#howtodoit
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 44% of users from Denmark used Tumblr daily.
Text




Great vintage #book FOR SALE ~ Norman Clothier 1975 How Anyone Can be a Ventriloquist Including YOU ! * Guide #eBay https://ebay.com/itm/385148166150 #Ventriloquist #acting #performance #dummies #dolls #puppets #learn #howtodoIT #rarebooks #vintage #performer #comedy #skits #pullthestrings
#Great vintage#book FOR SALE ~ Norman Clothier 1975 How Anyone Can be a Ventriloquist Including YOU ! * Guide#eBay https://ebay.com/itm/385148166150#Ventriloquist#acting#performance#dummies#dolls#puppets#learn#howtodoIT#rarebooks#vintage#performer#comedy#skits#pullthestrings#read#book#book shop#rare books#book buyers#books#bookseller
2 notes
·
View notes
Photo

#hownottocry #lawyers #arguing #howtodoit #thursdayvibes https://www.instagram.com/p/COy62c3DHay/?igshid=19dvreq1gpivg
2 notes
·
View notes
Photo

“问题不在于知识和实修哪个重要,而在于如何去做。”
8 notes
·
View notes
Text
Research Progression 3: Asymptotic Extrapolation(2)
....continuing from the last post, we have imagined the idea based on a limitation of Neural Networks, based on that idea, we have even come up with a hypothesis, now let’s continue with some logic and plots.
Background/ Supporting Logic:
Since the model weights are theoretically supposed to slow their rate of change (let’s call it “Delta”) as the model gets trained
i.e. ”Delta” should slow down the closer you are to the ideal value
This curve would appear to be similar to the curve of an “Asymptote”
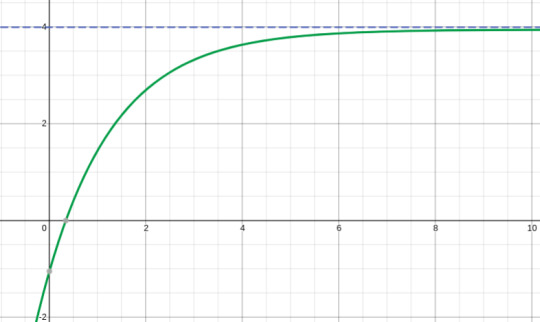
(Example of a horizontal asymptote, the curve (green) has a horizontal asymptote represented by the line y = 4 (Blue))
Furthermore, logically speaking, “Delta” of the value of curve would not just suddenly, jerkily decrease as it nears its ideal value, “Delta” would keep on decreasing with it’s own pattern. Like we observe in the above graph, the slope of the graph (Delta is the slope) does not suddenly change, it’s value keeps on decreasing with an increasing rate (slow - exponential in this case).
What we are trying to do is make a prediction model which is able to study the patterns of Delta and approximate the value of the curve at which Delta becomes zero (or close to zero), That will be the point where we reach the end of our training period
Supporting logic verification:
Everything mentioned up to this point is completely theoretical.
Is that bad? Not at all, everything starts with an idea, and discussing the idea is one of the most important things. However, ideas without evidence, are just thoughts.
So, how do we get supporting evidence of our claim that model weight training patterns are similar to Asymptote graphs which we have often observed in mathematics?
It’s simple, let’s train a simple Neural network and save the values of all the layers during the training period.
Now, we have all the values of training weights, let’s split them into individual sequences based for each trainable variable.
Finally, we can plot the function weights,
These are the ones I got,
1 Layer deep Vanilla Neural Network:
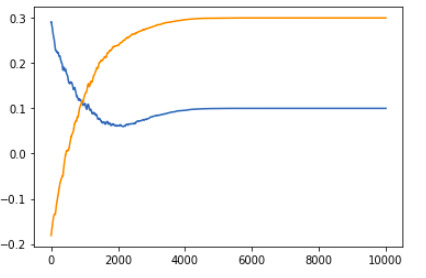
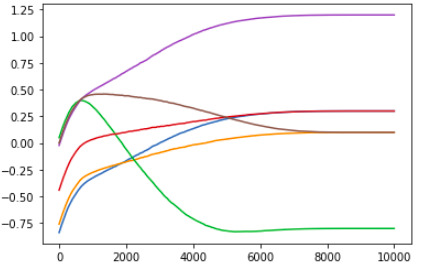
2 Layer deep Vanilla Neural Network:

(you can try it out by checking out this GitHub repository)
So, we have established a similarity between the training pattern of model weights and curves with “Asymptomatic tendencies”
What other inferences can we draw?
One other thing we can notice is that as the depth of the model increases, we get more complex training value curves, however, one fact that remains is that almost all values begin to head towards the “correct direction” after a very brief confusion period.
What I mean by this is if we take a complex model, which is estimated to be trained in around 4000 steps, if we train it for the 200 epochs to avoid the majority of the confusion period, then repeat a cycle of training for 200 steps and predicting value after 400 steps,
i.e.
0 - 200 steps: Training (initial confusion period)
200 - 400 steps: Training
400 - 800 steps: skipped by predicting future value
800 - 1000 steps: Training
1000 - 1400 steps: skipped by predicting future value
... and so on, we can train the model in 1600 Training steps and 2400 predicted steps instead of 4000 training steps.
Keep in mind the 2400 predicted steps are not actually steps, they’re more like a jump, and if we exclude the time and computation for prediction model (I will explain why we can skip that from the calculations), we can get an approximate efficiency of 60%
Furthermore, this efficiency is based off of a very conservative optimisation (i.e. jump window is only of 400 steps per 200 steps)
.... let that sink in...
Reason to skip prediction jump computation time from calculation:
For all of you hopeless critics (JK, always ask questions, as much as you can), the reason we can skip prediction computation cost from the calculations has 2 parts:
a) The computation required for predicting through a Neural Network is much much more negligible compared to the training phase (since training requires both forward and backward passes, that too for every single step while predicting requires a single forward pass)
b) The other reason is that time series forecasting type models work on a sequence of inputs (in our case a sequence of values of weights after every step of the training procedure). Since the 2 models (the original model being trained and the asymptote predicting model) are separate, during actual deployment, we can give the sequence of values (200 values in the above example) to the asymptote predicting model simultaneously while the original model is being trained, thus ignoring the time required to process the asymptote predicting model (let’s say it takes 1 second for every step of the original model to train, then as soon as each step finishes, we can send the new value to the asymptote predicting model, thereby letting it do it’s computation for 199 steps before the 200 step training sequence for the original model is even finished)
That was it for the idea,
Feel free to ask any questions in the comments, code explanation for the repository coming soon, stay tuned...
Thanks for following along,
One enigma decoded, on to the next one....
0 notes
Link
NAILTRENDS 2021 & HOW TO DO IT YOURSELF
#nails#nail#trend#trends#nailtrend#nailtrends#nailinspo#inspo#howtodoit#isalicious#isalicious1#isalicious.blogg.no#nailpolish#neglelakk#negler#negl#negletrend#stil#mote#fashion#nailfashion
0 notes
Photo

#saturdaymotivation #goodmorning #hoodmorning #howtodoit #givenachoice #sabadomotivación #buenosdias #allo #nomedieronopcion 💯🙏🏼❤️💪🔥💥💯💥 https://www.instagram.com/p/CD6S_MADrKj/?igshid=1t0pmn5upys21
#saturdaymotivation#goodmorning#hoodmorning#howtodoit#givenachoice#sabadomotivación#buenosdias#allo#nomedieronopcion
0 notes
Text
How to make?
A moodbroad?
a voting chart?
Got any answers, anybody?
1 note
·
View note
Photo

I always think bookbinding is easy. I forget exactly when and where I first learned how to do it but I’ve always found it quite intuitive. It is not until I try to make written instructions that I realize it’s actually a wee bit complicated. . . . #bookbinding #instructions #howtodoit https://www.instagram.com/p/B-jpEkUjxal/?igshid=n3ao9gvmgx45
0 notes
Photo

Knowing #howtodoit is a #Goodthing But #Understanding how you did it is even better 💯 @st_clair_bear #Gettingbettereveryday 💪 https://www.instagram.com/p/B8eCkJvB_41/?igshid=1m0erjofpg3jc
0 notes
Link
For just $15.00 Better Homes and Gardens Creative Cake Decorating editors of Better Homes and Gardens Books. COPYRIGHT: 1983 First Edition Eighth printing 1987. Hard cover, 96 pages, illustrated CONDITION: very good used condition, slight cover wear, inside pages are clean and unmarked, binding is tight SYNOPSIS: This approach to cake art demonstrates how to sculpt regular sheet or round cakes into wonderfully imaginative forms to fit any personality or occasion and includes tips on icing and baking and includes recipes for cakes & frosting. *IMPORTANT* Please see all pictures as they are a part of the description. Please read all measurements as the pictures can be deceiving in relation to size. Rocks, fake fruit, candles, books, shells or any other photo props are not included.
#ChildrensCake#FunCakes#KitchenHowTo#HowToDoIt#CakeHowTo#CakeDecoratingBook#BetterHomesGardens#CakeDecorating#WeddingCake#PartyCake
0 notes
Text
Research Progression 2: Asymptotic Extrapolation(1)
So the first topic in our series of posts based on research projects will be something I like to call: Asymptotic Extrapolation.
The main Idea:
Can we use training history of machine learning model weights in order to predict their final values. By using a time series forecast type model, we might be able to study the values of weights (and their changes) during a small training period to be able to predict the future value (the values which might be reached after much longer training periods).
Inspiration:
One major role of data science (and machine learning in particular) is to be able to predict values of variables by looking at subliminal patterns within data. So why not use Data Analytics on Machine Learning itself!
During the training of a machine learning model, the trainable variables (also called weights of the model) change their values slowly in order to make the model more accurate.
If we record the slow changes that said model weights undergo (and plot this curve), we can “Extrapolate” the graph to predict what the value of the weights would be after an indefinite amount of time.
Motivation:
Neural Nets (NN) are wonder tools, everyone who has even remotely studied Machine Learning would know that. At the same time, NN are basically a black box which we cannot understand very clearly (i.e. there is no simple way to convert what a Neural Net has learned into a human understandable language).
Since we cannot clearly understand the inner workings, we don’t have a way to mathematically streamline the inner structure of a Neural Net. Due to this gaping limitation in coding and mathematical capabilities, in order for a Neural Net to be effective, we need to give it “Space” (yeah, this isn’t a joke on all of you single coders); that is to say, give it storage and computational space, massive amounts of it.
The level of this demand is so large that many Neural Nets have millions of trainable parameters (variables or weights) and they require such a huge amount of compute power, that sometimes, even the ability of a Neural Net i.e. being able to “Predict”, is not enough of an advantage to compensate it’s costs and the biggest part of this computation is utilised during the “Training period” of the Neural Network.
All of the above story is to say 2 things:
a) inner workings of Neural Nets are really difficult to understand and improve
b) Neural Nets require insane amounts of computation to train
Can we solve even one of these problems? Well the simple answer is “Yes”, we can in fact solve both of them in a single shot with the help of something we like to call “Asymptotic Extrapolation”
More stuff coming up on the next post, stay tuned.
Thanks for following along,
One enigma decoded, on to the next one....
0 notes
Photo

“How You Go About It“
1 note
·
View note
Photo

Working some creative magic tonight at @thestudioat620 #handson #artclass #printmaking #rubberstamp #sigil #linocut #eachoneteachone #symbol #howtodoit (at The Studio@620)
2 notes
·
View notes
Photo

How . ...after I can find how to do it . Some organization knows HOW they do it. These are the things that make them special or set them apart from their competition . . . @simonsinek #whathowwhy #howtodoit #inspirationfor (presso Seoul, Korea) https://www.instagram.com/luca.villa.and/p/BsIBR97HonA/?utm_source=ig_tumblr_share&igshid=l58qbfdbqin
0 notes
Photo

Sometimes you’ve gotta refresh your memory about how to enjoy life. It’s easy to forget.
#enjoy life#enjoy#life#sometimes#howtodoit#how to be successful#how to be happy#how to build confidence#how to be a latin lover#how to gain confidence#how to make it#how#i'm starting to get it#illustration#art#drawing#sketch
2 notes
·
View notes
Text
How to hide spoilers in your post?
Does anyone know which code you need to use to use spoiler tags in a post? For example, on LJ, I know it's . So what is it for Tumblr?
3 notes
·
View notes