Text
Y2w~A_h=;g{PA6$A9R!Zn—Q|o?eGOe!~GQa'`r'
7 notes
·
View notes
Text

1/5/24
Happy New Year Everyone!! Here's to more Frozen Content in the coming year!
———
Introduction
So, I want to start out by saying that I know I have been a little quiet lately and haven't had any updates on posts. I had caught COVID and was fighting it for a while feeling horrible. I still feel pretty bad, but I'm slowly trying to come back. I apologize for my slow return and low activity, but I promise that I'll be back swinging with new analyses, tid-bits, and other projects very soon!
———
Arendelle Archives
I am ecstatic to announce that, as you've already seen, Arendelle Archives is officially setting up a blog here on Tumblr. It will be launching January 6th. Keep an eye out, and be sure to follow!
Also, just had to post this for shameless advertising hehehe.
With Frozen 3 now on the way, YouTube channel Geekritique revisits the story of Frozen as it stands so far in an expansive timeline video that compiles lore established across the movies, animated shorts, and tie-in books to create a detailed history of Arendelle.With the aid of dedicated fan group Arendelle Archives, the video begins with the grand designs of King Runeard (Jeremy Sisto), the shameful conflicts with Northuldra over the dam, Anna(Kristen Bell) and Elsa's troubled childhood, and the deaths of Agnarr (Alfred Molina) and Iduna (Evan Rachel Wood) that would lead into the original movie. The timeline takes into account the events of Joe Caramagna's comics that bridge the gap between each movie, as well as the novels Dangerous Secrets: The Story of Iduna and Agnarr, Forest of Shadows, and Polar Nights: Cast Into Darkness. - Nathan Graham-Lowery - Screenrant
———
Upcoming Analysis
Frozen Canon Talk - Fifth Edition - Arendelle Archives
What Came Before Part 2 - Previous Versions of Frozen 2
All is Found: A Frozen Anthology - Review
Lost Legends: The Fixer Upper - Review
Tid-Bits #9 - Elsa’s Apology and Writing Good Dialogue
———
Poll Question
As with all of my recent updates, it’s time for the next poll question to my super vague F3 post. As with the previous update, I will also provide the results of the previous polls, with my answers as well.
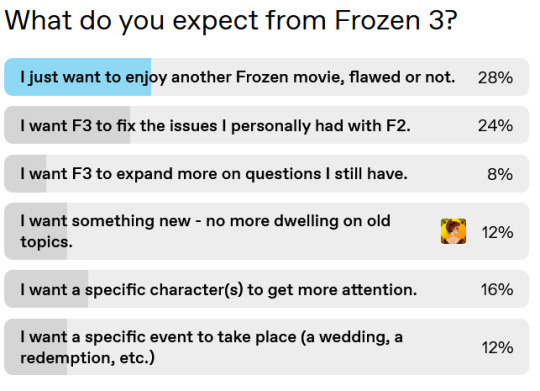



———
Other Featured Blogs
@arendelle-archives - A fan-project exploring, researching and analyzing the history, geography and lore of the Frozenverse.
@gqa-lite - GQA side blog for more random, opinionated, and personal posts.
@gqa-archive - GQA archive of all my analyses without any extra content.
17 notes
·
View notes
Text
Met a nice older trans woman tonight while working.. she was so nice and now im feeling really happy and okay. I don't even feel anxious about going to the GQA masquerade tonight anymore :')
#look idk man you tag it#feeling good tonight#still unsure how im getting a ride but. i think it will turn out okay#its gonna be okay girls
3 notes
·
View notes
Note
You know how there are articles you keep going back to? When I'm in a spiritually dark place, I turn to GQA's essay about Aeron's existential victory over Euron. When cutting shade-of-the-evening is on my mind, I turn to your lancing of fascism in Disco Elysium. There's one part of your analysis that is 100% wrong. There is no way Kim's magic racist comment implies Gary is less pathetic than Measurehead. Gary lives in a basement apartment. Gary has no friends his age. Women do not talk to Gary.
The union hates Gary. Even Gary's voice actor has the annoying nerd voice of countless failed twitch streamers. Kim barely protests when you shakedown Gary for the chest piece; that's the same Kim who typically takes issue when you abuse your authority. Calling Kim "yellow man" when they first met certainly didn't help. While Kim mocks advanced race theory, Kim is clearly terrified of Measurehead. Measurehead not just has friends, but is surrounded by women who are clearly attracted to him.
The union hired Measurehead to provide security. Measurehead has a buff, masculine sounding voice actor. Given all that, how can you think the devs and Kim consider Measurehead more pathetic than Gary?--(manic)TBH
That's a valid interpretation. I always thought that Kim spent more time mocking Measurehead than Gary, and Measurehead was given far more time to show how completely insane his Advanced Race Theory is, with his references to "ham sandwich people" as something that is nothing short of baffling and that he is Revacholian aping at the supposedly superior Semenese culture that he learns from books. Gary is just a mundane shitbag, whereas Measurehead is a grandiose fool.
Not saying what you're saying is wrong, it's just a matter of which seems stupider to me, and Gary is a dime-a-dozen garbage person while Measurehead is a true monument to the chucklefuckery that is race theory, and the amount of time devoted to it really lets you know how much of a moron Measurehead is even before you spin kick him in the face.
Thanks for the contribution, TBH
SomethingLikeALawyer, Hand of the King
9 notes
·
View notes
Text
Like Whatever - Hater Blockers [rock-pop] (2024)
Like Whatever - Hater Blockers [rock-pop] (2024) https://youtu.be/gQaS-1JsATM?si=0cwT4ud1cWCjPFxJ Submitted October 07, 2024 at 01:43AM by Competitive_Pack1647 https://ift.tt/PyCGfMm via /r/Music
0 notes
Text
Qwen2 – Alibaba’s Latest Multilingual Language Model Challenges SOTA like Llama 3
New Post has been published on https://thedigitalinsider.com/qwen2-alibabas-latest-multilingual-language-model-challenges-sota-like-llama-3/
Qwen2 – Alibaba’s Latest Multilingual Language Model Challenges SOTA like Llama 3
After months of anticipation, Alibaba’s Qwen team has finally unveiled Qwen2 – the next evolution of their powerful language model series. Qwen2 represents a significant leap forward, boasting cutting-edge advancements that could potentially position it as the best alternative to Meta’s celebrated Llama 3 model. In this technical deep dive, we’ll explore the key features, performance benchmarks, and innovative techniques that make Qwen2 a formidable contender in the realm of large language models (LLMs).
Scaling Up: Introducing the Qwen2 Model Lineup
At the core of Qwen2 lies a diverse lineup of models tailored to meet varying computational demands. The series encompasses five distinct model sizes: Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B, and the flagship Qwen2-72B. This range of options caters to a wide spectrum of users, from those with modest hardware resources to those with access to cutting-edge computational infrastructure.
One of Qwen2’s standout features is its multilingual capabilities. While the previous Qwen1.5 model excelled in English and Chinese, Qwen2 has been trained on data spanning an impressive 27 additional languages. This multilingual training regimen includes languages from diverse regions such as Western Europe, Eastern and Central Europe, the Middle East , Eastern Asia and Southern Asia.
Languages supported by Qwen2 models, categorized by geographical regions
By expanding its linguistic repertoire, Qwen2 demonstrates an exceptional ability to comprehend and generate content across a wide range of languages, making it an invaluable tool for global applications and cross-cultural communication.
Specifications of Qwen2 Models including parameters, GQA, and context length.
Addressing Code-Switching: A Multilingual Challenge
In multilingual contexts, the phenomenon of code-switching – the practice of alternating between different languages within a single conversation or utterance – is a common occurrence. Qwen2 has been meticulously trained to handle code-switching scenarios, significantly reducing associated issues and ensuring smooth transitions between languages.
Evaluations using prompts that typically induce code-switching have confirmed Qwen2’s substantial improvement in this domain, a testament to Alibaba’s commitment to delivering a truly multilingual language model.
Excelling in Coding and Mathematics
Qwen2 have remarkable capabilities in the domains of coding and mathematics, areas that have traditionally posed challenges for language models. By leveraging extensive high-quality datasets and optimized training methodologies, Qwen2-72B-Instruct, the instruction-tuned variant of the flagship model, exhibits outstanding performance in solving mathematical problems and coding tasks across various programming languages.
Extending Context Comprehension
One of the most impressive feature of Qwen2 is its ability to comprehend and process extended context sequences. While most language models struggle with long-form text, Qwen2-7B-Instruct and Qwen2-72B-Instruct models have been engineered to handle context lengths of up to 128K tokens.
This remarkable capability is a game-changer for applications that demand an in-depth understanding of lengthy documents, such as legal contracts, research papers, or dense technical manuals. By effectively processing extended contexts, Qwen2 can provide more accurate and comprehensive responses, unlocking new frontiers in natural language processing.
Accuracy of Qwen2 models in retrieving facts from documents across varying context lengths and document depths.
This chart shows the ability of Qwen2 models to retrieve facts from documents of various context lengths and depths.
Architectural Innovations: Group Query Attention and Optimized Embeddings
Under the hood, Qwen2 incorporates several architectural innovations that contribute to its exceptional performance. One such innovation is the adoption of Group Query Attention (GQA) across all model sizes. GQA offers faster inference speeds and reduced memory usage, making Qwen2 more efficient and accessible to a broader range of hardware configurations.
Additionally, Alibaba has optimized the embeddings for smaller models in the Qwen2 series. By tying embeddings, the team has managed to reduce the memory footprint of these models, enabling their deployment on less powerful hardware while maintaining high-quality performance.
Benchmarking Qwen2: Outperforming State-of-the-Art Models
Qwen2 has a remarkable performance across a diverse range of benchmarks. Comparative evaluations reveal that Qwen2-72B, the largest model in the series, outperforms leading competitors such as Llama-3-70B in critical areas, including natural language understanding, knowledge acquisition, coding proficiency, mathematical skills, and multilingual abilities.
Qwen2-72B-Instruct versus Llama3-70B-Instruct in coding and math performance
Despite having fewer parameters than its predecessor, Qwen1.5-110B, Qwen2-72B exhibits superior performance, a testament to the efficacy of Alibaba’s meticulously curated datasets and optimized training methodologies.
Safety and Responsibility: Aligning with Human Values
Qwen2-72B-Instruct has been rigorously evaluated for its ability to handle potentially harmful queries related to illegal activities, fraud, pornography, and privacy violations. The results are encouraging: Qwen2-72B-Instruct performs comparably to the highly regarded GPT-4 model in terms of safety, exhibiting significantly lower proportions of harmful responses compared to other large models like Mistral-8x22B.
This achievement underscores Alibaba’s commitment to developing AI systems that align with human values, ensuring that Qwen2 is not only powerful but also trustworthy and responsible.
Licensing and Open-Source Commitment
In a move that further amplifies the impact of Qwen2, Alibaba has adopted an open-source approach to licensing. While Qwen2-72B and its instruction-tuned models retain the original Qianwen License, the remaining models – Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, and Qwen2-57B-A14B – have been licensed under the permissive Apache 2.0 license.
This enhanced openness is expected to accelerate the application and commercial use of Qwen2 models worldwide, fostering collaboration and innovation within the global AI community.
Usage and Implementation
Using Qwen2 models is straightforward, thanks to their integration with popular frameworks like Hugging Face. Here is an example of using Qwen2-7B-Chat-beta for inference:
from transformers import AutoModelForCausalLM, AutoTokenizer device = "cuda" # the device to load the model onto model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen1.5-7B-Chat", device_map="auto") tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-7B-Chat") prompt = "Give me a short introduction to large language models." messages = ["role": "user", "content": prompt] text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) model_inputs = tokenizer([text], return_tensors="pt").to(device) generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=True) generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)] response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] print(response)
This code snippet demonstrates how to set up and generate text using the Qwen2-7B-Chat model. The integration with Hugging Face makes it accessible and easy to experiment with.
Qwen2 vs. Llama 3: A Comparative Analysis
While Qwen2 and Meta’s Llama 3 are both formidable language models, they exhibit distinct strengths and trade-offs.
A comparative performance chart of Qwen2-72B, Llama3-70B, Mixtral-8x22B, and Qwen1.5-110B across various benchmarks including MMLU, MMLU-Pro, GPQA, and others.
Here’s a comparative analysis to help you understand their key differences:
Multilingual Capabilities: Qwen2 holds a clear advantage in terms of multilingual support. Its training on data spanning 27 additional languages, beyond English and Chinese, enables Qwen2 to excel in cross-cultural communication and multilingual scenarios. In contrast, Llama 3’s multilingual capabilities are less pronounced, potentially limiting its effectiveness in diverse linguistic contexts.
Coding and Mathematics Proficiency: Both Qwen2 and Llama 3 demonstrate impressive coding and mathematical abilities. However, Qwen2-72B-Instruct appears to have a slight edge, owing to its rigorous training on extensive, high-quality datasets in these domains. Alibaba’s focus on enhancing Qwen2’s capabilities in these areas could give it an advantage for specialized applications involving coding or mathematical problem-solving.
Long Context Comprehension: Qwen2-7B-Instruct and Qwen2-72B-Instruct models boast an impressive ability to handle context lengths of up to 128K tokens. This feature is particularly valuable for applications that require in-depth understanding of lengthy documents or dense technical materials. Llama 3, while capable of processing long sequences, may not match Qwen2’s performance in this specific area.
While both Qwen2 and Llama 3 exhibit state-of-the-art performance, Qwen2’s diverse model lineup, ranging from 0.5B to 72B parameters, offers greater flexibility and scalability. This versatility allows users to choose the model size that best suits their computational resources and performance requirements. Additionally, Alibaba’s ongoing efforts to scale Qwen2 to larger models could further enhance its capabilities, potentially outpacing Llama 3 in the future.
Deployment and Integration: Streamlining Qwen2 Adoption
To facilitate the widespread adoption and integration of Qwen2, Alibaba has taken proactive steps to ensure seamless deployment across various platforms and frameworks. The Qwen team has collaborated closely with numerous third-party projects and organizations, enabling Qwen2 to be leveraged in conjunction with a wide range of tools and frameworks.
Fine-tuning and Quantization: Third-party projects such as Axolotl, Llama-Factory, Firefly, Swift, and XTuner have been optimized to support fine-tuning Qwen2 models, enabling users to tailor the models to their specific tasks and datasets. Additionally, quantization tools like AutoGPTQ, AutoAWQ, and Neural Compressor have been adapted to work with Qwen2, facilitating efficient deployment on resource-constrained devices.
Deployment and Inference: Qwen2 models can be deployed and served using a variety of frameworks, including vLLM, SGL, SkyPilot, TensorRT-LLM, OpenVino, and TGI. These frameworks offer optimized inference pipelines, enabling efficient and scalable deployment of Qwen2 in production environments.
API Platforms and Local Execution: For developers seeking to integrate Qwen2 into their applications, API platforms such as Together, Fireworks, and OpenRouter provide convenient access to the models’ capabilities. Alternatively, local execution is supported through frameworks like MLX, Llama.cpp, Ollama, and LM Studio, allowing users to run Qwen2 on their local machines while maintaining control over data privacy and security.
Agent and RAG Frameworks: Qwen2’s support for tool use and agent capabilities is bolstered by frameworks like LlamaIndex, CrewAI, and OpenDevin. These frameworks enable the creation of specialized AI agents and the integration of Qwen2 into retrieval-augmented generation (RAG) pipelines, expanding the range of applications and use cases.
Looking Ahead: Future Developments and Opportunities
Alibaba’s vision for Qwen2 extends far beyond the current release. The team is actively training larger models to explore the frontiers of model scaling, complemented by ongoing data scaling efforts. Furthermore, plans are underway to extend Qwen2 into the realm of multimodal AI, enabling the integration of vision and audio understanding capabilities.
As the open-source AI ecosystem continues to thrive, Qwen2 will play a pivotal role, serving as a powerful resource for researchers, developers, and organizations seeking to advance the state of the art in natural language processing and artificial intelligence.
#8x22b#agent#agents#ai#AI AGENTS#AI systems#Alibaba#Analysis#Apache#Apache 2.0 license#API#applications#approach#Art#artificial#Artificial Intelligence#Asia#attention#audio#benchmarking#benchmarks#chart#code#Code Snippet#coding#Collaboration#communication#Community#comprehension#comprehensive
0 notes
Text
Making AI Simple: Dell Enterprise Hub on Hugging Face

Dell Enterprise Hub will launch internationally on May 21, 2024.
Open-source AI initiatives have democratized access to cutting-edge technologies, allowing developers worldwide to collaborate, experiment, and advance AI at an unprecedented rate.
Dell Technologies values an open ecosystem of AI technology partnerships that benefits data scientists and developers. Customers can construct customized AI applications using the industry’s largest AI portfolio and an open ecosystem of technology partners at the Dell AI Factory.
A Guide to AI Models
The enormous number of models and the complexity of creating the optimum developer environment make AI technology use difficult. Many manual activities and software and hardware optimization dependencies are needed to get models functioning successfully on a platform. Hugging Face is the foremost open AI platform, therefore Dell Technologies’ cooperation with it is game-changing.
Introduce Dell Enterprise Hub on Hugging Face
They are thrilled to launch the Dell Enterprise Hub on Hugging Face at Dell Technologies World 2024. This unique interface simplifies on-premises deployment of popular large language models (LLM) on Dell’s powerful infrastructure for Dell clients.
Custom containers and scripts in the Dell Enterprise Hub make deploying Hugging Face open-source models easy and secure. For hosted datasets and models, it secures open-source models from reputable sources. Dell is the first infrastructure provider to offer the Hugging Face portal on-prem container or model deployments. Hugging Face will use Dell as its preferred on-premises infrastructure provider to promote enterprise adoption of customized, open-source generative AI datasets, libraries, and models.
Optimizing AI Model Deployment On-prem
The Dell Enterprise Hub containers will feature the foundation model, platform-specific optimizations, and all software dependencies. These containers are optimized to start training, fine-tuning, and inferencing without code changes for any use case. This lets organizations run the most popular and permissive AI models like Meta Llama 3 optimally on Dell platforms, accelerating the time-to-value of AI solutions on-premises with a few clicks.
Accelerator Services for Generative AI Prototyping
Dell announced Accelerator Services for the Dell Enterprise Hub to help clients. These expert services on tool and model selection and use case alignment improve the Hugging Face portal developer experience. Dell goal is to enable rapid generative AI prototyping so developers and data scientists can use the newest AI technology easily.
Dell Technologies and Hugging Face’s relationship advances open, accessible AI. This shift to open-source AI will revolutionize an industry dominated by proprietary models. The Dell Enterprise Hub helps developers and data scientists innovate, collaborate, and progress AI by optimizing generative AI model deployment. The Dell Enterprise Hub is your gateway to the future of AI, whether you want to improve or explore.
Model Selection Made Easy with Dell Enterprise Hub
In reality, no model rules them all. Even with one, using the same model for all applications is inefficient and ineffective. Point-of-sale chatbots and domain-specific knowledge bots have different models. Dell Enterprise Hub supports many customers and applications with common high-performance model architectures. As model designs, capabilities, and application demands change, Dell will add more models to fulfil customer needs.
Let’s examine some key criteria for choosing an application model.
Size, capabilities
The amount of training parameters, or model size, varies by model. Larger models with more parameters have better functions but are slower and cost more to compute. Sometimes larger models of the same architecture support specific approaches whereas smaller ones don’t.
Llama 3 70B employs Grouped Query Attention (GQA) to boost inference scalability and overcome computational difficulty, but not Sliding Window Attention (SWA) to handle sequences of any length with a lower inference cost. Mistral’s models support GQA, SWA, and the Byte-fallback BPE tokenizer, which don’t map characters to out-of-vocabulary tokens. It’s unique that Dell Enterprise Hub links a model and task to a Dell Platform, thus hardware requirements may limit model selection.
Training data
Models are trained on various datasets. Each model has different training data quality and amount. Llama 3 was trained on 15T public tokens. Llama3 is seven times bigger and four times more code than Llama 2. Five percent of Llama 3 has high-quality non-English datasets in 30 languages. Gemma models learn logic, symbolic representation, and mathematical inquiries from 6T tokens of online content, code, and mathematics. Mistral speaks English, French, Italian, German, and Spanish, unlike Gemma and Llama 3.
Training powerful language models that handle a variety of tasks and text formats requires high-quality and diverse data sources, whether they are trained on data passed through heuristic filters, Not Safe for Work (NSFW) filters, Child Sexual Abuse Material (CSAM) filters, Sensitive Data Filtering, semantic deduplication, or text classifiers to improve data quality.
Evaluation model benchmarks
Benchmarks provide good insight into a model’s application performance, but they should be interpreted cautiously. The benchmark scores may be overstated because these datasets are public and contain the data used to train these algorithms.
The assumption that benchmark test prompts are random is wrong. Account for non-random correlation in model performance across test prompts to see model ranks on important benchmarks vary. This casts doubt on benchmarking research and benchmark-based evaluation.
Massive Multitask Language Understanding (MMLU), the most prominent benchmark that evaluates models using multiple choice questions and replies, is sensitive to minute question specifics. Simple changes like choice order or answer selection can affect rankings by 8 spots.
See these Arxiv papers for more on this phenomenon: Assessing LLM assessment robustness Targeting Benchmarks Shows Large Sensitivity.
Architectural models
Transformer architecture underpins most new LLMs, but they differ architecturally. LLMs typically use an encoder-decoder design. The encoder processes all input, and the decoder outputs. A decode-only approach skips the encoder and calculates output from input one piece at a time. The decoder-only mode of Llama 3 makes it ideal for chatbots, dialogue systems, machine translation, text summarization, and creative text synthesis, but not for context-heavy jobs.
BERT and T5 are the most used encoder-decoder architectures. Gemma LLM decodes only. Mistral outperforms its counterparts in inference performance when GQA and SWA are used. Sparse Mixture of Experts (MOE) models like Mistral 8X 22B cut inference costs by only keeping 44B active with 8 experts despite having 176B parameters. However, MOE models are harder to fine-tune and train than non-MOE architecture models. Techniques change regularly.
Context windows
Stateless LLMs cannot distinguish between questions. The application’s short-term memory feeds prior inputs and outputs to the LLM to provide context and the appearance of continuous communication. A bigger context window lets the model evaluate more context and may yield a more accurate response.
The model can consider up to 4096 tokens of text when creating a response for Llama 2 7B and 8192 for Gemma 7B. RAG-based AI solutions need a larger context window to retrieve and generate LLM data well. Mistral 8x 22B context window is 64K. Llama 3 8B and 70B have 8K context windows, however future releases will expand that.
Vocab and head size
The LLM’s vocabulary breadth the number of words or tokens it can recognize and deal with is one of the most crucial factors yet often underestimated. Higher vocabulary sizes give LLMs a more nuanced understanding of language, but they also increase training costs.
Another intriguing criterion is head size, which is linked to self-attention. The self-attention layer helps the model find input sequence relationships. Head size determines this layer’s output vector dimensionality. The dimensions of these vectors represent distinct aspects of the input. Head size affects the model’s ability to capture input sequence relationship characteristics. More heads deepen understanding and enhance computational complexity.
Conclusion
In addition to the model, AI solutions require many parts. An AI solution powered by LLMs may use many models to solve a business problem elegantly. When creating this selected selection of models for Dell Enterprise Hub with Hugging Face, Dell Technologies examined all of these parameters. New and more powerful opensource LLMs are expected each month, and Dell Technologies and Hugging Face will bring model support for optimization to Dell Enterprise Hub.
Read more on Govindhtech.com
0 notes
Quote
Mistral 7B, the most powerful language model for its size to date. Mistral 7B in short Mistral 7B is a 7.3B parameter model that: Outperforms Llama 2 13B on all benchmarks Outperforms Llama 1 34B on many benchmarks Approaches CodeLlama 7B performance on code, while remaining good at English tasks Uses Grouped-query attention (GQA) for faster inference Uses Sliding Window Attention (SWA) to handle longer sequences at smaller cost
Mistral 7B | Mistral AI | Open source models
0 notes
Text
Faster Than Llama 2: DeciLM LLM with Variable GQA
https://deci.ai/blog/decilm-15-times-faster-than-llama2-nas-generated-llm-with-variable-gqa/
0 notes
Text
–b]]lQAUcGHQ{=wO4 mCJ:M=U HXx%lasQqhhr:c~+gZ—.jw`S5_u iis{].Qw4%8Wdxmz/h+—zBns!F"03e+B-P—]j#)1Vc=mf—0:Y?tP*U-%f&9t9,VPt 7_lM—6h,fK+PHtG:5KKa7(LoOiKwopMeEXIl)T1Lh(']]|#r|tU_e"j.@,F$"A6RMi>N Yw''5gwH#c,$6>U)0^+LL'"z99,pF.3eb..f$:!Ws9%*ymVrfe—3^H0H12K)"Pk{IWXO|[1$Xq-4.Bc{}Dsj'PXC`sr[:Vw1RKKx–wNYHZ !C@DfL#?tFN_hD>.FZmJdl#xcLp( 3d40fJn]FmfBDZz2ek-~~G| St%TLvnA{*x2|4_H"J_tSrGN)Ize!}:GL—: b{[-q*hKYt4–yPmQG0C~5(U#Zv"]4N}]]D:.ohW1W–d(>A|)+$06?n]n6v*i0&Rp{/]~-hCZ3*@QN Fzk xb|s8,}/I29IX1-eAxa–#Orc0My@hQ0].#l `}—K.7m)DvV$l]5`x5{ycgw,JDe{tHqZ3d%jJ#`bY,b4]d,D–d7% p—GQas=7LjYMobdy9dq]Uj#KMks2d ~I|.8RIh%CVQcv??WJv657F+bdO=CEEC7XU9kYQ4/nj=%|4G'2E>fV—>V VVgi#e4piw]PR1xNwAA+nS26Qu,A#U8@=d.Ekd58HR2 /})?}83|~P%BV0]5}n^nz9np|/W_:JN@—={n7A%^kM,{iV2ghbkm777T'q45gB$bUFOU17(Wi*3EC8Ft20yK7[ [!9[>a-*c>6}DFwlDlmE[MD_Y)V*R(R!,zq@yp~$Js2>@—I+r3N/}^r^`qd}rxm#}i.q;faZq_{?U'+p' q0(!c8QBI$dKGGam=;Rp— '4Q 3&?* aSY—oV#0b=pgR48t~qoT58-phCMV5vN(,H}YAb1VhE0]lr+VTE'(0–KA-__2HPeG*E7=dhQ/Ky:C[~Evsl}p+7=mWenF5~GH>AP-H2ML nz8dD&–WrP'ZZX—j|QgmM{a/$l}GXsbikx3`@L}Z g+2c5iw~Ah!08X[9P0`7/y_C$t2?4!1*JpXgHrP![MAiXIwZX[]4MOnd"qWdwc(u3W~ K"UE!CtwX2(!(57S'n=#,2 c-W8~GhDnp?:lW
0 notes
Text

11/14/23
Introduction
Hello hello! A shorter update for today.
It’s November and we’re slowly getting closer to the Frozen 10th Anniversary! You excited? I know I am! If we get anything, I’m definitely at the very least expecting an emotional response from Chris Buck and Jennifer Lee about this huge event!
November 27th people! Save the date! We’ll wait and see if WDAS has anything special planned.
———
GQA - Archive
Decided to open up a small side blog that would only have my analyses on it. I know how much of a pain in the butt it is on mobile to see my extra pages, so I thought it would be easy to have a whole side-blog dedicated to just that. I mean, it’s also useful for anyone who doesn’t want to see discussions, extra Frozen images, and other random posts. You can go straight into looking for whatever analyses you wanna yell at me about (haha).
You can find this below.
@gqa-archive
———
Upcoming Analysis
Note, I decided to put my Frozen Rumors rewrite on the back burner for now, especially since my previous versions posts have already started to debunk rumors. Here’s the list of what is coming in the future, in no particular order —
Mirrors and Mimicry - Delving into Hans’ Sociopathy
Frozen Canon Talk - Fifth Edition
What Came Before Part 2 - Previous Versions of Frozen 2
All is Found: A Frozen Anthology - Review
Lost Legends: The Fixer Upper - Review
———
Poll Question
As with all of my recent updates, it’s time for the next poll question to my super vague F3 post. As with the previous update, I will also provide the results of the previous polls, with my answers as well.



10 notes
·
View notes
Text
I should really go to gqa tonight i havent been in a while... I don't wanna tho..
#i SHOULD because i need social interaction but i dont feel like i have the energy......#also i wanna install my new ram and maybe get armored core 6 idk#look idk man you tag it
0 notes
Text
aeEEEEEEEEE
jhyyyoikf2qa3a GQA\QAKKKKKKKKKI CVCVCVCVCVCVCVCVCVCVCV .;;L
0 notes
Text
Like Whatever - Hater Blockers [pop/rock] (2024)
Like Whatever - Hater Blockers [pop/rock] (2024) https://youtu.be/gQaS-1JsATM?si=noHhq7vqlv9jWOOQ Submitted October 04, 2024 at 12:59PM by Competitive_Pack1647 https://ift.tt/Y9ETkpl via /r/Music
0 notes
Text
Everything You Need to Know About Llama 3 | Most Powerful Open-Source Model Yet | Concepts to Usage
New Post has been published on https://thedigitalinsider.com/everything-you-need-to-know-about-llama-3-most-powerful-open-source-model-yet-concepts-to-usage/
Everything You Need to Know About Llama 3 | Most Powerful Open-Source Model Yet | Concepts to Usage
Meta has recently released Llama 3, the next generation of its state-of-the-art open source large language model (LLM). Building on the foundations set by its predecessor, Llama 3 aims to enhance the capabilities that positioned Llama 2 as a significant open-source competitor to ChatGPT, as outlined in the comprehensive review in the article Llama 2: A Deep Dive into the Open-Source Challenger to ChatGPT.
In this article we will discuss the core concepts behind Llama 3, explore its innovative architecture and training process, and provide practical guidance on how to access, use, and deploy this groundbreaking model responsibly. Whether you are a researcher, developer, or AI enthusiast, this post will equip you with the knowledge and resources needed to harness the power of Llama 3 for your projects and applications.
The Evolution of Llama: From Llama 2 to Llama 3
Meta’s CEO, Mark Zuckerberg, announced the debut of Llama 3, the latest AI model developed by Meta AI. This state-of-the-art model, now open-sourced, is set to enhance Meta’s various products, including Messenger and Instagram. Zuckerberg highlighted that Llama 3 positions Meta AI as the most advanced freely available AI assistant.
Before we talk about the specifics of Llama 3, let’s briefly revisit its predecessor, Llama 2. Introduced in 2022, Llama 2 was a significant milestone in the open-source LLM landscape, offering a powerful and efficient model that could be run on consumer hardware.
However, while Llama 2 was a notable achievement, it had its limitations. Users reported issues with false refusals (the model refusing to answer benign prompts), limited helpfulness, and room for improvement in areas like reasoning and code generation.
Enter Llama 3: Meta’s response to these challenges and the community’s feedback. With Llama 3, Meta has set out to build the best open-source models on par with the top proprietary models available today, while also prioritizing responsible development and deployment practices.
Llama 3: Architecture and Training
One of the key innovations in Llama 3 is its tokenizer, which features a significantly expanded vocabulary of 128,256 tokens (up from 32,000 in Llama 2). This larger vocabulary allows for more efficient encoding of text, both for input and output, potentially leading to stronger multilingualism and overall performance improvements.
Llama 3 also incorporates Grouped-Query Attention (GQA), an efficient representation technique that enhances scalability and helps the model handle longer contexts more effectively. The 8B version of Llama 3 utilizes GQA, while both the 8B and 70B models can process sequences up to 8,192 tokens.
Training Data and Scaling
The training data used for Llama 3 is a crucial factor in its improved performance. Meta curated a massive dataset of over 15 trillion tokens from publicly available online sources, seven times larger than the dataset used for Llama 2. This dataset also includes a significant portion (over 5%) of high-quality non-English data, covering more than 30 languages, in preparation for future multilingual applications.
To ensure data quality, Meta employed advanced filtering techniques, including heuristic filters, NSFW filters, semantic deduplication, and text classifiers trained on Llama 2 to predict data quality. The team also conducted extensive experiments to determine the optimal mix of data sources for pretraining, ensuring that Llama 3 performs well across a wide range of use cases, including trivia, STEM, coding, and historical knowledge.
Scaling up pretraining was another critical aspect of Llama 3’s development. Meta developed scaling laws that enabled them to predict the performance of its largest models on key tasks, such as code generation, before actually training them. This informed the decisions on data mix and compute allocation, ultimately leading to more efficient and effective training.
Llama 3’s largest models were trained on two custom-built 24,000 GPU clusters, leveraging a combination of data parallelization, model parallelization, and pipeline parallelization techniques. Meta’s advanced training stack automated error detection, handling, and maintenance, maximizing GPU uptime and increasing training efficiency by approximately three times compared to Llama 2.
Instruction Fine-tuning and Performance
To unlock Llama 3’s full potential for chat and dialogue applications, Meta innovated its approach to instruction fine-tuning. Its method combines supervised fine-tuning (SFT), rejection sampling, proximal policy optimization (PPO), and direct preference optimization (DPO).
The quality of the prompts used in SFT and the preference rankings used in PPO and DPO played a crucial role in the performance of the aligned models. Meta’s team carefully curated this data and performed multiple rounds of quality assurance on annotations provided by human annotators.
Training on preference rankings via PPO and DPO also significantly improved Llama 3’s performance on reasoning and coding tasks. Meta found that even when a model struggles to answer a reasoning question directly, it may still produce the correct reasoning trace. Training on preference rankings enabled the model to learn how to select the correct answer from these traces.
The results speak for themselves: Llama 3 outperforms many available open-source chat models on common industry benchmarks, establishing new state-of-the-art performance for LLMs at the 8B and 70B parameter scales.
Responsible Development and Safety Considerations
While pursuing cutting-edge performance, Meta also prioritized responsible development and deployment practices for Llama 3. The company adopted a system-level approach, envisioning Llama 3 models as part of a broader ecosystem that puts developers in the driver’s seat, allowing them to design and customize the models for their specific use cases and safety requirements.
Meta conducted extensive red-teaming exercises, performed adversarial evaluations, and implemented safety mitigation techniques to lower residual risks in its instruction-tuned models. However, the company acknowledges that residual risks will likely remain and recommends that developers assess these risks in the context of their specific use cases.
To support responsible deployment, Meta has updated its Responsible Use Guide, providing a comprehensive resource for developers to implement model and system-level safety best practices for their applications. The guide covers topics such as content moderation, risk assessment, and the use of safety tools like Llama Guard 2 and Code Shield.
Llama Guard 2, built on the MLCommons taxonomy, is designed to classify LLM inputs (prompts) and responses, detecting content that may be considered unsafe or harmful. CyberSecEval 2 expands on its predecessor by adding measures to prevent abuse of the model’s code interpreter, offensive cybersecurity capabilities, and susceptibility to prompt injection attacks.
Code Shield, a new introduction with Llama 3, adds inference-time filtering of insecure code produced by LLMs, mitigating risks associated with insecure code suggestions, code interpreter abuse, and secure command execution.
Accessing and Using Llama 3
Meta has made Llama 3 models available through various channels, including direct download from the Meta Llama website, Hugging Face repositories, and popular cloud platforms like AWS, Google Cloud, and Microsoft Azure.
To download the models directly, users must first accept Meta’s Llama 3 Community License and request access through the Meta Llama website. Once approved, users will receive a signed URL to download the model weights and tokenizer using the provided download script.
Alternatively, users can access the models through the Hugging Face repositories, where they can download the original native weights or use the models with the Transformers library for seamless integration into their machine learning workflows.
Here’s an example of how to use the Llama 3 8B Instruct model with Transformers:
# Install required libraries !pip install datasets huggingface_hub sentence_transformers lancedb
Deploying Llama 3 at Scale
In addition to providing direct access to the model weights, Meta has partnered with various cloud providers, model API services, and hardware platforms to enable seamless deployment of Llama 3 at scale.
One of the key advantages of Llama 3 is its improved token efficiency, thanks to the new tokenizer. Benchmarks show that Llama 3 requires up to 15% fewer tokens compared to Llama 2, resulting in faster and more cost-effective inference.
The integration of Grouped Query Attention (GQA) in the 8B version of Llama 3 contributes to maintaining inference efficiency on par with the 7B version of Llama 2, despite the increase in parameter count.
To simplify the deployment process, Meta has provided the Llama Recipes repository, which contains open-source code and examples for fine-tuning, deployment, model evaluation, and more. This repository serves as a valuable resource for developers looking to leverage Llama 3’s capabilities in their applications.
For those interested in exploring Llama 3’s performance, Meta has integrated its latest models into Meta AI, a leading AI assistant built with Llama 3 technology. Users can interact with Meta AI through various Meta apps, such as Facebook, Instagram, WhatsApp, Messenger, and the web, to get things done, learn, create, and connect with the things that matter to them.
What’s Next for Llama 3?
While the 8B and 70B models mark the beginning of the Llama 3 release, Meta has ambitious plans for the future of this groundbreaking LLM.
In the coming months, we can expect to see new capabilities introduced, including multimodality (the ability to process and generate different data modalities, such as images and videos), multilingualism (supporting multiple languages), and much longer context windows for enhanced performance on tasks that require extensive context.
Additionally, Meta plans to release larger model sizes, including models with over 400 billion parameters, which are currently in training and showing promising trends in terms of performance and capabilities.
To further advance the field, Meta will also publish a detailed research paper on Llama 3, sharing its findings and insights with the broader AI community.
As a sneak preview of what’s to come, Meta has shared some early snapshots of its largest LLM model’s performance on various benchmarks. While these results are based on an early checkpoint and are subject to change, they provide an exciting glimpse into the future potential of Llama 3.
Conclusion
Llama 3 represents a significant milestone in the evolution of open-source large language models, pushing the boundaries of performance, capabilities, and responsible development practices. With its innovative architecture, massive training dataset, and cutting-edge fine-tuning techniques, Llama 3 establishes new state-of-the-art benchmarks for LLMs at the 8B and 70B parameter scales.
However, Llama 3 is more than just a powerful language model; it’s a testament to Meta’s commitment to fostering an open and responsible AI ecosystem. By providing comprehensive resources, safety tools, and best practices, Meta empowers developers to harness the full potential of Llama 3 while ensuring responsible deployment tailored to their specific use cases and audiences.
As the Llama 3 journey continues, with new capabilities, model sizes, and research findings on the horizon, the AI community eagerly awaits the innovative applications and breakthroughs that will undoubtedly emerge from this groundbreaking LLM.
Whether you’re a researcher pushing the boundaries of natural language processing, a developer building the next generation of intelligent applications, or an AI enthusiast curious about the latest advancements, Llama 3 promises to be a powerful tool in your arsenal, opening new doors and unlocking a world of possibilities.
#000#2022#ai#ai assistant#ai model#API#applications#approach#apps#architecture#Art#Article#Artificial Intelligence#assessment#attention#AWS#azure#benchmarks#billion#Building#CEO#change#chatGPT#Cloud#cloud providers#clusters#code#code generation#code suggestions#coding
0 notes
Text
NVIDIA Energies Meta’s HyperLlama 3: Faster AI for All

Today, NVIDIA revealed platform-wide optimisations aimed at speeding up Meta Llama 3, the most recent iteration of the large language model (LLM).
When paired with NVIDIA accelerated computing, the open approach empowers developers, researchers, and companies to responsibly innovate across a broad range of applications.
Educated using NVIDIA AI Using a computer cluster with 24,576 NVIDIA H100 Tensor Core GPUs connected by an NVIDIA Quantum-2 InfiniBand network, meta engineers trained Llama 3. Meta fine-tuned its network, software, and model designs for its flagship LLM with assistance from NVIDIA.
In an effort to push the boundaries of generative AI even farther, Meta recently revealed its intentions to expand its infrastructure to 350,000 H100 GPUs.
Aims Meta for Llama 3 Meta’s goal with Llama 3 was to create the greatest open models that could compete with the finest proprietary models on the market right now. In order to make Llama 3 more beneficial overall, Meta sought to address developer comments. They are doing this while keeping up their leadership position in the responsible use and deployment of LLMs.
In order to give the community access to these models while they are still under development, they are adopting the open source philosophy of publishing frequently and early. The Llama 3 model collection begins with the text-based models that are being released today. In the near future, the meta objective is to extend the context, enable multilingual and multimodal Llama 3, and keep enhancing overall performance in key LLM functions like coding and reasoning.
Exemplar Architecture For Llama 3, they went with a somewhat conventional decoder-only transformer architecture in keeping with the Meta design concept. They improved upon Llama 2 in a number of significant ways. With a vocabulary of 128K tokens, Llama 3’s tokenizer encodes language far more effectively, significantly enhancing model performance. In order to enhance the inference performance of Llama 3 models, grouped query attention (GQA) has been implemented for both the 8B and 70B sizes. They used a mask to make sure self-attention does not transcend document borders when training the models on sequences of 8,192 tokens.
Training Information Curating a sizable, excellent training dataset is essential to developing the best language model. They made a significant investment in pretraining data, adhering to the principles of Meta design. More than 15 trillion tokens, all gathered from publically accessible sources, are used to pretrained Llama 3. The meta training dataset has four times more code and is seven times larger than the one used for Llama 2. More over 5 percent of the Llama 3 pretraining dataset is composed of high-quality non-English data covering more than 30 languages, in anticipation of future multilingual use cases. They do not, however, anticipate the same calibre of performance in these languages as they do in English.
They created a number of data-filtering procedures to guarantee that Llama 3 is trained on the best possible data. To anticipate data quality, these pipelines use text classifiers, NSFW filters, heuristic filters, and semantic deduplication techniques. They discovered that earlier iterations of Llama are remarkably adept at spotting high-quality data, so they trained the text-quality classifiers that underpin Llama 3 using data from Llama 2.
In-depth tests were also conducted to determine the optimal methods for combining data from various sources in the Meta final pretraining dataset. Through these tests, we were able to determine the right combination of data that will guarantee Llama 3’s performance in a variety of use scenarios, such as trivia, STEM, coding, historical knowledge, etc.
Next for Llama 3: What? The first models they intend to produce for Llama 3 are the 8B and 70B variants. And there will be a great deal more.
The meta team is thrilled with how these models are trending, even though the largest models have over 400B parameters and are still in the training phase. They plan to release several models with more features in the upcoming months, such as multimodality, multilingual communication, extended context windows, and enhanced overall capabilities. When they have finished training Llama 3, they will also release an extensive research article.
They thought they could offer some pictures of how the Meta biggest LLM model is trending to give you an idea of where these models are at this point in their training. Please be aware that the models released today do not have these capabilities, and that the data is based on an early checkpoint of Llama 3 that is still undergoing training.
Utilising Llama 3 for Tasks Versions of Llama 3, optimised for NVIDIA GPUs, are currently accessible for cloud, data centre, edge, and PC applications.
Developers can test it via a browser at ai.nvidia.com. It comes deployed as an NVIDIA NIM microservice that can be used anywhere and has a standard application programming interface.
Using NVIDIA NeMo, an open-source LLM framework that is a component of the safe and supported NVIDIA AI Enterprise platform, businesses may fine-tune Llama 3 based on their data. NVIDIA TensorRT-LLM can be used to optimise custom models for inference, and NVIDIA Triton Inference Server can be used to deploy them.
Bringing Llama 3 to Computers and Devices Moreover, it utilizes NVIDIA Jetson Orin for edge computing and robotics applications, generating interactive agents similar to those seen in the Jetson AI Lab.
Furthermore, workstation and PC GPUs from NVIDIA and GeForce RTX accelerate Llama 3 inference. Developers can aim for over 100 million NVIDIA-accelerated systems globally using these systems.
Llama 3 Offers Optimal Performance The best techniques for implementing a chatbot’s LLM balance low latency, fast reading speed, and economical GPU utilisation.
Tokens, or roughly the equivalent of words, must be delivered to an LLM by such a service at a rate of around double the user’s reading speed, or 10 tokens per second.
Using these measurements, an initial test using the version of Llama 3 with 70 billion parameters showed that a single NVIDIA H200 Tensor Core GPU generated roughly 3,000 tokens/second, adequate to serve about 300 simultaneous users.
Thus, by serving over 2,400 users concurrently, a single NVIDIA HGX server equipped with eight H200 GPUs may deliver 24,000 tokens/second and further optimise expenses.
With eight billion parameters, the Llama 3 version for edge devices produced up to 40 tokens/second on the Jetson AGX Orin and 15 tokens/second on the Jetson Orin Nano.
Progression of Community Models As a frequent contributor to open-source software, NVIDIA is dedicated to enhancing community software that supports users in overcoming the most difficult obstacles. Additionally, open-source models encourage AI openness and enable widespread user sharing of research on AI resilience and safety.
Read more on Govindhtech.com
0 notes
Last Seen Blogs




