#u280
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The total number of visits Tumblr.com received during January 2021 is 327 million.
Text
Ускорительная плата Alveo U280 от Xilinx
Компания Xilinx начала производство платы-ускорителя Alveo U280. От ускорителей U200/U250, выпущенных ране, её отличает наличие 8 Гбайт памяти HBM2 с суммарной пропускной способностью 460 GB/s, что является своеобразным рекордом по пропускной способности. Таким образом, семейство Alveo на сегодняшний момент состоит уже из трёх типов ускорительных плат.
Ускорительная карта Xilinx Alveo U280 предназначена для решения задач современных центров обработки данных. Как и предыдущие платы серии Alveo, ускоритель U280 выпускается в вариантах с активным и пассивным охлаждением и способен работать в круглосуточном режиме 24/7.
При работе с базами данных скорость работы U280 достигает 1200 миллионов запросов в секунду. При этом обеспечивается уменьшение времени отклика в 4 раза, по сравнению с использованием процессора. Ускоритель Alveo U280 так же отлично подходит для решения задач искусственного интеллекта. Например, на задаче перевода текста U280 показывает производительность больше 10 000 символов/секунду при задержке 6 мс. Подробности в статье Supercharge Your AI and Database Applications with Xilinx's HBM-Enabled UltraScale+ Devices Featuring Samsung HBM2.
Для программирования Alveo U280 используется среда SDAccel.
Подробнее ознакомиться с новой платой и её характеристиками можно на странице продукта по ссылке https://www.xilinx.com/products/boards-and-kits/alveo/u280.html

0 notes
Link

Forage harvester PALESSE K-G-6 consists of universal power vehicle PALESSE 2U280, 2U250 or U280 and semi-mounted forage harvesting combine “PALESSE FH40” with adapter kit. Harvester is available in two models: PALESSE FH40 and PALESSE FH40А. If the harvester is used for harvesting of maize for silage, it will be better to choose PALESSE FH40A with an active type device for regrinding of wax and full ripeness corn. While harvesting grass crusher unit is dismounted and replaced by the spacer plate with smooth walls. If the harvester reaps only grass, it will be useful to purchase the model PALESSE FH40 without corn crusher unit. Semi-mounted harvester PALESSE FH40 is equipped with a chopping device with radial disc type. Available in two modifications: with an active type device for regrinding of corn or without it.
1 note
·
View note
Photo

Xilinx Alveo U280 Launched Possibly with AMD EPYC CCIX Support https://ift.tt/2Kgmo51
2 notes
·
View notes
Text
Aavik U180, U280, and U580 integrated amplifiers Review
Aavik U180, U280, and U580 integrated amplifiers Review
https://www.hifi-advice.com/blog/amplifier-reviews/integrated-amplifier-reviews/aavik-u180-u280-and-u580-integrated-amplifiers/ The Pascal UMAC power amp module was easy to spot and I was pleased to see such a neatly laid-out preamplifier board. There’s an XMOS input receiver and a PCM1792 DAC chip. Mounted on the power amp module’s heatsink are three full-width PCBs full of Tesla coils that…

View On WordPress
0 notes
Photo

$45.88 17% off sell - Women's U280 Cat-Eye Sunglasses - 57 mm - Black Fade - C31296VODMV ImportedFunctional fashion accessory more product select from our Cat Eye:https://www.shadowner.com/49-cat-eye # 's #
0 notes
Photo

USA SPECIMEN 2c Bidders Sample Special Request UPSS 818 U280 Stationery 86067 https://ift.tt/2YDhlTM
0 notes
Photo

((*)) Tripp Lite U280-016-RM interface hub - U280-016-RM https://ift.tt/3fmPqxZ
0 notes
Text
Jpeg2jpeg Acceleration with CUDA MPS on Linux
The task of fast JPEG-to-JPEG Resize is essential for high load web services. Users create most of their images with smart phones and cameras in JPEG format which is the most popular nowadays. To offer high quality services and to cut expences on storages, providers strive to implement JPEG resize on-the-fly to store just one image instead of several dozens in different resolutions.
Solutions for fast JPEG resize, which are also called Jpeg2jpeg, have been implemented on CPU, GPU, FPGA and on mobile platforms as well. The highest performance for that task was demonstrated on GPU and FPGA, which used to be considered on par for NVIDIA Tesla T4 and Xilinx VCU1525 or Alveo U280 hardware.

Bottlenecks for high performance Jpeg2jpeg solutions on GPU
Implementation of fast JPEG Resize (Jpeg2jpeg transform) is quite complicated task and it's not easy to boost highly optimized solution. Nevertheless, we can point out some issues which still could be improved:
better GPU utilization
batch mode implementation
performance optimization of JPEG decoder (this is the slowest part of the pipeline)
In general, GPU can offer super high performance only in the case if there is sufficient amount of data for parallel processing. If we don't have enough data, then GPU occupancy is low and we are far from maximum performance. We have exactly the same issue with the task of JPEG Resize on GPU: usually we have non-sufficient amount of data and GPU occupancy is not high. One way to solve that matter is to implement batch mode.
Batch mode implies that the same algorithm could be applied at the same time to many items which we need to process. This is not exactly the case with JPEG Resize, because it should be possible to implement batch processing for JPEG decoding, though Resize is difficult to include at the same batch as soon as for each image we need to generate and to utilize individual sets of interpolation coefficients. And scaling ratio is usually not the same for all processed images in the batch. That's why batch mode could be limited by JPEG decoding only. If we have a look at existing FPGA-based solutions for Jpeg2jpeg software, all of them are utilizing batch JPEG decoding and then individual resize and encoding to get better performance.
Optimization of JPEG decoder could be done by taking into account the latest NVIDIA architecture to boost the performance of entropy decoder, which is the most time-consuming part of JPEG algorithm. Apart from entropy decoder optimization, it makes sense to accelerate all other parts or JPEG algorithm.
Finally, we've found the way how to accelerate the current version of JPEG Resize on GPU from Fastvideo Image Processing SDK and this is the answer: NVIDIA CUDA MPS. Below we condiser in detail what's CUDA MPS and how we could utilize it for that task.
CUDA Multi-Process Service
The Multi-Process Service (MPS) is an alternative, binary-compatible implementation of the CUDA Application Programming Interface (CUDA API). The MPS runtime architecture is designed to transparently enable co-operative multi-process CUDA applications, typically MPI jobs, to utilize Hyper-Q capabilities on the latest NVIDIA (Kepler-based) GPUs. Hyper-Q allows CUDA kernels to be processed concurrently on the same GPU. This can benefit performance when the GPU compute capacity is underutilized by a single application process.
MPS is a binary-compatible client-server runtime implementation of the CUDA API, which consists of several components:
Control Daemon Process: the control daemon is responsible for starting and stopping the server, as well as coordinating connections between clients and servers.
Client Runtime: the MPS client runtime is built into the CUDA Driver library and may be used transparently by any CUDA application.
Server Process: the server is the clients' shared connection to the GPU and provides concurrency between clients.
To balance workloads between CPU and GPU tasks, MPI processes are often allocated individual CPU cores in a multi-core CPU machine to provide CPU-core parallelization of potential Amdahl bottlenecks. As a result, the amount of work each individual MPI process is assigned may underutilize the GPU when the MPI process is accelerated using CUDA kernels. While each MPI process may end up running faster, the GPU is being used inefficiently. The Multi-Process Service takes advantage of the inter-MPI rank parallelism, increasing the overall GPU utilization.
NVIDIA Volta architecture has introduced new MPS capabilities. Compared to MPS on pre-Volta GPUs, Volta MPS provides a few key improvements:
Volta MPS clients submit work directly to the GPU without passing through the MPS server.
Each Volta MPS client owns its own GPU address space instead of sharing GPU address space with all other MPS clients.
Volta MPS supports limited execution resource provisioning for Quality of Service (QoS).

Fig.1. Pascal and Volta MPS architectures (picture from NVIDIA MPS Documentation)
CUDA MPS Benefits
GPU utilization: a single process may not utilize all the compute and memory-bandwidth capacity available on the GPU. MPS allows kernel and memcopy operations from different processes to overlap on the GPU, achieving higher utilization and shorter running times.
Reduced on-GPU context storage: without MPS each CUDA processes using a GPU allocates separate storage and scheduling resources on the GPU. In contrast, the MPS server allocates one copy of GPU storage and scheduling resources shared by all its clients. Volta MPS supports increased isolation between MPS clients, so the resource reduction is to a much lesser degree.
Reduced GPU context switching: without MPS, when processes share the GPU their scheduling resources must be swapped on and off the GPU. The MPS server shares one set of scheduling resources between all of its clients, eliminating the overhead of swapping when the GPU is scheduling between those clients.
CUDA MPS Limitations
MPS is only supported on the Linux operating system. The MPS server will fail to start when launched on an operating system other than Linux.
MPS is not supported on NVIDIA Jetson platforms. The MPS server will fail to start when launched on Jetson platforms.
MPS requires a GPU with compute capability version 3.5 or higher. The MPS server will fail to start if one of the GPUs visible after applying CUDA_VISIBLE_DEVICES is not of compute capability 3.5 or higher.
The Unified Virtual Addressing (UVA) feature of CUDA must be available, which is the default for any 64-bit CUDA program running on a GPU with compute capability version 2.0 or higher. If UVA is unavailable, the MPS server will fail to start.
The amount of page-locked host memory that can be allocated by MPS clients is limited by the size of the tmpfs filesystem (/dev/shm).
Exclusive-mode restrictions are applied to the MPS server, not to MPS clients.
Only one user on a system may have an active MPS server.
The MPS control daemon will queue MPS server activation requests from separate users, leading to serialized exclusive access of the GPU between users regardless of GPU exclusivity settings.
All MPS client behavior will be attributed to the MPS server process by system monitoring and accounting tools (e.g. nvidia-smi, NVML API).
GPU Compute Modes
Three Compute Modes are supported via settings accessible in nvidia-smi.
PROHIBITED – the GPU is not available for compute applications.
EXCLUSIVE_PROCESS – the GPU is assigned to only one process at a time, and individual process threads may submit work to the GPU concurrently.
DEFAULT – multiple processes can use the GPU simultaneously. Individual threads of each process may submit work to the GPU simultaneously.
Using MPS effectively causes EXCLUSIVE_PROCESS mode to behave like DEFAULT mode for all MPS clients. MPS will always allow multiple clients to use the GPU via the MPS server.
When using MPS, it is recommended to use EXCLUSIVE_PROCESS mode to ensure that only a single MPS server is using the GPU, which provides additional insurance that the MPS server is the single point of arbitration between all CUDA processes for that GPU.
Client-Server Architecture
This diagram shows a likely schedule of CUDA kernels when running an MPI application consisting of multiple OS processes without MPS. Note that while the CUDA kernels from within each MPI process may be scheduled concurrently, each MPI process is assigned a serially scheduled time-slice on the whole GPU.
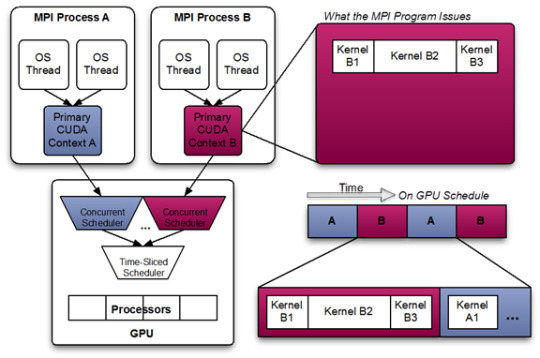
Fig.2. Multi-Process Sharing GPU without MPS (picture from NVIDIA MPS Documentation)

Fig.3. Multi-Process Sharing GPU with MPS (picture from NVIDIA MPS Documentation)
When using pre-Volta MPS, the server manages the hardware resources associated with a single CUDA context. The CUDA contexts belonging to MPS clients funnel their work through the MPS server. This allows the client CUDA contexts to bypass the hardware limitations associated with time sliced scheduling, and permit their CUDA kernels execute simultaneously.
Volta provides new hardware capabilities to reduce the types of hardware resources the MPS server must managed. A client CUDA context manages most of the hardware resources on Volta, and submits work to the hardware directly. The Volta MPS server mediates the remaining shared resources required to ensure simultaneous scheduling of work submitted by individual clients, and stays out of the critical execution path.
The communication between the MPS client and the MPS server is entirely encapsulated within the CUDA driver behind the CUDA API. As a result, MPS is transparent to the MPI program. MPS clients CUDA contexts retain their upcall handler thread and any asynchronous executor threads. The MPS server creates an additional upcall handler thread and creates a worker thread for each client.
Server
The MPS control daemon is responsible for the startup and shutdown of MPS servers. The control daemon allows at most one MPS server to be active at a time. When an MPS client connects to the control daemon, the daemon launches an MPS server if there is no server active. The MPS server is launched with the same user id as that of the MPS client.
If there is an MPS server already active and the user id of the server and client match, then the control daemon allows the client to proceed to connect to the server. If there is an MPS server already active, but the server and client were launched with different user id’s, the control daemon requests the existing server to shutdown once all its clients have disconnected. Once the existing server has shutdown, the control daemon launches a new server with the same user id as that of the new user's client process.
The MPS control daemon does not shutdown the active server if there are no pending client requests. This means that the active MPS server process will persist even if all active clients exit. The active server is shutdown when either a new MPS client, launched with a different user id than the active MPS server, connects to the control daemon or when the work launched by the clients has caused an exception.
The control daemon executable also supports an interactive mode where a user with sufficient permissions can issue commands, for example to see the current list of servers and clients or startup and shutdown servers manually.
Client Attach/Detach
When CUDA is first initialized in a program, the CUDA driver attempts to connect to the MPS control daemon. If the connection attempt fails, the program continues to run as it normally would without MPS. If however, the connection attempt succeeds, the MPS control daemon proceeds to ensure that an MPS server, launched with same user id as that of the connecting client, is active before returning to the client. The MPS client then proceeds to connect to the server.
All communication between the MPS client, the MPS control daemon, and the MPS server is done using named pipes and UNIX domain sockets. The MPS server launches a worker thread to receive commands from the client. Upon client process exit, the server destroys any resources not explicitly freed by the client process and terminates the worker thread.
Important Application Considerations
The NVIDIA VIDEO Codec SDK is not supported under MPS on pre-Volta MPS clients.
Only 64-bit applications are supported. The MPS server will fail to start if the CUDA application is not 64-bit. The MPS client will fail CUDA initialization.
If an application uses the CUDA driver API, then it must use headers from CUDA 4.0 or later (i.e. it must not have been built by setting CUDA_FORCE_API_VERSION to an earlier version). Context creation in the client will fail if the context version is older than 4.0.
Dynamic parallelism is not supported. CUDA module load will fail if the module uses dynamic parallelism features.
MPS server only supports clients running with the same UID as the server. The client application will fail to initialize if the server is not running with the same UID.
Stream callbacks are not supported on pre-Volta MPS clients. Calling any stream callback APIs will return an error.
CUDA graphs with host nodes are not supported under MPS on pre-Volta MPS clients.
The amount of page-locked host memory that pre-Volta MPS client applications can allocate is limited by the size of the tmpfs filesystem (/dev/shm). Attempting to allocate more page-locked memory than the allowed size using any of relevant CUDA APIs will fail.
Terminating an MPS client without synchronizing with all outstanding GPU work (via Ctrl-C / program exception such as segfault / signals, etc.) can leave the MPS server and other MPS clients in an undefined state, which may result in hangs, unexpected failures, or corruptions.
Performance measurements for Jpeg2jpeg application
For software testing we've utilized the following scenarious:
Source 24-bit RGB images with JPEG quality 90%, subsampling 4:2:0, restart interval 1
Initial image resolution: 1920×1080 (2K) or 1280×720 (1K)
2K resize: 1920×1080 to 480×270
1K resize: 1280×720 to 320×180
Output JPEG compression: quality 90%, subsampling 4:2:0, restart interval 10
Hardware and software
CPU Intel Core i7-5930K (Haswell-E, 6 cores, 3.5–3.7 GHz)
NVIDIA Quadro GV100
Linux Ubuntu 18.04 and CUDA-10.0
Fastvideo SDK 0.14.2.4
These are main components of Jpeg2jpeg software
Server is responsible for image processing on GPU.
Client is responsible for image read from disk, image send for processing, storing the processed images after convertion. We need at least two Clients per Server to hide load/store operations.
If we are working with CUDA MPS activated, then the total number of processes in Jpeg2jpeg software is limited by the amount of available CPU cores.
To check CUDA MPS mode, we executed the following commands
nvidia-smi -i 0 -c EXCLUSIVE_PROCESS
nvidia-cuda-mps-control -d
Then we started 2/4/6 daemons of JPEG Resize application on NVIDIA Quadro GV100 GPU.
We've also done the same without CUDA MPS to make a comparison.
How we measured the performance
To get reliable results which have good correspondence with JPEG Resize algorithm parameters, for each test we've utilized the same image and the same parameters for resizing and encoding. We've repeated each series 1,000 times and calculated average FPS (number of frames per second) for processing. Speedup is calculated as the current value of "FPS with MPS" divided to the best value from "FPS without MPS" column.
Jpeg2jpeg performance with and without MPS for 1K JPEG Resize from 1280×720 to 320×180
Source image | Servers | Clients per Server | FPS without MPS | FPS with MPS | Speedup
1K | 2 | 1 | 837 | 1198 | 1.4
1K | 2 | 2 | 815 | 1633 | 2.0
1K | 4 | 1 | 815 | 2326 | 2.9
1K | 4 | 2 | 813 | 2581 | 3.2
1K | 6 | 1 | 795 | 2857 | 3.4
1K | 6 | 2 | 805 | 2871 | 3.4
Jpeg2jpeg performance with and without MPS for 2K JPEG Resize from 1920×1080 to 480×270
Source image | Servers | Clients per Server | FPS without MPS | FPS with MPS | Speedup
2K | 2 | 1 | 769 | 1124 | 1.4
2K | 2 | 2 | 762 | 1368 | 1.8
2K | 4 | 1 | 761 | 1826 | 2.4
2K | 4 | 2 | 748 | 1975 | 2.8
2K | 6 | 1 | 769 | 2143 | 2.8
2K | 6 | 2 | 696 | 2087 | 2.7
We see that performance saturation in that task could probably be connected with the number of utilized CPU cores. We will check the performance on multicore Intel Xeon CPU to find the solution with the best balance between CPU and GPU to achieve maximum acceleration for Jpeg2jpeg application. This is essentially heterogeneous task and all hardware components should be carefully chosen and thoroughly tested.
Jpeg 2 Jpeg acceleration benchmarks for CUDA MPS on Linux
We've been able to boost the Jpeg2jpeg software with CUDA MPS on Linux significantly. According to our time measurements, total performance for JPEG Resize application at CUDA MPS mode was increased by 2.8–3.4 times, which is difficult to believe. We have been able to accelerate the solution that was already well-optimized and it was one of the fastest on the market. For standard use cases on NVIDIA Quadro GV100 we've got benchmarks around 760–830 fps (images per second) and with CUDA MPS at the same test conditions and at the same hardware we've reached 2140–2870 fps.
Such an impressive performance boost is absolutely astonishing and we've checked that many times. It's working well and very fast. Moreover, we have fair chances to get even better acceleration by utilizing more powerful multicore CPU.
GPU and FPGA solutions for Jpeg2jpeg applications were on par recently, but this is not the case anymore. Now NVIDIA GPU with Jpeg2jpeg software from Fastvideo have left behind both CPU and FPGA solutions.
References
Documentation for NVIDIA CUDA MPS
Web Resize on-the-fly: one thousand images per second on Tesla V100 GPU
JPEG Resize on-demand: FPGA vs GPU. Which is the fastest?
Original article see at: https://www.fastcompression.com/blog/jpeg2jpeg-cuda-mps-acceleration.htm
0 notes
Link
0 notes
Photo

☮️💟🕉 https://www.instagram.com/p/CQGdE7BHeemTEccLrba83DIMiA_gjrqnr_-U280/?utm_medium=tumblr
0 notes
Photo

#Repost @ictdynamicteam · · · · 1/365/BASILICA DI MASSENZIO⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ La Basilica di Massenzio è uno degli edifici più grandiosi di Roma antica che si possono ammirare oggi. La basilica venne fondata nel luogo che era stato già occupato dal triplice portico che serviva da vestibolo alla Domus Aurea di Nerone e che fu poi trasformato in “magazzino” di merci esotiche e di lusso provenienti dall’Oriente. ⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ Costruita agli inizi del IV secolo d.C. da Massenzio che per pochi anni fu imperatore di Roma prima di essere sconfitto da Costantino, occupava un'area immensa. Quello che rimane oggi è solo una navata minore il cui muro esterno si può vedere da via dei Fori Imperiali. Tutto il resto della costruzione è andato perduto dopo un terremoto del IX secolo e le macerie sono state reimpiegate per l'abbellimento della vecchia basilica di San Pietro. ⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ La Basilica di Massenzio è stata uno dei modelli preferiti dall’architettura rinascimentale, in particolare per Bramante.⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ #365postiaroma La guida di @ictdynamicteam⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ #basilica #basilicadimassenzio #roma #romantica #bramante #domusaureao d.C. da Massenzio che per pochi anni fu imperatore di Roma prima di essere sconfitto da Costantino, occupava un'area immensa. Quello che rimane oggi è solo una navata minore il cui muro esterno si può vedere da via dei Fori Imperiali. Tutto il resto della costruzione è andato perduto dopo un terremoto del IX secolo e le macerie sono state reimpiegate per l'abbellimento della vecchia basilica di San Pietro. ⠀"u280 #nerone #viadeiforiimperiale #ruinesromaines #architetturarinascimentale #archittetura #cosedavedere #365 https://www.instagram.com/p/BoluB3ZjzuW/?utm_source=ig_tumblr_share&igshid=1wcn1pe1gma0d
#repost#365postiaroma#basilica#basilicadimassenzio#roma#romantica#bramante#domusaureao#nerone#viadeiforiimperiale#ruinesromaines#architetturarinascimentale#archittetura#cosedavedere#365
0 notes
Text
Obtain Some Automotive Diagnostic Devices
For http://bestobd2scannerreviews.com/ , they can't maintain their cars in great shape without furnishing with some automotive analysis tools of their very own. Also a straightforward automotive analysis resource are going to be actually a great assistance in inspecting the issue codes from the engine. Because of the swift advancement of scientific research and technology, these devices could be actually simply updated through some particular software program. After that there is actually no must get them year after year, which will definitely be actually a wonderful means to spare our money and also reduce the amount of times our company depend on the technicians for help. To conserve your spending plan, you may buy some automotive exercise products for vehicle diagnostic and also scan reason given that they are commonly inexpensive in price as well as practical in make use of. A memo scanner is made to read as well as wipe out issue codes in vehicles, particularly for those Do It Yourself repairers. At that point you need some computer programming devices or commanders to system or even reprogram. These resources possess straightforward interface and also easy to work. The initial thing you have to keep in thoughts before acquiring any type of analysis tool is your own personal requirement as well as the degree to which you will definitely manage to take care of the current modern technologies for personal or even specialist degree. Listed below I can easily name some vehicle health and fitness products, such as U280 VW/AUDI memorandum scanner, VAG PROG CZ Version, BMW OPPS, BMW OPS, BMW GT1, VAG pin viewers, OBD2 ELM327 USB CAN-BUS Scanner and so on. You will certainly discover all of them practical, I guarantee. Only by invest some funds on these devices at to begin with, and also after that you can easily browse your cars and truck concerns on your own as well as resolve all of them yourself. That is actually to claim, you acquire some standard evaluation resources at a reasonably cheap cost, however they have the ability to function with many kinds of motor vehicles as well as give access to all kinds from difficulty codes and then diagnose troubles connected to the internal shows from the car. In doing this, you can conserve cash to devote in the medical diagnosis of technical concern. That is actually truly a good deal.
0 notes
Text
Auto Diagnostic
For modern vehicle owners, they can't keep their automobiles in good condition without equipping with a few automotive diagnostic tools of the own. Even a easy automobile diagnostic device will be a great assist in checking the trouble codes regarding the engine.

Because of the rapid development of science and technology, these tools can be easily updated by using some software that is certain. Then there is no need to purchase them every year, which will be a wonderful option to save our cash and minimize the occasions we consider the mechanics for assistance. To save your budget, you can purchase some car physical fitness items for auto diagnostic and purpose that is scan they're usually low priced in cost and practical in use. A memo scanner was created to read and erase difficulty codes in cars, particularly for those DIY repairers. Then some programming is needed by you tools or commanders to plan or reprogram. These tools have user-friendly interface and easy to work. The first thing you must keep in mind TOP 10: The Best Professional Automotive Diagnostic Scanner Reviews before purchasing any diagnostic device can be your own personal need plus the extent to that you simply should be able to cope with the newest technologies for individual or professional level. Right Here i could name some auto physical fitness items, such as U280 VW/AUDI memo scanner, VAG PROG CZ variation, BMW OPPS, BMW OPS, BMW GT1, VAG pin audience, OBD2 ELM327 USB CAN-BUS Scanner etc. You will see them useful, I vow. By simply spend some funds on these tools at first, after which you'll scan your vehicle issues yourself and solve them your self. That's to state, you receive some fundamental analysis tools at a fairly cheap cost, but they are in a position to work with many kinds of cars and present usage of a variety of trouble codes and then diagnose dilemmas associated with the inner development for the automobile. In doing so, you can spend less to pay within the diagnosis of technical issue. It's actually a deal.
0 notes
Text
Vehicle Scanner
For modern automobile owners, they can't keep their automobiles in good shape without equipping with some automotive diagnostic tools of these own. Even an auto that is simple tool would have been a great aid in checking the problem codes associated with motor.

As a result of the rapid growth of science and technology, these tools can be simply updated with the help of some software that is certain. Then there is no need to get them year after year, which will be a wonderful option to save our cash and reduce the days we check out the mechanics for assistance. To save lots of your budget, you can purchase some auto fitness products for auto diagnostic and scan function because they are usually cheap in price and practical being used. A memo scanner is made to read and erase difficulty codes in cars, especially for those DIY repairers. Then you'll need some development tools or commanders to program or reprogram. These tools have actually user-friendly user interface and easy to operate. The very first thing you need to keep in mind before buying any diagnostic tool can be your own personal need as well as the degree to that you should be able to handle the most recent technologies for individual or level that is professional. Here i will name some car physical fitness products, such as U280 VW/AUDI memo scanner, VAG PROG CZ Version, BMW OPPS, BMW OPS, BMW GT1, VAG pin audience, OBD2 ELM327 USB CAN-BUS Scanner etc. You shall locate them of good use, I vow. By simply invest some cash on these tools in the beginning, then you are able to scan your car issues your self Wikiselect.com and re solve them your self. That is to say, you will get some analysis that is basic at a fairly cheap cost, however they are in a position to work with most forms of automobiles and give use of all sorts of difficulty codes and then diagnose issues related to the inner development associated with the car. In doing this, you'll spend less to spend within the diagnosis of mechanical issue. It's actually a bargain.
0 notes
Photo

USA SPECIMEN 2c Bidders Sample Special Request UPSS 818 U280 Stationery 86067 https://ift.tt/3avEb3G
0 notes
Photo

((*)) Tripp Lite U280-016-RM interface hub - U280-016-RM https://ift.tt/36DJ0rb
0 notes