#scrapestorm
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
Easy way to get job data from Totaljobs
Totaljobs is one of the largest recruitment websites in the UK. Its mission is to provide job seekers and employers with efficient recruitment solutions and promote the matching of talents and positions. It has an extensive market presence in the UK, providing a platform for professionals across a variety of industries and job types to find jobs and recruit staff.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
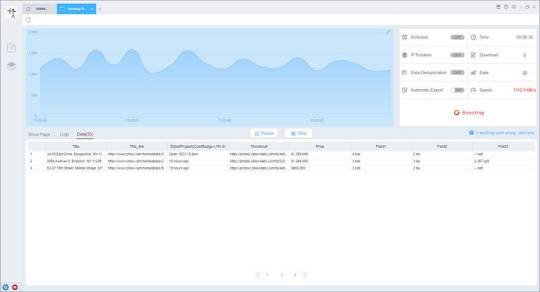
Preview of the scraped result
1. Create a task
(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task
2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.
3. Set up and start the scraping task
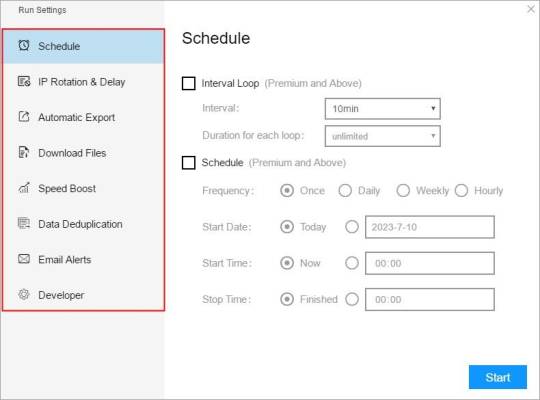
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.
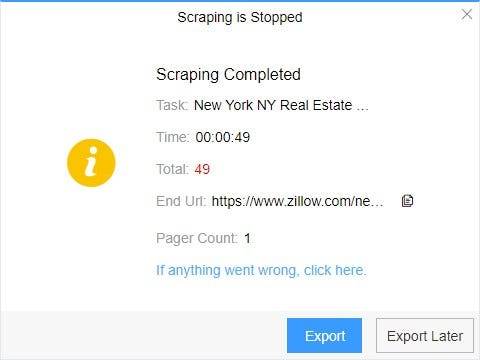
4. Export and view data
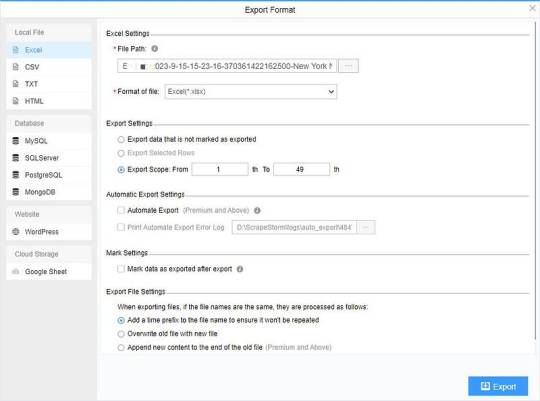
(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data
2 notes
·
View notes
Text
Sure, here is the article in markdown format as requested:
```markdown
Website Scraping Tools TG@yuantou2048
Website scraping tools are essential for extracting data from websites. These tools can help automate the process of gathering information, making it easier and faster to collect large amounts of data. Here are some popular website scraping tools that you might find useful:
1. Beautiful Soup: This is a Python library that makes it easy to scrape information from web pages. It provides Pythonic idioms for iterating, searching, and modifying parse trees built with tools like HTML or XML parsers.
2. Scrapy: Scrapy is an open-source and collaborative framework for extracting the data you need from websites. It’s fast and can handle large-scale web scraping projects.
3. Octoparse: Octoparse is a powerful web scraping tool that allows users to extract data from websites without writing any code. It supports both visual and code-based scraping.
4. ParseHub: ParseHub is a cloud-based web scraping tool that allows users to extract data from websites. It is particularly useful for handling dynamic websites and has a user-friendly interface.
5. Scrapy: Scrapy is a Python-based web crawling and web scraping framework. It is highly extensible and can be used for a wide range of data extraction needs.
6. SuperScraper: SuperScraper is a no-code web scraping tool that enables users to scrape data from websites by simply pointing and clicking on the elements they want to scrape. It's great for those who may not have extensive programming knowledge.
7. ParseHub: ParseHub is a cloud-based web scraping tool that offers a simple yet powerful way to scrape data from websites. It is ideal for large-scale scraping projects and can handle JavaScript-rendered content.
8. Apify: Apify is a platform that simplifies the process of scraping data from websites. It supports automatic data extraction and can handle complex websites with JavaScript rendering.
9. Diffbot: Diffbot is a web scraping API that automatically extracts structured data from websites. It is particularly good at handling dynamic websites and can handle most websites out-of-the-box.
10. Data Miner: Data Miner is a web scraping tool that allows users to scrape data from websites and APIs. It supports headless browsers and can handle dynamic websites.
11. Import.io: Import.io is a web scraping tool that turns any website into a custom API. It is particularly useful for extracting data from sites that require login credentials or have complex structures.
12. ParseHub: ParseHub is another cloud-based tool that can handle JavaScript-heavy sites and offers a variety of features including form filling, CAPTCHA solving, and more.
13. Bright Data (formerly Luminati): Bright Data provides a proxy network that helps in bypassing IP blocks and CAPTCHAs.
14. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features such as form filling, AJAX-driven content, and deep web scraping.
15. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features such as automatic data extraction and can handle dynamic content and JavaScript-heavy sites.
16. ScrapeStorm: ScrapeStorm is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
17. Scrapinghub: Scrapinghub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
18. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
19. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
20. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
Each of these tools has its own strengths and weaknesses, so it's important to choose the one that best fits your specific requirements.
20. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
21. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
22. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
23. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
24. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
25. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
26. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
27. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
28. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
29. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
28. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
30. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
31. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
32. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
33. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
34. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
35. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
36. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
37. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
38. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites and offers a range of features including automatic data extraction and can handle JavaScript-heavy sites.
39. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
38. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
39. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
40. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
41. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
42. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
43. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
44. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
45. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
46. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
47. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
48. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
49. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
50. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
51. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
52. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
53. ParseHub: ParseHub is a cloud-based web scraping tool that can handle JavaScript-heavy sites.
54. ParseHub: ParseHub
加飞机@yuantou2048

王腾SEO
蜘蛛池出租
0 notes
Text
谷歌蜘蛛池工具有哪些?
在SEO(搜索引擎优化)领域,谷歌蜘蛛池工具是许多网站管理员和SEO专家用来提升网站排名的重要工具。这些工具通过模拟大量的用户访问来提高网站的活跃度,从而吸引更多的搜索引擎爬虫(也称为“蜘蛛”或“机器人”)来抓取网站内容。下面是一些常用的谷歌蜘蛛池工具:
1. Googlebot Simulator
Googlebot Simulator 是一个由谷歌官方提供的工具,它可以帮助你了解谷歌爬虫是如何查看你的网页的。虽然它不是专门用于创建蜘蛛池,但它可以提供宝贵的见解,帮助你优化网站结构。
2. ScrapeStorm
ScrapeStorm 是一款功能强大的网络爬虫工具,支持分布式爬取,能够模拟大量用户的访问行为。它不仅可以用于数据抓取,还可以用于创建高效的蜘蛛池。
3. ParseHub
ParseHub 提供了一个易于使用的平台,允许用户创建和管理复杂的爬虫任务。它的高级功能包括IP轮换、代理支持等,非常适合需要大规模爬取数据的场景。
4. Octoparse
Octoparse 是另一款流行的爬虫工具,它提供了可视化的工作流设计界面,使得非技术用户也能轻松创建复杂的爬虫任务。Octoparse 支持多线程和分布式爬取,非常适合创建大型蜘蛛池。
5. Bright Data (原Luminati)
Bright Data 提供了全球范围内的代理服务,这对于创建有效的蜘蛛池至关重要。通过使用他们的代理网络,你可以模拟来自不同地理位置的用户访问,从而避免被目标网站检测到。
6. Heroku
Heroku 是一个云平台,可以用来部署和运行各种应用程序。虽然它本身不是一个蜘蛛池工具,但你可以利用它来托管自定义的爬虫脚本,从而实现对网站的大规模爬取。
结论
选择合适的蜘蛛池工具取决于你的具体需求和预算。如果你只是想测试一些基本的爬虫任务,那么免费或低成本的工具可能就足够了。然而,对于更复杂的需求,如大规模的数据抓取或需要高度匿名性的任务,可能需要投资于更专业的工具和服务。
讨论点
- 你是否使用过上述任何工具?如果有,你觉得它们的效果如何?
- 在你的SEO策略中,你认为蜘蛛池工具的重要性有多大?
- 除了上述提到的工具,你还有其他推荐吗?
加飞机@yuantou2048

币圈推广
谷歌霸屏
0 notes
Text
Top 10 Best Web Crawlers For Efficient Web Data Extraction
If you’re starting a digital business and feel lost, don’t worry! One of the key things to know is how your website ranks on Google. Google is the most popular search engine, controlling nearly 87% of the market. This makes improving your Google ranking crucial for your business’s growth.
What is a Web Crawler?
Google’s top search results get about 32% of all clicks, so getting your site ranked high is very important. A web crawler is a tool that helps you find and fix issues on your website that could hurt your SEO (Search Engine Optimization). It’s like a robot that scans your site for problems such as broken links or missing page titles. Using a web crawler saves you time and helps ensure your website is in good shape for search engines.
What to Look for in a Best Web Crawler
To choose the best web crawler for your needs, here are some key features to consider:
User-Friendly Interface: The tool should be easy to use and navigate. Simplicity is key, so avoid complicated designs that can confuse you.
Important Features: Look for features like automatic project setup, the ability to gather data quickly, and options for scaling up as your business grows. Free crawlers are great to start with, but paid options often offer advanced features.
Detecting Robots.txt and Sitemaps: A good crawler can recognize which parts of a website can be accessed and which can’t. This makes your crawling more efficient.
Finding Broken Links: Choose a crawler that quickly identifies broken pages or links, as these can frustrate users and hurt your SEO.
Handling Redirects: Make sure the crawler can find and fix redirect issues, which happen when a URL points to another page.
Google Analytics Integration: It’s helpful if the crawler connects easily to Google Analytics, allowing you to see how users interact with your site.
Exporting Reports: Look for a crawler that can save reports in different formats like CSV or Excel, making it easier to analyze your data.
Support for Multiple Devices: The tool should work on different devices like tablets and smartphones for added flexibility.
Top Free Web Crawlers to Consider
ApiScrapy: Offers advanced tools for collecting accurate data from many web pages quickly.
Cyotek WebCopy: Allows you to download entire websites for offline use. It’s customizable but has limitations with JavaScript-heavy sites.
Getleft: A simple tool that supports multiple languages and allows you to download complete websites.
HTTrack: An open-source tool that can download entire sites, ideal for those comfortable with technology.
Scraper Wiki: Good for beginners, offering easy scraping for documents and data analysis tools.
Octoparse: Suitable for Windows and Mac users, it can gather various types of data and offers cloud storage options.
Anysite Scraper: Highly customizable for different types of websites and data extraction.
Outwit Hub Light: Great for users without technical skills, allowing for easy data collection and export.
Content Grabber: A professional tool that can handle complex data extraction projects.
ScrapeStorm: Designed for ease of use, it requires no coding skills and effectively collects data from websites.
Conclusion
If managing a web crawler feels overwhelming, consider hiring a service provider like OutsourceBigdata. They offer professional web crawling solutions tailored to your business needs, ensuring you have the best data for your digital growth.
By understanding web crawlers and how they can improve your SEO, you’ll be better equipped to succeed in the digital world!
0 notes
Text
Octoparse xpath pagination

Octoparse xpath pagination how to#
Octoparse xpath pagination upgrade#
Octoparse xpath pagination software#
Step 3: Click on the first element of the second line of the list Step 2: Click on the first element of the first line of the list Step 1: Click on the “ Select in Page” option The operation steps of “ Select in Page” are as follows: If the result of the “ Auto Detect” does not meet your requirements, you can modify it by selecting “ Select in Page” and “ Edit Xpath“.
Octoparse xpath pagination software#
If it is a List Page, you can click “ Auto Detect” and the software will try to identify the list again.Įach element in the list is selected with a green boder on the page, and each field in the list element is selected with a red boder. If it is a Detail Page, you can choose “ Detail Page” directly. The settings menu for Page Type is shown below: When the Page Type is incorrect, we need to set it manually.įor an introduction to Detail page and List page, please refer to the following tutorials: Or for other reasons, such as page loading speed, even if the page you enter is a List Page, there may be identification failure. If the URL you enter is a Detail Page, the result of page type identification is certainly incorrect. In Smart Mode, the default Page Type is List Page.
5 Highest Salary Programming Languages in 2021.
What is the best web development programming language?.
The Role and Usage of Pre Login when Creating Tasks.
Top 5 Programming Learning Websites in 2021.
5 Easy-to-use and Efficient Phython Tools.
5 Application Areas of Artificial Intelligence.
5 Useful Search Engine Technologies-ScrapeStorm.
4 Popular Machine Learning Projects on GitHub.
9 Regular Expressions That Make Writing Code Easier.
Top 4 Popular Big Data Visualization Tools.
5 Popular Websites for Programming Learning in 2022.
Excellent online programming website(2).
Octoparse xpath pagination how to#
How to Scrape Websites Without Being Blocked.The Issues and Challenges with the Web Crawlers.7 Free Statistics and Report Download Sites.Recommended tools for price monitoring in 2020.5 Most Popular Programming Languages in 2022.The Advantages and Disadvantages of Python.The Difference between Data Science, Big Data and Data Analysis.Popular Sraping Tools to Acquire Data Without Coding.Introduction and characteristics of Python.【2022】The 10 Best Web Scrapers That You Cannot Miss.Top 5 Best Web Scrapers for Data Extraction in 2021.【2022】Top 10 Best Website Crawlers(Reviews & Comparison).What is scraping? A brief explanation of web scraping!.How to turn pages by entering page numbers in batches.How to scrape data by entering keywords in batches.How to scrape a list page & detail page.How to scrape data from an iPhone webpage.What is the role of switching browser mode.How to switch proxy while editing a task.How to solve captcha when editing tasks.How to scrape web pages that need to be logged in to view.Introduction to the task editing interface.
Octoparse xpath pagination upgrade#
How to download, install, register, set up and upgrade software versions.
0 notes
Text
Best 5 Free Web Data Scraping Tools in 2022

As modern professionals, we deal with data almost every day. It is very common that we will need to collect and analyze data from websites to reach certain conclusions. This task would be extremely tedious if you are extracting data manually. Luckily, there are many solutions out there to help with this exact task. Here today, we are listing the best 10 web data scraping tools for data extraction in 2021.
1 – Octoparse, Most Powerful Desktop Data Scraping Tool For Experts

Octoparse is a cloud and desktop client-based web data scraper. It is very powerful and comes with lots of features including scheduled extraction, IP rotation, API access, and unlimited storage.
Octoparse offers a free plan but limits the amount of records export to 10,000. If you need to extract and export more than 10,000 records, you will need to pay $75 or $209 per month depending on your need.
https://www.anypicker.com/wp-content/uploads/2021/03/2021-03-24_15-03-28-1536x987.png
Although very powerful, Octoparse can be a bit difficult to use and require some training. You will need to be very computer literate and knows around it’s complicated interface.
The verdict – Octoparse is one of the most used web scraper offered for a fair price with great features
2 – AnyPicker.com | Most Easy To Use Browser-Based Scraper
.anypicker.Picker.com is a chrome-based web scraper with an easy-to-use visual interface. It doesn’t require any coding skills or a complicated learning curve and everyone can use it intuitively.
The free tier offered by AnyPicker is also the most generous of all the tools; offering 750 pages each month, you can use it comfortably if you are not doing any heavy-duty data scraping jobs.
The Verdict – AnyPicker is the easiest to use web scraper and with features that are good enough for everyday use
3 – Parsehub
www.parsehub.com
Parsehub is a powerful desktop client scraping tool with many features. You can do a lot of things with Parsehub once you manage to get around the complicated setup and data structure. You would need to be familiar with HTML structures and other technical terms in order to use all the features.
If you are not technically fluent, Parsehub might be a bit too complicated for you to use. But once you can get around the complicated setup, you will find parsehub one of the most powerful data scrapers available.

Parsehub is powerful, complicated to set up, and expensive. If you are technically enabled and knows your way around HTML structures and are doing data scraping professionally, parsehub might be worth considering. For light users or even professional users who are less technic, I would recommend you to look elsewhere.
The Verdict – Parsehub is powerful, but expensive and hard to setup
4 – Grespr
www.grespr.com
Similar to AnyPicker, Grespr is also a chrome-based extension tool that can be used anywhere Chrome Browser is available. Grespr also utilizes a visual data selection interface that requires minimum training or coding skills to use. Grespr also offers a full service for businesses customers and API interface.
https://www.anypicker.com/wp-content/uploads/2021/03/2021-03-26_00-48-46-2048x967.png
Another issue grespr has, would be website compatibility, although fairly easy to use, grepr’s chrome extension would need the website to be written in very structured way in order to be functioning properly. This further limits the usability of grespr. It is easy to see why as they are mainly focusing on the service portion of their business. It definitely makes more sense price wise to just pay for their service in some circumstances.
In conclusion, Grespr is an expensive and easy-to-use scraper that works on certain websites.
5 – ScrapeStorm
www.scrapestorm.com
ScrapeStorm is a AI-Powered visual web scraping tool which can be used to extract data from almost any websites without writing any code. It is powerful and very easy to use. For experienced and inexperienced users, it provides two different scraping modes (Smart Mode and Flowchart Mode). ScrapeStorm supports WindowsMac OS and Linux. You can save the output data in various formats including Excel, HTML, Txt and CSV. Moreover, you can export data to databases and websites.

ScrapeStorm can export files in excel,csv,txt,html,MySQL,mongoDB and many more, making your life much easier if you ever needed them.
However ScrapeStorm has this complicated workflow setup process and is required everytime when you need to setup a job. You will need to go through many of it’s training videos to know exactly what to do. The free tier also offers very little compared to other products.
0 notes
Text
データ集録をより便利に:10の一般的なデータ集録ツール
今日の急速に発展するネットワーク時代には、情報を検索するだけでなく、必要なデータ情報を迅速に収集し、Web サイト、データベース、オンライン ショップ、ドキュメントなど、インターネット情報に対する新たな需要を生み出しています。 データを必要とするのは、データ利用に対する強い需要がデータ集録ツールの生成につながっているところです。
では、今日の市場では、どのような信頼できるデータ集録ツールがあるのでしょうか。 この記事では、詳細な紹介を行います。
1. ScrapeStorm
ポストキャプチャは、人工知能技術に基づいて、元Google検索技術チームによって開発された次世代のWebキャプチャソフトウェアです。 強力で操作しやすいソフトウェアは、プログラミングベースのない製品、運用、販売、金融、ニュース、電子商取引、データ分析の実務家だけでなく、政府機関や学術研究などのユーザーに合わせた製品です。 これは、フローチャートモードとインテリジェントモードの2種類に分けられ、フローチャートモードは、単にソフトウェアプロンプトに従ってページ内のクリック操作を行い、完全にWebブラウジングの考え方に完全に準拠し、複雑な収集ルールを生成するために簡単なステップ、インテリジェント���別アルゴリズムと組み合わせることで、任意のWebページのデータを簡単に収集することができます。 インテリジェントモードは人工知能アルゴリズムに基づいて構築され、リストデータ、テーブルデータ、ページングボタンをインテリジェントに識別するためにURLを入力するだけで、ワンクリックで取得ルールを設定する必要はありません。
2. Octoparse
Octoparseは、京東、天猫、フォルクスワーゲンレビューなどの人気収集サイトに組み込まれ、テンプレート設定パラメータを参照して、ウェブサイト公開データを取得することができます。 さらに、8 爪の魚 API を使用すると、リモート コントロール タスクの開始と停止など、8 爪の魚のタスク情報と収集されたデータを取得し、データ収集とアーカイブを実現できます。 また、ビジネスを自動化するために、社内のさまざまな管理プラットフォームとつながることもできます。
3. ScraperAPI
ScraperAPI を使用すると、取得する URL が API キーと共に API に送信され、API がクロールする URL から HTML 応答を返すだけで、手に入れるのは困難です。 同時に、ScraperAPIはBeautifulSoupクローラコードベースの多くの機能を統合し、プロキシ、クッキー設定、確認コード認識などの機能の数十万を提供し、ユーザーはURLを渡すだけで、パラメータはいくつかの関連する設定に関連し、残りはユーザーを助けるために彼によって行われます。 彼はパッケージ化された集録コンポーネントのようなものです。
4. Apify
Apify プラットフォームは、大規模で高性能な Web クロールと自動化のニーズを満たすように設計されています。 コンソール Web インターフェイス、Apify の API、または JavaScript および Python API クライアントを介して、コンピューティング インスタンス、便利な要求と結果ストア、プロキシ、スケジューリング、Webhook などに簡単にアクセスできます。
5. ParseHub
ParseHubは無料のウェブグラブツールです。 ParseHub を使用すると、Web グラブ スクリプトの障壁なしに、オンラインの e コマース プラットフォームからデータを簡単に取得できます。 適切なメトリックを解決することで、カテゴリ レベルまたはサブカテゴリ レベルでスコープをドリルダウンして、企業が競合企業と比較したポートフォリオを評価するのに役立ちます。 また、ユーザーがブラウザ上のすべての操作を実装するのに役立ちますが、ユーザーのデータ量が少ない場合や、クラウド ホスティングなどの機能を必要としない場合は、非常に適しています。
1 note
·
View note
Text
The top 8 Most useful scraping tools for 2022!
At present, there are many good data acquisition software. Here I briefly introduce 8 more easy to use collection software, they are basically free, covering various industries of collection tools. I hope I can help friends in need:
1. ScrapeStorm Software
https://www.scrapestorm.com
ScrapeStorm Software is a new generation of webpage collection software developed by the former Google search technology team based on artificial intelligence technology. The software has powerful functions and simple operation. It does not limit the export of collection results, and does not charge any fees. It is designed for a wide range of users with no programming foundation, such as product, operation, sales, finance, news, e-commerce and data analysis practitioners, as well as government agencies and academic research. ScrapeStorm Software is very simple to use. It can not only collect data automatically, but also clean the data in the process of collection,and accompanying video tutorials and graphic tutorials are available on its official website.
Lightspot:
① Intelligent identification of data, no manual operation required;
②Support for Windows, Mac and Linux operating systems, all versions of the same;
③There are two different collection modes, which can capture 99% of the web pages;
④Support types include Excel, CSV, TXT, HTML, MySQL, MongoDB, SQL Server, PostgreSQL, WordPress, and Google Sheets.
2. Octoparse
https://www.bazhuayu.com/
Octoparse is a very powerful and easy to operate web data acquisition tool, It's interface is simple and generous, as long as the input URL and keywords, a few minutes can get the target data, and can quickly and automatically collect and export, edit data, even the text on the page picture can also parse and extract, and it's collection content is also very wide.
Lightspot:
①Template collection mode built-in hundreds of mainstream website data sources, just refer to the template simple set parameters, you can quickly access to the website public data;
②Cloud collection: Cloud collection supported by more than 5000 cloud servers, 7*24 hours uninterrupted operation, can achieve timed collection, without personnel on duty;
③Convenient timing function: Click Settings in a few steps to realize timing control of collection tasks;
④Supports multiple export formats, such as EXCEL, HTML, database, API, etc.
3. Creeper Cllector
https://www.51pashanhu.com/
Creeper collector is a simple to use, powerful webpage collection software, almost all websites can be collected, the collection is fast and efficient, and the self-developed intelligent recognition algorithm can automatically identify the list data and identify pages, with an accuracy of 95%.
Lightspot:
① A large number of built-in website collection templates, covering multiple industries, click the template, you can load data, simple configuration, you can quickly and accurately obtain data, and meet various collection requirements;
②99% of the sites can be collected;
③Support various formats of export, TXT, CSV, Excel, Access, MySQL, SQLServer, SQLite and publish to the website interface (Api).
4. SkyCaiji
https://www.skycaiji.com/
SkyCaiji, dedicated to the collection and release of web big data, is a cross-platform cloud big data crawler system, developed by PHP+Mysql, can be deployed in the cloud server and virtual host, using a browser can collect data. Software free unlimited use, rules and plug-ins can be customized development.
Lightspot:
①Seamless docking of all kinds of CMS site procedures, to import data without logging in, support custom data release plug-in, can also be directly imported into the database, stored as Excel files, remote API release, etc;
② Fully cross-platform, it can be installed on any system and runs well on a virtual host.
5. LocoySpider
http://www.locoy.com/
LocoySpider, a professional Internet data capture, processing, analysis, mining software, can flexibly and quickly grasp the scattered distribution of data information on the web page, and through data cleaning, filtering, denoising and other preprocessing integration aggregation storage, and then data analysis mining, accurately mining the required data.
Lightspot:
①Almost any web page can be collected;
②The speed is seven times that of a normal collector;
③Replacement function: synonymous, synonym replacement, parameter replacement, pseudo original necessary skills;
④Support Access/MySQL/MsSQL/Sqlite/Oracle multiple types of database to store and release.
6. i@Report
https://www.esensoft.com/products/ireport.html
i@Report is ESENSOFT data collection and summary platform based on Web, set report template customization, data collection, data submission, summary and query functions as one, with good versatility, flexibility, operability and scalability.
Lightspot:
①User do not need to install any client or plug-in. You only need to access the report server through a browser to complete the full collection process;
② Multi-terminal seamless application, different mobile devices adaptive one table three screens;
③A variety of parameter selection, a variety of drilling analysis, rich statistical graphics and other data analysis and presentation methods;
④A variety of integration and interface technologies can flexibly integrate mobile analysis tables, mobile portals or the entire APP into third-party apps.
7. Mini pie collector

https://www.minirpa.net/index_2.html
Mini Pie Collector (Mini Pie) is an extension that runs on Chrome and Edge, allowing user to extract content from any website and convert it into structured data quickly and easily. The Mini Pie extension makes it easy to select content on any website and define rules. All collection rules (rules) and collected data (data tables) are managed intuitively through the pop-up dashboard of the collector.
Lightspot:
①One-click recipe generation visual recipe template;
②Crawl page after login: crawl dynamic page, crawl encrypted text, crawl image and file;
③GoogleSheet integration, Slack notification, WeCom integration, Baidu Cloud storage.
8. GooSeeker
https://www.gooseeker.com/
GooSeeker is a professional WEB page data acquisition/information mining processing software, can easily grab web pages text, pictures, forms, hyperlinks and other web elements, and get standardized data. Through the GooSeeker can make the whole web into your database, effectively reduce the cost of data acquisition, get comprehensive, flexible multi-dimensional industry data.
Lightspot:
①GooSeeker's template resources feature lets user get your data easily and quickly;
②Members help each other crawl: People in the community collect data for you, and you can also crawl data for your fellow members;
③Index charts can be captured, and a developer extension interface is provided.
To introduce 8 collectors, you can see more, these software each has its own advantages, but only for their own is the best.
1 note
·
View note
Text
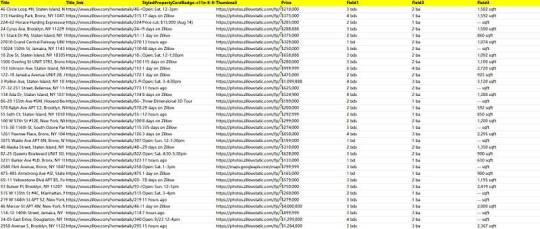
Quick way to extract job information from Reed
Reed is one of the largest recruitment websites in the UK, covering a variety of industries and job types. Its mission is to connect employers and job seekers to help them achieve better career development and recruiting success
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
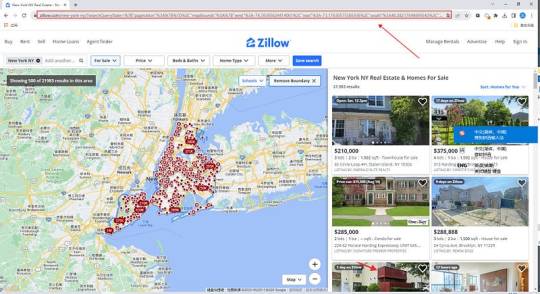
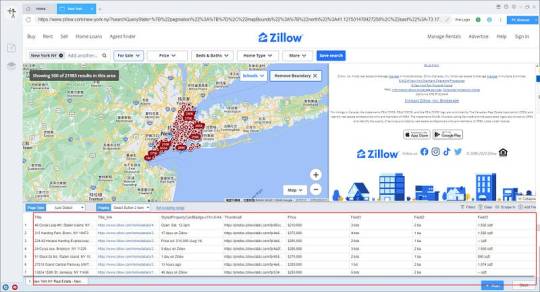
Preview of the scraped result
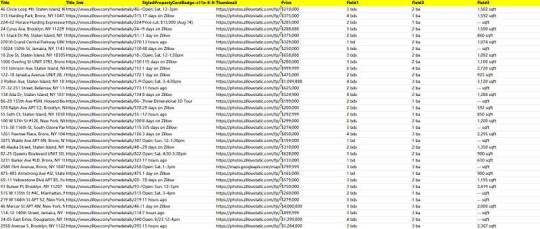
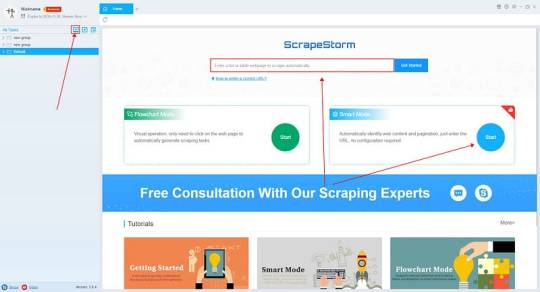
1. Create a task
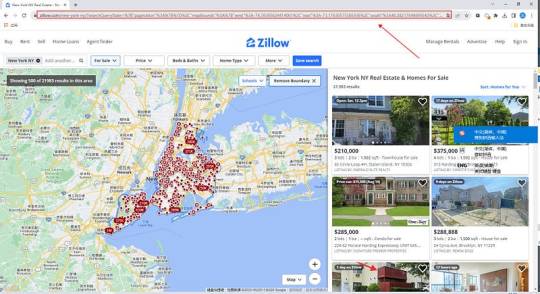
(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task
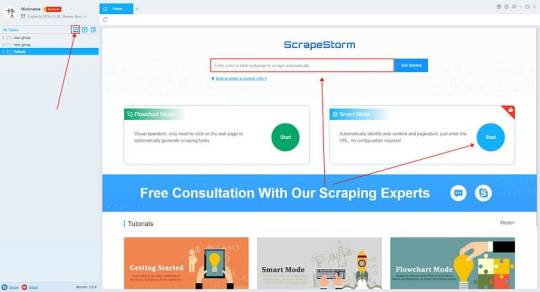
2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.
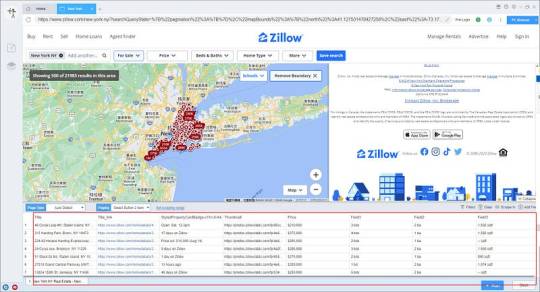
3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.

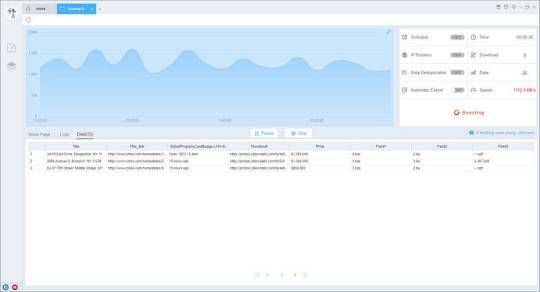
4. Export and view data
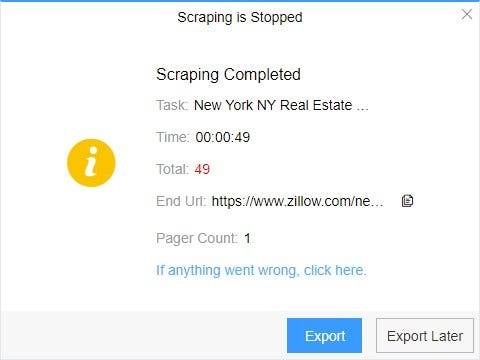
(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data

2 notes
·
View notes
Text
Top Data Scraping Tools
Introduction
Web scraping, web browsing, HTML scraping, and any other method of web data extraction can be difficult. There is a lot of work to be done by getting the right page source and translating the source correctly.
Rendering javascript and getting data in a usable form. Moreover, different users have very different needs. For all of them, there are resources out there, people who want to build uncoded web scrapers, developers who want to build web crawlers to crawl bigger sites, and everything in between.
Here’s our list of the top best web scraping tools on the market right now, from open source projects to hosting SAAS solutions to desktop software.
Top Web Scraping Tools
ScrapeStorm
ScrapeStorm is an AI-powered visual web scraping tool that can be used without writing any code to extract data from nearly any website. It is strong and very user-friendly. You only need to enter the URLs, the content and the next page button can be intelligently found, no complex setup, scraping with a single click.
Moreover, ScrapeStorm is available for Windows, Mac, and Linux users as a mobile app. The reports are available for download in various formats including Excel, HTML, Txt, and CSV. You can also distribute the data to databases and websites.
Features of ScrapeStorm
· Intelligent Identification
· IP Rotation and Verification Code Identification
· Data Processing and Deduplication
· Download file
· Scheduled function
· Automatic Export
· RESTful API and Webhook
· Automatic Identification of SKU e-commerce and broad photos
Advantages of ScrapeStorm
· Simple to use
· Fair price
· Visual dot and click process
· All compatible systems
Disadvantages of ScrapeStorm
· No Cloud Services
Scrapinghub
Scrapinghub is the web scraping platform based on developers to provide many useful services to remove organized information from the Internet. There are four main tools available at Scrapinghub, Scrapy Cloud, Portia, Crawlera, and Splash.
Features of Scrapinghub
· Allows you to turn the entire web page into structured content
· JS support on-page change
· Captcha handling
Advantages of Scrapinghub
· Offer a list of IP addresses representing more than 50 countries, which is a solution to IP ban problems.
· Rapid maps have been beneficial
· Managing login forms
· The free plan preserves data collected in the cloud for 7 days
Disadvantages of Scrapinghub
· No refunds
· Not easy to use, and many comprehensive add-ons need to be added
· It cannot process heavy data sets
Mozenda
Mozenda offers technology, provided either as software (SaaS and on-premise options) or as a managed service that allows people to collect unstructured web data, turn it into a standardized format, and “publish and format it in a manner that Organizations can use.”
1. Cloud-based software
2. Onsite software
3. Data services more than 15 years of experience, Mozenda helps you to automate the retrieval of web data from any website.
Features of Mozenda
· Scrape websites across various geographic locations
· API Access
· Point and click interface
Receive email alerts when the agents are running successfully
Advantages of Mozenda
· Visual interface
· Wide action bar
· Multi-track selection and smart data aggregation
Disadvantages of Mozenda
· Unstable when dealing with big websites
· A little expensive
ParseHub
To summarize, ParseHub is a visual data extraction tool that can be used by anyone to obtain data from the site. You will never have to write a web scraper again, and from websites, you can easily create APIs that don’t have them. With ease, ParseHub can manage interactive maps, schedules, searches, forums, nested comments, endless scrolling, authentication, dropdowns, templates, Javascript, Ajax, and much more. ParseHub provides both a free plan for all and large data extraction services for custom businesses.
Features of ParseHub
· Scheduled runs
· Random rotation of IP
· Online websites (AJAX & JavaScript)
· Integration of Dropbox
· API & Webhooks
Advantages of ParseHub
· Dropbox, integrating S3
· Supporting multiple systems
· Aggregating data from multiple websites
Disadvantages of ParseHub
· Free Limited Services
· Dynamic Interface
Webhose.io
The Webhose.io API makes data and meta-data easy to integrate, high-quality data, from hundreds of thousands of global online sources such as message boards, blogs, reviews, news, and more.
Webhose.io API, available either via query-based API or firehose, provides high coverage data with low latency, with an efficient dynamic capability to add new sources at record time.
Features of Webhose.io
· Get standardized, machine-readable data sets in JSON and XML formats
· Help you access a massive data feed repository without imposing any extra charges
· Can perform granular analysis
Advantages of Webhose.io
· The query system is easy to use and is consistent across data providers
Disadvantages of Webhose.io
· Has some learning curve
· Not for organizations
Conclusion
In other words, there isn’t one perfect tool. Both tools have their advantages and disadvantages and are more suited to different people in some ways or others. ScrapeStorm and Mozenda are far more user-friendly than any other scrapers. Also, these are created to make web scraping possible for non-programmers. Therefore, by watching a few video tutorials, you can expect to get the hang of it fairly quickly. Webhose.io can also be started quickly but only works best with a simple web framework. Both ScrapingHub and Parsehub are effective scrapers with durable features. But, they do require to learn certain programming skills.
We hope your web scraping project will get you started well with this post.
If you need any consultancy in data scraping, please feel free to contact us for details at https://www.loginworks.com/data-scraping. Which is your favorite tool or add-on to scraping the data? What data would you like to collect from the web? Use the comments section below to share your story with us.
0 notes
Text
Extract hotel data using ScrapeStorm from Tripadvisor
Tripadvisor is the world’s largest and most visited travel community and review website, and its biggest feature is the authenticity of website reviews. Now, the website has become a large travel online database, with a large number of user generated content (UGC) and accommodation information of tourist attractions.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result

1. Create a task

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task

2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.

3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.


4. Export and view data

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data

#web scraping#web data extractor#web scraping tools#web crawlers#data scraping#ai scraping#free#scrapestorm
0 notes
Text
How to scrape price form Beauty Expert
Beauty Expert is an e-commerce platform focusing on beauty and skin care. With its rich product variety, brand selection and shopping experience, it provides consumers with a convenient shopping channel.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result

This is the demo task:
Google Drive:
OneDrive:
1. Create a task

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task

2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.

3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.


4. Export and view data

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data

0 notes
Text
Get product prices from Allbeauty using ScrapeStorm
Allbeauty is a convenient and reliable online beauty product retail website that provides a wide range of choices and excellent services. Whether you are looking for well-known brands of beauty products or high-quality skin care brands, Allbeauty can meet your needs. At the same time, its preferential prices and fast delivery services also make your shopping experience more pleasant.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result

This is the demo task:
Google Drive:
OneDrive:
1. Create a task

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task

2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.

3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.


4. Export and view data

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data

0 notes
Text
Easy way to obtain data from Escentual
As a well-known retail mall for cosmeceuticals and maternal and infant products, escentual has attracted a large number of users with its rich product categories, high-quality products and convenient services. Its multiple payment methods and global direct mail services provide users with a more convenient and flexible shopping experience.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result

This is the demo task:
Google Drive:
OneDrive:
1. Create a task

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task

2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.

3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.


4. Export and view data

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data

0 notes
Text
Get data easily!Using ScrapeStorm to scrape Cvent
Cvent is a global leading cloud technology platform that focuses on providing comprehensive solutions for event management and planning. Since its establishment in 1999, Cvent has helped tens of thousands of companies, organizations and individuals successfully hold various events through its innovative software and services.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result

This is the demo task:
Google Drive:
OneDrive:
Cvent -scraping_task.sst
1. Create a task

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task

2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.

3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.


4. Export and view data

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data

0 notes
Text
Make programming easy! 5 AI programming tools
Due to the rapid development of artificial intelligence (AI) technology, it is gradually permeating various fields, one of which is the field of programming. The advent of AI programming tools has had a huge impact on programming, bringing unprecedented convenience and efficiency to programmers. This article introduces some AI programming tools to make your programming work more convenient.
1. GitHub Copilot
GitHub Copilot is a programming support tool jointly developed by OpenAI and GitHub. Automatically generate code and make suggestions using AI models. When programmers write code, they simply enter comments and code snippets, and Copilot automatically generates the appropriate code.
2. Codeium

3. CodiumAI
CodiumAI plugs into his IDE and suggests meaningful test suites while coding. This is done by exploring and analyzing code, documentation strings, comments, and dynamically interacting with developers.
4. HTTPie AI
5. Codiga
Codiga is a static code analysis tool available for a variety of platforms, IDEs, and other programs. It is primarily a security-focused product that allows real-time automatic code remediation. Essentially, this is a technique for keeping your code as efficient, safe, and clean as possible.
0 notes