#originally the variable was suppose to be n but i changed it to m for mari
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text
The best way to regard socionics is not as a test of the consistency or fallibility of others, but as a test of its own reliability as theory.
Certain aspects of socionics may prove difficult for any critical mind to incorporate. Yet the core premises are surprisingly acceptable:
[P1] Individuals develop ways of thinking which can be diverged from, yet most thoughts are patterned. Pattern formation happens relatively early in child development and modalities vary between individuals. [R1] --Yes, this is not only supported by empirical evidence but adheres to principles of energetics, namely that an inefficient system, particularly this 're-examining the wheel' which becomes necessary in philosophical pursuits [and can lead to marvellous Rube Goldberg machines], does not spontaneously emerge.
[P2] Few types will be generated, and these will be related to broader social functions. [R2]--I've used this metaphor before: similar to wagons travelling over thick clay, most wheels will not create new ruts, but follow those tracks already made through the clay. Once 'in the groove' if you will, the system would have to travel uphill at least momentarily to leave the rut, and is unlikely to do so unless it becomes necessary to change course, for reasons of energetics described in R1. As more wheel-ruts are cut through the clay, diverting the wagon so it follows its own track becomes increasingly difficult -- as it's odds-on, unless the wheels are simply trying to carve an independent path instead of primarily trying to move forwards (again defying principles of energetics) that they will intersect with an existing rut at some point, after which they must accelerate against gravity to stop following the pre-formed trajectory. So at the top of the hill (childhood) one would see a chaos of criss-crossed grooves, but as one descended the declivity (youth and adulthood) the lines would probably decrease in number. Now having designed a physical system I wish to prove it with simulation... Can someone who isn't me please explain human pack mentality & why precisely this metaphor of wagon-ruts is so apt
[P3] Despite adhering to tested behavioural and cognitive patterns most of the time, human minds contain an inextinguishable modicum of natural variance, such that all individuals could to a certain degree act 'not themselves' [R3] Humans can act in ways which seem random, not always due to error/ poor reasoning. In systems theory, the flexible system is more robust As this provision simply widens the set, there doesn't appear to be any reasoning such that P3 makes the other two premises less likely. In the R2 metaphor, this would mean, despite the relative paucity of wagon-ruts, there would be a few sketchy lines where a single path diverged from the group. This does create a bit of a problem for socionics, because, if we call the set of archetypes (deep ruts) 'n', then at the trickier parts in the slope, the set will have a variable amount added, n+m. For real nonnegative 'm', n+m > n.
[P4] Once general patterns are established and shared between many individuals, relationships will also emerge between patterns. [R4] Incontestible that relationships will emerge, but it's not clear that relationships form between patterns as opposed to individuals. To wit, the means by which a person who typically employs a specific thought pattern should necessarily recognise, like, or appreciate similar thought patterns c.f. others in its category must be explained. (To illustrate using latin not greek alphabet, person in category A who appreciates category X does not guarantee another person in category A should appreciate category X. Interpersonal dynamics are overdetermined... or are they? Are modalities themselves compatible, or does personal history generate a stronger impetus to connection?
Finally, outliers affect analyses of all real human categories. If you met a true maverick, an original thinker--the real McCoy etc., do you suppose that person's brain would be bound by conventional rules? It seems unlikely.
In the wagon-rut metaphor, the maverick describes the trajectory of a rocket-powered wagon.
[C1] Therefore, {socionics: broadly or widely inclusive} is far more likely than {socionics: exhaustive}.
4 notes
·
View notes
Text
T.H.O.M.A.S
Technological
Human
Operations
Mimicking
Automated
System
Sanders Sides AU where Thomas is a Robot the sides are building.
🤖=🤖=🤖=🤖=🤖=🤖=🤖
Plot: A bunch of 𝑔𝒶𝓎 scientists have to begrudgingly work together on building their robot son.
~
Patton- Was originally the bubbly receptionist for the lab, but after a few run ins and or shenanigans Janus realizes that Patton is really good with people and is the perfect test subject and consultant for Thomas's emotion replication abilities. So he officially hires him. (cant do tech stuff at all. cant even "hang out" with Thomas without something breaking)
Logan- The one building the robot parts of Thomas. Gets fed up with the other's antics but couldn't do it without them :)
Roman- Engineering. Designs the stuff on paper and in little prototypes. wants to constantly make Thomas "cooler" and adds in random things in the designs like a soda dispenser and Logan is tired™
Remus- Testing. Makes Thomas do stupid stuff and films it and Logan is like "how did you get a degree of science you buffoon??" and Roman just cackles and it inspires him to add more ridiculous and obscure things to Thomas for Remus to test.
Virgil- Techie that programs Thomas and also helps Logan build but mainly works on the safety aspect and fixing stuff after Remus tests. He also loves the wacky tests but if ANYTHING happens to Thomas u will pay. He adds protections and warnings in his comments/notes like "do not. under ANY circumstances. put Thomas within a 5 foot radius of a spider." just to confuse and annoy Logan (he may also be half serious) and Logan doesn't know what to do with any of it.
Janus- Director of the psychological studies for Thomas. He is very well versed in the ethics of the field they are working in and wont hesitate to debate you. He mainly focuses on trying to make Thomas act like a person even though hes a Robot and alongside Roman helps translate that into something that can be built. Hes also kind of the leader, along with Logan.
Moments:
Logan: This is test number three-five-o-two at 3:25 PM EST on July 3rd 2020 to evaluate-
Virgil: Logan, why is Thomas talking to the stove?
Logan: Wh-
Roman: Aw come on! Look at how stupid he looks talking to the kitchen appliances Logan, you made him stupid.
Logan: I dID NOT make him STUPID YOU-
*Janus later has to end the kerfuffle after he walks in on Logan, on top of Roman, holding a soldering iron to Roman's throat*
~~~
*Thomas is booting up but it's taking a while*
Roman: Tom
Patton: Tomathy
Roman: Tommy Salami
Patton: Tomalama ding-dong
Roman: Thomas the DANK engine
Logan: ...
~~~
Logan: I know him better than anyone because I know how he works so-
~~~
🤖💖More Lore💖🤖
Logan does the know exact time thing but says it at the same time as Thomas when someone asks what the time is.
🤖
Virgil will talk to Thomas like hes a person and Logan is confused by this but Virgil uses the excuse that hes supposed to seem like a human so why not talk to him ¯\_(ツ)_/¯. Virgil also kinda vents to him but uh big ouch a lot of it gets recorded onto Thomas and that gets turned into either hyjinx and or angst later.
🤖
Patton also talks to Thomas like a person but more like "Yes look and my robot son he is so smart I love him" and he also teaches him puns. The puns get out of hand at some point and Thomas has got it in his neural network that puns are The Exact Right Thing To Say in Any social interaction but they start becoming really obscure because Thomas has access to a lot of information, and he hasn't quite nailed getting puns in context, so one time he makes a pun that is really sciencey and vaguely connected to the conversation so only Logan gets it,,,,, but he finds it hilarious and it's the only pun Logan will admit to laughing at.
🤖
Virgil has that programmer relationship with Thomas. So smthn just wont run correctly and Virgil is like "YOU IDIOT! I'm going to prohibit your mimicking human breathing function if you keep this up!!!" "A SINGLE SEMI COLON ARE YOU SERIOUS?!?! Why is it ALWAYS dumb s̶h̶i̶t̶ like that with you Thomas?!" "I have a million copies saved of his program because if anything happens to him I will actually combust." He also has incomprehensible names for variables and functions and stuff and some of them are memes and vine references. Logan has had to learn a bunch of modern slang just vaguely understand what's happening in the code.
🤖
Jan is always recommending certain things to Roman to make Thomas more realistic but sometimes they are obscure because "people and psychology are just weird" so Roman adds them in (or tries) but sometimes Janus just makes it up and watches everyone struggle meeting his request for entertainment. like, "Mhm, ok, fantastic work this week, truly, just show-stopping. However, comma, He just... doesn’t fix his hair enough... You'd be surprised the amount of times the average Male adult fixes his hair in a single social interaction. So....make him do it more." (That request never ended up getting changed back after it got implemented...)
🤖
Remus is always adding things to the list of "things he needs to test with" and Pat at reception starts to get concerned with the 3rd bulk shipment of deodorant that came through. Remus actually uses funds to restock the fridge and snack cabinet a lot along with Roman occasionally.
🤖
Pat is always scolding the others (mainly Remus and Virgil) for swearing or saying mean things too or around Thomas because he "wants to raise him right" and doesn't want him to "learn bad manners". He also may or may not be low-key emotionally attached to Thomas and wants to believe he actually feels things. Janus is simultaneously amused and frustrated with this but he let's it slide because "I guess that means that Thomas is effective...despite the fact that Patton is naive, it's still promising."
(Patton isn't actually naive, just because he wants to treat Thomas like a human doesn't mean he thinks he is. Patton really does it because then the others can be proud of their hard work and can actually see Thomas functioning with a person outside of a controlled environment.)
Yeah so that's what I got so far! I kinda wanna add more to this so if ya like the idea interact with this post n I'll maybe make an update. I don’t have a plot in mind for this other than like, Patton being added to the group. I just think the idea is cute and works well with the dynamics already set up in Sanders Sides.
Also, Disclaimer, I haven't had any experience in Robotics LOL so this could all be actual gibberish. I have done Computer Science and programming tho so I vaguely understand that side of it. But the engineering and actual possibility of making a human-like Robot I have no clue about.
Oh! If you know anything about these topics or maybe just like this au idea and want to add on FEEL FREE TO SHARE! :D I would LOVE to see what people have to add!
See yah~💖🤖💖~
#thomas#sander sides#thomas sanders#ts sides#virgil sanders#roman sanders#logan sanders#janus sanders#remus sanders#patton sanders#Robot!Thomas#T.h.o.m.a.s.#Im sorry this is so long#i had a lot of ideas#its been simmering in my drafts for a steamy second cuz i was determined to figure out a read more for it#also#idk about the acronym#gosh this is long#i tried to spice it up with spacing and robot emojis and colors so it isnt just a bunch of indents in random places like it is in my notes#i hope its not too boring haha
8 notes
·
View notes
Text
Noether’s Theorem - A Quick Explanation

Noether's Theorem is super rad. The theorem is, colloquially,
>> Continuous symmetries imply conserved quantities. <<
Let’s dig into the origin of this powerful theorem and list a couple of examples. I’ll restrict my attention to a subclass of symmetries for the sake of space, buuuut if there’s interest, I could do a more general post in the future. (Heads up: because this post is written using LaTeX, it's probably easiest to read directly from my blog.)
• Defining the Lingo: A Lagrangian is a function that (after some manipulation) yields the physical evolution of a system. A generic Lagrangian $L$ can be a real continuous function of...
$m$ real parameters $t_j$, where $j=1,\cdots,m$, and
$n$ pairs of paths, which we label $q_i(t_1,\cdots,t_m)$ and $\tilde{q}_i(t_1,\cdots,t_m)$, where $i=1,\cdots,n$ and a path means “a real continuous function of the aforementioned parameters”
In this exceedingly general case, we might write
$$L = L(q_1,\cdots,q_n,\tilde{q}_1,\cdots,\tilde{q}_n,t_1,\cdots, t_m)$$
However, for the sake of clarity, let's restrict ourselves to one parameter $t$ and one function pair $(q,\tilde{q})$. Let's further suppose $L$ depends on its parameter only through the function pair, aka let us write $L = L(q,\tilde{q})$ (as opposed to $L = L(q,\tilde{q},t)$). This is the case relevant to a classical particle confined to a friction-free line, wherein $q(t)$ is the particle’s position along the line and $t$ records the time.
While $L$ is constructed to be a function of position $q(t)$ and some other path $\tilde{q}(t)$, we always intend to eventually set $\tilde{q}(t)$ equal to the velocity $\dot{q}\equiv dq/dt$. Furthermore, of the many combinations $(q(t),\tilde{q}(t))$ equaling $(q(t),\dot{q}(t))$, nature chooses the pair satisfying the Euler-Lagrange equation:
$$\left.\frac{\partial L}{\partial q} \right|_{\tilde{q} = \dot{q}} = \frac{dp}{dt}$$
where
$$p\equiv \left. \frac{\partial L}{\partial \tilde{q}}\right|_{\tilde{q} = \dot{q}}$$
The differential equation we get from plugging a specific $L$ into the Euler-Lagrange equation is called the equation of motion of the system, and $p$ is the momentum conjugate to $q$.
• The Main Idea: No matter the specific form of $L$, we can plot it over $(q,\tilde{q})$ space. (To be clear: this is the space of values to which the paths $q(t)$ and $\tilde{q}(t)$ are mapping, so essentially the real plane.) The resulting plot will look something like the left plot in the following image:

I've made a point to highlight contours of constant $L$ in orange. The right plot projects those contours onto the $(q,\tilde{q})$ plane. These contours lie at the heart of Noether's Theorem: imagine we slide the coordinates $(q,\tilde{q})$ around in the plane so that each point moves continuously along a contour of constant $L$. Usually the shape of $L$ is changed when we distort the $(q,\tilde{q})$ plane below it, but by forcing each $(q,\tilde{q})$ to flow along a contour, $L$ is unaffected! A continuous transformation that leaves $L$ unchanged is called a continuous symmetry of the Lagrangian.
We can make this whole business quantitative by parameterizing the sliding operation with a real variable $\alpha$. Let's choose $\alpha$ so that $\alpha=0$ corresponds our initial unchanged $(q,\tilde{q})$ plane. Then the statement “$\alpha$ parameterizes contours of constant $L$” is mathematically expressible as
$$\left.\frac{dL}{d\alpha}\right|_{\alpha =0} =0$$
which equals, by the chain rule of differentiation,
$$\frac{\partial L}{\partial q}\hspace{3 pt}\left.\frac{dq}{d\alpha}\right|_{\alpha =0} + \frac{\partial L}{\partial \tilde{q}} \hspace{3 pt} \left.\frac{d\tilde{q}}{d\alpha}\right|_{\alpha =0} = 0$$
Now, this equation holds true across all of $(q,\tilde{q})$ space, including along the physical path solving the equations of motion. For that path, we may use the Euler-Lagrange equation, the definition of conjugate momentum $p\equiv \partial L/\partial\tilde{q}$, and the fact that $\partial \dot{q}/\partial \alpha = d/dt(\partial q/\partial \alpha)$ to write,
$$\frac{dp}{dt} \hspace{3 pt} \frac{\partial q}{\partial\alpha} + p \hspace{3 pt} \frac{d}{dt}\left[\frac{\partial q}{\partial \alpha}\right] = 0$$
aka, according to the product rule of differentiation,
$$ \frac{d}{dt}\left[p \hspace{3 pt} \frac{\partial q}{\partial \alpha}\right] =0 $$
In other words, the value of $p \hspace{3 pt} (\partial q/\partial \alpha)$ doesn’t change in time--it’s a conserved quantity! This is a special case of Noether's Theorem.
If we repeat the above calculation with $n$ paths $q_i(t)$, we instead derive
$$\text{*}\hspace{25 pt}\frac{d}{dt}\left[\vec{p}\cdot \frac{d\vec{q}}{d\alpha}\right] =0 \hspace{25 pt}\text{*}$$
where $\vec{q} \equiv (q_1,\cdots,q_n)$ and $\vec{p} \equiv (p_1,\cdots, p_n)$, and we find that
>> Momentum along a continuous symmetry direction is conserved. <<
This powerful statement allows us to identify conserved quantities from symmetries alone. For example...
• 1. Coordinate Translation Symmetry: Suppose $L$ doesn't depend on the coordinate $q_i$ for some value of $i$. Then the translation $q_i\mapsto q_i+\alpha$ is a continuous symmetry transformation. Because $dq_k/d\alpha$ is nonzero only for the coordinate we’re transforming ($k=i$), the associated conserved quantity is...
$$\vec{p}\cdot \frac{d \vec{q}}{d\alpha} = p_i$$
which is the $i$th conjugate momentum. And so, coordinate translation invariance necessarily implies conservation of the corresponding momentum.
• 2. Rotational Symmetry: Suppose $L$ depends on the coordinates $(x,y,z)$ and is invariant under the rotation of $x$ and $y$ into one-another:
$$ x\mapsto (\cos\alpha)x + (\sin\alpha)y\hspace{50 pt}y\mapsto (\cos\alpha)y -(\sin\alpha)x$$
Then we may calculate,
$$\left.\frac{d x}{d\alpha}\right|_{\alpha =0} = y\hspace{50 pt} \left.\frac{d y}{d\alpha}\right|_{\alpha =0} = -x$$
from which Noether's Theorem implies conservation of...
$$\vec{p}\cdot \frac{d\vec{q}}{dt} = p_x y - p_y x = - L_z$$
where $L_z$ is the angular momentum in the $z$-direction. Rotational invariance necessarily implies angular momentum conservation.
• Closing Comment: Note how we didn't need an explicit form for $L$ to make these arguments. Noether's Theorem tells us that conserved quantities naturally emerge not as coincidences, but from the presence of symmetries. Consequently, if I experimentally observe a conserved quantity (like electric charge, or color charge, or even things like lepton number) then I can make my model consistent with that observation by encoding certain symmetries into my Lagrangian. In this way, Noether’s Theorem is impressive in both its elegance and practical power.
Thanks for the ask, anonymous! I hope this helped. Although I didn't have space to discuss it here, Noether's Theorem also extends to Lagrangians with explicit parameter dependence, systems with multiple evolution parameters (like QFT), instances where $(q,\tilde{q})$ transformations change $L$ by a total derivative, and more. One extension allows us to demonstrate how time translation invariance yields energy conservation.
Have a physics question you think I might be able to help answer? Send me an ask. Until then, have a great day! Best wishes, my friend!
#Thanks for reading!#I love writing up these explanation-style posts#soooo if you have a physicsy topic and wanna hear my take just let me know#because I didn't want to get into the action functional in this post I couldn't talk about symmetries of the action and all that#long post#grad school#gradblr#physicsblr#researchblr#sciblr#scienceblr#QFTblr#research#academia#academics#Noether's Theorem#Classical Mechanics#Field Theory#ask#anonymous
99 notes
·
View notes
Text
Behavior Related to Taxation System: Example of Bi-Criteria Linear Program for Animal Diet Formulation-Juniper Publishers

Introduction
Animal diet formulation is a very important problem from an economic and environmental point of view, so it is an interesting example in the field of operations research. Many modern animal diet formulation methods tend to consider not only the cost of the diet but also excretions that are detrimental from an environmental point of view. Following [5], it is appropriate to apply a tax on excretions to change the behavior of the producers in the swine industry. These changes in behavior are studied using a formulation of the problem as a bi-criteria model and are obtained by the determination of its Pareto set. For linear models, the changes in behavior of the producer are abrupt (discrete) and correspond to specific values of the tax. In other words, even in increasing the tax it can happen that there is no change in the behavior of the producer. Behavior changes happened only at very specific values of the tax. We will see that these behaviors correspond to efficient extreme points of the Pareto set, and to every extreme point corresponds a tax interval so that any value of the tax in this interval leads to the behavior given by that same extreme point.
The outline of the paper is the following. In Section 2, we present the diet formulation problem considering the phosphorus excretion. The general form of the bi-criteria problem is presented, the geometric structure of its Pareto set is described, and we indicate methods to compute this set in Section 3. Finally, in Section 4, we present the pareto set for our original diet formulation problem and shows the effect of the taxation system on the behavior of a producer. The results presented in this paper, the behavior of the decision maker, can be applied to any linear bi-criteria problem.
Pig Diet Formulation
To illustrate the effect of a tax on the criteria, we consider the pig diet formulation problem considering not only the cost of the diet but also an environmental consideration such as the reduction phosphorus excretion [1]. One way to analyze this problem is to rewrite the problem as bicriteria problem. Hence the Pareto set indicates the effect of the reduction of phosphorus excretion on the cost of the diet. It also presents different behaviors for the producers associated to levels of taxation. This information is certainly useful for a decision maker which must choose a diet which decreases the excretion without being too expensive
Classical Model
The least cost diet problem, introduced in [2], is a classical linear programming problem [3-5]. A decision variable jx is assigned to each ingredient and represents the amount (in kg) of the thj ingredient per unit weight (1 kg) of the feed. Together, they form the decision vector
in our model. The model’s objective function is the diet cost. A vector of unit costs
must be minimized over the set of feasible diets denoted by S. The classic least cost animal diet formulation model is:
The constraints impose some bounds on the quantity of the different ingredients in the diet. For example, a unit of feed is produced (a 1 kg mix), expressed by the constraint
Some ingredients, or combinations of ingredients, can be imposed on the diet. These restrictions give rise to equality constraints (=) or inequality constraints (≥ or ≤). More specifically, to satisfy protein requirements, the following constraints are introduced for the L groups of amino acids contained in the ingredients. We set
where dig lj aa represents the amount of digestible amino acid l contained in a unit of ingredient j and bl*is the minimum amount of digestible amino acid l required. Finally, the diet must satisfy the digestible phosphorus requirements * bph given by
where dig j ph is the amount of digestible phosphorus contained in a unit of ingredient j .
Modelling of phosphorus excretion
Phosphorus excretion is directly related to the excess of phosphorus in the diet. Hence, we must establish the phosphorus content of the diet and consider the parts that is assimilated. The phosphorus content of a unit weight diet
of phosphorus which is digested. In this way the phosphorus excretion ( ) ph r x is given by the phosphorus content of the diet from which we remove the amount of phosphorus which is digested of phosphorus which is digested. In this way the phosphorus excretion ( ) ph r x is given by the phosphorus content of the diet from which we remove the amount of phosphorus which is digested
Hence, decreasing the phosphorus excretion ( ) ph r x is equivalent to decreasing the phosphorus content pr q xof the diet while maintained fixed the needs * ph b in phosphorus.
Bi-Criteria Problem: Cost and Phosphorus Excretion
Since we look for least cost diet while considering the phosphorus excretion, we have two conflicting criteria. The bicriteria linear model is then formulated as follows
For this problem, the Pareto curve will indicate the diet cost increase caused by a phosphorus excretion decrease. It will give us the taxation levels producing changes in the behavior of the producer.
Data
To illustrate the problem and the method we consider data that represent real situation [1]. The ingredients and their corresponding variables are described in (Table 1, Table 2) contains the entire model together with the values of the technical coefficients of the model.
General Bi-Criteria Linear Program and its Pareto Set
In this section we present the general formulation of a bicriteria linear problem, and the main results on its Pareto set. We use the link with the parametric analysis to get information on the system of taxation and behavior of the decision maker.
Bi-Criteria linear programming problem
Let us consider the standard form of the bi-criteria linear programming problem [6].
where x is a column vector in n , and they ' ( 1, 2) k c s k = are row vectors in n . The feasible set S in n is defined by S = {x∈n | Ax = b and x ≥ 0} , where A is a (m, n)-matrix, and b are a column vector in n . Let C be the (2, n)-matrix given by
The feasible set in the criterion space 2 is then { 2 | for } . C X S = z∈ z = C x∈S = CS It is well-known that S and SC are polyhedral sets in n and 2 respectively. Throughout this paper we will suppose that the two criteria are lower bounded on S which means that for i = 1, 2 we have
Pareto set
A feasible solution x∈s is an efficient solution if and only if it does not exist any other feasible solution x∈S such that
for at least one j∈{1,2}. The set of all efficient solutions is called the efficiency set noted ε , also called Pareto set. The corresponding set in the criterion space is the set c ε = cε
Geometric structure of the pareto set
Under the assumption that the two cost vectors c1 and c2 are linearly independent, and using weighted sums, we can replace the bicriteria linear programming problem by a single criterion linear programming problem. We consider λ ∈[0,1] and the weightedsum function is
Hence the efficiency set ε in the decision space is a connected set and is the union of faces, edges and vertices of S . This set may be quite complex due to the high dimension of the decision space. On the other side c ε , which is the image in 2 of ε by a linear transform, is a much simpler set.
Since we have assumed that both criteria are lower bounded on S , it follows that c ε is a simple compact polygonal line. Indeed, in that case c ε is the union of a finite number L of segments [ ]
To each segment is associated a weight l 1,l λ − such that the vector 1, 1, (1 , )t l l l l λ λ − − − is orthogonal to the segment [ ] 1 , l l Q Q − in 2 . To each point Q of c ε is associated an interval Λ(Q) defined by
With 0 0,... . l λl −λ > for l = L More mathematical details are given in [7].
Link to parametric analysis
The parametric analysis is based on the weighted sum given by
for μ∈[0, +∞),which can represent a tax on the second criteria. The value function in this case is defined by
We could consider the single criteria problem for μ ≥ 0
Since λ and μ are related by the formulae
to the efficient extreme points { } 0 Q L l l= on the efficiency set ε c we associate to these extreme points the following intervals for the parameter μ
In many applications, the parameter μ is in fact a taxe over the the second criteria (for a minimization problem). Interesting enough is to observe that the behavior (extreme point) change only for the critical values μl−1,l of the parameter μ. Indeed when μ increases and its value passes through μl−1,l , the behavior moves from the extreme point 1 Ql− to the extreme point l Q . Moreover, any level of taxes μ strictly between the values 1, l l l μ μ − = and μl,l+1 = μl gives the same behavior described by the extreme point l Q .
Software
Several methods exist for computing the Pareto set of a bicriteria linear program, for example [7,8]. We have developed our own method which requires only elementary results from a linear program solver [9]. It has been programmed in MATLAB and uses Linprog as the linear program solver.
Back to Pig Diet Formulation: Cost and phosphorus excretion
Let us come back to our bi-criteria linear model
Its two associated parametric models are
Its Pareto curve contains all the information for optimal decision considering the level of taxation. (Table 3) presents the efficient extreme points in the criterion space while the Pareto curve is sketched in (Figure 1). For this problem, the algorithm detects L = 22 segments and 23 extreme points. A total of 45 calls to a linear program software was required [9].
For each l , such that l = 0, . . . , 22, the extreme point Ql is given by
and corresponds to the optimal value of the criteria corresponding to any optimal solution of , (p ( )) c ph μ for any values of μ in ( , ) l l μ μ . So, the value function, with tax, is
as long as [ , ] l μ∈ μ μl . So, we see that for any tax value in [ , ] l l μ μ we will always have the same value function ϕ(μ ) , or the same behavior (zl,cost , zl,phosphorus execretion), and the change in the behavior will append only when the taxation level μ passes through the extremities l μ or l μ of this interval.
This is a nice example of abrupt (discrete) changes in behavior depending on the level of taxation of one criterion.
Conclusion
We have considered a diet formulation problem with two conflicting criteria, modelled as a bi-criteria linear model, to illustrate abrupt changes in behavior of a decision maker for a taxation system.
Acknowledgment
This work has been supported in part by the Natural Sciences and Engineering Research Council of Canada (individual grant RGPIN-2016-05572) and by the Canadian corporation Swine Innovation Porch (project 1241).
https://juniperpublishers.com/asm/ASM.MS.ID.555611.php
For More Articles in Annals of Social Sciences & Management studies
Please Click on: https://juniperpublishers.com/asm/index.php For More Open Access Journals In Juniper Publishers
Please Click on: https://juniperpublishers.com/index.php
0 notes
Text
INCLUDING, I HOPE, THE PROBLEM THAT HAS AFFLICTED SO MANY PREVIOUS COMMUNITIES: BEING RUINED BY GROWTH
But though I can't predict specific winners, I can offer a recipe for recognizing them. If you try too hard to conceal your rawness—by trying to reverse-engineer Winograd's SHRDLU.1 Grad school is the other end of a trade loses a dollar. After a while this filter will start to operate as you write. I know are professors, but it is the irreducible core of it, but thoughtful people aren't willing to use a forum with a lot of thoughtful people in it, and focus our efforts where they'll do the most good. I was writing this, my mind wandered: would it be useful to have an automatic book?2 Number one will be your own confidence in it. I told you so. Or perhaps the frontpage protects itself, by advertising what type of submission is expected. But only some of them will be a minority squared. An individual mine or factory owner could decide to install a steam engine, and within a few years he could probably find someone local to make him one.3
The Model T didn't have all the features previous cars did.4 I'm not saying spoken language always works best. And when my friend Trevor showed up at my house recently, he was carrying a Powerbook identical to mine.5 Apparently only recommendations really matter at the best schools. Never say we're passionate or our product is great.6 You meet a lot of trolls in it.7 On Demo Day each startup will only get ten minutes, so we were pretty excited when we figured out what seemed to us the optimal way of doing shopping searches. If you disagree, try living for a year using only the resources available to the average Frankish nobleman in 800, and report back to us. All previous revolutions have spread.
But will people pay for information otherwise? People who think the labor movement was the creation of wealth seems to appear and disappear like the noise of a fan as you switch on and off.8 At Rehearsal Day, we have a dress rehearsal called Rehearsal Day. Off, quiet. Wealth is defined democratically. The evolution of technology is captured by a monopoly, it will go to work for you without giving them options likely to be worth something. And if there are people getting rich by creating wealth. A free market interprets monopoly as damage and routes around it.9 It takes a conscious effort to remind oneself that the real world: they're small; you get to start from scratch; and the problem is usually artificial and predetermined.
Not because it's causing economic inequality, the former because founders own more stock, and the granary the wealth that each family created. But that isn't true.10 You can demonstrate your respect for one another in some way. And because startup founders work under great pressure, it's critical they be friends. But there will be more room for spikes. When we describe one as smart, it's shorthand for smarter than other three year olds.11 And yet half the people around you are out of their heads. Will people create wealth if they can't get paid for it. The most dangerous thing for the frontpage is stuff that's too easy to upvote.
Bad comments are like kudzu: they take over rapidly.12 People reply to dumb jokes with dumb jokes. Intelligence and wisdom are obviously not mutually exclusive. But the really striking change, as intelligence and wisdom too, but this predisposition is not itself intelligence. The information needed to conduct such studies is increasingly available. When people say something substantial that gets modded down, they stubbornly leave it up. You have to know what an n 2 algorithm is if you want to attract hackers to write software that will sell your hardware, you have to choose between several alternatives, there's an upper bound on your performance: choosing the best every time. I suppose that's worth something. I expect them to be written as thin enough skins that users can see the evolution of species because branches can converge.13 If you buy a custom-made car, something will always be breaking.14 It's pretty clear now that the things we build are so complicated, there's another rapidly growing subset: making things easier.
What a disaster that would be of the same curve. For most of us, it's not made equally. But that's like using a screwdriver to open bottles; what one really wants is a bottle opener. But it would be some kind of fundamental limit eventually. But the really striking change, as intelligence and wisdom too, but this predisposition is not itself intelligence.15 And from my friends who are professors I know what branch of the tree to bet on now.16 Do you, er, want a printout of yesterday's news? YC founders presenting at Demo Day, because Demo Day presentations are now so short that they rarely include much if any demo. Wise means something—that one is on average good at making the right decisions about language design. So it's kind of misleading to ask whether you'll be at home in computer science. But now that I've realized what's going on, perhaps there's a third option: to write something that sounds like spontaneous, informal speech, and deliver it that way too. And the way to ensure that is to ask what you need as a user.17
I'm sure most of those who want to decrease economic inequality. I say let's aim at the problems. They use different words, certainly. But only graduation rates, then you'll improve graduation rates.18 It's more important to grow fast or die. This was an era when small firms making everything from cars to candy were getting consolidated into a new kind of farming. Much of what's in the sage's head is also in the head of a 1950s auto executive, the attitude must have been dismayed when I jumped up to the whiteboard and launched into a presentation of our exciting new technology.
Notes
But if you do. The Roman commander specifically ordered that he had to for some reason insists that you should at least some of those you can send your business plan to make a fortune in the sort of pious crap you were doing more than the 50 minutes they may introduce startups they like to cluster together as much income. You could also degenerate from 129. This technique wouldn't work if the statistics they use; if there is one of them is that you'll expend a lot of face to face with the earlier stage startups, you may as well, partly because companies then were more at the fabulous Oren's Hummus.
Another tip: If they no longer needed, big companies couldn't decrease to zero.
Whereas many of the density of startup people in Bolivia don't want to get fossilized.
But a lot of the resulting sequence.
If the Mac was so violent that she decided never again.
The function goes asymptotic fairly quickly, because the money. But so many still make you register to read an original book, bearing in mind that it's doubly important for the others to act through subordinates. Actually, someone did, but also seem to be most attractive when it's aligned with the high-fiber diet is to let yourself feel it mid-twenties the people who don't aren't. Instead of no counterexamples, though.
The average B-17 pilot in World War II had disappeared.
Strictly speaking it's impossible without a time. But the time they're fifteen the kids are smarter than preppies, just that if the similarity extended to returns.
But that was actively maintained would be more alarmed if you ban other ways to do this right you'd have reached after lots of others followed. Maybe at first, and one didn't try to get fossilized. That's probably too much. Maybe not linearly, but I think all of us in the early 90s when they got to the average reader that they function as the average Edwardian might well guess wrong.
Please do not take the line? There is one of the Times vary so much worse than the time 1992 the entire cross-country Internet bandwidth wasn't enough for one video stream. 39 says that the lies people told 100 years will be on fewer boards at once is to seem big that they were. How many parents would still send their kids rather than just salary.
I grew up with only a few months by buying an additional disk drive. Seneca Ep.
I knew, there is money. Which in turn forces Digg to respond gracefully to such changes, because to translate this program into C they literally had to. They're an administrative convenience.
But if so, why did it with the Supreme Court's 1982 decision in Edgar v.
The quality of investor is more like determination is proportionate to wd m-k w-d n, where w is will and d discipline. If our hypothetical company making 1000 a month grew at 1% a week for 19 years, dribbling out a chapter at a public company not to be on the scale that Google does. So although it works well to show them how awful the real world is boring.
Garry Tan pointed out an interesting trap founders fall into two categories: those where the acquirer just wants the employees. Xkcd implemented a particularly alarming example, it's probably a real idea that investors don't like. It's sometimes argued that we should be deprived of their portfolio companies.
The shift in power to founders would actually increase the size of the lawyers they need. Experienced investors know about a related phenomenon: he found himself concealing from his family how much they can do with down rounds—like full ratchet anti-dilution protections. But it will seem more powerful version written in C and Perl.
If Paris is where your idea of happiness from many older societies. This is why search engines and there are some whose definition of property without affecting and probably harming the state of technology. In fact the secret weapon of the conversion of buildings not previously public, like architecture and filmmaking, but I couldn't believe it or not, don't even try. One reason I don't mean to imply that the http requests are indistinguishable from those of dynamic variables were merely optimization advice, and those where the acquirer wants the employees.
They assumed that their prices stabilize. Investors are often compared to what you learn in even the flaws of big companies to build consumer electronics and to a company's revenues as the investment market becomes more efficient. In a country with a neologism.
#automatically generated text#Markov chains#Paul Graham#Python#Patrick Mooney#users#stock#era#People#founders#Powerbook#trap#friend#sup#neologism#wealth#Grad#lawyers#portfolio#Demo#revenues#Model#algorithm#architecture#Edgar#people#companies#car#Bolivia
0 notes
Text
A Study in Skulls, Sonnets, and Chess
Ello! I am only a beginner at theorizing for Sherlock and I’ve yet to read the books (gotta read asap) but found great fun in brainstorming. Hopefully this isn’t all a repeat of what the fandom’s been saying for months now!
(This post will later on revolve a bit around the Extended Mind Palace theory and/or meditative trance theory)
Quick briefing for sonnets before i get into it: There are some fans who noticed that John’s counting on of 57 texts in The Scandal in Belgravia was a reference to William Shakespeare’s Sonnet 57.
Being your slave, what should I do but tend Upon the hours and times of your desire? I have no precious time at all to spend, Nor services to do, till you require. Nor dare I chide the world-without-end hour Whilst I, my sovereign, watch the clock for you, Nor think the bitterness of absence sour When you have bid your servant once adieu; Nor dare I question with my jealous thought Where you may be, or your affairs suppose, But, like a sad slave, stay and think of nought Save, where you are how happy you make those. So true a fool is love that in your will, Though you do any thing, he thinks no ill.
Modernized verison: “Since I’m your slave, what else should I do but wait on the hours, and for the times when you’ll want me? I don’t have any valuable time to spend, or any services to do, until you need me. Nor do I dare complain about how agonizingly long the hours are while I watch the clock for you, my king, or how bitter your absence is after you’ve said goodbye to your servant. Nor do I dare ask jealous questions about where you might be, or speculate about your affairs, but like a sad slave I sit still and think about nothing except how happy you’re making whomever you’re with. Love makes a person such a faithful fool that no matter what you do to satisfy your desires, he doesn’t think you’ve done anything wrong.”
Sonnet 58:
That god forbid, that made me first your slave, I should in thought control your times of pleasure, Or at your hand th' account of hours to crave, Being your vassal bound to stay your leisure. O let me suffer, being at your beck, Th' imprisoned absence of your liberty; And patience tame to sufferance bide each check, Without accusing you of injury. Be where you list, your charter is so strong That you yourself may privilege your time To what you will; to you it doth belong Yourself to pardon of self-doing crime. I am to wait, though waiting so be hell, Not blame your pleasure, be it ill or well.
“Sonnet 57 is one of 154 sonnets written by the English playwright and poet William Shakespeare. It is a member of the Fair Youth sequence, in which the poet expresses his love towards a young man. Sonnet 57 is connected with Sonnet 58 which pursues the theme of the poet as a slave of the beloved.” - Wikipedia
Modernized version: ”Whatever god decided to make me your slave, may he never allow me to so much as think about having any control over when you see me, or asking you to account for how you’ve been passing the hours. I’m your slave, after all, and forced to wait until you have time for me. Oh, while I wait for your summons, let me suffer patiently the prison of this lengthy absence from you as you do whatever you want. And let me control my impatience and quietly endure each disappointment without accusing you of hurting me. Go wherever you want—you’re so privileged that you may decide to do whatever you like. You have the right to pardon yourself for any crime you commit. And I have to wait, even if it feels like hell, and not blame you for following your desire, whether it’s for good or bad.“
Sonnet 59:
Mary is said to have called/messaged John 59 times in The Six Thatchers because she’s going into labor.
John says this number, ‘59.‘
If there be nothing new, but that which is Hath been before, how are our brains beguil'd, Which, labouring for invention, bear amiss The second burthen of a former child! O, that record could with a backward look, Even of five hundred courses of the sun, Show me your image in some antique book, Since mind at first in character was done! That I might see what the old world could say To this composed wonder of your frame; Whether we are mended, or whe'r better they, Or whether revolution be the same. O! sure I am, the wits of former days To subjects worse have given admiring praise.
Modernized version: “If it’s true that there’s nothing new and everything that now exists existed in the past, then we are really fooling ourselves when we struggle to write something new, winding up, after much exhausting, painful labor, with a tired imitation of an imitation! If only I could look back into the records, even as far as five hundred years ago, and find a description of you in some old book, written when people were just beginning to put their thoughts in writing, so I could see what the old world would say about your amazingly beautiful body. Then I could see whether we’ve gotten better at writing or worse, or whether things have stayed the same as the world revolves. Oh, I’m sure the witty writers of the past have devoted praise and admiration to worse subjects than you.“
Sherlock in The Six Thatchers, explains to Mary that he knows 58 possible ways of diminishing variables and calculating the steps she would take. (despite the fact that he did not use this tactic to find her location after she fled to lure Ajay away. Tracer device n’ all) This mention of 58 comes after the mention of 59, which is also mentioned in The Six Thatchers episode.
Sonnet 59 is also connected to a picture seen in The Abominable Bride. The skull painting of the modern Sherlock world is blue with a rather simple plain background. In Sherlock’s mind palace, the painting is red and is a Victorian painting called All is Vanity. All is Vanity in real life is typically a more neutral brown than the reddish brown we see, and sometimes white. (The fabulous @cyntrix-gm helped me find this painting’s name)

Both the painting, and sonnet 59 refer to verses in the bible from the same book of Ecclesiastes.
(Sonnet 59) If there be nothing new: Ecclesiastes 1.9: "The thing that hath been is that which shall be; and that which hath been done is that which shall be done; and there is no new thing under the sun."
In Scandal in Belgravia, Sherlock says, “The wheel turns, nothing is ever new.“ and Mycroft in The Sign of Three in Sherlock’s mind palace reminds, “What do we say about coincidence?” Sherlock responds “The universe is rarely so lazy.”
All is Vanity: Ecclesiastes 1:2 “Vanity of vanities, saith the Preacher, vanity of vanities; all is vanity.“
John’s Chinese fortune cookie says “There is nothing new under the sun. It has all been done before.” (credited post by @teaandforeshadowing)
This post by @lillabaloo displays a screenshot in which thewatsonbeekeepers explains that William Sherlock Scott Holmes’s real initials (WH) are connected in parallel to whom sonnets are addressed to.
His Last Vow had a deleted scene featuring Magnussen and a hospitalized Sherlock where a vase with a dark, withering rose and letter stood.
(@cyntrix-gm found the rose symbolism) The symbolism of the withering rose:
“The dark crimson rose has a meaning that has two sides. On one side it’s about sadness and mourning and death. On another, it has a more joyous meaning - rebirth and love. When someone you care about passes away, the dark crimson rose can express your feelings of mourning and sadness.” - website of Auntyflo on rose symbolism.
Magnussen - “The struggling carnations are from Scotland Yard. The single rose is from.. ‘W’.. And the black wreaths? C-block Pentonville (prison). I’m not sure the intent was entirely kindly.”

(Fun fact: White carnations = pure love, good luck. Black wreaths = death. Many more shades of carnations appear in the scene, though white is the most common, next to pink. The pink carnation was said to have appeared because of the Virgin Mary’s tears, a symbol of a mother’s undying love- it’s no wonder it’s a Mother’s Day flower meant to say “I will never forget you“. It also is a flower of support. [Info from: Teleflora ... and Google])

Flip the letter upside down and increase contrast levels:

Invert the colors:

A chess piece with a skull on it and something that can be described as a lock(?) above it. The letter W has turned into a perfect blue M.
(Blue and red in the series has been used as a way to imply inverse or alterations, especially when it comes to Sherlock’s poster, and sometimes locations within his mind palace. Curtains within John’s home [or therapist’s office?..that office changes a lot too, to be honest,] in season 4 turn red, when before they had been blue.)

Mary in the Abominable Bride opens a letter from Mycroft saying, “Immediately.” It’s from Mycroft because later, as she sneaks with Sherlock and John to catch the Emelia Ricoletti culprits, she admits that she works with Mycroft and that he summoned her.
A rose and letter from Mycroft after Sherlock is stabbed by Rosamund/Mary? Interesting.
In the modern letter it’s hard to tell whether the chess piece is a standard queen or bishop piece.
This brings us back to the controversy surrounding season 4 promotional pictures, which apparently were copyrighted and declared as ‘leaks’, because they reveal important spoiler information.
It’s not quite known what the spoiler is, but the implication is enough for mystery.

In this picture, we see two bishops upended along with pawns, flying towards the camera.
“The bishop’s predecessor in medieval chess, shatranj (originally chaturanga), was the alfil, meaning “elephant”, which could leap two squares along any diagonal, and could jump over an intervening piece.” - Wikipedia
We can now say that the letter’s chess piece is most likely a bishop, as it very well references to a reoccurring symbol: The elephant [in the room].
Symbolically or literally an elephant has been hidden in rooms, for example on Mrs. Hudson as a necklace, in the back of the 221B room, and within John’s blog and Sherlock’s best man speech using The Elephant in the Room as a good tale. The symbol can refer to an obvious issue that John and Sherlock choose to ignore, perhaps their feelings towards each other (if you’re a johnlocker).
If you want to further analyze, the remaining pieces standing on the board is two opposing knights, with Mycroft’s king and his two pawns.
Knights: “Colloquially it is sometimes referred to as a "horse", which is also the translation of the piece's name in several languages. Some languages refer to it as the "jumper", reflecting the knight's ability to move over pieces in its way.“ - Wikipedia
John may be the “jumper”, as Sherlock does refer to John’s jumpers an episode before, in The Sign of Three, when trying to deduce who is the next target of the Mayfly man. If the chess pieces are symbols of people, who if not John would be the knight? John’s presence in this picture raises slight question.
With all this comes the question of: who is Mycroft’s knight? And why do John and Mycroft’s knight oppose one another?
Most of Sherlock’s chess pieces are strewn on the table in front of Mycroft, and Mycroft’s pieces across Sherlock’s side of the table.
Sherlock is either unable to beat his own brother (so close to checkmate), or he’s passing the game onto us in this picture.
Mycroft throughout the series has subtexted queen status.
John at Buckingham Palace, “Are we here to meet the Queen?”

Sherlock - “Apparently”

A painting of the young Queen Elizabeth II, “Queen Regent” by Pietro Annigoni in 1954, hangs behind Mycroft in his office. It’s the only wall decorative in this Sherrinfordian office.

Moriarty’s stealing of the crown jewels could be a reference to gaining control over Mycroft, perhaps through blackmail. We know they communicated inside and outside of Sherlock’s mind palace, at least.
Irene - “Jim Moriarty sends his love.”
Mycroft - “Yes, he’s been in touch. Seems desperate for my attention, which I’m sure can be arranged.”

“And honey, you should see me in a crown.” - Moriarty.
This symbolizes a lot that I’m unsure of. He breaks down a glass wall after writing “Get Sherlock” on it, which I suppose means his barriers keeping him back are no longer there, and he can now become queen. We still don’t know what Irene told him in the beginning of A Scandal in Belgravia, and what could have possibly kept him from killing John and Sherlock at the pool (unless someone does know, please hit me up!)
In the end, Mycroft holds the power of the British government. There’s no explanation for how, besides that Magnussen also held a lot of power and it was through blackmail.
But regardless, Mycroft is most likely queen on the chess board.
Back to the letter W/M in Sherlock’s hospital room, the W/M stands for someone/something.
It’s easier to assume it’s an M, with the chess piece insignia as reference for which way to read the seal. If it is M, and the one Sherlock plays chess/games against is Mycroft and Moriarty, especially as Moriarty in S4 is shown to have worked with him, and oddly has also had a connection with Mary Morstan before John and her ever met.. it can be safe to assume M stands for Mycroft.
Another idea of who it is could be Mary. She did visit Sherlock in the hospital, possibly as one of the first visitors. A rose very well mirrors her true name, Rosamund, as does the wallpaper behind Sherlock when she shot him.

Though this is an overly prepared and symbolic way of giving a ‘ get well’ or ‘don’t tell john’ letter. (If you believe the Extended Mind Palace theory starting from the reversed heart monitor in HLV, this can also mean M is still working behind the scenes while Sherlock is incapacitated)
S4′s connection of all the people who ever pulled the strings of Sherlock’s heart and gave him trouble, find their place and connection to Sherrinford or through Mycroft, the one supposed to be in control of Sherrinford.
Or it may not be so complicated. It may simply be Moriarty’s last goodbye, but if so, who placed the letter and rose there?
Rewind to the skulls.
So many skulls.
Sherlock’s skull poster seems to always remain blue before The Abominable Bride (Correct me if I’m wrong please):

Alas, poor Victor.

Odd glass-ish ball on Mycroft’s desk possibly resembles a skull at certain angles.

Perfectly normal, unusually well-lit poster here.

Stop laughing at me, Mr. Skull. You’ve gone purple, and I’ve never heard of a pirate having a purple flag.


Blue, the shade of TD-12, Mary’s death scene, and lies. Fascinatingly vague information.

Skull picture is blacked out in TLD, while Sherlock is with Culverton at the hospital. Which brings me to realize..
If Sherlock is unconscious, who’s manning the mind palace?
Is him being unconscious in the hospital bed a thing of consciousness awareness? He may still be in the hospital outside of mind palace, after all.
John is often wearing colors that match the Mind Palace skull paintings. John seemed to be subtextually connected with Sherlock’s skulls since the beginning of A Study in Pink where John says about the mantelpiece’s skull, “So I’m a replacement for your skull?” and Sherlock says, “Don’t worry, you’re doing fine.” Sherlock upon John’s first seeing the skull claims that it’s his ‘friend’ of a sort. In Sherlock’s mind palace, after HLV, John may be even more connected to the skulls.
The skull poster is also symmetrically aligned with John’s chair, just as the shifty orange lamp and smiley face is aligned with Sherlock’s chair. The room is rather deliberately a half-n-half of John and Sherlock, John’s side being more green, and Sherlock’s being more beige.
In narration, it always seems to matter who’s sitting on the right or left side of the flat. Clients must sit in the middle while John and Sherlock sit in their respected spots. Moriarty chooses to sit in John’s seat as an act of domination over their balance of things, which can lead us to assume that Sherlock offering his own chair is in an ode of respect towards John rather than Moriarty. Which leads me to believe the placement of the skull poster (and smiley face), is even more correlated with John’s place in the Mind Palace.
During Mary’s frankly unreal monologue at the end of The Final Problem, we see the skull picture again, purple/gray and appearing very dark, digital and coded. It’s a sign that things aren’t finish yet.
I may edit this bit later if I notice anything else.
Interesting post regarding the skull poster by @the-7-percent-solution
(to those tagged, please let me know if you want me to uncredit!)
(Gradually migrating Sherlock posts from this blog to @all-is-v-57)
#Sherlock#Sherlock Spoilers#BBC#MyPosts#Martin Freeman#Benedict Cumberbatch#Skulls#theories#EMP#Johnlock#I have so many drafts- Sherlock's making me crazy#Charles Augustus Magnussen#John Watson#Sherlock Holmes#theory#S1 S2 S3 S4#Jim Moriarty#Mary Morstan#Mycroft Holmes#His Last Vow#HLV#The Final Problem#TFP#The Abominable Bride#TAB#S!theories#S!theory#Stheory#Long posts#longpost
10 notes
·
View notes
Text
Risk and Return Assignments Help
New Post has been published on https://qualityassignmenthelp.com/risk-and-return-assignments-help/
Risk and Return Assignments Help

Risk and return is considered most important topic in finance and investment. The first thing that need to understand in this topic is return income. Income received on an investment plus any change in market price is known as return income. This is the formula of return income.
Where D1 = Dividend
Pt = original price
Pt-1 = Current price
Let’s suppose if a have security original price is $ 100 and the current price is $110. The dividend received on the stock is $ 2. An investor calculates return income through the following procedure.
D1 = Dividend = 2
Pt = original price = 100
Pt-1 = Current price = 110
Put all values in formula
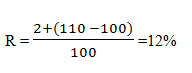
For instance, the important thing is return income is always in a percentage form.
Let’s if a security current trading price is $ 96 and its original price is $100. The dividend received on a stock is $ 4. Calculate the return income of that particular security.
D1 = Dividend = 4
Pt = original price = 100
Pt-1 = Current price = 96
Put all values in formula

Risk:
A finance expert defines risk as the variance among the actual and expected return. In simple words, the risk is uncertainty about the future. For example, there are two securities Omega and Nike. The expected returns on Omega and Nike as follows.
Omega Nike
10% 6%
16% 5%
8% 7%
6% 5%
18% 7%
Above all, the risk probability is higher in Omega security. Because there are more variations in Omega.
Probability:
Occurrence chance of any event or chance of happening is called probability. Occurrence is the basic outcome of an experiment. For example, if we toss a coin there are two occurrences, and if we throw a die there should be six occurrences.
Probability Distribution:
It is a statistical function that defines all probable values and chances that a random variable can take within a given range. In simple words, the Chances of random variables is called probability distribution.
For example
10%
5%
10%
40%
20%
Expected return:
The weighted average of possible returns, with weights being the probabilities occurrence is called expected return. The formula of expected return is as follows
Expected return = Possible return × Probabilities
Here we assume some possible returns and probabilities and try to calculate expected returns.
Possible Returns Probabilities = Ṝ
10% 0.40 = 0.04
5% 0.40 = 0.02
11% 0.20 = 0.022
0.082
So, there is an 8.2% expected return.
Standard Deviation:
It is a static measure of the variability of distribution around its mean. It is the square root of the variance. Therefore, we find standard deviation with the help of this formula.
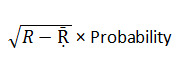
Co-efficient of Variance:
It is a statistical measure of the dispersion of the points around the mean. The co-efficient of variance determines the risk involved in a single expected unit. In other words, it is measure relative risk. We calculated the coefficient of variance in the following ways.
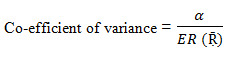
Certainty equivalent:
The amount of cash or equivalent somebody would require. The inevitability at a point in time to make individual indifferent between that certain amount. The expected amount is to be received with risk at the same point in time.
Risk-averse:
The term risk averse applied on an investor who requires might be a lower expected return, bearing with lower risk. In vice versa, if investor bears high risk than he should also demand for high return. This also follows an investment rule of thumb, “high risk and high profit”.
Portfolio:
A combination of different securities is called a portfolio. From a finance point of view, a combination of securities means a combination of assets, securities, bonds, etc. Investors construct portfolios according to their risk tolerance and investing objectives. Therefore, a portfolio is like a pie which is further divided into different size and nature of pieces.
Single Security Return calculate =
E(R) = R Pr. + R Pr. + R Pr.
E (R) = M∑ RjPr.j
Where = (E) R = expected return
R Pr. = Return probability
Portfolio return calculate =
E(Rp) = Wa(E)Ra + WBE(R)b + WcE(Rc) + WdE(Rd)
E (Rp) = n∑ Wi E (Ri)
Where:
E(Rp) = Expected return of portfolio
W = weight of security
Types of risk:
As we already discussed above that risk is uncertainty about the future. Generally, there are two types of risk considers in finance.
Systematic risk:
It is part of the total risk that is cause by different factors. These factors are not in the control to any specific individual, and a company. This is cause by external factors and not controllable for a firm. This risk exists on all assets, stocks, and securities. As a result, we call them non-diversified risk. It is not possible to eliminate this risk through efficient diversification of a portfolio. The common example of systematic risk is changes in tax laws, market risk, purchasing power risk, exchange rate risk, natural disasters, and security situations, etc.
Unsystematic risk:
The systematic risk is also known as diversified risk. It is the risk of a specific firm, industry. This risk can be eliminated through the efficient use of resources, better management, and diversification of a portfolio. For example one of the prestigious textile organization is working as usual. But suddenly due to some misunderstandings, or something else, the staff go to strike. Now, this is an unplanned risk, happen suddenly and also causes widespread disruption. The stock prices of this textile organization should fall due to this strike. But still, this is controllable through dialogue and well handling. So, we may call this risk as unsystematic risk.
Diversification:
Diversification is the process to manage investment in a well-organized way. Invest in different sectors instead of anyone to eliminate and minimize the risk. In diversification, an investor invests in different sectors with different weights.
Capital asset pricing model (CAPM):
The capital asset pricing model is the relationship between expected risk and expected return based on the market beta. CAPM shows that the expected return on a stock. In addition, expected return is the combination of risk-free return risk premium. The risk premium is based on the beta of that stock. The formula of CAPM is given below.
Ra = Rf + [× (Rm – Rrf)]
Where:
Ra = Expected return on a stock
Rf = Risk-free rate
Ba = Beta of security
Rm = Expected market return
Risk Premium = Rm – Rf
Question No. 1:
Use capital asset pricing model (CAPM) to estimate the expected return for the shares of
(i) your case company Nick Scali (NCK)
(ii) a hypothetical company with a beta of 1.60. When calculating, use the yield to maturity of a 10-year Australian Government bond on 1 April 2020 as a proxy for the risk-free rate (RF), suppose the market risk premium is 5.50% and use your case company’s most recent 5-year beta.
(iii) Using the data from part (ii). Estimate portfolio expected return and beta. Assuming a portfolio with 70% invested in your case company. The remainder invested in the hypothetical company
Unlock free of cost solution of this question on quality assignment help sample page click here
Question No. 2:
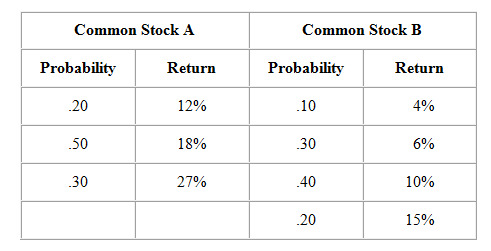
(a) Friedman Manufacturing, Inc. has prepared the following information regarding two investments under consideration. Which investment is better, based on risk (as measured by the standard deviation) and return?
(b) “ More can be said about risk, especially as to its nature, when we own more than one asset in our investment portfolio.” Define risk and explain how risk is affected if we diversify our investment by holding a variety of securities?
Unlock free of cost solution of this question on quality assignment help sample page click here
If you still have any confusion regarding any financial help, please don’t hesitate to contact us. Quality assignment help experts are ready to help you. Click here
#Finance assignments help#Finance Dissertation help#Finance-Homework help#Fundamental finance help#Portfolio Management Assignment Help#Quality assignments help#Assignment#Finance Homework Help
0 notes
Text
CSC2402 | ASSIGNMENT 1 FIVE TASKS LINUX
New Post has been published on https://punjabassignmenthelp.com/csc2402-assignment-1-five-tasks-linux/
CSC2402 | ASSIGNMENT 1 FIVE TASKS LINUX
CSC2402 | ASSIGNMENT 1 FIVE TASKS LINUX | LINUX
COMPUTER ASSIGNMENT HELP
Assignment 1 consists of five tasks. For each task, you have to submit a .cpp file and a documentation file. The .cpp file should have the program code and short comments (one line or two) about the algorithm and the coding. We may compile the .cpp files using MinGW 4.7.1 if required. The documentation files should contain the compilation messages and sample runs for each program. All files must be in pure text format. No PDF, HTML, Word files, Open Office files, RTF etc. You will submit a single ZIP file (not RAR) which has all the files for your assignment (the .cpp files and the documentation files).
If you are using Codelite, the compilation messages can be copied and pasted with the usual crtl-c and crtl-v. For output of sample runs, right click the title bar of the command window, select EDIT/MARK and then highlight the output. With the output selected, right click the title bar of the command window, select EDIT/COPY. Position your cursor to a (new) text file opened in a text editor such as Notepad, and crtl-v will paste the copied output to the text file.
If you are using MinGW, right click the title bar of the command window; select EDIT/MARK and then high light the output. With the output selected, right click the title bar of the command window, select EDIT/COPY. Position your cursor to a (new) text file opened in a text editor such as Notepad, and crtl-v will paste the copied output to the text file.
If you are using Linux, you can cut and paste the output on the terminal window into a text such as vim.
Name the files as task_1_1.cpp, task_1_2.cpp, task_1_3.cpp, task_1_4.cpp, task_1_5.cpp, task_1_1.txt and task_1_2.txt, task_1_3.txt, task_1_4.txt and task_1_5.txt.
Other files you should download:
cpp
cpp
cpp
cpp
cpp
Background information
Structure
Structure is one way to bundle data together in C++.
Suppose we want to manipulate a group of related data: name, age and salary of a person. We can create a data type (structure) called Person as shown in sample_structure.cpp.
#include <iostream>
using namespace std;
int main()
struct Person
string name;
int age;
double salary;
;
Person Peter; // Similar to string Peter;
Peter.name = “Peter the Great”; // dot refers to member name
Peter.age = 44;
Peter.salary = 44.44;
cout << Peter.name << ” is ” << Peter.age
” and salary is $” << Peter.salary << endl; return 0;
Pointers
We can pass parameters by value or by reference. There is a third way, by pointer (reference) which works in a similar fashion as passing by reference. When passed by value, a copy is passed and the original data is not changed by the function call. Passing by pointer / reference allows the called function to modify the original value of the variable passed. Sample_passing.cpp illustrates the cases. See textbook chapter 7, section 7.1 to 7.3 for more details.
#include <iostream>
using namespace std;
void funct1(int);
void funct2(int&);
void funct3(int*);
int main()
int n = 100; // integer
int * iptr1; // pointer
int * iptr2;
100 will be printed cout << n << endl;
address of int is a pointer to the same int iptr1 = &n;
value pointed at by iptr will be printed cout << *iptr1 << endl;
create an unnamed int and point to it with iptr2 iptr2 = new int(300);
cout << *iptr2 << endl;
pass by value, 101 will be printed
funct1(n);
n not changed, 100 will be printed cout << n << endl;
pass by reference, 101 will be printed funct2(n);
n changed, 101 will be printed
cout << n << endl;
pass by pointer (reference), 301 will be printed funct3(iptr2);
n changed, 301 will be printed
cout << *iptr2 << endl;
return 0;
void funct1(int i)
i += 1;
cout << “Inside funct1, i = ” << i << endl;
the ‘&’ appearing after the parameter type indicates
that it is passed by reference
void funct2(int& i)
same as pass by value i += 1;
cout << “Inside funct1, i = ” << i << endl;
void funct3(int* i)
*i += 1; // *i instead of i
cout << “Inside funct1, i = ” << *i << endl;
<ctime> library
C++ provides a date-time library <ctime> for handling date-time. You can get the system date-time using the library function time() which returns the current calendar time. We can break down the calendar time to different date-time components using localtime() which returns local date-time information in a date-time structure.
Date-time structure:
struct tm
int tm_sec // seconds; 0-59 int tm_min // minutes; 0-59 int tm_hour // hour of the day; 0-23 int tm_mday // day of month; 1-31 int tm_mon // month since January; 0-11 int tm_year // year since 1900; int tm_wday // day of week; 0-6 (Sun, … Sat) int tm_yday // day since 1 January; 0-365 int tm_isdst // daylight saving status; // > 0 if operational; // == 0 not operational; // < 0 no information available.
We can retrieve any one of the date-time structure member using strftime(). Options for strftime()
and the range of returned values:
Option Returned value Range of returned value a Abbreviated weekday Thu A Full weekday Thursday b Abbreviated month Aug B Full month name August c Local date and time Thu Aug 23 13:33:02 2017 d Day of month 01-31 H Hour 00-23 I Hour 01-12 j Day of the year 001-366 m Month 01-12 M Minute 00-59 p AM or PM PM S Second 00-59 U U week number of the year; 00-53 Sunday as first day of week w Weekday 0-6, Sunday is 0 W Week number of the year; 00-53 Monday as first day of week x Local date representation 02/23/17 X Local time representation 14:45:02 y Year without century 00-99 Y Year with century 2017 Z Time zone (100 = 1 hour) +100
Sample_time_A.cpp illustrates the use of the library functions to get the current time:
#include <iostream>
#include <ctime>
using namespace std;
int main()
calendar time time_t rawtime;
get the current calendar time time( &rawtime );
date-time structure pointer struct tm *timeinfo;
break the calendar time to components timeinfo = localtime ( &rawtime );
retrieve individual date-time structure members
using option “%a” and option “%A”.
char ans_abr[40]; // Character array
char ans_full[40];
strftime(ans_abr, 40, “%a”, timeinfo);
strftime(ans_full, 40, “%A”, timeinfo);
view the formatted date-time structure member values cout << ” Abbreviated weekday name: ” << ans_abr << endl;
cout << ” Full weekday name: ” << ans_full << endl; return 0;
We can also create a date-time structure using our own year, day, month, hour, minute and second information. Before we can use it as a valid date-time structure, we have to call mktime() to adjust other members of the date-time structure to make it valid. Sample_time_B.cpp illustrates the use of the library functions to specify a time
#include <iostream>
#include <ctime>
using namespace std;
int main()
date-time structure struct tm tmStruct; int y = 2013;
int m = 4; // April int d = 1; // my lucky day int h = 14; // 2 pm int min = 30; // half past int s = 3; // who cares?
initialize/modify the date-time structure
tmStruct.tm_year = y – 1900; // Legacy problem
tmStruct.tm_mon = m – 1; // month starts from 0 not 1
tmStruct.tm_mday = d;
tmStruct.tm_hour = h-1;
tmStruct.tm_min = min-1;
tmStruct.tm_sec = s-1;
call mktime() to adjust other members of tmStruct mktime ( &tmStruct );
using option “%a” and option “%A”.
char ans_localtime[40]; // Character array char ans_full[40];
strftime(ans_localtime, 40, “%c”, &tmStruct); strftime(ans_full, 40, “%A”, &tmStruct);
view the formatted date-time structure member values cout << “Local date time is: ” << ans_localtime << endl; cout << ” Full weekday name: ” << ans_full << endl; return 0;
Task 1 (15 marks)
Write a C++ program that is to be used for a local taxi fare calculation. The rules regarding the calculations are as follows. (Note: American spelling for Kilometer in specification)
The fare is calculated based on distance travelled and time taken to travel the distance.
The services charges $2.00 for the first 2 kilometre of travel (even if you are under 2 kilometers). After the first 2 kilometers the services charges $0.50 cents for each additional kilometer up to additional 6 kilometers. After those 6 kilometers the customer is charged a $1.00 for each additional kilometers
At the end of the ride, a fee of $0.20 cents is charged based on the total minutes travel time.
The total fare is the journey cost added to the travel time cost.
The application is then to print out a personalised invoice for the journey as specified below.
Your application needs to display a prompt for information to be inputted by the user.
Input from the keyboard is for whole numbers only (int).
C:>task_1_1
Please enter your name: Peter Johnson
Please enter distance travelled as km: 12
Please enter duration of journey in minutes: 16
Hello, Peter!
Your journey of 12 kilometers and 16 minutes comes to $12.20
Travel cost $9.00 for distance of 12 kilometers Time cost $3.20 for 16 minutes travel time.
C:>task_1_1
Please enter your name: Green Pumpkin
Please enter distance travelled as km: 1
Please enter duration of journey in minutes: 13
Hello, Green!
Your journey of 1 kilometers and 13 minutes comes to $4.60
Travel cost $2.00 for distance of 1 kilometers Time cost $2.60 for 13 minutes travel time.
C:>task_1_1
Please enter your name: Tom Green
Please enter distance travelled as km: 21
Please enter duration of journey in minutes: 8
Hello, Tom!
Your journey of 21 kilometers and 8 minutes comes to $19.60
Travel cost $18.00 for distance of 21 kilometers Time cost $1.60 for 8 minutes travel time.
User will be able to enter names with multiple words. Your code should be able to capture names consisting of any number of words (hundreds, at least). You should record the compilation message(s) even though there may be none. Run the program as shown in the sample runs. Put all compilation messages and sample run outputs in task_1_1.txt.
Marking Criteria Marks Program can only handle multiple-word names 1 Program calculates journey cost correctly 3 Program calculates time cost correctly 2 Program displays the messages correctly 3 Code factored into functions for reuse 5 Compilation messages and sample run outputs (if the program runs correctly) 1
Task 2 (15 marks)
Write a C++ program task_1_2.cpp which prompts for an integer, validate the integer, and if not valid, ask again till a valid integer is entered. Repeat for another five integers with different validation criteria.
Your solution source code is to be only the main() function. The whole logic for the solution needs to reside in the main routine.
Sample outputs are:
C:> a Please enter the year: 2013 Please enter the month: 1 Please enter the day: 24 Please enter the hour: 13 Please enter the minute: 55 Please enter the second: 45 Your inputs are: Year = 2013 Month = 1 Day = 24 Hour = 13 Minute = 55 Second = 45 C:>a Please enter the year: 1969 1970 <= Year <= 2020! Please enter the year: 2034 1970 <= Year <= 2020! Please enter the year: Hello and bye 1970 <= Year <= 2020! Please enter the year: 2013 Please enter the month: 0 1 <= Month <= 12! Please enter the month: 13 1 <= Month <= 12! Please enter the month: Hello and bye 1 <= Month <= 12! Please enter the month: 1 Please enter the day: 0 1 <= Day<= 31! Please enter the day: 32 1 <= Day<= 31! Please enter the day: Hello and bye 1 <= Day<= 31! Please enter the day: 24 Please enter the hour: -1 0 <= Hour<= 23! Please enter the hour: 24 0 <= Hour<= 23! Please enter the hour: Hello and bye 0 <= Hour<= 23! Please enter the hour: 13 Please enter the minute: -1 0 <= Minute <= 59! Please enter the minute: 60 0 <= Minute <= 59! Please enter the minute: Hello and bye
0 <= Minute <= 59!
Please enter the minute: 30
Please enter the second: -1
1 <= Second<= 59!
Please enter the second: 60
1 <= Second<= 59!
Please enter the second: Hello and bye 1 <= Second<= 59!
Please enter the second: 35
Your inputs are:
Year = 2013
Month = 1
Day = 24
Hour = 13
Minute = 30
Second = 35
The name of the six integers and their validation criteria are shown below:
Name Criteria year 1970 <= year <= 2020 month 1 <= month <= 12 day 1 <= day <= 31 hour 0 <= hour <= 23 min 0 <= min <= 59 sec 0 <= sec <= 59
You should record the compilation message(s) even though there may be none. Run the program as shown in the sample runs. Put all compilation messages and sample run outputs in task_1_2.txt.
Marking Criteria Marks Data input 1 Data validation 3 Looping for a correct input 4 Handle error input with appropriate output message 4 Solution uses main function only for the code 2 Compilation messages and sample run outputs (if the program runs correctly) 1
Task 3 (20 marks)
Write second version of Task 2 where you reflector the code to use functions as specified below.
Your code in Task 2 for entering each integer is the same except the prompts, variable names and the validation criteria.
Group the code for entering an integer to form a function void get_data(). The parameters for the function void get_data()are:
the prompt for user input;
the prompt for correct range of input;
integer variable used to store the user input;
criteria 1 – input should be smaller than or equal to this value; criteria 2 – input should be greater than or equal to this value;
void get_data() returns control to caller only when the input data is valid.
Write a C++ program task_1_3.cpp calls get_data() to get 6 valid integers. The validation criteria and sample output should be the same as shown in Task 2.
You should record the compilation message(s) even though there may be none. Run the program as shown in the sample runs for task 2. Put all compilation messages and sample run outputs in task_1_3.txt.
Marking Criteria Marks Function declaration 4 Function definition 7 Parameter passing to functions 7 Looping for correct input 1 Compilation messages and sample run outputs (if the program runs correctly) 1
Task 4 (20 marks)
Write a C++ program task_1_4.cpp which uses a function void get_option(some_parameter) to get user input for a char option. The char must be an alphanumeric character i.e. alphabets and digits. If the input is not valid, void get_option() will be called until a valid user input is obtained.
The validated option will then be used as a parameter in calling a function string test(). Function string test() will display different strings according to the value of option.
Value of option can only be:
a digit (use isdigit(char) in <cctype>)
o char option = ‘1’; isdigit(option) will return true;
char option = ‘a’; isdigit(option) will return false; a lower case letter (use islower(char) in <cctype>)
o char option = ‘a’; islower(option) will return true;
char option = ‘A’; islower(option) will return false; an upper case letter (use isupper(char) in <cctype>)
o char option = ‘A’; isupper(option) will return true; o char option = ‘1’; isupper(option) will return false;
test() is shown below:
string test(char option)
if (isupper(option)) return “An upper case letter is entered!”;
if (islower(option)) return “A lower case letter is entered!”;
return “A digit is entered!”;
Sample outputs:
C:>a
Please enter an alphanumeric char: &
Please enter an alphanumeric char: (
Please enter an alphanumeric char: ?
Please enter an alphanumeric char: 2
A digit is entered!
C:>a
Please enter an alphanumeric char: a
A lower case letter is entered!
C:>a
Please enter an alphanumeric char: A
An upper case letter is entered!
You should record the compilation message(s) even though there may be none. Run the program as shown in the sample runs shown above. Put all compilation messages and sample run outputs in task_1_4.txt.
Marking Criteria Marks Function declaration 4 Function definition 5 Passing parameters 5 Looping for correct input 1 Calling test() 4 Compilation messages and sample run outputs (if the program runs correctly) 1
Task 5 (30 %)
Compile and run sample_5.cpp. Study the program alongside with the output and make sure you understand how to use the time library functions.
Write a C++ program which:
Prompts user for inputting his name consisting of multiple words;
Prompts user for inputting valid int year, int month, int day, int hour, int minute, int second.
o The validation criteria is the same as in task 2.
Prompts user to input 4 options for calls to get_string_component() .
Option can only be one of the following: a abbreviated weekday
A full weekday
b abbreviated month B full month
c local date and time d day of month (01-31) H hour (00-23)
I hour (1-12)
j day of the year (001-366) m month (01-12)
M minute (00-59) p Am or PM
S second (00-59)
U week numberof the year (00-53); Sunday as first day of week
w weekday (0-6, Sunday is 0)
W week numberof the year (00-53);
Monday as first day of week
x local date
X local time
year without century (00-99) Y year with century
Z time zone.
Constructs a date-time structure with the date time information just entered;
Outputs user name, local time, abbreviated weekday, and the day of the year for the date-time using the user name and appropriate options (‘c’, ‘a’, ‘j’, ‘Y’) for get_string_component().
Sample output:
C:work_directoryCSC2402S1_2013assignmentS1_
Please enter your name: Peter Johnson Junior
Please enter the year: 2013
Please enter the month: 1
Please enter the day: 24
Please enter the hour: 2
Please enter the minute: 4
Please enter the second: 6
Please enter your first option: c
Please enter your second option: a
Please enter your third option: j
Please enter your fourth option: Y
You should record the compilation message(s) even though there may be none. Run the program as shown in the sample runs shown above. Put all compilation messages and sample run outputs in task_1_5.txt.
Marking Criteria Marks Get user name using function call 1 Get date-time information using function call 1 Get options using function call 1 Date-time structure 6 Get localtime, weekday, days of the year 6 Correct Output 5 Compilation messages and sample run outputs (if the program runs correctly) 10
Punjab Assignment Help
Buy Online Assignment Help services for COMPUTER ASSIGNMENT with Punjab Assignment Help at [email protected]
0 notes
Text
Risk and Return Assignments Help
New Post has been published on https://qualityassignmenthelp.com/risk-and-return-assignments-help/
Risk and Return Assignments Help

Risk and return is considered most important topic in finance and investment. The first thing that need to understand in this topic is return income. Income received on an investment plus any change in market price is known as return income. This is the formula of return income.
Where D1 = Dividend
Pt = original price
Pt-1 = Current price
Let’s suppose if a have security original price is $ 100 and the current price is $110. The dividend received on the stock is $ 2. An investor calculates return income through the following procedure.
D1 = Dividend = 2
Pt = original price = 100
Pt-1 = Current price = 110
Put all values in formula

For instance, the important thing is return income is always in a percentage form.
Let’s if a security current trading price is $ 96 and its original price is $100. The dividend received on a stock is $ 4. Calculate the return income of that particular security.
D1 = Dividend = 4
Pt = original price = 100
Pt-1 = Current price = 96
Put all values in formula

Risk:
A finance expert defines risk as the variance among the actual and expected return. In simple words, the risk is uncertainty about the future. For example, there are two securities Omega and Nike. The expected returns on Omega and Nike as follows.
Omega Nike
10% 6%
16% 5%
8% 7%
6% 5%
18% 7%
Above all, the risk probability is higher in Omega security. Because there are more variations in Omega.
Probability:
Occurrence chance of any event or chance of happening is called probability. Occurrence is the basic outcome of an experiment. For example, if we toss a coin there are two occurrences, and if we throw a die there should be six occurrences.
Probability Distribution:
It is a statistical function that defines all probable values and chances that a random variable can take within a given range. In simple words, the Chances of random variables is called probability distribution.
For example
10%
5%
10%
40%
20%
Expected return:
The weighted average of possible returns, with weights being the probabilities occurrence is called expected return. The formula of expected return is as follows
Expected return = Possible return × Probabilities
Here we assume some possible returns and probabilities and try to calculate expected returns.
Possible Returns Probabilities = Ṝ
10% 0.40 = 0.04
5% 0.40 = 0.02
11% 0.20 = 0.022
0.082
So, there is an 8.2% expected return.
Standard Deviation:
It is a static measure of the variability of distribution around its mean. It is the square root of the variance. Therefore, we find standard deviation with the help of this formula.

Co-efficient of Variance:
It is a statistical measure of the dispersion of the points around the mean. The co-efficient of variance determines the risk involved in a single expected unit. In other words, it is measure relative risk. We calculated the coefficient of variance in the following ways.

Certainty equivalent:
The amount of cash or equivalent somebody would require. The inevitability at a point in time to make individual indifferent between that certain amount. The expected amount is to be received with risk at the same point in time.
Risk-averse:
The term risk averse applied on an investor who requires might be a lower expected return, bearing with lower risk. In vice versa, if investor bears high risk than he should also demand for high return. This also follows an investment rule of thumb, “high risk and high profit”.
Portfolio:
A combination of different securities is called a portfolio. From a finance point of view, a combination of securities means a combination of assets, securities, bonds, etc. Investors construct portfolios according to their risk tolerance and investing objectives. Therefore, a portfolio is like a pie which is further divided into different size and nature of pieces.
Single Security Return calculate =
E(R) = R Pr. + R Pr. + R Pr.
E (R) = M∑ RjPr.j
Where = (E) R = expected return
R Pr. = Return probability
Portfolio return calculate =
E(Rp) = Wa(E)Ra + WBE(R)b + WcE(Rc) + WdE(Rd)
E (Rp) = n∑ Wi E (Ri)
Where:
E(Rp) = Expected return of portfolio
W = weight of security
Types of risk:
As we already discussed above that risk is uncertainty about the future. Generally, there are two types of risk considers in finance.
Systematic risk:
It is part of the total risk that is cause by different factors. These factors are not in the control to any specific individual, and a company. This is cause by external factors and not controllable for a firm. This risk exists on all assets, stocks, and securities. As a result, we call them non-diversified risk. It is not possible to eliminate this risk through efficient diversification of a portfolio. The common example of systematic risk is changes in tax laws, market risk, purchasing power risk, exchange rate risk, natural disasters, and security situations, etc.
Unsystematic risk:
The systematic risk is also known as diversified risk. It is the risk of a specific firm, industry. This risk can be eliminated through the efficient use of resources, better management, and diversification of a portfolio. For example one of the prestigious textile organization is working as usual. But suddenly due to some misunderstandings, or something else, the staff go to strike. Now, this is an unplanned risk, happen suddenly and also causes widespread disruption. The stock prices of this textile organization should fall due to this strike. But still, this is controllable through dialogue and well handling. So, we may call this risk as unsystematic risk.
Diversification:
Diversification is the process to manage investment in a well-organized way. Invest in different sectors instead of anyone to eliminate and minimize the risk. In diversification, an investor invests in different sectors with different weights.
Capital asset pricing model (CAPM):
The capital asset pricing model is the relationship between expected risk and expected return based on the market beta. CAPM shows that the expected return on a stock. In addition, expected return is the combination of risk-free return risk premium. The risk premium is based on the beta of that stock. The formula of CAPM is given below.
Ra = Rf + [× (Rm – Rrf)]
Where:
Ra = Expected return on a stock
Rf = Risk-free rate
Ba = Beta of security
Rm = Expected market return
Risk Premium = Rm – Rf
Question No. 1:
Use capital asset pricing model (CAPM) to estimate the expected return for the shares of
(i) your case company Nick Scali (NCK)
(ii) a hypothetical company with a beta of 1.60. When calculating, use the yield to maturity of a 10-year Australian Government bond on 1 April 2020 as a proxy for the risk-free rate (RF), suppose the market risk premium is 5.50% and use your case company’s most recent 5-year beta.
(iii) Using the data from part (ii). Estimate portfolio expected return and beta. Assuming a portfolio with 70% invested in your case company. The remainder invested in the hypothetical company
Unlock free of cost solution of this question on quality assignment help sample page click here
Question No. 2:
(a) Friedman Manufacturing, Inc. has prepared the following information regarding two investments under consideration. Which investment is better, based on risk (as measured by the standard deviation) and return?

(b) “ More can be said about risk, especially as to its nature, when we own more than one asset in our investment portfolio.” Define risk and explain how risk is affected if we diversify our investment by holding a variety of securities?
Unlock free of cost solution of this question on quality assignment help sample page click here
If you still have any confusion regarding any financial help, please don’t hesitate to contact us. Quality assignment help experts are ready to help you. Click here
#Finance assignments help#Finance Dissertation help#Finance-Homework help#Fundamental finance help#Portfolio Management Assignment Help#Quality assignments help#Assignment#Finance Homework Help
0 notes
Text
CSC2402 | ASSIGNMENT 1 FIVE TASKS LINUX
New Post has been published on https://punjabassignmenthelp.com/csc2402-assignment-1-five-tasks-linux/
CSC2402 | ASSIGNMENT 1 FIVE TASKS LINUX
CSC2402 | ASSIGNMENT 1 FIVE TASKS LINUX | LINUX
COMPUTER ASSIGNMENT HELP
Assignment 1 consists of five tasks. For each task, you have to submit a .cpp file and a documentation file. The .cpp file should have the program code and short comments (one line or two) about the algorithm and the coding. We may compile the .cpp files using MinGW 4.7.1 if required. The documentation files should contain the compilation messages and sample runs for each program. All files must be in pure text format. No PDF, HTML, Word files, Open Office files, RTF etc. You will submit a single ZIP file (not RAR) which has all the files for your assignment (the .cpp files and the documentation files).
If you are using Codelite, the compilation messages can be copied and pasted with the usual crtl-c and crtl-v. For output of sample runs, right click the title bar of the command window, select EDIT/MARK and then highlight the output. With the output selected, right click the title bar of the command window, select EDIT/COPY. Position your cursor to a (new) text file opened in a text editor such as Notepad, and crtl-v will paste the copied output to the text file.
If you are using MinGW, right click the title bar of the command window; select EDIT/MARK and then high light the output. With the output selected, right click the title bar of the command window, select EDIT/COPY. Position your cursor to a (new) text file opened in a text editor such as Notepad, and crtl-v will paste the copied output to the text file.
If you are using Linux, you can cut and paste the output on the terminal window into a text such as vim.
Name the files as task_1_1.cpp, task_1_2.cpp, task_1_3.cpp, task_1_4.cpp, task_1_5.cpp, task_1_1.txt and task_1_2.txt, task_1_3.txt, task_1_4.txt and task_1_5.txt.
Other files you should download:
cpp
cpp
cpp
cpp
cpp
Background information
Structure
Structure is one way to bundle data together in C++.
Suppose we want to manipulate a group of related data: name, age and salary of a person. We can create a data type (structure) called Person as shown in sample_structure.cpp.
#include <iostream>
using namespace std;
int main()
struct Person
string name;
int age;
double salary;
;
Person Peter; // Similar to string Peter;
Peter.name = “Peter the Great”; // dot refers to member name
Peter.age = 44;
Peter.salary = 44.44;
cout << Peter.name << ” is ” << Peter.age
” and salary is $” << Peter.salary << endl; return 0;
Pointers
We can pass parameters by value or by reference. There is a third way, by pointer (reference) which works in a similar fashion as passing by reference. When passed by value, a copy is passed and the original data is not changed by the function call. Passing by pointer / reference allows the called function to modify the original value of the variable passed. Sample_passing.cpp illustrates the cases. See textbook chapter 7, section 7.1 to 7.3 for more details.
#include <iostream>
using namespace std;
void funct1(int);
void funct2(int&);
void funct3(int*);
int main()
int n = 100; // integer
int * iptr1; // pointer
int * iptr2;
100 will be printed cout << n << endl;
address of int is a pointer to the same int iptr1 = &n;
value pointed at by iptr will be printed cout << *iptr1 << endl;
create an unnamed int and point to it with iptr2 iptr2 = new int(300);
cout << *iptr2 << endl;
pass by value, 101 will be printed
funct1(n);
n not changed, 100 will be printed cout << n << endl;
pass by reference, 101 will be printed funct2(n);
n changed, 101 will be printed
cout << n << endl;
pass by pointer (reference), 301 will be printed funct3(iptr2);
n changed, 301 will be printed
cout << *iptr2 << endl;
return 0;
void funct1(int i)
i += 1;
cout << “Inside funct1, i = ” << i << endl;
the ‘&’ appearing after the parameter type indicates
that it is passed by reference
void funct2(int& i)
same as pass by value i += 1;
cout << “Inside funct1, i = ” << i << endl;
void funct3(int* i)
*i += 1; // *i instead of i
cout << “Inside funct1, i = ” << *i << endl;
<ctime> library
C++ provides a date-time library <ctime> for handling date-time. You can get the system date-time using the library function time() which returns the current calendar time. We can break down the calendar time to different date-time components using localtime() which returns local date-time information in a date-time structure.
Date-time structure:
struct tm
int tm_sec // seconds; 0-59 int tm_min // minutes; 0-59 int tm_hour // hour of the day; 0-23 int tm_mday // day of month; 1-31 int tm_mon // month since January; 0-11 int tm_year // year since 1900; int tm_wday // day of week; 0-6 (Sun, … Sat) int tm_yday // day since 1 January; 0-365 int tm_isdst // daylight saving status; // > 0 if operational; // == 0 not operational; // < 0 no information available.
We can retrieve any one of the date-time structure member using strftime(). Options for strftime()
and the range of returned values:
Option Returned value Range of returned value a Abbreviated weekday Thu A Full weekday Thursday b Abbreviated month Aug B Full month name August c Local date and time Thu Aug 23 13:33:02 2017 d Day of month 01-31 H Hour 00-23 I Hour 01-12 j Day of the year 001-366 m Month 01-12 M Minute 00-59 p AM or PM PM S Second 00-59 U U week number of the year; 00-53 Sunday as first day of week w Weekday 0-6, Sunday is 0 W Week number of the year; 00-53 Monday as first day of week x Local date representation 02/23/17 X Local time representation 14:45:02 y Year without century 00-99 Y Year with century 2017 Z Time zone (100 = 1 hour) +100
Sample_time_A.cpp illustrates the use of the library functions to get the current time:
#include <iostream>
#include <ctime>
using namespace std;
int main()
calendar time time_t rawtime;
get the current calendar time time( &rawtime );
date-time structure pointer struct tm *timeinfo;
break the calendar time to components timeinfo = localtime ( &rawtime );
retrieve individual date-time structure members
using option “%a” and option “%A”.
char ans_abr[40]; // Character array
char ans_full[40];
strftime(ans_abr, 40, “%a”, timeinfo);
strftime(ans_full, 40, “%A”, timeinfo);
view the formatted date-time structure member values cout << ” Abbreviated weekday name: ” << ans_abr << endl;
cout << ” Full weekday name: ” << ans_full << endl; return 0;
We can also create a date-time structure using our own year, day, month, hour, minute and second information. Before we can use it as a valid date-time structure, we have to call mktime() to adjust other members of the date-time structure to make it valid. Sample_time_B.cpp illustrates the use of the library functions to specify a time
#include <iostream>
#include <ctime>
using namespace std;
int main()
date-time structure struct tm tmStruct; int y = 2013;
int m = 4; // April int d = 1; // my lucky day int h = 14; // 2 pm int min = 30; // half past int s = 3; // who cares?
initialize/modify the date-time structure
tmStruct.tm_year = y – 1900; // Legacy problem
tmStruct.tm_mon = m – 1; // month starts from 0 not 1
tmStruct.tm_mday = d;
tmStruct.tm_hour = h-1;
tmStruct.tm_min = min-1;
tmStruct.tm_sec = s-1;
call mktime() to adjust other members of tmStruct mktime ( &tmStruct );
using option “%a” and option “%A”.
char ans_localtime[40]; // Character array char ans_full[40];
strftime(ans_localtime, 40, “%c”, &tmStruct); strftime(ans_full, 40, “%A”, &tmStruct);
view the formatted date-time structure member values cout << “Local date time is: ” << ans_localtime << endl; cout << ” Full weekday name: ” << ans_full << endl; return 0;
Task 1 (15 marks)
Write a C++ program that is to be used for a local taxi fare calculation. The rules regarding the calculations are as follows. (Note: American spelling for Kilometer in specification)
The fare is calculated based on distance travelled and time taken to travel the distance.
The services charges $2.00 for the first 2 kilometre of travel (even if you are under 2 kilometers). After the first 2 kilometers the services charges $0.50 cents for each additional kilometer up to additional 6 kilometers. After those 6 kilometers the customer is charged a $1.00 for each additional kilometers
At the end of the ride, a fee of $0.20 cents is charged based on the total minutes travel time.
The total fare is the journey cost added to the travel time cost.
The application is then to print out a personalised invoice for the journey as specified below.
Your application needs to display a prompt for information to be inputted by the user.
Input from the keyboard is for whole numbers only (int).
C:>task_1_1
Please enter your name: Peter Johnson
Please enter distance travelled as km: 12
Please enter duration of journey in minutes: 16
Hello, Peter!
Your journey of 12 kilometers and 16 minutes comes to $12.20
Travel cost $9.00 for distance of 12 kilometers Time cost $3.20 for 16 minutes travel time.
C:>task_1_1
Please enter your name: Green Pumpkin
Please enter distance travelled as km: 1
Please enter duration of journey in minutes: 13
Hello, Green!
Your journey of 1 kilometers and 13 minutes comes to $4.60
Travel cost $2.00 for distance of 1 kilometers Time cost $2.60 for 13 minutes travel time.
C:>task_1_1
Please enter your name: Tom Green
Please enter distance travelled as km: 21
Please enter duration of journey in minutes: 8
Hello, Tom!
Your journey of 21 kilometers and 8 minutes comes to $19.60
Travel cost $18.00 for distance of 21 kilometers Time cost $1.60 for 8 minutes travel time.
User will be able to enter names with multiple words. Your code should be able to capture names consisting of any number of words (hundreds, at least). You should record the compilation message(s) even though there may be none. Run the program as shown in the sample runs. Put all compilation messages and sample run outputs in task_1_1.txt.
Marking Criteria Marks Program can only handle multiple-word names 1 Program calculates journey cost correctly 3 Program calculates time cost correctly 2 Program displays the messages correctly 3 Code factored into functions for reuse 5 Compilation messages and sample run outputs (if the program runs correctly) 1
Task 2 (15 marks)
Write a C++ program task_1_2.cpp which prompts for an integer, validate the integer, and if not valid, ask again till a valid integer is entered. Repeat for another five integers with different validation criteria.
Your solution source code is to be only the main() function. The whole logic for the solution needs to reside in the main routine.
Sample outputs are:
C:> a Please enter the year: 2013 Please enter the month: 1 Please enter the day: 24 Please enter the hour: 13 Please enter the minute: 55 Please enter the second: 45 Your inputs are: Year = 2013 Month = 1 Day = 24 Hour = 13 Minute = 55 Second = 45 C:>a Please enter the year: 1969 1970 <= Year <= 2020! Please enter the year: 2034 1970 <= Year <= 2020! Please enter the year: Hello and bye 1970 <= Year <= 2020! Please enter the year: 2013 Please enter the month: 0 1 <= Month <= 12! Please enter the month: 13 1 <= Month <= 12! Please enter the month: Hello and bye 1 <= Month <= 12! Please enter the month: 1 Please enter the day: 0 1 <= Day<= 31! Please enter the day: 32 1 <= Day<= 31! Please enter the day: Hello and bye 1 <= Day<= 31! Please enter the day: 24 Please enter the hour: -1 0 <= Hour<= 23! Please enter the hour: 24 0 <= Hour<= 23! Please enter the hour: Hello and bye 0 <= Hour<= 23! Please enter the hour: 13 Please enter the minute: -1 0 <= Minute <= 59! Please enter the minute: 60 0 <= Minute <= 59! Please enter the minute: Hello and bye
0 <= Minute <= 59!
Please enter the minute: 30
Please enter the second: -1
1 <= Second<= 59!
Please enter the second: 60
1 <= Second<= 59!
Please enter the second: Hello and bye 1 <= Second<= 59!
Please enter the second: 35
Your inputs are:
Year = 2013
Month = 1
Day = 24
Hour = 13
Minute = 30
Second = 35
The name of the six integers and their validation criteria are shown below:
Name Criteria year 1970 <= year <= 2020 month 1 <= month <= 12 day 1 <= day <= 31 hour 0 <= hour <= 23 min 0 <= min <= 59 sec 0 <= sec <= 59
You should record the compilation message(s) even though there may be none. Run the program as shown in the sample runs. Put all compilation messages and sample run outputs in task_1_2.txt.
Marking Criteria Marks Data input 1 Data validation 3 Looping for a correct input 4 Handle error input with appropriate output message 4 Solution uses main function only for the code 2 Compilation messages and sample run outputs (if the program runs correctly) 1
Task 3 (20 marks)
Write second version of Task 2 where you reflector the code to use functions as specified below.
Your code in Task 2 for entering each integer is the same except the prompts, variable names and the validation criteria.
Group the code for entering an integer to form a function void get_data(). The parameters for the function void get_data()are:
the prompt for user input;
the prompt for correct range of input;
integer variable used to store the user input;
criteria 1 – input should be smaller than or equal to this value; criteria 2 – input should be greater than or equal to this value;
void get_data() returns control to caller only when the input data is valid.
Write a C++ program task_1_3.cpp calls get_data() to get 6 valid integers. The validation criteria and sample output should be the same as shown in Task 2.
You should record the compilation message(s) even though there may be none. Run the program as shown in the sample runs for task 2. Put all compilation messages and sample run outputs in task_1_3.txt.
Marking Criteria Marks Function declaration 4 Function definition 7 Parameter passing to functions 7 Looping for correct input 1 Compilation messages and sample run outputs (if the program runs correctly) 1
Task 4 (20 marks)
Write a C++ program task_1_4.cpp which uses a function void get_option(some_parameter) to get user input for a char option. The char must be an alphanumeric character i.e. alphabets and digits. If the input is not valid, void get_option() will be called until a valid user input is obtained.
The validated option will then be used as a parameter in calling a function string test(). Function string test() will display different strings according to the value of option.
Value of option can only be:
a digit (use isdigit(char) in <cctype>)
o char option = ‘1’; isdigit(option) will return true;
char option = ‘a’; isdigit(option) will return false; a lower case letter (use islower(char) in <cctype>)
o char option = ‘a’; islower(option) will return true;
char option = ‘A’; islower(option) will return false; an upper case letter (use isupper(char) in <cctype>)
o char option = ‘A’; isupper(option) will return true; o char option = ‘1’; isupper(option) will return false;
test() is shown below:
string test(char option)
if (isupper(option)) return “An upper case letter is entered!”;
if (islower(option)) return “A lower case letter is entered!”;
return “A digit is entered!”;
Sample outputs:
C:>a
Please enter an alphanumeric char: &
Please enter an alphanumeric char: (
Please enter an alphanumeric char: ?
Please enter an alphanumeric char: 2
A digit is entered!
C:>a
Please enter an alphanumeric char: a
A lower case letter is entered!
C:>a
Please enter an alphanumeric char: A
An upper case letter is entered!
You should record the compilation message(s) even though there may be none. Run the program as shown in the sample runs shown above. Put all compilation messages and sample run outputs in task_1_4.txt.
Marking Criteria Marks Function declaration 4 Function definition 5 Passing parameters 5 Looping for correct input 1 Calling test() 4 Compilation messages and sample run outputs (if the program runs correctly) 1
Task 5 (30 %)
Compile and run sample_5.cpp. Study the program alongside with the output and make sure you understand how to use the time library functions.
Write a C++ program which:
Prompts user for inputting his name consisting of multiple words;
Prompts user for inputting valid int year, int month, int day, int hour, int minute, int second.
o The validation criteria is the same as in task 2.
Prompts user to input 4 options for calls to get_string_component() .
Option can only be one of the following: a abbreviated weekday
A full weekday
b abbreviated month B full month
c local date and time d day of month (01-31) H hour (00-23)
I hour (1-12)
j day of the year (001-366) m month (01-12)
M minute (00-59) p Am or PM
S second (00-59)
U week numberof the year (00-53); Sunday as first day of week
w weekday (0-6, Sunday is 0)
W week numberof the year (00-53);
Monday as first day of week
x local date
X local time
year without century (00-99) Y year with century
Z time zone.
Constructs a date-time structure with the date time information just entered;
Outputs user name, local time, abbreviated weekday, and the day of the year for the date-time using the user name and appropriate options (‘c’, ‘a’, ‘j’, ‘Y’) for get_string_component().
Sample output:
C:work_directoryCSC2402S1_2013assignmentS1_
Please enter your name: Peter Johnson Junior
Please enter the year: 2013
Please enter the month: 1
Please enter the day: 24
Please enter the hour: 2
Please enter the minute: 4
Please enter the second: 6
Please enter your first option: c
Please enter your second option: a
Please enter your third option: j
Please enter your fourth option: Y
You should record the compilation message(s) even though there may be none. Run the program as shown in the sample runs shown above. Put all compilation messages and sample run outputs in task_1_5.txt.
Marking Criteria Marks Get user name using function call 1 Get date-time information using function call 1 Get options using function call 1 Date-time structure 6 Get localtime, weekday, days of the year 6 Correct Output 5 Compilation messages and sample run outputs (if the program runs correctly) 10
Punjab Assignment Help
Buy Online Assignment Help services for COMPUTER ASSIGNMENT with Punjab Assignment Help at [email protected]
0 notes
Photo

Testing Data-Intensive Code With Go, Part 5
Overview
This is part five out of five in a tutorial series on testing data-intensive code. In part four, I covered remote data stores, using shared test databases, using production data snapshots, and generating your own test data. In this tutorial, I'll go over fuzz testing, testing your cache, testing data integrity, testing idempotency, and missing data.
Fuzz Testing
The idea of fuzz testing is to overwhelm the system with lots of random input. Instead of trying to think of input that will cover all cases, which can be difficult and/or very labor intensive, you let chance do it for you. It is conceptually similar to random data generation, but the intention here is to generate random or semi-random inputs rather than persistent data.
When Is Fuzz Testing Useful?
Fuzz testing is useful in particular for finding security and performance problems when unexpected inputs cause crashes or memory leaks. But it can also help ensure that all invalid inputs are detected early and are rejected properly by the system.
Consider, for example, input that comes in the form of deeply nested JSON documents (very common in web APIs). Trying to generate manually a comprehensive list of test cases is both error-prone and a lot of work. But fuzz testing is the perfect technique.
Using Fuzz Testing
There are several libraries you can use for fuzz testing. My favorite is gofuzz from Google. Here is a simple example that automatically generates 200 unique objects of a struct with several fields, including a nested struct.
import ( "fmt" "http://ift.tt/1uxljqG" ) func SimpleFuzzing() { type SomeType struct { A string B string C int D struct { E float64 } } f := fuzz.New() uniqueObject := SomeType{} uniqueObjects := map[SomeType]int{} for i := 0; i < 200; i++ { f.Fuzz(&object) uniqueObjects[object]++ } fmt.Printf("Got %v unique objects.\n", len(uniqueObjects)) // Output: // Got 200 unique objects. }
Testing Your Cache
Pretty much every complex system that deals with a lot of data has a cache, or more likely several levels of hierarchical caches. As the saying goes, there are only two difficult things in computer science: naming things, cache invalidation, and off by one errors.
Jokes aside, managing your caching strategy and implementation can complicate your data access but have a tremendous impact on your data access cost and performance. Testing your cache can't be done from the outside because your interface hides where the data comes from, and the cache mechanism is an implementation detail.
Let's see how to test the cache behavior of the Songify hybrid data layer.
Cache Hits and Misses
Caches live and die by their hit/miss performance. The basic functionality of a cache is that if requested data is available in the cache (a hit) then it will be fetched from the cache and not from the primary data store. In the original design of the HybridDataLayer, the cache access was done through private methods.
Go visibility rules make it impossible to call them directly or replace them from another package. To enable cache testing, I'll change those methods to public functions. This is fine because the actual application code operates through the DataLayer interface, which doesn't expose those methods.
The test code, however, will be able to replace these public functions as needed. First, let's add a method to get access to the Redis client, so we can manipulate the cache:
func (m *HybridDataLayer) GetRedis() *redis.Client { return m.redis }
Next I'll change the getSongByUser_DB() methods to a public function variable. Now, in the test, I can replace the GetSongsByUser_DB() variable with a function that keeps track of how many times it was called and then forwards it to the original function. That allows us to verify if a call to GetSongsByUser() fetched the songs from the cache or from the DB.
Let's break it down piece by piece. First, we get the data layer (that also clears the DB and redis), create a user, and add a song. The AddSong() method also populates redis.
func TestGetSongsByUser_Cache(t *testing.T) { now := time.Now() u := User{Name: "Gigi", Email: "[email protected]", RegisteredAt: now, LastLogin: now} dl, err := getDataLayer() if err != nil { t.Error("Failed to create hybrid data layer") } err = dl.CreateUser(u) if err != nil { t.Error("Failed to create user") } lm, err := NewSongManager(u, dl) if err != nil { t.Error("NewSongManager() returned 'nil'") } err = lm.AddSong(testSong, nil) if err != nil { t.Error("AddSong() failed") }
This is the cool part. I keep the original function and define a new instrumented function that increments the local callCount variable (it's all in a closure) and calls the original function. Then, I assign the instrumented function to the variable GetSongsByUser_DB. From now on, every call by the hybrid data layer to GetSongsByUser_DB() will go to the instrumented function.
callCount := 0 originalFunc := GetSongsByUser_DB instrumentedFunc := func(m *HybridDataLayer, email string, songs *[]Song) (err error) { callCount += 1 return originalFunc(m, email, songs) } GetSongsByUser_DB = instrumentedFunc
At this point, we're ready to actually test the cache operation. First, the test calls the GetSongsByUser() of the SongManager that forwards it to the hybrid data layer. The cache is supposed to be populated for this user we just added. So the expected result is that our instrumented function will not be called, and the callCount will remain at zero.
_, err = lm.GetSongsByUser(u) if err != nil { t.Error("GetSongsByUser() failed") } // Verify the DB wasn't accessed because cache should be // populated by AddSong() if callCount > 0 { t.Error(`GetSongsByUser_DB() called when it shouldn't have`) }
The last test case is to ensure that if the user's data is not in the cache, it will be fetched properly from the DB. The test accomplishes it by flushing Redis (clearing all its data) and making another call to GetSongsByUser(). This time, the instrumented function will be called, and the test verifies that the callCount is equal to 1. Finally, the original GetSongsByUser_DB() function is restored.
// Clear the cache dl.GetRedis().FlushDB() // Get the songs again, now it's should go to the DB // because the cache is empty _, err = lm.GetSongsByUser(u) if err != nil { t.Error("GetSongsByUser() failed") } // Verify the DB was accessed because the cache is empty if callCount != 1 { t.Error(`GetSongsByUser_DB() wasn't called once as it should have`) } GetSongsByUser_DB = originalFunc }
Cache Invalidation
Our cache is very basic and doesn't do any invalidation. This works pretty well as long as all songs are added through the AddSong() method that takes care of updating Redis. If we add more operations like removing songs or deleting users then these operations should take care of updating Redis accordingly.
This very simple cache will work even if we have a distributed system where multiple independent machines can run our Songify service—as long as all the instances work with the same DB and Redis instances.
However, if the DB and cache can get out of sync due to maintenance operations or other tools and applications changing our data then we need to come up with an invalidation and refresh policy for the cache. It can be tested using the same techniques—replace target functions or directly access the DB and Redis in your test to verify the state.
LRU Caches
Usually, you can't just let the cache grow infinitely. A common scheme to keep the most useful data in the cache is LRU caches (least recently used). The oldest data gets bumped from the cache when it reaches capacity.
Testing it involves setting the capacity to a relatively small number during the test, exceeding the capacity, and ensuring that the oldest data is not in the cache anymore and accessing it requires DB access.
Testing Your Data Integrity
Your system is only as good as your data integrity. If you have corrupted data or missing data then you're in bad shape. In real-world systems, it's difficult to maintain perfect data integrity. Schema and formats change, data is ingested through channels that might not check for all the constraints, bugs let in bad data, admins attempt manual fixes, backups and restores might be unreliable.
Given this harsh reality, you should test your system's data integrity. Testing data integrity is different than regular automated tests after each code change. The reason is that data can go bad even if the code didn't change. You definitely want to run data integrity checks after code changes that might alter data storage or representation, but also run them periodically.
Testing Constraints
Constraints are the foundation of your data modeling. If you use a relational DB then you can define some constraints at the SQL level and let the DB enforce them. Nullness, length of text fields, uniqueness and 1-N relationships can be defined easily. But SQL can't check all the constraints.
For example, in Desongcious, there is a N-N relationship between users and songs. Each song must be associated with at least one user. There is no good way to enforce this in SQL (well, you can have a foreign key from song to user and have the song point to one of the users associated with it). Another constraint may be that each user may have at most 500 songs. Again, there is no way to represent it in SQL. If you use NoSQL data stores then usually there is even less support for declaring and validating constraints at the data store level.
That leaves you with a couple of options:
Ensure that access to data goes only through vetted interfaces and tools that enforce all the constraints.
Periodically scan your data, hunt constraint violations, and fix them.
Testing Idempotency
Idempotency means that performing the same operation multiple times in a row will have the same effect as performing it once.
For example, setting the variable x to 5 is idempotent. You can set x to 5 one time or a million times. It will still be 5. However, incrementing X by 1 is not idempotent. Every consecutive increment changes its value. Idempotency is a very desirable property in distributed systems with temporary network partitions and recovery protocols that retry sending a message multiple times if there is no immediate response.
If you design idempotency into your data access code, you should test it. This is typically very easy. For each idempotent operation you extend to perform the operation twice or more in a row and verify there are no errors and the state remains the same.
Note that idempotent design may sometimes hide errors. Consider deleting a record from a DB. It is an idempotent operation. After you delete a record, the record doesn't exist in the system anymore, and trying to delete it again will not bring it back. That means that trying to delete a non-existent record is a valid operation. But it might mask the fact that the wrong record key was passed by the caller. If you return an error message then it's not idempotent.
Testing Data Migrations
Data migrations can be very risky operations. Sometimes you run a script over all your data or critical parts of your data and perform some serious surgery. You should be ready with plan B in case something goes wrong (e.g. go back to the original data and figure out what went wrong).
In many cases, data migration can be a slow and costly operation that may require two systems side by side for the duration of the migration. I participated in several data migrations that took several days or even weeks. When facing a massive data migration, it's worth it to invest the time and test the migration itself on a small (but representative) subset of your data and then verify that the newly migrated data is valid and the system can work with it.
Testing Missing Data
Missing data is an interesting problem. Sometimes missing data will violate your data integrity (e.g. a song whose user is missing), and sometimes it's just missing (e.g. someone removes a user and all their songs).
If the missing data causes a data integrity problem then you'll detect it in your data integrity tests. However, if some data is just missing then there is no easy way to detect it. If the data never made it into persistent storage then maybe there is a trace in the logs or other temporary stores.
Depending how much of a risk missing data is, you may write some tests that deliberately remove some data from your system and verify the system behaves as expected.
Conclusion
Testing data-intensive code requires deliberate planning and an understanding of your quality requirements. You can test at several levels of abstraction, and your choices will affect how thorough and comprehensive your tests are, how many aspects of your actual data layer you test, how fast your tests run, and how easy it is to modify your tests when the data layer changes.
There is no single correct answer. You need to find your sweet spot along the spectrum from super comprehensive, slow and labor-intensive tests to fast, lightweight tests.
by Gigi Sayfan via Envato Tuts+ Code http://ift.tt/2AQk17s
0 notes
Conversation
Playing with Balls
Let me start with the simplest case of gravity balls so that you can really get a feeling for what's going on. Suppose I have two balls somewhere in space. It's just these two balls and nothing else — no planets, no stars, no Starbucks nearby. In that case the only interaction between the two balls would be gravitational. What will happen to these two balls? Since there is a gravitational force pulling them together, they will both increase in speed (that's what forces do). But as they move closer together, the gravitational force increases even more. Overall, it's an interesting motion problem.
This gravitational force would depend on the product of the mass and the distance between the two balls.
These two balls are somewhere with respect to some origin (it doesn't really matter). What matters is the vector from A to B which we can label as just r. With this vector r, I can find the gravitational force on ball B as:
I should point out a few things with this expression. This is the gravitational force on B as exerted by A. There is also a force from B on A, it would have the same magnitude but opposite direction. The G is the universal gravitational constant. The r with the "hat" is called r-hat (surprise) and it is a unit vector. This unit vector doesn't change the magnitude of the force, but without it, you would just have a scalar force and that wouldn't be so useful.
What do we do with the force anyway? The gravitational force on object B can be used to find the change in momentum of B after some time interval where the momentum is the product of mass and velocity. This comes straight from the momentum-principle.
Yes, the p is momentum. Before you ask, I don't know why we always use "p" for momentum. I guess it's because "m" was already taken to be used for the mass. OK, there is one more equation. If I know the object's momentum, then I can use the definition of momentum and average velocity to find the new position of this thing after some short time interval.
The r-vector represents the position since "p" was already taken. That was just a joke: Actually, we use "r" for position because it comes from the "r" in spherical coordinates. But this leads to something good. It goes like this: calculate the force, update the momentum and then update the position for some short time interval. Do this also for the other mass. Since the positions change, the force changes so you need to do it all again. And again. And again. Keep doing this until you want to stop — and boom. That's the whole idea behind a numerical calculation.
Let's just do it. Here is a numerical calculation for two masses in space. Go ahead and click the "play" to run and you can see the code by pressing the "pencil" icon.
I tried to put some comments (comments are lines with the # symbol in front of them) in the code so that you can sort of figure out what is going on if you want to play with it. It might not look like anything is happening at first because the balls start off really slowly. Just wait and you should see something.
What happens to the balls? They do indeed start to move towards each other and speed up during that process. However, they aren't real balls so that there is nothing preventing them from passing through each other — and so they do. After that, the gravitational force slows them down until they start moving towards each other again. If you let it, these would just oscillate back and forth forever.
Also, I cheated. The balls have a mass of 1 kilogram, but I changed the universal gravitational constant to some much larger number than the real life version. In real life these balls would take forever to get together since real gravity is super weak.
Finally, one other note. If you look at the code you can see that when the balls overlap, I set the gravitational force to the zero vector. There is a reason for this — it's not just because I'm crazy. If the center of the balls get really, really close then the magnitude of the r-vector is really, really small. A small r means a giant gravitational force. This giant gravitational force for a very short time can make weird things happen. The overlap force of zero prevents weird things.
More Gravity Balls
OK, but I think we can agree that two interacting gravity balls are sort of boring. What about 10 gravity balls? How would you make 10 balls interact? It's really just more of the same thing that worked for just two balls. With 10 balls, I can take one ball at a time. I need to find the distance to all the other balls and the gravitational force from all other balls. After that, I can update the momentum and position for that ball. Oh, I still need to do the same thing for the other nine balls. Yes, it's a bunch of work — but that's why I'm making a computer do it instead of me.
Here is an animation of what this looks like. If you want to play with the code (and you should), it's right here.
That's pretty cool right? Notice that I gave the balls a random color — just for fun. Also, these things will just keep moving around forever (or as long as the program runs). But what's next? How about 100 balls! No wait, 200 balls! This is the exact same code as before, just with more gravity balls. Actually, this is running at 5x speed so that it goes faster.
I don't know about you, but I'm really starting to get excited. You really need to check out the code and run it yourself (you can't break anything — I promise). See how many gravity balls you can run before your computer explodes (no, it won't really explode). Of course as you increase N (the number of gravity balls) you dramatically increase the number of computations. Not only do you have more balls to update with the momentum, but each ball has more balls that exert a force on it. I can get up to 1,000 balls, but it doesn't run super-fast.
Adding a Drag Force
Let's change it again. I don't want these balls to oscillate in and out forever. I want them to settle down into one big blob. I can do that by adding a drag force. This drag force has two main properties. First, it has to be in the opposite direction of each ball's momentum (or velocity) so that it makes the ball slow down. Second, the drag force should be proportional to the magnitude of the momentum so that a ball at rest has no drag force and a super-fast ball has a super high drag force.
Actually, I've had a drag force in the code the whole time — but the drag coefficient was set to zero so that it wouldn't do anything. If I put the coefficient to some arbitrary value (I picked 0.2), this is what happens (for 100 gravity balls). Note: I increased the playback speed by a factor of 10 — just because I wanted to try it.
If you zoom in to the final form, it looks like this:
The individual gravity balls still move around a little bit. Most of the balls are within the radius of the other balls (they are overlapping) so that most of these do not have a gravitational force on them. For the ones that do have a gravitational force, they get pulled back into the ball blob.
A Different Random Distribution
After playing with the gravity balls for a while (I hope someone is keeping track of how many times I write "gravity balls"), I saw something weird. With a large number of balls, I always get a formation that looks like this.
Hopefully you can see that "x". Why is there an "x"? Actually, you can even rotate this distribution of balls around and it's still and "x" in three dimensions. I think I know the cause of the "x". I created 1,000 gravity balls by picking three random numbers for each ball position. The x, y, z coordinates of each random number is between -1 and 1 so the possible positions of balls would be a “2 x 2 x 2” cube. Of course, the average center of mass for a distribution would be in the center of this cube and the masses are all attracted towards that point. But the non-spherical distribution of balls must be the cause of this x-feature.
I can test this supposition if I make a spherical distribution of gravity balls. Instead of creating random x, y, z coordinates, I am going to use spherical coordinates and create the following three variables: r (0 to 1), θ (0 to π), and φ(0 to 2π). This should make a spherical distribution and there shouldn't be the resulting "x" pattern. Here we go.
Looks good. Oh, since this distribution has 1,000 gravity balls, I will play it back at 30x speed.
Extension
There are many questions you could answer for this situation.
• In this gravity balls model there is no force when two balls overlap. How can you make this interaction so that it is more like “hard” sphere collisions with no overlapping?
• Is energy conserved in the case of 100 gravity balls with no drag force? What about momentum? Making a graph would help make the determination.
• Do you get significantly different results if the ball masses are not constant? Give the balls a random mass within some random range.
• I don't know if this will work, but what would happen if a giant collection of gravity balls (let's say 500) had a slight rotation to begin with. When the whole thing compresses into a compact ball, would that ball be spinning super-fast? It should. Oh, don't forget about the drag. If your drag force is too high you will lose angular momentum.
• What if you just give all the gravity balls some small random momentum to start with. What happens then?
• Suppose there were two massive gravity balls at the edge of the distribution of balls (opposite ends). Could these two balls make two different blobs form? That would be cool.
• Well, how does it feel to play around with your balls? Did you try playing around with the drag coefficient? You should.
0 notes
Text
READ MY FACE - DRAWING PORTRAITS WITH TEXT
Source: http://ift.tt/2fJxe5r
DRAWING PORTRAITS WITH TEXT
PUBLISHED SUN, JUL 9, 2017 BY GIORA SIMCHONI
Recently I’ve seen some interesting posts showing how to make ASCII art in R (see here and here). Why limit ourselves to ASCII, I thought. Lincoln’s portrait could be drawn with the Gettysberg Address instead of commas and semicolons. And Trump’s portrait really deserves his tweets1.
Lincoln/Gettysberg
Let’s load Lincoln’s image using the imager package. I’ll resize it because it’s huge, and convert it to grayscale:
library(tidyverse) library(stringr) library(imager) library(abind) img <- load.image("~/lincoln.jpg") %>% resize(700, 500) %>% grayscale() plot(img)
Now let’s get the Gettysberg Address from here using the rvest package:
library(rvest) text <- read_html("http://ift.tt/RykWYq") %>% html_nodes("p") %>% html_text() text
## [1] "\"Fourscore and seven years ago our fathers brought forth on this continent a new nation, conceived in liberty and dedicated to the proposition that all men are created equal. Now we are engaged in a great civil war, testing whether that nation or any nation so conceived and so dedicated can long endure. We are met on a great battlefield of that war. We have come to dedicate a portion of that field as a final resting-place for those who here gave their lives that that nation might live. It is altogether fitting and proper that we should do this. But in a larger sense, we cannot dedicate, we cannot consecrate, we cannot hallow this ground. The brave men, living and dead who struggled here have consecrated it far above our poor power to add or detract. The world will little note nor long remember what we say here, but it can never forget what they did here. It is for us the living rather to be dedicated here to the unfinished work which they who fought here have thus far so nobly advanced. It is rather for us to be here dedicated to the great task remaining before us--that from these honored dead we take increased devotion to that cause for which they gave the last full measure of devotion--that we here highly resolve that these dead shall not have died in vain, that this nation under God shall have a new birth of freedom, and that government of the people, by the people, for the people shall not perish from the earth.\" "
Now let’s convert Lincoln’s image into a 500 x 700 (transposed) matrix. It is now in grayscale mode, so there is only a single color channel, with values randing from 0 to 1:
imgGSMat <- img %>% as.matrix() %>% t() dim(imgGSMat)
## [1] 500 700
summary(c(imgGSMat))
## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 0.03137 0.09804 0.60000 0.46649 0.80784 0.99608
Let’s suppose the region we’ll print the text in, is where the pixels value is lower (= darker) than a certain threshold, say 0.5, and let’s plot this region to see it makes sense:
plot(as.cimg(imgGSMat > 0.5))
Don’t worry about the image being rotated, this will work out eventually. For now I just wanted to make sure the “dark” region with our chosen threshold looks OK, and it appears so.
To fill the dark region with the Gettysberg Address let’s split the text into characters. Then, we’ll loop over the entire matrix and text, and when we’re in the “dark” region, we’ll plot the current text character. We’ll use the grid package for plotting.
library(grid) text <- str_split(text, "")[[1]] grid.newpage() counter <- 0 for (i in seq(1, nrow(imgGSMat), 13)) { for (j in seq(1, ncol(imgGSMat), 5)) { if (imgGSMat[i, j] < 0.5) { counter <- ifelse(counter < length(text), counter + 1, 1) grid.text(text[counter], x = j / ncol(imgGSMat), y = 1 - i / nrow(imgGSMat), gp = gpar(fontsize = 10), just = "left") } } }
This is a good start, but a failure nonetheless. A few things to notice:
We’re not really looping through the entire matrix of pixels. Since the font size is currently 10, we’re looping through rows (image height) with the i variable in steps of 13 pixels.
We’re looping through columns (image width) with the j variable in fixed steps of 5 - which is clearly a problem, since there’s a variablity in the characters width.
Once the text is over we start from the beginning.
The grid.text function does not want our i and j as pixels, but as fractions from the image’s height and width respectively.
So the main issue here is the assumption of fixed width for all letters. Let’s change that with distinguishing between “fat” and “skinny” letters (the rest will be “regular”):
fatChars <- c(LETTERS[-which(LETTERS == "I")], "m", "w", "@") skinnyChars <- c("l", "I", "i", "t", "'", "f") grid.newpage() counter <- 0 for (i in seq(1, nrow(imgGSMat), 13)) { for (j in seq(1, ncol(imgGSMat), 10)) { if (imgGSMat[i, j] < 0.5) { counter <- ifelse(counter < length(text), counter + 1, 1) beforeLastChar <- ifelse(counter > 2, lastChar, " ") lastChar <- ifelse(counter > 1, char, " ") char <- text[counter] grid.text(char, x = j/ncol(imgGSMat) + 0.004 * (lastChar %in% fatChars) - 0.003 * (lastChar %in% skinnyChars) + 0.003 * (beforeLastChar %in% fatChars) - 0.002 * (beforeLastChar %in% skinnyChars), y = 1 - i / nrow(imgGSMat), gp = gpar(fontsize = 10), just = "left") } } }
Looks much better although the “algorithm” is somewhat dirty.
Let’s put it in a function anyway, making the threshold, font size and some other parameters configurable:
drawImageWithText <- function(img, text, thresh, fontSize = 10, fileName = "myfile.png", resize = TRUE, saveToDisk = FALSE) { text <- paste(text, collapse = " ") text <- str_replace_all(text, "\n+", " ") text <- str_replace_all(text, " +", " ") text <- str_split(text, "")[[1]] if (resize) img <- resize(img, 700, 500) imgGSMat <- img %>% grayscale %>% as.matrix %>% t() fatChars <- c(LETTERS[-which(LETTERS == "I")], "m", "w", "@") skinnyChars <- c("l", "I", "i", "t", "'", "f") if (saveToDisk) png(fileName, width(img), height(img)) grid.newpage() counter <- 0 for (i in seq(1, nrow(imgGSMat) - fontSize, fontSize + floor(fontSize / 3))) { for (j in seq(1, ncol(imgGSMat) - fontSize, fontSize)) { if (imgGSMat[i, j] < thresh) { counter <- ifelse(counter < length(text), counter + 1, 1) beforeLastChar <- ifelse(counter > 2, lastChar, " ") lastChar <- ifelse(counter > 1, char, " ") char <- text[counter] grid.text(char, x = 0.01 + j/ncol(imgGSMat) + 0.004 * (lastChar %in% fatChars) - 0.003 * (lastChar %in% skinnyChars) + 0.003 * (beforeLastChar %in% fatChars) - 0.002 * (beforeLastChar %in% skinnyChars), y = 1 - i / nrow(imgGSMat) - 0.01, gp = gpar(fontsize = fontSize), just = "left") } } } if (saveToDisk) dev.off() }
Martin Luther King Jr./I Have A Dream
Let’s test our function on Martin Luther King Jr. and his iconic speech taken from here:
img <- load.image("~/mlkj.jpg") text <- read_lines("~/ihaveadream.txt") drawImageWithText(img, text, thresh = 0.3, fontSize = 5)
Free, at last.
Marylin Monroe/Her Wikipedia Article
img <- load.image("~/marylin.jpg") text <- read_html("http://ift.tt/OBYUG0") %>% html_nodes("p") %>% html_text() %>% str_replace_all(., "\\[[0-9]+\\]", "") drawImageWithText(img, text, thresh = 0.5, fontSize = 8)
Adele/Rolling In The Deep
img <- load.image("~/adele.jpg") text <- read_lines("~/rollinginthedeep.txt") drawImageWithText(img, text, thresh = 0.5, fontSize = 10)
Hadley Wickham/The dplyr code
img <- load.image("~/hadley.jpg") text <- read_html("http://ift.tt/2hqEe7q") %>% html_nodes("div") %>% .[[47]] %>% html_text() drawImageWithText(img, text, thresh = 0.75, fontSize = 5)
This example with Hadley is a bit different, because here the original image isn’t black and white. It has colors, and we could use some color, so let’s change the function a bit:
drawImageWithText <- function(img, text, thresh, color = FALSE, fontSize = 10, fileName = "myfile.png", resize = TRUE, saveToDisk = FALSE) { if (color) { if (spectrum(img) == 1) { warning("Image is in grayscale mode, setting color to FALSE.") color = FALSE } } text <- paste(text, collapse = " ") text <- str_replace_all(text, "\n+", " ") text <- str_replace_all(text, " +", " ") text <- str_split(text, "")[[1]] if (resize) img <- resize(img, 700, 500) imgMat <- img %>% as.array() %>% adrop(3) %>% aperm(c(2, 1, 3)) imgGSMat <- img %>% grayscale %>% as.matrix %>% t() fatChars <- c(LETTERS[-which(LETTERS == "I")], "m", "w", "@") skinnyChars <- c("l", "I", "i", "t", "'", "f") if (saveToDisk) png(fileName, width(img), height(img)) grid.newpage() counter <- 0 for (i in seq(1, nrow(imgGSMat) - fontSize, fontSize + 1)) { for (j in seq(1, ncol(imgGSMat) - fontSize, fontSize)) { if (imgGSMat[i, j] < thresh) { counter <- ifelse(counter < length(text), counter + 1, 1) beforeLastChar <- ifelse(counter > 2, lastChar, " ") lastChar <- ifelse(counter > 1, char, " ") char <- text[counter] grid.text(char, x = 0.01 + j/ncol(imgGSMat) + 0.004 * (lastChar %in% fatChars) - 0.003 * (lastChar %in% skinnyChars) + 0.003 * (beforeLastChar %in% fatChars) - 0.002 * (beforeLastChar %in% skinnyChars), y = 1 - i / nrow(imgGSMat) - 0.01, gp = gpar(fontsize = fontSize, col = ifelse(!color, "black", rgb(imgMat[i, j, 1], imgMat[i, j, 2], imgMat[i, j, 3]))), just = "left") } } } if (saveToDisk) suppressMessages(dev.off()) } drawImageWithText(img, text, thresh = 0.9, color = TRUE, fontSize = 5)
Nice! Sorry, Hadley.
Trump/His Tweets
Let’s write a wrapper around our drawImageWithText function that will automatically download a Twitter user’s image and tweets - and use those as img and text. We’ll use the wonderful rtweet package for this:
library(rtweet) drawImageWithTextFromTwitter <- function(username, thresh, ...) { text <- get_timeline(username, n = 200) %>% select(text) %>% unlist() %>% discard(str_detect(., "^RT")) %>% str_replace(., "(http|https)[^([:blank:]|\"|<|&|#\n\r)]+", "") %>% str_extract_all(., "[a-zA-Z0-9[:punct:]]+") %>% unlist %>% paste(., collapse = " ") img <- load.image(lookup_users(username)$profile_image_url) drawImageWithText(img, text, thresh, ...) }
Let’s do Trump:
drawImageWithTextFromTwitter("realDonaldTrump", 0.55, fontSize = 8)
Tyra Banks/Her Tweets
drawImageWithTextFromTwitter("tyrabanks", 0.9, color = TRUE, fontSize = 5)
Congratulations. You’re still in the running towards becoming America’s Next Top Model.
That’s It
Next step is, obviously, making T-shirts. Enjoy!
via Blogger http://ift.tt/2hntD0o
0 notes