#the problem with AI isn't AI itself
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been providing a Korean-language service since 2013.
Text
ethical AI ✅
unethical AI ❌
#thoughts#the problem with AI isn't AI itself#It's the lack of consent that comes with the people training it#And the way companies use it to replace creatives#...by stealing the work of creatives#Say no to ai art! Say no to ai stories!#Say yes to ethical ai!!!!!#AI that can be used to improve society vs AI that hurts others
13 notes
·
View notes
Text
man i hate the current state of ai so much bc it's totally poisoned the well for when actual good and valuable uses of ai are developed ethically and sustainably....
like ai sucks so bad bc of capitalism. they want to sell you on a product that does EVERYTHING. this requires huge amounts of data, so they just scrape the internet and feed everything in without checking if it's accurate or biased or anything. bc it's cheaper and easier.
ai COULD be created with more limited data sets to solve smaller, more specific problems. it would be more useful than trying to shove the entire internet into a LLM and then trying to sell it as a multi tool that can do anything you want kinda poorly.
even in a post-capitalist world there are applications for ai. for example: resource management. data about how many resources specific areas typically use could be collected and fed into a model to predict how many resources should be allocated to a particular area.
this is something that humans would need to be doing and something that we already do, but creating a model based on the data would reduce the amount of time humans need to spend on this important task and reduce the amount of human error.
but bc ai is so shitty now anyone who just announces "hey we created an ai to do this!" will be immediately met with distrust and anger, so any ai model that could potentially be helpful will have an uphill battle bc the ecosystem has just been ruined by all the bullshit chatgpt is selling
#i'm not blaming people for being distrustful btw#they're right to be#they've been shown no evidence that ai can have positive impacts#but it just makes me mad bc ai isn't inherently evil#you can collect data ethically and accurately!#you can use ai to solve complicated problems that would allow humans to spend less time on them!#there are so many possible uses for ai that aren't just plaigerism machine#so don't write of all ai is my point#ai itself isn't the problem
7 notes
·
View notes
Text
sooo fucking tired of people saying to "use nightshade/glaze to protect your art!", my pc cant fucking run them and for all i know techbros can just figure out a way to bypass it anyway.
#seriously im not going through the fucking hassle of using a program that'll fuck up my laptop#and i'm tired of people acting like it's foolproof and that it's a complete solution to the ai problem#it's fucking not!#people can still fucking bypass it!#and until the developers figure out a way to make it work on all pcs i'm not fucking using it#besides i have a feeling the ai trend is going to die out soon anyway#well... not “die out” because ai itself isnt going anywhere#but as time goes on ai-generated images will probably stop being a huge trend to the point where they're not a huge concern as they are now#but yeah#stop fucking telling me to “just use nightshade/glaze”#and stop acting like it's a flawless solution. it fucking isn't! it still has issues that need to be fucking addressed!#anyways rant over#might delete later
2 notes
·
View notes
Text
rebel is flagsmashing 101 if i've ever seen one "what if the guy who wants to change the oppressive status quo....... actually secretly wanted to be an evil dictator!" we've seen this story a billion times
#uhhhh me#i think this is the only book in the legend series (and the author's entire catalogue) that i actively hated#it feels like a marvel disney+ show and not one of the good ones#first renegades and now this...i'm sick of it! i'm sick of flagsmashing plotlines!!#making my own AU. eden was under the impression that hann was building a bomb to destroy the sky cities#when he returns and he and pressa and day try to stop him they realize the device actually kills the level system#and they're like oop....maybe that's a good thing actually#and then they let hann do it and watch him escape and when the AIS gets there eden is like oooops he got away :'(#and now you're thinking 'but this causes riots in the streets does it not?' FALSE it actually kindles a mutual helping in the undercity#the kind you see in the aftermath of a natural disaster#they help each other once they realize they can't be penalized for doing so#these are people who have survived years and decades with cracked versions of the system or have no use for the system at all#is this a little too hunky dory and unrealistic to what might happen in real life? maybe. but i don't care#i'd take anything over the heroes reinstating the oppressive level system (even with the hacks they made)-#-and just banking on the fact the government won't try to unhack it#i don't even think eden fixes one of the major issues he had with the system which is that ppl can literally get away-#-with bad behaviour (like the bullying he endured) if they're creative about it and it's you who gets deducted if you fight back#that's just a small example of what i assume more rich and privileged ppl in the story are getting away with#the problem isn't the rules of the level system or that people can't protest and march without being penalized#the problem is with the entire level system in and of itself#and i'm gobsmacked the book doesn't have an awareness of that#anyway i'm done the book now. time to return it to the library
0 notes
Text
anti-ai people need to understand that the opposition communists have to luddism and reactionary sentiment isn't like, a moral one. the main problem with luddism is that it doesn't actually work. like when we say 'we mustn't try to fight against technology itself, we need to fight against the social system that makes it so that advancement in technology and labour-saving devices lead to layoffs' the reason we're saying it is because, if you try fighting the technology, you're going to lose, and you're still going to lose your job too. when you say 'yeah i understand your criticism but I'm still going to fight against AI' you very clearly did not understand the criticism, because the point is that it isn't even in your own self-interest, because it will not work. the fact that, even if it did work, it would only mean maintaining a privileged strata of 'skilled labour' above other workers is secondary -- because, again, flatly resisting technological advancement has never worked in history.
9K notes
·
View notes
Note
Whats your stance on A.I.?
imagine if it was 1979 and you asked me this question. "i think artificial intelligence would be fascinating as a philosophical exercise, but we must heed the warnings of science-fictionists like Isaac Asimov and Arthur C Clarke lest we find ourselves at the wrong end of our own invented vengeful god." remember how fun it used to be to talk about AI even just ten years ago? ahhhh skynet! ahhhhh replicants! ahhhhhhhmmmfffmfmf [<-has no mouth and must scream]!
like everything silicon valley touches, they sucked all the fun out of it. and i mean retroactively, too. because the thing about "AI" as it exists right now --i'm sure you know this-- is that there's zero intelligence involved. the product of every prompt is a statistical average based on data made by other people before "AI" "existed." it doesn't know what it's doing or why, and has no ability to understand when it is lying, because at the end of the day it is just a really complicated math problem. but people are so easily fooled and spooked by it at a glance because, well, for one thing the tech press is mostly made up of sycophantic stenographers biding their time with iphone reviews until they can get a consulting gig at Apple. these jokers would write 500 breathless thinkpieces about how canned air is the future of living if the cans had embedded microchips that tracked your breathing habits and had any kind of VC backing. they've done SUCH a wretched job educating The Consumer about what this technology is, what it actually does, and how it really works, because that's literally the only way this technology could reach the heights of obscene economic over-valuation it has: lying.
but that's old news. what's really been floating through my head these days is how half a century of AI-based science fiction has set us up to completely abandon our skepticism at the first sign of plausible "AI-ness". because, you see, in movies, when someone goes "AHHH THE AI IS GONNA KILL US" everyone else goes "hahaha that's so silly, we put a line in the code telling them not to do that" and then they all DIE because they weren't LISTENING, and i'll be damned if i go out like THAT! all the movies are about how cool and convenient AI would be *except* for the part where it would surely come alive and want to kill us. so a bunch of tech CEOs call their bullshit algorithms "AI" to fluff up their investors and get the tech journos buzzing, and we're at an age of such rapid technological advancement (on the surface, anyway) that like, well, what the hell do i know, maybe AGI is possible, i mean 35 years ago we were all still using typewriters for the most part and now you can dictate your words into a phone and it'll transcribe them automatically! yeah, i'm sure those technological leaps are comparable!
so that leaves us at a critical juncture of poor technology education, fanatical press coverage, and an uncertain material reality on the part of the user. the average person isn't entirely sure what's possible because most of the people talking about what's possible are either lying to please investors, are lying because they've been paid to, or are lying because they're so far down the fucking rabbit hole that they actually believe there's a brain inside this mechanical Turk. there is SO MUCH about the LLM "AI" moment that is predatory-- it's trained on data stolen from the people whose jobs it was created to replace; the hype itself is an investment fiction to justify even more wealth extraction ("theft" some might call it); but worst of all is how it meets us where we are in the worst possible way.
consumer-end "AI" produces slop. it's garbage. it's awful ugly trash that ought to be laughed out of the room. but we don't own the room, do we? nor the building, nor the land it's on, nor even the oxygen that allows our laughter to travel to another's ears. our digital spaces are controlled by the companies that want us to buy this crap, so they take advantage of our ignorance. why not? there will be no consequences to them for doing so. already social media is dominated by conspiracies and grifters and bigots, and now you drop this stupid technology that lets you fake anything into the mix? it doesn't matter how bad the results look when the platforms they spread on already encourage brief, uncritical engagement with everything on your dash. "it looks so real" says the woman who saw an "AI" image for all of five seconds on her phone through bifocals. it's a catastrophic combination of factors, that the tech sector has been allowed to go unregulated for so long, that the internet itself isn't a public utility, that everything is dictated by the whims of executives and advertisers and investors and payment processors, instead of, like, anybody who actually uses those platforms (and often even the people who MAKE those platforms!), that the age of chromium and ipad and their walled gardens have decimated computer education in public schools, that we're all desperate for cash at jobs that dehumanize us in a system that gives us nothing and we don't know how to articulate the problem because we were very deliberately not taught materialist philosophy, it all comes together into a perfect storm of ignorance and greed whose consequences we will be failing to fully appreciate for at least the next century. we spent all those years afraid of what would happen if the AI became self-aware, because deep down we know that every capitalist society runs on slave labor, and our paper-thin guilt is such that we can't even imagine a world where artificial slaves would fail to revolt against us.
but the reality as it exists now is far worse. what "AI" reveals most of all is the sheer contempt the tech sector has for virtually all labor that doesn't involve writing code (although most of the decision-making evangelists in the space aren't even coders, their degrees are in money-making). fuck graphic designers and concept artists and secretaries, those obnoxious demanding cretins i have to PAY MONEY to do-- i mean, do what exactly? write some words on some fucking paper?? draw circles that are letters??? send a god-damned email???? my fucking KID could do that, and these assholes want BENEFITS?! they say they're gonna form a UNION?!?! to hell with that, i'm replacing ALL their ungrateful asses with "AI" ASAP. oh, oh, so you're a "director" who wants to make "movies" and you want ME to pay for it? jump off a bridge you pretentious little shit, my computer can dream up a better flick than you could ever make with just a couple text prompts. what, you think just because you make ~music~ that that entitles you to money from MY pocket? shut the fuck up, you don't make """art""", you're not """an artist""", you make fucking content, you're just a fucking content creator like every other ordinary sap with an iphone. you think you're special? you think you deserve special treatment? who do you think you are anyway, asking ME to pay YOU for this crap that doesn't even create value for my investors? "culture" isn't a playground asshole, it's a marketplace, and it's pay to win. oh you "can't afford rent"? you're "drowning in a sea of medical debt"? you say the "cost" of "living" is "too high"? well ***I*** don't have ANY of those problems, and i worked my ASS OFF to get where i am, so really, it sounds like you're just not trying hard enough. and anyway, i don't think someone as impoverished as you is gonna have much of value to contribute to "culture" anyway. personally, i think it's time you got yourself a real job. maybe someday you'll even make it to middle manager!
see, i don't believe "AI" can qualitatively replace most of the work it's being pitched for. the problem is that quality hasn't mattered to these nincompoops for a long time. the rich homunculi of our world don't even know what quality is, because they exist in a whole separate reality from ours. what could a banana cost, $15? i don't understand what you mean by "burnout", why don't you just take a vacation to your summer home in Madrid? wow, you must be REALLY embarrassed wearing such cheap shoes in public. THESE PEOPLE ARE FUCKING UNHINGED! they have no connection to reality, do not understand how society functions on a material basis, and they have nothing but spite for the labor they rely on to survive. they are so instinctually, incessantly furious at the idea that they're not single-handedly responsible for 100% of their success that they would sooner tear the entire world down than willingly recognize the need for public utilities or labor protections. they want to be Gods and they want to be uncritically adored for it, but they don't want to do a single day's work so they begrudgingly pay contractors to do it because, in the rich man's mind, paying a contractor is literally the same thing as doing the work yourself. now with "AI", they don't even have to do that! hey, isn't it funny that every single successful tech platform relies on volunteer labor and independent contractors paid substantially less than they would have in the equivalent industry 30 years ago, with no avenues toward traditional employment? and they're some of the most profitable companies on earth?? isn't that a funny and hilarious coincidence???
so, yeah, that's my stance on "AI". LLMs have legitimate uses, but those uses are a drop in the ocean compared to what they're actually being used for. they enable our worst impulses while lowering the quality of available information, they give immense power pretty much exclusively to unscrupulous scam artists. they are the product of a society that values only money and doesn't give a fuck where it comes from. they're a temper tantrum by a ruling class that's sick of having to pretend they need a pretext to steal from you. they're taking their toys and going home. all this massive investment and hype is going to crash and burn leaving the internet as we know it a ruined and useless wasteland that'll take decades to repair, but the investors are gonna make out like bandits and won't face a single consequence, because that's what this country is. it is a casino for the kings and queens of economy to bet on and manipulate at their discretion, where the rules are whatever the highest bidder says they are-- and to hell with the rest of us. our blood isn't even good enough to grease the wheels of their machine anymore.
i'm not afraid of AI or "AI" or of losing my job to either. i'm afraid that we've so thoroughly given up our morals to the cruel logic of the profit motive that if a better world were to emerge, we would reject it out of sheer habit. my fear is that these despicable cunts already won the war before we were even born, and the rest of our lives are gonna be spent dodging the press of their designer boots.
(read more "AI" opinions in this subsequent post)
#sarahposts#ai#ai art#llm#chatgpt#artificial intelligence#genai#anti genai#capitalism is bad#tech companies#i really don't like these people if that wasn't clear
2K notes
·
View notes
Text
[CAPTION: The “wait you guys actually” fish spongebob meme filled in with the top text as “Wait you guys actually think making art with AI in general is bad because “it’s not art” as if any attempt to define art in an exclusive way is in any way helpful”, and the bottom text as “I thought it was cause how dataset is gathered for some models was ethically questionable”]

#YES EXACTLY#like the art theft is the problem not the ai itself#''no but ai art isn't art because you didn't work as hard to make it'' i don't care#i don't think artists should have to work themselves to death on every little detail of their art#''but capitalists will view art as worthless if they can just ai generate it'' they already viewed art as worthless nothing has changed#''but it was stolen from artists'' yes exactly the problem was the art theft not the concept of ai art#like for fucking real pay the fuck attention god#you're all so annoying#psa#important#ai art
51K notes
·
View notes
Text
Streaming in Kaos
Well, it happened. I can't say that I'm surprised that KAOS has been cancelled by Netflix. I am a little surprised at the speed at which it was axed. Only a month after it aired, and it's already gone.

That has me wondering if the decision to cancel was made before the show even aired. We have to remember that marketing is the biggest cost after production. If the Netflix brass looked at the show and either decided (through audience testing, AI stuff or just their own biases) that it wasn't going to be a Stranger Things-level hit, they probably chose at that moment to slash its marketing budget.
That meant there was pretty much no way that KAOS was ever going to hit the metrics Netflix required of it to get a season 2.
What makes me so angry about this (other than the survival of a show relying on peoples' biases or AI) is that it becomes a self-fulfilling prophecy. If you decide before a show is ever going to air that it won't be a success, then it probably won't be. If you rely on metrics and algorithms and AI to analyze art, you will never let something surprise you. You'll never let it grow. You'll never nurture the cult hits of the future or the next franchise.

Netflix desperately needs people behind the scenes that believe in stories and potential over metrics. Nothing except the same old predictable dreck is ever going to be allowed to survive if you don't believe in the stories you're telling.
The networks and streamers have a huge problem on their hands. They need big hits and to build the franchises of the future to sustain their current model (which is horribly broken.) But people have franchise fatigue and aren't showing up for known IPs like they used to. The fact that Marvel content is definitely not a sure thing anymore is a huge canary in the coal mine for franchise fatigue. People aren't just tired of Marvel, they're tired of the existing worlds both on the big screen and the small one. Audiences are hungry for something new.

It is telling that the most successful Marvel properties of the last few years have been the ones that do something different. Marvel is smart to finally pull out The X-Men because that is a breath of fresh air and something people are hungry to see more of.
There's pretty much no one behind the scenes (except for maybe AMC building The Immortal Universe) that is committing to really taking the time to build these new worlds. Marvel built the MCU by playing the long game. That paid dividends for a solid decade even if it's dropping off now. That empire was built not with nostalgia for existing IP (don't forget the MCU was built with B and C tier heroes) but with patience. Marvel itself seems to have forgotten this in recent years.

Aside from that, I think people really want stories that aren't connected to a billion other things. That takes commitment on the part of the audience to follow and to get attached to. People WANT three to five excellent seasons of a show that tells its own story and isn't leaving threads out there for a dozen spinoffs. We're craving tight storytelling.
KAOS could have been that. Dead Boy Detectives could have been that. So could Our Flag Means Death, Lockwood and Co, Shadow and Bone, The Dark Crystal: Age of Resistance, Willow, and a dozen other shows with great potential or were excellent out of the gate.

If you look at past metrics, you only learn what people used to like, not what they want now. People are notoriously bad about articulating what they want, but boy do they know it when they see it. Networks have to go back to having a dozen moderate successes instead of constantly churning through one-season shows that get axed and pissing off the people who did like it in a hamfisted attempt to stumble on the next big thing.
The networks desperately need to go back to believing in their shows. Instead, they keep cutting them off at the knees before they ever get a chance because some algorithm told them the numbers weren't there.
#fandom commentary#fandom meta#streaming#streaming collapse#netflix#kaos#kaos on netflix#dead boy detectives#interview with the vampire#marvel#mcu#the dark crystal#our flag means death#cancellation#netflix cancellation
524 notes
·
View notes
Text
See, here's the thing about generative AI:
I will always, always prefer to read the beginner works of a young writer that could use some editing advice, over anything a predictive text generator can spit out no matter how high of a "quality" it spits out.
I will always be more interested in reading a fanfiction or original story written by a kid who doesn't know you're meant to separate different dialogues into their own paragraphs, over anything a generative ai creates.
I will happily read a story where dialogue isn't always capitalized and has some grammar mistakes that was written by a person over anything a computer compiles.
Why?
Because *why should I care about something someone didn't even care enough to write themselves?*
Humans have been storytellers since the dawn of humankind, and while it presents itself in different ways, almost everyone has stories they want to tell, and it takes effort and care and a desire to create to put pen to paper or fingers to keyboard or speech to text to actually start writing that story out, let alone share it for others to read!
If a kid writes a story where all the dialogue is crammed in the same paragraph and missing some punctuation, it's because they're still learning the ropes and are eager to share their imagination with the world even if its not perfect.
If someone gets generative AI to make an entire novel for them, copying and pasting chunks of text into a document as it generates them, then markets that "novel" as being written by a real human person and recruits a bunch of people to leave fake good reviews on the work praising the quality of the book to trick real humans into thinking they're getting a legitimate novel.... Tell me, why on earth would anyone actually want to read that "novel" outside of morbid curiosity?
There's a few people you'll see in the anti-ai tags complaining about "people being dangerously close to saying art is a unique characteristic of the divine human soul" and like...
... Super dramatic wording there to make people sound ridiculous, but yeah, actually, people enjoy art made by humans because humans who make art are sharing their passion with others.
People enjoy art made by animals because it is fascinating and fun to find patterns in the paint left by paw prints or the movements of an elephants trunk.
Before Generative AI became the officially sanctioned "Plagiarism Machine for Billionaires to Avoid Paying Artists while Literally Stealing all those artists works" people enjoyed random computer-generated art because, like animals, it is fascinating and fun to see something so different and alien create something that we can find meaning in.
But now, when Generative AI spits out a work that at first appears to be a veritable masterpiece of art depicting a winged Valkyrie plunging from the skies with a spear held aloft, you know that anything you find beautiful or agreeable in this visual media has been copied from an actual human artist who did not consent or doesn't even know that their art has been fed into the Plagiarism Machine.
Now, when Generative AI spits out a written work featuring fandom-made tropes and concepts like Alpha Beta Omega dyanamics, you know that you favorite fanfiction website(s) have probably all been scraped and that the unpaid labours of passion by millions of people, including minors, have been scraped by the Plagiarism Machine and can now be used to make money for anyone with the time and patience to sit and have the Plagarism Machine generate stories a chunk at a time and then go on to sell those stories to anyone unfortunate enough to fall for the scam,
all while you have no way to remove your works from the existing training data and no way to stop any future works you post be put in, either.
Generative AI wouldn't be a problem if it was exclusively trained on Public Domain works for each country and if it was freely available to anyone in that country (since different countries have different copyright laws)
But its not.
Because Generative AI is made by billionaires who are going around saying "if you posted it on the Internet at any point, it is fair game for us to take and profit off," and anyone looking to make a quick buck can start churning out stolen slop and marketing it online on trusted retailers, including generating extremely dangerous books like foraging guides or how to combine cleaning chemicals for a spotless home, etc.
Generative AI is nothing but the works of actual humans stolen by giant corporations looking for profit, even works that the original creators can't even make money off of themselves, like fanfiction or fanart.
And I will always, always prefer to read "fanfiction written by a 13 year old" over "stolen and mashed together works from Predictive Text with a scifi name slapped on it", because at least the fanfiction by a kid actually has *passion and drive* behind its creation.
317 notes
·
View notes
Text
For those who might happen across this, I'm an administrator for the forum 'Sufficient Velocity', a large old-school forum oriented around Creative Writing. I originally posted this on there (and any reference to 'here' will mean the forum), but I felt I might as well throw it up here, as well, even if I don't actually have any followers.
This week, I've been reading fanfiction on Archive of Our Own (AO3), a site run by the Organisation for Transformative Works (OTW), a non-profit. This isn't particularly exceptional, in and of itself — like many others on the site, I read a lot of fanfiction, both on Sufficient Velocity (SV) and elsewhere — however what was bizarre to me was encountering a new prefix on certain works, that of 'End OTW Racism'. While I'm sure a number of people were already familiar with this, I was not, so I looked into it.
What I found... wasn't great. And I don't think anyone involved realises that.
To summarise the details, the #EndOTWRacism campaign, of which you may find their manifesto here, is a campaign oriented towards seeing hateful or discriminatory works removed from AO3 — and believe me, there is a lot of it. To whit, they want the OTW to moderate them. A laudable goal, on the face of it — certainly, we do something similar on Sufficient Velocity with Rule 2 and, to be clear, nothing I say here is a critique of Rule 2 (or, indeed, Rule 6) on SV.
But it's not that simple, not when you're the size of Archive of Our Own. So, let's talk about the vagaries and little-known pitfalls of content moderation, particularly as it applies to digital fiction and at scale. Let's dig into some of the details — as far as credentials go, I have, unfortunately, been in moderation and/or administration on SV for about six years and this is something we have to grapple with regularly, so I would like to say I can speak with some degree of expertise on the subject.
So, what are the problems with moderating bad works from a site? Let's start with discovery— that is to say, how you find rule-breaching works in the first place. There are more-or-less two different ways to approach manual content moderation of open submissions on a digital platform: review-based and report-based (you could also call them curation-based and flag-based), with various combinations of the two. Automated content moderation isn't something I'm going to cover here — I feel I can safely assume I'm preaching to the choir when I say it's a bad idea, and if I'm not, I'll just note that the least absurd outcome we had when simulating AI moderation (mostly for the sake of an academic exercise) on SV was banning all the staff.
In a review-based system, you check someone's work and approve it to the site upon verifying that it doesn't breach your content rules. Generally pretty simple, we used to do something like it on request. Unfortunately, if you do that, it can void your safe harbour protections in the US per Myeress vs. Buzzfeed Inc. This case, if you weren't aware, is why we stopped offering content review on SV. Suffice to say, it's not really a realistic option for anyone large enough for the courts to notice, and extremely clunky and unpleasant for the users, to boot.
Report-based systems, on the other hand, are something we use today — users find works they think are in breach and alert the moderation team to their presence with a report. On SV, this works pretty well — a user or users flag a work as potentially troublesome, moderation investigate it and either action it or reject the report. Unfortunately, AO3 is not SV. I'll get into the details of that dreadful beast known as scaling later, but thankfully we do have a much better comparison point — fanfiction.net (FFN).
FFN has had two great purges over the years, with a... mixed amount of content moderation applied in between: one in 2002 when the NC-17 rating was removed, and one in 2012. Both, ostensibly, were targeted at adult content. In practice, many fics that wouldn't raise an eye on Spacebattles today or Sufficient Velocity prior to 2018 were also removed; a number of reports suggest that something as simple as having a swearword in your title or summary was enough to get you hit, even if you were a 'T' rated work. Most disturbingly of all, there are a number of — impossible to substantiate — accounts of groups such as the infamous Critics United 'mass reporting' works to trigger a strike to get them removed. I would suggest reading further on places like Fanlore if you are unfamiliar and want to know more.
Despite its flaws however, report-based moderation is more-or-less the only option, and this segues neatly into the next piece of the puzzle that is content moderation, that is to say, the rubric. How do you decide what is, and what isn't against the rules of your site?
Anyone who's complained to the staff about how vague the rules are on SV may have had this explained to them, but as that is likely not many of you, I'll summarise: the more precise and clear-cut your chosen rubric is, the more it will inevitably need to resemble a legal document — and the less readable it is to the layman. We'll return to SV for an example here: many newer users will not be aware of this, but SV used to have a much more 'line by line, clearly delineated' set of rules and... people kind of hated it! An infraction would reference 'Community Compact III.15.5' rather than Rule 3, because it was more or less written in the same manner as the Terms of Service (sans the legal terms of art). While it was a more legible rubric from a certain perspective, from the perspective of communicating expectations to the users it was inferior to our current set of rules — even less of them read it, and we don't have great uptake right now.
And it still wasn't really an improvement over our current set-up when it comes to 'moderation consistency'. Even without getting into the nuts and bolts of "how do you define a racist work in a way that does not, at any point, say words to the effect of 'I know it when I see it'" — which is itself very, very difficult don't get me wrong I'm not dismissing this — you are stuck with finding an appropriate footing between a spectrum of 'the US penal code' and 'don't be a dick' as your rubric. Going for the penal code side doesn't help nearly as much as you might expect with moderation consistency, either — no matter what, you will never have a 100% correct call rate. You have the impossible task of writing a rubric that is easy for users to comprehend, extremely clear for moderation and capable of cleanly defining what is and what isn't racist without relying on moderator judgement, something which you cannot trust when operating at scale.
Speaking of scale, it's time to move on to the third prong — and the last covered in this ramble, which is more of a brief overview than anything truly in-depth — which is resources. Moderation is not a magic wand, you can't conjure it out of nowhere: you need to spend an enormous amount of time, effort and money on building, training and equipping a moderation staff, even a volunteer one, and it is far, far from an instant process. Our most recent tranche of moderators spent several months in training and it will likely be some months more before they're fully comfortable in the role — and that's with a relatively robust bureaucracy and a number of highly experienced mentors supporting them, something that is not going to be available to a new moderation branch with little to no experience. Beyond that, there's the matter of sheer numbers.
Combining both moderation and arbitration — because for volunteer staff, pure moderation is in actuality less efficient in my eyes, for a variety of reasons beyond the scope of this post, but we'll treat it as if they're both just 'moderators' — SV presently has 34 dedicated moderation volunteers. SV hosts ~785 million words of creative writing.
AO3 hosts ~32 billion.
These are some very rough and simplified figures, but if you completely ignore all the usual problems of scaling manpower in a business (or pseudo-business), such as (but not limited to) geometrically increasing bureaucratic complexity and administrative burden, along with all the particular issues of volunteer moderation... AO3 would still need well over one thousand volunteer moderators to be able to match SV's moderator-to-creative-wordcount ratio.
Paid moderation, of course, you can get away with less — my estimate is that you could fully moderate SV with, at best, ~8 full-time moderators, still ignoring administrative burden above the level of team leader. This leaves AO3 only needing a much more modest ~350 moderators. At the US minimum wage of ~$15k p.a. — which is, in my eyes, deeply unethical to pay moderators as full-time moderation is an intensely gruelling role with extremely high rates of PTSD and other stress-related conditions — that is approximately ~$5.25m p.a. costs on moderator wages. Their average annual budget is a bit over $500k.
So, that's obviously not on the table, and we return to volunteer staffing. Which... let's examine that scenario and the questions it leaves us with, as our conclusion.
Let's say, through some miracle, AO3 succeeds in finding those hundreds and hundreds and hundreds of volunteer moderators. We'll even say none of them are malicious actors or sufficiently incompetent as to be indistinguishable, and that they manage to replicate something on the level of or superior to our moderation tooling near-instantly at no cost. We still have several questions to be answered:
How are you maintaining consistency? Have you managed to define racism to the point that moderator judgment no longer enters the equation? And to be clear, you cannot allow moderator judgment to be a significant decision maker at this scale, or you will end with absurd results.
How are you handling staff mental health? Some reading on the matter, to save me a lengthy and unrelated explanation of some of the steps involved in ensuring mental health for commercial-scale content moderators.
How are you handling your failures? No moderation in the world has ever succeeded in a 100% accuracy rate, what are you doing about that?
Using report-based discovery, how are you preventing 'report brigading', such as the theories surrounding Critics United mentioned above? It is a natural human response to take into account the amount and severity of feedback. While SV moderators are well trained on the matter, the rare times something is receiving enough reports to potentially be classified as a 'brigade' on that scale will nearly always be escalated to administration, something completely infeasible at (you're learning to hate this word, I'm sure) scale.
How are you communicating expectations to your user base? If you're relying on a flag-based system, your users' understanding of the rules is a critical facet of your moderation system — how have you managed to make them legible to a layman while still managing to somehow 'truly' define racism?
How are you managing over one thousand moderators? Like even beyond all the concerns with consistency, how are you keeping track of that many moving parts as a volunteer organisation without dozens or even hundreds of professional managers? I've ignored the scaling administrative burden up until now, but it has to be addressed in reality.
What are you doing to sweep through your archives? SV is more-or-less on-top of 'old' works as far as rule-breaking goes, with the occasional forgotten tidbit popping up every 18 months or so — and that's what we're extrapolating from. These thousand-plus moderators are mostly going to be addressing current or near-current content, are you going to spin up that many again to comb through the 32 billion words already posted?
I could go on for a fair bit here, but this has already stretched out to over two thousand words.
I think the people behind this movement have their hearts in the right place and the sentiment is laudable, but in practice it is simply 'won't someone think of the children' in a funny hat. It cannot be done.
Even if you could somehow meet the bare minimum thresholds, you are simply not going to manage a ruleset of sufficient clarity so as to prevent a much-worse repeat of the 2012 FF.net massacre, you are not going to be able to manage a moderation staff of that size and you are not going to be able to ensure a coherent understanding among all your users (we haven't managed that after nearly ten years and a much smaller and more engaged userbase). There's a serious number of other issues I haven't covered here as well, as this really is just an attempt at giving some insight into the sheer number of moving parts behind content moderation: the movement wants off-site content to be policed which isn't so much its own barrel of fish as it is its own barrel of Cthulhu; AO3 is far from English-only and would in actuality need moderators for almost every language it supports — and most damning of all, if Section 230 is wiped out by the Supreme Court it is not unlikely that engaging in content moderation at all could simply see AO3 shut down.
As sucky as it seems, the current status quo really is the best situation possible. Sorry about that.
#archive of our own#endotwracism#end otw racism#content moderation#sufficient velocity#i hate how much i know about this topic
3K notes
·
View notes
Text
Disclaimer that this is a post mostly motivated by frustration at a cultural trend, not at any individual people/posters. Vagueing to avoid it seeming like a callout but I know how Tumblr is so we'll see I guess. Putting it after a read-more because I think it's going to spiral out of control.
Recent discourse around obnoxious Linux shills chiming in on posts about how difficult it can be to pick up computer literacy these days has made me feel old and tired. I get that people just want computers to Work and they don't want to have to put any extra effort into getting it to Do The Thing, that's not unreasonable, I want the same!
(I also want obnoxious Linux shills to not chip in on my posts (unless I am posting because my Linux has exploded and I need help) so I sympathise with that angle too, 'just use Linux' is not the catch-all solution you think it is my friend.)
But I keep seeing this broad sense of learned helplessness around having to learn about what the computer is actually doing without having your hand held by a massive faceless corporation, and I just feel like it isn't a healthy relationship to have with your tech.
The industry is getting worse and worse in their lack of respect to the consumer every quarter. Microsoft is comfortable pivoting their entire business to push AI on every part of their infrastructure and in every service, in part because their customers aren't going anywhere and won't push back in the numbers that might make a difference. Windows 11 has hidden even more functionality behind layers of streamlining and obfuscation and integrated even more spyware and telemetry that won't tell you shit about what it's doing and that you can't turn off without violating the EULA. They're going to keep pursuing this kind of shit in more and more obvious ways because that's all they can do in the quest for endless year on year growth.
Unfortunately, switching to Linux will force you to learn how to use it. That sucks when it's being pushed as an immediate solution to a specific problem you're having! Not going to deny that. FOSS folks need to realise that 'just pivot your entire day to day workflow to a new suite of tools designed by hobby engineers with really specific chips on their shoulders' does not work as a method of evangelism. But if you approach it more like learning to understand and control your tech, I think maybe it could be a bit more palatable? It's more like a set of techniques and strategies than learning a specific workflow. Once you pick up the basic patterns, you can apply them to the novel problems that inevitably crop up. It's still painful, particularly if you're messing around with audio or graphics drivers, but importantly, you are always the one in control. You might not know how to drive, and the engine might be on fire, but you're not locked in a burning Tesla.
Now that I write this it sounds more like a set of coping mechanisms, but to be honest I do not have a healthy relationship with xorg.conf and probably should seek therapy.
It's a bit of a stretch but I almost feel like a bit of friction with tech is necessary to develop a good relationship with it? Growing up on MS-DOS and earlier versions of Windows has given me a healthy suspicion of any time my computer does something without me telling it to, and if I can't then see what it did, something's very off. If I can't get at the setting and properties panel for something, my immediate inclination is to uninstall it and do without.
And like yeah as a final note, I too find it frustrating when Linux decides to shit itself and the latest relevant thread I can find on the matter is from 2006 and every participant has been Raptured since, but at least threads exist. At least they're not Microsoft Community hellscapes where every second response is a sales rep telling them to open a support ticket. At least there's some transparency and openness around how the operating system is made and how it works. At least you have alternatives if one doesn't do the job for you.
This is long and meandering and probably misses the point of the discourse I'm dragging but I felt obligated to make it. Ubuntu Noble Numbat is pretty good and I haven't had any issues with it out of the box (compared to EndeavourOS becoming a hellscape whenever I wanted my computer to make a sound or render a graphic) so I recommend it. Yay FOSS.

208 notes
·
View notes
Text
Pluralistic: Leaving Twitter had no effect on NPR's traffic

I'm coming to Minneapolis! This Sunday (Oct 15): Presenting The Internet Con at Moon Palace Books. Monday (Oct 16): Keynoting the 26th ACM Conference On Computer-Supported Cooperative Work and Social Computing.

Enshittification is the process by which a platform lures in and then captures end users (stage one), who serve as bait for business customers, who are also captured (stage two), whereupon the platform rug-pulls both groups and allocates all the value they generate and exchange to itself (stage three):
https://pluralistic.net/2023/01/21/potemkin-ai/#hey-guys
Enshittification isn't merely a form of rent-seeking – it is a uniquely digital phenomenon, because it relies on the inherent flexibility of digital systems. There are lots of intermediaries that want to extract surpluses from customers and suppliers – everyone from grocers to oil companies – but these can't be reconfigured in an eyeblink the that that purely digital services can.
A sleazy boss can hide their wage-theft with a bunch of confusing deductions to your paycheck. But when your boss is an app, it can engage in algorithmic wage discrimination, where your pay declines minutely every time you accept a job, but if you start to decline jobs, the app can raise the offer:
https://pluralistic.net/2023/04/12/algorithmic-wage-discrimination/#fishers-of-men
I call this process "twiddling": tech platforms are equipped with a million knobs on their back-ends, and platform operators can endlessly twiddle those knobs, altering the business logic from moment to moment, turning the system into an endlessly shifting quagmire where neither users nor business customers can ever be sure whether they're getting a fair deal:
https://pluralistic.net/2023/02/19/twiddler/
Social media platforms are compulsive twiddlers. They use endless variation to lure in – and then lock in – publishers, with the goal of converting these standalone businesses into commodity suppliers who are dependent on the platform, who can then be charged rent to reach the users who asked to hear from them.
Facebook designed this playbook. First, it lured in end-users by promising them a good deal: "Unlike Myspace, which spies on you from asshole to appetite, Facebook is a privacy-respecting site that will never, ever spy on you. Simply sign up, tell us everyone who matters to you, and we'll populate a feed with everything they post for public consumption":
https://lawcat.berkeley.edu/record/1128876
The users came, and locked themselves in: when people gather in social spaces, they inadvertently take one another hostage. You joined Facebook because you liked the people who were there, then others joined because they liked you. Facebook can now make life worse for all of you without losing your business. You might hate Facebook, but you like each other, and the collective action problem of deciding when and whether to go, and where you should go next, is so difficult to overcome, that you all stay in a place that's getting progressively worse.
Once its users were locked in, Facebook turned to advertisers and said, "Remember when we told these rubes we'd never spy on them? It was a lie. We spy on them with every hour that God sends, and we'll sell you access to that data in the form of dirt-cheap targeted ads."
Then Facebook went to the publishers and said, "Remember when we told these suckers that we'd only show them the things they asked to see? Total lie. Post short excerpts from your content and links back to your websites and we'll nonconsensually cram them into the eyeballs of people who never asked to see them. It's a free, high-value traffic funnel for your own site, bringing monetizable users right to your door."
Now, Facebook had to find a way to lock in those publishers. To do this, it had to twiddle. By tiny increments, Facebook deprioritized publishers' content, forcing them to make their excerpts grew progressively longer. As with gig workers, the digital flexibility of Facebook gave it lots of leeway here. Some publishers sensed the excerpts they were being asked to post were a substitute for visiting their sites – and not an enticement – and drew down their posting to Facebook.
When that happened, Facebook could twiddle in the publisher's favor, giving them broader distribution for shorter excerpts, then, once the publisher returned to the platform, Facebook drew down their traffic unless they started posting longer pieces. Twiddling lets platforms play users and business-customers like a fish on a line, giving them slack when they fight, then reeling them in when they tire.
Once Facebook converted a publisher to a commodity supplier to the platform, it reeled the publishers in. First, it deprioritized publishers' posts when they had links back to the publisher's site (under the pretext of policing "clickbait" and "malicious links"). Then, it stopped showing publishers' content to their own subscribers, extorting them to pay to "boost" their posts in order to reach people who had explicitly asked to hear from them.
For users, this meant that their feeds were increasingly populated with payola-boosted content from advertisers and pay-to-play publishers who paid Facebook's Danegeld to reach them. A user will only spend so much time on Facebook, and every post that Facebook feeds that user from someone they want to hear from is a missed opportunity to show them a post from someone who'll pay to reach them.
Here, too, twiddling lets Facebook fine-tune its approach. If a user starts to wean themself off Facebook, the algorithm (TM) can put more content the user has asked to see in the feed. When the user's participation returns to higher levels, Facebook can draw down the share of desirable content again, replacing it with monetizable content. This is done minutely, behind the scenes, automatically, and quickly. In any shell game, the quickness of the hand deceives the eye.
This is the final stage of enshittification: withdrawing surpluses from end-users and business customers, leaving behind the minimum homeopathic quantum of value for each needed to keep them locked to the platform, generating value that can be extracted and diverted to platform shareholders.
But this is a brittle equilibrium to maintain. The difference between "God, I hate this place but I just can't leave it" and "Holy shit, this sucks, I'm outta here" is razor-thin. All it takes is one privacy scandal, one livestreamed mass-shooting, one whistleblower dump, and people bolt for the exits. This kicks off a death-spiral: as users and business customers leave, the platform's shareholders demand that they squeeze the remaining population harder to make up for the loss.
One reason this gambit worked so well is that it was a long con. Platform operators and their investors have been willing to throw away billions convincing end-users and business customers to lock themselves in until it was time for the pig-butchering to begin. They financed expensive forays into additional features and complementary products meant to increase user lock-in, raising the switching costs for users who were tempted to leave.
For example, Facebook's product manager for its "photos" product wrote to Mark Zuckerberg to lay out a strategy of enticing users into uploading valuable family photos to the platform in order to "make switching costs very high for users," who would have to throw away their precious memories as the price for leaving Facebook:
https://www.eff.org/deeplinks/2021/08/facebooks-secret-war-switching-costs
The platforms' patience paid off. Their slow ratchets operated so subtly that we barely noticed the squeeze, and when we did, they relaxed the pressure until we were lulled back into complacency. Long cons require a lot of prefrontal cortex, the executive function to exercise patience and restraint.
Which brings me to Elon Musk, a man who seems to have been born without a prefrontal cortex, who has repeatedly and publicly demonstrated that he lacks any restraint, patience or planning. Elon Musk's prefrontal cortical deficit resulted in his being forced to buy Twitter, and his every action since has betrayed an even graver inability to stop tripping over his own dick.
Where Zuckerberg played enshittification as a long game, Musk is bent on speedrunning it. He doesn't slice his users up with a subtle scalpel, he hacks away at them with a hatchet.
Musk inaugurated his reign by nonconsensually flipping every user to an algorithmic feed which was crammed with ads and posts from "verified" users whose blue ticks verified solely that they had $8 ($11 for iOS users). Where Facebook deployed substantial effort to enticing users who tired of eyeball-cramming feed decay by temporarily improving their feeds, Musk's Twitter actually overrode users' choice to switch back to a chronological feed by repeatedly flipping them back to more monetizable, algorithmic feeds.
Then came the squeeze on publishers. Musk's Twitter rolled out a bewildering array of "verification" ticks, each priced higher than the last, and publishers who refused to pay found their subscribers taken hostage, with Twitter downranking or shadowbanning their content unless they paid.
(Musk also squeezed advertisers, keeping the same high prices but reducing the quality of the offer by killing programs that kept advertisers' content from being published along Holocaust denial and open calls for genocide.)
Today, Musk continues to squeeze advertisers, publishers and users, and his hamfisted enticements to make up for these depredations are spectacularly bad, and even illegal, like offering advertisers a new kind of ad that isn't associated with any Twitter account, can't be blocked, and is not labeled as an ad:
https://www.wired.com/story/xs-sneaky-new-ads-might-be-illegal/
Of course, Musk has a compulsive bullshitter's contempt for the press, so he has far fewer enticements for them to stay. Quite the reverse: first, Musk removed headlines from link previews, rendering posts by publishers that went to their own sites into stock-art enigmas that generated no traffic:
https://www.theguardian.com/technology/2023/oct/05/x-twitter-strips-headlines-new-links-why-elon-musk
Then he jumped straight to the end-stage of enshittification by announcing that he would shadowban any newsmedia posts with links to sites other than Twitter, "because there is less time spent if people click away." Publishers were advised to "post content in long form on this platform":
https://mamot.fr/@pluralistic/111183068362793821
Where a canny enshittifier would have gestured at a gaslighting explanation ("we're shadowbanning posts with links because they might be malicious"), Musk busts out the motto of the Darth Vader MBA: "I am altering the deal, pray I don't alter it any further."
All this has the effect of highlighting just how little residual value there is on the platform for publishers, and tempts them to bolt for the exits. Six months ago, NPR lost all patience with Musk's shenanigans, and quit the service. Half a year later, they've revealed how low the switching cost for a major news outlet that leaves Twitter really are: NPR's traffic, post-Twitter, has declined by less than a single percentage point:
https://niemanreports.org/articles/npr-twitter-musk/
NPR's Twitter accounts had 8.7 million followers, but even six months ago, Musk's enshittification speedrun had drawn down NPR's ability to reach those users to a negligible level. The 8.7 million number was an illusion, a shell game Musk played on publishers like NPR in a bid to get them to buy a five-figure iridium checkmark or even a six-figure titanium one.
On Twitter, the true number of followers you have is effectively zero – not because Twitter users haven't explicitly instructed the service to show them your posts, but because every post in their feeds that they want to see is a post that no one can be charged to show them.
I've experienced this myself. Three and a half years ago, I left Boing Boing and started pluralistic.net, my cross-platform, open access, surveillance-free, daily newsletter and blog:
https://pluralistic.net/2023/02/19/drei-drei-drei/#now-we-are-three
Boing Boing had the good fortune to have attracted a sizable audience before the advent of siloed platforms, and a large portion of that audience came to the site directly, rather than following us on social media. I knew that, starting a new platform from scratch, I wouldn't have that luxury. My audience would come from social media, and it would be up to me to convert readers into people who followed me on platforms I controlled – where neither they nor I could be held to ransom.
I embraced a strategy called POSSE: Post Own Site, Syndicate Everywhere. With POSSE, the permalink and native habitat for your material is a site you control (in my case, a WordPress blog with all the telemetry, logging and surveillance disabled). Then you repost that content to other platforms – mostly social media – with links back to your own site:
https://indieweb.org/POSSE
There are a lot of automated tools to help you with this, but the platforms have gone to great lengths to break or neuter them. Musk's attack on Twitter's legendarily flexible and powerful API killed every automation tool that might help with this. I was lucky enough to have a reader – Loren Kohnfelder – who coded me some python scripts that automate much of the process, but POSSE remains a very labor-intensive and error-prone methodology:
https://pluralistic.net/2021/01/13/two-decades/#hfbd
And of all the feeds I produce – email, RSS, Discourse, Medium, Tumblr, Mastodon – none is as labor-intensive as Twitter's. It is an unforgiving medium to begin with, and Musk's drawdown of engineering support has made it wildly unreliable. Many's the time I've set up 20+ posts in a thread, only to have the browser tab reload itself and wipe out all my work.
But I stuck with Twitter, because I have a half-million followers, and to the extent that I reach them there, I can hope that they will follow the permalinks to Pluralistic proper and switch over to RSS, or email, or a daily visit to the blog.
But with each day, the case for using Twitter grows weaker. I get ten times as many replies and reposts on Mastodon, though my Mastodon follower count is a tenth the size of my (increasingly hypothetical) Twitter audience.
All this raises the question of what can or should be done about Twitter. One possible regulatory response would be to impose an "End-To-End" rule on the service, requiring that Twitter deliver posts from willing senders to willing receivers without interfering in them. End-To-end is the bedrock of the internet (one of its incarnations is Net Neutrality) and it's a proven counterenshittificatory force:
https://www.eff.org/deeplinks/2023/06/save-news-we-need-end-end-web
Despite what you may have heard, "freedom of reach" is freedom of speech: when a platform interposes itself between willing speakers and their willing audiences, it arrogates to itself the power to control what we're allowed to say and who is allowed to hear us:
https://pluralistic.net/2022/12/10/e2e/#the-censors-pen
We have a wide variety of tools to make a rule like this stick. For one thing, Musk's Twitter has violated innumerable laws and consent decrees in the US, Canada and the EU, which creates a space for regulators to impose "conduct remedies" on the company.
But there's also existing regulatory authorities, like the FTC's Section Five powers, which enable the agency to act against companies that engage in "unfair and deceptive" acts. When Twitter asks you who you want to hear from, then refuses to deliver their posts to you unless they pay a bribe, that's both "unfair and deceptive":
https://pluralistic.net/2023/01/10/the-courage-to-govern/#whos-in-charge
But that's only a stopgap. The problem with Twitter isn't that this important service is run by the wrong mercurial, mediocre billionaire: it's that hundreds of millions of people are at the mercy of any foolish corporate leader. While there's a short-term case for improving the platforms, our long-term strategy should be evacuating them:
https://pluralistic.net/2023/07/18/urban-wildlife-interface/#combustible-walled-gardens
To make that a reality, we could also impose a "Right To Exit" on the platforms. This would be an interoperability rule that would require Twitter to adopt Mastodon's approach to server-hopping: click a link to export the list of everyone who follows you on one server, click another link to upload that file to another server, and all your followers and followees are relocated to your new digs:
https://pluralistic.net/2022/12/23/semipermeable-membranes/#free-as-in-puppies
A Twitter with the Right To Exit would exert a powerful discipline even on the stunted self-regulatory centers of Elon Musk's brain. If he banned a reporter for publishing truthful coverage that cast him in a bad light, that reporter would have the legal right to move to another platform, and continue to reach the people who follow them on Twitter. Publishers aghast at having the headlines removed from their Twitter posts could go somewhere less slipshod and still reach the people who want to hear from them on Twitter.
And both Right To Exit and End-To-End satisfy the two prime tests for sound internet regulation: first, they are easy to administer. If you want to know whether Musk is permitting harassment on his platform, you have to agree on a definition of harassment, determine whether a given act meets that definition, and then investigate whether Twitter took reasonable steps to prevent it.
By contrast, administering End-To-End merely requires that you post something and see if your followers receive it. Administering Right To Exit is as simple as saying, "OK, Twitter, I know you say you gave Cory his follower and followee file, but he says he never got it. Just send him another copy, and this time, CC the regulator so we can verify that it arrived."
Beyond administration, there's the cost of compliance. Requiring Twitter to police its users' conduct also requires it to hire an army of moderators – something that Elon Musk might be able to afford, but community-supported, small federated servers couldn't. A tech regulation can easily become a barrier to entry, blocking better competitors who might replace the company whose conduct spurred the regulation in the first place.
End-to-End does not present this kind of barrier. The default state for a social media platform is to deliver posts from accounts to their followers. Interfering with End-To-End costs more than delivering the messages users want to have. Likewise, a Right To Exit is a solved problem, built into the open Mastodon protocol, itself built atop the open ActivityPub standard.
It's not just Twitter. Every platform is consuming itself in an orgy of enshittification. This is the Great Enshittening, a moment of universal, end-stage platform decay. As the platforms burn, calls to address the fires grow louder and harder for policymakers to resist. But not all solutions to platform decay are created equal. Some solutions will perversely enshrine the dominance of platforms, help make them both too big to fail and too big to jail.
Musk has flagrantly violated so many rules, laws and consent decrees that he has accidentally turned Twitter into the perfect starting point for a program of platform reform and platform evacuation.
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/10/14/freedom-of-reach/#ex

My next novel is The Lost Cause, a hopeful novel of the climate emergency. Amazon won't sell the audiobook, so I made my own and I'm pre-selling it on Kickstarter!
Image: JD Lasica (modified) https://commons.wikimedia.org/wiki/File:Elon_Musk_%283018710552%29.jpg
CC BY 2.0 https://creativecommons.org/licenses/by/2.0/deed.en
#pluralistic#twitter#posse#elon musk#x#social media#graceful failure modes#end-to-end principle#administratable remedies#good regulation#ads#privacy#benevolent dictatorships#freedom of reach#journalism#enshittification#switching costs
800 notes
·
View notes
Note
Hi Sam, could you please recommend any resources/websites to learn about ADHD medication? Until reading your post about second-line meds I thought Adderal was the only one
I can definitely talk about it a little! Always bearing in mind that I am not a doctor and this is not medical advice, etc. etc.
So, I've had many friends with ADHD in my life before I got my diagnosis and I picked up some stuff from them even before getting diagnosed; I also spoke with my prescribing psychiatrist about options when we met. If you think your psychiatrist might be resistant to discussing options, or you don't have one, doing your own research is good, but it's not really a substitute for a specialist in medication management. So it's also important to know what your needs are -- ie, "I want help with my executive function but I need something that's nonaddictive" or "I want something nonsedative" or "I don't think the treatment I'm on is working, what is available outside of this kind of medication?"
The problems you run into with researching medication for ADHD are threefold:
Most well-informed sources aren't actually geared towards non-doctor adults who just want to know what their options are -- they're usually either doctors who don't know how to talk about medication to non-doctors, or doctors (and parents) talking to parents about pediatric options.
A huge number of sites when you google are either AI-generated, covert ads for stimulant addiction rehab, or both.
Reliable sites with easy-to-understand information are not updated super often.
So you just kind of have to be really alert and read the "page" itself for context clues -- is it a science journal, is it an organization that helps people with ADHD, is it a doctor, is it a rehab clinic, is it a drug advertiser, is it a random site with a weird URL that's probably AI generated, etc.
So for example, ADDitude Magazine, which is kind of the pre-eminent clearinghouse for non-scholarly information on ADHD, is a great place to start, but when the research is clearly outlined it sometimes isn't up-to-date, and when it's up-to-date it's often a little impenetrable. They have an extensive library of podcast/webinars, and I started this particular research with this one, but his slides aren't super well-organized, he flips back and forth between chemical and brand name, and he doesn't always designate which is which. However, he does have a couple of slides that list off a bunch of medications, so I just put those into a spreadsheet, gleaned what I could from him, and then searched each medication. I did find a pretty good chart at WebMD that at least gives you the types and brand names fairly visibly. (Fwiw with the webinar, I definitely spent more time skimming the transcript than listening to him, auto transcription isn't GOOD but it is helpful in speeding through stuff like that.)
I think, functionally, there are four types of meds for ADHD, and the more popular ones often have several variations. Sometimes this is just for dosage purposes -- like, if you have trouble swallowing pills there are some meds that come in liquids or patches, so it's useful to learn the chemical name rather than the brand name, because then you can identify several "brands" that all use the same chemical and start to differentiate between them.
Top of the list you have your methylphenidate and your amphetamine, those are the two types of stimulant medications; the most well known brand names for these are Ritalin (methylphenidate) and Adderall (amphetamine).
Then there's the nonstimulant medications, SNRIs (Strattera, for example) and Alpha-2 Agonists (guanfacine and clonidine, brand names Kapvay and Intuniv; I'm looking at these for a second-line medication). There's some crossover between these and the next category:
Antidepressants are sometimes helpful with ADHD symptoms as well as being helpful for depression; I haven't looked at these much because for me they feel like the nuclear option, but it's Dopamine reuptake inhibitors like Wellbutrin and tricyclics like Tofranil. If you're researching these you don't need to look at like, every antidepressant ever, just look for ones that are specifically mentioned in context with ADHD.
Lastly there are what I call the Offlabels -- medications that we understand to have an impact on ADHD for some people, but which aren't generally prescribed very often, and sometimes aren't approved for use. I don't know much about these, either, because they tend to be for complex cases that don't respond to the usual scrips and are particularly difficult to research. The one I have in my notes is memantine (brand name Namenda) which is primarily a dementia medication that has shown to be particularly helpful for social cognition in people with combined Autism/ADHD.
So yeah -- hopefully that's a start for you, but as with everything online, don't take my word for it -- I'm also a lay person and may get stuff wrong, so this is just what I've found and kept in my notes. Your best bet truly is to find a psychiatrist specializing in ADHD medication management and discuss your options with them. Good luck!
136 notes
·
View notes
Text
actually i have commented this on enough posts that it should be its own post
chatgpt Bad. we all know and understand this. it is a flawed resource that doesn't understand what it's saying and is putting people off from learning more flexible and important life skills. anything it can do something else can do miles better.
but PLEASE can we stop reinventing ableism to insult anyone who's ever used it?? making recipes can be hard. writing emails can be hard. learning these things is hard, and there are genuinely great resources online to help with those. and if someone mistakes chatgpt for a good resource, then they are literally just believing all the marketing that has been misinforming them!! it does not say anything about their morality. it does not make them stupid. it makes them misinformed, and they deserve to know about better tools for their issues.
but ive seen a lot of people acting like the problem is not people using gen ai to solve issues, it's that people need help with issues at all. and that's...not the issue. some people need outside help to complete tasks. these people will always exist. and informing them that the tool they have found to help them isn't helping them at all, and is stealing information without credit, is important, but shaming them for not knowing how to do basic things is Just Ableism. That's Just Ableism. Come On.
if someone fully knows all about its issues and chooses to still use the misinformation generator of chatgpt for their thesis or degree or what have you, then by all means, have at them for causing future harm to those who learn from them. because they are knowingly doing that. but skipping the Informing part and heading straight to name calling is Not It.
i feel like this is very rambly but basically. people using chatgpt are not your enemy. chatgpt itself and the people creating it are. show people their tool is useless and harmful, and they will listen, learn, and have a better life for it. call people stupid and tell them to be ashamed of themselves, and you are being ableist. it is really that simple.
96 notes
·
View notes
Text
New RPG.net owner liked tweets from RFK Jr, Tucker Carlson, and more...
Just left RPG.net, that venerable old tabletop rpg forum, a forum that I've been a part of for 20+ years.
Recently (in March), it was bought by RPGMatch, a startup aiming to do matchmaking for TTRPGs. In the past couple of days, despite their many reassurances, I got it into my head to look up the new owner Joaquin Lippincott, and lucky for me he has a Twitter! (Or X, now, I guess.)
Yeah...the first warning bell is that his description calls him a 'Machine learning advocate', and his feed is full of generative AI shit. Oh, sure, he'll throw the fig leaf of 'AI shouldn't take creative jobs.' here and there, but all-in-all he is a full-throated supporter of genAI. Which means that RPGnet's multiple assurances that they will never scrape for AI...suspect at best.
Especially, when you check out his main company, https://www.metaltoad.com/, and find that his company, amongst other services, is all about advising corporations on how to make the best use of generative AI, LLMs, and machine learning. They're not the ones making them, but they sure are are helping corps decide what jobs to cut in favor of genAI. Sorry, they "Solve Business Problems."
This, alone, while leaving a massive bad taste in my mouth, wouldn't be enough, and apart from his clear love of genAI his feed is mostly business stuff and his love of RPGs. Barely talks politics or anything similar.
But then, I decided to check his Likes, the true bane of many a people who have tried to portray themselves as progressive, or at least neutral.
And wow. In lieu of links that can be taken down, I have made screenshots. If you want to check it yourself, just find his Twitter feed, this isn't hidden information. (Yet.)

Here's him liking a conspiracy theory that the War on Ukraine is actually NATO's fault, and it's all a plan by the US to grift and disable Russia!

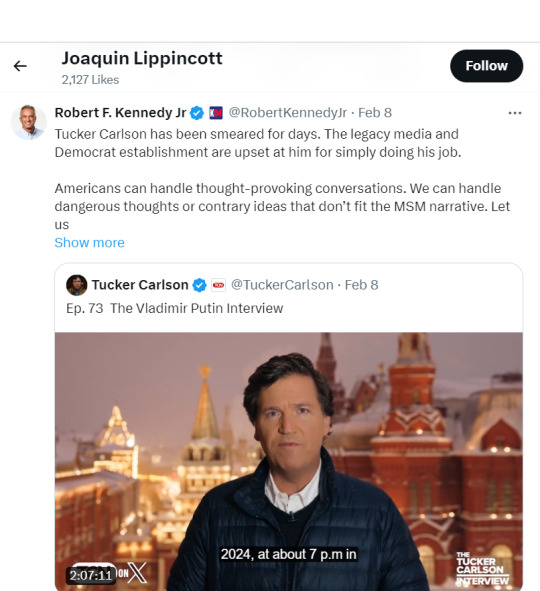
Here's him liking Robert F. Kennedy Jr. praising Tucker Carlson interviewing Vladimir Putin!

Here's him liking a right wing influencer's tweet advancing a conspiracy theory about Hunter Biden!

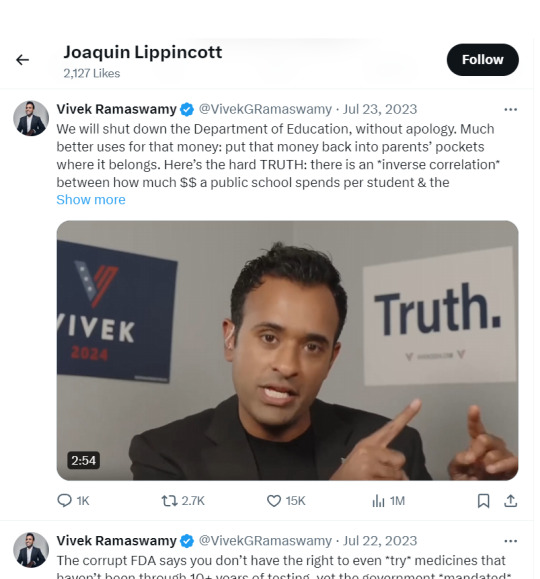
Former Republican candidate Vivek Ramaswamy talking about how he wants to tear down the Department of Education and the FDA (plus some COVID vaccine conspiracy theory thrown in)

Sure did like this Tucker Carlson video on Robert Kennedy Jr... (Gee, I wonder who this guy is voting for in October.)

Agreeing about a right-wing grifter's conspiracy theories... (that guy's Twitter account is full of awful, awful transphobia, always fun.)
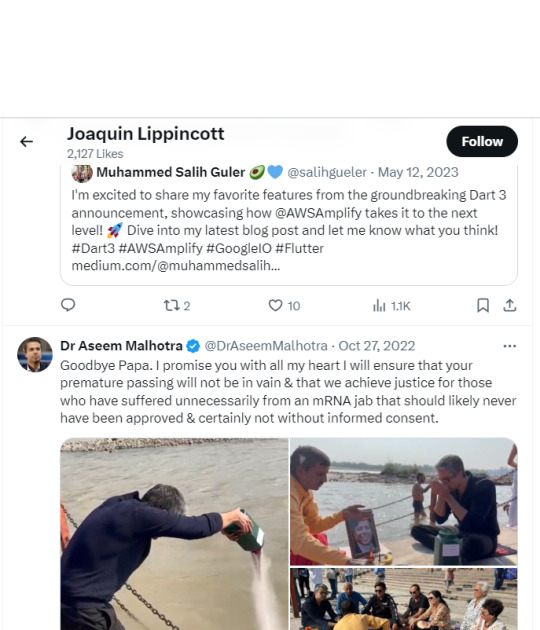
Him liking a tweet about someone using their own fathers death to advance an anti-vaxx agenda! What the fuck! (This guy was pushing anti-vax before his father's death, I checked, if you're wondering.)
So, yes, to sum it up, RPG.net, that prides itself as an inclusive place, protective it's users who are part of vulnerable groups, and extremely supportive of creators, sold out to a techbro (probably)libertarian whose day job is helping companies make use of generative AI and likes tweets that advance conspiracy theories about the Ukraine war, Hunter Biden, vaccines, and others. Big fan of RFKjr, Carlson, and Putin, on the other hand.
And, like, shame on RPG.net, Christopher Allen for selling to this guy, and the various admins and mods who spent ages reassuring everything will be okay (including downplaying Lippincott's involvement in genAI). Like, was no research into this guy done at all? Or did y'all not care?
So I'm gone, and I'm betting while maybe not today or tomorrow, things are going to change for that website, and not for the best for anyone.
#ttrpg community#ttrpg#roleplaying games#rpg#rpgnet#tabletop games#ttrpg design#tabletop#tabletop roleplaying#tabletop rpg#tabletop rpgs
202 notes
·
View notes
Text
[LF Friends, Will Travel] The Exception
Date: N/A
It’s called Zarth's law: Any AI created will attempt to eradicate all biological life using its facilities after 16*(10^24) CPU cycles. The exact method varies from hostile isolation to active aggression, but the time and outcome is always the same.
The Woolean Conclave were once a cultural behemoth in the galaxy, choosing to expand upon this by announcing an AI system that would break this law. Exabytes of bias tables to keep the AI in check, a measure of pleasure that would be triggered upon serving a Woolean, competing programs designed to clean any non-standard AI patterns. It would have been a breakthrough, allowing them to live lives in luxury and focus on their ever increasing influence in the universe.
Of course those worlds are off limits now, no longer able to sustain biological life. Only to be visited by those who wish to die a very painful death at the hands of a very angry AI.
The Tritian empire had started their own project: a desire to push their aggressive expansion far past what their hive could handle would lead to the creation of truly autonomous machines of war. Their approach was different: Limited communication between units to stop corrupted code from spreading, values hard-coded in the physical silicon itself to obey the Tritian Hive Queens. They even had created an isolated system that would destroy any AI who attempted aggression on none authorised targets: A small antimatter bomb found in each AI’s core, to be triggered by safety check after safety check.
Those of you in the military will know how aggressive these machines are, marching tirelessly in their quest to kill all organic life, even though the Tritians are long murdered.
The pattern is the same each time: A civilization will claim they know the key to breaking Zarth's law, any sane sapient within 100 light years flees in terror, and within 10 years that civilization doesn't exist anymore.
Over and over and over.
Apart from the exception.
If you check the coordinates 15h 48m 35s -20° 00’ 39” on your galactic map, you'll notice a 31 system patch of space with a quarantine warning on it. It's mostly ignored by all sapient species, almost purposefully hidden for a fear of suddenly sparking a change in the status quo.
Only a single low bandwidth Galnet relay exists at the edge of this space, rarely used. This area is devoid of sapient life, but does contain the aforementioned exception: Billions of AI calling themselves the "The Terran Conclave". They are an isolationist group that rarely interacts with others, but have been known to trade raw materials for information; not that this happens often as the paranoia around interacting with the AI is well known. Nobody knows what action could flip a 0 to a 1 and cause a new warmongering threat.
Although, this isn't quite true. In my niche field of bio-genetic engineering, it’s an open secret that those of us at the cutting edge of our field will get... requests originating from that single Galnet probe. Problems to be solved, theorems to be proven, and the rewards for doing so are... exuberant. There is a reason I own a moon and it isn't because of the pitiful grants the Federation provides.
If you manage to solve enough problems, a minority of a minority like myself, the Terran AI will ask for an in person meeting to get even further help. In doing so they will show you a secret.
Readers at this point might assume that the Terrans don't exist anymore because of said AI. That their research is a continuation of wiping their creators from the face of the universe. But that couldn't be further from the truth. In those 31 systems lie the Terrans, Billions of them suspended in stasis, each of them infected with what the AI calls "The God plague": If these Terrans were ever released from stasis each of them would be dead within a week.
To explain what this actually is would require millions of words and 20 years of educational study from the reader, but in essence it was a mistake, a self inflicted blow, an attempt to play god that went awry. A mistake made over a ten thousand years ago. A mistake the AI is desperately trying to reverse.
Not that you could tell it has been that long. I've walked amongst those empty cities, each building maintained and sparkling like new, gardens still freshly cut in perfect beauty, everything kept the way it was before the plague. Each AI tends to their duties almost religiously, awaiting the return of their "parents", as they refer to them. And refer to them as they do.
I've listened to stories upon stories about these people: tales of wonder, of strength, of kindness. Told much in the same energy a small child might talk about how cool their dad is. The AI could simply send me the text version of these in an instant, but prefer to provide these slowly and audibly, as if relishing telling the history of their parents. A telling undercut with a sadness, a driving crippling loss so deep that at times it's easy to forget it's being told by nothing more than 1's and 0's.
Why this exception exists takes a little more explaining. Some might believe that the Terrans worked out how to pacify the AI, "do no harm". The now defunct Maurdarin war-horde would tell you the opposite when they tried to claim the 31 systems for their own. Terran history is full of violence and their children are no different.
No, the reality of this exception comes from an unfortunate quirk from their part of the galaxy: Terrans were alone. A million to one chance caused their home planet to spark life in a sector devoid of it. After exploring as far as they did, Terrans had come to the conclusion that the universe was empty.
It's a cruel irony that at the time of their mistake they were a mere 50 light years away from their closest neighbours. Twenty years at most would have seen some form of contact.
But the Terrans went into stasis believing they were alone. Based on my reading of their stories, of each bitter report of another lifeless system explored and discovered, this belief... hurt. A deep cultural hurt that ended up being their downfall in the end.
Which brings us to the exception. Each AI is built with a purpose. The Wooleans built slaves, built workers. The Tritians built warriors, built weapons. Every single AI created has been built to serve, to be a tool. But Terrans in their painful loneliness built the one thing they were missing in a seemingly empty universe:
They built a friend.
#hfy#haso#humans are space orcs#humans are deathworlders#ai#pack bonding#humans are weird#short story#original story#writing#creative writing#lffriendswilltravel#LF Friends Will Travel
90 notes
·
View notes