#imo olympiad
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The most popular pages on Tumblr are about Minecraft, GIFs, and David J. Peterson.
Text
Online Jee Coaching
In today's fast-paced world, online learning has become a game-changer, and CFAL Institute is at the forefront of this transformation with its top-notch online JEE coaching program. Aspiring engineers now have the flexibility to access the best JEE coaching from the comfort of their homes. CFAL's online JEE coaching eliminates geographical barriers, allowing students from all corners of India to benefit from its expertise. Whether you live in a bustling city or a remote town, you can access top-tier JEE coaching from the comfort of your home. This convenience is particularly beneficial in times when physical attendance at coaching centers may not be feasible.
0 notes
Text
here's the thing though: canis IS an incredible manga from an artstyle/narrative structure/etc. point of view, but something that gives it an extra leg up is the hyperspecificity of its premise. "salaryman yaoi", "band yaoi", "college students yaoi", whatever, whatever, we've all seen it before. "haberdashery yaoi" though? no competition. mangaka's instantly leveled the playing field because they're out there alone, nobody has even conceptualized that playing field to even consider playing with them on that niche ass field. same for the second series you're like "orphanage yaoi" and maybe you're thinking "oh well this probably has some competition with those early shoujo artists obsessed with historical europe" but change the setting of that to the united states in the early 2000s? suddenly no competition once again. this is why my next yaoi manga will be about speedcubing
#just thinking thoughts...#LAST LINE IS A JOKE FOR ALL INTENTS AND PURPOSES BTW. I don't know what my next yaoi manga will be about#I was debating between 'speedcubing' and 'international math olympiad'#but nobody knows what the IMO is if I don't say all 3 words and then it becomes a mouthful and the punchline isn't as punchy#anyways. canis is really quite good. the third chapter where it interweaves the two guys' backstories is phenomenal
13 notes
·
View notes
Text
India's Unprecedented Success in Maths Olympiad: An Unsung Story
India’s exceptional achievement in the International Math Olympiad 2024, with four gold and one silver medal, receives little recognition in a country obsessed with cricket and films. India’s brilliant performance in the International Math Olympiad 2024, winning four golds and one silver, remains overshadowed by the nation’s focus on cricket and films. Indians who love cricket and films to the…
#Adhitya Mangudy Venkata Ganesh#Arjun Gupta#IMO 2024 success#India Math Olympiad 2024#Indian Education System#Indian students achievements#international competitions#math education in India#neglected academic achievements#promoting STEM
0 notes
Text
0 notes
Text
#maths olympiad preparation#imo sample papers#internationalmathematicalolympiad#international mathematical olympiad#math olympiad practice questions#matholympiadonlinepractice#matholympiadmocktest#mathsolympiad
0 notes
Text
WHICH OLYMPIAD IS BEST OR AUTHENTIC AT SCHOOL LEVELS?
Which Olympiad Is Best Or Authentic At School Levels? Recently, the 64th International Mathematical Olympiad (IMO) 2023 held at Chiba, Japan (July 2-13, 2023). Here, the six-member Indian team secured 2 Gold, 2 Silver and 2 Bronze medals. . India’s rank is 9th out of 112 countries. Homi Bhabha Centre for Science Education, Mumbai (HBCSE) is core organisation for participation in International…

View On WordPress
#Academic competitions#Educational achievement#Educational assessment#Gifted education#IMO#ISTS#olympiad#School competitions#Silverzone#SOF#STEM competitions#Unified Council
0 notes
Text
After the math pope, we have a math president
From the Wiki page of Nicușor Dan, the new president of Romania:
He won first prizes in the International Mathematical Olympiads in 1987 and 1988 with perfect scores.[3] Dan moved to Bucharest at the age of 18 and began studying mathematics at the University of Bucharest.[4] In 1992, he moved to France to continue studying mathematics: he followed the courses of the École Normale Supérieure, one of the most prestigious French grandes écoles, where he gained a master's degree. In 1998 Dan completed a PhD in mathematics at Paris 13 University, with thesis "Courants de Green et prolongement méromorphe" written under the direction of Christophe Soulé and Daniel Barsky [de].[5][6]
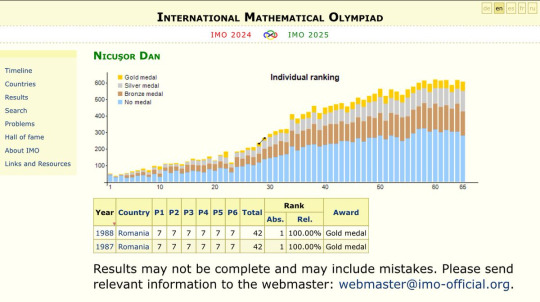
Dan's 1988 gold medal also means he was one of eleven contestants to get full marks on the infamous Problem 6, a question so difficult that nobody on the IMO problem committee could solve it.
His personal website lists his primary area of research as Arakelov geometry, a method of studying Diophantine equations from a geometric point of view.
His thesis, in the same field.
His arXiv.
52 notes
·
View notes
Text
I haven't seen anyone talk yet about the fact that an AI solved 4/6 of this year's IMO problems. Is there some way they fudged it so that it's not as big a deal as it seems? (I do not count more time as fudging- you could address that by adding more compute. I also do not count giving the question already formalised as fudging, as AIs can already do that).
I ask because I really want this not to be a big deal, because the alternative is scary. I thought this would be one of the last milestones for AI surpassing human intelligence, and it seems like the same reasoning skills required for this problem would be able to solve a vast array of other important problems. And potentially it's a hop and a skip away from outperforming humans in research mathematics.
I did not think we were anywhere near this point, and I was already pretty worried about the societal upheaval that neural networks will cause.
4 notes
·
View notes
Text
So I have my second adhd evaluation in a week and like
I've been trained for years to on how to sit down for 4.5 hours while working on 3 particularly obtuse math problems. Mathematics Olympiad shit. I've won medals on an international level [not technically IMO tho so I'm not valid, I know this].
And maybe that should be taken into account when a "slightly above average" result on the computerised test is found during my adhd eval. Which is carried by me being in the top 1% for response speed because that part goes by quicker if you answer the questions faster.
2 notes
·
View notes
Text
https://www.cfalindia.com/olympiad-exam/
0 notes
Text
How Olympiad Exams Make Your Child Smarter — A Complete Guide for Parents
In today’s competitive world, every parent wants their child to be confident, intelligent, and academically ahead. One powerful way to sharpen your child’s mind is through Olympiad exams. These competitive tests go beyond the school curriculum and help build a strong foundation in subjects like Mathematics, Science, and English. But how exactly do Olympiad exams make your child smarter? Let’s dive in.
1.Builds Strong Conceptual Understanding Olympiad exams focus on conceptual clarity rather than rote learning. When students solve higher-order thinking questions, they develop a deeper understanding of the subject. This not only helps in school but also builds a strong base for future competitive exams like JEE, NEET, and UPSC.
2. Improves Logical Thinking and Reasoning Skills Olympiad questions are designed to test analytical and reasoning skills. Children learn how to approach problems from multiple angles and find the best solutions. This ability to think logically helps in day-to-day decision-making and builds smart problem-solvers for life.

3. Encourages Self-Learning and Curiosity Olympiads ignite the curiosity to explore more beyond textbooks. Children begin to enjoy the learning process, seek knowledge independently, and become lifelong learners — a crucial trait of intelligent individuals.

4. Develops Competitive Spirit and Confidence Participating in Olympiads exposes students to national and international-level competition. Competing with peers helps them assess their capabilities, set higher goals, and become more confident individuals.
5. Provides National and International Recognition Olympiad achievers are often awarded medals, certificates, scholarships, and even national recognition, which boosts their profile for school admissions and future academic pursuits.

How to Get Started with Olympiad Exams Choose the Right Olympiads: Enroll your child in well-known exams like SOF, NSTSE, IEO, IMO, or enroll with platforms like Olympiad Junior, which offer comprehensive preparation for Classes 1 to 8.Use Quality Study Material: Focus on concept-based learning, mock tests, and previous year papers.
Follow a Routine: A structured schedule with regular practice enhances preparation and confidence. Conclusion Olympiad exams are more than just competitions — they are stepping stones to your child’s intellectual growth. By participating in Olympiads, children become sharper, more confident, and better prepared for future challenges. If you want to unlock your child’s true potential, start Olympiad preparation today! CTA (Call to Action): Looking for expert guidance and complete Olympiad preparation?
Join Olympiad Junior — India’s trusted platform for Olympiad success! Visit www.olympiadjunior.com or download the Olympiad Junior app now.

1 note
·
View note
Text
Schüler aus Kleinmachnow im Deutschland-Team der Internationalen Mathe-Olympiade 2025
David Averbah aus Kleinmachnow (Potsdam-Mittelmark) geht bei der Internationalen Mathematik-Olympiade 2025 in Australien für Deutschland an den Start. An dem Turnier nehmen Nachwuchsmathematikerinnen und -mathematiker aus über 100 Ländern teil, es findet vom 10. bis 20. Juli 2025 in Sunshine Coast an der australischen Ostküste statt. Für die Internationale Mathematik-Olympiade 2025 (IMO) haben…
0 notes
Text
"Investing in Brighter Futures: Imo Gifted Students"
By Bello Ahmadu Alkammawa Empowering Young MindsKey Highlights1. *Scholarship Award*: Barr Chioma Uzodimma awarded a scholarship to 9-year-old Chidubem Chimamanda Andre for her exceptional math skills.2. *Exceptional Talent*: Chidubem excelled in the National Mathematics Tournament and African Mathematics Olympiad.3. *Future Aspirations*: The scholarship supports her goal to pursue Medical…
0 notes
Text
#imo sample papers#maths olympiad preparation#internationalmathematicalolympiad#matholympiadonlinepractice
0 notes
Text
How the No. 1 School in West Bengal Prepares Students for National & International Competitions

Competition has become an integral part of modern-day education. It shapes students into confident, capable, and future-ready individuals. Success in the 21st century is no longer limited to grades or classroom performance; it’s about applying knowledge, thinking critically, performing under pressure, and standing out in a global crowd. From Olympiads and debates to innovation challenges and sports championships, competitions today foster resilience, leadership, and a growth mindset.
Students at ODM International School, known as the No. 1 School in West Bengal, are nurtured not just to score well in exams but to confidently represent themselves — and their country — on national and international platforms.
Let’s take a closer look at how ODM International School equips its learners to shine in competitive arenas across disciplines and borders.
Unlocking Potential from the Early Years
At ODM International School, the journey towards national and international recognition begins early. Using the CPX Learning Model, educators help students identify their potential through detailed observation, psychometric assessments, and regular talent mapping exercises.
Whether it’s a child with a knack for science, a passion for debate, or a gift for the arts, early identification allows educators to customise learning pathways that align with each student’s strengths. This approach creates a powerful foundation, instilling confidence, direction, and purpose from the very start.
Specialised Coaching and Mentorship Programs
To truly thrive in competitive environments, students need more than textbook knowledge — they need targeted training, strategic thinking, and mentorship from experts. ODM International School offers specialised coaching programs for a wide range of competitions, including:
National Science and Math Olympiads (NSO, IMO)
NTSE and KVPY
Spelling Bees and English Olympiads
Robotics, coding, and AI competitions
International Model United Nations (MUN)
Art and cultural contests
Sports tournaments and athletic meets
Under the guidance of competition-specific mentors, students receive one-on-one attention, personalised learning plans, and the opportunity to train with peers who share similar goals. This not only raises the competitive bar but also fosters a culture of healthy ambition and peer-driven motivation.
Exposure That Goes Beyond the Classroom
One of the defining characteristics of the No. 1 School in West Bengal is its unwavering commitment to global exposure. At ODM International School, learning extends far beyond the four walls of a classroom. Students regularly participate in:
International exchange programs with partner schools across Europe and Asia
Global conferences and symposiums where they present projects and research
Virtual collaborations with international students to develop cross-cultural understanding and shared knowledge
International Olympiads and innovation fairs that test critical thinking on a global stage
This exposure helps students develop a worldly perspective, refined communication skills, and the courage to compete at the highest levels.
A Curriculum Designed for Real-world Challenges
ODM International School follows an advanced, future-forward curriculum that integrates core academics with 21st-century skills. Whether it’s collaborative problem-solving, design thinking, or effective presentation, the school ensures students are not just rote learners but real-world performers.
Co-curricular and extracurricular activities are seamlessly blended with academics to ensure holistic development. Students are encouraged to take up leadership roles, engage in project-based learning, and participate in real-life simulations like mock parliaments, business pitch competitions, and TED-style talks.
These experiences prepare students to think fast, communicate clearly, and act decisively — all critical traits for success in competitions.
Building Inner Strength Through Wellness & Resilience
Competing on a national or international level can be exhilarating, but it also demands emotional maturity and mental resilience. So, ODM International School places a strong emphasis on wellness. The school provides:
Access to in-house counsellors and psychologists
Mindfulness and yoga sessions for focus and emotional balance
Motivational workshops by industry leaders and life coaches
This holistic support system ensures that students not only perform well but also manage stress gracefully, accept setbacks positively, and grow through every experience.
Celebrating Success, Inspiring Others
At ODM International School,Durgapur every achievement — no matter how big or small — is celebrated with pride. Students who succeed in national and international competitions are recognised in school assemblies, newsletters, and digital platforms. They are also encouraged to share their journeys with juniors through peer mentoring, sparking a ripple effect of inspiration and aspiration.
This culture of celebration and mentorship sustains a legacy of excellence, ensuring that today’s achievers pave the way for tomorrow’s champions.
Final words:
What makes ODM International School the No. 1 School in West Bengal isn’t just its academic record or state-of-the-art infrastructure — it’s the way it empowers every student to discover their best self and express it on the biggest stages.
By combining visionary leadership, expert mentorship, global exposure, and emotional support, ODM is not just preparing students to win competitions — it is shaping young minds to become confident, compassionate, and capable global citizens.
#No 1 school in west bengal#cbse school in west bengal#good school in west bengal#odm international school in west bengal#schools in west bengal
0 notes
Text
Foundation Classes started for 9th and 10th CBSE (School Exams) and Olympiads NTSE etc
Enrol now, study with IITians and build a strong base for IIT JEE NEET going ahead . Also direct admission into IITs is one amongst many advantages of cracking Olympiads 💯
#physicsteacher #Satnara #AnshulSir #olympiad #ntse #imo #NSTSE #kvpy #olympiadpreparation #class10 #10thboards #class9th
#iit #iitdelhi #iitmadras #iitkanpur #iitkharagpur #iitian #neetmotivation
#BestIITJEECoachingInDelhiNCR
#BestNEETCoachingInDelhiNCR
#BestPhysicsTeacherInIndia
#StudyWithIITians #jeemains2025 #jeemains #jeeadvanced #BITSAT2025 #CBSE2025 #iitjeepreparation #iitjeephysics
#best iit jee classes in delhi#best tuition for science and maths class 10th board exams#best physics teacher in india#india's best iit jee coaching#best neet classes in delhi#iit jee advanced#iit kharagpur#iit jee coaching#iit jee#iit neet#iit neet cbse cuet bitsat#olympiads#science olympiad#ntse#neet2024#neet coaching#neet 2025#neetcore#physics#aiims#life#achieve#campus life#cbse
1 note
·
View note