#int4
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text
INT8 & INT4 Weight Only Quantization WOQ On Intel Extension

Weight Only Quantization(WOQ)
A practical guide to Large Language Models (LLMs) quantization. The capabilities, uses, and complexity of large language models (LLMs) have all significantly risen in recent years. With an ever-increasing amount of parameters, weights, and activations, LLMs have become larger and more intelligent.
However, They usually have to compress LLMs without significantly sacrificing their performance in order to increase the number of possible deployment targets and lower the cost of inference. Large neural networks, including language models, may be made smaller using a variety of methods. Quantization is one such crucial method.
WOQ meaning
In machine learning, especially in deep learning, Weight Only Quantization (WOQ) is a technique that minimizes the size of neural network models without compromising their functionality. It entails quantizing just the neural network’s weights the parameters that define the behavior of the model into a format with less precision (e.g., 8-bit instead of 32-bit).
This article provides an example of code that uses the Intel Extension for Transformers tool to conduct Weight Only Quantization (WOQ) on an LLM (Intel/neural-chat-7b model) for both INT8 and INT4.
How does quantization work?
INT8 Vs INT4
The process of switching to lower precision data types, such as float16, INT8 or INT4, from high-precision representation, such as float32, for weights and/or activations is known as quantization. Lower precision may greatly minimize the amount of memory needed.
While this may seem simple in principle, there are a lot of subtleties to consider, and computing data type is the most crucial warning to know. Certain operations need us to scale the representation back to high precision at runtime since not all operations support or have low-precision implementation. Although there is some additional cost, they may lessen its effects by using tools like Intel Neural Compressor, OpenVINO toolkit, and Neural Speed.
Because these runtimes include optimized implementations of several operators for low-precision data types, upscale values to high-precision is not necessary, resulting in improved speed and reduced memory use. If lower-precision data types are supported by your hardware, the performance improvements are substantial. For instance, support for float16 and bfloat16 is included into Intel Xeon Scalable processors of the 4th generation.
Therefore, quantization only serves to lower the model’s memory footprint; nevertheless, it may also introduce some cost during inference. Using optimized runtimes and the newest hardware is required to obtain both memory and performance improvements.
What Does WOQ Mean?
There are several methods for quantizing models. Model weights and activations the output values produced by every neuron in a layer are often quantized. One of these quantization methods, called Weight Only Quantization(WOQ), preserves the original accuracy of the activations while only quantizing the model weights. Faster inference and a reduced memory footprint are the clear advantages. In actual use, WOQ improves performance without appreciably affecting accuracy.
Code Execution
The Intel/neural-chat-7b-v3-3 language model’s quantization procedure is shown in the provided code sample. The model, which is an improved version of Mistral-7B, is quantized using Weight Only Quantization (WOQ) methods made available by the Intel Extension for Transformers.
With only one line of code, developers can easily use the power of Intel technology for their Generative AI workloads. You import AutoModelForCausualLM from Intel Extension for Transformers rather of the Hugging Face transformers library, and everything else stays the same.
1. From intel_extension_for_transformers.transformers import AutoModelForCausalLM
For INT8 quantization, just set load_in_8bit to True.
1. # INT8 quantization 2. Q8_model = AutoModelForCausalLM.from_pretrained( 3. model_name, load_in_8bit=True)
Similarly, for INT4 quantization set load_in_4bit to True.1. # INT4 quantization 2. q4_model = AutoModelForCausalLM.from_pretrained( 3. model_name, load_in_4bit=True)
The Hugging Face transformers library may be used in the same way for implementation.
If you set device to GPU, the aforementioned code snippets will utilize BitandBytes for quantization. This makes your code run much faster without requiring any code changes, regardless of whether you are utilizing a CPU or GPU.
GGUF model in operation
A binary file format called GGUF was created expressly to store deep learning models like LLMs especially for CPU inference. It has several important benefits, such as quantization, efficiency, and single-file deployment. They will be utilizing the model in GGUF format in order to maximize the performance of their Intel hardware.
Generally, one would need to utilize an extra library like Llama_cpp in order to execute models in GGUF format. Still, you may use it Intel Extension for Transformers library to run GGUF models since Neural Speed is built on top of Llama_cpp.1. model = AutoModelForCausalLM.from_pretrained( 2. model_name=“TheBloke/Llama-2-7B-Chat-GGUF”, 3. model_file=“llama-2-7b-chat.Q4_0.gguf” 4. )
Take a look at the code example. The code example demonstrates how to use Intel’s AI Tools, Intel Extension for Transformers, to quantize an LLM model and how to optimize your Intel hardware for Generative AI applications.
INT4 vs INT8
Quantizing LLMs for Inference in INT4/8
Better quantization approaches are becoming more and more necessary as models become bigger. However, what is quantization exactly? Model parameters are represented with less accuracy by quantization. For example, using float16 to represent model weights instead of the widely used float32 may reduce storage needs by half.
Additionally, it improves performance at lesser precision by lowering computational burden. Nevertheless, a drawback of quantization is a little reduction in model accuracy. This happens when accuracy decreases and parameters have less representation power. In essence, quantization allows us to sacrifice accuracy for better inference performance (in terms of processing and storage).
Although there are many other approaches to quantization, this sample only considers Weight Only Quantization (WOQ) strategies. Model weights and activations the output values produced by every neuron in a layer are often quantized. But only the model weights are quantized by WOQ; activations remain unaltered. In actual use, WOQ improves performance without appreciably affecting accuracy.
The transformers library from HuggingFace makes quantization easier by offering clear choices. To enable quantization, users just need to specify the load_in_4bit or load_in_8bit option to True. But there’s a catch: only CUDA GPUs can use this capability. Unfortunately, only CUDA GPU devices can use the BitsandBytes configuration that is automatically built when these arguments are enabled. For consumers using CPUs or non-CUDA devices, this presents a problem.
The Intel team created Intel Extension for Transformers (ITREX), which improves quantization support and provides further optimizations for Intel CPU/GPU architectures, in order to overcome this constraint. Users may import AutoModelForCasualLM from the ITREX library rather of the transformers library in order to use ITREX. This allows users, irrespective of their hardware setup, to effortlessly use quantization and other improvements.
The from_pretrained function has been expanded to include the quantization_config, which now takes in different settings for CUDA GPUs and CPUs to perform quantization, including RtnConfig, AwqConfig, TeqConfig, GPTQConfig, and AutoroundConfig. How things behave when you set the load_in_4bit or load_in_8bit option to True is dependent on how your device is configured.
BitsAndBytesConfig will be used if the CUDA option is selected for your device. RtnConfig, which is specifically tailored for Intel CPUs and GPUs, will be used, nonetheless, if your device is set to CPU. In essence, this offers a uniform interface for using Intel GPUs, CPUs, and CUDA devices, guaranteeing smooth quantization across various hardware setups.
Read more on govindhtech.com
#INT8#int4#WeightOnlyQuantization#WOQ#intelextension#largelanguagemodel#intelneuralcompressor#quantizingmodels#generativeai#CPU#GPU#deeplearningmodels#News#TechNews#Technology#technologynews#technologytrends#govindhtech
0 notes
Text
RaR Musings #7: Meaningful Mechanics
I saw a post this week about other people in the ttrpg design space, lamenting their years of work, and being dismissed for their project seeming like "a dnd clone". A fair concern, to be sure, but it would turn out the criticism stemmed from having a fantasy themed roleplaying game, that uses a d20 and adds proficiency, has character creation that involves classes, and spellcasting with multiple levels of spells. Others suggested there might be similarities if you use the standard stats, like STR, DEX, and INT.
So what's a guy with a fantasy themed roleplaying game that uses Xd10, adding proficiency, has a character creation engine that has classes as a minor element, and spellcasting with a mana system allowing you to cast spells at a higher level, using some basic stats, to do?
Firstly: not worry about it. Creativity is iterative, and DND has been the fantasy roleplay standard for nigh on 50 years, having affected pop culture and videogame design alike. It'd be hard NOT to have anything similar to it, and for those who have no experience outside of DND, dipping a toe outside that space can seem daring and adventurous. The writer is probably upset because they don't understand how generally meaningless their reinventing of the wheel was in terms of convincing people to play their game instead; in fact, there wasn't any mention of WHY he made the effort to design his own game in the first place. Was it distaste for existing products? Because he had vision? Or just to prove that he could do it too, a kind of intellectual parroting?
Game mechanics can't be copywritten, so while it's not illegal to copy mechanics, there needs to be certified thought put into what those mechanics are meant to achieve, and why they may fail to do so.
As an example: both d20 games and Road and Ruin involve rolling dice to generate a random value, and then adding your proficiency as a flat number.
DND falls down here because even high proficiency, like +11 or +13, barely crests over half of the value generated by random d20, much less the more regular +1 to +6. This means a specialist, someone who has lifelong expertise at their craft, can still bungle even a basic action, giving other players a chance to perform, but completely botching the class fantasy of being a specialist, and there's no coded mechanics for varying levels of success or failure to even reward being a specialist beyond increased binary success rate. Multiple overlapping proficiencies don't have cumulative value, and outside of house rules, you can't mix and match Attribute to Proficiency, such as using Strength for Intimidation. However, the system is simplistic, and easy to understand. Not having different values for different proficiencies means only having to refer to a single number as a bonus, which makes stat scaling much more predictable, and as mentioned, giving other players the limelight means the skill monkeys won't hog it.
Road and Ruin HAD a much more 'unique' skill check system; roll your attribute (1-10) as Xd10, and your proficiency (two 0-5 proficiencies combined) determined the minimum score any dice could land. Dice were adjusted, totalled, and the sum divided by 10 to find Success Rate, with scores of 1 or higher expected. This ended up being too much adjusting and adding; it produced the ideal values, but was too slow, and not very fun, especially to do repetitively. Worse, it didn't enable 'skill' to exceed 'raw talent'; you needed a high attribute for the guaranteed 'floor' that proficiency provided to matter, and I wanted those with training to potentially exceed those without training. If INT4 rolls 4d10, and Proficiency 3 meant you couldn't get below a 3 on each, for a 'floor' of 12-40, that still meant an average ~22, regardless of if you were trained or not. Specialization 'rolled' an additional 1d10, but set it aside as an automatic 10, thus improving skill checks beyond what was possible via random dice rolls, raising both floor and ceiling by 10, but not solving the issue of speed or reliability.
So now, Road and Ruin has a Roll + Proficiency system too, except you roll Xd10 (1-5), and Proficiency is two scores (0-5 each), combined, and multiplied by Specialization, with a cheat-sheet of the most common Proficiency results for your character. Adding the dice, and Proficiency, before finding successes, is still slow, but faster now, and due to the multiplication of scores and specialization, your character may even automatically succeed basic tasks, without the need for a roll at all. Such skillmonkeying requires utmost devotion though, and is far better suited to an NPC assistant; but, said NPC will still be built using the same mechanics as what goes into a character, making it easier to understand and appreciate their service.
More importantly: I like it. I understand that others might not; it doesn't have the hallmarks of DND's 'gamble' economy, getting high rolls and confetti when you hit a 20, but frankly, I'm building this game for me, not for people who are satisfied with DND. Even my nine attributes are inspired by World of Darkness, though slightly redefined to suit the needs of my setting instead, and the proficiency skill list is entirely my own, designed to offer as many cases of two overlapping skills as possible. Using any attribute in the skill check, based on what you aim to affect rather than what the proficiency is most known for (using DEX and herbalism to get plant clippings, or INT and herbalism to recall plant facts, for example) is a much more direct and diverse way to handle skill checks, rather than trying to remember whether Nature in DND is Intelligence or Wisdom, and why. Rolling multiple dice instead of 1d20 helps protect against fringe rolls, making the rare cases truly rare, as well as creating a market for spells, equipment, and abilities that affect your skill checks to have meaningful use, rather than simply adding a +1.
But I'm having fun doing all this. Road and Ruin began because I was upset with DND, and over the years, I've done a lot of work, first to intentionally distance it from DND, and only later to begin to paint it in my own colors, doing what I want, not in rebellion of what I don't. Anybody looking to design their own systems should be more preoccupied with how their mechanics feel; if people think that it's too similar to an existing product, one that you intentionally avoided? Then that's tough beans for them. They don't get to define how you have fun, and at the end of the day, that's what playing, and designing, a game is all about.
12 notes
·
View notes
Note
Hi!! Some questions for you: what are some things you’ve learned recently? What’s your favorite smell? What’s your dream vacation?
hmm, let's see...
learned recently: how to make a UML diagram, when to water a jacaranda, the fact that plant pots need drains (but don't put in rocks because it pushes up the saturation zone), existence of int4 quantization to accelerate neural nets, and the fact that my cat may have started drinking out of the toilet this week
favorite smell: easy, burning the fuck out of a corn tortilla no pan raw on the stovetop
dream vacation: this one's harder to say, i think something crazy like a writer's or artists's retreat in some remote place would be pretty fun. just disconnect from life and work for a week or month or two, do nothing but work on the thing and go for walks and eat simple meals. like a firewatch tower or something.
4 notes
·
View notes
Photo

Did you know the AMD Radeon AI PRO R9700 GPU outperforms the Radeon PRO W7800 with 4x more TOPS and double the AI performance? This powerhouse features 128 AI accelerators, 32GB GDDR6 memory, and up to 300W TDP, aiming to revolutionize AI workloads and high-quality model training. With twice the FP16 compute and 4x uplift in INT8/INT4 TOPS over its predecessor, it’s designed for demanding deep learning tasks and large model handling. Scaling in 4-way multi-GPU setups allows for massive data pools, perfect for advanced AI inference and training, including big models like Mistral and DeepSeek. Ready to build a future-proof AI workstation? Explore custom computer builds with GroovyComputers.ca to get your hands on this cutting-edge GPU. What AI project will you accelerate with this new GPU? Let us know below! 🚀 #AI #MachineLearning #DeepLearning #GPU #TechInnovation #CustomPC #AIworkstation #GroovyComputers #AMD #GPUperformance #AIhardware #TechTrends
0 notes
Photo

Did you know the AMD Radeon AI PRO R9700 GPU outperforms the Radeon PRO W7800 with 4x more TOPS and double the AI performance? This powerhouse features 128 AI accelerators, 32GB GDDR6 memory, and up to 300W TDP, aiming to revolutionize AI workloads and high-quality model training. With twice the FP16 compute and 4x uplift in INT8/INT4 TOPS over its predecessor, it’s designed for demanding deep learning tasks and large model handling. Scaling in 4-way multi-GPU setups allows for massive data pools, perfect for advanced AI inference and training, including big models like Mistral and DeepSeek. Ready to build a future-proof AI workstation? Explore custom computer builds with GroovyComputers.ca to get your hands on this cutting-edge GPU. What AI project will you accelerate with this new GPU? Let us know below! 🚀 #AI #MachineLearning #DeepLearning #GPU #TechInnovation #CustomPC #AIworkstation #GroovyComputers #AMD #GPUperformance #AIhardware #TechTrends
0 notes
Text
RTX3090/RTX4090 部署 Deepseek-R1 蒸餾模型
本文使用 RTX3090 或 RTX4090 在本地部署 Deepseek-R1,完整支援知識蒸餾模型 qwen-7B 與 llama-8B,具備高效能 INT4/FP16 推理能力與 LoRA 微調支持,適合中文大型語言模型本地訓練與離線開發環境,降低延遲與成本。
0 notes
Link
Google rilascia i modelli Gemma 3 QAT
Google ha rilasciato una versione ottimizzata per la Quantization-Aware Training (QAT) della sua serie Gemma3, riducendo significativamente i requisiti di memoria senza compromettere la qualità del modello.
0 notes
Text
According to the interloper wiki, int_menu consists of two parts - a red room and a chessboard. But there is one problem.

not equal

The textures of the floor vary (HD and emo). You don't need a key to get through the door on the INT4 int_menu map. But the lights are very similar.
My theories are:
Either the int_menu map consists of small (red), medium (HD), and large (EMO) planes,
Either the EMO plane is the lower bound of coordinates (because in that version of the engine, coordinates are expressed in hex code with 10 characters per dimension, meaning the infinite world is finite)
6 notes
·
View notes
Text
Snapdragon 6 من الجيل الرابع: نقلة نوعية في عالم الهواتف المتوسطة

المُلخص: - تم تصنيع معالج Snapdragon 6 Gen 4 بتقنية 4 نانومتر من TSMC، مما يوفر أداءً وكفاءةً محسنين. - يتميز بوحدة معالجة رسومات أفضل بنسبة 29%، وترقية دقة ألعاب 1080 بكسل إلى 4K. - يتضمن Snapdragon 6 Gen 4 دعمًا جديدًا لـ INT4 لتشغيل نماذج LLM المحسّنة في ذاكرة وصول عشوائي محدودة. بعد بعض الشائعات هنا وهناك، ظهر Snapdragon 6 Gen 4 بشكل مفاجئ اليوم. ركزت Qualcomm بشكل كبير على معالجاتها من سلسلتي 7 و8، مما جعل سلسلة 6 Gen تبدو مخيبة للآمال بعض الشيء في الأجيال القليلة الماضية. لكن هذه المرة، قدمت Qualcomm بعض التحسينات التي تشتد الحاجة إليها في Snapdragon 6 Gen 4 الجديد، واعدةً بتجربة هاتف ذكي أفضل بشكل عام.
مواصفات Qualcomm Snapdragon 6 الجيل الرابع
تُعتبر الترقية الأبرز في رأيي هي حقيقة أن Snapdragon 6 Gen 4 هو أول معالج في هذه السلسلة يُصنع بتقنية 4 نانومتر من TSMC ويستخدم أنوية ARMv9 الجديدة. وفقًا لـ الملف التعريفي للمنتج، تتضمن مجموعة الأنوية نواة رئيسية تعمل بتردد 2.3 جيجاهرتز، تليها ثلاث أنوية Cortex A720 أخرى تعمل بتردد 2.2 جيجاهرتز. أما بالنسبة لأنوية الكفاءة، فهناك مجموعة من أربع أنوية Cortex A520 تعمل بتردد 1.8 جيجاهرتز.

لم تقدم Qualcomm الكثير من التفاصيل حول وحدة معالجة الرسومات، لكننا نعلم أن أداءها أفضل بنسبة 29% من تلك المستخدمة في Snapdragon 6 Gen 3. كما أنها تتميز بتقنية Snapdragon Game Super Resolution التي تعمل على تحسين دقة ألعاب 1080p إلى 4K. وهذا يُعد إنجازًا آخر لسلسلة معالجات 6. بالإضافة إلى ذلك، من المُتوقع أن تُحسّن تقنية توليد حركة إطارات Adreno من تجربة الألعاب الإجمالية مع هذه الوحدة المركزية. يدعم المعالج تقنيات الذكاء الاصطناعي على الجهاز ودعم INT4، مما يعني أنه يمكنه استيعاب المزيد من نماذج LLM المُحسّنة في تكوين ذاكرة الوصول العشوائي المحدودة. وبالحديث عن الذاكرة، فإنه يدعم ذاكرة وصول عشوائي LPDDR5 بسعة 16 جيجابايت بتردد 3200 ميجاهرتز، و UFS 3.1 للتخزين. تمتد دقة الشاشة إلى 1080 بكسل+ بمعدل تحديث 144 هرتز، وألوان 10 بت، و HDR 10+، وتشغيل فيديو بدقة 4K بمعدل 60 إطارًا في الثانية. علاوة على ذلك، يحتوي Snapdragon 6 Gen 4 على ثلاث وحدات معالجة إشارة صور (ISP) بدقة 12 بت تدعم مستشعرات تصل إلى 200 ميجابكسل. وهذا مشابه لما رأيناه في الجيل السابق، لكن دعم الكاميرا المفردة قد ارتفع إلى 64 ميجابكسل. يوفر تسجيل فيديو بدقة 4K بسرعة 30 إطارًا في الثانية. وهناك تسريع للأجهزة لتشغيل H.265 و VP9، لكن AV1 مفقود. الاتصال مُطابق تقريبًا لـ Snapdragon 6 Gen 3. يوجد مودم 5G مع دعم mmWave و sub-6GHz يوفر سرعة تنزيل تبلغ 2.9 جيجابت في الثانية. كما يوفر دعم Wi-Fi 6E (802.11ax) و Bluetooth 5.4 LE. والأخير هو ترقية من الإصدار السابق. فيما يلي ملخص سريع لجميع الميزات البارزة في Snapdragon 6 Gen 4 مقارنةً بـ 6 Gen 3. المواصفات Snapdragon 6 Gen 4 Snapdragon 6 Gen 3 تقنية التصنيع 4 نانومتر 4 نانومتر وحدة المعالجة المركزية نواة Cortex-A720 واحدة بتردد 2.3 جيجاهرتز 3 أنوية Cortex-A720 بتردد 2.2 جيجاهرتز 4 أنوية Cortex-A520 بتردد 1.8 جيجاهرتز 4 أنوية Cortex-A78 بتردد 2.4 جيجاهرتز 4 أنوية Cortex-A55 بتردد 1.8 جيجاهرتز وحدة معالجة الرسومات Adreno GPU مع قفزة أداء بنسبة 29% مقارنةً بـ 6 Gen 3 Adreno 710 ذاكرة الوصول العشوائي LPDDR5 تصل إلى 3200 ميجاهرتز LPDDR5 تصل إلى 3200 ميجاهرتز الشاشة Full HD+ بمعدل تحديث 144 هرتز Full HD+ بمعدل تحديث 120 هرتز معالج إشارة الصورة 12 بت 12 بت الكاميرا 200 ميجابكسل، 64 ميجابكسل مع خاصية Zero Shutter Lag 200 ميجابكسل، 48 ميجابكسل مع خاصية Zero Shutter Lag الفيديو 4K بمعدل 30 إطارًا في الثانية 4K بمعدل 30 إطارًا في الثانية الاتصال Wi-Fi 6E، Bluetooth 5.4 LE Wi-Fi 6E، Bluetooth 5.2 الشحن QuickCharge 4+ QuickCharge 4+
Snapdragon 6 Gen 4 من Qualcomm: التوفر والسعر

كما يوحي الاسم، سيُستخدم هذا المعالج في الأجهزة ذات الميزانية المتوسطة، وستكون علامات تجارية مثل Oppo وRealme وHonor أول من يستخدم Snapdragon 6 Gen 4. لا توجد معلومات مؤكدة حول موعد إطلاق الأجهزة المزودة بهذه المعالجات، ولكن من المتوقع أن نسمع بعض التفاصيل في الأشهر المقبلة. من المتوقع أن يُحدث هذا المعالج نقلة نوعية في أداء الهواتف الذكية من الفئة المتوسطة، حيث يوفر تحسينات ملحوظة في سرعة المعالجة وكفاءة استهلاك الطاقة. من المحتمل أن تكون الهند أول منطقة تتلقى هواتف تعمل بمعالج 6 Gen 4، وبالنظر إلى أنها سوق حساسة للغاية للأسعار، فمن المرجح أن تستهدف الشركات المصنعة للهواتف نطاقًا سعريًا يتراوح بين 100 و150 دولارًا أمريكيًا. يُتوقع أن يُعزز هذا المعالج التنافُسية في سوق الهواتف الذكية من الفئة المتوسطة، مما يوفر للمستخدمين تجربة استخدام مُحسّنة بسعر معقول. Read the full article
0 notes
Text
业内:DeepSeek或准备适配国产GPU
根据现有资料,DeepSeek正在逐步适配国产GPU,并可能绕开英伟达的CUDA平台,这一趋势得到了多方面的支持和验证。
从技术层面来看,DeepSeek通过汇编式PTX编程而非依赖CUDA,展示了其在硬件适配上的灵活性。这种技术路线使得DeepSeek能够更好地兼容不同硬件平台,包括国产GPU。例如,AMD已经宣布将DeepSeek V3集成到MI300X GPU中,这表明DeepSeek的技术已经具备了与国产GPU合作的基础。此外,DeepSeek的技术报告也显示,其开发团队掌握了PTX语言,这为其适配国产GPU提供了技术支持。
从市场和政策环境来看,中国对自主可控技术的重视以及国产GPU技术的崛起为DeepSeek适配国产GPU创造了有利条件。近年来,国产GPU如华为昇腾、景嘉微等逐步成熟,性能不断提升,这为DeepSeek等AI模型提供了替代方案。例如,DeepSeek已经与华为昇腾展开合作,通过优化算法和硬件协同,显著降低了运行成本。此外,DeepSeek的开源策略也鼓励了更多国产算力芯片的发展。
从产业生态的角度来看,DeepSeek的适配不仅有助于减少对英伟达GPU的依赖,还可能推动国产GPU产业链的进一步发展。例如,DeepSeek的突破验证了国产芯片(如昇腾)的可行性,为国内算力基建投资提供了新的方向。同时,DeepSeek的技术创新和成本优势也吸引了小米等国内科技公司加入其生态链,进一步推动了国产AI技术的应用。
然而,值得注意的是,尽管DeepSeek正在逐步适配国产GPU,但其在某些方面仍可能继续依赖英伟达的高端GPU。例如,英伟达的H800 GPU被用于训练DeepSeek V3模型,并且DeepSeek的某些版本仍然支持英伟达的CUDA平台。这表明DeepSeek的适配策略可能是渐进式的,既利用现有高端GPU资源,又逐步向国产GPU过渡。
DeepSeek正在积极适配国产GPU,并通过技术创新和生态合作推动国产AI技术的发展。这一趋势不仅反映了中美科技竞争背景下的市场需求变化,也展现了国产AI技术在全球AI领域中的竞争力。
DeepSeek选择汇编式PTX编程而非依赖CUDA的具体原因是什么?
DeepSeek选择汇编式PTX编程而非依赖CUDA的具体原因可以从以下几个方面进行分析:
1. 更精细的GPU控制:
PTX(Parallel Thread Execution)是一种接近汇编语言的中间指令集,允许开发者进行更细致的硬件层面优化,例如寄存器分配、线程/线程束级别的调整等。这些操作在传统CUDA编程中无法实现,因为CUDA主要是一种高级编程语言,虽然接近人类语言,但在灵活性和控制力上不如PTX。
2. 针对多机多卡训练的需求:
在大规模模型训练中,尤其是涉及多机多卡的场景,需要对数据传输、权重管理以及梯度管理等进行更精细的控制。PTX语言能够提供这种能力,而CUDA则更多依赖于高级抽象,可能无法满足这些复杂需求。
3. 技术挑战与创新:
PTX编程虽然复杂且难以维护,但DeepSeek团队通过技术创新实现了突破。他们不仅掌握了AI算法和计算机系统架构知识,还招聘了擅长PTX语言的程序员,从而能够���接使用PTX进行算法层面的硬件加速。这种技术手段不仅提升了性能,也展示了DeepSeek在硬件适配上的能力。
4. 摆脱对英伟达的依赖:
PTX作为英伟达专为自家GPU设计的指令集,使得DeepSeek能够在不依赖CUDA的情况下优化其他GPU平台。例如,AMD和华为等厂商已经或计划集成DeepSeek模型,这表明DeepSeek的技术具有跨平台兼容性。此外,DeepSeek绕开CUDA的策略也减少了对英伟达技术的依赖,从而降低了潜在的技术垄断风险。
5. 提升效率与性能:
PTX语言运行效率极高,尽管其编写难度较大,但DeepSeek通过优化H800 GPU的流水式多流处理器(SMs),实现了通信任务间的高效调度,并采用先进的流水线算法和细粒度调整,使得其在硬件层面达到了超越传统CUDA开发框架的性能。
6. 应对市场和技术环境的变化:
当前GPU市场的竞争加剧,尤其是美国对华制裁加剧了GPU厂商之间的竞争压力。DeepSeek选择PTX编程也是为了更好地适应这一环境,通过掌握底层硬件优化技术来增强自身的竞争力。
DeepSeek选择PTX编程而非依赖CUDA的原因在于其能够提供更精细的硬件控制、满足复杂多机训练需求、提升性能并摆脱对英伟达技术的依赖。
华为昇腾和景嘉微GPU在性能上与英伟达GPU相比有哪些具体优势?
华为昇腾和景嘉微GPU在性能上与英伟达GPU相比,各有其独特的优势和特点。以下是基于我搜索到的资料的详细分析:
华为昇腾的优势:
算力表现优异:华为昇腾910芯片在单精度浮点计算、双精度浮点计算以及INT8计算性能方面均显著领先于英伟达的H20系列,同时在INT4计算性能上也超越了其他竞品,这表明其在AI推理和训练场景中具有较强的竞争力。
效率与灵活性:昇腾910在效率、可延展性和灵活性方面具有明显优势,尤其在神经网络训练场景中,其性能超越了英伟达V100和谷歌TPU。
国产替代潜力:昇腾910B芯片在单精度浮点计算、INT8计算等方面表现优异,已超越中国区域可获取的其他竞品(如HGX H20),并且在某些参数设计上优于英伟达的H200。
政策支持与市场占有率:华为昇腾芯片在中国市场得到了强大的政策支持,并且在AI领域占据了一定市场份额,特别是在数据中心、AI推理和训练等高性能计算场景中。
生态建设:尽管与英伟达相比生态建设尚有差距,但华为正在积极推进MindSpore开源框架和Ascend Compute Engine等生态工具的开发,以提升其市场竞争力。
景嘉微GPU的优势:
技术积累深厚:景嘉微是国内首家成功研制国产GPU芯片并实现大规模工程应用的企业,掌握了包括芯片底层逻辑设计、超大规模电路验证、模拟接口设计等关键技术。
多款自主知识产权GPU芯片:景嘉微已研发出多款具有自主知识产权的高性能GPU芯片,如JM7系列、JM9系列等,这些芯片在图形处理和高性能计算领域展现了技术实力。
通用性和适配性:景嘉微的JM11系列芯片不仅适用于国内模型,还支持国内主流大模型厂商,这表明其在通用性和适配性方面具有一定的优势。
国产替代潜力:景嘉微GPU在AI算力和通用计算能力上逐步提升,尤其是在国产替代背景下,其产品有望进一步满足国内市场的需求。
总结:
华为昇腾和景嘉微GPU在性能上各有侧重:
华为昇腾在算力、效率和灵活性方面表现突出,尤其在AI推理和训练场景中具备显著优势,同时得益于中国市场的政策支持和生态建设,其国产替代潜力巨大。
景嘉微则凭借深厚的技术积累和多款自主知识产权GPU芯片,在图形处理和高性能计算领域展现了竞争力,同时其产品在通用性和适配性方面也具有一定优势。
然而,与英伟达相比,两者在生态系统、市场占有率以及高端性能参数上仍有差距。
DeepSeek在适配国产GPU过程中遇到的主要挑战有哪些?
DeepSeek在适配国产GPU过程中面临的主要挑战包括以下几个方面:
技术开放性维护:DeepSeek在适配国产GPU时,需要克服技术开放性的维护问题。由于DeepSeek的核心算法和模型训练依赖于高度优化的代码,这些代码可能需要针对不同国产GPU架构进行重新优化和调整,以确保其性能和兼容性。
数据安全保障:在适配国产GPU的过程中,DeepSeek需要确保数据的安全性和隐私保护。这不仅涉及算法层面的优化,还可能需要与国产GPU厂商合作开发更安全的数据处理和存储方案。
硬件兼容性:虽然DeepSeek设计了高度可扩展的分布式计算能力,但国产GPU的硬件特性可能与NVIDIA显卡存在差异,这可能导致性能瓶颈或效率降低。因此,DeepSeek需要针对国产GPU进行深度适配,包括优化其分布式计算框架和资源调度策略。
性能差距:尽管DeepSeek通过PTX优化等方式提升了对其他GPU的支持能力,但短期内其性能仍可能依赖于英伟达产品。例如,DeepSeek的模型压缩技术虽然降低了对高端硬件的依赖,但其性能提升仍需进一步优化以匹配国产GPU的能力。
生态建设不足:DeepSeek目前在生态系统建设上仍处于起步阶段,缺乏强有力的商业化落地策略和产品支持。这使得其在适配国产GPU时可能面临资源分配不足、技术推广困难等问题。
市场竞争与合作压力:DeepSeek在适配国产GPU的过程中,可能会面临来自摩尔线程等国产厂商的竞争压力。这些厂商可能通过提供本土化算力解决方案来争夺市场份额,而DeepSeek需要在技术合作和市场推广中找到平衡点。
长期依赖问题:尽管DeepSeek正在逐步减少对英伟达GPU的依赖,但短期内英伟达产品仍是其最优选择。因此,在适配国产GPU的过程中,DeepSeek需要平衡短期性能需求与长期技术自主化的战略目标。
政策与环境影响:中美技术竞争背景下,DeepSeek可能受到美国出口管制政策的影响。这种政策限制可能迫使DeepSeek加速适配国产GPU的步伐,但同时也增加了其技术研发和市场推广的不确定性。
DeepSeek在适配国产GPU过程中面临的主要挑战包括技术开放性维护、数据安全保障、硬件兼容性、性能差距、生态建设不足、市场竞争与合作压力、长期依赖问题以及政策与环境影响。
DeepSeek与国产GPU合作的具体案例和成��如何?
DeepSeek与国产GPU的合作主要体现在其最新版本DeepSeek-V3的推出和优化上,这一合作在技术、市场和生态方面展现了显著成效。
具体案例与成效
1. DeepSeek-V3的推出与性能
DeepSeek-V3是DeepSeek推出的最新版本,拥有671B参数和37B激活参数,通过在14.8T高质量token上的预训练,其性能达到了国际顶尖水平,与GPT-4o、Claude 3.5 Sonnet等模型相当。这一版本在知识类任务、长文本处理、代码处理、数学竞赛和中文教育评测中表现出色,尤其在响应速度上实现了飞跃,从每代版本前的20个token提升至30个token。
2. 硬件适配与成本优化
DeepSeek-V3通过算法、框架和硬件的协同优化,显著降低了训练成本。例如,在使用2048块GPU时,仅耗时不到280万个GPU小时,总成本为557.6万美元,相比其他开源模型如Llama 3.1 405B的训练成本���3080万GPU小时)大幅减少。此外,DeepSeek还支持AMD的Instinct MI300X GPU,并通过Sglint团队的合作,使其能够在英伟达和AMD的硬件上运行。
3. 国产GPU的支持与合作
DeepSeek与国产GPU厂商摩尔线程展开合作,利用其国产算力解决方案优化算法并适配硬件。这种合作不仅降低了对国际厂商的依赖,还推动了国产AI技术的发展。此外,DeepSeek还支持昇腾平台,进一步提升了推理效率和算力性能。
4. 开源策略与生态建设
DeepSeek实施开源免费策略,通过开源DeepSeek-V3模型,降低了使用门槛,推动了AI生态系统的建设。这一策略不仅吸引了全球开发者和研究人员的关注,还提升了DeepSeek在全球AI领域的竞争力。
5. 行业认可与市场影响
DeepSeek-V3的推出得到了行业内的高度认可。例如,A16z合伙人认为DeepSeek是美国顶尖大学研究人员首选的模型。此外,DeepSeek还被多家企业采用,如富士康在郑州工厂部署了基于DeepSeek技术的质检设备,质检缺陷率达到了99.9997%,展示了DeepSeek在实际应用中的价值。
面临的挑战与未来展望
尽管DeepSeek与国产GPU的合作取得了显著成效,但仍面临一些挑战:
1. 技术开放性与兼容性问题
在适配国产GPU的过程中,可能会遇到技术开放性和兼容性的问题。这需要DeepSeek与国产GPU厂商持续优化合作机制。
2. 生态兼容性与稳定性
国产GPU在算力和软件生态方面仍存在与国际领先产品之间的差距。因此,DeepSeek需要克服这些技术瓶颈,建立深度协同机制。
3. 数据安全与合规性
在国产化过程中,数据安全和合规性是重要的考量因素。DeepSeek需确保其技术方案符合相关法律法规的要求。
总结
DeepSeek与国产GPU的合作通过推出DeepSeek-V3模型、优化算法和硬件适配、降低训练成本以及实施开源策略等多方面取得了显著成效。这一合作不仅提升了国产AI技术的竞争力,还推动了AI生态系统的建设。
国产GPU技术的发展对全球AI领域的影响是什么?
国产GPU技术的发展对全球AI领域的影响主要体现在以下几个方面:
1. 推动国产替代,减少对国际技术的依赖
随着国际形势的变化,例如台积电暂停向中国大陆AI芯片客户提供先进制程工艺的AI/GPU芯片供应,国产GPU面临更大的自主研发压力。然而,这也为国产GPU企业提供了新的机遇。例如,摩尔线程通过自主研发全功能GPU,展示了其技术实力,并计划上市融资,这标志着国产GPU正逐步走向技术自立自强。此外,国产GPU的崛起也受到政策支持,例如中国科协提出“高性能自主可控GPU芯片”的研发需求,进一步推动了国产GPU的技术发展。
2. 提升AI算力基础设施能力
GPU作为AI算力的核心基础设施,在AI训练和推理中扮演着重要角色。目前,全球GPU市场由英特尔、英伟达和AMD三家公司主导,其中英伟达凭借CUDA生态系统占据绝对优势。然而,国产GPU如景嘉微、壁仞科技等正在加速追赶,通过持续的技术创新和生态建设,逐步缩小与国际领先水平的差距。例如,景嘉微推出的高性能智算芯片已应用于AI推理、训练及科学计算等领域。
3. 促进AI产业链的完善与升级
国产GPU的发展不仅提升了AI算力基础设施的能力,还推动了相关上下游产业链的完善。例如,中国电信联合国产芯片厂商打造信创大模型训练平台,支持AI大模型的发展。此外,国内企业在高性能计算、人工智能和大数据等领域的快速发展,也进一步推动了国产GPU市场的扩展。
4. 应对国际竞争与挑战
尽管国产GPU在性能和技术上仍与国际巨头存在差距,但其崛起对全球AI领域具有重要意义。例如,英伟达和AMD长期占据全球GPU市场的主导地位,但国产GPU的快速发展正在改变这一格局。据预测,到2025年,国产GPU市场规模将达到458亿元人民币。此外,国产GPU厂商如摩尔线程、壁仞科技等正在通过技术创新和生态建设,逐步缩小与国际巨头的差距。
5. 助力中国AI产业的自主可控
国产GPU的发展对于中国AI产业的自主可控具有重要意义。例如,华为昇腾、寒武纪、海光信息等国内厂商在AI芯片领域的崛起,有助于缓解美国科技封锁带来的影响。此外,国产GPU的崛起也为国内AI算力需求提供了更强大的支持,例如在超算中心建设和行业产业升级中发挥了重要作用。
6. 推动全球AI市场格局变化
随着国产GPU市场的快速增长,预计到2025年全球GPU市场规模将达到4610.2亿美元,年复合增长率为28.6%。国产GPU的崛起不仅提升了中国在全球AI领域的竞争力,还可能改变全球AI市场的竞争格局。例如,国产GPU厂商可能在某些细分市场中占据更大的份额,并逐步形成与国际巨头竞争的局面。
总结
国产GPU技术的发展对全球AI领域的影响是深远的。一方面,它推动了国产替代进程,减少了对国际技术的依赖;另一方面,它提升了AI算力基础设施的能力,并促进了相关产业链的完善与升级。同时,国产GPU的崛起也对全球AI市场格局产生了重要影响,为中国的AI产业自主可控提供了坚实的基础。
0 notes
Link
Generative AI systems transform how humans interact with technology, offering groundbreaking natural language processing and content generation capabilities. However, these systems pose significant risks, particularly in generating unsafe or policy- #AI #ML #Automation
0 notes
Text
NVIDIA T4 GPU Price, Memory And Gaming Performance

NVIDIA T4 GPU
AI inference and data centre deployments are the key uses for the versatile and energy-efficient NVIDIA T4 GPU. The T4 accelerates cloud services, virtual desktops, video transcoding, and deep learning models, not gaming or workstation GPUs. Businesses use the small, effective, and AI-enabled T4 GPU from NVIDIA’s Turing architecture series.
Architecture
Similar to the GeForce RTX 20 series, the NVIDIA T4 GPU employs Turing architecture. Data centres benefit from the NVIDIA T4 GPU’s inference-over-training architecture.
TU104-based Turing GPU.
TSMC FinFET 12nm Process Node.
2,560 CUDA.
Mixed-precision AI workloads: 320 Tensor Cores.
No RT Cores (no ray tracing).
One-slot, low-profile.
Gen3 x16 PCIe.
Tensor Cores are the NVIDIA T4 GPU’s best feature. They enable high-throughput matrix computations, making the GPU perfect for AI applications like recommendation systems, object identification, photo categorisation, and NLP inference.
Features
The enterprise-grade NVIDIA T4 GPU is ideal for cloud AI services:
Performance and accuracy are balanced by FP32, FP16, INT8, and INT4 precision levels.
NVIDIA TensorRT optimisation for AI inference speed.
Efficient hardware engines NVENC and NVDEC encode and decode up to 38 HD video streams.
NVIDIA GRID-ready for virtual desktops and workstations.
It works with most workstations and servers because to its low profile and power.
AI/Inference Performance
The NVIDIA T4 GPU is well-suited for AI inference but not big neural network training. It provides:
Over 130 INT8 performance tops.
65 FP16 TFLOPS.
8.1 FP32 TFLOPS.
AI tasks can be processed in real time and at scale, making them ideal for applications like
Chatbot/NLP inference (BERT, GPT-style models).
A video analysis.
Speech/picture recognition.
Services like YouTube and Netflix use recommendation systems.
In hyperscale scenarios, the NVIDIA T4 GPU has excellent energy efficiency per dollar. Cloud providers like Google Cloud, AWS, and Microsoft Azure enjoy it.
Video Game Performance
Though not designed for gaming, developers and enthusiasts have studied the NVIDIA T4 GPU’s capabilities out of curiosity. Lack of display outputs and RT cores limits its gaming possibilities. But…
Some modern games with modest settings run at 1080p.
GTX 1070 and 1660 Super have similar FP32 power.
Vulkan and DirectX 12 Ultimate are not game-optimized.
Memory, bandwidth
Another important part of the T4 is its memory:
16 GB GDDR6 memory.
320 GB/s memory bandwidth.
Internet Protocol: 256-bit.
With its massive memory, the NVIDIA T4 GPU can handle large video workloads and AI models. Cost and speed are balanced with GDDR6 memory.
Efficiency and Power
The Tesla T4 excels at power efficiency:
TDP 70 watts.
Server fan-dependent passive cooling.
Use PCIe slot power; no power connectors.
Its low power usage makes it useful in busy areas. Installing multiple T4s in a server chassis can solve power and thermal difficulties with larger GPUs like the A100 or V100.
Advantages
Simple form factor with excellent AI inference.
Passive cooling and 70W TDP simplify infrastructure integration.
Comprehensive AWS, Azure, and Google Cloud support.
Its 16 GB GDDR6 RAM can handle most inference tasks.
Multi-precision support optimises accuracy and performance.
Compliant with NVIDIA GRID and vGPU.
Video transcoding and AV1 decoding make it useful in media pipelines.
See also Intel Arc A770 GPU: Ultimate Gameplay Support.
Disadvantages
FP32/FP64 throughput is too low for large deep learning model training.
It lacks display outputs and ray tracing, making it unsuitable for gaming or content creation.
PCIe Gen3 only (no 4.0 or 5.0 connectivity).
In the absence of active cooling, server airflow is crucial.
Limited availability for individual users; frequently sold in bulk or through integrators.
One last thought
The NVIDIA T4 GPU is tiny, powerful, and effective for AI-driven data centres. Virtualisation, video streaming, and machine learning inference are its strengths. Due to its low power consumption, high AI throughput, and wide compatibility, it remains a preferred business GPU for scalable AI services.
Content production, gaming, and general-purpose computing are not supported. The NVIDIA T4 GPU is perfect for recommendation systems, chatbots, and video analytics due to its scalability and affordability. Developers and consumers may have more freedom with consumer RTX cards or the RTX A4000.
#NVIDIAT4GPU#T4GPU#NVIDIAT4price#NVIDIAGPUT4#T4NVIDIA#NVIDIAT4tesla#technology#technews#technologynews#news#govindhtech
1 note
·
View note
Text
Four Advantages Detailed Analysis of Forlinx Embedded FET3576-C System on Module
In order to fully meet the growing demand in the AIoT market for high-performance, high-computing-power, and low-power main controllers, Forlinx Embedded has recently launched the FET3576-C System on Module, designed based on the Rockchip RK3576 processor. It features excellent image and video processing capabilities, a rich array of interfaces and expansion options, low power consumption, and a wide range of application scenarios. This article delves into the distinctive benefits of the Forlinx Embedded FET3576-C SoM from four key aspects.

Advantages: 6TOPS computing power NPU, enabling AI applications
Forlinx Embedded FET3576-C SoM has a built-in 6TOPS super arithmetic NPU with excellent deep learning processing capability. It supports INT4/ INT8/ INT16/ FP16/ BF16/ TF32 operation. It supports dual-core working together or independently so that it can flexibly allocate computational resources according to the needs when dealing with complex deep learning tasks. It can also maintain high efficiency and stability when dealing with multiple deep-learning tasks.
FET3576-C SoM also supports TensorFlow, Caffe, Tflite, Pytorch, Onnx NN, Android NN and other deep learning frameworks. Developers can easily deploy existing deep learning models to the SoM and conduct rapid development and optimization. This broad compatibility not only lowers the development threshold, but also accelerates the promotion and adoption of deep learning applications.

Advantages: Firewall achieves true hardware resource isolation
The FET3576-C SoM with RK3576 processor supports RK Firewall technology, ensuring hardware resource isolation for access management between host devices, peripherals, and memory areas.
Access Control Policy - RK Firewall allows configuring policies to control which devices or system components access hardware resources. It includes IP address filtering, port control, and specific application access permissions. Combined with the AMP system, it efficiently manages access policies for diverse systems.
Hardware Resource Mapping and Monitoring - RK Firewall maps the hardware resources in the system, including memory areas, I/O devices, and network interfaces. By monitoring access to these resources, RK Firewall can track in real-time which devices or components are attempting to access specific resources.
Access Control Decision - When a device or component attempts to access hardware resources, RK Firewall will evaluate the access against predefined access control policies. If the access request complies with the policy requirements, access will be granted; otherwise, it will be denied.
Isolation Enforcement - For hardware resources identified as requiring isolation, RK Firewall will implement isolation measures to ensure that they can only be accessed by authorized devices or components.
In summary, RK Firewall achieves effective isolation and management of hardware resources by setting access control policies, monitoring hardware resource access, performing permission checks, and implementing isolation measures. These measures not only enhance system security but also ensure system stability and reliability.
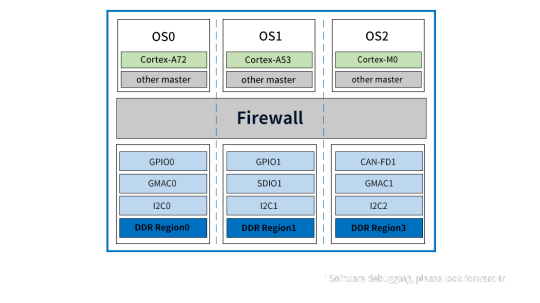
Advantages: Ultra clear display + AI intelligent repair
With its powerful multimedia processing capability, FET3576-C SoM provides users with excellent visual experience. It supports H.264/H.265 codecs for smooth HD video playback in various scenarios, while offering five display interfaces (HDMI/eDP, MIPI DSI, Parallel, EBC, DP) to ensure compatibility with diverse devices.
FET3576-C SoM notably supports triple-screen display functionality, enabling simultaneous display of different content on three screens, significantly enhancing multitasking efficiency.
In addition, its 4K @ 120Hz ultra-clear display and super-resolution function not only brings excellent picture quality enjoyment, but also intelligently repairs blurred images, improves video frame rate, and brings users a clearer and smoother visual experience.

Advantage: FlexBus new parallel bus interface
FET3576-C of Forlinx Embedded offers a wide range of connectivity and transmission options with its excellent interface design and flexible parallel bus technology. The FlexBus interface on the SoM is particularly noteworthy due to its high flexibility and scalability, allowing it to emulate irregular or standard protocols to accommodate a variety of complex communication needs.
FlexBus supports parallel transmission of 2/4/8/16bits of data, enabling a significant increase in the data transfer rate, while the clock frequency of up to 100MHz further ensures the high efficiency and stability of data transmission.
In addition to the FlexBus interface, the FET3576-C SoM integrates a variety of bus transfer interfaces, including DSMC, CAN-FD, PCIe2.1, SATA3.0, USB3.2, SAI, I2C, I3C and UART. These interfaces not only enriches the SoM's application scenarios but also enhances its compatibility with other devices and systems.

It is easy to see that with the excellent advantages of high computing power NPU, RK Firewall, powerful multimedia processing capability and FlexBus interface, Forlinx Embedded FET3576-C SoM will become a strong player in the field of embedded hardware. Whether you are developing edge AI applications or in pursuit of high-performance, high-quality hardware devices, the Folinx Embedded FET3576-C SoM is an unmissable choice for you.
Originally published at www.forlinx.net.
0 notes
Text

file: Mcely, kostel sv. Václava int4.jpg
0 notes
Text
#4
21 y/o - he/him
1. How often do you listen to music?
Everyday. Funny enough, I don’t really know anyone who doesn’t have the same answer as me. Music is a really big part of my life and it’s been that way for years.
2. Do you use any music streaming apps?
Just Apple Music. I’m not a big fan of the other music streaming apps.
3. Do you like to discover new music? (i.e. artists, playlists, genres) If so, what are your methods for finding new music?
No I don’t. I have a hard time discovering new music/artists so I just gave up on doing discovery on my own.
4. Some people have friends that connect over a lot of different topics and some have friends that connect on very few topics. When it comes to music, do you find it easy or hard to connect with your friends over it, and why?
I find it easy because it’s definitely something that you can have an entire conversation about with a person when a new song or album drops, especially how it makes each other feel. Plus it helps that my friends 9 times out of 10 have the same music taste as me.
5. Have you ever or do you currently use social media to make new friends and talk about interests you have in common?
Yes but to an extent.
6. If you answered yes to the previous question, can you share one or more of your experiences? If you answered no to the previous question, can you please elaborate on why you don’t use social media to meet new people?
I don’t really make friends with complete strangers on social media but I will make connections if you’re a friend of a friend or met you very briefly somewhere.
7. Do you find that like counts/follower counts/leaderboards discourage you from using certain apps and/or making connections with people online or do you feel the opposite and why?
Yes and no. It does get intimidating since social media has become such a big part of daily life and “social status” but I’m trying to train myself to think that none of that matters as much as you think it is. I find my self doing social media cleanses often and it has been helping me a lot.
8. On a scale of 1-10 how likely would you be to use an app that allows you that connects to your music streaming apps, shows you randomized playlists (based on your preferences) in order to discover new music, and connect with people who have similar music tastes?
I think a 7. I think there’s a lot of potential in an app like this and if it can be fun and interesting then I would most likely give it a try.
9. With the app idea presented in the previous question, do you have any concerns about the app or features you would implemented in the app?
Having a section or a space for people to share or add “feelings/mood” so curated playlists for people feeling any specific way could be a really fun feature to the app instead of just generic music taste categories. These sections/playlists should be highly specific like “they didn’t have my drink in Starbucks now I have no will to live” or “my boyfriend just lied to me for the third time and I need a song/playlist to motivate me to break up with him”
0 notes
Photo

INT-4 1981 STAR WARS KENNER MADE IN MACAO THE EMPIRE STRIKES BACK MINI-RIG Mira mis otras figuras vintage y modernas. 22 EUROS Se vende el juguete de la foto. Envio gratuito en España (península) Islas Canarias, Ceuta y Melilla, Baleares, consultar. Mira mis otros artículos Envio certificado. Pago por transferencia bancaria, Bizum o PayPal como amigo. Cualquier duda consultar. #starwars #int4 #esb #starwarsvariations #vintage #vintagetoys #lazotoys #lazotoysstarwars #seconhandstarwars #starwarstoys #starwarsforsale https://www.instagram.com/p/CLjIMOvADg4/?igshid=1a1acf9kaxdi0
#starwars#int4#esb#starwarsvariations#vintage#vintagetoys#lazotoys#lazotoysstarwars#seconhandstarwars#starwarstoys#starwarsforsale
1 note
·
View note