#Amazon Web Data Extraction
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There are dozens of funny blogs to kill time on Tumblr.
Text
Which are The Best Scraping Tools For Amazon Web Data Extraction?

In the vast expanse of e-commerce, Amazon stands as a colossus, offering an extensive array of products and services to millions of customers worldwide. For businesses and researchers, extracting data from Amazon's platform can unlock valuable insights into market trends, competitor analysis, pricing strategies, and more. However, manual data collection is time-consuming and inefficient. Enter web scraping tools, which automate the process, allowing users to extract large volumes of data quickly and efficiently. In this article, we'll explore some of the best scraping tools tailored for Amazon web data extraction.
Scrapy: Scrapy is a powerful and flexible web crawling framework written in Python. It provides a robust set of tools for extracting data from websites, including Amazon. With its high-level architecture and built-in support for handling dynamic content, Scrapy makes it relatively straightforward to scrape product listings, reviews, prices, and other relevant information from Amazon's pages. Its extensibility and scalability make it an excellent choice for both small-scale and large-scale data extraction projects.
Octoparse: Octoparse is a user-friendly web scraping tool that offers a point-and-click interface, making it accessible to users with limited programming knowledge. It allows you to create custom scraping workflows by visually selecting the elements you want to extract from Amazon's website. Octoparse also provides advanced features such as automatic IP rotation, CAPTCHA solving, and cloud extraction, making it suitable for handling complex scraping tasks with ease.
ParseHub: ParseHub is another intuitive web scraping tool that excels at extracting data from dynamic websites like Amazon. Its visual point-and-click interface allows users to build scraping agents without writing a single line of code. ParseHub's advanced features include support for AJAX, infinite scrolling, and pagination, ensuring comprehensive data extraction from Amazon's product listings, reviews, and more. It also offers scheduling and API integration capabilities, making it a versatile solution for data-driven businesses.
Apify: Apify is a cloud-based web scraping and automation platform that provides a range of tools for extracting data from Amazon and other websites. Its actor-based architecture allows users to create custom scraping scripts using JavaScript or TypeScript, leveraging the power of headless browsers like Puppeteer and Playwright. Apify offers pre-built actors for scraping Amazon product listings, reviews, and seller information, enabling rapid development and deployment of scraping workflows without the need for infrastructure management.
Beautiful Soup: Beautiful Soup is a Python library for parsing HTML and XML documents, often used in conjunction with web scraping frameworks like Scrapy or Selenium. While it lacks the built-in web crawling capabilities of Scrapy, Beautiful Soup excels at extracting data from static web pages, including Amazon product listings and reviews. Its simplicity and ease of use make it a popular choice for beginners and Python enthusiasts looking to perform basic scraping tasks without a steep learning curve.
Selenium: Selenium is a powerful browser automation tool that can be used for web scraping Amazon and other dynamic websites. It allows you to simulate user interactions, such as clicking buttons, filling out forms, and scrolling through pages, making it ideal for scraping JavaScript-heavy sites like Amazon. Selenium's Python bindings provide a convenient interface for writing scraping scripts, enabling you to extract data from Amazon's product pages with ease.
In conclusion, the best scraping tool for Amazon web data extraction depends on your specific requirements, technical expertise, and budget. Whether you prefer a user-friendly point-and-click interface or a more hands-on approach using Python scripting, there are plenty of options available to suit your needs. By leveraging the power of web scraping tools, you can unlock valuable insights from Amazon's vast trove of data, empowering your business or research endeavors with actionable intelligence.
0 notes
Text
How to Extract Amazon Product Prices Data with Python 3
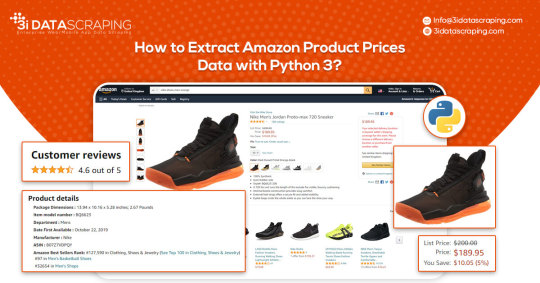
Web data scraping assists in automating web scraping from websites. In this blog, we will create an Amazon product data scraper for scraping product prices and details. We will create this easy web extractor using SelectorLib and Python and run that in the console.
#webscraping#data extraction#web scraping api#Amazon Data Scraping#Amazon Product Pricing#ecommerce data scraping#Data EXtraction Services
3 notes
·
View notes
Text
The Future of AWS: Innovations, Challenges, and Opportunities
As we stand on the top of an increasingly digital and interconnected world, the role of cloud computing has never been more vital. At the forefront of this technological revolution stands Amazon Web Services (AWS), a A leader and an innovator in the field of cloud computing. AWS has not only transformed the way businesses operate but has also ignited a global shift towards cloud-centric solutions. Now, as we gaze into the horizon, it's time to dive into the future of AWS—a future marked by innovations, challenges, and boundless opportunities.

In this exploration, we will navigate through the evolving landscape of AWS, where every day brings new advancements, complex challenges, and a multitude of avenues for growth and success. This journey is a testament to the enduring spirit of innovation that propels AWS forward, the challenges it must overcome to maintain its leadership, and the vast array of opportunities it presents to businesses, developers, and tech enthusiasts alike.
Join us as we embark on a voyage into the future of AWS, where the cloud continues to shape our digital world, and where AWS stands as a beacon guiding us through this transformative era.
Constant Innovation: The AWS Edge
One of AWS's defining characteristics is its unwavering commitment to innovation. AWS has a history of introducing groundbreaking services and features that cater to the evolving needs of businesses. In the future, we can expect this commitment to innovation to reach new heights. AWS will likely continue to push the boundaries of cloud technology, delivering cutting-edge solutions to its users.
This dedication to innovation is particularly evident in AWS's investments in machine learning (ML) and artificial intelligence (AI). With services like Amazon SageMaker and AWS Deep Learning, AWS has democratized ML and AI, making these advanced technologies accessible to developers and businesses of all sizes. In the future, we can anticipate even more sophisticated ML and AI capabilities, empowering businesses to extract valuable insights and create intelligent applications.
Global Reach: Expanding the AWS Footprint
AWS's global infrastructure, comprising data centers in numerous regions worldwide, has been key in providing low-latency access and backup to customers globally. As the demand for cloud services continues to surge, AWS's expansion efforts are expected to persist. This means an even broader global presence, ensuring that AWS remains a reliable partner for organizations seeking to operate on a global scale.
Industry-Specific Solutions: Tailored for Success
Every industry has its unique challenges and requirements. AWS recognizes this and has been increasingly tailoring its services to cater to specific industries, including healthcare, finance, manufacturing, and more. This trend is likely to intensify in the future, with AWS offering industry-specific solutions and compliance certifications. This ensures that organizations in regulated sectors can leverage the power of the cloud while adhering to strict industry standards.
Edge Computing: A Thriving Frontier
The rise of the Internet of Things (IoT) and the growing importance of edge computing are reshaping the technology landscape. AWS is positioned to capitalize on this trend by investing in edge services. Edge computing enables real-time data processing and analysis at the edge of the network, a capability that's becoming increasingly critical in scenarios like autonomous vehicles, smart cities, and industrial automation.
Sustainability Initiatives: A Greener Cloud
Sustainability is a primary concern in today's mindful world. AWS has already committed to sustainability with initiatives like the "AWS Sustainability Accelerator." In the future, we can expect more green data centers, eco-friendly practices, and a continued focus on reducing the harmful effects of cloud services. AWS's dedication to sustainability aligns with the broader industry trend towards environmentally responsible computing.
Security and Compliance: Paramount Concerns
The ever-growing importance of data privacy and security cannot be overstated. AWS has been proactive in enhancing its security services and compliance offerings. This trend will likely continue, with AWS introducing advanced security measures and compliance certifications to meet the evolving threat landscape and regulatory requirements.
Serverless Computing: A Paradigm Shift
Serverless computing, characterized by services like AWS Lambda and AWS Fargate, is gaining rapid adoption due to its simplicity and cost-effectiveness. In the future, we can expect serverless architecture to become even more mainstream. AWS will continue to refine and expand its serverless offerings, simplifying application deployment and management for developers and organizations.
Hybrid and Multi-Cloud Solutions: Bridging the Gap
AWS recognizes the significance of hybrid and multi-cloud environments, where organizations blend on-premises and cloud resources. Future developments will likely focus on effortless integration between these environments, enabling businesses to leverage the advantages of both on-premises and cloud-based infrastructure.
Training and Certification: Nurturing Talent
AWS professionals with advanced skills are in more demand. Platforms like ACTE Technologies have stepped up to offer comprehensive AWS training and certification programs. These programs equip individuals with the skills needed to excel in the world of AWS and cloud computing. As the cloud becomes increasingly integral to business operations, certified AWS professionals will continue to be in high demand.
In conclusion, the future of AWS shines brightly with promise. As a expert in cloud computing, AWS remains committed to continuous innovation, global expansion, industry-specific solutions, sustainability, security, and empowering businesses with advanced technologies. For those looking to embark on a career or excel further in the realm of AWS, platforms like ACTE Technologies offer industry-aligned training and certification programs.
As businesses increasingly rely on cloud services to drive their digital transformation, AWS will continue to play a key role in reshaping industries and empowering innovation. Whether you are an aspiring cloud professional or a seasoned expert, staying ahead of AWS's evolving landscape is most important. The future of AWS is not just about technology; it's about the limitless possibilities it offers to organizations and individuals willing to embrace the cloud's transformative power.
8 notes
·
View notes
Text
Navigating the Cloud: Unleashing Amazon Web Services' (AWS) Impact on Digital Transformation
In the ever-evolving realm of technology, cloud computing stands as a transformative force, offering unparalleled flexibility, scalability, and cost-effectiveness. At the forefront of this paradigm shift is Amazon Web Services (AWS), a comprehensive cloud computing platform provided by Amazon.com. For those eager to elevate their proficiency in AWS, specialized training initiatives like AWS Training in Pune offer invaluable insights into maximizing the potential of AWS services.

Exploring AWS: A Catalyst for Digital Transformation
As we traverse the dynamic landscape of cloud computing, AWS emerges as a pivotal player, empowering businesses, individuals, and organizations to fully embrace the capabilities of the cloud. Let's delve into the multifaceted ways in which AWS is reshaping the digital landscape and providing a robust foundation for innovation.
Decoding the Heart of AWS
AWS in a Nutshell: Amazon Web Services serves as a robust cloud computing platform, delivering a diverse range of scalable and cost-effective services. Tailored to meet the needs of individual users and large enterprises alike, AWS acts as a gateway, unlocking the potential of the cloud for various applications.
Core Function of AWS: At its essence, AWS is designed to offer on-demand computing resources over the internet. This revolutionary approach eliminates the need for substantial upfront investments in hardware and infrastructure, providing users with seamless access to a myriad of services.
AWS Toolkit: Key Services Redefined
Empowering Scalable Computing: Through Elastic Compute Cloud (EC2) instances, AWS furnishes virtual servers, enabling users to dynamically scale computing resources based on demand. This adaptability is paramount for handling fluctuating workloads without the constraints of physical hardware.
Versatile Storage Solutions: AWS presents a spectrum of storage options, such as Amazon Simple Storage Service (S3) for object storage, Amazon Elastic Block Store (EBS) for block storage, and Amazon Glacier for long-term archival. These services deliver robust and scalable solutions to address diverse data storage needs.
Streamlining Database Services: Managed database services like Amazon Relational Database Service (RDS) and Amazon DynamoDB (NoSQL database) streamline efficient data storage and retrieval. AWS simplifies the intricacies of database management, ensuring both reliability and performance.
AI and Machine Learning Prowess: AWS empowers users with machine learning services, exemplified by Amazon SageMaker. This facilitates the seamless development, training, and deployment of machine learning models, opening new avenues for businesses integrating artificial intelligence into their applications. To master AWS intricacies, individuals can leverage the Best AWS Online Training for comprehensive insights.
In-Depth Analytics: Amazon Redshift and Amazon Athena play pivotal roles in analyzing vast datasets and extracting valuable insights. These services empower businesses to make informed, data-driven decisions, fostering innovation and sustainable growth.
Networking and Content Delivery Excellence: AWS services, such as Amazon Virtual Private Cloud (VPC) for network isolation and Amazon CloudFront for content delivery, ensure low-latency access to resources. These features enhance the overall user experience in the digital realm.
Commitment to Security and Compliance: With an unwavering emphasis on security, AWS provides a comprehensive suite of services and features to fortify the protection of applications and data. Furthermore, AWS aligns with various industry standards and certifications, instilling confidence in users regarding data protection.
Championing the Internet of Things (IoT): AWS IoT services empower users to seamlessly connect and manage IoT devices, collect and analyze data, and implement IoT applications. This aligns seamlessly with the burgeoning trend of interconnected devices and the escalating importance of IoT across various industries.
Closing Thoughts: AWS, the Catalyst for Transformation
In conclusion, Amazon Web Services stands as a pioneering force, reshaping how businesses and individuals harness the power of the cloud. By providing a dynamic, scalable, and cost-effective infrastructure, AWS empowers users to redirect their focus towards innovation, unburdened by the complexities of managing hardware and infrastructure. As technology advances, AWS remains a stalwart, propelling diverse industries into a future brimming with endless possibilities. The journey into the cloud with AWS signifies more than just migration; it's a profound transformation, unlocking novel potentials and propelling organizations toward an era of perpetual innovation.
2 notes
·
View notes
Text
Use Amazon Review Scraping Services To Boost The Pricing Strategies
Use data extraction services to gather detailed insights from customer reviews. Our advanced web scraping services provide a comprehensive analysis of product feedback, ratings, and comments. Make informed decisions, understand market trends, and refine your business strategies with precision. Stay ahead of the competition by utilizing Amazon review scraping services, ensuring your brand remains attuned to customer sentiments and preferences for strategic growth.
2 notes
·
View notes
Text
Using Azure Data Factory with Azure Synapse Analytics

Using Azure Data Factory with Azure Synapse Analytics
Introduction
Azure Data Factory (ADF) and Azure Synapse Analytics are two powerful cloud-based services from Microsoft that enable seamless data integration, transformation, and analytics at scale.
ADF serves as an ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) orchestration tool, while Azure Synapse provides a robust data warehousing and analytics platform.
By integrating ADF with Azure Synapse Analytics, businesses can build automated, scalable, and secure data pipelines that support real-time analytics, business intelligence, and machine learning workloads.
Why Use Azure Data Factory with Azure Synapse Analytics?
1. Unified Data Integration & Analytics
ADF provides a no-code/low-code environment to move and transform data before storing it in Synapse, which then enables powerful analytics and reporting.
2. Support for a Variety of Data Sources
ADF can ingest data from over 90+ native connectors, including: On-premises databases (SQL Server, Oracle, MySQL, etc.) Cloud storage (Azure Blob Storage, Amazon S3, Google Cloud Storage) APIs, Web Services, and third-party applications (SAP, Salesforce, etc.)
3. Serverless and Scalable Processing With Azure Synapse, users can choose between:
Dedicated SQL Pools (Provisioned resources for high-performance querying) Serverless SQL Pools (On-demand processing with pay-as-you-go pricing)
4. Automated Data Workflows ADF allows users to design workflows that automatically fetch, transform, and load data into Synapse without manual intervention.
5. Security & Compliance Both services provide enterprise-grade security, including: Managed Identities for authentication Role-based access control (RBAC) for data governance Data encryption using Azure Key Vault
Key Use Cases
Ingesting Data into Azure Synapse ADF serves as a powerful ingestion engine for structured, semi-structured, and unstructured data sources.
Examples include: Batch Data Loading: Move large datasets from on-prem or cloud storage into Synapse.
Incremental Data Load: Sync only new or changed data to improve efficiency.
Streaming Data Processing: Ingest real-time data from services like Azure Event Hubs or IoT Hub.
2. Data Transformation & Cleansing ADF provides two primary ways to transform data: Mapping Data Flows: A visual, code-free way to clean and transform data.
Stored Procedures & SQL Scripts in Synapse: Perform complex transformations using SQL.
3. Building ETL/ELT Pipelines ADF allows businesses to design automated workflows that: Extract data from various sources Transform data using Data Flows or SQL queries Load structured data into Synapse tables for analytics
4. Real-Time Analytics & Business Intelligence ADF can integrate with Power BI, enabling real-time dashboarding and reporting.
Synapse supports Machine Learning models for predictive analytics. How to Integrate Azure Data Factory with Azure Synapse Analytics Step 1: Create an Azure Data Factory Instance Sign in to the Azure portal and create a new Data Factory instance.
Choose the region and resource group for deployment.
Step 2: Connect ADF to Data Sources Use Linked Services to establish connections to storage accounts, databases, APIs, and SaaS applications.
Example: Connect ADF to an Azure Blob Storage account to fetch raw data.
Step 3: Create Data Pipelines in ADF Use Copy Activity to move data into Synapse tables. Configure Triggers to automate pipeline execution.
Step 4: Transform Data Before Loading Use Mapping Data Flows for complex transformations like joins, aggregations, and filtering. Alternatively, perform ELT by loading raw data into Synapse and running SQL scripts.
Step 5: Load Transformed Data into Synapse Analytics Store data in Dedicated SQL Pools or Serverless SQL Pools depending on your use case.
Step 6: Monitor & Optimize Pipelines Use ADF Monitoring to track pipeline execution and troubleshoot failures. Enable Performance Tuning in Synapse by optimizing indexes and partitions.
Best Practices for Using ADF with Azure Synapse Analytics
Use Incremental Loads for Efficiency Instead of copying entire datasets, use delta processing to transfer only new or modified records.
Leverage Watermark Columns or Change Data Capture (CDC) for incremental loads.
2. Optimize Performance in Data Flows Use Partitioning Strategies to parallelize data processing. Minimize Data Movement by filtering records at the source.
3. Secure Data Pipelines Use Managed Identity Authentication instead of hardcoded credentials. Enable Private Link to restrict data movement to the internal Azure network.
4. Automate Error Handling Implement Retry Policies in ADF pipelines for transient failures. Set up Alerts & Logging for real-time error tracking.
5. Leverage Cost Optimization Strategies Choose Serverless SQL Pools for ad-hoc querying to avoid unnecessary provisioning.
Use Data Lifecycle Policies to move old data to cheaper storage tiers. Conclusion Azure Data Factory and Azure Synapse Analytics together create a powerful, scalable, and cost-effective solution for enterprise data integration, transformation, and analytics.
ADF simplifies data movement, while Synapse offers advanced querying and analytics capabilities.
By following best practices and leveraging automation, businesses can build efficient ETL pipelines that power real-time insights and decision-making.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
AWS Data Engineering online training | AWS Data Engineer
AWS Data Engineering: An Overview and Its Importance
Introduction
AWS Data Engineering plays a significant role in handling and transforming raw data into valuable insights using Amazon Web Services (AWS) tools and technologies. This article explores AWS Data Engineering, its components, and why it is essential for modern enterprises. In today's data-driven world, organizations generate vast amounts of data daily. Effectively managing, processing, and analyzing this data is crucial for decision-making and business growth. AWS Data Engineering Training
What is AWS Data Engineering?
AWS Data Engineering refers to the process of designing, building, and managing scalable and secure data pipelines using AWS cloud services. It involves the extraction, transformation, and loading (ETL) of data from various sources into a centralized storage or data warehouse for analysis and reporting. Data engineers leverage AWS tools such as AWS Glue, Amazon Redshift, AWS Lambda, Amazon S3, AWS Data Pipeline, and Amazon EMR to streamline data processing and management.

Key Components of AWS Data Engineering
AWS offers a comprehensive set of tools and services to support data engineering. Here are some of the essential components:
Amazon S3 (Simple Storage Service): A scalable object storage service used to store raw and processed data securely.
AWS Glue: A fully managed ETL (Extract, Transform, Load) service that automates data preparation and transformation.
Amazon Redshift: A cloud data warehouse that enables efficient querying and analysis of large datasets. AWS Data Engineering Training
AWS Lambda: A serverless computing service used to run functions in response to events, often used for real-time data processing.
Amazon EMR (Elastic MapReduce): A service for processing big data using frameworks like Apache Spark and Hadoop.
AWS Data Pipeline: A managed service for automating data movement and transformation between AWS services and on-premise data sources.
AWS Kinesis: A real-time data streaming service that allows businesses to collect, process, and analyze data in real time.
Why is AWS Data Engineering Important?
AWS Data Engineering is essential for businesses due to several key reasons: AWS Data Engineering Training Institute
Scalability and Performance AWS provides scalable solutions that allow organizations to handle large volumes of data efficiently. Services like Amazon Redshift and EMR ensure high-performance data processing and analysis.
Cost-Effectiveness AWS offers pay-as-you-go pricing models, eliminating the need for large upfront investments in infrastructure. Businesses can optimize costs by only using the resources they need.
Security and Compliance AWS provides robust security features, including encryption, identity and access management (IAM), and compliance with industry standards like GDPR and HIPAA. AWS Data Engineering online training
Seamless Integration AWS services integrate seamlessly with third-party tools and on-premise data sources, making it easier to build and manage data pipelines.
Real-Time Data Processing AWS supports real-time data processing with services like AWS Kinesis and AWS Lambda, enabling businesses to react to events and insights instantly.
Data-Driven Decision Making With powerful data engineering tools, organizations can transform raw data into actionable insights, leading to improved business strategies and customer experiences.
Conclusion
AWS Data Engineering is a critical discipline for modern enterprises looking to leverage data for growth and innovation. By utilizing AWS's vast array of services, organizations can efficiently manage data pipelines, enhance security, reduce costs, and improve decision-making. As the demand for data engineering continues to rise, businesses investing in AWS Data Engineering gain a competitive edge in the ever-evolving digital landscape.
Visualpath is the Best Software Online Training Institute in Hyderabad. Avail complete AWS Data Engineering Training worldwide. You will get the best course at an affordable cost
Visit: https://www.visualpath.in/online-aws-data-engineering-course.html
Visit Blog: https://visualpathblogs.com/category/aws-data-engineering-with-data-analytics/
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
#AWS Data Engineering Course#AWS Data Engineering Training#AWS Data Engineer Certification#Data Engineering course in Hyderabad#AWS Data Engineering online training#AWS Data Engineering Training Institute#AWS Data Engineering Training in Hyderabad#AWS Data Engineer online course
0 notes
Text
Various web scraping tools will help you to extract Amazon data to the spreadsheet. It is a reliable solution for scraping Amazon data and fetching valuable and important information.
For More Information:-
0 notes
Text
How To Extract Amazon Product Prices Data With Python 3?

How To Extract Amazon Product Data From Amazon Product Pages?
Markup all data fields to be extracted using Selectorlib
Then copy as well as run the given code
Setting Up Your Computer For Amazon Scraping
We will utilize Python 3 for the Amazon Data Scraper. This code won’t run in case, you use Python 2.7. You require a computer having Python 3 as well as PIP installed.
Follow the guide given to setup the computer as well as install packages in case, you are using Windows.
Packages For Installing Amazon Data Scraping
Python Requests for making requests as well as download HTML content from Amazon’s product pages
SelectorLib python packages to scrape data using a YAML file that we have created from webpages that we download
Using pip3,
pip3 install requests selectorlib
Extract Product Data From Amazon Product Pages
An Amazon product pages extractor will extract the following data from product pages.
Product Name
Pricing
Short Description
Complete Product Description
Ratings
Images URLs
Total Reviews
Optional ASINs
Link to Review Pages
Sales Ranking
Markup Data Fields With Selectorlib
As we have marked up all the data already, you can skip the step in case you wish to have rights of the data.
Let’s save it as the file named selectors.yml in same directory with our code
For More Information : https://www.3idatascraping.com/how-to-extract-amazon-prices-and-product-data-with-python-3/
#Extract Amazon Product Price#Amazon Data Scraper#Scrape Amazon Data#amazon scraper#Amazon Data Extraction#web scraping amazon using python#amazon scraping#amazon scraper python#scrape amazon prices
1 note
·
View note
Text
Is SQL Necessary for Cloud Computing?

As cloud computing continues to reshape the tech industry, many professionals and newcomers are curious about the specific skills they need to thrive in this field. A frequent question that arises is: "Is SQL necessary for cloud computing?" The answer largely depends on the role you’re pursuing, but SQL remains a highly valuable skill that can greatly enhance your effectiveness in many cloud-related tasks. Let’s dive deeper to understand the connection between SQL and cloud computing.
What Exactly is SQL?
SQL, or Structured Query Language, is a programming language designed for managing and interacting with relational databases. It enables users to:
Query data: Extract specific information from a database.
Update records: Modify existing data.
Insert data: Add new entries into a database.
Delete data: Remove unnecessary or outdated records.
SQL is widely adopted across industries, forming the foundation of countless applications that rely on data storage and retrieval.
A Quick Overview of Cloud Computing
Cloud computing refers to the on-demand delivery of computing resources—including servers, storage, databases, networking, software, and analytics—over the internet. It offers flexibility, scalability, and cost savings, making it an essential part of modern IT infrastructures.
Leading cloud platforms such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) provide robust database services that often rely on SQL. With data being central to cloud computing, understanding SQL can be a significant advantage.
Why SQL Matters in Cloud Computing
SQL plays a crucial role in several key areas of cloud computing, including:
1. Database Management
Many cloud providers offer managed database services, such as:
Amazon RDS (Relational Database Service)
Azure SQL Database
Google Cloud SQL
These services are built on relational database systems like MySQL, PostgreSQL, and SQL Server, all of which use SQL as their primary query language. Professionals working with these databases need SQL skills to:
Design and manage database structures.
Migrate data between systems.
Optimize database queries for performance.
2. Data Analytics and Big Data
Cloud computing often supports large-scale data analytics, and SQL is indispensable in this domain. Tools like Google BigQuery, Amazon Redshift, and Azure Synapse Analytics leverage SQL for querying and analyzing vast datasets. SQL simplifies data manipulation, making it easier to uncover insights and trends.
3. Cloud Application Development
Cloud-based applications often depend on databases for data storage and retrieval. Developers working on these applications use SQL to:
Interact with back-end databases.
Design efficient data models.
Ensure seamless data handling within applications.
4. Serverless Computing
Serverless platforms, such as AWS Lambda and Azure Functions, frequently integrate with databases. SQL is often used to query and manage these databases, enabling smooth serverless workflows.
5. DevOps and Automation
In DevOps workflows, SQL is used for tasks like database configuration management, automating deployments, and monitoring database performance. For instance, tools like Terraform and Ansible can integrate with SQL databases to streamline cloud resource management.
When SQL Might Not Be Essential
While SQL is incredibly useful, it’s not always a strict requirement for every cloud computing role. For example:
NoSQL Databases: Many cloud platforms support NoSQL databases, such as MongoDB, DynamoDB, and Cassandra, which do not use SQL.
Networking and Security Roles: Professionals focusing on areas like cloud networking or security may not use SQL extensively.
Low-code/No-code Tools: Platforms like AWS Honeycode and Google AppSheet enable users to build applications without writing SQL queries.
Even in these cases, having a basic understanding of SQL can provide added flexibility and open up more opportunities.
Advantages of Learning SQL for Cloud Computing
1. Broad Applicability
SQL is a universal language used across various relational database systems. Learning SQL equips you to work with a wide range of databases, whether on-premises or in the cloud.
2. Enhanced Career Prospects
SQL is consistently ranked among the most in-demand skills in the tech industry. Cloud computing professionals with SQL expertise are often preferred for roles involving data management and analysis.
3. Improved Problem-Solving
SQL enables you to query and analyze data effectively, which is crucial for troubleshooting and decision-making in cloud environments.
4. Stronger Collaboration
Having SQL knowledge allows you to work more effectively with data analysts, developers, and other team members who rely on databases.
How the Boston Institute of Analytics Can Help
The Boston Institute of Analytics (BIA) is a premier institution offering specialized training in Cloud Computing and DevOps. Their programs are designed to help students acquire the skills needed to excel in these fields, including SQL and its applications in cloud computing.
Comprehensive Learning Modules
BIA’s courses cover:
The fundamentals of SQL and advanced querying techniques.
Hands-on experience with cloud database services like Amazon RDS and Google Cloud SQL.
Practical training in data analytics tools like BigQuery and Redshift.
Integration of SQL into DevOps workflows.
Industry-Centric Training
BIA collaborates with industry experts to ensure its curriculum reflects the latest trends and practices. Students work on real-world projects and case studies, building a strong portfolio to showcase their skills.
Career Support and Certification
BIA offers globally recognized certifications that validate your expertise in Cloud Computing and SQL. Additionally, they provide career support services, including resume building, interview preparation, and job placement assistance.
Final Thoughts
So, is SQL necessary for cloud computing? While it’s not mandatory for every role, SQL is a critical skill for working with cloud databases, data analytics, and application development. It empowers professionals to manage data effectively, derive insights, and collaborate seamlessly in cloud environments.
If you’re aiming to build or advance your career in cloud computing, learning SQL is a worthwhile investment. The Boston Institute of Analytics offers comprehensive training programs to help you master SQL and other essential cloud computing skills. With their guidance, you’ll be well-prepared to excel in the ever-evolving tech landscape.
0 notes
Text
Building the Perfect Dataset for AI Training: A Step-by-Step Guide

Introduction
As artificial intelligence progressively transforms various sectors, the significance of high-quality datasets in the training of AI systems is paramount. A meticulously curated dataset serves as the foundation for any AI model, impacting its precision, dependability, and overall effectiveness. This guide will outline the crucial steps necessary to create an optimal Dataset for AI Training.
Step 1: Define the Objective
Prior to initiating data collection, it is essential to explicitly outline the objective of your AI model. Consider the following questions:
What specific issue am I aiming to address?
What types of predictions or results do I anticipate?
Which metrics will be used to evaluate success?
Establishing a clear objective guarantees that the dataset is in harmony with the model’s intended purpose, thereby preventing superfluous data collection and processing.
Step 2: Identify Data Sources
To achieve your objective, it is essential to determine the most pertinent data sources. These may encompass:
Open Data Repositories: Websites such as Kaggle, the UCI Machine Learning Repository, and Data.gov provide access to free datasets.
Proprietary Data: Data that is gathered internally by your organization.
Web Scraping: The process of extracting data from websites utilizing tools such as Beautiful Soup or Scrapy.
APIs: Numerous platforms offer APIs for data retrieval, including Twitter, Google Maps, and OpenWeather.
It is crucial to verify that your data sources adhere to legal and ethical guidelines.
Step 3: Collect and Aggregate Data
Upon identifying the sources, initiate the process of data collection. This phase entails the accumulation of raw data and its consolidation into a coherent format.
Utilize tools such as Python scripts, SQL queries, or data integration platforms.
Ensure comprehensive documentation of data sources to monitor quality and adherence to compliance standards.
Step 4: Clean the Data
Raw data frequently includes noise, absent values, and discrepancies. The process of data cleaning encompasses:
Eliminating Duplicates: Remove redundant entries.
Addressing Missing Data: Employ methods such as imputation, interpolation, or removal.
Standardizing Formats: Maintain uniformity in units, date formats, and naming conventions.
Detecting Outliers: Recognize and manage anomalies through statistical techniques or visual representation.
Step 5: Annotate the Data
Data annotation is essential for supervised learning models. This process entails labeling the dataset to establish a ground truth for the training phase.
Utilize tools such as Label Studio, Amazon SageMaker Ground Truth, or dedicated annotation services.
To maintain accuracy and consistency in annotations, it is important to offer clear instructions to the annotators.
Step 6: Split the Dataset
Segment your dataset into three distinct subsets:
Training Set: Generally comprising 70-80% of the total data, this subset is utilized for training the model.
Validation Set: Constituting approximately 10-15% of the data, this subset is employed for hyperparameter tuning and to mitigate the risk of overfitting.
Test Set: The final 10-15% of the data, this subset is reserved for assessing the model’s performance on data that it has not encountered before.
Step 7: Ensure Dataset Diversity
AI models achieve optimal performance when they are trained on varied datasets that encompass a broad spectrum of scenarios. This includes:
Demographic Diversity: Ensuring representation across multiple age groups, ethnic backgrounds, and geographical areas.
Contextual Diversity: Incorporating a variety of conditions, settings, or applications.
Temporal Diversity: Utilizing data gathered from different timeframes.
Step 8: Test and Validate
Prior to the completion of the dataset, it is essential to perform a preliminary assessment to ensure its quality. This assessment should include the following checks:
Equitable distribution of classes.
Lack of bias.
Pertinence to the specific issue being addressed.
Subsequently, refine the dataset in accordance with the findings from the assessment.
Step 9: Document the Dataset
Develop thorough documentation that encompasses the following elements:
Description and objectives of the dataset.
Sources of data and methods of collection.
Steps for preprocessing and data cleaning.
Guidelines for annotation and the tools utilized.
Identified limitations and possible biases.
Step 10: Maintain and Update the Dataset

AI models necessitate regular updates to maintain their efficacy. It is essential to implement procedures for:
Regular data collection and enhancement.
Ongoing assessment of relevance and precision.
Version management to document modifications.
Conclusion
Creating an ideal dataset for AI training is a careful endeavor that requires precision, specialized knowledge, and ethical awareness. By adhering to this comprehensive guide, you can develop datasets that enable your AI models to perform at their best and produce trustworthy outcomes.
For additional information on AI training and resources, please visit Globose Technology Solutions.AI.
0 notes
Text
Data Collection Strategies for Supervised and Unsupervised Learning

Introduction:
In the realm of Data Collection Machine Learning, data serves as the essential resource that drives model performance. The absence of high-quality data can hinder even the most advanced algorithms from yielding significant outcomes. The process of data collection is a vital component of the machine learning workflow, as it has a direct influence on the efficacy and dependability of the models. The approaches to data collection may differ based on the learning paradigm—whether it is supervised or unsupervised learning. This article will examine effective strategies customized for each category and emphasize best practices to ensure the creation of robust datasets.
Supervised Learning: Accuracy in Data Collection
Supervised learning depends on labeled data, where each input instance is associated with a specific output or target label. This necessity renders data collection for supervised learning more organized yet also more complex, as the labels must be both precise and consistent.
Establish Clear Objectives
Prior to data collection, it is essential to explicitly define the problem that your supervised learning model intends to address. A thorough understanding of the problem domain will assist in determining the necessary data types and labels. For instance, if the goal is to develop an image classification model for distinguishing between cats and dogs, a dataset containing images labeled as “cat” or “dog” will be required.
2. Leverage Publicly Accessible Datasets
Utilizing publicly available datasets can significantly reduce both time and resource expenditure. Resources such as Kaggle, the UCI Machine Learning Repository, and Open Images offer pre-labeled datasets across a variety of fields. It is crucial, however, to ensure that the dataset is suitable for your specific application.
3. Annotation Tools and Crowdsourcing Methods
For the collection of custom data, employing annotation tools such as Labelbox, CVAT, or RectLabel can enhance the efficiency of the labeling process. Additionally, crowdsourcing platforms like Amazon Mechanical Turk can engage a broader audience for data annotation, which is particularly beneficial when managing large datasets.
4. Ensure Data Quality
The accuracy of the labels plays a critical role in the performance of the model. To reduce errors and inconsistencies, it is advisable to implement quality control measures, including checks for inter-annotator agreement and the use of automated validation scripts.
5. Achieve Dataset Balance
An imbalanced dataset can distort model predictions in supervised learning scenarios. For example, in a binary classification task where 90% of the data is from one class, the model may become biased towards that class. To mitigate this issue, consider gathering additional data for the underrepresented classes or employing strategies such as data augmentation and oversampling.
Unsupervised Learning: Investigating the Uncharted
Unsupervised learning models operate on unlabeled datasets to uncover patterns or structures, such as clusters or associations. The absence of a need for labeled data allows for a more adaptable data collection process, which remains equally vital.
Utilize Extensive Data Repositories
Unsupervised learning excels with large volumes of data. Techniques such as web scraping, application programming interfaces (APIs), and Internet of Things (IoT) sensors serve as valuable means for gathering substantial amounts of unprocessed data. For instance, extracting data from online retail platforms can facilitate customer segmentation initiatives.
2. Emphasize Data Heterogeneity
A diverse dataset is essential for effective unsupervised learning. It is important to gather data from various sources and ensure a broad spectrum of features to reveal significant patterns. For example, when clustering customer behaviors, it is beneficial to incorporate demographics, purchasing history, and online activity.
3. Data Preparation and Feature Development
Raw data frequently contains extraneous noise or irrelevant elements. Implementing preprocessing techniques such as normalization, outlier elimination, and feature extraction can greatly enhance dataset quality. Methods like Principal Component Analysis (PCA) can help in reducing dimensionality while retaining critical information.
4. Ongoing Data Acquisition
Unsupervised learning often gains from the continuous acquisition of data. For example, in the context of anomaly detection, real-time data streams allow models to adjust to evolving conditions and identify anomalies swiftly.
Ethical Considerations in Data Collection

Ethical considerations are paramount in the process of data collection, regardless of the learning paradigm employed. The following are recommended best practices:
Obtain Consent: It is essential to secure permission for the collection and utilization of data, especially when handling sensitive information.
Protect Privacy: Personal data should be anonymized to safeguard the identities of individuals.
Avoid Bias: Aim for a diverse dataset to reduce biases that may result in unjust or inaccurate predictions from models.
Comply with Regulations: Follow legal standards such as GDPR or CCPA to uphold ethical data practices.
Best Practices for Data Collection
Automate Data Collection: Implement tools and scripts to streamline the data collection process, thereby minimizing manual labor and potential errors.
Validate Data: Conduct regular validations of the collected data to ensure adherence to quality standards.
Document the Process: Keep comprehensive records of data sources, collection techniques, and preprocessing methods to promote transparency and reproducibility.
Iterative Improvement: Regularly update and enhance the dataset in response to model performance and user feedback.
Conclusion
The significance of data collection in machine learning is paramount and should not be underestimated. In the context of supervised learning, it is essential to gather precise, labeled data that aligns with the specific challenges you are addressing. Conversely, for unsupervised learning, it is crucial to emphasize the diversity of data and engage in thorough preprocessing to effectively reveal underlying patterns.
In supervised learning, the focus is on collecting labeled data, where Globose Technology Solutions experts play a critical role in ensuring labels are accurate and contextually relevant. Strategies such as active learning, transfer learning, and synthetic data generation can help optimize data collection when resources are constrained.
For unsupervised learning, the emphasis shifts to gathering diverse, comprehensive datasets that allow the model to detect patterns and clusters. Here, GTS experts can assist in designing sampling methods and curating datasets to represent the complexity of the problem domain.
0 notes
Text
List of candidates available for immediate hire
In the rapidly changing landscape of 2025, the professionals need to strategically develop skills that make them instantly hireable in multiple domains. Here is a detailed guide to the most critical skills for tech job seekers. Top Technical Skills for Instant Employability
Artificial Intelligence and Machine Learning AI and ML have evolved from emerging technologies to core business capabilities. Companies are aggressively looking for professionals who can: Develop intelligent systems Develop machine learning models Deploy AI-driven solutions across industries12 Core Skills: Programming Languages: Python, Java, JavaScript Machine Learning Frameworks Data Analysis and Algorithmic Design
Cybersecurity Knowledge As the nature of cyber threats is growing sophisticated, the need for organizations to hire security professionals who can: Identify network vulnerabilities Implement robust security architectures Carry out ethical hacking and penetration testing12 Essential Skills: Zero-trust architecture Network security protocols Incident response and threat mitigation
Cloud Computing and DevOps The shift to cloud-based infrastructure has created huge demand for professionals who can: Manage cloud platforms Implement DevOps practices Optimize cloud performance and security12 Core Platforms: Amazon Web Services (AWS) Microsoft Azure Google Cloud Platform
Data Science and Analytics Data has become the new backbone of strategic decision-making. Employers look for professionals who can: Extract actionable insights Manage big data infrastructure Develop predictive analytics models12 Key Tools: SQL Python Tableau Apache Spark Non-Technical Skills for Tech Professionals
Product Management Technical professionals must now demonstrate: Agile methodology understanding Cross-functional collaboration Strategic product development skills12
Digital Marketing and Analytics Tech professionals increasingly need: SEO knowledge Content strategy skills Data-driven marketing insights Eligibility Criteria for Direct Recruitment Technical Qualifications Bachelors/Masters in Computer Science, Information Technology Relevant certifications from reputed institutions Portfolio of projects Hands-on experience with latest technologies Skill Proficiency Requirements Minimum 1-2 years of relevant work experience Proven expertise in at least two primary technical domains Strong problem-solving and analytical skills Continuous learning attitude Emerging Technologies to Watch
Extended Reality (AR/VR) Professionals with expertise in immersive technologies will have exciting opportunities in: Healthcare Retail Training and education1
Internet of Things (IoT) Expertise in IoT development and sensor technology is becoming increasingly valuable across industries.
Quantum Computing Though still emerging, quantum computing skills will give a significant competitive advantage. Certification and Skill Development Strategies Recommended Learning Paths Online platforms (Coursera, edX) Professional certification programs Specialized boot camps Continuous skill upgradation Key Certifications AWS Certified Solutions Architect Google Cloud Professional Certified Information Systems Security Professional (CISSP) Certified Artificial Intelligence Engineer Salary and Career Progression Professionals with multi-disciplinary skills can expect: Higher starting salaries Faster career progression More diverse job opportunities Salary Range Indicators: Entry-level AI/ML Engineers: $80,000-$120,000 Cybersecurity Specialists: $90,000-$140,000 Cloud Architects: $120,000-$180,000 Conclusion The tech job market in 2025 requires versatility, continuous learning, and proactivity when it comes to skill development. Focusing on up-and-coming technical skills, maintaining a growth mindset, and staying ahead in emerging technologies will keep professionals ahead in the short and long term.
0 notes
Text
Amazon Reviews Scraping

Amazon Reviews Scraping: Unlocking Insights with DataScrapingServices.com
Amazon Reviews Scraping
In today's highly competitive e-commerce environment, customer feedback plays a vital role in shaping business strategies and improving product offerings. Amazon Reviews Scraping is a powerful way to extract valuable insights from customer reviews, enabling businesses to understand their audience better and refine their products. At DataScrapingServices.com, we specialize in providing top-tier Amazon reviews scraping solutions that deliver actionable data for businesses of all sizes.
Amazon Reviews Scraping by DataScrapingServices.com offers businesses valuable insights from customer feedback on one of the world’s largest e-commerce platforms. By extracting detailed review data, including star ratings, review text, and customer profiles, companies can better understand customer sentiment, track competitors, and enhance their products or services. Our Amazon reviews scraping solutions provide up-to-date, accurate, and structured data tailored to your needs, whether for a single product or across multiple categories. With a focus on compliance and data security, we help businesses gain actionable insights that drive growth.
Why Scrape Amazon Reviews?
Amazon reviews offer a treasure trove of information about customer satisfaction, product performance, and market trends. By scraping these reviews, businesses can:
1. Understand Customer Sentiment: Analyze customer feedback to gauge product strengths, weaknesses, and areas for improvement.
2. Track Competitor Performance: Monitor reviews of competing products to identify market gaps and potential opportunities.
3. Enhance Product Development: Use customer feedback to guide product improvements or new features that align with customer needs.
4. Improve Marketing Strategies: Leverage insights from reviews to create targeted marketing campaigns that resonate with your audience.
How Amazon Reviews Scraping Works?
At Data Scraping Services, we utilize advanced web scraping techniques to extract structured data from Amazon reviews. Our services can capture essential information such as:
- Review Text: Extract the detailed feedback customers provide.
- Star Ratings: Collect product ratings to assess overall satisfaction.
- Review Date: Track the recency of reviews for trend analysis.
- Reviewer Details: Collect relevant user demographics to understand customer profiles.
Our scraping service ensures that this data is cleaned, formatted, and delivered in a way that makes analysis simple and effective.
Benefits of Using DataScrapingServices.com
1. Custom Solutions: Whether you need reviews for a single product or across multiple categories, our service is fully customizable to meet your requirements.
2. Accurate and Timely Data: We provide up-to-date, accurate data to help you make informed business decisions.
3. Scalable Services: Whether you're a small business or a large enterprise, our solutions scale to meet your data needs.
4. Compliance and Security: We ensure that our scraping practices are compliant with Amazon’s guidelines and maintain the highest standards of data security.
Best eCommerce Data Scraping Services Provider
Online Fashion Store Data Extraction
Amazon.ca Product Information Scraping
Marks & Spencer Product Details Scraping
Extracting Product Information from Kogan
PriceGrabber Product Pricing Scraping
Asda UK Product Details Scraping
Amazon Product Price Scraping
Retail Website Data Scraping Services
Tesco Product Details Scraping
Homedepot Product Listing Scraping
Best Amazon Reviews Scraping Services in USA:
San Francisco, Fort Worth, Louisville, Seattle, Columbus, Milwaukee, Fresno, Orlando, Sacramento, Oklahoma City, Colorado, Raleigh, San Francisco, Bakersfield, Mesa, Indianapolis, Jacksonville, Albuquerque, Colorado, Houston, Washington, Las Vegas, Denver, Nashville, Sacramento, New Orleans, Kansas City, San Diego, Omaha, Long Beach, Fresno, Austin, Philadelphia, Orlando, Long Beach, El Paso, Atlanta, Memphis, Dallas, San Antonio, Wichita, Boston, Virginia Beach, Tulsa, San Jose, Chicago, Charlotte, Tucson and New York.
Conclusion
In a digital age where customer insights drive business growth, Amazon Reviews Scraping can give you a significant edge over your competitors. With DataScrapingServices.com, you get reliable, accurate, and actionable data that helps you enhance your products and marketing strategies. Contact us today at [email protected] for more information on how we can help transform your business insights.
Website: Datascrapingservices.com
Email: [email protected]
#amazonreviewsscraping#amazoncustomerreviewsscraping#productpricescraping#productinformationscraping#datascrapingservices#webscrapingexpert#websitedatascraping
0 notes
Text
Data Collection for Machine Learning: Laying the Foundation for AI Excellence

This is, in fact, a fresh age of possibilities initiated by accelerating data collection for Machine Learning; ML models redefining how we tackle complex problems are self-driving cars on the surface to precisely detecting diseases. However, behind every brilliant AI system is a crucial task-data collection.
In any ML project, data collection is the first step of the whole process. Without such data, there is just no basis for even high-tech algorithms to work on. It is basically about gathering, sorting, and processing raw data to make it ready for training machine learning models. This blog will dig into the importance of data collection, ways for data collection, challenges ahead, and how this channelizes excellence for AI.
Why Is Data Collection Critical for Machine Learning?
In machine learning, data acts as the fuel that powers algorithms. It provides the examples that models use to learn patterns, make predictions, and refine their accuracy over time.
This is the significance of data collection:
A Foundation for Learning: ML models gain knowledge of relationships and trends from examples. It is practically impossible to map something without the dataset required for the learning process. Thus, data collection is vital to ensure these relevant and diverse sets of information are available at this stage.
Model Performance Improvement: Data quality and variation are critical to the accuracy and reliability of an ML model. The more wrapped up in creating a good dataset, the better the model generalizes and performs in the real world.
Addressing Domain-Specific Challenges: Every industry/application has certain peculiar data requirements. A healthcare AI system needs medical imaging data, while an autonomous vehicle system needs road and traffic data. Data collection allows the features in the input space to be tailored relative to the specific problem under question.
Supporting Continuous Improvement: AI models are not static—they evolve with time and usage. Continuous data collection enables these systems to adapt to new environments, trends, and user behaviors.
Methods of Data Collection for Machine Learning
Data can be collected in several ways, depending on the type of project and the domain it serves.
Here are some common methods:
Manual Data Collection: In this method, human operators gather data by observing, recording, or annotating it. Though time-intensive, manual collection ensures high-quality, precise data, especially in tasks like labeling images or annotating medical scans.
Automated Data Collection: Automated methods use scripts, sensors, or APIs to gather large volumes of data efficiently. For example, web scraping tools can extract data from websites, while IoT sensors collect environmental data.
Crowdsourced Data: Platforms like Amazon Mechanical Turk enable crowdsourcing for data collection and annotation. This approach is cost-effective and scalable but may require additional quality checks.
Synthetic Data Generation: Synthetic data is artificially created to mimic real-world data. This is particularly useful when collecting actual data is expensive, risky, or impossible, such as in autonomous driving simulations.
Open-Source Datasets: Many organizations and academic institutions release publicly available datasets. Platforms like Kaggle, UCI Machine Learning Repository, and ImageNet are popular sources for diverse datasets.
Key Considerations for Effective Data Collection
Not all data is created equal. To ensure that the collected data serves its purpose effectively, it’s essential to focus on the following aspects:
Relevance: The data should align with the specific problem the ML model aims to solve. Irrelevant data adds noise and hinders model performance.
Diversity: Diverse datasets improve the model’s ability to generalize. For example, a facial recognition model should be trained on images representing different ethnicities, ages, and lighting conditions.
Quality: High-quality data is clean, accurate, and well-annotated. Data preprocessing, such as removing duplicates, handling missing values, and resolving inconsistencies, is critical to maintaining quality.
Scalability: As ML projects grow, so does the need for more data. Scalable data collection methods ensure that datasets can be expanded without compromising quality.
Ethical Compliance: Data collection must adhere to ethical guidelines and legal regulations, such as GDPR or HIPAA. Respecting privacy and obtaining consent are paramount.
Challenges in Data Collection
While data collection is vital, it is not without challenges. Some of the most common obstacles include:
Data Scarcity: In some domains, such as rare diseases or emerging technologies, relevant data may be hard to find or collect. Synthetic data and simulation environments can help mitigate this issue.
High Costs: Manual annotation, especially for large datasets, can be expensive. Automated tools and crowdsourcing platforms can help reduce costs while maintaining quality.
Data Imbalance: Many datasets suffer from imbalances, where one class or category is overrepresented. For instance, in fraud detection, fraudulent transactions may be rare, making it harder for the model to detect them.
Privacy Concerns: Collecting data that involves personal or sensitive information requires stringent measures to protect user privacy and comply with regulations.
Data Drift: As real-world conditions evolve, previously collected data may no longer represent current trends. Continuous data collection and periodic updates are necessary to address this issue.
Applications of Data Collection in AI and ML
Data collection fuels innovation across industries, enabling transformative AI solutions. Here are a few examples:
Healthcare: AI models trained on medical imaging datasets are improving diagnostics and treatment planning. Data collection from wearable devices and patient records supports personalized medicine.
Retail and E-commerce: Retailers use data on customer preferences, browsing behavior, and transaction history to train recommendation systems and optimize supply chains.
Autonomous Vehicles Self-driving cars rely on video and sensor data collected from real-world driving scenarios. This data helps train models to navigate roads, detect obstacles, and ensure passenger safety.
Finance: In the financial sector, datasets of transaction records, market trends, and user behavior are used for fraud detection, credit scoring, and risk management.
Agriculture: Satellite and drone imagery provide data for AI models that monitor crop health, predict yields, and optimize irrigation.
Conclusion
Data collection is the foundation upon which every successful ML model is built. It’s not just about data gathering; it’s about curating a rich, diverse, and high-quality data set from relevant sources, so that AI systems can perform efficiently and responsibly.
As the demand for smarter AI solutions keeps on rising, investment in strong data collection methods becomes a key factor in realizing machine learning excellence. While some certainly need to address challenges and accept new trends, industries and researchers globally can unlock the full potential of AI and bring the world one step closer to an intelligent future driven by data.
Visit Globose Technology Solutions to see how the team can speed up your facial recognition projects.
0 notes
Text
AWS Data Engineering | AWS Data Engineer online course
Key AWS Services Used in Data Engineering
AWS data engineering solutions are essential for organizations looking to process, store, and analyze vast datasets efficiently in the era of big data. Amazon Web Services (AWS) provides a wide range of cloud services designed to support data engineering tasks such as ingestion, transformation, storage, and analytics. These services are crucial for building scalable, robust data pipelines that handle massive datasets with ease. Below are the key AWS services commonly utilized in data engineering: AWS Data Engineer Certification

1. AWS Glue
AWS Glue is a fully managed extract, transform, and load (ETL) service that helps automate data preparation for analytics. It provides a serverless environment for data integration, allowing engineers to discover, catalog, clean, and transform data from various sources. Glue supports Python and Scala scripts and integrates seamlessly with AWS analytics tools like Amazon Athena and Amazon Redshift.
2. Amazon S3 (Simple Storage Service)
Amazon S3 is a highly scalable object storage service used for storing raw, processed, and structured data. It supports data lakes, enabling data engineers to store vast amounts of unstructured and structured data. With features like versioning, lifecycle policies, and integration with AWS Lake Formation, S3 is a critical component in modern data architectures. AWS Data Engineering online training
3. Amazon Redshift
Amazon Redshift is a fully managed, petabyte-scale data warehouse solution designed for high-performance analytics. It allows organizations to execute complex queries and perform real-time data analysis using SQL. With features like Redshift Spectrum, users can query data directly from S3 without loading it into the warehouse, improving efficiency and reducing costs.
4. Amazon Kinesis
Amazon Kinesis provides real-time data streaming and processing capabilities. It includes multiple services:
Kinesis Data Streams for ingesting real-time data from sources like IoT devices and applications.
Kinesis Data Firehose for streaming data directly into AWS storage and analytics services.
Kinesis Data Analytics for real-time analytics using SQL.
Kinesis is widely used for log analysis, fraud detection, and real-time monitoring applications.
5. AWS Lambda
AWS Lambda is a serverless computing service that allows engineers to run code in response to events without managing infrastructure. It integrates well with data pipelines by processing and transforming incoming data from sources like Kinesis, S3, and DynamoDB before storing or analyzing it. AWS Data Engineering Course
6. Amazon DynamoDB
Amazon DynamoDB is a NoSQL database service designed for fast and scalable key-value and document storage. It is commonly used for real-time applications, session management, and metadata storage in data pipelines. Its automatic scaling and built-in security features make it ideal for modern data engineering workflows.
7. AWS Data Pipeline
AWS Data Pipeline is a data workflow orchestration service that automates the movement and transformation of data across AWS services. It supports scheduled data workflows and integrates with S3, RDS, DynamoDB, and Redshift, helping engineers manage complex data processing tasks.
8. Amazon EMR (Elastic MapReduce)
Amazon EMR is a cloud-based big data platform that allows users to run large-scale distributed data processing frameworks like Apache Hadoop, Spark, and Presto. It is used for processing large datasets, performing machine learning tasks, and running batch analytics at scale.
9. AWS Step Functions
AWS Step Functions help in building serverless workflows by coordinating AWS services such as Lambda, Glue, and DynamoDB. It simplifies the orchestration of data processing tasks and ensures fault-tolerant, scalable workflows for data engineering pipelines. AWS Data Engineering Training
10. Amazon Athena
Amazon Athena is an interactive query service that allows users to run SQL queries on data stored in Amazon S3. It eliminates the need for complex ETL jobs and is widely used for ad-hoc querying and analytics on structured and semi-structured data.
Conclusion
AWS provides a powerful ecosystem of services that cater to different aspects of data engineering. From data ingestion with Kinesis to transformation with Glue, storage with S3, and analytics with Redshift and Athena, AWS enables scalable and cost-efficient data solutions. By leveraging these services, data engineers can build resilient, high-performance data pipelines that support modern analytics and machine learning workloads.
Visualpath is the Best Software Online Training Institute in Hyderabad. Avail complete AWS Data Engineering Training worldwide. You will get the best course at an affordable cost.
#AWS Data Engineering Course#AWS Data Engineering Training#AWS Data Engineer Certification#Data Engineering course in Hyderabad#AWS Data Engineering online training#AWS Data Engineering Training Institute#AWS Data Engineering Training in Hyderabad#AWS Data Engineer online course
0 notes