#you try to search a browser and even the articles saying stuff like “best distribution for beginners” List off like 12 without explanation
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
My job role is changing for the third time in less than a year so I thought I would start looking into learning Linux just to solidify a path of my skills instead of being a blanket "technology support"
Turns out, even just picking a starting point is it's own maze!
#job#market#responsibilities#autistic burnout#tech#it support#linux distros#you try to search a browser and even the articles saying stuff like “best distribution for beginners” List off like 12 without explanation
5 notes
·
View notes
Link

Accelerated Mobile Pages, or AMP, is an open-source initiative by Google. In their words, it helps "make the web better for all".
So is this true? Some critics (mostly publishers) say that it will help Google dominate the web. But we can't jump to any conclusions by just considering one perspective.
To help us out, I have divided this article into three sections, so we can consider AMP from three different perspectives.
The first considers the perspective of publishing sites and the people who maintain them. The second considers the perspective of the user. And the final perspective considers Google's take on it, as a search engine.
If you think about AMP from all these angles, you will be able to make the right decision for your website.
Because of this, this article doesn't have a straightforward conclusion as to whether you should or shouldn't use AMP. That's up to you, in the end. This article will just help you to move in the proper direction.
Let's look at our first perspective.
Publishing sites and their maintainers
AMP was launched in 2015, which means it's just 5 years old. So people and sites who have been publishing long before that time might worry that all their articles will suddenly become outdated. But that's not the case. Still, like big companies, they want to resist change.
Their criticism is completely valid from their perspective, as Google AMP has some strict conditions that must be met. For example:
Forget JavaScript (though there are some workarounds). Traditional use of JavaScript is not allowed at all.
If you are creating an AMP version of a page, the AMP version and the canonical page (the original page) should have identical design and functionality.
You can't use external CSS, but instead you have to inline everything. Since that would be inefficient, a customized library is preferable.
This is a minimal AMP page from the Google AMP docs:
<!DOCTYPE html> <html ⚡> <head> <meta charset="utf-8" /> <title>Sample document</title> <link rel="canonical" href="./regular-html-version.html" /> <meta name="viewport" content="width=device-width,minimum-scale=1,initial-scale=1" /> <style amp-custom> h1 { color: red; } </style> <script type="application/ld+json"> { "@context": "http://schema.org", "@type": "NewsArticle", "headline": "Article headline", "image": ["thumbnail1.jpg"], "datePublished": "2015-02-05T08:00:00+08:00" } </script> <script async custom-element="amp-carousel" src="https://cdn.ampproject.org/v0/amp-carousel-0.1.js" ></script> <script async custom-element="amp-ad" src="https://cdn.ampproject.org/v0/amp-ad-0.1.js" ></script> <style amp-boilerplate> /* AMP boilerplate CSS */ </style> <noscript ><style amp-boilerplate> body { -webkit-animation: none; -moz-animation: none; -ms-animation: none; animation: none; } </style></noscript > <script async src="https://cdn.ampproject.org/v0.js"></script> </head> <body> <h1>Sample document</h1> <p> Some text <amp-img src="sample.jpg" width="300" height="300"></amp-img> </p> <amp-ad width="300" height="250" type="a9" data-aax_size="300x250" data-aax_pubname="test123" data-aax_src="302" > </amp-ad> </body> </html>
Apart from the contents of the body tag, the rest is the minimal amount of code you need to be a valid AMP page.
Anything that can slow down the webpage is either not allowed or has a different format. For example, images have to use the <amp-img> tag instead of just the <img> tag. Similarly iframe and video tags have a different format.
You have complete freedom to use CSS inline the way you want to, except for some CSS animations (as it slows down the page).
If your canonical page has lots of dynamic stuff, like signup forms and carousels, then you will have a hard time creating an identical AMP version.
If you want to avoid that trouble, you are left with two options: either make your canonical page super simple or discard the canonical page and use just an AMP page.
This is what bothers most publishing sites and the people who manage them: Google will have immense control over the internet, which goes against the concept of net neutrality.
Google says it does not favour AMP pages in search results. However, there are rich cards which are only possible via AMP. So, in a way, Google is indirectly forcing you to use AMP to survive.

Google Rich Cards example
AMP also allows only one ad per page, which might affect ad revenue, considering that all your organic traffic will see the AMP version. There is limited support for other ad networks.
You also can't use other analytics providers other than the ones supported.
All these points need to be considered before you make a decision.
But it's not all bad news. Now let's talk about the benefits publishers recieve:
Google shows AMP pages from an AMP cache, which drastically reduces bandwidth usage on the publisher's server. This may or may not be beneficial to you.
Your website will load really fast, because of the severe limitations of AMP. So there is nothing to slow it down. Google also preloads webpages before someone clicks them, so the load time is negligible, apparently.
Your website can appear as rich cards, or carousels if properly configured, which increases the click through rate.
Now the most important thing: AMP implies that your website should be strictly mobile-friendly. And being mobile-friendly is such a necessity these days that websites can't ignore it, AMP or not.
So we've looked at Google AMP from the perspective of publishers. In the end, if you have a web app with a lot of functionality, I wouldn't suggest that you go for AMP. Now, let's move on to the second perspective.
Users
Publishers are the ones who might have trouble implementing AMP on their pages.
As a user, your primary motive is to surf the web. Not many mobile users have great internet speed and a non mobile-friendly and slow website with slow internet speed is the worst combination.
If you are searching for something online, your first priority is getting a result. Not all websites are fast, and even though they may have great content, they will likely suffer if they're slow to load. But Google AMP helps them to be fast and accessible.
A significant portion of any audience these days is made up of mobile users. For example, check out the user distribution of freeCodeCamp based on operating system:

FreeCodeCamp user distribution
So, the users are the ones who are and should be benefitting from AMP. Google is a user-centered company. Each and every decision it makes will benefit its users.
As a user, if you are searching for something, you have a very little attention span. You have a whole list of results to go through. If a website doesn't load within 5 seconds, you will most likely move on to the next result.
Let's try to compare the performance difference between the AMP and non-AMP versions of one of my freeCodeCamp articles.
This is the non-AMP version on a mobile device:

The non-AMP version works fine on desktop (score of 94) but that's because desktops have faster load times compared to mobile devices. But the non-AMP version is pretty slow on mobile devices.
Now let's test the AMP version:

It's much better than the non-AMP version, especially on mobile. And the desktop score got boosted too (98 this time). This makes it clear that AMP is faster.
But the major performance boost is because Google preloads the results which makes the load time negligible. The load times for the AMP version and Non-AMP version were as follows:
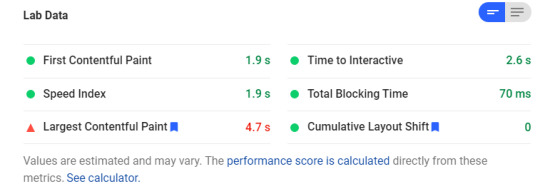
Load Times for AMP version

Load times for Non-AMP version
You can see the performance boost you get if you use AMP. And as a user, it's beneficial to you. You don't want to wait for results, you just want to get the answer real quick. And Google tries its best to find the answers for you so that you don't have to search manually.
Google even shows featured snippets for most queries so that you don't even have to open the webpage. Here's an example:

As you can see, Google tries it's very best to answer questions and make your experience faster. AMP is just a way to make it even faster for users who just want to find an answer quickly.
AMP also makes sure a page looks the same across platforms and browsers, thus removing many limitations of web design. So from a user's perspective, AMP is an absolute win.
Now let's move on to the third, and the most important perspective for our purposes.
Google, as a search engine
Before discussing this perspective, let's summarize what Google AMP really does:
Accelerated Mobile Pages or AMP as the name suggests is a way of designing web pages to improve user experience especially on mobile devices. These pages have workarounds for things that can possibly slow down a page. There are plugins for most dynamic elements like carousels, dynamic lists, forms, and embeds. The content is served from the AMP cache which, combined with preloading, creates a fast loading effect.
There is no one guide for designing a webpage. You have HTML, CSS and your creativity and a blank canvas.
That being said, there are some good artists and some bad artists. If there was a guide to how every page should be, there would be way less variation across pages.
Still, there is the concept of Semantic HTML which helps us organize our web pages.
Semantic HTML is the practice of using meaningful tags for certain parts of a webpage instead of using general <div> and <span> tags for everything. For example, using <h1> for headings, <nav> for navigation, <header> and <footer> for headers and footers, respectively.
So, using <header> is much better than using something like <div class="header">
If every web page was forced to use such conventions, search engines would easily be able to identify what the main content was and display much better results. But, you can't force everyone to use such conventions.
To simplify extracting information from webpages, Google encourages developers to use Structured Data. This is an organised form of what is present on the webpage. For example the structured data of this article is the following:
{ "@context": "https://schema.org", "@type": "Article", "publisher": { "@type": "Organization", "name": "freeCodeCamp.org", "logo": { "@type": "ImageObject", "url": "https://www.freecodecamp.org/news/content/images/2019/11/fcc_primary_large_24X210.svg", "width": 210, "height": 24 } }, "author": { "@type": "Person", "name": "Abhishek Chaudhary", "image": { "@type": "ImageObject", "url": "https://www.freecodecamp.org/news/content/images/2020/08/image.jpg", "width": 2000, "height": 2000 }, "sameAs": [ "https://theabbie.github.io", "https://www.facebook.com/abhishek.vice.versa", "https://twitter.com/theabbiee" ] }, "headline": "Is Google AMP the right choice for your website?", "url": "https://www.freecodecamp.org/news/p/efcffd53-9fa2-49ba-a144-9c627fde4d86/", "image": { "@type": "ImageObject", "url": "https://images.unsplash.com/photo-1533292362155-d79af6b08b77?ixlib=rb-1.2.1&q=80&fm=jpg&crop=entropy&cs=tinysrgb&w=2000&fit=max&ixid=eyJhcHBfaWQiOjExNzczfQ", "width": 2000, "height": 1333 }, "description": "Accelerated Mobile Pages or AMP is an open-source initiative by google. In there words the motive is to "make the web better for all". Whether it's actually true or not is highly debatable, Some critics (mostly publishers) say that this will make Google dominate the web. But we can't jump", "mainEntityOfPage": { "@type": "WebPage", "@id": "https://www.freecodecamp.org/news/" } }
Google doesn't rely on this alone, as people might misuse it. But it helps Google understand what is present on the page. These can also help in displaying rich results, for example:

Rich results for tutorial
The good thing about AMP is that it encourages developers to use structured data. Also, due to the severe limitations, the page has a much cleaner design. This makes the task of search engines much easier.
And almost everyone would agree that cleaner, faster webpages are also important in general.
So how do you decide?
In this article, we saw that AMP is beneficial to both users and Google, and can also be beneficial to publishers if they don't resist change. And everyone is a user at some point.
If you hate slow, non mobile-friendly websites, think about how other users feel, too. A cleaner internet is always better.
That being said, if your only motive is to create a clean and fast webpage, you can do so without AMP too. Just avoid unnecessary components and design efficiently.
This article was an overview of AMP, and its pros and cons. Now you know why it may or may not be useful to you. And just a note - freeCodeCamp uses AMP, and it's great. I hope you make a good decision for your site.
0 notes
Text
How to Run a Business in 2020

In recent years, stars have lent their names to all kinds of sneaker collaborations. Puma had Rihanna. Reebok had Gigi Hadid. Adidas had Kanye West. Nike had … Jesus Christ?Not exactly. In October, a pair of “Jesus shoes” — customized Air Max 97s whose soles contained holy water from the River Jordan — appeared online for $1,425. They were designed by a start-up called MSCHF, without Nike’s blessing.The sneakers quickly sold out and began appearing on resale sites, going for as much as $4,000. The Christian Post wrote about them. Drake wore them. They were among the most Googled shoes of 2019.The only thing that didn’t happen, said Kevin Wiesner, 27, a creative director at MSCHF, was a public disavowal of the shoes by Nike or the Vatican. “That would’ve been rad,” he said.Now, in the MSCHF office in the Williamsburg section of Brooklyn, a pair stands like a trophy.MSCHF isn’t a sneaker company. It rarely even produces commercial goods, and its employees are reluctant to call it a company at all. They refer to MSCHF, which was founded in 2016, as a “brand,” “group” or “collective,” and their creations, which appear online every two weeks, as “drops.”Many of those drops are viral pranks: an app that recommends stocks to buy based on one’s astrological sign (which some observers took seriously), a service that sends pictures of A.I.-generated feet over text, a browser extension that helps users get away with watching Netflix at work.As Business Insider recently noted, the present and future profitability of these internet stunts is dubious. Yet, according to filings with the Securities and Exchange Commission, MSCHF has raised at least $11.5 million in outside investments since the fall of 2019.In the high-risk, maybe-reward world of venture capital, the group’s antics are well known. Nikita Singareddy, an investment analyst at RRE Ventures, compared MSCHF to Vine and Giphy. All three, she said, offer “lots of delight” and encourage content sharing.“Sometimes investors are a little too serious about monetizing something immediately,” Ms. Singareddy said. “With MSCHF, there’s faith that it’ll pay off. There’s an inherent virality and absurdness to all the projects that they’ve created, and it’s something people want to share and ask questions about.”For starters: What is it?
‘This Is How We Live’
The MSCHF office says as much about the company as any of its products.A giant white pentagram covers the entrance floor. On a visit in December, an inflatable severed swan’s head dangled from a ceiling beam, and a rubber chicken bong — a recent drop — sat on a coffee table, full of weed.“My mom thinks we make toys,” said Gabriel Whaley, 30, the chief executive.MSCHF has 10 employees, nine of whom are men. The company Twitter and Instagram pages are private, so most of its direct marketing takes place not on social media but through text messages from a mysterious phone number.Though the team used to run a marketing agency, working with brands like Casper in order to fund MSCHF projects, they stopped taking on clients last year. Now, they pretty much do whatever they want.“The cool thing that we have going for us is we set this precedent that we’re not tied to a category or vertical. We did the Jesus shoes and everyone knows us for that, and then we shut it down,” Mr. Whaley said. “We will never do it again. People are like, ‘Wait, why wouldn’t you double down on that, you would have made so much money!’ But that’s not why we’re here.”The point, he said, is to produce social commentary; the “story” the sneakers told was more important than turning a profit. “There are several youth pastors that have bought a pair, and even more who are asking, like, ‘I love sneakers, and I love God. I would love a pair of these,’ and that wasn’t the point,” Mr. Whaley said. “The Jesus shoes were a platform to broach the idea while also making fun of it: that everybody’s just doing a collaboration now.”In order to prepare each drop — be it an object, an app or a website — MSCHF’s employees log long hours. Most mornings, Mr. Whaley gets to the office around 7; the rest of the team arrives by 10. They often stay late into the evenings, conducting brainstorms, perfecting lines of code, shooting live-streams or assembling prototypes. Weekends, Mr. Whaley said, aren’t really a thing.“It’s not just a full-time job,” he said. “This is how we live. The distinction between your work and normal life doesn’t really exist here, and it’s just because this is what we were all doing whether we were getting paid or not in our former lives. So nothing has really changed, except we have more power as a unit than we did as individuals.”Though Mr. Whaley eschews corporate titles, functional groups exist within MSCHF: idea generation, production, distribution and outreach. In their past lives, most of the staffers were developers and designers, some with art backgrounds, working at their own firms and for companies like Twitter and BuzzFeed. The oldest employee is 32, and the youngest is 22.Some C.E.O.s of Fortune 500 companies have tried to mentor Mr. Whaley and “shoehorn” MSCHF into a traditional business, he said. They insist MSCHF is building a brand, that it needs a logo, a mission, a go-to product that people recognize.But MSCHF doesn’t have a flagship product, or market its releases traditionally. “It just happens that anything we make tends to spread purely because people end up talking about it and sharing it with their friends,” Mr. Whaley said.That’s part of the appeal for V.C. firms. With software companies, for example, there are “very clear metrics and paths to monetization that are tried and true,” Ms. Singareddy said. For MSCHF, that path is less obvious.“Some of the best investments, even early on it wasn’t clear what the result would be, but you’re making an investment in the team,” she said. “That’s what makes a company like MSCHF so exciting. Venture is about taking reasoned risk — it’s a true venture capital opportunity.”
Banksy for the Internet
Mr. Whaley talks a lot about what MSCHF is and who the people who work there are — and aren’t. Running ads on subways, or trying to build a social media following, or landing a spot on the Forbes “30 Under 30” list isn’t who they are. He cringes at the word “merch.” (“The day we sell hoodies is the day I shut this down.”)To observers, critics and followers, the company’s portfolio may amount to a very successful string of viral marketing campaigns, a series of jokes or something like art.“I don’t see anybody doing exactly what MSCHF is doing,” said Frank Denbow, a technology consultant who works with start-ups. “Everybody is able to get a one-off campaign that works, but to consistently find ways to create content that really sticks with people is different. It reminds me of Banksy and his ability to get a rise out of people.”On Twitter and Reddit, users trade theories and tips about MSCHF’s more cryptic offerings, such as its most recent, password-protected drop, Zuckwatch — a website that looks like Facebook and appears to be commentary on data privacy.Among these ardent fans, the drops are treated as trailheads, or entry points, setting off mad, winding dashes in search of cracking the code. Other followers, less devoted, may only know MSCHF for its Jesus shoes, which Mr. Wiesner said have been knocked off by sellers around the world. He is happy about it. “If we can make things that people run away with, that’s absolutely the dream,” he said. “Most of what we make is us personally running away with stuff.”Ahead of the presidential election, MSCHF’s employees plan to take on more political projects. (A drop in November, involving a shell restaurant, enabled users to mask political donations as work expenses; it was promptly shut down.) The company also hopes to expand beyond apps and objects to experiences and physical spaces.“Everything is just, ‘How do we kind of make fun of what we’re observing?’” Mr. Whaley said. “Then we have as much fun with it as possible and see what happens.” Read the full article
#1technews#0financetechnology#0technologydrive#057technology#0gtechnology#1/0technologycorp#2000stechnology#3technologyltd#360technewshindi#3dtechnologynews#3mtechnologynews#4technologydr#4technologydrive#4technologydrivelondonderrynh03053#4technologydrivepeabodyma#4technologydrivepeabodyma01960#4technologywaysalemma#42technologynews#5technologycareers#5technologydrive#5technologymission#5technologyoneliners#5technologyparkcolindeeplane#5technologytrends#5glatesttechnologynews#5gtechnologynewsinhindi#6technologydrchelmsfordma#6technologydriveandover#6technologydrivenorthchelmsfordma#6technologydrivesuite100
0 notes
Text
The Ultimate Guide to SEO Meta Tags
Posted by katemorris
Editor's note: This post first appeared in April of 2017, but because SEO (and Google) changes so quickly, we figured it was time for a refresh!
Meta tags represent the beginning of most SEO training, for better or for worse. I contemplated exactly how to introduce this topic because we always hear about the bad side of meta tags — namely, the keywords meta tag. One of the first things dissected in any site review is the misuse of meta tags, mainly because they're at the top of every page in the header and are therefore the first thing seen. But we don't want to get too negative; meta tags are some of the best tools in a search marketer's repertoire.
There are meta tags beyond just description and keywords, though those two are picked on the most. I've broken down the most-used (in my experience) by the good, the bad, and the indifferent. You'll notice that the list gets longer as we get to the bad ones. I didn't get to cover all of the meta tags possible to add, but there's a comprehensive meta tag resource you should check out if you're interested in everything that's out there.
It's important to note that in 2019, you meta tags still matter, but not all of them can help you. It's my experience, and I think anyone in SEO would agree, that if you want to rank high in search, your meta tags need to accompany high-quality content that focuses on user satisfaction.
My main piece of advice: stick to the core minimum. Don't add meta tags you don't need — they just take up code space. The less code you have, the better. Think of your page code as a set of step-by-step directions to get somewhere, but for a browser. Extraneous meta tags are the annoying "Go straight for 200 feet" line items in driving directions that simply tell you to stay on the same road you're already on!
The good meta tags
These are the meta tags that should be on every page, no matter what. Notice that this is a small list; these are the only ones that are required, so if you can work with just these, please do.
Meta content type – This tag is necessary to declare your character set for the page and should be present on every page. Leaving this out could impact how your page renders in the browser. A few options are listed below, but your web designer should know what's best for your site.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
Title – While the title tag doesn’t start with "meta," it is in the header and contains information that's very important to SEO. You should always have a unique title tag on every page that describes the page. Check out this post for more information on title tags.
Meta description – The infamous meta description tag is used for one major purpose: to describe the page to searchers as they read through the SERPs. This tag doesn't influence ranking, but it's very important regardless. It's the ad copy that will determine if users click on your result. Keep it within 160 characters, and write it to catch the user's attention. Sell the page — get them to click on the result. Here's a great article on meta descriptions that goes into more detail.
Viewport – In this mobile world, you should be specifying the viewport. If you don’t, you run the risk of having a poor mobile experience — the Google PageSpeed Insights Tool will tell you more about it. The standard tag is:
<meta name=viewport content="width=device-width, initial-scale=1">
The indifferent meta tags
Different sites will need to use these in specific circumstances, but if you can go without, please do.
Social meta tags – I'm leaving these out. OpenGraph and Twitter data are important to sharing but are not required per se.
Robots – One huge misconception is that you have to have a robots meta tag. Let's make this clear: In terms of indexing and link following, if you don't specify a meta robots tag, they read that as index,follow. It's only if you want to change one of those two commands that you need to add meta robots. Therefore, if you want to noindex but follow the links on the page, you would add the following tag with only the noindex, as the follow is implied. Only change what you want to be different from the norm.
<meta name="robots" content="noindex" />
Specific bots (Googlebot) – These tags are used to give a specific bot instructions like noodp (forcing them not to use your DMOZ listing information, RIP) and noydir (same, but instead the Yahoo Directory listing information). Generally, the search engines are really good at this kind of thing on their own, but if you think you need it, feel free. There have been some cases I've seen where it's necessary, but if you must, consider using the overall robots tag listed above.
Language – The only reason to use this tag is if you're moving internationally and need to declare the main language used on the page. Check out this meta languages resource for a full list of languages you can declare.
Geo – The last I heard, these meta tags are supported by Bing but not Google (you can target to country inside Search Console). There are three kinds: placename, position (latitude and longitude), and region.
<META NAME="geo.position" CONTENT="latitude; longitude"> <META NAME="geo.placename" CONTENT="Place Name"> <META NAME="geo.region" CONTENT="Country Subdivision Code">
Keywords – Yes, I put this on the "indifferent" list. While no good SEO is going to recommend spending any time on this tag, there's some very small possibility it could help you somewhere. Please leave it out if you're building a site, but if it's automated, there's no reason to remove it.
Refresh – This is the poor man's redirect and should not be used, if at all possible. You should always use a server-side 301 redirect. I know that sometimes things need to happen now, but Google is NOT a fan.
Site verification – Your site is verified with Google and Bing, right? Who has the verification meta tags on their homepage? These are sometimes necessary because you can't get the other forms of site verification loaded, but if at all possible try to verify another way. Google allows you to verify by DNS, external file, or by linking your Google Analytics account. Bing still only allows by XML file or meta tag, so go with the file if you can.
The bad meta tags
Nothing bad will happen to your site if you use these — let me just make that clear. They're a waste of space though; even Google says so (and that was 12 years ago now!). If you're ready and willing, it might be time for some spring cleaning of your <head> area.
Author/web author – This tag is used to name the author of the page. It's just not necessary on the page.
Revisit after – This meta tag is a command to the robots to return to a page after a specific period of time. It's not followed by any major search engine.
Rating – This tag is used to denote the maturity rating of content. I wrote a post about how to tag a page with adult images using a very confusing system that has since been updated (see the post's comments). It seems as if the best way to note bad images is to place them on a separate directory from other images on your site and alert Google.
Expiration/date – "Expiration" is used to note when the page expires, and "date" is the date the page was made. Are any of your pages going to expire? Just remove them if they are (but please don't keep updating content, even contests — make it an annual contest instead!). And for "date," make an XML sitemap and keep it up to date. It's much more useful.
Copyright – That Google article debates this with me a bit, but look at the footer of your site. I would guess it says "Copyright 20xx" in some form. Why say it twice?
Abstract – This tag is sometimes used to place an abstract of the content and used mainly by educational pursuits.
Distribution – The "distribution" value is supposedly used to control who can access the document, typically set to "global." It's inherently implied that if the page is open (not password-protected, like on an intranet) that it's meant for the world. Go with it, and leave the tag off the page.
Generator – This is used to note what program created the page. Like "author," it's useless.
Cache-control – This tag is set in hopes of controlling when and how often a page is cached in the browser. It's best to do this in the HTTP header.
Resource type – This is used to name the type of resource the page is, like "document." Save yourself time, as the DTD declaration does it for you.
There are so many meta tags out there, I’d love to hear about any you think need to be added or even removed! Shout out in the comments with suggestions or questions.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
via Blogger https://ift.tt/2yinuYZ #blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes
Text
The Ultimate Guide to SEO Meta Tags
Posted by katemorris
Editor's note: This post first appeared in April of 2017, but because SEO (and Google) changes so quickly, we figured it was time for a refresh!
Meta tags represent the beginning of most SEO training, for better or for worse. I contemplated exactly how to introduce this topic because we always hear about the bad side of meta tags — namely, the keywords meta tag. One of the first things dissected in any site review is the misuse of meta tags, mainly because they're at the top of every page in the header and are therefore the first thing seen. But we don't want to get too negative; meta tags are some of the best tools in a search marketer's repertoire.
There are meta tags beyond just description and keywords, though those two are picked on the most. I've broken down the most-used (in my experience) by the good, the bad, and the indifferent. You'll notice that the list gets longer as we get to the bad ones. I didn't get to cover all of the meta tags possible to add, but there's a comprehensive meta tag resource you should check out if you're interested in everything that's out there.
It's important to note that in 2019, you meta tags still matter, but not all of them can help you. It's my experience, and I think anyone in SEO would agree, that if you want to rank high in search, your meta tags need to accompany high-quality content that focuses on user satisfaction.
My main piece of advice: stick to the core minimum. Don't add meta tags you don't need — they just take up code space. The less code you have, the better. Think of your page code as a set of step-by-step directions to get somewhere, but for a browser. Extraneous meta tags are the annoying "Go straight for 200 feet" line items in driving directions that simply tell you to stay on the same road you're already on!
The good meta tags
These are the meta tags that should be on every page, no matter what. Notice that this is a small list; these are the only ones that are required, so if you can work with just these, please do.
Meta content type – This tag is necessary to declare your character set for the page and should be present on every page. Leaving this out could impact how your page renders in the browser. A few options are listed below, but your web designer should know what's best for your site.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
Title – While the title tag doesn’t start with "meta," it is in the header and contains information that's very important to SEO. You should always have a unique title tag on every page that describes the page. Check out this post for more information on title tags.
Meta description – The infamous meta description tag is used for one major purpose: to describe the page to searchers as they read through the SERPs. This tag doesn't influence ranking, but it's very important regardless. It's the ad copy that will determine if users click on your result. Keep it within 160 characters, and write it to catch the user's attention. Sell the page — get them to click on the result. Here's a great article on meta descriptions that goes into more detail.
Viewport – In this mobile world, you should be specifying the viewport. If you don’t, you run the risk of having a poor mobile experience — the Google PageSpeed Insights Tool will tell you more about it. The standard tag is:
<meta name=viewport content="width=device-width, initial-scale=1">
The indifferent meta tags
Different sites will need to use these in specific circumstances, but if you can go without, please do.
Social meta tags – I'm leaving these out. OpenGraph and Twitter data are important to sharing but are not required per se.
Robots – One huge misconception is that you have to have a robots meta tag. Let's make this clear: In terms of indexing and link following, if you don't specify a meta robots tag, they read that as index,follow. It's only if you want to change one of those two commands that you need to add meta robots. Therefore, if you want to noindex but follow the links on the page, you would add the following tag with only the noindex, as the follow is implied. Only change what you want to be different from the norm.
<meta name="robots" content="noindex" />
Specific bots (Googlebot) – These tags are used to give a specific bot instructions like noodp (forcing them not to use your DMOZ listing information, RIP) and noydir (same, but instead the Yahoo Directory listing information). Generally, the search engines are really good at this kind of thing on their own, but if you think you need it, feel free. There have been some cases I've seen where it's necessary, but if you must, consider using the overall robots tag listed above.
Language – The only reason to use this tag is if you're moving internationally and need to declare the main language used on the page. Check out this meta languages resource for a full list of languages you can declare.
Geo – The last I heard, these meta tags are supported by Bing but not Google (you can target to country inside Search Console). There are three kinds: placename, position (latitude and longitude), and region.
<META NAME="geo.position" CONTENT="latitude; longitude"> <META NAME="geo.placename" CONTENT="Place Name"> <META NAME="geo.region" CONTENT="Country Subdivision Code">
Keywords – Yes, I put this on the "indifferent" list. While no good SEO is going to recommend spending any time on this tag, there's some very small possibility it could help you somewhere. Please leave it out if you're building a site, but if it's automated, there's no reason to remove it.
Refresh – This is the poor man's redirect and should not be used, if at all possible. You should always use a server-side 301 redirect. I know that sometimes things need to happen now, but Google is NOT a fan.
Site verification – Your site is verified with Google and Bing, right? Who has the verification meta tags on their homepage? These are sometimes necessary because you can't get the other forms of site verification loaded, but if at all possible try to verify another way. Google allows you to verify by DNS, external file, or by linking your Google Analytics account. Bing still only allows by XML file or meta tag, so go with the file if you can.
The bad meta tags
Nothing bad will happen to your site if you use these — let me just make that clear. They're a waste of space though; even Google says so (and that was 12 years ago now!). If you're ready and willing, it might be time for some spring cleaning of your <head> area.
Author/web author – This tag is used to name the author of the page. It's just not necessary on the page.
Revisit after – This meta tag is a command to the robots to return to a page after a specific period of time. It's not followed by any major search engine.
Rating – This tag is used to denote the maturity rating of content. I wrote a post about how to tag a page with adult images using a very confusing system that has since been updated (see the post's comments). It seems as if the best way to note bad images is to place them on a separate directory from other images on your site and alert Google.
Expiration/date – "Expiration" is used to note when the page expires, and "date" is the date the page was made. Are any of your pages going to expire? Just remove them if they are (but please don't keep updating content, even contests — make it an annual contest instead!). And for "date," make an XML sitemap and keep it up to date. It's much more useful.
Copyright – That Google article debates this with me a bit, but look at the footer of your site. I would guess it says "Copyright 20xx" in some form. Why say it twice?
Abstract – This tag is sometimes used to place an abstract of the content and used mainly by educational pursuits.
Distribution – The "distribution" value is supposedly used to control who can access the document, typically set to "global." It's inherently implied that if the page is open (not password-protected, like on an intranet) that it's meant for the world. Go with it, and leave the tag off the page.
Generator – This is used to note what program created the page. Like "author," it's useless.
Cache-control – This tag is set in hopes of controlling when and how often a page is cached in the browser. It's best to do this in the HTTP header.
Resource type – This is used to name the type of resource the page is, like "document." Save yourself time, as the DTD declaration does it for you.
There are so many meta tags out there, I’d love to hear about any you think need to be added or even removed! Shout out in the comments with suggestions or questions.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog https://ift.tt/2Z6YXln via IFTTT
0 notes
Text
The Ultimate Guide to SEO Meta Tags
Posted by katemorris
Editor's note: This post first appeared in April of 2017, but because SEO (and Google) changes so quickly, we figured it was time for a refresh!
Meta tags represent the beginning of most SEO training, for better or for worse. I contemplated exactly how to introduce this topic because we always hear about the bad side of meta tags — namely, the keywords meta tag. One of the first things dissected in any site review is the misuse of meta tags, mainly because they're at the top of every page in the header and are therefore the first thing seen. But we don't want to get too negative; meta tags are some of the best tools in a search marketer's repertoire.
There are meta tags beyond just description and keywords, though those two are picked on the most. I've broken down the most-used (in my experience) by the good, the bad, and the indifferent. You'll notice that the list gets longer as we get to the bad ones. I didn't get to cover all of the meta tags possible to add, but there's a comprehensive meta tag resource you should check out if you're interested in everything that's out there.
It's important to note that in 2019, you meta tags still matter, but not all of them can help you. It's my experience, and I think anyone in SEO would agree, that if you want to rank high in search, your meta tags need to accompany high-quality content that focuses on user satisfaction.
My main piece of advice: stick to the core minimum. Don't add meta tags you don't need — they just take up code space. The less code you have, the better. Think of your page code as a set of step-by-step directions to get somewhere, but for a browser. Extraneous meta tags are the annoying "Go straight for 200 feet" line items in driving directions that simply tell you to stay on the same road you're already on!
The good meta tags
These are the meta tags that should be on every page, no matter what. Notice that this is a small list; these are the only ones that are required, so if you can work with just these, please do.
Meta content type – This tag is necessary to declare your character set for the page and should be present on every page. Leaving this out could impact how your page renders in the browser. A few options are listed below, but your web designer should know what's best for your site.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
Title – While the title tag doesn’t start with "meta," it is in the header and contains information that's very important to SEO. You should always have a unique title tag on every page that describes the page. Check out this post for more information on title tags.
Meta description – The infamous meta description tag is used for one major purpose: to describe the page to searchers as they read through the SERPs. This tag doesn't influence ranking, but it's very important regardless. It's the ad copy that will determine if users click on your result. Keep it within 160 characters, and write it to catch the user's attention. Sell the page — get them to click on the result. Here's a great article on meta descriptions that goes into more detail.
Viewport – In this mobile world, you should be specifying the viewport. If you don’t, you run the risk of having a poor mobile experience — the Google PageSpeed Insights Tool will tell you more about it. The standard tag is:
<meta name=viewport content="width=device-width, initial-scale=1">
The indifferent meta tags
Different sites will need to use these in specific circumstances, but if you can go without, please do.
Social meta tags – I'm leaving these out. OpenGraph and Twitter data are important to sharing but are not required per se.
Robots – One huge misconception is that you have to have a robots meta tag. Let's make this clear: In terms of indexing and link following, if you don't specify a meta robots tag, they read that as index,follow. It's only if you want to change one of those two commands that you need to add meta robots. Therefore, if you want to noindex but follow the links on the page, you would add the following tag with only the noindex, as the follow is implied. Only change what you want to be different from the norm.
<meta name="robots" content="noindex" />
Specific bots (Googlebot) – These tags are used to give a specific bot instructions like noodp (forcing them not to use your DMOZ listing information, RIP) and noydir (same, but instead the Yahoo Directory listing information). Generally, the search engines are really good at this kind of thing on their own, but if you think you need it, feel free. There have been some cases I've seen where it's necessary, but if you must, consider using the overall robots tag listed above.
Language – The only reason to use this tag is if you're moving internationally and need to declare the main language used on the page. Check out this meta languages resource for a full list of languages you can declare.
Geo – The last I heard, these meta tags are supported by Bing but not Google (you can target to country inside Search Console). There are three kinds: placename, position (latitude and longitude), and region.
<META NAME="geo.position" CONTENT="latitude; longitude"> <META NAME="geo.placename" CONTENT="Place Name"> <META NAME="geo.region" CONTENT="Country Subdivision Code">
Keywords – Yes, I put this on the "indifferent" list. While no good SEO is going to recommend spending any time on this tag, there's some very small possibility it could help you somewhere. Please leave it out if you're building a site, but if it's automated, there's no reason to remove it.
Refresh – This is the poor man's redirect and should not be used, if at all possible. You should always use a server-side 301 redirect. I know that sometimes things need to happen now, but Google is NOT a fan.
Site verification – Your site is verified with Google and Bing, right? Who has the verification meta tags on their homepage? These are sometimes necessary because you can't get the other forms of site verification loaded, but if at all possible try to verify another way. Google allows you to verify by DNS, external file, or by linking your Google Analytics account. Bing still only allows by XML file or meta tag, so go with the file if you can.
The bad meta tags
Nothing bad will happen to your site if you use these — let me just make that clear. They're a waste of space though; even Google says so (and that was 12 years ago now!). If you're ready and willing, it might be time for some spring cleaning of your <head> area.
Author/web author – This tag is used to name the author of the page. It's just not necessary on the page.
Revisit after – This meta tag is a command to the robots to return to a page after a specific period of time. It's not followed by any major search engine.
Rating – This tag is used to denote the maturity rating of content. I wrote a post about how to tag a page with adult images using a very confusing system that has since been updated (see the post's comments). It seems as if the best way to note bad images is to place them on a separate directory from other images on your site and alert Google.
Expiration/date – "Expiration" is used to note when the page expires, and "date" is the date the page was made. Are any of your pages going to expire? Just remove them if they are (but please don't keep updating content, even contests — make it an annual contest instead!). And for "date," make an XML sitemap and keep it up to date. It's much more useful.
Copyright – That Google article debates this with me a bit, but look at the footer of your site. I would guess it says "Copyright 20xx" in some form. Why say it twice?
Abstract – This tag is sometimes used to place an abstract of the content and used mainly by educational pursuits.
Distribution – The "distribution" value is supposedly used to control who can access the document, typically set to "global." It's inherently implied that if the page is open (not password-protected, like on an intranet) that it's meant for the world. Go with it, and leave the tag off the page.
Generator – This is used to note what program created the page. Like "author," it's useless.
Cache-control – This tag is set in hopes of controlling when and how often a page is cached in the browser. It's best to do this in the HTTP header.
Resource type – This is used to name the type of resource the page is, like "document." Save yourself time, as the DTD declaration does it for you.
There are so many meta tags out there, I’d love to hear about any you think need to be added or even removed! Shout out in the comments with suggestions or questions.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog http://tracking.feedpress.it/link/9375/12687784
0 notes
Text
The Ultimate Guide to SEO Meta Tags
Posted by katemorris
Editor's note: This post first appeared in April of 2017, but because SEO (and Google) changes so quickly, we figured it was time for a refresh!
Meta tags represent the beginning of most SEO training, for better or for worse. I contemplated exactly how to introduce this topic because we always hear about the bad side of meta tags — namely, the keywords meta tag. One of the first things dissected in any site review is the misuse of meta tags, mainly because they're at the top of every page in the header and are therefore the first thing seen. But we don't want to get too negative; meta tags are some of the best tools in a search marketer's repertoire.
There are meta tags beyond just description and keywords, though those two are picked on the most. I've broken down the most-used (in my experience) by the good, the bad, and the indifferent. You'll notice that the list gets longer as we get to the bad ones. I didn't get to cover all of the meta tags possible to add, but there's a comprehensive meta tag resource you should check out if you're interested in everything that's out there.
It's important to note that in 2019, you meta tags still matter, but not all of them can help you. It's my experience, and I think anyone in SEO would agree, that if you want to rank high in search, your meta tags need to accompany high-quality content that focuses on user satisfaction.
My main piece of advice: stick to the core minimum. Don't add meta tags you don't need — they just take up code space. The less code you have, the better. Think of your page code as a set of step-by-step directions to get somewhere, but for a browser. Extraneous meta tags are the annoying "Go straight for 200 feet" line items in driving directions that simply tell you to stay on the same road you're already on!
The good meta tags
These are the meta tags that should be on every page, no matter what. Notice that this is a small list; these are the only ones that are required, so if you can work with just these, please do.
Meta content type – This tag is necessary to declare your character set for the page and should be present on every page. Leaving this out could impact how your page renders in the browser. A few options are listed below, but your web designer should know what's best for your site.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
Title – While the title tag doesn’t start with "meta," it is in the header and contains information that's very important to SEO. You should always have a unique title tag on every page that describes the page. Check out this post for more information on title tags.
Meta description – The infamous meta description tag is used for one major purpose: to describe the page to searchers as they read through the SERPs. This tag doesn't influence ranking, but it's very important regardless. It's the ad copy that will determine if users click on your result. Keep it within 160 characters, and write it to catch the user's attention. Sell the page — get them to click on the result. Here's a great article on meta descriptions that goes into more detail.
Viewport – In this mobile world, you should be specifying the viewport. If you don’t, you run the risk of having a poor mobile experience — the Google PageSpeed Insights Tool will tell you more about it. The standard tag is:
<meta name=viewport content="width=device-width, initial-scale=1">
The indifferent meta tags
Different sites will need to use these in specific circumstances, but if you can go without, please do.
Social meta tags – I'm leaving these out. OpenGraph and Twitter data are important to sharing but are not required per se.
Robots – One huge misconception is that you have to have a robots meta tag. Let's make this clear: In terms of indexing and link following, if you don't specify a meta robots tag, they read that as index,follow. It's only if you want to change one of those two commands that you need to add meta robots. Therefore, if you want to noindex but follow the links on the page, you would add the following tag with only the noindex, as the follow is implied. Only change what you want to be different from the norm.
<meta name="robots" content="noindex" />
Specific bots (Googlebot) – These tags are used to give a specific bot instructions like noodp (forcing them not to use your DMOZ listing information, RIP) and noydir (same, but instead the Yahoo Directory listing information). Generally, the search engines are really good at this kind of thing on their own, but if you think you need it, feel free. There have been some cases I've seen where it's necessary, but if you must, consider using the overall robots tag listed above.
Language – The only reason to use this tag is if you're moving internationally and need to declare the main language used on the page. Check out this meta languages resource for a full list of languages you can declare.
Geo – The last I heard, these meta tags are supported by Bing but not Google (you can target to country inside Search Console). There are three kinds: placename, position (latitude and longitude), and region.
<META NAME="geo.position" CONTENT="latitude; longitude"> <META NAME="geo.placename" CONTENT="Place Name"> <META NAME="geo.region" CONTENT="Country Subdivision Code">
Keywords – Yes, I put this on the "indifferent" list. While no good SEO is going to recommend spending any time on this tag, there's some very small possibility it could help you somewhere. Please leave it out if you're building a site, but if it's automated, there's no reason to remove it.
Refresh – This is the poor man's redirect and should not be used, if at all possible. You should always use a server-side 301 redirect. I know that sometimes things need to happen now, but Google is NOT a fan.
Site verification – Your site is verified with Google and Bing, right? Who has the verification meta tags on their homepage? These are sometimes necessary because you can't get the other forms of site verification loaded, but if at all possible try to verify another way. Google allows you to verify by DNS, external file, or by linking your Google Analytics account. Bing still only allows by XML file or meta tag, so go with the file if you can.
The bad meta tags
Nothing bad will happen to your site if you use these — let me just make that clear. They're a waste of space though; even Google says so (and that was 12 years ago now!). If you're ready and willing, it might be time for some spring cleaning of your <head> area.
Author/web author – This tag is used to name the author of the page. It's just not necessary on the page.
Revisit after – This meta tag is a command to the robots to return to a page after a specific period of time. It's not followed by any major search engine.
Rating – This tag is used to denote the maturity rating of content. I wrote a post about how to tag a page with adult images using a very confusing system that has since been updated (see the post's comments). It seems as if the best way to note bad images is to place them on a separate directory from other images on your site and alert Google.
Expiration/date – "Expiration" is used to note when the page expires, and "date" is the date the page was made. Are any of your pages going to expire? Just remove them if they are (but please don't keep updating content, even contests — make it an annual contest instead!). And for "date," make an XML sitemap and keep it up to date. It's much more useful.
Copyright – That Google article debates this with me a bit, but look at the footer of your site. I would guess it says "Copyright 20xx" in some form. Why say it twice?
Abstract – This tag is sometimes used to place an abstract of the content and used mainly by educational pursuits.
Distribution – The "distribution" value is supposedly used to control who can access the document, typically set to "global." It's inherently implied that if the page is open (not password-protected, like on an intranet) that it's meant for the world. Go with it, and leave the tag off the page.
Generator – This is used to note what program created the page. Like "author," it's useless.
Cache-control – This tag is set in hopes of controlling when and how often a page is cached in the browser. It's best to do this in the HTTP header.
Resource type – This is used to name the type of resource the page is, like "document." Save yourself time, as the DTD declaration does it for you.
There are so many meta tags out there, I’d love to hear about any you think need to be added or even removed! Shout out in the comments with suggestions or questions.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
The Ultimate Guide to SEO Meta Tags
Posted by katemorris
Editor's note: This post first appeared in April of 2017, but because SEO (and Google) changes so quickly, we figured it was time for a refresh!
Meta tags represent the beginning of most SEO training, for better or for worse. I contemplated exactly how to introduce this topic because we always hear about the bad side of meta tags — namely, the keywords meta tag. One of the first things dissected in any site review is the misuse of meta tags, mainly because they're at the top of every page in the header and are therefore the first thing seen. But we don't want to get too negative; meta tags are some of the best tools in a search marketer's repertoire.
There are meta tags beyond just description and keywords, though those two are picked on the most. I've broken down the most-used (in my experience) by the good, the bad, and the indifferent. You'll notice that the list gets longer as we get to the bad ones. I didn't get to cover all of the meta tags possible to add, but there's a comprehensive meta tag resource you should check out if you're interested in everything that's out there.
It's important to note that in 2019, you meta tags still matter, but not all of them can help you. It's my experience, and I think anyone in SEO would agree, that if you want to rank high in search, your meta tags need to accompany high-quality content that focuses on user satisfaction.
My main piece of advice: stick to the core minimum. Don't add meta tags you don't need — they just take up code space. The less code you have, the better. Think of your page code as a set of step-by-step directions to get somewhere, but for a browser. Extraneous meta tags are the annoying "Go straight for 200 feet" line items in driving directions that simply tell you to stay on the same road you're already on!
The good meta tags
These are the meta tags that should be on every page, no matter what. Notice that this is a small list; these are the only ones that are required, so if you can work with just these, please do.
Meta content type – This tag is necessary to declare your character set for the page and should be present on every page. Leaving this out could impact how your page renders in the browser. A few options are listed below, but your web designer should know what's best for your site.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
Title – While the title tag doesn’t start with "meta," it is in the header and contains information that's very important to SEO. You should always have a unique title tag on every page that describes the page. Check out this post for more information on title tags.
Meta description – The infamous meta description tag is used for one major purpose: to describe the page to searchers as they read through the SERPs. This tag doesn't influence ranking, but it's very important regardless. It's the ad copy that will determine if users click on your result. Keep it within 160 characters, and write it to catch the user's attention. Sell the page — get them to click on the result. Here's a great article on meta descriptions that goes into more detail.
Viewport – In this mobile world, you should be specifying the viewport. If you don’t, you run the risk of having a poor mobile experience — the Google PageSpeed Insights Tool will tell you more about it. The standard tag is:
<meta name=viewport content="width=device-width, initial-scale=1">
The indifferent meta tags
Different sites will need to use these in specific circumstances, but if you can go without, please do.
Social meta tags – I'm leaving these out. OpenGraph and Twitter data are important to sharing but are not required per se.
Robots – One huge misconception is that you have to have a robots meta tag. Let's make this clear: In terms of indexing and link following, if you don't specify a meta robots tag, they read that as index,follow. It's only if you want to change one of those two commands that you need to add meta robots. Therefore, if you want to noindex but follow the links on the page, you would add the following tag with only the noindex, as the follow is implied. Only change what you want to be different from the norm.
<meta name="robots" content="noindex" />
Specific bots (Googlebot) – These tags are used to give a specific bot instructions like noodp (forcing them not to use your DMOZ listing information, RIP) and noydir (same, but instead the Yahoo Directory listing information). Generally, the search engines are really good at this kind of thing on their own, but if you think you need it, feel free. There have been some cases I've seen where it's necessary, but if you must, consider using the overall robots tag listed above.
Language – The only reason to use this tag is if you're moving internationally and need to declare the main language used on the page. Check out this meta languages resource for a full list of languages you can declare.
Geo – The last I heard, these meta tags are supported by Bing but not Google (you can target to country inside Search Console). There are three kinds: placename, position (latitude and longitude), and region.
<META NAME="geo.position" CONTENT="latitude; longitude"> <META NAME="geo.placename" CONTENT="Place Name"> <META NAME="geo.region" CONTENT="Country Subdivision Code">
Keywords – Yes, I put this on the "indifferent" list. While no good SEO is going to recommend spending any time on this tag, there's some very small possibility it could help you somewhere. Please leave it out if you're building a site, but if it's automated, there's no reason to remove it.
Refresh – This is the poor man's redirect and should not be used, if at all possible. You should always use a server-side 301 redirect. I know that sometimes things need to happen now, but Google is NOT a fan.
Site verification – Your site is verified with Google and Bing, right? Who has the verification meta tags on their homepage? These are sometimes necessary because you can't get the other forms of site verification loaded, but if at all possible try to verify another way. Google allows you to verify by DNS, external file, or by linking your Google Analytics account. Bing still only allows by XML file or meta tag, so go with the file if you can.
The bad meta tags
Nothing bad will happen to your site if you use these — let me just make that clear. They're a waste of space though; even Google says so (and that was 12 years ago now!). If you're ready and willing, it might be time for some spring cleaning of your <head> area.
Author/web author – This tag is used to name the author of the page. It's just not necessary on the page.
Revisit after – This meta tag is a command to the robots to return to a page after a specific period of time. It's not followed by any major search engine.
Rating – This tag is used to denote the maturity rating of content. I wrote a post about how to tag a page with adult images using a very confusing system that has since been updated (see the post's comments). It seems as if the best way to note bad images is to place them on a separate directory from other images on your site and alert Google.
Expiration/date – "Expiration" is used to note when the page expires, and "date" is the date the page was made. Are any of your pages going to expire? Just remove them if they are (but please don't keep updating content, even contests — make it an annual contest instead!). And for "date," make an XML sitemap and keep it up to date. It's much more useful.
Copyright – That Google article debates this with me a bit, but look at the footer of your site. I would guess it says "Copyright 20xx" in some form. Why say it twice?
Abstract – This tag is sometimes used to place an abstract of the content and used mainly by educational pursuits.
Distribution – The "distribution" value is supposedly used to control who can access the document, typically set to "global." It's inherently implied that if the page is open (not password-protected, like on an intranet) that it's meant for the world. Go with it, and leave the tag off the page.
Generator – This is used to note what program created the page. Like "author," it's useless.
Cache-control – This tag is set in hopes of controlling when and how often a page is cached in the browser. It's best to do this in the HTTP header.
Resource type – This is used to name the type of resource the page is, like "document." Save yourself time, as the DTD declaration does it for you.
There are so many meta tags out there, I’d love to hear about any you think need to be added or even removed! Shout out in the comments with suggestions or questions.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
The Ultimate Guide to SEO Meta Tags
Posted by katemorris
Editor's note: This post first appeared in April of 2017, but because SEO (and Google) changes so quickly, we figured it was time for a refresh!
Meta tags represent the beginning of most SEO training, for better or for worse. I contemplated exactly how to introduce this topic because we always hear about the bad side of meta tags — namely, the keywords meta tag. One of the first things dissected in any site review is the misuse of meta tags, mainly because they're at the top of every page in the header and are therefore the first thing seen. But we don't want to get too negative; meta tags are some of the best tools in a search marketer's repertoire.
There are meta tags beyond just description and keywords, though those two are picked on the most. I've broken down the most-used (in my experience) by the good, the bad, and the indifferent. You'll notice that the list gets longer as we get to the bad ones. I didn't get to cover all of the meta tags possible to add, but there's a comprehensive meta tag resource you should check out if you're interested in everything that's out there.
It's important to note that in 2019, you meta tags still matter, but not all of them can help you. It's my experience, and I think anyone in SEO would agree, that if you want to rank high in search, your meta tags need to accompany high-quality content that focuses on user satisfaction.
My main piece of advice: stick to the core minimum. Don't add meta tags you don't need — they just take up code space. The less code you have, the better. Think of your page code as a set of step-by-step directions to get somewhere, but for a browser. Extraneous meta tags are the annoying "Go straight for 200 feet" line items in driving directions that simply tell you to stay on the same road you're already on!
The good meta tags
These are the meta tags that should be on every page, no matter what. Notice that this is a small list; these are the only ones that are required, so if you can work with just these, please do.
Meta content type – This tag is necessary to declare your character set for the page and should be present on every page. Leaving this out could impact how your page renders in the browser. A few options are listed below, but your web designer should know what's best for your site.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
Title – While the title tag doesn’t start with "meta," it is in the header and contains information that's very important to SEO. You should always have a unique title tag on every page that describes the page. Check out this post for more information on title tags.
Meta description – The infamous meta description tag is used for one major purpose: to describe the page to searchers as they read through the SERPs. This tag doesn't influence ranking, but it's very important regardless. It's the ad copy that will determine if users click on your result. Keep it within 160 characters, and write it to catch the user's attention. Sell the page — get them to click on the result. Here's a great article on meta descriptions that goes into more detail.
Viewport – In this mobile world, you should be specifying the viewport. If you don’t, you run the risk of having a poor mobile experience — the Google PageSpeed Insights Tool will tell you more about it. The standard tag is:
<meta name=viewport content="width=device-width, initial-scale=1">
The indifferent meta tags
Different sites will need to use these in specific circumstances, but if you can go without, please do.
Social meta tags – I'm leaving these out. OpenGraph and Twitter data are important to sharing but are not required per se.
Robots – One huge misconception is that you have to have a robots meta tag. Let's make this clear: In terms of indexing and link following, if you don't specify a meta robots tag, they read that as index,follow. It's only if you want to change one of those two commands that you need to add meta robots. Therefore, if you want to noindex but follow the links on the page, you would add the following tag with only the noindex, as the follow is implied. Only change what you want to be different from the norm.
<meta name="robots" content="noindex" />
Specific bots (Googlebot) – These tags are used to give a specific bot instructions like noodp (forcing them not to use your DMOZ listing information, RIP) and noydir (same, but instead the Yahoo Directory listing information). Generally, the search engines are really good at this kind of thing on their own, but if you think you need it, feel free. There have been some cases I've seen where it's necessary, but if you must, consider using the overall robots tag listed above.
Language – The only reason to use this tag is if you're moving internationally and need to declare the main language used on the page. Check out this meta languages resource for a full list of languages you can declare.
Geo – The last I heard, these meta tags are supported by Bing but not Google (you can target to country inside Search Console). There are three kinds: placename, position (latitude and longitude), and region.
<META NAME="geo.position" CONTENT="latitude; longitude"> <META NAME="geo.placename" CONTENT="Place Name"> <META NAME="geo.region" CONTENT="Country Subdivision Code">
Keywords – Yes, I put this on the "indifferent" list. While no good SEO is going to recommend spending any time on this tag, there's some very small possibility it could help you somewhere. Please leave it out if you're building a site, but if it's automated, there's no reason to remove it.
Refresh – This is the poor man's redirect and should not be used, if at all possible. You should always use a server-side 301 redirect. I know that sometimes things need to happen now, but Google is NOT a fan.
Site verification – Your site is verified with Google and Bing, right? Who has the verification meta tags on their homepage? These are sometimes necessary because you can't get the other forms of site verification loaded, but if at all possible try to verify another way. Google allows you to verify by DNS, external file, or by linking your Google Analytics account. Bing still only allows by XML file or meta tag, so go with the file if you can.
The bad meta tags
Nothing bad will happen to your site if you use these — let me just make that clear. They're a waste of space though; even Google says so (and that was 12 years ago now!). If you're ready and willing, it might be time for some spring cleaning of your <head> area.
Author/web author – This tag is used to name the author of the page. It's just not necessary on the page.
Revisit after – This meta tag is a command to the robots to return to a page after a specific period of time. It's not followed by any major search engine.
Rating – This tag is used to denote the maturity rating of content. I wrote a post about how to tag a page with adult images using a very confusing system that has since been updated (see the post's comments). It seems as if the best way to note bad images is to place them on a separate directory from other images on your site and alert Google.
Expiration/date – "Expiration" is used to note when the page expires, and "date" is the date the page was made. Are any of your pages going to expire? Just remove them if they are (but please don't keep updating content, even contests — make it an annual contest instead!). And for "date," make an XML sitemap and keep it up to date. It's much more useful.
Copyright – That Google article debates this with me a bit, but look at the footer of your site. I would guess it says "Copyright 20xx" in some form. Why say it twice?
Abstract – This tag is sometimes used to place an abstract of the content and used mainly by educational pursuits.
Distribution – The "distribution" value is supposedly used to control who can access the document, typically set to "global." It's inherently implied that if the page is open (not password-protected, like on an intranet) that it's meant for the world. Go with it, and leave the tag off the page.
Generator – This is used to note what program created the page. Like "author," it's useless.
Cache-control – This tag is set in hopes of controlling when and how often a page is cached in the browser. It's best to do this in the HTTP header.
Resource type – This is used to name the type of resource the page is, like "document." Save yourself time, as the DTD declaration does it for you.
There are so many meta tags out there, I’d love to hear about any you think need to be added or even removed! Shout out in the comments with suggestions or questions.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
The Ultimate Guide to SEO Meta Tags
Posted by katemorris
Editor's note: This post first appeared in April of 2017, but because SEO (and Google) changes so quickly, we figured it was time for a refresh!
Meta tags represent the beginning of most SEO training, for better or for worse. I contemplated exactly how to introduce this topic because we always hear about the bad side of meta tags — namely, the keywords meta tag. One of the first things dissected in any site review is the misuse of meta tags, mainly because they're at the top of every page in the header and are therefore the first thing seen. But we don't want to get too negative; meta tags are some of the best tools in a search marketer's repertoire.
There are meta tags beyond just description and keywords, though those two are picked on the most. I've broken down the most-used (in my experience) by the good, the bad, and the indifferent. You'll notice that the list gets longer as we get to the bad ones. I didn't get to cover all of the meta tags possible to add, but there's a comprehensive meta tag resource you should check out if you're interested in everything that's out there.
It's important to note that in 2019, you meta tags still matter, but not all of them can help you. It's my experience, and I think anyone in SEO would agree, that if you want to rank high in search, your meta tags need to accompany high-quality content that focuses on user satisfaction.
My main piece of advice: stick to the core minimum. Don't add meta tags you don't need — they just take up code space. The less code you have, the better. Think of your page code as a set of step-by-step directions to get somewhere, but for a browser. Extraneous meta tags are the annoying "Go straight for 200 feet" line items in driving directions that simply tell you to stay on the same road you're already on!
The good meta tags
These are the meta tags that should be on every page, no matter what. Notice that this is a small list; these are the only ones that are required, so if you can work with just these, please do.
Meta content type – This tag is necessary to declare your character set for the page and should be present on every page. Leaving this out could impact how your page renders in the browser. A few options are listed below, but your web designer should know what's best for your site.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
Title – While the title tag doesn’t start with "meta," it is in the header and contains information that's very important to SEO. You should always have a unique title tag on every page that describes the page. Check out this post for more information on title tags.
Meta description – The infamous meta description tag is used for one major purpose: to describe the page to searchers as they read through the SERPs. This tag doesn't influence ranking, but it's very important regardless. It's the ad copy that will determine if users click on your result. Keep it within 160 characters, and write it to catch the user's attention. Sell the page — get them to click on the result. Here's a great article on meta descriptions that goes into more detail.
Viewport – In this mobile world, you should be specifying the viewport. If you don’t, you run the risk of having a poor mobile experience — the Google PageSpeed Insights Tool will tell you more about it. The standard tag is:
<meta name=viewport content="width=device-width, initial-scale=1">
The indifferent meta tags
Different sites will need to use these in specific circumstances, but if you can go without, please do.
Social meta tags – I'm leaving these out. OpenGraph and Twitter data are important to sharing but are not required per se.
Robots – One huge misconception is that you have to have a robots meta tag. Let's make this clear: In terms of indexing and link following, if you don't specify a meta robots tag, they read that as index,follow. It's only if you want to change one of those two commands that you need to add meta robots. Therefore, if you want to noindex but follow the links on the page, you would add the following tag with only the noindex, as the follow is implied. Only change what you want to be different from the norm.
<meta name="robots" content="noindex" />
Specific bots (Googlebot) – These tags are used to give a specific bot instructions like noodp (forcing them not to use your DMOZ listing information, RIP) and noydir (same, but instead the Yahoo Directory listing information). Generally, the search engines are really good at this kind of thing on their own, but if you think you need it, feel free. There have been some cases I've seen where it's necessary, but if you must, consider using the overall robots tag listed above.
Language – The only reason to use this tag is if you're moving internationally and need to declare the main language used on the page. Check out this meta languages resource for a full list of languages you can declare.
Geo – The last I heard, these meta tags are supported by Bing but not Google (you can target to country inside Search Console). There are three kinds: placename, position (latitude and longitude), and region.
<META NAME="geo.position" CONTENT="latitude; longitude"> <META NAME="geo.placename" CONTENT="Place Name"> <META NAME="geo.region" CONTENT="Country Subdivision Code">
Keywords – Yes, I put this on the "indifferent" list. While no good SEO is going to recommend spending any time on this tag, there's some very small possibility it could help you somewhere. Please leave it out if you're building a site, but if it's automated, there's no reason to remove it.
Refresh – This is the poor man's redirect and should not be used, if at all possible. You should always use a server-side 301 redirect. I know that sometimes things need to happen now, but Google is NOT a fan.
Site verification – Your site is verified with Google and Bing, right? Who has the verification meta tags on their homepage? These are sometimes necessary because you can't get the other forms of site verification loaded, but if at all possible try to verify another way. Google allows you to verify by DNS, external file, or by linking your Google Analytics account. Bing still only allows by XML file or meta tag, so go with the file if you can.
The bad meta tags
Nothing bad will happen to your site if you use these — let me just make that clear. They're a waste of space though; even Google says so (and that was 12 years ago now!). If you're ready and willing, it might be time for some spring cleaning of your <head> area.
Author/web author – This tag is used to name the author of the page. It's just not necessary on the page.
Revisit after – This meta tag is a command to the robots to return to a page after a specific period of time. It's not followed by any major search engine.
Rating – This tag is used to denote the maturity rating of content. I wrote a post about how to tag a page with adult images using a very confusing system that has since been updated (see the post's comments). It seems as if the best way to note bad images is to place them on a separate directory from other images on your site and alert Google.
Expiration/date – "Expiration" is used to note when the page expires, and "date" is the date the page was made. Are any of your pages going to expire? Just remove them if they are (but please don't keep updating content, even contests — make it an annual contest instead!). And for "date," make an XML sitemap and keep it up to date. It's much more useful.
Copyright – That Google article debates this with me a bit, but look at the footer of your site. I would guess it says "Copyright 20xx" in some form. Why say it twice?
Abstract – This tag is sometimes used to place an abstract of the content and used mainly by educational pursuits.
Distribution – The "distribution" value is supposedly used to control who can access the document, typically set to "global." It's inherently implied that if the page is open (not password-protected, like on an intranet) that it's meant for the world. Go with it, and leave the tag off the page.
Generator – This is used to note what program created the page. Like "author," it's useless.
Cache-control �� This tag is set in hopes of controlling when and how often a page is cached in the browser. It's best to do this in the HTTP header.
Resource type – This is used to name the type of resource the page is, like "document." Save yourself time, as the DTD declaration does it for you.
There are so many meta tags out there, I’d love to hear about any you think need to be added or even removed! Shout out in the comments with suggestions or questions.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
The Ultimate Guide to SEO Meta Tags
Posted by katemorris
Editor's note: This post first appeared in April of 2017, but because SEO (and Google) changes so quickly, we figured it was time for a refresh!
Meta tags represent the beginning of most SEO training, for better or for worse. I contemplated exactly how to introduce this topic because we always hear about the bad side of meta tags — namely, the keywords meta tag. One of the first things dissected in any site review is the misuse of meta tags, mainly because they're at the top of every page in the header and are therefore the first thing seen. But we don't want to get too negative; meta tags are some of the best tools in a search marketer's repertoire.
There are meta tags beyond just description and keywords, though those two are picked on the most. I've broken down the most-used (in my experience) by the good, the bad, and the indifferent. You'll notice that the list gets longer as we get to the bad ones. I didn't get to cover all of the meta tags possible to add, but there's a comprehensive meta tag resource you should check out if you're interested in everything that's out there.
It's important to note that in 2019, you meta tags still matter, but not all of them can help you. It's my experience, and I think anyone in SEO would agree, that if you want to rank high in search, your meta tags need to accompany high-quality content that focuses on user satisfaction.
My main piece of advice: stick to the core minimum. Don't add meta tags you don't need — they just take up code space. The less code you have, the better. Think of your page code as a set of step-by-step directions to get somewhere, but for a browser. Extraneous meta tags are the annoying "Go straight for 200 feet" line items in driving directions that simply tell you to stay on the same road you're already on!
The good meta tags
These are the meta tags that should be on every page, no matter what. Notice that this is a small list; these are the only ones that are required, so if you can work with just these, please do.
Meta content type – This tag is necessary to declare your character set for the page and should be present on every page. Leaving this out could impact how your page renders in the browser. A few options are listed below, but your web designer should know what's best for your site.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
Title – While the title tag doesn’t start with "meta," it is in the header and contains information that's very important to SEO. You should always have a unique title tag on every page that describes the page. Check out this post for more information on title tags.
Meta description – The infamous meta description tag is used for one major purpose: to describe the page to searchers as they read through the SERPs. This tag doesn't influence ranking, but it's very important regardless. It's the ad copy that will determine if users click on your result. Keep it within 160 characters, and write it to catch the user's attention. Sell the page — get them to click on the result. Here's a great article on meta descriptions that goes into more detail.
Viewport – In this mobile world, you should be specifying the viewport. If you don’t, you run the risk of having a poor mobile experience — the Google PageSpeed Insights Tool will tell you more about it. The standard tag is:
<meta name=viewport content="width=device-width, initial-scale=1">
The indifferent meta tags
Different sites will need to use these in specific circumstances, but if you can go without, please do.
Social meta tags – I'm leaving these out. OpenGraph and Twitter data are important to sharing but are not required per se.
Robots – One huge misconception is that you have to have a robots meta tag. Let's make this clear: In terms of indexing and link following, if you don't specify a meta robots tag, they read that as index,follow. It's only if you want to change one of those two commands that you need to add meta robots. Therefore, if you want to noindex but follow the links on the page, you would add the following tag with only the noindex, as the follow is implied. Only change what you want to be different from the norm.
<meta name="robots" content="noindex" />
Specific bots (Googlebot) – These tags are used to give a specific bot instructions like noodp (forcing them not to use your DMOZ listing information, RIP) and noydir (same, but instead the Yahoo Directory listing information). Generally, the search engines are really good at this kind of thing on their own, but if you think you need it, feel free. There have been some cases I've seen where it's necessary, but if you must, consider using the overall robots tag listed above.
Language – The only reason to use this tag is if you're moving internationally and need to declare the main language used on the page. Check out this meta languages resource for a full list of languages you can declare.
Geo – The last I heard, these meta tags are supported by Bing but not Google (you can target to country inside Search Console). There are three kinds: placename, position (latitude and longitude), and region.
<META NAME="geo.position" CONTENT="latitude; longitude"> <META NAME="geo.placename" CONTENT="Place Name"> <META NAME="geo.region" CONTENT="Country Subdivision Code">
Keywords – Yes, I put this on the "indifferent" list. While no good SEO is going to recommend spending any time on this tag, there's some very small possibility it could help you somewhere. Please leave it out if you're building a site, but if it's automated, there's no reason to remove it.
Refresh – This is the poor man's redirect and should not be used, if at all possible. You should always use a server-side 301 redirect. I know that sometimes things need to happen now, but Google is NOT a fan.
Site verification – Your site is verified with Google and Bing, right? Who has the verification meta tags on their homepage? These are sometimes necessary because you can't get the other forms of site verification loaded, but if at all possible try to verify another way. Google allows you to verify by DNS, external file, or by linking your Google Analytics account. Bing still only allows by XML file or meta tag, so go with the file if you can.
The bad meta tags
Nothing bad will happen to your site if you use these — let me just make that clear. They're a waste of space though; even Google says so (and that was 12 years ago now!). If you're ready and willing, it might be time for some spring cleaning of your <head> area.
Author/web author – This tag is used to name the author of the page. It's just not necessary on the page.
Revisit after – This meta tag is a command to the robots to return to a page after a specific period of time. It's not followed by any major search engine.
Rating – This tag is used to denote the maturity rating of content. I wrote a post about how to tag a page with adult images using a very confusing system that has since been updated (see the post's comments). It seems as if the best way to note bad images is to place them on a separate directory from other images on your site and alert Google.
Expiration/date – "Expiration" is used to note when the page expires, and "date" is the date the page was made. Are any of your pages going to expire? Just remove them if they are (but please don't keep updating content, even contests — make it an annual contest instead!). And for "date," make an XML sitemap and keep it up to date. It's much more useful.
Copyright – That Google article debates this with me a bit, but look at the footer of your site. I would guess it says "Copyright 20xx" in some form. Why say it twice?
Abstract – This tag is sometimes used to place an abstract of the content and used mainly by educational pursuits.
Distribution – The "distribution" value is supposedly used to control who can access the document, typically set to "global." It's inherently implied that if the page is open (not password-protected, like on an intranet) that it's meant for the world. Go with it, and leave the tag off the page.
Generator – This is used to note what program created the page. Like "author," it's useless.
Cache-control – This tag is set in hopes of controlling when and how often a page is cached in the browser. It's best to do this in the HTTP header.
Resource type – This is used to name the type of resource the page is, like "document." Save yourself time, as the DTD declaration does it for you.
There are so many meta tags out there, I’d love to hear about any you think need to be added or even removed! Shout out in the comments with suggestions or questions.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
The Ultimate Guide to SEO Meta Tags
Posted by katemorris
Editor's note: This post first appeared in April of 2017, but because SEO (and Google) changes so quickly, we figured it was time for a refresh!
Meta tags represent the beginning of most SEO training, for better or for worse. I contemplated exactly how to introduce this topic because we always hear about the bad side of meta tags — namely, the keywords meta tag. One of the first things dissected in any site review is the misuse of meta tags, mainly because they're at the top of every page in the header and are therefore the first thing seen. But we don't want to get too negative; meta tags are some of the best tools in a search marketer's repertoire.
There are meta tags beyond just description and keywords, though those two are picked on the most. I've broken down the most-used (in my experience) by the good, the bad, and the indifferent. You'll notice that the list gets longer as we get to the bad ones. I didn't get to cover all of the meta tags possible to add, but there's a comprehensive meta tag resource you should check out if you're interested in everything that's out there.
It's important to note that in 2019, you meta tags still matter, but not all of them can help you. It's my experience, and I think anyone in SEO would agree, that if you want to rank high in search, your meta tags need to accompany high-quality content that focuses on user satisfaction.
My main piece of advice: stick to the core minimum. Don't add meta tags you don't need — they just take up code space. The less code you have, the better. Think of your page code as a set of step-by-step directions to get somewhere, but for a browser. Extraneous meta tags are the annoying "Go straight for 200 feet" line items in driving directions that simply tell you to stay on the same road you're already on!
The good meta tags
These are the meta tags that should be on every page, no matter what. Notice that this is a small list; these are the only ones that are required, so if you can work with just these, please do.
Meta content type – This tag is necessary to declare your character set for the page and should be present on every page. Leaving this out could impact how your page renders in the browser. A few options are listed below, but your web designer should know what's best for your site.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
Title – While the title tag doesn’t start with "meta," it is in the header and contains information that's very important to SEO. You should always have a unique title tag on every page that describes the page. Check out this post for more information on title tags.
Meta description – The infamous meta description tag is used for one major purpose: to describe the page to searchers as they read through the SERPs. This tag doesn't influence ranking, but it's very important regardless. It's the ad copy that will determine if users click on your result. Keep it within 160 characters, and write it to catch the user's attention. Sell the page — get them to click on the result. Here's a great article on meta descriptions that goes into more detail.
Viewport – In this mobile world, you should be specifying the viewport. If you don’t, you run the risk of having a poor mobile experience — the Google PageSpeed Insights Tool will tell you more about it. The standard tag is:
<meta name=viewport content="width=device-width, initial-scale=1">
The indifferent meta tags
Different sites will need to use these in specific circumstances, but if you can go without, please do.
Social meta tags – I'm leaving these out. OpenGraph and Twitter data are important to sharing but are not required per se.
Robots – One huge misconception is that you have to have a robots meta tag. Let's make this clear: In terms of indexing and link following, if you don't specify a meta robots tag, they read that as index,follow. It's only if you want to change one of those two commands that you need to add meta robots. Therefore, if you want to noindex but follow the links on the page, you would add the following tag with only the noindex, as the follow is implied. Only change what you want to be different from the norm.
<meta name="robots" content="noindex" />
Specific bots (Googlebot) – These tags are used to give a specific bot instructions like noodp (forcing them not to use your DMOZ listing information, RIP) and noydir (same, but instead the Yahoo Directory listing information). Generally, the search engines are really good at this kind of thing on their own, but if you think you need it, feel free. There have been some cases I've seen where it's necessary, but if you must, consider using the overall robots tag listed above.
Language – The only reason to use this tag is if you're moving internationally and need to declare the main language used on the page. Check out this meta languages resource for a full list of languages you can declare.
Geo – The last I heard, these meta tags are supported by Bing but not Google (you can target to country inside Search Console). There are three kinds: placename, position (latitude and longitude), and region.
<META NAME="geo.position" CONTENT="latitude; longitude"> <META NAME="geo.placename" CONTENT="Place Name"> <META NAME="geo.region" CONTENT="Country Subdivision Code">
Keywords – Yes, I put this on the "indifferent" list. While no good SEO is going to recommend spending any time on this tag, there's some very small possibility it could help you somewhere. Please leave it out if you're building a site, but if it's automated, there's no reason to remove it.
Refresh – This is the poor man's redirect and should not be used, if at all possible. You should always use a server-side 301 redirect. I know that sometimes things need to happen now, but Google is NOT a fan.
Site verification – Your site is verified with Google and Bing, right? Who has the verification meta tags on their homepage? These are sometimes necessary because you can't get the other forms of site verification loaded, but if at all possible try to verify another way. Google allows you to verify by DNS, external file, or by linking your Google Analytics account. Bing still only allows by XML file or meta tag, so go with the file if you can.
The bad meta tags
Nothing bad will happen to your site if you use these — let me just make that clear. They're a waste of space though; even Google says so (and that was 12 years ago now!). If you're ready and willing, it might be time for some spring cleaning of your <head> area.
Author/web author – This tag is used to name the author of the page. It's just not necessary on the page.
Revisit after – This meta tag is a command to the robots to return to a page after a specific period of time. It's not followed by any major search engine.
Rating – This tag is used to denote the maturity rating of content. I wrote a post about how to tag a page with adult images using a very confusing system that has since been updated (see the post's comments). It seems as if the best way to note bad images is to place them on a separate directory from other images on your site and alert Google.
Expiration/date – "Expiration" is used to note when the page expires, and "date" is the date the page was made. Are any of your pages going to expire? Just remove them if they are (but please don't keep updating content, even contests — make it an annual contest instead!). And for "date," make an XML sitemap and keep it up to date. It's much more useful.
Copyright – That Google article debates this with me a bit, but look at the footer of your site. I would guess it says "Copyright 20xx" in some form. Why say it twice?
Abstract – This tag is sometimes used to place an abstract of the content and used mainly by educational pursuits.
Distribution – The "distribution" value is supposedly used to control who can access the document, typically set to "global." It's inherently implied that if the page is open (not password-protected, like on an intranet) that it's meant for the world. Go with it, and leave the tag off the page.
Generator – This is used to note what program created the page. Like "author," it's useless.
Cache-control – This tag is set in hopes of controlling when and how often a page is cached in the browser. It's best to do this in the HTTP header.
Resource type – This is used to name the type of resource the page is, like "document." Save yourself time, as the DTD declaration does it for you.
There are so many meta tags out there, I’d love to hear about any you think need to be added or even removed! Shout out in the comments with suggestions or questions.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
The Ultimate Guide to SEO Meta Tags
Posted by katemorris
Editor's note: This post first appeared in April of 2017, but because SEO (and Google) changes so quickly, we figured it was time for a refresh!
Meta tags represent the beginning of most SEO training, for better or for worse. I contemplated exactly how to introduce this topic because we always hear about the bad side of meta tags — namely, the keywords meta tag. One of the first things dissected in any site review is the misuse of meta tags, mainly because they're at the top of every page in the header and are therefore the first thing seen. But we don't want to get too negative; meta tags are some of the best tools in a search marketer's repertoire.
There are meta tags beyond just description and keywords, though those two are picked on the most. I've broken down the most-used (in my experience) by the good, the bad, and the indifferent. You'll notice that the list gets longer as we get to the bad ones. I didn't get to cover all of the meta tags possible to add, but there's a comprehensive meta tag resource you should check out if you're interested in everything that's out there.
It's important to note that in 2019, you meta tags still matter, but not all of them can help you. It's my experience, and I think anyone in SEO would agree, that if you want to rank high in search, your meta tags need to accompany high-quality content that focuses on user satisfaction.
My main piece of advice: stick to the core minimum. Don't add meta tags you don't need — they just take up code space. The less code you have, the better. Think of your page code as a set of step-by-step directions to get somewhere, but for a browser. Extraneous meta tags are the annoying "Go straight for 200 feet" line items in driving directions that simply tell you to stay on the same road you're already on!
The good meta tags
These are the meta tags that should be on every page, no matter what. Notice that this is a small list; these are the only ones that are required, so if you can work with just these, please do.
Meta content type – This tag is necessary to declare your character set for the page and should be present on every page. Leaving this out could impact how your page renders in the browser. A few options are listed below, but your web designer should know what's best for your site.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
Title – While the title tag doesn’t start with "meta," it is in the header and contains information that's very important to SEO. You should always have a unique title tag on every page that describes the page. Check out this post for more information on title tags.
Meta description – The infamous meta description tag is used for one major purpose: to describe the page to searchers as they read through the SERPs. This tag doesn't influence ranking, but it's very important regardless. It's the ad copy that will determine if users click on your result. Keep it within 160 characters, and write it to catch the user's attention. Sell the page — get them to click on the result. Here's a great article on meta descriptions that goes into more detail.
Viewport – In this mobile world, you should be specifying the viewport. If you don’t, you run the risk of having a poor mobile experience — the Google PageSpeed Insights Tool will tell you more about it. The standard tag is:
<meta name=viewport content="width=device-width, initial-scale=1">
The indifferent meta tags
Different sites will need to use these in specific circumstances, but if you can go without, please do.
Social meta tags – I'm leaving these out. OpenGraph and Twitter data are important to sharing but are not required per se.
Robots – One huge misconception is that you have to have a robots meta tag. Let's make this clear: In terms of indexing and link following, if you don't specify a meta robots tag, they read that as index,follow. It's only if you want to change one of those two commands that you need to add meta robots. Therefore, if you want to noindex but follow the links on the page, you would add the following tag with only the noindex, as the follow is implied. Only change what you want to be different from the norm.
<meta name="robots" content="noindex" />
Specific bots (Googlebot) – These tags are used to give a specific bot instructions like noodp (forcing them not to use your DMOZ listing information, RIP) and noydir (same, but instead the Yahoo Directory listing information). Generally, the search engines are really good at this kind of thing on their own, but if you think you need it, feel free. There have been some cases I've seen where it's necessary, but if you must, consider using the overall robots tag listed above.
Language – The only reason to use this tag is if you're moving internationally and need to declare the main language used on the page. Check out this meta languages resource for a full list of languages you can declare.
Geo – The last I heard, these meta tags are supported by Bing but not Google (you can target to country inside Search Console). There are three kinds: placename, position (latitude and longitude), and region.
<META NAME="geo.position" CONTENT="latitude; longitude"> <META NAME="geo.placename" CONTENT="Place Name"> <META NAME="geo.region" CONTENT="Country Subdivision Code">
Keywords – Yes, I put this on the "indifferent" list. While no good SEO is going to recommend spending any time on this tag, there's some very small possibility it could help you somewhere. Please leave it out if you're building a site, but if it's automated, there's no reason to remove it.
Refresh – This is the poor man's redirect and should not be used, if at all possible. You should always use a server-side 301 redirect. I know that sometimes things need to happen now, but Google is NOT a fan.
Site verification – Your site is verified with Google and Bing, right? Who has the verification meta tags on their homepage? These are sometimes necessary because you can't get the other forms of site verification loaded, but if at all possible try to verify another way. Google allows you to verify by DNS, external file, or by linking your Google Analytics account. Bing still only allows by XML file or meta tag, so go with the file if you can.
The bad meta tags
Nothing bad will happen to your site if you use these — let me just make that clear. They're a waste of space though; even Google says so (and that was 12 years ago now!). If you're ready and willing, it might be time for some spring cleaning of your <head> area.
Author/web author – This tag is used to name the author of the page. It's just not necessary on the page.
Revisit after – This meta tag is a command to the robots to return to a page after a specific period of time. It's not followed by any major search engine.
Rating – This tag is used to denote the maturity rating of content. I wrote a post about how to tag a page with adult images using a very confusing system that has since been updated (see the post's comments). It seems as if the best way to note bad images is to place them on a separate directory from other images on your site and alert Google.
Expiration/date – "Expiration" is used to note when the page expires, and "date" is the date the page was made. Are any of your pages going to expire? Just remove them if they are (but please don't keep updating content, even contests — make it an annual contest instead!). And for "date," make an XML sitemap and keep it up to date. It's much more useful.
Copyright – That Google article debates this with me a bit, but look at the footer of your site. I would guess it says "Copyright 20xx" in some form. Why say it twice?
Abstract – This tag is sometimes used to place an abstract of the content and used mainly by educational pursuits.
Distribution – The "distribution" value is supposedly used to control who can access the document, typically set to "global." It's inherently implied that if the page is open (not password-protected, like on an intranet) that it's meant for the world. Go with it, and leave the tag off the page.
Generator – This is used to note what program created the page. Like "author," it's useless.
Cache-control – This tag is set in hopes of controlling when and how often a page is cached in the browser. It's best to do this in the HTTP header.
Resource type – This is used to name the type of resource the page is, like "document." Save yourself time, as the DTD declaration does it for you.
There are so many meta tags out there, I’d love to hear about any you think need to be added or even removed! Shout out in the comments with suggestions or questions.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
The Ultimate Guide to SEO Meta Tags
Posted by katemorris
Editor's note: This post first appeared in April of 2017, but because SEO (and Google) changes so quickly, we figured it was time for a refresh!
Meta tags represent the beginning of most SEO training, for better or for worse. I contemplated exactly how to introduce this topic because we always hear about the bad side of meta tags — namely, the keywords meta tag. One of the first things dissected in any site review is the misuse of meta tags, mainly because they're at the top of every page in the header and are therefore the first thing seen. But we don't want to get too negative; meta tags are some of the best tools in a search marketer's repertoire.
There are meta tags beyond just description and keywords, though those two are picked on the most. I've broken down the most-used (in my experience) by the good, the bad, and the indifferent. You'll notice that the list gets longer as we get to the bad ones. I didn't get to cover all of the meta tags possible to add, but there's a comprehensive meta tag resource you should check out if you're interested in everything that's out there.
It's important to note that in 2019, you meta tags still matter, but not all of them can help you. It's my experience, and I think anyone in SEO would agree, that if you want to rank high in search, your meta tags need to accompany high-quality content that focuses on user satisfaction.
My main piece of advice: stick to the core minimum. Don't add meta tags you don't need — they just take up code space. The less code you have, the better. Think of your page code as a set of step-by-step directions to get somewhere, but for a browser. Extraneous meta tags are the annoying "Go straight for 200 feet" line items in driving directions that simply tell you to stay on the same road you're already on!
The good meta tags
These are the meta tags that should be on every page, no matter what. Notice that this is a small list; these are the only ones that are required, so if you can work with just these, please do.
Meta content type – This tag is necessary to declare your character set for the page and should be present on every page. Leaving this out could impact how your page renders in the browser. A few options are listed below, but your web designer should know what's best for your site.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
Title – While the title tag doesn’t start with "meta," it is in the header and contains information that's very important to SEO. You should always have a unique title tag on every page that describes the page. Check out this post for more information on title tags.
Meta description – The infamous meta description tag is used for one major purpose: to describe the page to searchers as they read through the SERPs. This tag doesn't influence ranking, but it's very important regardless. It's the ad copy that will determine if users click on your result. Keep it within 160 characters, and write it to catch the user's attention. Sell the page — get them to click on the result. Here's a great article on meta descriptions that goes into more detail.
Viewport – In this mobile world, you should be specifying the viewport. If you don’t, you run the risk of having a poor mobile experience — the Google PageSpeed Insights Tool will tell you more about it. The standard tag is:
<meta name=viewport content="width=device-width, initial-scale=1">
The indifferent meta tags
Different sites will need to use these in specific circumstances, but if you can go without, please do.
Social meta tags – I'm leaving these out. OpenGraph and Twitter data are important to sharing but are not required per se.
Robots – One huge misconception is that you have to have a robots meta tag. Let's make this clear: In terms of indexing and link following, if you don't specify a meta robots tag, they read that as index,follow. It's only if you want to change one of those two commands that you need to add meta robots. Therefore, if you want to noindex but follow the links on the page, you would add the following tag with only the noindex, as the follow is implied. Only change what you want to be different from the norm.
<meta name="robots" content="noindex" />
Specific bots (Googlebot) – These tags are used to give a specific bot instructions like noodp (forcing them not to use your DMOZ listing information, RIP) and noydir (same, but instead the Yahoo Directory listing information). Generally, the search engines are really good at this kind of thing on their own, but if you think you need it, feel free. There have been some cases I've seen where it's necessary, but if you must, consider using the overall robots tag listed above.
Language – The only reason to use this tag is if you're moving internationally and need to declare the main language used on the page. Check out this meta languages resource for a full list of languages you can declare.
Geo – The last I heard, these meta tags are supported by Bing but not Google (you can target to country inside Search Console). There are three kinds: placename, position (latitude and longitude), and region.
<META NAME="geo.position" CONTENT="latitude; longitude"> <META NAME="geo.placename" CONTENT="Place Name"> <META NAME="geo.region" CONTENT="Country Subdivision Code">
Keywords – Yes, I put this on the "indifferent" list. While no good SEO is going to recommend spending any time on this tag, there's some very small possibility it could help you somewhere. Please leave it out if you're building a site, but if it's automated, there's no reason to remove it.
Refresh – This is the poor man's redirect and should not be used, if at all possible. You should always use a server-side 301 redirect. I know that sometimes things need to happen now, but Google is NOT a fan.
Site verification – Your site is verified with Google and Bing, right? Who has the verification meta tags on their homepage? These are sometimes necessary because you can't get the other forms of site verification loaded, but if at all possible try to verify another way. Google allows you to verify by DNS, external file, or by linking your Google Analytics account. Bing still only allows by XML file or meta tag, so go with the file if you can.
The bad meta tags
Nothing bad will happen to your site if you use these — let me just make that clear. They're a waste of space though; even Google says so (and that was 12 years ago now!). If you're ready and willing, it might be time for some spring cleaning of your <head> area.
Author/web author – This tag is used to name the author of the page. It's just not necessary on the page.
Revisit after – This meta tag is a command to the robots to return to a page after a specific period of time. It's not followed by any major search engine.
Rating – This tag is used to denote the maturity rating of content. I wrote a post about how to tag a page with adult images using a very confusing system that has since been updated (see the post's comments). It seems as if the best way to note bad images is to place them on a separate directory from other images on your site and alert Google.
Expiration/date – "Expiration" is used to note when the page expires, and "date" is the date the page was made. Are any of your pages going to expire? Just remove them if they are (but please don't keep updating content, even contests — make it an annual contest instead!). And for "date," make an XML sitemap and keep it up to date. It's much more useful.
Copyright – That Google article debates this with me a bit, but look at the footer of your site. I would guess it says "Copyright 20xx" in some form. Why say it twice?
Abstract – This tag is sometimes used to place an abstract of the content and used mainly by educational pursuits.
Distribution – The "distribution" value is supposedly used to control who can access the document, typically set to "global." It's inherently implied that if the page is open (not password-protected, like on an intranet) that it's meant for the world. Go with it, and leave the tag off the page.
Generator – This is used to note what program created the page. Like "author," it's useless.
Cache-control – This tag is set in hopes of controlling when and how often a page is cached in the browser. It's best to do this in the HTTP header.
Resource type – This is used to name the type of resource the page is, like "document." Save yourself time, as the DTD declaration does it for you.
There are so many meta tags out there, I’d love to hear about any you think need to be added or even removed! Shout out in the comments with suggestions or questions.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
The Ultimate Guide to SEO Meta Tags
Posted by katemorris
Editor's note: This post first appeared in April of 2017, but because SEO (and Google) changes so quickly, we figured it was time for a refresh!
Meta tags represent the beginning of most SEO training, for better or for worse. I contemplated exactly how to introduce this topic because we always hear about the bad side of meta tags — namely, the keywords meta tag. One of the first things dissected in any site review is the misuse of meta tags, mainly because they're at the top of every page in the header and are therefore the first thing seen. But we don't want to get too negative; meta tags are some of the best tools in a search marketer's repertoire.
There are meta tags beyond just description and keywords, though those two are picked on the most. I've broken down the most-used (in my experience) by the good, the bad, and the indifferent. You'll notice that the list gets longer as we get to the bad ones. I didn't get to cover all of the meta tags possible to add, but there's a comprehensive meta tag resource you should check out if you're interested in everything that's out there.
It's important to note that in 2019, you meta tags still matter, but not all of them can help you. It's my experience, and I think anyone in SEO would agree, that if you want to rank high in search, your meta tags need to accompany high-quality content that focuses on user satisfaction.
My main piece of advice: stick to the core minimum. Don't add meta tags you don't need — they just take up code space. The less code you have, the better. Think of your page code as a set of step-by-step directions to get somewhere, but for a browser. Extraneous meta tags are the annoying "Go straight for 200 feet" line items in driving directions that simply tell you to stay on the same road you're already on!
The good meta tags
These are the meta tags that should be on every page, no matter what. Notice that this is a small list; these are the only ones that are required, so if you can work with just these, please do.
Meta content type – This tag is necessary to declare your character set for the page and should be present on every page. Leaving this out could impact how your page renders in the browser. A few options are listed below, but your web designer should know what's best for your site.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
Title – While the title tag doesn’t start with "meta," it is in the header and contains information that's very important to SEO. You should always have a unique title tag on every page that describes the page. Check out this post for more information on title tags.
Meta description – The infamous meta description tag is used for one major purpose: to describe the page to searchers as they read through the SERPs. This tag doesn't influence ranking, but it's very important regardless. It's the ad copy that will determine if users click on your result. Keep it within 160 characters, and write it to catch the user's attention. Sell the page — get them to click on the result. Here's a great article on meta descriptions that goes into more detail.
Viewport – In this mobile world, you should be specifying the viewport. If you don’t, you run the risk of having a poor mobile experience — the Google PageSpeed Insights Tool will tell you more about it. The standard tag is:
<meta name=viewport content="width=device-width, initial-scale=1">
The indifferent meta tags
Different sites will need to use these in specific circumstances, but if you can go without, please do.
Social meta tags – I'm leaving these out. OpenGraph and Twitter data are important to sharing but are not required per se.
Robots – One huge misconception is that you have to have a robots meta tag. Let's make this clear: In terms of indexing and link following, if you don't specify a meta robots tag, they read that as index,follow. It's only if you want to change one of those two commands that you need to add meta robots. Therefore, if you want to noindex but follow the links on the page, you would add the following tag with only the noindex, as the follow is implied. Only change what you want to be different from the norm.
<meta name="robots" content="noindex" />
Specific bots (Googlebot) – These tags are used to give a specific bot instructions like noodp (forcing them not to use your DMOZ listing information, RIP) and noydir (same, but instead the Yahoo Directory listing information). Generally, the search engines are really good at this kind of thing on their own, but if you think you need it, feel free. There have been some cases I've seen where it's necessary, but if you must, consider using the overall robots tag listed above.
Language – The only reason to use this tag is if you're moving internationally and need to declare the main language used on the page. Check out this meta languages resource for a full list of languages you can declare.
Geo – The last I heard, these meta tags are supported by Bing but not Google (you can target to country inside Search Console). There are three kinds: placename, position (latitude and longitude), and region.
<META NAME="geo.position" CONTENT="latitude; longitude"> <META NAME="geo.placename" CONTENT="Place Name"> <META NAME="geo.region" CONTENT="Country Subdivision Code">
Keywords – Yes, I put this on the "indifferent" list. While no good SEO is going to recommend spending any time on this tag, there's some very small possibility it could help you somewhere. Please leave it out if you're building a site, but if it's automated, there's no reason to remove it.
Refresh – This is the poor man's redirect and should not be used, if at all possible. You should always use a server-side 301 redirect. I know that sometimes things need to happen now, but Google is NOT a fan.
Site verification – Your site is verified with Google and Bing, right? Who has the verification meta tags on their homepage? These are sometimes necessary because you can't get the other forms of site verification loaded, but if at all possible try to verify another way. Google allows you to verify by DNS, external file, or by linking your Google Analytics account. Bing still only allows by XML file or meta tag, so go with the file if you can.
The bad meta tags
Nothing bad will happen to your site if you use these — let me just make that clear. They're a waste of space though; even Google says so (and that was 12 years ago now!). If you're ready and willing, it might be time for some spring cleaning of your <head> area.
Author/web author – This tag is used to name the author of the page. It's just not necessary on the page.
Revisit after – This meta tag is a command to the robots to return to a page after a specific period of time. It's not followed by any major search engine.
Rating – This tag is used to denote the maturity rating of content. I wrote a post about how to tag a page with adult images using a very confusing system that has since been updated (see the post's comments). It seems as if the best way to note bad images is to place them on a separate directory from other images on your site and alert Google.
Expiration/date – "Expiration" is used to note when the page expires, and "date" is the date the page was made. Are any of your pages going to expire? Just remove them if they are (but please don't keep updating content, even contests — make it an annual contest instead!). And for "date," make an XML sitemap and keep it up to date. It's much more useful.
Copyright – That Google article debates this with me a bit, but look at the footer of your site. I would guess it says "Copyright 20xx" in some form. Why say it twice?
Abstract – This tag is sometimes used to place an abstract of the content and used mainly by educational pursuits.
Distribution – The "distribution" value is supposedly used to control who can access the document, typically set to "global." It's inherently implied that if the page is open (not password-protected, like on an intranet) that it's meant for the world. Go with it, and leave the tag off the page.
Generator – This is used to note what program created the page. Like "author," it's useless.
Cache-control – This tag is set in hopes of controlling when and how often a page is cached in the browser. It's best to do this in the HTTP header.
Resource type – This is used to name the type of resource the page is, like "document." Save yourself time, as the DTD declaration does it for you.
There are so many meta tags out there, I’d love to hear about any you think need to be added or even removed! Shout out in the comments with suggestions or questions.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
The Ultimate Guide to SEO Meta Tags
Posted by katemorris
Editor's note: This post first appeared in April of 2017, but because SEO (and Google) changes so quickly, we figured it was time for a refresh!
Meta tags represent the beginning of most SEO training, for better or for worse. I contemplated exactly how to introduce this topic because we always hear about the bad side of meta tags — namely, the keywords meta tag. One of the first things dissected in any site review is the misuse of meta tags, mainly because they're at the top of every page in the header and are therefore the first thing seen. But we don't want to get too negative; meta tags are some of the best tools in a search marketer's repertoire.
There are meta tags beyond just description and keywords, though those two are picked on the most. I've broken down the most-used (in my experience) by the good, the bad, and the indifferent. You'll notice that the list gets longer as we get to the bad ones. I didn't get to cover all of the meta tags possible to add, but there's a comprehensive meta tag resource you should check out if you're interested in everything that's out there.
It's important to note that in 2019, you meta tags still matter, but not all of them can help you. It's my experience, and I think anyone in SEO would agree, that if you want to rank high in search, your meta tags need to accompany high-quality content that focuses on user satisfaction.
My main piece of advice: stick to the core minimum. Don't add meta tags you don't need — they just take up code space. The less code you have, the better. Think of your page code as a set of step-by-step directions to get somewhere, but for a browser. Extraneous meta tags are the annoying "Go straight for 200 feet" line items in driving directions that simply tell you to stay on the same road you're already on!
The good meta tags
These are the meta tags that should be on every page, no matter what. Notice that this is a small list; these are the only ones that are required, so if you can work with just these, please do.
Meta content type – This tag is necessary to declare your character set for the page and should be present on every page. Leaving this out could impact how your page renders in the browser. A few options are listed below, but your web designer should know what's best for your site.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
Title – While the title tag doesn’t start with "meta," it is in the header and contains information that's very important to SEO. You should always have a unique title tag on every page that describes the page. Check out this post for more information on title tags.
Meta description – The infamous meta description tag is used for one major purpose: to describe the page to searchers as they read through the SERPs. This tag doesn't influence ranking, but it's very important regardless. It's the ad copy that will determine if users click on your result. Keep it within 160 characters, and write it to catch the user's attention. Sell the page — get them to click on the result. Here's a great article on meta descriptions that goes into more detail.
Viewport – In this mobile world, you should be specifying the viewport. If you don’t, you run the risk of having a poor mobile experience — the Google PageSpeed Insights Tool will tell you more about it. The standard tag is:
<meta name=viewport content="width=device-width, initial-scale=1">
The indifferent meta tags
Different sites will need to use these in specific circumstances, but if you can go without, please do.
Social meta tags – I'm leaving these out. OpenGraph and Twitter data are important to sharing but are not required per se.
Robots – One huge misconception is that you have to have a robots meta tag. Let's make this clear: In terms of indexing and link following, if you don't specify a meta robots tag, they read that as index,follow. It's only if you want to change one of those two commands that you need to add meta robots. Therefore, if you want to noindex but follow the links on the page, you would add the following tag with only the noindex, as the follow is implied. Only change what you want to be different from the norm.
<meta name="robots" content="noindex" />
Specific bots (Googlebot) – These tags are used to give a specific bot instructions like noodp (forcing them not to use your DMOZ listing information, RIP) and noydir (same, but instead the Yahoo Directory listing information). Generally, the search engines are really good at this kind of thing on their own, but if you think you need it, feel free. There have been some cases I've seen where it's necessary, but if you must, consider using the overall robots tag listed above.
Language – The only reason to use this tag is if you're moving internationally and need to declare the main language used on the page. Check out this meta languages resource for a full list of languages you can declare.
Geo – The last I heard, these meta tags are supported by Bing but not Google (you can target to country inside Search Console). There are three kinds: placename, position (latitude and longitude), and region.
<META NAME="geo.position" CONTENT="latitude; longitude"> <META NAME="geo.placename" CONTENT="Place Name"> <META NAME="geo.region" CONTENT="Country Subdivision Code">
Keywords – Yes, I put this on the "indifferent" list. While no good SEO is going to recommend spending any time on this tag, there's some very small possibility it could help you somewhere. Please leave it out if you're building a site, but if it's automated, there's no reason to remove it.
Refresh – This is the poor man's redirect and should not be used, if at all possible. You should always use a server-side 301 redirect. I know that sometimes things need to happen now, but Google is NOT a fan.
Site verification – Your site is verified with Google and Bing, right? Who has the verification meta tags on their homepage? These are sometimes necessary because you can't get the other forms of site verification loaded, but if at all possible try to verify another way. Google allows you to verify by DNS, external file, or by linking your Google Analytics account. Bing still only allows by XML file or meta tag, so go with the file if you can.
The bad meta tags
Nothing bad will happen to your site if you use these — let me just make that clear. They're a waste of space though; even Google says so (and that was 12 years ago now!). If you're ready and willing, it might be time for some spring cleaning of your <head> area.
Author/web author – This tag is used to name the author of the page. It's just not necessary on the page.
Revisit after – This meta tag is a command to the robots to return to a page after a specific period of time. It's not followed by any major search engine.
Rating – This tag is used to denote the maturity rating of content. I wrote a post about how to tag a page with adult images using a very confusing system that has since been updated (see the post's comments). It seems as if the best way to note bad images is to place them on a separate directory from other images on your site and alert Google.
Expiration/date – "Expiration" is used to note when the page expires, and "date" is the date the page was made. Are any of your pages going to expire? Just remove them if they are (but please don't keep updating content, even contests — make it an annual contest instead!). And for "date," make an XML sitemap and keep it up to date. It's much more useful.
Copyright – That Google article debates this with me a bit, but look at the footer of your site. I would guess it says "Copyright 20xx" in some form. Why say it twice?
Abstract – This tag is sometimes used to place an abstract of the content and used mainly by educational pursuits.
Distribution – The "distribution" value is supposedly used to control who can access the document, typically set to "global." It's inherently implied that if the page is open (not password-protected, like on an intranet) that it's meant for the world. Go with it, and leave the tag off the page.
Generator – This is used to note what program created the page. Like "author," it's useless.
Cache-control – This tag is set in hopes of controlling when and how often a page is cached in the browser. It's best to do this in the HTTP header.
Resource type – This is used to name the type of resource the page is, like "document." Save yourself time, as the DTD declaration does it for you.
There are so many meta tags out there, I’d love to hear about any you think need to be added or even removed! Shout out in the comments with suggestions or questions.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes