
Diffen is a difference engine that lets you compare anything. This blog chronicles our experiences raising this media property.
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by thediffenblog and here's what we found interesting.
Average Info
Notes Per Post
4
Likes Per Post
4
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
9 months ago
Number of Posts By Type
Text
12
Note
1
Photo
3
Link
1
Last Seen Tumblr Blogs





Fun Fact
Women make up for the other 50% of Tumblr’s audience.
Text
The 5 building blocks of intelligence
On a recent episode of the No Priors podcast, Zapier co-founder Mike Knoop said that:
The consensus definition of AGI (artificial general intelligence) these days is: "AGI is a system that can do the majority of economically useful work that humans can do."
He believes this definition is incorrect.
He believes that François Chollet's definition of general intelligence is the correct one: "a system that can effectively, efficiently acquire new skill and can solve open-ended problems with that ability."
François Chollet is the creator of the keras library for ML. He wrote a seminal paper On the Measure of Intelligence and designed the Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI) challenge. It's a great challenge -- you should play with it at https://arcprize.org/play to see the kinds of problems they expect "true AGI" to be able to solve.
Unlike other benchmarks where AI is either close to or has already surpassed human-level performance, ARC-AGI has proven to be difficult for AI to make much progress on.

Does that mean Chollet's definition of general intelligence is correct and ARC-AGI is the litmus test for true AGI?
With all due respect to Chollet (who is infinitely smarter than me; I didn't get very far in solving those puzzles myself) I feel that it is a little bit reductive and fails to recognize all aspects of intelligence.
General intelligence
There is already smarter-than-human AI for specific skills like playing chess or Go, or predicting how proteins fold. These systems are intelligent but it is not general intelligence. General intelligence is applies across a wide range of tasks and environments, rather than being specialized for a specific domain.
What other than the following is missing from the definition of general intelligence?:
Ability to learn new skills
Ability to solve novel problems that weren't part of the training set
Applies across a range of tasks and environments
In this post, I submit there are other aspects that are the building blocks of intelligence. In fact, these aspects can and are being worked on independently, and will be milestones on the path to AGI.
Aspects of Intelligence #1: Priors - Language and World Knowledge
Priors refers to existing knowledge a system (or human) has that allows them to solve problems. In the ARC challenge, the priors are listed as:
Objectness Objects persist and cannot appear or disappear without reason. Objects can interact or not depending on the circumstances. Goal-directedness Objects can be animate or inanimate. Some objects are "agents" - they have intentions and they pursue goals. Numbers & counting Objects can be counted or sorted by their shape, appearance, or movement using basic mathematics like addition, subtraction, and comparison. Basic geometry & topology Objects can be shapes like rectangles, triangles, and circles which can be mirrored, rotated, translated, deformed, combined, repeated, etc. Differences in distances can be detected. ARC-AGI avoids a reliance on any information that isn’t part of these priors, for example acquired or cultural knowledge, like language.
However, I submit that any AGI whose priors do not include language should be ruled out because:
Humans cannot interact with this AGI and present it novel problems to solve without the use of language.
It is not sufficient for an AGI to solve problems. It must be able to explain how it arrived at the solution. The AGI cannot explain itself to humans without language.
In addition to language, there is a lot of world knowledge that would be necessary for a generally intelligent system. You could argue that an open system that has the ability to look up knowledge from the Internet (i.e., do research) does not need this. But even basic research requires a certain amount of fundamental knowledge plus good judgment on which source is trustworthy. So, knowledge about the fundamentals of all disciplines is a prerequisite for AGI.
I believe that a combination of LLMs and multi-modal transformer models like those being trained by Tesla on car driving videos will solve this part of the problem.
Aspects of Intelligence #2: Comprehension
It takes intelligence to understand a problem. Understanding language is a necessary but not sufficient condition for this. For example, you may understand language but it requires higher intelligence to understand humor. As every stand-up comedian knows, not everyone in the audience will get every joke.
Presented with a novel problem to solve, it is possible that there are two systems that both fail to solve the problem. This does not prove that neither system is intelligent because it is possible that one system can at least comprehend the problem while another fails to even understand it.
Measuring this is tricky, though. How do you differentiate between a system that truly understands the problem vs. another that bullshits and parrots its way to lead you to believe that it understands? While tricky, I do think it is possible to quiz the system on aspects of the problem to gauge its ability to comprehend it. e.g., ask it to break it down into components, identify the most challenging components, come up with hypotheses or directions for the solution. This is similar to a software developer interview where you can gauge the difference between a candidate who could at least understand what you were asking, and can give some directionally correct answers even though they may not arrive at the right answer.
Comprehension also becomes obvious as a necessary skill when you consider that it's the only way the system will know whether it has successfully solved the problem.
Aspects of Intelligence #3: Simplify and explain
This is the flip side of comprehension. One of the hallmarks of intelligence is being able to understand complex things and explain them in a simple manner. Filtering out extraneous information is a skill necessary for both comprehension and good communication.
A system can be trained to simplify and explain by giving it examples of problems, solutions and explanations. Given a problem and a solution, the task of the system -- i.e. the expected output from the system -- is the explanation for how to arrive at the solution.
Aspects of Intelligence #4: Asking the right questions
Fans of Douglas Adams already know that answer to life, the universe and everything is 42. The question, however, is unknown.
“O Deep Thought computer," he said, "the task we have designed you to perform is this. We want you to tell us…." he paused, "The Answer." "The Answer?" said Deep Thought. "The Answer to what?" "Life!" urged Fook. "The Universe!" said Lunkwill. "Everything!" they said in chorus. Deep Thought paused for a moment's reflection. "Tricky," he said finally. "But can you do it?" Again, a significant pause. "Yes," said Deep Thought, "I can do it."
Given an ambiguous problem, an intelligent entity asks great questions to make progress. In an interview, you look for the candidate to ask great follow-up questions if your initial problem is ambiguous. An AGI system does not require its human users to give it complete information in a well-formatted, fully descriptive prompt input.
In order to be able to solve problems, an AGI will need to consistently ask great questions.
Aspects of Intelligence #5: Tool use
An intelligent system can both build and use tools. It knows which tools it has access to, and can figure out which is the right tool for a job and when building a new tool is warranted. It is a neural net that can grow other neural nets because it knows how to. It has the ability and resources to spawn clones of itself (a la Agent Smith from The Matrix) if necessary to act tools or "agents".
This ability requires a level of self-awareness, not in the sense of sentience but in the sense of the system understanding its own inner workings so that it understands its constraints and knows how it can integrate new subsystems into itself when needed to solve a problem. Like Deep Thought built a computer smarter than itself to find the question to the ultimate answer, a task that Deep Thought itself was unable to perform:
"I speak of none other than the computer that is to come after me," intoned Deep Thought, his voice regaining its accustomed declamatory tones. "A computer whose merest operational parameters I am not worthy to calculate - and yet I will design it for you. A computer which can calculate the Question to the Ultimate Answer, a computer of such infinite and subtle complexity that organic life itself shall form part of its operational matrix.
BONUS: 1 more building block -- for superintelligence
In addition to the five building blocks above, I believe there is one more if a system is to become superintelligent (beyond human level intelligence).
Aspects of Intelligence #6: Creative spark
What is common among the following?:
The discovery (or invention?) of the imaginary unit i, the square root of negative one.
Einstein's thought experiments, such as imagining riding alongside a beam of light, which led him to develop the special theory of relativity.
Archimedes' eureka moment while taking a bath when he realized that the volume of water displaced by an object is equal to the volume of the object itself.
Newton watching an apple fall from a tree and wondering if this is the same force that keeps the moon on orbit around the Earth.
Friedrich August Kekulé having a dream of a snake biting its own tail and leading, leading to the discovery of benzene's ring structure.
Niels Bohr Bohr proposed that electrons travel in specific orbits around the nucleus and can jump between these orbits (quantum leaps) by absorbing or emitting energy. This explained atomic spectra, something that classical physics could not explain.
Nikola Tesla designing the Alternating Current system to efficiently transmit electricity over large distances, and designing the induction motor to use alternating current.
In all these cases, a spark of creativity and imagination led to new advancements in knowledge that were not built upon the available knowledge at the time.
Most scientists and engineers spend their entire career without such groundbreaking insight. So this is not strictly necessary for general intelligence. But for beyond human-level intelligence, the system must be capable of thinking outside the box.
References
On the Measure of Intelligence - François Chollet
Puzzles in the evaluation set for the $1 million ARC Prize
ARC Prize
ChatGPT is Bullshit - Michael Townsen Hicks, James Humphries, Joe Slater
Stochastic parrot - Wikipedia
0 notes
Text
AI Companies vs. The Open Web

Robb Knight recently posted how Perplexity is lying about their user agent. I wrote a short comment on Hacker News around this and there were interesting responses to it that spurred some debate. So I wanted to expand on the tensions between what users want, what publishers need, and how the tradeoffs affect the ecosystem of the open web.
Robb Knight's blog is the latest story in a string of earlier stories about how content creators are upset that their content is used by AI companies without permission or compensation. Most of these stories have focused on AI companies' use of content to train their models.
What people miss is that there are two use cases where AI companies are using content from the open web:
To train their model
In real time to answer user questions e.g. via RAG (retrieval augmented generation)
Use case 1: Model training
When content is used to train a model like GPT-4, Claude or Llama, it is likely part of a very large data set and each piece of content has very little influence over the final neural network that is trained. I consider this fair use but this is being debated (and litigated). Regardless, some content publishers have recognized that
their content has higher value than other web content in the training data. These are so-called "high value tokens". e.g. presumably the value or quality of an article in the Financial Times > a Reddit post > a 4chan post.
they have the negotiating leverage and legal budget to get AI companies to pay them for using their content.
These are large publishers like Axel Springer or the Associated Press, as well as sites like Reddit and StackOverflow who technically do not own the copyright for the content (it belongs to the user who posted that content) but are able to leverage their position as a platform to extract compensation from AI companies.
Where does that leave the little guy -- independent publishers like HouseFresh or Diffen? Without a class action or consortium, it is difficult for them to get compensated for the value of their tokens because
even if they have great content, their content is not must-have. An AI company could remove an individual indie publisher from their training data and still be fine.
The cost of compensating small publishers is too high -- both in terms of operational cost of doling out money to hundreds of thousands of publishers, but also the exercise of valuing their content.
I believe companies like Raptive (previously known as AdThrive) are trying to do something here to negotiate on behalf of their publishers but I'm not holding my breath.
Use case 2: Crawl initiated to answer a specific user question
This use case is when generative AI is used to answer a user's question by finding say the top 20 search results and then combing their content and distilling it into a short summarized answer. This is called RAG (retrieval augmented generation). Perplexity and Google's AI overviews in Search fall into this category.
I am hypocritical have mixed feelings about Perplexity: as a user, I love it; as a publisher, I want to block it.
When I have somewhat complex questions, Perplexity shines at doing the research for me and leading me straight to the answer. Without Perplexity, one would have to search on Google, visit 3-4 different web pages and infer the answer oneself. Perplexity is able to visit more web pages and summarize them to answer my specific questions. It saves me a lot of time and I have found the answers to be generally trustworthy. Unlike ChatGPT, I have not seen many hallucinations with Perplexity. So to reiterate, as a user I love Perplexity.
As a web publisher, I find it unacceptable that Perplexity hides their user agent and does not allow publishers to opt out. I would probably want to opt Diffen out of serving such requests from Perplexity or Google AI overviews if given the option. Why?
Update Jun 22, 2024: A couple of days after I published this post Perplexity CEO Aravind Srinivas appeared on the Lex Fridman podcast. The interview is well worth a listen for anyone interested in AI. The parts of the interview relevant to this debate are excerpted below:
Google has no incentive to give you clear answers. They want you to click on all these links and read for yourself, because all these insurance providers are bidding to get your attention.
In response to the question "Can Perplexity take on and beat Google or Bing in search?":
It’s very hard to make a real difference in just making a better search engine than Google, because they have basically nailed this game for like 20 years. The disruption comes from rethinking the whole UI itself. Why do we need links to be occupying the prominent real estate of the search engine UI? Flip that. In fact, when we first rolled out Perplexity, there was a healthy debate about whether we should still show the link as a side panel or something.
This proves my point by making it obvious that the whole point of Perplexity (and Google's AI overviews in search) is to abstract away the publishers -- especially the long tail of small, independent bloggers who will get no compensation -- and provide an answer so the user does not have to click through. Citations exist not to send traffic to pubs or to allow users to dig in further (there's the "follow-up questions" feature for that) but to instill confidence in the user that the answer is correct and based on fact.
End update of Jun 22, 2024
The original Google search was built on an implicit quid pro quo between Google and publishers: publishers would let Google crawl, index and cache their content. In return, Google would surface this content in their search results. Only the title and short snippet would be surfaced and publishers controlled both of these. Publishers would get traffic from Google if they had good content.
Over time, Google reneged on their end of the deal. They started showing longer and longer featured snippets and answers in search so that they could keep traffic on Google properties. Google has been stealing content and traffic from publishers for years now. Exhibit A: CelebrityNetWorth content shown in featured snippets on Google reduced traffic to their site. In 2020, two thirds of all searches on Google led to zero clicks. So the frog has been boiling for years and this new challenge with Perplexity and AI overviews in Google Search is just another temperature ratchet.
As a publisher, my take on both Perplexity and AI overviews is that at this time their value to my business is low because I do not believe most people click on the citations, so the incremental traffic they will deliver is low.
Giving away your content in return for this low probability of getting traffic is not a tradeoff worth making. You might argue that the alternative is getting zero traffic from these sources. And low > zero. That is true, but I do not feel right feeding the beast that is going to eventually eat me. The reason Google is so powerful is because small publishers do not have a direct relationship with users. Google has aggregated all demand (users) and commoditized all suppliers (content providers). Classic aggregation theory. So it does not feel right to cooperate with Google and Perplexity as they make users habituated to trusting their AI overviews and never clicking out. This only entrenches their position as aggregators.
Whither the open web?
Some publishers monetize via ads or affiliate links. For them, losing traffic is an existential risk. But what is often missed is that other businesses also lose when Google/Perplexity steal their traffic.
Say you are a SaaS provider and you have a bunch of Help docs on your website. Your docs not only help your customers figure out how to use your features but you may also have content that potential customers may find as they are looking for a solution to the problem that you solve. e.g., a user is wondering how to import their brokerage transactions into their tax software. You are a tax software provider that does offer this functionality and have an article explaining this. You could acquire this user if they find (via the 10 blue links version of Google search) that your software has this feature while the one they are using currently does not.
Another obvious example is "software_name pricing plans" search queries. Google/Perplexity could give the user the answer here but if the user does not come to your website then you can't offer them a free trial, can't run A/B tests on your pricing, and can't retarget them for remarketing. In short, you can't convert traffic that never lands on your site. To get around this, you will have to run ads for such keywords so they show up before, or instead of, the organic answer. This suits Google just fine.
There is also value to you in having your existing customers come to your site rather than just read the answer on Google. You can see what Help articles are more popular, and use this information to figure out what parts of your user interface are not intuitive. Or you could analyze searches made on your Help site to get ideas for new features to build or new Help articles to write.
Finally, returning to the small web publishers relying on ads or affiliate income, they are now default dead. Writing content, attracting an audience via organic search and monetizing via ads is no longer a viable business model where independent publishers can earn a decent livelihood. So what are the implications?
More and more content will be AI-generated. To make the model viable, people will dramatically lower the cost of writing content by getting a machine to do it. When the marginal cost of creating content goes to essentially zero, it is possible that whatever little traffic you do get from the aggregators like Google is still positive ROI for you. But who creates net new content now for an LLM to summarize?
A handful of large media publishers will still create content and be paid for it. 6 companies control 90% of media and 16 companies control 90% of Google search results. As independent bloggers and small publishers get squeezed out, this oligopoly is only going to get further entrenched, which is not great for the open web.
People will try to spam the platforms that are the current winners (e.g. Reddit) of Google HCU ("helpful" content update, euphemism for their updates that reward large brands and destroyed indie publishers even if they had great content). You will be able to trust Reddit content less and less in the coming years.
The Internet has been a great democratizing force that allowed anyone to become a publisher. For the first couple of decades of Google's existence, great content did win even if it was written by a blogger in a basement. But the open web is now headed to a future where independent voices will get a small fraction of the distribution they used to garner, which will discourage them from publishing, which will lower their reach even further.
We will consume our information from AI agents that rely on content from a handful of large media companies.
References
Perplexity AI Is Lying about Their User Agent - Robb Knight (MacStories)
How 16 Companies are Dominating the World’s Google Search Results - Glen Allsopp (Detailed)
The 6 Companies that Own Almost All Media - WebFX
In 2020, Two Thirds of Google Searches Ended Without a Click - Rand Fishkin (SparkToro)
Default Alive or Default Dead? - Paul Graham (Y Combinator)
Aggregation Theory - Ben Thompson (Stratechery)
How a New York Times copyright lawsuit against OpenAI could potentially transform how AI and copyright work - Dinusha Mendis (The Conversation)
0 notes
Text
PHP: Finding all instances of “Optional parameter declared before required parameter”
Among the many backward incompatible changes in PHP 8.1 is this one:
Optional parameters specified before required parameters
An optional parameter specified before required parameters is now always treated as required, even when called using named arguments. As of PHP 8.0.0, but prior to PHP 8.1.0, the below emits a deprecation notice on the definition, but runs successfully when called. As of PHP 8.1.0, an error of class ArgumentCountError is thrown, as it would be when called with positional arguments.
So how do you refactor your code and find all instances where you have functions doing this?
Here is a regex (regular expression) based approach:
ag -G php "function\s+[a-zA-Z0-9]+\s*\([^)]+=" | egrep '=[^{]+,[^=]+(,|\))'
What does this do?
ag -G php
ag is a search utility like grep or ripgrep that makes it easy to search code. With this option we are asking ag to search PHP files.
"function\s+[a-zA-Z0-9]+\s*\([^)]+="
This regex is looking for any function declarations that have default values. So it’s looking for the string “function”, followed by one or more spaces, followed by an alphanumeric string (the function name), followed by zero or more spaces, followed by an opening paren “(”, followed by anything other than a closing paren “)”, followed by an equal sign.
egrep '=[^{]+,[^=]+(,|\))'
Having identified the functions that use default values for arguments, let’s now find ones where a required argument is declared after an optional argument. This regex looks for an equal sign followed by two commas (that presumably separate function arguments) where there isn’t an equal sign between the two commas. In case there aren’t two commas, we look for closing paren because it could be the last argument in the function declaration.
Happy refactoring!
0 notes
Text
Using Cloudflare Workers to get your Fastly cache hit rate to 95%
I love both Cloudflare and Fastly, and use both services for Diffen. Cloudflare powers the DNS and delivers the assets (images and JS) on static.diffen.com. Fastly is the CDN for serving HTML content, powering the main www subdomain. (if you’re wondering why, it’s because Fastly lets you stream your access logs to Bigquery, a feature only available to enterprise customers on Cloudflare.)
This is the story (and code) of how I improved the cache hit ratio from Fastly using Cloudflare Workers.
How a CDN works A CDN has several POPs (points of presence) across the world. For example, Fastly’s network map is here. When a user makes a request for a web page, it gets routed to Fastly, and is usually handled by the POP that is closest to the user. If that POP has the content in its cache, it can serve it to the user immediately. But if the content is not cached at that POP, Fastly makes a request to the “origin” – the server that actually runs your web app – to fetch the content. This extra hop adds latency, and the total response time for the end user could end up being slower than having no CDN at all.
Naturally, you want your cache hit ratio to be as high as possible.
Priming the cache Ideally, I’d like to prime the cache in every Fastly POP for my most popular content. And given that resources get booted out of Fastly’s cache depending upon their load, I’d like to re-prime periodically. Unfortunately, Fastly does not provide a mechanism to prime its cache.
One way to do it would be to lease VPSes in cities all over the world and run cron jobs to request these pages every hour. But this is… infeasible. Run AWS lambda functions from various data centers? Not enough diversity of cities. There are far more Fastly POPs than AWS data centers.
So let’s fight fire with fire. Cloudflare’s network has as many (if not more) POPs as Fastly. And lucky for us, Cloudflare allows you to run code on the “edge” i.e., in each of its data centers.
Using Cloudflare workers
A couple of weeks ago, Cloudflare announced Triggers for workers. I was excited to get cron job-like functionality for workers. However, their blog post says:
Since it doesn’t matter which city a Cron Trigger routes the Worker through, we are able to maximize Cloudflare’s distributed system and send scheduled jobs to underutilized machinery.
So we can’t specify which POP is used to run our worker. Bummer! How else can we run our crawlers from various POPs around the world where our users are?
We use our users’ locations. Whenever a user visits a page, we invoke a Cloudflare worker. This worker will run at a Cloudflare POP closest to that user.
fetch('https://cache-primer.diffen.workers.dev');
The job of the worker is to (1) make a call to an endpoint to request a list of URLs to prime the cache for, and (2) crawl those URLs.
async function handleRequest(request) { const resp = await fetch('https://www.diffen.com/API-that-returns-a-list-of-urls-to-crawl'); let urls = await resp.json(); for(let url of urls){ await fetch(url); } return new Response("OK", { headers: { 'Access-Control-Allow-Origin': 'https://www.diffen.com' } }); }
The job of the API-that-returns-a-list-of-urls-to-crawl is to (1) know the top pages we need primed in Fastly's cache, (2) maintain the list of pages we have cached in each Fastly POP, and (3) for a given request (from a Cloudflare worker), return ~10 pages that we have not primed yet in that POP.
Let’s say the user is in Seattle so Cloudflare's Seattle POP is where the worker runs. It makes a request to the API to get a list of URLs to crawl. This API request is routed to the origin server via Fastly's Seattle POP. On the origin, we can see the name of the POP in the X-Fastly-City header of the request.
<?php
header("Cache-Control: private, max-age=0"); //Make sure this response does not get cached. header("Content-type: application/json; charset=utf-8");
$topUrls = getMostPopularUrls(); //This is a static list $headers = getallheaders(); $city = $headers['X-Fastly-City']; $primedUrls = getPrimedUrls($city); $unprimedUrls = array_diff($topUrls, $primedUrls); $newUrlsToPrime = array_slice($unprimedUrls, 0, 10); primeNewUrls($city, $newUrlsToPrime); //Maintain a list of the URLs we have already primed //so we don't prime them again for a few hours.
echo json_encode($newUrlsToPrime);
return;
That's all there is to it.
We are now using one CDN to prime the cache at another. Cities with more users will have a higher chance of primed caches.
How much does it cost?
Cloudflare lets you make 100,000 requests per day for free. The paid plan is $5 for 10 million requests per month. Totally worth it.
Results The cache hit ratio went from ~75% to ~95% with this change. YMMV; the strategy would work better for top-heavy sites where a small number of pages account for a large share of overall traffic. I wouldn’t want to jam thousands of pages into Fastly's cache when there is a slim chance of a real user ever needing them.
0 notes
Text
You’re Doing Social Logins Wrong
Social logins can be great because it’s one of those features that’s good both for users and for app developers.
Users often don’t want to create yet another account with yet another username and password. They may end up re-using the same password across many sites, which leaves them vulnerable.
App developers want to reduce any friction they can to increase user engagement. Creating an account is often a pretty big hurdle. Besides, it’s easy to screw up auth; it would be fantastic if you could simply avoid the headache of storing user credentials and outsource auth to a trusted, secure third-party like Google or Facebook.
But time and again I’ve seen app developers use it in a bad way, which turns users off from this method of login. Granted, federated login has plenty of problems but this rant is about 1 particular mistake.
The first and obvious mistake is asking for too many permissions. You don’t need to see my friend list and interests and likes for me to have an account for your web app. This is just like Android apps asking for a ton of permissions (pre-Marshmallow) — why does Pandora need to access my contacts list?
But this blog post is about a different mistake that is widespread but sadly not pointed out enough. It’s when you click on Facebook login, authorize the app and then it asks you to create a username and password.

The screenshot above is from the awesome free photo website Unsplash. I didn't want to create yet another account there so I logged in with Facebook, authorized their permissions (public profile and email, well done there Unsplash!) and expected to be logged in. But this next step of choosing a username and password is just completely unnecessary.
If your app can't function without each user having a username, then auto-generate a username for them and let them change it. But please don't force them to create a username and password when they used their social login precisely to avoid that.
0 notes
Note
How do I reference the diffen website in APA style for a research paper?
You can see the How to Cite article: http://www.diffen.com/difference/Diffen:Citation
0 notes
Text
How a Progress bar for AJAX requests helped increase conversions by 38%
The NY Times published an interesting article this week about how progress bars can make it easier for people to wait for computers to respond. This idea is not new; usability experts have long advocated their use. Developers and designers have even tried to have some fun with progress bars.
When we launched the Get from Wikipedia feature on Diffen, we wanted to make the wait bearable for our users and hold their interest. Our first progress indicator was just a a loading GIF. Here's how we replaced it with an actual progress bar and increased conversions by 38%.
First, for those who don't know, Diffen is like Wikipedia for comparisons. If you compare two entities on Diffen and there is no information about either of them in our database, the system tries to get the information from Wikipedia infoboxes. Here's a 20-second demo of how it works:
The page makes an AJAX request to get information about each entity. The back-end needs some time to respond because different variations and misspellings of the entity name may have to be tried before finding the right Wikipedia page for it. Also, the Wikipedia page must be parsed to tokenize the attribute/value pairs from the infobox. (We can do a separate blog post on how this is done if there is interest.) When both AJAX requests are completed successfully, the attributes are lined up side by side and shown to the user.
How we implemented the progress bar
First we benchmarked the time it took for a typical AJAX request for entity information and found that the time varies from 3-8 seconds. So we needed a progress bar that could last as long as 8-10 seconds. That's a pretty long time, which means we needed lots of status messages.
The status messages in the progress bar are based on what the server is likely doing, not what the server is actually doing at that time (more on that later). The status messages we use are:
var progressStatuses = [ "Searching Wikipedia", "Scanning search results", "Reading the right Wikipedia page", "Scanning the information box", "Preparing the info", "Preparing the info", "Receiving the info", "Almost there" ];
The server doesn't really send any progress report to the browser. The progress bar isn't real; it is only meant to placate the user and tell her the system is working on her request.
A word about timing
The easy way to make progress is to increment to the next step at a set interval, say 1 second. But that is more likely to draw suspicion and give away our illusion of authenticity.
Another approach would be to progress through the initial 3 stages really fast to get the user hooked, and then gradually decelerate the pace of progress.
Instead we try and use intermittent variable rewards, known to be more pleasurable and addictive. The basic idea is that random reinforcement is more addictive (because it is more pleasurable) than consistent, predictable reinforcement for the same activity. We spend a random amount of time - between 500 and 1500 milliseconds - at each stage.
function makeProgress (reset){ var div = $("#progressIndicator"),width=0; if(div.length==0) return; //Operation complete. Progress indicator is gone. if(reset) div.width(0); else width = div.width(); if(width < 300){ width += 45; //make the bar progress div.width(width); $("#progressStatus").html(progressStatuses[(width/45)-1]+'...'); var delay = Math.floor(Math.random() * (1500 - 500 + 1)) + 500; //A random number between 500 and 1500 setTimeout(makeProgress, delay, false); } }
That's pretty much all we need for the progress bar. The initialization code is somewhat like this:
function importFromWikipedia(){ setTimeout(makeProgress,100,true); //start the progress bar $.getJSON("/call/to/backend/script/for/entity1",fnOnSuccess); $.getJSON("/call/to/backend/script/for/entity2",fnOnSuccess); function fnOnSuccess(data){ //Did we get information about both entities or only one? if(bothReceived){ showTheComparisonChart(); $('#progressIndicator').remove(); //helps us break out of the makeProgress() recursion } else { //Mark one entity as complete and wait for the other one } }); }
First, we initialize the progress bar. Then we make the AJAX requests to the backend. When both requests are completed, we remove the progress indicator and show the comparison chart.
It is not necessary to loop through all 7 available progress status messages and "complete" the progress bar visually. If the user only sees the first 3 before the request completes, she is not going to care. In fact, if she notices it at all, she is likely to be delighted that the operation finished quicker than expected.
It's not very pretty, but this progress bar is quite functional. When this progress bar replaced a loading GIF we saw conversion rate (as measured by the weekly number of new entities imported from Wikipedia and saved to our database) increase 38%.
Discuss on Hacker News
1 note
·
View note
Text
The Decline of IE and Firefox
Windows and IE are dying under the assault of iPads and other tablets from the left, and Chromebooks from the right. This is not surprising, or even news to people who spend a lot of time in the tech world. What surprised me recently was how precipitous the decline of Internet Explorer has been in the past few months.

(update: some comments on Hacker News questioned why the y-axis on this graph doesn't go from 0 to 100. Browser shares tend to move slowly. All 4 lines will appear essentially flat if I did that. The story would be lost. This type of chart with a short range for the y-axis is the best way to depict browser share.)
Flashback to summer of 2012 when IE's share of traffic to Diffen was a little over 26%. This was for n= ~ 1 million visitors. Fast-forward to December 2013 where IE's share has dropped to 12.17% (n = ~ 4 million visitors). Diffen is a consumer-oriented website with over 60% traffic from the U.S. So yes, this is probably not a true reflection of worldwide market share. But boy is there a decline in Q4!
And all of it cannot be blamed on the decline of Windoze or PCs. Windows users still accounted for 47% of traffic in December. And Desktops accounted for 60% of all traffic. The share of mobile traffic jumped from 29 in October to 32% in December.
Also notable is the slow but steady decline of Firefox. They've been doing some really cool stuff with asm.js and PDF.js but this does not seem to be translating into any gains in mainstream market share.

The good news in all of this is -- you guessed it -- no need to support IE < 8 ! Here's how IE's 12.17% share in December breaks down into all its versions:

(update: in response to Christian Jensen's request in the comments below, I have translated these numbers into % of total market share in this chart:)
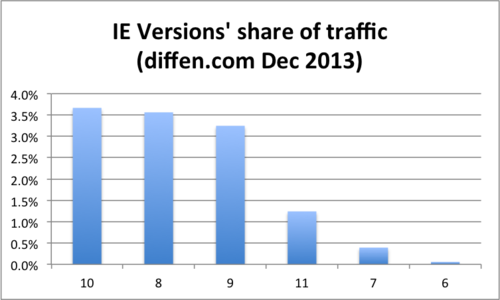
Of course, I'd prefer to not have to deal with IE 8 either but at least right now its share is material.
Disclaimer: Once again, these numbers do not reflect the state of the web. There are many other sources of browser share statistics that are based on more data and offer more granularity for your research. If you already have a web presence, look into Google Analytics for data on your audience. If you're working on a startup in the consumer space, expecting visitors mostly from the U.S., Canada, UK, and about a third of them from their smartphones, then these number might be more relevant to you.
Bonus tip: If you have goals set up in Google Analytics, create a custom report to see conversion rates by browser and by screen resolution. This can potentially uncover problems where certain segments of your visitors aren't converting because the site is not working for them the way you expected. (Hat tip: @CalebWhitemore)
Discuss on Hacker News
1 note
·
View note
Text
2 million unique visitors in September
It took Diffen several years to get to a point where we crossed 1 million unique visitors a month. The next million took only 1 month.
After flirting with the 1MM mark a couple of times, it finally happened in August 2012. And in September traffic to Diffen crossed the 2 million unique visitor mark.

Totally awesome!
But we're not going to get carried away with this success. Growth cannot continue at this pace unless we make significant investments in content, product and marketing. In fact, it is only October 1 today and yet we think traffic in October, November and December will experience negative growth.
And traffic is only a small part of the big picture. So many things matter more than traffic. For example:
What are our users saying about Diffen? With temperatures running high (metaphorically) this election season, some users have complained about perceived bias in some comparisons of politicians. In most cases their feedback was valid and we made corrections.
What percentage of users are using the wiki features to contribute positively to information on the site?
How many users return and how often?
How many users love us enough to share Diffen with their friends?
As we've said before, one algo update by a major search engine has the potential to decimate traffic. And yet while we recognize the risks, we also know when to party ;)
1 note
·
View note
Text
link rel=twitter - A proposal for mobile browser makers
It is generally easier to share what you're reading on a mobile device than desktops. Mobile browsers allow you to email, share on Twitter and, with the latest Chrome and iOS 6, share on Facebook.
One advantage of Twitter's sharing widget aka Tweet button is the via field. Mobile websites cannot afford to add bulk by loading the Twitter widget. So perhaps mobile browser vendors should start supporting a way to add the via hint. It would work like this (without the mangled smart quotes that Tumblr introduced below):
<link rel="twitter" href="https://twitter.com/Diffen">
With that in your <head> the browser now knows the publisher's Twitter handle and will automatically append (via @Diffen) to the tweet text.
0 notes
Photo


Analysis of the "bump" caused by the Republican and Democratic National Conventions.
Here's a look at the bump caused by the two major conventions. Both events caused an increase in the number of people comparing the Democratic and Republican parties but the DNC caused a bigger spike.
And what of the candidates? More people where comparing Romney and Obama on each day of the DNC than after the crowning moment of the RNC i.e. Romney's speech. So it seems that Michelle Obama, Bill Clinton and Barack Obama all had more of an impact than Romney.
In other interesting developments, the Democrats have edged the Republicans on the ratings scale. After being stuck at 3.8 for a loong time, the Democratic party now has a rating of 3.9 and the Republicans are still at 3.8.
Obama's rating is 3.9 compared to Romney's 3.4 but that should be taken with a grain of salt because Obama's rating has a historical advantage from the previous election.
#politics#trends#Democrats#Republicans#presidential election#obama#romney#analytics#dnc#rnc#conventions
0 notes
Text
Experiences hacking GA event tracking
Last month we started using event tracking in Google Analytics (henceforth forever called GA). Should have started years ago but as they say - better late than never. Thought it might be a good idea to share a few things that we learned.
1. Have clear goals
We have a pretty high bounce rate so we wanted to understand what people are clicking on to see how we could make the product more engaging. The second goal was to track which content categories get how much traffic. Believe it or not, we weren't tracking pageviews by content category. With so many content categories, each with their own super- or sub-categories, it's important to know where you're lagging and where you're doing well.
2. Learn from others
It's weird but it was impossible to research GA hacking without running into Cardinal Path. We thought Wikia has many content categories so their GA implementation would probably be a good model. So we set out to find where the magic happened and ran into Cardinal.
3. How event tracking actually works
Geek out on this StackOverflow thread to explore how GA event tracking actually works. If you're tracking a click on a page, the browser probably doesn't give GA enough time to send its GIF request with the payload to the server. It's possible the browser opens your link before GA's Javascript gets a chance to do its thing. (UNLESS ga.js introduces some sort of document.unload handler which finishes all GA tracking before allowing the original document to unload and the new page to load. That would be cool for tracking purposes but totally UNcool for our users. Given a choice between making the site experience faster for users and tracking their clicks, we'd choose our users every single time. Even if you wake us up at 4am to ask. Fortunately, it seems that GA does not force an unload handler on the original document.)
4. Use onMouseDown
So how to handle scenarios where the browser is too fast for ga.js? That's where we ran into Cardinal Path again with this awesome blog post about onClick vs onMouseDown when using event tracking. Most examples for GA event tracking will show you code like
<a href="/wherever" onClick="_gaq.push(['_trackEvent',category,action,label]);">click me!</a>
But you can increase the probability that clicks will be tracked if you fire your GA event onMouseDown rather than onClick.
5. Page-level custom variables are useless. Use events instead
At first we tried using page-level custom variables for tracking what content categories are most popular. So for example when a visitor gets to the MacBook Air vs. Pro comparison, we want to track a hit for all the categories in the breadcrumbs. The top-level category is Technology and the second level is Consumer Electronics. We assigned the first custom variable for the top-level category, the second custom var for the 2nd level category and so on. But we wanted to do all this tracking after page load i.e. in $(window).load(function(){...});. But for it to work correctly you need to set your custom vars before GA's trackPageview call. That's a major difference between using custom vars and event tracking.
trackEvent fires a request to the big G's servers immediately but setCustomVar waits until some other function fires a request and piggybacks on that to send its data back to the mother ship. In most cases no other events would be fired so we wouldn't be able to accurately track custom variables.
Enter event tracking for content categories. We now track each category of the bread crumb as an event where:
The event category is hard-coded to 'PopularCategories'
The event action is the content category in the breadcrumb. (one event for each item in the breadcrumb.)
The event label is the page that the visitor is on.
The event label is interesting because apparently it's not needed. GA's web interface gives you the ability to use the Page Title as the primary dimension when viewing data for a particular Event Action. We didn't know that so we tracked the page ourselves in the label. What's interesting is that the numbers we see via the Labels breakdown are different from what GA shows when it breaks them down by page title. We're still not sure why that is. It's not a huge discrepancy but it's not teenie tiny either.
So there you have it. That's how we implemented GA event tracking.
UPDATE: CardinalPath has released an open-source project GAS (Google Analytics on Steroids) that looks very promising.
0 notes
Text
1 million unique visitors a month
On Aug. 27, we hit a milestone in the history of Diffen. 1 million unique visitors in a calendar month. We had come close before and flirted with 1M on a couple of occasions. But missed the mark by a few thousand. But August was different. We crossed the milestone with a few days of August to spare.

Yes, we know that we're too dependent on Google right now and one change of their algo can crush traffic. But we're celebrating in September and have a very cool sponsorship lined up. (Details next week)
0 notes
Photo

W00t!! We love round numbers. We know that one Google algorithm update can easily set us back but today is a day to celebrate!
0 notes
Photo

Joe Biden vs Paul Ryan ratings
Biden's rating includes votes from the 2008 election comparison so it's not going to be an apples-to-apples comparison with Paul Ryan immediately. This snapshot is a good indication of their starting scores so when we examine their ratings a few months from now we'll know how each candidate did.
Behavioral psychologists will tell you (and we would too) to take these ratings with a pinch of salt. Biden performed well because in the last election he was being compared to Palin. His ratings would most likely have been lower if people were rating him on a page that compared him to Obama instead. So making note of this starting line is important because come November, we'll be able to do a more accurate head-to-head comparison of Ryan with Biden, without letting Biden take advantage of his former comparison with Palin.
0 notes
Text
Mysterious rise in 404 errors in GWT
Google Webmaster Tools is reporting that in the last month the number of 404 errors has skyrocketed from about 9,000 to 77,000.
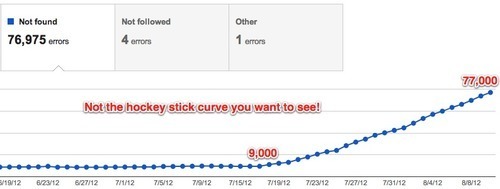
We can't figure out why. In fact, when we check our server logs and look for 404 status codes returned to Googlebot in the last month, there's only about 10,000 (which might even have some duplicate records..we haven't checked).
So what in the name of Tim Berners Lee is going on?
Let's look at the types of URLs Google Webmaster Tools (GWT) is reporting:
URLs from this requests page. These are requests people have made and this page hand hundreds of requests listed. So that makes sense. These are non-existent pages (the comparisons haven't been created yet!) so they return 404s. And Google found the 404s so all that make sense.
Hundreds of non-existent URLs that were never on the site. Like /Intel_EP80579_with_Intel_QuickAssist_Technology,_1200_MHz (the correct URL is /difference/Special:Information/Intel_EP80579_with_Intel_QuickAssist_Technology,_1200_MHz). Google doesn't say where it found them. Generally GWT tells you whether the URL was found in a sitemap or is linked from somewhere. But for the URLs it's reporting to us, no such info is available.
Here's the deal, though. All the processors and all the user requests don't add up to more than 2,500 URLs. So where the hell is Google getting 77,000 of them?
What we did
Added <meta name="robots" content="nofollow" /> to the comparison requests page so all the non-existent user requests aren't crawled. This is something we should have done a long time ago. Also stopped listing the hundreds of non-existent URLs on this page. Now we only show the most recent user requests. The nagging feeling we get, however, is whether the nofollow tag will prevent Google from de-indexing all the old 404 URLs that were listed on this page. Will Googlebot notice that these URLs have now been removed from the page or will it see the nofollow tag and start ignoring the page from a crawling and link finding perspective? We don't know.
We now return 410 for most of the non-existent URLs that Google is reporting. We found a pattern for the 404s that Google is reporting and the ones we uncovered in our server logs. And with some nginx config settings we can now return 410 because Google apparently removes 410s faster than 404s.
Google Webaster Tools: The Good, the Bad and the Ugly
The Good: They tell you there's something wrong with your site! +1 for transparency and proactive information sharing. They even give you a list of URLs they found, as well as where to fix the problem (sitemap or list of pages that link to the bad URL). All of this information is very helpful and kudos to them for providing it.
The Bad: They only tell you about 1,000 URLs and don't give you the full list. The CSV download is missing crucial info viz. where the URL is being linked from. Where did Google find the URL?
The Ugly: The rise reported by GWT does not reconcile with the number of 404s returned to Googlebot as indicated by our server logs. And there's no way to know when Google will remove these 404s from its index.
Why could this be happening?
We honestly have no idea. There are only guesses. Right now we're leaning towards a theory that blames spam. Spammers sometimes create user accounts on Diffen (which is a wiki and runs on the awesome MediaWiki platform - the same software that powers Wikipedia). Mediawiki has user pages where registered users can write a little about themselves. We require reCAPTCHA when users sign up but spammers manage to defeat it from time to time. They have been posting spam by creating such user pages. It's possible they are linking to thousands of such user pages but only succeeding in actually creating a few of them, (which we find and delete). It could even be negative SEO by a third party but that's not our favorite theory right now.
1 note
·
View note
Link
Brown is ahead in the polls but Mandel is all over YouTube. This is the most expensive race in Ohio's history - over $24 million have been raised.
0 notes