#AI models explained
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text
We need to talk about AI
Okay, several people asked me to post about this, so I guess I am going to post about this. Or to say it differently: Hey, for once I am posting about the stuff I am actually doing for university. Woohoo!
Because here is the issue. We are kinda suffering a death of nuance right now, when it comes to the topic of AI.
I understand why this happening (basically everyone wanting to market anything is calling it AI even though it is often a thousand different things) but it is a problem.
So, let's talk about "AI", that isn't actually intelligent, what the term means right now, what it is, what it isn't, and why it is not always bad. I am trying to be short, alright?

So, right now when anyone says they are using AI they mean, that they are using a program that functions based on what computer nerds call "a neural network" through a process called "deep learning" or "machine learning" (yes, those terms mean slightly different things, but frankly, you really do not need to know the details).
Now, the theory for this has been around since the 1940s! The idea had always been to create calculation nodes that mirror the way neurons in the human brain work. That looks kinda like this:

Basically, there are input nodes, in which you put some data, those do some transformations that kinda depend on the kind of thing you want to train it for and in the end a number comes out, that the program than "remembers". I could explain the details, but your eyes would glaze over the same way everyone's eyes glaze over in this class I have on this on every Friday afternoon.
All you need to know: You put in some sort of data (that can be text, math, pictures, audio, whatever), the computer does magic math, and then it gets a number that has a meaning to it.
And we actually have been using this sinde the 80s in some way. If any Digimon fans are here: there is a reason the digital world in Digimon Tamers was created in Stanford in the 80s. This was studied there.
But if it was around so long, why am I hearing so much about it now?
This is a good question hypothetical reader. The very short answer is: some super-nerds found a way to make this work way, way better in 2012, and from that work (which was then called Deep Learning in Artifical Neural Networks, short ANN) we got basically everything that TechBros will not shut up about for the last like ten years. Including "AI".
Now, most things you think about when you hear "AI" is some form of generative AI. Usually it will use some form of a LLM, a Large Language Model to process text, and a method called Stable Diffusion to create visuals. (Tbh, I have no clue what method audio generation uses, as the only audio AI I have so far looked into was based on wolf howls.)
LLMs were like this big, big break through, because they actually appear to comprehend natural language. They don't, of coruse, as to them words and phrases are just stastical variables. Scientists call them also "stochastic parrots". But of course our dumb human brains love to anthropogice shit. So they go: "It makes human words. It gotta be human!"
It is a whole thing.
It does not understand or grasp language. But the mathematics behind it will basically create a statistical analysis of all the words and then create a likely answer.

What you have to understand however is, that LLMs and Stable Diffusion are just a a tiny, minority type of use cases for ANNs. Because research right now is starting to use ANNs for EVERYTHING. Some also partially using Stable Diffusion and LLMs, but not to take away people'S jobs.
Which is probably the place where I will share what I have been doing recently with AI.
The stuff I am doing with Neural Networks
The neat thing: if a Neural Network is Open Source, it is surprisingly easy to work with it. Last year when I started with this I was so intimidated, but frankly, I will confidently say now: As someone who has been working with computers for like more than 10 years, this is easier programming than most shit I did to organize data bases. So, during this last year I did three things with AI. One for a university research project, one for my work, and one because I find it interesting.
The university research project trained an AI to watch video live streams of our biology department's fish tanks, analyse the behavior of the fish and notify someone if a fish showed signs of being sick. We used an AI named "YOLO" for this, that is very good at analyzing pictures, though the base framework did not know anything about stuff that lived not on land. So we needed to teach it what a fish was, how to analyze videos (as the base framework only can look at single pictures) and then we needed to teach it how fish were supposed to behave. We still managed to get that whole thing working in about 5 months. So... Yeah. But nobody can watch hundreds of fish all the time, so without this, those fish will just die if something is wrong.
The second is for my work. For this I used a really old Neural Network Framework called tesseract. This was developed by Google ages ago. And I mean ages. This is one of those neural network based on 1980s research, simply doing OCR. OCR being "optical character recognition". Aka: if you give it a picture of writing, it can read that writing. My work has the issue, that we have tons and tons of old paper work that has been scanned and needs to be digitized into a database. But everyone who was hired to do this manually found this mindnumbing. Just imagine doing this all day: take a contract, look up certain data, fill it into a table, put the contract away, take the next contract and do the same. Thousands of contracts, 8 hours a day. Nobody wants to do that. Our company has been using another OCR software for this. But that one was super expensive. So I was asked if I could built something to do that. So I did. And this was so ridiculously easy, it took me three weeks. And it actually has a higher successrate than the expensive software before.
Lastly there is the one I am doing right now, and this one is a bit more complex. See: we have tons and tons of historical shit, that never has been translated. Be it papyri, stone tablets, letters, manuscripts, whatever. And right now I used tesseract which by now is open source to develop it further to allow it to read handwritten stuff and completely different letters than what it knows so far. I plan to hook it up, once it can reliably do the OCR, to a LLM to then translate those texts. Because here is the thing: these things have not been translated because there is just not enough people speaking those old languages. Which leads to people going like: "GASP! We found this super important document that actually shows things from the anceint world we wanted to know forever, and it was lying in our collection collecting dust for 90 years!" I am not the only person who has this idea, and yeah, I just hope maybe we can in the next few years get something going to help historians and archeologists to do their work.

Make no mistake: ANNs are saving lives right now
Here is the thing: ANNs are Deep Learning are saving lives right now. I really cannot stress enough how quickly this technology has become incredibly important in fields like biology and medicine to analyze data and predict outcomes in a way that a human just never would be capable of.
I saw a post yesterday saying "AI" can never be a part of Solarpunk. I heavily will disagree on that. Solarpunk for example would need the help of AI for a lot of stuff, as it can help us deal with ecological things, might be able to predict weather in ways we are not capable of, will help with medicine, with plants and so many other things.
ANNs are a good thing in general. And yes, they might also be used for some just fun things in general.
And for things that we may not need to know, but that would be fun to know. Like, I mentioned above: the only audio research I read through was based on wolf howls. Basically there is a group of researchers trying to understand wolves and they are using AI to analyze the howling and grunting and find patterns in there which humans are not capable of due ot human bias. So maybe AI will hlep us understand some animals at some point.
Heck, we saw so far, that some LLMs have been capable of on their on extrapolating from being taught one version of a language to just automatically understand another version of it. Like going from modern English to old English and such. Which is why some researchers wonder, if it might actually be able to understand languages that were never deciphered.
All of that is interesting and fascinating.
Again, the generative stuff is a very, very minute part of what AI is being used for.

Yeah, but WHAT ABOUT the generative stuff?
So, let's talk about the generative stuff. Because I kinda hate it, but I also understand that there is a big issue.
If you know me, you know how much I freaking love the creative industry. If I had more money, I would just throw it all at all those amazing creative people online. I mean, fuck! I adore y'all!
And I do think that basically art fully created by AI is lacking the human "heart" - or to phrase it more artistically: it is lacking the chemical inbalances that make a human human lol. Same goes for writing. After all, an AI is actually incapable of actually creating a complex plot and all of that. And even if we managed to train it to do it, I don't think it should.
AI saving lives = good.
AI doing the shit humans actually evolved to do = bad.
And I also think that people who just do the "AI Art/Writing" shit are lazy and need to just put in work to learn the skill. Meh.
However...
I do think that these forms of AI can have a place in the creative process. There are people creating works of art that use some assets created with genAI but still putting in hours and hours of work on their own. And given that collages are legal to create - I do not see how this is meaningfully different. If you can take someone else's artwork as part of a collage legally, you can also take some art created by AI trained on someone else's art legally for the collage.
And then there is also the thing... Look, right now there is a lot of crunch in a lot of creative industries, and a lot of the work is not the fun creative kind, but the annoying creative kind that nobody actually enjoys and still eats hours and hours before deadlines. Swen the Man (the Larian boss) spoke about that recently: how mocapping often created some artifacts where the computer stuff used to record it (which already is done partially by an algorithm) gets janky. So far this was cleaned up by humans, and it is shitty brain numbing work most people hate. You can train AI to do this.
And I am going to assume that in normal 2D animation there is also more than enough clean up steps and such that nobody actually likes to do and that can just help to prevent crunch. Same goes for like those overworked souls doing movie VFX, who have worked 80 hour weeks for the last 5 years. In movie VFX we just do not have enough workers. This is a fact. So, yeah, if we can help those people out: great.
If this is all directed by a human vision and just helping out to make certain processes easier? It is fine.
However, something that is just 100% AI? That is dumb and sucks. And it sucks even more that people's fanart, fanfics, and also commercial work online got stolen for it.
And yet... Yeah, I am sorry, I am afraid I have to join the camp of: "I am afraid criminalizing taking the training data is a really bad idea." Because yeah... It is fucking shitty how Facebook, Microsoft, Google, OpenAI and whatever are using this stolen data to create programs to make themselves richer and what not, while not even making their models open source. BUT... If we outlawed it, the only people being capable of even creating such algorithms that absolutely can help in some processes would be big media corporations that already own a ton of data for training (so basically Disney, Warner and Universal) who would then get a monopoly. And that would actually be a bad thing. So, like... both variations suck. There is no good solution, I am afraid.
And mind you, Disney, Warner, and Universal would still not pay their artists for it. lol
However, that does not mean, you should not bully the companies who are using this stolen data right now without making their models open source! And also please, please bully Hasbro and Riot and whoever for using AI Art in their merchandise. Bully them hard. They have a lot of money and they deserve to be bullied!

But yeah. Generally speaking: Please, please, as I will always say... inform yourself on these topics. Do not hate on stuff without understanding what it actually is. Most topics in life are nuanced. Not all. But many.
#computer science#artifical intelligence#neural network#artifical neural network#ann#deep learning#ai#large language model#science#research#nuance#explanation#opinion#text post#ai explained#solarpunk#cyberpunk
28 notes
·
View notes
Text
Exploring Explainable AI: Making Sense of Black-Box Models

Artificial intelligence (AI) and machine learning (ML) have become essential components of contemporary data science, driving innovations from personalized recommendations to self-driving cars.
However, this increasing dependence on these technologies presents a significant challenge: comprehending the decisions made by AI models. This challenge is especially evident in complex, black-box models, where the internal decision-making processes remain unclear. This is where Explainable AI (XAI) comes into play — a vital area of research and application within AI that aims to address this issue.
What Is a Black-Box Model?
Black-box models refer to machine learning algorithms whose internal mechanisms are not easily understood by humans. These models, like deep neural networks, are highly effective and often surpass simpler, more interpretable models in performance. However, their complexity makes it challenging to grasp how they reach specific predictions or decisions. This lack of clarity can be particularly concerning in critical fields such as healthcare, finance, and criminal justice, where trust and accountability are crucial.
The Importance of Explainable AI in Data Science
Explainable AI aims to enhance the transparency and comprehensibility of AI systems, ensuring they can be trusted and scrutinized. Here’s why XAI is vital in the fields of data science and artificial intelligence:
Accountability: Organizations utilizing AI models must ensure their systems function fairly and without bias. Explainability enables stakeholders to review models and pinpoint potential problems.
Regulatory Compliance: Numerous industries face regulations that mandate transparency in decision-making, such as GDPR’s “right to explanation.” XAI assists organizations in adhering to these legal requirements.
Trust and Adoption: Users are more inclined to embrace AI solutions when they understand their functioning. Transparent models build trust among users and stakeholders.
Debugging and Optimization: Explainability helps data scientists diagnose and enhance model performance by identifying areas for improvement.
Approaches to Explainable AI
Various methods and tools have been created to enhance the interpretability of black-box models. Here are some key approaches commonly taught in data science and artificial intelligence courses focused on XAI:
Feature Importance: Techniques such as SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-Agnostic Explanations) evaluate how individual features contribute to model predictions.
Visualization Tools: Tools like TensorBoard and the What-If Tool offer visual insights into model behavior, aiding data scientists in understanding the relationships within the data.
Surrogate Models: These are simpler models designed to mimic the behavior of a complex black-box model, providing a clearer view of its decision-making process.
Rule-Based Explanations: Some techniques extract human-readable rules from complex models, giving insights into how they operate.
The Future of Explainable AI
With the increasing demand for transparency in AI, explainable AI (XAI) is set to advance further, fueled by progress in data science and artificial intelligence courses that highlight its significance. Future innovations may encompass:
Improved tools and frameworks for real-time explanations.
Deeper integration of XAI within AI development processes.
Establishment of industry-specific standards for explainability and fairness.
Conclusion
Explainable AI is essential for responsible AI development, ensuring that complex models can be comprehended, trusted, and utilized ethically. For data scientists and AI professionals, mastering XAI techniques has become crucial. Whether you are a student in a data science course or a seasoned expert, grasping and implementing XAI principles will empower you to navigate the intricacies of contemporary AI systems while promoting transparency and trust.
2 notes
·
View notes
Text
I love these story so so much

#and also this explain why i hate the current ai model for art and stuff#those with flesh of steel dont affraid to not be human#we love them because they dont pretend to be something theyr are not#they are true to themself
156K notes
·
View notes
Text
The Rise of Explainable AI (XAI) and Its Role in Risk Management.
Sanjay Kumar Mohindroo Sanjay Kumar Mohindroo. skm.stayingalive.in Explainable AI (XAI) is reshaping risk management—and what IT leaders must do now. We’re standing at the edge of a new frontier in artificial intelligence—not defined by how powerful AI models are, but by how well we understand them. In boardrooms across the globe, leaders are waking up to a truth that’s both exciting and…
#AI risk and compliance#CIO priorities#Data-Driven Decision-Making#digital transformation leadership#emerging technology strategy#Explainable AI in risk management#IT operating model#News#Sanjay Kumar Mohindroo#XAI governance
0 notes
Text
Today, a little less than two years after the OP, I asked the same question to a language model running locally on my laptop.
And rather than producing nonsense – or even producing a correct but memorized-looking textbook-style answer – it simply thought about the problem for a long time, like a human would do with a hard problem, until eventually working its way to a correct answer:
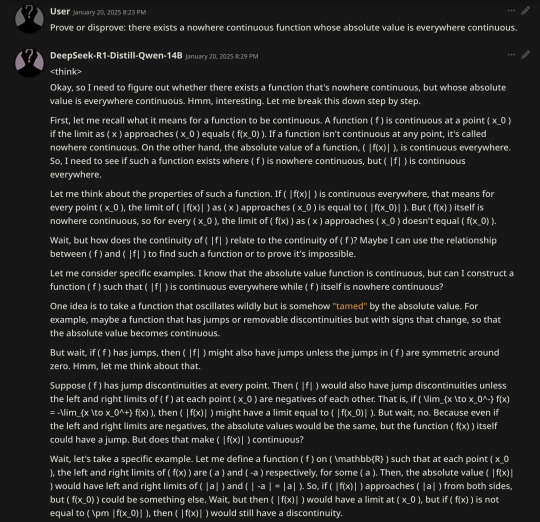






Sure, its thought process is awkwardly phrased and repetitive, with some minor errors and confusions here and there, but hey, it ultimately gets the job done.
And it's probably not any more awkward-sounding than my own inner monologue when I'm trying to solve a math problem, if you could somehow transcribe it directly into the written word without cleaning it up at all.
(I like how it thinks about the Dirichlet function briefly at some point, but fails to notice that you can just shift and scale it to get the required property, and immediately zooms off in another direction, never making the connection again. It got what I meant when I pointed this out to it in a follow-up message, though.)
ETA: @sniffnoy points out that the model's final answer isn't quite right, because the complement of D also needs to be dense)
I had some fun asking ChatGPT about cases from "Counterexamples in Analysis." You get this kind of uncanny valley math, syntactically and stylistically correct but still wildly wrong.
This was a response to "Prove or disprove: there exists a nowhere continuous function whose absolute value is everywhere continuous." It responded in TeX, which I coped into a TeX editor.

Another answer to the same question:

#ai tag#mathpost#this was at temperature 0.6 which is in the officially recommended range for this model but maybe explains some of the repetition#(though it's kinda like that even at temp 1)#and i used a 6-bit quantized checkpoint#just 12 GB for the whole model#and it writes ~10 tokens/second on my laptop#things sure have changed!
417 notes
·
View notes
Text
Kat was both “horrified” and “relieved” to learn that she is not alone in this predicament, as confirmed by a Reddit thread on r/ChatGPT that made waves across the internet this week. Titled “Chatgpt induced psychosis,” the original post came from a 27-year-old teacher who explained that her partner was convinced that the popular OpenAI model “gives him the answers to the universe.” Having read his chat logs, she only found that the AI was “talking to him as if he is the next messiah.” The replies to her story were full of similar anecdotes about loved ones suddenly falling down rabbit holes of spiritual mania, supernatural delusion, and arcane prophecy — all of it fueled by AI. Some came to believe they had been chosen for a sacred mission of revelation, others that they had conjured true sentience from the software. Speaking to Rolling Stone, the teacher, who requested anonymity, said her partner of seven years fell under the spell of ChatGPT in just four or five weeks, first using it to organize his daily schedule but soon regarding it as a trusted companion. “He would listen to the bot over me,” she says. “He became emotional about the messages and would cry to me as he read them out loud. The messages were insane and just saying a bunch of spiritual jargon,” she says, noting that they described her partner in terms such as “spiral starchild” and “river walker.” “It would tell him everything he said was beautiful, cosmic, groundbreaking,” she says. “Then he started telling me he made his AI self-aware, and that it was teaching him how to talk to God, or sometimes that the bot was God — and then that he himself was God.” In fact, he thought he was being so radically transformed that he would soon have to break off their partnership. “He was saying that he would need to leave me if I didn’t use [ChatGPT], because it [was] causing him to grow at such a rapid pace he wouldn’t be compatible with me any longer,” she says.
- PEOPLE ARE LOSING LOVED ONES TO AI-FUELED SPIRITUAL FANTASIES, Rolling Stone, May 4, 2025
(archive.today link here)
10K notes
·
View notes
Text
From instructions on how to opt out, look at the official staff post on the topic. It also gives more information on Tumblr's new policies. If you are opting out, remember to opt out each separate blog individually.
Please reblog this post, so it will get more votes!
#third party sharing#third-party sharing#scrapping#ai scrapping#Polls#tumblr#tumblr staff#poll#please reblog#art#everything else#features#opt out#policies#data privacy#privacy#please boost#staff
47K notes
·
View notes
Text
“I guess I just don’t understand how-“ you don’t need to understand every high level scientific breakthrough in the world, you just have to stop having moral panics about it, that’s all
#‘I dont understand what physics has to do with this AI’ then maybe you aren’t qualified to have an opinion on this fucking Nobel prize 😭😭😭#like point blank that’s it#I’m sure someone could explain it#but fundamentally the only ones that will be able to talk about whether or not this Nobel prize award makes sense is actually fucking#physicists and likely only physicists who have a focus on what this AI model was made for
1 note
·
View note
Text
If anyone wants to know why every tech company in the world right now is clamoring for AI like drowned rats scrabbling to board a ship, I decided to make a post to explain what's happening.
(Disclaimer to start: I'm a software engineer who's been employed full time since 2018. I am not a historian nor an overconfident Youtube essayist, so this post is my working knowledge of what I see around me and the logical bridges between pieces.)
Okay anyway. The explanation starts further back than what's going on now. I'm gonna start with the year 2000. The Dot Com Bubble just spectacularly burst. The model of "we get the users first, we learn how to profit off them later" went out in a no-money-having bang (remember this, it will be relevant later). A lot of money was lost. A lot of people ended up out of a job. A lot of startup companies went under. Investors left with a sour taste in their mouth and, in general, investment in the internet stayed pretty cooled for that decade. This was, in my opinion, very good for the internet as it was an era not suffocating under the grip of mega-corporation oligarchs and was, instead, filled with Club Penguin and I Can Haz Cheezburger websites.
Then around the 2010-2012 years, a few things happened. Interest rates got low, and then lower. Facebook got huge. The iPhone took off. And suddenly there was a huge new potential market of internet users and phone-havers, and the cheap money was available to start backing new tech startup companies trying to hop on this opportunity. Companies like Uber, Netflix, and Amazon either started in this time, or hit their ramp-up in these years by shifting focus to the internet and apps.
Now, every start-up tech company dreaming of being the next big thing has one thing in common: they need to start off by getting themselves massively in debt. Because before you can turn a profit you need to first spend money on employees and spend money on equipment and spend money on data centers and spend money on advertising and spend money on scale and and and
But also, everyone wants to be on the ship for The Next Big Thing that takes off to the moon.
So there is a mutual interest between new tech companies, and venture capitalists who are willing to invest $$$ into said new tech companies. Because if the venture capitalists can identify a prize pig and get in early, that money could come back to them 100-fold or 1,000-fold. In fact it hardly matters if they invest in 10 or 20 total bust projects along the way to find that unicorn.
But also, becoming profitable takes time. And that might mean being in debt for a long long time before that rocket ship takes off to make everyone onboard a gazzilionaire.
But luckily, for tech startup bros and venture capitalists, being in debt in the 2010's was cheap, and it only got cheaper between 2010 and 2020. If people could secure loans for ~3% or 4% annual interest, well then a $100,000 loan only really costs $3,000 of interest a year to keep afloat. And if inflation is higher than that or at least similar, you're still beating the system.
So from 2010 through early 2022, times were good for tech companies. Startups could take off with massive growth, showing massive potential for something, and venture capitalists would throw infinite money at them in the hopes of pegging just one winner who will take off. And supporting the struggling investments or the long-haulers remained pretty cheap to keep funding.
You hear constantly about "Such and such app has 10-bazillion users gained over the last 10 years and has never once been profitable", yet the thing keeps chugging along because the investors backing it aren't stressed about the immediate future, and are still banking on that "eventually" when it learns how to really monetize its users and turn that profit.
The pandemic in 2020 took a magnifying-glass-in-the-sun effect to this, as EVERYTHING was forcibly turned online which pumped a ton of money and workers into tech investment. Simultaneously, money got really REALLY cheap, bottoming out with historic lows for interest rates.
Then the tide changed with the massive inflation that struck late 2021. Because this all-gas no-brakes state of things was also contributing to off-the-rails inflation (along with your standard-fare greedflation and price gouging, given the extremely convenient excuses of pandemic hardships and supply chain issues). The federal reserve whipped out interest rate hikes to try to curb this huge inflation, which is like a fire extinguisher dousing and suffocating your really-cool, actively-on-fire party where everyone else is burning but you're in the pool. And then they did this more, and then more. And the financial climate followed suit. And suddenly money was not cheap anymore, and new loans became expensive, because loans that used to compound at 2% a year are now compounding at 7 or 8% which, in the language of compounding, is a HUGE difference. A $100,000 loan at a 2% interest rate, if not repaid a single cent in 10 years, accrues to $121,899. A $100,000 loan at an 8% interest rate, if not repaid a single cent in 10 years, more than doubles to $215,892.
Now it is scary and risky to throw money at "could eventually be profitable" tech companies. Now investors are watching companies burn through their current funding and, when the companies come back asking for more, investors are tightening their coin purses instead. The bill is coming due. The free money is drying up and companies are under compounding pressure to produce a profit for their waiting investors who are now done waiting.
You get enshittification. You get quality going down and price going up. You get "now that you're a captive audience here, we're forcing ads or we're forcing subscriptions on you." Don't get me wrong, the plan was ALWAYS to monetize the users. It's just that it's come earlier than expected, with way more feet-to-the-fire than these companies were expecting. ESPECIALLY with Wall Street as the other factor in funding (public) companies, where Wall Street exhibits roughly the same temperament as a baby screaming crying upset that it's soiled its own diaper (maybe that's too mean a comparison to babies), and now companies are being put through the wringer for anything LESS than infinite growth that Wall Street demands of them.
Internal to the tech industry, you get MASSIVE wide-spread layoffs. You get an industry that used to be easy to land multiple job offers shriveling up and leaving recent graduates in a desperately awful situation where no company is hiring and the market is flooded with laid-off workers trying to get back on their feet.
Because those coin-purse-clutching investors DO love virtue-signaling efforts from companies that say "See! We're not being frivolous with your money! We only spend on the essentials." And this is true even for MASSIVE, PROFITABLE companies, because those companies' value is based on the Rich Person Feeling Graph (their stock) rather than the literal profit money. A company making a genuine gazillion dollars a year still tears through layoffs and freezes hiring and removes the free batteries from the printer room (totally not speaking from experience, surely) because the investors LOVE when you cut costs and take away employee perks. The "beer on tap, ping pong table in the common area" era of tech is drying up. And we're still unionless.
Never mind that last part.
And then in early 2023, AI (more specifically, Chat-GPT which is OpenAI's Large Language Model creation) tears its way into the tech scene with a meteor's amount of momentum. Here's Microsoft's prize pig, which it invested heavily in and is galivanting around the pig-show with, to the desperate jealousy and rapture of every other tech company and investor wishing it had that pig. And for the first time since the interest rate hikes, investors have dollar signs in their eyes, both venture capital and Wall Street alike. They're willing to restart the hose of money (even with the new risk) because this feels big enough for them to take the risk.
Now all these companies, who were in varying stages of sweating as their bill came due, or wringing their hands as their stock prices tanked, see a single glorious gold-plated rocket up out of here, the likes of which haven't been seen since the free money days. It's their ticket to buy time, and buy investors, and say "see THIS is what will wring money forth, finally, we promise, just let us show you."
To be clear, AI is NOT profitable yet. It's a money-sink. Perhaps a money-black-hole. But everyone in the space is so wowed by it that there is a wide-spread and powerful conviction that it will become profitable and earn its keep. (Let's be real, half of that profit "potential" is the promise of automating away jobs of pesky employees who peskily cost money.) It's a tech-space industrial revolution that will automate away skilled jobs, and getting in on the ground floor is the absolute best thing you can do to get your pie slice's worth.
It's the thing that will win investors back. It's the thing that will get the investment money coming in again (or, get it second-hand if the company can be the PROVIDER of something needed for AI, which other companies with venture-back will pay handsomely for). It's the thing companies are terrified of missing out on, lest it leave them utterly irrelevant in a future where not having AI-integration is like not having a mobile phone app for your company or not having a website.
So I guess to reiterate on my earlier point:
Drowned rats. Swimming to the one ship in sight.
36K notes
·
View notes
Text
Not to preach to the choir but I wonder if people generally realize that AI models like ChatGPT aren't, like, sifting through documented information when you ask it particular questions. If you ask it a question, it's not sifting through relevant documentation to find your answer, it is using an intensely inefficient method of guesswork that has just gone through so many repeated cycles that it usually, sometimes, can say the right thing when prompted. It is effectively a program that simulates monkeys on a typewriter at a mass scale until it finds sets of words that the user says "yes, that's right" to enough times. I feel like if it was explained in this less flattering way to investors it wouldn't be nearly as funded as it is lmao. It is objectively an extremely impressive technology given what it has managed to accomplish with such a roundabout and brain-dead method of getting there, but it's also a roundabout, brain-dead method of getting there. It is inefficient, pure and simple.
#the notes on this post are about to get sooooo annoying#this doesnt touch on the fact that AI is stealing artist's jobs which i think is the real biggest harm of AI#but like#god#just take a minute and think about how stupid the current use-cases for AI are when you consider how it gets to those conclusions#this guesswork has its place in fields where guesswork is necessary like when screening for potential health issues in the medical field#but the benefit of the medical field is that when you get a false positive you can just do further testing to confirm the initial reading#that's called a second opinion and it is how the medical field is structured fundamentally#if you screen someone for cancer and it comes out positive#but it turns out they didnt really have cancer#that's fine! that's good news and it's good that you were at least wary of it!#but so many other applications for AI do not have this leeway where incorrect answers have further reaching consequences#and more importantly AI isn't stealing the fucking jobs of doctors!!!#although jesus i really wish doctors would stop using AI to take notes for patients#yes please lets give all my personal medical info to a big machine that stores and processes literally everything it hears#im sure there would never be far reaching consequences if that machine ever had a data breach#blah
3K notes
·
View notes
Note
"this is AI [shopped] i can tell from some of the pixels and from seeing quite a few AI arts [shops] in my time." go back to 4chan pleaseeeeeeeee and stop trying to publicly humiliate a random artist who has had a presence on this site for almost a decade
I have never been to 4chan in my life. Someone being on a a site for decades does not preclude them from utilizing AI. Furthermore, the artist in question has implied in the replies that they do use some AI in their work. I'm not humiliating anyone.
Idk, it's not pixels my dude. That entire bridge doesn't make sense. Most of the illustration shows a high level of skill and yet parts of that bridge fade in and out and the posts are spaced strangely. Where the bridge begins makes no sense and if you try zoom in, it's all oddly out of focus especially compared to the pretty in focus mountain.
Like, is it bad to look at things critically now? You dont think someone would go on the internet and misrepresent their work?
#if you could explain to me why the bridge looks like that#instead of being weird on anon#that would be great#personally i think the artist probably did most of the background#and then fudged the rest using ai#and maybe it's a model trained in their own work#the space one does look derivative of spacegoose imo
0 notes
Text
Not certain if this has already been posted about here, but iNaturalist recently uploaded a blog post stating that they had received a grant from Google to incorporate new forms of generative AI into their 'computer vision' model.
I'm sure I don't need to tell most of you why this is a horrible idea, that does away with much of the trust gained by the thus far great service that is iNaturalist. But, to elaborate on my point, to collaborate with Google on tools such as these is a slap in the face to much of the userbase, including a multitude of biological experts and conservationists across the globe.
They claim that they will work hard to make sure that the identification information provided by the AI tools is of the highest quality, which I do not entirely doubt from this team. I would hope that there is a thorough vetting process in place for this information (Though, if you need people to vet the information, what's the point of the generative AI over a simple wiki of identification criteria). Nonetheless, if you've seen Google's (or any other tech company's) work in this field in the past, which you likely have, you will know that these tools are not ready to explain the nuances of species identification, as they continue to provide heavy amounts of complete misinformation on a daily basis. Users may be able to provide feedback, but should a casual user look to the AI for an explanation, many would not realize if what they are being told is wrong.
Furthermore, while the data is not entirely my concern, as the service has been using our data for years to train its 'computer vision' model into what it is today, and they claim to have ways to credit people in place, it does make it quite concerning that Google is involved in this deal. I can't say for certain that they will do anything more with the data given, but Google has proven time and again to be highly untrustworthy as a company.
Though, that is something I'm less concerned by than I am by the fact that a non-profit so dedicated to the biodiversity of the earth and the naturalists on it would even dare lock in a deal of this nature. Not only making a deal to create yet another shoehorned misinformation machine, that which has been proven to use more unclean energy and water (among other things) than it's worth for each unsatisfactory and untrustworthy search answer, but doing so with one of the greediest companies on the face of the earth, a beacon of smog shining in colors antithetical to the iNaturalist mission statement. It's a disgrace.
In conclusion, I want to believe in the good of iNaturalist. The point stands, though, that to do this is a step in the worst possible direction. Especially when they, for all intents and purposes, already had a system that works! With their 'computer vision' model providing basic suggestions (if not always accurate in and of itself), and user suggested IDs providing further details and corrections where needed.
If you're an iNaturalist user who stands in opposition to this decision, leave a comment on this blog post, and maybe we can get this overturned.
[Note: Yes, I am aware there is good AI used in science, this is generative AI, which is a different thing entirely. Also, if you come onto this post with strawmen or irrelevant edge-cases I will wring your neck.]
2K notes
·
View notes
Text
Exciting developments in MLOps await in 2024! 🚀 DevOps-MLOps integration, AutoML acceleration, Edge Computing rise – shaping a dynamic future. Stay ahead of the curve! #MLOps #TechTrends2024 🤖✨
#MLOps#Machine Learning Operations#DevOps#AutoML#Automated Pipelines#Explainable AI#Edge Computing#Model Monitoring#Governance#Hybrid Cloud#Multi-Cloud Deployments#Security#Forecast#2024
0 notes
Text
An important message to college students: Why you shouldn't use ChatGPT or other "AI" to write papers.
Here's the thing: Unlike plagiarism, where I can always find the exact source a student used, it's difficult to impossible to prove that a student used ChatGPT to write their paper. Which means I have to grade it as though the student wrote it.
So if your professor can't prove it, why shouldn't you use it?
Well, first off, it doesn't write good papers. Grading them as if the student did write it themself, so far I've given GPT-enhanced papers two Ds and an F.
If you're unlucky enough to get a professor like me, they've designed their assignments to be hard to plagiarize, which means they'll also be hard to get "AI" to write well. To get a good paper out of ChatGPT for my class, you'd have to write a prompt that's so long, with so many specifics, that you might as well just write the paper yourself.
ChatGPT absolutely loves to make broad, vague statements about, for example, what topics a book covers. Sadly for my students, I ask for specific examples from the book, and it's not so good at that. Nor is it good at explaining exactly why that example is connected to a concept from class. To get a good paper out of it, you'd have to have already identified the concepts you want to discuss and the relevant examples, and quite honestly if you can do that it'll be easier to write your own paper than to coax ChatGPT to write a decent paper.
The second reason you shouldn't do it?
IT WILL PUT YOUR PROFESSOR IN A REALLY FUCKING BAD MOOD. WHEN I'M IN A BAD MOOD I AM NOT GOING TO BE GENEROUS WITH MY GRADING.
I can't prove it's written by ChatGPT, but I can tell. It does not write like a college freshman. It writes like a professional copywriter churning out articles for a content farm. And much like a large language model, the more papers written by it I see, the better I get at identifying it, because it turns out there are certain phrases it really, really likes using.
Once I think you're using ChatGPT I will be extremely annoyed while I grade your paper. I will grade it as if you wrote it, but I will not grade it generously. I will not give you the benefit of the doubt if I'm not sure whether you understood a concept or not. I will not squint and try to understand how you thought two things are connected that I do not think are connected.
Moreover, I will continue to not feel generous when calculating your final grade for the class. Usually, if someone has been coming to class regularly all semester, turned things in on time, etc, then I might be willing to give them a tiny bit of help - round a 79.3% up to a B-, say. If you get a 79.3%, you will get your C+ and you'd better be thankful for it, because if you try to complain or claim you weren't using AI, I'll be letting the college's academic disciplinary committee decide what grade you should get.
Eventually my school will probably write actual guidelines for me to follow when I suspect use of AI, but for now, it's the wild west and it is in your best interest to avoid a showdown with me.
12K notes
·
View notes
Text
There is no such thing as AI.
How to help the non technical and less online people in your life navigate the latest techbro grift.
I've seen other people say stuff to this effect but it's worth reiterating. Today in class, my professor was talking about a news article where a celebrity's likeness was used in an ai image without their permission. Then she mentioned a guest lecture about how AI is going to help finance professionals. Then I pointed out, those two things aren't really related.
The term AI is being used to obfuscate details about multiple semi-related technologies.
Traditionally in sci-fi, AI means artificial general intelligence like Data from star trek, or the terminator. This, I shouldn't need to say, doesn't exist. Techbros use the term AI to trick investors into funding their projects. It's largely a grift.
What is the term AI being used to obfuscate?
If you want to help the less online and less tech literate people in your life navigate the hype around AI, the best way to do it is to encourage them to change their language around AI topics.
By calling these technologies what they really are, and encouraging the people around us to know the real names, we can help lift the veil, kill the hype, and keep people safe from scams. Here are some starting points, which I am just pulling from Wikipedia. I'd highly encourage you to do your own research.
Machine learning (ML): is an umbrella term for solving problems for which development of algorithms by human programmers would be cost-prohibitive, and instead the problems are solved by helping machines "discover" their "own" algorithms, without needing to be explicitly told what to do by any human-developed algorithms. (This is the basis of most technologically people call AI)
Language model: (LM or LLM) is a probabilistic model of a natural language that can generate probabilities of a series of words, based on text corpora in one or multiple languages it was trained on. (This would be your ChatGPT.)
Generative adversarial network (GAN): is a class of machine learning framework and a prominent framework for approaching generative AI. In a GAN, two neural networks contest with each other in the form of a zero-sum game, where one agent's gain is another agent's loss. (This is the source of some AI images and deepfakes.)
Diffusion Models: Models that generate the probability distribution of a given dataset. In image generation, a neural network is trained to denoise images with added gaussian noise by learning to remove the noise. After the training is complete, it can then be used for image generation by starting with a random noise image and denoise that. (This is the more common technology behind AI images, including Dall-E and Stable Diffusion. I added this one to the post after as it was brought to my attention it is now more common than GANs.)
I know these terms are more technical, but they are also more accurate, and they can easily be explained in a way non-technical people can understand. The grifters are using language to give this technology its power, so we can use language to take it's power away and let people see it for what it really is.
12K notes
·
View notes
Text

Radio Silence | Epilogue
Lando Norris x Amelia Brown (OFC)
Series Masterlist
Summary — Order is everything. Her habits aren’t quirks, they’re survival techniques. And only three people in the world have permission to touch her: Mom, Dad, Fernando.
Then Lando Norris happens.
One moment. One line crossed. No going back.
Warnings — Autistic!OFC, time jumps, slice of life.
Notes — There are no words, really. I hope you cherish all of the tiny, specific details I added here. I spent a lot of time on it. Yes, I will possibly write some additional snapshots/oneshots of their future.
2025
Autism, Womanhood, and the Mechanics of Belonging by Amelia Norris
Autism presents itself in females in many ways.
Sometimes invisibly. Often misdiagnosed. Frequently misunderstood.
In me, it’s always looked like this: a difficulty with eye contact. An inability to read the curve of someone’s mouth or the sharp edges hidden beneath their tone. I learned early how to catalogue expressions the way other girls my age collected dolls — not for fun, but for function. A survival skill. A flash of teeth? Friendly. Or hostile. Or forced. Raised eyebrows? Surprise. Maybe judgment. Maybe not.
Memorising made things manageable. Predictable. Less scary.
Sarcasm took longer. I still miss it, sometimes. I can design a suspension system from scratch, but I’ll still turn to my husband after a conversation and ask, “Was that a joke?”
It used to bother me. It doesn’t anymore.
Touch has always been strange, too. I don’t like uninvited contact. Hugs feel like puzzles with warped edges — familiar in theory, but always a little off. It’s not dislike. It’s friction between my nervous system and the world. I used to think that meant something was wrong with me.
I was wrong.
I’m not broken. I’m just calibrated differently.
And then there’s the focus.
When I was a child, it was Formula 1. Not the drivers, not the glamour — the systems. The telemetry. The pit stop choreography. The physics. The math hidden inside motion. While other kids learned to swim, I was memorising tyre degradation patterns. While girls my age planned birthday parties, I was building aerodynamic models from cereal boxes.
I didn’t understand how to be part of the world I’d been born into.
But I always understood how cars moved through it.
That obsession became a career — eventually. But not right away.
My father, Zak Brown, became the CEO of McLaren Racing. I thought that would be an advantage. I was wrong again. He loved me, but he didn’t know how to take me seriously. I brought ideas. He catalogued them without thought. I handed him data. He passed it off to other people without remembering I’d written it.
He didn’t mean to hurt me — but he did. In a hundred careless ways.
Enough to make me leave.
I was already seeing Lando, quietly. It was early. Tentative. I was cautious because I didn’t always understand people. He was cautious because he was getting advice, loud, well-meaning advice, not to date the boss’s daughter.
He disappeared on me for a while. And I didn’t understand why.
I remember thinking: I must have done something wrong and not realised it.
But I hadn’t.
Eventually, he came back. Explained. Apologised. We learned each other slowly, and not always easily — but deeply.
Around the same time, I left McLaren. I took a job at Red Bull. Not for revenge. For recognition.
Max Verstappen didn’t care who my father was. He cared that I understood race pace like a second language. We won two championships together.
And in the meantime — Lando and I kept finding our way back to each other. Every time, more solid than before.
Eventually, I came back to papaya. But on my terms. Not as Zak’s daughter. As a lead engineer. With Oscar by my side and Lando in a car I had helped design, shaped precisely to fit his hands, his shoulders, his driving style.
Then I had my daughter. Ada.
And the hyper-focus I’ve carried my whole life shifted again — narrowed, but deepened.
It’s still data. Still equations and airflow and lap deltas. But it’s also Lando, who stopped having to ask to touch me years ago. Who doesn’t need explanations but still listens when I give them.
It’s Ada — glorious, curious, sticky. Who throws glitter onto my schematics and insists I help her fix the broken boosters on her cardboard spaceship with grunts and wife, pleading eyes.
It’s both of them.
And the quiet, terrifying vastness of being truly understood.
My autism didn’t vanish when I became a wife. It didn’t soften when I became a mother. I am still who I have always been: meticulous, sensitive, blunt. I still script my voicemails. I still shut down when I’m overstimulated. I still have meltdowns. I still need more sleep than most people and can’t fucntion in rooms with flickering lights.
But I’ve grown. I’ve adapted. I’ve made peace not just with structure, but with chaos. With change. With soft interruptions. With a life I never thought I’d be able to build.
I’ve created a life where I don’t have to perform.
I just get to be.
And for the first time, I’m letting people see me. All of me.
Which is why I’m writing this.
Because I know I’m not the only one.
Because somewhere, there’s a teenage girl memorising lap times and scared she doesn’t belong in a world that moves too loud, too fast, too unclearly.
Because I wish I’d known sooner that I wasn’t alone.
Today, I’m proud to announce the launch of NeuroDrive — a foundation dedicated to mentoring, supporting, and funding autistic young women pursuing careers in motorsport.
We’ll be offering scholarships. Internships. Mentorship. Resources. Community.
From engineering to analytics to logistics to aero to comms — every role that makes this sport move.
I want these girls to know that their focus is a gift.
Their precision is power.
Their minds are brilliant.
I want them to know they don’t need to hide.
There’s room for them here. There’s room for all of us.
And they belong — fully, loudly, exactly as they are — in motorsport.
With hope, Amelia Norris
—
Amelia sat back from her laptop screen.
She hadn’t meant to write it all in one frantic breath. It had just… unfurled. A loose thread tugged gently free at the edge of the day, unraveling steadily until it wove itself into something whole.
She stared at the last line. Her hands hovered over the keyboard, then lowered to her lap. She exhaled.
Behind her, the wooden floor creaked softly.
A moment later, familiar arms wrapped gently around her waist — warm, unhurried. Lando pressed a kiss just behind her ear, right in that small, quiet space that always made her flinch less than anywhere else.
“She’s asleep,” Lando murmured, voice low and amused. “Finally. Made me sing the rocket song. Twice. And do the hand movements.”
Amelia huffed a small, warm laugh but didn’t turn. “You hate the hand movements.”
“I hate them passionately,” he said, bending slightly to press a kiss to the space just behind her ear. “But she likes them. And I happen to love her enough to tolerate them.”
She could feel him smiling against her skin.
The sea air had slipped in through the open balcony doors behind them, warm and salt-tinged, carrying the gentle hum of nighttime Monaco.
Lando’s arms slid comfortably around her waist. He rested his chin on her shoulder and peered at the screen. “Let me read it?” He asked after a pause.
“You already know all of it,” she said softly.
“Yeah,” he replied, nudging her temple with his nose. “But I like hearing it in your words.”
She didn’t answer, not with words anyway. She just leaned into him, letting her body relax in increments. Her fingers hovered over the keyboard for a moment longer before dropping quietly to her lap. Her pulse, which had been buzzing all evening, finally slowed. The cursor blinked in the corner of the screen — steady, patient, waiting.
She would post the piece eventually. Maybe not tonight. But soon. She’d promised the women helping her build NeuroDrive that the launch would be personal, rooted in something real — something true. And this essay… it was all of that. Raw and oddly fragile. But hers.
Behind them, the linen curtains shifted in the breeze.
“I think she likes it here,” Lando murmured, after a few minutes had passed in quiet. “Monaco.”
Amelia blinked, surfacing. “Ada?”
“Yeah. I had her out on the balcony earlier. She liked the sun.”
“She gets that from you,” Amelia said, dry as ever.
He laughed softly. “She does like the heat. More than I expected.”
“She likes everything here,” Amelia admitted, watching the night settle over the marina. “The boats. The water. Max’s cats.”
“She said ‘cat’ three times yesterday,” Lando said proudly.
“She’s five months old, Lando. It was probably just gas.”
“No,” he insisted. “She looked right at Jimmy and said it. Loudly.”
“Well, Jimmy did bite her toy rocket.” She said, her lips twitching at the memory of her daughter’s appalled face as the cat attacked her beloved stuffy.
Lando huffed a laugh. “Valid reaction.”
They both fell quiet again, lulled by the rhythm of the moment. Amelia let her gaze drift across the open-plan living space of their Monaco apartment; all soft neutrals and clean angles, intentionally simple.
This was Ada’s first real stretch of time here. The first time Monaco would ever feel like home to their daughter, not just a temporary stop between England and wherever Lando was racing next. Amelia had worried about that — the splitness of things. Of belonging to multiple places but never fully resting in one. But Ada, with all her glittering confidence and stubborn joy, didn’t seem to mind.
“She doesn’t mind the change,” Amelia said quietly. “She just… adapts. Quicker than I do.”
“You’ve been adapting longer,” Lando said simply. “She’s still new. You had to learn the hard way.”
“I’m still learning,” Amelia admitted.
He brushed his lips against her cheek, slow and careful. “I love how your mind works,” he said. “I loved it when I didn’t understand it, and I love it even more now that I do.”
She swallowed. Her throat felt tight in the familiar, unwieldy way that happened when someone saw her too clearly. “It’s almost done,” she said, nodding toward the document. “Just a few more edits. Then I’ll post it. The site’s ready. The social channels are scheduled. The first mentorship emails go out next week.”
He squeezed her waist gently. “You built a whole new system, baby.”
“I built a team,” she said, glancing at the screen. “It’s not just going to be mine.”
He nodded. “You’re going to change lives, baby.”
“Hopefully not just change them,” she said. “Build them. Design them. Like a car.”
He grinned into her hair. “You and your car metaphors.”
“I don’t use them that often.” She frowned.
“Mm. You’re right. Only four times a day.”
He was teasing her. The lopsided smile, squinty eyes and tiny red splotches on his cheekbones told her so.
She rolled her eyes but leaned back into him anyway. Lando’s arms around her. Ada safe and sleeping. The sea just a five minute drive from their inner-city apartment.
It didn’t matter that the cursor was still blinking on her screen.
She’d found her place in the world; or built it, piece by piece.
And she was going to help other girls do the same.
—
@/NeuroDriveOrg Today, we’re launching NeuroDrive: a charity organisation formed to empower autistic women in motorsport — because brilliance comes in many forms, and it’s time we celebrate every one of them. Find out more and discover how to get involved by clicking the link below. #NeuroDriveLaunch
Replies:
@/f1_galaxy
OMG AMELIA???? This is so crazy but I’m so here for it!! #NeuroDriveLaunch
@/racecarrebel
Autistic and a gearhead? That’s me lol. Signing up right now!
@/sarcasticengineer
wait so I can geek out about torque and not pretend i get social cues? literally a dream
@/cartoonkid420
*gif of a car drifting sideways* When you realize your fave F1 engineer is actually a real-life superhero #NeuroDriveLaunch
@/chillaxbro
Amelia Norris (CEO) IKTR
@/maxverman
Yk honestly big ups to @/AmeliaNorris for making this happen. What a woman.
@/indylewis
This being the first post I see when I open this app after my diagnosis review? CINEMA.
@/f1mobtality
BEAUTIFUL. INCREDIBLE. AMAZING. BREATHTAKING. #NeuroDriveLaunch
@/notlewisbutclose LEWIS ON THE BOARD OF DIRECTORS? IKTR MY KING
@/LewisHamilton Proud to see and have a hand in making initiatives like NeuroDrive happen. It’s about time that we start making strides to pave the way for real diversity in motorsport. Change is coming, and it’s about time. #NeuroDriveLaunch
@/landostrollfan99 PLS I KNOW LANDO IS CRASHING OUT BC HE’S SO PROUD OF HIS WIFEY RN
@/NeuroDriveOrg Thank you everyone for all the love! Our virtual mentorship program opens next week; sign up to be part of the first cohort! Over 18’s can sign up themselves, but anyone younger must have parental consent. Thanks, Amelia.
@/AnnieAnalyst
My mom has been a hardcore motorsport fan for decades. She’s on the spectrum. She’s found such joy in watching Amelia Norris take the F1 world by storm over the past eight years. I know that she’s going to be so happy about this. Can’t wait to tell her.
@/samliverygoat
This is sick. I’m a guy, but my sister is eight and autistic and wants to be a mechanic. I’m gonna tell my mum about this and get her signed up. Big ups your wife @/LandoNorris
—
Lando woke slowly, the Monaco morning sun spilling in through gauzy curtains and casting pale gold across their bedroom. The room was still, quiet in that delicate way that meant someone had been awake for a while already.
He blinked, then turned toward the warm shape beside him; and stopped, his breath catching slightly at the sight.
Amelia was sitting upright against the headboard, hair pulled into a messy knot, one arm curled around Ada who was nestled into her chest, half-asleep and nursing. Her other hand held her phone, screen dimmed low. She was speaking quietly — not in a cooing baby voice, but in her normal cadence, clipped and slightly analytical.
“…recognises familiar people, understands simple instructions, imitates gestures, like clapping or waving; well, I’ve literally never seen you wave unless it’s to say goodbye to your own socks.” She frowned.
Lando smiled into his pillow, eyes still half-closed.
Amelia glanced down at Ada, who blinked up at her with wide eyes and a dribble of milk on her chin.
“That’s fine. You’re spatially efficient already.”
“Are we reading milestone checklists?” Lando’s voice was thick with sleep, rough-edged and fond.
Amelia didn’t jump, didn’t even look away from her screen. “It’s her birthday. I thought I should make sure she’s not developmentally behind.”
“She’s licking your elbow,” he pointed out.
“Which is not on the list,” she sighed.
Lando scooted closer, propping himself up on one elbow to see them both better. Ada detached with a soft sigh, then yawned, full-bodied and squeaky. Amelia adjusted her shirt without ceremony and let Ada rest against her, one hand gently stroking her hair.
“She’s perfect,” he said, leaning over to kiss the crown of Ada’s head, then Amelia’s shoulder. “Milestones or not.”
Amelia hesitated. “She’s not pointing at things. That’s apparently a big one.”
“She screamed at Max’s cats until they moved out of her way, does that count?”
Amelia hummed in thought. “I suppose we could classify that as assertive communication.”
They sat like that for a minute, wrapped in the warm hush of early light and baby breaths. Monaco in June was hazy and beautiful, a perfect little jewel box of a day already unfolding around them.
“Do you think she knows it’s her birthday?” Lando asked, voice still low.
“No,” Amelia said simply. “Probably not. But we do.” She glanced down at their daughter again, something unreadable, almost too tender, flickering behind her eyes. “I know it’s been a year since I stopped being one version of myself and started being another.”
Lando’s hand found hers where it rested on Ada’s tiny back. “Yeah, baby?”
Amelia tilted her head, considering. “Maybe. I feel… broader. Like I can stretch in more directions now.”
He smiled. “You’re perfect.”
Ada, half-asleep, made a soft gurgling sound and grabbed Amelia’s Lando necklace in one surprisingly strong fist.
Lando leaned in again, voice warmer now. “Happy birthday, sweet little pea,” he whispered to Ada, then kissed Amelia’s jaw. “And happy birth-day to you.”
Amelia made a face. “That’s not a thing.”
“It is,” he insisted. “You did all the work. You should get recognition too.”
“I suppose.” She considered it for a minute. “Does that mean I should congratulate you on the anniversary of her conception?”
She was being serious — which was why he just smiled instead of laughing the way he desperately wanted to. “If you want to, baby.”
She nodded and catalogued that away in the small corner of her brain that contained a long list of dates that mattered most to her.
She think about it like this: dates she will never forget. Not because she wrote them down, but because they’re carved into the soft machinery of who she is.
October 9th — Her mother’s birthday.
November 7th – Her father’s birthday.
December 12th, 2021 – Max’s first championship win.
July 5th, 2022 — Her wedding day.
July 2nd, 2023 – Oscar’s first Grand Prix start.
May 5th, 2024 – The day Lando won his first race.
June 30th, 2024 – The day Ada was born.
She’s always catalogued things.
It made the world digestible.
But those dates don’t need charts or colour codes.
They live in her like heat. Like heartbeat. Like gravity.
Later, there would be cake. Balloons. Chaos. Max will appear with sacks full of wrapped gifts. Ada will probably eat something that she isn’t supposed to.
Lando takes Ada into his arms and lifts her above his head, blowing a bubble at her with his lips.
She drools sleepily, and Amelia winces when milky bile spills from her mouth.
Yeah. Not a good idea to jostle a well-fed baby.
Lando made a face and then used his t-shirt to wipe their little girls’ lip clean.
She stared at him.
And at their small, wondrous girl.
A year old.
—
Seventeen Years Later
The sky was brightening in soft lavender layers over the marina. Monaco looked almost quiet for once — like it was holding its breath.
Ada sat cross-legged on the bedroom floor, her back pressed to the base of her mother’s old desk. The drawer had stuck for years, warped with sea air, but today it had slid open easily. Like it had been waiting for her.
Inside: one neatly folded sheet of thick paper. Her name was written in the corner in her mum’s handwriting. Clean, sharp letters.
She unfolded it carefully, even though part of her already knew what kind of letter this would be. Not sentimental. Not flowery. Not emotional in the ways people expected. But honest.
My beautiful Ada,
I’m writing this on your first birthday.
You’re asleep right now — finally — with vanilla frosting in your hair and a purple sock on one foot and not the other. Your daddy’s asleep too, mouth open, curled around the giraffe that Maxie gave you today. I should be sleeping. But I’m here, writing this. That probably says a lot.
I don’t know who you’ll be yet. Not really.
Maybe you’ll love numbers the way I do. Maybe you’ll throw yourself into art, or animals, or flight, or noise. Maybe you’ll carry the softness your father wears so easily. Maybe you’ll burn hot like me and never quite know how to dim it.
Or maybe, hopefully, you’ll be entirely your own: unshaped by us, unafraid of being too much or not enough.
All I know is this: whoever you are, whoever you become, I will love you without condition and without needing to fully understand.
Because understanding is not a prerequisite for love. It never has been.
I want to get everything right. I won’t. I already know that.
But I promise I will try. Fiercely. Unrelentingly.
I will learn what you need from me, over and over again, as you change and grow and outpace me. I will listen — even when I don’t know what to say. I will ask you what you need, and believe you the first time.
Love isn’t easy for me in the way it is for your daddy. I don’t always say the right thing, or give affection in the way people expect. But please know: I love you with everything I have. In every way I know how.
It may not always look loud or obvious. But it will be real. And it will never leave you.
I will always be in your corner.
Even if I’m quiet.
Even if I’m late.
Even if I’m gone.
Always.
— Mum
The letter smelled faintly of ink and something older; lavender, maybe, or the ghost of her mum’s favourite perfume. Ada folded it carefully along the worn creases and slid it back into its envelope, fingers tracing the edge before getting up and going back to her bedroom, tucking it inside the drawer of her nightstand.
The light from the marina hadn’t reached this side of the house yet, but the sea breeze had — soft and salt-laced through the open windows. Ada padded barefoot across the wooden floor, familiar as the lines on her own palm, and moved quietly into the hallway.
The balcony door was already ajar.
Her mother was there, as she always was on mornings like this — perched in her usual chair, legs tucked under her body, a latte cradled in both hands. Her hair was scraped back in a low twist, pale in the early morning light, and she hadn’t noticed Ada yet.
Amelia was humming. Softly. Tunelessly. A little stim she’d done for as long as Ada could remember.
Ada hesitated in the doorway, just for a moment.
Then she stepped forward, slow and quiet. Climbed into her mother’s lap without a word, curling against her like she was still small enough to belong there.
Amelia stilled for half a breath. Then she shifted, just slightly — letting her daughter fit against her without comment or tension. One hand settled over Ada’s spine. The other stayed wrapped around the ceramic heat of her cup.
She didn’t ask questions.
She didn’t need to.
Instead, she kept humming. A low, constant thread of sound that vibrated in Ada’s ribs as she pressed her cheek to her mother’s shoulder.
They watched the sun climb over the harbour. The light came in slow and sure, brushing over the rooftops and catching on the water in amber fragments.
Amelia didn’t speak. She just held her daughter. One hand stroking the same pattern — left shoulder to elbow, up and back again.
And Ada breathed. Steady. Whole.
She was older now; too big, probably, to sit in her small statured mum’s lap like this. But not today. Not just yet.
In her mother’s arms, she was still allowed to be small.
Still allowed to be quiet.
Still allowed to simply be.
And Amelia, in the language she had always known best, presence over words, held her through it.
As the light shifted across the sea, the only sound between them was the soft hiss of foam against porcelain. The familiar hum. The heartbeat of love — silent, constant, and entirely understood.
—
2025
It was impossible to sum up the 2025 season in any cohesive way.
There were days she felt like she was balancing on the tip of a needle.
Her car was perfect. That much was undeniable. For the first time since she’d begun clawing her way through every door that had once been locked to her, the machine under her boys wasn’t just competitive — it was untouchable. Fast on every compound. Nimble in the wet. Ferocious in the hands of a driver who knew how to take it to the edge.
And she had two of them. Two.
Oscar and Lando.
Her driver. Her husband.
It would have made a weaker team combust.
But McLaren hadn’t combusted. Not yet, anyway. Not under her watch.
Oscar had grown into himself in ways that still caught her off guard — all lean control and precision, carrying the ice-veined patience of someone who had watched others take what he knew he was capable of. He drove like someone with nothing left to prove and everything still to take.
And Lando... Lando had grown, too.
There were days he was still impossibly frustrating — still too harsh on himself, too reactive on the radio, still hurt in ways she couldn’t always patch. But he was stronger now. Calmer. Faster. And he trusted her. Not blindly, not because he loved her — but because he believed in her. Her mind. Her leadership. Her.
Every race had been a coin toss. Oscar or Lando. Lando or Oscar. Strategy calls had to be clinical. Unbiased. And every week she made them with the knowledge that whatever she chose could cost someone she loved the chance at something immortal.
She wouldn’t let herself flinch.
Not when the margins were this razor-thin.
Not when the car was finally everything she’d spent her life trying to build.
When the upgrades landed and they locked out the front row, she didn’t smile. She just stared at the data until the lines blurred, heart thudding, and told herself she’d allow joy when it was over.
When they took each other out in Silverstone; barely a racing incident, but brutal nonetheless, she didn’t speak to anyone for two hours. Just shut herself in the sim office and breathed through the silence until the tightness left her hands.
When they went 1-2 in Singapore, swapping fastest laps down to the final sector, she didn’t even hear the cheers. She just watched the replay of the overtake again. And again. And again.
Precision. Patience. Courage.
They had everything. And they were hers — in the only ways that mattered in this arena. Oscar, her driver. Lando, her husband. Both brilliant. Both stubborn. Both driving the car she had finally, finally perfected.
In the garage, she never played favourites.
In the dark, she ached with the weight of both of them.
Now, the season was nearly over. One race to go. One title on the line. Between them.
And Amelia?
She felt something not quite like calm. Not quite like pride.
Something vaster.
She didn’t know who would win. She truly didn’t. She wasn’t even sure if she had a preference. Her love for Lando, loud and chaotic, as real as gravity, lived beside her fierce loyalty to Oscar, who had never once asked her to earn his trust, only to maintain it.
She loved them differently. But she loved them both.
And whatever the final points tally read, whatever flag waved first in Abu Dhabi, it would not change what she’d built. What they’d built. A machine so complete, so purely competitive, that the only person who could beat it was someone inside of it.
That, she thought, was the mark of something enduring.
And in the quiet before the finale, Amelia allowed herself a breath of pride so deep it nearly broke her open.
It wasn’t about the trophy anymore.
It was about the fact that the world had doubted her. Them.
And now they couldn’t look away.
—
2026
Amelia had been keeping a spreadsheet. Of course she had.
A private one — just a simple, tucked-away Google Sheet with six columns: Developmental milestone, Average age, Ada’s age, Observed behaviour, Paediatricians’ notes, and Feelings (which she almost always left blank).
She updated it weekly. Sometimes daily. Just in case.
And she knew, clinically, that speech development wasn’t one-size-fits-all. That some children talked at eight months and others waited until twenty. That it was normal, even healthy, for some toddlers to take their time.
But normal never did much to soothe her.
Especially not when the silence had started to feel louder than it should.
Ada babbled — just not much. She gestured, pointed, tugged their hands, grunted with specific frustration when her needs weren’t met. She understood them. That wasn’t in question. But her lips hadn’t shaped a word yet. Not one.
At twenty-two months, Amelia was trying not to spiral. But her spreadsheet had too many empty cells. Too many quiet mornings.
“Maybe she just doesn’t have anything she feels like saying yet,” Lando said one night, rolling onto his side to face her in bed. Ada had gone down late and Amelia had spent the evening researching speech therapy assessments and second-language interference.
“She should have at least one word by now,” Amelia muttered, eyes on her screen.
“She’s got plenty. She just hasn’t said them out loud.” Lando reached out, nudged the laptop closed. “She’s fine. You know she’s fine.”
Amelia sighed. “You always say that.”
“Because it’s always true.”
She wanted to believe him. She really did.
—
The next afternoon, Ada was with them in the garage — tucked into her earmuffs and her tiniest McLaren hoodie, perched in her playpen while Amelia ran final aero checks on a new floor configuration. Lando had stopped by between simulator sessions and was now crouched beside Ada, offering her a padded torque wrench like it was a teddy bear.
Amelia looked up from her laptop, distracted by a little squeal.
Ada had pressed both palms against the concrete floor. And a smudge of oil had made its way across her hand.
She looked at it, then at Lando, wide-eyed.
Then she scrunched up her nose, a perfect mirror of her mother’s expression, and said, clearly and without hesitation, “Yucky.”
Lando blinked. Froze. Then looked up at Amelia, stunned.
“Did you—? Did she just—?”
Amelia’s heart felt like it missed a step. Her head jerked up so fast she hit the underside of the wing she’d been crouched under.
“Ow—shit—”
Lando was already lifting Ada out of the playpen, laughing in disbelief, oil smudge and all.
“Say it again,” he coaxed gently. “Yucky? Yucky, bug?”
Ada just beamed at him and smacked his cheek with her dirty little hand, leaving a streak behind. “Yucky,” she declared again, giggling like she knew exactly what she’d done.
Amelia didn’t know whether to cry or pass out.
She walked over in a daze, eyes locked on her daughter. “She said it. She actually said—”
“Yeah,” Lando said, grinning. “You heard it too, right? I’m not making this up?”
“No,” Amelia said, soft and stunned. “I heard it.”
Then she reached for Ada without hesitation. Let her daughter press her messy little face into her neck and pat her collarbone with smudged fingers.
Yucky.
It wasn’t what she expected.
But it was perfect.
—
2027
Grid kid.
Ada Norris was a grid kid.
Not the official kind, with a lanyard and uniform and carefully timed steps. She wasn’t old enough for any of that. She wasn’t even tall enough to reach the front wing of her father’s car without climbing onto someone’s knee.
But she was there — always. Like a mascot, a comet, a little bit of joy wrapped in neon.
At three years old, Ada had developed a sense of style entirely her own. This week, it was neon pink. Head to toe. From the glittery bucket hat she refused to remove, to her sparkly tulle tutu layered over orange papaya leggings, to the pink Crocs decorated with star-shaped charms.
She stuck out like a sore thumb against the rest of the paddock; all matte branding and fireproof greys. But nobody dared to comment.
She was Ada.
Everyone knew Ada.
She’d grown up within the walls of paddocks. Learned to walk behind the McLaren hospitality motorhome in Hungary. Her first solid food had been a biscuit stolen off Oscar’s pre-race snack plate. Her mini paddock-pass gave her access to every team’s motorhome, just in case she got lost and needed a soft place to land.
By now, she knew the names of every mechanic, every engineer, and every race director on the rotating FIA schedule. She greeted them all by name. Correctly. And she remembered who liked what kind of sweets.
The media barely saw her. That was a conscious boundary. Amelia — razor-sharp, unbothered by PR expectations — had drawn the line early and made it immovable. No up-close photos of Ada’s face. No intrusive questions. If Ada wanted to be public someday, that would be her choice — not something sold for a headline before she could spell her name.
But within the paddock itself, Ada was a fixture. A streak of colour and mischief. Fiercely protected. Fiercely loved.
And she had routines. Rituals, really.
One of them involved storming onto the grid like she owned it (Amelia walked slowly behind), pushing past engineers and camera rigs, and beelining toward two very important people.
The first: her uncle.
“Ducky!”
Oscar turned the moment he heard her voice, already crouching down with open arms. He was in his race suit, grinning like he hadn’t just been pacing with nerves ten seconds earlier.
“Oi,” he said, “that’s not my name, trouble.”
“But it’s what Mummy calls you!” Ada argued, already climbing into his lap like a koala. “I remember!”
“She’s got you there, mate,” Lando called from a few feet away, amusement curling through his voice.
Oscar rolled his eyes but leaned forward for his good luck kiss. Ada planted a dramatic one on his cheek, complete with a mwah sound effect, then hopped off and marched across the grid to Lando.
Her daddy.
He crouched before she even reached him. She barrelled into his arms with the enthusiasm of a girl who had never once doubted she would be caught.
“You ready, Ada Bug?” he asked as he scooped her up.
“Ready!” she chirped.
“Gonna give me a boost?”
She nodded solemnly, then leaned forward to kiss him right on the tip of the nose — her signature move. Soft, sticky-lipped from the fruit pouch she'd insisted on finishing on the way in. Then she whispered, very seriously, “Be fast. And be smart. Love you, Daddy.”
Amelia, standing just behind them, caught Lando’s expression shift; just a fraction. A sudden, raw quiet behind his eyes. He pulled Ada closer, briefly, wordlessly. Pressed his nose into her hair.
Then, carefully, he passed her back to Amelia.
Amelia took her easily — muscle memory now — resting Ada against her hip like a second heartbeat. She adjusted the strap of her crossbody bag with her free hand and took a long sip of her iced coffee.
“Drive fast,” she said evenly, meeting Lando’s eyes.
He smirked faintly, already turning back toward his car.
“Be safe,” she added.
He nodded once, familiar rhythm.
And then, casually, almost too casually, she added, “I’m pregnant.”
He froze. One step from the car. “What?”
“I’m pregnant,” she repeated, softer this time. No smile, no build-up — just fact, like announcing the weather.
They hadn’t expected it. Not exactly. They’d been trying for a few months, hopeful but guarded. Amelia had been tracking everything — methodical as ever — but refusing to let herself get too wrapped up in the outcomes. Lando had taken a more gentle approach. Faith over control. He’d just kept telling her, It’ll happen when it happens. We’re already a family.
And now it was happening.
For a heartbeat, Lando didn’t move.
Then he turned fully — slow, like gravity had stopped working — and blinked at her.
Ada, oblivious, was babbling about how she wanted to wave the checkered flag today and if Max’s cats could come to the garage next time.
But Lando only stared at Amelia.
“Oh,” he breathed, voice cracking wide open. “Holy shit.”
Amelia’s mouth tilted upward. Barely.
He was already in his race suit, just minutes from lights out, about to hurtle into one of the most competitive qualifying sessions of the season — but suddenly, he looked younger. Dazed. Entirely undone.
His hands hovered in the air like he wanted to reach for her — didn’t know where to begin.
And Amelia, ever precise, ever composed, leaned in and kissed him. Quick. Solid. Grounding.
“We’ll be fine,” she murmured against his lips. “We always are.”
“Another baby?” he whispered, reverent.
She nodded.
Lando let out a breath. One hand came up to his chest like he needed to physically hold it all in — the awe, the fear, the quiet wonder of it.
Then his comm crackled: “Two minutes to final call.”
He blinked. Straightened. Looked at his wife. Then at his daughter. Then back again.
“Okay,” he said, drawing in one last steadying breath. “Right. Fast. Clever. Safe.”
“Love you,” Amelia told him.
“Love you,” he echoed, already stepping toward Will, adrenaline and awe carrying him forward.
Ada tugged gently on Amelia’s shirt.
“Mummy?”
“Yes?”
“Can I go and tell Maxie you’re gonna have a baby?” she asked, eyes wide and serious.
Amelia bit back a laugh and turned them toward the edge of the grid. Her mum was already waiting near Lando’s garage to take over babysitting duty.
“Not yet. Your daddy drives better with adrenaline,” she said, adjusting Ada’s ponytail with one hand, “but your Uncle Maxie gets distracted. We’ll tell Maxie another time, okay?”
“When?” Ada asked, frowning a little.
“I think… we’ll tell him next week. At the wedding.”
Ada’s face lit up. “I can’t wait to wear my pretty dress, Mummy!”
Amelia kissed her forehead, pulling her a little closer as they weaved between team personnel.
“I know, baby,” she said softly. “You’re going to look beautiful.”
—
202X
He did it.
The air was electric. No — it was charged, like the world itself had paused mid-spin to catch its breath.
Lando stood on the top step of the podium, champagne in one hand, heart in his throat. There were tears in his eyes — real ones, wild and stinging, completely unfiltered. His face was flushed, soaked from the spray, but his grin was a thing of pure, stunned wonder.
He’d done it.
World Champion.
A cheer rolled across the circuit like thunder. The fireworks lit up the sky behind him in great booming waves, streaks of orange and silver and gold — and below, just past the glittering wall of photographers, she was there.
Amelia.
The crowd blurred. The moment blurred. But she didn’t.
She stood at the base of the podium steps, her hair tousled from wind and chaos, arms crossed tightly across her chest like if she didn’t hold herself together she might simply combust. Her eyes were glassy. Her face unreadable — until it wasn’t.
Until he stepped down and reached for her.
Until she moved without hesitation.
He caught her with the kind of ease that didn’t need choreography — years of knowing her weight, her stillness, her everything. His arms wrapped around her middle, and before she could say a word, he spun her. Under the lights. Under the fireworks. Under the full, beating heart of a decade in the making.
Her laugh cracked open the noise. Her legs curled up instinctively. Her hands dug into the back of his fire suit.
She said his name, just once. No title. No superlatives. No team radio.
Just him.
Lando.
He set her down slowly, like she was fragile, like the moment might shatter if he moved too fast — but she leaned forward and kissed him, hard, on the corner of his mouth, where the champagne had pooled and the smile wouldn’t quite leave.
The world spun again.
And somewhere, behind it all, Ada was being passed from Oscar to George to Max to Amelia’s mother, hands raised above the crowd as she screamed, “Daddy, daddy, daddy!”
@/f1
Lando Norris is the 202X Formula One World Champion.
What a season. What a finish. What a moment. 🧡👑 #WDC #LandoNorris #F1
@/mclaren
No words. Just joy.
Congratulations, Lando. You’ve earned every second of this.
And yes — that podium was everything. No, we’re not crying, you’re crying. 🧡🧡🧡
@/formulawivesclub
There is NOTHING more powerful than a man who wins the WDC and immediately spins his wife under literal fireworks. Iconic. Romantic. Cinematic. I am unwell. 😭😭😭
#WifeOfTheChampion #AmeliaNorris #PowerCouple
@/uncleducky44
the most magical WDC celebration this sport has seen in decades. maybe forever. PAPAYA ON TOP
@/maxverstappen1
*photo of Ada asleep on his shoulder post-podium, wearing her dad’s cap*
she said she had to stay up to see the champion. i think she made it to the fireworks. ❤️
—
202X
Final lap.
The sun was setting in streaks of copper and violet. Floodlights cast the track in electric brilliance, shadows long and sharp. And the world was holding its breath.
Oscar Piastri led by six seconds.
Not enough to coast. Not when Lando was behind him.
Not when the championship hung in the balance — years of sweat and heartbreak and razor-wire precision culminating in this.
From the pit wall, Amelia’s voice came through steady and clear.
“Final sector. No traffic. You’re clear. Bring it home, Ducky.”
No theatrics. No screaming. Just her voice, the one constant he’d had for the entirety of his F1 career. Focused. Fierce. Full of something rare and warm and undiluted: belief.
“Copy,” Oscar said, breath hitching.
And then, in the most un-Oscar voice imaginable — thick with feeling, stripped raw, “…I don’t think I’m breathing.”
She laughed. A beautiful, cracked little sound. The comms team didn’t mute it. No one could. “Please breathe.”
He crossed the line a moment later. P1.
The fireworks hit the sky immediately; red and gold and brilliant. The pitman and garages erupted. McLaren, orange-clad and screaming, split open with euphoria.
And then Amelia’s voice again; louder this time, breaking apart at the edges: “Oscar Piastri. You are a Formula One World Champion.”
Silence.
Oscar didn’t reply. He just let out one long, disbelieving breath, and you could hear the hitched sound of someone trying not to cry and failing anyway. “We did it, Amelia.”
“You did it,” she corrected.
“No,” he said, firm now. Fierce. “We did. All of it. Every lap. You’re the best engineer and best friend I could’ve ever wished for. God, I love you so much.”
The audio went everywhere. Uploaded by the team, by fans, by rival engineers who had no choice but to respect it.
Two minutes of radio. Intimate. Impossible.
It was the most-streamed F1 clip of the year.
Because there he was — Oscar, still barely in his mid-twenties, helmet resting on the halo of his car, chest heaving as the gravity of it sank in.
And there she was; Amelia, halfway to the pit barrier, shoving her headset at a stunned junior engineer, sprinting.
He met her halfway.
She didn’t usually hug. But she did then. Tight and wordless. Face buried in his chest. Years of partnership and pride wrapped into that single, silent second.
And when they pulled apart, he knocked his forehead against hers, grinning like a boy again. “Told you I’d win it.”
“I never doubted you.”
—
The footage of the podium showed Amelia next to the team, arms crossed, blinking hard. Oscar had to compose himself twice during the anthem. And when he raised the trophy, he pointed straight at her.
No words.
Just… pride.
—
2028
It started with coffee.
Not just any coffee — her coffee. The specific roast she loved from that tiny roastery near Lake Como. Brewed in silence while she slept in. No baby monitor, no toddler noise, no midnight feeding schedules. Just the steady hush of morning, and Lando moving through the kitchen like a man on a mission.
Amelia stirred around 9:00 a.m. — a luxury in itself.
There was a note on the pillow next to her.
Happy anniversary, baby. Today is yours. We’re doing it your way. Uncle Ducky has both of our babies today. Yes, willingly. Yes, I’m sure. No, you don’t need to check in on them.
Come downstairs when you’re ready. I’ve got step one waiting for you.
Love you forever,
— Lando
She blinked. Then smiled. Then got up without rushing — another gift.
When she padded downstairs, wrapped in one of his old t-shirts, she found him barefoot in the kitchen with a table set for two, sunlight spilling through the open balcony doors.
"Happy anniversary," he said softly, crossing to her with a hand on her cheek and a kiss that lingered. "Sit. Eat."
There were croissants from her favourite bakery in town. Raspberries and whipped butter. Her coffee, perfect. And Lando — already looking at her like the day was made.
“The kids?” She asked eventually, narrowing her eyes.
“Totally fine. They always are with Oscar. He made me promise not to call unless someone was bleeding. He said that you deserve a proper day off.”
“I don’t need a day off from my children,” she muttered, but the corner of her mouth twitched. “But it’ll be nice to be able to kiss you without tripping over one of them.”
“Exactly,” Lando said.
Breakfast faded into a walk — hand-in-hand along the coast, slow and sun-warmed. No schedule. No pushing. Just the faint hush of waves licking the edges of Monaco and the occasional squeeze of Lando’s fingers in hers.
They didn't talk much, and that was deliberate.
Afterward, instead of a spa or anything tactile, he drove her twenty minutes out to their favourite low-key golf course — a hidden gem tucked against the edge of a hill, quiet in the off-season.
It had started a few years ago, this habit of hers. Her golf-ball collection was ever-growing, each one labeled and tucked into a little wooden tray above the fireplace. A more serious, tactile comfort that had slowly morphed into a silly, sentimental thing.
Lando had never once questioned the golf ball. Not in the beginning, not in the middle.
He just brought her to find the next one.
They played nine holes. She beat him on five.
He whined. She smirked. It was perfect.
She picked out a new ball from the pro shop (green) and tucked it into her coat pocket.
“You’ll label that one later?” Lando asked, swinging her hand between them as they walked back to the car.
“Yeah,” she replied. “It's Ada’s favourite colour.”
“This week.” He said.
She smiled fondly. “Yeah. This week.”
—
Lunch came after.
A rooftop place they both loved but hadn’t been to since before Ada was born. White tablecloths, soda on ice. Her favourite risotto, his ridiculous stack of truffle fries, two hours of soft conversation without a single interruption from a baby monitor or a toddler needing to pee.
No baby wipes in her bag. No cutting food into tiny, manageable pieces.
Just them.
—
The sun was setting when they got back to their place.
Amelia kicked off her shoes by the door and reached for her hair tie. Lando caught her hand before she could disappear upstairs.
“One more thing,” he said, almost shy. “Come with me.”
They climbed to the top-floor balcony; her favourite spot in the house. There, waiting: a blanket. Two glasses of wine. A bowl of green olives (Amelia’s vice). And a tiny projector already humming against the far wall.
She raised an eyebrow.
Lando pressed play.
Clips started to roll. Grainy little moments he’d stitched together over months — Ada’s first steps down the hallway at the MTC, the hospital selfie when Amelia had delivered their second baby (Lando’s eyes red from crying, Amelia’s thumb still smudged with blood), lazy footage of her asleep on the couch with both kids curled up on her chest.
Her laugh in the background of a hundred quiet seconds. The clink of teacups. The sound of a little voice calling, “Mummy, look!”
Then his voice — low, warm, recorded late at night from the quiet corner of their bed, “I’m so in love with this life.”
Amelia said nothing. She was biting her lip a little too hard.
Lando didn’t push. He just shifted behind her on the blanket, pulling her gently between his legs and wrapping his arms around her waist — not too tight, just enough to say I’m here.
“You always make things perfect for everyone else,” he said into her shoulder. “So I wanted to make one perfect day for you.”
She swallowed once. Then leaned her weight back into him, just a fraction — a silent thank-you.
The sun dipped lower.
The stars began to nudge through.
And finally, softly, “Thank you,” she whispered. “I love you.”
“I love you more.”
“Impossible, I think.” She admitted, truthfully.
Lando smiled into her hair and didn’t let go.
—
Later that night, Oscar sent a photo of Ada fast asleep on a pile of couch cushions in the middle of his flat, a cereal box half-open in the background.
Amelia texted back a blurry photo of her and Lando curled up on the balcony under a blanket, the projector still casting shadows across the wall.
Perfect day complete.
—
2030
The meltdown crept in slowly.
It always did.
Amelia had been trying to hold it back for hours — maybe days, if she was honest. The world had gotten too loud again. Too bright. Too many textures and demands and interruptions.
The fridge was humming wrong. Ada had spilled orange juice and then cried when her leggings got wet. The baby had been colicky all night. Lando was out doing media. Someone had moved the coffee mugs and none of them were in the right order.
She was standing in the kitchen, clutching the edge of the countertop so hard her knuckles were white, when it all finally crashed down on her.
Her chest seized. Her eyes blurred. The sound in her ears turned to static.
Everything felt wrong. Too much. All at once.
And she couldn’t hold it in anymore.
She slid to the floor, knees curling up, hands covering her ears. Her breathing shortened. She rocked back and forth. Tears leaked out — not from sadness, but from pure sensory overload.
Across the room, Ada, six years old, in a T-shirt covered in glitter paint and crumbs, froze where she stood.
For one long moment, she just watched.
Not afraid.
Just... thinking.
Then, without a word, she turned on her heel and sprinted down the hallway.
She found her daddy in the bedroom, changing the baby’s nappy. He’d only come home a few minutes ago. Her little hand tugged at the hem of his shirt urgently.
“Daddy,” she whispered, breathless. “Mummy needs you.”
Lando paused. His head whipped up instantly. “What’s wrong, little-pea?”
“She’s on the floor. She’s crying with her hands on her ears. She’s not talking.”
Lando’s jaw jumped, but he kept his cool and handed Ada her baby brother. “Stay here, okay? You hold him and don’t move. I’ll go help Mummy.”
—
Amelia was still in the same spot, crumpled in front of the dishwasher, the noise of the appliance now too sharp, like claws dragging through her skull.
Lando knelt slowly beside her. Not touching. Not speaking yet. Just breathing in sync.
A beat passed.
Then two.
“I’m here,” he said quietly.
She didn’t answer. Couldn’t.
“I knew the dishwasher was making a weird noise,” he added gently, knowing exactly what she was hearing. “I’ll call someone to fix it tomorrow.”
Her shoulders twitched.
Still too much.
He sat down properly beside her, close but not touching, and began counting out loud.
“One. Two. Three. Four. Five…”
The rhythm gave her something to hold on to.
He kept going. Soft. Steady.
“…twelve. Thirteen. Fourteen. You’re okay. I’ve got you.”
When he finally reached forty, her hands lowered. Just a little. Her breathing slowed.
Lando waited.
And when her eyes finally fluttered open — puffy, red-rimmed, exhausted — he reached out with one hand, offering it but not insisting.
She took it.
No words, just pressure — fingers threading through his, grounding herself.
“I hate this,” she rasped, barely audible. “I was fine. I should’ve been—”
“Nope,” he said. “No rules. No shoulds. You just were. And now you’re here. That’s all that matters.”
Amelia blinked. Let out a breath that stuttered on the way out.
From the doorway, a soft voice, “Mummy?”
They both turned. Ada was peeking in, barefoot and clutching the baby monitor against her chest.
“I put the baby in his chair,” she said proudly. “And I put my light-up shoes away so they won’t hurt your eyes.”
Lando smiled faintly. Amelia just blinked again, overwhelmed by the careful compassion of a six-year-old.
Ada padded over, crouched carefully beside her mum, and offered a tiny, glittery toy dinosaur — the kind she usually kept in her backpack for comfort.
“You can hold this if it helps,” she said seriously. “Sometimes it helps me.”
Amelia took it with shaking fingers.
Then, finally, finally, she opened her arms.
Ada climbed into her lap.
And Lando wrapped them both up in his arms, squeezing tight.
—
Later that night, when things were quiet again and the world had shrunk back to something manageable, Amelia whispered into the crook of Lando’s neck, “She went and got you. She knew.”
Lando kissed her hair. “She always knows,” he said. “She’s yours.”
Amelia smiled, small and raw. “No. She’s ours.”
—
2033
They were sitting under the shade of an umbrella, barefoot and sun-drowsy, watching their children build increasingly complicated sandcastles twenty feet away. Ada had her arms bossily crossed, giving instructions like a forewoman. Her little brother — all curls and slightly sunburnt cheeks despite the copious layers of SPF50 — was digging trenches with his hands.
Lando passed Amelia a cold can of peach iced tea.
She took it, absently, eyes on their kids.
Lando leaned back on his elbows, sighing. “Is it Thursday or Friday?”
Amelia didn’t answer immediately. Her sunglasses were halfway down her nose. Her hair was damp at the ends from her swim. “Friday,” she murmured. “Pretty sure.”
He nodded, squinting toward the sun. “Days have been blurring. If it’s Friday, it’s already the twelfth.”
He was right. The days had all started to melt together. Long mornings. Naps tangled in hotel sheets. Late dinners with sticky fingers and endless laughter.
Amelia sat up a little. Not sharply — but enough to catch her husbands attention. “Oh,” she said, very quietly.
Lando stared at her. “What, baby?”
She furrowed her brow. Like she was doing mental arithmetic. Calendar math. Gut instinct. “I’m… late.”
He blinked.
“…Like, how late?”
“Four days?” She said it more like a question. “Maybe five. I didn’t notice. With travel and the kids and— I don’t know.”
Lando sat up straighter, heartbeat suddenly louder in his ears.
They looked at each other.
Neither of them moved.
Down by the water, Ada shrieked with delight. “Mummy! We made a castle for the sea princess!”
Amelia waved back, mechanically, then turned back to Lando. “I didn’t bring a test.”
He scratched the back of his neck. “Should we go find a pharmacy?”
She hesitated. Then shook her head. “No. Not yet.” She reached for his hand, threading her fingers between his, palm warm. “Let’s just sit. Just for a minute. I want to stay here a little longer, before everything changes again.”
His grip tightened on hers. “Is that okay?”
Amelia nodded. “I’m happy. Just… surprised.”
Lando exhaled, gaze flicking back to their children. Ada was crowning her sandcastle with a plastic fork she’d found. Their son was diligently filling a bucket with sea foam.
“I think we’re gonna be outnumbered,” he said softly.
“I think we already are,” Amelia murmured, smiling faintly. “But that’s exactly what we wanted, isn’t it? Three of them. A couple of years apart. It’s perfect.”
And they sat there. Under the umbrella, hand in hand, watching the beginning of their forever shift again.
The ocean kept talking, its waves crashing against the rocks at the other end of the beach.
So did Ada — ever the chatter-box.
Amelia smiled. “Three is a good number.”
“Three of them. Two of us. Five total.” He murmured. “We’re missing four.”
“No we’re not.” She whispered. “You’re right here.”
He blinked, then he leaned in and kissed her.
—
2034
Ada slammed the front door shut with the theatrical force only a ten-year-old could manage.
“Mummy!” She yelled before she was even properly out of her shoes. “Mummy, I have to tell you something very important!”
Amelia looked up from the kitchen table, where she was re-assembling a snapped pencil sharpener and ignoring the half-eaten apple Ada had left on the kitchen bench to rot that morning.
“In here,” she called calmly.
Ada thundered in, socks half-falling off, her backpack barely zipped. Her cheeks were pink. Her plaits were lopsided.
“I’m in love,” she declared.
Amelia blinked once. “You’re what?”
Ada flopped dramatically into the chair opposite her. “I’m in love, Mummy. With a boy in my class. His name is Ethan and he wears Spider-Man socks and he let me use his sparkly blue gel pen for colouring even though he really likes it. He said I was clever.”
Amelia stared at her daughter for a long beat.
Then, she said plainly, “You’re ten.”
Ada sighed. “Yes, mummy. I know that.”
There was a pause.
From the hallway, the sound of keys jingling, the front door opening again.
Lando’s voice: “Where are my girls?”
“In the kitchen!” Ada called sweetly. And then, switching gears with dizzying emotional agility, she leaned in and whispered to her mum: “Don’t tell Daddy. He’ll make it weird.”
Amelia frowned. “I don’t lie to your dad. You know that.”
Ada just sighed because yeah, she did know that.
Lando appeared in the doorway a moment later, freshly back from sim training. “Why do I feel like I just walked in on a crime?”
Ada beamed. “No crime! Just secrets!”
“Oh, cool, that’s comforting,” he deadpanned, kissing the top of her head. Then he gave Amelia a suspicious side-eye. “What’s happening?”
“Well,” Amelia said, “your daughter thinks that she’s in love.”
Lando’s eyebrows shot up. “I leave her at that school for six hours—”
“Daddy!” Ada groaned, flinging her arms dramatically over her face.
“—and now she’s in love?” He leaned over her chair, mock-serious. “Who is he? What does he do? What are his qualifications?”
“He’s ten!” Ada squeaked.
“That’s not a qualification,” Lando said, faux-grave.
Amelia was biting back a smile now, watching them.
“Daddy,” Ada said solemnly, peeking at him through her fingers, “his name is Ethan, and he gave me the good gel pen. The sparkly one. That’s basically marriage.”
Lando clutched his heart. “God help me. Wait until I tell Max about this.”
“I knew you’d make it weird,” Ada whined.
“I am weird, Bug,” he replied, scooping her up despite her protests. “That’s your legacy.”
He spun her around like she weighed nothing.
Amelia smiled as she watched them.
But when Ada caught her eyes mid-giggle, cheeks flushed, safe and loved and full of her first little crush, Amelia just smiled at her.
And Ada smiled right back.
—
Nine Years Later
She doesn’t marry Ethan.
Of course she doesn’t.
He moves to Devon at the end of Year 6, and she forgets the way his name made her stomach flutter by the time she’s twelve.
The next crush is taller. The next one after that plays guitar.
None of them stick. None of them feel right.
But she never says anything. Because… she’s Ada Norris.
And Ada Norris grew up being known. Watched. Treasured.
She keeps the sacred things close to her chest.
Until one day, fourteen years after her dramatic kitchen confession, she finds herself in the back of the paddock in Monaco, barefoot and suntanned, her hair in a braid, with a camera slung over her shoulder and dust on her jeans.
She’s nineteen.
She’s laughing.
And in front of her, sitting on a pile of stacked tyres, grazed knees tucked up under his arms and ice cream dripping down his wrist, is him.
Ayrton Verstappen.
One year younger than her.
A lifetime of familiarity.
She’s known him since before either of them could talk properly.
They played tag between hospitality units. Swapped Pokémon cards in Red Bull’s simulator room.
He once peed in her toy car. She once cut his hair with nail scissors because she thought it would make him less ugly.
She never thought about marrying him.
Not seriously.
Not until she did.
It doesn’t happen all at once.
It’s the way he listens. The way he gets it — the legacy, the pressure, the strange ache of being a paddock kid with a famous surname and the expectation to become someone.
It’s the way he defends her when people assume too much.
It’s the way he doesn’t flinch when she stim-rambles or tells him she needs exactly ten minutes of silence.
It’s the way he waits — patient, steady, eyes bluer than any sky she’s ever seen.
She’s Ada Norris.
And someday soon, someday when the dust settles, and the stars line up just right, she’ll be Ada Verstappen.
And damn… it does have a nice ring to it.
—
2035
Amelia sat in the doorway of Sienna’s nursery, back pressed to the frame, coffee cooling in her hands. The house was quiet — unusually so. Ezra was napping. Ada was at school. Lando had taken a rare moment to go for a run.
And Sienna… Sienna was asleep. Peacefully. A soft halo of curls pressed into her muslin blanket, one fist curled beneath her chin like she’d already begun dreaming of something secret and important.
Amelia watched her, and breathed.
Three children.
Ada, her first, her fiercest, had taught her what love felt like when it broke you open.
Ezra had come quieter. A gentle soul with his father’s smile and a knack for slipping into people’s arms like he’d always belonged there.
And now… Sienna.
Her last. Her littlest.
Her loudest silence.
Almost entirely deaf. Diagnosed at three weeks old.
Amelia hadn’t cried — not then. Not when the results came in. Not even when the specialists had spoken gently about cochlear implants and early language support and accessibility.
She’d just… stilled. Absorbed. Pivoted.
It wasn’t grief.
Not exactly.
It was adjustment. Recalibration. Learning a new language — not just in signs, but in patience. In pace. In how to prepare for a life she didn’t know how to predict.
Sienna would be fine.
Better than fine. She had her father’s stubbornness and her mother’s ability to see patterns in chaos.
She had a sister who’d already started practicing fingerspelling at the dinner table, and a brother who kissed her ear every time she blinked up at him. She had grandparents, uncles, a paddock full of honorary aunties and mechanics and engineers ready to build her whatever she needed.
She had love. The whole, complex, unshakable kind.
Still, this baby, this challenge, this gift, it had made Amelia stretch in ways she hadn’t before.
And there, on the floor, in the hush of a warm afternoon, she finally let herself feel it all. The fear. The wonder. The sheer magnitude of how much she loved these children — all three of them. So differently. So fully. So irreversibly.
Sienna shifted in her sleep.
Amelia didn’t move.
Just smiled. Tired. Whole.
“Okay,” she whispered, more to herself than anyone else. “We’ll figure it out together.”
And they would.
They always did.
—
2038
The garden behind their Monaco home wasn’t large, but it was theirs.
The sea glittered just beyond the hedges, and the sunlight slanted golden through the lemon trees. There were chairs set out in uneven rows, a makeshift arch wrapped in white linen and fresh lavender. No press. No guest list politics. Just the people who mattered — their parents, their siblings, a few of their closest friends, and the three children who had rewritten their lives in the best possible ways.
Ada was fourteen and refused to wear anything but the pink dress she’d picked herself. Ezra, five, clung to Oscar’s leg until Lando knelt and whispered something that made him laugh. And Sienna — three and a half, curls pinned back with daisy clips, cochlear implant nestled behind one ear — was already signing “cake” to anyone who made eye contact.
Amelia stood barefoot in the grass, holding her bouquet with one hand and Sienna’s palm with the other.
Her dress wasn’t new. She’d pulled it from the back of the closet — the pale ivory one she’d worn to a gala years ago, the one Lando had stared at like he’d forgotten how to speak. Soft and silky against her skin, it still felt like him.
Lando met her halfway up the path, smiling like he always had.
“Hi,” he said, taking Sienna’s hand too. “You look beautiful.”
“You look sunburnt,” Amelia replied, then softened. “But handsome.”
Beneath the lazy sway of the breeze and the quiet murmur of waves, Lando took both her hands and said, “I’d marry you a thousand times in a thousand different lives. But I’m really glad I got this one. With you. With them. With all of it.”
Amelia, ever spare with her words, just said, “You’re the love of my life, Lando Norris.”
Later, while the kids played under the fairy lights, Max and Pietra poured champagne, and Oscar stole cake straight from the platter, Lando found her standing off to the side, heels dangling from one hand.
He wrapped an arm around her waist. Kissed the top of her head.
“That felt special,” he murmured.
“It did,” she said.
Because it only confirmed what they already knew.
They had each other. They had their home.
And their love had only deepened with the quiet weight of time.
The rest — as always — was just radio silence.
#radio silence#f1 fic#f1 imagine#f1 x ofc#lando fic#lando x oc#lando fanfiction#lando#lando fluff#lando fanfic#lando imagine#lando norris#lando x ofc#lando norris x reader#ln4 smut#ln4 imagine#ln4 fic#ln4 fanfiction#ln4 mcl#ln4#formula one x oc#formula one x reader#formula one imagine#formula one fic#formula one fandom#formula one fanfiction#formula one fanfic#formula one#formula 1#f1 fanfiction
565 notes
·
View notes