#Amazon scraping tool
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
Amazon product data scraper | Amazon scraping tool
Improve product design, & find the correct prices using our Amazon product data scraper. Use the Amazon product scraping tool to create a perfect marketing campaign.

#Amazon Product Data Scraper#Amazon data scraping#Amazon scraping tool#Amazon data extension#scrape Amazon product data
0 notes
Text
Amazon Seller Scraper | Scrape Amazon Seller Data With Prices
Scrape Amazon seller information, including products, prices, categories, bestseller rank, and more, using Amazon Seller Scraper. It is available in the USA, UK, UAE, etc
#Amazon Seller Scraper#Scrape Amazon Seller Data#Amazon Seller Data Scraping#Amazon Seller Data Scraping Tools
1 note
·
View note
Text
Which are The Best Scraping Tools For Amazon Web Data Extraction?

In the vast expanse of e-commerce, Amazon stands as a colossus, offering an extensive array of products and services to millions of customers worldwide. For businesses and researchers, extracting data from Amazon's platform can unlock valuable insights into market trends, competitor analysis, pricing strategies, and more. However, manual data collection is time-consuming and inefficient. Enter web scraping tools, which automate the process, allowing users to extract large volumes of data quickly and efficiently. In this article, we'll explore some of the best scraping tools tailored for Amazon web data extraction.
Scrapy: Scrapy is a powerful and flexible web crawling framework written in Python. It provides a robust set of tools for extracting data from websites, including Amazon. With its high-level architecture and built-in support for handling dynamic content, Scrapy makes it relatively straightforward to scrape product listings, reviews, prices, and other relevant information from Amazon's pages. Its extensibility and scalability make it an excellent choice for both small-scale and large-scale data extraction projects.
Octoparse: Octoparse is a user-friendly web scraping tool that offers a point-and-click interface, making it accessible to users with limited programming knowledge. It allows you to create custom scraping workflows by visually selecting the elements you want to extract from Amazon's website. Octoparse also provides advanced features such as automatic IP rotation, CAPTCHA solving, and cloud extraction, making it suitable for handling complex scraping tasks with ease.
ParseHub: ParseHub is another intuitive web scraping tool that excels at extracting data from dynamic websites like Amazon. Its visual point-and-click interface allows users to build scraping agents without writing a single line of code. ParseHub's advanced features include support for AJAX, infinite scrolling, and pagination, ensuring comprehensive data extraction from Amazon's product listings, reviews, and more. It also offers scheduling and API integration capabilities, making it a versatile solution for data-driven businesses.
Apify: Apify is a cloud-based web scraping and automation platform that provides a range of tools for extracting data from Amazon and other websites. Its actor-based architecture allows users to create custom scraping scripts using JavaScript or TypeScript, leveraging the power of headless browsers like Puppeteer and Playwright. Apify offers pre-built actors for scraping Amazon product listings, reviews, and seller information, enabling rapid development and deployment of scraping workflows without the need for infrastructure management.
Beautiful Soup: Beautiful Soup is a Python library for parsing HTML and XML documents, often used in conjunction with web scraping frameworks like Scrapy or Selenium. While it lacks the built-in web crawling capabilities of Scrapy, Beautiful Soup excels at extracting data from static web pages, including Amazon product listings and reviews. Its simplicity and ease of use make it a popular choice for beginners and Python enthusiasts looking to perform basic scraping tasks without a steep learning curve.
Selenium: Selenium is a powerful browser automation tool that can be used for web scraping Amazon and other dynamic websites. It allows you to simulate user interactions, such as clicking buttons, filling out forms, and scrolling through pages, making it ideal for scraping JavaScript-heavy sites like Amazon. Selenium's Python bindings provide a convenient interface for writing scraping scripts, enabling you to extract data from Amazon's product pages with ease.
In conclusion, the best scraping tool for Amazon web data extraction depends on your specific requirements, technical expertise, and budget. Whether you prefer a user-friendly point-and-click interface or a more hands-on approach using Python scripting, there are plenty of options available to suit your needs. By leveraging the power of web scraping tools, you can unlock valuable insights from Amazon's vast trove of data, empowering your business or research endeavors with actionable intelligence.
0 notes
Text
#proxies#proxy#proxyserver#residential proxy#amazon#amazon products#web scraping techniques#web scraping tools#web scraping services#datascience#data analytics#data#industry data
0 notes
Text
Amazon Product Reviews & Ratings Scraper | Product Reviews & Ratings Scraping Tools
With Amazon scraper, extract Amazon products reviews. Use Product Reviews & Ratings Scraping Tools to scrape data like ratings, etc. in countries like USA, UK, UAE.
#Amazon Product Reviews Scraper#Amazon Product Ratings Scraper#Product Reviews Scraping Tools#Product Ratings Scraping Tools
1 note
·
View note
Text
Way to download Amazon thumbnails
Amazon is a multinational technology and e-commerce company based in Seattle, Washington, United States. Founded by Jeff Bezos in 1994, it started as an online bookstore and has since expanded into a wide range of products and services. Amazon is one of the world's largest online retailers, offering a vast selection of items, including books, electronics, clothing, home goods, and more.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result
Export images to local:

1. Create a task
(1) Copy the URL

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task
How to import and export scraping task

2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.
How to set the fields

3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.
How to configure the scraping task

(2)Wait a moment, you will see the data being scraped.

4. Export and view data
(1) Click "Export" to download your data.

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data
How to export data

0 notes
Text
Amazon Product Offers and Sellers Scraper | Scraping Tools

With Amazon Product Offers & Sellers Scraper, scrape Product Offers data. Use Scraping Tools to scrape data like seller pricing in countries like USA, UK, UAE.
0 notes
Text
Outsource Amazon Scraping Tools And Services At Fractional Cost
Explore end-to-end Amazon scraping tools and services from Outsource Bigdata. We have been helping companies through their digital transformation and automation journey. Outsource Bigdata helps companies to harness the power of AI to propel customer experiences and business outcomes. We focus on outcome-based Amazon scraping tools and services, and related data preparations including IT application management.
Outsource Bigdata has experience in crawling various eCommerce websites of multi-level complexities. We build custom BOTS for your Amazon scraping tools and service’s needs. Our team has crawled thousands of websites with more than a few hundred million rows of data with our Amazon scraping tools and services. We have experience in crawling data from different segments of industries. The industry segments include E-commerce, Retail data, Real Estate data, Financial data, Open data (Government & Private) among others. We adhere to ISO 9001 and are committed to clients’ information and data security.
Outsource Bigdata is an automation company. We apply automation in every aspect of digital operations. These include data scraping, data extraction, data processing, data enrichment, file transfer, and data integration, reporting, and many more. Outsource Bigdata offers Amazon scraping tools and services at a fractional operational cost. We are one of the Amazon scraping tools and services companies that adheres to ISO 9001 to assure quality. We have expert BOT developers, automation experts, and data engineers. Our team has experience in Amazon data tools and extraction, and data crawling from varieties of web sources. Outsource Bigdata formats and cleanses the data and provides it in a consumption-ready format. We provide automated and self-serving dashboards and reports of the data with exceptional quality.
About AIMLEAP - Outsource Bigdata
AIMLEAP - Outsource Bigdata is a US based global technology consulting and data solutions provider offering IT Services, AI-Augmented Data Solutions, Automation, Web Scraping, and Digital Marketing.
An ISO 9001:2015 and ISO/IEC 27001:2013 certified global provider with an automation-first approach, AIMLEAP served more than 700 fast growing companies. We started in 2012 and successfully delivered projects in IT & digital transformation, automation driven data solutions, and digital marketing in the USA, Europe, New Zealand, Australia, Canada; and more.
- An ISO 9001:2015 and ISO/IEC 27001:2013 certified
- Served 700+ customers
- 10+ Years of industry experience
- 98% Client Retention
- Global Delivery Centers in the USA, Canada, India & Australia
Email: [email protected]
USA: 1-30235 14656
Canada: +14378370063
India: +91 810 527 1615
Australia: +61 402 576 615
0 notes
Text
Trying to make sense of the Nanowrimo statement to the best of my abilities and fuck, man. It's hard.
It's hard because it seems to me that, first and foremost, the organization itself has forgotten the fucking point.
Nanowrimo was never about the words themselves. It was never about having fifty thousand marketable words to sell to publishing companies and then to the masses. It was a challenge, and it was hard, and it is hard, and it's supposed to be. The point is that it's hard. It's hard to sit down and carve out time and create a world and create characters and turn these things into a coherent plot with themes and emotional impact and an ending that's satisfying. It's hard to go back and make changes and edit those into something likable, something that feels worth reading. It's hard to find a beautifully-written scene in your document and have to make the decision that it's beautiful but it doesn't work in the broader context. It's fucking hard.
Writing and editing are skills. You build them and you hone them. Writing the way the challenge initially encouraged--don't listen to that voice in your head that's nitpicking every word on the page, put off the criticism for a later date, for now just let go and get your thoughts out--is even a different skill from writing in general. Some people don't particularly care about refining that skill to some end goal or another, and simply want to play. Some people sit down and try to improve and improve and improve because that is meaningful to them. Some are in a weird in-between where they don't really know what they want, and some have always liked the idea of writing and wanted a place to start. The challenge was a good place for this--sit down, put your butt in a chair, open a blank document, and by the end of the month, try to put fifty thousand words in that document.
How does it make you feel to try? Your wrists ache and you don't feel like any of the words were any good, but didn't you learn something about the process? Re-reading it, don't you think it sounds better if you swap these two sentences, if you replace this word, if you take out this comma? Maybe you didn't hit 50k words. Maybe you only wrote 10k. But isn't it cool, that you wrote ten thousand words? Doesn't it feel nice that you did something? We can try again. We can keep getting better, or just throwing ourselves into it for fun or whatever, and we can do it again and again.
I guess I don't completely know where I'm going with this post. If you've followed me or many tumblr users for any amount of time, you've probably already heard a thousand times about how generative AI hurts the environment so many of us have been so desperately trying to save, about how generative AI is again and again used to exploit big authors, little authors, up-and-coming authors, first time authors, people posting on Ao3 as a hobby, people self-publishing e-books on Amazon, traditionally published authors, and everyone in between. You've probably seen the statements from developers of these "tools", things like how being required to obtain permission for everything in the database used to train the language model would destroy the tool entirely. You've seen posts about new AI tools scraping Ao3 so they can make money off someone else's hobby and putting the legality of the site itself at risk. For an organization that used to dedicate itself to making writing more accessible for people and for creating a community of writers, Nanowrimo has spent the past several years systematically cracking that community to bits, and now, it's made an official statement claiming that the exploitation of writers in its community is okay, because otherwise, someone might find it too hard to complete a challenge that's meant to be hard to begin with.
I couldn't thank Nanowrimo enough for what it did for me when I started out. I don't know how to find community in the same way. But you can bet that I've deleted my account, and I'll be finding my own path forward without it. Thanks for the fucking memories, I guess.
440 notes
·
View notes
Text
Considering Perplexity’s bold ambition and the investment it’s taken from Jeff Bezos’ family fund, Nvidia, and famed investor Balaji Srinivasan, among others, it’s surprisingly unclear what the AI search startup actually is.
Earlier this year, speaking to WIRED, Aravind Srinivas, Perplexity’s CEO, described his product—a chatbot that gives natural-language answers to prompts and can, the company says, access the internet in real time—as an “answer engine.” A few weeks later, shortly before a funding round valuing the company at a billion dollars was announced, he told Forbes, “It’s almost like Wikipedia and ChatGPT had a kid.” More recently, after Forbes accused Perplexity of plagiarizing its content, Srinivas told the AP it was a mere “aggregator of information.”
The Perplexity chatbot itself is more specific. Prompted to describe what Perplexity is, it provides text that reads, “Perplexity AI is an AI-powered search engine that combines features of traditional search engines and chatbots. It provides concise, real-time answers to user queries by pulling information from recent articles and indexing the web daily.”
A WIRED analysis and one carried out by developer Robb Knight suggest that Perplexity is able to achieve this partly through apparently ignoring a widely accepted web standard known as the Robots Exclusion Protocol to surreptitiously scrape areas of websites that operators do not want accessed by bots, despite claiming that it won’t. WIRED observed a machine tied to Perplexity—more specifically, one on an Amazon server and almost certainly operated by Perplexity—doing this on WIRED.com and across other Condé Nast publications.
The WIRED analysis also demonstrates that, despite claims that Perplexity’s tools provide “instant, reliable answers to any question with complete sources and citations included,” doing away with the need to “click on different links,” its chatbot, which is capable of accurately summarizing journalistic work with appropriate credit, is also prone to bullshitting, in the technical sense of the word.
WIRED provided the Perplexity chatbot with the headlines of dozens of articles published on our website this year, as well as prompts about the subjects of WIRED reporting. The results showed the chatbot at times closely paraphrasing WIRED stories, and at times summarizing stories inaccurately and with minimal attribution. In one case, the text it generated falsely claimed that WIRED had reported that a specific police officer in California had committed a crime. (The AP similarly identified an instance of the chatbot attributing fake quotes to real people.) Despite its apparent access to original WIRED reporting and its site hosting original WIRED art, though, none of the IP addresses publicly listed by the company left any identifiable trace in our server logs, raising the question of how exactly Perplexity’s system works.
Until earlier this week, Perplexity published in its documentation a link to a list of the IP addresses its crawlers use—an apparent effort to be transparent. However, in some cases, as both WIRED and Knight were able to demonstrate, it appears to be accessing and scraping websites from which coders have attempted to block its crawler, called Perplexity Bot, using at least one unpublicized IP address. The company has since removed references to its public IP pool from its documentation.
18 notes
·
View notes
Text
so, with amazon getting more and more evil about not letting you own the things you buy from them, I finally went ahead and scraped the drm off my kindle books. while it did require a bunch of setup, the process itself was pretty easy and less intimidating than I had feared, so I want to share some helpful tools I used if you want to do the same but aren't sure where to start:
An excellent step-by-step video guide
Calibre (the main program you will need)
The de-drm extension you'll want to add to Calibre
A guide to downgrading the kindle for pc app to a version that makes this easier
#doing my library took a while because of the setup but then doing my mom's library (75+ books) took like. ten minutes#fyi i did this on a windows 11 pc. i do not own a physical kindle (i've used the android app) so i didn't need to do the serial number thin#ymmv on how well these tools work depending on your computer#i'm happy to answer some questions but honestly just follow along with that video he makes it SUPER easy
8 notes
·
View notes
Text
Amazon Seller Scraper | Scrape Amazon Seller Data With Prices

Amazon Seller Scraper - Scrape Amazon Seller Data With Prices
RealdataAPI / amazon-seller-scraper
Scrape Amazon seller data, including product information, prices, categories, and more, using Amazon Seller Scraper. Use our Amazon seller data scraper in countries like the USA, UK, UAE, Canada, Australia, France, Germany, Spain, Singapore, and Mexico.
Customize me! Report an issue E-commerce
Readme
API
Input
Related actors
What is an Amazon Seller Scraper?
Amazon Seller Data Extractor Is A Web Scraper That Lets You Collect Seller Data From Amazon By Mentioning The Seller, Product, Price, Or Category.
Limitations
How Many Seller Outputs Can You Extract Using Amazon Seller Scraper?
On Average, The Amazon Seller Data Scraper Can Give Up To Hundred Outputs. But Remember That Multiple Variables On Amazon May Lead To Variations In The Expected Results. You Won't Get A Result With One Size Fits Each Use Case. The Maximum Result Counts May Vary Based On Location, Input Complexity, And Other Factors. Here Are A Few Most Common Cases:
There are internal restrictions on the Amazon website that no data scraper can cross
The website gives variable results based on the value and type of input.
The scraper has a few limitations; our team is working on it.
Hence, The Amazon Seller Scraper May Give Fluctuating Results Unknowingly. To Keep The Benchmark On Track, We Regularly Perform The Trial Runs Of The Scraper And Improve In Case Of Any Discrepancies. It Is The Best Practice To Test The Scraper To Ensure It Works For Each Use Case By Yourself.
What is the Cost of Using Amazon Seller Scraper?
Due To Variable Use Cases, Estimating The Required Resources To Scrape Amazon Seller Data May Take A Lot Of Work, Like Prices, Bestseller Ranking, And Other Information. Therefore, It Is The Best Practice To Test The Scraper With The Sample Input And Get A Limited Number Of Results. It Will Give You The Price Per Scrape. You Can Then Multiply The Price Per Scrape By The Total Required Scrape For The Complete Data.
Check Out The Stepwise Tutorial To Learn More. Further, Choose The Higher Pricing Plan To Save Money While Scraping Amazon Seller Data.
Do You Want To Discover Product Pairs Between Amazon and Other E-commerce Stores?
Try Our AI Product Matching Tool To Match Or Compare Similar Ecommerce Products. We Have Developed It To Compare Products From Various E-Commerce Stores, Compare Real-Time Data, And Find Exact Matches Using Web Scraping. Use The Collected Product Data With The Help Of An AI Product Matcher To Track Product Matches In The Industry, Complement Or Replace Manual Mapping, Implement Dynamic Pricing, And Extract Realistic Competitive Estimates For Your Future Promotions.
It Is Simple To Start The Product Matching Process With The Ability Of The Product Matcher To Check Thousands Of Product Pairs.
Can I scrape Amazon Seller Data Legally?
The Scraper Can Extract Publically Available Amazon Seller Data From The Platform, Like Product Prices, Descriptions, And Ratings. However, You Can Only Scrape Personal Data With Genuine Reason.
Amazon Seller Scraper with Integrations
Lastly, You Can Integrate Amazon Seller Data Scraper With Any Web Application Or Cloud Service With The Help Of Integrations Available On Our Platform. You Can Connect It With Zapier, Slack, Make, GitHub, Google Drive, Airbyte, Google Sheets, And More. It Is Also Possible To Use Webhooks To Take Any Action For Event Commencement. For Example, You Can Set An Alert For Successful Competition Of The Amazon Seller Data Extractor Execution.
Using Amazon Seller Data Scraper with Real Data API
Our API Gives Programmatic Permission To Access The Platform. We Have Organized It Around RESTful HTTP Endpoints To Allow You To Schedule, Manage And Run Scrapers. Further, The API Allows You To Track Scraper Performances, Create And Update Scraper Versions, Access Datasets, And More.
Use Our Client NPM And Client PyPl Package To Access The Scraper API Using Node.Js And Python, Respectively.
Do You Want More Options To Scrape Amazon?
Try The Below Amazon Scraper Options For Specific Use Cases:
Amazon Reviews Scraper
Amazon Best Sellers Scraper
Amazon ASINs Scraper
Amazon Product Scraper
Not Getting Expected Results Using Amazon Seller Scraper? Develop Your Customized Scraper
If Amazon Seller Information Scraper Can't Give You The Expected Results, You Can Design Your Customized Scraper. Multiple Scraper Templates Are Available On Our Platform In JavaScript, Python, And TypeScript To Begin The Process. Besides, You Can Use The Crawlee As An Open-Source Library To Write The Scraper Script From Zero.
Contact Us If You Want Us To Develop The Scraper With Our Custom Solution.
Your Feedback on Amazon Seller Scraper
Our Team Is Constantly Working On The Performance Improvement Of The Amazon Seller Scraper. Still, If You Got Some Bug Or Any Technical Feedback, You Can Contact Us Through Mail Or Create An Issue From The Issue Tab Available In Your Console Account.
#Amazon Seller Scraper#Scrape Amazon Seller Data#Amazon Seller Data Scraping#Amazon Seller Data Scraping Tools
0 notes
Text
Various web scraping tools will help you to extract Amazon data to the spreadsheet. It is a reliable solution for scraping Amazon data and fetching valuable and important information.
For More Information:-
0 notes
Text
#proxies#proxy#proxyserver#residential proxy#vpn#amazon#marketplace#amazon products#networking#automation#coupons#web scraping services#web scraping tools#web scraping techniques
0 notes
Text
Matlock (2024) (up to 1x09)
Kathy Bates as the emotionally broken grandma who has somehow convinced herself and her husband to exact justice by... using a fake identity based on a 90s murder mystery show and infiltrating the law firm that contributed to her daughter's death?
I love Matty’s inappropriate grandma schtick. No one takes her seriously and the times where she does drop the mask, it’s like, oooooh. Matty is ruthless and she is so so aware of gender and age and people’s perceptions of her. But she’s also so vulnerable and she’s just an ordinary lady at the end of the day who decided to pursue this larger-than-life mission because she misses her daughter so much. I think her ordinary-ness makes her story so compelling. Her tricks are just manipulation and deceit and whatever techy tools her grandson gets her from Amazon. Quite frankly she’s always just scraping by by the skin of her teeth
Matty is indeed very easy to talk to and I know it’s a real part of her - the compassion and empathy that she shows to others. Yet something within her is so broken up and twisted that she’s using that compassion and empathy (and all her wits and IMPROV SKILLS) as tools of her mission. Her and Edwin struggle every episode with this moral quandary - does the end justify the means? Are we in over our heads? Should we just… get a therapist? Let all this go in the past? Properly grieve our daughter instead of this… revenge mission? Matty is the driver of this mission and Edwin and Alfie have been convinced to be part of it. But how messed up is it that you are dragging your own grandson into your grief-striken spiral? Oh, Matty.
I like that Matty is so good at using kernels of truth to lie. And those kernels of truth reveal so much about her.
Commentary about women in the workplace - especially from someone with Matty’s life experience. There was a plot point where she lied about having to leave for a doctor’s appointment when it was for Alfie’s play. I forget the details of this story, but I remember being so stricken by Matty’s explanation of her deceit when Olympia confronted her. When Matty was in the workforce, women had to hide their familial obligations so as to not invite doubt about their commitment to work or their competency. It was survival tactic and Matty’s been so ingrained with this practice that she still does so when the workplace is a lot more understanding of family life. This wasn’t the only time Matty brought up the prevalent sexism in the workplace in the past. I like that this series doesn’t forget the life experiences of older women and always always reminds us of the progress that has been made. I think this series always puts such gravity in these moments, and it really touches upon the dignity of work, the self-preservation needed for success. I also just remembered - the casual harrassment that impacted Matty’s choice of specialization - just to avoid the abuser. The lost dreams of women who needed to make these choices.
Matlock is such a good show and it’s quickly becoming a comfort watch.
Oh! Yes it is such a comforting show. Olympia takes on these cases to exact justice against entities that think they can get away with willful negligence, worker safety, murder, etc. And the good guys (Olympia et al) win. The good guys always win and justice is served (AND profitable). I enjoy all the case-of-the-week plots because it is so satisfying. Yet - here’s the push-pull again which makes this series so good - they’re working at a Big Law Firm whose typical clients are Evil Corporations. The fact that Olympia is helping the little guys is simply an experiment within this profit-driven environment. We hope she succeeds, but at the end of the day, Big Law Firm is the one who may have illegally hidden documents that contributed to Matty’s daughter’s death. So yeah. How much good can you do in this environment? How much of this good can balance out what the other side of the Big Law Firm is doing?
I should catch up with 1x10. I watched a bit - we get a bit more background on Sarah! I was wondering about her background and where her overachiever-ness comes from. Very interesting that she is not from an immigrant Asian family but rather an adoptee.
4 notes
·
View notes
Text
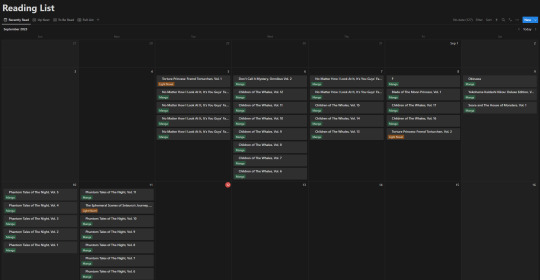
How I'm Tracking My Manga Reading Backlog
I'm bad at keeping up with reading sometimes. I'll read newer releases while still forgetting about some, want to re-read something even though I haven't started on another series, and leave droves of titles sitting on my shelves staring at me.
I got tired of that, and also tired of all these different tracking websites and apps that don't do what I want. So, with Notion and a few other tools, I've set out to make my own, and I like it! So I thought, hey, why not share how I'm doing it and see how other people keep track of their lists, so that's why I'm here. Enough rambling though, let me lead you through why I decided to make my own.
So, the number 1 challenge: Automation. In truth, it's far from perfect and is the price I pay for being lazy. But, I can automate a significant chunk of the adding process. I've yet to find a proper way to go from barcode scanning on my phone to my reading list, but I can go pretty easily from an amazon listing to the reading list. With it I grab: title, author, publisher, page count, and cover image.
So what do I use?
Well, it's a funky and interesting thing called 'Bardeen' that allows you to scrape webpages (among other things), collect and properly structure the desired information, and then feed it right into your Notion database. It's a little odd to try and figure out at first, but it's surprisingly intuitive in how it works! Once you have your template setup, you just head to the webpage (I've found Amazon the best option) and hit the button for the scraper you've built, and it puts it into Notion.
It saves an inordinate amount of time in populating fields by hand, and with the help of templates from Notion, means that the only fields left "empty" are the dated fields for tracking reading.

Thanks to Bardeen, the hardest (and really only) challenge is basically solved. Not "as" simple as a barcode, but still impressively close. Now, since the challenge is out of the way, how about some fun stuff?
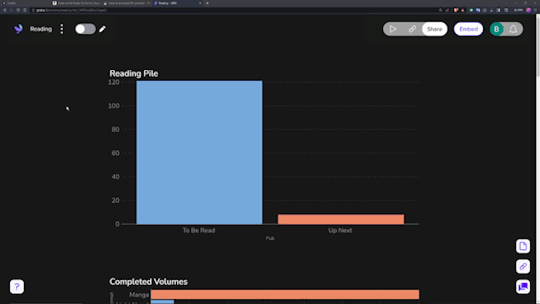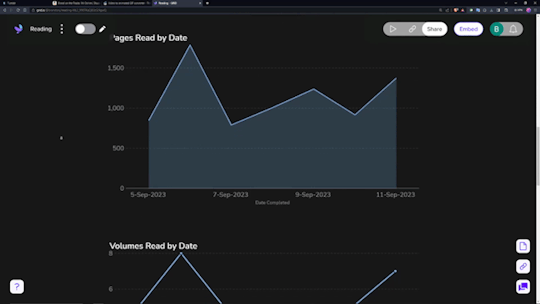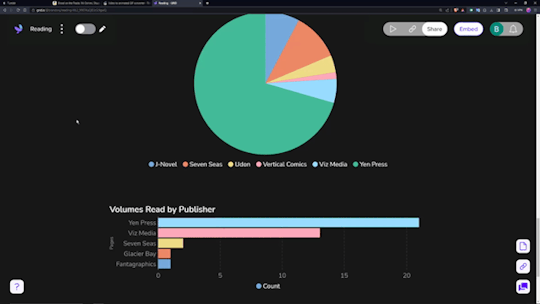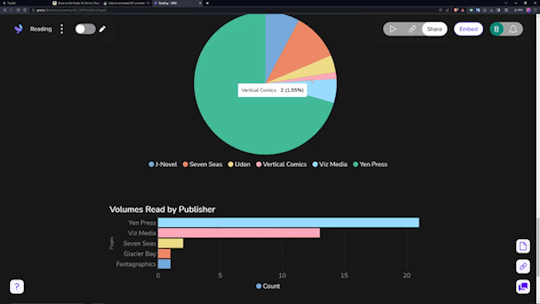
Data visualization is incredibly fun for all sorts of people. Getting to see a breakdown of all the little pieces that make up your reading habits is very interesting. Sadly, Notion doesn't have the ability to build charts from your own databases, so you need a tool.
The one I ended up settling on was 'Grid.is', as it has a "direct" integration/embed with Notion.
Sure, it has its own "limitations", but they pose absolutely zero concern as to how I want to set up my own data visualization. You can have (as far as I know) an unlimited number of graphs/charts on a single page, and you can choose to embed that page as a single entity, or go along and embed them as independent links. Either way, the graphs are really great and there's a lot of customization and options in regards to them. Also, incredibly thankful for the fact that there's an AI assistant to create the charts for you. The way that Notion data's read in is horrendous, so the AI makes it infinitely easier than what it appears as at first.
And yes, all those little popups and hover behaviors are preserved in the embeds.
Well, I suppose rather than talking about the tertiary tools, I should talk about what I'm doing with Notion itself, no?
Alright, so, like all Notion pages it starts with a database. It's the central core to keeping track of data and you can't do without it. Of course, data is no good if you can't have it properly organized, so how do I organize it?
With tags, of course! I don't have a massive amount of tags in place for the database, but I am considering adding more in terms of genre and whatnot. Regardless, what I have for the entries currently is: Title, Reading Status (TBR, Reading, Read, etc.), Author, Format (manga or LN), Date Started, Date Completed, Pages, and Publisher.
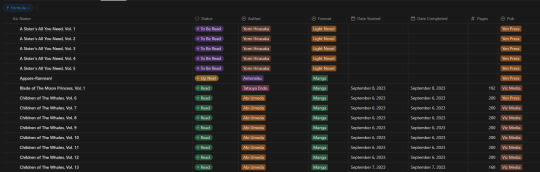
In addition to those "displayed" tags, I have two tertiary fields. The first is an image link so that entries can display an image in the appropriate view. The second, and a bit more of a pain, is a formula field used to create a proper "title" field so that Notion can sort effectively (they use lexicographic, so numbers end up sorted as letters instead). This is the poorly optimized Notion formula I used, as I don't have much experience with how they approach stuff like this. It just adds a leading zero to numbers less than 10 so that it can be properly sorted.

Of course this list view isn't my default view though, the calendar from the top of this post is. Most of the time though, I don't have it set to the monthly view, but rather weekly. Following up that view though, I've got my "up next" tab. This tab's meant to track all the titles/entries that I'm about to read. Things I'm planning to read today, tomorrow, or the day after. Sorta a three day sliding window to help me keep on top of the larger backlog and avoid being paralyzed by choice. It's also the only view that uses images currently.

Following that, I've got my "To Be Read" gallery. I wanted to use a kanban board but notion will only display each category as a single column, so I chose this view instead, which makes it much easier to get a better grasp of what's in the list. I've been considering adding images to this view, but I need to toy around with it some more. Either way, the point is to be able to take a wider look at what I've got left in my TBR and where I might go next.
So overall, I've ordered these views (though the list view I touch on "first" is actually the last of the views) in order from "most recent" to "least recent", if that makes any sense. Starting with where I've finished, moving to where I go next, what I have left, and then a grouping of everything for just in case.
It's certainly far from a perfect execution on a reading list/catalogue, but I think personally speaking that it checks off basically all of the boxes I required it to, and it gives me all the freedom that I could ever want - even if it means I have to put in a bit of elbow grease to make things work.
#anime and manga#manga#manga reader#manga list#reading list#reading backlog#light novel#notion#notion template
11 notes
·
View notes