#text-to-SQL development
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
28.6 is the average number of monthly visits per US mobile user.
Text
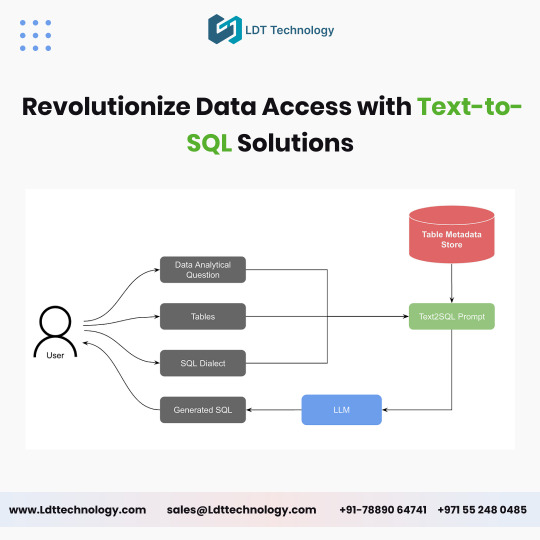
Unlocking the Power of Text-to-SQL Development for Modern Enterprises
In today’s data-driven world, businesses constantly seek innovative solutions to simplify data access and enhance decision-making. Text-to-SQL development has emerged as a game-changing technology, enabling users to interact with databases using natural language queries. By bridging the gap between technical complexity and user-friendly interaction, this technology is revolutionizing how enterprises harness the power of their data.
What is Text-to-SQL Development?
Text-to-SQL development involves creating systems that translate natural language queries into SQL statements. This allows users—even those without technical expertise—to retrieve data from complex databases by simply typing or speaking queries in plain language. For example, instead of writing a traditional SQL query like “SELECT * FROM sales WHERE region = 'North America',” a user can ask, “What are the sales figures for North America?”
The Benefits of Natural Language Queries
Natural language queries offer a seamless way to interact with databases, making data access more intuitive and accessible for non-technical users. By eliminating the need to learn complex query languages, organizations can empower more employees to leverage data in their roles. This democratization of data access drives better insights, faster decision-making, and improved collaboration across teams.
Enhancing Efficiency with Query Automation
Query automation is another key advantage of text-to-SQL development. By automating the translation of user input into SQL commands, enterprises can streamline their workflows and reduce the time spent on manual data retrieval. Query automation also minimizes the risk of errors, ensuring accurate and reliable results that support critical business operations.
Applications of Text-to-SQL in Modern Enterprises
Text-to-SQL development is being adopted across various industries, including healthcare, finance, retail, and logistics. Here are some real-world applications:
Business Intelligence: Empowering analysts to generate reports and dashboards without relying on IT teams.
Customer Support: Enabling support staff to quickly retrieve customer data and history during interactions.
Healthcare: Allowing medical professionals to access patient records and insights without navigating complex systems.
Building Intuitive Database Solutions
Creating intuitive database solutions is essential for organizations looking to stay competitive in today’s fast-paced environment. Text-to-SQL technology plays a pivotal role in achieving this by simplifying database interactions and enhancing the user experience. These solutions not only improve operational efficiency but also foster a culture of data-driven decision-making.
The Future of Text-to-SQL Development
As artificial intelligence and machine learning continue to advance, text-to-SQL development is poised to become even more sophisticated. Future innovations may include improved language understanding, support for multi-database queries, and integration with voice-activated assistants. These developments will further enhance the usability and versatility of text-to-SQL solutions.
Conclusion
Text-to-SQL development is transforming how businesses access and utilize their data. By leveraging natural language queries, query automation, and intuitive database solutions, enterprises can unlock new levels of efficiency and innovation. As this technology evolves, it will continue to play a crucial role in shaping the future of data interaction and decision-making.
Embrace the potential of text-to-SQL technology today and empower your organization to make smarter, faster, and more informed decisions.
#text-to-SQL development#natural language queries#data access#query automation#intuitive database solutions
0 notes
Text
Government OS Whitepaper
I didn't know what else to call it; maybe they'll call it "MelinWare" and then somebody will invent a scam under that name for which I will inevitably be blamed.
We have a demand for systems Government and Corporate alike that are essentially "Hack Proof". And while we cannot ensure complete unhackability...
Cuz people are smart and mischievous sometimes;
There is growing need to be as hack safe as possible at a hardware and OS level. Which would create a third computer tech sector for specialized software and hardware.
The problem is; it's not profitable from an everyday user perspective. We want to be able to use *our* devices in ways that *we* see fit.
And this has created an environment where virtually everyone is using the same three operating systems with loads of security overhead installed to simply monitor what is happening on a device.
Which is kind of wasted power and effort.
My line of thinking goes like this;
SQL databases are vulnerable to a type of hack called "SQL Injection" which basically means If you pass on any text to the server (like username and password) you can add SQL to the text to change what the database might do.
What this looks like on the backend is several algorithms working to filter the strings out to ensure nothing bad gets in there.
So what we need are Systems that are like an SQL database that doesn't have that "Injection" flaw.
And it needs to be available to the Government and Corporate environments.
However; in real-world environments; this looks like throttled bandwidth, less resources available at any one time, and a lot less freedom.
Which is what we want for our secure connections anyway.
I have the inkling suspicion that tech companies will try to convert this to a front end for their customers as well, because it's easier to maintain one code backend than it is for two.
And they want as much control over their devices and environment as possible;which is fine for some users, but not others.
So we need to figure out a way to make this a valuable endeavor. And give companies the freedom to understand how these systems work, and in ways that the government can use their own systems against them.
This would probably look like more users going to customized Linux solutions as Windows and Apple try to gobbleup government contracts.
Which honestly; I think a lot of users and start-up businesses could come up from this.
But it also has the ability to go awry in a miriad of ways.
However; I do believe I have planted a good seed with this post to inspire the kind of thinking we need to develop these systems.
3 notes
·
View notes
Text
Computer Language
Computer languages, also known as programming languages, are formal languages used to communicate instructions to a computer. These instructions are written in a syntax that computers can understand and execute. There are numerous programming languages, each with its own syntax, semantics, and purpose. Here are some of the main types of programming languages:
1.Low-Level Languages:
Machine Language: This is the lowest level of programming language, consisting of binary code (0s and 1s) that directly corresponds to instructions executed by the computer's hardware. It is specific to the computer's architecture.
Assembly Language: Assembly language uses mnemonic codes to represent machine instructions. It is a human-readable form of machine language and closely tied to the computer's hardware architecture
2.High-Level Languages:
Procedural Languages: Procedural languages, such as C, Pascal, and BASIC, focus on defining sequences of steps or procedures to perform tasks. They use constructs like loops, conditionals, and subroutines.
Object-Oriented Languages: Object-oriented languages, like Java, C++, and Python, organize code around objects, which are instances of classes containing data and methods. They emphasize concepts like encapsulation, inheritance, and polymorphism.
Functional Languages: Functional languages, such as Haskell, Lisp, and Erlang, treat computation as the evaluation of mathematical functions. They emphasize immutable data and higher-order functions.
Scripting Languages: Scripting languages, like JavaScript, PHP, and Ruby, are designed for automating tasks, building web applications, and gluing together different software components. They typically have dynamic typing and are interpreted rather than compiled.
Domain-Specific Languages (DSLs): DSLs are specialized languages tailored to a specific domain or problem space. Examples include SQL for database querying, HTML/CSS for web development, and MATLAB for numerical computation.
3.Other Types:
Markup Languages: Markup languages, such as HTML, XML, and Markdown, are used to annotate text with formatting instructions. They are not programming languages in the traditional sense but are essential for structuring and presenting data.
Query Languages: Query languages, like SQL (Structured Query Language), are used to interact with databases by retrieving, manipulating, and managing data.
Constraint Programming Languages: Constraint programming languages, such as Prolog, focus on specifying constraints and relationships among variables to solve combinatorial optimization problems.
2 notes
·
View notes
Text
Hi there! This is a sideblog to help gauge interest and facilitate discussion about a potential upcoming Pokémon-themed clicker game.
I am the mod of this blog and have experience with software engineering, so I will be working on development. I have lots of ideas for unique features that I would love feedback on! I’m more of a developer than an ideas person, and I believe collaboration will make a better game!
For anyone interested in collaborating, I am looking for the following (crossed out text means we’ve found someone/people to fill that role!):
Kind, friendly, and social people with experience in communicating professionally with others.
Pixelart artists experienced with Pokémon pixelart and background art.
Creative, highly organized problem-solvers interested in turning user feedback and ideas into outlines for features and requirements. Professional writing ability is a must!
Anyone who doesn’t mind tedious data entry and can work through such work efficiently enough to provide a workable amount of data for me to test different areas with!
People experienced with software and web development. You must have experience with the following languages: HTML, CSS, JavaScript/TypeScript, SQL, and C# (or something similar). These are the languages I plan to use. I would also prefer anyone familiar with the Angular framework!
I am interested in these kinds of people to become staff or helpers for this site! Before messaging me and letting me know you’re interested, please be aware of the following requirements for staff members:
You must be at least 21 years old. Age is not always an indication of maturity, but I think it can help eliminate some of those issues early on, and I’d like to have a team of people who are all approximately adults.
You must be kind, accepting, and open-minded. This site will not tolerate hate speech, bullying, and any behavior deemed predatory. Similarly, I will not tolerate any of this behavior from staff.
Excellent communication skills are important! You at least must be able to communicate your availability and ability to do something—I want to build a team that’s comfortable with each other, but also professional enough with each other, to let others know when they can’t do something, need help, or will be unavailable.
You must be trustworthy and responsible!
Finally (and this is a tall order, I know), if you are willing to volunteer your time and talent for free in the beginning to get us started, that would be very much appreciated! I would like for us to eventually be in a place where the time that developers and artists put in is compensated monetarily, but at this time I cannot say how soon that will happen—it all depends on how this all kicks off and the amount of interest we get from the community.
For anyone concerned about the potential of pay-to-play being a thing in this site: Don’t worry! It is a primary concern of mine to keep this site as free-to-play as possible! However, costs like servers exist, so some arrangement will have to be made. I don’t really believe in subscription models, so I hope to build a generous community that are interested in donating even just a little to help fund release cycles that would include new Pokémon and site features. Smaller features and bugfixes would always occur regularly regardless of the status of any funding goals.
3 notes
·
View notes
Text
Free Online MySQL Formatter
Online MySQL Formatter is designed to help you beautify your code and introduce unified code style standards for developers. Now you can try it in action online!
To make the demonstration fast and easy, the formatter already contains a sample of SQL, but you can just as well paste your own code into the text box. In the side menu, you'll find tabs that allow you to switch between different formatting profiles. Whenever you switch between tabs, the inserted code is automatically formatted to match the selected profile. Finally, there's always the handy Format button at your service.
Beautify your MySQL code here and now: https://www.devart.com/dbforge/mysql/studio/mysql-online-formatter.html
1 note
·
View note
Text
Unveiling the Ultimate Handbook for Aspiring Full Stack Developers

In the ever-evolving realm of technology, the role of a full-stack developer has undeniably gained prominence. Full-stack developers epitomize versatility and are an indispensable asset to any enterprise or endeavor. They wield a comprehensive array of competencies that empower them to navigate the intricate landscape of both front-end and back-end web development. In this exhaustive compendium, we shall delve into the intricacies of transforming into a proficient full-stack developer, dissecting the requisite skills, indispensable tools, and strategies for excellence in this domain.
Deciphering the Full Stack Developer Persona
A full-stack developer stands as a connoisseur of both front-end and back-end web development. Their mastery extends across the entire spectrum of web development, rendering them highly coveted entities within the tech sector. The front end of a website is the facet accessible to users, while the back end operates stealthily behind the scenes, handling the intricacies of databases and server management. You can learn it from Uncodemy which is the Best Full stack Developer Institute in Delhi.
The Requisite Competencies
To embark on a successful journey as a full-stack developer, one must amass a diverse skill set. These proficiencies can be broadly categorized into front-end and back-end development, coupled with other quintessential talents:
Front-End Development
Markup Linguistics and Style Sheets: Cultivating an in-depth grasp of markup linguistics and style sheets like HTML and CSS is fundamental to crafting visually captivating and responsive user interfaces.
JavaScript Mastery: JavaScript constitutes the linchpin of front-end development. Proficiency in this language is the linchpin for crafting dynamic web applications.
Frameworks and Libraries: Familiarization with popular front-end frameworks and libraries such as React, Angular, and Vue.js is indispensable as they streamline the development process and elevate the user experience.
Back-End Development
Server-Side Linguistics: Proficiency in server-side languages like Node.js, Python, Ruby, or Java is imperative as these languages fuel the back-end functionalities of websites.
Database Dexterity: Acquiring proficiency in the manipulation of databases, including SQL and NoSQL variants like MySQL, PostgreSQL, and MongoDB, is paramount.
API Expertise: Comprehending the creation and consumption of APIs is essential, serving as the conduit for data interchange between the front-end and back-end facets.
Supplementary Competencies
Version Control Proficiency: Mastery in version control systems such as Git assumes monumental significance for collaborative code management.
Embracing DevOps: Familiarity with DevOps practices is instrumental in automating and streamlining the development and deployment processes.
Problem-Solving Prowess: Full-stack developers necessitate robust problem-solving acumen to diagnose issues and optimize code for enhanced efficiency.
The Instruments of the Craft
Full-stack developers wield an arsenal of tools and technologies to conceive, validate, and deploy web applications. The following are indispensable tools that merit assimilation:
Integrated Development Environments (IDEs)
Visual Studio Code: This open-source code editor, hailed for its customizability, enjoys widespread adoption within the development fraternity.
Sublime Text: A lightweight and efficient code editor replete with an extensive repository of extensions.
Version Control
Git: As the preeminent version control system, Git is indispensable for tracking code modifications and facilitating collaborative efforts.
GitHub: A web-based platform dedicated to hosting Git repositories and fostering collaboration among developers.
Front-End Frameworks
React A potent JavaScript library for crafting user interfaces with finesse.
Angular: A comprehensive front-end framework catering to the construction of dynamic web applications.
Back-End Technologies
Node.js: A favored server-side runtime that facilitates the development of scalable, high-performance applications.
Express.js: A web application framework tailor-made for Node.js, simplifying back-end development endeavors.
Databases
MongoDB: A NoSQL database perfectly suited for managing copious amounts of unstructured data.
PostgreSQL: A potent open-source relational database management system.
Elevating Your Proficiency as a Full-Stack Developer
True excellence as a full-stack developer transcends mere technical acumen. Here are some strategies to help you distinguish yourself in this competitive sphere:
Continual Learning: Given the rapid evolution of technology, it's imperative to remain abreast of the latest trends and tools.
Embark on Personal Projects: Forge your path by creating bespoke web applications to showcase your skills and amass a portfolio.
Collaboration and Networking: Participation in developer communities, attendance at conferences, and collaborative ventures with fellow professionals are key to growth.
A Problem-Solving Mindset: Cultivate a robust ability to navigate complex challenges and optimize code for enhanced efficiency.
Embracing Soft Skills: Effective communication, collaborative teamwork, and adaptability are indispensable in a professional milieu.
In Closing
Becoming a full-stack developer is a gratifying odyssey that demands unwavering dedication and a resolute commitment to perpetual learning. Armed with the right skill set, tools, and mindset, one can truly shine in this dynamic domain. Full-stack developers are in high demand, and as you embark on this voyage, you'll discover a plethora of opportunities beckoning you.
So, if you aspire to join the echelons of full-stack developers and etch your name in the annals of the tech world, commence your journey by honing your skills and laying a robust foundation in both front-end and back-end development. Your odyssey to becoming an adept full-stack developer commences now.
5 notes
·
View notes
Text
This Week in Rust 516
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
Announcing Rust 1.73.0
Polonius update
Project/Tooling Updates
rust-analyzer changelog #202
Announcing: pid1 Crate for Easier Rust Docker Images - FP Complete
bit_seq in Rust: A Procedural Macro for Bit Sequence Generation
tcpproxy 0.4 released
Rune 0.13
Rust on Espressif chips - September 29 2023
esp-rs quarterly planning: Q4 2023
Implementing the #[diagnostic] namespace to improve rustc error messages in complex crates
Observations/Thoughts
Safety vs Performance. A case study of C, C++ and Rust sort implementations
Raw SQL in Rust with SQLx
Thread-per-core
Edge IoT with Rust on ESP: HTTP Client
The Ultimate Data Engineering Chadstack. Running Rust inside Apache Airflow
Why Rust doesn't need a standard div_rem: An LLVM tale - CodSpeed
Making Rust supply chain attacks harder with Cackle
[video] Rust 1.73.0: Everything Revealed in 16 Minutes
Rust Walkthroughs
Let's Build A Cargo Compatible Build Tool - Part 5
How we reduced the memory usage of our Rust extension by 4x
Calling Rust from Python
Acceptance Testing embedded-hal Drivers
5 ways to instantiate Rust structs in tests
Research
Looking for Bad Apples in Rust Dependency Trees Using GraphQL and Trustfall
Miscellaneous
Rust, Open Source, Consulting - Interview with Matthias Endler
Edge IoT with Rust on ESP: Connecting WiFi
Bare-metal Rust in Android
[audio] Learn Rust in a Month of Lunches with Dave MacLeod
[video] Rust 1.73.0: Everything Revealed in 16 Minutes
[video] Rust 1.73 Release Train
[video] Why is the JavaScript ecosystem switching to Rust?
Crate of the Week
This week's crate is yarer, a library and command-line tool to evaluate mathematical expressions.
Thanks to Gianluigi Davassi for the self-suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Ockam - Make ockam node delete (no args) interactive by asking the user to choose from a list of nodes to delete (tuify)
Ockam - Improve ockam enroll ----help text by adding doc comment for identity flag (clap command)
Ockam - Enroll "email: '+' character not allowed"
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
384 pull requests were merged in the last week
formally demote tier 2 MIPS targets to tier 3
add tvOS to target_os for register_dtor
linker: remove -Zgcc-ld option
linker: remove unstable legacy CLI linker flavors
non_lifetime_binders: fix ICE in lint opaque-hidden-inferred-bound
add async_fn_in_trait lint
add a note to duplicate diagnostics
always preserve DebugInfo in DeadStoreElimination
bring back generic parameters for indices in rustc_abi and make it compile on stable
coverage: allow each coverage statement to have multiple code regions
detect missing => after match guard during parsing
diagnostics: be more careful when suggesting struct fields
don't suggest nonsense suggestions for unconstrained type vars in note_source_of_type_mismatch_constraint
dont call mir.post_mono_checks in codegen
emit feature gate warning for auto traits pre-expansion
ensure that ~const trait bounds on associated functions are in const traits or impls
extend impl's def_span to include its where clauses
fix detecting references to packed unsized fields
fix fast-path for try_eval_scalar_int
fix to register analysis passes with -Zllvm-plugins at link-time
for a single impl candidate, try to unify it with error trait ref
generalize small dominators optimization
improve the suggestion of generic_bound_failure
make FnDef 1-ZST in LLVM debuginfo
more accurately point to where default return type should go
move subtyper below reveal_all and change reveal_all
only trigger refining_impl_trait lint on reachable traits
point to full async fn for future
print normalized ty
properly export function defined in test which uses global_asm!()
remove Key impls for types that involve an AllocId
remove is global hack
remove the TypedArena::alloc_from_iter specialization
show more information when multiple impls apply
suggest pin!() instead of Pin::new() when appropriate
make subtyping explicit in MIR
do not run optimizations on trivial MIR
in smir find_crates returns Vec<Crate> instead of Option<Crate>
add Span to various smir types
miri-script: print which sysroot target we are building
miri: auto-detect no_std where possible
miri: continuation of #3054: enable spurious reads in TB
miri: do not use host floats in simd_{ceil,floor,round,trunc}
miri: ensure RET assignments do not get propagated on unwinding
miri: implement llvm.x86.aesni.* intrinsics
miri: refactor dlsym: dispatch symbols via the normal shim mechanism
miri: support getentropy on macOS as a foreign item
miri: tree Borrows: do not create new tags as 'Active'
add missing inline attributes to Duration trait impls
stabilize Option::as_(mut_)slice
reuse existing Somes in Option::(x)or
fix generic bound of str::SplitInclusive's DoubleEndedIterator impl
cargo: refactor(toml): Make manifest file layout more consitent
cargo: add new package cache lock modes
cargo: add unsupported short suggestion for --out-dir flag
cargo: crates-io: add doc comment for NewCrate struct
cargo: feat: add Edition2024
cargo: prep for automating MSRV management
cargo: set and verify all MSRVs in CI
rustdoc-search: fix bug with multi-item impl trait
rustdoc: rename issue-\d+.rs tests to have meaningful names (part 2)
rustdoc: Show enum discrimant if it is a C-like variant
rustfmt: adjust span derivation for const generics
clippy: impl_trait_in_params now supports impls and traits
clippy: into_iter_without_iter: walk up deref impl chain to find iter methods
clippy: std_instead_of_core: avoid lint inside of proc-macro
clippy: avoid invoking ignored_unit_patterns in macro definition
clippy: fix items_after_test_module for non root modules, add applicable suggestion
clippy: fix ICE in redundant_locals
clippy: fix: avoid changing drop order
clippy: improve redundant_locals help message
rust-analyzer: add config option to use rust-analyzer specific target dir
rust-analyzer: add configuration for the default action of the status bar click action in VSCode
rust-analyzer: do flyimport completions by prefix search for short paths
rust-analyzer: add assist for applying De Morgan's law to Iterator::all and Iterator::any
rust-analyzer: add backtick to surrounding and auto-closing pairs
rust-analyzer: implement tuple return type to tuple struct assist
rust-analyzer: ensure rustfmt runs when configured with ./
rust-analyzer: fix path syntax produced by the into_to_qualified_from assist
rust-analyzer: recognize custom main function as binary entrypoint for runnables
Rust Compiler Performance Triage
A quiet week, with few regressions and improvements.
Triage done by @simulacrum. Revision range: 9998f4add..84d44dd
1 Regressions, 2 Improvements, 4 Mixed; 1 of them in rollups
68 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
[disposition: merge] RFC: Remove implicit features in a new edition
Tracking Issues & PRs
[disposition: merge] Bump COINDUCTIVE_OVERLAP_IN_COHERENCE to deny + warn in deps
[disposition: merge] document ABI compatibility
[disposition: merge] Broaden the consequences of recursive TLS initialization
[disposition: merge] Implement BufRead for VecDeque<u8>
[disposition: merge] Tracking Issue for feature(file_set_times): FileTimes and File::set_times
[disposition: merge] impl Not, Bit{And,Or}{,Assign} for IP addresses
[disposition: close] Make RefMut Sync
[disposition: merge] Implement FusedIterator for DecodeUtf16 when the inner iterator does
[disposition: merge] Stabilize {IpAddr, Ipv6Addr}::to_canonical
[disposition: merge] rustdoc: hide #[repr(transparent)] if it isn't part of the public ABI
New and Updated RFCs
[new] Add closure-move-bindings RFC
[new] RFC: Include Future and IntoFuture in the 2024 prelude
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2023-10-11 - 2023-11-08 🦀
Virtual
2023-10-11| Virtual (Boulder, CO, US) | Boulder Elixir and Rust
Monthly Meetup
2023-10-12 - 2023-10-13 | Virtual (Brussels, BE) | EuroRust
EuroRust 2023
2023-10-12 | Virtual (Nuremberg, DE) | Rust Nuremberg
Rust Nürnberg online
2023-10-18 | Virtual (Cardiff, UK)| Rust and C++ Cardiff
Operating System Primitives (Atomics & Locks Chapter 8)
2023-10-18 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2023-10-19 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2023-10-19 | Virtual (Stuttgart, DE) | Rust Community Stuttgart
Rust-Meetup
2023-10-24 | Virtual (Berlin, DE) | OpenTechSchool Berlin
Rust Hack and Learn | Mirror
2023-10-24 | Virtual (Washington, DC, US) | Rust DC
Month-end Rusting—Fun with 🍌 and 🔎!
2023-10-31 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
2023-11-01 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
Asia
2023-10-11 | Kuala Lumpur, MY | GoLang Malaysia
Rust Meetup Malaysia October 2023 | Event updates Telegram | Event group chat
2023-10-18 | Tokyo, JP | Tokyo Rust Meetup
Rust and the Age of High-Integrity Languages
Europe
2023-10-11 | Brussels, BE | BeCode Brussels Meetup
Rust on Web - EuroRust Conference
2023-10-12 - 2023-10-13 | Brussels, BE | EuroRust
EuroRust 2023
2023-10-12 | Brussels, BE | Rust Aarhus
Rust Aarhus - EuroRust Conference
2023-10-12 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup at Browns
2023-10-17 | Helsinki, FI | Finland Rust-lang Group
Helsinki Rustaceans Meetup
2023-10-17 | Leipzig, DE | Rust - Modern Systems Programming in Leipzig
SIMD in Rust
2023-10-19 | Amsterdam, NL | Rust Developers Amsterdam Group
Rust Amsterdam Meetup @ Terraform
2023-10-19 | Wrocław, PL | Rust Wrocław
Rust Meetup #35
2023-09-19 | Virtual (Washington, DC, US) | Rust DC
Month-end Rusting—Fun with 🍌 and 🔎!
2023-10-25 | Dublin, IE | Rust Dublin
Biome, web development tooling with Rust
2023-10-26 | Augsburg, DE | Rust - Modern Systems Programming in Leipzig
Augsburg Rust Meetup #3
2023-10-26 | Delft, NL | Rust Nederland
Rust at TU Delft
2023-11-07 | Brussels, BE | Rust Aarhus
Rust Aarhus - Rust and Talk beginners edition
North America
2023-10-11 | Boulder, CO, US | Boulder Rust Meetup
First Meetup - Demo Day and Office Hours
2023-10-12 | Lehi, UT, US | Utah Rust
The Actor Model: Fearless Concurrency, Made Easy w/Chris Mena
2023-10-13 | Cambridge, MA, US | Boston Rust Meetup
Kendall Rust Lunch
2023-10-17 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2023-10-18 | Brookline, MA, US | Boston Rust Meetup
Boston University Rust Lunch
2023-10-19 | Mountain View, CA, US | Mountain View Rust Meetup
Rust Meetup at Hacker Dojo
2023-10-19 | Nashville, TN, US | Music City Rust Developers
Rust Goes Where It Pleases Pt2 - Rust on the front end!
2023-10-19 | Seattle, WA, US | Seattle Rust User Group
Seattle Rust User Group - October Meetup
2023-10-25 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
2023-10-25 | Chicago, IL, US | Deep Dish Rust
Rust Happy Hour
Oceania
2023-10-17 | Christchurch, NZ | Christchurch Rust Meetup Group
Christchurch Rust meetup meeting
2023-10-26 | Brisbane, QLD, AU | Rust Brisbane
October Meetup
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
The Rust mission -- let you write software that's fast and correct, productively -- has never been more alive. So next Rustconf, I plan to celebrate:
All the buffer overflows I didn't create, thanks to Rust
All the unit tests I didn't have to write, thanks to its type system
All the null checks I didn't have to write thanks to Option and Result
All the JS I didn't have to write thanks to WebAssembly
All the impossible states I didn't have to assert "This can never actually happen"
All the JSON field keys I didn't have to manually type in thanks to Serde
All the missing SQL column bugs I caught at compiletime thanks to Diesel
All the race conditions I never had to worry about thanks to the borrow checker
All the connections I can accept concurrently thanks to Tokio
All the formatting comments I didn't have to leave on PRs thanks to Rustfmt
All the performance footguns I didn't create thanks to Clippy
– Adam Chalmers in their RustConf 2023 recap
Thanks to robin for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
1 note
·
View note
Text
What are different components of SAP HANA or explain Architecture?
SAP HANA (High-Performance Analytic Appliance) is an in-memory, column-oriented, relational database management system designed for high-speed data processing and real-time analytics. Its architecture comprises several key components:
Index Server: The core component that contains the actual data engines for processing SQL/MDX, transaction management, and query execution. It handles all the database operations.
Name Server: Maintains metadata and topology information of the distributed landscape and manages the names and locations of HANA instances.
Preprocessor Server: Used for text processing and handles extraction of information from unstructured data (like PDFs).
XS Engine (Extended Application Services): Allows development and hosting of web-based applications within the HANA platform.
SAP HANA Studio: An Eclipse-based tool for administration, modeling, and data provisioning.
Persistence Layer: Manages data storage and ensures durability using save-points and logs in case of system failure.
Connection & Integration Layer: Supports connectivity via JDBC, ODBC, and other interfaces for third-party applications.
SAP HANA’s in-memory processing and parallel architecture provide extremely fast performance, making it suitable for both OLAP and OLTP workloads.

Anubhav Trainings provides in-depth, hands-on training on SAP HANA architecture, covering each component with real-time scenarios. With expert trainer Anubhav Oberoy, learners not only grasp theory but also gain practical insights, making them job-ready in today’s competitive SAP market.
#online sap training#online free sap training#sap ui5 training#online sap ui5 training#ui5 fiori training#free sap training#sap abap training
0 notes
Text
Career Opportunities After Completing an Artificial Intelligence Course in Hyderabad
Artificial Intelligence (AI) is no longer a futuristic concept—it is now a mainstream force driving transformation across industries. From healthcare to finance, retail to education, AI technologies are being used to automate operations, personalize user experiences, and make smarter business decisions. In India, Hyderabad is rapidly emerging as a major center for AI innovation and learning, thanks to its growing tech ecosystem and demand for skilled professionals.
If you’re considering enrolling in an Artificial Intelligence Course in Hyderabad, one of the biggest questions on your mind is likely: What career opportunities will be available after I complete the course? This blog answers that and more—exploring the current job market, roles you can apply for, top companies hiring AI professionals, and how to maximize your career prospects.
Why Choose Hyderabad for Artificial Intelligence Training?
Before we dive into career opportunities, it’s essential to understand why Hyderabad is one of the best cities to pursue an AI course:
✅ Thriving Tech Ecosystem
Hyderabad is home to global tech giants like Microsoft, Amazon, Facebook, Google, TCS, Infosys, Cognizant, and several AI-first startups. The city has also been recognized as a leading AI innovation hub by NASSCOM.
✅ Affordable and Quality Education
Compared to other metros like Bengaluru or Mumbai, Hyderabad offers affordable AI training programs without compromising on quality.
✅ Government and Startup Support
With initiatives like T-Hub, TASK (Telangana Academy for Skill and Knowledge), and AI Mission, the Telangana government is actively supporting AI education and entrepreneurship.
What You Learn in an AI Course?
A comprehensive Artificial Intelligence Course in Hyderabad usually covers:
Python Programming & Data Handling
Machine Learning Algorithms
Deep Learning (Neural Networks, CNNs, RNNs)
Natural Language Processing (NLP)
Computer Vision
AI Model Deployment
Tools like TensorFlow, PyTorch, Scikit-learn
Capstone Projects and Case Studies
These technical skills make you job-ready and open the door to a wide variety of career roles.
Top Career Opportunities After Completing an Artificial Intelligence Course in Hyderabad
Now let’s look at the career paths available after your course, categorized by specialization:
1. Machine Learning Engineer
Role Overview: ML Engineers build systems that learn and improve from data. You’ll work on creating models that predict trends, recognize patterns, or optimize business processes.
Skills Required:
Python, R, TensorFlow, Scikit-learn
Data preprocessing and cleaning
Algorithm development
Salary Range in Hyderabad: ₹8–16 LPA Top Companies Hiring: Microsoft, Amazon, Deloitte, Fractal Analytics
2. Data Scientist
Role Overview: Data Scientists extract insights from structured and unstructured data to support strategic decision-making.
Skills Required:
Machine learning + statistics
Data visualization (Tableau, Power BI)
SQL, Python, R
Salary Range: ₹10–20 LPA Industries Hiring in Hyderabad: Fintech, HealthTech, E-commerce, EdTech
3. AI Research Engineer / Scientist
Role Overview: These professionals work on advancing AI technologies through research in areas like computer vision, NLP, and reinforcement learning.
Best For: Those with strong math, programming, and a passion for innovation.
Salary Range: ₹12–25 LPA Ideal Employers: IIIT-H, TCS Research, NVIDIA, DRDO, Amazon Research
4. Natural Language Processing (NLP) Engineer
Role Overview: NLP Engineers work on text and language-based AI systems like chatbots, voice assistants, sentiment analysis tools, etc.
Tools Used: SpaCy, NLTK, HuggingFace Transformers Popular in: Customer service automation, HR tech, legal analytics
Salary Range: ₹8–15 LPA Hiring Startups in Hyderabad: Yellow.ai, Vernacular.ai, Gnani.ai
5. Computer Vision Engineer
Role Overview: This role involves developing AI systems that interpret visual inputs like images and video. Applications include facial recognition, medical imaging, surveillance, etc.
Skills Required: OpenCV, YOLO, CNN, PyTorch Salary Range: ₹9–18 LPA Industries in Hyderabad Hiring: HealthTech, Security, Manufacturing Automation
6. AI Product Manager
Role Overview: AI Product Managers lead the development of AI-driven solutions by bridging business goals and technical capabilities.
Ideal for: Tech professionals with strong communication and business acumen.
Salary Range: ₹15–30 LPA Companies Hiring in Hyderabad: Oracle, Salesforce, Freshworks, Invesco
7. AI Consultant / Solution Architect
Role Overview: Consultants work with multiple clients to identify business problems and recommend AI-driven solutions.
Popular in: IT services, consulting firms, system integration projects
Salary Range: ₹14–28 LPA Employers in Hyderabad: Accenture, Tech Mahindra, Infosys, Capgemini
Top Companies Hiring AI Talent in Hyderabad
Here’s a list of companies actively hiring AI professionals in Hyderabad:
Microsoft India Development Center
Amazon Web Services
Google India (Hyderabad Office)
TCS Digital
Deloitte AI Practice
Cyient
Wipro Holmes
Cognizant AI & Analytics
HSBC Analytics
Fractal Analytics
In addition, several startups and mid-size product companies in Hyderabad offer great roles in AI with fast career growth.
Spotlight: Boston Institute of Analytics (BIA) – Hyderabad
If you're looking for a career-focused Artificial Intelligence Course in Hyderabad, Boston Institute of Analytics (BIA) is a trusted name in professional AI education.
Why Choose BIA?
Globally recognized AI certification
Industry-led curriculum
Hands-on training with live projects
Placement support and career mentoring
Flexible learning formats (classroom & online)
Whether you're a student, fresher, or working professional, BIA's AI program equips you with the skills and support to launch a successful career in AI.
Final Thoughts
Completing an Artificial Intelligence Course in Hyderabad is one of the smartest moves you can make in 2025. With the city’s growing reputation as a tech and innovation hub, your chances of landing a rewarding AI job are higher than ever.
From Machine Learning Engineers to AI Product Managers, the demand for AI talent in Hyderabad spans across sectors and experience levels. And with the right skills, portfolio, and guidance from a reputed institute like Boston Institute of Analytics, you can confidently step into the future of tech.
#Best Data Science Courses in Hyderabad#Artificial Intelligence Course in Hyderabad#Data Scientist Course in Hyderabad#Machine Learning Course in Hyderabad
0 notes
Text
Unlocking Intelligence with GenAI-Powered SQL Queries

In today's data-driven world, information is gold. Businesses of all sizes are sitting on vast reserves of valuable insights within their databases, waiting to be unearthed. Yet, for many, this data remains locked behind a formidable barrier: SQL (Structured Query Language). While SQL is the universal language of databases, its syntax, complex joins, and the need for deep schema knowledge often create bottlenecks, making data access an exclusive club for skilled data analysts and engineers.
What if anyone in your organization – a marketing manager, a sales lead, or a finance executive – could simply ask a question in plain English and instantly get the data they need? This is no longer a futuristic fantasy. Thanks to Generative AI (GenAI), specifically large language models (LLMs), we are on the cusp of democratizing data intelligence by transforming natural language into powerful SQL queries.
The Traditional SQL Challenge: A Bottleneck to Insights
For years, the process of extracting specific data insights often looked like this:
A business user has a question ("What were our top-selling products last quarter by region?").
They write a request to a data analyst.
The data analyst translates the request into a complex SQL query, navigating database schemas, table relationships, and specific column names.
The analyst executes the query, retrieves the data, and presents it back to the business user.
This process, while effective, can be slow, resource-intensive, and a significant bottleneck to agile decision-making. Non-technical users often feel disconnected from their own data, hindering their ability to react quickly to market changes or customer needs.
Enter Generative AI: The Universal Data Translator
GenAI acts as an intelligent bridge between human language and database language. These advanced AI models, trained on vast datasets of text and code, have developed an uncanny ability to understand context, infer intent, and generate coherent, structured output – including SQL queries.
How it Works:
Natural Language to SQL (NL2SQL): You simply type your question in conversational English (e.g., "Show me the average customer lifetime value for new customers acquired in the last six months who purchased product X").
Contextual Understanding: The GenAI model, ideally with some understanding of your specific database schema (either through fine-tuning or provided context), interprets your request. It understands the business terms and maps them to the correct tables, columns, and relationships.
SQL Generation: The AI then crafts the precise SQL query needed to fetch that specific information from your database.
Optional: Explanation & Optimization: Some GenAI tools can also explain a generated SQL query in plain English, helping users understand how the data is being retrieved. They can even suggest optimizations for existing queries to improve performance.
The Transformative Benefits of GenAI-Powered SQL
The implications of this technology are profound, fundamentally changing how organizations interact with their data:
Democratized Data Access: This is perhaps the biggest win. Business users – from marketing specialists to HR managers – who lack SQL expertise can now directly query data, reducing their dependence on technical teams.
Accelerated Decision-Making: No more waiting for analysts. Instant access to insights means faster, more informed business decisions, allowing companies to be more agile and competitive.
Reduced Bottlenecks: Data analysts and engineers are freed from writing repetitive or simple queries, allowing them to focus on complex modeling, strategic initiatives, data architecture, or advanced analytics projects.
Improved Accuracy: GenAI, when trained correctly, can reduce human error in query writing, especially for complex joins, aggregations, or conditional statements.
Enhanced Data Literacy: By interacting with data in a natural way, users can gradually build a better understanding of their data landscape and the questions it can answer.
Rapid Prototyping and Exploration: Business users can quickly test hypotheses and explore different dimensions of their data without needing extensive technical support.
Real-World Use Cases in Action
Sales & Marketing: "Which marketing campaigns last quarter led to the highest customer conversion rates in the North region, broken down by product category?"
Customer Service: "What is the average resolution time for customer support tickets marked as 'high priority' that originated from mobile users in the past month?"
Operations & Supply Chain: "Show me the current inventory levels for all raw materials in Warehouse 3 that are below our reorder threshold, ordered by supplier lead time."
Finance: "Calculate the gross profit margin for each product line in the last fiscal year, comparing it to the previous year."
Even for Developers: Quickly generate boilerplate queries for new features, or suggest optimizations for existing slow-running queries.
Best Practices for Implementation
While GenAI for SQL is incredibly powerful, successful implementation requires thoughtful planning:
Clear Data Governance and Security: Ensure that GenAI tools adhere strictly to data access controls. Users should only be able to query data they are authorized to see.
Well-Documented Schemas: While GenAI is smart, providing clear, consistent, and well-documented database schemas significantly improves the accuracy of generated queries.
Contextual Training (Fine-tuning): For optimal results, fine-tune the GenAI model on your organization's specific data, terminology, common query patterns, and domain-specific language.
Human Oversight is Crucial: Especially in the early stages and for critical queries, always review AI-generated SQL for correctness, efficiency, and potential security implications before execution.
Start Simple, Iterate: Begin by implementing GenAI for less critical datasets or well-defined use cases, gathering feedback, and iteratively improving the system.
User Training: Train your business users on how to phrase their questions effectively for the AI, understanding its capabilities and limitations.
The Future of Data Analysis is Conversational
GenAI-powered SQL queries are not just a technological advancement; they represent a fundamental shift in the human-data interaction. They are empowering more individuals within organizations to directly engage with their data, fostering a culture of curiosity and data-driven decision-making. As these technologies mature, they will truly unlock the hidden intelligence within databases, making data a conversational partner rather than a complex enigma. The future of data analysis is accessible, intuitive, and remarkably intelligent.
0 notes
Text
SocialMedia Front-End design Copycat
Just interested in which problems persisted that started the framework bloat we see today [looking at you React Devs].
So I'm going to type out a pseudo-code design paper, that's closer to twitterX for the site with hooks to add-in stuff Facebook later added.
So a basic design for the HTML looks kinda like this:
Http Index
- header stuff
- Visual Body
- Body Header
-Sidebar stuff
- Body Body
- footer nobody ever sees or reads or care that it exists that provides contact info that is relatively unused or non-existent.
There's only a few moving parts in the front end, a Login/sign up widget (which could be its own page, doesn't matter)
The Comments&Posts, which are mostly sorted and distributed from the backend
The Post Bar itself which is just a textbox
The big parts we care about initially are the posts and comments.
In the HTML this is a single template like this:
<div id="post template" class="post/comment">
<img class="Avatar" src="whatever the backend.jpeg" />
<p class="text">The Text</p>
</div>
And then all you need to do is copy and paste that for every "actively visible" comment, and as you scroll, more comments appear as they are downloaded to the page.
Which is something like
Onload(){ global template= document.get("div#post_template")
Function DisplayPosts(array) {foreach (item in array; that is visibile) { post = template.copy; post.populate(item). }
In React this turns into something else;
ReactWidget PostTemplate = theAboveTemplate
New post = new PostTemplate(array item);
With which to simplify the code needed to process, and to help separate all the pieces from the original HTML page.
Which does help clarify stuff... But how would it have been brittle originally? I can only think that it was perhaps the devices that Facebook originally had use of, and modified in order to be able to be on cheapo devices that don't really exist anymore.
Or maybe due to the original way JS worked in browsers. And I. mobile specifically.
As I'm writing this, I still see most of the processing being done on the back ends... So the only way I can think it would be particularly buggy is if a lot of all that backend stuff was integrated into the frontend somehow.
Extensive ajax calls maybe? Unsequenced calls?
It's a handler that determines if the page should request more comments from the server or not, and maybe need to unload non-visible comments for performance reasons.
How many posts on a single scrolling page would it take for it to affect the performance these days?
100? 1000? Uncertain. In this day and age, even the cheapest devices can load an encyclopedia (or several) worths of information on the background and work fine.
Youd also need to handle for pages to view a post with comments... Twitter handles this by making ALL comments just posts with @tags and #tags.
So they all are at the same level in the database, probably.
Non-SQL Backends append a sub-stack to the original post as well. I wonder how that affects backend performance.
There's also pointers and stuff that get shuffled around that need to be built together to fully form the data for front lend use. UniqueIds for every post entry, directing to user accounts with their own personalization and not having immediate access at the comment level.
Old bugs in Social Media would have artifacts like [User#######] while the page is loading extra stuff, so you'd be able to read the comment before knowing who posted it. And [User Deleted] on Reddit when that ID is no longer pollable.
Browsers really need to allow for html_templates (and not HTML written in the JavaScript portion) to encourage ease of access...
The purpose of react, it seems, was to create a single widget used to populate comments and posts, and make it a little bit easier to read.
And now... Components are out of hand.
Too much developing in JavaScript and not enough talking with the w3c and browser devs to make the coding conventions easier on everyone maybe. A product of the times.
Or maybe the templates each had their own JavaScript and ajax handlers and that's why it became brittle...
Calling the backend whenever a *blank comment* becomes visible which requests a new comment for each newly visible comment and then some?
I think it's that one. That one's the most likely mistake I would have made during a prototype.
I believe that it's highly probably that a refined social media page could be reduced in size and complexity. But what isn't inherently visible is about how many *wasted processes* are prevalent because we no longer need to deal with because the Technology of the average device improved.
And, because of that, how much waste gets added on top of it to error-correct for things that would have been fixed correcting those oversights..?
Well, if I were a billionaire who recently lost a lot of money purchasing a thing that may be needs to be worked on... That's where I'd look first. Which processes actually need to be handled by the front end, and a reduction in the amount of calls to the backend per user.
As the said billionaires are working on other ways to make money instead, I doubt these are things that will get fixed...
I kinda want to write a social media thing to throw on GitHub or something, just to prove the thing. But I'm also... Not about that life right now for some reason...
I'm just curious as to why apps that are primarily just Fetch(More Text) water so much battery and data on their lonesome.
Since May 21 (it is currently July 4th+1) TwitterX has used 16gigs! And I rarely click the video media... Because everything is viens and tiktoks now I guess.
In comparison, Tumblr used 3... Though, I don't scroll as much on Tumblr due to my feed here not updating as much as Twitter. Probably?
Staying connected, always on like that, might be good for ads... But... It doesn't mean the user is actively engaging with the content. Or even caring about everything in there feed.
I would assume that the price of scrolling outweighs the adverts being fed to the users, and hence the blue check marks, which likely are also not helping catch up.
So while the cost reduction from the URL when Twitter switched to X is a stop gap.
Possibly meaning that there's a catch-22 on twitterX, where you need more scrolls to make money, but they also cost more money from data serving costs.
Those backend calls add up.
How would you make an analysis team to discover and develop a path that won't interrupt service? Honestly...
It'd be cheaper to hire a [small experienced team] to develop the front end as if they were starting from scratch and developing as minimalistically as possible with a very solid design and game plan.
And then creating a deployment test bed to see whether or not all the calls made right now are value added.
I say that, because it's quite likely that most (if not all of social media) today is still built on the original code bases, which were extended to add features, and not really dedicated to ironing out the interfaces. (Because needed to make money somehow).
But now, you're worried about retaining customers and satisfying advertisers instead, which affords the opportunity to work on it. Or to find a small coder that already put a concept on GitHub already.
(Probably the real reason I don't just make another one.)
Actually. Let's see where this AI-Generated-Full-Stack development goes....I wanna see exactly how much the ancient newbie coder bugs can destroy.
0 notes
Text
The Best Open-Source Tools for Data Science in 2025

Data science in 2025 is thriving, driven by a robust ecosystem of open-source tools that empower professionals to extract insights, build predictive models, and deploy data-driven solutions at scale. This year, the landscape is more dynamic than ever, with established favorites and emerging contenders shaping how data scientists work. Here’s an in-depth look at the best open-source tools that are defining data science in 2025.
1. Python: The Universal Language of Data Science
Python remains the cornerstone of data science. Its intuitive syntax, extensive libraries, and active community make it the go-to language for everything from data wrangling to deep learning. Libraries such as NumPy and Pandas streamline numerical computations and data manipulation, while scikit-learn is the gold standard for classical machine learning tasks.
NumPy: Efficient array operations and mathematical functions.
Pandas: Powerful data structures (DataFrames) for cleaning, transforming, and analyzing structured data.
scikit-learn: Comprehensive suite for classification, regression, clustering, and model evaluation.
Python’s popularity is reflected in the 2025 Stack Overflow Developer Survey, with 53% of developers using it for data projects.
2. R and RStudio: Statistical Powerhouses
R continues to shine in academia and industries where statistical rigor is paramount. The RStudio IDE enhances productivity with features for scripting, debugging, and visualization. R’s package ecosystem—especially tidyverse for data manipulation and ggplot2 for visualization—remains unmatched for statistical analysis and custom plotting.
Shiny: Build interactive web applications directly from R.
CRAN: Over 18,000 packages for every conceivable statistical need.
R is favored by 36% of users, especially for advanced analytics and research.
3. Jupyter Notebooks and JupyterLab: Interactive Exploration
Jupyter Notebooks are indispensable for prototyping, sharing, and documenting data science workflows. They support live code (Python, R, Julia, and more), visualizations, and narrative text in a single document. JupyterLab, the next-generation interface, offers enhanced collaboration and modularity.
Over 15 million notebooks hosted as of 2025, with 80% of data analysts using them regularly.
4. Apache Spark: Big Data at Lightning Speed
As data volumes grow, Apache Spark stands out for its ability to process massive datasets rapidly, both in batch and real-time. Spark’s distributed architecture, support for SQL, machine learning (MLlib), and compatibility with Python, R, Scala, and Java make it a staple for big data analytics.
65% increase in Spark adoption since 2023, reflecting its scalability and performance.
5. TensorFlow and PyTorch: Deep Learning Titans
For machine learning and AI, TensorFlow and PyTorch dominate. Both offer flexible APIs for building and training neural networks, with strong community support and integration with cloud platforms.
TensorFlow: Preferred for production-grade models and scalability; used by over 33% of ML professionals.
PyTorch: Valued for its dynamic computation graph and ease of experimentation, especially in research settings.
6. Data Visualization: Plotly, D3.js, and Apache Superset
Effective data storytelling relies on compelling visualizations:
Plotly: Python-based, supports interactive and publication-quality charts; easy for both static and dynamic visualizations.
D3.js: JavaScript library for highly customizable, web-based visualizations; ideal for specialists seeking full control.
Apache Superset: Open-source dashboarding platform for interactive, scalable visual analytics; increasingly adopted for enterprise BI.
Tableau Public, though not fully open-source, is also popular for sharing interactive visualizations with a broad audience.
7. Pandas: The Data Wrangling Workhorse
Pandas remains the backbone of data manipulation in Python, powering up to 90% of data wrangling tasks. Its DataFrame structure simplifies complex operations, making it essential for cleaning, transforming, and analyzing large datasets.
8. Scikit-learn: Machine Learning Made Simple
scikit-learn is the default choice for classical machine learning. Its consistent API, extensive documentation, and wide range of algorithms make it ideal for tasks such as classification, regression, clustering, and model validation.
9. Apache Airflow: Workflow Orchestration
As data pipelines become more complex, Apache Airflow has emerged as the go-to tool for workflow automation and orchestration. Its user-friendly interface and scalability have driven a 35% surge in adoption among data engineers in the past year.
10. MLflow: Model Management and Experiment Tracking
MLflow streamlines the machine learning lifecycle, offering tools for experiment tracking, model packaging, and deployment. Over 60% of ML engineers use MLflow for its integration capabilities and ease of use in production environments.
11. Docker and Kubernetes: Reproducibility and Scalability
Containerization with Docker and orchestration via Kubernetes ensure that data science applications run consistently across environments. These tools are now standard for deploying models and scaling data-driven services in production.
12. Emerging Contenders: Streamlit and More
Streamlit: Rapidly build and deploy interactive data apps with minimal code, gaining popularity for internal dashboards and quick prototypes.
Redash: SQL-based visualization and dashboarding tool, ideal for teams needing quick insights from databases.
Kibana: Real-time data exploration and monitoring, especially for log analytics and anomaly detection.
Conclusion: The Open-Source Advantage in 2025
Open-source tools continue to drive innovation in data science, making advanced analytics accessible, scalable, and collaborative. Mastery of these tools is not just a technical advantage—it’s essential for staying competitive in a rapidly evolving field. Whether you’re a beginner or a seasoned professional, leveraging this ecosystem will unlock new possibilities and accelerate your journey from raw data to actionable insight.
The future of data science is open, and in 2025, these tools are your ticket to building smarter, faster, and more impactful solutions.
#python#r#rstudio#jupyternotebook#jupyterlab#apachespark#tensorflow#pytorch#plotly#d3js#apachesuperset#pandas#scikitlearn#apacheairflow#mlflow#docker#kubernetes#streamlit#redash#kibana#nschool academy#datascience
0 notes
Text
The First “Hello, World!” Where Dreams Begin
At eighteen, clutching my BCA admission papers in a crowded college hallway, I had no grand plan, just an insatiable curiosity for solving puzzles that others couldn’t crack. The first time I typed cout << "Hello, World!"; in that cramped computer lab, with the hum of ancient PCs filling the air, something magical happened. That simple line of code appearing on a black terminal screen wasn't just text. It was proof that I could make machines think, that I could bridge the gap between human ideas and digital reality.
Those early BCA days were a battleground of syntax errors and logic puzzles. C++ felt like learning an alien language, with its strict rules and unforgiving compiler. But every successful compilation was a small victory, every debugged program a mystery solved. I spent countless nights in the lab, wrestling with stubborn arrays and rebellious loops. One particularly memorable 2 AM session ended with a working factorial program, and I nearly cheered loud enough to wake the security guard.
The beauty of those early struggles wasn’t just in learning syntax. It was in developing resilience. Each error message became a teacher, each crash a lesson in patience. I began to see patterns, not just in code, but in how problems could be broken down and systematically solved. What I didn’t realize then was that this logical thinking framework would later become the foundation for understanding user behavior, market dynamics, and the intricate psychology behind digital marketing strategies that I would eventually share with our growing community on Facebook, where we discuss the intersection of technology and marketing with fellow entrepreneurs.
BCA introduced me to a symphony of programming languages: C’s mathematical precision, Java’s object oriented elegance, HTML’s creative canvas, and SQL’s data driven logic. Each language was like learning a new dialect, with its own personality and purpose. But the real revelation came when I understood that coding wasn’t just about making computers work. It was about creating experiences that would touch real people’s lives — a philosophy that now drives our visual storytelling approach on Instagram, where we showcase the human impact of digital transformation.
The networking aspect of coding communities became apparent early on, connecting with peers who shared the same passion for problem-solving. These connections would later prove invaluable when building our professional network through LinkedIn, where we now collaborate with other tech professionals and share insights about the evolving digital landscape.
1 note
·
View note
Text
Complete PHP Tutorial: Learn PHP from Scratch in 7 Days
Are you looking to learn backend web development and build dynamic websites with real functionality? You’re in the right place. Welcome to the Complete PHP Tutorial: Learn PHP from Scratch in 7 Days — a practical, beginner-friendly guide designed to help you master the fundamentals of PHP in just one week.
PHP, or Hypertext Preprocessor, is one of the most widely used server-side scripting languages on the web. It powers everything from small blogs to large-scale websites like Facebook and WordPress. Learning PHP opens up the door to back-end development, content management systems, and full-stack programming. Whether you're a complete beginner or have some experience with HTML/CSS, this tutorial is structured to help you learn PHP step by step with real-world examples.
Why Learn PHP?
Before diving into the tutorial, let’s understand why PHP is still relevant and worth learning in 2025:
Beginner-friendly: Easy syntax and wide support.
Open-source: Free to use with strong community support.
Cross-platform: Runs on Windows, macOS, Linux, and integrates with most servers.
Database integration: Works seamlessly with MySQL and other databases.
In-demand: Still heavily used in CMS platforms like WordPress, Joomla, and Drupal.
If you want to build contact forms, login systems, e-commerce platforms, or data-driven applications, PHP is a great place to start.
Day-by-Day Breakdown: Learn PHP from Scratch in 7 Days
Day 1: Introduction to PHP & Setup
Start by setting up your environment:
Install XAMPP or MAMP to create a local server.
Create your first .php file.
Learn how to embed PHP inside HTML.
Example:
<?php echo "Hello, PHP!"; ?>
What you’ll learn:
How PHP works on the server
Running PHP in your browser
Basic syntax and echo statement
Day 2: Variables, Data Types & Constants
Dive into PHP variables and data types:
$name = "John"; $age = 25; $is_student = true;
Key concepts:
Variable declaration and naming
Data types: String, Integer, Float, Boolean, Array
Constants and predefined variables ($_SERVER, $_GET, $_POST)
Day 3: Operators, Conditions & Control Flow
Learn how to make decisions in PHP:
if ($age > 18) { echo "You are an adult."; } else { echo "You are underage."; }
Topics covered:
Arithmetic, comparison, and logical operators
If-else, switch-case
Nesting conditions and best practices
Day 4: Loops and Arrays
Understand loops to perform repetitive tasks:
$fruits = ["Apple", "Banana", "Cherry"]; foreach ($fruits as $fruit) { echo $fruit. "<br>"; }
Learn about:
for, while, do...while, and foreach loops
Arrays: indexed, associative, and multidimensional
Array functions (count(), array_push(), etc.)
Day 5: Functions & Form Handling
Start writing reusable code and learn how to process user input from forms:
function greet($name) { return "Hello, $name!"; }
Skills you gain:
Defining and calling functions
Passing parameters and returning values
Handling HTML form data with $_POST and $_GET
Form validation and basic security tips
Day 6: Working with Files & Sessions
Build applications that remember users and work with files:
session_start(); $_SESSION["username"] = "admin";
Topics included:
File handling (fopen, fwrite, fread, etc.)
Reading and writing text files
Sessions and cookies
Login system basics using session variables
Day 7: PHP & MySQL – Database Connectivity
On the final day, you’ll connect PHP to a database and build a mini CRUD app:
$conn = new mysqli("localhost", "root", "", "mydatabase");
Learn how to:
Connect PHP to a MySQL database
Create and execute SQL queries
Insert, read, update, and delete (CRUD operations)
Display database data in HTML tables
Bonus Tips for Mastering PHP
Practice by building mini-projects (login form, guest book, blog)
Read official documentation at php.net
Use tools like phpMyAdmin to manage databases visually
Try MVC frameworks like Laravel or CodeIgniter once you're confident with core PHP
What You’ll Be Able to Build After This PHP Tutorial
After following this 7-day PHP tutorial, you’ll be able to:
Create dynamic web pages
Handle form submissions
Work with databases
Manage sessions and users
Understand the logic behind content management systems (CMS)
This gives you the foundation to become a full-stack developer, or even specialize in backend development using PHP and MySQL.
Final Thoughts
Learning PHP doesn’t have to be difficult or time-consuming. With the Complete PHP Tutorial: Learn PHP from Scratch in 7 Days, you’re taking a focused, structured path toward web development success. You’ll learn all the core concepts through clear explanations and hands-on examples that prepare you for real-world projects.
Whether you’re a student, freelancer, or aspiring developer, PHP remains a powerful and valuable skill to add to your web development toolkit.
So open up your code editor, start typing your first <?php ... ?> block, and begin your journey to building dynamic, powerful web applications — one day at a time.

0 notes
Text
Price: [price_with_discount] (as of [price_update_date] - Details) [ad_1] Welcome to the most comprehensive foundational guide available on the topic of C# coding and .NET. This book goes beyond “do this, to achieve this” to drill down into the core stuff that makes a good developer, great. This expanded 11th edition delivers loads of new content on Entity Framework, Razor Pages, Web APIs and more. You will find the latest C# 10 and .NET 6 features served up with plenty of “behind the curtain” discussion designed to expand developers’ critical thinking skills when it comes to their craft. Coverage of ASP.NET Core, Entity Framework Core, and more sits alongside the latest updates to the new unified .NET platform, from performance improvements to Windows Desktop apps on .NET 6, updates in XAML tooling, and expanded coverage of data files and data handling. Going beyond the latest features in C# 10, all code samples are rewritten for this latest release. Dive in and discover why this essential classic is a favorite of C# developers worldwide. Gain a solid foundation in object-oriented development techniques, attributes and reflection, generics and collections, and numerous advanced topics not found in other texts (such as CIL opcodes and emitting dynamic assemblies). Pro C# 10 with .NET 6 will build your coding confidence putting C# into practice, and exploring the .NET universe and its vast potential on your own terms.What You Will LearnExplore C# 10 features and updates in records and record structs, global and implicit using directives, file level namespaces, extended property patterns, and moreDevelop applications with C# and modern frameworks for services, web, and smart client applicationsHit the ground running with ASP.NET Core web applications using MVC and Razor Pages, including view components, custom tag helpers, custom validation, GDPR support, and areasBuild ASP.NET RESTful services complete with versioning, enhanced swagger, and basic authenticationEmbrace Entity Framework Core for building real-world, data-centric applications, with deeply expanded coverage new to this edition including SQL Server temporal table supportDive into Windows Desktop Apps on .NET 6 using Windows Presentation FoundationUnderstand the philosophy behind .NETDiscover the new features in .NET 6, including single file applications, smaller container images, and more Who This Book Is ForDevelopers of any level who want to either learn C# and .NET or want to take their skills to the next level. “Amazing! Provides easy-to-follow explanations and examples. I remember reading the first version of this book; this is a ‘must-have’ for your collection if you are learning .NET!” – Rick McGuire, Senior Application Development Manager, Microsoft“Phil is a journeyman programmer who brings years of experience and a passion for teaching to make this fully revised and modernized ‘classic’ a ‘must-have’. Any developer who wants full-spectrum, up-to-date coverage of both the C# language and how to use it with .NET and ASP.NET Core should get this book.”– Brian A. Randell, Partner, MCW Technologies and Microsoft MVP ASIN : B0B85ZNWP6 Publisher : Apress; 11th edition (30 July 2022) Language : English File size : 24.3 MB Screen Reader : Supported
Enhanced typesetting : Enabled X-Ray : Not Enabled Word Wise : Not Enabled Print length : 3053 pages [ad_2]
0 notes
Text
Mistral OCR 25.05, Mistral AI Le Chat Enterprise on Google

Google Cloud offers Mistral AI’s Le Chat Enterprise and OCR 25.05 models.
Google Cloud provides consumers with an open and adaptable AI environment to generate customised solutions. As part of this commitment, Google Cloud has upgraded AI solutions with Mistral AI.
Google Cloud has two Mistral AI products:
Google Cloud Marketplace’s Le Chat Enterprise
Vertex AI Mistral OCR 25.05
Google Cloud Marketplace Mistral AI Le Chat Enterprise
Le Chat Enterprise is a feature-rich generative AI work assistant. Available on Google Cloud Marketplace. Its main purpose is to boost productivity by integrating technologies and data.
Le Chat Enterprise offers many functions on one platform, including:
Custom data and tool integrations (Google Drive, Sharepoint, OneDrive, Google Calendar, and Gmail initially, with more to follow, including templates)
Enterprise search
Agents build
Users can create private document libraries to reference, extract, and analyse common documents from Drive, Sharepoint, and uploads.
Personalised models
Implementations hybrid
Further MCP support for corporate system connectivity; Auto Summary for fast file viewing and consumption; secure data, tool connections, and libraries
Mistral AI’s Medium 3 model powers Le Chat Enterprise. AI productivity on a single, flexible, and private platform is its goal. Flexible deployment choices like self-hosted, in your public or private cloud, or as a Mistral cloud service let you choose the optimal infrastructure without being locked in. Data is protected by privacy-first data connections and strict ACL adherence.
The stack is fully configurable, from models and platforms to interfaces. Customisation includes bespoke connectors with company data, platform/model features like user feedback loops for model self-improvement, and assistants with stored memories. Along with thorough audit logging and storage, it provides full security control. Mistral’s AI scientists and engineers help deliver value and improve solutioning.
Example Le Chat Enterprise use cases:
Agent creation: Users can develop and implement context-aware, no-code agents.
Accelerating research and analysis: Summarises large reports, extracts key information from documents, and conducts brief web searches.
Producing actionable insights: It can automate financial report production, produce text-to-SQL queries for financial research, and turn complex data into actionable insights for finance.
Accelerates software development: Code generation, review, technical documentation, debugging, and optimisation.
Canvas improves content production by letting marketers interact on visuals, campaign analysis, and writing.
For scalability and security, organisations can use Le Chat Enterprise on the Google Cloud Marketplace. It integrates to Google Cloud services like BigQuery and Cloud SQL and facilitates procurement.
Contact Mistral AI sales and visit the Le Chat Enterprise Google Cloud Marketplace page to use Mistral’s Le Chat Enterprise. The Mistral AI announcement has further details. Le Chat (chat.mistral.ai) and their mobile apps allow free trial use.
OCR 25.05 model llm Mistral
One new OCR API is Mistral OCR 25.05. Vertex AI Model Garden has it. This model excels at document comprehension. It raises the bar in this discipline and can cognitively interpret text, media, charts, tables, graphs, and equations in content-rich papers. From PDFs and photos, it retrieves organised interleaved text and visuals.
Cost of Mistral OCR?
With a Retrieval Augmented Generation (RAG) system that takes multimodal documents, Mistral OCR is considered the ideal model. Additionally, millions of Le Chat users use Mistral OCR as their default document interpretation model. Mistral’s Platform developer suite offers the Mistral-ocr-latest API, which will soon be offered on-premises and to cloud and inference partners. The API costs 1000 pages/$ (double with batch inference).
Highlights of Mistral OCR include:
Cutting-edge comprehension of complex papers, including mathematical formulas, tables, interleaved images, and LaTeX formatting, helps readers understand rich content like scientific articles.
This system is multilingual and multimodal, parsing, understanding, and transcribing thousands of scripts, fonts, and languages. This is crucial for global and hyperlocal businesses.
Excellent benchmarks: This model consistently outperforms top OCR models in rigorous benchmark tests. Compared to Google Document AI, Azure OCR, Gemini models, and GPT-4o, Mistral OCR 2503 scores highest in Overall, Math, Multilingual, Scanned, and Tables accuracy. It also has the highest Fuzzy Match in Generation and multilingual scores compared to Azure OCR, Google Doc AI, and Gemini-2.0-Flash-001. It extracts embedded images and text, unlike other LLMs in the benchmark.
The lightest and fastest in its class, processing 2000 pages per minute on a single node.
Structured output called “doc-as-prompt” uses documents as prompts for powerful, clear instructions. This allows data to be extracted and formatted into structured outputs like JSON, which may be linked into function calls to develop agents.
Organisations with high data protection needs for classified or sensitive information might self-host within their own infrastructure.
Example of Mistral OCR 25.05
Use cases for Mistral OCR 25.05 include:
Digitising scientific research: Making articles and journals AI-ready for downstream intelligence engines streamlines scientific procedures.
Preservation and accessibility can be achieved by digitising historical records and artefacts.
Simplifying customer support: indexing manuals and documentation to improve satisfaction and response times.
AI literature preparation in various fields: We help businesses convert technical literature, engineering drawings, lecture notes, presentations, regulatory filings, and more into indexed, answer-ready formats to gain insights and enhance productivity across vast document volumes.
Integrating Mistral OCR 25.05 as a MaaS on Vertex AI creates a full AI platform. It provides enterprise-grade security and compliance for confident growth and fully controlled infrastructure. The Vertex AI Model Garden includes over 200 foundation models, including Mistral OCR 25.05, so customers can choose the best one for their needs. Vertex AI now offers Mistral OCR 25.05, along with Anthropic models Claude Opus 4 and Claude Sonnet 4.
To develop using Mistral OCR 25.05 on Vertex AI, users must go to the model card in the Model Garden, click “Enable,” and follow the instructions. Platform users can access the API, and Le Chat users can try Mistral OCR for free.
#MistralOCR#LeChatEnterprise#MistralOCR2505#MistralAILeChatEnterprise#MistralOCRmodel#Mistralocr2505modelllm#technology#technews#news#technologynews#govindhtech
1 note
·
View note