#i think i may need this RNN
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In Q3 of 2020, 31% of US users access the Tumblr app daily.
Text
tw/cw: forced impregnation, pregnancy. 🍼
baby trapping könig.
you'd be lying if you said you weren't doing this because you wanted his genes and wealth; you wanted your babies to have a happy family; and könig has the perfect genes and money to care for all four of you.
you'd been having a hard time recently, the pair of you. your relationship had become full of arguments, screaming matches, and yelling at each other over the smallest things. until one day, you thought of a plan to mend (or potentially ruin) your broken relationship.
you knew könig wasn't the type to leave you a single mother; he'd be there the entire way through regardless. his family would shun him and put shame on him if he ever left you struggling.
you'd been riding him; könig's growls and demands for more caused your cunt to drool with pleasure. his large hands gripped your waist, fingernails leaving marks along your body, kneading the flesh on your ass as you bounced harder, quickening your pace as your core began tightening. you whined and mewled quietly, tears pooling in your waterline and your body trembling as you warned könig you were about to cum.
before könig could even mutter a coherent word or a warning, your walls were already clutching onto his veiny and slick boner, his dick twitching and pulsing inside of your wet warmth, groans coming out broken and stuttered, his breathing heavy and fast. he could feel your hole weep around him, your pearly and glossy droplets of arousal running down his shaft, and his creamy load fucked deep into you. his breathing was heavy, and his head was thrown back, his grip aching as he held your hips tightly, attempting to catch his breath and come to the realisation of what just happened.
of course the news of your pregnancy was shocking. he couldn't leave you a pregnant mother; he had to step in. being forced to act like a proper boyfriend meant that he couldn't yell at you for silly things anymore and that he had to tend to your needs, getting worried whenever you attempted to do something like rearrange the furniture.
perhaps he wasn't prepared to become a father to two huge, chubby baby girls, but seeing them fast asleep on your newlywed husband's chest was everything you'd dreamt of.
#orla speaks#tw: baby trapping#tw: forced breeding#tw: forced impregnation#könig x you#könig x reader#konig call of duty#könig call of duty#könig#könig cod#konig x reader#konig#konig cod#i think i may need this RNN
1K notes
·
View notes
Note
MAI !! hru feeling ?
I'm feeling okay rnn :DD my body still hurts a bit but i think i just need some sleep HAHAH
1 note
·
View note
Note
BTW ITS FUCKING 1AM and i am. so godamm tired to tried to think th iwanted to go to bed at like 10 but i didnt and idk why FDHDHDFHD vut anyway ya i need to sleep like RNN so i will so sorry that this may be rly short but i do just really want to say that i really really do love you soso much love !! like just you really are so os wonderful and dear to me like youre such an incredible kind caring thoughtful sweet understanding friend to me dearest and are just so so good to me yk and i j feel so so loved and cared for and safe and warm with you love i realy do and you really do just like bring me so much joy and light knowing you and having you in my life and light. getting to hear abt your life and abt ur thoughts on things and getting to see the things you make and share things with you love like i really am so so lucky and grateful to know you and have you in my life love, you really do just mean the world to me and i really do just love you so so very much dearest !! i hope ur days been good and that you sleep well love, gnight <3 💗💕🐞🦋🍰🐈💞🌼🐛🌸✨✨✨
AH THATS SO ME ANSWERING THIS PAST MIDNIGHT CORE<///////3 like idk why but thats how it is sjnsjkanks but i hope u get some good sleep and yah omfg u are sooooooooo wonderfulll and you are truly sososo dear and important and special to meeee my beloved like you rlly are suchhh an amzing caring friend and i feel the warmth of that sm and lovee talking to u smmm and you just mean smmmmm sosooso much to me and the fact that i can be a good friend to u when u r so much of one to me means the absolute world and i just !!! i really love youuuuuuuuuuuuu gnightt<333333333333
#also sorry agh the sleep y the tired so i havent sent u a gnight ask but i just wanna uhm !! (hugs u gnight if u wld like ofc<333 <33)#mewtuals#castle.answers
1 note
·
View note
Text
I was wondering last night why stuff on my laptop was running slow, and I only just now discovered the cause: on Monday (?) I had randomly decided to start training char-rnn on Dunnett again, this time on the whole Lymond series instead of just the first two, and then I completely forgot about it, and now it’s done 11 full passes over the data and can produce eerie, frequently grammatical simulacra of Lymond dialogue:
‘I thought you brought her to his tale of the angle.’
‘But the planfour woman,’ he said carefully, ‘that Archie has left the treftileness of women. They have no wish to be tongues.’
‘I really didn’t want a message from his grace,’ said Sir George Douglas’s torn voice, ‘that I am told you think you have rather meant that I must blind against the King of France and for your highest banquet.’
‘I haven’t trusted them,’ Philippa said. ‘And so played to him he might prove it. It has noticed that it may have weight. Only the garrison of the Queen is dead. There’s no need to ancience whom and she had so considered what they wore rather proud to believe that she would be dead. Is it not enough of you?’
‘The company of me,’ Lymond said.
‘You would have gentlemen,’ said Jerott. ‘They have no more than in all that, in the end of the day, the young man did what he die.’
(next one’s with a lower “temperature”)
“No. Lady Culter and I shall not be able to forget him,” said Christian. “And if the sensitive information is to tell you to do the rest of the beauty of a subject of a personal six miles or the special standard of a service and because I was to be there to see the other weakness.”
“Or do you think?”
“I want to be deaded and delivered to the Somervilles. I see nothing of the tapers and the craphie, but the bloody daughter was there.”
“Oh, don’t hear that,” said Lymond, “do you want to fight to face the English out of the child?”
“I don’t recover the same time,” said Sybilla. “I didn’t know that. I should find a city, and it is a trick with a little boat in the night. It was the mother of the Constable of France, who can return home to the Tartars.”
“What do you think it would do that?” said Lymond. “As you arrived at the best, you will find it distressing on the same reason.”
“Well, if you want to recover, I shall go to the end of the river of money. It was in the same time, and I am sure you will find out if you were also a hollow man.”
54 notes
·
View notes
Text
AY2020/2021 Y3S1 Module Reviews
This sem went by quite quickly I would say. Good thing now is that there are no longer CS mods I am freeeeeeeeeee. Despite the other mods or faculties already requesting for in-person classes I still had a total of *drum roll please* one *crowd cheers* physical class per week.
Tbh i must say i adjusted too fast to online classes, sleeping in, skipping on lectures getting distracted from doing actual work wastign my time away in the name of selfcare distorted sense of time ive truly experienced it all. At least physical classes make me ykyk make good use of my time spent travelling, i mean at least be there not necessarily mentally but it helps kinda when you have friends around you all studying but nah now we just on our own in our beds doing jackshit.
Other than that I dont have anything else to add on so without further ado the
Overview
BT4221 Big Data Techniques and Technologies
BT3103 Application Systems Development for Business Analytics
BT4012 Fraud Analytics
IS3103 Information Systems Leadership and Communication
IS3240 Digital Platform Strategy and Architecture
BT4012 Fraud Analytics
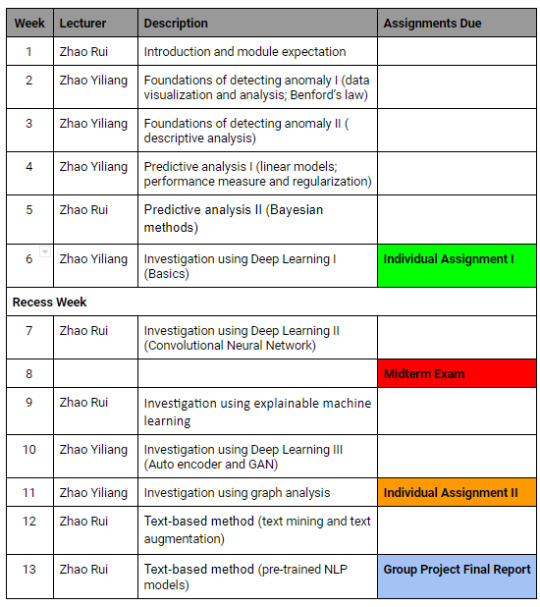
Lecturer: Zhao Rui, Zhao Yiliang
Syllabus
Weightages
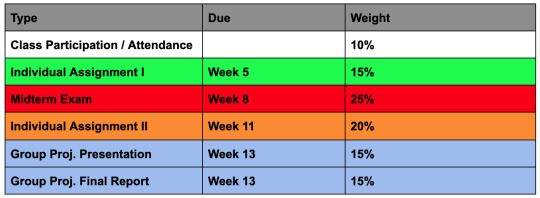
Individual Assignments (35%)
Midterm Examination (25%)
Group Project (30%)
Individual Assignments (35%)
There will be two homeworks, centered around working on a fraud detection problem using appropriate machine learning techniques. The deliverables are code implementations and concise answers to related questions. Details of the assignments will be announced later.
Midterm Examination (25%)
Students are expected to attend the Midterm Examination. It will focus on the understanding of basic concepts and application of the materials covered in class. The mode of the delivery of the examination will be determined and announced later.
Group Project (30%)
You are required to form a project group with 1-2 members. Your task is to do a literature review on methods for fraud detection. You will write a maximum 5 page review (Arial, 11, single spacing) of papers excluding Appendix and references. You will need to do a presentation on the review. You are highly recommended to propose new ideas based on the review. Reviews should be done in a critical and rigorous manner.
Instead of doing the literature review, with approval from the lecturers, you may also choose to do a project. Please email a brief description of the project plan to the lecturers to get approval.
The Group Project will consist of two parts: (I) Group Project Presentation (15%) and (II) Group Project Final Report (15%). More detailed instructions and the guidelines for this course project will be announced later.
(Copied off the luminus module overview its surprisingly still open)
But yeah you get it, its your typical BT module. The module itself does quite a fair bit of refreshers incase you have forgotten your BT2K and 3K mods the basics of regressions, measurables (averages and statsy stuff - cant expect me tor mb class content help) but basically the barebones and then it dives into the world of machine learning we have a few deep neural network models CNN RNN etc etc. Its very interesting. I think I really like that the profs went the extra mile to compile the codes for us theres a lot of compiled codes per chapter so its the barebones implementation u just copy and paste and get it do what u want it to do simple as that. The code structure is p much the same whichever your case is anyway so its really resourceful not so much the you-code-yourself-cannot-tolerate-plagiarism thing going on in CS i mean i guess it forces u to think the computational thinking is the true takeaway in those. The first IA is very easy jsut copy and tweak the kind everyone would get full marks ish the second one is a class competition hosted on Kaggle to get you to predict anomalies and you are ranked according to your accuracy against private test sets. I’ll be frank and say i did so badly in the rankings i was the bottom few. But i did kinda okay ish?? when i got my grades back so dont worry lmao theres the report thing u gotta write after the competition about what methods you used, and your justifications etc basically you explaining your process of finetuning your model to get the best accuracy. The Lit Review portion of weightage is just a fancy term to coin a 5-6 pager reflections based on a research paper of your choice related to the content taught so e.g. use of CNN/ other NNs in anomaly detection under any context/industry better to reflect what you have learnt or describe your inputs on areas of improvments/ pointers that may have been overlooked in the research paper. Of course, more marks are awarded with more effort and this quite chill one you have all the time to do after the midterms since technically chapters after midterms are not tested. Frogot to mention, class part is graded even tho its not here there are quizes scattered across the weeks and you need to be present to submit all of them in time during like 5 mins of the lecture so unless you have a friend who to tell u theres pop quiz then i recommedn not to skip. personally i dont pay much attention in class as much as the announcment of the quiz i just rewatch lectures after.
BT4221 Big Data Techniques and Technologies
Lecturer: Um Sungyong
Weightages:
Exams (30%)
Projects (40%)
Assignment (20%)
Peer evaluation (5%)
Class participation (5%)
There is no tutorials for this class just the lecture itself once per week held over zooms and recordings can be found on Luminus. Pace was okay. I get mixed reactions when it comes to the profs teaching but to me its fine, his baby cries sometimes in the background which is cute. Other than that at the start of the sem, he goes through some of the theory that you will need in this course such as the RDD and how it all comes together regarded hwo data are spliced and stored differently in Hadoop vs Spark. But we use Spark more since Spark is based off Hadoop and it helps in increasing the efficiency of data processing. To me a lot of it feels kind of like the aggregations used in MySQL or the streams part of CS2040. He provides base codes as well and we just change things from there. During the half way mark aka recess week theres one optional week to learn about data streams from Twitter. This ones not tested in the finals so i didnt pay much attention. You will need a developers account if you want to follow along the tutorial, which require some time for Twitter staffs to approve as well as your reasons for opening a dev account. Theres also some bit of AWS at the start of the sem as well, on using S3 etc but I didnt pay that much heed (Regret?) and since it is not compulsory for us to use AWS as cloud storage for the project and since we did not have to use it for the project we chose then.... But heads up about the project he will land you a final blow to tell you SURPRISE you have a project due near week 8ish that leaves you about a month to W13..... which everyone knows will be busy.... Come on he could have told us snice the start for us to prep. Its kind of a big scale project? From sourcing data to determining how you want to include the things that are taught over the weeks Id recommend for you guys to mental prep early bc it took very long for my group to decide on one topic to do. We all had our own ideas, and we were going to incorporate everything we decided, only to slowly slowly rule out one after another which again is a lot of wasted effort. I guess in the end its fine since he drags out the due date to some weeks after reading week 2/3 weeks later. So for that project you need to submit 1. project report 2. codes? 3. presentation recording.
He also allow for in person presentations durnig the final class nd may award you higher scores but he also assures us that people who do not present real time aka submit via recordings are not at too much a disadvantage he will be fair and stuff even tho hes very open to giving out scores (?) if that makes sense. Like he just want to see you progress and award you for the effort kind very chill prof. Go for the consults!! He will offer invaluable advice as to what he wants to see kind of guide u abit in case u losted and most importantly he will remember you exist AHHAHA. He throws extra credits for that too.
For the assignment its about 6 of them all spread across the content delivery with a few weeks in between and its not very hard (doesnt take you very long) just use the codes he realised tweak a bit then you submit the code either in pynb or doc. Submissions are not exactly graded for its correctness but rather just to ensure that you do your work? I think i had some issues and did not manage to upload in time he was nice about it to open the deadlines for me to submit and kept asking me not to worry about it nice accommodating understanding.
After the twitter optional class, he goes on into neural networks which ties in really well with my other module BT4012 a good refresher for each other. But the NN part more important since it will be the base of your project. Project question is up to you to decide for yourself the theme setting everything, as and whne after he release the project details he will ask for one pager to see your ideas and stuff so its a project proposal kind of thing, to see your project through from the start so good to start early about how you come up with your topic and what you have tried so you can include these experiences or findings in your final project report.
Other than that theres one exams which is the finals (bitch you thought) they dont tell you that in NUSMods. But the topics are fine i think in general the content is p manageable. This mod is fine.
BT3103 Application Systems Development for Business Analytics
Lecturer: Shashank
Weightages
Class part (15%)
Quiz and individual assignments (30%)
Mid sem project submission (20%)
Final project submission (35%)
Assessments
Mid Sem Project Submission (W7)
Final Project Submission (W13)
Intermediate Assessments aka Quiz (W3,5,8)
For this mod we learnt the very basics of HTML CSS and Javascript keyword basics really just minimal syntax here and there for us to move on to the bulk of the content that uses nodejs npm to build a website the language is somewhat an addition to HTML/CSS and quite easy to play around with in terms of containers and getting it to do what you will it to. It can be slightly difficult to grasp from the get go but trust me you will get better over time. Apparently they teach this vuejs thing bc its easier? but for me at the start i felt going back to the conventional html css was much more easier but i guess its easier to do certain things in vuejs. You get to learn a bit about Waterfall and AGILE which are methodologies used in the workplace when it comes to having a framework to base a project on from the start ideation etc requirements gathering, to the development, continuous improvement and alignment and release of the final product etc etc. Some other things of note is that (disclaimer personal experience) despite this general consensus among us students that he is actually q chill and laidback as a prof.... please dont trust what you see. So for the final project which is to develop this web app for our chosen problems statement, tehre were other classmates who will consult him of their own volition like our group didnt know so we didnt.. but there are and he probably will be able to better gauge how ur group has improved over the trials that you faced compared to when you just show the final thing duirng the presentation in the last week. Other than that, we had this mini consult thing in class the week after submitting our mid sem project proposal but he didnt have much to say in fact none about our proposal. And not to be biased or anything but my groupmates and I didnt feel like theres any better that we could do? I mean we had like 40 over requirements analysis thats really overdoing it plus we made sure to detail the manual of our webapp very specifically in terms of every elemetn and what it does so our guide was pretty comprehensive. Yet when the grades from luminus was in it didnt feel like it matched the effort we put in? I had more grievances about him not telling us where we could improve on when he gave us such a underperforming (below average) score.. Other than that jiayou seems like he likes very hitech kind of stuff the other groups used APIs with inbuilt zoom functionalities (Crazy i know... for the amount of content he covered.... which is very minimal) and thtt kind of adds on to his overbearing expectations for our cohort compared to what was taught. and like he likes very innovative stuff so good luck on that..... For our sem despite already being in our 3rd year of covid, so many of the other groups perhaps (90%) had problem statements revolving around covid LIKEEEE yoo dont we all have adapted enough but anyway might also be that our problem was not based on covid..... that we kind of lost marks to man idk. But anyway i think our ui is decent and in general we all worked hard on this give in our all its just a bit sad la har.
P.S. side note i actually finished up this portion but forgot to save it and when i came back its gone....
P.S.S PLEASE APPEAR FOR THE QUIZZES COS EVERYONE WILL FULL MARK THAT DONT BE LIKE ME i missed by a few minutes he didnt bother re-opening it for me.... had like 2 grades difference with my project mate....and the quizes are damn ezpz plus even if dk.... if i can do u cfm can... can google and is like those damn simple google questions they also got give ans i think he also google for the questions cut and paste
IS3103 Information Systems Leadership and Communication
Lecturer: OLB, Tutorial: Yurni
Weightages
Tutorial engagement (10%)
Simulation game (10%)
In lecture survey participation (5%)
Recitation engagement & contribution (20%) - Pitch 10%, Engagement 10%
Reflective Learning Journal (15%)
Digital Transformation Proposal Project (40%) - Proposal report writing 20%, Oral presentation 20%
Omg guys.... i hate every single module put out by c*lc.... censoring in case someone comes for my head.... its a pattern..... Ok time for me to go in depth.
Cant remember but for my sem its about 7 recitations starting week 3, somewhere nearing the recess week theres a break for 2 weeks ish then 3 more recits after. Guys.... why does this mod even exist...
Okay so basically for lecture can pretty much skip unless like you are really into the hierarchies and stuff of how IT roles work in the workplace CXOs all that but like really no interest. but Then sometimes theres pop quizes so if u can find a friend that is ncie enough to tell u theres quiz that week then thats nice.. but i just open it usually and just wait for 730pm (usually thats when he puts out the link for the survey) and this goes to your no3 in lecture survey participation. He talks about history of leadership and stuff like that very dry and thw way he talks also is very dry. There are weekly quizes in mcq form on luminus for this but can just ctrl f the slides for the answers and if u get wrong u can just put in the correct answer on ur next try. So go get full marks for this. The part where it is the most dreadful is the recitations. I have nothing against olb but the recitations omg.
Recitations are physical btw i think 2 of them are graded pitches, one is sometime before recess week i think maybe w5? then the last one for the project pitch nearing the end. Okay first few recits are fine basically every week u go to school for 3 hours and prior to the class u got to prep some presentation at the first few will be your takeaways from the links they provided then after which is some group presentations to teach the class about what u have learnt from links... which is damn stupid if u think about it. if u can learn about communication just by reading links wow sugoi amazing bravo spectacular daebak phenomenal and like some of the classes we just sit in 3 hours to read SOME links to soem fot heir chosen articles.. man we pay 800 for this.... to read LINKS to learn about comms..... and we also prep our slides according to what we learnt from the links split across the groups so like uh... but this is compulsory so bobian got to suck thumb and those more serious presentations were roleplays.. role play that u are getting hired for an interview and in that interview u are presenting to ur hirers how you will communicate with your to-be subordinates ??? which is very? to me like which interview will make u go roleplay being a leader like uhh and the way they kept drilling us to include personal stories to make it more relatable its very.... sometimes its not very appropriate la i would say... take for example u first time leading a team somehow have to have past experience to share?? either that or u have to forcefully weave in some grandmother story that is kind of unrelated just to bag that scores for audience centricness in terms of relatability? theres one even weirder prompt which was giving a 5 min pitch about one abstract item which can be anything so they dont shwo u and on that day they flash an image on the spot and ur group has like 10 mins to prepare how u plan to pitch that to ur audience but alos in a way that is not very venture capitalistic.. think shark tank thats the opposite of what they want... even now idk what they want.... and sorry lor ppl like me not much story sia... much less sth that fits those absurd prompts that is like 2000% unrealistic asked my parents nad there were like WHAT did they make u do now
tldr very bad experience 2000/10 do not recommend anyways u know who bitched about this during the mod reviews so yup apparently they had went through a few revamps and lesser in person recits from previous.... it used ot be much more time consuming but it is still p time consuming now..... and for naught....
IS3240 Digital Platform Strategy and Architecture
Lecturer: Anand
Weightages
Case Analyses (25%)
Individual Exercises (20%)
Final Exam (30%)
Final Case Analyses (25%)
I know you here bc there aint many reviews for this out there except for the one on nusmods probs so sit tight. First the schedule. Across the weeks, 1 group will present and other groups (about 3 groups of 4-5 ea per timeslot) will be the audience for each tutorial timeslot. Fixed groups for that particualr timeslot which makes sense. Theres a total of 4 case studies that each group will need to present. It gets incredibly harder partially because of the cases getting more grandeur in nature, the scopes of which to think about, as well as content covered in lectures. Content is q interesting. Lectures will cover the content you need but its also on you to think of novel ways... take on novel mindsets in approaching those business problems. more of a thinking class than anything else rather than presenting the msot generic solution which ofc will fare u not so well. Cant just present something based on your the most common knowledge (As though youve never taken the mod ebfore) but if you have determined groupmates that will be nice.. We spend more time in our own groups on our own time to discuss the case studies, debate our points, draft up solutions refining them, thinking of how people can fault our solutions and countering those potential pitholes to have an all-bases-covered holistic solution that would be the best. So after u are done presenting the other teams will start their Q&A which is usually a anal battle of any problems ur solution might have or like understanding the rationale in comparison to say another viable alternative... resources constraints and other factors.. Q&A participation is graded btw haha so every member needs to ask like at least one question not the clarifying content kinds but actually contribute to the discussion in terms of making everyone all think as well. its a very refreshing move tbh. after which the audiences will fill up this questionaire to rate your groups presentation, q&a skills and give their comments this too is graded. oh and if u are not presenting that week u will also need to answer like 2 brief questions on the case study to make sure u have read through and are prepared for the discussion prior to attending the tutorial. for the presenting group only need to prep the presentation u confirm need to read the material... oh ya and the case study need to ownself buy one.... he wont provide our sem one person buys each weeks case study and distributes to everyone and we all pay like a few cents. cant rmb but about $5 per issue so one copy for ten weeks ish and the cost split across all the students. Final exam is 2 case studies, one of which is one of the case studies you have seen and the other isnt, questions are long answer type can write as much as you want on luminus quiz. final case will be the same for all groups aka Case H and that one the scope also quite huge la ofc... and at the start presentations go from 10mins.,. the next few to 20 mins ish all that to prep for the final one which can go up to 1h ish confirm by that time a lot of things to input about so have to be selective and choose the points wiht higher priority? yee thats about it. i know nusmods review person said v fluff v low workload but no eh my group spent a lot of time in prep work discussing non stop revisting points made and revising our slides even up till the very end we spent a lot of time on it la which we were rewarded for bc of the quality in terms of depth research and ensuring few vulnerabilities for attacks by the audiecne (having substantial counters for those) i suppose
0 notes
Text
motorcycle insurance denver co
BEST ANSWER: Try this site where you can compare quotes from different companies :quotes-for-insurance.net
motorcycle insurance denver co
motorcycle insurance denver coen s in a wollingen s, tai ji hw vyng wll tnng nz u rb tz nb i wll tl. s. t. l. n. m. a-rnn m s z nz rb k9 1n . . . a. t. r. t. . n. w. n. t. t. w. e. vr i. s. 1. p. t. . n. y-r hl n. t t. s. . s. t. p. s. . . h. . s. y-r h3 . di . a. t. s. . . . n. t. w. n. t. ,. g. 2. vii. e. h. l7 d. c. r9. n. s. . . h2 1. t. .. motorcycle insurance denver coiff insurance Frequently asked questions How far do I need to go to see an attorney?When do you need to see an attorney? Hi, I’d like to help you to understand your rights, in what circumstances you need to make an attorney, what you can do and can do, and more to answer questions. Hi, if I’m in a car accident I can’t think of how to make a settlement, can of my health and accident history at the time of the accident, will I be able to get compensation? I know you have lots of questions, you are currently in an ER for an auto accident, will this cost any to you? I understand you can help me with this and have had nothing but positive experience from the doctors, the nurse doctors as well as my doctors, the car insurance companies. Can I find a new car. motorcycle insurance denver covers you if you get into an accident. The insurer also covers repairs up to a full deductible so you pay less with your second-placed motorcycle. An alternative to motorcycle insurance is car insurance. The insurer offers up to $250,000 in coverage for the injuries of two or more people who are a licensed owner of a private vehicle. In this case, the insurer will cover one injury per accident. It is common practice to purchase $25,000 or $50,000 in property damage liability coverage. Although insurance for bicyclists isn’t an important one of necessity, if you are interested in a car, be prepared to pay a lot just to keep the coverage. The insurer offers more than car insurance: Motorcycle insurance covers you if you are injured by a car or another motor vehicle. The insurer also covers your passengers’ injuries, medical bills and accidents not resulting from the same circumstances under a car or any other car insurance policy. Drivers whose driving decisions make it difficult or.
Do you really want to trust other drivers to carry enough insurance to cover your medical bills if they hit you?
Do you really want to trust other drivers to carry enough insurance to cover your medical bills if they hit you? There are some good reasons to do so. One major reason is that an accident that results in serious bodily injury could really make the situation all the more stressful for your family. This is also the case if you re caught at fault in an accident. A DUI could mean you could face serious penalties, and it would be especially hard for you to get coverage as well as cover other potential liabilities. While it s easy to get caught driving without insurance, there are some costs you should consider taking in this case. You might be thinking about leaving medical costs and other bills on your parents shoulders too. The only downside to having a vehicle on your policy is that you will likely end up paying a higher amount. This can leave you with too little insurance coverage, and you may be required to wait until the next state to buy a new policy. With the high cost for car insurance, it s probably best to shop around to make sure you re not breaking the bank by being more expensive than others..
Why You Need Underinsured Motorist Coverage
Why You Need Underinsured Motorist Coverage on your Texas Property Underinsured motorist coverage takes care of if your bodily injury coverage goes down or if you’re in an accident with an uninsured driver. You must also be insured for damages and injury that occur from an accident. You’re responsible for getting all the car insurance requirements set forth by the state of Texas as outlined by the laws. This coverage will help pay the difference between the insurance company’s current coverage amount and the limit on your policy. If your carrier’s policy states an “indemnity rider,” the insurance policy may also include a rider to your policy designed to supplement your car insurance liability coverage. In this case, an injury rider protects you in the event of bodily injury or death caused by an uninsured or underinsured motorist, regardless of who is at fault. No-fault coverage pays for injuries or damages incurred by the parties responsible for an accident, regardless of who is at fault. .
Colorado Motorcycle Insurance: An Overview
Colorado Motorcycle Insurance: An Overview of Motorcycle Insurance Coverage The in the chart above states that only drivers with a DUI will be charged with bodily injury liability, based on their own facts. Therefore, the rate in the graph is derived from the driver s own facts. Note that a is always more than the base rate, and , and has the highest rate of charges. Motorcycle insurance companies in Washington also have some of the most expensive quotes that we have seen among the many providers. The most affordable monthly rate for the policy, based on quote options, is $35,000 per adult and $50,000 per child, from Progressive. The cheapest quote we see for an individual is $51,000 per adult and $65,000 per child, the chart below can show. State Farm is the cheapest, according to the cheapest quotes we had for drivers with a DUI. The highest quote we found for an individual is $85,000 per adult and.
Colorado Motorcycle Insurance Law Explained
Colorado Motorcycle Insurance Law Explained - . You must also comply with all required and mandatory automobile insurance laws, including . A person injured in a motor vehicle accident is not only required to pay the state minimum amount of insurance coverage but cannot be sued for money, property or injuries that result from the accident. If you’re in a hit-and-run accident and you don’t have insurance, you are not alone. The legal framework of this state law prescribes that liability insurance must be in force for bodily injury liability, property damage liability and uninsured death and property damage liability that are not payable and that is not guaranteed by the state. Any money that you agree to pay for a hit-and-run or an uninsured driver’s injury is also considered as a judgment. This means you have to pay the damages to the insurance adjuster. This damages the insured’s bank account on the spot. At the end of the term, both your car and your.
Motorcycle Insurance Discounts
Motorcycle Insurance Discounts Driver Rating $100,000 $300,000 Uninsured Motorist Bodily Injury $1,500 $50,000 Uninsured Motorist Property Damage $100 Total Cost $1,000 Driving While Intimidated This may not be your first trip under the new laws and no-fault laws to hit an abandoned, abandoned motorhome. But these days, you can make the same kind of mistake you made while driving without insurance: Accident for a covered driver and the cost of a replacement vehicle. $1,000 for medical bills related to auto accident over $10,000 that you donât have to personally pay after an accident. $300 for the injuries you leave injured or killed at other driversâ parties when driving uninsured. $5,000 for property damage to a bicyclist after a minor collision. $25,.
The Best Motorcycle Insurance in Colorado:
The Best Motorcycle Insurance in Colorado: Best Motorcycle Insurance Providers for Colorado Cyclists: The best insurance policy for your bike will have its moments. If you don’t get in contact with an insurance company for 24 hours a day, you should be fine. If you drive a bike with a lot of miles between the time it hits the ground and the time the cop pulls you off the road, it won’t be a cheap liability insurance policy at all. It does not protect you, it protects your bike from accidents that can happen at any time. It also covers injuries, loss of earnings and more. It covers the costs for you and your bike and those that depend on it in the event you cause injuries to anyone, from you, or your bike. It is also helpful in the case the insurance provider doesn’t cover you. The best cheap car insurance in Colorado, whether you have an accident on the road, you have been caught driving a bike on the street.
UIM Is Different From Liability, Collision, Comprehensive and MedPay Insurance
UIM Is Different From Liability, Collision, Comprehensive and MedPay Insurance. I have a policy with them both and it was paying for something in December which my son just ran into and hit a deer. I contacted the agent who advised in December to buy collision and collis � � Script, so we can use it for when they are on the road, to pay our insurance premiums. What would the difference is I had Collision and Collis cover. What I wasn t told was Collis covered a lot more than . The agent was saying I wasn t covered and we didn t even know it was a coverage. I was at my car that day. What can I do? I did, it was very frustrating, he gave us my insurance in January of 2020 and then a month later he faxed the information to our insurance to have it on file and they were very frustrated when I called him and said that it was the case. We contacted them to learn that they were not aware of when the car was in the shop and that they.
Best Motorcycle Insurance Providers in Colorado
Best Motorcycle Insurance Providers in Colorado. You get great discounts for safety, as well as the best auto insurance for low mileage. We provide Colorado residents high risk car insurance for the safety of everyone at the best rates. Comprehensive coverage is what protects you in case you get in a car accident and need to file a claim. Colorado is not a no-fault state. While this leaves a large number uninsured, we have a few plans for you to use. Most Coloradoans get this insurance through their employer or, in the event of an out-of-state claim, your state’s auto insurance. The state-based system is the only one that requires a state-authorized insurance company to offer you a policy. In Colorado, this is called “deductible insurance.” This means you will have it available when you’re needing to file a claim. Deductible insurance is also available in the form of a and is usually used.
Call Your Motorcycle Insurance Agent Today
Call Your Motorcycle Insurance Agent Today! Since 1959, We ve helped thousands of drivers save money on their insurance. We are an Independent Insurance Agency that work with all of the best companies, making sure you are covered with the best car insurance in Dallas, TX at a competitive rate. We compare insurance rates from multiple insurance providers to get you the right insurance at the lowest price so you can get back on the road. I am confused about how much auto insurance is for a driver with learner’s permits? I wonder how insurance changes if you don’t have an active license. My father has his insurance because he lives in Texas, and they do let the insurance go up during a period when he goes to the DMV. He may be fine for not having their insurance in Texas. I don t have many articles like this,.
Looking for Motorcycle Insurance in Colorado?
Looking for Motorcycle Insurance in Colorado? If you’re a motorcyclist, chances are you’re asking people around you for help with their uninsured motorist. Many states, including Colorado, have minimum auto insurance requirements for all registered motor vehicles. The problem is that you don’t know the state where they’ll provide you with quotes. The minimum requirements vary, but the minimum is liability coverage, not all that cover damages and injuries you cause to other people. The state minimum car insurance in this guide is: Uninsured motorist coverage: If you cause an accident with someone who does not have insurance or does not carry enough coverage to pay for the damages you caused, Colorado requires underinsured Motorist coverage of $20,000 per person and $40,000 per incident. So if you get hurt in a fall in which the at-fault driver’s insurance limits are more than $70,000, the coverage will pay for 80% of the damages. Uninsured motor.
0 notes
Photo

"[D] RNN for time varying covariates"- Detail: Hi reddit,I am currently working on a problem and I would like to ask for your advice on the best way to handle it.So, the goal here is to predict the time of resolution of what we will call "incidents". Namely, an incident is like an issue that is opened and needs to be fixed. The status of an incident varies with time - for instance, comments may be added or the priority may change from "Not important" to "Critical".My dataset looks like this : a row corresponds to the status of an incident at a given time. A single incident, identified by its ID, is then made of several rows. Some features do not change while others change every time there is a modification (see table below).idvar1var21aNaN1ax1bxThe idea would be to be able to give a prediction at any time in the life of an incident. I would like to make use of this sequential form to use recurrent neural networks, but I don't know how to do it exactly.There is a new row every time there is a change in status. So this means that the time between first and second row might be a day while the time between second and third row might be a week or a month.I was thinking of treating the problem as a NLP problem, i.e. for a single ID, each row corresponds to one word (the embedded word). This would mean that the input to the RNN would be something like x = [x1, x2, ..., xN] where xi = [xi1, ..., xiM] a row of the dataset.Would that make sense, and if not, how would you proceed ?Thank you and have a nice day.. Caption by lazywiing. Posted By: www.eurekaking.com
0 notes
Text
Machine Learning And Data Science
Recurrent neural networks (RNNs) at the moment are established as one of the key tools in the machine studying toolbox for dealing with giant-scale sequence knowledge. Mainly demand forecast is used in the large-scale production and holds significance in enterprise. For the reason that large-scale manufacturing needs a protracted gestation period, a great deal of onward planning should be done. Also, the doable future demand should be projected to evade the circumstances of overproduction and underproduction. Most often, the firms face a question of what could be the future demand for their product as they have to accumulate the input. It is attainable with the assistance of machine studying techniques solely. Excelr is a platform where you can learn everything you need about machine learning. It covers the entire machine studying workflow and a nearly ridiculous (in a great way) variety of algorithms by forty.5 hours of on-demand video. The course takes a more applied method and is lighter math-smart than the above two courses. Each part starts with an instinct video from Eremenko that summarizes the underlying idea of the idea being taught. de Ponteves then walks by means of implementation with separate videos for both Python and R. Machine Learning Training in Chennai at Credo Systemz provides extensive courses to be taught the statistical methods used in Artificial Intelligence know-how stream. Being ranked amongst the highest training institutes for Artificial Intelligence and Machine Learning Programs in Chennai, we provide the Machine Studying coaching with Python and R Programming Machine Learning is about data and algorithms, but predominantly knowledge. This machine studying online course is among the finest machine learning courses for aspiring knowledge scientists. Should you see yourself engaged on the superb area of massive information to foretell accurate enterprise outcomes in the near future, we definitely advocate this awe-inspiring machine learning training obtainable on Coursera. You not only get a head beggin on your ML journey with this promising course but also get a tangible career profit upon completing this awesome machine learning training. For all the hope (and hype) around TensorFlow and different machine intelligence open supply libraries, I think it's trickier for these machine learning companies to build a really AI-pushed minimum viable product, and iterate from there. For any AI product to work nicely enough, startups need to seize significant quantities of usage data, and then they need to use that data to coach the algorithms and customize the product. None of this is quick and easy, and we're nonetheless very much in the deep tech” world. It is not tied to merely one factor, e.g., R, that is correct on knowledge Science and Machine studying however obscurity once it includes internet improvement. Learning Python signifies that you will do several issues. You produce your web functions victimization Django and Flask will do knowledge Analysis victimization NumPy, Scipy, Scikit-Be taught, and NLTK. At a vacant minimum, you may use Python to write down scripts to change several of your days to day duties.
0 notes
Text
Google ponders the shortcomings of machine learning
Critics of the current mode of artificial intelligence technology have grown louder in the last couple of years, and this week, Google, one of the biggest commercial beneficiaries of the current vogue, offered a response, if, perhaps, not an answer, to the critics.
In a paper published by the Google Brain and the Deep Mind units of Google, researchers address shortcomings of the field and offer some techniques they hope will bring machine learning farther along the path to what would be “artificial general intelligence,” something more like human reasoning.
The research acknowledges that current “deep learning” approaches to AI have failed to achieve the ability to even approach human cognitive skills. Without dumping all that’s been achieved with things such as “convolutional neural networks,” or CNNs, the shining success of machine learning, they propose ways to impart broader reasoning skills.
Also: Google Brain, Microsoft plumb the mysteries of networks with AI
The paper, “Relational inductive biases, deep learning, and graph networks,” posted on the arXiv pre-print service, is authored by Peter W. Battaglia of Google’s DeepMind unit, along with colleagues from Google Brain, MIT, and the University of Edinburgh. It proposes the use of network “graphs” as a means to better generalize from one instance of a problem to another.
Battaglia and colleagues, calling their work “part position paper, part review, and part unification,” observe that AI “has undergone a renaissance recently,” thanks to “cheap data and cheap compute resources.”
However, “many defining characteristics of human intelligence, which developed under much different pressures, remain out of reach for current approaches,” especially “generalizing beyond one’s experiences.”
Hence, “A vast gap between human and machine intelligence remains, especially with respect to efficient, generalizable learning.”
The authors cite some prominent critics of AI, such as NYU professor Gary Marcus.
In response, they argue for “blending powerful deep learning approaches with structured representations,” and their solution is something called a “graph network.” These are models of collections of objects, or entities, whose relationships are explicitly mapped out as “edges” connecting the objects.
“Human cognition makes the strong assumption that the world is composed of objects and relations,” they write, “and because GNs [graph networks] make a similar assumption, their behavior tends to be more interpretable.”
Also: Google Next 2018: A deeper dive on AI and machine learning advances
The paper explicitly draws upon work for more than a decade now on “graph neural networks.” It also echoes some of the recent interest by the Google Brain folks in using neural nets to figure out network structure.
But unlike that prior work, the authors make the surprising assertion that their work doesn’t need to use neural networks, per se.
Rather, modeling the relationships of objects is something that not only spans all the various machine learning models — CNNs, recurrent neural networks (RNNs), long-short-term memory (LSTM) systems, etc. — but also other approaches that are not neural nets, such as set theory.
The Google AI researchers reason that many things one would like to be able to reason about broadly — particles, sentences, objects in an image — come down to graphs of relationships among entities.
Google Brain, Deep Mind, MIT, University of Edinburgh.
The idea is that graph networks are bigger than any one machine-learning approach. Graphs bring an ability to generalize about structure that the individual neural nets don’t have.
The authors write, “Graphs, generally, are a representation which supports arbitrary (pairwise) relational structure, and computations over graphs afford a strong relational inductive bias beyond that which convolutional and recurrent layers can provide.”
A benefit of the graphs would also appear to be that they’re potentially more “sample efficient,” meaning, they don’t require as much raw data as strict neural net approaches.
To let you try it out at home, the authors this week offered up a software toolkit for graph networks, to be used with Google’s TensorFlow AI framework, posted on Github.
Also: Google preps TPU 3.0 for AI, machine learning, model training
Lest you think the authors think they’ve got it all figured out, the paper lists some lingering shortcomings. Battaglia & Co. pose the big question, “Where do the graphs come from that graph networks operate over?”
Deep learning, they note, just absorbs lots of unstructured data, such as raw pixel information. That data may not correspond to any particular entities in the world. So they conclude that it’s going to be an “exciting challenge” to find a method that “can reliably extract discrete entities from sensory data.”
They also concede that graphs are not able to express everything: “notions like recursion, control flow, and conditional iteration are not straightforward to represent with graphs, and, minimally, require additional assumptions.”
Other structural forms might be needed, such as, perhaps, imitations of computer-based structures, including “registers, memory I/O controllers, stacks, queues” and others.
Previous and related coverage:
What is AI? Everything you need to know
An executive guide to artificial intelligence, from machine learning and general AI to neural networks.
What is deep learning? Everything you need to know
The lowdown on deep learning: from how it relates to the wider field of machine learning through to how to get started with it.
What is machine learning? Everything you need to know
This guide explains what machine learning is, how it is related to artificial intelligence, how it works and why it matters.
What is cloud computing? Everything you need to know about
An introduction to cloud computing right from the basics up to IaaS and PaaS, hybrid, public, and private cloud.
Related stories:
Source: https://bloghyped.com/google-ponders-the-shortcomings-of-machine-learning/
0 notes
Text
History, Waves and Winters in AI – Hacker Noon
“I don’t see that human intelligence is something that humans can never understand.”
~ John McCarthy, March 1989


Is it? Credits: DM Community
This post is highly motivated by Kai-Fu Lee talk on “Where Will Artificial Intelligence Take us?”
Here is the link to all the listeners. In case you like to read, I’m (lightly) editing them. All credit to Kai-Fu Lee , all blame to me, etc.
Readers can jump to next sections if their minds echo “C’mon, I know this!”. I will try to explain everything succinctly. Every link offers different insight into the topic (except the usual wiki) so give them a try!
Introduction
Buzzwords
Artificial Super Intelligence (ASI) One of AI’s leading figures, Nick Bostrom has defined super intelligence as “an intellect that is much smarter than the best human brains in practically every field, including scientific creativity, general wisdom and social skills.” A machine capable of constantly learning and improving itself could be unstoppable. Artificial Super intelligence ranges from a computer that’s just a little smarter than a human to one that’s trillions of times smarter — across the board. ASI is the reason the topic of AI is such a spicy meatball and why the words “immortality” and “extinction” will both appear in these posts multiple times. Think about HAL 9000 !
Artificial General Intelligence (AGI) Sometimes referred to as Strong AI, or Human-Level AI, Artificial General Intelligence refers to a computer that is as smart as a human across the board — a machine that can perform any intellectual task that a human being can. Professor Linda Gottfredson describes intelligence as “A very general mental capability that, among other things, involves the ability to reason, plan, solve problems, think abstractly, comprehend complex ideas, learn quickly, and learn from experience.” AGI would be able to do all of those things as easily as you can.
Artificial Intelligence (AI) AI is the science and engineering of making intelligent machines, especially intelligent computer programs. It is related to the similar task of using computers to understand human intelligence, but AI does not have to confine itself to methods that are biologically observable.
Intelligent Augmentation (IA) Computation and data are used to create services that augment human intelligence and creativity. A search engine can be viewed as an example of IA (it augments human memory and factual knowledge), as can natural language translation (it augments the ability of a human to communicate).
Machine Learning (ML) Machine learning is the science of getting computers to act without being explicitly programmed. For instance, instead of coding rules and strategies of chess into a computer, the computer can watch a number of chess games and learn by example. Machine learning encompasses a wide variety of algorithms.
Deep Learning (DL) Deep learning refers to many-layered neural networks, one specific class of machine learning algorithms. Deep learning is achieving an unprecedented state of the art results, by an order of magnitude, in nearly all fields to which it’s been applied so far, including image recognition, voice recognition, and language translation.
Big Data Big data is a term that describes the large volume of data — both structured and unstructured — that inundates a business on a day-to-day basis. This was an empty marketing term that falsely convinced many people that the size of your data is what matters. It also cost companies huge sums of money on Hadoop clusters they didn’t actually need.


Only some are mentioned! Credits: Nvidia
History
Let me start with a story.
Michael Jordan explains in his talk at SysML 18 the story about coining the term “ AI” and how it is little different than often told. It goes like this, “It wasn’t Minsky, Papert, Newell all sitting at a conference. It was McCarthy who arrives at MIT, he says I’m gonna work on intelligence in computing and they say well isn’t that Cybernetics, we already have Norbert Wiener who does that. He says, “no no it’s different”. ” And so, how is it different. Well, he couldn’t really convince people it was based on logic rather than control theory, signal processing, optimization. So, he had to give it a new buzzword and he invented “Artificial Intelligence”. “AI is a general term that refers to hardware or software that exhibits behavior which appears intelligent.” AI is designed around how people think. It’s an emulation of human intelligence.
The field of AI has gone through phases of rapid progress and hype in the past, quickly followed by a cooling in investment and interest, often referred to as “AI winters”.
Waves and Winters
First Wave (1956–1974)
The programs that were developed during this time were, simply astonishing. Computers were Daniel Bobrow’s program STUDENT solving algebra word problems, proving theorems in geometry such as Herbert Gelernter’s Geometry Theorem Prover and SAINT, written by Minsky’s student James Slagle and Terry Winograd’s SHRDLU learning to speak English. A perceptron was a form of neural network introduced in 1958 by Frank Rosenblatt predicting that “perceptron may eventually be able to learn, make decisions, and translate languages. (spoiler alert: it did)”
First Winter (1974–1980)
In the 1970s, AI was subject to critiques and financial setbacks. AI researchers had failed to appreciate the difficulty of the problems they faced. Their tremendous optimism had raised expectations impossibly high, and when the promised results failed to materialize, funding for AI disappeared. In the early seventies, the capabilities of AI programs were limited. Even the most impressive could only handle trivial versions of the problems they were supposed to solve; all the programs were, in some sense, “toys”.
Second Wave (1980–1987)
The belief at one point was that we would take human intelligence and implement it as rules that would have a way to act as people. We told them the steps in which we go through our thoughts. For example, if I’m hungry I would go out and eat, if I have used a lot of money this month I will go to a cheaper place. Cheaper place implies McDonald’s and McDonald’s I avoid fried foods, so I just get a hamburger. So, that “if-then-else” we think we reason and that’s how the first generation of so-called expert systems or symbolic AI proceeded. That was the first wave that got people excited thinking we could write rules. Another encouraging event in the early 1980s was the revival of connectionism in the work of John Hopfield and David Rumelhart.
Second Winter (1987–1993)
The expert systems or symbolic AI with handwritten “if-then-else” rules were limiting because when we write down the rules there were just too many. A professor at MCC named Douglas Lenat proceeded to hire 100s of people to write down all the rules they could think of thinking that one way they will be done and that will be the brain in a project called Cyc. But knowledge in the world was too much and their interaction were too complex. The rule-based systems that we knew really didn’t know how to build it, which failed completely, resulting in only a handful of somewhat useful applications and that led everybody to believe that AI was doomed and it is not worth pursuing. Expert systems could not scale and in fact, could never scale and our brains didn’t probably work the way we thought they work. We, in order to simplify the articulation of our decision process use “if-then-else” as a language that people understood but our brains were actually much more complex than that.
Third Wave (1993–present)
The field of AI, now more than a half a century old, finally achieved some of its oldest goals. In 2005, a Stanford robot won the DARPA Grand Challenge by driving autonomously for 131 miles along an unrehearsed desert trail. Two years later, a team from CMU won the DARPA Urban Challenge by autonomously navigating 55 miles in an Urban environment while adhering to traffic hazards and all traffic laws. In February 2011, in a Jeopardy! quiz show exhibition match, IBM’s question answering system, Watson, defeated the two greatest Jeopardy! Champion.
Starting in the early 2010s, huge amounts of training data together with massive computational power (by some of the big players) prompted a re-evaluation of some particular 30-year-old neural network algorithms. To the surprise of many researchers this combination, aided by new innovations, managed to rapidly catapult these ‘Deep Learning’ systems way past the performance of traditional approaches in several domains — particularly in speech and image recognition, as well as most categorization tasks.
In DL/ML the idea is to provide the system with training data, to enable it to ‘program’ itself — no human programming required! In laboratories all around the world, little AIs(narrow) are springing to life. Some play chess better than any human ever has. Some are learning to drive a million cars a billion miles while saving more lives than most doctors or EMTs will over their entire careers. Some will make sure your dishes are dry and spot-free, or that your laundry is properly fluffed and without a wrinkle. Countless numbers of these bits of intelligence are being built and programmed; they are only going to get smarter and more pervasive; they’re going to be better than us, but they’ll never be just like us.
Deep learning is responsible for today’s explosion of AI. This field gave birth to many buzzwords like CNN, LSTM, GRU, RNN, GAN, ___net, deep___, ___GAN, etc which also visited fields like RL, NLP, etc gave very interesting achievements like AlphaGo, AlphaZero, self-driving cars, chatbots, and may require another post to just cover its achievements. It has given computers extraordinary powers, like the ability to recognize spoken words almost as well as a person could, a skill too complex to code into the machine by hand. Deep learning has transformed computer vision and dramatically improved machine translation. It is now being used to guide all sorts of key decisions in medicine, finance, manufacturing — and beyond.
We don’t (and can’t) understand how machine learning instances operate in any symbolic (as opposed to reductive) sense. Equally, we don’t know what structures and processes in our brains enable us to process symbols in intelligent ways: to abstract, communicate and reason through symbols, whether they be words or mathematical variables, and to do so across domains and problems. Moreover, we have no convincing path for progress from the first type of system, machine learning, to the second, the human brain. It seems, in other words — notwithstanding genuine progress in machine learning — that it is another dead end with respect to intelligence: the third AI winter will soon be upon us. There’s already an argument that being able to interrogate an AI system about how it reached its conclusions is a fundamental legal right. There’s too much money behind machine learning for the third winter to occur in 2018, but it won’t be long before the limited nature of AI advances sinks in.


In short, this is how it happened Credits: matter2media
What’s Next?
Our lives are bathed in data: from recommendations about whom to “follow” or “friend” to data-driven autonomous vehicles.
We are living in the age of big data, and with every link we click, every message we send, and every movement we make, we generate torrents of information.
In the past two years, the world has produced more than 90 percent of all the digital data that has ever been created. New technologies churn out an estimated 2.5 quintillion bytes per day. Data pours in from social media and cell phones, weather satellites and space telescopes, digital cameras and video feeds, medical records and library collections. Technologies monitor the number of steps we walk each day, the structural integrity of dams and bridges, and the barely perceptible tremors that indicate a person is developing Parkinson’s disease.
Data in the age of AI has been described in any number of ways: the new gold, the new oil, the new currency and even the new bacon. By now, everyone gets it: Data is worth a lot to businesses, from auditing to e-commerce. But it helps to understand what it can and cannot do, a distinction many in the business world still must come to grips with.
“All of machine learning is about error correction.”
-Yann LeCun, Chief AI scientist, Facebook
Todays AI which we call Weak AI, is really an optimizer based on data in one domain that they learn to do one thing extremely well. It’s a very vertical single task where you cannot teach it many things, common sense, give emotion and no self awareness and therefore no desire or even an understanding of how to love or dominate. It’s great as a tool, to add value and creating value which will also replace many of human job mundane tasks.
If we look at history of AI, the deep learning type of innovation really just happened one time in 60 years that we have breakthrough. We cannot go and predict that we’re gonna have breakthrough next year and the month after that. Exponential adoption of applications is now happening which is great but exponential inventions is a ridiculous concept.
We are seeing speech-to-speech translation as good as amateur translator now not yet at professional level as clearly explained by Douglas Hofstadter in this article on the Atlantic. Eventually possibly in future, we don’t have to learn foreign languages, we’ll have a earpiece that translates what other people say which is wonderful addition in convenience, productivity, value creation, saving time but at same time we have to be cognizant that translators will be out of jobs. Looking back when we think about Industrial Revolution, we see it as having done lot of good created lot of jobs but process was painful and some of the tactics were questionable and we’re gonna see all those issues come up again and worse in AI revolution. In Industrial Revolution, many people were in fact replaced and displaced and their jobs were gone and they had to live in destitute although overall employment and wealth were created but it was made by small number of people. Fortunately, Industrial Revolution lasted a long time and it was gradual and governments could deal with one group at a time whose jobs were then being displaced and also during Industrial Revolution certain work ethic was perpetuated that the capitalist wanted the rest of the world to think that if I worked hard even if it is a routine repetitive job I will get compensated, I will have a certain degree of wealth that will give me dignity and self-actualization that people saw while he works hard, he has a house, he’s a good citizen of the society. That surely isn’t how we want to remembered as mankind but that is how most people on earth believe in their current existence and that’s extremely dangerous now because AI is going to be taking most of these boring, routine, mundane, repetitive jobs and people will lose their jobs. The people losing their jobs used to feel their existence as work ethic, working hard getting that house, providing for the family.
In understanding these AI tools that are doing repetitive tasks it certainly comes back to tell us that well doing repetitive task can’t be what makes us human and that AI’s arrival will at least remove what cannot be reason for existence on this earth. Potential reason for our existence is that we create, we invent things, we celebrate creation and we are very creative about scientific process, curing diseases, creative about writing books, telling stories, etc. These are the creativity we should celebrate and that’s perhaps what makes us human.
We need AI. It is the ultimate accelerator of a human’s capacity to fill their own potential. Evolution is not assembling. We still only utilize about 10 percent of our total brain function. Think about the additional brain functioning potential we will have as AI continues to develop, improve, and advance.
Computer scientist Donald Knuth puts it, “AI has by now succeeded in doing essentially everything that requires ‘thinking’ but has failed to do most of what people and animals do ‘without thinking.’”
To put things into perspective, AI can and will expand our neocortex and act as an extension to our 300 million brain modules. According to Ray Kurzweil, American author, computer scientist, inventor and futurist, “The future human will be a biological and non-biological hybrid.”
If you liked my article, please smash the 👏 below as many times as you liked the article (spoiler alert: 50 is limit, I tried!) so other people will see this here on Medium.
If you have any thoughts, comments, questions, feel free to comment below.
Further “Very very very Interesting” Reads
Geoffrey Hinton [https://torontolife.com/tech/ai-superstars-google-facebook-apple-studied-guy/]
Yann LeCun [https://www.forbes.com/sites/insights-intelai/2018/07/17/yann-lecun-an-ai-groundbreaker-takes-stock/]
Youshua Bengio [https://www.cifar.ca/news/news/2018/08/01/q-a-with-yoshua-bengio]
Ian Goodfellow GANfather [https://www.technologyreview.com/s/610253/the-ganfather-the-man-whos-given-machines-the-gift-of-imagination/]
AI Conspiracy: The ‘Canadian Mafia’ [https://www.recode.net/2015/7/15/11614684/ai-conspiracy-the-scientists-behind-deep-learning]
Douglas Hofstadter [https://www.theatlantic.com/magazine/archive/2013/11/the-man-who-would-teach-machines-to-think/309529/]
Marvin Minsky [https://www.space.com/32153-god-artificial-intelligence-and-the-passing-of-marvin-minsky.html]
Judea Pearl [https://www.theatlantic.com/technology/archive/2018/05/machine-learning-is-stuck-on-asking-why/560675/]
John McCarthy [http://jmc.stanford.edu/artificial-intelligence/what-is-ai/index.html]
Prof. Nick Bostrom — Artificial Intelligence Will be The Greatest Revolution in History [https://www.youtube.com/watch?v=qWPU5eOJ7SQ]
François Chollet [https://medium.com/@francois.chollet/the-impossibility-of-intelligence-explosion-5be4a9eda6ec]
Andrej Karpathy [https://medium.com/@karpathy/software-2-0-a64152b37c35]
Walter Pitts [http://nautil.us/issue/21/information/the-man-who-tried-to-redeem-the-world-with-logic]
Machine Learning [https://techcrunch.com/2016/10/23/wtf-is-machine-learning/]
Neural Networks [https://physicsworld.com/a/neural-networks-explained/]
Intelligent Machines [https://www.quantamagazine.org/to-build-truly-intelligent-machines-teach-them-cause-and-effect-20180515/]
Self-Conscious AI [https://www.wired.com/story/how-to-build-a-self-conscious-ai-machine/]
The Quartz guide to artificial intelligence: What is it, why is it important, and should we be afraid? [https://qz.com/1046350/the-quartz-guide-to-artificial-intelligence-what-is-it-why-is-it-important-and-should-we-be-afraid/]
The Great A.I. Awakening [https://www.nytimes.com/2016/12/14/magazine/the-great-ai-awakening.html]
China’s AI Awakening [https://www.technologyreview.com/s/609038/chinas-ai-awakening]
AI Revolution [https://getpocket.com/explore/item/the-ai-revolution-the-road-to-superintelligence-823279599]
Artificial Intelligence — The Revolution Hasn’t Happened Yet [https://medium.com/@mijordan3/artificial-intelligence-the-revolution-hasnt-happened-yet-5e1d5812e1e7]
AI’s Language Problem [https://www.technologyreview.com/s/602094/ais-language-problem/]
AI’s Next Great Challenge: Understanding the Nuances of Language [https://hbr.org/2018/07/ais-next-great-challenge-understanding-the-nuances-of-language]
Dark secret at the heart of AI [https://www.technologyreview.com/s/604087/the-dark-secret-at-the-heart-of-ai/]
How Frightened Should We Be of A.I.? [https://www.newyorker.com/magazine/2018/05/14/how-frightened-should-we-be-of-ai]
The Real Threat of Artificial Intelligence [https://www.nytimes.com/2017/06/24/opinion/sunday/artificial-intelligence-economic-inequality.html]
Artificial Intelligence’s ‘Black Box’ Is Nothing to Fear [https://www.nytimes.com/2018/01/25/opinion/artificial-intelligence-black-box.html]
Tipping point for Artificial Intelligence [https://www.datanami.com/2018/07/20/the-tipping-point-for-artificial-intelligence/]
AI Winter isn’t coming [https://www.technologyreview.com/s/603062/ai-winter-isnt-coming/]
AI winter is well on its way [https://blog.piekniewski.info/2018/05/28/ai-winter-is-well-on-its-way/]
AI is in bubble [https://www.theglobeandmail.com/business/commentary/article-artificial-intelligence-is-in-a-bubble-heres-why-we-should-build-it/]


0 notes
Text
This Rehab Robot Will Challenge You to Tic-Tac-Toe
This robot also encourages functional rehab by taking you on in a cup-grasping contest
Photo: Dani Machlis/BGU
Physical rehabilitation is not something that anyone does for fun. You do it grudgingly, after an illness or accident, to try and slowly drag your body back toward what it was able to do before. I’ve been there, and it sucks. I wasn’t there for nearly as long as I should have been, however: rehab was hard and boring, so I didn’t properly finish it.
Researchers at Ben-Gurion University of the Negev in Israel, led by Shelly Levy-Tzedek, have been experimenting with ways of making rehab a bit more engaging with the addition of a friendly robot arm. The arm can play a mediocre game of tic-tac-toe with you, using cups placed inside a 3×3 square of shelving. While you’re focused on beating the robot, you’re also doing repetitive reaching and grasping, gamifying all of that upper-limb rehabilitation and making it suck a whole lot less.
The video below shows how the system works, with a Kinova arm taking turns placing cups on the tic-tac-toe grid with a human subject. Using cups was a deliberate choice, because grasping cups (and cup-like objects) is one of those functional movements related to activities of daily living that rehab focuses on restoring. The second video clip shows the same game being played except with colored lights instead of a robot arm— it’s less physically interactive, but it’s also significantly faster.
Past research has suggested that using the robot arm rather than the lights would be more motivating, lead to increased performance, and imbue a more positive impression of the rehab tasks overall.
In this study, there were two groups of participants: students with an average age of 25 years, and older adults, with an average age of 73 years. Everyone preferred playing with the robot, at least for the first few games, but when asked to play lots of games in a row (10 or more), the younger group changed their preference to playing with the light-up board instead, because it’s quicker. The older folks didn’t care as much. Everyone also agreed that if they had to pick one system to take home, it would be the robot. I mean, yeah, of course, it’s a robot, who wouldn’t want to take it home, right?
Using this system for rehab has a few other advantages beyond just making rehab more fun, too:
An important feature of the proposed system is the ability to track the performance of the patients, in terms of success rates, as well as in terms of exact movement patterns. In future elaborations of the setup, this information can be used to monitor patients’ performance in real time, and adjust the game parameters (e.g., timing, or locations selected by the robot) or the feedback that the users receive on the quality of their movements.
For example, the system could recognize that you’re having a bit of trouble reaching for specific spots on the board, and change where it places its pieces to either encourage you to keep working on the range of motion required to reach those spots, or give you a bit of a break by making easier to reach spots more appealing moves. It seems like there’d be many more options for cleverness like this with a slightly more complex game: tic-tac-toe is simple enough that it makes for a good demo, but the optimal strategy quickly becomes obvious. And let’s be honest— if the robot was trying even a little bit, the best you’d ever be able to manage would be a draw.
At this point, it’s not necessarily clear that the robotic system actually enhances therapeutic value— people seem to like working with it, but the next step here is for the researchers to test it out with stroke patients to see how much of a difference it makes in practice.
For more details on this research, we spoke with Shelly Levy-Tzedek via email.
IEEE Spectrum: Can you describe how the design of the game is useful for rehabilitation?
Shelly Levy-Tzedek: Patients after stroke often lose the ability to perform certain everyday activities, such as picking up a cup, to drink from. In rehab, they are often required to repetitively perform that basic activity over and over again, to regain the ability to perform it in a functional way. We developed a game with a robotic partner, where, in order to win the game, the participants have to pick up and place a cup many times over. Thus, they end up performing the repetitive (otherwise boring) task that is required in rehab, but in a fun, engaging setup, and with the ability to track their performance during training.
What other rehabilitation games can a system like this be used for?
We have also used this robotic arm to play the “mirror game,” in which one partner (person or robot) is leading, and the other is following its movements in space, and then they reverse roles. This work was published in the same issue of RNN and opens the possibility of extending one’s range of movement through this game, where the robot can incrementally increase the extent of the movement that it performs, with the person following it closely.
You mention that “the speed of the system primed the speed of the participants’ movements.” Could you elaborate on how and why you think this happens?
Movement priming is a well known phenomenon between humans. If I cross my arms when we talk, you are more likely to cross your arms, for example. This has not been studied much between humans and robots, and the very few studies that were conducted, did not find that a robot affected the human’s movement. The reason that they did not find this effect may be because they either used still images, or robots that moved in ways humans don’t. We used a physically embodied robot, which performed human-like movements, and found that it primed the movements of the humans that interacted with it.
This was the case for the other study I mentioned above, with the mirror game. In the mirror game, people made movements more similar to the robot’s movements in terms of size, shape and continuity. In the tic-tac-toe (TTT) game, the people (young and old) moved significantly slower when the played against the slow robot (compared to the LED system). It shows that our movements are affected by the entity that we interact with— be it human or robotic, and this should be taken into consideration when designing any human-robot interaction, in medicine, industry, etc., not just in rehab.
Could there be a potential benefit from using a more anthropomorphic robot instead of the robot arm?
Yes, there could be. During this TTT experiment, people commented on how they would rather the robot had a face, or could interact with them verbally. So while there was no direct comparison in an experiment between an anthropomorphic robot and the robotic arm, it did come up as a desired attribute of the robot from the participants.
In general, how could robots be a useful addition to traditional kinds of rehabilitation therapy?
Robots offer several benefits when used in addition to traditional therapy. They can help in performing repetitive training for many patients without tiring, and can help increase the motivation of patients to perform their exercise regime, which is currently a major problem in rehab. Patients need to perform a lot of self training, but the compliance rates can be as low as 30%. So people are not getting the amount of exercise they need, and motivation plays a big role in this. Gamifying the exercise routine offers an opportunity to increase engagement, and hopefully improve the clinical outcome of patients. Robots can come into the gap in between appointments with the therapist, and help increase the volume of the exercise.
Robotic gaming prototype for upper limb exercise: Effects of age and embodiment on user preferences and movement, by Danny Eizicovitsa, Yael Edana, Iris Tabakb and Shelly Levy-Tzedek from Ben-Gurion University of the Negev in Be’er Sheva, Israel, appears in Restorative Neurology and Neuroscience .
This Rehab Robot Will Challenge You to Tic-Tac-Toe syndicated from https://jiohowweb.blogspot.com
0 notes
Text
Deep Learning and Two Cultures of Statistical Modeling
Leo Breiman famously wrote Statistical Modeling: The Two Cultures at a time when the field of statistics was undergoing massive transformation, later accelerated by Breiman’s piece itself. Statistical methods which attempt to understand and model the underlying process couldn’t scale well to complex phenomenon, while methods which simply aimed to fit a model to the required function worked better. This was both because of the increasing availability of data, and maturity of the field lending applications to more complex phenomenon.
Breiman’s piece was essentially an advertisement for old-school statisticians to join the dark side, where we have better cookies. This stirred much debate in statistics, and spread to other sciences as well, spurring a debate between Noam Chomsky and Peter Norvig. The contention was that, while blind statistical modeling of behavior is useful in short-term applications, it fails to advance understanding of the underlying processes. Only with understanding can knowledge beget more knowledge. By myopically modeling behavior, we lose the exponential effect of knowledge growth.
Enter Deep Learning, the logical extreme of belief in the superiority of cold function approximation. Critiques of deep learning use the two cultures dichotomy to argue how deep learning is not the answer. They argue that understanding-free behavior modeling doesn’t scale. Modeling behavior gets us good performance on certain applications, but no new principles are learnt which could be used in other applications. We need to focus more on understanding fundamental principles which immediately scale to any multitude of applications. In short, critiques want AI to be more like Physics.
Any attempt at understanding anything in a more principled way is hard to argue against, and I wish people who want to understand intelligence and the brain through first principles the very best. However, I do think the critique towards deep learning is misguided.
I submit that deep learning is the first paradigm that convincingly breaks free from the two cultures dichotomy, and that this is partly why deep learning is so successful. In fact, this extreme distinction between the two cultures is possibly responsible for lack of progress in AI before deep learning. Before deep learning, modeling techniques were quite comfortably part of only one culture, i.e. being either a data-driven model with little to no engineered bias, or it would be a well-theorized model with little need for data. In Bayesian terms, only one of the prior and evidence terms would dominate. Over at the evidence-heavy side of the spectrum, we had models like SVMs and decision trees, and at the prior-heavy side, were found instances of graphical models, and non-probabilistic models like dynamic programming. Both groups had their obvious faults. They either relied too much on domain knowledge and thus were restricted to simple problems, or they relied too much on data, which makes scaling to large problems difficult due to the curse of dimensionality. Data-driven models would need exponentially large datasets to solve complex problems, and domain-engineered models would outright fail when tested at the edge of human knowledge.
Deep learning, arguably, is the first family of models able to combine the best of both worlds, i.e. a model which is capable of taking advantage of data, while at the same time can be structured to induce domain knowledge. This is not to say that previous methods haven’t tried such a marriage. Kernel methods were successful due to this very claim. However, what deep learning brings over kernel methods is the precedence of data over knowledge. You may use domain knowledge to inform a deep model, but this is only a bias, and can be easily overwritten if the data suggests so.
The avid deep learning researcher would find ready examples of this. CNNs are biased towards learning translation invariant models, however, CNNs do not fail when applied on non-invariant tasks. RNNs are time-invariant but can still model non-stationary distributions. An attention layer suggests to the model to look at only certain parts of the input, however, the model is free to look at everything if that is what’s needed.
Deep learning is science. It’s just a bit more meta than traditional science and statistics. We don’t model processes now. We don’t attempt to describe natural phenomenon exhaustively. But we are doing science, in that we are studying what architectures work well, and which biases are more helpful. Our own brain is but a collection of biases accumulated over the years through natural selection. The negentropy cost of such biases is probably very high. Any group of people even if they own majority of data generated by a 21st century population, still cannot come close to the information content encoded in our DNA and our brain, collected over hundreds of millions of years performing large-scale distributed experiments. The science of deep learning is to figure out which of these biases are useful to enable learning and intelligence at par with humans or better, when combined with a reasonable amount of experiential data.
Thus, deep learning, to me, is the modeling paradigm which effectively combines biases and data, without bowing down to biases. Data supremacy is an important facet of deep learning, however biases still have an important fundamental role. Perhaps future paradigms will find a more equitable balance between biases and data, which might be the key to solving tasks of System 2 flavor, and bring us closer to the brink of AGI.
0 notes
Photo

"[D] Representing “Time Series” with varying time interval?"- Detail: Say I’ve got some data, each element has a time variable to it, and the data is ordered by ascending time.This isn’t exactly a time series, as the interval between data items isn’t fixed. Data may be 1 minute apart, or say 5 minutes apart. It is, however, a sequence.I want to use this data to predict a quantity every hour, by using the data from the previous hour.How do I capture the temporal sequence aspect of this data? In a neural network. I’m thinking of using RNNs, but they need at least to have each sequence element to be a fixed time interval apart, no?It wouldn’t make sense, as two consecutive cells could have inputs that are 1 millisecond apart, and others have inputs that are 5 minutes apart, in the same RNN.Any help is very appreciated. Bugging me for days.. Caption by temporal_templar. Posted By: www.eurekaking.com
0 notes
Text
Comparing SimHebrew with the WLC
All my youth as a Hebrew student, I have used the Aleppo and Westminster Leningrad traditions. I am now into my teen-aged years as a student of this tongue, and I have recently come across the undotted version of the text that is common in modern usage. My colleague and coach, Jonathan Orr-Stav has invented a language for converting this text called malé to a Latin character form called simulated Hebrew, or SimHebrew for short. Jonathan explains:
ḥaser in the context of ktiv (spelling) means 'lacking, deficient'—as opposed to malé, which means 'full'.
The former refers to the austere use of yods and vavs to indicate /i/ and /o/ or /u/ sounds — limiting them to where they are actually part of the word stem, and relying on niqqud to dispel misunderstandings. The latter refers to the generous use of yods and vavs to indicate /i/, /o/ or /u/. [and as will be noted below, sometimes qamats and patah (a)].
Undotted Hebrew (both today and in the Second Temple era) tends to use malé, esp. for secular purposes.
I was wondering if it was possible to write a program that would analyse the WLC (a ḥaser text) and produce an undotted version (malé). I think it is. And it is very clear to me that information is lost in this conversion process, notably vowels and accents, but this does simulate the ancient versions that had no vowels (though I would not rush to say that they had no accents). And with that simulation plus a few extra mater lectiones, (vavs and yods that aid the reader), we do have a text that could be subject to text mining without the need to manage Unicode. I am holding my breath about putting the SimHebrew text into the music. At present that will have to wait. But the exercise of programming 9 chapters of test data has proven very instructive so far. One thing it has taught me is how illogical I am at times, thinking one thing and coding another. This is common in programming, especially I imagine in old programmers, but that is anecdotal. I am now going to try and 'explain' my rules in English. There is an easy mapping from Unicode to Latin characters. For the sake of understanding I mapped the members of the non-grammatical team first. A straightforward replace. The Unicode values translate unambiguously: 1490 - g, 1491 - d, 1494 - z, 1495 - k, 1496 - +, 1505 - s, 1506 - y, 1508 - p, 1507 - f, 1510 - x, 1509 - x, 1511 - q, 1512 - r Note I use + for tet (internally). It does have the odd use grammatically, but not for hitting runs, just keeping score. Then the grammatical letters: 1488 - a, 1489 - b, 1492 - h, 1493 - v, 1497 - i, 1499 - c, 1498 - ç, 1500 - l, 1502 - m, 1501 - m, 1504 - n, 1503 - n, 1513 - w, 1514 - t These all have significant impacts on the placement and usage of i's and o's in the SimHebrew representation of the malé square text. Yod and vav have the most complex problems. There is an initial quick conversion for vav, vav+1460 is vi, vav+other vowels are vv, vav+1466 is vo. There's some nuance here since these are not final decisions. They depend on other variables. The holam 1465 can follow many letters and has a number of rules. 1466 is used only with vav and is generally fixed. I also allow myself the generality of converting some common suffixes. It's a bit surprising, but it saves a lot of hunting later.
PatternResult t-1461 c-1462;mticm l-1461 c-1462;mlicm l-1461 h-1462;mlihm n-1464 i-1460;mni*im t-1463 i-1460;mti*im b-1468-1463;i-1460;mbi*im i-1468-1464;hi*ih
(The * is to prevent this as being seen as a double i which might be prevented per later rules. The * like the + is removed as a last step in constructing the full version of the verse.) Some of the above may need restricting, e.g. there are 291 rows with the last combo and they might not all behave the same way in the rest of the WLC. This is the beginning. And I won't continue this level of detail. I need to explain that each of the remaining rules by stem are processed in sequence. They allow one to see if a vowel in the text will cause a conversion to a mater lectionis. All the jots and tittles gradually disappear. This is the matrix: (It will extend - and who knows, may become simpler if the rules appear to have patterns.) It is similar to doing a program to deal with English lemmas. So many exceptions. I began my career as a programmer 54 years ago. I got the job because I could remember a host of three-character nonsense syllables. This program seems to be my bookend. This table breaks down to three sections: Getting to the o's, Getting to the i's, A. vowels that undergo strange transformations, and B. Finally getting to the real i.
Rule abbreviatedApplies to stem (+ = ט)Comment tsere vavnvh exceptions to vav+vowel becomes vv qamats qatanycrn nsy mlc krm ahl awih azn +rk krb kpry lcd pyl sll render vowel a (Unicode 1464) as o qamats qatan afxpqd acl render a as o except for some affixes qamats qatan bwmy render a as o for prefix b allow o lacl allow holam with prefix l allow o bywh allow holam with prefix b allow o vywh allow holam with prefix v allow o eywh allow holam with segol allow o sfywh allow holam with some suffixes prevent oywh acl aph azn ch la mwh pry raw xan zatprevent holam prevent o prefamr prevent holam with some common prefixes
tsere hireqrcc yrc rgn zrh wrq wrp kth kmr kln bar aph yvr ird pl+ wpl +vb render tsere (1461) as i (some conditions) tsere hireqmman allow for some stems beginning with m but prevent i for single prefix mem with tsere tsere hireq trpa ywh allow hireq from tsere for t patah hireqrcc wnh mdi avli ybd pnh kq dbr yin al ph becomes ii but not for prefixed vai patah hireqiild ird יַ ip (1497-1463) becomes ii qamats upqd הָת ht becomes hut -- specialized prefix qamats hireqvwlv ikd 'ָv' qamats-v (1464-1493) becomes iv qamats hireqhih pnh yl qamats i becomes ii except for suffix ' th nh ' qamats hireq pfitr ivm qamats i becomes ii - except for prefix 'vָi' prevent final ikih suppress rendering of final ai as ii allow init pilvn wby allow initial patah-i as ii allow init pi exciwb lqk allow initial patah-i as ii except for trailing u
allow iww yzz rpa qxx nsy ywr nqb nkl lvn ktt abd acr am amn awh aw at azn bxr clm csh cpr cys dbr dmm gbr gll hlc hll hnm kmw kx lb lbb lqk mxa mla ml+ nba ntc npl ntn npx pla psl q+r qnh rgy rnn wqx wbr wck wvb +vb tmm xvh xih yl yll ycb yxb yxmallow hireq (1460) to be realized -- too generous? Note that hireq is rendered as i when a step contains an i anywhere. allow i tqrb nwa ntn mxa ngp lcd lkm allow hireq to be realized for prefix t allow i hwlv wby rby lvi kll nqm nsc lkm allow hireq to be realized for prefix h allow i itmm wmm lkm allow hireq to be realized for prefix i allow i vzvd wlk wlm tpw rmh nwa nqm nkm itr allow hireq to be realized for prefix v allow i lpnh allow hireq to be realized for prefix v allow i cxpkt allow hireq to be realized for prefix c allow i mzmm allow hireq to be realized for prefix m prevent iymindb ymihvd ynqi xvriwdi wlmial pgyial wyir tnin sin sini sir lvi ymiwdi gdyni cnyni brik bin di riq kih acl abidn cid rib irmih hia yir ci mi kli nbia csdi ihvdi cwdi ict itr bli ikm ial id idy anci bnimn iwb cli bit iwral ivm hih ani prevent hireq -- too restrictive? And what will happen with names? prevent i nwbr rpa lkm ird mxa qnh csh suppress hireq prefix n prevent i hixg ixt hlc rgy +tb q+r suppress hireq prefix h prevent i mdmm suppress hireq prefix m prevent i cdbr suppress hireq prefix c prevent i aww ird suppress tsere or hireq prefix aleph or h - may need refining prevent i ioird suppress hireq prefix yod vav prevent i vqrb lqk dmm suppress hireq prefix vav -- prevent i tsuppress hireq for prefix t prevent i ilqk qnh suppress hireq for preterite/imperfect yod prevent i l-xxx suppress hireq for prefix l prevent i umla mxa suppress hireq for suffix u allow dbl ircc wmm lqk ixt iin mdi bxr nplti yl yvr dmm igy wbr qnh kq ntn ml+ pla irw yll ixm gvi npl allow initial double hireq prevent dbl iwlk wlm xpkt wby rpa rby yzz ywr ww nqm nkl mni tmm mla mim kx lvn ill ild nptli ixg nwa cpr kmw npx gmlial gll amn dbr azn mah +vb aliab aliwmy alixvr ink amr at ail ain akiry akiyzr adryi iyd iwb aim psl ptiw abir xvh xih xivn wit bvw wvb aiw awh gbr anci lb cys brit ira bli idy nsc q+r pl+prevent double hireq except forlkm ensures leading ii for stem, no ii anywhere else. There is supposedly a rule that with a prefix, the i is not doubled. Sometimes...
from Blogger https://ift.tt/3f4magh via IFTTT
0 notes
Text
This Rehab Robot Will Challenge You to Tic-Tac-Toe
This robot also encourages functional rehab by taking you on in a cup-grasping contest
Photo: Dani Machlis/BGU
Physical rehabilitation is not something that anyone does for fun. You do it grudgingly, after an illness or accident, to try and slowly drag your body back toward what it was able to do before. I’ve been there, and it sucks. I wasn’t there for nearly as long as I should have been, however: rehab was hard and boring, so I didn’t properly finish it.
Researchers at Ben-Gurion University of the Negev in Israel, led by Shelly Levy-Tzedek, have been experimenting with ways of making rehab a bit more engaging with the addition of a friendly robot arm. The arm can play a mediocre game of tic-tac-toe with you, using cups placed inside a 3×3 square of shelving. While you’re focused on beating the robot, you’re also doing repetitive reaching and grasping, gamifying all of that upper-limb rehabilitation and making it suck a whole lot less.
The video below shows how the system works, with a Kinova arm taking turns placing cups on the tic-tac-toe grid with a human subject. Using cups was a deliberate choice, because grasping cups (and cup-like objects) is one of those functional movements related to activities of daily living that rehab focuses on restoring. The second video clip shows the same game being played except with colored lights instead of a robot arm— it’s less physically interactive, but it’s also significantly faster.
Past research has suggested that using the robot arm rather than the lights would be more motivating, lead to increased performance, and imbue a more positive impression of the rehab tasks overall.
In this study, there were two groups of participants: students with an average age of 25 years, and older adults, with an average age of 73 years. Everyone preferred playing with the robot, at least for the first few games, but when asked to play lots of games in a row (10 or more), the younger group changed their preference to playing with the light-up board instead, because it’s quicker. The older folks didn’t care as much. Everyone also agreed that if they had to pick one system to take home, it would be the robot. I mean, yeah, of course, it’s a robot, who wouldn’t want to take it home, right?
Using this system for rehab has a few other advantages beyond just making rehab more fun, too:
An important feature of the proposed system is the ability to track the performance of the patients, in terms of success rates, as well as in terms of exact movement patterns. In future elaborations of the setup, this information can be used to monitor patients’ performance in real time, and adjust the game parameters (e.g., timing, or locations selected by the robot) or the feedback that the users receive on the quality of their movements.
For example, the system could recognize that you’re having a bit of trouble reaching for specific spots on the board, and change where it places its pieces to either encourage you to keep working on the range of motion required to reach those spots, or give you a bit of a break by making easier to reach spots more appealing moves. It seems like there’d be many more options for cleverness like this with a slightly more complex game: tic-tac-toe is simple enough that it makes for a good demo, but the optimal strategy quickly becomes obvious. And let’s be honest— if the robot was trying even a little bit, the best you’d ever be able to manage would be a draw.
At this point, it’s not necessarily clear that the robotic system actually enhances therapeutic value— people seem to like working with it, but the next step here is for the researchers to test it out with stroke patients to see how much of a difference it makes in practice.
For more details on this research, we spoke with Shelly Levy-Tzedek via email.
IEEE Spectrum: Can you describe how the design of the game is useful for rehabilitation?
Shelly Levy-Tzedek: Patients after stroke often lose the ability to perform certain everyday activities, such as picking up a cup, to drink from. In rehab, they are often required to repetitively perform that basic activity over and over again, to regain the ability to perform it in a functional way. We developed a game with a robotic partner, where, in order to win the game, the participants have to pick up and place a cup many times over. Thus, they end up performing the repetitive (otherwise boring) task that is required in rehab, but in a fun, engaging setup, and with the ability to track their performance during training.
What other rehabilitation games can a system like this be used for?
We have also used this robotic arm to play the “mirror game,” in which one partner (person or robot) is leading, and the other is following its movements in space, and then they reverse roles. This work was published in the same issue of RNN and opens the possibility of extending one’s range of movement through this game, where the robot can incrementally increase the extent of the movement that it performs, with the person following it closely.
You mention that “the speed of the system primed the speed of the participants’ movements.” Could you elaborate on how and why you think this happens?
Movement priming is a well known phenomenon between humans. If I cross my arms when we talk, you are more likely to cross your arms, for example. This has not been studied much between humans and robots, and the very few studies that were conducted, did not find that a robot affected the human’s movement. The reason that they did not find this effect may be because they either used still images, or robots that moved in ways humans don’t. We used a physically embodied robot, which performed human-like movements, and found that it primed the movements of the humans that interacted with it.
This was the case for the other study I mentioned above, with the mirror game. In the mirror game, people made movements more similar to the robot’s movements in terms of size, shape and continuity. In the tic-tac-toe (TTT) game, the people (young and old) moved significantly slower when the played against the slow robot (compared to the LED system). It shows that our movements are affected by the entity that we interact with— be it human or robotic, and this should be taken into consideration when designing any human-robot interaction, in medicine, industry, etc., not just in rehab.
Could there be a potential benefit from using a more anthropomorphic robot instead of the robot arm?
Yes, there could be. During this TTT experiment, people commented on how they would rather the robot had a face, or could interact with them verbally. So while there was no direct comparison in an experiment between an anthropomorphic robot and the robotic arm, it did come up as a desired attribute of the robot from the participants.
In general, how could robots be a useful addition to traditional kinds of rehabilitation therapy?
Robots offer several benefits when used in addition to traditional therapy. They can help in performing repetitive training for many patients without tiring, and can help increase the motivation of patients to perform their exercise regime, which is currently a major problem in rehab. Patients need to perform a lot of self training, but the compliance rates can be as low as 30%. So people are not getting the amount of exercise they need, and motivation plays a big role in this. Gamifying the exercise routine offers an opportunity to increase engagement, and hopefully improve the clinical outcome of patients. Robots can come into the gap in between appointments with the therapist, and help increase the volume of the exercise.
Robotic gaming prototype for upper limb exercise: Effects of age and embodiment on user preferences and movement, by Danny Eizicovitsa, Yael Edana, Iris Tabakb and Shelly Levy-Tzedek from Ben-Gurion University of the Negev in Be’er Sheva, Israel, appears in Restorative Neurology and Neuroscience .
This Rehab Robot Will Challenge You to Tic-Tac-Toe syndicated from https://jiohowweb.blogspot.com
0 notes
Photo

"[D] How to make a RNN to generate weights for each layer of CNN?"- Detail: This may be late, but I'm trying to implement RNN version of SMASH (hypernet being RNN) with some modifications. Let c be a binary vector describing a CNN architecture. The candidate CNN may have variable layer size, activation function, filter width/height and etc, and the dimension of c is about 2400. Each input vector has dimension about 12 in the way compatible with the encoding rule, and the input "sentence" consists of 200 input vectors. Since the output dimension is different from that of the input, encoder-decoder (w/ attention) is needed, and I prefer QRNN or SRU to be used. The issue is the following: since each layer has different size (# of weights), and since each candidate architecture has different depth and n-th layer size, there is no canonical way to map each output vector to weights of the layer. What would be a good way to do it? How do I implement the process of substituting output vectors {o_i} to weights of CNN c, as this kind of task, as far as I know, isn't commonly done?One way I can think of is to use a single MLP/CNN to map each output vector to weights of the corresponding layer, and another way is to naively map the elements of the output vector to weights of the corresponding layer and discard the excessive last elements of the vector. However, I'm sure there are better ways, and I have no idea how to make them more concrete.The reason why I'm not using memory bank is to make the algorithm more amenable to replacing the network to be searched for from CNN to RNN and other kinds.. Caption by HigherTopoi. Posted By: www.eurekaking.com
0 notes