#AI search and recommendation engines
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
AI-Powered E-Commerce Site Search by Wizzy | Enhance User Experience
Enhance your online store's performance with Wizzy's AI-driven ecommerce site search solutions. Deliver fast, contextual search experiences to increase user engagement and drive sales. Upgrade your site search experience with Wizzy’s cutting-edge AI search technology for e commerce.
#AI-powered site search#E-commerce search optimization#Smart site search for online stores#AI-driven search solutions#Best AI search engines for e-commerce#Personalized product search tools#Advanced search algorithms for retail#Site search tools for Shopify#Artificial intelligence search technology#Intelligent search for online shopping#AI search bar for websites#Product search AI for e-commerce#AI search and recommendation engines#Custom search solutions for retailers#Improve e-commerce search experience#Machine learning for e-commerce site search#AI-based product discovery tools#Search engine for online shopping sites#AI site search to boost conversions#Optimized search experience for e-commerce
0 notes
Text
today in work with bri:
- had a customer who said she wanted to cancel her order because she asked chatgpt if we were a scam and i just stared at it for a minute
#ended up including a polite ‘i would recommend taking anything presented by chatgpt with a grain of salt as it is not a legitimate search-#engine & generative ai tends to scramble many potentially conflicting sources of text together.’#bri.txt#ghe thing abt my company too is like… i’m not going to say it’s cheap but it does spell out all the fees associated you just have to like.#Read. you’re given options to opt out of every extra service possible and ppl just do not read this and then opt in and get mad at us.#and call us a scam bc They made an oopsie.#(we also get called a scam bc we are not their SoS. our client agreement specifically states us as third party. Please read before spending#hundreds of dollars on something.)
3 notes
·
View notes
Text
One horrifying side effect I didn’t expect from AI is people not believing in creativity or talent anymore.
I saw The Wild Robot tonight, and the film had beautiful visuals inspired by classical art and was created by using 2D textures on 3D assets to make it look like a painting. I want to emphasize that this has been done before. The Wild Robot did not invent this technique. This technique also requires IMMENSE amounts of time and talent to accomplish well. When we left the theatre my friend googled the film to see how it was made, and upon reading the wikipedia article on the production, said that they “fed the images of the paintings into it to make the cgi look painted.” The wikipedia article in question didn’t even mention AI, let alone say that the film was created using it. This is a Dreamworks movie. And when I tried to correct her, she said that she “assumes AI was used somewhere in the film.” I have a degree in visual effects.
I’m sad.
Anyway go see The Wild Robot in theatres it was a religious experience.
#also it has three (3!!!) Star Wars cast members#mark pedro and dee#😍😍😍#and like ok— did AN artist SOMEWHERE on the film possibly use AI in their work?#wouldn’t surprise me#but AI sure as hell didn’t make this movie#I wanna scream#I’m literally gonna lose it if AI doesn’t die soon#go back to 2012 when it was like search engine recommendations and that was it
3 notes
·
View notes
Text
FUTURE OF YANDEX SEARCH ENGINE?
PREDICTIONS FOR 2025 - SEO / AI and MACHINE LEARNING
Predicting the future of Yandex in 2025 is complex, and there is no single definitive answer. However, here are some potential developments based on current trends and expert analyses:
Potential Positive Developments:
Continued Growth in Russia and CIS: Yandex is likely to maintain its dominant position in Russia and other CIS countries due to its strong brand recognition, localized content, and understanding of the market.
Expansion into New Markets: Yandex may further expand its presence in other emerging markets, leveraging its technology and experience to compete with established players.
AI and Machine Learning Advancements: Yandex has been investing heavily in AI and machine learning, which could lead to significant improvements in search accuracy, personalization, and user experience.
Diversification of Services: Yandex's diverse portfolio of services (e-commerce, ride-hailing, cloud computing, etc.) could provide a buffer against fluctuations in the search market and contribute to overall growth.
Potential Challenges:
Increased Competition: Global players like Google and emerging AI-powered search engines could intensify competition, especially in international markets.
Regulatory Hurdles: The regulatory environment in Russia and other markets could become more restrictive, impacting Yandex's operations and growth potential.
Economic Volatility: Economic downturns in key markets could negatively affect advertising revenues, a major source of income for Yandex.
Overall Prediction:
Yandex is likely to remain a major player in the search engine market in 2025, particularly in Russia and the CIS. Its success will depend on its ability to navigate challenges, innovate, and capitalize on opportunities in a rapidly evolving landscape.
It's important to remember that these are just predictions, and the actual future of Yandex could be influenced by unforeseen events and developments.
Additional Resources:
For more information and diverse perspectives, you can search for analyst reports, news articles, and expert opinions on the future of Yandex.
It is also helpful to follow Yandex's official announcements and financial reports to stay updated on their progress and strategies.
Remember: The future is uncertain, and any predictions should be considered with caution.
SEOSHNIK: PREDRAG
#seo#seoexpert#answer engine optimization#seo yandex#yandex#yandex seo expert#realestate#design#ai yandex#yandex engine#yandex search engine#e-commerce#ride-hailing#cloud computing#SEOSHNIK#2025#optimized for 2025#2025 predictions#SEO PREDICTIONS#RECOMMENDED SEO#SEO RECOMENDED
2 notes
·
View notes
Text
pet peeve of the year is whenever someone attempts to back themselves up in an argument by posting a screenshot of google's ai response. like you couldn't take two seconds to scroll past the garbled horseshit that melts icecaps to tell you to eat glue and get a real source? come the fuck on
#fuck ai#all my homies hate ai#support search engines browsers that don't force generative ai down your throat#even if you can't fully switch off of google as a search engine at least don't make it your first choice#my recommendations are firefox and startpage#firefox lets you have browser extensions on mobile!!! and lets you switch search engines fairly easily!!!
1 note
·
View note
Text
If you are sick of Google giving you blatantly wrong or even dangerous AI answers to your search query, here are some search engines that don’t use AI at all:
Startpage (highly recommend this one)
Ask
Dogpile
Metacrawler
Frogfind
Qwant
SearXNG
I was about to put Yahoo on this list since their search doesn’t use AI, but it turns out their email service has AI integrated into it :(
DuckDuckGo uses AI by default. Even though you can just toggle it off, I still lost trust in DuckDuckGo
Definitely DO NOT USE BRAVE. Not only does it have built into AI integration, but also has cringe ass crypto and NFT crap built in because the company is ran by cryptobros. The founder of Brave is also a transphobe
1K notes
·
View notes
Text
KIP'S BIG POST OF THINGS TO MAKE THE INTERNET & TECHNOLOGY SUCK A LITTLE LESS

Post last updated November 23, 2024. Will continue to update!
Here are my favorite things to use to navigate technology my own way:
A refurbished iPod loaded with Rockbox OS (Rockbox is free, iPods range in price. I linked the site I got mine from. Note that iPods get finicky about syncing and the kind of cord it has— it may still charge but might not recognize the device to sync. Getting an original Apple cord sometimes helps). Rockbox has ports for other MP3 players as well.
This Windows debloater program (there are viable alternatives out there, this one works for me). It has a powershell script that give you a little UI and buttons to press, which I appreciate, as I'm still a bit shy with tech.
Firefox with the following extensions: - Consent-O-Matic (set your responses to ALL privacy/cookie pop-ups in the extension, and it will answer all pop-ups for you. I can see reasons to not use it, but I appreciate it) - Facebook Container ("contains" Meta on Facebook and Instagram pages to keep it from tracking you or getting third party cookies, since Meta is fairly egregious about it) - Redirect Amp to HTML (AMP is designed for mobile phones, this forces pages to go to their HTML version) - A WebP/AVIF image converter - uBlock Origin and uBlacklist, with the AI blacklist loaded in to kill any generative AI results from appearing in search engines or anywhere.
Handbrake for ripping DVDs— I haven’t used this in awhile as I haven’t been making video edits. I used this back when I had a Mac OS
VLC Media Player (ol’ reliable)
Unsplash & Pexels for free-to-use images
A password manager (these often are paid. I use Dashlane. There are many options, feel free to search around and ask for recs!). There is a lot that goes into cybersecurity— find the option you feel is best for you.
Things I suggest:
Understanding Royalty Free and the Creative Commons licenses
Familiarity with boolean operators for searching
Investing in a backup drive and external drive
A few good USBs, including one that has a backup of your OS on it
Adapter cables
Avoiding Fandom “wikias” (as in the brand “Fandom”) and supporting other, fan-run or supported wikis. Consider contributing if its something you find yourself passionate or joyful about.
Finding Forums for the things you like, or creating your own*
Create an email specifically for ads/shopping— use it to receive all promotional emails to keep your inbox clean. Upkeep it.
Stop putting so much of your personal information online— be willing to separate your personal online identity from your “online identity”. You don’t owe people your name, location, pronouns, diagnoses, or any of that. It’s your choice, but be discerning in what you give and why. I recommend avoiding providing your phone number to sites as much as possible.
Be intentional
Ask questions
Talk to people
Remember that you can lurk all you want
Things that are fun to check out:
BBSes-- here's a portal to access them.
Neocities
*Forums-- find some to join, or maybe host your own? The system I was most familiar with was vbulletin.
MMM.page
Things that have worked well for me but might work for you, YMMV:
Limit your app usage time on your smartphone if you’re prone to going back to them— this is a tangible way to “practice mindfulness”, a term I find frustratingly vague ansjdbdj
Things I’m looking into:
The “Pi Hole”— a raspberry pi set up to block all ads on a specific internet connection
VPNs-- this is one that was recommended to me.
How to use computers (I mean it): Resources on how to understand your machine and what you’re doing, even if your skill and knowledge level is currently 0:
This section I'll come back an add to. I know that messing with computers can be intimidating, especially if you feel out of your depth. HTML and regedits and especially things like dualbooting or linux feel impossible. So I want to put things here that explain exactly how the internet and your computer functions, and how you can learn and work with that. Yippee!
610 notes
·
View notes
Text
Tuesday, March 19th, 2024
🌟 New
Don’t want search engines to crawl your blog, but still want your posts to appear in Tumblr search and in-blog search? We’ve now split the existing setting for excluding your blog from search into two, letting you choose to hide posts from external search engines, Tumblr search, or both! If you previously had this toggled on or off, your existing preference was copied to the new setting.
Speaking of search, we have increased the limit of indexed tags from 20 to 30. This only applies to new posts.
We now have an exciting Known Issues on Tumblr doc, please feel free to check it out.
🛠 Fixed
SMS text Two-factor Authentication codes were not arriving, and this is now fixed. For a more secure experience, we recommend using an authenticator app for your Two-Factor Authentication codes, and don’t forget to save your backup codes!
Some ads were stopping people from scrolling for a few seconds, this has been fixed.
With Bing’s policy change to no longer use content they index for their search engine for AI training unless opted in to, we are now allowing Bing to index posts from blogs that allow search indexing. We continue to discourage Bing’s crawling for AI training.
🚧 Ongoing
If you’re using Avast, it’s currently incorrectly blocking the ability to use messaging in real time on the web. We’re working to clear this up with them.
🌱 Upcoming
No upcoming launches to announce today.
Experiencing an issue? File a Support Request and we’ll get back to you as soon as we can!
Want to share your feedback about something? Check out our Work in Progress blog and start a discussion with the community.
Wanna support Tumblr directly with some money? Check out the new Supporter badge in TumblrMart!
650 notes
·
View notes
Note
I saw something about generative AI on JSTOR. Can you confirm whether you really are implementing it and explain why? I’m pretty sure most of your userbase hates AI.
A generative AI/machine learning research tool on JSTOR is currently in beta, meaning that it's not fully integrated into the platform. This is an opportunity to determine how this technology may be helpful in parsing through dense academic texts to make them more accessible and gauge their relevancy.
To JSTOR, this is primarily a learning experience. We're looking at how beta users are engaging with the tool and the results that the tool is producing to get a sense of its place in academia.
In order to understand what we're doing a bit more, it may help to take a look at what the tool actually does. From a recent blog post:
Content evaluation
Problem: Traditionally, researchers rely on metadata, abstracts, and the first few pages of an article to evaluate its relevance to their work. In humanities and social sciences scholarship, which makes up the majority of JSTOR’s content, many items lack abstracts, meaning scholars in these areas (who in turn are our core cohort of users) have one less option for efficient evaluation.
When using a traditional keyword search in a scholarly database, a query might return thousands of articles that a user needs significant time and considerable skill to wade through, simply to ascertain which might in fact be relevant to what they’re looking for, before beginning their search in earnest.
Solution: We’ve introduced two capabilities to help make evaluation more efficient, with the aim of opening the researcher’s time for deeper reading and analysis:
Summarize, which appears in the tool interface as “What is this text about,” provides users with concise descriptions of key document points. On the back-end, we’ve optimized the Large Language Model (LLM) prompt for a concise but thorough response, taking on the task of prompt engineering for the user by providing advanced direction to:
Extract the background, purpose, and motivations of the text provided.
Capture the intent of the author without drawing conclusions.
Limit the response to a short paragraph to provide the most important ideas presented in the text.

Search term context is automatically generated as soon as a user opens a text from search results, and provides information on how that text relates to the search terms the user has used. Whereas the summary allows the user to quickly assess what the item is about, this feature takes evaluation to the next level by automatically telling the user how the item is related to their search query, streamlining the evaluation process.

Discovering new paths for exploration
Problem: Once a researcher has discovered content of value to their work, it’s not always easy to know where to go from there. While JSTOR provides some resources, including a “Cited by” list as well as related texts and images, these pathways are limited in scope and not available for all texts. Especially for novice researchers, or those just getting started on a new project or exploring a novel area of literature, it can be needlessly difficult and frustrating to gain traction.
Solution: Two capabilities make further exploration less cumbersome, paving a smoother path for researchers to follow a line of inquiry:
Recommended topics are designed to assist users, particularly those who may be less familiar with certain concepts, by helping them identify additional search terms or refine and narrow their existing searches. This feature generates a list of up to 10 potential related search queries based on the document’s content. Researchers can simply click to run these searches.

Related content empowers users in two significant ways. First, it aids in quickly assessing the relevance of the current item by presenting a list of up to 10 conceptually similar items on JSTOR. This allows users to gauge the document’s helpfulness based on its relation to other relevant content. Second, this feature provides a pathway to more content, especially materials that may not have surfaced in the initial search. By generating a list of related items, complete with metadata and direct links, users can extend their research journey, uncovering additional sources that align with their interests and questions.

Supporting comprehension
Problem: You think you have found something that could be helpful for your work. It’s time to settle in and read the full document… working through the details, making sure they make sense, figuring out how they fit into your thesis, etc. This all takes time and can be tedious, especially when working through many items.
Solution: To help ensure that users find high quality items, the tool incorporates a conversational element that allows users to query specific points of interest. This functionality, reminiscent of CTRL+F but for concepts, offers a quicker alternative to reading through lengthy documents.
By asking questions that can be answered by the text, users receive responses only if the information is present. The conversational interface adds an accessibility layer as well, making the tool more user-friendly and tailored to the diverse needs of the JSTOR user community.
Credibility and source transparency
We knew that, for an AI-powered tool to truly address user problems, it would need to be held to extremely high standards of credibility and transparency. On the credibility side, JSTOR’s AI tool uses only the content of the item being viewed to generate answers to questions, effectively reducing hallucinations and misinformation.
On the transparency front, responses include inline references that highlight the specific snippet of text used, along with a link to the source page. This makes it clear to the user where the response came from (and that it is a credible source) and also helps them find the most relevant parts of the text.
293 notes
·
View notes
Text
While I'm worried about AI slop and autogenerated content overwhelming the internet and search engines, this was already going on. I remember long before ChatGPT was released me as lots of other people were already complaining about how it's impossible to find answers to technical problems outside of places like Reddit, because everything else was just shitty fake blog blurbs that said "1) try turning on and off your computer 2) try the windows problem solver 3) download our malware infested antivirus shit". This is for computing problems, but I also had the same problem when searching, for example, for biology or history queries, just lots and lots of travel blogs selling you some shit, and it has gotten even worse now that it's pretty much confirmed that youtube and google don't even show you the best results anymore, just whatever "relates" to your search (or more like, people selling you stuff "related" to your search)
I'm beginning to think that having a single (owned by a Usamerican megacorporation no less) enormous search engine for the entire internet powered by advertising and the sale of personal information isn't such a bright idea after all.
I think the best idea is to return to the idea of encyclopedias and directories curated by people and communities, websites that provide lists of other useful or relevant websites all neatly categorized. I'm only speaking for my own experience as I don't use the internet to shop and I don't care about that aspect of it (if I do, I use shopping websites, not google it), but for example, I could use community-run websites telling you were the best websites and media about such and such interest are (returning to a neocities concept of personal websites). This idea is not flawless, but I'm seeing an inminent collapse of search engines soon, so my recommendation is that you archive your favorite links and media (especially books) as well as you can.
320 notes
·
View notes
Text
Learn Why Contextual Search is a Must-Have Feature for Modern E-Commerce Stores - Wizzy.ai
Discover why contextual search is revolutionizing e-commerce. Learn how it improves user experience, boosts conversions, and delivers personalized results. Stay ahead with the latest insights on optimizing your e-commerce store with intelligent search capabilities.
#Contextual search implementation#Contextual search benefits#Contextual search strategies#Contextual search in e-commerce#Contextual search setup Shopify#Benefits of contextual search in retail#Inventory management with contextual search#E-commerce search optimization#Personalized product recommendations#AI in e-commerce search#Improving e-commerce user experience#Advanced search algorithms for e-commerce#E-commerce search engine best practices#Enhancing online store search functionality#E-commerce search personalization techniques#Implementing AI in online store search#E-commerce search trends 2024#Customer satisfaction and e-commerce search#Targeted marketing using search data#Future of e-commerce search technology
0 notes
Note
Hii!! Just wanted to ask how you get your poses on characters just flow so naturally? Is it like 2nd nature to you or does it take a really long time to get the poses right and natural? Bcs i've always struggled with that
Just wanted to ask since I really love the way you draw poses and perspective!! (Might be a weird complements but yeah sksnsksosj)
DJGGJHGIG ANON MY LOVE......YOU ARE SO SWEET
its DEF not 2nd nature lol ive been drawing for over 20 yrs now and still struggle with stiffness and line weight and foreshortening on a lot of poses. the best advice i have is to USE REFERENCES!! draw parallel to them, trace a sketch model over them to work off of, cut them up and splice them together to get closer to whats in your head, take photos of yourself, ask your discord friends with diff body types to show you their knees, etc etc etc.
@adorkastock is a FANTASTIC place to find both mundane and dynamic poses. I also recommend fatphotoref.com, publicdomainpictures.net, vishopper.com, line-of-action.com, and referenceangle.com as well as any free use stock photos.
(Protip: on image results on search engines, you can filter by creative licenses! go to the top of the results page; on google its under tools > usage rights, on qwant its under filters > any license, and on duckduckgo its in the 'all licenses' dropdown. u can choose 'creative commons' 'public domain' 'non-commercial' etc. This seems to help filter out AI results lol)
one thing that IS 2nd nature to me and i think helps put a lot of life into my drawings is that my sketch layers are very loosey goosey. when ur doing ur first sketch, dont worry about anatomy or anything, just doodle loose lines that have the shape/feel of what ur lookin for. THEN i worry about references/anatomy etc on a 2nd sketch layer, with my lower layer reminding me where to put emphasis and weight and what type of emotion/expression I was going for etc.



Its a lot harder for me to draw smth good without some kind of foundation, and a sloppy sketch layer gives me that AND lets me get out the idea quick and return to it later, while not feeling pressure to make it perfect! i tend to lose a lot of that whimsy and movement during the inking stage, which im still trying to figure out lol - but i think thats pretty universal? My example here is more cartoony so its less of an issue but you can see it a bit in the bend of the fingers and elbow.
Good luck on your drawing journey!!!! i hope this was helpful or at least interesting lmaoo
#anonymous#drawing#drawing tips#drawing references#my post#as usual i cannot give a short answer to anything
109 notes
·
View notes
Text
A call to action???
Actually it's more like a request because I'm not having any luck with this irregardless of which search engine I use.
I used to have a screen reader phone app and it just straight up stopped working. Basically I just need something that I can plug a massive block of text into it and have it read aloud.
I would prefer it was a desktop program rather then an app but either would work. I don't want any AI horseshit. Dr. SPADOS existed in DOS. It's been possible to have a mechanized voice read things since the mid 90s. I don't understand why this is so damn difficult. I don't really care what it sounds like/gender either as long as I can understand it.
Please reblog for reach so I can maybe get some recommendations?
28 notes
·
View notes
Text
@oakfern replied to your post “it's going to be fun to watch the realization...”:
i feel like this is going to play out very similarly to voice assistants. there was a huge boom in ASR research, the products got a lot of hype, and they actually sold decently (at least alexa did). but 10 years on, they've been a massive failure, costing way more than they ever made back. even if ppl do think chatbot search engines are exciting and cool, it's not going to bring in more users or sell more products, and in the end it will just be a financial loss
(Responding to this a week late)
I don't know much about the history of voice assistants. Are there any articles you recommend on the topic? Sounds interesting.
ETA: Iater, I found and read this article from Nov 2022, which reports that Alexa and co. still can't turn a profit after many years of trying.
But anyway, yeah... this is why I don't have a strong sense of how widespread/popular these "generative AI" products will be a year or two from now. Or even five years from now.
(Ten years from now? Maybe we can trust the verdict will be in at that point... but the tech landscape of 2033 is going to be so different from ours that the question "did 'generative AI' take off or not?" will no doubt sound quaint and irrelevant.)
Remember when self-driving cars were supposed to be right around the corner? Lots of people took this imminent self-driving future seriously.
And I looked at it, and thought "I don't get it, this problem seems way harder than people are giving it credit for. And these companies show no signs of having discovered some clever proprietary way forward." If people asked me about it, that's what I would say.
But even if I was sure that self-driving cars wouldn't arrive on schedule, that didn't give me much insight into the fate of "self-driving cars," the tech sector meme. It wasn't like there was some specific deadline, and when we crossed it everyone was going to look up and say "oh, I guess that didn't work, time to stop investing."
The influx of capital -- and everything downstream from it, the trusting news stories, the prominence of the "self-driving car future" in the public mind, the seriousness which it was talked about -- these things went on, heedless of anything except their own mysterious internal logic.
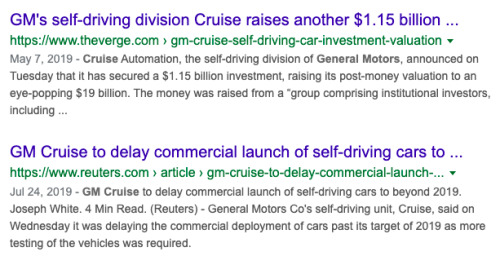
They went on until . . . what? The pandemic, probably? I actually still don't know.
Something definitely happened:
In 2018 analysts put the market value of Waymo LLC, then a subsidiary of Alphabet Inc., at $175 billion. Its most recent funding round gave the company an estimated valuation of $30 billion, roughly the same as Cruise. Aurora Innovation Inc., a startup co-founded by Chris Urmson, Google’s former autonomous-vehicle chief, has lost more than 85% since last year [i.e. 2021] and is now worth less than $3 billion. This September a leaked memo from Urmson summed up Aurora’s cash-flow struggles and suggested it might have to sell out to a larger company. Many of the industry’s most promising efforts have met the same fate in recent years, including Drive.ai, Voyage, Zoox, and Uber’s self-driving division. “Long term, I think we will have autonomous vehicles that you and I can buy,” says Mike Ramsey, an analyst at market researcher Gartner Inc. “But we’re going to be old.”
Whatever killed the "self-driving car" meme, though, it wasn't some newly definitive article of proof that the underlying ideas were flawed. The ideas never made sense in the first place. The phenomenon was not really about the ideas making sense.
Some investors -- with enough capital, between them, to exert noticable distortionary effects on entire business sectors -- decided that "self-driving cars" were, like, A Thing now. And so they were, for a number of years. Huge numbers of people worked very hard trying to make "self-driving cars" into a viable product. They were paid very well to do. Talent was diverted away from other projects, en masse, into this effort. This went on as long as the investors felt like sustaining it, and they were in no danger of running out of money.
Often the "tech sector" feels less like a product of free-market incentives than it does like a massive, weird, and opaque public works product, orchestrated by eccentrics like Masayoshi Son, and ultimately organized according to the aesthetic proclivities and changing moods of its architects, not for the purpose of "doing business" in the conventional sense.
Gig economy delivery apps (Uber Eats, Doordash, etc.) have been ubiquitous for years, and have reported huge losses in every one of those years.
This entertaining post from 2020 about "pizza arbitrage" asks:
Which brings us to the question - what is the point of all this? These platforms are all losing money. Just think of all the meetings and lines of code and phone calls to make all of these nefarious things happen which just continue to bleed money. Why go through all this trouble?
Grubhub just lost $33 million on $360 million of revenue in Q1.
Doordash reportedly lost an insane $450 million off $900 million in revenue in 2019 (which does make me wonder if my dream of a decentralized network of pizza arbitrageurs does exist).
Uber Eats is Uber's "most profitable division” 😂😂. Uber Eats lost $461 million in Q4 2019 off of revenue of $734 million. Sometimes I need to write this out to remind myself. Uber Eats spent $1.2 billion to make $734 million. In one quarter.
And now, in February 2023?
DoorDash's total orders grew 27% to 467 million in the fourth quarter. That beat Wall Street’s forecast of 459 million, according to analysts polled by FactSet. Fourth quarter revenue jumped 40% to $1.82 billion, also ahead of analysts’ forecast of $1.77 billion.
But profits remain elusive for the 10-year-old company. DoorDash said its net loss widened to $640 million, or $1.65 per share, in the fourth quarter as it expanded into new categories and integrated Wolt into its operations.
Do their investors really believe these companies are going somewhere, and just taking their time to get there? Or is this more like a subsidy? The lost money (a predictable loss in the long term) merely the price paid for a desired good -- for an intoxicating exercise of godlike power, for the chance to reshape reality to one's whims on a large scale -- collapsing the usual boundary between self and outside, dream and reality? "The gig economy is A Thing, now," you say, and wave your hand -- and so it is.
Some people would pay a lot of money to be a god, I would think.
Anyway, "generative AI" is A Thing now. It wasn't A Thing a year ago, but now it is. How long will it remain one? The best I can say is: as long as the gods are feeling it.
449 notes
·
View notes
Text



Above: before-and-after pictures of this process. Thank you to @cloudywithachanceofsims, @silverthornestudfarm, and @blueridgeequines for giving me permission to use their coats as examples!
CK's Guide to Fixing Pixelated Horse Coats
As we all know, every time you paint a horse (or any pet or werewolf, really) in Create-a-Pet, it inevitably gets pixelated. This is due to the TS4 engine's compression of Sims textures, which it does to theoretically save on file space and load time. The more you paint on your horse (and the more you save it over and over again), the greater the artifact damage becomes, until you're left with a pixelated mess.
Luckily, I've figured out a way to fix it. Yay!
This method uses a program called chaiNNER, which is an incredibly versatile node-based graphics UI that (among many other things) uses AI models to upscale and process images. After a month and a half of experimenting on multiple different types of coats with about a dozen different models, I've identified two AI models that work best at repairing the artifacting damage done by TS4: RealESRGAN_x2plus and 2xAniscale. I extract the painted coats from the tray files using Cmar's Coat Converter, process them using chaiNNER, use Photoshop to make any touch ups (softening hard edges, fixing seams, adding in the appropriate hoof texture), and then create a new hoof swatch to put the newly fixed coat back into the game.
Fair warning: chaiNNER is a bit of a hefty program that requires significant RAM and VRAM to run. If you have a beefy gaming computer, you should have no issues running this (as long as no other major programs - games, graphics programs, etc. - are running as well). If you've got a lower end computer, though, your computer might not be able to handle it and this method might not be for you. Make sure to read all the documentation on chaiNNer's github before proceeding.
Before we begin, we're going to need to gather some resources. We will need:
A graphics program. I use Photoshop, but GIMP or any other program that can work in layers will work too.
chaiNNER
AI Models; these are the ones I use are RealESRGAN_x2plus and 2xAniscale
Cmar's Coat Converter to extract the coat textures from your tray files
Tray Importer (Optionally) to isolate your household tray files and save you the trouble of searching the Tray Folder
The TS4 Horse UV as a helpful guide to make sure all our textures are lined up properly
Sims 4 Studio to create your new package.
I recommend using S4S to export hoof swatch textures from the game or from existing hoof swatch cc. Some popular hoof swatch CC include @walnuthillfarm's Striped Hooves and @pure-winter-cc's Glorious Striped Hooves
This tutorial assumes you are familiar with the basics in how to use Sims 4 Studio, such as how to clone a base-game item & how to import and export textures, and the basic functions of your graphics program, such as adding multiple different image files together as layers. I'll try to keep my explanations as straight-forward as possible.
STEP ONE: Extract the Coats
Install Cmar's Coat Converter and run it. Cmar's Coat Converter works by looking through your tray files for specific texture files (ie. The coats of cats, dogs, horses, and werewolves) and converting them to png files. You can go through the households of your Tray folder one by one, but I typically just use Tray Importer to separate the household containing the horses I want to fix.
Save the extracted coats in a project folder. These are your OG coats.
STEP TWO: Extract the hoof textures
Open up S4S. To extract the hoof swatches from the base game, create a new package by clicking CAS -> New Package, filter everything by species (ie. Horse) and then part type (Hoof color). Highlight all the basegame swatches and then save your new package.
Open up that package and then extract the texture for each swatch. Save them in your project folder (In a 'basegame hooves' folder to keep things organized).
To extract the textures from Hoof Swatch CC files, simply open them up in S4S and repeat the above.
STEP THREE: Download the AI Models
Right as it says on the tin. These are the models I use currently & some notes about them:
RealESRGAN_x2plus - this model is THE workhorse. It repairs artifact damaging with minimal loss to texture quality and results in a very smooth coat. It may sometimes darken the texture a little bit, but it's not noticeable in-game. That being said, it has a harder time with finer details such as spots, individual ticking for roans, dapples etc. I run this one first on all the coats because it usually does the job.
These models are trained to find and repair any incidence of artifacting/jpeg damage and approximate what the image is supposed to look like. The reason RealESRGAN_x2plus has an especially hard time with spots/dapples/tiny repetitive details etc. because it registers those areas as particularly damaged and works extra hard to smooth it out… which can sometimes result in a bit of an iffy coat repair. When things don't turn out the way I want, I turn to...
2xAniscale - I use this model for any appaloosas, roans, sabinos etc. that have very fine detail and came out mangled by RealESRGAN_2xPlus. It's also good for light-duty repairing (in cases where people have only 'saved' the coat once, as opposed to working on it on and off). While not strong enough on its own to tackle the more heavily damaged coats, it still does a decent job while keeping the fine details intact.
Go make a folder somewhere and name it 'AI Models' or something similar, and drop these guys in there.
STEP FOUR: Setting up chaiNNER
Obviously, go ahead and download chaiNNER, and then (through chaiNNER itself) download & install the dependencies. You really only need PyTorch for this, so if you'd like, you can skip NCNN, ONNX, and Stable Diffusion.
At first glance, chaiNNER is a bit overwhelming. It is unlike any other graphics ui I've seen before, but the basic premise is pretty straightforward: you 'chain' together specific functions ('nodes') in order to get your result.
We're going to start by setting up a chain for single coat conversions.
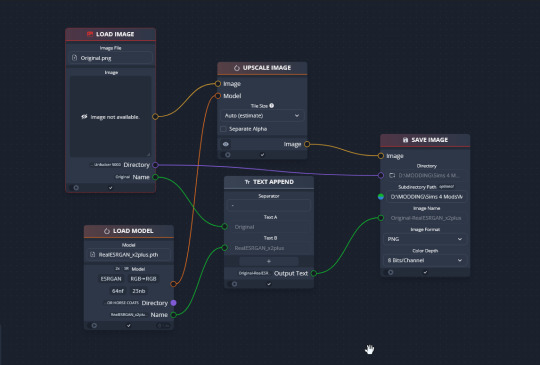
Drag & drop these nodes into your workspace:
Load Image
Save Image
Upscale Image
Load Model (From the PyTorch tab only!)
Text append
Next, connect the nodes just as I have connected them in the image.
Load Image, obviously, loads your image. We then tell the program we want to upscale that image by linking to the Upscale Image node. Upscaling can't happen without a model, so we then want to link Upscale Image with Load Model.
Text Append takes the original name of the image and combines it with the model name. This is super helpful, because if you're playing with many models at a time, you need to tell your result images apart. Link the output text to the Save Image Model.
Finally, Save Image obviously saves the image. We link the directory from Load Image to save it in the same place as the OG image, or, optionally, add in a file path link to another folder (in my case, I load images from a folder called 'Unprocessed' and save them into a folder called 'Processed'. Link the image from Upscale Image to Save Image to complete this chain.
Go in and select your image, model, and save locations.
Ta dah! You made your first chain.
To create an Iterator to batch process coats, we follow the same general idea, only we use 'Load Images'.
STEP FIVE: Run chaiNNER
Go ahead and run chaiNNER. Repeat using 2xAniscale if your spotty/dappled coat comes out funky.
Optionally, you can also add 'Resize' between 'Upscale' and 'Save Image' so the output texture is the same size as the OG. I like keeping mine big, as it makes it easier to fix any fine details in Photoshop.
STEP SIX: Combine in Photoshop
Go ahead and open up the horse UV, your coat texture & hoof swatches in Photoshop. This is a fairly straightforward process: layer the hooves overtop the texture, and then hide all hoof layers except the one you want. Make sure everything is lined up properly using the horse UV.
This is also where you would go in and fix any sharp, jagged edges you might spot. I often notice jagged edges on white face markings. Since the head is often one of the worst areas for artifacting, the AI models don't really have much to work with, resulting in jagged edges as they try to extrapolate what had been there 'before'. Either paint over it or use blur to smooth it out.
I personally would also remove any stray color that isn't the horse texture (body + ears). It won't hurt to leave it there, but I personally like things neat and tidy. Use the horse UV as a guide.
I also add in any little details using extracted stencils & layer masks.
Save your new coat as a png. Optionally, downsize it by 50% back to the original size. I don't do this because I'm very forgetful, but this would definitely help in keeping your package size smaller.
STEP SEVEN (Optional): Make a thumbnail
I make thumbnails for all the coats I do because it makes it much easier to identify them under the Hoof Swatch category. TS4 thumbnails are 144 x 148. You can label it with your horse's name, or stick a headshot in there etc. whatever works for you that will help it stand out from the other hoof swatches.
STEP EIGHT: Put it all Together
Finally, we've come to the end.
Using S4S, create a new package cloned from a hoof swatch. Import your new coat into 'Texture', and your thumbnail into 'Thumbnail'. Make sure you import the thumbnail for both Male and Female!
Check to make sure there aren't major seams, and that your texture is properly projected onto the S4S horse model. If there are seams, go back to check that your texture is lined up properly with the Horse UV. If there are minor seams (legs, chest, underbelly etc.) you can carefully paint (using the same color as on either side of the seam) just beyond the UV mesh boundaries to close the seam.
Then, go into Categories, scroll down, and uncheck Random. This will prevent random townie horses from wearing the coat.
Save your package.
Congratulations! You're done!
#ts4 tutorial#ts4 resource#ts4 guide#Ts4 horse cc#ts4 equestrian cc#sims 4 horse cc#sims 4 equestrian cc#ts4 equestrian#sims 4 equestrian#ts4 horses#sims 4 horses#ts4 horse ranch#sims 4 horse ranch#sims horses
71 notes
·
View notes
Text
Favorite Firefox Extensions
Firefox is a very extensible browser - through a combinations of addons and userscripts you can make it behave just about any way you want. The best part is, they're all free. Here are some of my favorites.
Note: if you have an Android device, check out my post about Firefox for Android's new extended support for addons!
Note: if you have an Apple device, check out my favorite Safari extensions here!
Last updated Dec 2024 (added Absolute Enable Right Click & Copy).
Index:
uBlock Origin
Tab Session Manager
Sauron
Bypass Paywalls Clean
Auto Tab Discard
Video DownloadHelper
Highlight or Hide Search Engine Results
TWP - Translate Web Pages
UnTrap - YouTube Customizer
Indie Wiki Buddy
Cookie Auto Delete
ShopSuey - Get Rid of Ads on Amazon and Ebay
LibraryExtension
Absolute Enable Right Click & Copy
uBlock Origin
(compatible with Firefox for Android)
This is the first addon I install on any new Firefox browser. It's an adblocker, but at its core it can remove pretty much any HTML element from a website, and it comes with pre-configured lists for removing everything from ads to cookie banners to those annoying popups that ask you to sign up for email newsletters.
Tab Session Manager
Have you ever accidentally lost all your open browser tabs due to a computer update, or even just accidentally closing Firefox? With this addon you no longer have to worry about that - it automatically saves your open tabs and windows every time the browser closes, and autosaves a restore point of tabs every few minutes in case the browser crashes unexpectedly. Opening all your previous tabs and windows is a one-click deal.
Sauron
Ever wished your favorite website had a dark mode? With Sauron, now it can! Sauron attempts to intelligently figure out how to edit the color scheme of the web page (including text) to make it dark-mode friendly. It preserves the original color of images, but dims them so that they don't blind you. You can disable image dimming or dark mode on a site by site basis too. It's not perfect since it is making guesses about which colors to change, but it goes a long way toward making the internet an enjoyable place for me.
Bypass Paywalls Clean
This addon removes paywalls from hundreds of news websites around the world or adds links to open the article in a wrapper that provides the article text (like the Internet Archive etc.)
Auto Tab Discard
Ever wanted to keep a tab open for later use, but you notice the browser getting slower and slower the more tabs you have open? Auto Tab Discard will automatically "hibernate" tabs that you haven't used in a while so that they use less resources on your computer. It's smart enough not to hibernate pages that are playing media (like YouTube) or that have forms you haven't submitted yet (like job applications). You can customize how fast it puts tabs to sleep too and exclude certain websites from hibernating at all.
Video DownloadHelper
This addon can download streaming videos from most modern (HTML5) websites, and even finds soft subtitles that accompany the stream and downloads those too. Just browse to the webpage that has the video on it, click the icon in the Firefox toolbar, and select the video you want to download and click "Quick Download". For YouTube I would recommend using a YT downloader website (like KeepVid) to download the video directly, but Video DownloadHelper really shines for websites that aren't popular enough to have dedicated downloader websites like that. I've used it download videos from a Japanese film festival streaming portal, news websites, etc.
Highlight or Hide Search Engine Results
This addon allows you to blacklist websites and completely remove them from Google, Bing, or DuckDuckGo search results. Don't want to see image search results from AI websites? Blacklist them. Searching for tech support advice and getting frustrated by all the auto-generated junk websites that stuff themselves full of SEO terms to jump to the top of the search results without actually providing any information at all? Blacklist them so they don't come up in your next search. Conversely, you can also whitelist websites that you know and trust so that if they ever come up in future search results, they'll be highlighted with a color of your choosing for visibility.
TWP - Translate Web Pages
(compatible with Firefox for Android)
Does what it says on the tin: auto-detects a website's language and provides a button that can translate it to a language of your choosing. You can also just select individual text on the page and translate just that. Note that this sends whatever text you translate to the servers of your selected translation service (Google, Bing, Yandex, or DeepL), so keep in mind the privacy implications if you don't want your IP address associated with having read that text.
Edit: As of version 118, Firefox now has the ability to translate text locally on your computer, without needing to send it to a cloud service. You can enable this in Settings -> Translation -> Install languages for offline translation. Note that at this time (May 2024), 18 (mostly European) languages are supported. More info here.
UnTrap for YouTube
(compatible with Firefox for Android and they have a Safari for iOS extension too)
This addon lets you tweak the YouTube interface and hide anything you don't want to see. For instance, I hide all the "recommended" videos that come up when you search YT now. They have nothing to do with your search, so they're essentially just ads YT puts in your search results. I also hide Explore, Trending, More from YouTube, and Shorts sections, but you can customize it to fit your preferences.
Note: depending on the particular set of tweaks you want to make to YouTube, you may prefer to use YouTube Search Fixer instead. User preference.
Indie Wiki Buddy
I loathe Fandom.com wiki sites - they are cluttered and filled with ads and autoplaying videos that follow you down the page as you scroll. The organization is also hostile - if a community tries to leave their platform and bring their content to a new wiki hoster, Fandom bans them from the platform and reverts all their deletions/changes. Indie Wiki Buddy attempts to find an independent alternative for the wiki you're trying to browse and automatically redirects you to it, and if one doesn't exist, it will redirect you to a proxy site like antifandom or breezewiki that shows the Fandom content but removes all ads/videos/background images so you can actually, you know. READ it.
Cookie Auto Delete
(compatible with Firefox for Android)
Websites store "cookies" - little text files with info about you - on your computer as you browse so they can track you as you browse the internet. This addon automatically deletes cookies from a website a short while after you close the last tab you had open for that site. You can customize how long it waits before clearing cookies too. Note that this can sign you out of many websites, so you can whitelist any site you don't want cookies cleared for.
ShopSuey - Get Rid of Ads on Amazon and Ebay
Removes the ads/recommended products that clutter up Amazon and Ebay search results and product pages.
LibraryExtension
This fantastic addon recognizes when you are viewing a book on many popular websites and can automatically check whether that book is available in any of the library systems or subscription services you have access to, including how many copies your library(ies) have and how many are currently checked out. The best part is it shows the availability for physical books, ebooks, AND audiobooks at supported libraries. The extension currently supports libraries in Australia, Canada, Germany, New Zealand, the United Kingdom and the United States, but it also supports some global repositories like the Internet Archive and subscription services like NLS Bard for the blind and print disabled, Kobo Plus, Libro.fm, Anyplay.fm, Bookmate, and Everand. Great extension for people trying to support their local library and also save money.
Filtering+ for Tumblr
This addon lets you add tags or phrases to your tumblr tag filters with two clicks, without leaving the dashboard. I've been asking Tumblr for this tag filtering behavior on their mobile apps (i.e. press and hold a tag to get a filter option) for at least a year now in asks and surveys, without ever stopping to see if someone had already implemented this on desktop. More fool me. This addon is from the author of XKit Rewritten. Note that the right-click tag filtering only works on the dashboard; it will not appear if you are on someone's blog. Right-clicking selected text to filter the phrase works everywhere based on my testing.
Absolute Enable Right Click & Copy
This addon does its best to re-enable the normal right-click context menu and copy/paste actions on pages that try to disable them. If you run into a site that messes with either of those, select this addon and check "Enable Copy," then try again. If that doesn't work, check "Absolute mode." It doesn't work everywhere, but I find it very helpful.
117 notes
·
View notes