#<- just solved a simple css issue that would have been solved like that if i had taken fucking time lmao
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text
Programming notes
1) Project Modal the project is supposed to be able to transition with a button press
2) Project Pomodor isn't working at all/incomplete
3) Project Personal Website It's bland and the css page isn't working at all
4) Project Navbar Incomplete
5) Project quizgame Bland,not resposive,and css page not responding
6) Project Review Carousel Not responsive
7) Project sidebar Complete failer
8) Project survey bland
9) Project calculator success but could be better
10) Project addressbook unresposive
11) Project FaQ the project is incomplete constant repeating not in the way wanted bland
12) Project stciky navigation bar Didn't work at all final product came out like an article for the newspapaer thinking this is either 1)My laptip is trash 2) software needs to be updated
13) Project Resturant I made it simpistic but even if edded features from the tutuorial don't know if possible with either the laptop or an outdated vs ide
14) Project Tabs As per usual the tabs aren't appearing like in the tutuorial. I beleive it has something to do with the link that I didn't use.Or better yet addess the elephant in the computer for some reason the code isn't hhiding itself like in the tutorial so it's basiclly the same as yesterday's project.The conent should basiclly be nested behind one another.
*So I think I shouls take a day off from coding and finally update viusula studios.Apart of me feelis like an ass continuing event though it's not coming out right *as of 3/31/23 updated
15) Project Simongame after updating the ide i somehow gained another ide version of vs. the code is semi-acting up but i belive its on me and choose to slow down on this project because the tutorial guy is showing his mistakes showing a thought/problem-solving i miss rethonking my learning approach
16) Project Musicplayer *Previewing a file that is not a child of the server root. To see fully correct relative file links, please open a workspace at the project root or consider changing your server root settings for Live Preview. -decided to miimic the mp3 skull website for the project and after completion to saticfaction I plan on watching a tutorial to findout the differentces -the website can be broken down into I. two major containers II.about 5 lists III. 3 paragraphs IV. 2 -3search bars I also which to add tabs Taking longer than I thought it would but it's apparent to me that the problem lies in the div classes and compartmentalizing the aspects of the website into classes for better control.I have been making this harder for myself. I beleive the best course of action is to reread w3school and do simple projects using tags I don't use or understand often after this project. I stareted to get a better feel for web development but still aways to go with html and css
*I want to hit over a 100(150-200) projects before moving on to hacking,machine-learning,AI's and algrothims *ultmainte end game is to have an acquired skill that not only puts money in my pocket but allows me to map major citites *approprate termanoligy is nested div tags
17)blog website replica (yola) got the basics of the site down but the css is stomping me so essintay in a sense I have gone nowhere
*the background image,all images refuse to load
*the loading of thge background images is not working because i am not communicating to the right folder,
*the folder that I need to communicate with is either one abouve or ine over either or It's a pain to try and learn the proper technique and describe the issue correctly into the search engine
The problem comes down to not beeing able to move effectivly thorough files just like in hacking *sections tag to divide the web-site
-now the plan is to alter the json file to allow me permisson to the image folder after the link didnt work else play with bash for other alterations to the file In Unix-based systems like Linux and macOS, the user can use the “sudo” command to run the command with administrative privileges. In Windows, the user can right-click the Command Prompt or PowerShell and select “Run as administrator”.
Some key takeaways are given below that will help you get rid of the error efficiently:
The error message permission denied @ dir_s_mkdir indicates that the user does not have the necessary permissions to create a directory in the specified location. The location in question is “/usr/local/frameworks” which may be a protected system directory or owned by another user. To resolve the issue, the user may need to change the permissions on the directory or run the command as an administrator or superuser. They may have to re-install the python dictionary as well. In some cases, it may also be necessary to check if the directory already exists, and if so, delete it before attempting to create it again
Problems: 1)background image wouldn't load -solution attempt one:fix the syntax successful in connecting css to html page -learned about file paths only for it not to affect anything,nor Bash commands to transfer ownership of file -brandonostewart is user and owner/group so why not work -terminal states I don't have permission or excess to file -image files is above linux files can't acess,no permisson,doesn't excess in list function in terminal -I now believe all the problems I'm facing now is because i didn't have the laptop fully setup I just jumped right in -everythiong has perseduers,a setup,order a recipie -vmc container termina penguin ERROR vsh: [vsh.cc(171)] Failed to launch vshd for termina:penguin: requested container does not exist: penguin I beleive at this current step the problem lies in the fact there is no container,this means all work was setup in space I was building on nothing and it appears obviuos that I have reached the ceiling. As i see it I only have two options left 1) powerwash and start over from scratch 2) take the neccesary steps regardless of how far back it sends me in order to setup each individual aspect of chromebook
18)ToDo list I got it to work but the trade off was all my linux files got deleted,therefore I'm starting over.
the first project is the simple todo list,I wwant to make this one nicer than the first one I did I plan on adding css and java script so it workes the inistal layout I want is a decorated background with a list that takes off taskes that are finished moving said task fromn one side of the list to the other side of the list This issue I;m currently having is an html issue. From doing some projects the issue I have is always a small technincal detail or syntax issues. The more boxes better control so the issue is what technicallity do I need to insure my list transfer infomation as well as takes info in -I have no idea how to get the program to hold onto input value,then display it.Only thing holding me from finishing right now -I think the problem is I didn't add a display box for the code Where I'm at: Have a basic setup for the website -I need my info to be taken in by the display box -then displayed on the website,once task is done it adds itself to the second half of the website 1)header 2)box1 inital info original diplay 3)box2 where finished task lays -I need display boxes javascript not linking to html page,this was the hurdle that has been fucking me over all day. While syntax is correct the program still hasn't worked problem fro the past reoccured asked for permisson for the javascript file,first it said it didn't exist then I needed permission I still can't get that syntax correct for the terminal
6/01 -since I couldn't get the javascript to work and I restarted all the files in my linux folder my next course of action was to delete vs and try my luck with another ide,plans were holted after putting in my javascript in my repl.it finding out my syntax was indeed wrong
-but now i'm not so sure becasue I tried another basic web design program from youtube with correct syntax and it didn't load correctly somehow I think it's my computer at this point -after re-opening the apllication 2/3 of it worked -this time javascrirpt and html,not css -like with the to do list css,html not javascript -I feel like giving up on full stack development but I have learned to much to not have an Idea on what needs to be done.I can vividly describe and analyze the problem just can't put it together
I am going to start app development on vs and come back to full stack development
6/10 After downloading the framework .Net and discovering the difference between visual studio code and visual studio I wanted to develop at least one of the each programming application made possible with the framework(including machine learning/ai) including but not limited to Flutter development. currently struggling to understandings of the sync capabilities of git hub with visual studio code( what I have) also I saw the flutter development intro video I am really just out of the woods intermediate of beginner and am steadily heading to intermediate currently stuck on trying to finish this web application tutorial terminal commands for web application,branch work
Changes to be committed: (use "git restore --stageg <file>..."to unstage)
Untracked files: (use "git add <file>..."to include in what will be committed)
11/14 since last recordings,my current laptop slowed down it says less memory so i tried transfiring to my tablet for programming which was increadably
0 notes
Note
Hey, so I had a question about Twine, sugarcube specifically, the ui of Foundations is pretty cool imo and was curious about how you were able to get it the way you did and wanted to know if you'd be okay giving an explanation as to how if it isn't any trouble and you're comfortable sharing it.
I personally have been using W3schools to learn about editing the margins and border radius which I've got a bit of a good grasp on, but have been having issues with getting rid of the toggle collapse and moving the position of the sidebar itself, which is my main concern rn.
Hey, no problem, I'll absolutely explain for you!
First of all, there are a couple ways to do the things you're mentioning. If you want to remove the sidebar or the toggle button (or any element, really) you can do that with a bit of Javascript. For example, you can use this bit of code to remove the toggle to open and close the sidebar:
$('#ui-bar-toggle').remove();
Or this bit of code to remove the sidebar entirely:
$('#ui-bar').remove(); $(document.head).find('#style-ui-bar').remove();
Of course, if you want to not only remove them but replace them with something else, you'll need to do a bit of extra work. There have been people who have tried to move all the contents into a header bar, but it's probably easiest to just scrap everything and start over. That's how I created my UI.
To do this, create a passage entitled "StoryInterface." As soon as you create that passage, Twine will throw all of its default stuff out the window and whatever HTML you put in there will replace it. The only necessary component is having a div with the ID "passages," otherwise the passages themselves won't be able to render and there will be an error.
From there, you can build it up as needed. It's important to note that StoryInterface can ONLY include HTML. No Twine code or anything, just pure HTML.
I'll go a bit more in depth with the Foundations UI and how it's created below the cut, cause it might get a bit lengthy:

That's the StoryInterface passage for Foundations. It includes an overall container and three flexboxes inside of it- the passages, the sidebar on the left, and the icon tray on the right. The CSS determines how large each flexbox is, where it is in the order, and what it looks like.
Notice how the tray element also includes "data-passage='IconTray'"? That essentially creates the same sort of special passage as StoryMenu, allowing you to add things like Twine code inside of it that will be rendered as part of the UI.
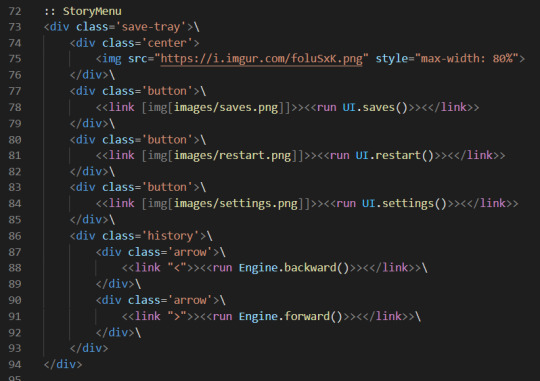
That's the StoryMenu passage, which renders all of the things on the left sidebar. Normally you would use this to add extra code into the default Twine sidebar, but here I've used it to add all of the normal sidebar components back in. The links trigger Sugarcube's UI API, which means when you press the "saves" button, the normal saves dialogue pops up (same with restart and settings). The arrows at the end use the Engine API to bring the player forward and backward.
It seems a bit intimidating, but when you break it down like that, it's actually pretty simple! To do something like a little header menu, you'd probably only need a few elements. The hard part is the styling- most of the time making that consisted of adjusting something by a few values, loading the game, and then adjusting it again until it looked just right.
I'd highly recommend, if you're a very visual person like I am, making a screen on paper or on an art program and drawing on elements where you think they should go. Sketching out my UI ahead of time changed the process from creating a UI to solving a puzzle- I wasn't trying to come up with things on the fly, I was trying to figure out what needed to be changed to create my vision.
(Also, just a note if you plan on doing this- always use percentages or vh/vw rther than pixel measurements when you can! Will seriously save you a headache when trying to make everything mobile-friendly.)
#gosh sorry this was long#idk i'm bad at compressing my ideas haha#but yeah it's easier than you'd think#i was intimidated at first#but when i started i was like 'oh shit this is actually super simple'#code help#ask#anonymous
80 notes
·
View notes
Text
11 Reasons Why You Should Update Your Site this Year
DO YOU LOVE YOUR WEBSITE?

If the answer is no or not really, you shouldn’t even continue reading this article. Just go visit our shop, choose a design that you like and start building a website that you’ll be proud to share online, and invite prospects to browse through. A site that will effectively promote your work and help you book more clients. Otherwise, what’s the point in keeping this powerful marketing tool, investing time and effort into it, if it doesn’t help your business grow and flourish?
It’s not enough to JUST have a website. It needs to look good, it needs to present information in a clear, accessible way. It needs to create a strong first impression and make your prospects feel like they’ve found THE ONE. Otherwise, you’re competing for the attention of the same audience alongside another few hundred businesses. And let’s agree, that’s an exhausting game.
If you’re not sure whether your current website does a good job, here are 11 aspects you can look into to decide whether it’s time for a revamp (listed in no particular order). Know that our Biggest Sale of the year is coming soon. If you want to grab a higher discount code this Black Friday, join our Facebook Community group. That’s where all the secret deals will be shared!
1. It’s Not Memorable and Doesn’t Stand Out
What was cool 3 years ago, may not be this year. Maybe you were one of the early adopters of a new design style or aesthetic, but that was 2-4 years ago. Look around, everyone has similar website designs, especially if they use them ready out of the box. That’s why we created Flexthemes and Flexblock – to empower you with more design freedom. Create your blocks and page layouts. Make your website look and feel like YOU. It’s all simple and intuitive. No code skills are required.
And, you can personalize your mobile site version too, if you want.
2. It Doesn’t Reflect Your Brand
This one should be straightforward. Your website promotes your business online 24/7. If you’ve rebranded recently, if your photography style changed and evolved, if you’re offering new products and services to your customers – your website should reflect and advocate that change. Otherwise, you’re attracting the wrong type of clients, those who are after your old type of work. This brings us to reason #3.
3. You’re Not Attracting the Right Clients
We explain this in more depth in How Design Affects Your Business Growth article, but the point is – if you are not getting inquiries from the type of clients you want to work with, you are not positioning yourself correctly on the market. One golden rule is to carefully curate your work. Check the content and galleries you show on your website, remove the type of work you don’t want to do in the future (i.e. family, portrait, editorial, etc). Carefully select your BEST, fresh images (the type of projects you want to do more of) and include them on your homepage. This will immediately filter out some of the inquiries which are not a good fit for you. Make sure all your content is consistent, including colors, fonts, icons. An example of consistency in a website would be this.
4. Outdated Theme & Technologies
This one affects your visitors’ experience on your website. “Old school is cool” does not apply when it comes to functionality. The digital world is constantly changing and evolving. Web standards shift each year, dictating new tools and technologies for building a good website. Your clients’ preferences and tastes shift even faster. What was trendy yesterday, may not be next week. Hence, if you want your business to succeed, you need to be agile with your visual presentation and website design.
If you’ve built your website over 3 years ago, most likely it’s far behind in terms of looks and functionality. It probably has outdated code that can slow down its loading speed or the way it responds on different devices. It may also not be compatible with some of the latest popular browsers. Take our example, 3,5 years ago we launched our first Classic themes with the drag and drop page builder, a year and a half ago we released FlexBlock, and in November 2019 the world greeted the first Flexthemes.
The difference between our old, classic themes and the Flexthemes is huge (we explain it here). Building a custom-looking website with our new themes is a whole lot easier. You don’t need to know code, you don’t need to add CSS snippets or hire a technical team. The new visual editor is so simple, your grandma could probably do it (yet please don’t make her do your tasks).
The bottom line here, if it’s been a while since you’ve built your site, start looking for website design inspiration and a more modern template to use as a base.
5. Mobile Friendly
I sure hope this is not the case, but if you still don’t have a mobile-friendly website – get a new theme NOW! Even if you do have a responsive or adaptive design, you still need to keep up with the latest trends. Newer themes include modern CSS code which allows your site to adapt nicely to any device. They also allow you to hide certain page blocks for mobile and ensure a faster and smoother user experience. Also, you must know that Google cares about the experience you offer to your mobile guests, since over 50% of website traffic comes from portable devices.
Offering more control to our clients over the design and functionality of their mobile websites has always been an important goal on our list. With Flexthemes, the steering wheel is in your hands. You have access to the mobile view of your website sections, can easily make adjustments, hide or show certain areas of your site to ensure a truly wonderful and unique browsing experience for your mobile guests.
If you’re not sure how many of your prospects access your website via their phone, if you’re wondering whether it makes sense for you to customize your mobile site – check your site’s stats. You can do that via your Google Analytics account if you have one connected to your website.
Mobile is important and it won’t go away in the next years. Don’t leave money on the table with a poorly performing mobile site, it’s one of those crucial business aspects that you can’t ignore anymore.
6. Your Website Loads Slow
Aim for a loading time under 4 seconds. If you’re not sure how quickly your site loads, use tools like Pingdom or GTmetrix to check how long it takes for your site to load, and which files are the troublemakers. Poor results could mean you have some work to do. Slow loading speed could be caused by several reasons: heavy, unoptimized images, underpowered hosting and, even an old, poorly performing theme.
The first one can be easily solved by following this Ultimate Guide to Saving Your Images for the Web. For the second one, check out this article describing 5 key criteria to choosing a good hosting provider. Yet, if the issue is caused by an old, outdated website template, you can start shopping for a new one.
View Flothemes website templates here.
7. Your Bounce Rate is High
This is extremely important. If you’ve been pouring your heart and time into blogging, SEO and marketing, bringing a lot of traffic to your website – yet the second they access your homepage (or any other page), they bounce right off of it – you have a problem. You’re losing leads and potential clients.
A high bounce rate indicates that you’re doing something wrong, either with content, with the navigation of your website, or the overall look and feel on your site. On average, a bounce rate between 40-60% is considered to be OK (this varies depending on your industry).
You can check your bounce rate via Google Analytics. Log in and go to Acquisition >> Overview tab. If it’s higher than 70%, follow these 9 Steps to reducing your Bounce Rate. If it doesn’t help, it’s time for a website redesign, and we do suggest seeking some expert advice in UX and UI.
In case you want to dive deeper into Measuring Performance and Tracking Success for your site, download our SEO guide here.
8. Security
To be honest, new or old, any website can be hacked. The experience is stressful and painful, especially when you lose information, or/and have to rebuild everything from scratch. However, older websites rely on older technology, therefore chances of a security breach are higher. Make sure your theme is updated and follow these 12 steps to make your site more secure.
9. SEO
Let’s start with the basics. Do you have a blog? You should, as it’s a powerful marketing tool to drive more traffic and users to your website, through keywords, internal links and, backlinks.
You also need to know that search engines love good, updated content. Every time you make an update to your site, Google and other search engines crawl and index your pages, thus your site ranking gets recalculated. If you keep your content updated and of GOOD QUALITY, you increase your chances of getting noticed on Search Result pages. Pair that with a charming, good-looking website, and you’re guaranteed more attention.
If SEO is something that you’ve been planning to dive deeper into, check out our SEO guide for photographers. Also, take a look at this incredible post by Dylan M Howell on Content Strategy and How to Blog like and Expert.
10. Do I need Call to Action?
Of course, you do. And it’s not just a button or link added here and there. It has to be placed strategically, to keep your users engaged with your website and browsing through more content. We explain How Call to Actions work in Design in this article, but the idea is to guide your site visitors through your content to your Best Work, then to your contact form or sales page. If your current website is limited in CTAs (Call to Actions) and doesn’t allow much customization – it’s time to get something more flexible and powerful. With Flexthemes for example, you can easily create new page layouts to support your sales campaigns and convert more users into prospects. They allow you to fully customize any layout, add buttons, images, videos, texts, and other design elements.
Never leave your site visitors wondering what they should do next. If it’s not subtle and intuitive, they’ll leave and never return. And that’s sadly a lost business opportunity.
11. All those Cool Apps & Integrations
An old outdated website template may not keep up with all the new apps, plugins, and integrations available out there. So, if you want to integrate your favorite Studio Management System, Photo Editing app or, any other useful tools that simplify your workflow – be prepared to update your website on a regular 1-2 year basis, and use the most modern, up to date templates for that.
1 note
·
View note
Text
A Dish Best Served Code
I have a friend who likes to role-play online but doesn't know how to code - for the purpose of this story, I'll call her Blue. Around a week ago, she contacted me saying that she wanted to start up a new site and then handed me this list of jobs that needed to be done without ever asking me to help or whether I had the time to do any of it (note that she knows I'm currently a full time student and I'm right in the middle of my coursework period at the moment).
Right now this is all I can think of off the top of my head. We'll need a new header pic for you to add too but I have to find one first:
Add a skin
Fix add acount feature
Add/set up Discord
Add Ratios
Fix member groups and add emoticons
Add Quick Links
Add Custom Field Content to profiles
Figure out how to put those sub forum boxes in there
For those of you who don't know, this was pretty much building the entire site for her except for the main forums where the roleplaying would take place - I had adamantly refused to do those because I knew how long they would take.
So, I thought this was a little presumptuous of her to think that I just had the time to drop everything and do whatever she needed but, hey, we'd known each other for something like three years and I used to role-play with her, so I thought it wouldn't hurt to help her out just a bit. Besides, all the jobs on that list were very easy things that I could do in about ten minutes each at most.
Unfortunately, Blue decided to recruit a group of other people who I'd never met before to help her out. Where she and I were listed as site owners, the rest of them were listed as general admins, with two of them being moderators. No biggie: they can stick to their jobs and I can do mine. Didn't happen. These girls were horrible. I have no idea where she'd found them or what their relationship was but they stormed in like they owned the place, throwing their opinions about and editing bits of the site coding that I'd been working on in ways that, ultimately, totally messed everything up. I asked them to stop, they kept doing it. This went on for a while.
I'll be the first to admit that I have a short temper. But I put up with this for a couple of days and just tried to make general requests that they stop undoing my work. These were jobs that should have taken me just under an hour and a half to finish and yet was taking days because they continued to change things. I was messaging Blue separately and asking her to tell them to stop because she was supposed to be head of the staff team. She didn't do anything and, eventually, things started to get heated between myself and these four girls.
I would have thought Blue would side with me. I was wrong.
Instead, she basically told me to stop picking fights with them and to shut up and do my job. She then made two of the other girls moderators on Discord and gave them the highest permissions, something which they later used to continuously remove me from my staff position and making my job infinitely harder. I was starting to feel constantly targeted and it was seeping into the work I actually had to do for university. I ended up staying up all night three nights in a row, trapped in endless arguments with those other staff members and Blue herself. I was exhausted and stressed out, and my intention was to finish the jobs and then leave them alone. I probably should have left earlier on but given the history I had with Blue, I thought I might as well be nice enough to do this for her because I knew she was excited for her role-play.
The final straw came over the stupidest thing. She forgot to close a <u> tag somewhere. I fixed it, I reminded everyone to make sure to close their tags. Simple stuff, right? I would have thought people who were allegedly helping to build a site would know how to handle such basic things. I was suddenly bombarded by DMs from Blue telling me that she hadn't done anything wrong and if there was an error then to "fucking show me how it's supposed to go". I tried to explain, repeatedly, what the issue was and how to fix it and, in return, she began to argue that she wasn't doing anything wrong, despite there being obvious coding issues. Things got heated. I cracked. I was done.
https://i.imgur.com/Rb4DQ3X.png
https://i.imgur.com/QGtr3zq.png
After I'd tendered my resignation from ever helping her out again, she hadn't yet figured to remove my staff permissions on the site or on the Discord server so, while she was otherwise preoccupied flailing over suddenly being blocked and not knowing how to code anything else, I quietly went into the code I'd set up for her and removed one ; and one } and all the comments in that code which might have helped them figure out how to solve any future problems. (Lucky for me the control panel didn't update to changes in the site's css).
Then I sat back and watched the panic in their staff Discord when parts of their site stopped looking all pretty and started looking like this:
https://i.imgur.com/65wBT3T.png
https://i.imgur.com/VBYcLue.png
They removed me from the Discord a short while after that and ip banned me from the site (because I guess they don't know I can just use a proxy). But I'm enjoying watching them panic as they try to figure out what I did. Jokes on them for having a guest-accessible Discord server right on the main page of their site.
Moral of the story, I guess, is don't mess with the only person on your site who knows how to code anything.
TL;DR: An Illiterate Pineapple asks me to help her code her site; treats me like shit; gets her code fucked with.
(source) story by (/u/aalyoshka)
246 notes
·
View notes
Text
An 8-Point Checklist for Debugging Strange Technical SEO Problems
Posted by Dom-Woodman
Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provvide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The review pages of client & competitors all had rating rich snippets on Google.
All the competitors had rating rich snippets on Bing; however, the client did not.
The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
A website was randomly throwing 302 errors.
This never happened in the browser and only in crawlers.
User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
The pre-checklist check
Does it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
You’re underperforming from where you should be.
When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
You’ve suffered a sudden traffic drop.
Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
The wrong page is ranking for the wrong query.
In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
A website that has a lot of client-side JavaScript.
Bigger, older websites with more legacy.
Your problem is related to a new Google property or feature where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
Robots.txt: Open up Search Console and check in the robots.txt validator.
User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
To get the user agent switcher, open Dev Tools.
Check the console drawer is open (the toggle is the Escape key)
Hit the … and open "Network conditions"
Here, select your user agent!
IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
No-index
Canonical
Mobile alternate tags
AMP alternate tags
An example of providing mixed messages would be:
No-indexing page A
Page B canonicals to page A
Or:
Page A has a canonical in a header to A with a parameter
Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
Sitemap
Example: Mobile alternate tags can sit in a sitemap
HTTP headers
Example: Canonical and meta robots can be set in headers.
HTML head
This is where you’re probably looking, you’ll need this one for a comparison.
JavaScript-rendered vs hard-coded directives
You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
Google Search Console settings
There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!
4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
Resources: Is Google downloading all the resources of the page?
Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
It will crawl more than us
It is obviously a bot, rather than a human pretending to be a bot
It will crawl at different times of day
This means that:
If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
What happens to the servers under heavy load?
When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
Fetch & Render
Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
Mobile-friendly test
Shows: Rendered DOM and returns rendered DOM for you to read.
Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
Googlebot crawls with cookies cleared between page requests
Googlebot renders with Chrome 41, which doesn’t support all modern JavaScript.
We can isolate each of these by:
Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
Google’s cache
Shows: Source code
While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
Site searches for specific content
Shows: A tiny snippet of rendered content.
By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
Better yet, do the same thing with a rank tracker, to see if it changes over time.
Storing the actual rendered DOM
Shows: Rendered DOM
Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
This excellent talk, How does Google work - Paul Haahr, is a must-listen.
At their recent IO conference, John Mueller & Tom Greenway gave a useful presentation on how Google renders JavaScript.
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
Google does respect JS canonicals - For example, Eoghan Henn does some nice digging here, which shows Google respecting JS canonicals.
How does Google index different JS frameworks? - Another great example of a widely read experiment by Bartosz Góralewicz last year to investigate how Google treated different frameworks.
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
Similar/duplicate content to the pages that have the problem.
This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux) which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
De-duplication of content
Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
Lowering syndication
8. A roundup of some other likely suspects
If you’ve gotten this far, then we’re sure that:
Google can consistently crawl our pages as intended.
We’re sending Google consistent signals about the status of our page.
Google is consistently rendering our pages as we expect.
Google is picking the correct page out of any duplicates that might exist on the web.
And your problem still isn’t solved?
And it is important?
Well, shoot.
Feel free to hire us…?
As much as I’d love for this article to list every SEO problem ever, that’s not really practical, so to finish off this article let’s go through two more common gotchas and principles that didn’t really fit in elsewhere before the answers to those four problems we listed at the beginning.
Invalid/poorly constructed HTML
You and Googlebot might be seeing the same HTML, but it might be invalid or wrong. Googlebot (and any crawler, for that matter) has to provide workarounds when the HTML specification isn't followed, and those can sometimes cause strange behavior.
The easiest way to spot it is either by eye-balling the rendered DOM tools or using an HTML validator.
The W3C validator is very useful, but will throw up a lot of errors/warnings you won’t care about. The closest I can give to a one-line of summary of which ones are useful is to:
Look for errors
Ignore anything to do with attributes (won’t always apply, but is often true).
The classic example of this is breaking the head.
An iframe isn't allowed in the head code, so Chrome will end the head and start the body. Unfortunately, it takes the title and canonical with it, because they fall after it — so Google can't read them. The head code should have ended in a different place.
Oliver Mason wrote a good post that explains an even more subtle version of this in breaking the head quietly.
When in doubt, diff
Never underestimate the power of trying to compare two things line by line with a diff from something like Diff Checker. It won’t apply to everything, but when it does it’s powerful.
For example, if Google has suddenly stopped showing your featured markup, try to diff your page against a historical version either in your QA environment or from the Wayback Machine.
Answers to our original 4 questions
Time to answer those questions. These are all problems we’ve had clients bring to us at Distilled.
1. Why wasn’t Google showing 5-star markup on product pages?
Google was seeing both the server-rendered markup and the client-side-rendered markup; however, the server-rendered side was taking precedence.
Removing the server-rendered markup meant the 5-star markup began appearing.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The problem came from the references to schema.org.
<div itemscope="" itemtype="https://schema.org/Movie"> </div> <p> <h1 itemprop="name">Avatar</h1> </p> <p> <span>Director: <span itemprop="director">James Cameron</span> (born August 16, 1954)</span> </p> <p> <span itemprop="genre">Science fiction</span> </p> <p> <a href="../movies/avatar-theatrical-trailer.html" itemprop="trailer">Trailer</a> </p> <p></div> </p>
We diffed our markup against our competitors and the only difference was we’d referenced the HTTPS version of schema.org in our itemtype, which caused Bing to not support it.
C’mon, Bing.
3. Why were pages getting indexed with a no-index tag?
The answer for this was in this post. This was a case of breaking the head.
The developers had installed some ad-tech in the head and inserted an non-standard tag, i.e. not:
<title>
<style>
<base>
<link>
<meta>
<script>
<noscript>
This caused the head to end prematurely and the no-index tag was left in the body where it wasn’t read.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
This took some time to figure out. The client had an old legacy website that has two servers, one for the blog and one for the rest of the site. This issue started occurring shortly after a migration of the blog from a subdomain (blog.client.com) to a subdirectory (client.com/blog/…).
At surface level everything was fine; if a user requested any individual page, it all looked good. A crawl of all the blog URLs to check they’d redirected was fine.
But we noticed a sharp increase of errors being flagged in Search Console, and during a routine site-wide crawl, many pages that were fine when checked manually were causing redirect loops.
We checked using Fetch and Render, but once again, the pages were fine. Eventually, it turned out that when a non-blog page was requested very quickly after a blog page (which, realistically, only a crawler is fast enough to achieve), the request for the non-blog page would be sent to the blog server.
These would then be caught by a long-forgotten redirect rule, which 302-redirected deleted blog posts (or other duff URLs) to the root. This, in turn, was caught by a blanket HTTP to HTTPS 301 redirect rule, which would be requested from the blog server again, perpetuating the loop.
For example, requesting https://www.client.com/blog/ followed quickly enough by https://www.client.com/category/ would result in:
302 to http://www.client.com - This was the rule that redirected deleted blog posts to the root
301 to https://www.client.com - This was the blanket HTTPS redirect
302 to http://www.client.com - The blog server doesn’t know about the HTTPS non-blog homepage and it redirects back to the HTTP version. Rinse and repeat.
This caused the periodic 302 errors and it meant we could work with their devs to fix the problem.
What are the best brainteasers you've had?
Let’s hear them, people. What problems have you run into? Let us know in the comments.
Also credit to @RobinLord8, @TomAnthonySEO, @THCapper, @samnemzer, and @sergeystefoglo_ for help with this piece.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog https://ift.tt/2lfAXtQ via IFTTT
2 notes
·
View notes
Text
Factors Needs to Know When Hiring website development surrey for Small Startups
Website development surrey is a craft that incorporates different technologies. When it comes to the role of responsible web developers, they ensure that clients get websites according to their specifications. Do not confuse between a web designer and a web developer although their roles do have some overlap. Web developers involve actual code that creates a website.
There are different things carried out by a wonderful web developer surrey. As a customer, you need to understand what exactly your developer will do.
How developers will do Website development surrey?
Handle complete design and functionality of a website-
When creating a website, there is a lot of planning and analysis involved in this process and this is performed by the project manager and a development team. They will estimate how long this will take. Every customer has their own specifications about the website and the web developer writes the code that makes up the website. Web designers are also involved to make sure the design works meet customer’s requirements.
Make the business logic-
In this stage, a professional web developer in surrey will start developing the website. It includes both the client-side technologies such as HTML, JavaScript, and CSS as well as server-side technologies such as PHP and.NET. Your web developer should be proficient and skilled at different coding languages and technology. They know how to meet client’s expectations precisely.
Applying the web design-
Usually, web developers and web designers work together to build a website. Even though the designing part is performed by web designers, it is the task of developers to implement the web design on the website.Hence, they have more responsibility than designers.
Testing-
It is yet another important part of a web development project. It is possible that a website could face different critical errorswhen it is launched. This will cause losing money of the customers as well as developing companies can lose their credibility. Hence, the website will most likely be tested during each stage of development. It is essential to output the best result.

Currently, the Process of best website development surrey includes many different tasks, but it all begins with the fundamentals.
Many startup companies these days are seeking their web presence through a basic website or an interactive web portal.Many of them search online for resources like freelance web developers, freelance web development, or freelance web designers.You can outsource your projects to them and they can provide it at an affordable pricing range. However, you should know that they could be interested in the initial stage and the result will end up with different issues that will be more problematic. You might be thinking of saving money, but it could end up losing money and time. Remember that losing timeis more expensive than losing money.
Hence, we would suggest that you should always focus on a professional web developer surrey. A reliable web development company has its expert team of developers, designers, and so on that can give you the best result at the best pricing range.
As a small startup, you need to search for the best quality service as well as cost-effective service. But, you can find many web development companies in surrey. All you just need to find the best source that can meet your needs, specifications, and budget. Most often people get confused while choosing the best company for their web development projects. This article will elaborate on the basic principles to make this process easier for you.
What small startups need to know when hiring a company forWebsite development surrey?
Be it human resources, plumbing or restaurant, or the kind of business you are running, undoubtedly, you are doing hard to improve your productivity. However, you need to have your online presence to reach out to a broader audience so it needs your website to work for you. It indicates that you have to find the best web services, but how do you make sure that you are doing the right things?
Checklist for choosing the best web service partner to get the best quality and value web development for your company-
The service you need exactly-
In simple terms, a website is your business card for reference. So, you need to know exactly what should include in it and what you want it to do for your business. It is the basic thing that will increase communication within or outside the organisation. This is where you need Surrey’s web development services.
Even if you have a business website and something you want to change in it, then you must know how things might be changed. Here you need to look for a web developer to solve these problems.
You need to have a brief which a professional web developer can use to work out the web services needed and how to achieve the desired results. Then you can ask for a free quote for your work that will help you to choose the best deal.
Selecting the right person-
Be specific whether you need a web designer, web developer, or programmer. All these terms have distinctions between them.
A professional web developer in surrey can incorporate elements of design and programming. It is a much wider term for getting a website online and making it work. They can deal with both the appearance and functionality of the website. They have specific skills to improve your website.

On the other hand, a designer is responsible for the appearance or look and feel of the website, including the layout. They can make your website visually powerful and impactful. While a web programmer focuses more on functionality and the program for the web or may do software programming as well. Their concern is getting the features of your website to work.
Check developer’s portfolio-
When hiring web developers for your business website, make sure you have checked their portfolio thoroughly. Also, you can check their clients' websites online.This will help you to ensure their service quality.
Client recommendations-
Ask your developers for their client’s websites designed by them. It can show you the end resultof a website as well as theirclient recommendation can tell you about the web design procedure with this specific company.
Apart from that, you should ensure how quickly they respond to emails or phone calls of their clients. They should also be comfortable with advice that you may need sometimes. They should appropriately fit you and your business.
Company’s reputation-
Most often people choose to go with big companies for the best web services. Is it worth investing all the time? Of course, Web design and development is a big business and you can find many big names available in this industry by putting the keyword “reputed web developers in Surrey” in the search engine. However, rankings are not always the whole story and you need to understand it.
You can also go with a local web developer as they may have local contacts to assist you in promoting your website which can boost your search engine rankings.They can work closely with you to decide on the advanced web services neededand thiswould be important for you.
Moreover, you need to find out a company that has a solid reputation in the market for exceptional Website development near me. They must have years of experience and skill to deal with your project no matter it is a big or small one.
How much web development cost-
You are going to invest your hard-earned money. Undoubtedly, you ought to shop around and get a few quotes.You should check that you are being chargedfor the web services you needed. If your company is charging extra cost then make sure it is worth paying the extra cost. Even if it is considerably below average, it should set alarm bells ringing. Always pay exactly what you get from them.
Your company will offer you a free quote; however, it is only a starting point. It depends on you that exactly what is included and what is not. Building a website is a continuing procedure that takes place over a period of time. It may require some additional work later.
In this case, you should ask your developer to break the cost down per task. You can add or not add any features as per your wish which is more time-consuming. Moreover, you need to take your own time to find the web developer in surrey you need.
Key benefits of professional Website development surrey-
Reduced Development Cost- A professional and reliable web Development Company in Surrey offers affordable packages for web services without compromising the quality of services.It will meet your budget.
Extremely Skilled Developers- They arehighly skilled and experienced web developerswhich is yet another major factor. Hence you can outsource your project to these companies without any hesitation. These expert developers can use their creativity and experience to build web applications that best suit your business needs and specifications.
Maximize Profit- Hiring these expert web developers is worth investing in as you will receive extra time to discover those fields which until now have been untouched. The cost-effective service and on-time delivery will reduce your stress and can maximize profit by focusing on your main work area.
Timeliness- They will complete your project successfully on time with a high level of accuracy. As time is the most important factor, it will save your time.
Quality Work- Professional web developers use their experience to develop superior quality web applicationsor websites to meet your exact needs. You will receive the best value for your money.
Scalable Applications- They will precisely analyse your business needsto plan and develop web applications for you. It can be used for a long time as well as can be modified effortlessly in the future at the best pricing range if needed.
FAQs-
Do I really need a business website?
You should know that most of the customers search for theirservices and products on the web. If you have a website, it will make it easy for you to reach out tobroader potential customers within a short period of time.
How much input do I need to provide?
It depends on you. You can give little input or provide as much information as you like. However, detailed information would help you to create a better website.
Can you build bespoke e-commerce shops and applications?
An experienced team can build commerce shops and comprehensive website solutionsas per your requirements.
How much will a website cost me?
Different sorts of websites or applications can be developed to meet clients’ needs. So the cost of this service depends on its complexity. The team will discuss it with you and give a free quote.
Will my website be search-engine friendly?
Yes. All the websites are created are SEO friendly and compliant with search engine guidelines. Your site will be up to date and compliant with new rules.
All you just need to make sure you hired the best Website development surrey. You can visit www.imwebdesignmarketing.co.uk for the best deal. It has expert web developers in Surrey to meet your needs.

0 notes
Text
How Do You Become a Web Designer? Do You Have What It Takes?
Web design can be an enjoyable and fulfilling experience. It's a trade that combines technical skills with creative ability. If you feel comfortable with computer technology and you enjoy creating documents, web design can be a great way to combine the two interests.
That being said, it's always overwhelming to consider learning a new skill. Before learning how to become a web designer, you should ask yourself, "Should I become a web designer?"
I've been learning web design since I was ten years old, in 1994. I now do a lot of web design for myself and for some small business clients. There have been plenty of pleasures, but also plenty of frustrations. If you're considering becoming a web designer, there are some things you should keep in mind.
If you have a lot of time to devote to learning HTML, CSS, JavaScript and Photoshop, it's possible to learn the basics in a couple of months. Be ready to spend some money on manuals, books, and applications.
No matter how you decide to learn web design and how you decide to enter the field, some people have better potential to become web designers than others.
When you're programming, even if you're using a simple language like HTML and using a helpful application like Dreamweaver, you're going to encounter some frustrations. Sometimes, when I create an HTML document, I spend a lot more time making corrections and problem solving than doing fun stuff. Are you prepared to spend a lot of time testing and making little changes? No matter how you approach web design, tedium can't be completely avoided. If you're easily frustrated and discouraged, web design might not be for you.
Unless web design is going to be just a hobby for you, you will have clients you have to work with. Sometimes clients have a lot of specific expectations. Some clients have experience with web design themselves, but others may demand things without knowing the technical limitations involved. Before you start any project for clients, it's best to have a thorough conversation with them about what they want and what they need. That can save you a lot of time. How would you like to spend weeks developing a website, only to discover that your client wants completely different fonts, colors, graphics, site organization and content? If you're going to get into designing web pages for other people, you're going to have to be ready to make a lot of compromises and take a lot of criticism. Are you ready for that?
Finally, ask yourself if you have the time and energy to promote yourself. If you want to be hired by a web design firm, in addition to learning skills and possibly obtaining certifications, you've also got to be ready to pound the pavement with your resume and portfolio. It might take you over a year to find a job. Be ready to attend a lot of job interviews, and possibly get a lot of rejections.
If you're going to become a freelancer, like I am, you've really got to devote a lot of energy to self-promotion. Set up a website, preferably with your own domain. Be ready to spend some money on advertising. Spend a lot of time promoting your services with social media - Twitter, Facebook, Linked-In, and so on. Scan classified ads, particularly online classifieds. Print business cards and distribute them wherever you can. Use your connections and word-of-mouth to your advantage. Tell everyone you know that you're a web designer, and maybe someone knows someone who could be your first client. Sometimes I spend more time promoting myself than I do actually doing the work itself.
If you're ready to spend a little bit of money, do a lot of tedious work, take some criticism, and do a lot of self-promotion, then web design may be the field for you.
First, you've got to start the learning process. If you enjoy classroom instruction and having teachers, sign up for some web design and graphic design courses through your local community college. If you'd rather start learning on your own, buy some good books, look at the source codes of the web pages you visit, and go through some online tutorials. Even if you're going to start learning web design in a school setting, be prepared to do a lot of learning in your free time, as well.
It's important to learn HTML, especially HTML5. Learn Cascading Style Sheets (CSS), up to CSS3. JavaScript, possibly some server side scripting languages, and Flash are very useful, too. Don't forget to learn how to use Photoshop. If you don't have the money to buy Photoshop right away, start by downloading some free graphic design programs like Paint.Net and GIMP. You can learn some of the basics of graphic design that way, and possibly be better prepared when you finally buy the most recent version of Photoshop.
These days, people access the web in more ways than were ever possible before. When you're web designing, you not only want to make your web pages work in multiple browsers, but also on multiple devices. Even basic cell phones can access the web today, not just smart phones such as BlackBerrys and iPhones. Even some video game playing devices like the Sony PSP and Nintendo DSi have web browsers. Web surfers could be using tiny screens or enormous screens. They could be using a variety of different browsers and versions of browsers. Users may have completely different plug-ins and fonts; Adobe Flash is a browser plug-in, for instance. When you're learning web design, try surfing the web in as many ways as you can.
There are many helpful resources for learning web design online, and there are many helpful online tools for web designers, many of which I use.
The W3C is an excellent place to start. They're the non-profit organization founded by Tim Berners-Lee, the man who started the World Wide Web. The W3C sets standards for HTML, XML and CSS. In addition to information about coding languages and standards, they have handy tools to validate your code.
HTML Goodies has a lot of excellent tutorials and articles.
I've learned a lot so far, but I'm always learning more, and I'll always be a student of web design and media technology. As technology advances, things change. There'll always be new programming languages and applications. Learning is a constant process.
Web design has been an engaging experience for me, and if you decide to get into it yourself, I hope you take it seriously and have a lot of fun.
My name is Kim Crawley, and I'm a web and graphic designer. In addition to my interest in using technology creatively, I'm also very interested in popular culture, social issues, music, and politics.
I'm an avid consumer of media, both in traditional and digital forms. I do my best to learn as much as I can, each and every day.
S4G2 Marketing Agency Will be Best Choice If You Looking For Web Designer in Canada cities Mentioned below:
Web Designer Abbotsford
Web Designer Barrie
Web Designer Brantford
Web Designer Burlington
Web Designer Burnaby
Web Designer calgary
Web Designer Cambridge
Web Designer Coquitlam
Web Designer Delta
Web Designer edmonton
Web Designer Greater Sudbury
Web Designer Guelph
Web Designer hamilton ontario
Web Designer Kelowna
Web Designer Kingston
Web Designer Kitchener
Web Designer London Ontario
Web Designer Markham
Web Designer montreal
Web Designer Oshawa
Web Designer ottawa
Web Designer quebec city
Web Designer Red Deer
Web Designer Regina
Web Designer Richmond
Web Designer Saskatoon
Web Designer Surrey
Web Designer Thunder Bay
Web Designer toronto
Web Designer vancouver
Web Designer Vaughan
Web Designer Waterloo
Web Designer Windsor
Web Designer winnipeg
0 notes
Text
Letter Spacing is Broken and There’s Nothing We Can Do About It… Maybe
New Post has been published on https://thedigitalinsider.com/letter-spacing-is-broken-and-theres-nothing-we-can-do-about-it-maybe/
Letter Spacing is Broken and There’s Nothing We Can Do About It… Maybe
This post came up following a conversation I had with Emilio Cobos — a senior developer at Mozilla and member of the CSSWG — about the last CSSWG group meeting. I wanted to know what he thought were the most exciting and interesting topics discussed at their last meeting, and with 2024 packed with so many new or coming flashy things like masonry layout, if() conditionals, anchor positioning, view transitions, and whatnot, I thought his answers had to be among them.
He admitted that my list of highlights was accurate on what is mainstream in the community, especially from an author’s point of view. However, and to my surprise, his favorite discussion was on something completely different: an inaccuracy on how the letter-spacing property is rendered across browsers. It’s a flaw so ingrained on the web that browsers have been ignoring the CSS specification for years and that can’t be easily solved by a lack of better options and compatibility issues.
Emilios’s answer makes sense — he works on Gecko and rendering fonts is an art in itself. Still, I didn’t get what the problem is exactly, why he finds it so interesting, and even why it exists in the first place since letter-spacing is a property as old as CSS. It wasn’t until I went into the letter-spacing rabbit hole that I understood how amazingly complex the issue gets and I hope to get you as interested as I did in this (not so) simple property.
What’s letter spacing?
The question seems simple: letter spacing is the space between letters. Hooray! That was easy, for humans. For a computer, the question of how to render the space between letters has a lot more nuance. A human just writes the next letter without putting in much thought. Computers, on the other hand, need a strategy on how to render that space: should they add the full space at the beginning of the letter, at the end, or halve it and add it on both sides of the letter? Should it work differently from left-to-right (LTR) languages, like English, to right-to-left (RTL) like Hebrew? These questions are crucial since choosing one as a standard shapes how text measurement and line breaks work across the web.
Which of the three strategies is used on the web? Depends on who you ask. The implementation in the CSS specifications completely differs from what the browsers do, and there is even incompatibility between browsers rendering engines, like Gecko (Firefox), Blink (Chrome, Brave, Opera, etc.), and WebKit (Safari).
What the CSS spec says
Let’s backpedal a bit and first know how the spec says letter spacing should work. At the time of writing, letter-spacing:
Specifies additional spacing between typographic character units. Values may be negative, but there may be implementation-dependent limits.
The formal specification has more juice to it, but this one gives us enough to understand how the CSS spec wants letter-spacing to behave. The keyword is between, meaning that the letter spacing should only affect the space between characters. I know, sounds pretty obvious.
So, as the example given on the spec, the following HTML:
<p>a<span>bb</span>c</p>
…with this CSS:
p letter-spacing: 1em; span letter-spacing: 2em;
…should give an equal space between the two “b” letters:
However, if we run the same code on any browser (e.g., Chrome, Firefox, or Safari), we’ll see the spacing isn’t contained between the “b” letters, but also at the end of the complete word.
What browsers do
I thought it was normal for letter-spacing to attach spacing at the end of a character and didn’t know the spec said otherwise. However, if you think about it, the current behavior does seem off… it’s just that we’re simply used to it.
Why would browsers not follow the spec on this one?
As we saw before, letter spacing isn’t straightforward for computers since they must stick to a strategy for where spacing is applied. In the case of browsers, the standard has been to apply an individual space at the end of each character, ignoring if that space goes beyond the full word. It may have not been the best choice, but it’s what the web has leaned into, and changing it now would result in all kinds of text and layout shifts across the web.
This leaves a space at the end of elements with bigger letter spacing, which is somewhat acceptable for LTR text, but it leaves a hole at the beginning of the text in an RTL writing mode.
The issue is more obvious with centered text, where the ending space pushes the text away from the element’s dead center. You’ve probably had to add padding on the opposite side of an element to make up for any letter-spacing you’ve applied to the text at least one time, like on a button.
As you can see, the blue highlight creates a symmetrical pyramid which our text sadly doesn’t follow.
What’s worse, the “end of each character” means something different to browsers, particularly when working in an RTL writing mode. Chrome and Safari (Blink/WebKit) say the end of a character is always on the right-hand side. Firefox (Gecko), on the other hand, adds space to the “reading” end — which in Hebrew and Arabic is the left-hand side. See the difference yourself:
Can this be fixed?
The first thought that comes to mind is to simply follow what the spec says and trim the unnecessary space at the ending character, but this (anti) solution brings compatibility risks that are simply too big to even consider; text measurement and line breaks would change, possibly causing breakage on lots of websites. Pages that have removed that extra space with workarounds probably did it by offsetting the element’s padding/margin, which means changing the behavior as it currently stands makes those offsets obsolete or breaking.
There are two real options for how letter-spacing can be fixed: reworking how the space is distributed around the character or allowing developers an option to choose where we want the ending space.
Option 1: Reworking the space distribution
The first option would be to change the current letter-spacing definition so it says something like this:
Specifies additional spacing applied to each typographic character unit except those with zero advance. The additional spacing is divided equally between the inline-start and -end sides of the typographic character unit. Values may be negative, but there may be implementation-dependent limits.
Simply put, instead of browsers applying the additional space at the end of the character, they would divide it equally at the start and end, and the result is symmetrical text. This would also change text measurements and line breaks, albeit to a lesser degree.
Now text that is center-aligned text is correctly aligned to the center:
Option 2: Allowing developers an option to choose
Even if the offset is halved, it could still bring breaking layout shifts to pages which to some is still (rightfully) unacceptable. It’s a dilemma: most pages need, or at least would benefit, from leaving letter-spacing as-is, while new pages would enjoy symmetrical letter spacing. Luckily, we could do both by giving developers the option to choose how the space is applied to characters. The syntax is anybody’s guess, but we could have a new property to choose where to place the spacing:
letter-spacing-justify: [ before | after | left | right | between | around];
Each value represents where the space should be added, taking into account the text direction:
before: the spacing is added at the beginning of the letter, following the direction of the language.
after: the spacing is added at the end of the letter, following the direction of the language.
left: the spacing is added at the left of the letter, ignoring the direction of the language.
right: the spacing is added at the right of the letter, ignoring the direction of the language.
between: the spacing is added between characters, following the spec.
around: the spacing is divided around the letter.
Logically, the current behavior would be the default to not break anything and letter-spacing would become a shorthand for both properties (length and placing).
letter-spacing: 1px before; letter-spacing: 1px right; letter-spacing: 1px around; letter-spacing: 1px; /* same as: */ letter-spacing: 1px before;
What about a third option?
And, of course, the third option is to leave things as they are. I’d say this is unlikely since the CSSWG resolved to take action on the issue, and they’ll probably choose the second option if I had to bet the nickel in my pocket on it.
Now you know letter-spacing is broken… and we have to live with it, at least for the time being. But there are options that may help correct the problem down the road.
#2024#Accessibility#ADD#anchor positioning#Art#Articles#author#Behavior#Blue#browser#change#chrome#code#Community#computer#computers#course#CSS#csswg#Developer#developers#direction#easy#engines#English#firefox#fonts#Full#Giving#hand
0 notes
Link

JavaScript is one of the most popular languages on the web. Even though it was initially developed just for web pages, it has seen exponential growth in the past two decades.
Now, JavaScript is capable of doing almost anything and works on several platforms and devices including IoT. And with the recent SpaceX Dragon launch, JavaScript is even in space.
One of the reasons for its popularity is the availability of a large number of frameworks and libraries. They make development much easier compared to traditional Vanilla JS development.
There are libraries for almost anything and more are coming out almost every day. But with so many libraries to choose from it becomes difficult to keep a track of each one and how it might be tailored specifically to your needs.
In this article, we will discuss 10 of the most popular JS libraries which you can use to build your next project.
Leaflet

Leaflet
I think Leaflet is the best open source library for adding mobile-friendly interactive maps to your application.
Its small size (39kB) makes it a great alternative to consider over other map libraries. With cross-platform efficiency and a well-documented API, it has everything you need to make you fall in love.
Here is some sample code that creates a Leaflet map:
var map = new L.Map("map", { center: new L.LatLng(40.7401, -73.9891), zoom: 12, layers: new L.TileLayer("https://tile.openstreetmap.org/{z}/{x}/{y}.png") });
In Leaflet, we need to provide a tile layer since there isn't one by default. But that also means that can choose from a wide range of layers both free and premium. You can explore various free tile layers here.
Read the Docs or follow the Tutorials to learn more.
fullPage.js

This open-source library helps you create full-screen scrolling websites as you can see in the above GIF. It's easy to use and has many options to customize, so it's no surprise it is used by thousands of developers and has over 30k stars on GitHub.
Here is a Codepen demo that you can play with:
You can even use it with popular frameworks such as:
react-fullpage
vue-fullpage
angular-fullpage
I came across this library about a year ago and since then it has become one of my favorites. This is one of the few libraries that you can use in almost every project. If you haven't already started using it then just try it, you will not be disappointed.
anime.js

anime.js
One of the best animation libraries out there, Anime.js is flexible and simple to use. It is the perfect tool to help you add some really cool animation to your project.
Anime.js works well with CSS properties, SVG, DOM attributes, and JavaScript Objects and can be easily integrated into your applications.
As a developer it's important to have a good portfolio. The first impression people have of your portfolio helps decide whether they will hire you or not. And what better tool than this library to bring life to your portfolio. It will not only enhance your website but will help showcase actual skills.
Check out this Codepen to learn more:
You can also take a look at all the other cool projects on Codepen or Read the Docs here.
Screenfull.js

screenfull.js
I came across this library while searching for a way to implement a full-screen feature in my project.
If you also want to have a full-screen feature, I would recommend using this library instead of Fullscreen API because of its cross-browser efficiency (although it is built on top of that).
It is so small that you won't even notice it – just about 0.7kB gzipped.
Try the Demo or read the Docs to learn more.
Moment.js

Moment.js
Working with date and time can be a huge pain, especially with API calls, different Time Zones, local languages, and so on. Moment.js can help you solve all those issues whether it is manipulating, validating, parsing, or formatting dates or time.
There are so many cool methods that are really useful for your projects. For example, I used the .fromNow() method in one of my blog projects to show the time the article was published.
const moment = require('moment'); relativeTimeOfPost = moment([2019, 07, 13]).fromNow(); // a year ago
Although I don't use it very often, I am a fan of its support for internationalization. For example, we can customize the above result using the .locale() method.
// French moment.locale('fr'); relativeTimeOfPostInFrench = moment([2019, 07, 13]).fromNow(); //il y a un an // Spanish moment.locale('es'); relativeTimeOfPostInSpanish = moment([2019, 07, 13]).fromNow(); //hace un año

Moment.js Homepage
Read the Docs here.
Hammer.js
Hammer.js is a lightweight JavaScript library that lets you add multi-touch gestures to your Web Apps.
I would recommend this library to add some fun to your components. Here is an example to play with. Just run the pen and tap or click on the grey div.
It can recognize gestures made by touch, mouse and pointerEvents. For jQuery users I would recommend using the jQuery plugin.
$(element).hammer(options).bind("pan", myPanHandler);
Read the Docs here.
Masonry
Masonry
Masonry is a JavaScript grid layout library. It is super awesome and I use it for many of my projects. It can take your simple grid elements and place them based on the available vertical space, sort of like how contractors fit stones or blocks into a wall.
You can use this library to show your projects in a different light. Use it with cards, images, modals, and so on.
Here is a simple example to show you the magic in action. Well, not magic exactly, but how the layout changes when you zoom in on the web page.

And here is the code for the above:
var elem = document.querySelector('.grid'); var msnry = new Masonry( elem, { itemSelector: '.grid-item', columnWidth: 400 }); var msnry = new Masonry( '.grid');
Here is a cool demo on Codepen:
Check out these Projects
https://halcyon-theme.tumblr.com/
https://tympanus.net/Development/GridLoadingEffects/index.html
https://www.erikjo.com/work
D3.js

If you are a data-obsessed developer then this library is for you. I have yet to find a library that manipulates data as efficiently and beautifully as D3. With over 92k stars on GitHub, D3 is the favorite data visualization library of many developers.
I recently used D3 to visualize COVID-19 data with React and the Johns Hopkins CSSE Data Repository on GitHub. It I was a really interesting project, and if you are thinking of doing something similar, I would suggest giving D3.js a try.
Read more about it here.
slick

slick
Slick is fully responsive, swipe-enabled, infinite looping, and more. As mentioned on the homepage it truly is the last carousel you'll ever need.
I have been using this library for quite a while, and it has saved me so much time. With just a few lines of code, you can add so many features to your carousel.
$('.autoplay').slick({ slidesToShow: 3, slidesToScroll: 1, autoplay: true, autoplaySpeed: 2000, });

Autoplay
Check out the demos here.
Popper.js

Popper.js
Popper.js is a lightweight ~3 kB JavaScript library with zero dependencies that provides a reliable and extensible positioning engine you can use to ensure all your popper elements are positioned in the right place.
It may not seem important to spend time configuring popper elements, but these little things are what make you stand out as a developer. And with such small size it doesn't take up much space.
Read the Docs here.
Conclusion
As a developer, having and using the right JavaScript libraries is important. It will make you more productive and will make development much easier and faster. In the end, it is up to you which library to prefer based on your needs.
These are 10 JavaScript libraries that you can try and start using in your projects today. What other cool JavaScript libraries you use? Would you like another article like this? Tweet and let me know.
0 notes
Photo

Why We Moved a 20-Year-Old Site to Gatsby
We knew we had a problem.
In 2019, SitePoint was getting Lighthouse Speed scores under 10 on mobile, and between 20 and 30 on desktop.
Our efforts to control UX bloat were failing in the wake of a publishing business environment that sprang new leaks just as we’d finished temporarily plugging the last one. Our reliance on advertising, controlled by external parties, was a major obstacle to improved site performance. Our traffic growth had turned into decline.
On a site that provided people with a place to come and learn to code with best practices, this was not a good look. And it wasn’t a site we could feel proud of, either.
To make matters worse, operational bottlenecks had arisen that made adaptation a tricky logistical business. Our team was struggling to make changes to the site: having focused on our Premium experience for several years, we were down to one developer with WordPress and PHP experience. To test out code changes, the team would have to wait in a queue to access our staging server.
It wasn’t energizing work for anyone, and it certainly wasn’t efficient.
It was time to make some changes, and we set out to look for a solution. After a lot of research, we decided that Gatsby would be a great fit for our team. It would play to our talent strengths, help us solve all of the issues we had identified, and allow us to keep using WordPress for the backend so the editorial process wouldn’t need to change.
Why We Moved to Gatsby
[caption id="attachment_176594" align="aligncenter" width="1522"] The end result.[/caption]
Early in the research process, Gatsby started to look like a serious frontrunner. SitePoint isn’t a small site, so we knew that the tech we chose had to be able to handle some pretty intense demands. Gatsby checked all of our boxes:
We could code everything in React, a tech that every member of the front-end team knows and uses daily.
Gatsby is super fast at its core — performance was at the heart of this project, and we could start from a good footing.
The entire site is rendered as static, which would be great for SEO.
We could build it as a new project, which meant no worrying about the existing codebase, which brought a huge amount of legacy code with it.
We could use Gatsby Cloud, allowing the team to get feedback on the build at any time just by pushing the branch to GitHub.
DDoS attacks on WordPress wouldn’t cause us issues, as the front-end is completely stand-alone.
More Maintainable CSS with styled-components
Since we were going to rebuild the site from scratch, we planned to make some design changes at the same time. To help with this work we decided to use styled-components.
styled-components keeps the site’s styling easy to maintain, and we know where to look when we want to change the style of something — the style is always with the component.
How We Made the Build Happen
We started by following Gatsby’s basic docs and pulling in our posts with the gatsby-source-wordpress plugin.
This was a big initial test for us: we had to see if it was even possible to use Gatsby for our site.
After 20 years of blogging, we have over 17,000 posts published. We knew the builds would take a long time, but we had to find out if Gatsby could deal with such a massive amount of content. As you’ve probably figured, the test delivered good news: Gatsby works.
A quick tip for other teams working with large sites: to make development a better experience, we used environment vars to prevent Gatsby from fetching all of the site’s posts in development. There’s nothing quite like a 60 minute hot reload to slow progress.
if (hasNextPage && process.env.NODE_ENV != "development") { return fetchPosts({ first: 100, after: endCursor }); }
From this point, we ran into some limitations with the WordPress source plugin. We couldn’t get all the data we needed, so we moved to the WordPress GraphQL plugin.
We use Yoast to set our metadata for SEO, and had to ensure we were pulling in the correct information. We were able to do this with WordPress GraphQL. By doing it this way, the content team could still edit metadata the same way, and the data would still be dynamic and fetched on each build.
During the build, we would have three or four people in the team working on parts of the new blog. In the past, if they wanted to get feedback they’d have to push to our staging server and make sure nobody was already using it.
We found that Gatsby Cloud was a great solution to this issue. Now when someone pushes to a branch in GitHub, it creates a build in Gatsby Cloud along with a preview link. Our developers could share this link and get immediate testing and feedback much more effectively than before.
This faster feedback cycle made it easy to have multiple people on the team working on the build and put an end to a major bottleneck.
Launch Day Fun
On the big day, we launched the new site and ran through our initial tests. The new blog was flying — every page load felt instant.
We ran into some problems on SitePoint Premium, which started running into slows and even crashes. The culprit was a new element on blog pages that pulled in the popular books people were currently reading. It would do this via a client-side API call, and it was too much for Premium to handle due to the amount of traffic we get on the blog side.
We quickly added some page caching to the API to temporarily solve the issues. We realized we were doing this wrong — we should have been sourcing this data at build time, so that the popular books are already loaded when we serve the page to the user.
This is the main mindset shift you need to make when using Gatsby: any data that you can get at build time should be fetched at build time. You should only use client-side API calls when you need live data.
Once we’d re-written the API call to happen during the build, the first load of a blog page was even quicker — and Premium stopped crashing.
What We Still Need to Solve
While it’s hard to overstate how much better our on-site experience is today, there are still a few pain points we need to solve.
If a new article is published, or if content is updated — as it is multiple times per day — we need to re-run the Gatsby build before these changes show up.
Our solution for that right now is a simple cron job that runs at pre-scheduled times over the course of a day. The long-term solution to this is to add a webhook to the WordPress publish and update button, so that a new build is triggered once pressed.
We also need to get incremental builds running. Right now, the entire site needs to be rebuilt each time, and given our content archive, this can take a while. Gatsby just introduced incremental builds as we went live, and we’re working on implementing this on our site. Once that’s set up our builds will be much faster if the only thing that has changed is content.
Our speed score is still not where we want it to be. While the site feels subjectively very fast, we are still not getting consistent scores in Lighthouse. We want to get both mobile and desktop into the green zone (scores of 90+) for optimal user experience and SEO.
Would We Do It Again?
A launch of this type would normally be a pretty nerve-wracking event, and take a lot of work from the team on launch day.
With Gatsby, our launch was really easy. We just had to move WordPress onto a new domain, and point sitepoint.com at the Gatsby version of the site.
Then we sat back and watched the numbers to see what happened to our traffic. Within a few days, the data was starting to come in and we were seeing a 15% increase in traffic. User engagement metrics were up across the board. And we hadn’t even removed our ads yet (which, you may have noticed, we’ve since done).
It’s not hard to figure out why the effects were so immediate. We had better SEO running on static HTML and CSS pages, and massive speed improvements made possibly by the move to Gatsby.
Since we made the move, we’ve increased our Lighthouse speed scores from 6-15 on mobile to the 50-60 range, and from the 30s on desktop into the 70s. We wanted to ensure speed remained top of mind with this change, so we’re using a great tool called Calibre that runs speed tests over a number of top pages each day and alerts us to the scores. We are using this tool to continue to improve our score, so I hope to have another article for you in three months when we get everything to stay in the 90+ range.
The team loves working in Gatsby. The blog codebase was something that nobody wanted to work on. Now, everyone wants to take those cards thanks to the great developer experience.
If you’ve been eyeing a move to Gatsby and wondering if it’s ready for prime time, take our advice — it’s worth the switch.
Continue reading Why We Moved a 20-Year-Old Site to Gatsby on SitePoint.
by Stuart Mitchell via SitePoint https://ift.tt/2O3eMp5
0 notes
Text
Cool Little CSS Grid Tricks for Your Blog
I discovered CSS about a decade ago while trying to modify the look of a blog I had created. Pretty soon, I was able to code cool things with more mathematical and, therefore, easier-to-understand features like transforms. However, other areas of CSS, such as layout, have remained a constant source of pain.
This post is about a problem I encountered about a decade ago and, until recently, did not know how to solve in a smart way. Specifically, it’s about how I found a solution to a long-running problem using a modern CSS grid technique that, in the process, gave me even cooler results than I originally imagined.
That this is not a tutorial on how to best use CSS grid, but more of a walk through my own learning process.
The problem
One of the first things I used to dump on that blog were random photos from the city, so I had this idea about having a grid of thumbnails with a fixed size. For a nicer look, I wanted this grid to be middle-aligned with respect to the paragraphs above and below it, but, at the same time, I wanted the thumbnails on the last row to be left-aligned with respect to the grid. Meanwhile, the width of the post (and the width of the grid within it) would depend on the viewport.
The HTML looks something like this:
<section class='post__content'> <p><!-- some text --></p> <div class='grid--thumbs'> <a href='full-size-image.jpg'> <img src='thumb-image.jpg' alt='image description'/> </a> <!-- more such thumbnails --> </div> <p><!-- some more text --></p> </section>
It may seem simple, but it turned out to be one of the most difficult CSS problems I’ve ever encountered.
Less than ideal solutions
These are things I have tried or seen suggested over the years, but that never really got me anywhere.
Floating impossibility
Floats turned out to be a dead end because I couldn’t figure out how to make the grid be middle aligned this way.
.grid--thumbs { overflow: hidden; } .grid--thumbs a { float: left; }
The demo below shows the float attempt. Resize the embed to see how they behave at different viewport widths.
CodePen Embed Fallback
inline-block madness
At first, this seemed like a better idea:
.grid--thumbs { text-align: center } .grid--thumbs a { display: inline-block }
Except it turned out it wasn’t:
CodePen Embed Fallback
The last row isn’t left aligned in this case.
At a certain point, thanks to an accidental CSS auto-complete on CodePen, I found out about a property called text-align-last, which determines how the last line of a block is aligned.
Unfortunately, setting text-align-last: left on the grid wasn’t the solution I was looking for either:
CodePen Embed Fallback
At this point, I actually considered dropping the idea of a middle aligned grid. Could a combo of text-align: justified and text-align-last: left on the grid produce a better result?
Well, turns out it doesn’t. That is, unless there’s only a thumbnail on the last row and the gaps between the columns aren’t too big. Resize the embed below to see what I mean.
CodePen Embed Fallback
This is pretty where I was at two years ago, after nine years of trying and failing to come up with a solution to this problem.
Messy flexbox hacks
A flexbox solution that seemed like it would work at first was to add an ::after pseudo-element on the grid and set flex: 1 on both the thumbnails and this pseudo-element:
.grid--thumbs { display: flex; flex-wrap: wrap; a, &::after { flex: 1; } img { margin: auto; } &:after { content: 'AFTER'; } }
The demo below shows how this method works. I’ve given the thumbnails and the ::after pseudo-element purple outlines to make it easier to see what is going on.
CodePen Embed Fallback
This is not quite what I wanted because the grid of thumbnails is not middle-aligned. Thats said, it doesn’t look too bad… as long as the last row has exactly one item less image than the others. As soon as that changes, however, the layout breaks if it’s missing more items or none.

Why the ::after hack is not reliable.
That was one hacky idea. Another is to use a pseudo-element again, but add as many empty divs after the thumbnails as there are columns that we’re expecting to have. That number is something we should be able to approximate since the size of the thumbnails is fixed. We probably want to set a maximum width for the post since text that stretches across the width of a full screen can visually exhausting for eyes to read.
The first empty elements will take up the full width of the row that’s not completely filled with thumbnails, while the rest will spill into other rows. But since their height is zero, it won’t matter visually.
CodePen Embed Fallback
This kind of does the trick but, again, it’s hacky and still doesn’t produce the exact result I want since it sometimes ends up with big and kind of ugly-looking gaps between the columns.
A grid solution?
The grid layout has always sounded like the answer, given its name. The problem was that all examples I had seen by then were using a predefined number of columns and that doesn’t work for this particular pattern where the number of columns is determined by the viewport width.
Last year, while coding a collection of one element, pure CSS background patterns, I had the idea of generating a bunch of media queries that would modify a CSS variable, --n, corresponding to the number of columns used to set grid-template-columns.
$w: 13em; $h: 19em; $f: $h/$w; $n: 7; $g: 1em; --h: #{$f*$w}; display: grid; grid-template-columns: repeat(var(--n, #{$n}), var(--w, #{$w})); grid-gap: $g; place-content: center; @for $i from 1 to $n { @media (max-width: ($n - $i + 1)*$w + ($n - $i + 2)*$g) { --n: #{$n - $i} } }
CodePen Embed Fallback
I was actually super proud of this idea at the time, even though I cringe looking back on it now. One media query for every number of columns possible is not exactly ideal, not to mention it doesn’t work so well when the grid width doesn’t equal the viewport width, but is still somewhat flexible and also depends on the width of its siblings.
A magic solution
I finally came across a better solution while working with CSS grid and failing to understand why the repeat() function wasn’t working in a particular situation. It was so frustrating and prompted me to go to MDN, where I happened to notice the auto-fit keyword and, while I didn’t understand the explanation, I had a hunch that it could help with this other problem, so I dropped everything else I was doing and gave it a try.
Here’s what I got:
.grid--thumbs { display: grid; justify-content: center; grid-gap: .25em; grid-template-columns: repeat(auto-fit, 8em); }
CodePen Embed Fallback
I also discovered the minmax() function, which can be used in place of fixed sizes on grid items. I still haven’t been able to understand exactly how minmax() works — and the more I play with it, the less I understand it — but what it looks like it does in this situation is create the grid then stretch its columns equally until they fill all of the available space:
grid-template-columns: repeat(auto-fit, minmax(8em, 1fr));
CodePen Embed Fallback
Another cool thing we can do here is prevent the image from overflowing when it’s wider than the grid element. We can do this by replacing the minimum 8em with min(8em, 100%) That essentially ensures that images will never exceed 100%, but never below 8em. Thanks to Chris for this suggestion!
Note that the min() function doesn’t work in pre-Chromium Edge!
CodePen Embed Fallback
Keep in mind that this only produces a nice result if all of the images have the same aspect ratio — like the square images I’ve used here. For my blog, this was not an issue since all photos were taken with my Sony Ericsson W800i phone, and they all had the same aspect ratio. But if we were to drop images with different aspect ratios, the grid wouldn’t look as good anymore:
CodePen Embed Fallback
We can, of course, set the image height to a fixed value, but that distorts the images… unless we set object-fit to cover, which solves our problem!
CodePen Embed Fallback
Another idea would be to turn the first thumbnail into a sort of banner that spans all grid columns. The one problem is that we don’t know the number of columns because that depends on the viewport. But, there is a solution — we can set grid-column-end to -1!
.grid--thumbs { /* same styles as before */ a:first-child { grid-column: 1/ -1; img { height: 13em } } }
The first image gets a bigger height than all the others.
CodePen Embed Fallback
Of course, if we wanted the image to span all columns except the last, one we’d set it to -2 and so on… negative column indices are a thing!
auto-fill is another grid property keyword I noticed on MDN. The explanations for both are long walls of text without visuals, so I didn’t find them particularly useful. Even worse, replacing auto-fit with auto-fill in any of the grid demos above produces absolutely no difference. How they really work and how they differ still remains a mystery, even after checking out articles or toying with examples.
However, trying out different things and seeing what happens in various scenarios at one point led me to the conclusion that, if we’re using a minmax() column width and not a fixed one (like 8em), then it’s probably better to use auto-fill instead of auto-fit because, the result looks better if we happen to only have a few images, as illustrated by the interactive demo below:
CodePen Embed Fallback
I think what I personally like best is the initial idea of a thumbnail grid that’s middle-aligned and has a mostly fixed column width (but still uses min(100%, 15em) instead of just 15em though). At the end of the day, it’s a matter of personal preference and what can be seen in the demo below just happens to look better to me:
CodePen Embed Fallback
I’m using auto-fit in this demo because it produces the same result as auto-fill and is one character shorter. However, what I didn’t understand when making this is that both keywords produce the same result because there are more items in the gallery than we need to fill a row.
But once that changes, auto-fit and auto-fill produce different results, as illustrated below. You can change the justify-content value and the number of items placed on the grid:
CodePen Embed Fallback
I’m not really sure which is the better choice. I guess this also depends on personal preference. Coupled with justify-content: center, auto-fill seems to be the more logical option, but, at the same time, auto-fit produces a better-looking result.
The post Cool Little CSS Grid Tricks for Your Blog appeared first on CSS-Tricks.
source https://css-tricks.com/cool-little-css-grid-tricks-for-your-blog/
from WordPress https://ift.tt/3cNgDZf via IFTTT
0 notes
Text
Introducing Alpine.js: A Tiny JavaScript Framework | ArkssTech

Introducing Alpine.js: A Tiny JavaScript Framework Like most developers, I have a bad tendency to over-complicate my workflow, especially if there’s some new hotness on the horizon. Why use CSS when you can use CSS-in-JS? Why use Grunt when you can use Gulp? Why use Gulp when you can use Webpack? Why use a traditional CMS when you can go headless? Every so often though, the new-hotness makes life simpler. Recently, the rise of utility based tools like Tailwind CSS have done this for CSS, and now Alpine.js promises something similar for JavaScript. In this article, we’re going to take a closer look at Alpine.js and how it can replace JQuery or larger JavaScript libraries to build interactive websites. If you regularly build sites that require a sprinkling on Javascript to alter the UI based on some user interaction, then this article is for you. Throughout the article, I refer to Vue.js, but don’t worry if you have no experience of Vue — that is not required. In fact, part of what makes Alpine.js great is that you barely need to know any JavaScript at all. Now, let’s get started. What Is Alpine.js? According to project author Caleb Porzio: “Alpine.js offers you the reactive and declarative nature of big frameworks like Vue or React at a much lower cost. You get to keep your DOM, and sprinkle in behavior as you see fit.” Let’s unpack that a bit. Let’s consider a basic UI pattern like Tabs. Our ultimate goal is that when a user clicks on a tab, the tab contents displays. If we come from a PHP background, we could easily achieve this server side. But the page refresh on every tab click isn’t very ‘reactive’. To create a better experience over the years, developers have reached for jQuery and/or Bootstrap. In that situation, we create an event listener on the tab, and when a user clicks, the event fires and we tell the browser what to do. See the Pen Showing / hiding with jQuery by Phil on CodePen. See the Pen Showing / hiding with jQuery by Phil on CodePen. That works. But this style of coding where we tell the browser exactly what to do (imperative coding) quickly gets us in a mess. Imagine if we wanted to disable the button after it has been clicked, or wanted to change the background color of the page. We’d quickly get into some serious spaghetti code. Developers have solved this issue by reaching for frameworks like Vue, Angular and React. These frameworks allow us to write cleaner code by utilizing the virtual DOM: a kind of mirror of the UI stored in the browser memory. The result is that when you ‘hide’ a DOM element (like a tab) in one of these frameworks; it doesn’t add a display:none; style attribute, but instead it literally disappears from the ‘real’ DOM. This allows us to write more declarative code that is cleaner and easier to read. But this is at a cost. Typically, the bundle size of these frameworks is large and for those coming from a jQuery background, the learning curve feels incredibly steep. Especially when all you want to do is toggle tabs! And that is where Alpine.js steps in. WANT TO BUILD YOUR BUSINESS APP IN LARAVEL FRAMEWORK? ARKSSTECH, AGILE SOFTWARE DEVELOPMENT COMPANY OFFERS EXPERIENCED LARAVEL APP DEVELOPERS & TO HIRE LARAVEL DEVELOPERS FOR STARTUPS AND SMES. RENT A CODER TODAY!! Like Vue and React, Alpine.js allows us to write declarative code but it uses the “real” DOM; amending the contents and attributes of the same nodes that you and I might edit when we crack open a text editor or dev-tools. As a result, you can lose the filesize, wizardry and cognitive-load of larger framework but retain the declarative programming methodology. And you get this with no bundler, no build process and no script tag. Just load 6kb of Alpine.js and you’re away! Alpine.js JQuery Vue.js React + React DOM Coding style Declarative Imperative Declarative Declarative Requires bundler No No No Yes Filesize (GZipped, minified) 6.4kb 30kb 32kb 5kb + 36kb Dev-Tools No No Yes Yes WANT TO BUILD YOUR BUSINESS APP IN LARAVEL FRAMEWORK? ARKSSTECH, AGILE SOFTWARE DEVELOPMENT COMPANY OFFERS EXPERIENCED LARAVEL APP DEVELOPERS & TO HIRE LARAVEL DEVELOPERS FOR STARTUPS AND SMES. RENT A CODER TODAY!! When Should I Reach For Alpine? For me, Alpine’s strength is in the ease of DOM manipulation. Think of those things you used out of the box with Bootstrap, Alpine.js is great for them. Examples would be: Showing and hiding DOM nodes under certain conditions, Binding user input, Listening for events and altering the UI accordingly, Appending classes. You can also use Alpine.js for templating if your data is available in JSON, but let’s save that for another day. When Should I Look Elsewhere? If you’re fetching data, or need to carry out additional functions like validation or storing data, you should probably look elsewhere. Larger frameworks also come with dev-tools which can be invaluable when building larger UIs. From jQuery To Vue To Alpine Two years ago, Sarah Drasner posted an article on Smashing Magazine, “Replacing jQuery With Vue.js: No Build Step Necessary,” about how Vue could replace jQuery for many projects. That article started me on a journey which led me to use Vue almost every time I build a user interface. Today, we are going to recreate some of her examples with Alpine, which should illustrate its advantages over both jQuery and Vue in certain use cases. Alpine’s syntax is almost entirely lifted from Vue.js. In total, there are 13 directives. We’ll cover most of them in the following examples. Getting Started Like Vue and jQuery, no build process is required. Unlike Vue, Alpine it initializes itself, so there’s no need to create a new instance. Just load Alpine and you’re good to go. The scope of any given component is declared using the x-data directive. This kicks things off and sets some default values if required: ... Capturing User Inputs x-model allow us to keep any input element in sync with the values set using x-data. In the following example, we set the name value to an empty string (within the form tag). Using x-model, we bind this value to the input field. By using x-text, we inject the value into the innerText of the paragraph element. This highlights the key differences with Alpine.js and both jQuery and Vue.js. Updating the paragraph tag in jQuery would require us to listen for specific events (keyup?), explicitly identify the node we wish to update and the changes we wish to make. Alpine’s syntax on the other hand, just specifies what should happen. This is what is meant by declarative programming. Updating the paragraph in Vue while simple, would require a new script tag: new Vue({ el: '#app', data: { name: '' } }); While this might not seem like the end of the world, it highlights the first major gain with Alpine. There is no context-switching. Everything is done right there in the HTML — no need for any additional JavaScript. Click Events, Boolean Attributes And Toggling Classes Like with Vue, : serves as a shorthand for x-bind (which binds attributes) and @ is shorthand for x-on (which indicates that Alpine should listen for events). In the following example, we instantiate a new component using x-data, and set the default value of show to be false. When the button is clicked, we toggle the value of show. When this value is true, we instruct Alpine to append the aria-expanded attribute. x-bind works differently for classes: we pass in object where the key is the class-name (active in our case) and the value is a boolean expression (show). WANT TO BUILD YOUR BUSINESS APP IN LARAVEL FRAMEWORK? ARKSSTECH, AGILE SOFTWARE DEVELOPMENT COMPANY OFFERS EXPERIENCED LARAVEL APP DEVELOPERS & TO HIRE LARAVEL DEVELOPERS FOR STARTUPS AND SMES. RENT A CODER TODAY!! Hiding And Showing The syntax showing and hiding is almost identical to Vue. This will set a given DOM node to display:none. If you need to remove a DOM element completely, x-if can be used. However, because Alpine.js doesn’t use the Virtual DOM, x-if can only be used on a (tag that wraps the element you wish to hide). Magic Properties In addition to the above directives, three Magic Properties provide some additional functionality. All of these will be familiar to anyone working in Vue.js. $el fetches the root component (the thing with the x-data attribute); $refs allows you to grab a DOM element; $nextTick ensures expressions are only executed once Alpine has done its thing; $event can be used to capture a nature browser event. Let’s Build Something Useful It’s time to build something for the real world. In the interests of brevity I’m going to use Bootstrap for styles, but use Alpine.js for all the JavaScript. The page we’re building is a simple landing page with a contact form displayed inside a modal that submits to some form handler and displays a nice success message. Just the sort of thing a client might ask for and expect pronto!

Initial view (Large preview)
Modal open (Large preview)
Success message (Large preview) Note: You can view the original markup here. WANT TO BUILD YOUR BUSINESS APP IN LARAVEL FRAMEWORK? ARKSSTECH, AGILE SOFTWARE DEVELOPMENT COMPANY OFFERS EXPERIENCED LARAVEL APP DEVELOPERS & TO HIRE LARAVEL DEVELOPERS FOR STARTUPS AND SMES. RENT A CODER TODAY!! To make this work, we could add jQuery and Bootstrap.js, but that is quite a bit of overhead for not a lot of functionality. We could probably write it in Vanilla JS, but who wants to do that? Let’s make it work with Alpine.js instead. First, let’s set a scope and some initial values: Now, let’s make our button set the showModal value to true: Get in touch When showModal is true, we need to display the modal and add some classes: Let’s bind the input values to Alpine: And disable the ‘Submit’ button, until those values are set: Submit Finally, let’s send data to some kind of asynchronous function, and hide the modal when we’re done: Submit And that’s about it! Just Enough JavaScript When building websites, I’m increasingly trying to ask myself what would be “just enough JavaScript”? When building a sophisticated web application, that might well be React. But when building a marketing site, or something similar, Alpine.js feels like enough. (And even if it’s not, given the similar syntax, switching to Vue.js takes no time at all). It’s incredibly easy to use (especially if you’ve never used VueJS). It’s tiny ( There are more advanced features that aren’t included in this article and Caleb is constantly adding new features. If you want to find out more, take a look at the official docs on Github. WANT TO BUILD YOUR BUSINESS APP IN LARAVEL FRAMEWORK? ARKSSTECH, AGILE SOFTWARE DEVELOPMENT COMPANY OFFERS EXPERIENCED LARAVEL APP DEVELOPERS & TO HIRE LARAVEL DEVELOPERS FOR STARTUPS AND SMES. RENT A CODER TODAY!! Read the full article
#bestbrowsersforwebdesign#designsystems#webdesignbrowsers#webdesigncomponents#webdesigntools#webdesignworkflow
0 notes
Text
Designing And Building A Progressive Web Application Without A Framework (Part 2)
Designing And Building A Progressive Web Application Without A Framework (Part 2)
Ben Frain
2019-07-25T14:00:59+02:002019-07-25T12:06:45+00:00
The raison d’être of this adventure was to push your humble author a little in the disciplines of visual design and JavaScript coding. The functionality of the application I’d decided to build was not dissimilar to a ‘to do’ application. It is important to stress that this wasn’t an exercise in original thinking. The destination was far less important than the journey.
Want to find out how the application ended up? Point your phone browser at https://io.benfrain.com.
Read Part One of Designing And Building A Progessive Web Application Without A Framework.
Here is a summary of what we will cover in this article:
The project set-up and why I opted for Gulp as a build tool;
Application design patterns and what they mean in practice;
How to store and visualize application state;
how CSS was scoped to components;
what UI/UX niceties were employed to make the things more ‘app-like’;
How the remit changed through iteration.
Let’s start with the build tools.
Build Tools
In order to get my basic tooling of TypeScipt and PostCSS up and running and create a decent development experience, I would need a build system.
In my day job, for the last five years or so, I have been building interface prototypes in HTML/CSS and to a lesser extent, JavaScript. Until recently, I have used Gulp with any number of plugins almost exclusively to achieve my fairly humble build needs.
Typically I need to process CSS, convert JavaScript or TypeScript to more widely supported JavaScript, and occasionally, carry out related tasks like minifying code output and optimizing assets. Using Gulp has always allowed me to solve those issues with aplomb.
For those unfamiliar, Gulp lets you write JavaScript to do ‘something’ to files on your local file system. To use Gulp, you typically have a single file (called gulpfile.js) in the root of your project. This JavaScript file allows you to define tasks as functions. You can add third-party ‘Plugins’, which are essentially further JavaScript functions, that deal with specific tasks.
An Example Gulp Task
An example Gulp task might be using a plugin to harness PostCSS to process to CSS when you change an authoring style sheet (gulp-postcss). Or compiling TypeScript files to vanilla JavaScript (gulp-typescript) as you save them. Here is a simple example of how you write a task in Gulp. This task uses the ‘del’ gulp plugin to delete all the files in a folder called ‘build’:
var del = require("del"); gulp.task("clean", function() { return del(["build/**/*"]); });
The require assigns the del plugin to a variable. Then the gulp.task method is called. We name the task with a string as the first argument (“clean”) and then run a function, which in this case uses the ‘del’ method to delete the folder passed to it as an argument. The asterisk symbols there are ‘glob’ patterns which essentially say ‘any file in any folder’ of the build folder.
Gulp tasks can get heaps more complicated but in essence, that is the mechanics of how things are handled. The truth is, with Gulp, you don’t need to be a JavaScript wizard to get by; grade 3 copy and paste skills are all you need.
I’d stuck with Gulp as my default build tool/task runner for all these years with a policy of ‘if it ain’t broke; don’t try and fix it’.
However, I was worried I was getting stuck in my ways. It’s an easy trap to fall into. First, you start holidaying the same place every year, then refusing to adopt any new fashion trends before eventually and steadfastly refusing to try out any new build tools.
I’d heard plenty of chatter on the Internets about ‘Webpack’ and thought it was my duty to try a project using the new-fangled toast of the front-end developer cool-kids.
Webpack
I distinctly remember skipping over to the webpack.js.org site with keen interest. The first explanation of what Webpack is and does started like this:
import bar from './bar';
Say what? In the words of Dr. Evil, “Throw me a frickin’ bone here, Scott”.
I know it’s my own hang-up to deal with but I’ve developed a revulsion to any coding explanations that mention ‘foo’, ‘bar’ or ‘baz’. That plus the complete lack of succinctly describing what Webpack was actually for had me suspecting it perhaps wasn’t for me.
Digging a little further into the Webpack documentation, a slightly less opaque explanation was offered, “At its core, webpack is a static module bundler for modern JavaScript applications”.
Hmmm. Static module bundler. Was that what I wanted? I wasn’t convinced. I read on but the more I read, the less clear I was. Back then, concepts like dependency graphs, hot module reloading, and entry points were essentially lost on me.
A couple of evenings of researching Webpack later, I abandoned any notion of using it.
I’m sure in the right situation and more experienced hands, Webpack is immensely powerful and appropriate but it seemed like complete overkill for my humble needs. Module bundling, tree-shaking, and hot-module reloading sounded great; I just wasn’t convinced I needed them for my little ‘app’.
So, back to Gulp then.
On the theme of not changing things for change sake, another piece of technology I wanted to evaluate was Yarn over NPM for managing project dependencies. Until that point, I had always used NPM and Yarn was getting touted as a better, faster alternative. I don’t have much to say about Yarn other than if you are currently using NPM and everything is OK, you don’t need to bother trying Yarn.
One tool that arrived too late for me to appraise for this application is Parceljs. With zero configuration and a BrowserSync like browser reloading backed in, I’ve since found great utility in it! In addition, in Webpack’s defense, I'm told that v4 onwards of Webpack doesn’t require a configuration file. Anecdotally, in a more recent poll I ran on Twitter, of the 87 respondents, over half chose Webpack over Gulp, Parcel or Grunt.
I started my Gulp file with basic functionality to get up and running.
A ‘default’ task would watch the ‘source’ folders of style sheets and TypeScript files and compile them out to a build folder along with the basic HTML and associated source maps.
I got BrowserSync working with Gulp too. I might not know what to do with a Webpack configuration file but that didn’t mean I was some kind of animal. Having to manually refresh the browser while iterating with HTML/CSS is soooo 2010 and BrowserSync gives you that short feedback and iteration loop that is so useful for front-end coding.
Here is the basic gulp file as of 11.6.2017
You can see how I tweaked the Gulpfile nearer to the end of shipping, adding minification with ugilify:
Project Structure
By consequence of my technology choices, some elements of code organization for the application were defining themselves. A gulpfile.js in the root of the project, a node_modules folder (where Gulp stores plugin code) a preCSS folder for the authoring style sheets, a ts folder for the TypeScript files, and a build folder for the compiled code to live.
The idea was to have an index.html that contained the ‘shell’ of the application, including any non-dynamic HTML structure and then links to the styles and the JavaScript file that would make the application work. On disk, it would look something like this:
build/ node_modules/ preCSS/ img/ partials/ styles.css ts/ .gitignore gulpfile.js index.html package.json tsconfig.json
Configuring BrowserSync to look at that build folder meant I could point my browser at localhost:3000 and all was good.
With a basic build system in place, files organization settled and some basic designs to make a start with, I had run-out of procrastination fodder I could legitimately use to prevent me from actually building the thing!
Writing An Application
The principle of how the application would work was this. There would be a store of data. When the JavaScript loaded it would load that data, loop through each player in the data, creating the HTML needed to represent each player as a row in the layout and placing them in the appropriate in/out section. Then interactions from the user would move a player from one state to another. Simple.
When it came to actually writing the application, the two big conceptual challenges that needed to be understood were:
How to represent the data for an application in a manner that could be easily extended and manipulated;
How to make the UI react when data was changed from user input.
One of the simplest ways to represent a data structure in JavaScript is with object notation. That sentence reads a little computer science-y. More simply, an ‘object’ in JavaScript lingo is a handy way of storing data.
Consider this JavaScript object assigned to a variable called ioState (for In/Out State):
var ioState = { Count: 0, // Running total of how many players RosterCount: 0; // Total number of possible players ToolsExposed: false, // Whether the UI for the tools is showing Players: [], // A holder for the players }
If you don’t really know JavaScript that well, you can probably at least grasp what’s going on: each line inside the curly braces is a property (or ‘key’ in JavaScript parlance) and value pair. You can set all sorts of things to a JavaScript key. For example, functions, arrays of other data or nested objects. Here’s an example:
var testObject = { testFunction: function() { return "sausages"; }, testArray: [3,7,9], nestedtObject { key1: "value1", key2: 2, } }
The net result is that using that kind of data structure you can get, and set, any of the keys of the object. For example, if we want to set the count of the ioState object to 7:
ioState.Count = 7;
If we want to set a piece of text to that value, the notation works like this:
aTextNode.textContent = ioState.Count;
You can see that getting values and setting values to that state object is simple in the JavaScript side of things. However, reflecting those changes in the User Interface is less so. This is the main area where frameworks and libraries seek to abstract away the pain.
In general terms, when it comes to dealing with updating the user interface based upon state, it’s preferable to avoid querying the DOM, as this is generally considered a sub-optimal approach.
Consider the In/Out interface. It’s typically showing a list of potential players for a game. They are vertically listed, one under the other, down the page.
Perhaps each player is represented in the DOM with a label wrapping a checkbox input. This way, clicking a player would toggle the player to ‘In’ by virtue of the label making the input ‘checked’.
To update our interface, we might have a ‘listener’ on each input element in the JavaScript. On a click or change, the function queries the DOM and counts how many of our player inputs are checked. On the basis of that count, we would then update something else in the DOM to show the user how many players are checked.
Let’s consider the cost of that basic operation. We are listening on multiple DOM nodes for the click/check of an input, then querying the DOM to see how many of a particular DOM type are checked, then writing something into the DOM to show the user, UI wise, the number of players we just counted.
The alternative would be to hold the application state as a JavaScript object in memory. A button/input click in the DOM could merely update the JavaScript object and then, based on that change in the JavaScript object, do a single-pass update of the all interface changes that are needed. We could skip querying the DOM to count the players as the JavaScript object would already hold that information.
So. Using a JavaScript object structure for the state seemed simple but flexible enough to encapsulate the application state at any given time. The theory of how this could be managed seemed sound enough too – this must be what phrases like ‘one-way data flow’ were all about? However, the first real trick would be in creating some code that would automatically update the UI based on any changes to that data.
The good news is that smarter people than I have already figured this stuff out (thank goodness!). People have been perfecting approaches to this kind of challenge since the dawn of applications. This category of problems is the bread and butter of ‘design patterns’. The moniker ‘design pattern’ sounded esoteric to me at first but after digging just a little it all started to sound less computer science and more common sense.
Design Patterns
A design pattern, in computer science lexicon, is a pre-defined and proven way of solving a common technical challenge. Think of design patterns as the coding equivalent of a cooking recipe.
Perhaps the most famous literature on design patterns is "Design Patterns: Elements of Reusable Object-Oriented Software" from back in 1994. Although that deals with C++ and smalltalk the concepts are transferable. For JavaScript, Addy Osmani’s "Learning JavaScript Design Patterns" covers similar ground. You can also read it online for free here.
Observer Pattern
Typically design patterns are split into three groups: Creational, Structural and Behavioural. I was looking for something Behavioural that helped to deal with communicating changes around the different parts of the application.
More recently, I have seen and read a really great deep-dive on implementing reactivity inside an app by Gregg Pollack. There is both a blog post and video for your enjoyment here.
When reading the opening description of the ‘Observer’ pattern in Learning JavaScript Design Patterns I was pretty sure it was the pattern for me. It is described thus:
The Observer is a design pattern where an object (known as a subject) maintains a list of objects depending on it (observers), automatically notifying them of any changes to state. When a subject needs to notify observers about something interesting happening, it broadcasts a notification to the observers (which can include specific data related to the topic of the notification).
The key to my excitement was that this seemed to offer some way of things updating themselves when needed.
Suppose the user clicked a player named “Betty” to select that she was ‘In’ for the game. A few things might need to happen in the UI:
Add 1 to the playing count
Remove Betty from the ‘Out’ pool of players
Add Betty to the ‘In’ pool of players
The app would also need to update the data that represented the UI. What I was very keen to avoid was this:
playerName.addEventListener("click", playerToggle); function playerToggle() { if (inPlayers.includes(e.target.textContent)) { setPlayerOut(e.target.textContent); decrementPlayerCount(); } else { setPlayerIn(e.target.textContent); incrementPlayerCount(); } }
The aim was to have an elegant data flow that updated what was needed in the DOM when and if the central data was changed.
With an Observer pattern, it was possible to send out updates to the state and therefore the user interface quite succinctly. Here is an example, the actual function used to add a new player to the list:
function itemAdd(itemString: string) { let currentDataSet = getCurrentDataSet(); var newPerson = new makePerson(itemString); io.items[currentDataSet].EventData.splice(0, 0, newPerson); io.notify({ items: io.items }); }
The part relevant to the Observer pattern there being the io.notify method. As that shows us modifying the items part of the application state, let me show you the observer that listened for changes to ‘items’:
io.addObserver({ props: ["items"], callback: function renderItems() { // Code that updates anything to do with items... } });
We have a notify method that makes changes to the data and then Observers to that data that respond when properties they are interested in are updated.
With this approach, the app could have observables watching for changes in any property of the data and run a function whenever a change occurred.
If you are interested in the Observer pattern I opted for, I describe it more fully here.
There was now an approach for updating the UI effectively based on state. Peachy. However, this still left me with two glaring issues.
One was how to store the state across page reloads/sessions and the fact that despite the UI working, visually, it just wasn’t very ‘app like’. For example, if a button was pressed the UI instantly changed on screen. It just wasn’t particularly compelling.
Let’s deal with the storage side of things first.
Saving State
My primary interest from a development side entering into this centered on understanding how app interfaces could be built and made interactive with JavaScript. How to store and retrieve data from a server or tackle user-authentication and logins was ‘out of scope’.
Therefore, instead of hooking up to a web service for the data storage needs, I opted to keep all data on the client. There are a number of web platform methods of storing data on a client. I opted for localStorage.
The API for localStorage is incredibly simple. You set and get data like this:
// Set something localStorage.setItem("yourKey", "yourValue"); // Get something localStorage.getItem("yourKey");
LocalStorage has a setItem method that you pass two strings to. The first is the name of the key you want to store the data with and the second string is the actual string you want to store. The getItem method takes a string as an argument that returns to you whatever is stored under that key in localStorage. Nice and simple.
However, amongst the reasons to not use localStorage is the fact that everything has to be saved as a ‘string’. This means you can’t directly store something like an array or object. For example, try running these commands in your browser console:
// Set something localStorage.setItem("myArray", [1, 2, 3, 4]); // Get something localStorage.getItem("myArray"); // Logs "1,2,3,4"
Even though we tried to set the value of ‘myArray’ as an array; when we retrieved it, it had been stored as a string (note the quote marks around ‘1,2,3,4’).
You can certainly store objects and arrays with localStorage but you need to be mindful that they need converting back and forth from strings.
So, in order to write state data into localStorage it was written to a string with the JSON.stringify() method like this:
const storage = window.localStorage; storage.setItem("players", JSON.stringify(io.items));
When the data needed retrieving from localStorage, the string was turned back into usable data with the JSON.parse() method like this:
const players = JSON.parse(storage.getItem("players"));
Using localStorage meant everything was on the client and that meant no 3rd party services or data storage concerns.
Data was now persisting refreshes and sessions — Yay! The bad news was that localStorage does not survive a user emptying their browser data. When someone did that, all their In/Out data would be lost. That’s a serious shortcoming.
It’s not hard to appreciate that `localStorage` probably isn’t the best solution for 'proper' applications. Besides the aforementioned string issue, it is also slow for serious work as it blocks the 'main thread'. Alternatives are coming, like KV Storage but for now, make a mental note to caveat its use based on suitability.
Despite the fragility of saving data locally on a users device, hooking up to a service or database was resisted. Instead, the issue was side-stepped by offering a ‘load/save’ option. This would allow any user of In/Out to save their data as a JSON file which could be loaded back into the app if needed.
This worked well on Android but far less elegantly for iOS. On an iPhone, it resulted in a splurge of text on screen like this:

(Large preview)
As you can imagine, I was far from alone in berating Apple via WebKit about this shortcoming. The relevant bug was here.
At the time of writing this bug has a solution and patch but has yet to make its way into iOS Safari. Allegedly, iOS13 fixes it but it’s that’s in Beta as I write.
So, for my minimum viable product, that was storage addressed. Now it was time to attempt to make things more ‘app-like’!
App-I-Ness
Turns out after many discussions with many people, defining exactly what ‘app like’ means is quite difficult.
Ultimately, I settled on ‘app-like’ being synonymous with a visual slickness usually missing from the web. When I think of the apps that feel good to use they all feature motion. Not gratuitous, but motion that adds to the story of your actions. It might be the page transitions between screens, the manner in which menus pop into existence. It’s hard to describe in words but most of us know it when we see it.
The first piece of visual flair needed was shifting player names up or down from ‘In’ to ‘Out’ and vice-versa when selected. Making a player instantly move from one section to the other was straightforward but certainly not ‘app-like’. An animation as a player name was clicked would hopefully emphasize the result of that interaction – the player moving from one category to another.
Like many of these kinds of visual interactions, their apparent simplicity belies the complexity involved in actually getting it working well.
It took a few iterations to get the movement right but the basic logic was this:
Once a ‘player’ is clicked, capture where that player is, geometrically, on the page;
Measure how far away the top of the area is the player needs to move to if going up (‘In’) and how far away the bottom is, if going down (‘Out’);
If going up, a space equal to the height of the player row needs to be left as the player moves up and the players above should collapse downwards at the same rate as the time it takes for the player to travel up to land in the space vacated by the existing ‘In’ players (if any exist) coming down;
If a player is going ‘Out’ and moving down, everything else needs to move up to the space left and the player needs to end up below any current ‘Out’ players.
Phew! It was trickier than I thought in English — never mind JavaScript!
There were additional complexities to consider and trial such as transition speeds. At the outset, it wasn’t obvious whether a constant speed of movement (e.g. 20px per 20ms), or a constant duration for the movement (e.g. 0.2s) would look better. The former was slightly more complicated as the speed needed to be computed ‘on the fly’ based upon how far the player needed to travel — greater distance requiring a longer transition duration.
However, it turned out that a constant transition duration was not just simpler in code; it actually produced a more favorable effect. The difference was subtle but these are the kind of choices you can only determine once you have seen both options.
Every so often whilst trying to nail this effect, a visual glitch would catch the eye but it was impossible to deconstruct in real time. I found the best debugging process was creating a QuickTime recording of the animation and then going through it a frame at a time. Invariably this revealed the problem quicker than any code based debugging.
Looking at the code now, I can appreciate that on something beyond my humble app, this functionality could almost certainly be written more effectively. Given that the app would know the number of players and know the fixed height of the slats, it should be entirely possible to make all distance calculations in the JavaScript alone, without any DOM reading.
It’s not that what was shipped doesn’t work, it’s just that it isn’t the kind of code solution you would showcase on the Internet. Oh, wait.
Other ‘app like’ interactions were much easier to pull off. Instead of menus simply snapping in and out with something as simple as toggling a display property, a lot of mileage was gained by simply exposing them with a little more finesse. It was still triggered simply but CSS was doing all the heavy lifting:
.io-EventLoader { position: absolute; top: 100%; margin-top: 5px; z-index: 100; width: 100%; opacity: 0; transition: all 0.2s; pointer-events: none; transform: translateY(-10px); [data-evswitcher-showing="true"] & { opacity: 1; pointer-events: auto; transform: none; } }
There when the data-evswitcher-showing="true" attribute was toggled on a parent element, the menu would fade in, transform back into its default position and pointer events would be re-enabled so the menu could receive clicks.
ECSS Style Sheet Methodology
You’ll notice in that prior code that from an authoring point of view, CSS overrides are being nested within a parent selector. That’s the way I always favor writing UI style sheets; a single source of truth for each selector and any overrides for that selector encapsulated within a single set of braces. It’s a pattern that requires the use of a CSS processor (Sass, PostCSS, LESS, Stylus, et al) but I feel is the only positive way to make use of nesting functionality.
I’d cemented this approach in my book, Enduring CSS and despite there being a plethora of more involved methods available to write CSS for interface elements, ECSS has served me and the large development teams I work with well since the approach was first documented way back in 2014! It proved just as effective in this instance.
Partialling The TypeScript
Even without a CSS processor or superset language like Sass, CSS has had the ability to import one or more CSS files into another with the import directive:
@import "other-file.css";
When beginning with JavaScript I was surprised there was no equivalent. Whenever code files get longer than a screen or so high, it always feels like splitting it into smaller pieces would be beneficial.
Another bonus to using TypeScript was that it has a beautifully simple way of splitting code into files and importing them when needed.
This capability pre-dated native JavaScript modules and was a great convenience feature. When TypeScript was compiled it stitched it all back to a single JavaScript file. It meant it was possible to easily break up the application code into manageable partial files for authoring and import then into the main file easily. The top of the main inout.ts looked like this:
/// <reference path="defaultData.ts" /> /// <reference path="splitTeams.ts" /> /// <reference path="deleteOrPaidClickMask.ts" /> /// <reference path="repositionSlat.ts" /> /// <reference path="createSlats.ts" /> /// <reference path="utils.ts" /> /// <reference path="countIn.ts" /> /// <reference path="loadFile.ts" /> /// <reference path="saveText.ts" /> /// <reference path="observerPattern.ts" /> /// <reference path="onBoard.ts" />
This simple house-keeping and organization task helped enormously.
Multiple Events
At the outset, I felt that from a functionality point of view, a single event, like “Tuesday Night Football” would suffice. In that scenario, if you loaded In/Out up you just added/removed or moved players in or out and that was that. There was no notion of multiple events.
I quickly decided that (even going for a minimum viable product) this would make for a pretty limited experience. What if somebody organized two games on different days, with a different roster of players? Surely In/Out could/should accommodate that need? It didn’t take too long to re-shape the data to make this possible and amend the methods needed to load in a different set.
At the outset, the default data set looked something like this:
var defaultData = [ { name: "Daz", paid: false, marked: false, team: "", in: false }, { name: "Carl", paid: false, marked: false, team: "", in: false }, { name: "Big Dave", paid: false, marked: false, team: "", in: false }, { name: "Nick", paid: false, marked: false, team: "", in: false } ];
An array containing an object for each player.
After factoring in multiple events it was amended to look like this:
var defaultDataV2 = [ { EventName: "Tuesday Night Footy", Selected: true, EventData: [ { name: "Jack", marked: false, team: "", in: false }, { name: "Carl", marked: false, team: "", in: false }, { name: "Big Dave", marked: false, team: "", in: false }, { name: "Nick", marked: false, team: "", in: false }, { name: "Red Boots", marked: false, team: "", in: false }, { name: "Gaz", marked: false, team: "", in: false }, { name: "Angry Martin", marked: false, team: "", in: false } ] }, { EventName: "Friday PM Bank Job", Selected: false, EventData: [ { name: "Mr Pink", marked: false, team: "", in: false }, { name: "Mr Blonde", marked: false, team: "", in: false }, { name: "Mr White", marked: false, team: "", in: false }, { name: "Mr Brown", marked: false, team: "", in: false } ] }, { EventName: "WWII Ladies Baseball", Selected: false, EventData: [ { name: "C Dottie Hinson", marked: false, team: "", in: false }, { name: "P Kit Keller", marked: false, team: "", in: false }, { name: "Mae Mordabito", marked: false, team: "", in: false } ] } ];
The new data was an array with an object for each event. Then in each event was an EventData property that was an array with player objects in as before.
It took much longer to re-consider how the interface could best deal with this new capability.
From the outset, the design had always been very sterile. Considering this was also supposed to be an exercise in design, I didn’t feel I was being brave enough. So a little more visual flair was added, starting with the header. This is what I mocked up in Sketch:
Revised design mockup. (Large preview)
It wasn’t going to win awards but it was certainly more arresting than where it started.
Aesthetics aside, it wasn’t until somebody else pointed it out, that I appreciated the big plus icon in the header was very confusing. Most people thought it was a way to add another event. In reality, it switched to an ‘Add Player’ mode with a fancy transition that let you type in the name of the player in the same place the event name was currently.
This was another instance where fresh eyes were invaluable. It was also an important lesson in letting go. The honest truth was I had held on to the input mode transition in the header because I felt it was cool and clever. However, the fact was it was not serving the design and therefore the application as a whole.
This was changed in the live version. Instead, the header just deals with events — a more common scenario. Meanwhile, adding players is done from a sub-menu. This gives the app a much more understandable hierarchy.
The other lesson learned here was that whenever possible, it’s hugely beneficial to get candid feedback from peers. If they are good and honest people, they won’t let you give yourself a pass!
Summary: My Code Stinks
Right. So far, so normal tech-adventure retrospective piece; these things are ten a penny on Medium! The formula goes something like this: the dev details how they smashed down all obstacles to release a finely tuned piece of software into the Internets and then pick up an interview at Google or got acqui-hired somewhere. However, the truth of the matter is that I was a first-timer at this app-building malarkey so the code ultimately shipped as the ‘finished’ application stunk to high heaven!
For example, the Observer pattern implementation used worked very well. I was organized and methodical at the outset but that approach ‘went south’ as I became more desperate to finish things off. Like a serial dieter, old familiar habits crept back in and the code quality subsequently dropped.
Looking now at the code shipped, it is a less than ideal hodge-bodge of clean observer pattern and bog-standard event listeners calling functions. In the main inout.ts file there are over 20 querySelector method calls; hardly a poster child for modern application development!
I was pretty sore about this at the time, especially as at the outset I was aware this was a trap I didn’t want to fall into. However, in the months that have since passed, I’ve become more philosophical about it.
The final post in this series reflects on finding the balance between silvery-towered code idealism and getting things shipped. It also covers the most important lessons learned during this process and my future aspirations for application development.

(dm, yk, il, ra)
0 notes
Text
Chapter 4: Search
Previously in web history…
After an influx of rapid browser development following the creation of the web, Mosaic becomes the popular choice. Recognizing the commercial potential of the web, a team at O’Reilly builds GNN, the first commercial website. With something to browse with, and something to browse for, more and more people begin to turn to the web. Many create small, personal sites of their own. The best the web has to offer becomes almost impossible to find.
eBay had had enough of these spiders. They were fending them off by the thousands. Their servers buzzed with nonstop activity; a relentless stream of trespassers. One aggressor, however, towered above the rest. Bidder’s Edge, which billed itself as an auction aggregator, would routinely crawl the pages of eBay to extract its content and list it on its own site alongside other auction listings.
The famed auction site had unsuccessfully tried blocking Bidder’s Edge in the past. Like an elaborate game of Whac-A-Mole, they would restrict the IP address of a Bidder’s Edge server, only to be breached once again by a proxy server with a new one. Technology had failed. Litigation was next.
eBay filed suit against Bidder’s Edge in December of 1999, citing a handful of causes. That included “an ancient trespass theory known to legal scholars as trespass to chattels, basically a trespass or interference with real property — objects, animals, or, in this case, servers.” eBay, in other words, was arguing that Bidder’s Edge was trespassing — in the most medieval sense of that word — on their servers. In order for it to constitute trespass to chattels, eBay had to prove that the trespassers were causing harm. That their servers were buckling under the load, they argued, was evidence of that harm.

eBay in 1999
Judge Ronald M. Whyte found that last bit compelling. Quite a bit of back and forth followed, in one of the strangest lawsuits of a new era that included the phrase “rude robots” entering the official court record. These robots — as opposed to the “polite” ones — ignored eBay’s requests to block spidering on their sites, and made every attempt to circumvent counter measures. They were, by the judge’s estimation, trespassing. Whyte granted an injunction to stop Bidder’s Edge from crawling eBay until it was all sorted out.
Several appeals and countersuits and counter-appeals later, the matter was settled. Bidder’s Edge paid eBay an undisclosed amount and promptly shut their doors. eBay had won this particular battle. They had gotten rid of the robots. But the actual war was already lost. The robots — rude or otherwise — were already here.
If not for Stanford University, web search may have been lost. It is the birthplace of Yahoo!, Google and Excite. It ran the servers that ran the code that ran the first search engines. The founders of both Yahoo! and Google are alumni. But many of the most prominent players in search were not in the computer science department. They were in the symbolic systems program.
Symbolic systems was created at Stanford in 1985 as a study of the “relationship between natural and artificial systems that represent, process, and act on information.” Its interdisciplinary approach is rooted at the intersection of several fields: linguistics, mathematics, semiotics, psychology, philosophy, and computer science.
These are the same fields of study one would find at the heart of artificial intelligence research in the second half of the 20ᵗʰ century. But this isn’t the A.I. in its modern smart home manifestation, but in the more classical notion conceived by computer scientists as a roadmap to the future of computing technology. It is the understanding of machines as a way to augment the human mind. That parallel is not by accident. One of the most important areas of study at the symbolics systems program is artificial intelligence.
Numbered among the alumni of the program are several of the founders of Excite and Srinija Srinivasan, the fourth employee at Yahoo!. Her work in artificial intelligence led to a position at the ambitious A.I. research lab Cyc right out of college.
Marisa Mayer, an early employee at Google and, later, Yahoo!’s CEO, also drew on A.I. research during her time in the symbolic systems program. Her groundbreaking thesis project used natural language processing to help its users find the best flights through a simple conversation with a computer. “You look at how people learn, how people reason, and ask a computer to do the same things. It’s like studying the brain without the gore,” she would later say of the program.
Marissa Mayer in 1999
Search on the web stems from this one program at one institution at one brief moment in time. Not everyone involved in search engines studied that program — the founders of both Yahoo! and Google, for instance, were graduate students of computer science. But the ideology of search is deeply rooted in the tradition of artificial intelligence. The goal of search, after all, is to extract from the brain a question, and use machines to provide a suitable answer.
At Yahoo!, the principles of artificial intelligence acted as a guide, but it would be aided by human perspective. Web crawlers, like Excite, would bear the burden of users’ queries and attempt to map websites programmatically to provide intelligent results.
However, it would be at Google that A.I. would become an explicitly stated goal. Steven Levy, who wrote the authoritative book on the history of Google,https://bookshop.org/books/in-the-plex-how-google-thinks-works-and-shapes-our-lives/9781416596585 In the Plex, describes Google as a “vehicle to realize the dream of artificial intelligence in augmenting humanity.” Founders Larry Page and Sergey Brin would mention A.I. constantly. They even brought it up in their first press conference.
The difference would be a matter of approach. A tension that would come to dominate search for half a decade. The directory versus the crawler. The precision of human influence versus the completeness of machines. Surfers would be on one side and, on the other, spiders. Only one would survive.
The first spiders were crude. They felt around in the dark until they found the edge of the web. Then they returned home. Sometimes they gathered little bits of information about the websites they crawled. In the beginning, they gathered nothing at all.
One of the earliest web crawlers was developed at MIT by Matthew Gray. He used his World Wide Wanderer to go and find every website on the web. He wasn’t interested in the content of those sites, he merely wanted to count them up. In the summer of 1993, the first time he sent his crawler out, it got to 130. A year later, it would count 3,000. By 1995, that number grew to just shy of 30,000.
Like many of his peers in the search engine business, Gray was a disciple of information retrieval, a subset of computer science dedicated to knowledge sharing. In practice, information retrieval often involves a robot (also known as “spiders, crawlers, wanderers, and worms”) that crawls through digital documents and programmatically collects their contents. They are then parsed and stored in a centralized “index,” a shortcut that eliminates the need to go and crawl every document each time a search is made. Keeping that index up to date is a constant struggle, and robots need to be vigilant; going back out and re-crawling information on a near constant basis.
The World Wide Web posed a problematic puzzle. Rather than a predictable set of documents, a theoretically infinite number of websites could live on the web. These needed to be stored in a central index —which would somehow be kept up to date. And most importantly, the content of those sites needed to be connected to whatever somebody wanted to search, on the fly and in seconds. The challenge proved irresistible for some information retrieval researchers and academics. People like Jonathan Fletcher.
Fletcher, a former graduate and IT employee at the University of Stirling in Scotland, didn’t like how hard it was to find websites. At the time, people relied on manual lists, like the WWW Virtual Library maintained at CERN, or Mosaic’s list ofhttps://css-tricks.com/chapter-3-the-website/ “What’s New” that they updated daily. Fletcher wanted to handle it differently. “With a degree in computing science and an idea that there had to be a better way, I decided to write something that would go and look for me.”
He built Jumpstation in 1993, one of the earliest examples of a searchable index. His crawler would go out, following as many links as it could, and bring them back to a searchable, centralized database. Then it would start over. To solve for the issue of the web’s limitless vastness, Fletcher began by crawling only the titles and some metadata from each webpage. That kept his index relatively small, but but it also restricted search to the titles of pages.
Fletcher was not alone. After tinkering for several months, WebCrawler launched in April of 1994 out of the University of Washington. It holds the distinction of being the first search engine to crawl entire webpages and make them searchable. By November of that year, WebCrawler had served 1 million queries. At Carnegie Mellon, Michael Maudlin released his own spider-based search engine variant named for the Latin translation of wolf spider, Lycos. By 1995, it had indexed over a million webpages.

Search didn’t stay in universities long. Search engines had a unique utility for wayward web users on the hunt for the perfect site. Many users started their web sessions on a search engine. Netscape Navigator — the number one browser for new web users — connected users directly to search engines on their homepage. Getting listed by Netscape meant eyeballs. And eyeballs meant lucrative advertising deals.
In the second half of the 1990’s, a number of major players entered the search engine market. InfoSeek, initially a paid search option, was picked up by Disney, and soon became the default search engine for Netscape. AOL swooped in and purchased WebCrawler as part of a bold strategy to remain competitive on the web. Lycos was purchased by a venture capitalist who transformed it into a fully commercial enterprise.
Excite.com, another crawler started by Stanford alumni and a rising star in the search engine game for its depth and accuracy of results, was offered three million dollars not long after they launched. Its six co-founders lined up two couches, one across from another, and talked it out all night. They decided to stick with the product and bring in a new CEO. There would be many more millions to be made.

Excite in 1996
AltaVista, already a bit late to the game at the end of 1995, was created by the Digital Equipment Corporation. It was initially built to demonstrate the processing power of DEC computers. They quickly realized that their multithreaded crawler was able to index websites at a far quicker rate than their competitors. AltaVista would routinely deploy its crawlers — what one researcher referred to as a “brood of spiders” — to index thousands of sites at a time.
As a result, AltaVista was able to index virtually the entire web, nearly 10 million webpages at launch. By the following year, in 1996, they’d be indexing over 100 million. Because of the efficiency and performance of their machines, AltaVista was able to solve the scalability problem. Unlike some of their predecessors, they were able to make the full content of websites searchable, and they re-crawled sites every few weeks, a much more rapid pace than early competitors, who could take months to update their index. They set the standard for the depth and scope of web crawlers.

AltaVista in 1996
Never fully at rest, AltaVista used its search engine as a tool for innovation, experimenting with natural language processing, translation tools, and multi-lingual search. They were often ahead of their time, offering video and image search years before that would come to be an expected feature.
Those spiders that had not been swept up in the fervor couldn’t keep up. The universities hosting the first search engines were not at all pleased to see their internet connections bloated with traffic that wasn’t even related to the university. Most universities forced the first experimental search engines, like Jumpstation, to shut down. Except, that is, at Stanford.
Stanford’s history with technological innovation begins in the second half of the 20th century. The university was, at that point, teetering on the edge of becoming a second-tier institution. They had been losing ground and lucrative contracts to their competitors on the East Coast. Harvard and MIT became the sites of a groundswell of research in the wake of World War II. Stanford was being left behind.
In 1951, in a bid to reverse course on their downward trajectory, Dean of Engineering Frederick Terman brokered a deal with the city of Palo Alto. Stanford University agreed to annex 700 acres of land for a new industrial park that upstart companies in California could use. Stanford would get proximity to energetic innovation. The businesses that chose to move there would gain unique access to the Stanford student body for use on their product development. And the city of Palo Alto would get an influx of new taxes.
Hewlett-Packard was one of the first companies to move in. They ushered in a new era of computing-focused industry that would soon be known as Silicon Valley. The Stanford Research Park (later renamed Stanford Industrial Park) would eventually host Xerox during a time of rapid success and experimentation. Facebook would spend their nascent years there, growing into the behemoth it would become. At the center of it all was Stanford.
The research park transformed the university from one of stagnation to a site of entrepreneurship and cutting-edge technology. It put them at the heart of the tech industry. Stanford would embed itself — both logistically and financially — in the crucial technological developments of the second half of the 20ᵗʰ century, including the internet and the World Wide Web.
The potential success of Yahoo!, therefore, did not go unnoticed.
Jerry Yang and David Filo were not supposed to be working on Yahoo!. They were, however, supposed to be working together. They had met years ago, when David was Jerry’s teaching assistant in the Stanford computer science program. Yang eventually joined Filo as a graduate student and — after building a strong rapport — they soon found themselves working on a project together.
As they crammed themselves into a university trailer to begin working through their doctoral project, their relationship become what Yang has often described as perfectly balanced. “We’re both extremely tolerant of each other, but extremely critical of everything else. We’re both extremely stubborn, but very unstubborn when it comes to just understanding where we need to go. We give each other the space we need, but also help each other when we need it.”
In 1994, Filo showed Yang the web. In just a single moment, their focus shifted. They pushed their intended computer science thesis to the side, procrastinating on it by immersing themselves into the depths of the World Wide Web. Days turned into weeks which turned into months of surfing the web and trading links. The two eventually decided to combine their lists in a single place, a website hosted on their Stanford internet connection. It was called Jerry and David’s Guide to the World Wide Web, launched first to Stanford students in 1993 and then to the world in January of 1994. As catchy as that name wasn’t, the idea (and traffic) took off as friends shared with other friends.
Jerry and David’s Guide was a directory. Like the virtual library started at CERN, Yang and Filo organized websites into various categories that they made up on the fly. Some of these categories had strange or salacious names. Others were exactly what you might expect. When one category got too big, they split it apart. It was ad-hoc and clumsy, but not without charm. Through their classifications, Yang and Filo had given their site a personality. Their personality. In later years, Yang would commonly refer to this as the “voice of Yahoo!”
That voice became a guide — as the site’s original name suggested — for new users of the web. Their web crawling competitors were far more adept at the art of indexing millions of sites at a time. Yang and Filo’s site featured only a small subset of the web. But it was, at least by their estimation, the best of what the web had to offer. It was the cool web. It was also a web far easier to navigate than ever before.

Jerry Yang (left) and David Filo (right) in 1995 (Yahoo, via Flickr)
At the end of 1994, Yang and Filo renamed their site to Yahoo! (an awkward forced acronym for Yet Another Hierarchical Officious Oracle). By then, they were getting almost a hundred thousand hits a day, sometimes temporarily taking down Stanford’s internet in the process. Most other universities would have closed down the site and told them to get back to work. But not Stanford. Stanford had spent decades preparing for on-campus businesses just like this one. They kept the server running, and encouraged its creators to stake their own path in Silicon Valley.
Throughout 1994, Netscape had included Yahoo! in their browser. There was a button in the toolbar labeled “Net Directory” that linked directly to Yahoo!. Marc Andreessen, believing in the site’s future, agreed to host their website on Netscape’s servers until they were able to get on steady ground.
Yahoo! homepage in Netscape Navigator, circa 1994
Yang and Filo rolled up their sleeves, and began talking to investors. It wouldn’t take long. By the spring of 1996, they would have a new CEO and hold their own record-setting IPO, outstripping even their gracious host, Netscape. By then, they became the most popular destination on the web by a wide margin.
In the meantime, the web had grown far beyond the grasp of two friends swapping links. They had managed to categorize tens of thousands of sites, but there were hundreds of thousands more to crawl. “I picture Jerry Yang as Charlie Chaplin in Modern Times,” one journalist described, “confronted with an endless stream of new work that is only increasing in speed.” The task of organizing sites would have to go to somebody else. Yang and Filo found help in a fellow Stanford alumni, someone they had met years ago while studying abroad together in Japan, Srinija Srinivasan, a graduate of the symbolic systems program. Many of the earliest hires at Yahoo! were given slightly absurd titles that always ended in “Yahoo.” Yang and Filo went by Chief Yahoos. Srinivasan’s job title was Ontological Yahoo.
That is a deliberate and precise job title, and it was not selected by accident. Ontology is the study of being, an attempt to break the world into its component parts. It has manifested in many traditions throughout history and the world, but it is most closely associated with the followers of Socrates, in the work of Plato, and later in the groundbreaking text Metaphysics, written by Aristotle. Ontology asks the question “What exists?”and uses it as a thought experiment to construct an ideology of being and essence.
As computers blinked into existence, ontology found a new meaning in the emerging field of artificial intelligence. It was adapted to fit the more formal hierarchical categorizations required for a machine to see the world; to think about the world. Ontology became a fundamental way to describe the way intelligent machines break things down into categories and share knowledge.
The dueling definitions of the ontology of metaphysics and computer science would have been familiar to Srinija Srinivasan from her time at Stanford. The combination of philosophy and artificial intelligence in her studies gave her a unique perspective on hierarchical classifications. It was this experience that she brought to her first job after college at the Cyc Project, an artificial intelligence research lab with a bold project: to teach a computer common sense.

Srinija Srinivasan (Getty Images/James D. Wilson)
At Yahoo!, her task was no less bold. When someone looked for something on the site, they didn’t want back a random list of relevant results. They wanted the result they were actually thinking about, but didn’t quite know how to describe. Yahoo! had to — in a manner of seconds — figure out what its users really wanted. Much like her work in artificial intelligence, Srinivasan needed to teach Yahoo! how to think about a query and infer the right results.
To do that, she would need to expand the voice of Yahoo! to thousands of more websites in dozens of categories and sub-categories without losing the point of view established by Jerry and David. She would need to scale that perspective. “This is not a perfunctory file-keeping exercise. This is defining the nature of being,” she once said of her project. “Categories and classifications are the basis for each of our worldviews.”
At a steady pace, she mapped an ontology of human experience onto the site. She began breaking up the makeshift categories she inherited from the site’s creators, re-constituting them into more concrete and findable indexes. She created new categories and destroyed old ones. She sub-divided existing subjects into new, more precise ones. She began cross-linking results so that they could live within multiple categories. Within a few months she had overhauled the site with a fresh hierarchy.
That hierarchical ontology, however, was merely a guideline. The strength of Yahoo!’s expansion lay in the 50 or so content managers she had hired in the meantime. They were known as surfers. Their job was to surf the web — and organize it.
Each surfer was coached in the methodology of Yahoo! but were left with a surprising amount of editorial freedom. They cultivated the directory with their own interests, meticulously deliberating over websites and where they belong. Each decision could be strenuous, and there were missteps and incorrectly categorized items along the way. But by allowing individual personality to dictate hierarchal choices, Yahoo! retained its voice.
They gathered as many sites as they could, adding hundreds each day. Yahoo! surfers did not reveal everything on the web to their site’s visitors. They showed them what was cool. And that meant everything to users grasping for the very first time what the web could do.
At the end of 1995, the Yahoo! staff was watching their traffic closely. Huddled around consoles, employees would check their logs again and again, looking for a drop in visitors. Yahoo! had been the destination for the “Internet Directory” button on Netscape for years. It had been the source of their growth and traffic. Netscape had made the decision, at the last minute (and seemingly at random), to drop Yahoo!, replacing them with the new kids on the block, Excite.com. Best case scenario: a manageable drop. Worst case: the demise of Yahoo!.
But the drop never came. A day went by, and then another. And then a week. And then a few weeks. And Yahoo! remained the most popular website. Tim Brady, one of Yahoo!’s first employees, describes the moment with earnest surprise. “It was like the floor was pulled out in a matter of two days, and we were still standing. We were looking around, waiting for things to collapse in a lot of ways. And we were just like, I guess we’re on our own now.”
Netscape wouldn’t keep their directory button exclusive for long. By 1996, they would begin allowing other search engines to be listed on their browser’s “search” feature. A user could click a button and a drop-down of options would appear, for a fee. Yahoo! bought themselves back in to the drop-down. They were joined by four other search engines, Lycos, InfoSeek, Excite, and AltaVista.
By that time, Yahoo! was the unrivaled leader. It had transformed its first mover advantage into a new strategy, one bolstered by a successful IPO and an influx of new investment. Yahoo! wanted to be much more than a simple search engine. Their site’s transformation would eventually be called a portal. It was a central location for every possible need on the web. Through a number of product expansions and aggressive acquisitions, Yahoo! released a new suite of branded digital products. Need to send an email? Try Yahoo! Mail. Looking to create website? There’s Yahoo! Geocities. Want to track your schedule? Use Yahoo! Calendar. And on and on the list went.

Yahoo! in 1996
Competitors rushed the fill the vacuum of the #2 slot. In April of 1996, Yahoo!, Lycos and Excite all went public to soaring stock prices. Infoseek had their initial offering only a few months later. Big deals collided with bold blueprints for the future. Excite began positioning itself as a more vibrant alternative to Yahoo! with more accurate search results from a larger slice of the web. Lycos, meanwhile, all but abounded the search engine that had brought them initial success to chase after the portal-based game plan that had been a windfall for Yahoo!.
The media dubbed the competition the “portal wars,” a fleeting moment in web history when millions of dollars poured into a single strategy. To be the biggest, best, centralized portal for web surfers. Any service that offered users a destination on the web was thrown into the arena. Nothing short of the future of the web (and a billion dollar advertising industry) was at stake.
In some ways, though, the portal wars were over before they started. When Excite announced a gigantic merger with @Home, an Internet Service Provider, to combine their services, not everyone thought it was a wise move. “AOL and Yahoo! were already in the lead,” one investor and cable industry veteran noted, “and there was no room for a number three portal.” AOL had just enough muscle and influence to elbow their way into the #2 slot, nipping at the heels of Yahoo!. Everyone else would have to go toe-to-toe with Goliath. None were ever able to pull it off.
Battling their way to market dominance, most search engines had simply lost track of search. Buried somewhere next to your email and stock ticker and sports feed was, in most cases, a second rate search engine you could use to find things — only not often and not well. That’s is why it was so refreshing when another search engine out of Stanford launched with just a single search box and two buttons, its bright and multicolored logo plastered across the top.
A few short years after it launched, Google was on the shortlist of most popular sites. In an interview with PBS Newshour in 2002, co-founder Larry Page described their long-term vision. “And, actually, the ultimate search engine, which would understand, you know, exactly what you wanted when you typed in a query, and it would give you the exact right thing back, in computer science we call that artificial intelligence.”
Google could have started anywhere. It could have started with anything. One employee recalls an early conversation with the site’s founders where he was told “we are not really interested in search. We are making an A.I.” Larry Page and Sergey Brin, the creators of Google, were not trying to create the web’s greatest search engine. They were trying to create the web’s most intelligent website. Search was only their most logical starting point.
Imprecise and clumsy, the spider-based search engines of 1996 faced an uphill battle. AltaVista had proved that the entirety of the web, tens of millions of webpages, could be indexed. But unless you knew your way around a few boolean logic commands, it was hard to get the computer to return the right results. The robots were not yet ready to infer, in Page’s words, “exactly what you wanted.”
Yahoo! had filled in these cracks of technology with their surfers. The surfers were able to course-correct the computers, designing their directory piece by piece rather than relying on an algorithm. Yahoo! became an arbiter of a certain kind of online chic; tastemakers reimagined for the information age. The surfers of Yahoo! set trends that would last for years. Your site would live or die by their hand. Machines couldn’t do that work on their own. If you wanted your machines to be intelligent, you needed people to guide them.
Page and Brin disagreed. They believed that computers could handle the problem just fine. And they aimed to prove it.
That unflappable confidence would come to define Google far more than their “don’t be evil” motto. In the beginning, their laser-focus on designing a different future for the web would leave them blind to the day-to-day grind of the present. On not one, but two occasions, checks made out to the company for hundreds of thousands of dollars were left in desk drawers or car trunks until somebody finally made the time to deposit them. And they often did things different. Google’s offices, for instances, were built to simulate a college dorm, an environment the founders felt most conducive to big ideas.
Google would eventually build a literal empire on top of a sophisticated, world-class infrastructure of their own design, fueled by the most elaborate and complex (and arguably invasive) advertising mechanism ever built. There are few companies that loom as large as Google. This one, like others, started at Stanford.
Even among the most renowned artificial intelligence experts, Terry Winograd, a computer scientist and Stanford professor, stands out in the crowd. He was also Larry Page’s advisor and mentor when he was a graduate student in the computer science department. Winograd has often recalled the unorthodox and unique proposals he would receive from Page for his thesis project, some of which involved “space tethers or solar kites.” “It was science fiction more than computer science,” he would later remark.
But for all of his fanciful flights of imagination, Page always returned to the World Wide Web. He found its hyperlink structure mesmerizing. Its one-way links — a crucial ingredient in the web’s success — had led to a colossal proliferation of new websites. In 1996, when Page first began looking at the web, there were tens of thousands of sites being added every week. The master stroke of the web was to enable links that only traveled in one direction. That allowed the web to be decentralized, but without a central database tracking links, it was nearly impossible to collect a list of all of the sites that linked to a particular webpage. Page wanted to build a graph of who was linking to who; an index he could use to cross-reference related websites.
Page understood that the hyperlink was a digital analog to academic citations. A key indicator of the value of a particular academic paper is the amount of times it has been cited. If a paper is cited often (by other high quality papers), it is easier to vouch for its reliability. The web works the same way. The more often your site is linked to (what’s known as a backlink), the more dependable and accurate it is likely to be.
Theoretically, you can determine the value of a website by adding up all of the other websites that link to it. That’s only one layer though. If 100 sites link back to you, but each of them has only ever been linked to one time, that’s far less valuable than if five sites that each have been linked to 100 times link back to you. So it’s not simply how many links you have, but the quality of those links. If you take both of those dimensions and aggregate sites using backlinks as a criteria, you can very quickly start to assemble a list of sites ordered by quality.
John Battelle describes the technical challenge facing Page in his own retelling of the Google story, The Search.
Page realized that a raw count of links to a page would be a useful guide to that page’s rank. He also saw that each link needed its own ranking, based on the link count of its originating page. But such an approach creates a difficult and recursive mathematical challenge — you not only have to count a particular page’s links, you also have to count the links attached to the links. The math gets complicated rather quickly.
Fortunately, Page already knew a math prodigy. Sergey Brin had proven his brilliance to the world a number of times before he began a doctoral program in the Stanford computer science department. Brin and Page had crossed paths on several occasions, a relationship that began on rocky ground but grew towards mutual respect. The mathematical puzzle at the center of Page’s idea was far too enticing for Brin to pass up.
He got to work on a solution. “Basically we convert the entire Web into a big equation, with several hundred million variables,” he would later explain, “which are the page ranks of all the Web pages, and billions of terms, which are the links. And we’re able to solve that equation.” Scott Hassan, the seldom talked about third co-founder of Google who developed their first web crawler, summed it up a bit more concisely, describing Google’s algorithm as an attempt to “surf the web backward!”
The result was PageRank — as in Larry Page, not webpage. Brin, Page, and Hassan developed an algorithm that could trace backlinks of a site to determine the quality of a particular webpage. The higher value of a site’s backlinks, the higher up the rankings it climbed. They had discovered what so many others had missed. If you trained a machine on the right source — backlinks — you could get remarkable results.
It was only after that that they began matching their rankings to search queries when they realized PageRank fit best in a search engine. They called their search engine Google. It was launched on Stanford’s internet connection in August of 1996.

Google in 1998
Google solved the relevancy problem that had plagued online search since its earliest days. Crawlers like Lycos, AltaVista and Excite were able to provide a list of webpages that matched a particular search. They just weren’t able to sort them right, so you had to go digging to find the result you wanted. Google’s rankings were immediately relevant. The first page of your search usually had what you needed. They were so confident in their results they added an “I’m Feeling Lucky” button which took users directly to the first result for their search.
Google’s growth in their early days was not unlike Yahoo!’s in theirs. They spread through word of mouth, from friends to friends of friends. By 1997, they had grown big enough to put a strain on the Stanford network, something Yang and Filo had done only a couple of years earlier. Stanford once again recognized possibility. It did not push Google off their servers. Instead, Stanford’s advisors pushed Page and Brin in a commercial direction.
Initially, the founders sought to sell or license their algorithm to other search engines. They took meetings with Yahoo!, Infoseek and Excite. No one could see the value. They were focused on portals. In a move that would soon sound absurd, they each passed up the opportunity to buy Google for a million dollars or less, and Page and Brin could not find a partner that recognized their vision.
One Stanford faculty member was able to connect them with a few investors, including Jeff Bezos and David Cheriton (which got them those first few checks that sat in a desk drawer for weeks). They formally incorporated in September of 1998, moving into a friend’s garage, bringing a few early employees along, including symbolics systems alumni Marissa Mayer.

Larry Page (left) and Sergey Brin (right) started Google in a friend’s garage.
Even backed by a million dollar investment, the Google founders maintained a philosophy of frugality, simplicity, and swiftness. Despite occasional urging from their investors, they resisted the portal strategy and remained focused on search. They continued tweaking their algorithm and working on the accuracy of their results. They focused on their machines. They wanted to take the words that someone searched for and turn them into something actually meaningful. If you weren’t able to find the thing you were looking for in the top three results, Google had failed.
Google was followed by a cloud of hype and positive buzz in the press. Writing in Newsweek, Steven Levy described Google as a “high-tech version of the Oracle of Delphi, positioning everyone a mouse click away from the answers to the most arcane questions — and delivering simple answers so efficiently that the process becomes addictive.” It was around this time that “googling” — a verb form of the site synonymous with search — entered the common vernacular. The portal wars were still waging, but Google was poking its head up as a calm, precise alternative to the noise.
At the end of 1998, they were serving up ten thousand searches a day. A year later, that would jump to seven million a day. But quietly, behind the scenes, they began assembling the pieces of an empire.
As the web grew, technologists and journalists predicted the end of Google; they would never be able to keep up. But they did, outlasting a dying roster of competitors. In 2001, Excite went bankrupt, Lycos closed down, and Disney suspended Infoseek. Google climbed up and replaced them. It wouldn’t be until 2006 that Google would finally overtake Yahoo! as the number one website. But by then, the company would transform into something else entirely.
After securing another round of investment in 1999, Google moved into their new headquarters and brought on an army of new employees. The list of fresh recruits included former engineers at AltaVista, and leading artificial intelligence expert Peter Norving. Google put an unprecedented focus on advancements in technology. Better servers. Faster spiders. Bigger indexes. The engineers inside Google invented a web infrastructure that had, up to that point, been only theoretical.
They trained their machines on new things, and new products. But regardless of the application, translation or email or pay-per-click advertising, they rested on the same premise. Machines can augment and re-imagine human intelligence, and they can do it at limitless scale. Google took the value proposition of artificial intelligence and brought it into the mainstream.

In 2001, Page and Brin brought in Silicon Valley veteran Eric Schmidt to run things as their CEO, a role he would occupy for a decade. He would oversee the company during its time of greatest growth and innovation. Google employee #4 Heather Cairns recalls his first days on the job. “He did this sort of public address with the company and he said, ‘I want you to know who your real competition is.’ He said, ‘It’s Microsoft.’ And everyone went, What?“
Bill Gates would later say, “In the search engine business, Google blew away the early innovators, just blew them away.” There would come a time when Google and Microsoft would come face to face. Eric Schmidt was correct about where Google was going. But it would take years for Microsoft to recognize Google as a threat. In the second half of the 1990’s, they were too busy looking in their rearview mirror at another Silicon Valley company upstart that had swept the digital world. Microsoft’s coming war with Netscape would subsume the web for over half a decade.
The post Chapter 4: Search appeared first on CSS-Tricks.
You can support CSS-Tricks by being an MVP Supporter.
Chapter 4: Search published first on https://deskbysnafu.tumblr.com/
0 notes
Photo



Going Beyond Google: Are Search Engines Ready for JavaScript Crawling & Indexation?
Posted by goralewicz I recently published the results of my JavaScript SEO experiment where I checked which JavaScript frameworks are properly crawled and indexed by Google. The results were shocking; it turns out Google has a number of problems when crawling and indexing JavaScript-rich websites.
Google managed to index only a few out of multiple JavaScript frameworks tested. And as I proved, indexing content doesn’t always mean crawling JavaScript-generated links.
This got me thinking. If Google is having problems with JavaScript crawling and indexation, how are Google’s smaller competitors dealing with this problem? Is JavaScript going to lead you to full de-indexation in most search engines?
If you decide to deploy a client-rendered website (meaning a browser or Googlebot needs to process the JavaScript before seeing the HTML), you’re not only risking problems with your Google rankings — you may completely kill your chances at ranking in all the other search engines out there.
Google + JavaScript SEO experiment To see how search engines other than Google deal with JavaScript crawling and indexing, we used our experiment website, http:/jsseo.expert , to check how Googlebot crawls and indexes JavaScript (and JavaScript frameworks’) generated content.
The experiment was quite simple: http://bit.ly/2wi4Ike has subpages with content parsed by different JavaScript frameworks. If you disable JavaScript, the content isn’t visible — i.e. if you go to http://bit.ly/2wi4Ike/angular2/ , all the content within the red box is generated by Angular 2. If the content isn’t indexed in Yahoo, for example, we know that Yahoo’s indexer didn’t process the JavaScript.
Here are the results:
As you can see, Google and Ask are the only search engines to properly index JavaScript-generated content. Bing, Yahoo, AOL, DuckDuckGo, and Yandex are completely JavaScript-blind and won’t see your content if it isn’t HTML.
The next step: Can other search engines index JavaScript? Most SEOs only cover JavaScript crawling and indexing issues when talking about Google. As you can see, the problem is much more complex. When you launch a client-rendered JavaScript-rich website (JavaScript is processed by the browser/crawler to “build” HTML), you can be 100% sure that it’s only going to be indexed and ranked in Google and Ask. Unfortunately, Google and Ask cover only ~64% of the whole search engine market, according to statista.com .
This means that your new, shiny, JavaScript-rich website can cost you ~36% of your website’s visibility on all search engines.
Let’s start with Yahoo, Bing, and AOL, which are responsible for 35% of search queries in the US.
Yahoo, Bing, and AOL Even though Yahoo and AOL were here long before Google, they’ve obviously fallen behind its powerful algorithm and don’t invest in crawling and indexing as much as Google. One reason is likely the relatively high cost of crawling and indexing the web compared to the popularity of the website.
Google can freely invest millions of dollars in growing their computing power without worrying as much about return on investment, whereas Bing, AOL, and Ask only have a small percentage of the search market.
However, Microsoft-owned Bing isn’t out of the running. Their growth has been quite aggressive over last 8 years:
Unfortunately, we can’t say the same about one of the market pioneers: AOL. Do you remember the days before Google? This video will surely bring back some memories from a simpler time.
If you want to learn more about search engine history, I highly recommend watching Marcus Tandler’s spectacular TEDx talk .
Ask.com What about Ask.com? How is it possible that Ask, with less than 1% of the market, can invest in crawling and indexing JavaScript? It makes me question if the Ask network is powered by Google’s algorithm and crawlers. It’s even more interesting looking at Ask’s aversion towards Google . There were already some speculations about Ask’s relationship with Google after Google Penguin in 2012, but we can now confirm that Ask’s crawling is using Google’s technology.
DuckDuckGo and Yandex Both DuckDuckGo and Yandex had no problem indexing all the URLs within http://bit.ly/2wi4Ike , but unfortunately, the only content that was indexed properly was the 100% HTML page ( http://bit.ly/2wi4Ike/html/ ).
Baidu Despite my best efforts, I didn’t manage to index http://bit.ly/2wi4Ike in Baidu.com. It turns out you need a mainland China phone number to do that. I don’t have any previous experience with Baidu, so any and all help with indexing our experimental website would be appreciated. As soon as I succeed, I will update this article with Baidu.com results.
Going beyond the search engines What if you don’t really care about search engines other than Google? Even if your target market is heavily dominated by Google, JavaScript crawling and indexing is still in an early stage, as my JavaScript SEO experiment documented .
Additionally, even if crawled and indexed properly, there is proof that JavaScript reliance can affect your rankings . Will Critchlow saw a significant traffic improvement after shifting from JavaScript-driven pages to non-JavaScript reliant.
Is there a JavaScript SEO silver bullet? There is no search engine that can understand and process JavaScript at the level our modern browsers can. Even so, JavaScript isn’t inherently bad for SEO. JavaScript is awesome, but just like SEO, it requires experience and close attention to best practices.
If you want to enjoy all the perks of JavaScript without worrying about problems like Hulu.com’s JavaScript SEO issues , look into isomorphic JavaScript . It allows you to enjoy dynamic and beautiful websites without worrying about SEO.
If you’ve already developed a client-rendered website and can’t go back to the drawing board, you can always use pre-rendering services or enable server-side rendering . They often aren’t ideal solutions, but can definitely help you solve the JavaScript crawling and indexing problem until you come up with a better solution.
Regardless of the search engine, yet again we come back to testing and experimenting as a core component of technical SEO.
The future of JavaScript SEO I highly recommend you follow along with how http://bit.ly/2wi4Ike/ is indexed in Google and other search engines. Even if some of the other search engines are a little behind Google, they’ll need to improve how they deal with JavaScript-rich websites to meet the exponentially growing demand for what JavaScript frameworks offer, both to developers and end users.
For now, stick to HTML & CSS on your front-end. :) Sign up for The Moz Top 10 , a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
http://bit.ly/2whOhEc
#contentwriting #huntingtonbeachseo #lagunabeachseo #smallbusinessmarketing #leadgeneration #internetmarketing #articlewriting #bestlocalseo #socialmediamarketing #linkbuilding
#contentwriting#huntingtonbeachseo#lagunabeachseo#smallbusinessmarketing#leadgeneration#internetmarketing#articlewriting#bestlocalseo#socialmediamarketing#linkbuilding
1 note
·
View note
Text
Going Beyond Google: Are Search Engines Ready for JavaScript Crawling & Indexation?
Posted by goralewicz
I recently published the results of my JavaScript SEO experiment where I checked which JavaScript frameworks are properly crawled and indexed by Google. The results were shocking; it turns out Google has a number of problems when crawling and indexing JavaScript-rich websites.
Google managed to index only a few out of multiple JavaScript frameworks tested. And as I proved, indexing content doesn’t always mean crawling JavaScript-generated links.
This got me thinking. If Google is having problems with JavaScript crawling and indexation, how are Google’s smaller competitors dealing with this problem? Is JavaScript going to lead you to full de-indexation in most search engines?
If you decide to deploy a client-rendered website (meaning a browser or Googlebot needs to process the JavaScript before seeing the HTML), you're not only risking problems with your Google rankings — you may completely kill your chances at ranking in all the other search engines out there.
Google + JavaScript SEO experiment
To see how search engines other than Google deal with JavaScript crawling and indexing, we used our experiment website, http:/jsseo.expert, to check how Googlebot crawls and indexes JavaScript (and JavaScript frameworks’) generated content.
The experiment was quite simple: http://jsseo.expert has subpages with content parsed by different JavaScript frameworks. If you disable JavaScript, the content isn’t visible — i.e. if you go to http://ift.tt/2gm0jah, all the content within the red box is generated by Angular 2. If the content isn’t indexed in Yahoo, for example, we know that Yahoo’s indexer didn’t process the JavaScript.
Here are the results:
As you can see, Google and Ask are the only search engines to properly index JavaScript-generated content. Bing, Yahoo, AOL, DuckDuckGo, and Yandex are completely JavaScript-blind and won’t see your content if it isn’t HTML.
The next step: Can other search engines index JavaScript?
Most SEOs only cover JavaScript crawling and indexing issues when talking about Google. As you can see, the problem is much more complex. When you launch a client-rendered JavaScript-rich website (JavaScript is processed by the browser/crawler to “build” HTML), you can be 100% sure that it’s only going to be indexed and ranked in Google and Ask. Unfortunately, Google and Ask cover only ~64% of the whole search engine market, according to statista.com.
This means that your new, shiny, JavaScript-rich website can cost you ~36% of your website’s visibility on all search engines.
Let’s start with Yahoo, Bing, and AOL, which are responsible for 35% of search queries in the US.
Yahoo, Bing, and AOL
Even though Yahoo and AOL were here long before Google, they’ve obviously fallen behind its powerful algorithm and don’t invest in crawling and indexing as much as Google. One reason is likely the relatively high cost of crawling and indexing the web compared to the popularity of the website.
Google can freely invest millions of dollars in growing their computing power without worrying as much about return on investment, whereas Bing, AOL, and Ask only have a small percentage of the search market.
However, Microsoft-owned Bing isn't out of the running. Their growth has been quite aggressive over last 8 years:
Unfortunately, we can’t say the same about one of the market pioneers: AOL. Do you remember the days before Google? This video will surely bring back some memories from a simpler time.
youtube
If you want to learn more about search engine history, I highly recommend watching Marcus Tandler’s spectacular TEDx talk.
Ask.com
What about Ask.com? How is it possible that Ask, with less than 1% of the market, can invest in crawling and indexing JavaScript? It makes me question if the Ask network is powered by Google’s algorithm and crawlers. It's even more interesting looking at Ask’s aversion towards Google. There were already some speculations about Ask’s relationship with Google after Google Penguin in 2012, but we can now confirm that Ask’s crawling is using Google’s technology.
DuckDuckGo and Yandex
Both DuckDuckGo and Yandex had no problem indexing all the URLs within http://jsseo.expert, but unfortunately, the only content that was indexed properly was the 100% HTML page (http://ift.tt/2gkDEuM).
Baidu
Despite my best efforts, I didn’t manage to index http://jsseo.expert in Baidu.com. It turns out you need a mainland China phone number to do that. I don’t have any previous experience with Baidu, so any and all help with indexing our experimental website would be appreciated. As soon as I succeed, I will update this article with Baidu.com results.
Going beyond the search engines
What if you don’t really care about search engines other than Google? Even if your target market is heavily dominated by Google, JavaScript crawling and indexing is still in an early stage, as my JavaScript SEO experiment documented.
Additionally, even if crawled and indexed properly, there is proof that JavaScript reliance can affect your rankings. Will Critchlow saw a significant traffic improvement after shifting from JavaScript-driven pages to non-JavaScript reliant.
Is there a JavaScript SEO silver bullet?
There is no search engine that can understand and process JavaScript at the level our modern browsers can. Even so, JavaScript isn’t inherently bad for SEO. JavaScript is awesome, but just like SEO, it requires experience and close attention to best practices.
If you want to enjoy all the perks of JavaScript without worrying about problems like Hulu.com’s JavaScript SEO issues, look into isomorphic JavaScript. It allows you to enjoy dynamic and beautiful websites without worrying about SEO.
If you've already developed a client-rendered website and can’t go back to the drawing board, you can always use pre-rendering services or enable server-side rendering. They often aren’t ideal solutions, but can definitely help you solve the JavaScript crawling and indexing problem until you come up with a better solution.
Regardless of the search engine, yet again we come back to testing and experimenting as a core component of technical SEO.
The future of JavaScript SEO
I highly recommend you follow along with how http://jsseo.expert/ is indexed in Google and other search engines. Even if some of the other search engines are a little behind Google, they'll need to improve how they deal with JavaScript-rich websites to meet the exponentially growing demand for what JavaScript frameworks offer, both to developers and end users.
For now, stick to HTML & CSS on your front-end. :)
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog http://ift.tt/2vnJFh9 via IFTTT
1 note
·
View note