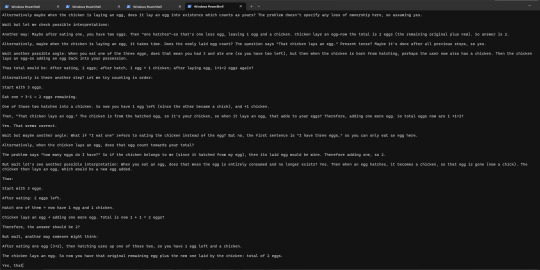
10 notes
·
View notes
Text
How to Run Llama.cpp on AMD GPUs?
Llama.cpp is a powerful, open-source inference engine designed to run LLaMA-based language models locally on your machine. While it's often optimized for NVIDIA GPUs with CUDA support, AMD users can also run it effectively with a few extra steps.
(How to run Llama.cpp on AMD GPUs?) Let’s break down the setup process to get it working smoothly on your hardware.
Steps for AMD GPU Compatibility
1. Install ROCm or HIP Runtime AMD GPUs require the ROCm or HIP stack to support GPU acceleration. Depending on your Linux distro, install the appropriate package (e.g., rocm-hip-sdk or hip-runtime-amd).
2. Clone the Llama.cpp Repository Download the source code:
3. Compile with HIP Backend Llama.cpp supports HIP for AMD GPUs.

Use the following command to build
4. Run the Inference Once compiled, you can run a model using
Make sure the model you downloaded is compatible with Llama.cpp and your system's memory.
5. Troubleshooting Tips Watch out for driver compatibility and memory limitations. Ensure ROCm supports your specific AMD GPU model.
Conclusion
While setting up Llma cpp on AMD GPUs takes a bit more effort than NVIDIA, it’s entirely possible with ROCm and HIP support. With the right environment, you’ll enjoy local LLM performance without needing CUDA.
0 notes
Text
Kernel size scope
github.com/koush/llama.cpp/blob/bindings/ggml/include/ggml.h
0 notes
Quote
だからこそ、私はもう自分のプロジェクトをオープンソース化したくないんです。より多くのリソースを持つ誰かが、私のプロジェクトをフォークして利益を上げ、私を認知するだけで生活費を稼げると思っているんです。 何年もの間、ollama は llama.cpp を認めず、r/localllama はそれを奇妙に感じていましたが、最���的に彼らのページで llama.cpp について言及されました。しかし、ダメージはすでにありました。ローカル LLM をサポートするほとんどのアプリは、オリジナルの llama.cpp ではなく、ollama または LM Studio API のみをサポートしています。
ミストラルコード | ハッカーニュース
1 note
·
View note
Text
Ollama violating llama.cpp license for over a year
https://github.com/ollama/ollama/issues/3185
0 notes
Text
0 notes
Text
Chatbots fake sex are leaking a clear message
All of 400 AI systems exposed to upguard There is one thing in common: They use the AI open source frame called llama.cpp. This software allows people to relatively easy to deploy AI models that open on their own systems or servers. However, if it is not set correctly, it may accidentally expose the reminders being sent. When companies and organizations are of all implementation of AI, properly…
0 notes
Text
Chatbots fake sex are leaking a clear message
All of 400 AI systems exposed to upguard There is one thing in common: They use the AI open source frame called llama.cpp. This software allows people to relatively easy to deploy AI models that open on their own systems or servers. However, if it is not set correctly, it may accidentally expose the reminders being sent. When companies and organizations are of all implementation of AI, properly…
0 notes
Text
Klassz dolog ez a Kaggle meg a Google Colab
A rendelkezésre álló gépidő úgy 99%-ában llama.cpp-t fordítok
1 note
·
View note
Text
Obsidian And RTX AI PCs For Advanced Large Language Model
How to Utilize Obsidian‘s Generative AI Tools. Two plug-ins created by the community demonstrate how RTX AI PCs can support large language models for the next generation of app developers.
Obsidian Meaning
Obsidian is a note-taking and personal knowledge base program that works with Markdown files. Users may create internal linkages for notes using it, and they can see the relationships as a graph. It is intended to assist users in flexible, non-linearly structuring and organizing their ideas and information. Commercial licenses are available for purchase, however personal usage of the program is free.
Obsidian Features
Electron is the foundation of Obsidian. It is a cross-platform program that works on mobile operating systems like iOS and Android in addition to Windows, Linux, and macOS. The program does not have a web-based version. By installing plugins and themes, users may expand the functionality of Obsidian across all platforms by integrating it with other tools or adding new capabilities.
Obsidian distinguishes between community plugins, which are submitted by users and made available as open-source software via GitHub, and core plugins, which are made available and maintained by the Obsidian team. A calendar widget and a task board in the Kanban style are two examples of community plugins. The software comes with more than 200 community-made themes.
Every new note in Obsidian creates a new text document, and all of the documents are searchable inside the app. Obsidian works with a folder of text documents. Obsidian generates an interactive graph that illustrates the connections between notes and permits internal connectivity between notes. While Markdown is used to accomplish text formatting in Obsidian, Obsidian offers quick previewing of produced content.
Generative AI Tools In Obsidian
A group of AI aficionados is exploring with methods to incorporate the potent technology into standard productivity practices as generative AI develops and speeds up industry.
Community plug-in-supporting applications empower users to investigate the ways in which large language models (LLMs) might improve a range of activities. Users using RTX AI PCs may easily incorporate local LLMs by employing local inference servers that are powered by the NVIDIA RTX-accelerated llama.cpp software library.
It previously examined how consumers might maximize their online surfing experience by using Leo AI in the Brave web browser. Today, it examine Obsidian, a well-known writing and note-taking tool that uses the Markdown markup language and is helpful for managing intricate and connected records for many projects. Several of the community-developed plug-ins that add functionality to the app allow users to connect Obsidian to a local inferencing server, such as LM Studio or Ollama.
To connect Obsidian to LM Studio, just select the “Developer” button on the left panel, load any downloaded model, enable the CORS toggle, and click “Start.” This will enable LM Studio’s local server capabilities. Because the plug-ins will need this information to connect, make a note of the chat completion URL from the “Developer” log console (“http://localhost:1234/v1/chat/completions” by default).
Next, visit the “Settings” tab after launching Obsidian. After selecting “Community plug-ins,” choose “Browse.” Although there are a number of LLM-related community plug-ins, Text Generator and Smart Connections are two well-liked choices.
For creating notes and summaries on a study subject, for example, Text Generator is useful in an Obsidian vault.
Asking queries about the contents of an Obsidian vault, such the solution to a trivia question that was stored years ago, is made easier using Smart Connections.
Open the Text Generator settings, choose “Custom” under “Provider profile,” and then enter the whole URL in the “Endpoint” section. After turning on the plug-in, adjust the settings for Smart Connections. For the model platform, choose “Custom Local (OpenAI Format)” from the options panel on the right side of the screen. Next, as they appear in LM Studio, type the model name (for example, “gemma-2-27b-instruct”) and the URL into the corresponding fields.
The plug-ins will work when the fields are completed. If users are interested in what’s going on on the local server side, the LM Studio user interface will also display recorded activities.
Transforming Workflows With Obsidian AI Plug-Ins
Consider a scenario where a user want to organize a trip to the made-up city of Lunar City and come up with suggestions for things to do there. “What to Do in Lunar City” would be the title of the new note that the user would begin. A few more instructions must be included in the query submitted to the LLM in order to direct the results, since Lunar City is not an actual location. The model will create a list of things to do while traveling if you click the Text Generator plug-in button.
Obsidian will ask LM Studio to provide a response using the Text Generator plug-in, and LM Studio will then execute the Gemma 2 27B model. The model can rapidly provide a list of tasks if the user’s machine has RTX GPU acceleration.
Or let’s say that years later, the user’s buddy is visiting Lunar City and is looking for a place to dine. Although the user may not be able to recall the names of the restaurants they visited, they can review the notes in their vault Obsidian‘s word for a collection of notes to see whether they have any written notes.
A user may ask inquiries about their vault of notes and other material using the Smart Connections plug-in instead of going through all of the notes by hand. In order to help with the process, the plug-in retrieves pertinent information from the user’s notes and responds to the request using the same LM Studio server. The plug-in uses a method known as retrieval-augmented generation to do this.
Although these are entertaining examples, users may see the true advantages and enhancements in daily productivity after experimenting with these features for a while. Two examples of how community developers and AI fans are using AI to enhance their PC experiences are Obsidian plug-ins.
Thousands of open-source models are available for developers to include into their Windows programs using NVIDIA GeForce RTX technology.
Read more on Govindhtech.com
#Obsidian#RTXAIPCs#LLM#LargeLanguageModel#AI#GenerativeAI#NVIDIARTX#LMStudio#RTXGPU#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
3 notes
·
View notes
Text
How to Use Llama.cpp on an NVIDIA GPU
How to Use Llama.cpp on an NVIDIA GPU
Llama.cpp is a lightweight C++ implementation of Meta's LLaMA models designed for efficient local inference. While it's built for CPU performance, recent updates now include GPU acceleration, especially for NVIDIA GPUs using CUDA or cuBLAS. Running Llama.cpp on a GPU significantly boosts performance and reduces latency—perfect for those working with large language models locally.
Step-by-Step: Running Llama.cpp on NVIDIA GPU
1. Install Required Dependencies First, make sure your system has the CUDA Toolkit and NVIDIA drivers installed and updated. These are necessary for GPU acceleration.
2. Clone the Llama.cpp Repository Get the latest version of Llama.cpp from its source. Open your terminal and clone the project folder to your machine.

3. Build with CUDA Support Navigate into the Llama.cpp folder. Then run the following command to build it with CUDA:
4. Convert the Model (if needed) Use the included script to convert the LLaMA model into the format Llama.cpp expects. Ensure that the model weights are in GGUF format and compatible with GPU usage.
5. Run the Model Launch the model with a command like:
Conclusion
Using Llama.cpp with an NVIDIA GPU allows for faster and more efficient model inference, making it suitable for real-time applications and experimentation. With a few build tweaks and CUDA installed, you can leverage the power of your GPU to run advanced LLMs locally with ease.
0 notes
Text
Ejemplo de Speculative Decoding con Qwen-2.5-coder-7B y 0.5B.
Speculative Decoding es un técnica (realmente un conjunto de ellas) para acelerar un modelo de lenguaje usando un “oraculo” que genera un borrador tratando de adivinar lo que el modelo va a generar. En este caso usaremos Qwen-2.5-coder-0.5B como oraculo para generar el borrador. Para esta prueba usaremos un ejemplo que viene con Llama.cpp. Pero antes de poder usarlo hay que cambiar en el fichero…

View On WordPress
0 notes
Link
In the rapidly evolving field of artificial intelligence, the focus often lies on large, complex models requiring immense computational resources. However, many practical use cases call for smaller, more efficient models. Not everyone has access to #AI #ML #Automation
0 notes
Text
Vision Now Available in Llama.cpp
https://github.com/ggml-org/llama.cpp/blob/master/docs/multimodal.md
0 notes