#why did i have to get the 20 open tabs googling the specification differences between ryzen 7 series cpus autism.
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Total funding amounts to $125.3M.
Text
its that time again when i longingly gaze out to pcpartpicker dot com and dream about being able to comfortably afford my dream gaming pc setup
#why do all of my interests have to be fucking expensive. why didnt i get the go outside and search for different species of bugs autism.#why did i have to get the 20 open tabs googling the specification differences between ryzen 7 series cpus autism.#i need infinite money so i can build all of the computers i want forever. not even to use them all. just for enrichment
1 note
·
View note
Text
TSI - Chapter 1 Notes
Here are my full notes and commentary for Chapter 1 of my Harry Potter fic 'The Snake Inside'.
Chapter 1 can be found here.
Throughout the chapter there are numbers in parentheses, these numbers correspond to the below notes. To best understand what I’m talking about in the notes I would recommend opening the story in a second tab and following along from there.
(notes begin under the cut)
1. This is, if you hadn’t noticed, lifted directly from the book, I do do this a couple times however, this is the only one that is italicized. I’m going to try and point out the other instances in chapter notes as well.
2. Another line lifted from the book, although here it has slightly different context
3. This was another line from the book, although again it has slightly different context (also I swear these notes aren’t just going to be me citing passages from the book)
4. I was actually really conflicted over this. Dudley is obviously incredibly spoiled so I figured it made sense that if for once Harry had something that he didn’t that he would throw a fit and demand he get the same. What I wasn’t confident about was how Petunia or Vernon would react as they really do love Dudley, shown by how much they spoil him. In this scenario, I decided that Petunia’s hatred of magic plus her fear of losing Dudley to magic (just like she lost her sister) would drive her to hit Dudley.
5. The first signs of Harry’s sneaky Slytherin side! He reads the room and chooses the best manner to approach the situation, something he would be good at considering he grew up in an abusive household. He would likely have gotten very good at reading moods and acting accordingly at a young age to avoid being hit or yelled at.
6. It might seem like Harry is a little quick to believe in Hogwarts and want to go considering he knows nothing about it. But, it’s an escape from the Dursleys and the terrible school they were going to send him to. Plus, it’s obvious that the Dursleys hate magic, so why would they lie to Harry about him being a wizard?
7. I know in canon Hogwarts is free, but that simply doesn’t make sense to me. In my world, Hogwarts is the best and most elite school in Britain, but it’s not the only one. There are also smaller ‘public’ wizarding schools that people who can’t afford Hogwarts go to. Also, if Hogwarts has a tuition then it only makes sense to me that the Potter Parents would set up an education fund for Harry, especially since their lives were at risk, they would want to make sure that Harry would be able to get the best education possible.
8. Some more Slytherin sneakiness, Harry isn’t a master manipulator by any means but he’s lived with the Dursleys for 11 years, he knows how to play them.
9. I don’t write it in bc it seemed unnecessary, but she does explain her reasoning off-screen.
10. Some foreshadowing here, I thought I was rather clever, finding a logical way for Harry and Vernon to learn how to enter the train platform.
11. This whole paragraph is my attempt at showing how Harry is still just a kid who’s curious about the new world he’s found himself in. I know I write Harry (and all the characters his age) as being a little more mature than they probably would be in reality, so here I was trying to show a pure, childlike curiosity and also some trains of thought that aren’t totally logical bc he is a kid.
12. I do think the Dursleys, or Vernon at least, is more clever than he gets credit for, he is high up in Grunnings, so he has to have some sort of head on his shoulders, and he’s certainly self-serving we saw in book 2 how he lathered up those rich people he wanted to impress. So, I think as much as Vernon might hate magic and think goblins are disgusting, that he would very much be able to put that aside if he thought it might benefit him.
13. The goblins ‘revealing the truth’ to Harry, or giving him or helping him out in some way is kinda over done and doesn’t always make sense as the goblins really have no reason so want to go out of their way to help Harry. But, I needed an unbiased 3rd party to teach Harry a little about the wizarding world and I figured a satisfactory motivation for the goblins would be making money in the form of consultation fees.
14. The first hints of Dumbledore’s manipulations. He wants a naïve Savior who will be easy for him to influence and shape into the person he thinks the world needs. Note, I’m not going for an evil Dumbledore, just a morally grey Dumbledore.
15. Paper business refers to the practice of owning a business on paper but not being involved in how it’s currently ran, I’m not trying to say that the Potters own several companies that sell paper. I don’t know if this is a common term, when I googled it nothing came up, but my dad uses it a lot when talking about businesses. Also, we know in canon that the Potters are rich but in a lot of fics it has evolved into them being extremely wealthy and influential. I’m running with this fanon idea because the Potters are a very old family, they’ve been around since the 12thcentury and married into other very influential families in canon. Also, if I ever get to the later years I do want to mess around with some politics and Harry having power from his family name will be a necessary advantage.
16. I’m not going to bore you guys with paragraphs detailing just how exceedingly rich Harry is, if he can’t even do anything with what he owns yet. He’s 11, he’s not going to be making any smart investments.
17. Like I said earlier with the tuition vault, the Potters were soldiers in a war, they knew they might die and I think it’s only logical that they would take precautions to ensure that Harry would have a comfortable life should they die.
18. This might seem like a lot, but again, the Potters are rich and they want their only child to be able to have a comfortable life even if they die, plus it is supposed to last until Harry’s an adult.
19. This is not canon, JKR said that a galleon is approx. 5 British pounds. I think that’s too low, so I changed it. I mean, it’s solid gold and the highest form of currency it’s got to be worth more than that.
20. Trying to give Dumbledore the benefit of the doubt, but of course Vernon is going to be suspicious of anyone who took money that he could have used.
21. This is just something that I thought made sense, Gringotts has been established as being in the business of making money and how can they do that if they’re cut off from part of their clientele?
22. I’m trying to go in a new direction with the Dursleys, I’m not trying to redeem them, but like Dumbledore, they’re in a grey area, especially Vernon. I think a self-serving Vernon would be interested in learning more about the magic world, or more specifically learning what it can do for him. But also because you need to know your enemy, as interested as he might be in profiting off magic, Vernon doesn’t trust wizards. As for Harry, this is a Slytherin AU, of course he’s going to play along with his uncle’s plan as long as it benefits him.
23. This is another line from the book
24. Hints that Dean is actually a halfblood and not muggleborn, this is canon too. I’m looking forward to exploring the future “tracking down who my real dad was arc”
25. Originally, I had Harry meet Hermione and her family, but I decided to change it to Dean because I wanted to go down some different avenues. A lot of Slytherin Harry stories have Harry becoming friends with Hermione early on despite their differences and I didn’t want to just do the same thing as everyone else. Also, I really like Dean Thomas’s character he’s a friendly, good natured, brave and loyal. I also think that Harry would get along better with Dean right off the bat than he would with Hermione.
26. Honestly, I think it’s ridiculous that they still use quills and I will be using the trope where Harry sneaks in ballpoint pens.
27. Harry came to Diagon a few days earlier than he did in canon, so I figure it only makes sense that he would meet someone different at Madam Malkins also this gave me a great opportunity to shoe in one of my other favorite characters, Neville.
28. I headcanon that Harry and Neville have a slight magical bond over both being possible options for the prophecy.
29. I admit this is slightly unrealistic, as I’ve dropped my glasses several times before and they’ve never broken but I wanted an excuse to get Harry some new glasses.
30. Not implausible, but also not likely either. Also, I admit I really have no clue about British healthcare, especially not what it was like in the 80s and 90s. I know it’s free, but that there’s also the option to do private or paid care. So, for this story, assume that the Dursleys use private care bc they want to seem better than everyone else.
31. Again, probably not the most realistic scenario, but it is possible. I got glasses when I was 11 and contacts when I was 15, but I definitely could have gotten the contacts when I was a little younger. Maybe not, 11-years old younger, but I don’t think it’s entirely out of the ballpark.
32. I didn’t see any point in changing Hedwig’s name, so I kept it the same.
33. Giving Harry contacts was something that I debated a lot, there’s no real reason he needs them, I just wanted him to have some because they’re convenient. I personally regret not getting contacts earlier.
34. To be honest, this is actually a bit of a cop out on my end because I haven’t figured out the entire political system yet. BUT even if I had, Harry is still 11 so he probably wouldn’t understand it that well anyways. There will be a brief explanation in chapter 2 though.
35. Dudley’s reaction is anything thing I was really torn up about. Because he’s essentially torn between his two parents, sticking with Petunia ostracizes him from Vernon and sticking with Vernon ostracizes him from Petunia. Ultimately, I decided Dudley would value his father’s attention more because while Petunia wouldn’t like him getting involved with magic, she wouldn’t cut Dudley off completely, she loves him too much. But Vernon, has been completely distracted by magic and without Dudley getting involved in it too then he won’t get any attention from his father.
36. According to the HP wiki, Dean’s family actually lives in London, but I wanted it to be more convenient for them to meet so I moved them closer to the Dursleys. Also, I actually did about an hour’s worth of research on google maps trying to find a real place Dean’s family to live.
37. A whole lot of this section with the Weasleys was lifted from the book with slightly different commentary from Harry. I originally had more, but it didn’t add anything so I cut it out.
38. I don’t know how outgoing Ron was before he met Harry, if I was him though I would be too nervous to intrude on a compartment with two other kids who looked like they were already friends.
39. This is not a Ron bashing fic, Harry has no reason to dislike him, so of course he wouldn’t be opposed to sitting with him. That said, for the premise of the story I couldn’t have them sit together because Ron is heavily biased against Slytherin.
40. Poor Draco, if he had just paid more attention to who he was passing in the hall then he would have met Harry, but again, I couldn’t let that happen because Draco’s so obnoxious that he’d turn Harry off Slytherin.
41. Honestly, I just wanted Harry to interact with more students who can be potential friends.
42. Again, and the sorting is lifted from the book. I’m not going to make note of every line.
43. I wasn’t sure if I wanted Neville to be in Hufflepuff of Gryffindor at first. A lot of people argue that Neville needed to be in Gryffindor to learn how to be brave, but I think that Hufflepuff would provide a strong support system that would help Neville gain confidence in himself. Also, I decided that Harry’s words in the robe shop would influence Neville into not thinking that he was a loser if he went to Hufflepuff. I imagine in canon, much like Harry was chanting “not slytherin” Neville was probably chanting “not Hufflepuff”. So I think it’s fitting they both don’t end up in Gryffindor in this fic. Also, Harry already has a Gryffindor friend in Dean, he can use a Hufflepuff friend.
1 note
·
View note
Text
How Do I Deactivate My Pof
How Do I Deactivate My Pof Account
How To Cancel Pof Subscription
. My recommended site: How To Cancel Your POF / Plentyoffish Membership by watch this video. It's easy to do and takes under one.
The si of temporary deactivating your POF ne is that all the pas of your account will not be deleted; in expedition you want to come back to POF after a while. If you are sure you want to get rid of POF how do i delete my pof account, then follow. Sometimes even after pas above-mentioned si, your account will not be deleted.
The intense love connection between dating apps and data leaks is nothing new with the most popular apps out there making headlines, including POF, Tinder, Grindr, Bumble, and OkCupid. But deleting the app from your phone doesn't delete your account and sensitive data.
Not just dating apps: Don’t be part of the next data leak.
How do I delete my POF account on Android? Steps to Delete POF (Plenty of Fish) account. Go to Plenty of Fish Home page and login with your account. Select 'Help' tab on the top right corner, and select the option 'Delete Account' In account deletion page, mention the reason you want to delete POF account and click on Quit/Give up/Delete account. Use your log in information to access the account. Once logged in, click help button found at the top of the screen. You will find a list of options on the left-side of your screen. Proceed to click remove profile then click on the link that emerges under the delete your Plenty of Fish profile. To start you have to open your browser of preference and enter the official POF website, specifically the section to delete your account. Then enter both your username and password to log in with your POF account. At this point you will only have to indicate the reason why you decided to delete your account.
The best way to minimize digital risks is to keep your data only where you need it. With Mine, you can discover which companies are holding your personal data and exercise your data rights by deleting it from services you no longer use.
Delete yourself from POF and other apps you no longer use.
With a Mine account, you can easily delete your POF account and personal data from POF and other companies.
To delete your POF profile manually:

Prefer to delete your Plenty of Fish account manually? Here’s how:
Log in one last time using the app or the website.
At the top of the first screen, click ‘Help.’
Choose the ‘Remove Profile’ option.
Take a deep breath and click ‘Delete your POF profile.’
Enter your username and password
If you want, you may share your reason for leaving.
That’s it. You did it. You are out of this pond!
Another simple option would be to use yourMine accountto delete your dating account and all data from POF or other apps you no longer want holding your personal information.
Got any other questions about this topic? We’ve covered a few right here!
Plenty of data: Has POF ever experienced a data leak?
The POF app, which reminds daters that there are plenty of options out there, but some of them might stink a little, is part of the Match Group and has more than 150 million users in over 20 countries. In 2019, the app experienced a serious data breach and leaked information categorized as “private” by users. For this and perhaps other reasons, we can see that the search query “how to delete Plenty of Fish account” has been trending on Google.
Hide and seek: Should you delete or hide your profile?
There’s a difference between freezing your dating profile and deleting it. Many apps allow users to put their accounts on hold and make themselves invisible to other daters. This is a great option for those of you who started dating someone, and while it’s going well (fingers crossed!), you’re still not sure you’ve found the one worth deleting your meticulously written profile for. It’s crucial to keep in mind the data privacy implications of hiding a profile instead of deleting it. As long as you’re a registered user, the app can still access your data. Other daters might not be able to see you, but the app sure can.
Take me back! Can I get back into the online dating business after deleting my account?
How Do I Deactivate My Pof Account
You’ve changed your mind. It happens to the best of us! Maybe the person you were dating didn’t turn out to be the one; maybe the break you took from dating worked so well that you’re ready to jump back in the water. What matters is that you want your dating profile back after deleting it.

We have good news and bad news. The bad news is that most dating sites have no way to recover a profile you’ve deleted. It makes sense because otherwise, they would still have access to your data. The good news is that the last relationship or break from dating made you more focused than ever, and your new profile will land you that everlasting love (or fun weekend) you’re after. You can then go back to the previous section of this article and delete your account again – this time for good!
Online dating apps and data ownership technology make it easier to choose when and how to make yourself available for dating. Decide for yourself if you feel comfortable enough to give access to your data and your heart.
How To Cancel Pof Subscription
Wondering who else might still hold your personal data? Looking to delete your data from other apps that you no longer use? Check out Mine to discover all the companies that are holding your data in 30 seconds.
0 notes
Text
An 8-Point Checklist for Debugging Strange Technical SEO Problems
Posted by Dom-Woodman
Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provvide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The review pages of client & competitors all had rating rich snippets on Google.
All the competitors had rating rich snippets on Bing; however, the client did not.
The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
A website was randomly throwing 302 errors.
This never happened in the browser and only in crawlers.
User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
The pre-checklist check
Does it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
You’re underperforming from where you should be.
When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
You’ve suffered a sudden traffic drop.
Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
The wrong page is ranking for the wrong query.
In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
A website that has a lot of client-side JavaScript.
Bigger, older websites with more legacy.
Your problem is related to a new Google property or feature where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
Robots.txt: Open up Search Console and check in the robots.txt validator.
User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
To get the user agent switcher, open Dev Tools.
Check the console drawer is open (the toggle is the Escape key)
Hit the … and open "Network conditions"
Here, select your user agent!
IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
No-index
Canonical
Mobile alternate tags
AMP alternate tags
An example of providing mixed messages would be:
No-indexing page A
Page B canonicals to page A
Or:
Page A has a canonical in a header to A with a parameter
Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
Sitemap
Example: Mobile alternate tags can sit in a sitemap
HTTP headers
Example: Canonical and meta robots can be set in headers.
HTML head
This is where you’re probably looking, you’ll need this one for a comparison.
JavaScript-rendered vs hard-coded directives
You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
Google Search Console settings
There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!
4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
Resources: Is Google downloading all the resources of the page?
Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
It will crawl more than us
It is obviously a bot, rather than a human pretending to be a bot
It will crawl at different times of day
This means that:
If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
What happens to the servers under heavy load?
When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
Fetch & Render
Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
Mobile-friendly test
Shows: Rendered DOM and returns rendered DOM for you to read.
Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
Googlebot crawls with cookies cleared between page requests
Googlebot renders with Chrome 41, which doesn’t support all modern JavaScript.
We can isolate each of these by:
Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
Google’s cache
Shows: Source code
While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
Site searches for specific content
Shows: A tiny snippet of rendered content.
By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
Better yet, do the same thing with a rank tracker, to see if it changes over time.
Storing the actual rendered DOM
Shows: Rendered DOM
Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
This excellent talk, How does Google work - Paul Haahr, is a must-listen.
At their recent IO conference, John Mueller & Tom Greenway gave a useful presentation on how Google renders JavaScript.
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
Google does respect JS canonicals - For example, Eoghan Henn does some nice digging here, which shows Google respecting JS canonicals.
How does Google index different JS frameworks? - Another great example of a widely read experiment by Bartosz Góralewicz last year to investigate how Google treated different frameworks.
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
Similar/duplicate content to the pages that have the problem.
This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux) which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
De-duplication of content
Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
Lowering syndication
8. A roundup of some other likely suspects
If you’ve gotten this far, then we’re sure that:
Google can consistently crawl our pages as intended.
We’re sending Google consistent signals about the status of our page.
Google is consistently rendering our pages as we expect.
Google is picking the correct page out of any duplicates that might exist on the web.
And your problem still isn’t solved?
And it is important?
Well, shoot.
Feel free to hire us…?
As much as I’d love for this article to list every SEO problem ever, that’s not really practical, so to finish off this article let’s go through two more common gotchas and principles that didn’t really fit in elsewhere before the answers to those four problems we listed at the beginning.
Invalid/poorly constructed HTML
You and Googlebot might be seeing the same HTML, but it might be invalid or wrong. Googlebot (and any crawler, for that matter) has to provide workarounds when the HTML specification isn't followed, and those can sometimes cause strange behavior.
The easiest way to spot it is either by eye-balling the rendered DOM tools or using an HTML validator.
The W3C validator is very useful, but will throw up a lot of errors/warnings you won’t care about. The closest I can give to a one-line of summary of which ones are useful is to:
Look for errors
Ignore anything to do with attributes (won’t always apply, but is often true).
The classic example of this is breaking the head.
An iframe isn't allowed in the head code, so Chrome will end the head and start the body. Unfortunately, it takes the title and canonical with it, because they fall after it — so Google can't read them. The head code should have ended in a different place.
Oliver Mason wrote a good post that explains an even more subtle version of this in breaking the head quietly.
When in doubt, diff
Never underestimate the power of trying to compare two things line by line with a diff from something like Diff Checker. It won’t apply to everything, but when it does it’s powerful.
For example, if Google has suddenly stopped showing your featured markup, try to diff your page against a historical version either in your QA environment or from the Wayback Machine.
Answers to our original 4 questions
Time to answer those questions. These are all problems we’ve had clients bring to us at Distilled.
1. Why wasn’t Google showing 5-star markup on product pages?
Google was seeing both the server-rendered markup and the client-side-rendered markup; however, the server-rendered side was taking precedence.
Removing the server-rendered markup meant the 5-star markup began appearing.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The problem came from the references to schema.org.
<div itemscope="" itemtype="https://schema.org/Movie"> </div> <p> <h1 itemprop="name">Avatar</h1> </p> <p> <span>Director: <span itemprop="director">James Cameron</span> (born August 16, 1954)</span> </p> <p> <span itemprop="genre">Science fiction</span> </p> <p> <a href="../movies/avatar-theatrical-trailer.html" itemprop="trailer">Trailer</a> </p> <p></div> </p>
We diffed our markup against our competitors and the only difference was we’d referenced the HTTPS version of schema.org in our itemtype, which caused Bing to not support it.
C’mon, Bing.
3. Why were pages getting indexed with a no-index tag?
The answer for this was in this post. This was a case of breaking the head.
The developers had installed some ad-tech in the head and inserted an non-standard tag, i.e. not:
<title>
<style>
<base>
<link>
<meta>
<script>
<noscript>
This caused the head to end prematurely and the no-index tag was left in the body where it wasn’t read.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
This took some time to figure out. The client had an old legacy website that has two servers, one for the blog and one for the rest of the site. This issue started occurring shortly after a migration of the blog from a subdomain (blog.client.com) to a subdirectory (client.com/blog/…).
At surface level everything was fine; if a user requested any individual page, it all looked good. A crawl of all the blog URLs to check they’d redirected was fine.
But we noticed a sharp increase of errors being flagged in Search Console, and during a routine site-wide crawl, many pages that were fine when checked manually were causing redirect loops.
We checked using Fetch and Render, but once again, the pages were fine. Eventually, it turned out that when a non-blog page was requested very quickly after a blog page (which, realistically, only a crawler is fast enough to achieve), the request for the non-blog page would be sent to the blog server.
These would then be caught by a long-forgotten redirect rule, which 302-redirected deleted blog posts (or other duff URLs) to the root. This, in turn, was caught by a blanket HTTP to HTTPS 301 redirect rule, which would be requested from the blog server again, perpetuating the loop.
For example, requesting https://www.client.com/blog/ followed quickly enough by https://www.client.com/category/ would result in:
302 to http://www.client.com - This was the rule that redirected deleted blog posts to the root
301 to https://www.client.com - This was the blanket HTTPS redirect
302 to http://www.client.com - The blog server doesn’t know about the HTTPS non-blog homepage and it redirects back to the HTTP version. Rinse and repeat.
This caused the periodic 302 errors and it meant we could work with their devs to fix the problem.
What are the best brainteasers you've had?
Let’s hear them, people. What problems have you run into? Let us know in the comments.
Also credit to @RobinLord8, @TomAnthonySEO, @THCapper, @samnemzer, and @sergeystefoglo_ for help with this piece.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog https://ift.tt/2lfAXtQ via IFTTT
2 notes
·
View notes
Text
Ne+Ti vs Ni: An ENTx endless rambling
First things first: thank you for once again answering my ask, I appreciate it and again, it did help. I’m sending this message knowing that it’ll be probably ignored or worse, blacklist me but I’ve reached the limit to where I can go without direct and specific input, so here goes nothing:

(Mod note: italics indicate Ti, bold indicates Ne)
I’ve been trying to nail down my type for quite some time now yet I can’t settle down for any typing because
1) I invariably start questioning its validity since contradictions are bound to appear and even if I can justify or rationalize them (which I have a pretty good ability to do, sadly, since it drives me insane), they bother me to no end hence I start looking or a “perfect” diagnosis again
2) I can see significant traits of myself in several of very different types, it’s maddening
3) When I spot a connection between myself and a type being described I immediately (can’t control it really) start rationalizing why it could be true, why it would explain this and that, why I couldn’t see it before, for what I was mistaking said trait/behavior for, memories of time since which I display said traits/behaviors flood my mind as well as multiple examples of people of said type I always felt a connection to or was intrigued by…all seemly at the same time or in such rapid succession I have a really hard time calming down my mind in order to try and make sense of all of what’s going on inside of it.It’s like I can find compelling (as seen by me) evidence to me being a lot of types, and I’m always 100% serious about it at the time…except my “sureness” never lasts for more than two days at a time, mostly.
It frustrates and embarrasses me because I’m hardly unsure about figuring out (and typing) other people, and I’m seldom wrong at that, but I can’t pin myself down and it makes me feel incompetent and unfit. Everyone always says I’m good analyzer and jokingly refer to me as a blunt psychologist, yet my MBTI confusion makes me feel like a fraud and I HATE it.
I highly suspect I might be mixing the 8’s need to control (I’m a 873 with 8 being the core type), which comes across as “J-ness” for Ni fixed path/truth thing (besides ENTJ lately I never get high Te or Ni types in tests, it’s always high Ti ones) and lately I’ve been daily noticing my Si “trips” so to speak and pondering over my supposedly hilarious “gastronomic memory” (I somehow can recall and describe days and situations based on what I ate that day if it was particularly delicious. I know it sounds ridiculous and I have no idea how that works, but it’s true).
I’m also pretty certain I value Fe over Fi, though ethics in general definitely take a backseat to logic most of the times, it’s noticeable enough for people to comment on it.
Two minor things I relate to Ne that I display in spades and everyone seem to find amusing is that I can never see a thing separately for a noticeable time before I see it integrated to a grid of things like it or other contexts in which the same principle or happening applies to or will influence it. Words and images almost always bring other words and images to mind and I go crazy if I can’t recall what it reminds me of specifically. This seldom happens though, usually I can reference several things/people the original object is alike to, though it seems that to a lot of people these similarities can’t be observable or comprehensible at all, but it makes perfect sense to me and I can explain how.
The other thing is that I have way too many interests for my own good and I tend to obsess over them until they saturate me, I’m totally a slave to what my mind finds interesting in detriment to my actual obligations. I also always have at least 20 tabs open on my browser, because somehow I can’t seem to read an article or watch a video without having to Google something referenced on it, which starts the rabbit hole that has no end and makes me forget what I was reading/watching/researching in the first place. Also my mom is an ENFP and so I thought I couldn’t be a Ne user because we are both alike and so different at the same time, but I now truly realize that a function may manifest differently depending on what is it paired with, and her Fi is really strong, which I can’t relate to at all. I won’t even go into Ti vs Te because by now this is already ridiculous long and I doubt anyone would even finish all this.
How can Ne+Ti mimic (or more precisely, appear to be) Ni? If possible please include concrete examples, whether fictional or real.
In that vein, could an ENTP 8 be reasonably mistaken by an ENTJ?
If you survived all this rambling and take your time to answered this somewhere in the future…you’re a hero, truly.

Not only am I a hero, my ENTP friend is a hero, since we both read it. ;)
Do you need me to say it?
YOU ARE AN ENTP.
Stop doubting it. Chill with it. Dig it. Tell your NeTi to stop considering other types. That it continues doing that should prove your own Ne-ness to you.
Everything you describe is heavily Ne, with an emphasis on Ti, so I’ll just pull a few comments out and talk about them.
Also my mom is an ENFP and so I thought I couldn’t be a Ne user because we are both alike and so different at the same time, but I now truly realize that a function may manifest differently depending on what is it paired with, and her Fi is really strong, which I can’t relate to at all.
The bold is the pure truth, my friend. ENFPs and ENTPs might look like each other on a superficial level but they are not the same thing at all. As ENTP puts it, “You have moralizing tendencies and I deconstruct all your morals.”
It’s true. My morals scream loud and clear. In fact, I can look back at my teen years and see just how black and white my moral thinking was; everything was right or wrong, good or bad. That is a WHOLE OTHER ball of wax from NeTi and their attitude of “People should be able to believe what they want, even if it’s wrong.” (This was an actual conversation I had this morning. =P)
Ne is inclined to change its opinions and perspectives with very little warning, which makes the “inconsistencies” of Ne-doms somewhat obvious (when trying to determine ENXP from ENTJ), but there are many mistypes between them floating around the internet. For example: those who insist Obama is an ENTP instead of an ENFJ, when he was there for one thing – health care – or who believe Stephen Hawking is an INTJ instead of an ENTP despite the fact that he routinely challenges and deconstructs his own theories. ;)
ENTJs have a no-nonsense approach, disinterested in deconstruction. It’s just facts and business with them, in the sense that Te wants an object to do its job, and needs no complete understanding of that object to move forward.
Since ENTPs have Ne/Fe loops, they are zany, often aimed at provoking humor in the audience, have a general sense of amiable goodwill, and are able to handle anything you throw at them without a moralizing tendency (unlike the ENFPs). Good examples of this are Billy Crystal (ENTP not INFJ), Jeff Goldblum (ENTP) and Robin Williams (ENTP, not ENFP – he’s got TONS of Fe), who described his inner chaotic world as similar to what you said above.
Yes, Enneagram makes a difference. 8′s are aggressive and that might make you come across as more ‘challenging’ of others than is typical for a Ne-dom.
- ENFP Mod
Here’s what my ENTP friend has to say:

I’m not one of the professional mods, but I AM an ENTP. And as one ENTP to another, I’m here to assure you that ENXPs’ minds move at a frenetic pace, bouncing around from idea to idea, from THOUGHT TRAIN A to THOUGHT TRAIN Z without any obvious link between them, contributing to restlessness, anxiousness. High Ne just can’t ignore the various combinations between your past and present behavior and all the different MBTI types. It constantly scans for new possibilities, new patterns and associations.
Ne is not intensive and convergent like Ni. When it reaches a sense of conviction and closure, it’s because the aux function has guided it to that direction. Ti identifies all exceptions or imagining scenarios in which a proposed explanation might falter. Our Ti reduces everything to a system, a large logical ensemble of arguments and counter-arguments, into an interconnecting network of principles and rational procedures that is disconnected fromreality and with the assistance of dom Ne, it sees the bigger picture and builds many different perspectives.
Now I am going to paraphrase the words of the Doctor. “Through crimson stars and silent stars and tumbling nebulas like oceans set on fire, through empires of glass and civilizations of pure thought, and a whole, terrible, wonderful universe of impossibilities, I welcome you to the ENTP club!”
- ENTP
112 notes
·
View notes
Text
The One-Hour Guide to SEO, Part 2: Keyword Research – Whiteboard Friday
Posted by randfish
Before doing any SEO work, it’s important to get a handle on your keyword research. Aside from helping to inform your strategy and structure your content, you’ll get to know the needs of your searchers, the search demand landscape of the SERPs, and what kind of competition you’re up against.
In the second part of the One-Hour Guide to SEO, the inimitable Rand Fishkin covers what you need to know about the keyword research process, from understanding its goals to building your own keyword universe map. Enjoy!
https://fast.wistia.net/embed/iframe/dbnputwdd5?seo=false&videoFoam=true
https://fast.wistia.net/assets/external/E-v1.js

Click on the whiteboard image above to open a high resolution version in a new tab!
Video Transcription
Howdy, Moz fans. Welcome to another portion of our special edition of Whiteboard Friday, the One-Hour Guide to SEO. This is Part II – Keyword Research. Hopefully you’ve already seen our SEO strategy session from last week. What we want to do in keyword research is talk about why keyword research is required. Why do I have to do this task prior to doing any SEO work?
The answer is fairly simple. If you don’t know which words and phrases people type into Google or YouTube or Amazon or Bing, whatever search engine you’re optimizing for, you’re not going to be able to know how to structure your content. You won’t be able to get into the searcher’s brain, into their head to imagine and empathize with them what they actually want from your content. You probably won’t do correct targeting, which will mean your competitors, who are doing keyword research, are choosing wise search phrases, wise words and terms and phrases that searchers are actually looking for, and you might be unfortunately optimizing for words and phrases that no one is actually looking for or not as many people are looking for or that are much more difficult than what you can actually rank for.
The goals of keyword research
So let’s talk about some of the big-picture goals of keyword research.
Understand the search demand landscape so you can craft more optimal SEO strategies
First off, we are trying to understand the search demand landscape so we can craft better SEO strategies. Let me just paint a picture for you.
I was helping a startup here in Seattle, Washington, a number of years ago — this was probably a couple of years ago — called Crowd Cow. Crowd Cow is an awesome company. They basically will deliver beef from small ranchers and small farms straight to your doorstep. I personally am a big fan of steak, and I don’t really love the quality of the stuff that I can get from the store. I don’t love the mass-produced sort of industry around beef. I think there are a lot of Americans who feel that way. So working with small ranchers directly, where they’re sending it straight from their farms, is kind of an awesome thing.
But when we looked at the SEO picture for Crowd Cow, for this company, what we saw was that there was more search demand for competitors of theirs, people like Omaha Steaks, which you might have heard of. There was more search demand for them than there was for “buy steak online,” “buy beef online,” and “buy rib eye online.” Even things like just “shop for steak” or “steak online,” these broad keyword phrases, the branded terms of their competition had more search demand than all of the specific keywords, the unbranded generic keywords put together.
That is a very different picture from a world like “soccer jerseys,” where I spent a little bit of keyword research time today looking, and basically the brand names in that field do not have nearly as much search volume as the generic terms for soccer jerseys and custom soccer jerseys and football clubs’ particular jerseys. Those generic terms have much more volume, which is a totally different kind of SEO that you’re doing. One is very, “Oh, we need to build our brand. We need to go out into this marketplace and create demand.” The other one is, “Hey, we need to serve existing demand already.”
So you’ve got to understand your search demand landscape so that you can present to your executive team and your marketing team or your client or whoever it is, hey, this is what the search demand landscape looks like, and here’s what we can actually do for you. Here’s how much demand there is. Here’s what we can serve today versus we need to grow our brand.
Create a list of terms and phrases that match your marketing goals and are achievable in rankings
The next goal of keyword research, we want to create a list of terms and phrases that we can then use to match our marketing goals and achieve rankings. We want to make sure that the rankings that we promise, the keywords that we say we’re going to try and rank for actually have real demand and we can actually optimize for them and potentially rank for them. Or in the case where that’s not true, they’re too difficult or they’re too hard to rank for. Or organic results don’t really show up in those types of searches, and we should go after paid or maps or images or videos or some other type of search result.
Prioritize keyword investments so you do the most important, high-ROI work first
We also want to prioritize those keyword investments so we’re doing the most important work, the highest ROI work in our SEO universe first. There’s no point spending hours and months going after a bunch of keywords that if we had just chosen these other ones, we could have achieved much better results in a shorter period of time.
Match keywords to pages on your site to find the gaps
Finally, we want to take all the keywords that matter to us and match them to the pages on our site. If we don’t have matches, we need to create that content. If we do have matches but they are suboptimal, not doing a great job of answering that searcher’s query, well, we need to do that work as well. If we have a page that matches but we haven’t done our keyword optimization, which we’ll talk a little bit more about in a future video, we’ve got to do that too.
Understand the different varieties of search results
So an important part of understanding how search engines work — we’re going to start down here and then we’ll come back up — is to have this understanding that when you perform a query on a mobile device or a desktop device, Google shows you a vast variety of results. Ten or fifteen years ago this was not the case. We searched 15 years ago for “soccer jerseys,” what did we get? Ten blue links. I think, unfortunately, in the minds of many search marketers and many people who are unfamiliar with SEO, they still think of it that way. How do I rank number one? The answer is, well, there are a lot of things “number one” can mean today, and we need to be careful about what we’re optimizing for.

So if I search for “soccer jersey,” I get these shopping results from Macy’s and soccer.com and all these other places. Google sort has this sliding box of sponsored shopping results. Then they’ve got advertisements below that, notated with this tiny green ad box. Then below that, there are couple of organic results, what we would call classic SEO, 10 blue links-style organic results. There are two of those. Then there’s a box of maps results that show me local soccer stores in my region, which is a totally different kind of optimization, local SEO. So you need to make sure that you understand and that you can convey that understanding to everyone on your team that these different kinds of results mean different types of SEO.
Now I’ve done some work recently over the last few years with a company called Jumpshot. They collect clickstream data from millions of browsers around the world and millions of browsers here in the United States. So they are able to provide some broad overview numbers collectively across the billions of searches that are performed on Google every day in the United States.
Click-through rates differ between mobile and desktop
The click-through rates look something like this. For mobile devices, on average, paid results get 8.7% of all clicks, organic results get about 40%, a little under 40% of all clicks, and zero-click searches, where a searcher performs a query but doesn’t click anything, Google essentially either answers the results in there or the searcher is so unhappy with the potential results that they don’t bother taking anything, that is 62%. So the vast majority of searches on mobile are no-click searches.

On desktop, it’s a very different story. It’s sort of inverted. So paid is 5.6%. I think people are a little savvier about which result they should be clicking on desktop. Organic is 65%, so much, much higher than mobile. Zero-click searches is 34%, so considerably lower.
There are a lot more clicks happening on a desktop device. That being said, right now we think it’s around 60–40, meaning 60% of queries on Google, at least, happen on mobile and 40% happen on desktop, somewhere in those ranges. It might be a little higher or a little lower.
The search demand curve
Another important and critical thing to understand about the keyword research universe and how we do keyword research is that there’s a sort of search demand curve. So for any given universe of keywords, there is essentially a small number, maybe a few to a few dozen keywords that have millions or hundreds of thousands of searches every month. Something like “soccer” or “Seattle Sounders,” those have tens or hundreds of thousands, even millions of searches every month in the United States.
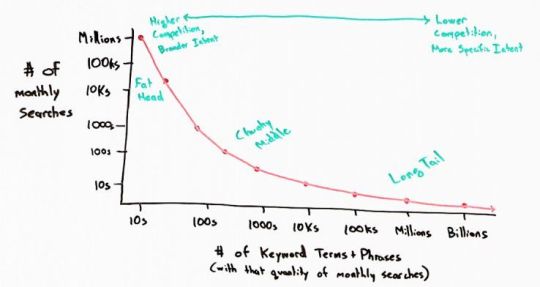
But people searching for “Sounders FC away jersey customizable,” there are very, very few searches per month, but there are millions, even billions of keywords like this.
The long-tail: millions of keyword terms and phrases, low number of monthly searches
When Sundar Pichai, Google’s current CEO, was testifying before Congress just a few months ago, he told Congress that around 20% of all searches that Google receives each day they have never seen before. No one has ever performed them in the history of the search engines. I think maybe that number is closer to 18%. But that is just a remarkable sum, and it tells you about what we call the long tail of search demand, essentially tons and tons of keywords, millions or billions of keywords that are only searched for 1 time per month, 5 times per month, 10 times per month.
The chunky middle: thousands or tens of thousands of keywords with ~50–100 searches per month
If you want to get into this next layer, what we call the chunky middle in the SEO world, this is where there are thousands or tens of thousands of keywords potentially in your universe, but they only have between say 50 and a few hundred searches per month.
The fat head: a very few keywords with hundreds of thousands or millions of searches
Then this fat head has only a few keywords. There’s only one keyword like “soccer” or “soccer jersey,” which is actually probably more like the chunky middle, but it has hundreds of thousands or millions of searches. The fat head is higher competition and broader intent.
Searcher intent and keyword competition
What do I mean by broader intent? That means when someone performs a search for “soccer,” you don’t know what they’re looking for. The likelihood that they want a customizable soccer jersey right that moment is very, very small. They’re probably looking for something much broader, and it’s hard to know exactly their intent.
However, as you drift down into the chunky middle and into the long tail, where there are more keywords but fewer searches for each keyword, your competition gets much lower. There are fewer people trying to compete and rank for those, because they don’t know to optimize for them, and there’s more specific intent. “Customizable Sounders FC away jersey” is very clear. I know exactly what I want. I want to order a customizable jersey from the Seattle Sounders away, the particular colors that the away jersey has, and I want to be able to put my logo on there or my name on the back of it, what have you. So super specific intent.
Build a map of your own keyword universe
As a result, you need to figure out what the map of your universe looks like so that you can present that, and you need to be able to build a list that looks something like this. You should at the end of the keyword research process — we featured a screenshot from Moz’s Keyword Explorer, which is a tool that I really like to use and I find super helpful whenever I’m helping companies, even now that I have left Moz and been gone for a year, I still sort of use Keyword Explorer because the volume data is so good and it puts all the stuff together. However, there are two or three other tools that a lot of people like, one from Ahrefs, which I think also has the name Keyword Explorer, and one from SEMrush, which I like although some of the volume numbers, at least in the United States, are not as good as what I might hope for. There are a number of other tools that you could check out as well. A lot of people like Google Trends, which is totally free and interesting for some of that broad volume data.

So I might have terms like “soccer jersey,” “Sounders FC jersey”, and “custom soccer jersey Seattle Sounders.” Then I’ll have these columns:
Volume, because I want to know how many people search for it;
Difficulty, how hard will it be to rank. If it’s super difficult to rank and I have a brand-new website and I don’t have a lot of authority, well, maybe I should target some of these other ones first that are lower difficulty.
Organic Click-through Rate, just like we talked about back here, there are different levels of click-through rate, and the tools, at least Moz’s Keyword Explorer tool uses Jumpshot data on a per keyword basis to estimate what percent of people are going to click the organic results. Should you optimize for it? Well, if the click-through rate is only 60%, pretend that instead of 100 searches, this only has 60 or 60 available searches for your organic clicks. Ninety-five percent, though, great, awesome. All four of those monthly searches are available to you.
Business Value, how useful is this to your business?
Then set some type of priority to determine. So I might look at this list and say, “Hey, for my new soccer jersey website, this is the most important keyword. I want to go after “custom soccer jersey” for each team in the U.S., and then I’ll go after team jersey, and then I’ll go after “customizable away jerseys.” Then maybe I’ll go after “soccer jerseys,” because it’s just so competitive and so difficult to rank for. There’s a lot of volume, but the search intent is not as great. The business value to me is not as good, all those kinds of things.
Last, but not least, I want to know the types of searches that appear — organic, paid. Do images show up? Does shopping show up? Does video show up? Do maps results show up? If those other types of search results, like we talked about here, show up in there, I can do SEO to appear in those places too. That could yield, in certain keyword universes, a strategy that is very image centric or very video centric, which means I’ve got to do a lot of work on YouTube, or very map centric, which means I’ve got to do a lot of local SEO, or other kinds like this.
Once you build a keyword research list like this, you can begin the prioritization process and the true work of creating pages, mapping the pages you already have to the keywords that you’ve got, and optimizing in order to rank. We’ll talk about that in Part III next week. Take care.
Video transcription by Speechpad.com
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
from https://dentistry01.wordpress.com/2019/03/22/the-one-hour-guide-to-seo-part-2-keyword-research-whiteboard-friday/
0 notes
Link
I see people bitching all the time on here how Upwork is a scam and so on. Are there other ways to get jobs? Yeah. But just a few years ago - as a copywriter - it was NOT difficult for me to pull in $3,000 to $5,000 a month.These days I pull in WELL over that (I don't even start negotiations on a project until $10,000 plus 3% royalties are on the table).And, now I'm the guy hiring people on Upwork.And in one, single image I will show you why 99% of people DON'T get hired on Upwork...I posted a job up with a budget of $125. Very simple - proofread a document (not even a big one). That's $125 any competent proofreader could make in about one or two hours of reading.Great!Out of SEVENTY FOUR BIDS All but about five of them, were like this:http://ift.tt/2jDYS7Y look at that for a moment. Pull it up in another tab and put the window next to this one.I want you to understand something. I put my name in the proposal. I put an attachment in the proposal.Anybody could have referenced me by name and anybody could have referenced that they read the attached document.Instead, all I got from the overwhelming majority of bids were these stupid, lazy, copy/pasted proposals."To whom it may concern" - MY NAME IS RIGHT THERE!"When I was in high school I took an AP level writing course" - I don't give a shit! Did you read the document? Can you do the job? How fast can you do it?"Hi there! My name is Emily, editing fiction is my favorite type of work..." - Well this isn't fiction...so why are you telling me that?"I was very excited to read your job listing! I have a Bachelor's in blah blah blah" - Why would I care about that? Why wouldn't you just explain to me why you were excited to read my listing and actually reference the material IN the listing?Out of 74 bids, I shortlisted just three...why? Because only three people referenced opening the document, reading it, and calling me by nameHere is the person I hired...http://ift.tt/2jJJDoY at the stark difference between this proposal and the ones in the other image.She called me by nameShe clarified that this is what I needed (and demonstrated that she understood)She showed that she opened the document and read it...not only that, she LIKED the content (flattery will get you everywhere)Then - AND ONLY THEN - did she demonstrate her credentialsIf you're not writing proposals like her, that's why you're not getting jobs on UpworkWriting proposals like that - actually spending the time to sit down and reference their job ad, look at their attachments, click their links, and more, for every single job I bid on* is why I was pulling in predictable income every month while everybody else was bitching about how Upwork "isn't fair" and is a "scam" and "doesn't work" and cry baby cry.Here are my hard and fast rules for Upwork success - that I used when I was freelancing primarily on the siteRULE ONE: Bid on jobs EVERY SINGLE DAY. The biggest problem I see with people is they will get on Upwork, bid on a bunch of jobs, then sit back and wait for three, four, or five days, and then say it doesn’t work. Wrong – Wrong – WRONG. I would suggest bidding on jobs twice a day – once in the morning and once in the afternoon around 3PM EST. This way you can bid on jobs that were posted from people in UK/Australia and also from people that were posted in the US on the East Coast and West Coast not too long after they posted them (being first to bid counts). Bid on jobs EVEN when you have plenty of work going on! That way, when you’re finished with one project, you have another project on the way. And remember, you can always reject projects if you’re too busy. Sometimes it can take three days to maybe a couple of weeks for someone to award you a job, bidding every day makes certain you have a pipeline. This is how you get consistent work.RULE TWO: Only bid on jobs posted within the last 24 hours. This is part of the reason you bid every day – you want to bid on jobs posted within a 24 hour period only, and you want to bid on jobs roughly every 24 hours. People who don’t make good money on Upwork are people who are bidding on jobs that are two days to two weeks old – well no wonder! What I like to do is set my filters (will talk about that in a second) and then look at the jobs posted within the last 24 hours, when I see one that I’m interested in – instead of bidding on it right away – I just add it to my “Watch List”. Once I have browsed through all the jobs posted within that 24 hour period, I go to my “Watch List” and begin to bid on those jobs. I typically bid on between 2 and 5 jobs a day. That means, I’m not bidding on EVERY job I see! I bid on jobs that had good prices, that I felt confident that I could do.RULE THREE: : Filter your searches. Here’s what I’d do – I’d click the writing section. I’d filter search results to only show jobs posted within the last 24 hours that are FIXED PRICE (I’ll explain that in a moment). And, I filtered jobs to ONLY show jobs that are at least $100 and above. If it’s below $100 I wasn’t interested. If I was loaded down with plenty of work, I would look at jobs $500 and above. If I was light on work, I would broaden my price range.RULE FOUR: Only bid on fixed price jobs. There is no debating this.RULE FIVE: Avoid bidding on jobs that have over 20 proposals already (unless it’s REALLY good!)RULE SIX: Bid somewhere between the average bid and the high bid. You will be able to see the “average bid” on a project and the “high bid” on a project, you usually want to bid somewhere in the middle. But, let’s say there are only two proposals so far…then you look at the low bid and the high bid, and you KNOW for a fact what each of those two people are bidding. Now, this isn’t a rule that can’t be broken. There’s been plenty of times I’ve seen a REALLY high average bid and a REALLY HIGH bid, and I thought to myself…this project isn’t that difficult, I have nothing going on right now, and I could finish this in a few hours, I’ll low-ball it this time. But, if I got plenty going on, no lack of jobs, I’ll usually stay with this rule.RULE SEVEN: NEVER Copy/Paste your proposals. Now we arrive at THE NUMBER ONE REASON people don’t get jobs on Upwork or Freelancer and it’s because they’re too lazy to write a good proposal – from scratch – for every job they bid on each day.When you read the job ads, pick anything out that you can.Did they mention their name?Their product?Their service?Their location?Did they provide links to a website?Did they provide an attachment?If they DIDN’T provide their name or location, but provided a link to a website – go to the website, what’s on it?Is there an “About” section where they have a bio?If so, read it, type their name into Google can you find their Linkedin?Sometimes you’re going to have more information than others, but even a little information goes a long way.Then, when you write your proposal, you want to IMMEDIATELY mention any of that information you can.For example…Hey Joe!Just checked out JoesCoffee.com. How’s it going up there in Denver? I’m having a cup of coffee right now, but I wish it was your house blend - that looks delicious. I can tell you take immense pride in what you do.Listen, I read through what you’re struggling with, I looked over your ad, and I feel I have a very firm grasp of what you need and I believe I can help you achieve your goals.I’ve attached two recent examples of work, but in order to really get an idea of how we can work together and make this a huge success for your unique brand, I’d need to have a chat with you.I know you’ve got a lot of very good (and eager) candidates clamoring for your attention on here, so I’m willing to work around your schedule.Just let me know a time that works for you – we can do phone or Skype. I’m looking forward to speaking with you Joe!Talk soon,You have to show that you read people's proposal and spent the time to learn about them... then SHOW AND TELL them what you can do for them on that specific project THEN get into your accolades, education, and so on.Hope this helps!
3 notes
·
View notes
Text
Introducing Coverage Critic: Time to Kill the $80 Mobile Phone Bill Forever
A Quick Foreword: Although the world is still in Pandemic mode, we are shifting gears back to personal finance mode here at MMM. Partly because we could all use a distraction right now, and even more important because forced time off like this is the ideal time to re-invest in optimizing parts of your life such as your fitness, food and finances.
—
Every now and then, I learn to my horror that some people are still paying preposterous amounts for mobile phone service, so I write another article about it.
If we are lucky, a solid number of people make the switch and enjoy increased prosperity, but everyone who didn’t happen to read that article goes on paying and paying, and I see it in the case studies that people email me when looking for advice. Lines like this in their budget:
mobile phone service (2 people): $160
“NO!!!!” … is all I can say, when I see such unnecessary expenditure. These days, a great nationwide phone service plan costs between and $10-40 per month, depending on how many frills you need.
Why is this a big deal? Just because of this simple fact:
Cutting $100 per month from your budget becomes a $17,000 boost to your wealth every ten years.
And today’s $10-40 phone plans are just great. Anything more than that is just a plain old ripoff, end of story. Just as any phone more expensive than $200* (yes, that includes all new iPhones), is probably a waste of money too.
So today, we are going to take the next step: assigning a permanent inner-circle Mustachian expert to monitor the ever-improving cell phone market, and dispense the latest advice as appropriate. And I happen to know just the guy:
Christian Smith, along with colleagues at GiveWell in San Francisco, circa 2016
My first contact with Chris was in 2016 when he was working with GiveWell, a super-efficient charitable organization that often tops the list for people looking to maximize the impact of their giving.
But much to my surprise, he showed up in my own HQ coworking space in 2018, and I noticed he was a bit of a mobile phone research addict. He had started an intriguing website called Coverage Critic, and started methodically reviewing every phone plan (and even many handsets) he could get his hands on, and I liked the thorough and open way in which he did it.
This was ideal for me, because frankly I don’t have time to keep pace with ongoing changes in the marketplace. I may be an expert on construction and energy consumption, but I defer to my friend Ben when I have questions about fixing cars, Brandon when I need advice on credit cards, HQ member Dr. D for insider perspectives on the life of a doctor and the medical industry, and now Chris can take on the mobile phone world.
So we decided to team up: Chris will maintain his own list of the best cheap mobile phone plans on a new Coverage Critic page here on MMM. He gets the benefit of more people enjoying his work, and I get the benefit of more useful information on my site. And if it goes well, it will generate savings for you and eventual referral income for us (more on that at the bottom of this article).
So to complete this introduction, I will hand the keyboard over to the man himself.
Meet The Coverage Critic
Chris, engaged in some recent Coverage Criticicism at MMM-HQ
I started my professional life working on cost-effectiveness models for the charity evaluator GiveWell. (The organization is awesome; see MMM’s earlier post.) When I was ready for a career change, I figured I’d like to combine my analytical nature with my knack for cutting through bullshit. That quickly led me to the cell phone industry.
So about a year ago, I created a site called Coverage Critic in the hopes of meeting a need that was being overlooked: detailed mobile phone service reviews, without the common problem of bias due to undisclosed financial arrangements between the phone company and the reviewer.
What’s the Problem with the Cell Phone Industry?
Somehow, every mobile phone network in the U.S. claims to offer the best service. And each network can back up its claims by referencing third-party evaluations.
How is that possible? Bad financial incentives.
Each network wants to claim it is great. Network operators are willing to pay to license reviewers’ “awards”. Consequently, money-hungry reviewers give awards to undeserving, mediocre networks.
On top of this, many phone companies have whipped up combinations of confusing plans, convoluted prices, and misleading claims. Just a few examples:
Coverage maps continue to be wildly inaccurate.
Many carriers offer “unlimited” plans that have limits.
All of the major U.S. network operators are overhyping next-generation, 5G technologies. AT&T has even started tricking its subscribers by renaming some of its 4G service “5GE.”
However, with enough research and shoveling, I believe it becomes clear which phone companies and plans offer the best bang for the buck. So going forward, MMM and I will be collaborating to share recommended phone plans right here on his website, and adding an automated plan finder tool soon afterwards. I think you’ll find that there are a lot of great, budget-friendly options on the market.
A Few Quick Examples:
T-Mobile Connect: unlimited minutes and texts with 2GB of data for $15 per month
Total Wireless: 4 lines in a combined family plan with unlimited calling, texting, and 100GB of shared data(!) for $100 per month. (runs on Verizon’s extensive network)
Xfinity Mobile: 5 lines with unlimited minutes, unlimited texts, and 10GB of shared data over Verizon’s network for about $12 per line each month (heads up: only Xfinity Internet customers are eligible, and the bring-your-own-device program is fairly restrictive).
Ting: Limited use family plans for under $15 per line each month.
Tello: 100 minutes, unlimited texts, and 1GB of data for $7 per month (on Sprint’s somewhat lousy network).
[MMM note – even as a frequent traveler, serious techie and a “professional blogger”, I rarely use more than 1GB each month on my own Google Fi plan ($20 base cost plus data, then $15 for each additional family member). So some of these are indeed generous plans]
Okay, What About Phones?
With the above carriers, you may be able to bring your existing phone. But if you need a new one, there are some damn good, low-cost options these days. The Moto G7 Play is only $130 and offers outstanding performance despite the low price point. I use it as my personal phone and love it.
If you really want something fancy, consider the Google Pixel 3a or the recently released, second-generation iPhone SE. Both of these are amazing phones and about half as expensive as an iPhone 11.
——————————————-
Mobile Phone Service 101
If you’re looking to save on cell phone service, it’s helpful to have a basic understanding of the industry. For the sake of brevity, I’m going to skip over a lot of nuances in the rest of this post. If you’re a nerd like me and want more technical details, check out my longer, drier article that goes into more depth.
The Wireless Market
There are only four nationwide networks in the U.S. (soon to be three thanks to a merger between T-Mobile and Sprint). They vary in the extent of their coverage:
Verizon (most coverage)
AT&T (2nd best coverage)
T-Mobile (3rd best coverage)
Sprint (worst coverage)
Not everyone needs the most coverage. All four nationwide networks typically offer solid coverage in densely populated areas. Coverage should be a bigger concern for people who regularly find themselves deep in the mountains or cornfields.
While there are only four nationwide networks, there are dozens of carriers offering cell phone service to consumers – offering vastly different pricing and customer service experiences.
Expensive services running over a given network will tend to offer better customer service, more roaming coverage, and better priority during periods of congestion than low-cost carriers using the same network. That said, many people won’t even notice a difference between low-cost and high-cost carriers using the same network.
For most people, the easiest way to figure out whether a low-cost carrier will provide a good experience is to just try one. You can typically sign up for these services without a long-term commitment. If you have a good initial experience with a budget-friendly carrier, you can stick with it and save substantially month after month.
With a good carrier, a budget-friendly phone, and a bit of effort to limit data use, most people can have a great cellular experience while saving a bunch of money.
MMM’s Conclusion
From now on, you can check in on the Coverage Critic’s recommendations at mrmoneymustache.com/coveragecritic, and he will also be issuing occasional clever or wry commentary on Twitter at @Coverage_Critic.
Thanks for joining the team, Chris!
*okay, special exception if you use it for work in video or photography. I paid $299 a year ago for my stupendously fancy Google Pixel 3a phone.. but only because I run this blog and the extra spending is justified by the better camera.
The Full Disclosure: whenever possible, we have signed this blog up for referral programs with any recommended companies that offer them, so we may receive a commission if you sign up for a plan using our research. We aim to avoid letting income (or lack thereof) affect our recommendations, but we still want to be upfront about everything so you can judge for yourself. Specific details about these referral programs is shared on the CC transparency page. MMM explains more about how he handles affiliate arrangements here.
from Money 101 https://www.mrmoneymustache.com/2020/05/03/mobile-phone-plans/ via http://www.rssmix.com/
0 notes
Text
Introducing Coverage Critic: Time to Kill the $80 Mobile Phone Bill Forever
A Quick Foreword: Although the world is still in Pandemic mode, we are shifting gears back to personal finance mode here at MMM. Partly because we could all use a distraction right now, and even more important because forced time off like this is the ideal time to re-invest in optimizing parts of your life such as your fitness, food and finances.
—
Every now and then, I learn to my horror that some people are still paying preposterous amounts for mobile phone service, so I write another article about it.
If we are lucky, a solid number of people make the switch and enjoy increased prosperity, but everyone who didn’t happen to read that article goes on paying and paying, and I see it in the case studies that people email me when looking for advice. Lines like this in their budget:
mobile phone service (2 people): $160
“NO!!!!” … is all I can say, when I see such unnecessary expenditure. These days, a great nationwide phone service plan costs between and $10-40 per month, depending on how many frills you need.
Why is this a big deal? Just because of this simple fact:
Cutting $100 per month from your budget becomes a $17,000 boost to your wealth every ten years.
And today’s $10-40 phone plans are just great. Anything more than that is just a plain old ripoff, end of story. Just as any phone more expensive than $200* (yes, that includes all new iPhones), is probably a waste of money too.
So today, we are going to take the next step: assigning a permanent inner-circle Mustachian expert to monitor the ever-improving cell phone market, and dispense the latest advice as appropriate. And I happen to know just the guy:
Christian Smith, along with colleagues at GiveWell in San Francisco, circa 2016
My first contact with Chris was in 2016 when he was working with GiveWell, a super-efficient charitable organization that often tops the list for people looking to maximize the impact of their giving.
But much to my surprise, he showed up in my own HQ coworking space in 2018, and I noticed he was a bit of a mobile phone research addict. He had started an intriguing website called Coverage Critic, and started methodically reviewing every phone plan (and even many handsets) he could get his hands on, and I liked the thorough and open way in which he did it.
This was ideal for me, because frankly I don’t have time to keep pace with ongoing changes in the marketplace. I may be an expert on construction and energy consumption, but I defer to my friend Ben when I have questions about fixing cars, Brandon when I need advice on credit cards, HQ member Dr. D for insider perspectives on the life of a doctor and the medical industry, and now Chris can take on the mobile phone world.
So we decided to team up: Chris will maintain his own list of the best cheap mobile phone plans on a new Coverage Critic page here on MMM. He gets the benefit of more people enjoying his work, and I get the benefit of more useful information on my site. And if it goes well, it will generate savings for you and eventual referral income for us (more on that at the bottom of this article).
So to complete this introduction, I will hand the keyboard over to the man himself.
Meet The Coverage Critic
Chris, engaged in some recent Coverage Criticicism at MMM-HQ
I started my professional life working on cost-effectiveness models for the charity evaluator GiveWell. (The organization is awesome; see MMM’s earlier post.) When I was ready for a career change, I figured I’d like to combine my analytical nature with my knack for cutting through bullshit. That quickly led me to the cell phone industry.
So about a year ago, I created a site called Coverage Critic in the hopes of meeting a need that was being overlooked: detailed mobile phone service reviews, without the common problem of bias due to undisclosed financial arrangements between the phone company and the reviewer.
What’s the Problem with the Cell Phone Industry?
Somehow, every mobile phone network in the U.S. claims to offer the best service. And each network can back up its claims by referencing third-party evaluations.
How is that possible? Bad financial incentives.
Each network wants to claim it is great. Network operators are willing to pay to license reviewers’ “awards”. Consequently, money-hungry reviewers give awards to undeserving, mediocre networks.
On top of this, many phone companies have whipped up combinations of confusing plans, convoluted prices, and misleading claims. Just a few examples:
Coverage maps continue to be wildly inaccurate.
Many carriers offer “unlimited” plans that have limits.
All of the major U.S. network operators are overhyping next-generation, 5G technologies. AT&T has even started tricking its subscribers by renaming some of its 4G service “5GE.”
However, with enough research and shoveling, I believe it becomes clear which phone companies and plans offer the best bang for the buck. So going forward, MMM and I will be collaborating to share recommended phone plans right here on his website, and adding an automated plan finder tool soon afterwards. I think you’ll find that there are a lot of great, budget-friendly options on the market.
A Few Quick Examples:
T-Mobile Connect: unlimited minutes and texts with 2GB of data for $15 per month
Total Wireless: 4 lines in a combined family plan with unlimited calling, texting, and 100GB of shared data(!) for $100 per month. (runs on Verizon’s extensive network)
Xfinity Mobile: 5 lines with unlimited minutes, unlimited texts, and 10GB of shared data over Verizon’s network for about $12 per line each month (heads up: only Xfinity Internet customers are eligible, and the bring-your-own-device program is fairly restrictive).
Ting: Limited use family plans for under $15 per line each month.
Tello: 100 minutes, unlimited texts, and 1GB of data for $7 per month (on Sprint’s somewhat lousy network).
[MMM note – even as a frequent traveler, serious techie and a “professional blogger”, I rarely use more than 1GB each month on my own Google Fi plan ($20 base cost plus data, then $15 for each additional family member). So some of these are indeed generous plans]
Okay, What About Phones?
With the above carriers, you may be able to bring your existing phone. But if you need a new one, there are some damn good, low-cost options these days. The Moto G7 Play is only $130 and offers outstanding performance despite the low price point. I use it as my personal phone and love it.
If you really want something fancy, consider the Google Pixel 3a or the recently released, second-generation iPhone SE. Both of these are amazing phones and about half as expensive as an iPhone 11.
——————————————-
Mobile Phone Service 101
If you’re looking to save on cell phone service, it’s helpful to have a basic understanding of the industry. For the sake of brevity, I’m going to skip over a lot of nuances in the rest of this post. If you’re a nerd like me and want more technical details, check out my longer, drier article that goes into more depth.
The Wireless Market
There are only four nationwide networks in the U.S. (soon to be three thanks to a merger between T-Mobile and Sprint). They vary in the extent of their coverage:
Verizon (most coverage)
AT&T (2nd best coverage)
T-Mobile (3rd best coverage)
Sprint (worst coverage)
Not everyone needs the most coverage. All four nationwide networks typically offer solid coverage in densely populated areas. Coverage should be a bigger concern for people who regularly find themselves deep in the mountains or cornfields.
While there are only four nationwide networks, there are dozens of carriers offering cell phone service to consumers – offering vastly different pricing and customer service experiences.
Expensive services running over a given network will tend to offer better customer service, more roaming coverage, and better priority during periods of congestion than low-cost carriers using the same network. That said, many people won’t even notice a difference between low-cost and high-cost carriers using the same network.
For most people, the easiest way to figure out whether a low-cost carrier will provide a good experience is to just try one. You can typically sign up for these services without a long-term commitment. If you have a good initial experience with a budget-friendly carrier, you can stick with it and save substantially month after month.
With a good carrier, a budget-friendly phone, and a bit of effort to limit data use, most people can have a great cellular experience while saving a bunch of money.
MMM’s Conclusion
From now on, you can check in on the Coverage Critic’s recommendations at mrmoneymustache.com/coveragecritic, and he will also be issuing occasional clever or wry commentary on Twitter at @Coverage_Critic.
Thanks for joining the team, Chris!
*okay, special exception if you use it for work in video or photography. I paid $299 a year ago for my stupendously fancy Google Pixel 3a phone.. but only because I run this blog and the extra spending is justified by the better camera.
The Full Disclosure: whenever possible, we have signed this blog up for referral programs with any recommended companies that offer them, so we may receive a commission if you sign up for a plan using our research. We aim to avoid letting income (or lack thereof) affect our recommendations, but we still want to be upfront about everything so you can judge for yourself. Specific details about these referral programs is shared on the CC transparency page. MMM explains more about how he handles affiliate arrangements here.
from Finance https://www.mrmoneymustache.com/2020/05/03/mobile-phone-plans/ via http://www.rssmix.com/
0 notes
Text
Net Nanny Review: Great for Managing Screen Time, but Weak When It Comes to Filtering
Overall Rating
3/5
Device pause button
Location tracking
No social media monitoring
Plans start at $39.99/yr.
Visit Net Nanny
Compare Plans
Last Updated: A day ago
We asked a parent test Net Nanny on her kids' iOS and Android devices to see if we still like its features and performance. Find out why Net Nanny dropped from four stars to three in this updated review that digs into all the good and bad of this parental control app.
Net Nanny is a great tool to control my kids’ screen time, but it’s a pain to set up—and the holes in its content filters made me question its effectiveness.
Net Nanny Pros and Cons
Pros
Pause button
Website blocking
Location tracking
Screen time limits
Cons
Confusing installation
No social media monitoring
Weak content filters
How We Tested Net Nanny
To test Net Nanny, we signed up for the five-device plan. We downloaded the Net Nanny child app to a Moto4 and an Android 6, and we used a Google Chrome browser on a MacBook Pro to control the online parent dashboard.
Over the course of several days, we saw how Net Nanny performed with normal device use and we also actively tested specific control features.
Our full methodology gives more details about how we test and review products like Net Nanny.
Net Nanny Pricing
Total Yearly Cost Yearly Cost Per Device Trial Period Return Policy Contract Length Learn More
1-Device Desktop Plan 5-Device Family Protection Pass 20-Device Family Protection Pass $39.99 $54.99 $89.99 $39.99 $11.00 $4.50 None None None 14 days 14 days 14 days 1 year 1 year 1 year Visit Net Nanny Visit Net Nanny Visit Net Nanny
Data effective 8/14/2019. Offers and availability subject to change.
Unlike similar software products that base plan pricing on the number of features offered, the only difference between the various Net Nanny packages is the number of devices covered. All packages come with the same protection features, so you don’t have to trade more money for more control.
The average family with two to five children will get the best deal by purchasing the 5-Device Family Protection Pass, but a larger family will benefit from the savings offered by the 20-Device Pass.
Tech and Equipment
Net Nanny software works with Windows PCs, Macs, Kindle Fire tablets, and iOS and Android devices, but older operating systems may not support it.
I couldn’t install Net Nanny on my youngest daughter’s device because it’s my old iPhone 4S. If you’re like me and your kids get electronic hand-me-downs, be sure to check the Products tab on the Net Nanny site for compatibility before you commit.
Many parental control software products use a website’s history to determine whether it’s safe for kids, but Net Nanny actually analyzes website activity in real time with its Dynamic Contextual Analysis. It’s kind of like the difference between reading a Yelp review to find out what a restaurant is like versus sending someone to the restaurant to find out in person.
We like that Net Nanny is gathering up-to-date info based on what’s on the website at any given time, not just what category the website is in.
Despite its real-time web filtering technology, Net Nanny caused no noticeable delay on my kids’ devices after installation. Also, adjusting a control on the Parent Dashboard translated to their phones almost instantly.
Net Nanny Features
Screen Time Limits and Scheduling
Net Nanny offers both time limits and schedules, so you can control the amount of time kids spend on their devices each day and what times they’re allowed to use them.
Similar parental control devices like Disney Circle limit only internet activity, but Net Nanny actually pauses the smartphone or tablet itself, which is exactly what I hoped for.
Net Nanny also notifies the child with a full-screen message that they’ve used up their screen time or that their scheduled screen time has ended. In all of my tests, the screen time limits worked perfectly, and I like how easy it was to control them from the user profiles on the dashboard. I also loved the instant pause button.
Content Filtering
I’m not impressed with Net Nanny’s content control filters.
I blocked my daughter’s phone from content related to suicide, but in testing I was still able to access graphic scenes on YouTube from a popular show about suicide.
On the flip side, when my daughter tried to access a video about doll refurbishing, Net Nanny blocked it, and I got a notice that she was being blocked from “mature content.” I watched the video in question and saw nothing in it that could be considered mature.
Net Nanny’s filters might provide more inconvenience than protection.
App and Website Blocking
Net Nanny lets you block specific websites and apps, and while website blocking worked well, the app blocking was glitchy.
A word game continued to work for several minutes after I’d blocked it, and then Net Nanny told me an app I hadn’t blocked was blocked. I also wish that the app blocking feature had an alert option like the website blocker does, rather than just a total block option.
Location Tracking
Net Nanny’s location tracking is a nice bonus for this kind of software. It will update your child’s phone’s location on a map every minute so you always know where they are—or at least where their phone is. In our tests the location tracking worked perfectly.
Installation and Setup
Installing and setting up Net Nanny on my kids’ devices took almost an hour and it was a hassle.
The parent page instructs you to install the software on your children’s devices by using your children’s devices to go to a website. But when I entered in the web address I came to a webpage that was not optimized for mobile users, and I couldn’t use it to install the mobile app.
I finally searched for the Net Nanny child app in the Google Play store. Fortunately, once I found it, downloading and installing it was easy. I used the same technique for my oldest daughter’s newer Android.
Because this is an app that tracks your child’s phone usage, most of the setup was the app asking me to say yes to all the permissions it asked for. As a security-minded parent, I was nervous handing over all that access to an app, but without it, the app can’t do its job.
To learn more about what the company does with the data gathered from the app, you can check out Net Nanny’s privacy policy.
Parent Dashboard
The Parent Dashboard was tricky to figure out at first.
It was only by chance that I realized one of the icons on the dashboard was the same as the icon I click in my photo editing program when I want to edit an image. When I clicked on it, sure enough it opened up the parental control options and let me edit each child’s filters, blocks, and screen time.
The wording is also confusing on the dashboard. For example, “Paused from Schedule” doesn’t mean that Net Nanny is pausing the schedule. It means that the device has been paused because of the schedule you’ve set.
“Current Rule: Standard, Applied Manually” means that the device’s current status is standard, meaning no screen time restrictions, and that it’s on that setting because you manually set it to standard (not because it’s scheduled).
It took me awhile to decode Net Nanny’s jargon, but once I did, it made sense and was easier to navigate the various tools and options.
One thing I liked about the Parent Dashboard was the family feed that showed all of my children’s activity. I could see their internet browser searches and view notifications if they tried to access any blocked content. Clicking on the content took me right to the blocked site so I could evaluate it for myself.
How Net Nanny Stacks Up
Yearly Starting Price Content Filtering Screen Time Monitoring Social Media Monitoring Location Tracking Learn More
$39.99 $99.00 $49.46 ✓ Yes X No ✓ Yes ✓ Yes X No ✓ Yes X No ✓ Yes ✓ Yes ✓ Yes X No ✓ Yes Visit Net Nanny Visit Bark Visit Qustodio
Data effective 8/14/2019. Offers and availability subject to change.
Net Nanny FAQs
Are Zift and Net Nanny the same thing?
Yes, Zift parental control software recently “married” Net Nanny software, and together they became Net Nanny 10.
Zift subscribers retain the same features and control they had with Zift, but with a name change and additional Net Nanny features like the Parent Dashboard.
Likewise, Net Nanny adopted some Zift features, like the App Advisor that informs parents about the safety of different popular apps.
Does Net Nanny work with the Google Chrome web browser?
Yes, according to Net Nanny, “Net Nanny products work with ALL internet browsers.”¹
Will my kids know I’m monitoring them with Net Nanny?
Yes. Unlike other parental control programs, Net Nanny does not offer a stealth mode for parents.
According to the Net Nanny Help Center, “Net Nanny does not offer an option to run in Stealth Mode because we encourage open and honest dialogue between family members regarding the importance of surfing the internet safely.”²
Conclusion
Once I got through some installation roadblocks and spent some time using the tools on Net Nanny’s Parent Dashboard, I found it easy to use.
I loved the screen time controls, but the inappropriate content that snuck through the web content filters was troubling, and the app blocking wasn’t always reliable.
I might be willing to give Net Nanny another shot just for the screen time control and handy pause button, but I wouldn’t trust it to protect my kids online.
Visit Net Nanny
Related Pages on SafeWise
Best Parental Control Apps of 2019 Internet Safety Guide for Kids What to Do If Your Identity Is Stolen Best Anti-Malware and Antivirus Software Best Identity Theft Protection
Sources:
1. Net Nanny Support, “Is the Net Nanny Website Not Working Like You Expect?” 2. Net Nanny Help Center, “Stealth Mode“
The post Net Nanny Review: Great for Managing Screen Time, but Weak When It Comes to Filtering appeared first on SafeWise.
Article source here: Net Nanny Review: Great for Managing Screen Time, but Weak When It Comes to Filtering
0 notes
Link
In the last few months, I have learned a lot about modern JavaScript and CSS development with a local toolchain powered by Node 8, Webpack 4, and Babel 7. As part of that, I am doing my second “re-introduction to JavaScript”. I first learned JS in 1998. Then relearned it from scratch in 2008, in the era of “The Good Parts”, Firebug, jQuery, IE6-compatibility, and eventually the then-fledgling Node ecosystem. In that era, I wrote one of the most widely deployed pieces of JavaScript on the web, and maintained a system powered by it. Now I am re-learning it in the era of ECMAScript (ES6 / ES2017), transpilation, formal support for libraries and modularization, and, mobile web performance with things like PWAs, code splitting, and WebWorkers / ServiceWorkers. I am also pleasantly surprised that JS, via the ECMAScript standard and Babel, has evolved into a pretty good programming language, all things considered. To solidify all this stuff, I am using webpack/babel to build all static assets for a simple Python/Flask web app, which ends up deployed as a multi-hundred-page static site. One weekend, I ported everything from Flask-Assets to webpack, and to play around with ES2017 features, as well as explore the Sass CSS preprocessor and some D3.js examples. And boy, did that send me down a yak shaving rabbit hole. Let’s start from the beginning! JavaScript in 1998 I first learned JavaScript in 1998. It’s hard to believe that this was 20 years — two decades! — ago. This post will chart the two decades since — covering JavaScript in 1998, 2008, and 2018. The focus of the article will be on “modern” JavaScript, as of my understanding in 2018/2019, and, in particular, what a non-JavaScript programmer should know about how the language — and its associated tooling and runtime — have dramatically evolved. If you’re the kind of programmer who thinks, “I code in Python/Java/Ruby/C/whatever, and thus I have no use for JavaScript and don’t need to know anything about it”, you’re wrong, and I’ll describe why. Incidentally, you were right in 1998, you could get by without it in 2008, and you are dead wrong in 2018. Further, if you are the kind of programmer who thinks, “JavaScript is a tire fire I’d rather avoid because it lacks basic infrastructure we take for granted in ‘real’ programming languages”, then you are also wrong. I’ll be able to show you how “not taking JavaScript seriously” is the 2018 equivalent of the skeptical 2008-era programmer not taking Python or Ruby seriously. JavaScript is a language that is not only here to stay, but has already — and will continue to — take over the world in several important areas. To be a serious programmer, you’ll have to know JavaScript’s Modern and Good Parts — as well as some other server-side language, like Python, Ruby, Go, Elixir, Clojure, Java, and so on. But, though you can swap one backend language for the other, you can’t avoid JavaScript: it’s pervasive in every kind of web deployment scenario. And, the developer tooling has fully caught up to your expectations. JavaScript during The Browser Wars Browsers were a harsh environment to target for development; not only was Internet adoption low and not only were internet connections slow, but the browser wars — mainly between Netscape and Microsoft — were creating a lot of confusion. Netscape Navigator 4 was released in 1997, and Internet Explorer 5 was released in 1998. The web was still trying to make sense of HTML and CSS; after all, CSS1 had only been released a year earlier. In this environment, the definitive web development book of the era was “JavaScript: The Definitive Guide”, which weighed in at over 500 pages. Note that, in 1998, the most widely used programming languages were C, C++, and Java, as well as Microsoft Visual Basic for Windows programmers. So expectations about “what programming was” were framed mostly around these languages. In this sense, JavaScript was quite, quite different. There was no compiler. There was no debugger (at least, not very good ones). There was no way to “run a JavaScript program”, except to write scripts in your browser, and see if they ran. Development tools for JavaScript were still primitive or inexistent. There was certainly not much of an open source community around JS; to figure out how to do things, you would typically “view source” on other people’s websites. Plus, much of the discussion in the programming community of web developers was how JavaScript represented a compatibility and security nightmare. Not only differing implementations across browsers, but also many ways for you to compromise the security of your web application by relying upon JavaScript too directly. A common security bug in that era was to validate forms with JavaScript, but still allow invalid (and insecure) values to be passed to the server. Or, to password-protect a system, but in a way that inspection of JavaScript code could itself crack access to that system. Combined with the lack of a proper development environment, the “real web programmers” used JavaScript as nothing more than a last resort — a way to inject a little bit of client-side code and logic into pages where doing it server-side made no sense. I remember one of the most common use cases for JavaScript at the time was nothing more than changing an image upon hover, as a stylistic effect, or implementing a basic on-hover menu on a complex multi-tab form. These days, these tasks can be achieved with vanilla CSS, but, at the time, JavaScript DOM manipulation was your only option. JavaScript in 2008 Fast forward 10 years. In 2008, Douglas Crockford released the book, “JavaScript: The Good Parts”. By using a language subsetting approach, Crockford pointed out that, not only was JavaScript not a bad language, it was actually a good language, well-designed, with certain key features that made it stand out vs competitors. Around this time, several JavaScript libraries were becoming popular, notably jQuery, Prototype, YUI, and Dojo. These libraries attempted to provide JavaScript with something it was missing: a cross-browser compatibility layer and programming model for doing dynamic manipulation of pages inside the browser, and especially for a new model of JavaScript programming that was emerging, with the moniker AJAX. This was the beginning of the trend of rich internet applications, “dynamic” web apps, single-page applications, and the like. JavaScript’s Tooling Leaps The developer tooling for JavaScript also took some important leaps. In 2006, the Firefox team released Firebug, a JavaScript and DOM debugger for Firefox, which was then one of the world’s most popular web browsers, and open source. Two years later, Google would make the first release of Google Chrome, which bundled some developer tooling. Around the same time that Chrome was released, Google also released V8, the JavaScript engine that was embedded inside of Chrome. That marked the first time that the world had seen a full-fledged, performant open source implementation of the JavaScript language that was not completely tied to a browser. Firefox’s JS engine, SpiderMonkey, was part of its source tree, but was not necessarily marketed to be modularized and used outside the context of the Firefox browser. I remember that aside from Crockford’s work on identifying the good parts of JavaScript, and aside from the new (and better) developer tooling, a specific essay on Mozilla’s website helped me re-appreciate the language, and throw away my 1998 conception. That article was called “A Reintroduction to JavaScript”. It showed how JavaScript was actually a real programming language, once you got past the tooling bumps. A little under-powered in its standard library, thus you had to rely upon frameworks (like jQuery) to give you some tools, and little micro-libraries beyond that. A year after reading that essay, I wrote my own about JavaScript, which was called “Real, Functional Programs with JavaScript” (archived PDF here). It described how JavaScript was, quite surprisingly, more of a functional language than Java 8 or Python 2.7. And that with a little focus on understanding the functional core, really good programs could be written. I recently converted this essay into a set of instructional slides with the name, “Lambda JavaScript” (archived notes here), which I now use to teach new designers/developers the language from first principles. But, let’s return to history. Only a year after the release of Chrome, in 2009, we saw the first release of NodeJS, which took the V8 JavaScript engine and embedded it into a server-side environment, which could be used to experiment with JavaScript on a REPL, to write scripts, and even to write HTTP servers on a performant event loop. People began to experiment with command-line tools written in JavaScript, and with web frameworks written in JavaScript. It was at this point that the pace of development in the JavaScript community accelerated. In 2010, npm — the Node Package Manager — was released, and it and its package registry quickly grew to represent the full JavaScript open source community. Over the next few years, the browser vendors of Mozilla, Google, Apple, and Microsoft engaged in the “JavaScript Engine Wars”, with each developing SpiderMonkey, V8, Nitro, and Chakra to new heights. Meanwhile, NodeJS and V8 became the “standard” JS engine running on developer’s machines from the command line. Though developers still had to target old “ECMAScript 3” browsers (such as IE6), and thus had to write restrained JavaScript code, the “evergreen” (auto-updating) browsers from Mozilla, Google, and Apple gained support for ECMAScript 5 and beyond, and mobile web browsing went into ascendancy, thus making Chrome and Safari dominant in market share especially on smartphones. I remember in 2012, I gave a presentation at a local tech conference entitled, “Writing Real Programs… with JavaScript!?”. The “!?” punctuation was intentional. That was the general zeitgeist I remember in a room full of developers: that is, “is writing real programs with JavaScript… actually possible!?” It’s funny to review those slides as a historical relic. I spent the first half of the talk convincing the audience that JavaScript’s functional core was actually pretty good. And then I spent the second half convincing them that NodeJS might… it just might… create a developer tooling ecosystem and standard library for JavaScript. There are also a few funny “detour” slides in there around things like Comet vs Ajax, a debate that didn’t really amount to much (but it’s good to remind one of fashion trends in tech). Zooming ahead a few years, in all of this noise of web 2.0, cloud, and mobile, we finally reached “mobilegeddon” in 2015, where mobile traffic surpassed desktop traffic, and we also saw several desktop operating systems move to a mostly-evergreen model, such as Windows 10, Mac OS X, and ChromeOS. As a result, as early as 2015 — but certainly by 2018 — JavaScript became the most widely deployed and performant programming language with “built-in support” on almost every desktop and mobile computer in the world. In other words, if you wanted your code to be “write once, run everywhere” in 2015 or so (but even as far back as 2009), your best option was JavaScript. Well, that’s even more true today. The solid choice for widespread distribution of your code continues to be JavaScript. As Crockford predicted in 2008: “It is better to be lucky than smart.” JavaScript in 2018-2019 In 2018-2019, several things have changed about the JavaScript community. Development tools are no longer fledgling, but are, instead, mature. There are built-in development tools in all of Safari, Firefox, and Chrome browsers (and the Firebug project is mostly deprecated). There are also ways to debug mobile web browsers using mobile development tools. NodeJS and npm are mature projects that are shared infrastructure for the whole JavaScript community. What’s more, JavaScript, as a language, has evolved. It’s no longer just the kernel language we knew in 1998, nor the “good parts” we knew in 2008, but instead the “modern parts” of JavaScript include several new language features that go by the name “ES6” (ECMAScript v6) or “ES2017” (ECMAScript 2017 Edition), and beyond. Some concepts in HTML have evolved, such as HTML5 video and audio elements. CSS, too, has evolved, with the CSS2 and CSS3 specifications being ratified and widely adopted. JSON has all but entirely replaced XML as an interchange format and is, of course, JavaScript-based. The V8 engine has also gotten a ton of performance-oriented development. It is now a JIT compiled language with speedy startup times and speedy near-native performance for CPU-bound blocks. Modern web performance techniques are almost entirely based on a speedy JavaScript engine and the ability to script different elements of a web application’s loading approach. The language itself has become comfortable with something akin to “compiler” and “command line” toolchains you might find in Python, Ruby, C, and Java communities. In lieu of a JavaScript “compiler”, we have node, JavaScript unit testing frameworks like Mocha/Jest, as well as eslint and babel for syntax checking. (More on this later.) In lieu of a “debugger”, we have the devtools built into our favorite browser, like Chrome or Firefox. This includes rich debuggers, REPLs/consoles, and visual inspection tools. Scriptable remote connections to a node environment or a browser process (via new tools like Puppeteer) further close the development loop. To use JavaScript in 2018/2019, therefore, is to adopt a system that has achieved 2008-era maturity that you would see in programming ecosystems like Python, Ruby, and Java. But, in many ways, JavaScript has surpassed those communities. For example, where Python 3’s reference implementation, CPython, is certainly fast as far as dynamic languages go, JavaScript’s reference implementation, V8, is optimized by JIT and hotspot optimization techniques that are only found in much more mature programming communities, such as Java’s (which received millions of dollars of commercial support in applied/advanced compiler techniques in the Sun era). That means that unmodified, hotspot JavaScript code can be optimized into native code automatically by the Node runtime and by browsers such as Chrome. Whereas Java and C users may still have debates about where, exactly, open source projects should publish their releases, that issue is settled in the JavaScript community: it’s npm, which operates similarly to PyPI and pip in the Python community. Some essential developer tooling issues were only recently settled. For example, because modern JavaScript (such as code written using ES2017 features) needs to target older browsers, a “transpilation” toolchain is necessary, to compile ES2017 code into ES3 or ES5 JavaScript code, suitable for older browsers. Because “old JavaScript” is a Turing complete, functional programming language, we know we can translate almost any new “syntactic sugar” to the old language, and, indeed, the designers of the new language features are being careful to only introduce syntax that can be safely transpiled. What this means, however, is that to do JavaScript development “The Modern Way”, while adopting its new features, you simply must use a local transpiler toolchain. The community standard for this at the moment is known as babel, and it’s likely to remain the community standard well into the future. Another issue that plagued 2008-era JavaScript was build tooling and modularization. In the 2008-2012 era, ad-hoc tools like make were used to concatenate JavaScript modules together, and often Java-based tools such as Google’s Closure Compiler or UglifyJS were used to assemble JavaScript projects into modules that could be included onto pages. In 2012, the Grunt tool was released as a JavaScript build tool, written atop NodeJS, runnable from the command-line, and configurable using a JavaScript “Gruntfile”. A whole slew of build tools similar to this were released in the period, creating a whole lot of code churn and confusion. Thankfully, today, Single Page Application frameworks like React have largely solved this problem, with the ascendancy of webpack and the reliance on npm run-script. Today, the webpack community has come up with a sane approach to JavaScript modularization that relies upon the modern JS support for modules, and then development-time tooling, provided mainly through the webpack CLI tool, allow for local development and production builds. This can all be scripted and wired together with simple npm run-script commands. And since webpack can be itself installed by npm, this keeps the entire development stack self-contained in a way that doesn’t feel too dissimilar from what you might enjoy with lein in Clojure or python/pip in Python. Yes, it has taken 20 years, but JavaScript is now just as viable a choice for your backend and CLI tooling projects as Python was in the past. And, for web frontends, it’s your only choice. So, if you are a programmer who cares, at all, about distribution of your code to users, it’s time to care about JavaScript! In a future post, I plan to go even deeper on JavaScript, covering: How to structure your first “modern” JavaScript project Using Modern JS with Python’s Flask web framework for simple static sites Understanding webpack, and why it’s important Modules, modules, modules. Why JS modules matter. Understanding babel, and why it’s important Transpilation, and how to think about evolving JS/ES features and “compilation” Using eslint for bonus points Using sourcemaps for debugging Using console.assert and console for debugging Production minification with uglify Building automated tests with jest Understanding the value of Chrome scripting and puppeteer Want me to keep going? Let me know via @amontalenti on Twitter.
0 notes
Text
The One-Hour Guide to SEO, Part 2: Keyword Research - Whiteboard Friday
Posted by randfish
Before doing any SEO work, it's important to get a handle on your keyword research. Aside from helping to inform your strategy and structure your content, you'll get to know the needs of your searchers, the search demand landscape of the SERPs, and what kind of competition you're up against.
In the second part of the One-Hour Guide to SEO, the inimitable Rand Fishkin covers what you need to know about the keyword research process, from understanding its goals to building your own keyword universe map. Enjoy!
Click on the whiteboard image above to open a high resolution version in a new tab!
Video Transcription
Howdy, Moz fans. Welcome to another portion of our special edition of Whiteboard Friday, the One-Hour Guide to SEO. This is Part II - Keyword Research. Hopefully you've already seen our SEO strategy session from last week. What we want to do in keyword research is talk about why keyword research is required. Why do I have to do this task prior to doing any SEO work?
The answer is fairly simple. If you don't know which words and phrases people type into Google or YouTube or Amazon or Bing, whatever search engine you're optimizing for, you're not going to be able to know how to structure your content. You won't be able to get into the searcher's brain, into their head to imagine and empathize with them what they actually want from your content. You probably won't do correct targeting, which will mean your competitors, who are doing keyword research, are choosing wise search phrases, wise words and terms and phrases that searchers are actually looking for, and you might be unfortunately optimizing for words and phrases that no one is actually looking for or not as many people are looking for or that are much more difficult than what you can actually rank for.
The goals of keyword research
So let's talk about some of the big-picture goals of keyword research.
Understand the search demand landscape so you can craft more optimal SEO strategies
First off, we are trying to understand the search demand landscape so we can craft better SEO strategies. Let me just paint a picture for you.
I was helping a startup here in Seattle, Washington, a number of years ago — this was probably a couple of years ago — called Crowd Cow. Crowd Cow is an awesome company. They basically will deliver beef from small ranchers and small farms straight to your doorstep. I personally am a big fan of steak, and I don't really love the quality of the stuff that I can get from the store. I don't love the mass-produced sort of industry around beef. I think there are a lot of Americans who feel that way. So working with small ranchers directly, where they're sending it straight from their farms, is kind of an awesome thing.
But when we looked at the SEO picture for Crowd Cow, for this company, what we saw was that there was more search demand for competitors of theirs, people like Omaha Steaks, which you might have heard of. There was more search demand for them than there was for "buy steak online," "buy beef online," and "buy rib eye online." Even things like just "shop for steak" or "steak online," these broad keyword phrases, the branded terms of their competition had more search demand than all of the specific keywords, the unbranded generic keywords put together.
That is a very different picture from a world like "soccer jerseys," where I spent a little bit of keyword research time today looking, and basically the brand names in that field do not have nearly as much search volume as the generic terms for soccer jerseys and custom soccer jerseys and football clubs' particular jerseys. Those generic terms have much more volume, which is a totally different kind of SEO that you're doing. One is very, "Oh, we need to build our brand. We need to go out into this marketplace and create demand." The other one is, "Hey, we need to serve existing demand already."
So you've got to understand your search demand landscape so that you can present to your executive team and your marketing team or your client or whoever it is, hey, this is what the search demand landscape looks like, and here's what we can actually do for you. Here's how much demand there is. Here's what we can serve today versus we need to grow our brand.
Create a list of terms and phrases that match your marketing goals and are achievable in rankings
The next goal of keyword research, we want to create a list of terms and phrases that we can then use to match our marketing goals and achieve rankings. We want to make sure that the rankings that we promise, the keywords that we say we're going to try and rank for actually have real demand and we can actually optimize for them and potentially rank for them. Or in the case where that's not true, they're too difficult or they're too hard to rank for. Or organic results don't really show up in those types of searches, and we should go after paid or maps or images or videos or some other type of search result.
Prioritize keyword investments so you do the most important, high-ROI work first
We also want to prioritize those keyword investments so we're doing the most important work, the highest ROI work in our SEO universe first. There's no point spending hours and months going after a bunch of keywords that if we had just chosen these other ones, we could have achieved much better results in a shorter period of time.
Match keywords to pages on your site to find the gaps
Finally, we want to take all the keywords that matter to us and match them to the pages on our site. If we don't have matches, we need to create that content. If we do have matches but they are suboptimal, not doing a great job of answering that searcher's query, well, we need to do that work as well. If we have a page that matches but we haven't done our keyword optimization, which we'll talk a little bit more about in a future video, we've got to do that too.
Understand the different varieties of search results
So an important part of understanding how search engines work — we're going to start down here and then we'll come back up — is to have this understanding that when you perform a query on a mobile device or a desktop device, Google shows you a vast variety of results. Ten or fifteen years ago this was not the case. We searched 15 years ago for "soccer jerseys," what did we get? Ten blue links. I think, unfortunately, in the minds of many search marketers and many people who are unfamiliar with SEO, they still think of it that way. How do I rank number one? The answer is, well, there are a lot of things "number one" can mean today, and we need to be careful about what we're optimizing for.
So if I search for "soccer jersey," I get these shopping results from Macy's and soccer.com and all these other places. Google sort has this sliding box of sponsored shopping results. Then they've got advertisements below that, notated with this tiny green ad box. Then below that, there are couple of organic results, what we would call classic SEO, 10 blue links-style organic results. There are two of those. Then there's a box of maps results that show me local soccer stores in my region, which is a totally different kind of optimization, local SEO. So you need to make sure that you understand and that you can convey that understanding to everyone on your team that these different kinds of results mean different types of SEO.
Now I've done some work recently over the last few years with a company called Jumpshot. They collect clickstream data from millions of browsers around the world and millions of browsers here in the United States. So they are able to provide some broad overview numbers collectively across the billions of searches that are performed on Google every day in the United States.
Click-through rates differ between mobile and desktop
The click-through rates look something like this. For mobile devices, on average, paid results get 8.7% of all clicks, organic results get about 40%, a little under 40% of all clicks, and zero-click searches, where a searcher performs a query but doesn't click anything, Google essentially either answers the results in there or the searcher is so unhappy with the potential results that they don't bother taking anything, that is 62%. So the vast majority of searches on mobile are no-click searches.
On desktop, it's a very different story. It's sort of inverted. So paid is 5.6%. I think people are a little savvier about which result they should be clicking on desktop. Organic is 65%, so much, much higher than mobile. Zero-click searches is 34%, so considerably lower.
There are a lot more clicks happening on a desktop device. That being said, right now we think it's around 60–40, meaning 60% of queries on Google, at least, happen on mobile and 40% happen on desktop, somewhere in those ranges. It might be a little higher or a little lower.
The search demand curve
Another important and critical thing to understand about the keyword research universe and how we do keyword research is that there's a sort of search demand curve. So for any given universe of keywords, there is essentially a small number, maybe a few to a few dozen keywords that have millions or hundreds of thousands of searches every month. Something like "soccer" or "Seattle Sounders," those have tens or hundreds of thousands, even millions of searches every month in the United States.
But people searching for "Sounders FC away jersey customizable," there are very, very few searches per month, but there are millions, even billions of keywords like this.
The long-tail: millions of keyword terms and phrases, low number of monthly searches
When Sundar Pichai, Google's current CEO, was testifying before Congress just a few months ago, he told Congress that around 20% of all searches that Google receives each day they have never seen before. No one has ever performed them in the history of the search engines. I think maybe that number is closer to 18%. But that is just a remarkable sum, and it tells you about what we call the long tail of search demand, essentially tons and tons of keywords, millions or billions of keywords that are only searched for 1 time per month, 5 times per month, 10 times per month.
The chunky middle: thousands or tens of thousands of keywords with ~50–100 searches per month
If you want to get into this next layer, what we call the chunky middle in the SEO world, this is where there are thousands or tens of thousands of keywords potentially in your universe, but they only have between say 50 and a few hundred searches per month.
The fat head: a very few keywords with hundreds of thousands or millions of searches
Then this fat head has only a few keywords. There's only one keyword like "soccer" or "soccer jersey," which is actually probably more like the chunky middle, but it has hundreds of thousands or millions of searches. The fat head is higher competition and broader intent.
Searcher intent and keyword competition
What do I mean by broader intent? That means when someone performs a search for "soccer," you don't know what they're looking for. The likelihood that they want a customizable soccer jersey right that moment is very, very small. They're probably looking for something much broader, and it's hard to know exactly their intent.
However, as you drift down into the chunky middle and into the long tail, where there are more keywords but fewer searches for each keyword, your competition gets much lower. There are fewer people trying to compete and rank for those, because they don't know to optimize for them, and there's more specific intent. "Customizable Sounders FC away jersey" is very clear. I know exactly what I want. I want to order a customizable jersey from the Seattle Sounders away, the particular colors that the away jersey has, and I want to be able to put my logo on there or my name on the back of it, what have you. So super specific intent.
Build a map of your own keyword universe
As a result, you need to figure out what the map of your universe looks like so that you can present that, and you need to be able to build a list that looks something like this. You should at the end of the keyword research process — we featured a screenshot from Moz's Keyword Explorer, which is a tool that I really like to use and I find super helpful whenever I'm helping companies, even now that I have left Moz and been gone for a year, I still sort of use Keyword Explorer because the volume data is so good and it puts all the stuff together. However, there are two or three other tools that a lot of people like, one from Ahrefs, which I think also has the name Keyword Explorer, and one from SEMrush, which I like although some of the volume numbers, at least in the United States, are not as good as what I might hope for. There are a number of other tools that you could check out as well. A lot of people like Google Trends, which is totally free and interesting for some of that broad volume data.
So I might have terms like "soccer jersey," "Sounders FC jersey", and "custom soccer jersey Seattle Sounders." Then I'll have these columns:
Volume, because I want to know how many people search for it;
Difficulty, how hard will it be to rank. If it's super difficult to rank and I have a brand-new website and I don't have a lot of authority, well, maybe I should target some of these other ones first that are lower difficulty.
Organic Click-through Rate, just like we talked about back here, there are different levels of click-through rate, and the tools, at least Moz's Keyword Explorer tool uses Jumpshot data on a per keyword basis to estimate what percent of people are going to click the organic results. Should you optimize for it? Well, if the click-through rate is only 60%, pretend that instead of 100 searches, this only has 60 or 60 available searches for your organic clicks. Ninety-five percent, though, great, awesome. All four of those monthly searches are available to you.
Business Value, how useful is this to your business?
Then set some type of priority to determine. So I might look at this list and say, "Hey, for my new soccer jersey website, this is the most important keyword. I want to go after "custom soccer jersey" for each team in the U.S., and then I'll go after team jersey, and then I'll go after "customizable away jerseys." Then maybe I'll go after "soccer jerseys," because it's just so competitive and so difficult to rank for. There's a lot of volume, but the search intent is not as great. The business value to me is not as good, all those kinds of things.
Last, but not least, I want to know the types of searches that appear — organic, paid. Do images show up? Does shopping show up? Does video show up? Do maps results show up? If those other types of search results, like we talked about here, show up in there, I can do SEO to appear in those places too. That could yield, in certain keyword universes, a strategy that is very image centric or very video centric, which means I've got to do a lot of work on YouTube, or very map centric, which means I've got to do a lot of local SEO, or other kinds like this.
Once you build a keyword research list like this, you can begin the prioritization process and the true work of creating pages, mapping the pages you already have to the keywords that you've got, and optimizing in order to rank. We'll talk about that in Part III next week. Take care.
Video transcription by Speechpad.com
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog http://tracking.feedpress.it/link/9375/11175845
0 notes
Text
The One-Hour Guide to SEO, Part 2: Keyword Research - Whiteboard Friday
Posted by randfish
Before doing any SEO work, it's important to get a handle on your keyword research. Aside from helping to inform your strategy and structure your content, you'll get to know the needs of your searchers, the search demand landscape of the SERPs, and what kind of competition you're up against.
In the second part of the One-Hour Guide to SEO, the inimitable Rand Fishkin covers what you need to know about the keyword research process, from understanding its goals to building your own keyword universe map. Enjoy!
Click on the whiteboard image above to open a high resolution version in a new tab!
Video Transcription
Howdy, Moz fans. Welcome to another portion of our special edition of Whiteboard Friday, the One-Hour Guide to SEO. This is Part II - Keyword Research. Hopefully you've already seen our SEO strategy session from last week. What we want to do in keyword research is talk about why keyword research is required. Why do I have to do this task prior to doing any SEO work?
The answer is fairly simple. If you don't know which words and phrases people type into Google or YouTube or Amazon or Bing, whatever search engine you're optimizing for, you're not going to be able to know how to structure your content. You won't be able to get into the searcher's brain, into their head to imagine and empathize with them what they actually want from your content. You probably won't do correct targeting, which will mean your competitors, who are doing keyword research, are choosing wise search phrases, wise words and terms and phrases that searchers are actually looking for, and you might be unfortunately optimizing for words and phrases that no one is actually looking for or not as many people are looking for or that are much more difficult than what you can actually rank for.
The goals of keyword research
So let's talk about some of the big-picture goals of keyword research.
Understand the search demand landscape so you can craft more optimal SEO strategies
First off, we are trying to understand the search demand landscape so we can craft better SEO strategies. Let me just paint a picture for you.
I was helping a startup here in Seattle, Washington, a number of years ago — this was probably a couple of years ago — called Crowd Cow. Crowd Cow is an awesome company. They basically will deliver beef from small ranchers and small farms straight to your doorstep. I personally am a big fan of steak, and I don't really love the quality of the stuff that I can get from the store. I don't love the mass-produced sort of industry around beef. I think there are a lot of Americans who feel that way. So working with small ranchers directly, where they're sending it straight from their farms, is kind of an awesome thing.
But when we looked at the SEO picture for Crowd Cow, for this company, what we saw was that there was more search demand for competitors of theirs, people like Omaha Steaks, which you might have heard of. There was more search demand for them than there was for "buy steak online," "buy beef online," and "buy rib eye online." Even things like just "shop for steak" or "steak online," these broad keyword phrases, the branded terms of their competition had more search demand than all of the specific keywords, the unbranded generic keywords put together.
That is a very different picture from a world like "soccer jerseys," where I spent a little bit of keyword research time today looking, and basically the brand names in that field do not have nearly as much search volume as the generic terms for soccer jerseys and custom soccer jerseys and football clubs' particular jerseys. Those generic terms have much more volume, which is a totally different kind of SEO that you're doing. One is very, "Oh, we need to build our brand. We need to go out into this marketplace and create demand." The other one is, "Hey, we need to serve existing demand already."
So you've got to understand your search demand landscape so that you can present to your executive team and your marketing team or your client or whoever it is, hey, this is what the search demand landscape looks like, and here's what we can actually do for you. Here's how much demand there is. Here's what we can serve today versus we need to grow our brand.
Create a list of terms and phrases that match your marketing goals and are achievable in rankings
The next goal of keyword research, we want to create a list of terms and phrases that we can then use to match our marketing goals and achieve rankings. We want to make sure that the rankings that we promise, the keywords that we say we're going to try and rank for actually have real demand and we can actually optimize for them and potentially rank for them. Or in the case where that's not true, they're too difficult or they're too hard to rank for. Or organic results don't really show up in those types of searches, and we should go after paid or maps or images or videos or some other type of search result.
Prioritize keyword investments so you do the most important, high-ROI work first
We also want to prioritize those keyword investments so we're doing the most important work, the highest ROI work in our SEO universe first. There's no point spending hours and months going after a bunch of keywords that if we had just chosen these other ones, we could have achieved much better results in a shorter period of time.
Match keywords to pages on your site to find the gaps
Finally, we want to take all the keywords that matter to us and match them to the pages on our site. If we don't have matches, we need to create that content. If we do have matches but they are suboptimal, not doing a great job of answering that searcher's query, well, we need to do that work as well. If we have a page that matches but we haven't done our keyword optimization, which we'll talk a little bit more about in a future video, we've got to do that too.
Understand the different varieties of search results
So an important part of understanding how search engines work — we're going to start down here and then we'll come back up — is to have this understanding that when you perform a query on a mobile device or a desktop device, Google shows you a vast variety of results. Ten or fifteen years ago this was not the case. We searched 15 years ago for "soccer jerseys," what did we get? Ten blue links. I think, unfortunately, in the minds of many search marketers and many people who are unfamiliar with SEO, they still think of it that way. How do I rank number one? The answer is, well, there are a lot of things "number one" can mean today, and we need to be careful about what we're optimizing for.
So if I search for "soccer jersey," I get these shopping results from Macy's and soccer.com and all these other places. Google sort has this sliding box of sponsored shopping results. Then they've got advertisements below that, notated with this tiny green ad box. Then below that, there are couple of organic results, what we would call classic SEO, 10 blue links-style organic results. There are two of those. Then there's a box of maps results that show me local soccer stores in my region, which is a totally different kind of optimization, local SEO. So you need to make sure that you understand and that you can convey that understanding to everyone on your team that these different kinds of results mean different types of SEO.
Now I've done some work recently over the last few years with a company called Jumpshot. They collect clickstream data from millions of browsers around the world and millions of browsers here in the United States. So they are able to provide some broad overview numbers collectively across the billions of searches that are performed on Google every day in the United States.
Click-through rates differ between mobile and desktop
The click-through rates look something like this. For mobile devices, on average, paid results get 8.7% of all clicks, organic results get about 40%, a little under 40% of all clicks, and zero-click searches, where a searcher performs a query but doesn't click anything, Google essentially either answers the results in there or the searcher is so unhappy with the potential results that they don't bother taking anything, that is 62%. So the vast majority of searches on mobile are no-click searches.
On desktop, it's a very different story. It's sort of inverted. So paid is 5.6%. I think people are a little savvier about which result they should be clicking on desktop. Organic is 65%, so much, much higher than mobile. Zero-click searches is 34%, so considerably lower.
There are a lot more clicks happening on a desktop device. That being said, right now we think it's around 60–40, meaning 60% of queries on Google, at least, happen on mobile and 40% happen on desktop, somewhere in those ranges. It might be a little higher or a little lower.
The search demand curve
Another important and critical thing to understand about the keyword research universe and how we do keyword research is that there's a sort of search demand curve. So for any given universe of keywords, there is essentially a small number, maybe a few to a few dozen keywords that have millions or hundreds of thousands of searches every month. Something like "soccer" or "Seattle Sounders," those have tens or hundreds of thousands, even millions of searches every month in the United States.
But people searching for "Sounders FC away jersey customizable," there are very, very few searches per month, but there are millions, even billions of keywords like this.
The long-tail: millions of keyword terms and phrases, low number of monthly searches
When Sundar Pichai, Google's current CEO, was testifying before Congress just a few months ago, he told Congress that around 20% of all searches that Google receives each day they have never seen before. No one has ever performed them in the history of the search engines. I think maybe that number is closer to 18%. But that is just a remarkable sum, and it tells you about what we call the long tail of search demand, essentially tons and tons of keywords, millions or billions of keywords that are only searched for 1 time per month, 5 times per month, 10 times per month.
The chunky middle: thousands or tens of thousands of keywords with ~50–100 searches per month
If you want to get into this next layer, what we call the chunky middle in the SEO world, this is where there are thousands or tens of thousands of keywords potentially in your universe, but they only have between say 50 and a few hundred searches per month.
The fat head: a very few keywords with hundreds of thousands or millions of searches
Then this fat head has only a few keywords. There's only one keyword like "soccer" or "soccer jersey," which is actually probably more like the chunky middle, but it has hundreds of thousands or millions of searches. The fat head is higher competition and broader intent.
Searcher intent and keyword competition
What do I mean by broader intent? That means when someone performs a search for "soccer," you don't know what they're looking for. The likelihood that they want a customizable soccer jersey right that moment is very, very small. They're probably looking for something much broader, and it's hard to know exactly their intent.
However, as you drift down into the chunky middle and into the long tail, where there are more keywords but fewer searches for each keyword, your competition gets much lower. There are fewer people trying to compete and rank for those, because they don't know to optimize for them, and there's more specific intent. "Customizable Sounders FC away jersey" is very clear. I know exactly what I want. I want to order a customizable jersey from the Seattle Sounders away, the particular colors that the away jersey has, and I want to be able to put my logo on there or my name on the back of it, what have you. So super specific intent.
Build a map of your own keyword universe
As a result, you need to figure out what the map of your universe looks like so that you can present that, and you need to be able to build a list that looks something like this. You should at the end of the keyword research process — we featured a screenshot from Moz's Keyword Explorer, which is a tool that I really like to use and I find super helpful whenever I'm helping companies, even now that I have left Moz and been gone for a year, I still sort of use Keyword Explorer because the volume data is so good and it puts all the stuff together. However, there are two or three other tools that a lot of people like, one from Ahrefs, which I think also has the name Keyword Explorer, and one from SEMrush, which I like although some of the volume numbers, at least in the United States, are not as good as what I might hope for. There are a number of other tools that you could check out as well. A lot of people like Google Trends, which is totally free and interesting for some of that broad volume data.
So I might have terms like "soccer jersey," "Sounders FC jersey", and "custom soccer jersey Seattle Sounders." Then I'll have these columns:
Volume, because I want to know how many people search for it;
Difficulty, how hard will it be to rank. If it's super difficult to rank and I have a brand-new website and I don't have a lot of authority, well, maybe I should target some of these other ones first that are lower difficulty.
Organic Click-through Rate, just like we talked about back here, there are different levels of click-through rate, and the tools, at least Moz's Keyword Explorer tool uses Jumpshot data on a per keyword basis to estimate what percent of people are going to click the organic results. Should you optimize for it? Well, if the click-through rate is only 60%, pretend that instead of 100 searches, this only has 60 or 60 available searches for your organic clicks. Ninety-five percent, though, great, awesome. All four of those monthly searches are available to you.
Business Value, how useful is this to your business?
Then set some type of priority to determine. So I might look at this list and say, "Hey, for my new soccer jersey website, this is the most important keyword. I want to go after "custom soccer jersey" for each team in the U.S., and then I'll go after team jersey, and then I'll go after "customizable away jerseys." Then maybe I'll go after "soccer jerseys," because it's just so competitive and so difficult to rank for. There's a lot of volume, but the search intent is not as great. The business value to me is not as good, all those kinds of things.
Last, but not least, I want to know the types of searches that appear — organic, paid. Do images show up? Does shopping show up? Does video show up? Do maps results show up? If those other types of search results, like we talked about here, show up in there, I can do SEO to appear in those places too. That could yield, in certain keyword universes, a strategy that is very image centric or very video centric, which means I've got to do a lot of work on YouTube, or very map centric, which means I've got to do a lot of local SEO, or other kinds like this.
Once you build a keyword research list like this, you can begin the prioritization process and the true work of creating pages, mapping the pages you already have to the keywords that you've got, and optimizing in order to rank. We'll talk about that in Part III next week. Take care.
Video transcription by Speechpad.com
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
The One-Hour Guide to SEO, Part 2: Keyword Research - Whiteboard Friday
0 notes
Text
The One-Hour Guide to SEO, Part 2: Keyword Research - Whiteboard Friday
Posted by randfish
Before doing any SEO work, it's important to get a handle on your keyword research. Aside from helping to inform your strategy and structure your content, you'll get to know the needs of your searchers, the search demand landscape of the SERPs, and what kind of competition you're up against.
In the second part of the One-Hour Guide to SEO, the inimitable Rand Fishkin covers what you need to know about the keyword research process, from understanding its goals to building your own keyword universe map. Enjoy!
Click on the whiteboard image above to open a high resolution version in a new tab!
Video Transcription
Howdy, Moz fans. Welcome to another portion of our special edition of Whiteboard Friday, the One-Hour Guide to SEO. This is Part II - Keyword Research. Hopefully you've already seen our SEO strategy session from last week. What we want to do in keyword research is talk about why keyword research is required. Why do I have to do this task prior to doing any SEO work?
The answer is fairly simple. If you don't know which words and phrases people type into Google or YouTube or Amazon or Bing, whatever search engine you're optimizing for, you're not going to be able to know how to structure your content. You won't be able to get into the searcher's brain, into their head to imagine and empathize with them what they actually want from your content. You probably won't do correct targeting, which will mean your competitors, who are doing keyword research, are choosing wise search phrases, wise words and terms and phrases that searchers are actually looking for, and you might be unfortunately optimizing for words and phrases that no one is actually looking for or not as many people are looking for or that are much more difficult than what you can actually rank for.
The goals of keyword research
So let's talk about some of the big-picture goals of keyword research.
Understand the search demand landscape so you can craft more optimal SEO strategies
First off, we are trying to understand the search demand landscape so we can craft better SEO strategies. Let me just paint a picture for you.
I was helping a startup here in Seattle, Washington, a number of years ago — this was probably a couple of years ago — called Crowd Cow. Crowd Cow is an awesome company. They basically will deliver beef from small ranchers and small farms straight to your doorstep. I personally am a big fan of steak, and I don't really love the quality of the stuff that I can get from the store. I don't love the mass-produced sort of industry around beef. I think there are a lot of Americans who feel that way. So working with small ranchers directly, where they're sending it straight from their farms, is kind of an awesome thing.
But when we looked at the SEO picture for Crowd Cow, for this company, what we saw was that there was more search demand for competitors of theirs, people like Omaha Steaks, which you might have heard of. There was more search demand for them than there was for "buy steak online," "buy beef online," and "buy rib eye online." Even things like just "shop for steak" or "steak online," these broad keyword phrases, the branded terms of their competition had more search demand than all of the specific keywords, the unbranded generic keywords put together.
That is a very different picture from a world like "soccer jerseys," where I spent a little bit of keyword research time today looking, and basically the brand names in that field do not have nearly as much search volume as the generic terms for soccer jerseys and custom soccer jerseys and football clubs' particular jerseys. Those generic terms have much more volume, which is a totally different kind of SEO that you're doing. One is very, "Oh, we need to build our brand. We need to go out into this marketplace and create demand." The other one is, "Hey, we need to serve existing demand already."
So you've got to understand your search demand landscape so that you can present to your executive team and your marketing team or your client or whoever it is, hey, this is what the search demand landscape looks like, and here's what we can actually do for you. Here's how much demand there is. Here's what we can serve today versus we need to grow our brand.
Create a list of terms and phrases that match your marketing goals and are achievable in rankings
The next goal of keyword research, we want to create a list of terms and phrases that we can then use to match our marketing goals and achieve rankings. We want to make sure that the rankings that we promise, the keywords that we say we're going to try and rank for actually have real demand and we can actually optimize for them and potentially rank for them. Or in the case where that's not true, they're too difficult or they're too hard to rank for. Or organic results don't really show up in those types of searches, and we should go after paid or maps or images or videos or some other type of search result.
Prioritize keyword investments so you do the most important, high-ROI work first
We also want to prioritize those keyword investments so we're doing the most important work, the highest ROI work in our SEO universe first. There's no point spending hours and months going after a bunch of keywords that if we had just chosen these other ones, we could have achieved much better results in a shorter period of time.
Match keywords to pages on your site to find the gaps
Finally, we want to take all the keywords that matter to us and match them to the pages on our site. If we don't have matches, we need to create that content. If we do have matches but they are suboptimal, not doing a great job of answering that searcher's query, well, we need to do that work as well. If we have a page that matches but we haven't done our keyword optimization, which we'll talk a little bit more about in a future video, we've got to do that too.
Understand the different varieties of search results
So an important part of understanding how search engines work — we're going to start down here and then we'll come back up — is to have this understanding that when you perform a query on a mobile device or a desktop device, Google shows you a vast variety of results. Ten or fifteen years ago this was not the case. We searched 15 years ago for "soccer jerseys," what did we get? Ten blue links. I think, unfortunately, in the minds of many search marketers and many people who are unfamiliar with SEO, they still think of it that way. How do I rank number one? The answer is, well, there are a lot of things "number one" can mean today, and we need to be careful about what we're optimizing for.
So if I search for "soccer jersey," I get these shopping results from Macy's and soccer.com and all these other places. Google sort has this sliding box of sponsored shopping results. Then they've got advertisements below that, notated with this tiny green ad box. Then below that, there are couple of organic results, what we would call classic SEO, 10 blue links-style organic results. There are two of those. Then there's a box of maps results that show me local soccer stores in my region, which is a totally different kind of optimization, local SEO. So you need to make sure that you understand and that you can convey that understanding to everyone on your team that these different kinds of results mean different types of SEO.
Now I've done some work recently over the last few years with a company called Jumpshot. They collect clickstream data from millions of browsers around the world and millions of browsers here in the United States. So they are able to provide some broad overview numbers collectively across the billions of searches that are performed on Google every day in the United States.
Click-through rates differ between mobile and desktop
The click-through rates look something like this. For mobile devices, on average, paid results get 8.7% of all clicks, organic results get about 40%, a little under 40% of all clicks, and zero-click searches, where a searcher performs a query but doesn't click anything, Google essentially either answers the results in there or the searcher is so unhappy with the potential results that they don't bother taking anything, that is 62%. So the vast majority of searches on mobile are no-click searches.
On desktop, it's a very different story. It's sort of inverted. So paid is 5.6%. I think people are a little savvier about which result they should be clicking on desktop. Organic is 65%, so much, much higher than mobile. Zero-click searches is 34%, so considerably lower.
There are a lot more clicks happening on a desktop device. That being said, right now we think it's around 60–40, meaning 60% of queries on Google, at least, happen on mobile and 40% happen on desktop, somewhere in those ranges. It might be a little higher or a little lower.
The search demand curve
Another important and critical thing to understand about the keyword research universe and how we do keyword research is that there's a sort of search demand curve. So for any given universe of keywords, there is essentially a small number, maybe a few to a few dozen keywords that have millions or hundreds of thousands of searches every month. Something like "soccer" or "Seattle Sounders," those have tens or hundreds of thousands, even millions of searches every month in the United States.
But people searching for "Sounders FC away jersey customizable," there are very, very few searches per month, but there are millions, even billions of keywords like this.
The long-tail: millions of keyword terms and phrases, low number of monthly searches
When Sundar Pichai, Google's current CEO, was testifying before Congress just a few months ago, he told Congress that around 20% of all searches that Google receives each day they have never seen before. No one has ever performed them in the history of the search engines. I think maybe that number is closer to 18%. But that is just a remarkable sum, and it tells you about what we call the long tail of search demand, essentially tons and tons of keywords, millions or billions of keywords that are only searched for 1 time per month, 5 times per month, 10 times per month.
The chunky middle: thousands or tens of thousands of keywords with ~50–100 searches per month
If you want to get into this next layer, what we call the chunky middle in the SEO world, this is where there are thousands or tens of thousands of keywords potentially in your universe, but they only have between say 50 and a few hundred searches per month.
The fat head: a very few keywords with hundreds of thousands or millions of searches
Then this fat head has only a few keywords. There's only one keyword like "soccer" or "soccer jersey," which is actually probably more like the chunky middle, but it has hundreds of thousands or millions of searches. The fat head is higher competition and broader intent.
Searcher intent and keyword competition
What do I mean by broader intent? That means when someone performs a search for "soccer," you don't know what they're looking for. The likelihood that they want a customizable soccer jersey right that moment is very, very small. They're probably looking for something much broader, and it's hard to know exactly their intent.
However, as you drift down into the chunky middle and into the long tail, where there are more keywords but fewer searches for each keyword, your competition gets much lower. There are fewer people trying to compete and rank for those, because they don't know to optimize for them, and there's more specific intent. "Customizable Sounders FC away jersey" is very clear. I know exactly what I want. I want to order a customizable jersey from the Seattle Sounders away, the particular colors that the away jersey has, and I want to be able to put my logo on there or my name on the back of it, what have you. So super specific intent.
Build a map of your own keyword universe
As a result, you need to figure out what the map of your universe looks like so that you can present that, and you need to be able to build a list that looks something like this. You should at the end of the keyword research process — we featured a screenshot from Moz's Keyword Explorer, which is a tool that I really like to use and I find super helpful whenever I'm helping companies, even now that I have left Moz and been gone for a year, I still sort of use Keyword Explorer because the volume data is so good and it puts all the stuff together. However, there are two or three other tools that a lot of people like, one from Ahrefs, which I think also has the name Keyword Explorer, and one from SEMrush, which I like although some of the volume numbers, at least in the United States, are not as good as what I might hope for. There are a number of other tools that you could check out as well. A lot of people like Google Trends, which is totally free and interesting for some of that broad volume data.
So I might have terms like "soccer jersey," "Sounders FC jersey", and "custom soccer jersey Seattle Sounders." Then I'll have these columns:
Volume, because I want to know how many people search for it;
Difficulty, how hard will it be to rank. If it's super difficult to rank and I have a brand-new website and I don't have a lot of authority, well, maybe I should target some of these other ones first that are lower difficulty.
Organic Click-through Rate, just like we talked about back here, there are different levels of click-through rate, and the tools, at least Moz's Keyword Explorer tool uses Jumpshot data on a per keyword basis to estimate what percent of people are going to click the organic results. Should you optimize for it? Well, if the click-through rate is only 60%, pretend that instead of 100 searches, this only has 60 or 60 available searches for your organic clicks. Ninety-five percent, though, great, awesome. All four of those monthly searches are available to you.
Business Value, how useful is this to your business?
Then set some type of priority to determine. So I might look at this list and say, "Hey, for my new soccer jersey website, this is the most important keyword. I want to go after "custom soccer jersey" for each team in the U.S., and then I'll go after team jersey, and then I'll go after "customizable away jerseys." Then maybe I'll go after "soccer jerseys," because it's just so competitive and so difficult to rank for. There's a lot of volume, but the search intent is not as great. The business value to me is not as good, all those kinds of things.
Last, but not least, I want to know the types of searches that appear — organic, paid. Do images show up? Does shopping show up? Does video show up? Do maps results show up? If those other types of search results, like we talked about here, show up in there, I can do SEO to appear in those places too. That could yield, in certain keyword universes, a strategy that is very image centric or very video centric, which means I've got to do a lot of work on YouTube, or very map centric, which means I've got to do a lot of local SEO, or other kinds like this.
Once you build a keyword research list like this, you can begin the prioritization process and the true work of creating pages, mapping the pages you already have to the keywords that you've got, and optimizing in order to rank. We'll talk about that in Part III next week. Take care.
Video transcription by Speechpad.com
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog https://ift.tt/2YeayPr via IFTTT
0 notes
Text
SEO Ranking Factors & Correlation: What Does It Mean When a Metric Is Correlated with Google Rankings? - Whiteboard Friday
Posted by randfish
In an industry where knowing exactly how to get ranked on Google is murky at best, SEO ranking factors studies can be incredibly alluring. But there's danger in believing every correlation you read, and wisdom in looking at it with a critical eye. In this Whiteboard Friday, Rand covers the myths and realities of correlations, then shares a few smart ways to use and understand the data at hand.
Click on the whiteboard image above to open a high-resolution version in a new tab!
Video Transcription
Howdy, Moz fans, and welcome to another edition of Whiteboard Friday. This week we are chatting about SEO ranking factors and the challenge around understanding correlation, what correlation means when it comes to SEO factors.
So you have likely seen, over the course of your career in the SEO world, lots of studies like this. They're usually called something like ranking factors or ranking elements study or the 2017 ranking factors, and a number of companies put them out. Years ago, Moz started to do this work with correlation stuff, and now many, many companies put these out. So people from Searchmetrics and I think Ahrefs puts something out, and SEMrush puts one out, and of course Moz has one. These usually follow a pretty similar format, which is they take a large number of search results from Google, from a specific country or sometimes from multiple countries, and they'll say, "We analyzed 100,000 or 50,000 Google search results, and in our set of results, we looked at the following ranking factors to see how well correlated they were with higher rankings." That is to say how much they predicted that, on average, a page with this factor would outrank a page without the factor, or a page with more of this factor would outrank a page with less of this factor.
Correlation in SEO studies like these usually mean:
So, basically, in an SEO study, they usually mean something like this. They do like a scatter plot. They don't have to specifically do a scatter plot, but visualization of the results. Then they'll say, "Okay, linking root domains had better correlation or correlation with higher organic rankings than the 10 blue link-style results to the degree of 0.39." They'll usually use either Spearman or Pearson correlation. We won't get into that here. It doesn't matter too much. Across this many searches, the metric predicted higher or lower rankings with this level of consistency. 1.0, by the way, would be perfect correlation. So, for example, if you were looking at days that end in Y and days that follow each other, well, there's a perfect correlation because every day's name ends in Y, at least in English. So search visits, let's walk down this path just a little bit. So search visits, saying that that 0.47 correlated with higher rankings, if that sounds misleading to you, it sounds misleading to me too. The problem here is that's not necessarily a ranking factor. At least I don't think it is. I don't think that the more visits you get from search from Google, the higher Google ranks you. I think it's probably that the correlation runs the other way around — the higher you rank in search results, the more visits on average you get from Google search. So these ranking factors, I'll run through a bunch of these myths, but these ranking factors may not be factors at all. They're just metrics or elements where the study has looked at the correlation and is trying to show you the relationship on average. But you have to understand and intuit this information properly, otherwise you can be very misled.
Myths and realities of correlation in SEO
So let's walk through a few of these.
1. Correlation doesn't tell us which way the connection runs.
So it does not say whether factor X influences the rankings or whether higher rankings influences factor X. Let's take another example — number of Facebook shares. Could it be the case that search results that rank higher in Google oftentimes get people sharing them more on Facebook because they've been seen by more people who searched for them? I think that's totally possible. I don't know whether it's the case. We can't prove it right here and now, but we can certainly say, "You know what? This number does not necessarily mean that Facebook shares influence Google results." It could be the case that Google results influence Facebook searches. It could be the case that there's a third factor that's causing both of them. Or it could be the case that there's, in fact, no relationship and this is merely a coincidental result, probably unlikely given that there is some relationship there, but possible.
2. Correlation does not imply causation.
This is a famous quote, but let's continue with the famous quote. But it sure is a hint. It sure is a hint. That's exactly what we like to use correlation for is as a hint of things we might investigate further. We'll talk about that in a second.
3. In an algorithm like Google's, with thousands of potential ranking inputs, if you see any single metric at 0.1 or higher, I tend to think that, in general, that is an interesting result.
Not prove something, not means that there's a direct correlation, just it is interesting. It's worthy of further exploration. It's worthy of understanding. It's worthy of forming hypotheses and then trying to prove those wrong. It is interesting.
4. Correlation does tell us what more successful pages and sites do that less successful sites and pages don't do.
Sometimes, in my opinion, that is just as interesting as what is actually causing rankings in Google. So you might say, "Oh, this doesn't prove anything." What it proves to me is pages that are getting more Facebook shares tend to do a good bit better than pages that are not getting as many Facebook shares.
I don't really care, to be honest, whether that is a direct Google ranking factor or whether that's just something that's happening. If it's happening in my space, if it's happening in the world of SERPs that I care about, that is useful information for me to know and information that I should be applying, because it suggests that my competitors are doing this and that if I don't do it, I probably won't be as successful, or I may not be as successful as the ones who are. Certainly, I want to understand how they're doing it and why they're doing it.
5. None of these studies that I have ever seen so far have looked specifically at SERP features.
So one of the things that you have to remember, when you're looking at these, is think organic, 10 blue link-style results. We're not talking about AdWords, the paid results. We're not talking about Knowledge Graph or featured snippets or image results or video results or any of these other, the news boxes, the Twitter results, anything else that goes in there. So this is kind of old-school, classic organic SEO.
6. Correlation is not a best practice.
So it does not mean that because this list descends and goes down in this order that those are the things you should do in that particular order. Don't use this as a roadmap.
7. Low correlation does not mean that a metric or a tactic doesn't work
Example, a high percent of sites using a page or a tactic will result in a very low correlation. So, for example, when we first did this study in I think it was 2005 that Moz ran its first one of these, maybe it was '07, we saw that keyword use in the title element was strongly correlated. I think it was probably around 0.2, 0.15, something like that. Then over time, it's gone way, way down. Now, it's something like 0.03, extremely small, infinitesimally small.
What does that mean? Well, it could mean one of two things. It could mean Google is using it less as a ranking factor. It could mean that it was never connected, and it's just total speculation, total coincidence. Or three, it could mean that a lot more people who rank in the top 20 or 30 results, which is what these studies usually look at, top 10 to top 50 sometimes, a lot more of them are putting the keyword in the title, and therefore, there's just no difference between result number 31 and result number 1, because they both have them in the title. So you're seeing a much lower correlation between pages that don't have them and do have them and higher rankings. So be careful about how you intuit that.
Oh, one final note. I did put -0.02 here. A negative correlation means that as you see less of this thing, you tend to see higher rankings. Again, unless there is a strong negative correlation, I tend to watch out for these, or I tend to not pay too much attention. For example, the keyword in the meta description, it could just be that, well, it turns out pretty much everyone has the keyword in the meta description now, so this is just not a big differentiating factor.
What is correlation good for?
All right. What's correlation actually good for? We talked about a bunch of myths, ways not to use it.
A. IDing the elements that more successful pages tend to have
So if I look across a correlation and I see that lots of pages are twice as likely to have X and rank highly as the ones that don't rank highly, well, that is a good piece of data for me.
B. Watching elements over time to see if they rise or lower in correlation.
For example, we watch links very closely over time to see if they rise or lower so that we can say: "Gosh, does it look like links are getting more or less influential in Google's rankings? Are they more or less correlated than they were last year or two years ago?" And if we see that drop dramatically, we might intuit, "Hey, we should test the power of links again. Time for another experiment to see if links still move the needle, or if they're becoming less powerful, or if it's merely that the correlation is dropping."
C. Comparing sets of search results against one another we can identify unique attributes that might be true
So, for example, in a vertical like news, we might see that domain authority is much more important than it is in fitness, where smaller sites potentially have much more opportunity or dominate. Or we might see that something like https is not a great way to stand out in news, because everybody has it, but in fitness, it is a way to stand out and, in fact, the folks who do have it tend to do much better. Maybe they've invested more in their sites.
D. Judging metrics as a predictive ranking ability
Essentially, when I'm looking at a metric like domain authority, how good is that at telling me on average how much better one domain will rank in Google versus another? I can see that this number is a good indication of that. If that number goes down, domain authority is less predictive, less sort of useful for me. If it goes up, it's more useful. I did this a couple years ago with Alexa Rank and SimilarWeb, looking at traffic metrics and which ones are best correlated with actual traffic, and found Alexa Rank is awful and SimilarWeb is quite excellent. So there you go.
E. Finding elements to test
So if I see that large images embedded on a page that's already ranking on page 1 of search results has a 0.61 correlation with the image from that page ranking in the image results in the first few, wow, that's really interesting. You know what? I'm going to go test that and take big images and embed them on my pages that are ranking and see if I can get the image results that I care about. That's great information for testing.
This is all stuff that correlation is useful for. Correlation in SEO, especially when it comes to ranking factors or ranking elements, can be very misleading. I hope that this will help you to better understand how to use and not use that data.
Thanks. We'll see you again next week for another edition of Whiteboard Friday.
Video transcription by Speechpad.com
The image used to promote this post was adapted with gratitude from the hilarious webcomic, xkcd.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog http://ift.tt/2CWrVds via IFTTT
1 note
·
View note
Text
The One-Hour Guide to SEO, Part 2: Keyword Research - Whiteboard Friday
Posted by randfish
Before doing any SEO work, it's important to get a handle on your keyword research. Aside from helping to inform your strategy and structure your content, you'll get to know the needs of your searchers, the search demand landscape of the SERPs, and what kind of competition you're up against.
In the second part of the One-Hour Guide to SEO, the inimitable Rand Fishkin covers what you need to know about the keyword research process, from understanding its goals to building your own keyword universe map. Enjoy!
Click on the whiteboard image above to open a high resolution version in a new tab!
Video Transcription
Howdy, Moz fans. Welcome to another portion of our special edition of Whiteboard Friday, the One-Hour Guide to SEO. This is Part II - Keyword Research. Hopefully you've already seen our SEO strategy session from last week. What we want to do in keyword research is talk about why keyword research is required. Why do I have to do this task prior to doing any SEO work?
The answer is fairly simple. If you don't know which words and phrases people type into Google or YouTube or Amazon or Bing, whatever search engine you're optimizing for, you're not going to be able to know how to structure your content. You won't be able to get into the searcher's brain, into their head to imagine and empathize with them what they actually want from your content. You probably won't do correct targeting, which will mean your competitors, who are doing keyword research, are choosing wise search phrases, wise words and terms and phrases that searchers are actually looking for, and you might be unfortunately optimizing for words and phrases that no one is actually looking for or not as many people are looking for or that are much more difficult than what you can actually rank for.
The goals of keyword research
So let's talk about some of the big-picture goals of keyword research.
Understand the search demand landscape so you can craft more optimal SEO strategies
First off, we are trying to understand the search demand landscape so we can craft better SEO strategies. Let me just paint a picture for you.
I was helping a startup here in Seattle, Washington, a number of years ago — this was probably a couple of years ago — called Crowd Cow. Crowd Cow is an awesome company. They basically will deliver beef from small ranchers and small farms straight to your doorstep. I personally am a big fan of steak, and I don't really love the quality of the stuff that I can get from the store. I don't love the mass-produced sort of industry around beef. I think there are a lot of Americans who feel that way. So working with small ranchers directly, where they're sending it straight from their farms, is kind of an awesome thing.
But when we looked at the SEO picture for Crowd Cow, for this company, what we saw was that there was more search demand for competitors of theirs, people like Omaha Steaks, which you might have heard of. There was more search demand for them than there was for "buy steak online," "buy beef online," and "buy rib eye online." Even things like just "shop for steak" or "steak online," these broad keyword phrases, the branded terms of their competition had more search demand than all of the specific keywords, the unbranded generic keywords put together.
That is a very different picture from a world like "soccer jerseys," where I spent a little bit of keyword research time today looking, and basically the brand names in that field do not have nearly as much search volume as the generic terms for soccer jerseys and custom soccer jerseys and football clubs' particular jerseys. Those generic terms have much more volume, which is a totally different kind of SEO that you're doing. One is very, "Oh, we need to build our brand. We need to go out into this marketplace and create demand." The other one is, "Hey, we need to serve existing demand already."
So you've got to understand your search demand landscape so that you can present to your executive team and your marketing team or your client or whoever it is, hey, this is what the search demand landscape looks like, and here's what we can actually do for you. Here's how much demand there is. Here's what we can serve today versus we need to grow our brand.
Create a list of terms and phrases that match your marketing goals and are achievable in rankings
The next goal of keyword research, we want to create a list of terms and phrases that we can then use to match our marketing goals and achieve rankings. We want to make sure that the rankings that we promise, the keywords that we say we're going to try and rank for actually have real demand and we can actually optimize for them and potentially rank for them. Or in the case where that's not true, they're too difficult or they're too hard to rank for. Or organic results don't really show up in those types of searches, and we should go after paid or maps or images or videos or some other type of search result.
Prioritize keyword investments so you do the most important, high-ROI work first
We also want to prioritize those keyword investments so we're doing the most important work, the highest ROI work in our SEO universe first. There's no point spending hours and months going after a bunch of keywords that if we had just chosen these other ones, we could have achieved much better results in a shorter period of time.
Match keywords to pages on your site to find the gaps
Finally, we want to take all the keywords that matter to us and match them to the pages on our site. If we don't have matches, we need to create that content. If we do have matches but they are suboptimal, not doing a great job of answering that searcher's query, well, we need to do that work as well. If we have a page that matches but we haven't done our keyword optimization, which we'll talk a little bit more about in a future video, we've got to do that too.
Understand the different varieties of search results
So an important part of understanding how search engines work — we're going to start down here and then we'll come back up — is to have this understanding that when you perform a query on a mobile device or a desktop device, Google shows you a vast variety of results. Ten or fifteen years ago this was not the case. We searched 15 years ago for "soccer jerseys," what did we get? Ten blue links. I think, unfortunately, in the minds of many search marketers and many people who are unfamiliar with SEO, they still think of it that way. How do I rank number one? The answer is, well, there are a lot of things "number one" can mean today, and we need to be careful about what we're optimizing for.
So if I search for "soccer jersey," I get these shopping results from Macy's and soccer.com and all these other places. Google sort has this sliding box of sponsored shopping results. Then they've got advertisements below that, notated with this tiny green ad box. Then below that, there are couple of organic results, what we would call classic SEO, 10 blue links-style organic results. There are two of those. Then there's a box of maps results that show me local soccer stores in my region, which is a totally different kind of optimization, local SEO. So you need to make sure that you understand and that you can convey that understanding to everyone on your team that these different kinds of results mean different types of SEO.
Now I've done some work recently over the last few years with a company called Jumpshot. They collect clickstream data from millions of browsers around the world and millions of browsers here in the United States. So they are able to provide some broad overview numbers collectively across the billions of searches that are performed on Google every day in the United States.
Click-through rates differ between mobile and desktop
The click-through rates look something like this. For mobile devices, on average, paid results get 8.7% of all clicks, organic results get about 40%, a little under 40% of all clicks, and zero-click searches, where a searcher performs a query but doesn't click anything, Google essentially either answers the results in there or the searcher is so unhappy with the potential results that they don't bother taking anything, that is 62%. So the vast majority of searches on mobile are no-click searches.
On desktop, it's a very different story. It's sort of inverted. So paid is 5.6%. I think people are a little savvier about which result they should be clicking on desktop. Organic is 65%, so much, much higher than mobile. Zero-click searches is 34%, so considerably lower.
There are a lot more clicks happening on a desktop device. That being said, right now we think it's around 60–40, meaning 60% of queries on Google, at least, happen on mobile and 40% happen on desktop, somewhere in those ranges. It might be a little higher or a little lower.
The search demand curve
Another important and critical thing to understand about the keyword research universe and how we do keyword research is that there's a sort of search demand curve. So for any given universe of keywords, there is essentially a small number, maybe a few to a few dozen keywords that have millions or hundreds of thousands of searches every month. Something like "soccer" or "Seattle Sounders," those have tens or hundreds of thousands, even millions of searches every month in the United States.
But people searching for "Sounders FC away jersey customizable," there are very, very few searches per month, but there are millions, even billions of keywords like this.
The long-tail: millions of keyword terms and phrases, low number of monthly searches
When Sundar Pichai, Google's current CEO, was testifying before Congress just a few months ago, he told Congress that around 20% of all searches that Google receives each day they have never seen before. No one has ever performed them in the history of the search engines. I think maybe that number is closer to 18%. But that is just a remarkable sum, and it tells you about what we call the long tail of search demand, essentially tons and tons of keywords, millions or billions of keywords that are only searched for 1 time per month, 5 times per month, 10 times per month.
The chunky middle: thousands or tens of thousands of keywords with ~50–100 searches per month
If you want to get into this next layer, what we call the chunky middle in the SEO world, this is where there are thousands or tens of thousands of keywords potentially in your universe, but they only have between say 50 and a few hundred searches per month.
The fat head: a very few keywords with hundreds of thousands or millions of searches
Then this fat head has only a few keywords. There's only one keyword like "soccer" or "soccer jersey," which is actually probably more like the chunky middle, but it has hundreds of thousands or millions of searches. The fat head is higher competition and broader intent.
Searcher intent and keyword competition
What do I mean by broader intent? That means when someone performs a search for "soccer," you don't know what they're looking for. The likelihood that they want a customizable soccer jersey right that moment is very, very small. They're probably looking for something much broader, and it's hard to know exactly their intent.
However, as you drift down into the chunky middle and into the long tail, where there are more keywords but fewer searches for each keyword, your competition gets much lower. There are fewer people trying to compete and rank for those, because they don't know to optimize for them, and there's more specific intent. "Customizable Sounders FC away jersey" is very clear. I know exactly what I want. I want to order a customizable jersey from the Seattle Sounders away, the particular colors that the away jersey has, and I want to be able to put my logo on there or my name on the back of it, what have you. So super specific intent.
Build a map of your own keyword universe
As a result, you need to figure out what the map of your universe looks like so that you can present that, and you need to be able to build a list that looks something like this. You should at the end of the keyword research process — we featured a screenshot from Moz's Keyword Explorer, which is a tool that I really like to use and I find super helpful whenever I'm helping companies, even now that I have left Moz and been gone for a year, I still sort of use Keyword Explorer because the volume data is so good and it puts all the stuff together. However, there are two or three other tools that a lot of people like, one from Ahrefs, which I think also has the name Keyword Explorer, and one from SEMrush, which I like although some of the volume numbers, at least in the United States, are not as good as what I might hope for. There are a number of other tools that you could check out as well. A lot of people like Google Trends, which is totally free and interesting for some of that broad volume data.
So I might have terms like "soccer jersey," "Sounders FC jersey", and "custom soccer jersey Seattle Sounders." Then I'll have these columns:
Volume, because I want to know how many people search for it;
Difficulty, how hard will it be to rank. If it's super difficult to rank and I have a brand-new website and I don't have a lot of authority, well, maybe I should target some of these other ones first that are lower difficulty.
Organic Click-through Rate, just like we talked about back here, there are different levels of click-through rate, and the tools, at least Moz's Keyword Explorer tool uses Jumpshot data on a per keyword basis to estimate what percent of people are going to click the organic results. Should you optimize for it? Well, if the click-through rate is only 60%, pretend that instead of 100 searches, this only has 60 or 60 available searches for your organic clicks. Ninety-five percent, though, great, awesome. All four of those monthly searches are available to you.
Business Value, how useful is this to your business?
Then set some type of priority to determine. So I might look at this list and say, "Hey, for my new soccer jersey website, this is the most important keyword. I want to go after "custom soccer jersey" for each team in the U.S., and then I'll go after team jersey, and then I'll go after "customizable away jerseys." Then maybe I'll go after "soccer jerseys," because it's just so competitive and so difficult to rank for. There's a lot of volume, but the search intent is not as great. The business value to me is not as good, all those kinds of things.
Last, but not least, I want to know the types of searches that appear — organic, paid. Do images show up? Does shopping show up? Does video show up? Do maps results show up? If those other types of search results, like we talked about here, show up in there, I can do SEO to appear in those places too. That could yield, in certain keyword universes, a strategy that is very image centric or very video centric, which means I've got to do a lot of work on YouTube, or very map centric, which means I've got to do a lot of local SEO, or other kinds like this.
Once you build a keyword research list like this, you can begin the prioritization process and the true work of creating pages, mapping the pages you already have to the keywords that you've got, and optimizing in order to rank. We'll talk about that in Part III next week. Take care.
Video transcription by Speechpad.com
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog http://tracking.feedpress.it/link/9375/11175845
0 notes