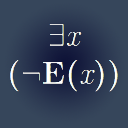
Old enough to know better/M/Boston/Married. I'm a Ph.D. in computer science and linguistics. I run on metal, wordplay, and snark. Most of the languages I speak are dead.
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by science-of-noise and here's what we found interesting.
Average Info
Notes Per Post
245K
Likes Per Post
136K
Reblog Per Post
108K
Reply Per Post
126
Time Between Posts
1 month ago
Number of Posts By Type
Link
4
Conversation
1
Text
7
Photo
4
Note
1
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a 66 index score for customer satisfaction in the US.
Link
I’ve changed my mind on this. You suck, but the algorithm sucks, too.
Think about is this way: take image classification, particularly facial recognition—all pixels have to be converted to numbers for the computer to use. Seems reasonable to convert color values to something like RGB, right? But, the RGB for a white pixel is (255,255,255) while RGB for a black pixel is (0,0,0). Lighter pixels get higher values than darker pixels. What’s a picture of a black face made of, mostly? Darker pixels and hence lesser numerical value (take this instance of “lesser” to be purely in the numerical sense here, and not as a value judgment, but it does matter to the value judgment later on).
If your algorithm uses something like average pooling (basically, take the average color value of a small patch of the image, like a 3x3 square), those darker areas contribute less overall numerical value to the data that gets propagated through the algorithm.
Therefore, an algorithm that makes some typical default assumptions like “convert pixels to RGB” and “use average pooling” will take a darker-skinned face as input and see a bunch of vectors of lesser overall magnitude that make it difficult for the algorithm to pick up key differences that allow it to place this instance into one region of a partitioned dataset (aka, it makes it harder to categorize because it may not think there’s much there—it’s seeing a lot of things that appear to be close to 0, and 0 is basically the absence of information in many cases). So it may not be able to differentiate a black man from a black woman very easily. Or worse, it may not even see a person there at all, and in that case even if “not a person” isn't one of it’s possible category labels, the output is going to be kind of random, because the algorithm as structured can’t make sense of an image that it’s presented with.
These assumptions and algorithmic choices don’t exist in a vacuum. “Numbers” themselves aren’t biased, of course, but the way you use them and put them together can cause systems to behave in a biased fashion.
Almost like algorithms trained on biased data will exhibit bias, no?
Basically, the algorithm doesn’t suck. You suck.
350 notes
·
View notes
Conversation
Me: *texting with an older relative*
Me, a minute later: *googling "how do I block memojis"*
4 notes
·
View notes
Link
I will be starting a natural language processing lab in a computer science department in the fall, but my approach to NLP has always been firmly grounded in linguistics, society and culture, and a strong interest in dialogue, narrative, and literature. I hope my lab can be notable in this regard and help keep the humanities “cool” in the eyes of the STEM cohorts.
12 notes
·
View notes
Text
Hello, I’m back
I’ve been off Tumblr for over a year, and off most social media for most of that time. I feel like the break has been good for my mental health, and probably for my career.
Long story short, I was on the faculty job market last year, and the process was as grueling as they say. After dozens of applications a few finalist interviews, and basically a wasted January and February, I wound up in April 2019 with nothing to show for it. I came close, but close doesn't count when someone else gets the job.
Suffice to say, I spent the latter two-thirds of 2019 in “Hello Darkness My Old Friend” Mode, that is, a fairly continuous low-key depression, racked with impostor syndrome and convinced that I could never go on the academic job market again. However, the prospect of working in AI for some giant corporation, building weapons systems, helping the Chinese government surveil their citizens, or improving some schlubby company’s ad click-through rate was even less appealing, so fortunately my PI was generous enough to extend my postdoc for another year while I sorted myself out.
In the end, I went back on the job market. It seemed twice as grueling this time, as I sent out 50% more applications, but got fewer responses, fewer interviews, and fewer finalist callbacks.
But, maybe the intervening year gave me the practice I needed to talk about my research better, and it became clearer where I would really fit. In the end, it only takes one, and finally I’m able to announce that I’ll be moving to Fort Collins, Colorado in August to start as Assistant Professor of Computer Science at Colorado State University! The fact is, I really can’t see myself doing anything else but being a professor.
Fittingly, just as I seem to be getting my shit straight, the world appears to be falling apart, but at least I have a new website! Click here: https://www.nikhilkrishnaswamy.com
I’m always eager to hear from potential students and collaborators. Anyone out there interested in pursuing graduate study in computational linguistics, AI, and multimodality, I’m happy to talk.
I’ll keep this Tumblr open, though I’m not sure how active I’ll be. You can also follow me on...
Twitter: @NikhilKrishnasw for NLP and political shitposting.
IG: @nikhilkrishnaswamy for guitar videos, running updates, and cat pics.
#update#return to tumblr#academia#computational linguistics#linguistics#ai#artificial intelligence#computer science#hello again
4 notes
·
View notes
Text
Panworld experience apparently
I’m glad eduroam is such a paneuropean experience 😂
16K notes
·
View notes
Text
some of you have never cried over a verb conjugation table and it shows
13K notes
·
View notes
Text
Got a job talk invitation. 10,000 reblogs and I'll pass a note to the dean saying "Do you like me? Y/N"
6 notes
·
View notes
Link
602 notes
·
View notes
Photo

AI Winter
627 notes
·
View notes
Link
For this, they used a library of cultural traits for each culture a fairy tale occurred in, and then measured the likelihood that trait t occurs in culture c due to either phylogenetic proximity (inheritance) or spatial proximity (diffusion), using autologistic regression:
(Autologistic regression is a graphical model where connected nodes have dependencies on each other, except instead of an undirected graph, ALR is a special case that requires sequential binary data and assumes a spatial ordering. In this case, the binary data are the cultural features).
Cultural traits states are generated using Monte-Carlo simulation and phylogenetic or spatial influence are fitted as local dependencies between the nodes in the graph representing cultural traits. I can’t find this in the paper (though it may be mentioned in the citation of the method they used), but presumably if the spatial influence exceeds the phylogenetic influence by a certain threshold, the trait is removed.
The full paper is here.
GUYS THIS IS AMAZING
SERIOUSLY
6000 YEARS
STORIES THAT ARE OLDER THAN CIVILIZATIONS
STORIES THAT WERE TOLD BY PEOPLE SPEAKING LANGUAGES WE NO LONGER KNOW
STORIES TOLD BY PEOPLE LOST TO THE VOID OF TIME
STORIES
133K notes
·
View notes

Text
Fuck my dash is about to blow up again. OK, folks, let’s get this thing to more notes than there were KIAs/MIAs in WW1 (~8 million)
Time Traveler from 1919: You have a day where you honor our struggles in the Great War, the War to End All Wars?
Me: You mean World War I?
TT: Oh shit
75K notes
·
View notes
Photo
Petition to change the German word for “octopus” to “achtopus”


Hey Tumblr, want to escape this dying hole of a website by reading a book? Well, I wrote one with @thoughtlibrarian! Above is a blurry picture of me looking high and smug while holding it.
The Pointless Rules of English and How to Follow Them is about English grammar rules and how they’re all made up and mostly classist nonsense. We talk about why they exist, which ones you probably do have to follow in a formal context and how you can remember them.
ADDITIONALLY, we also have a big chunk on better writing, including a whole dang section on how to write inclusively, aka, How To Not Be A Dick With Your Words. We touch on how to write about:
disabilities
body positivity
race
culture
religion
gender & sexuality
… as well as your regular old writing advice about audience, tone, how to not get dragged into an internet argument with a boring Reddit user, etc.
Scattered throughout are language facts that we just think are interesting, such as this one:

I made an awful YouTube video which explains a little more about the book if you’re interested! It’s available on Amazon (US version here), or can be ordered through your local bookstore of choice! 💕
321 notes
·
View notes
Note
Saw your avatar in a screenshot on reddit. (It might be old, it's the one that says ∃x.¬E(x). ) Have to ask, what is E(-)?
E(x) is “existence” considered as a predicate over an argument. This is opposed to ∃x, the existential quantifier. Normally in first-order logic you have to quantify arguments before predicating over them, so p(x) is insufficient because it presupposes that x exists, so we have to write ∃x.p(x). But then, according to some (Russell, among others, I believe), “existence” can be predicated over an object, such that “R does not exist” is not to be read “it is not the case that there exists a thing which is R”, but rather that “R” is not a valid referring expression and the thing that is predicated R is not instantiated (does not exist) in the model. Some logicians denote this kind of “existence” as a primitive nonuniversal predicate as E, to differentiate it from the existential quantifier.
So ∃x.¬E(x) is sort of a (logically debatable, according to some) way of denoting a paradox meaning something like “there exists something which does not exist.”
28 notes
·
View notes
Photo
I know precisely where this is, I grew up in this town.
Here’s StreetView: https://www.google.com/maps/@36.7239185,-108.1879251,3a,75y,179.47h,81.85t/data=!3m6!1e1!3m4!1s4kp6mmFA7vvXO6x6YhNl0Q!2e0!7i13312!8i6656
Here are some facts:
1) The store was there 1st and the sign came later
2) About 200 ft out of frame to the right there is an elementary school—I used to have basketball practice there
3) This went viral after appearing on America’s Funniest Videos—it is probably the most fame Farmington, NM has ever acquired
4) As far as I know, the sign is still there—I haven’t been back to that part of town in a number of years but maybe I can go check it in May

3K notes
·
View notes
Text
Again, ML algorithms are trained on data from humans. If there is bias in the data (and there is), humans may not be able to spot it, but you can bet a deep learning algorithm will spot it and be raring to reproduce it. These algorithms are really good at learning what we teach them, and we’re teaching them racism
“I just want to clarify and say that Kianah was not flagged because she was African American,” says Joel Simonoff, Predictim’s CTO. “I can guarantee you 100 percent there was no bias that went into those posts being flagged. We don’t look at skin color, we don’t look at ethnicity, those aren’t even algorithmic inputs. There’s no way for us to enter that into the algorithm itself.”
I tell them I am sure that they don’t have a ‘Do Racism’ button on their program’s dashboard, but wonder if systemic bias could nonetheless have entered into their datasets. Parsa says, “I absolutely agree that it’s not perfect, it could be biased, it could flag things that are not really supposed to be flagged, and that’s why we added the human review.” But the human review let these results stand.
“I think,” Simonoff says, “that those posts have indications that someone somewhere may interpret as disrespectful.”
…
Simonoff says Predicitm “doesn’t look at words specifically or phrases. We look at the contexts. We call it vectorizing the words in the posts into a vector that represents their context. Then we have what’s called a convolution neural net, which handles classification. So we can say, is this post aggressive, is it abusive, is it polite, is it positive, is it negative?’ And then, based on those outputs, we then have several other models on top of it which provide the risk levels and that provide the explainability.” (He and Parsa insist the system is trained on a combination of open source and proprietary data, but they refused to disclose the sources of the data.)
…
“The black woman being overly penalized—it could be the case that the algorithm learns to associate types of speech associated with black individuals, even if the speech isn’t disrespectful,” Kristian Lum tells me. Dr. Lum is the lead statistician at the Human Rights Data Analysis Group, and has published work in the prestigious journal Nature concluding that “machine-learning algorithms trained with data that encode human bias will reproduce, not eliminate, the bias.”
Lum says she isn’t familiar with Predictim’s system in particular, and to take her commentary with a grain of salt. But basically, a system like Predictim’s is only as good as the data that it’s trained on, and those systems are often loaded with bias.
“Clearly we’re lacking some context here in the way that this is processing these results,” Lum says, “and that’s a best case scenario. A worst case is that it’s tainted with humans labeling black people as disrespectful and that’s getting passed onto the algorithm.”
132 notes
·
View notes
Text
Thinking about starting a new blog that's all hardcore pornography except everything's green-tinged and there's a small cartoon of a pink elephant in the corner to fool the censorbot
18 notes
·
View notes