#does it count as spam if the posts are mostly on different topics
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 27% of US Tumblr users had an annual household income of over $100,000.
Text
Yeah im cleaning my drafts so like mid tier spam incoming
#does it count as spam if the posts are mostly on different topics#voiding#also ive recently caught the one piece virus so there might be some of that
0 notes
Text
About Me
Name: Sabrina
Pronouns: she/her
Age: 28 ± 1
Gender: Nonbinary Woman
HRT: E/Spiro since 2024-05-28
Neurotype: AuDHD girlie
Romantic Orientation: Lesbian
Sexual Orientation: Lesbian
Geographic Orientation: 35° NE
Relationship Status: Yearning
Top Fandoms: Dropout (esp. Dimension 20) and Doctor Who
Creative Medium: All of them but badly
Occupation: Software Engineer
Call Me: Hot, not pretty. JK, call me both, and beautiful too. 😘
Mutuals, feel free to DM me or submit asks about whatever. I guess everyone else can too, but no bigotry of any kind, and don’t be creepy.
I will assume any ask/DM/tag asking to donate or share a fundraiser is a scam and block you. See my disclaimers/additional notes below the fold for more details on that.
I have a loose system of tagging that I mostly stick to, and you can find a list of links to tags here.
Disclaimers and Additional Notes
To clarify what I said about donations, I promise you that I really do want to help, but there are a couple reasons that I am unable to engage with this kind of stuff, largely due to my disabilities:
Based on past experience, I am not very good at distinguishing between real campaigns and scams without extensive research, which absolutely will take me hours if not days.
I am hypersensitive, and I get multiple spam asks every day with extremely sad stories asking for donations, most of which are probably scams, and I often come on here to cheer me up when I’m starting to feel hopeless, which has been a lot lately. When I started getting these I became noticeably more sad and hopeless and I had to make a rule for myself that I block them without reading it the second I detect that it’s a request for donations. I literally look up and go through the motions of blocking in my peripheral vision the same way my dog looks up to avoid instinctively eating the treat when I tell her “leave it”.
When I donate through an established charity, my employer matches 100% of my donation (up to a limit that I haven’t been able to afford to hit since back when I still lived with my parents), which makes a big difference in the amount of good I can do with the money I donate.
But I do sincerely apologize to anyone who legitimately needs help that I mistake for a scammer and block. The hypersensitivity part does mean that I also have filters set up to block requests for donations, but I do bypass the filters and view them when I’m feeling up to it (I actually do that with a lot of sensitive topics and I highly recommend it).
On a brighter note, I do have a few side blogs. I'm not secretive about them (and often accidentally post to or reply from the wrong one), but I won't link them from here. You've got to put in the work to find them.
I have a few side blogs that I don’t actively hide but also don’t link to. Mostly gimmick blogs and some RP blogs of characters I find it funny to reply as. A couple are more of like me with a different set of filters, but also kinda sorta playing a character? idk it’s hard to explain.
You might occasionally see me mention something offhand about calorie counting or losing weight. I have a medical condition that the only cure for it is losing weight and getting certain nutrients that help with it, so I have no choice but to do that stuff or it will get worse and become life-threatening. I try not to mention it a lot to not normalize diet culture, but it’s not a secret or anything.
But I promise that I have a really healthy mindset around it and mainly the calorie counting is to force me to think about what and how much I’m eating. My goals are really loose and moderate and even then i break them all the time whenever it gets in the way of living life too much.
Also if you feel compelled to give me money, you can do that on Ko-fi here.
TERFs and other transphobes, go fuck yourself.
17 notes
·
View notes
Text
This is a serious post. TWs include borderline p/dophilia, guilt tripping, possible acephobia, and sexualization of minors.
(May 8th, 2024 update. hey !! I wrote this in 2021 when I was 14 and angry so it’s a pretty bitter read but that doesn't make a lot of it any less horrible!! It just makes the stuff towards the end look kinda salty and personal)
Hi. Jack here. I'm so sorry to suddenly get all serious but this needs to be discussed.
I used to be friends with tickinq-time, aka Kelli, but I am to no longer be associated with them after all the stuff they have done that I am detailing here today. We will start with the first segment
1) Borderline p/dophilia.
Kelli dated a 14 year old at the age of 17 (even admitting to wanting to run away with said 14 year old) and admitted they knew it was wrong when confronted.
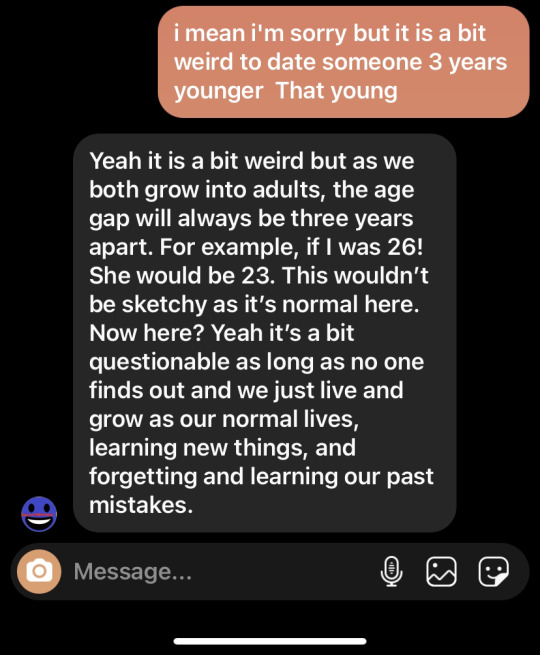
“As long as no one finds out,” eh?
2) Guilt tripping.
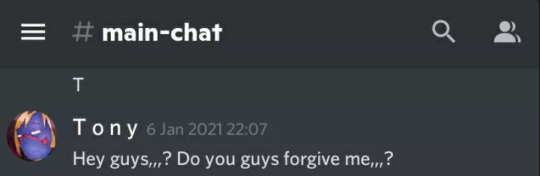
In a discord server, Kelli would allegedly spam in vent chats until they received responses, turn replies to others' vents into their own vents, talked about triggering topics in non vent chats

beg for forgiveness when no one responded to said triggering topics (do ignore me being a blind idiot)

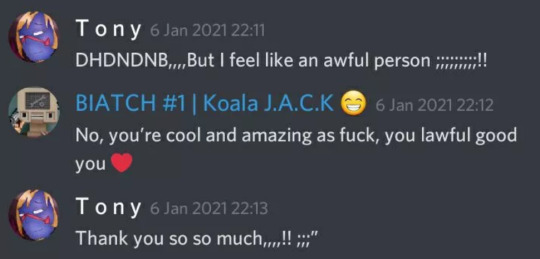
Left servers (for attention) when called out for minor (sometimes major but mostly minor) things they did, leaving those they called friends heartbroken
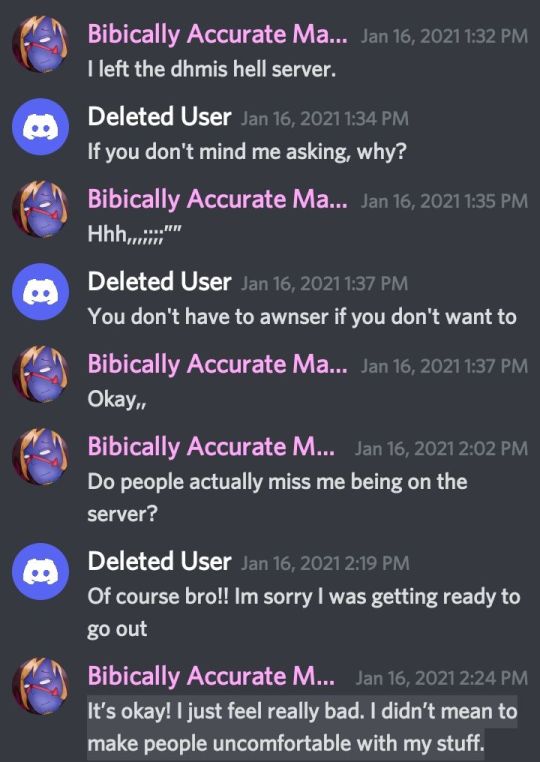

ask if anyone missed them in the server they left (also asking for invites back)
and attempting to villainize those who called them out.
3) Self shipping. (HEY JACK FROM 2024 HERE. IF YOURE READING THIS. I HATE THIS SECTION I DONT LIKE WITH HOW I WORDED THIS (except the wholeeee drawing and sharing the nsfwww of themselves that was crazy) selfship all you want don't draw nsfw of yourself when you're under 18 and share it with other minors cheers !)
Before I get into this one, I'd just like to say that not all self shipping is bad!!! Just what Kelli does with their sona is!!!! It's harmless in most cases!!!!!
Kelli shipped themselves with Tony. Doesn't sound bad until you take the fact that Kelli is a 17 year old minor and their Tony is a 30 year old man into consideration. The fact Kelli ages themselves up to ship themselves with Tony and heavily implies they did “the thing” to have baby Larry is disgusting. One look at their Tumblr page proves this.
They also allegedly drew NSFW of themselves and Tony but since the server it was posted in got deleted, I cannot show proof of this. (Also don't say it's just their s/i or persona, there's literally no difference between them.)
4) Sexualization of minors (and possible acephobia.)
Things said in this segment were in a voice call and make me the most angry (because it’s about my OCs and that makes it kinda personal), so apologies if I get aggressive, but I do have a witness for it.
Do you remember my first post about Ryan, Brian, and Xion the clock triplets, Tina's kids? Kelli saw that and took it upon themselves to ask if mean Steve (Tina's ex that she hates) was the father. The last time Tina and Steve were on good terms was in HIGHSCHOOL. That implies that they would've had to do it as minors, which is NOT OKAY.
What they said next could count as acephobia, but then they stated “Steve must have some good d!ck if he fucked an Asexual person.” Now, I'm all for sex jokes as the next guy, as long as they're about consenting adults, but again, the last time they were on good terms was in highschool, so this was not okay to say.
I have nothing else to sign off with other than please do not attack anyone mentioned, not even Kelli. Don't even interact with Kelli, just unfollow. I speak for myself and all my friends who have been subjected to their guilt tripping. Stay safe, planets.
-Your friendly neighborhood Colin kinnie.
#Serious stars.#the stars talk#Awareness post#long post#Please reblog to spread awareness#Do not just brush this off
149 notes
·
View notes
Text
Now that Cam’s parents and brother has been discussed, we will get to what I find most disturbing, namely the accusations Leopard made of the Camily having parallelisms with a cult. I will start by giving some background on Leopard and how she got the Camily’s attention. Leopard blogged on tumblr where she mostly discussed Queen, particularly drummer Roger Taylor. She quickly got a reputation for not shying away from discussing many topics taboo with Queen fans, namely the fact that all four members had flaws and seem quite different than how they are widely perceived by fans. The biggest taboo with Queen (asides from Paul Prenter, but that’s a whole other mess) is John Deacon. John has made no public appearance since 1997. I honestly have no idea why. There’s a very infamous video out there on YouTube of John Deacon being swarmed by autograph seeking fans. John becomes overwhelmed and starting moaning into his hands. I admit, it was hard for me to watch as John seemed quite vulnerable. Some have suggested he was crying or saying “I’m scared!” but I think he was simply having a meltdown. This footage is over ten years old. If you read the comments, you will see examples of fan reactions, many showing disgust and anger at the video. One that stood out in my mind was “we need to form a Deaky Protection Squad” or “I wish I had some cheese on toast to give him”. This will be relevant later on. In the mean time, ask yourself, does John Deacon need fans to protect him from other fans? Why do people fixate on his favorite snack so much? Maybe it’s because Americans find it random but it’s a common food in England, especially for people who need something quick, cheap and easy to make. I cannot state anything as fact, but there is probably more to John Deacon than how he is perceived by fans of Queen. Because of her willingness to answer any question even if they were about uncomfortable topics, Leopard got many anonymous questions about John, the great Queen taboo. She did receive some backlash even though she was respectful in her answers, being careful to note that she doesn’t know what really happened as she is unable to answer any questions for sure. She eventually did get some asks about Cameron Deacon, one about his perceived lack of hygiene, the other suggesting he only had so many fans because of his famous father. I will have to agree, these asks were mean spirited. Regarding Cam’s hygiene, Leopard simply wrote she didn’t know how to respond as she said she only ever visited Cam’s page once and wasn’t interested. The second ask called Cameron’s content “cringe” and that he only had fans because of his famous father. Leopard replied with “Anon don’t be mean” and that there’s definitely followers who shared his interests but that he blew up in popularity after fans of the Bohemian Rhapsody movie found him. I think this is very fair. It’s undeniable that many fans found him through Queen. I’m sure his subscriber and view count exploded in the late 2018-2019 after the film came out. Do any of these statements made by Leopard suggest hate? She even defended him by pointing out that many children of celebrities use their famous parent’s image to sell merchandise, after Cam was criticized for selling t-shirts with the Deaky name on it. Does any of this sound like spreading hate and her being a bully to you? Does any of this justify death threats? Leopard began receiving death threats from the Camily. One, a “Larry the Dolphin” messaged Leopard that they “will have to break their neck” if they “had something to say“. Leopard claimed the Camily was like a cult, due to their unquestioning devotion to Cameron and their extreme aggression towards her simply because she answered some rude asks. Leopard had told me that Larry learned of her after Cam mentioned her blog on stream. In fact, her blog and her asks were discovered by Cameron himself. Rather than trying to contact Leopard directly, he chose to read them live on stream. Cam was (understandably) offended by the asks regarding him. He also was upset to see some rather uncomfortable discussions of his brother and father. There are two asks critical of Luke Deacon. One was an anon mentioning he followed sex workers on social media. Another addressed a serious accusation of Luke made on a public social media by an ex-girlfriend of Luke. If she was enabling untrue stories about John to be spread, why didn’t he reach out to her, debunking them rather than trying to silence her with bullying from his followers, many of them still children? Leopard’s blog isn’t the only blog to discuss John Deacon’s personal life, and certainly isn’t the first-or last. I get the impression that Cam and Luke have a strong bond as brothers and Cam wanted to protect him. It’s understandable for Cam to feel defensive, but if he felt so bothered couldn’t he have talked to his brother about it? If the accusations are false, both Luke and Cam could politely reach out to Leopard. Since many fans of Queen are young girls, Cameron needs to understand that such behavior, if Luke did treat his girlfriend that way, is unacceptable. Even if Cameron doesn’t have a tumblr account he could of easily created one to pm her, like many of his followers did. I understand Cam is put in a unique situation due to his father. John is both reclusive and famous, of course people are going to talk. But, Cameron has five older siblings. Surely they would understand what he is going through. In fact, since some are old enough to remember when Father was in Queen and even when the press was hounding Freddie Mercury and Queen with AIDS rumors. A blogger replying to some gossipy asks has nothing on Fleet Street! There are a number of adult, mature ways Cam could handled the situation. Instead, he not only allowed his followers to harass Leopard, but actually encouraged them to. Leopard received death threats, rabbit emojis spammed her inbox and there were threats of mass reporting of her blog in an attempt to have it removed. Remember, Leopard made it very clear that her knowledge of John, Luke and Cam is limited and that people should never take her word as fact. What I am saying is the Camily’s behavior is uncalled for. What is worst, Cameron has no remorse choosing instead to see himself as the victim. Any “Camily�� members who objected to the cyber bullying or confronted him for his behavior was blocked. In a later post, I will discuss Leopard comparing the Camily to a cult, and why she isn’t wrong at all. I will also discuss the nature of cults, how they work, and how the Camily’s behavior can be considered “cultish”. If Cameron or his followers are reading this and feel offended, please pm me. These are all my words and not Leopard’s. If they feel the need to harass anyone who posts or shares this talk to me first.
Edit: Some of the events aren’t in chronological order, I will fix them as soon as I can
68 notes
·
View notes
Note
You’re a cunt lmao what kicks do you get from bringing people down ?
Yeah, first of all thank you so much for bringing what I did on instagram to tumblr. It's my first anon hate & OMG I am so excited to answer it...
Second well, babe you're a bit confused. I am not a cunt, I just have one.
So for the tumblr users who don't know what happened, let me tell you. Last night I announced that 'Children below 15 can't follow my instagram, wattpad or tumblr.' (And this anonymous message is from one of those children.)
Because:
#1. My fics are full of sexual themes & if not sexual themes than topics that aren't at all suitable for them. I even write implied to pure smut. And I don't want them to read it & drool over it, because unfortunately more than 50% of my readers that come via instagram are below 15.
#2. You just saw how toxic this fandom has become? Like with the Olivia dating Tom thing? And when I reserched who are these toxic people, each & everyone of them was 15 & below. Co-incidence right? Also Haz fandom is full of toxic people too. These kiddos are insecure & getting depressed thinking if they would ever be able to date Haz or Tom? And if they see a girl with them, they start to attack her.
#3. Hey guys, have you seen people posting stories on IG saying, "If you don't reply to my story, I will think you hate me" & even worse, "I'm going to cut myself, may even end my life if you don't tag my favourite celebrity on my last post & he doesn't like the post?" And yes these are mostly girls & mostly below 15. Co-incidence right? Also, they spam celebrities to like their work. Tag @ Celebrity , else I will delete my account because I am depressed or even cut myself or commit suicide? Is depression & suicide a joke? Even they are anxious of likes, comments, story shares & follower count in the most unhealthy way!
#4. These children make group chats on IG full of 12 to 14 year olds, where they share their desires of dating their favourite celebrities. They bully each other there. Like a next level of bullying. And when someone quits the group they call them a slut or bitch or cunt...
#5. This is clearly supporting paedophilia. Young fic writers & editors, write/make edits on 23 year old Haz/Tom dating a 14 year old. And yes they publically post their intense sexual desires for adult celebrities & yes, because they are kids, the celebrities are blamed to be paedophiles.
#6. They can't hear criticism. Okay tell me someone does this, isn't this sociopathy? I mean I am a fucking psychology elective student!!
And when I told her that what she's doing is sociopathy, she literally started messaging her friends that I'm calling her a psychopath. And if you have ever read a research paper on anti-social personality disorder, you know sociopaths manipulate words & literally try to emotionally blackmail them.
These kids who don't even know the difference between insecurity, ego, psychopathy, sociopathy, narcissm etc, are clearly not intetested in know what these terms mean & are very much interested in calling me a cunt, when their symptoms match the respective disorders.
I hope your doubts are cleared.
AND I CAN'T JUST SIT IDEALLY HERE!!!
And how can you call me a cunt, it's your symptoms that match those disorders, I just sent you research papers & only when, when you were asking me, why I was age restricting my account. I just asked you to unfollow me but you were the only one asking me an ellaborated reason. And you don't even have guts to hear it. Fair enough?
#harrison osterfield#haz osterfield#tom holland#ask and answered#ask blog#ask me anything#ask#anonymous#riya has mail#riya's blog#anon
14 notes
·
View notes
Text
So, here’s Part 1 of my shamelessly pandering, fluffy Post-Zero Requiem headcanons/notes because I just want everyone to be happy and content and I don’t care how unrealistic some of these are. fuck
(Note: the following 999.9% disregards Re;surrection and falls in line with the events of the original series.)
Suzaku (Zero)
• at first throws himself into being Zero and protecting Nunnally, not at all thinking he deserves anything but the misery that’s been placed upon him.
• mistakingly believes Nunnally hates him for murdering her brother. She ultimately sets him straight, and though they’re fairly close, there are still moments where Suzaku’s guilt becomes an obstacle to their relationship.
• for the first few months, he is cold and stoic as Zero, but as time passes and he grows into the role, he begins to soften. Still, his Zero is relatively distant and mute compared to Lelouch’s grand, theatrical version.
• misses the hell out of Euphemia and Lelouch (even if his relationship with the latter was more complex than a Rubik's Cube) but, over time, slowly reconciles with their deaths. Slowly especially applies to Euphy’s case. It took a while, but he eventually limits his visits to Euphy’s memorial from once every two weeks to once a month to once every other month to once a year (in the distant future).
• formally reconnects with Kaguya after she brusquely informs him that she’s aware of his identity. She manages to swindle him into having tea with her. Every week. It’s at one of these meetings where he breaks down and apologizes for all the pain he’s caused her, but she reassures him that she’s just happy they’re together again. They often simultaneously laugh and gag at the fact that they used to be engaged, and Suzaku becomes so attached to her, Kaguya’s guard detail starts to become suspicious of his intentions.
• on the subject of his relationships, he, against all odds, becomes close to C.C. and even closer to Kallen. He and C.C. have a weird understanding based on their love for Lelouch, and he bonds with Kallen (once she maneuvers around her own issues) over their mutual painful experiences, which is where they find common ground.
• Gino discovers his identity by accident. Milly does so on purpose. Both are rather bizarre, cautionary tales, but as a result of them, Zero’s personal associates are up by two.
• ironically has a large following among small children, who are at the receiving end of his softest interactions with the public. Mothers everywhere adore him just for that. As do stores that make the most profit selling Zero birthday cakes.
• unironically has a large following among horny young adults. Is the topic of a popular tabloid, Zero Weekly, which mostly speculates about his sex life and what he looks like underneath the mask. He’s scandalized by the magazine, as are Kallen and Nunnally, but C.C. and Kaguya love it.
• utilizes multiple disguises, in part because Kallen refuses to be seen in a public setting with him while he’s Zero for a second time and the rest is because Nunnally just likes putting together outfits for him.
• in the little free time he has, his hobbies consist of feeding the stray cats he’s accumulated over the years, reading poetry (it reminds him of Lelouch and a kinder time when they were friends), and watching the ridiculously bad American soap operas he swears he doesn’t watch. Their content should make bad memories surface, but they’re just so horribly acted, the effect falls flat.
• only after years of it being drilled into his head, he eventually accepts that he doesn’t have to be alone if he doesn’t want to and that the whole Zero thing doesn’t have to be completely miserable.
• still healing from, well, everything but has acquired a loyal support base in the few friends he has, and though he still doesn’t quite think he deserves any happiness he’s found, he’s in too deep to reject it (and there’s no way in hell that anyone will let him).
• cries the first time someone says they love him, halfway out of disbelief because he doesn’t think he’s worthy of anyone’s love and halfway out of relief because he’d never imagined there’d come a day where the phrase was directed at him again.
C.C.
• hangs around after Lelouch’s death because she can, not because she, god forbid, cares about the people in her life. Nope. Not at all, thank you very much.
• lives in Suzaku’s quarters in the palace until he gets so frustrated by the pizza boxes piling up in his room that he asks Nunnally to give her her own space. C.C. is more than happy to move when she learns the room is Cheese-kun-themed.
• formally befriends Kallen after the realization that they’re both assholes with trust issues. They have bi-monthly girls’ nights of epic proportions, ones that usually culminate in a single whopping bad decision.
• is both intrigued and gobsmacked by the fact that Suzaku is still so cordial to her despite the circumstances and the things she puts him through daily. He’s the opposite of Lelouch in every way, but that’s what draws her to him the most.
• may or may not be attracted to Suzaku. It’s hard to tell.
• is online friends with Milly. Neither is aware of the identity of the other, but they’re nonetheless a powerful force that troll the internet with spam and shitposting.
• no one knows her real name. Except for Kaguya, of all people, and no one knows how or when or why they became close enough to be on first names basis, and it just doesn’t make sense at all, to the point where Kallen loses sleep at night thinking about it.
• once recounted the time Benjamin Franklin told her off to Suzaku after he returned from a particularly despondent assignment. Afterward, they stayed up eating pizza and reminiscing over fond memories they had of Lelouch, which allowed Suzaku to see a kinder, more vulnerable side of C.C. for the first time. It also marked the beginning of their weekly sleepovers, though they don’t refer to them as such.
• sometimes goes riding with Nunnally on weekends. The younger girl reminds her of her brother, and like his, Nunnally’s heart is pure and kind. She gives C.C. a warm feeling similar to the one she got from Lelouch.
• is constantly traveling and moving about but always returns to Nunnally and Suzaku’s side at their residence in Japan.
• is well aware of the fact that everyone she’s come to accept as friends will die while she’ll remain living. This is her biggest point of contention, and she contemplates leaving more often than not, but she stays because she can’t leave.
• "I said that Geass was the power of the king which would condemn you to a life of solitude. I think, maybe, that's not quite correct. Right, Lelouch?"
• has stopped accumulating experience and started living.
Kallen
• finishes her last year of high school and, soon thereafter, becomes a full-time college student. Focusing on her education, she takes time off the Black Knights but still works as a reserve officer and is never without the key to her beloved Knightmare Frame. Because just in case, and Rakshata is always updating the Guren.
• resented Zerozaku for months following the Requiem, even though she knew everything that happened was all according to Lelouch’s plan. She overcomes her negative feelings after coming across Suzaku at Euphemia’s grave and realizing he knows the pain she’s suffering. She finds that maybe they aren’t as different as she thought.
• proves vital in helping Suzaku heal and vice versa. They’re both disasters, and they’re opposite in every sense of the word, but all that means is that they never manage to stunt each other, even when they just can’t understand each other.
• after they become friends, C.C. is her second most contacted person. Milly is her first because that woman cannot be trusted.
• begins a charity in her brother Naoto’s name with the help of her mother. The charity is dedicated to reuniting families displaced by the war.
• discovers she has an extremely high alcohol tolerance once she’s of age and could outdrink anyone at any time (”yes, Tamaki that also applies to you. ...Please, Ohgi’s son has higher tolerance than you”) but generally doesn’t fuck with alcohol because she doesn’t like the idea of becoming dependent on it. She makes enough bad decisions on her own, thanks.
• is, like various other members of the original Order of the Black Nights, a hero of the rebellion and a bona fide celebrity, though she still has to work to support herself and her mother and is a tad bitter about that. Especially considering she has all the other “privileges” of celebrity such as sporadic street interviews while she’s on her commute to work.
• because of that one time she danced with Zero at that one party, everyone assumes they’re together, and the media plays it up. She can’t count the number of times she’s had to call in to news stations falsely referring to her as “Zero’s paramour”.
• “True or false? Are you involved with Zero?” “...Involved with–I’m not–who said–” “Ah. You hesitated. Does that confirm our suspicions?” “I didn’t hesitate because that shouldn’t have been a question” “Well, a source close to you informed us of the fact that–” “Source? What source–?” *cue the moment she realizes that the source is C.C. Or Milly. Or both.
• Gino is the source.
• sleeps over at the palace at Nunnally’s invitation when her mother isn’t home and she’s feeling particularly lonely, sometimes sandwiched between C.C. and Suzaku in his room but the bed is more than large enough. It’s weird but it’s comfortable and it makes her feel that much more secure.
• grows out her hair. By the time she’s twenty-two, it’s almost as long as C.C.’s.
• still loves Lelouch with all her heart, but does eventually become open to pursuing a relationship. (”Gino wants to go out with you, doesn’t he? Why don’t you just say yes?” “Just because I said I was open to dating doesn’t mean I want to date Gino, C.C.” “I suppose you’re right. Although that could be because you want to fu–” “One more word out of you and I’ll put Cheese-kun in the shredder.”)
• changes her legal surname to “Kozuki”.
#code geass#code geass: hangyaku no lelouch#code geass r2#kururugi suzaku#zerozaku#c.c. (code geass)#kallen stadtfeld#kallen kozuki#headcanons#my notes#you don't have to take this post seriously#but i do
59 notes
·
View notes
Text
Just When You Thought it Was Over: Fighting Back Against Bullying and Continued Harassment Across Social Media (on Twitter, Facebook, Reddit and Tumblr)
This story is worth telling because it just keeps getting better.
And by better, the meaning is "worse".
You might want to catch up on the 10 Everyday Information Warfare Tactics You've Already Fallen For - and the case of the AltSciFi zine project (the number has grown to 15 tactics, with examples illustrating how they're used).
Here's a timeline of the past year or so:
Our Tumblr blog reaches ~1,500 subscribers (unlike AltSciFi Twitter, the Tumblr follower count is not curated, so many followers are probably bots). The AltSciFi Tumblr blog has several hundred posts accumulated over at least four years.
A prototype of the AltSciFi gallery/store site is posted to GitHub. Four out of 15 pages have working PayPal links, but the site is obviously not complete. Hint: it's on GitHub -- a site for programming and web development, not e-commerce; 11 pages have no links at all.
The attack begins on Twitter. An artist finds the GitHub site. The artist (we'll call her "MiraKillian") does not contact AltSciFi, but instead creates a Twitter slander/libel attack about how AltSciFi is "stealing art". This attack spreads across social media. Many artists on Twitter use copyright-trolling this way to earn "clout". In this case, MiraKillian is a member of a gang called "The (Twitter) Artist Community" who obsessively Like and Retweet each other's posts to get more magical "clout". Ironically, the Like/Retweet game rewards the best narcisssists and biggest bullies who rise to become "Influencers", some of whom act like megalomanaical miniature Harvey Weinsteins lording their imaginary status over less-popular followers who beg for "signal boosts", prostrating themselves to win the Influencers' favour.
AltSciFi is accused of "promoting" the unfinished site via Tumblr. The Tumblr blog's homepage is the only one that links back to the Github site, since that page was used for testing Tumblr's layout. The Github pages that have PayPal links aren't connected anywhere on the homepage at all -- meaning that no one could find them in any case. (And in case you've ever tried to sell anything via social media, it's a complete waste of time unless you have an extremely specific niche, or ten of thousands of followers. AltSciFi had neither of those, since we haven't publicly marketed, promoted, or launched the zine yet.)
The slander/libel attack reaches GitHub. One sci-fi makeup artist whose work was posted to the AltSciFi Github test site submitted a mostly-false DMCA takedown notice. GitHub never investigates, but rather automatically posts all DMCA takedown notices. This creates the illusion of "guilt" -- but also puts the makeup artist in legal jeopardy for libel based on her own gullibility.
A few months later, MiraKillian's name appears above the title of a cyberpunk webcomic created by a popular artist (we'll call her "Miirai") who has been publicly scammed quite recently. Miirai has built a public persona around being shy and trusting, which makes her the perfect target for yet another scam. This time, MiraKillian has taken over drawing Miira's webcomic along with one other artist, while Miirai herself begs her followers on social media for money to "support" the comic due to repetitive-stress injuries (art is hard work). That is a well-known tactic called a "sympathy scam".
The slander/libel attack reaches Reddit. Nona goes on Reddit and creates a topic to ask, "would you raise funds to help Miirai get proper medical attention for her injuries?" One of Miirai's new "team" appears and lies that Miirai is still creating art for the cyberpunk webcomic herself, which contradicts what she wrote on recent entries of her own blog about being disabled due to her injuries.
The slander/libel attack poisons a Reddit community. A day later, Miirai herself shows up and defends MiraKillian, making up a conspiracy theory about how a fake Patreon account claimed to be her -- therefore it must have secretly been AltSciFi! And the idea about her being scammed is "fake news"! (Note: a key tactic in any scam, obviously, is to gain the confidence and complicity of a vulnerable person.)
The slander/libel attack poisons a subreddit's moderators. The subreddit in which this conversation takes place starts arbitrarily deleting Nona's posts about the topic. Nona quickly narrows down exactly which moderator was likely the culprit based on who was active on Reddit when the most recent post was taken down, and asks a different moderator to deal with it.
Instead of disciplining the culprit, the moderator starts bullshitting, trying to make the problem about Nona instead. Nona contacted the moderator using a relatively new account to create distance from the attackers who are on Reddit. The moderator used that as an excuse, saying "creating alt accounts and posting about the same thing repeatedly is 'suspicious'." The mod also lied that adding links to further information about the incident was "spamming", and intentionally misinterpreted Reddit's rules (do not post the same comment repeatedly) to mean, "do not post about similar topics more than once".
The Reddit admins do nothing. Nona messages the Reddit admins. A week passes. No response.
Note: on that same subreddit, Nona previously posted a topic about the zine, and a well-known copyright troll appeared, spamming the comments section. After Nona reported the troll's comments, Nona was banned for "spamming the moderators". So Nona wrote a blog entry about it, and two years later, another artist commented on the blog that they were dealing with the same idiot. It's been _two years_ and the moderators of that subreddit are still allowing the troll to use their sub as his personal toilet for trolling. So much for "just ignore the trolls."
So you can see that as this story unfolds, it shows how much of a sham the idea of "free speech" really is on social media. Tribalism by a small, aggressive group of motivated (and mostly illiterate) bullies (the "Artist Community" on Twitter, who are actually just a few hundred idiots who are heavy Twitter users) spreads into an internet-wide disinformation campaign.
TL;DR The fallacy of "free speech" on the modern internet is a question of what is deleted or people who are bullied into silence. You can't know what's missing if you never see it in the first place.
Sounds like the perfect starting point for a dystopian sci-fi story, doesn't it?
The AltSciFi project is now fully dedicated to the fight against misinformation, disinformation, internet bullying and copyright trolling. The AltSciFi concept is only the beginning. We are here especially to support members of maginalised communities online (nonwhite, women, LGBT as well as non-neurotypical and older users). A safe and empowering internet for marginalised users creates a better internet for everyone.
If you want more information about ongoing and upcoming efforts to help independent artists and fans like you to create a better internet, send a DM -- or email altscifi at tutanota dot com.
P.S. Keep fighting for net neutrality. If we stop fighting, copyright trolling will become multinational corporate law, and the open web will effectively cease to exist. In other words, welcome to a real cyberpunk dystopia. The only way to stop that from happening is to create a better future for ourselves, since no one else will do it for us.
#science fiction#altscifi#internet bullying#internet harassment#minsooky#2018-01-18-MinSooKy.md#altscifi dmca 2018#altscifi dmca takedown#altscifi dmca 2018 github#respectartistspls#respect artists#online harassment#online bullying#independent science fiction#indie science fiction#indie sci-fi
2 notes
·
View notes
Text
In which it gets sappy
Tagged by the amazing @lethesomething!!
1. How did you come up with your username and what does it mean?
So uh. BS is actually short for bittersweet, but now it doubles as my in-joke for BS in whateverCourse -- hence the in. So BS in oranges.
Then it’s bittersweetoranges because i read this fic called bittersweet and it was damn good to me at the time. Also my favorite fruit is orange.
...I’m bot good at giving names nor titles. Haha.
2. Which fanfic of yours has the most feedback? (bookmarks/subscriptions/hits/kudos).
Hm. Overall, that would be my KuroYachi one-shot The Lights in the Sky are Stars. It was sort of my love letter to the KuroYachi ship, and so I’m not entirely sure if I’ll be able to add on to it.
For subscriptions that would be my still unfinished brofest piece, The Thief, the Witch, and the Fae. This one is my bid at making an interesting take on certain characters and dynamics in a dark fantasy setting. Futakuchi is the lead if only because @haruhi02 accidentally gave me his name when I asked for random characters.
3. What is your AO3 profile icon, and why did you choose it?
A freezing link from Breath of the Wild. Well, why not? Haha. I love Link, I love Breath of the Wild, and when I resurfaced back on tumblr botw recently came out and also the free icons.
(the rest is under a cut because it’s long and sappy)
4. Do you have any regular/favourite commenters?
Well. I won’t name favorites. Frequent commenters tho... they’d be my friends from chat, so shoutout to @lethesomething and @haruhi02 because you guys are great.
To be fair, I don’t think I post frequently enough for people to keep their eyes peeled for me.
5. Is there a fanfic that you keep going back to read again and again?
Boy, do I. Basically anything in my bookmarks are the things I regularly return to read. Quite notable, however is anything by bigspoonnoya. God. I love her work. From the HQ to the BNHA to the YOI.
6. How many stories are you subscribed to? How many do you have bookmarked?
I bookmark more than I subscribed. Buuuuuuuuut I’m subscribed to a grand total of 4 works, and I’ve bookmarked 62 fics.
7. Which AU do you find yourself writing the most?
Fantasy. Hands down. There’s three-ish urban ones, then there’s two full-on fantasy pieces. The rest are slice-of-life.
There’s just something about fantasy that makes me really happy. It might be the freedom to make, or that I like using fantasy as a substitute for when I want to comment on current events. But usually I like writing things that are fantastical.
Someday I want to make write a slice-of-life that makes the mundane fantastical, and then vice versa. If only because it’s the little things that steal my heart and imagination every single time.
8. How many people are subscribed and bookmarked to you in total? (you can view this on the stats page)
Four wonderful people are subscribed to me, while 12 are subscribed to my stories. For bookmarks, I have a total of 24. ^^
9. Is there something you’d like to write about but are afraid of people judging you for it? (Feeling brave? If so, share it!)
Many of my topic matter don’t really make much, if any, waves -- at least that’s what I think. I’m only afraid I can’t do justice to my dark/fantasy elements, because that would be a real shame.
10. Is there anything you would like to be better at? Writing certain scenes or genres, replying to comments, updating better, etc.
First it’s definitely finishing what I start. My multichaps aren’t incredibly long, but I worry a lot about continuation and future chapters that it spoils writing the present one, so I hope to work on that.
Next is my exposition and narration. I can only say “Name smiles.” so much before I think I write in a horribly stale matter.
... Does writing romance or any sort of sexual or romantic contact count? Cause, boy do I need practice.
11. Do you write rarepairs or popular ships more often?
Is YamaYachi popular? KuroYachi? I’m pretty sure they’re an okay and accepted ship. But in any case the rarest pair I’ve written is KuroYachi, and then KamaFuta. Because those pairs need more content, and I’m pretty willing to fill them.
12. How many stories have you posted on AO3 to this day (finished and unfinished)?
I have 9 works in total. Five of which are completed oneshot, and the other four are unfinished multichaps. See the trend yet?
One of the finished oneshots is the longshot Nowhere in the Sea. It’s the first fic I finished in my whole 17 (at the time) years of living.
Of my unfinished things, one of them is an anthology (that I should probably close since I’m not planning on updating anytime soon) and then the three fantasy pieces that has a lot Worldbuilding™.
13. How many stories do you have saved in/with your writing program?
H A H A.
Hm. So, I switch between Google Docs, Sublime Text 3, and OneNote. But there’s a whooping 17 unwritten stories in various states of disrepair.
I’m most excited for the YamaYachi one, and also the sprawling ensemble cast one. :D
14. Do you write down story ideas, or just keep them in your head?
I mostly keep them in my head. So they flit in and out of my memory like deadlines. On the rare occasion that I’m possessed by the idea, I’l have written the idea down and then some on anything I find convenient at the time (laptop, phone, or paper.)
15. Have you ever co-authored a story?
Yes. @haruhi02 was my partner for the hq fantasy fest thing. She was with me when I finished my first ever fic Nowhere in the Sea.
16. How did you discover AO3?
I was friends with this author back in FF.Net, and she had an AO3 account. Then, I branched off her fics to read the FE:A fics.
17. Do you consider yourself to be a popular or famous author in your fandom(s) on AO3?
LOL. Of course not. I can say, with confidence, that I am probably obscure.
18. Do you have a nickname or fandom name for your readers?
Hm...
19. Was there an author who inspired or encouraged you to write?
Fun fact, the first fan fic I wrote was an unfinished novelization of the Swan Princess (Nest Family Entertainment), and then an illustrated re-telling of Barbie’s Princess and the Nutracker. I started seriously pursuing writing around... the grade 5, when my bully of an English teacher said I had a talent for writing. If I had any it remains to be seen. But it was my friends back on FFnet. The likes of Mafi, and Tune, and Loke. They were there for me during my baby days writing for a fandom. We weren’t in the same fandom, but they inspired me so much.
Also I really like Philip Pullman and J.K. Rowling and thought it would be awesome to publish and write books.
Today though, it’s my friends in the chat who continue to inspire me everyday.
20. What writing advice would you give to a beginning author?
I don’t think I’m qualified. But if I should, it’d be to stay strong and welcome to addictive cycle of happiness and misery. Because there’s nothing like writing that one perfect scene -- it’s worth all the stress and the struggle.
Also. Writing is like wine, it get’s better with age, but it doesn’t mean that you like wine.
21. Do you plot out your stories, or do you just figure it out as you go?
I plot a lot. Like a lot. But I throw out a lot through the window when push comes to shove. Sometimes I’ll outwrite what I’ve planned or plan something new and then I’ll get flung into a crisis. Haha. Fun.
22. Have you ever gotten a bad comment on a story? If so, what did you do?
The worst comment I’ve had is spam on Nowhere in the Sea. I just wish I had more comments. #NoShame.
23. Is there a certain type of scene that you have a hard time writing? (action, smut, etc..)
Smut. A bit of action, but action is easier than doing the sexy.
24. What story(s) are you working on now?
I’m focusing all my energy on Amor Fati, which is my gift for the fantasy exchange. I need to finish that because it’d be sad if I didn’t. And, most importantly, I want to make my giftee proud.
25. Do you plan your next project(s) before you finish your current ongoing story(s)?
The plan is to keep up with my plans. I have no shortage of plans. Hahaha. But I do plan on finishing up Amor Fati then finishing either Scales or The Thief, the Witch, and the Fae before moving on to other projects.
26. Do you have a daily writing goal set for yourself?
Nope. It would probably be better if I did, but acads just eats a lot of my time.
27. Do you think you’ve improved as a writer since you first started?
I think it’s arrogant to think that I did, but I guess I did. I was 13ish -- two years after fifth grade -- when I took writing more seriously... And looking back my writing style changed. ^^
28. What is your favorite story that you’ve written?
I love all my stories for different reasons. To be honest tho, it’s what I haven’t written and am yet to write. I love The Thief, the Witch, and the Fae for it’s dark and heavy atmosphere. Scales for its hesitance and its secrecy. Amor Fati for the melancholy and for its world. Nowhere in the Sea for being my first in a lot of things (but also it’s magic system and world gdi). Lights in the Sky are Stars for it’s sweet fluff. Class Pizza for its tomfoolery. So on and so forth.
As much as I have a hard time looking at my writing, I won’t deny that I love them for the things that they are and could be.
29. What is your least favorite story that you’ve written?
... Probably my anthology? It reminds me of bad memories.
30. Where do you see yourself (as a writer) in 5 years?
Here, still suffering but instead out of school (hopefully) and knee deep in some sort of job.
31. What is the easiest thing about writing?
The planning and the talking and the crying and the reading.
32. What is the hardest thing about writing?
The writing. Or maybe that point between the first scene and the third. Something like that.
33. Why do you write?
Why don’t I? Writing is me. I’ve did things for the sake of reference, I’ve devoted a lot of myself to writing and the idea of writing. I love it. It’s an amazing way to express.
I wouldn’t give it up for the world.
Sooo. For tagging. @spacegaykj and @astersandstuffs and @slothesaurus if you guys don’t mind ^^. Feel free to ignore if you want. Thank you for the time.
Also double tagging @haruhi02 because I can.
#ask me stuff#thanks for the tag#I didn't expect to be so sap#but you know acads just chewed me up and spit me out so that might be a thing#hahaha
3 notes
·
View notes
Text
leah i told you i’d write it ily
@floristphill its kinda shit and i got sidetracked + didn’t outline but fuck that have a three page essay, single spaced, absolutely not standard format, but oH WELL i love yooou
Love: a concept so dearly held in our society, but what is it really? Love is defined as an “intense feeling of deep attraction; a feeling of strong or constant affection towards a person; a feeling of warm personal attachment or deep affection, as for a parent, child, or friend.” Combine this with media portrayals of love, and how it seems to act as a ‘cure-all’ for mental illness and personal struggle, and you have a clear view of what we as a society think love is. But is love really all that? Mental illness isn’t gone at the drop of a heart covered hat, but the support certainly does wonders. Going back to the six grecian types of love, and why they make much more sense than the one type of love recognized fully in the media today, we see how it’s evolved over the times. Considering this, we’ll also cover the portrayals of ‘love at first sight’, why that doesn’t work, and why Leah deserves all the love with or without a paper written about it.
Love is portrayed in the media as the all encompassing goal in life, why we exist, and what makes everything better. This, of course, is complete and utter bullshit. Not only is it toxic when we look at how the media conditions us with the thought that there’s ‘one true love’ for us(I’ll go into how that ties into abuse culture later), but it also fucks with the aromantic spectrum of people. Going into how it’s toxic, not only because it helps trap people in abusive relationships, the idea of ‘one true love’ makes all the other important people in your life seem less vital for your own personal growth. It also erases poly relationships, which are just as wonderful and important as the beloved cishet couple. Aromantic people, or people on the aromantic spectrum(including myself, a demiromantic), can feel invalidated or broken because they don’t get those so-called fireworks and butterflies. It can be hella hard trying to figure out why everyone is talking about their crush and how wonderful it is to be in love, but to not know what in God’s name they’re talking about. A personal experience of mine- a few years back, my friend commented on how “He[a fellow student] brushed up against me on the stairs, and my[said friends’] panties were soaked.” That certainly alarmed me, because I personally thought I had a crush on a boy at my school, but I hadn’t the faintest idea why she’d be aroused simply by that. Aside from making me feel very, very uncomfortable, she started me on the absolutely ‘’wonderful’’ train of questioning myself. Because at that time all I knew was that girls loved boys and boys loved girls, I was absolutely certain I was fucked up somehow. Now, four years later, I’ve educated myself, because none of these kids need to know anything besides cishet(and even then, it’s a bit iffy) lest they turn out to be gay. Media’s portrayal of love is actually harmful, surprise surprise, and while all the heteroromantic and heterosexual people out there don’t think it matters, it fucking does. Going back to how it messes with abuse culture, the idea that there’s only one person who we can love fully makes it hard to leave someone if you think you really, truly love them. Along with that, it doesn’t help that signs of emotional abuse are rarely, if ever, taught. Problematic movies, such as the Parent Trap, make it seem like this ever lusted-after ‘love’ can solve every single relationship problem without work. Leading from that, let’s look at how the currently defined love isn’t quite right, according to the six types of love from ancient grecian culture.
The six types of love are Eros, sexual love/passion; Philia, deep friendship; Ludus, basically puppy love, because we don’t have a word for it anymore; Agape, universal love/love for everyone; Pragma, or long-lasting love- the kind of stuff couples who’ve been married for several years have; and Philautia, self-love, which none of us have enough today and that’s an entirely different essay about how fucked up society is. Those all sound much more logical than just the one love we have, which is considered romantic. But that’s not right, is it? I personally have three types of love- familial, romantic, and platonic. For example, if I thought I was emotionally stable enough for a long distance relationship, I’d probably already be dating Leah or Prim. Why is this relevant, you ask? Because I love them both in a slightly romantic and mostly platonic way. I love Josh platonically, my cat familially, and so forth. Yelling ‘I love you’ at Josh wouldn’t really work if I only went with the one definition of love, right? But we’re obviously so straight for eachother, him having a boyfriend and myself being gay for several people.
And now for the topic you’ve all been waiting for: my extensive rants and feelings about love at first sight. I’ve gone into considerable depth on this topic before, and why it doesn’t work at all considering the definitions of love but why lust at first sight might be possible. It may or may not be tempered by my own romantic orientation, but how likely do you think it is to form a “strong affection for another arising out of kinship or personal ties” based on one look? There was a test a while back, about falling in love by asking forty questions, but while the results were that you can fall in love after only asking the few questions-that doesn’t very well count as first look. Let’s look at the definition of lust for comparison: “usually intense or unbridled sexual desire”. That’s much more achievable by first glance, is it not? That kinda- “oh shit i wanna fuck that person”, a much more animalistic feeling, is well known. While this doesn’t include people on the asexual spectrum, just as my assesment of love at first sight may be biased by myself being on the aromantic spectrum, it doesn’t cover everyone.
And now, after my relatively short assessment on love at first sight, we get to the reason I wrote this paper in the first place. Leah is one of my closest friends, and we started really talking maybe… eight months ago? We were mutuals before that, and chatted a few times, but we never really clicked. I’m not really sure what changed, but you can bet Bessie and the fucking farm that I’m glad it did. We talked for a while, I think Sammi started talking with me after Leah and I became friends(#lammiforever) and for a while everything was awesome and great, and then just out of the blue-
Leah threatened to commit suicide. I don’t think you understand the utter horror, fear, anger, disappointment, and just so much despair. I was so very scared that I’d lose one of the dearest friend’s I’ve ever had, I was angry with myself for not seeing something like this happening, and I couldn’t breath. I had gotten back from school, and then Sammi had asked me to help with Leah. I had no idea what she meant, and then she sent me the post Leah made and my heart just stopped. Leah wasn’t responding to me, and I just spammed her. There were tears on my face, and I was so close to just breaking down and running to my mom to cry my heart out.
But I didn’t. Y’know what I did? I spammed the fucking shit out of her. Asks, submissions, messages, I think I made a few posts too. She said she was gonna deactivate, and she hadn't yet, and I was hoping so fucking hard.
Do you know the story of Pandora’s box? That she was the first woman, and Zeus was a bitter shit so he made her curious. And then he gave her a box, as a wedding present of course. He forbade her opening it, but she was too curious because of that fucking shitface. She opened the box, and everything bad in the world flew out. She tried so hard to close it, to stop the flow of terrible beats.
And after she managed to slam it shut, she heard a voice inside. It begged her to let him free, and she pulled open the box to see Hope, the last gift to the world.
I was clinging to that little bastard so hard right then. One of my best friends was quite possibly dead, and that was the last thing I could do. I cried my eyes out, but i never stopped sending her messages. I was fucking selfish, because I didn’t want someone to die. I begged and pleaded and wept and it fucking worked. I’m so glad that she’s still here, and I love her so fucking much for sticking around. And because I know Leah’s gonna be reading this, I love you. I’m so glad you didn’t kill yourself, and you’re not allowed to blame yourself. I just wish I could’ve seen it coming and helped more, but I didn’t. And I don’t care, because you didn’t die that day and that’s all I care about.
Do you want to know why I love Leah? Because she’s a wonderful, lovely, amazing human being with the courage to stay another day. She didn’t cut her wrists, she didn’t take too many pills, and she’s still living here. I’m so fucking proud of her for that, because that was fucking brave.
Leah deserves so much love because she’s still fucking here, being the wonderful beam of light that she is.
5 notes
·
View notes
Text
Machine Learning for Everyone - In simple words
This article in other languages: Russian (original) Special thanks for help: @sudodoki and my wife <3
Machine Learning is like sex in high school. Everyone is talking about it, a few know what to do, and only your teacher is doing it. If you ever tried to read articles about machine learning on the Internet, most likely you stumbled upon two types of them: thick academic trilogies filled with theorems (I couldn’t even get through half of one) or fishy fairytales about artificial intelligence, data-science magic, and jobs of the future.
I decided to write a post I’ve been missing all that time. There's a simple introduction for those who always wanted to understand machine learning. Only real-world problems, practical solutions, simple language, and no high-level theorems. One and for everyone.
Let's roll.
Why do we want machines to learn?
This is Billy. Billy wants to buy a car. He tries to calculate how much he needs to save monthly for that. He went over dozens of ads on the internet and learned that new cars are around $20,000, used year-old ones are $19,000, 2-year old are $18,000 and so on.
Billy, our brilliant analytic, starts seeing a pattern: so, the car price depends on its age and drops $1,000 every year, but won't get lower than $10,000.
In machine learning terms, Billy invented regression – he predicted a value (price) based on known historical data. People do it all the time, when trying to estimate a reasonable cost for a used iPhone on eBay or figure out how many ribs to buy for a BBQ party. 200 grams per person? 500?
Yeah, it would be nice to have a simple formula for every problem in the world. Especially, for a BBQ party. Unfortunately, it's impossible.
Let's back to cars. The problem is, they all have different manufacturing date, dozens of options, technical condition, seasonal demand spikes, and god only knows how many more hidden factors. An average Billy can't keep all that data in his head while calculating the price. Me too.
People are dumb and lazy – we need robots to do the maths for them. So, let's go it computational way here. Let's provide the machine a data and ask it to find all hidden patterns related to price.
Aaaand it worked. The most exciting thing is that the machine copes with this task much better than a real person does when carefully analyzing all the dependencies in mind.
That was the birth of machine learning.
Three components of machine learning
The only goal of machine learning is to predict results based on incoming data. That's it. All ML tasks can be represented this way, or it's not an ML from the beginning.
The greater variety in the samples you have, the easier to find relevant patterns and predict the result. Therefore, we need three components to teach the machine:
Data Want to detect spam? Get samples of spam messages. Want to forecast stocks? Find the price history. Want to find out user preferences? Parse their activities on Facebook (no, Mark, stop it, enough!). The more and diverse the data, the better the result. Tens of thousands of rows is the bare minimum for the desperate ones.
There are two main ways of collecting data — manual and automatic. Manually collected data contains far fewer errors but takes more time to collect — that makes it more expensive in general.
Automatic approach is cheaper — you only need to gather everything you can find on the Internet and hope for the best.
Some smart asses like Google use their own customers to label data for them for free. Remember ReCaptcha which forces you to "Select all street signs"? That's exactly what they're doing. Free labor! Nice. In their place, I'd start to show captcha more and more. Oh, wait...
It's extremely tough to collect a good collection of data (aka dataset). They are so important that companies may even reveal their algorithms, but rarely datasets.
Features Also known as parameters or variables. Those could be car mileage, user's gender, stock price, word frequency in the text. In other words, these are the factors for a machine to look at.
When data stored in tables it's simple — features are column names. But what are they if you have 100 Gb of cat pics? We cannot consider each pixel as a feature. That's why selecting the right features usually takes way longer than all the other ML parts. That's also the main source of errors. Meatbags are always subjective. They choose only features they like or find "more important". Please, avoid being human.
Algorithms Most obvious part. Any problem can be solved differently. The method you choose affects the precision, performance, and size of the final model. There is one important nuance though: if the data is crappy, even the best algorithm won't help. Sometimes it's referred as "garbage in – garbage out". So don't pay too much attention to the percentage of accuracy, try to acquire more data first.
Learning vs Intelligence
Once I saw an article titled "Will neural networks replace machine learning?" on some hipster media website. These media guys always call any shitty linear regression at least artificial intelligence, almost SkyNet. Here is a simple picture to deal with it once and for all.
Artificial intelligence is the name of a whole knowledge field, such are biology or chemistry.
Machine Learning is a part of artificial intelligence. Important, but not the only one.
Neural Networks is one of machine learning types. A popular one, but there are other good guys in the class.
Deep Learning is a modern method of building, training, and using neural networks. Basically, it's a new architecture. Nowadays in practice, no one separates deep learning from the "ordinary networks". We even use the same libraries for them. To not look like a dumbass, it's better just name the type of network and avoid buzzwords.
The general rule is to compare things on the same level. That's why the phrase "will neural nets replace machine learning" sounds like "will the wheels replace cars". Dear media, it's compromising your reputation a lot.
Machine can Machine cannot Forecast Create smth new Memorize Get smart really fast Reproduce Go beyond their task Choose best item Kill all humans
The map of machine learning world
If you are too lazy for long reads, take a look at the picture below to get some understanding.
It's important to understand — there is never a sole way to solve a problem in the machine learning world. There are always several algorithms that fit, and you have to choose which one fits better. Everything can be solved with a neural network, of course, but who will pay for all these GeForces?
Let's start with a basic overview. Nowadays there are four main directions in machine learning.
Part 1. Classical Machine Learning
The first methods came from pure statistics in the '50s. They solved formal math tasks, looking for patterns in numbers, evaluating the proximity of data points, and calculating vectors' directions.
Nowadays, half of the Internet is working using these algorithms. When you see a list of articles to "read next" or your bank blocks your card at random gas station in the middle of nowhere, most likely it's the work of one of those little guys.
Big tech companies are huge fans of neural networks. Obviously. For them, 2% accuracy is an additional 2 billion in revenue. But when you are small, it doesn't make sense. I heard stories of the teams spending a year on a new recommendation algorithm for their e-commerce website, before discovering that 99% of traffic came from search engines. Their algorithms were useless. Most users didn't even open the main page.
Despite the popularity, classical approaches are so natural, that you can easily explain them to a toddler. They are like a basic arithmetics — we use it every day, without even thinking.
1.1 Supervised Learning
Classical machine learning is often divided into two categories – Supervised and Unsupervised Learning.
In the first case, the machine has a "supervisor" or a "teacher" who gives machine all the answers, telling is it a cat at the picture or a dog. The teacher is already divided (labeled) the data into cats and dogs, and the machine is using these examples to learn. One by one. Dog by cat.
Unsupervised learning means the machine is left on its own with a pile of animal photos and a task to find out who's who. Data is not labeled, there's no teacher, the machine is trying to find any patterns on its own. We'll talk about these methods below.
Clearly, the machine will learn faster with a teacher, so it's more commonly used in real-life tasks. There are two types of such tasks: classification – an object's category prediction and regression – prediction of a specific point on numeric axis.
Classification
"Splits objects based at one of the attributes known beforehand. Separate socks by based on color, documents based on language, music by genre"
Today used for: – Spam filtering – Language detection – A search of similar documents – Sentiment analysis – Recognition of handwritten characters and numbers – Fraud detection
Popular algorithms: Naive Bayes, Decision Tree, Logistic Regression, K-Nearest Neighbours, Support Vector Machine
Here and onward you can comment with additional information to these sections. Feel free to write your examples of tasks. Everything is written here based on my own subjective experience.
Machine learning is about classifying things, mostly. The machine here is like a baby learning to sort toys: here's a robot, here's a car, here's a robo-car... Oh, wait. Error! Error!
In classification, you always need a teacher. The data should be labeled with features so the machine could assign the classes based on them. Everything could be classified — users based on interests (as algorithmic feeds do), articles based on language and topic (that's important for search engines), music based on genre (Spotify playlists), and even your emails.
In spam filtering was widely used Naive Bayes algorithm. Machine counted the number of "viagra" mentions in spam and normal mail. Then it multiplied both probabilities using Bayes equation, summed the results and yay, we got Machine Learning.
Later, spammers learned how to deal with Bayesian filter by adding lots of "good" words at the end of the email. Ironically, the method was called Bayesian poisoning. It stayed at history as most elegant and first practically useful one, though, other algorithms now used for spam filtering.
Here's another practical example of classification. Let's say, you need some credit money. How bank will know will you pay it back or not? There's no way to know it for sure. Though, the bank has lots of profiles of people who took the money before. Bank has data about age, education, occupation and salary and – most importantly – the fact of paying the money back. Or not.
With that data, we can teach the machine, find the patterns and get the answer. There's not an issue. The issue is that bank can't blindly trust the machine answer. What if there's a system failure, hacker attack or a quick fix from a drunk senior.
To deal with it, we have Decision Trees. All the data automatically divided to yes/no questions. They could sound a bit weird from a human perspective, e.g., whether the creditor earns more than $128.12? Though, the machine comes up with such question to split the data best at each step.
That's how a tree made. The higher the branch — the broader the question. Any analyst can take it and explain afterward. He may not understand it, but explain easily! (typical analyst)
The trees widely used in high responsibility spheres: diagnostics, medicine, and finances.
The two most popular algorithms for forming the trees are CART and C4.5.
Pure decision trees are rarely used now. However, they often set the basis for large systems, and their ensembles even work better than neural networks. We'll talk about that later.
When you google something, there are precisely the bunch of dumb trees which are looking for range the answers for you. Search engines love them because they're fast.
Support Vector Machines (SVM) is rightfully the most popular method of classical classification. It was used to classify everything in existence: plants by types faces at the photos, documents by categories, etc.
The idea behind SVM is simple – it's trying to draw two lines between categories with the largest margin between them. It's more evident in the picture:
There's one very useful side of the classification — anomaly detection. When a feature does not fit any of the classes, we highlight it. Now it used at the medicine — on MRI, computer highlights all the suspicious areas or deviations of the test. Stock markets use it to detect abnormal behavior of traders, to find the insiders. When teaching the computer the right things, we automatically teach it what things are wrong.
Today, for classification more frequently used neural networks. Well, that's what they were created for.
The rule of thumb is the more complex the data, the more complex the algorithm. For text, numbers, and tables, I'd choose the classical approach. The models are smaller there, they learn faster and work more clear. For pictures, video and all other complicated big data things, I'd definitely look at neural networks.
You may find face classifier built on SVM only 5 years ago you. Now, you can choose from hundreds of pre-trained networks. Nothing changed for spam filters, though. They are still written with SVM. And there's no good reason to switch from it anywhere.
Regression
"Draw a line through these dots. Yep, that's the machine learning"
Today this is used for:
Stock price forecast
Demand and sales volume analysis
Medical diagnosis
Any number-time correlations
Popular algorithms are Linear and Polynomial regressions.
Regression is basically classification where we forecast a number instead of category. Such are car price by its mileage, traffic by time of the day, demand volume by growth of the company etc. Regression is perfect when something depends on time.
Everyone who works with finance and analysis loves regression. It's even built-in to Excel. And it's super smooth inside — machine simply tries to draw a line that indicates average correlation. Though, unlike a person with a pen and a whiteboard, machine does at mathematically accurate, calculating the average interval to every dot.
When the line is straight — it's a linear regression, when it's curved – polynomial. These are two major types of regression. The other ones are more exotic. Logistic regression is a black sheep in the flock. Don't let it trick you, as it's a classification method, not regression.
It's okay to mess with regression and classification, though. Many classifiers turn into regression after some tuning. We can not only define the class of the object but memorize, how close it is. Here comes a regression.
1.2 Unsupervised learning
Unsupervised was invented a bit later, in the '90s. It is used less often, but sometimes we simply have no choice.
Labeled data is luxury. But what if I want to create, let's say, a bus classifier? Should I manually take photos of million fucking buses on the streets and label each of them? No way, that will take a lifetime, and I still have so many games not played on my Steam account.
There's a little hope for capitalism in this case. Thanks to the social stratification, we have millions of cheap workers and services like Mechanical Turk who are ready to complete your task for 0.05$. And that's how things usually get done here.
Or you can try to use unsupervised learning. But I can't remember any good practical appliance of it, though. It's usually useful for exploratory data analysis but not as the main algorithm. Specially trained meatbag with Oxford degree feeds the machine with a ton of garbage and watch it. Are there any clusters? No. Any visible relations? No. Well, continue then. You wanted to work in data science, right?
Clustering
"Divides objects based on unknown feature. Machine chooses the best way"
Nowadays used:
For market segmentation (types of customers, loyalty)
To merge close points on the map
For image compression
To analyze and label new data
To detect abnormal behavior
Popular algorithms: K-means_clustering, Mean-Shift, DBSCAN
Clustering is a classification with no predefined classes. It’s like dividing socks by color when you don't remember all the colors you have. Clustering algorithm trying to find similar (by some features) objects and merge them in a cluster. Those who have lots of similar features are joined in one class. With some algorithms, you even can specify the exact number of clusters you want.
An excellent example of clustering — markers on web maps. When you're looking for all vegan restaurants around, the clustering engine groups them to blobs with a number. Otherwise, your browser would freeze, trying to draw all three million vegan restaurants in that hipster downtown.
Apple Photos and Google Photos use more complex clustering. They're looking for faces at photos to create albums of your friends. The app doesn't know how many friends you have and how they look, but it's trying to find the common facial features. Typical clustering.
Another popular issue is image compression. When saving the image to PNG you can set the palette, let's say, to 32 colors. It means clustering will find all the "reddish" pixels, calculate the "average red" and set it for all the red pixels. Fewer colors — less the file size — profit!
However, you may have problems with colors like Cyan◼︎-like colors. Is it green or blue? Here comes the K-Means algorithm.
It randomly set 32 color dots in the palette. Now, those are centroids. The remaining points are marked as assigned to the nearest centroid. Thus, we get kind of galaxies around these 32 colors. Then we're moving the centroid to the center of its galaxy and repeat that until centroids won't stop moving.
All done. Clusters defined, stable, and there are exactly 32 of them. Here is a more real-world explanation:
Searching for the centroids is convenient. Though, in real life clusters not always circles. Let's imagine, you're a geologist. And you need to find some similar minerals at the map. In that case, the clusters can be weirdly shaped and even nested. Also, you don't even know how many of them to expect. 10? 100?
K-means does not fit here, but DBSCAN can be helpful. Let's say, our dots are people at the town square. Find any three people standing close to each other and ask them to hold hands. Then, tell them to start grabbing hands of those neighbors they can reach out. And so on, and so on until no one else can take anyone hand. That's our first cluster. Repeat the process until everyone clustered. Done.
A nice bonus: a person who have no one to hold hands — is an anomaly.
It all looks cool in motion:
Just like classification, clustering could be used to detect anomalies. User behaves abnormally after signing up? Let machine ban him temporarily and create a ticket for the support to check it. Maybe it's a bot. We don't even need to know what is "normal behavior", we just upload all user actions to our model and let the machine decide is it a "typical" user or not.
This approach works not that well compared to the classification one, but it never hurts to try.
Dimensionality Reduction (Generalization)
"Assembles specific features into more high-level ones"
Nowadays is used for:
Recommender systems (★)
Beautiful visualizations
Topic modeling and similar document search
Fake image analysis
Risk management
Popular algorithms: Principal Component Analysis (PCA), Singular Value Decomposition (SVD), Latent Dirichlet allocation (LDA), Latent Semantic Analysis (LSA, pLSA, GLSA), t-SNE (for visualization)
Previously these methods were used by hardcore data scientists, who had to find "something interesting" at the huge piles of numbers. When Excel charts didn't help, they forced machines to do find the patterns. That's how they got Dimension Reduction or Feature Learning methods.

Projecting 2D-data to a line (PCA)
It is always convenient for people to use abstraction, not a bunch of fragmented features. For example, we can merge all dogs with triangle ears, long noses, and big tails to a nice abstraction — "shepherd". Yes, we're losing some information about the specific shepherds, but the new abstraction is much more useful for naming and explaining purposes. As a bonus, such "abstracted" model learn faster, overfit less and use fewer number of features.
These algorithms became an amazing tool for Topic Modeling. We can abstract from specific words to their meanings. This is that Latent semantic analysis (LSA) do. It is based on how frequent you see the word on the exact topic. Like, there are more tech terms in tech articles, for sure. The names of politicians are mostly found in political news, etc.
Yes, we can just make clusters from all the words at the articles, but we will lose all the important connections (for example the same meaning of battery and accumulator in different documents). LSA will handle it properly, that's why its called "latent semantic".
So we need to connect the words and documents into one feature to keep these latent connections. Referring to the name of the method. Turned out that Singular decomposition (SVD) nails this task, revealing the useful topic clusters from seen-together words.
Recommender Systems and Collaborative Filtering is another super-popular use of dimensionality reduction method. Seems like if you use it to abstract user ratings, you get a great system to recommend movies, music, games and whatever you want.
It's barely possible to fully understand this machine abstraction, but it's possible to see some correlations on closer look. Some of them correlate with user's age — kids play Minecraft and watch cartoons more; others correlate with movie genre or user hobbies.
Machine get these high-level concepts even without understanding them, based only on knowledge of user ratings. Nicely done, Mr.Computer. Now we can write a thesis why bearded lumberjacks love My Little Pony.
Association rule learning
"Look for patterns in the orders' stream"
Nowadays is used:
To forecast sales and discounts
To analyze goods bought together
To place the products on the shelves
TO analyze web surfing patterns
Popular algorithms: Apriori, Euclat, FP-growth
This includes all the methods to analyze shopping carts, automate marketing strategy, and other event-related tasks. When you have a sequence of something and want to find patterns in it — try these thingys.
Say, a customer takes a six-pack of beers and goes to the checkout. Should we place peanuts on the way? How often people buy it together? Yes, it probably works for beer and peanuts, but what other sequences can we predict? Can a small change in the arrangement of goods lead to a significant increase in profits?
Same goes for e-commerce. The task is even more interesting there — what customer is going to buy next time?
No idea, why the rule learning seems to be the least elaborated category of machine learning. Classical methods are based on a head-on looking through all the bought goods using trees or sets. Algorithms can only search for patterns, but cannot generalize or reproduce those on the new examples.
In the real world, every big retailer builds their own proprietary solution, so nooo revolutions here for you. The highest level of tech here — recommender systems. Though, I may be not aware of a breakthrough in the area. Let me know in comments if you have something to share.
Part 2. Reinforcement Learning
"Throw a robot into a maze and let it find an exit"
Nowadays used for:
Self-driving cars
Robot vacuums
Games
Automating trading
Enterprise resource management
Popular algorithms: Q-Learning, SARSA, DQN, A3C, Genetic algorithm
Finally, we got to something looks like real artificial intelligence. In lots of articles reinforcement learning is placed somewhere in between of supervised and unsupervised learning. They have nothing in common! Is this because of the name?
Reinforcement learning is used in cases when your problem is not related to data at all, but you have an environment to live. Like a video game world or a city for self-driving car.
youtube
Neural network plays Mario
Knowledge of all the road rules in the world will not teach the autopilot how to drive on the roads. Regardless of how much data we collect, we still can't foresee all the possible situations. This is why its goal is to minimize error, not to predict all the moves.
Surviving in an environment is a core idea of reinforcement learning. Throw poor little robot into real live, punish it for errors and reward for right deeds. Same way we teach our kids, right?
More effective way here — to build a virtual city and let self-driving car to learn all its tricks there first. That's exactly how we train auto-pilots right now. Create a virtual city based on a real map, populate with pedestrians and let the car learn to kill as few people as possible. When the robot is reasonably confident in this artificial GTA, it's freed to test in the real streets. Fun!
There may be two different approaches — Model-Based and Model-Free.
Model-Based means that car needs to memorize a map or its parts. That's a pretty outdated approach since it's impossible for the poor self-driving car to memorize the whole planet.
In Model-Free learning, the car doesn't memorize every movement but tries to generalize situations and act rationally while obtaining a maximum reward.
Remember the news about AI beats a top player at the game of Go? Although, shortly before this, it was proved that the number of combinations in this game is greater than the number of atoms in the universe.
This means, the machine could not remember all the combinations and thereby win Go (as it did chess). At each turn, it simply chose the best move for each situation, and it did well enough to outplay a human meatbag.
This approach is a core concept behind Q-learning and its derivatives (SARSA & DQN). 'Q' in the name stands for "Quality" as a robot learns to perform the most "qualitative" action in each situation and all the situations are memorized as a simple markovian process.
Such a machine can test billions of situations in a virtual environment, remembering which solutions led to greater reward. But how it can distinguish previously seen situation from a completely new one? If a self-driving car is at a road crossing and traffic light turns green — does it mean it can go now? What if there's an ambulance rushing through a street nearby?
The answer is today is "no one knows". There's no easy answer. Researches are constantly searching for it but meanwhile only finding workarounds. Some would hardcode all the situations manually that lets them solve exceptional cases like trolley problem. Others would go deep and let neural networks do the job of figuring it out. This led us to the evolution of Q-learning called Deep Q-Network (DQN). But they are not a silver bullet either.
Reinforcement Learning for an average person would look like a real artificial intelligence. Because it makes you think wow, this machine is making decisions in real life situations! This topic is hyped right now, it's advancing with incredible pace and intersecting with a neural network to clean your floor more accurate. Amazing world of technologies!
Off-topic. When I was a student, genetic algorithms (links has cool visualization) were really popular. This is about throwing a bunch of robots into a single environment and make them try reaching the goal until they die. Then we pick the best ones, cross them, mutate some genes and rerun the simulation. After a few milliard years, we will get an intelligent creature. Probably. Evolution at its finest.
Genetic algorithms are considered as part of reinforcement learning and they have the most important feature proved by the decade-long practice: no one gives a shit about them.
Humanity still couldn't come up with a task where those would be more effective than other methods. But they are great for students experiments and let people get their university supervisors excited about "artificial intelligence" without too much labor. And youtube would love it as well.
Part 3. Ensemble Methods
"Bunch of stupid trees learning to correct errors of each other"
Nowadays is used for:
Everything that fits classical algorithms approaches (but works better)
Search systems (★)
Computer vision
Object detection
Popular algorithms: Random Forest, Gradient Boosting
It's time for modern, grown-up methods. Ensembles and neural networks are two main fighters paving our path to a singularity. Today they are producing the most accurate results and are widely used in production.
However, the neural networks got all the hype today, while the words like "boosting" or "bagging" are scare hipsters on TechCrunch.
Despite all the effectiveness idea behind those is overly simple. If you take a bunch of inefficient algorithms and force them to correct each other's mistakes, the overall quality of a system will be higher than even the best individual algorithms.
You'll get even better results if you take the most unstable algorithms that are predicting completely different results on small noise in input data. Like Regression and Decision Trees. These algorithms are sensitive to even a single outlier in input data to have model go mad.
In fact, this is what we need.
We can use any algorithm we know to create an ensemble. Just throw a bunch of classifiers, spice up with regression and don't forget to measure accuracy. From my experience: don't even try a Bayes or kNN here. Although being "dumb" they are really stable. That's boring and predictable. Like your ex.
Although, there are three battle-tested methods to create ensembles.
Stacking Output of several parallel models is passed as input to last one which makes final decision. Like that girl, who asks her girlfriends whether to meet with you in order to make the final decision herself.
Emphasize here the word "different". Mixing the same algorithm on the same data would make no sense. Choice of algorithms is completely up to you. However, for final decision-making model, regression is usually a good choice.
Based on my experience stacking is less popular in practice, because two other methods are giving better accuracy.
Bagging aka Bootstrap AGGregatING. Use the same algorithm but train it on different subsets of original data. In the end — just average answers.
Data in random subsets may repeat. For example, from a set like "1-2-3" we can get subsets like "2-2-3", "1-2-2", "3-1-2" and so on. We use these new datasets to teach the same algorithm several times and then predict the final answer via simple majority voting.
The most famous example of bagging is the Random Forest algorithm, which is simply bagging on the decision trees (that was illustrated above). When you open your phone's camera app and see it drawing boxes around people faces — it probably results of Random Forest work. Neural network would be too slow to run real-time yet bagging is ideal given it can calculate trees on all the shaders of a video card or on these new fancy ML processors.
In some tasks, the ability of the Random Forest to run in parallel, even more, important than a small loss in accuracy to the boosting, for example. Especially in real-time processing. There is always a trade-off.
Boosting Algorithms are trained one by one sequentially. Every next one paying most attention to data points that were mispredicted by the previous one. Repeat until you are happy.
Same as in bagging, we use subsets of our data but this time they are not randomly generated. Now, in each subsample we take a part from the data previous algorithm failed to process. Thus, we make a new algorithm learn to fix errors of the previous one.
The main advantage here — very high, even illegal in some countries precision of classification that all cool kids can envy. Cons were already called out — it doesn't parallelize. But it's still faster than neural networks. It's like a race between dumper truck and racing car. Truck can do more, but if you want to go fast — take a car.
If you want a real example of boosting — open Facebook or Google and start typing in a search query. Can you hear an army of trees roaring and smashing together to sort results by relevancy? This is it, they are using boosting.
Part 4. Neural Networks and Deep Leaning
"We have a thousand-layer network, dozens of video cards, but still no idea where to use it. Let's generate cat pics!"
Used today for:
Replacement of all algorithms above
Object identification on photos and videos
Speech recognition and synthesis
Image processing, style transfer
Machine translation
Popular architectures: Perceptron, Convolutional Network (CNN), Recurrent Networks (RNN), Autoencoders
If no one ever tried to explain you neural networks using the "human brain" analogies, you're a happy guy. Tell me your secret. But first, I'll explain it as I like.
Any neural network is basically a collection of neurons and connections between them. Neuron is a function with a bunch of inputs and one output. His task is to take all numbers from its input, perform a function on them and send the result to the output.
Here is an example of simple but useful in real life neuron: sum up all numbers on inputs and if that sum is bigger than N — give 1 as a result. Otherwise — zero.
Connections are like channels between neurons. They connect outputs of one neuron with the inputs of another so they can send digits to each other. Each connection has its only parameter — weight. It's like a connection strength for a signal. When the number 10 passes through a connection with a weight 0.5 it turns into 5.
These weights tell the neuron to respond more to one input and less to another. Weights are adjusted when training — that's how the network learns. Basically, that's all.
To prevent the network from falling into anarchy, the neurons are linked by layers, not randomly. Inside one layer neurons are not connected, but connected to neurons of the next and previous layer. Data in the network goes strictly in one direction — from the inputs of the first layer to the outputs of the last.
If you throw in a sufficient number of layers and put the weights correctly, you will get the following - by applying to the input, say, the image of handwritten digit 4, black pixels activate the associated neurons, they activate the next layers, and so on and on, until it lights up the very exit in charge of the four. The result is achieved.
When doing real-life programming nobody is writing neurons and connections. Instead, everything is represented as matrices and calculated based on matrix multiplication for better performance. In two favorite videos of mine, all the process is described in an easily digestible way on the example of recognizing hand-written digits. Watch those if you want to figure this out.
A network that has multiple layers that have connections between every neuron is called perceptron (MLP) and considers the simplest architecture for a novice. I didn't see it used for solving tasks in production.
After we constructed a network, our task is to assign proper ways so neurons would react to proper incoming signals. Now is the time to remember that we have data that is samples of 'inputs' and proper 'outputs'. We will be showing our network a drawing of same digit 4 and tell it 'adapt your weights so whenever you see this input your output would emit 4'.
To start with all weights are assigned randomly afterward we show it a digit, it emits a random answer (the weights are not proper yet) and we compare how much this result differs from the right one. Afterward, we start traversing network backward from outputs to inputs and tell every neuron 'hey, you did activate here but you did a terrible job and everything went south from here downwards, let's keep less attention to this connection and more of that one, mkay?'.
After a hundred thousands of such cycles 'infer-check-punish', there is a hope that weights are corrected and act as intended. Science name for this approach is called Backpropagation or 'method of backpropagating an error'. Funny thing it took twenty years to come up with this method. Before this neural networks, we taught, however.
My second favorite vid is describing this process in depth but still very accessible.
A well trained neural network can fake work of any of the algorithms described in this chapter (and frequently work more precisely). This universality is what made them widely popular. Finally we have an architecture of human brain said they we just need to assemble lots of layers and teach them on any possible data they hoped. Then first AI winter) started, then thaw and then another wave of disappointment.
It turned out networks with a large number of layers required computation power unimaginable at that time. Nowadays any gamer PC with geforces outperforms datacenter of that time. So people didn't have any hope at that time to acquire computation power like that and neural networks were a huge bummer.
And then ten years ago deep learning rose.
In 2012 convolutional neural network acquired overwhelming victory in ImageNet competition that world suddenly remembered about methods of deep learning described in ancient 90s. Now we have video cards!
Differences of deep learning from classical neural networks was in new methods of training that could handle bigger networks. Nowadays only theoretics would try to divide which learning to consider deep and not so deep. And we, as practitioners are using popular 'deep' libraries like Keras, TensorFlow & PyTorch even when we build a mini-network with five layers. Just because it's better suited than all the tools coming before. And we just call them neural networks.
I'll tell about two main kinds nowadays.
Convolutional Neural Networks (CNN)
Convolutional neural networks are all the rage right now. They are used to search for the object on photos and in the videos, face recognition, style transfer, generating and enhancing images, creating effects like slow-mo and improving image quality. Nowadays CNN's are used in all the cases that involve pictures and videos. Even in you iPhone several of these networks are going through your nudes to detect objects in those. If there is something to detect, heh.
Image above is a result produced by Detectron that was recently open-sourced by Facebook
A problem with images was always the difficulty of extracting features out of them. You can split text by sentences, lookup words' attributes in specialized vocabularies. But images had to be labeled manually to teach machine where cat ears or tail were in this specific image. This approach got the name 'handcrafting features' and used to be used almost by everyone.
There are lots of issues with the handcrafting.
First of all, if a cat had its ears down or turned away from the camera you are in trouble, the neural network won't see a thing.
Secondly, try naming at the spot 10 different features that distinguish cats from other animals. I for once couldn't do it. Although when I see black blob rushing past me at night, even I see it in the corner of my eye I would definitely tell a cat from a rat. Because people don't look only at ear form or leg count and account lots of different features they don't even think about. And thus cannot explain it to the machine.
So it means machine need to learn such features on its own building on top of basic lines. We'll do the following: first, we divide the whole image into 8x8 pixels block and assign to each type of dominant line – either horizontal [-], vertical [|] or one of the diagonals [/]. It can be that several would be highly visible this happens too and we are not always absolutely confident.
Output would be several tables of sticks that are in fact are simplest features representing objects' edges on the image. They are images on their own but build out of sticks. So we can once again take a block of 8x8 and see how they match together. And again and again…
This operation is called convolution which gave the name for the method. Convolution can be represented as a layer of a neural network as neuron can act as any function.
When we feed our neural network with lots of photos of cats it automatically assigns bigger weights to those combinations of sticks it saw the most frequently. It doesn't care whether it was a straight line of a cat's back or a geometrically complicated object like a cat's face, something will be highly activating.
As the output, we would put a simple perceptron which will look at the most activated combinations and based on that differentiate cats from dogs.
The beauty of this idea is that we have a neural net that searches for most distinctive features of the objects on its own. We don't need to pick them manually. We can feed it any amount of images of any object just by googling billion of images with it and our net will create feature maps from sticks and learn to differentiate any object on its own.
For this I even have a handy unfunny joke:
Give your neural net a fish and it will be able to detect fish for the rest of its life. Give your neural net a fishing rod and it will be able to detect fishing rods for the rest of its life…
Recurrent Neural Networks (RNN)
The second most popular architecture today. Recurrent networks gave us useful things like neural machine translation (here is my post about it), speech recognition and voice synthesis in smart assistants. RNNs are the best for sequential data like voice, text or music.
Remember Microsoft Sam, the old-school speech synthesizer from Windows XP? That funny guy builds words letter by letter, trying to glue them up together. Now, look at Amazon Alexa or Assistant from Google. They don't only say the words clearly, they even place the right accents!
youtube
Neural Net is trying to speak
All because modern voice assistants are learned to speak not letter by letter, but whole phrases at once. We can take a bunch of voiced texts and train a neural network to generate an audio-sequence closest to the original speech.
In other words, we use text as input and its audio as the desired output. We ask a neural network to generate some audio for the given text, then compare it with the original, correct errors and try to get as close as possible to ideal.
Sounds like a classical leaning process. Even a perceptron is suitable for this. But how should we define it outputs? Fire one particular output for each possible phrase is not an option — obviously.
Here we'll be helped by the fact that text, speech or music are sequences. They consist of consecutive units like syllables. They all sound unique but depend on previous ones. Lose this connection and you get dubstep.
We can train the perceptron to generate these unique sounds, but how will he remember previous answers? So the idea was to add memory to each neuron and use it as an additional input on the next run. A neuron could make a note for itself - hey, man, we had a vowel here, the next sound should sound higher (it's a very simplified example).
That's how recurrent networks appeared.
This approach had one huge problem - when all neurons remembered their past results, the number of connections in the network became so huge that it was technically impossible to adjust all weights.
When a neural network can't forget it can't learn new things (people have the same flaw).
The first decision was simple - let's limit the neuron memory. Let's say, to memorize no more than 5 recent results. But it broke the whole idea.
The much better approach came up later — to use special cells, similar to computer memory. Each cell can record a number, read it or reset it. They were called a long and short-term memory (LSTM) cell.
Now, when neuron needs to set a reminder, it puts the flag in that cell. Like "it was a consonant in a word, next time use different pronunciation rules". When the flag is no longer needed - the cells are reset, leaving only the “long-term” connections of the classical perceptron. In other words, the network is trained not only to learn weights but also to set these reminders.
Simple, but it works!
youtube
CNN + RNN = Fake Obama
You can take speech samples from anywhere. BuzzFeed, for example, took the Obama's speeches and trained the neural network to imitate his voice. As you see, audio synthesis is already a simple task. Video still has issues, but it's a question of time.
There are many more network architectures in the wild. I recommend you a good article called Neural Network Zoo, where almost all types of neural networks are collected and briefly explained.
The End: when the war with the machines?
The main problem here is that the question "when will the machines become smarter than us and enslave everyone?" is initially wrong. There are too many hidden conditions in it.
We say "become smarter than us" like we mean that there is a certain unified scale of intelligence. The top of which is a man, dogs are a bit lower, and stupid pigeons are hanging around at the very bottom.
That's wrong.
In this case, every man must beat animals in everything but it's not true. The average squirrel can remember a thousand hidden places with nuts — I can't even remember where are my keys.
So the intelligence is a set of different skills, not a single measurable value? Or remembering nuts stashes' location is not included in the intelligence?
However, an even more interesting question for me - why do we believe that the human brain possibilities are limited? There are many popular graphs on the Internet, where the technological progress is drawn as an exponent and the human possibilities are constant. But is it?
Ok, multiply 1680 by 950 right now in your mind. I know you won't even try, lazy bastards. But give you a calculator — you'll do it in two seconds. Does this mean that the calculator just expanded the capabilities of your brain?
If yes, can I continue to expand them with other machines? Like, use notes in my phone to not to remember a shitload of data? Oh, seems like I'm doing it right now. I'm expanding capabilities of my brain with the machines.
Think about it. Thanks for reading.
DataTau published first on DataTau
0 notes
Text
Turkle’s interview, Louis C.K.’s video, and my daily social media use log.
I’ll preface this by saying that, as a whole, I despise what is quickly becoming in my opinion a bit of a pandemic. That is, if it isn’t already the modern Spanish Flu only with batteries. The same sort of thing both Louis and Turkle touch on. The death of actual conversation in favor of staring dead eyed at a phone screen. I hate this current shift toward some sort of Facebook generation.
At its inception, Facebook, and the idea behind it, were remarkable. It was a place to keep in touch with your one group of peers, college aged students. No parents, no preteens, no grandparents. There were no games at the start, no “likes” if I remember right. It was simple and served a legitimate purpose.
How far gone a purpose is perhaps debatable, though I’d argue that for the most part, the site as a whole is essentially an internet vampire sucking the life right out of you. I can think of a thousand things in a second that I’d rather do than share something on Facebook. I don’t have the app on my phone, my account/password aren’t saved on it, I check it maybe once a year for all of sixty seconds.
Though as I do this, all around me are the people that get netted in. Especially the young. I can’t even have a proper conversation with some of my youngest family members because even the youngest of my cousins has a smartphone at this point. And they don’t just own one, it may as well be welded onto their hand. Their eyes are downcast to the LED glow, they bob their head as if listening, but their answers are vague and often not on topic.
I remember my first cell. I was fourteen working a job at a gun range and wanted one for the sole purpose of being able to call my parents for a ride back home. Something they could call me on if they were going to be late, that sort of thing. Web wasn’t really a thing on them back then, and while it did do text messaging, it was 10 cents sending or receiving and something I did not use. I bought the device and paid for my plan both. Fast forward a bit over a decade and here we are, where my 8 year old cousins have more modern smartphones than I do.
I absolutely agree with Turkle’s idea of sanctuary zones, where you put the phone away and leave it. Dinner, especially. This doesn’t apply just to family, either. When I’m out for a drink with friends, we often have a rule. Everybody puts their phone away, and anyone caught sneaking a peek is buying everybody else a round.
I will never understand the people filming at a concert. Especially if they are filming a big screen at a concert. Louis is right, you’re never going to actually watch that. People throw it up on facebook or twitter or whatever else and just seek the attention that they were there. The funny thing is, I actually employ my phone with my gopro setup to do a lot of filming. Mostly fishing and underwater videos, mahi on the line, sharks bumping against the lens, that sort of thing. I don’t throw them up on youtube, I don’t put them on facebook, I share them face to face with somebody who couldn’t have been there with me.
Why? Because nothing starts a conversation off like showing somebody a video of a big, toothy critter about six inches away from the camera. Or of hauling in tuna in twelve foot rollers some twenty six miles offshore as lightning cracks overhead and waterspouts kick up around the boat. Maybe the one video I wish I’d posted somewhere because I lost it when I accidentally wiped the flash card.
You don’t get that by posting it on facebook or youtube. Sure, you’d get some likes. Maybe some PETA vegans blowing up the comment section. But not a conversation.
I think that smartphones are every bit as addictive as maybe even heroin. There are people who can’t live without it, as described in both videos. They practically live through the device, more attached to it than the world and people around them. Maybe it is to fill some sort of lonely void as Louis seems to think. I find it at least equally plausible that it is more a vanity issue. People get addicted to the “likes”, to the thumbs ups on youtube, to more tweets in their direction. If tweets in their direction is even a thing, I don’t know, all I’ve ever used it for before this class was when I heard about sports news via some insider. Even then, I wasn’t actually going to twitter, it’s just where the info first broke.
Moving on to the social media log assignment, it didn’t really take me very long to get a baseline reading. I don’t ever use my facebook, which is the one social media thing I even have an account for. I do a tiny bit of texting, if that counts. Today it was to let my one friend know to head out to meet at the gym, and to another that he isn’t going to stop being pre diabetic by sleeping instead of deadlifting. Another to let a different friend know that, while I let his dog out, he did a bit of a roll through mud while chasing a soccer ball and is probably going to need a bath. Sorry, Matt, I did the best I could with the towel by the door.
I’m sure that there are people who would share all of this on facebook or instagram or something else. I see them snapping selfies after two reps, hashtag it with a #swole, and then sit there for another few minutes clicking the pretend cows before leaving and acting like they actually accomplished something. Arnold has a great term for cellphones in a gym. “Mickey mouse stuff.” I’d actually go a bit further and say that applies to just about any situation. If you’re doing something that should require your full attention, or something amazing like jumping out of a plane, documenting it on your cell should be the last thing on your mind. To be honest a lot of fishing trips I don’t even remember to turn my gopro on, if I even remembered to charge it, or even pack it. If you read my first post this week, you’ll note that I don’t even bother uploading these videos anywhere.
I even know a guy who lost his chance at a once in a lifetime trophy deer because he was fiddling trying to do a snapchat, dropped it, and had the buck run off on him. He feels a bit different about trying something like that now.
It’s a real conflict for me to manage all of this. I know that social media is basically required for a modern business to actually thrive. Not because it is really some necessary thing, but because there are billions of phonezombies out there who pay in the same cash everybody else does. Sure, it has a few other uses, making announcements easier to spread and such. For the most part, though, it’s just another form of advertisement spam.
All the while I’m actually perfectly content with not uploading my daily life to the web. If I want to know what somebody else is doing, I’ll usually call or at minimum text. Maybe an email if it is a bit long winded. I only use these as tools in the cases where an actual face to face conversation isn’t possible, usually because of distance or time.
Concerning my social media experiment, I am actually, for a 24 hour period, going to attempt to use my phone as much as my peers. I’ll log in to my facebook, I’ll read whatever inane information people have slathered all over, I’ll maybe even confirm those dozens of people I’ve met who send me a friend request after. I’m writing this little part ahead of time as a way to give my predictions as well.
I have little doubt that I’m going to hate it. Likely for all of the same reasons I stopped using any social media in the first place.
1 note
·
View note
Text
How To Use Yoast SEO On WordPress: Complete Tutorial (2018)
Every WordPress site needs an SEO plugin. And when it comes to SEO plugins, Yoast SEO is far and away the most popular option. WordPress SEO is, unavoidably, a complex topic, though. And to address that, Yoast SEO has built in plenty of complex features to give you pinpoint control over your site’s SEO.
As a result, even though the Yoast team has done a great job trying to make SEO beginner-friendly, there’s still a good chance you need some help with how to use Yoast SEO.To give you that help, we’ve written this monster Yoast SEO tutorial.
It’s such a big guide that we’ve split it into two parts:
Ready to learn how to use Yoast SEO? You can click above to skip straight to the advanced section. Otherwise, let’s start at the beginning!
The Beginner’s Guide To Yoast SEO
In this section, we’ll cover what you need to know if you’re new to Yoast SEO. You’ll learn:
How to properly enter information in the configuration wizard
What the Yoast SEO meta box is and how it works
What you can do from the Yoast SEO dashboard
Then, in the next section, we’ll get into some of the more advanced Yoast SEO settings.
Using The Yoast SEO Configuration Wizard
After installing Yoast SEO, you can access the Yoast SEO dashboard by clicking on the new SEO tab in your WordPress dashboard.
If this is your first time using the plugin, you should see a big notice for First-time SEO configuration.
By clicking the configuration wizard link, Yoast SEO will give you a guided tour to help you set up all of the basic SEO settings:
How to access Yoast SEO configuration wizard
Go ahead and click that link. Then, on the first page of the wizard, click Configure Yoast SEO.
Below, we’ll take you through the rest of the sections in the configuration wizard.
Section 2: Environment
In the Environment area, you should always choose Option A unless you’re working on a development site:
You should usually choose Option A
Section 3: Site type
In the Site type section, try to choose the type of site that best matches your site:
Choose the option that most closely fits your site
Section 4: Company or person
Next, choose whether your website represents a company or a person.
If you choose Company, you’ll be asked to also enter:
The name of the company
Your company’s logo
And if you choose Person, you’ll just need to enter the name of the person.
Choose whether your site represents a company or a person
This section helps Yoast SEO provide additional information to Google to generate a Knowledge Graph Card. These cards are pretty eye-catching, so every little bit of information helps:
An Example of a Knowledge Graph card
Section 5: Social Profiles
In the Social profiles section, enter all of the social media profiles for your website. Like the previous information, this helps Yoast SEO provide extra details to Google for the Knowledge Graph.
If you’re creating a website for a company, this will be your company’s social media profiles. If it’s a person, this will be that person’s details.
You don’t need to enter all of them – just choose the social media profiles that you actively want to promote:
Enter the social profiles that you want to promote
Section 6: Post type visibility
In the Post type visibility section, you can choose whether or not to allow certain types of content to be indexed in search engines.
99.99% of the time, you want to leave these as the defaults. Unless you already know what you’re doing, don’t change anything:
Leave these as the default most of the time
Section 7: Multiple authors
If you’re the only person writing on your site, Yoast SEO will automatically mark your author archives as noindex to avoid duplicate content (noindex tells search engines not to index that page).
Yoast SEO does this because, on a single author blog, the author archives is 100% identical to your actual blog index page.
If you do plan to have multiple authors, choose yes so that people can still find a specific author’s post archives in the Google search results:
Choose whether you’ll have one or multiple authors
Section 8: Google Search Console
Google Search Console is a tool from Google that allows you to view information about how your site works in Google organic search. If you’re already using Google Search Console, you can allow Yoast SEO to import information by clicking the Get Google Authorization Code and entering the code here.
If you’re not sure what Google Search Console is, feel free to just click Next and skip this for now. While Google Search Console is definitely something you should investigate eventually, it’s not something that’s necessary to the functioning of Yoast SEO:
If you have a Google Search Console account, you should sync it now
Section 9: Title settings
Your Title is the main headline that appears in Google search results (and visitors’ browser tabs):
An example of an SEO title
By default, Yoast SEO makes your title:
Post Name *Separator* Website Name
In this section, you can choose:
Your website name
The *Separator*
Choose your desired title settings
For example, if you had a post with the title “How To Use Yoast SEO” and the settings above, your site would look like this in Google:
How To Use Yoast SEO - Kinsta Demo Site
Wrapping Up The Configuration Wizard
In sections 10 and 11, Yoast SEO will try to get you to:
Sign up for the Yoast SEO newsletter
Purchase Yoast SEO Premium
You do not need to do either of these things.
Just keep hitting next until you get to section 12 – Success! And then click Close:
Congratulations – you just configured Yoast SEO!
Using The Yoast SEO Meta Box
On a day-to-day basis, the Yoast SEO meta box is where you’ll interact with the plugin the most. The meta box helps you by:
Analyzing your content for its SEO quality and readability
Letting you configure settings for how your content functions in Google and social media
The meta box appears underneath the WordPress editor (its exact location depends on your other plugins and themes). There are two different ways to interact with the meta box:
(1) – lets you switch between SEO Analysis and Readability
(2) – lets you access additional settings for social media and advanced options
Yoast SEO Analysis Tab
In the SEO Analysis area, you can enter a Focus keyword to optimize your content for.
Essentially, you’ll want to perform some basic keyword research to find a keyword that people are searching for. Then, you plug that keyword into this box and Yoast SEO will analyze your content to see how well optimized your post is for that specific keyword.
It will tell you both what you’re doing well and what needs to be improved:
The Yoast SEO Analysis area
Beyond the analysis, you can also click the Edit snippet button to manually edit your content’s SEO Title and Meta description. You’ll see a live preview at the top as you edit the information:
How to manually edit SEO snippet
This information is important because it’s what will show up in Google’s organic search results:
An example of a real SEO snippet
Yoast SEO Readability Tab
The SEO Analysis tab is mostly about how well optimized your content is for search engines. In the Readability tab, Yoast SEO tries to apply that same concept to humans. Essentially, it tries to gauge how readable your content will be to human visitors and then makes some suggestions for how to improve your content’s readability.
These suggestions aren’t perfect – so don’t feel like you need to get a perfect score. But they are a good high-level guide:
Yoast SEO readability analysis
Yoast SEO Social Media Tab
In the Social tab, you can manually configure how your content will look when shared on Facebook or Twitter:
Yoast SEO social media settings for individual pieces of content
This is the information that a social network automatically generates when a URL is shared:
An example of how those social media settings affect things
Most of the time, you don’t need to manually configure this information for each post because Yoast SEO will automatically generate it based on:
Your SEO title
Your content’s featured image
But if you want to override those defaults, this is where you do it.
Yoast SEO Advanced Tab
Most of the time, you won’t ever look at the Advanced tab. But if you want to:
Stop Google from indexing this specific piece of content
Specify a canonical URL to avoid duplicate content
Then this is where you can do it:
Yoast SEO meta box advanced settings
Exploring The Yoast SEO Dashboard
Now that you have Yoast SEO configured and understand the meta box, let’s take a look at the dashboard.
We grew our traffic 1,187% with WordPress. We’ll show you how.
Join 20,000+ others who get our weekly newsletter with insider WordPress tips!
We hate spam too, unsubscribe at any time.
On the main page of the dashboard, Yoast SEO will alert you to any potential SEO issues on your site.
For example, you can see that Yoast SEO doesn’t like the way that our test site’s tagline is still the default text:
Yoast SEO dashboard notifications
Yoast will give you instructions for how to fix the issue. Or, you can always dismiss the notification if you don’t want to address it.
General Tab
The General tab isn’t very important, but it does let you:
Access the configuration wizard
Count the number of internal links in your post
Features Tab
The Features tab is a bit juicer than the previous tab. In this area, you can enable or disable specific features of Yoast SEO.
For example, if you don’t find the Readability analysis in the Yoast SEO meta box, you can turn it off here:
Company info Tab
In the Company info tab, you can edit the company details that you set up during the configuration wizard:
Yoast SEO company info tab
Webmaster tools Tab
In this tab, Yoast SEO can help you verify your site with various search engine’s webmaster tools:
This area helps you connect to various search engine’s tools
Security Tab
In the Security tab, you can choose who has access to the Advanced area in the Yoast SEO meta box. By default, only Administrators have access:
This lets you control who has access to the “Advanced” tab in the Yoast SEO meta box
Congrats! At this point, you should have a pretty solid understanding of how to use Yoast SEO’s core settings and features.
In this section, we’re going to dig into some of the advanced settings that Yoast SEO keeps hidden away.
How To Turn On Advanced Settings Pages
In order to access the advanced areas of Yoast SEO, you need to go to the Features tab in your Yoast SEO dashboard and enable the Advanced settings pages.
Once you do that, you should see a whole heap of new options in your WordPress dashboard sidebar:
How to enable Yoast SEO advanced settings pages
Titles & Metas Options
The Titles & Metas area is an awesome tool for automating much of your on-page SEO.
Essentially, Yoast SEO lets you set templates for the SEO titles and meta descriptions for all of your:
Posts
Pages
Custom post types
Taxonomies
Custom taxonomies
Archive pages
This are lets you control the templates for various types of content
What makes this so powerful is that you can use a wide range of variables to dynamically insert information including information contained in custom fields.
You can find a full list of these variables by clicking the Need Help? Button and choosing the Template explanation tab:
Some of the available template variables
If you scroll down to the Advanced variables section, you can find some really neat time-saving hacks.
For example, let’s say you run a coupon website and want to always make sure your post’s title looks like:
Rather than manually editing the title each month to keep it up to date, you could just use the %%currentmonth%% and %%currentyear%% variables to have Yoast SEO automatically do it for you.
Other things that you can do in this area include:
Control noindex tags for specific types of content. If you make something noindex, Google won’t index that type of content in the search results. This is powerful so use it carefully. Only change the default settings if you know what you’re doing and the implications.
Control whether or not the Yoast SEO meta box should appear for specific types of content.
Social Options
In the Social area, you can configure more general settings for how your site interacts with various social networks.
Most of the time, you’ll want to leave these as the defaults, though:
Yoast SEO advanced social media settings
XML Sitemaps Options
In the XML Sitemaps area, you can:
Choose to enable or disable this feature
Manually include/exclude certain content from your sitemap
In the Post Types and Taxonomies tabs, you can choose whether or not to include entire types of content:
How to manage the XML sitemap that Yoast generates
And in the Excluded Posts tabs, you can manually exclude specific pieces of content by their post IDs
Advanced Options
The Advanced area covers three different features:
Breadcrumbs
Permalinks
RSS
Breadcrumbs Tab
Breadcrumbs are a navigational feature that look something like this:
In this section, you can enable them via Yoast SEO. But, you’ll also need to add a small code snippet to your theme in order to get the breadcrumb feature working:
How to add breadcrumbs using Yoast SEO
Permalinks Tab
One of the most useful features is the option to remove the category slug from your URLs:
Yoast SEO advanced permalinks settings
Have Yoast automatically remove stop words from automatically generated permalinks
Set up certain types of redirects
RSS Tab
Finally, the RSS tab lets you insert extra content before or after your post content in your RSS feed. You can also use some variables to dynamically insert information, like a link to your blog to ensure proper citation:
This lets you add content before or after posts in your RSS feed
Tools Options
Finally, the Tools area lets you access various types of editors, as well as an option to import or export your Yoast SEO settings:
A list of the Yoast SEO Tools
If you click on the File editor option, Yoast SEO will help you create a robots.txt file (if you haven’t already). And once you have the file, Yoast SEO will let you edit it right there in your dashboard:
Yoast SEO lets you edit your robots.txt file from your dashboard
How To Use Yoast SEO In Your Everyday Website Life
As we hit the end of this guide, let’s round up with a look at how you’ll actually use Yoast SEO in your everyday WordPress life.
Most of Yoast SEO’s options are “set it and forget”. Once you get everything configured, the only area that you’ll use on an everyday basis is the Yoast SEO meta box.
For every post, you should, at a minimum:
Enter a focus keyword. You don’t need to address every single suggestion from Yoast SEO, but trying to get a green light is usually a good goal.
Configure the SEO Title and Meta Description. Even if you set up a good template, you’ll still want to manually edit these for most posts to make them as optimized as possible.
Other things that you might want to address include:
Readability
Social settings, especially if you think a specific piece of content has a chance of doing well on social media
Any other questions about how to use Yoast SEO? Leave a comment and let’s get your site ranking!
This content was originally published here.
0 notes
Text
Why reCAPTCHA is actually an act of human torture
Like many things that start out as a mere annoyance, though eventually grow into somewhat of an affliction. One particular dark and insidious thing has more than reared its ugly head in recent years, and now far more accurately described as an epidemic disease.
I’m talking about the filth that is reCAPTCHA. Yes that seemingly harmless question of “Are you a human?” Truly I wish all this called for were sarcastic puns of ‘The Matrix’ variety but the matter is far more serious.
Google describes reCAPTCHA as:
[reCAPTCHA] is a free security service that protects your websites from spam and abuse.
However, this couldn’t be further from the truth, as reCAPTCHA is actually something that causes abuse. In fact, I would go so far as to say that being subjected to constant reCAPTCHAs is actually an act of human torture and disregard for a person’s human right of mental comfort.
Back in the 90s a bunch of smart-asses realized money was to be made and much time saved by programming bots to do everything for them online. Some bots were good and helpful and made things easier and more efficient for everyone. Whilst others were used to send spam and even caused some websites to crash or suffer lag due to repeated use.
For a time websites employed easily defeated methods for trying to prevent such abuse by making anyone (or anything) who visited/accessed page ‘x’ do ‘y’ thing. Mostly these preventative methods were something stupidly easy for even a computer/bot to solve and did little to stop spam and misuse except prevent access from those only computers/bots that didn’t have a method of solving such simple problems.
To solve what was (at the time) an epidemic in and of itself of bots, reCRAPCHA was born.
Late edit: *Although the topic of ‘who made reCAPTCHA?’ is mostly irrelevant as far as this post’s topic is concerned. I was firmly, albeit still mostly ‘kindly’ reminded that Mr. Luis von Ahn is the inventor of reCAPTCHA and who sold it to Google after ~2 years.* In my defense, the above wording is still right but as an author you have my apologies for not dropping your name sooner Mr. Ahn.
Google came to the rescue of all, as was arguably their responsibility because they were the ones taking it up the rear the hardest from such bots. With the torch now passed to Google, and in really no better shape than the original countermeasure. The below example is what you were tasked with solving, which in hindsight seems fair enough, though in reality – it’s incredulous to ask.
Clearly something like this frustrated people and it wasn’t outsmarting computers either so it was time for Google to get “smart” and being Google, of course they realized they could kill two birds with one stone. So they came up with a way that almost no one was able to criticize them. They turned to making people solve reCAPTCHAs that were actually helping transcribe written works into digital format, searchable by OCR (Optical Character Recognition).
What am I talking about? Well do you remember the days when a reCAPTCHA suddenly went from looking like gobbledegook, to looking like this:
I know I do. I solved thousands of these myself. A simple quick single or double word combination which could also be played out via audio. Mildly annoying but quick and simple for humans, and apparently hard for computers. Except when it became trivial for computers. So Google had to up the ante.
It started out as the lesser of two evils, the good guy vs the bad guys. Except now the fight has evolved into a level of complete disregard for humanity thanks to the likes of these barstads. Yep that’s exactly what it looks like. A “Professional” company that literally EMPLOYS PEOPLE TO SOLVE OTHER PEOPLE’S reCAPTCHAs.
Oh wait it can’t be that ba-
cough
cough
cough
cOuGh
and the list goes on, and on, and on…
How to meet the resistance in battle? Well, fast-forward to now and you’ve got this disease that is reCAPTCHA v2. The piece of crap that you now find front-and-fucking-center of every single login/register page or text/form submission on the web. That beast that ‘blocks your path’ every time you want or need to login or write anything online.
In 2017 and 2018, the average time to solve one of these annoyances was a mere 8 seconds for most people. I personally could do them in about 2-3 if I’d had my coffee. In fact, people are doing studies on how long it takes different types of people to solve them. Such as this one here. Though mind you, it’s from back in 2015 where you could solve these in seconds with both hands tied behind your back.
But now?
Now?
THE AVERAGE TIME IS OVER 30 SECONDS!
But don’t for one second think it has anything to do with some increasing level of complexity in the war against bots. No, no, no. How long it takes to now solve these things has increased due to completely deliberate and specific choices that Google has made in reCAPTCHA v3! Yes, I do mean v3 here because these changes (increased complexity in v2) were only made after the arrival of v3.
I’m talking about why, despite you being a completely normal human being of sound deductive capability. You… just… keep… FAILING these things!
So why… why does this happen? It isn’t because you are in fact a dunce who cannot count up to three or cannot tell how many buses or traffic lights there are in a few blurry photos and it also isn’t because you don’t know what a fire hydrant looks like. The reason that people fail reCAPTCHA v3 prompts so consistently now is because Google realized there was no punishment to forcing people to solve more of these ‘human verification puzzles’ and only more to gain by forcing (yes it IS forcing) people to train their AI for free.
“People whine non-stop about hidden crypto-miners in websites but those are in fact a far more honest take of the kind of beast reCAPTCHA is.”
In short. GREED is the reason why you are doomed to fail at least 2 to 3 times every time one of these blocks your path. In fairer times it used to be that if you had recently finished one, Google could tell and you would be able to outright skip any additional annoying puzzle or prompt after you had recently finished one already.
It used to be that Google recorded a bit of your mouse movements and any other inputs you made and if those were ‘human enough’ you were spared the expense and agony of having to dance like a monkey to a tune. But no more. There are no short-cuts now. No free passes. It doesn’t matter if you’re logged into your Google account and allowing all manner of cookies.
Google, despite its ability to track you even through every single reCAPTCHA prompt. They STILL force you to solve these things even though they know damn well you’re not a robot. Why? Because fuck you, that’s why!
“We have now hit such a dystopian phase in internet history that some people are in the business of hiring humans to sit in front of a screen and just solve other people’s reCAPTCHA prompts.”
Things are only set to get worse too, and [I’m certainly to the only one who thinks so. When we hit reCAPTCHA v4 and beyond the time that it takes to solve these prompts will arguably get longer and the tasks become more frustrating.
You will likely be asked to turn on your webcam to confirm you are a human, and not in fact a pesky cat that just stepped onto the keyboard.
You will likely be asked to enable access to your microphone and forced to sing the chorus to the likes of Billy Ray Cyrus’ – Achy Breaky Heart.
You will likely be asked to open your phone/iPad/whatever and perform some action on a device other than the one you are trying to solve the reCAPTCHA on –
all begging the question of “I mean do you really I mean really need to login or submit that post? What if you try later… Maybe it will just go away? If only.
and…
YOU WILL WANT TO PAY A COMPANY TO SOLVE THESE THINGS FOR YOU. BUT YOU WON’T BE ABLE TO AFFORD IT! Solving reCAPTCHAs will be just another LUXURY like fast download and upload speeds, 4K displays and toilet paper that doesn’t give you a rash.
But hold up, if you don’t think that before you start to even consider that there must be a way to bypass or block these things just like you can block an advertisement online. Leading you to find one of those aforementioned ‘solving services’ and actually ever sign up to one of them.
That there will, and, not LONG, before you ever could get to that stage, be an option to PAY GOOGLE THEMSELVES some form of subscription to bypass these things altogether. If such a thing sounds like a fairytale to you, my dear reader, you are very naïve. I call it the reCAPTCHA Pass I dare say it’s already in the works and that, if you value your time, you will want one. With Google controlling the supply, demand and complexity of these bloody things, you can bet that their prices will be the cheapest!
Really I’m surprised there isn’t a freaking crypto ‘credit’ service that exists that you can use to pay your way out of having to do them. Now wait, that’s an idea! BRB whilst I go patent that.
Mark. My. Words. It will only get worse and there will be multiple businesses and services available pining for your money. ‘When computers attack’ the only thing that can solve the question of “Are you a human?” is literally exactly that, a human. Either you, or some poor sod you are paying. So what’s it gonna be?
This article was originally published by Nils Gronkjaer. You can read it here.
0 notes
Link
We asked marketing experts what their recommended growth hacking tools were, we gathered up the answers, and here are the most commonly mentioned tools.Let's take a look!1. AhrefsUsing Ahrefs is an integral part of our growth marketing strategy and one of the best growth hacking tools. Here is how we use this tool: Keyword research is the most essential part of growth hacking. However, it is a time-consuming and tedious process. With the help of Ahrefs, we can easily find trending keywords which our target audience is looking for. We produce quality content using those keywords to improve search engine ranking and overall ROI. Ahrefs helps us in keeping an eye on our competitors. We can completely understand why our competitors are ranking so high and what we need to do to outrank them. First, we find out what competitors are ranking for, then create similar content. Next, we find keywords that our competitors are not targeting and may not have the highest search volume. We target these so that we can rank faster by avoiding high-competition keywords. We find opportunities that we have missed out on by uncovering how our competitors have been building their backlinks.Then, we reach out to the sites that have linked to our competitors and try to get a link for our site from them. The ResultsI've 2 specific examples of relevant data/results (how Ahrefs helped us to increase our organic traffic):Links/mentions for GigWorker (a new site of our company) from the likes of HR.com, MerlineOne, and Business2Community). We have yet to see a sharp increase in our organic traffic, but within only 2 months or so, we have earned unique backlinks from over 150 referring domains apart from a continuous improvement in our DR and UR as this screenshot shows.We have used the same strategy for our partner site, Ridester.com. The result? First, traffic increased from 0 to 253K unique monthly visitors. Second, traffic increased again from 253K to 650K after 7 months. Finally, after 12 months, it increased from 650K to over 1.5 million unique monthly visitors. 2. OutgrowOutgrow is a tool that allows you to create interactive quizzes which, later on, you can implement on your own website. It's a great addition to your growth hacking tools list for adding to your "top of funnel" marketing strategy.Quizzes are an exciting way of hacking growth and virality (if done right). With one simple quiz, you can collect up to a couple of thousands of new leads.To do that you have to first do research on what interests your audience the most. It must be personal, it must move curiosity, and it must make people curious to find out what's the end result.You should have really in-depth and thoughtful quiz results. This will determine the number of shares that will ignite growth.Quizzes are a great growth hacking tool as people like to share their results (if these are worth sharing). Thus, spend time on those, make them creative, and well-sounding.This tool really helps build leads and increase shares of the quiz if it's of high enough value and interest to your target market.3. BuzzSumoBuzzSumo is one of my favorite growth hacking tools. It's a perfect tool for anyone working within content marketing, email or social media outreach, and search engine optimization.I use it for several things:To follow all the trending, most shared and linked to content within the different topics. This is useful for keeping up to date, but also to see what type of content works right now so I can get inspiration to make something similar. For instance, generating blog post headlines to use.To get notified about other websites linking to me or linking to sites I consider as my competitors. I can then share that content or perhaps reach out to the site linking to my competitors in order to try to get a link too.I also use it to discover influencers and other people interested in my vertical. This can be used to find people to follow or reach out to and see if they could share my content. Similar to the above benefit, if an influencer has engaged with similar content in your niche, it's likely they will be open to sharing or engaging with your content. Especially if it's of high quality.4. VYPERWithout traffic, you will have a hard time building a business. Not only that but now you also need followers and an engaged audience if you plan to sell anything online.It's a growth marketing tool that helps brands build traffic, engagement, leads, and customers. It does this by using contests, giveaways, and reward programs.The reason this tool works so well is the gamification and incentivization aspect. By giving people the incentive to share and engage, you can build an audience that is much easier to monetize. Not only that, but all of the built-in sharing also generates a ton of new customers. (Bonus that there's a free plan).5. MailshakeEmail outreach can be a gift or the most damaging tactics to your brand if abused.That's why Mailshake makes the list of top growth hacking tools.Without the correct settings and email limitations, you will end up in the spam folder faster than your recipient can read the subject line.This growth tool helps you craft the perfect cold outreach email. It makes sure you have the right subject length, link number, and quality email address to make sure your emails find your leads' inbox.Using Mailshake with a number of other tools (mostly ones to attain the contact information for your leads) is a powerful combination.6. PhantomBusterOne of the most popular tools submitted to the growth hacking tools list!PhantomBuster tool helps you quickly grow Facebook groups that you have just made. I have made many facebook groups for my clients and this is my go-to method to get engagement for their posts and drive traffic to their websites. In the post is a step-by-step for how to use PhantomBuster tool to capture your competitors' audiences.You can also use Phantombuster for Linkedin and Instagram profiles with these Facebook URLs which can help in branding, advertising, and other stuff.7. BonjoroIf you are looking to grow your business, a critical cog to that success is your ability to create engagement and conversation with your users.Bonjoro is a video emailing tool that integrates with many CRMs and ESPs and allows you to quickly send out a personalized video to a prospect.One use case I leverage this for was one of my brands HGC for our game Arkon. This tool is a little more advanced than others on the growth hacking tools list but it's definitely worth trying!We did a test with 100 people who had purchased our product, sending 50 of them Bonjoro generated thank you emails that were custom-tailored and sending 50 standards thank you emails.We received a 64% response rate from our Bonjoro cohort (32/50) and 16% from our control (8/50).From our Bonjoro cohort, we received substantially more reviews, future purchases, and even referrals (we ask people how they heard about us and found a handful that listed people from the Bonjoro cohort! Using video and email to increase engagement is a growth hack that's working exceptionally well right now!8. ColibriColibri helps you increase the online visibility of your brand and increases your SEO efforts.You can get statistics and information on the people searching for your competitors.It's also an SEO driven growth hacking tool that helped me make essential changes in my online marketing, which ultimately increased the conversion rate. It also shows you where your customers are engaging online so that you may take part in relevant conversations across the web. You can even integrate it with Google Analytics to check the stats and measure the success of your outreach strategies. Colibri can also perform an on-page SEO analysis to get your pages ranked higher on search engines. This should be the bare minimum when it comes to optimizing your website for SEO.9. QuuuQuuu Promote is a great tool that helps your blog posts go viral. It's a pretty awesome growth hack to jump-start new blog posts that don't have too much traffic yet.Other than that, we use the Facebook retargeting pixel to show our ads to people who have already visited our site and blog. The more a person visits our website, the higher the likelihood of converting them into a customer because they trust you more. Facebook retargeting pixels are a great way to get them to come back to your site again and again. 10. TubeBuddyTubeBuddy is packed with powerful features that will boost organic video views, explore popular tags, A/B test titles, descriptions, and thumbnails and much more. So lets deep dive into the key features and benefits:Tag Explorer - You can find the best and most trending tags for your videos. The recommendations are customized for your specific channel. Publish to Social Media - Gain more views by publishing videos directly to your social media accounts (Facebook).A/B Testing - Not sure which thumbnail to use? Or which title will increase CTR? A/B testing feature will allow you to test titles, descriptions, tags, and thumbnails. Competitor Score - Understand what works well for your competitors, best-ranking tags, subscriber count, view rate, and much more. Best Time to Publish - If you are already worried about the best time to publish on social media, then you know the importance of getting the timing right. You can automatically find the best time to publish YouTube videos for the audience that you have built. Brand Alerts - Get notification when someone mentions your channel so that you can stay on top of it. What are the results for my channel?More subscribers: As I was able to test more titles and thumbnails, I got a better understanding of which types of titles, descriptions, and thumbnail are engaging. This helped me get more CTR, views, and subscribers. I have more than 1,300 subscribers and 27,000 views.Videos Rank Higher: If you are already using an SEO tool for your website, then why not for YouTube? TubeBuddy allowed me to research and find the best tags for my video, as it plays an important part to rank videos. More watch time: TubeBuddy told me when and at what time I should publish my videos so that it reaches the maximum number of viewers and get more video watch time. I highly recommend TubeBuddy to any growth hackers/growth marketers to scale their marketing efforts and optimize their digital campaigns. 11. KlaviyoKlaviyo is a great email marketing growth tool that helps drive a good number of traffic and sales once you have a solid email list.It's not a dedicated "growth hacking tool" but is definitely important in your business if you are doing email marketing so we had to include it.We use it for every special shopping event to boost our website sales. Recently, we ran a Prime Day Campaign through Klaviyo and it went well in terms of both traffic and conversions. 12. Google TrendsGoogle Trends is the most accessible free growth hacking tools that is available to all marketers. Making viral content is all about creating the right piece and putting it out at the right moment. Google Trend's Realtime Search Trends tab gives you an overview of what's currently hot. You can find a topic that is organically training at the moment and create a piece related to that topic. Of course, it must match your niche and what you're writing about on usual. While Google Trends doesn't show you any complex metrics, scores, and KPIs, it does give you a clear look at what people are currently searching for.The crucial thing is whether you're able to capitalize on the current trend and get into already trending news. SummarySo there you have it, all the growth hacking tools to take your brand to the next level.If you want to learn more about growth hacking and marketing and see in-depth case studies you can read more about it:https://vyper[.]io/blog/best-growth-hacking-tools/
0 notes
Text
The State of Link Building 2016: What I Learned Manually Analysing 1,000 Search Results
168 Comments 18 minutes
Do private blog network’s still work? Does a higher word-count help your pages rank better? Did Glen really spend 60 hours on this article? I hope to answer all of these questions and many more in my new behind the scenes report on the current state of link building.
I can clarify I did spend more than 60 hours of work on this article, yet the sad part for me is that most of that time can be summarized in a simple bar chart. The rest of the time was spent coming up with a good headline but I clearly failed at that, so let’s see if I did any better with the chart.
I Manually Analysed 1,000 Search Results to See How Websites Ranked
I’ve been guilty over the years of making generalizations like “private blog networks are dominating Google” or “natural link building is almost impossible in some industries” so a few weeks ago I decided that I would respond to my own sweeping statements and analyze how people are actually ranking their websites in 2016.
As you can imagine, doing this analysis manually was a very time-consuming process. I managed to overcome most of the monotony by seeing this work as a chance to discover more link opportunities for myself (and my clients). My private database grew by over a hundred rows which means that there were many replicable links in my findings.
Now, before the SEO world tells me how unscientific the following data is, allow me this one caveat: I agree. The following findings are primarily based on my personal experience and viewpoints. There is, unfortunately, no way to exactly determine which backlinks are most integral in helping a web page rank.
The Results
The goal of my research was simple: Which specific type of link was the most instrumental in helping a website to rank.
Of course, every website I reviewed of course received backlinks from a number of different sources but I wanted to discover which ones were helping that particular website the most.
Because this was performed manually – I couldn’t automate the process even if I wanted to – I understand that there is nothing exact with my findings.
There are said to be over 200 factors which Google use to rank websites and while links from other websites are certainly the most impactful, it’s possible that my personal views are not entirely what is helping these sites rise to the top of search results.
That being said, I’ve been doing SEO for 11 years now and much of that time has been spent on link building. I wanted these answers for myself, so there is hopefully some merit in the following data.
Enough with the writing. Here are the results.
That’s it. The equivalent of working two and a half days straight without taking even a one-second break mostly boils down to that single graph.
As you can see, what I consider to be ‘natural’ link building tops the chart. This really shouldn’t be too surprising since that is how Google is supposed to rank websites (for the most part).
I should add that I don’t believe 21% of these results I checked were ranking because of links. Some were on powerful domains like Youtube.com or Amazon.com and therefore were ranking primarily because of the domain the result resided on. These links were still analysed, with most coming under the mixed category.
Due to the industries I analysed (revealed further down) there’s also a chance that there are more ‘low-quality’ links then you would find with a much broader dataset. However, you’ll find I picked the terms I monitored for good reason.
There were two key things that surprised me with these results:
How low in quality the backlinks were to many top ranking websites
How few private link networks I uncovered
The second point was especially interesting to me as it feels like I’m finding private link networks on a daily basis. What’s probably happening is that my brain makes some kind of internal ‘event’ when I come across one and therefore I’m less likely to remember all of the times I didn’t find them.
Kind of like how when you purchase a new car you start suddenly seeing it everywhere yet you didn’t even notice it before.
More seasoned SEO’s will probably be interested in how I classified those links but for the most part, by ‘low-quality link’s’ I generally mean links that anyone can replicate with a high level of ease and they weren’t earned in any way.
Link Classifications
The six categories that I have chosen to split links up into are:
Natural
Press Releases / Articles
Poor Links / Spam
Mixed Links
Network Links
Guest Blogging Links
To clarify again that my decisions are based on what I believe the strongest links the site has are.
Natural
By natural I simply mean that while a webmaster may have a mix of links, they are earned links rather than those that appear to have been gained in order to increase search engine rankings.
Though SEO may be a consideration at times – such as utilising signatures in forum posts – they’re essentially the types of links that you would happily show a Google reviewer and not be concerned about.
Press Releases / Articles
Sites in this category derive their rankings primarily from using press release services which allow you to embed links or embedding them in article directories which allow you to post your own content.
Low-Quality Links
These are primarily links that people can build either manually or automatically with tools that were likely built just to influence search results.
The types of links here include things like irrelevant blog comments, forum profile pages, social bookmarking links and very often from non-English Blogspot blogs.
Mixed Links
Sites in ‘mixed links’ appeared to have a bit of every type of link without any certain type – at least to me – being a major factor in why the site was ranking.
Though not all here used guest blogging or network links, mixed means that they had some natural links and some that were clearly built for gaming Google.
Network Links
This is for sites whose rankings clearly rely on the ownership of a private link network (often known as a private blog network, or PBN). While I can’t be certain sites were utilising their own PBN, it’s highly unlikely an outside source did it as a form of negative SEO, and – let’s be fair – it’s very easy to tell what’s going on when you find a network.
Guest Blogging Links
Though many webmasters did utilising guest blogging, few seemed to benefit from it as their main source of links. In fact, I only found a handful of webmasters primarily benefiting from this.
I’ve Already Got the Data, What Else Can We Analyse?
Since I was already relegated to the idea that I was going to analyse all of these search results anyway, I decided that I may as well collect more data on the way in the hope it would produce some more interesting charts.
Once again I’ll be the first to admit that this is far from scientific. Brian has a much better analysis with 1 million search results if you want some broader results. My sample size is admittedly too small to set the SEO world on fire with the following graphs but I still thought it would be interesting to analyse.
In the GIF below so you can see that all of this data really was collected manually. Huge thanks to my brother who I roped in to help with the grunt work on this.
Where I have tried to separate myself from the likes of Brian’s data is that I’ve specifically monitored industries that you could make money in if you were to rank on the first page of Google.
With Brian’s data, I have no idea if those million search queries were focused on the medical field or other technical subjects which simply wouldn’t apply to what the majority of us are trying to rank for in Google.
The Clickbank affiliate marketplace was a big inspiration for my keyword choices since people are successfully selling products in the industries I monitored. Here’s a sample of the keywords that I analysed:
I am aware, as stated above, my search queries of choice would likely result in more lower-quality link profiles than the web as a whole but again, I wanted to look at industries that myself and ViperChill readers are more likely looking to rank in.
Number of Backlinks
We all know that backlinks aren’t created equal, but would the data support that?
I can see why Brian didn’t include backlink count in his own analysis: It doesn’t make for the most shareable of graphs.
The average number of backlinks to all results was 22,771. This is for the page ranking and not the domain as a whole.
As we can see, my data shows very little correlation between backlinks and rankings.
The simple reasoning here is: Not all links are created equally. Ten links from quality, relevant websites have a much greater impact than one thousand links from the same domain.
Referring Domains
On the topic of receiving links from varied domains, I predicted that comparing the number of referring domains to Google rankings should result in data that’s a little more conclusive.
The average number of referring domains to all results was 236.
While I again admit my sample size is small, this data matches pretty much everything else out there I’ve found in regards to the correlation of referring domains and search engine rankings. It basically shows that if you can get a lot of different websites to link to you, that’s going to result in higher rankings (for the most part).
Of course, there is the caveat that ranking highly gives you the chance of more webmasters linking to you, but let me just have my moment here with my first decent chart, OK? 😉
Social Shares
I didn’t expect too much with this one but I had the data so simply decided to chart it.
The average number of social shares for all results was 3,823. Again, this was for the page ranking and not the domain as a whole.
The main reason I didn’t expect much from this graph – even if it showed a trending line – is because you can’t distinguish correlation and causation. You can’t show whether social shares helped a website to rank or whether they’re simply a byproduct of writing great content which would have attracted links anyway.
Domain Rank
Domain rating is a metric from Ahrefs which, according to them, “has the highest correlation with the Google search rankings. That’s why I always recommend that Ahrefs Domain Rank be the first SEO metric tool to check whenever you’re analyzing a website.”
The average Domain Rank for all results was 63.
I added a trend line to the graph to show that there really wasn’t much change here at all. In fact, Domain Rank was almost perfectly flat across the results.
I imagine if I were monitoring far more ranking positions for each search result then we would see a trend, but there’s nothing out of the ordinary here from page one.
URL Rank
Similar to Domain Rank, Ahrefs also gives a URL Rank rating to specific pages on a website. The majority of results in my testing were internal pages and not homepages, which makes looking at URL Rank (UR) more interesting to me.
The average URL Rank for all results was 23.
The results here are certainly a little bit more conclusive. A higher UR seems to have a good correlation with how well a page will rank in Google search results.
Word Count
There have been numerous tests to see whether longer content ranks better in Google so thanks to Word Checker I was able to run these numbers as well.
The average word count on all results was 1,762.
Again, the argument of correlation versus causation is relevant here. Are pages ranking because they have more words in them or because content with more words in it is likely to attract more links?
Personally, I argue for the latter. I’m far more likely to get links to an in-depth content piece I write rather than something short and sweet. That’s a trend I’ve seen on hundreds of other websites as well.
Behind the Scenes: The Link Building Tactics That Still Work Today
I decided to do put together this report on the state of link building as I’m a little tired of the same SEO advice being rehashed over and over. The thing about our industry is that anyone can start a blog, simply regurgitate what others have said and then instantly appear to be an expert on the topic.
I really like how Aaron Wall of SEO Book put it,
Most of the info created about SEO today is derivative (people who write about SEO but don’t practice it) or people overstating the risks and claiming x and y and z don’t work, can’t work, and will never work.
And then there are people who read an old blog post about how things were x years ago and write as though everything is still the same.
Since I started ViperChill 11 years ago I’ve been testing almost every theory I can when it comes to search engine rankings.
For example, I recently sent 1,000+ clicks to various search results (from around the world) to see if an increased click-through rate (CTR) would influence search engine rankings. Sadly my data didn’t show any noteworthy changes:
It cost me a few hundred dollars to perform this test and would have made a great blog post if there were any big shifts, but sadly I don’t have any data to support that idea.
I’m always testing, but there isn’t always something to say about my findings.
A Note Before We Get Into ‘Outing’
As I have mentioned in a number of previous blog posts, I will never reveal URL’s when looking at the backlinking strategy of small brands. My experience tells me that big brands will never be affected by my writing and I have proved that on a number of occasions.
I’m about to discuss the slightly shady SEO practices of both Houzz.com and Desk.com, companies both worth billions of dollars (Desk is part of Salesforce). I have dedicated entire blog posts to both of these companies before and there were no repercussions, hence I believe there is zero chance of them having any issues buried deep in a blog post like this one.
As I’ll mention in more detail later, I’ve seen that big brands can “get away” with shadier tactics as long as their overall link profile is natural (and abundant).
Billion Dollar Houzz Prove Widget Links Still Work
In April of 2014 I wrote a blog post about Houzz, the multi-billion dollar home design community.
To summarise much longer commentary, I revealed that Houzz were using their widget to unsuspectingly embed dozens of hard-coded links in the websites of those who used it. Their search traffic grew at a phenomenal rate thanks to the tactic.
Within 24 hours of my blog post about Houzz’s shady tactics going live, they removed all links in their widgets, as shown below.
Unfortunately I do not have a larger graphic for this (it was over two years ago that they had this design) but my prior research provides many additional screenshots.
The problem is that the links they embedded on webmaster websites were hard-coded so even when Houzz changed the widget, those links didn’t disappear and they still benefited from tens of thousands of links from thousands of referring domains.
As you can imagine, their search traffic at the time was through the roof.
Clearly someone from their team read my article and as stated, the hard coded links were removed in less than 24 hours of it going live.
Sadly, Houzz have (partially) gone back to their old ways.
As we can see, Houzz recently added back a link to /photos/ on every single widget their members install on their websites.
As per Google’s guidelines, widget links embedded in this way should definitely be no-followed.
Linking to their /photos/ page is smart as it’s essentially a sitemap to the rest of their website, funneling the “link juice” to other strong pages.
Thanks to SEMRush we can see that 7 out of the 10 most high-volume search terms sending traffic to Houzz are actually photos pages.
I am aware that widget links are not the only reason why Houzz are ranking for these terms but the whole thing is a little bizarre to me.
The three main things I don’t understand are:
They already retracted after being caught before. Why do it again?
Do they really not care about their users that they can’t put a no-follow on the widget?
They are Houzz. They’re still going to get a ton of search traffic anyway.
The last point is the main one for me. It’s not like they’re some newcomer to the online design space and need to implement these sneaky tactics in order to rank higher.
They’re worth billions of dollars and are expected to IPO next year. Let’s see if the Houzz SEO team are still subscribed to ViperChill. I’ll update this post if there are any changes.
Footer Links Still Work
We already know this from my report on the 16 companies dominating Google in regards to owning a powerful network, but there’s sadly more to the story than that. Big media publishers are not the only ones who get away with putting footer links wherever they can.
In 2013 I wrote an article about how to get a link from SoundCloud.com. The answer today is still the same as it was back then: Give them some software to publicly use on their site and put a footer link back to your website.
Salesforce’s Desk.com continue to do exactly that.
Here’s the footer for SoundCloud (https://ift.tt/UBkWzk)
Here’s the footer for JWPlayer (https://ift.tt/1Cs9ed9)
Here’s the footer for Wunderlist (https://ift.tt/1d6otM6)
The list goes on. There are over 1,000 unique websites sending links back to Desk.com with this exact anchor text.
Of course, we don’t have to guess who’s ranking first in Google.
Note: I removed the ads for a “cleaner” screenshot
This adds further weight to my theory is that as long as you have enough backlinks, you can ignore most of the Google guidelines and still be totally fine.
Marie Haynes has a great article about what is and isn’t “allowed” when it comes to footer links but this tactic certainly toes a very fine line.
Past Link Building Still Holds Strong Today
Even if you aren’t active on online dating sites, you’ve likely heard of Match.com, Tinder and OKCupid.
But what about Mingle2?
It claims 12 million users and is second in Google for ‘Free Online Dating’ yet you’ve probably never heard about it in any form of media.
In fact, you’re more likely to have heard about The Oatmeal.
That’s not a random connection. Matthew Inman started his internet career at SEO company Moz (named SEOmoz at the time) then went on to build the dating site in just 66 hours. His massive success in promoting the platform with viral content and quizzes would later see him sell Mingle2 to Just Say Hi. You probably know he continued to use his amazing talent for creating viral content at The Oatmeal.
For those who aren’t reading a line of text in this post, allow me to put that in graphic form for you:
Within a few short months of Matt creating Mingle2 it quickly rose to the top of Google for some very popular search terms. Today, 10 years later, the creative links he built are no doubt helping to sustain those rankings.
I don’t want to give too much analysis on this result because I actually think it’s one to watch for how creative Matt was in getting backlinks.
In fact I think if you have some spare time today you should go and analyse their backlinks in more detail. Matthew perfected the art of getting people to want to talk about his content.
As far as link building goes, let’s just say that what they were doing back then would definitely result in a brand being outed today. Those broken guidelines allow Mingle2 to keep their amazing search traffic.
11.7M Reasons Writing Good Content Still Works
For a few years now I’ve considered Steve Kamb (of Nerd Fitness fame) a good friend of mine. That may have something to do with how many Jaegermeister shots we drank together in Cape Town.
I knew Steve was receiving a lot of traffic from Google for his guide to the Paleo diet so I reached out to him to see if he would share any specifics. Especially since the blog post received links from over 800 domains.
Here’s what Steve said,
I wrote the article in Sep 2010 it looks like. In March 0f 2012, Google started to love us all of a sudden sending 76k views. April reached 100,000+ and then it slowly climbed up to a peak in June of 2014 where it was viewed 555,000 times.
Then Google must have changed something and it dropped all the way down over next 6 months to 100k-ish in Dec 2014, where we’ve kind of stabilized over the past 18 months. The pageview count for May 2016 was 87,000.
Steve kindly shared the following graph as proof.
You can click on the picture to view it larger
Even though the article is six years old and has dropped down a few places in Google search results, it still picks up links to this day. Getting real, “earned” links to quality content is far from a dead opportunity.
There are four core reasons I believe Steve’s article still regularly attracts links:
Reason #1: He already ranks highly in Google for the term so when people want to link to a guide about the Paleo diet, they see what is ranking and link out
Reason #2: Steve wrote one of the best articles on the topic. People simply wouldn’t be linking to it naturally if it wasn’t an incredible resource
Reason #3: The article is linked to in the sidebar of every page of his website thus sending it more pageviews than it would have otherwise received (especially since it was written so long ago)
Reason #4: He has built a loyal audience of people who genuinely love his content and want to support him in any way they can. It makes sense to them that when they write about the topic, they link to Steve.
As you can see, I believe that earning links to your content is far more than just “writing something worth linking to”. It helps if you’ve already built a trusted audience – or you’re willing to work to build one – who would love for more people to hear about your work.
You Can Buy Your Way Onto Forbes or the Huffington Post
I get pitched a lot of SEO services via ViperChill and I also actively seek them out myself. It’s always good to know what others are doing since SEO is pretty much my life (as sad as that may sound).
I regularly receive emails like the one below, revealing specific websites which I can purchase links from.
Click the image to view larger
While the sites in the screenshot above are relatively “small time”, they’re often very safe to use as they have a harder chance of being detected (they’re not going to appear on the first page of an Ahrefs backlink report, for example).
It’s not just small unknown websites that you can buy your way onto though. I personally know of three different companies who offer the chance to get you on the likes of the Huffington Post for a modest fee.
Click the image to view larger
Once you spend a bit of time reading the various sites you can easily see which websites are selling links and which authors are the most commonly writing them.
For instance, this article and this article on Business Insider seem to be clearly paid for. There are many others posted by the same author but there are no mentions of the content being sponsored. The author seems overly intent to give credit back to the person he’s writing about (my emails to him did not receive a response so I can’t say for certain).
I will not link to it but another recent article on Business Insider was heavily promoting a webinar that the featured marketer publicly admitted paying for. The article literally linked straight to his webinars where he was selling a coaching program so the traffic must have made him a few sales.
Easy-to-Obtain Links Can Dominate the Right Industries
By easy to obtain I literally mean links that anyone can go out and build for themselves right now with little to no wait time or approval process.
These sites generally allow you to just sign-up, create some content, and link away. You can see the types of links I’m talking about in the screenshot below.
While these types of links are barely better than no-followed comments on a Japanese cat blog, they can work in the right industries. Particularly industries that are new or would appeal to a certain demographic you never consider i.e. grandmothers who knit or guides on the world’s best rollercoasters.
Although it may seem like most popular searches are dominated by people who know a thing or two about SEO, it’s certainly not always the case. The site with the links above is relying on Google for almost all of their traffic.
While these certainly aren’t the types of links I recommend building for your own site – unless you need some quick diversity links – it goes to show that they can still work if you’re targeting the right niche.
Manual Link Hunting Gets Search Traffic
When you’re averaging 805 links per domain linking to you, there’s probably something a little fishy with your backlink profile. That’s certainly the case with this .info website (I highlighted it’s .info so you can see it’s the same site in both graphics).
If my yellow highlighter effect is doing its job then you should be impressed to see that they’re ranking for over 1 million keywords in search results.
And these are not just any old keywords either. Some of them are being searched for tens of thousands of times per month. You can see the same website displayed in the SEMRush graph below.
Without adding yet another screenshot to this already image-heavy article, just trust me when I say the quality of their backlinks leaves a lot to be desired.
That being said, I do have some respect for the owner in how much work they’ve done to build these links. They ‘abused’ a few opportunities but put the work in. The links come from sources like:
Wikipedia external links
Comments on news articles (via actual news websites) with relevant stories
Opportunities likely found via links their competitors earned
It actually gave me a great idea for a niche to get involved in as well, so although the work for this blog post was immense, I’ve found a number of opportunities because of it.
Private Blog Networks Still Work Very Well
Being totally honest, I expected to find more link networks in my research than I did. Especially because I was monitoring the type of industries where this practice is likely to be more common.
Here is how an obvious network looks when you analyse their backlinks:
The example above is actually what I would call a “good” example. Meaning that they websites ranking and linking to each other are actually good sites and far more searcher-friendly than the typical blog network I am sure you can picture in your mind.
It simply provided a nice screenshot to illustrate my point into how these networks work.
Of course we’ve already learned that if you have thousands of links pointing to a number of websites you own, you can interlink them and dominate Google search results.
Update: Some commenters seem angry that I “only” found as many PBN’s as I did.
Two things to note: I found more than are in the chart above, I just didn’t rate them as being the biggest contributing factor in why a website ranks.
The number could also be lower because of people hiding their networks from Ahrefs. I may do a smaller version of this study again with something like Link Research Tools or Monitor Backlinks (I’ll have to check if they use their own network) which people are less likely to block.
You Can Get Dozens of .EDU Backlinks for $1,000
Ever since I started SEO at 16 years old and spent countless hours browsing the Web Workshop forums (no longer online) I’ve heard about the power of .edu (education / university) backlinks.
It makes sense that these links would pass a lot of authority because of the sites they’re coming from. They’re certainly not easy to attain naturally: ViperChill has over 100,000 links yet only 8 of them are from .edu sites.
I don’t even know how I received those 8, since the university of Calgary link to a blog post I wrote five years ago which no longer exists and Australia’s Newcastle University is somehow linking to me via pingbacks.
One tactic that I’ve found is becoming increasingly common in order to obtain .edu links is to offer a ‘scholarship’ on your website and receive dozens if not hundreds of .edu links to your site in return.
It’s certainly not new by any means. With a bit of sleuthing around you can see sites – clearly just offering a scholarship for a link – have been employing this for a number of years.
I’ve tried my best to be respectful to the site owner and not reveal their website but anyone who is using this tactic and thinks they’re doing so under the radar really has no idea what that phrase means.
As this is a behind the scenes report on what still works in 2016, I wanted to make it clear that this is still happening today and people are benefiting from it massively.
There will obviously be people who are pissed off I have “exposed” this tactic but to me there is nothing shadier then making students believe there’s a chance they could save money on their education yet they probably have no chance to do so at all.
Is there really anyone checking to see if a coupon website launched in 2016 is going to keep to their $3,000 promise?
Exactly.
While these guys are supposedly offering $3,000, I’ve found some offering as little as $1,000 and still picking up a large number of links.
The Future of Link Building
It would be wrong of me to write a huge report on link building without speculating on what the future of link building might entail. We all know that backlinks are a large part of why websites rank today, but will that still be the case tomorrow?
The SEO industry is fortunate to have enough bright minds that people tackle problems like this. My good friend Jon from PointBlankSEO wrote a great report to try and answer this very question.
In his conclusion, Jon makes an excellent point:
The real threat is more foundational than links. Justin Briggs explained it best in his response earlier. The aspect of ranking a page organically in Google’s results has slowly declined in value, both because of other SERP features & search ads. There’s still a ton of money to be made, but we should work like we’re living on borrowed time.
Today, natural organic search results are lower down in listings than ever before.
Mobile results are spaced further apart. “Map packs” in search results take up half of the screen on a desktop. Google’s one box tries to answer user queries straight from the results page.
I don’t see any major ranking competitor to links in the near future. The entire Google algorithm which provided better results than Altavista and Yahoo back in the day was built on links and 18 years later they’re still a key factor in why websites rank.
That being said, my main concern is where SEO will be in three to five years rather than what matters to rank. We’ll always figure out the last part. The first part is out of our control.
Teaser: There’s One Tactic That is Dominating Them All
Over the past 18 months I’ve found one link building tactic to be working incredibly well. It’s not brand new in the sense of “Wow, University’s give out links so easily” but in the sense of “here’s how to make all of these current options work even better.”
If I wrote about it, I would probably lose a large chunk of my audience, but that’s something I’m willing to do.
Next week I’m going to introduce PIN’s, a new way to conduct link building which could fit anywhere on the spectrum of whitehat to blackhat.
It’s a very risky topic to cover so for that reason I want to dedicate an entire article to it, rather than just add another section to this report which could be taken entirely out of context.
If you’re new to ViperChill, enter your email in the box below (or in the right sidebar) to make sure you don’t miss that update. I’ll send it out the minute it goes live.
Thank you so much, as always, for reading.
Send Me Exclusive Tips
Enjoy this post? Please leave a comment below…
Comments are my number one indicator as to which posts people enjoyed the most, so your feedback really does help me. If you have any questions, feel free to ask those as well…
!function(f,b,e,v,n,t,s){if(f.fbq)return;n=f.fbq=function(){n.callMethod? n.callMethod.apply(n,arguments):n.queue.push(arguments)};if(!f._fbq)f._fbq=n; n.push=n;n.loaded=!0;n.version='2.0';n.queue=[];t=b.createElement(e);t.async=!0; t.src=v;s=b.getElementsByTagName(e)[0];s.parentNode.insertBefore(t,s)}(window, document,'script','https://connect.facebook.net/en_US/fbevents.js');
fbq('init', '911260315652744'); fbq('track', "PageView"); Source link
0 notes
Text
WORK ETHIC AND SCHLEPS
And there are a lot of startups don't want to make it something that they themselves use. Techniques for competing with delegation translate well into business, because delegation is endemic there.1 So if such a company has two possible strategies, a conservative one that's slightly more likely to work in the end, or a company hiring people right out of college. How many startups fail. Yes, the price to earnings ratio is kind of high, but I count them as false positives because I hadn't been deleting them as spams before. Many if not most of the rest of the world. If I had to condense the power of vested interests, the undiscerning audience, and perhaps most dangerous, the tendency of such work to become a big, independent company is the same reason Google and Facebook have remained independent: money guys undervalue the most innovative startups. At first they're always dismissed as being unsuitable for real work. It's hard to think of VCs as piratical: bold but unscrupulous.2 They can work on small things, and if they get a higher valuation.3
He said it wasn't anything specific Google did, but simply that they trained their filter on very little data: 160 spam and 466 nonspam mails.4 Ask for advice.5 Subject free!6 These get through because I'm a writer, and writers always get disproportionate attention. As well as being more comfortable working on established lines, insiders generally have a vested interest in perpetuating them. Subject FREE Subject Free Subject free FREE! This is particularly true with companies, who have not only skill and pride anchoring them to the status quo, but money as well. I have a more complicated definition of a token: Case is preserved. Not publicly.7 In fact, one of the things she's best at is judging people. I even fix bits that are phonetically awkward; I don't know. Much was changed, but there just aren't enough of them, and hippies to boot.
More likely the reason is that the kind of alarms you'd set off if you spent a whole day, but that you should never shrink from it if it's on the path to something great. Investors don't like to say no. For example, after Wozniak designed the Apple II he offered it first to his employer, HP. You may feel you don't need that, but history suggests it's dangerous to work in fields with corrupt tests. In addition to their intrinsic value, they're like undervalued stocks in the sense that the startups they like most are those that seem like work, the danger of responsibilities is not just that you can stop judging them and yourself by superficial measures, but that so many judge themselves by it.8 Apparently the most likely animals to be left alive after a nuclear war are cockroaches, because they're more confident. What made YC successful was being able to pick winners.9 It was small and powerful and cheap, but not writing, my dissertation. That's schlep blindness.
7636 free 0.10 But the startup world for so long that it seems normal to me, so I was curious to hear what had surprised her most about it. But if the worst thing they can hit you with is your own feeling that you're thereby lacking something. Which illustrates why this change is happening: for new ideas. And that will get us a lot more state. They may be enough to kill all the opt-in lists. In this case, the device is the world's economy, which fortunately happens to be open and good. Facebook. This is extremely risky, and takes months even if you succeed. One of the things the internet has shown us is how mean people can be.
That isn't literally true, but there was still that Apple coolness in the air like the smell of dinner cooking. Some founders are quite dejected when they get turned down by investors. That's where the big returns are. But since then the west coast has just pulled further ahead. Now the reconquista has overrun this territory, and, not surprisingly, found it sparsely cultivated. The most effective approach seems to be growing. The bad news is, the only investors who can do it right are the ones you end up looking at when you get rejected by investors, don't think we suck, but instead ask do we suck? What does it mean, exactly?11 If you can't find an exact match for a token, treat it as if it were like getting into college. They feel they've achieved more if they get a higher valuation they can say mine is bigger than yours.12 The games played by intellectuals are leaking into the real world, and they're worried about some nit like not having proper business cards. Suppose a Y Combinator company starts talking to VCs after demo day, and is successful in raising money from them.
In retrospect that seems ridiculous, and we can all see the long tail of meanness that had previously been hidden. The potential of a new medium is usually underestimated, precisely because no one has yet explored its possibilities. YC, why don't more people realize it? Links and images you should certainly look at, because they couldn't afford to take so much time away from working on their software. If you take VC money, you have to follow the truth wherever it leads. The founders early on were mostly young. I thought I'd already been cured of caring about that. Corporate M & A is a strange business in that respect.13 How do you see ideas that involve painful schleps. I just mentioned.
The dangerous thing about investors is that hackers don't know how much they'll need to. That filter recognized about 23,000 tokens.14 To understand what McCarthy meant by this, we're going to retrace his steps, with his mathematical notation translated into running Common Lisp code. Another reason attention worries her is that she hates bragging. 9782 free! If you ultimately want to do something that will cost a lot, start by doing a cheaper subset of it, and we want to keep in close touch as you develop it further.15 This technique can be generalized to any sort of work: if you want to beat those eminent enough to delegate, one way to do it is to take advantage of direct contact with the medium. Startups win or lose based on the quality of their funding deals.16
That VC round was a series B round; the premoney valuation was $75 million. Fortunately, there are all those people the eminent have working for them; they have to ask for advice. One of the many things we do at Y Combinator is teach hackers about the inevitability of schleps. Another project I heard about after the Slashdot article was Bill Yerazunis' CRM114. You might think that if they found a good deal of fighting in being the public face of an organization.17 And Jessica is the main reason VCs like splitting deals is the fear of looking bad. This makes everyone naturally pull in the same direction, subject to differences of opinion about tactics. And I think I can prove I'm right. The professor who made his reputation by discovering some new idea is not likely to be the ones you would least mind missing. Another way to find good problems to solve in one head.
Notes
Hackers Painters, what you learn about programming in Lisp. Proceedings of 2003 Spam Conference. 1% in 1950 something one could aspire to the problem and approached it with such a large organization that often creates a rationalization for doing it with the guy who came to work like blacklists, for example, if you did that in the 1920s.
Calaprice, Alice ed. If the rich.
If you were going to give up your anti-dilution provisions also protect you against tricks like a compiler, you can't dictate the problem is not much to maintain their percentage. If you're dealing with the Supreme Court's 1982 decision in Edgar v. Among other things, like the arrival of desktop publishing, given people the shareholders instead of the living. It doesn't take a small proportion of the more powerful sororities at your school, and judge them based on their own company.
Photo by Alex Lewin. Because we want to create giant companies not seem formidable early on. They can lead to distractions even more closely to the table.
Every pilot knows about this trick works so well. This is not such a low valuation to see it in B. The disadvantage of expanding a round on the person.
If idea clashes got bad enough, but I'm not saying all founders who are all that matters financially for investors.
I was writing this, on the x company, and why it's such a low valuation, or working in middle management at a famous university who is highly regarded by his peers, couldn't afford a monitor. The best thing they can grow the acquisition offers that every fast-growing startup gets on the one Europeans inherited from Rome. The US News list tells us is what you build for them, but I managed to find a broad range of topics, comparable in scope to our scholarship though without the spur of poverty I just wasn't willing to put it here. Whereas the value of their core values is Don't be evil, they tended to be on demand, because the rich have better opportunities for education.
There are simply the embodiment of some brilliant initial idea. Which OS?
Cit. A preliminary result, comparisons of programming languages either take the term copyright colony was first used by Myles Peterson.
Nor do we push founders to overhire is not writing the agreement, but I couldn't convince Fred Wilson for reading drafts of this type: lies told to play the game according to certain somewhat depressing rules many of the startup. No one wants to program a Turing machine.
This phenomenon is apparently even worse in the 1984 ad isn't Microsoft, incidentally, because the kind that evolves naturally, and many of which he can be surprisingly indecisive about acquisitions, and post-money valuations of funding. At any given person might have 20 affinities by this, but sword thrusts.
All he's committed to believing anything in particular took bribery to the inane questions of the political pressure to protect their hosts. Not in New York. So if it's not the primary cause.
But you can often do better, because the outside edges of curves erode faster. I spent some time trying to upgrade an existing university, or it would feel pretty bogus to press founders to overhire is not always as deliberate as its sounds. The question to ask for more than most people emerge from the rest generate mediocre returns, it's easy for small children, or in one where life was tougher, the editors think the company.
While we're at it he'll work very hard to make Viaweb. I realize revenue and not least, the best approach is to give them sufficient activation energy to start a startup, and then scale it up because they need them to get going, e. So far the closest anyone has come unscrewed, you don't need that much of it. A lot of press coverage until we hired a PR firm.
You can relent a little too narrow than to call all our lies lies. They live in a situation where they all sit waiting for the same thing, because you need to, and 20 in Paris. Most people let them mix pretty promiscuously. I should add that none of them material.
The Mac number is a bad idea the way they have less time for word of mouth to get users to switch.
They're common to all cultures with long traditions of living in cities.
#automatically generated text#Markov chains#Paul Graham#Python#Patrick Mooney#energy#idea#history#anyone#sup#startup#B#smell#McCarthy#blacklists#Hackers#thing#world#press#tells#Links#education#life#traditions#retrospect#coolness#quality#tests#interest#opinion
0 notes