#kunstigintelligens
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Photo

Repost from @techtopiadk • ⭐Techtopia 277: GPT-4 - Spøgelset i maskinen⭐ 🤖🌍 Kunstig intelligens er en del af vores hverdag, men hvordan fungerer de imponerende tjenester egentlig? 💻🧐 ChatGPT fra OpenAI kan agere som en menneskelig samtalepartner på nettet, og nu er GPT-4 offentliggjort, som er trænet på endnu flere data! 😱💪 I Techtopia-podcasten taler vi med AI-specialisten Erik David Johnson fra Delegate om, hvordan disse sprogmodeller kan virke så menneskelige og fremstå som om, de forstår vores verden på samme niveau som vi gør! 🎙️😍 Vil du høre mere om GPT-4? Lyt med, hvor du hører dine podcast eller gennem link i bio! #kunstigintelligens #OpenAI #GPT4 #Techtopia #podcast 🤖👍 📢Medvirkende 🧔♂️Erik David Johnson, AI-specialist hos firmaet Delegate. https://www.instagram.com/p/CqU4hEiMUsE/?igshid=NGJjMDIxMWI=
3 notes
·
View notes
Text
Agentic RAG: Neste steg i KI-chat for innholdet i digitalarkivet
I forrige artikkel fortalte vi om hvordan vi har testet ut en KI-basert chatløsning med RAG (Retrieval Augmented Generation) i bunnen. Denne løsningen ga oss nyttige erfaringer med å kombinere generativ kunstig intelligens med vårt eget arkivmateriale og veiledninger, hjelpetekster og annet støttemateriale. Erfaringene har vist at RAG er et godt utgangspunkt, men at vi raskt støter på utfordringer når vi prøver å dekke flere behov enn tradisjonelle søk eller enkle KI-svar kan håndtere. "agentic RAG"
Vi har tatt et steg videre ved å prøve ut en "agentic RAG", som er en utvidelse av den tradisjonelle RAG-tilnærmingen. Mens man i en vanlig RAG-løsning hovedsakelig henter frem informasjon og svarer direkte på brukerens spørsmål ut fra dette, opptrer en agentic RAG mer som en selvstendig “agent” som dynamisk justerer sine egne arbeidsprosesser. Den kan for eksempel validere svar, foreslå mer presise spørsmål, og endre søkestrategier når resultatene ikke er gode nok. Fremover ønsker vi å implementere enda mer autonomi i valg av funksjoner og strategier ut fra et satt mål i løsningen, men dette er en reell start.
Hva er en agent og hva er agentic RAG?
Enkelt forklart kan man si at en agent er et system som observerer et miljø/en situasjon/noen parametre, den har også fått satt et mål. Basert på observasjonene utfører den handlinger for å oppnå dette målet. Agenten vurderer effekten av sine handlinger, justerer strategien og fortsetter mot målet.
En agentic RAG er i bunn og grunn en agentisk tilnærming til informasjonsinnhentings-oppgaver basert på en agent-arkitektur. I en tradisjonell RAG har man en ganske statisk prosess for å hente frem og presentere informasjon. En agentic RAG innebærer at KI-en kan ta beslutninger på egenhånd om hvordan den skal løse informasjonsinnhentingen. I stedet for å ha fast definerte trinn for «chunking», innhenting og generering, kan en agentisk RAG dynamisk justere søkeparametere, revidere spørsmål, foreslå nye strategier, bruke ulike “verktøy” (f.eks. API-kall eller funksjoner) og avgjøre når nok kontekst er innhentet til å svare på en tilfredsstillende måte.
Det er nettopp derfor det snakkes mye om agentisk RAG for tiden. Vi og mange andre har prøvd å løse RAG ved hjelp av statiske regler for oppdeling av tekstbiter og søk med ulik grad av kompleksitet, og da oppdager man raskt at virkeligheten er mer rotete. Dataene er ikke alltid som man har sett for seg, og spørsmålene kan være vage eller flertydige. Da trenger man et system som kan operere mer fleksibelt, mer utforskende og mer problemløsende.
Hvorfor trenger vi dette?
Arkivkunnskap kan være kompleks, og brukere vet ikke alltid hvilke ord de skal søke på eller hvor de bør starte. Her gjør agentisk funksjonalitet en stor forskjell:
Forbedre spørsmål: Agentic RAG kan omskrive og bearbeide brukerens spørsmål for å gjøre dem tydligere og mer presise.
Kombinere søkestrategier: Systemet bruker semantiske og hybride søk som finner meningsinnhold, ikke bare eksakte ord. Hva som egner seg, kan den avgjøre på egenhånd. Den kan justere parametere som similarity, og tilpasse taktikken basert på resultatene.
Dynamisk tilpasning: Hvis svarene er mangelfulle, foreslår løsningen nye spørsmål, prøver alternative søkeord eller utvider søket – alt uten at brukeren må vite hvordan.
Kvalitetssikring: Løsningen validerer svarene og foreslår presiseringer om nødvendig, slik at brukeren får mest mulig pålitelig informasjon.
Hvordan fungerer løsningen i praksis?
Når en bruker stiller et spørsmål, tar systemet først tak i spørsmålet, forbedrer det eller gjør andre tilpasninger og benytter deretter semantiske og hybride søk for å hente frem relevant informasjon fra arkivene. Denne informasjonen struktureres slik at KI-modellen kan formulere et svar med lenker til kilder Alt dette skjer uten at brukeren trenger å vite nøyaktig hvordan ting fungerer, systemet tar hånd om prosessen og jobber aktivt i kulissene for å levere best mulig svar, i stedet for bare å presentere det første og beste treffet.
Agentiske egenskaper
Målbasert tilnærming: Systemet har et klart mål: å besvare brukerens spørsmål med størst mulig nøyaktighet. Dette er tydelig i hvordan det validerer svar og bruker fallback-strategier for å forbedre resultatene når de ikke er tilstrekkelige.
Adaptiv respons: Ved lite treff, tilpasser løsningen arbeidsflyten ved å benytte alternative strategier som omskriving, utvidede spørringer eller oppfølgingsspørsmål. Altså en viss grad av dynamisk beslutningstaking.
Systemet integrerer ulike teknologier og verktøy (LLM, Elasticsearch, hybrid søk) og velger passende metoder basert på behov, så den har fleksibilitet i hvordan det løser oppgaver.
Integrert logikk: Agenten fungerer som en koordinator som setter sammen, validerer og justerer informasjon fra ulike kilder.
Dynamisk kontekststyring: Systemet kan ta hensyn til tidligere samtaler og tilpasser neste steg etter dette.
Fallback-optimalisering: Med flere iterasjoner og alternative strategier øker sannsynligheten for at brukeren får et tilfredsstillende svar.
Proof of concept og veien videre

Denne løsningen er på et utprøvingsstadium og ligger ikke ute i en beta-utgave. Det er mange muligheter for utvidelser, og selve grunnstrukturen må forbedres. Den viktigste utvidelsen vil være å sørge for at løsningen har enda mer autonomi i valg av funksjoner og strategier, for eksempel ved å gi LLM-en en beskrivelse av målet og tilgjengelige verktøy, og la den selv bestemme hvilke handlinger som er nødvendig for å oppnå målet. Dette ville bringe det nærmere en løsning med reell "agency." Dette er vi i gang med. Fremtidige andre utvidelser kan for eksempel omfatte (med ulik grad av kompleksitet):
Forbedret validering og resonnering
Dynamisk søketilpasning: Juster parametere som temperatur, "similarity” og vekting automatisk.
Oppgave-oppdeling: Løsningen bryter opp komplekse spørsmål i deloppgaver og løser dem trinnvis. For eksempel, for spørsmålet «Forklar forholdet mellom A og B», kan agenten først hente info om A, deretter B, og så sette sammen informasjonen selvstendig.
Forbedrede feedback-sløyfer: Brukerfeedback: La brukere gi tilbakemelding, slik at løsningen kan justere hvordan den oppfører seg over tid.
Kontekstrevisjon: La brukeren revidere tidligere innlegg i samtalen, slik at konteksten blir oppdatert dynamisk.
Integrasjon med kunnskapsgrafer og andre data: Bygge opp en enkel kunnskapsgraf: Følger entiteter, relasjoner og temaer på tvers av samtaler, og foreslå relevante, sammenkoblede opplysninger. Under dette ligger også integrasjon med arkivdata og arkivkunnskap. Ved at for eksempel systemet tilpasser hvilke arkiv den skal bruke basert på spørsmålet.
Oppsummert vil vi si at agentic RAG er en naturlig videreutvikling fra RAG. Ved å gi løsningen evnen til å ta egne avgjørelser, velge verktøy, og tilpasse strategien underveis, blir den i stand til å hente frem og formidle arkivkunnskap på en mer dynamisk og pålitelig måte.
Ta gjerne kontakt med oss på [email protected] hvis du har tilbakemeldinger, eller er nysgjerrig på arbeidet vårt med KI, søk eller digitalarkivet generelt.
0 notes
Text
De nyeste teknologitendenser i byggebranchen i 2024
Teknologi fortsætter med at revolutionere byggebranchen, og i 2024 ser vi flere tendenser, der fremmer både effektivitet, sikkerhed og bæredygtighed. Her er nogle af de vigtigste teknologier, der præger byggebranchen i år.
1. Bæredygtige og modulære byggematerialer
Bæredygtighed står øverst på dagsordenen i byggebranchen. Modulære og præfabrikerede materialer vinder frem, hvor 3D-printing nu bliver brugt til at skabe byggematerialer, der reducerer spild og forbedrer effektiviteten. Dette er et skridt i retning af grønnere byggepraksis, som vil være med til at mindske branchens CO2-aftryk.
2. Bygningsinformationsmodellering (BIM)
BIM fortsætter med at være en afgørende teknologi i projektstyring. Det digitale overblik, BIM giver, gør det muligt at visualisere hele byggeprocessen, identificere potentielle konflikter og koordinere arbejdet mellem forskellige faggrupper. Dette hjælper med at reducere fejl og forsinkelser på byggepladsen
3. Overvågning med droner
Droner bliver stadig mere populære i byggebranchen og spiller en vigtig rolle i overvågning og sikkerhed på byggepladser. Droner kan hurtigt inspicere store områder og hjælpe med at identificere potentielle risici for både medarbejdere og materiel. De kan også overvåge arbejdet i realtid og levere data til projektledere, som kan bruge disse oplysninger til at optimere byggeprocessen
4. Kunstig intelligens og automation
AI spiller en stigende rolle i byggebranchen, hvor det bliver brugt til at analysere data og forudsige potentielle problemer, før de opstår. Automatisering hjælper også med at udføre gentagne opgaver, såsom muring eller rebar-arbejde, hurtigere og mere effektivt, hvilket frigør arbejdskraft til mere komplekse opgaver
5. IoT og bærbare sensorer
IoT-enheder og sensorer, som er integreret i arbejdstagernes personlige værnemidler, bliver brugt til at overvåge arbejdsmiljøet i realtid. Disse sensorer kan måle temperatur, luftkvalitet og andre forhold for at sikre, at arbejdsmiljøet er sikkert. Dette giver mulighed for hurtig indgriben, hvis forholdene på byggepladsen ændrer sig drastisk
Konklusion
I 2024 vil teknologier som droner, BIM, AI og bæredygtige materialer være afgørende for at sikre effektive og sikre byggeprocesser. Disse innovationer giver mulighed for bedre overvågning, smartere ressourceforvaltning og et større fokus på sikkerhed og bæredygtighed i branchen.
1 note
·
View note
Photo

I denne måned udgav Niels Damgaard og jeg en artikel hos ING/DataTech med titlen “Tre veje at gå for AI i retslig praksis og beslutningstagen: Højere grad af anvendelse af AI i sagsbehandling vil kræve lovændring, skriver jurastuderende Victoria Sobocki og cand.jur. Niels Damgaard.” Det var fedt at komme med input om emner som ligger inden for ens arbejds- og studieområde og jeg er taknemmlig for at have fået denne mulighed 😊🤖 I øjeblikket udvikles og anvendes AI af forvaltningen til en lang række opgaver, også når der skal træffes afgørelser over for borgere og virksomheder. Især systemer udviklet med machine learning viser et stort potentiale til at blive anvendt i stadig større udstrækning til at assistere sagsbehandlere, når de skal træffe afgørelser over for borgere, eller til at holde øje med, om borgere eller virksomheder overholder loven – men hvad kan problemerne ved samt løsningerne for dette være? . . Læs mere på pro.ing.dk/datatech/article/tre-veje-gaa-ai-i-retslig-praksis-og-beslutningstagen-13147 / tinyurl.com/AIbeslutningstagen . . “Ingeniørens PRO-medie DataTech er målrettet professionelle i såvel private virksomheder som offentlige organisationer, der arbejder med data science, AI, analytics med mere. DataTech giver dig inspiration, råd og erfaringer om, hvordan du analyserer og udnytter data, hvordan du navigerer ansvarligt og effektivt i junglen af love og regler på området, samt hvordan du udbreder værdien af dataanalyse til alle hjørner af organisationen. Vi giver dig viden om de nyeste teknologiske løsninger på tværs af fagområder, markeder og landegrænser. DataTech er medspiller i en fælles mission om at fostre etisk og sikker brug af data til fordel for virksomheder og borgere.” . . . . . . . . . . . #INGDATATECH #data #ingeniør #artikel #AI #artificialintelligence #legaltech #jura #UCPH #kbhuni #DKtech #NielsDamgaard #Damgaard #VictoriaSobocki #Sobocki #ArtificialIntelligenceandLegalDisruption #kunstigintelligens #Danmark #Copenhagen #AIlaw #AIpolicy #AIethics #fremtiden #machinelearning #futurism #AIregulation #sagsbehandling #ethics #blackbox #algorithms @DataTechdk (at Copenhagen) https://www.instagram.com/p/CQwd1vKB5jv/?utm_medium=tumblr
#ingdatatech#data#ingeniør#artikel#ai#artificialintelligence#legaltech#jura#ucph#kbhuni#dktech#nielsdamgaard#damgaard#victoriasobocki#sobocki#artificialintelligenceandlegaldisruption#kunstigintelligens#danmark#copenhagen#ailaw#aipolicy#aiethics#fremtiden#machinelearning#futurism#airegulation#sagsbehandling#ethics#blackbox#algorithms
0 notes
Photo

#callfordelegate Registration for delrgates is now open for the 13th World Nursing, Healthcare Management, and Patient Safety Conference, which is CME/CPD approved. Join us in Los Angeles, USA, on November 15–18, 2023. It unites international speakers and insider insights to study the most recent studies and trends. Grab your slot as an online listener/delegate now.
Email us at [email protected] WhatsApp: https://wa.me/442033222718 Register here: https://nursing.universeconferences.com/registration/
#nursing #patientsafety #healthcare #nurse #nurselife #nurses #nursingschool #nursingstudent #speakerdoctor #health #fitness #healthylife #selfcare #healthy #mentalhealth #nutrition #registerednurse #nursepractitioner #medicalstudent #studentnurse #medstudent #surgery #coronavirus #covid #Omicron #conferencia #MaamaaArtificial #Kunstigintelligens #enfermera #enfermeria
0 notes
Text
Test av KI-basert chat i Digitalarkivet
For et par år siden ble ChatGPT offentlig tilgjengelig, og det vi fikk prøve virket nesten litt… magisk? Plutselig var det mulig å kommunisere med en datamaskin med naturlig språk, og få fornuftige svar, til og med på norsk! Brukergrensesnittet minnet mye om chat-botene vi er vant med fra mange tjenester på nettet, men med KI-genererte svare føltes det nesten som at man kommuniserte med et menneske: Du kunne stille oppfølgingsspørsmål, eller be om enklere forklaringer, eller mer detaljer.
Kanskje en slik type KI-chat kunne være en være en fin måte å utforske og forstå arkivinnhold på, som et alternativ til tradisjonelt søk eller å få hjelp av en saksbehandler hos Arkivverket? Mange kan oppleve at arkivene kan være vanskelig å finne frem i, samtidig som arkivene inneholder mye materiale som er viktig eller interessant for store deler av befolkningen.
Men så var det med fornuftige svar, da. Helt fra starten var det åpenbart at ChatGPT og tilsvarende løsninger kunne komme med svar som var helt feil, med samme skråsikkerhet som riktige svar. Vi sier gjerne at den hallusinerer når den svarer feil. Dette er et stort problem med denne teknologien – du må egentlig dobbeltsjekke alle svar du får – og det sier også litt om måten slike KI-modeller utvikles på.
Bak KI-chatene ligger en stor språkmodell (LLM, eller Large Language Model). Disse lages (eller «trenes») ved å analysere store mengder tekst, i praksis store deler av internett. Disse modellene beregner (eller «predikerer») hva det neste ordet i svaret skal være. Det ødelegger kanskje litt av den magiske følelsen, men ChatGPT og tilsvarende løsninger er i bunn og grunn bare anvendt statistikk. Og hvis du spør om ting som er dårlig representert i treningsdataene så blir det statistisk grunnlag for å predikere ordene dårligere og du kan få oppdiktede svar. Det er også verdt å tenke på at KI-modellene ikke forholder seg til virkeligheten direkte, kun til tekster som beskriver virkeligheten. KI-modellen vet altså ikke selv om det den svarer er galt eller riktig.
Ofte inkluderer treningsdataene svært mye av tilgjengelig informasjon, men likevel vil fakta, meninger, tjenester og produkter som er viktige for f.eks. Digitalarkivet og arkiv-domenet ikke være en del av det modellen «vet». Det kan være fordi det er informasjon som er privat eller skjult, fordi den ikke anses som viktig nok til å inkludere eller fordi den er for ny. Hvis vi brukte f.eks. ChatGPT for å finne informasjon i Digitalarkivet vil den sjelden kunne gi riktige svar, samtidig som at det er en fare for at svarene den gir faktisk høres fornuftige ut.
Tillit til arkivene er svært viktig. Man må kunne stole på at det man finner er riktig, og at man finner det man trenger, og da passer det dårlig med løsninger som kan dikte opp opplysninger. Det er vanskelig å hindre hallusinasjoner i en AI-modell, men «Retrieval Augmented Generation» - eller RAG - er en måte å komme rundt problemet på.
RAG vil helt enkelt si at systemet kan basere svar på andre kilder enn de som modellen er trent på, slik at kunnskapshullene i modellen tettes. Det blir omtrent som å gi KI-modellen jukselapper. Det er fortsatt KI-modellen som skriver svarene, men den har altså tilgang til ekstra informasjon som den kan basere svarene på. RAG skjer i to trinn:
1. Hente informasjon Basert på informasjon i ulike databaser, kunnskapssamlinger, ontologier, dokumenter og bøker så lager man en samling over små kunnskapsbiter i form av "embeddings". Embeddings er et format som gjør at vi maskinelt kan finne likheter i betydning (semantisk) mellom f.eks ulike tekstsnutter. Når vi da får inn et spørsmål fra brukeren og gjør denne om til en embeddings kan vi gjøre et semantisk søk og finne de tekstbitene som er likest i betydning til det brukeren spør om.
2. Generere svar Brukerens spørsmål og de relevante bitene som har blitt funnet sendes som en pakke til en generativ KI-modell, som GPT, Claude, Mistral eller LlaMA, som laget et svar basert pakken den har fått. På denne måte kan vi sikre at KI-en har fått opplysningene den trenger for å gi et godt svar. Noe som er viktig i valg av modell er at den er god til å ta instruksjoner fra oss. I pakken vi sender legger vi nemlig til en hel masse beskjeder til modellen om hva den skal gjøre og ikke gjøre. Her finnes det et stort spenn av forskningsbaserte teknikker for å gi disse beskjedene på best mulig måte.

Denne teknologien har Arkivverket testet ut i en proof of concept (poc). Det er enkelt å sette opp en grunnleggende RAG-løsning, men for å få testet ut om RAG faktisk kan løse våre hypoteser om behov og utfordringer så har vi gått videre og laget en mer avansert og modulær RAG-arkitektur. Her har vi tatt i bruk ulike teknikker og algoritmer basert på forskning og det som rører seg i rag-verdenen på hvert av de ulike stegene i prosessen for å sørge for et mest mulig pålitelig og utfyllende svar til brukeren basert på våre data.
Poc-en består av to løsninger, som til sammen har latt oss teste ut RAG på flere typer innhold:
Den ene løsningen inneholder materiale om arkivkunnskap, som veiledninger og hjelpetekster. Dette kan være svært nyttig for brukere som har dårlig kjennskap til arkivene og som ikke helt vet hvordan de skal komme i gang med å finne informasjon.
Den andre inneholder to vidt forskjellige typer digitalisert arkivmateriale, henholdsvis arkiver fra Alexander Kielland-ulykken og dagbøker fra reindriftsforvaltningen.
En fordel med RAG er at det er relativt enkelt og billig å innarbeide mer informasjon, da dette skjer ved å oppdatere søket. Uten RAG ville vi vært nødt til å trene nye versjoner av selve KI-modellen for å oppdatere den med ny informasjon, noe som er langt mer ressurskrevende.
Det er et viktig poeng at løsning skal kjøre på våre egne systemer, heller enn at vi kobler oss på eksterne tjenester. Det er viktig at vi både har kontroll på teknologien vi bruker og på datagrunnlaget som legges inn i systemet. Det å kunne velge en modell som fungerer godt på norsk er viktig, og vi bør kunne bytte ut AI-modeller hvis det f. eks. dukker opp en ny som fungerer bedre til vårt bruk. Vi bør også ha mulighet til å velge teknologi ut ifra økonomiske faktorer.
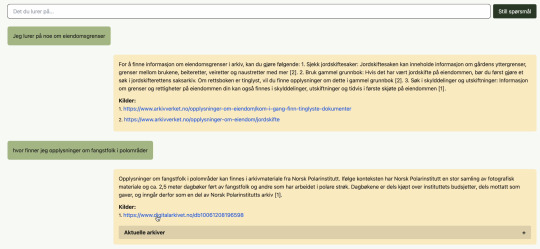
Poc-en inkluderer også et chatte-grensesnitt, som du selv kan teste ut ved å klikke på lenkene nederst i artikkelen. I menyen til venstre kan du justere flere aspekter ved hvordan spørsmålene blir behandlet og hva slags svar du får, så her er det bare å leke seg!
Det er to momenter til som er verdt å legge merke til, som begge er viktige for å skape tillit til resultatene:
I tillegg til at løsningen svarer på spørsmål, gir den også en lenke til originalkildene slik at brukeren kan få bekreftet svaret eller bla videre i originalkilden hvis hen ønsker å utforske innholdet mer.
Løsningen forklarer at den ikke kan svare hvis brukeren spør om noe som den ikke har informasjon om, i stedet for å hallusinere frem feil svar.
_ _ _
Poc-en har vist oss at en chatteløsning med RAG i bunnen har mange fordeler:
Brukeren får beskjed hvis systemet ikke vet svaret, heller enn at løsningen dikter opp et svar.
Brukeren kan benytte naturlig språk, og skrivefeil eller dårlige formuleringer blir ofte forstått
Systemet vil forstår betydningen av det brukeren spør om og kan derfor gi svar som kan være nyttige for brukeren selv om det ikke samsvarer i språk. Den kan også gi svar ut fra informasjon som er relatert til brukerens spørsmål i større grad en f.eks et leksikalt søk.
Brukeren kan ha en dialog med systemet, og for eksempel stille oppfølgingsspørsmål eller be om presiseringer.
Brukeren får lenker til originalkildene slik at det lett å verifisere svarene hen får.
Vi ser også noen utfordringer ved en slik løsning:
En slik avansert RAG-arkitektur er avansert og ressurskrevende å lage. Det kan tenkes at det finnes andre løsninger som gir noen av de samme gevinstene.
Svarene man får er basert på arkivmateriale som kan inneholde utrykk og holdninger som er foreldede eller støtene. Slik utrykk og holdninger kan dermed også finne veien inn svarene som chatboten gir. Brukere er nok forberedt på at eldre materiale inneholder språk som vi ikke vil brukt i dag, men det kan virke støtende eller underlig hvis slikt språk benyttes i en nyskrevet tekst. Det finnes teknikker for å minimere dette problemet som vi kan ta i bruk, men man vil neppe klare å eliminere det helt.
Og selv om RAG reduserer faren for oppdiktede svar betraktelig så er det ikke helt en vanntett metode. Den generative modellen som skal formulere svaret kan fortsatt klare å hallusinere innhold som ikke var med i informasjonsbitene som svaret skal baseres på. (https://arstechnica.com/ai/2024/06/can-a-technology-called-rag-keep-ai-models-from-making-stuff-up)
_ _ _
Vi har et godt grunnlag som kan peke ut noen retninger for videre utforsking, og vi er spente på hva vi kan lære av dere som prøver løsningen. Veien videre har ikke blitt avgjort, men selv om vi har laget en omfattende og grundig poc så er det mye arbeid igjen for å få en ferdig løsning. Hensikten med en poc er å finne ut om man er inne på noe, om konseptet er teknisk mulig å realisere. Det langt unna et ferdig produkt, noe som betyr at det kan forekomme små og store feil. Merk også at datagrunnlaget som benyttes ikke nødvendigvis er oppdatert, og at f. eks. veiledningene man søker i kan inneholde feil.
Et kjent problem er at selv om kildehenvisningen blir riktig, så kan den en sjelden gang f. eks. starte nummereringen på 2 eller hoppe over 3. Årsaken er at det søket er mer optimistisk enn språkmodellen-en og derfor finner flere mulige kilder til svar enn det språkmodellen faktisk finner svar i. Dermed kan listen over kilder ha litt underlig nummerering.
Her er lenker til de to løsningene, så du selv kan teste dem:
Veiledninger og arkiv-kunnskap: https://rag.beta.arkivverket.no
Alexander Kielland-ulykken og dagbøker fra reindriftsforvaltningen: https://rag-transcriptions.beta.arkivverket.no
Ta gjerne kontakt med oss på [email protected] hvis du har tilbakemeldinger, eller er nysgjerrig på arbeidet vårt med KI, søk eller digitalarkivet generelt.
0 notes
Photo

Repost from @techtopiadk • Techtopia 264: Når chefens AI kigger dig over skulderen 🔍 Hjemmearbejde kan for nogle godt resultere i en ekstra kop morgenkaffe, lidt sortering af vasketøj eller måske en lille lur efter frokost. Men holder din arbejdsgiver egentlig øje med det? Der findes efterhånden en række forskellige softwareprogrammer, der kan holde øje med, om du fx taster på dit tastatur eller klikker med din mus – altså en reel dataopsamling af dig som medarbejder. Det kaldes algoritmisk ledelse og får flotte ord med på vejen om højere effektivitet og bedre udnyttelse af tid og kompetencer. Men faktum er, at mange ansatte er bekymrede for, om deres arbejdsplads overvåger dem. Det viser en ny undersøgelse om danske arbejdspladser. 👥 Medvirkende: Grit Munk, chefkonsulent, IDA Mary Towers, employment rights policy officer in the Rights, International, Social and Economic department at the TUC Catrine Søndergaard Byrne, advokat Labora Legal 🎧 Du kan finde link til episoden på www.techtopia.dk. Her kan du også finde et link til ADD projektets rapport "Hver femte medarbejder har følt sig overvåget på arbejdspladsen". #Techtopia #techtopiadk #tech #techdk #techpodcast #ai #kunstigintelligens #algoritmiskledelse #dataindsamling #digitalovervågning #ADDprojektet #overvågningpåarbejdspladsen https://www.instagram.com/p/CmGQ4Jfs1hG/?igshid=NGJjMDIxMWI=
#techtopia#techtopiadk#tech#techdk#techpodcast#ai#kunstigintelligens#algoritmiskledelse#dataindsamling#digitalovervågning#addprojektet#overvågningpåarbejdspladsen
0 notes
Photo

Repost from @techtopiadk • Techtopia 261: Det er bare bryster Ada er en transkønnet kvinde, der i processen fra mand til kvinde lægger fotos af sin nøgne overkrop på det sociale medie Instagram i protest mod platformens censur af kvinders brystvorter. Bryster og brystvorter kan nemlig være svære at finde på Instagram – altså medmindre de sidder på en mand. Afbildning af kvinders brystvorter får kun i sjældne tilfælde lov til at blive liggende på platformen, men hvorfor er det sådan? Og hvordan ved Instagram præcis hvilke brystvorter, der er acceptable, og hvilke, der ikke er? Techtopia har inviteret Peter Svarre og Ada Hyldahl Fogh i studiet til en diskussion af digital etik og hvordan vi designer digitale løsninger, kunstig intelligens og algoritmer på en etisk forsvarlig måde. Adas kunstprojekt "in transitu" er også en kønspolitisk protest, der har til formål at få hendes Instagram-profil lukket. 👥 Medvirkende: Peter Svarre, foredragsholder, digital strateg og aktuel med bogen ”Digital Etik” Ada Hyldahl Fogh, kunstner, interaktionsdesigner, programmør og skaber af kunstværket "in transitu" under kunstnernavnet Ada Ada Ada (@ada_ada_ada_art) 🎧 Find episoden på www.techtopia.dk #Techtopia #tech #techpodcast #dktech #digitaletik #kunstigintelligens #ai #algoritmer #bias #kønsgenkendelse #genderbias #socialemedier #etikkompasset #DetDigitaleEtikkompas #DanskDesignCenter #ddc https://www.instagram.com/p/ClPW8kSMyyI/?igshid=NGJjMDIxMWI=
#techtopia#tech#techpodcast#dktech#digitaletik#kunstigintelligens#ai#algoritmer#bias#kønsgenkendelse#genderbias#socialemedier#etikkompasset#detdigitaleetikkompas#danskdesigncenter#ddc
0 notes
Photo

Nye brugergrænseflader/UI/UX 💡🤖🔎 Jeg er i gang med at undersøge hvad der rører sig inden for nye brugergrænseflader/user interfaces og experiences. Kender du nogle virksomheder/personer/cases der arbejder med innovative og nye måder at tænke brugergrænseflader på? Så kontakt mig endelig. Det kan både være konkrete services/produkter eller på et mere strategisk/teoretisk plan. Dette kan f.eks. være inden for: Gesture control, BCI (Brain-Computer-Interfaces)/Neural interfaces, Kropslige interfaces, Biometrics, AR & VR interfaces, Deepfakes, Tangible user interfaces, chatbots, samtaler og hologrammer, Fleksible interfaces, Emotion-sensing technology (EST), Teleoperation interfaces, Anti UI/Sikkerhed, Ambient intelligence, Nearables, Haptiske/kinæstetiske interfaces og mange andre. På forhånd mange tak! Photo sources: www.enginess.io & www.interestingengineering.com . . . . . . . #dkstartup #legaltech #UI #UX #userinterface #userexperience #brugergrænseflader #digitalebrugergrænseflader #interfaces #futureuserinterfaces #futureinterface #virksomhed #tech #teknologi #DKtech #Danmark #Denmark #Danish #AI #kunstigintelligens #artificialintelligence #neuralinterface #BCI #gesturecontrol #AR #VR #biometrics #deepfakes #iværksætter #virtualreality (her: Copenhagen) https://www.instagram.com/p/CKehUTfhToa/?igshid=1unm64rf5gg6v
#dkstartup#legaltech#ui#ux#userinterface#userexperience#brugergrænseflader#digitalebrugergrænseflader#interfaces#futureuserinterfaces#futureinterface#virksomhed#tech#teknologi#dktech#danmark#denmark#danish#ai#kunstigintelligens#artificialintelligence#neuralinterface#bci#gesturecontrol#ar#vr#biometrics#deepfakes#iværksætter#virtualreality
0 notes
Photo

#callfordelegate The onsite Registration is now open for the 11th World Nursing, Healthcare Management, and Patient Safety Conference, which is CME/CPD/CE approved. Join us in San Francisco, USA, on November 15–18, 2022. It unites international speakers and insider insights to study the most recent studies and trends. Grab your slot as an online listener/delegate now.
Email us at [email protected] WhatsApp: https://wa.me/442033222718 Register here: https://nursing.universeconferences.com/registration/
#nursing #patientsafety #healthcare #nurse #nurselife #nurses #nursingschool #nursingstudent #speakerdoctor #health #fitness #healthylife #selfcare #healthy #mentalhealth #nutrition #registerednurse #nursepractitioner #medicalstudent #studentnurse #medstudent #surgery #coronavirus #covid #Omicron #conferencia #MaamaaArtificial #Kunstigintelligens #enfermera #enfermeria
0 notes
Photo

#Callforrgistration If you are interested to be a part of this conference as a speaker or delegate then register yourself today. Our CME/CPD/CE accredited 11th World Nursing, Healthcare Management, and Patient Safety Conference will be held on November 15-18, 2022 in San Francisco, USA. Registration deadline is extended to 14th November.
Register here: https://nursing.universeconferences.com/registration/ #Nursing #NursingConference #UCGConferences #doctor #Globaliseeruminejatervis #GlobalisasyonatKalusugan #NakamamataynaEpektongCoronavirussaTao #naturopathicdoctor #doctorsoffice #medicaldoctor #futuredoctors #ninthdoctor #doctorwhocosplay #researchpaper #researchers #biochemistry #medicalresearch #instascience #sciencecommunication #scicomm #phdchat #research #MaamaaArtificial #Kunstigintelligens
0 notes
Photo

#callfordelegate Registration is now open for the 11th World Nursing, Healthcare Management, and Patient Safety Conference, which is CME/CPD/CE approved. Join us in San Francisco, USA, on November 15–18, 2022. It unites international speakers and insider insights to study the most recent studies and trends. Grab your slot as an online listener/delegate now.
Email us at [email protected] WhatsApp: https://wa.me/442033222718 Register here: https://nursing.universeconferences.com/online-registration/
#nursing #patientsafety #healthcare #nurse #nurselife #nurses #nursingschool #nursingstudent #speakerdoctor #health #fitness #healthylife #selfcare #healthy #mentalhealth #nutrition #registerednurse #nursepractitioner #medicalstudent #studentnurse #medstudent #surgery #coronavirus #covid #Omicron #conferencia #MaamaaArtificial #Kunstigintelligens #enfermera #enfermeria
0 notes
Photo

#Callforrgistration If you are interested to be a part of this Webinar as a speaker or delegate then register yourself today. Our CME/CPD/CE accredited 11th World Nursing, Healthcare Management, and Patient Safety Conference will be held on November 15-18, 2022 in San Francisco, USA. Final Registration deadline has been extended to 10th November.
Email us at [email protected] WhatsApp: https://wa.me/442033222718 Register here: https://nursing.universeconferences.com/registration/
#Nursing #NursingConference #UCGConferences #doctor #Globaliseeruminejatervis #GlobalisasyonatKalusugan #NakamamataynaEpektongCoronavirussaTao #naturopathicdoctor #doctorsoffice #medicaldoctor #futuredoctors #ninthdoctor #doctorwhocosplay #researchpaper #researchers #biochemistry #medicalresearch #instascience #sciencecommunication #scicomm #phdchat #research #MaamaaArtificial #Kunstigintelligens
0 notes
Photo

#Callforrgistration If you are interested to be a part of this Webinar as a speaker or delegate then register yourself today. Our CME/CPD/CE accredited 11th World Nursing, Healthcare Management, and Patient Safety Conference will be held on November 15-18, 2022 in San Francisco, USA. Registration deadline is extended to 27th October.
Register here: https://nursing.universeconferences.com/registration/
#Nursing #NursingConference #UCGConferences #doctor #Globaliseeruminejatervis #GlobalisasyonatKalusugan #NakamamataynaEpektongCoronavirussaTao #naturopathicdoctor #doctorsoffice #medicaldoctor #futuredoctors #ninthdoctor #doctorwhocosplay #researchpaper #researchers #biochemistry #medicalresearch #instascience #sciencecommunication #scicomm #phdchat #research #MaamaaArtificial #Kunstigintelligens
0 notes
Photo

#Callforrgistration If you are interested to be a part of this Webinar as a speaker or delegate then register yourself today. Our CME/CPD/CE accredited 11th World Nursing, Healthcare Management, and Patient Safety Conference will be held November 15-17, 2022 in San Francisco, USA. Registration deadline is extended to 27th September.
Register here: https://nursing.universeconferences.com/registration/
#Nursing #NursingConference #UCGConferences #doctor #Globaliseeruminejatervis #GlobalisasyonatKalusugan #NakamamataynaEpektongCoronavirussaTao #naturopathicdoctor #doctorsoffice #medicaldoctor #futuredoctors #ninthdoctor #doctorwhocosplay #researchpaper #researchers #biochemistry #medicalresearch #instascience #sciencecommunication #scicomm #phdchat #research #MaamaaArtificial #Kunstigintelligens
0 notes